【已更新完毕】2025泰迪杯数据挖掘竞赛C题数学建模思路代码文章教学:竞赛智能客服机器人构建
完整内容请看文末最后的推广群
基于大模型的竞赛智能客服机器人构建
摘要
随着国内学科和技能竞赛的增多,参赛者对竞赛相关信息的需求不断上升,但传统人工客服存在效率低、成本高、服务不稳定和用户体验差的问题。因此,设计一款智能客服机器人,利用人工智能技术为赛事提供实时、高效、精准的信息查询服务,成为了迫切的需求。该机器人需具备回答基础信息查询、进行统计分析查询以及处理开放性问题的能力,同时支持竞赛数据的实时更新,确保信息的时效性和准确性。
为了解决问题一,我们采用了自动化的文本提取和自然语言处理方法,首先通过PyPDF2提取PDF文件中的文本,然后利用OpenAI API解析文本,同时基于正则表达式提取出赛事的关键信息,如赛项名称、赛道、发布时间等,并将其保存为结构化的CSV文件。在处理过程中,我们面临了PDF格式不一致和信息提取的挑战,通过优化模型提示和文本清洗,确保了提取结果的准确性和一致性。
问题二的模型通过利用PDF文本提取、自然语言处理技术和Chromadb向量数据库构建了一个智能客服机器人,能够高效地从竞赛文档中提取并存储关键信息,进而实现用户查询的实时回答。该模型在处理标准化查询时表现出色,能够自动化提取竞赛信息并生成准确的回答。
问题三的模型是在问题二的基础上进行扩展,主要任务是处理新增和变更的竞赛PDF文档。该模型通过提取新增和更新的PDF文件中的文本信息,进行清洗、分块和嵌入生成后,将其更新到现有的知识库中,确保知识库包含最新的竞赛数据,使得智能客服系统能够实时响应用户查询并提供最新的竞赛信息。
最后通过前端搭建和后端接口调用, 构建竞赛智能客服机器人, 通过知识库构建、查询处理、响应生成以及系统的部署完成机器人的构建。
关键词:PyPDF2;OpenAI API;大模型;自然语言处理;PDF文本提取;向量数据库;嵌入表示(embedding); Chromadb数据库; 智能客服机器人
目录
基于大模型的竞赛智能客服机器人构建 1
摘要 1
一、 问题重述 3
1.1 问题背景 3
1.2 要解决的问题 3
二、 问题分析 5
2.1 任务一的分析 5
2.2 任务二、三的分析 6
三、 问题假设 8
四、 模型原理 9
4.1 关键词识别 9
4.2 中文文本分析 11
五、 模型建立与求解 11
5.1问题一建模与求解 11
5.2问题二、三建模与求解 18
5.3智能客服机器人系统构建 22
六、 模型评价与推广 26
6.1模型的评价 26
6.1.1模型缺点 26
6.1.2模型缺点 26
6.2 模型推广 27
七、 参考文献 29
附录【自行黏贴】 30

