基于Redis的3种分布式ID生成策略
在分布式系统设计中,全局唯一ID是一个基础而关键的组件。随着业务规模扩大和系统架构向微服务演进,传统的单机自增ID已无法满足需求。高并发、高可用的分布式ID生成方案成为构建可靠分布式系统的必要条件。
Redis具备高性能、原子操作及简单易用的特性,因此我们可以基于Redis实现全局唯一ID的生成。
分布式ID的核心需求
一个优秀的分布式ID生成方案应满足以下要求
- 全局唯一性:在整个分布式系统中保证ID不重复
- 高性能:能够快速生成ID,支持高并发场景
- 高可用:避免单点故障,确保服务持续可用
- 趋势递增:生成的ID大致呈递增趋势,便于数据库索引和分片
- 安全性(可选) :不包含敏感信息,不易被推测和伪造
1. 基于INCR命令的简单自增ID
原理
这是最直接的Redis分布式ID实现方式,利用Redis的INCR命令原子性递增一个计数器,确保在分布式环境下ID的唯一性。
代码实现
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;@Component
public class RedisSimpleIdGenerator {private final RedisTemplate<String, String> redisTemplate;private final String ID_KEY;public RedisSimpleIdGenerator(RedisTemplate<String, String> redisTemplate) {this.redisTemplate = redisTemplate;this.ID_KEY = "distributed:id:generator";}/*** 生成下一个ID* @return 唯一ID*/public long nextId() {Long id = redisTemplate.opsForValue().increment(ID_KEY);if (id == null) {throw new RuntimeException("Failed to generate id");}return id;}/*** 为指定业务生成ID* @param bizTag 业务标签* @return 唯一ID*/public long nextId(String bizTag) {String key = ID_KEY + ":" + bizTag;Long id = redisTemplate.opsForValue().increment(key);if (id == null) {throw new RuntimeException("Failed to generate id for " + bizTag);}return id;}/*** 获取当前ID值但不递增* @param bizTag 业务标签* @return 当前ID值*/