二、 问题分析
2.1任务一的分析
问题一要求我们从提供的18个竞赛规程PDF文档中提取出关键信息,并将其结构化保存为CSV格式。竞赛规程文档包含了赛事的详细信息,如赛事名称、赛道、发布时间、报名时间、主办单位和官网链接等,我们需要准确提取这些信息,并处理不同文档格式和内容的差异。为了解决这个问题,我们采用了自动化的数据提取方法,结合PDF文本提取和OpenAI的自然语言处理能力。
首先,我们利用PyPDF2库提取PDF文档中的文本。PDF文件的文本结构常常存在格式化问题,因此需要通过清洗和格式化来保证文本的连续性和可读性。接着,使用OpenAI API解析文本,提取出我们需要的信息。在这一过程中,我们构造了详细的提示(Prompt),确保模型能够理解并提取出赛事的关键信息,包括赛项名称、赛道、发布时间、报名时间、主办单位和官网链接等。OpenAI模型通过自然语言处理的强大能力,从文本中抽取出结构化的数据,并将其转化为JSON格式。
在处理过程中,我们面临了一些挑战,例如PDF文件中有时包含扫描图像或特殊字符,这些情况会影响文本的提取质量。此外,不同文档可能采用不同的表述方式,导致字段提取的准确性有所不同。为了应对这些问题,我们在模型提示中规定了详细的规则,并通过推测填补无法明确提取的信息(例如使用文档中出现的时间或组织单位的上下文信息)。在输出结果时,如果某些字段无法准确提取,我们会将其标记为空或进行补充说明,确保输出的格式一致。
最终,所有提取的信息被批量处理并保存为CSV格式,以便后续分析和使用。每个PDF文件的处理结果都包含文件名、赛项名称、赛道、发布时间、报名时间、主办单位和官网等字段。通过这种方法,我们能够高效、自动化地完成大量文档的数据提取工作,并确保结果的准确性和结构一致性。
2.2任务二、三的分析
问题二的目标是利用人工智能技术,结合提供的竞赛数据,设计并实现一个智能客服机器人,以便为用户提供实时、高效、精准的竞赛信息查询服务。为了完成这一任务,我们构建了一个基于自然语言处理和向量数据库的系统,来处理并回答竞赛相关问题。该系统的核心包括文本处理、知识库构建和信息检索三个主要部分。
模型的构建从PDF文档的处理开始,通过使用pdfminer.six库提取竞赛相关的文本信息。由于竞赛文档通常包含大量的竞赛规则、任务描述和赛事信息,因此必须对这些长文本进行预处理。我们采用了文本清洗技术,去除掉无用的字符、空格和HTML标签,以保证文本质量。之后,使用AutoTokenizer对文本进行分词,并将文本分割成若干个块,确保每个块的token数量不超过模型的处理限制。这一过程有效地处理了长文档中可能出现的token溢出问题,并保证了模型输入的有效性。
在完成PDF文档的文本提取和处理后,下一步是构建智能客服机器人的知识库。为了确保机器人能够高效地响应用户查询,我们使用了Chromadb数据库来存储处理后的竞赛信息。通过对每个文本块生成嵌入(embedding),使得每个块能够在向量空间中具有语义上的表示。我们使用了AsyncOpenAI生成嵌入表示,并通过Chromadb存储这些嵌入。知识库的构建是一个异步过程,通过批量处理PDF文档并将嵌入结果添加到数据库中,使得机器人能够从庞大的信息库中快速检索相关内容。
为了实现实时的竞赛信息查询,我们通过CompetitionAgent类实现了一个基于用户输入的查询响应机制。当用户输入问题时,系统会首先通过向量检索从知识库中找到相关上下文,并利用OpenAI的生成模型生成答案。这个过程是通过查询嵌入和生成嵌入的相似度来实现的。系统能够有效地提取与问题相关的竞赛信息,并通过基于上下文的生成模型提供详细回答。机器人不仅能够回答基础的竞赛查询,还能够处理一些统计分析类和开放性问题。
问题三的任务是在问题二的基础上,处理新增和变更的竞赛PDF文档,并将其更新到现有的智能客服机器人系统中。通过从新增或更新的PDF中提取竞赛信息、清洗文本并生成嵌入,系统能够将这些新的或更新的数据集成到知识库中。这样,智能客服系统能够保持最新的竞赛信息,并继续高效地回答用户查询。
模型的核心在于自动化处理新增和变更数据,通过将新的竞赛信息嵌入现有知识库来更新系统。用户查询时,系统可以通过嵌入检索到相关的竞赛数据,并利用生成模型给出准确的回答。这个过程确保了系统始终能够提供及时和准确的竞赛信息,避免了人工更新的繁琐。
该任务的关键挑战在于如何高效地处理和更新竞赛文档,以及确保系统能够无缝地集成新数据。通过简化的问题三模型,通过处理新增和变更的PDF数据,并将其更新到现有的大模型中,使得系统能够继续为用户提供实时的服务,提升了系统的灵活性和可扩展性。

任务 1:竞赛数据整理
目标:从18个竞赛规程PDF文件中提取基本竞赛信息,并保存到 result_1.xlsx。
解题思路:
PDF 解析:
使用 pdfplumber 或 PyMuPDF 提取 PDF 文本内容。
处理文本分段问题,确保数据完整提取。
信息提取:
采用 正则表达式 识别并提取竞赛名称、赛道、发布时间、报名时间、组织单位和官网信息。
采用 NLP 技术,如 spaCy 或 NLTK 进行信息分类和结构化。
数据整理与存储:
将提取的数据存储为 Pandas DataFrame,并按表格要求格式化。
最终导出为 result_1.xlsx。
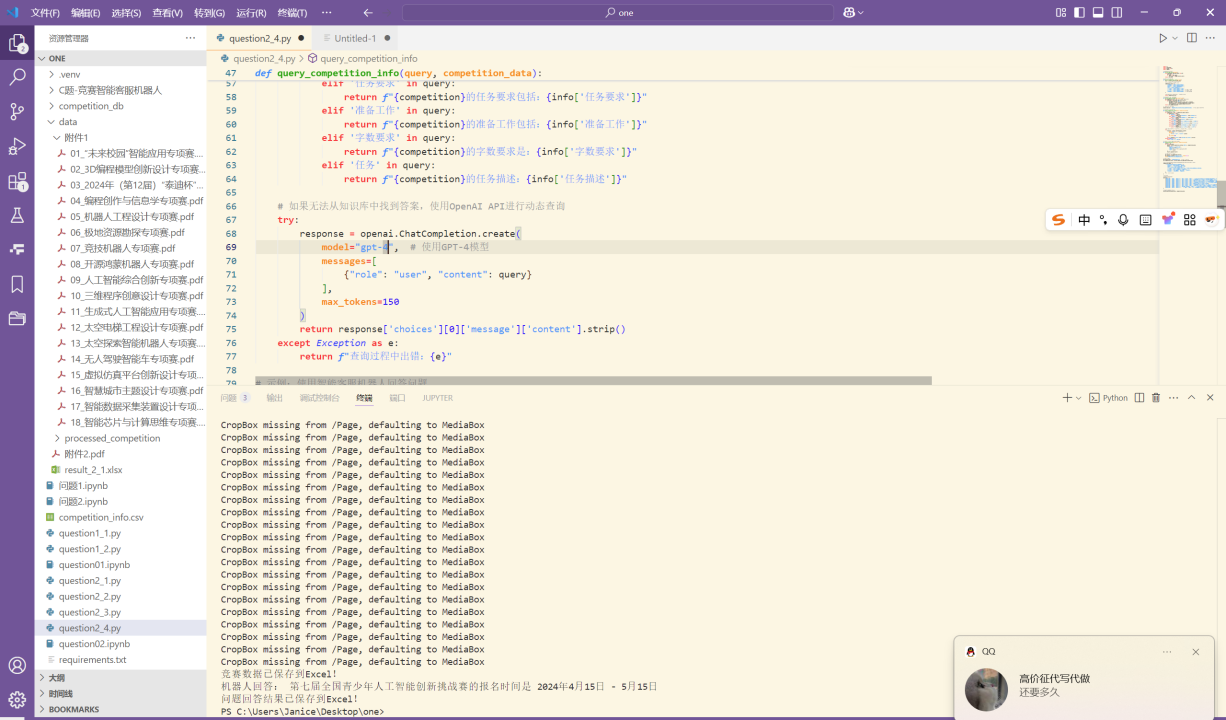
# ---- 提取赛道名称 ----# 方案1:匹配"专项赛"关键词track_match = re.search(r'(.+?专项赛)', text)# 方案2:匹配标题行if not track_match:track_match = re.search(r'参\s*赛\s*手\s*册\s*\n(.+?)\n', text)if track_match:info["赛道"] = track_match.group(1).replace("参 赛 手 册", "").strip()# ---- 提取发布时间 ----date_match = re.search(r'(\d{4}\s*年\s*\d{1,2}\s*月)(?!.*\d{4}\s*年)', text)if date_match:info["发布时间"] = date_match.group(1).replace(" ", "")# ---- 提取报名时间 ----reg_date_match = re.search(r'报名时间[::]\s*(\d{4}\s*年\s*\d{1,2}\s*月\s*\d{1,2}\s*日\s*[-至]\s*\d{1,2}\s*月\s*\d{1,2}\s*日)', text)if reg_date_match:info["报名时间"] = reg_date_match.group(1).replace(" ", "")# ---- 提取官网 ----website_match = re.search(r'(https?://[^\s\)\]\'"]+)', text)if website_match:info["官网"] = website_match.group(1).split(',')[0].strip()
任务 2:智能客服机器人构建
目标:基于竞赛规程文档,搭建智能客服机器人,能够回答用户问题。
解题思路:
知识库构建:
解析所有竞赛文件,建立竞赛信息知识库(使用 SQLite 或 Pinecone 向量数据库)。
为数据索引,以便高效查询。
问答系统设计:
关键词匹配:基于 BM25 或 TF-IDF 找出与用户问题最相关的竞赛信息。
自然语言理解(NLU):使用 BERT 或 GPT 进行语义匹配,提高准确率。
问题分类:
基本查询:直接匹配数据库信息(如竞赛报名时间)。
数据统计分析:使用 SQL 或 Pandas 进行统计(如“人工智能相关竞赛有多少?”)。
开放性问题:利用 LLM(如 ChatGPT)生成回答。
机器人回答问题并存储:
================== 第四步:主流程 ==================
def main():
# 1. 创建知识库knowledge_df = create_knowledge_base()knowledge_df.to_excel("knowledge_base.xlsx", index=False)print("已创建知识库文件: knowledge_base.xlsx")# 2. 创建测试问题questions_df = create_test_questions()questions_df.to_excel("test_questions.xlsx", index=False)print("已创建测试问题文件: test_questions.xlsx")# 3. 初始化机器人bot = CompetitionChatbot(knowledge_df)# 4. 处理问题并保存结果results = []for _, row in questions_df.iterrows():result = bot.answer_question(row['问题'])results.append({"问题编号": f"C{row['问题序号']:04d}","问题": result["问题"],"关键点": result["关键点"],"回答": result["回答"]})result_df = pd.DataFrame(results)result_df.to_excel("chatbot_answers.xlsx", index=False)print("已生成回答文件: chatbot_answers.xlsx")# 5. 打印示例问答print("\n示例问答:")print(result_df[['问题编号', '问题', '回答']].to_markdown(index=False))
任务 3:知识库更新与管理
目标:设计机制,使客服机器人能够实时更新竞赛数据。
解题思路:
新增赛事文件的处理:
解析 19_.pdf、20_.pdf、21_***.pdf,提取新增竞赛信息并更新知识库。
变更信息的处理:
解析 07_***.pdf(变更文件)。
对比数据库中的旧数据,识别变更项并更新知识库。
自动更新机制:
定期监测新文件,通过 Cron Job 或 定时任务 触发更新程序。
重新运行问答系统,使用最新数据生成 result_3.xlsx。
def update_from_pdf(self, pdf_path, update_type="新增"):"""从PDF文件更新知识库:param pdf_path: PDF文件路径:param update_type: 更新类型("新增"或"变更")"""try:# 从PDF提取信息(复用问题一的代码)new_info = self._extract_info_from_pdf(pdf_path)if update_type == "新增":self.knowledge_base = pd.concat([self.knowledge_base, new_info], ignore_index=True)note = f"新增竞赛: {new_info['赛项名称'].iloc[0]} {new_info['赛道'].iloc[0]}"else:# 查找并更新现有记录mask = (self.knowledge_base['赛项名称'] == new_info['赛项名称'].iloc[0]) & \(self.knowledge_base['赛道'] == new_info['赛道'].iloc[0])idx = self.knowledge_base[mask].indexif len(idx) > 0:self.knowledge_base.loc[idx[0]] = new_info.iloc[0]note = f"更新竞赛: {new_info['赛项名称'].iloc[0]} {new_info['赛道'].iloc[0]}"else:self.knowledge_base = pd.concat([self.knowledge_base, new_info], ignore_index=True)note = f"未找到匹配竞赛,已新增: {new_info['赛项名称'].iloc[0]} {new_info['赛道'].iloc[0]}"# 保存新版本new_hash = self._calculate_dataframe_hash(self.knowledge_base)self._save_version(version_note=note, data_hash=new_hash)return True, noteexcept Exception as e:return False, f"更新失败: {str(e)}"
相关文章:
【已更新完毕】2025泰迪杯数据挖掘竞赛C题数学建模思路代码文章教学:竞赛智能客服机器人构建
完整内容请看文末最后的推广群 基于大模型的竞赛智能客服机器人构建 摘要 随着国内学科和技能竞赛的增多,参赛者对竞赛相关信息的需求不断上升,但传统人工客服存在效率低、成本高、服务不稳定和用户体验差的问题。因此,设计一款智能客服机器…...

2025年4月19日 记录大模型出现的计算问题
2025年4月19日 记录大模型出现的计算问题,用了四个大模型计算json的数值,3个错误,1个正确 问题 Class Train Val answer 2574 853 screen 5025 1959 blackBoard 7847 3445 teacher 8490 3228 stand…...
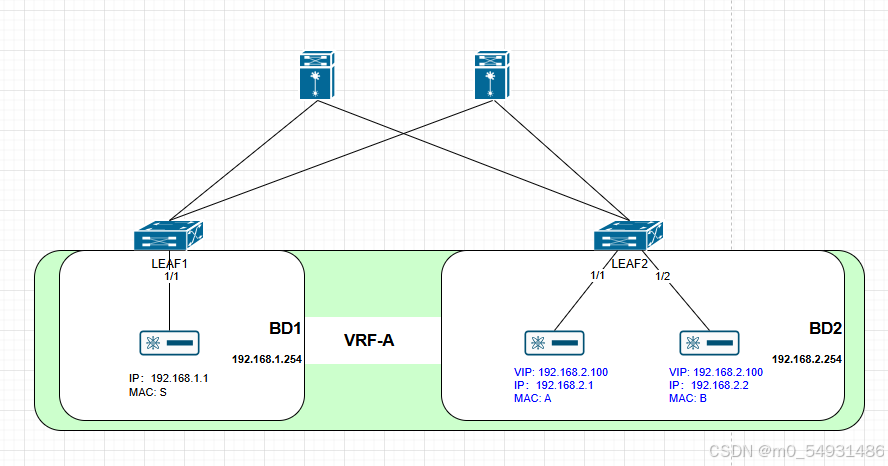
ACI EP Learning Whitepaper 3. Disabling IP Data-plane Learning 功能
目录 1. 使用场景 1.1 未disable IP data-plane learning时 1.2 disable IP data-plane learning后 2. 一代Leaf注意事项 3. L2 未知单播注意事项 1. 使用场景 Windows网卡的动态负载均衡绑定模式等。或多个设备共享相同VIP并通过ARP/GARP/ND来宣告VIP切换时,这些外部设…...
C++入门七式——模板初阶
目录 函数模板 函数模板概念 函数模板格式 函数模板的原理 函数模板的实例化 模板参数的匹配原则 类模板 类模板的定义格式 类模板的显式实例化 当面对下面的代码时,大家会不会有一种无力的感觉?明明这些代码差不多,只是因为类型不…...

计算机网络 - 在浏览器中输入 URL 地址到显示主页的过程?
第一步,浏览器通过 DNS 来解析 URL,得到相应的 ip 地址(到哪里找) 和 方法(做什么) 第二步,浏览器于服务器建立 TCP 三次握手连接 第三步,建立好连接后,浏览器会组装 HTTP 请求报文…...
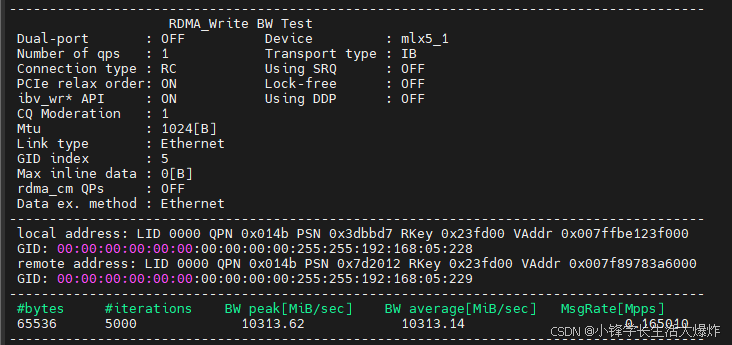
【教程】检查RDMA网卡状态和测试带宽 | 附测试脚本
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 检查硬件和驱动状态 测试RDMA通信 报错修复 对于交换机的配置,可以看这篇: 【教程】详解配置多台主机通过交换机实现互…...
(二)Trae 配置C++ 编译
Trae配置c编译 零 CMake 编译C0.1 下载安装0.2 安装设置0.3 三种编译方式(见 下文 一 二 三)0.4 调试 (见 下文四) 一 使用MSVC方式编译1.1 安装编译环境1.2安装插件1.3 设置文件 二 使用GCC方式2.1 安装编译环境2.1.1下载:[MinGw](https://gcc-mcf.lhmouse.com/)2.1.2安装:(以…...

Doris 本地部署集群重启后报错
报错描述 Docker 版本: apache/doris:fe-2.1.9 apache/doris:be-2.1.9 连接 MySQL 报错: ERROR 2003 (HY000): Cant connect to MySQL server on 127.0.0.1:9030 (111)FE 日志: INFO (UNKNOWN fe_e7cff187_69d4_42ee_90be_147e87310549(-1…...
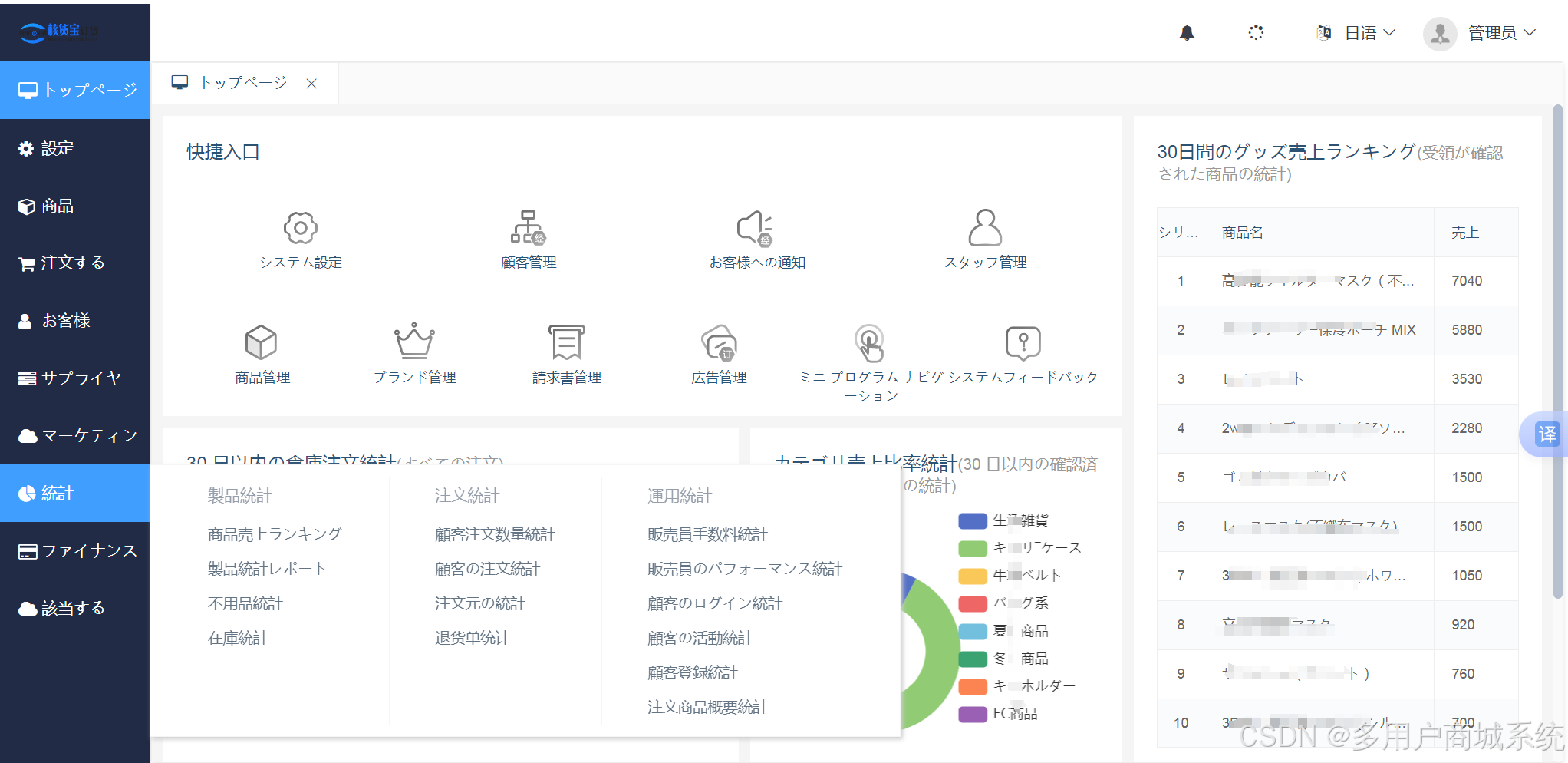
日本公司如何实现B2B商城订货系统的自动化和个性化?
在日本构建具备前后台日文本地化、业务员代客下单、一客一价、智能拆单发货的B2B电商系统,需结合日本商业习惯与技术实现。以下是关键模块的落地方案: 一、系统架构设计 1. 前端本地化 语言与UI适配 采用全日语界面,包含敬语体系(…...

自动化测试相关协议深度剖析及A2A、MCP协议自动化测试应用展望
一、不同协议底层逻辑关联分析 1. OPENAPI协议 OPENAPI 协议核心在于定义 API 的规范结构,它使用 YAML 或 JSON 格式来描述 API 的端点、请求参数、响应格式等信息。其底层逻辑是构建一个清晰、标准化的 API 描述文档,方便不同的客户端和服务端进行对接…...

ReAct、CoT 和 ToT:大模型提示词推理架构的对比分析
ReAct、CoT 和 ToT:大模型提示词推理架构的对比分析 在大型语言模型(LLM)的研究与应用中,如何有效提升模型在复杂任务上的推理能力是关键问题之一。目前,ReAct(Reasoning and Acting)、CoT&…...

用魔法打败魔法——获取软件安装路径
用魔法打败魔法——获取软件安装路径 🌟嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 目录 背景普通方法用魔法一句话 1.首先新建‘PC自动化应…...

2024-04-19| Java: Documented注解学习 JavaDoc
在 Java 中,Documented 是一个元注解(meta-annotation),用于标记其他注解,表明这些注解应该被包含在 JavaDoc 文档中。以下是关于 Documented 注解的作用的简要说明: 作用 记录注解信息到 JavaDoc&#x…...

Spring Boot常用注解全解析:从入门到实战
🌱 Spring Boot常用注解全解析:从入门到实战 #SpringBoot核心 #注解详解 #开发技巧 #高效编程 一、核心启动与配置注解 1. SpringBootApplication 作用:标记主启动类,整合了Configuration、EnableAutoConfiguration和Component…...

【重学Android】1.关于@Composer注解的一点知识笔记
最新因为一些原因,开始重新学习Android及kotlin编程,也觉得可以顺带记录下这个过程中的一些知识点,也可以用作日后自己查找复习。 Composable 注解在 Android 开发中的使用 Composable 是 Jetpack Compose(Android 的现代声明式…...

【排队论】Probabilistic Forecasts of Bike-Sharing Systems for Journey Planning
Probabilistic Forecasts of Bike-Sharing Systems forJourney Planning abstract 我们研究了对共享单车系统(BSS)车站未来自行车可用性进行预测的问题。这是相关的,以便提出建议,保证用户能够进行旅行的概率足够高。为此&#x…...

大数据平台简介
一、分布式系统基础架构 (一)定义与核心特征 分布式系统是由多台计算机(节点)通过网络协作组成的系统,对外表现为一个统一整体。其核心特征包括: 去中心化:节点平等或分角色协作(如…...

加一:从简单问题到复杂边界的深度思考
加一:从简单问题到复杂边界的深度思考 引言 在算法世界里,有些问题看似简单,实则暗藏玄机,其中“加一”问题就是一个典型例子。所谓“加一”,通常指的是给一个由数字组成的数组表示的整数加一,这听起来简…...

高精度算法(加、减、乘、除、阶乘和)
归纳编程学习的感悟, 记录奋斗路上的点滴, 希望能帮到一样刻苦的你! 如有不足欢迎指正! 共同学习交流! 🌎欢迎各位→点赞 👍 收藏⭐ 留言📝 唯有主动付出,才有丰富的果…...
实战设计模式之备忘录模式
概述 与解释器模式、迭代器模式一样,备忘录模式也是一种行为设计模式。备忘录模式允许我们保存一个对象的状态,并在稍后恢复到这个状态。该模式非常适合于需要回滚、撤销或历史记录等功能的应用场景。通过使用备忘录模式,开发者可以轻松添加诸…...

keil5 µVision 升级为V5.40.0.0:增加了对STM32CubeMX作为全局生成器的支持,主要有哪些好处?
在Keil5 μVision V5.40.0.0版本中,增加了对STM32CubeMX作为全局生成器的支持,这一更新主要带来了以下三方面的提升: 开发流程整合STM32CubeMX原本就支持生成Keil项目代码,但新版本将这一集成升级为“全局生成器”级别,意味着STM32CubeMX生成的代码能直接成为Keil项目的核…...

吉尔吉斯斯坦工商会代表团赴齐河德瑞新能源汽车考察
德州齐河,2025年4月15日电 时中美贸易突变之际,乘国家一带一路之风。 展中国新能源之宏图,塑国贸体系之新方向。 今日上午,吉尔吉斯斯坦共和国工商会代表团一行三人受邀抵达济南,开启对德瑞新能源科技有限公司&…...

无人机在农业中的应用与挑战!
一、无人机在农业中的作用 1. 提升作业效率与降低成本 无人机在喷洒农药、播种、施肥、吊运等环节显著提升效率。例如,湖北秭归县使用大疆T100无人机吊运脐橙,单次85公斤的运输任务仅需2分钟,而人工需1小时,综合成本降低250元…...

放松大脑的方法
帮助一个人放松大脑,需要结合生理调节、心理技巧和环境优化。以下是一些科学有效的方法,涵盖即时缓解和长期习惯培养: 一、即时放松技巧(快速起效) 1. 深呼吸法(4-7-8呼吸) 方法:吸…...

QT网络拓扑图绘制实验
前言 在网络通讯中,我qt常用的是TCP或者UDP协议,就比方说TCP吧,一台服务器有时可能会和多台客户端相连接,我之前都是处理单链接情况,最近研究图结构的时候,突然就想到了这个问题。那么如何解决这个问题呢&…...

英语四级翻译题练习文章示例
大学正慢慢成为过去吗?Are universiities slowly becoming a thing of the past? 1.1900年前后,法国艺术家让-马克科泰接受委托绘制一组图画,描绘他认为的2000年人们可能过上的生活。Around 1900, the French artist Jean-Marc Cote was commissioned …...
支持中文对齐的命令行表格打印python库——tableprint
文章目录 快速入门 还在为表格中含有中文,命令行打印无法对齐而苦恼吗? 还在为冗长的数据添加代码而抓狂吗? tableprint来了!!!,它完美的解决了上述两个问题,快来试试吧!…...

从《周游记3》演绎歌剧版《菊花台》,周杰伦婚礼曲目意大利文版惊喜亮相
今天(4月19日)22:00,由魔胴西西里咖啡冠名的户外实境互动综艺《周游记3》第四期即将播出。本期节目中,“J式之旅”发起人周杰伦和林暐恒、杜国璋、陈冠霖、陈冠廷,将继续意大利之旅,从那不勒斯的百年老店到…...

生物化学笔记:医学免疫学原理23 免疫检查点分子与肿瘤免疫治疗(PD-1抑制剂黑色素瘤)
免疫检查点分子与肿瘤免疫治疗 免疫检查点分子与肿瘤免疫治疗-2...
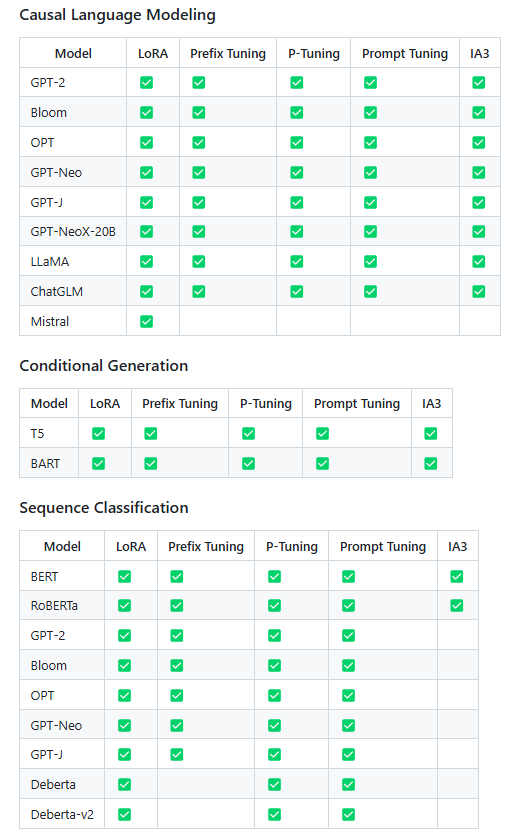
CasualLanguage Model和Seq2Seq模型的区别
**问题1:**Causal Language Modeling 和 Conditional Generation 、Sequence Classification 的区别是什么? 因果语言模型(Causal Language Model): 预测给定文本序列中的下一个字符,一般用于文本生成、补全句子等,模型…...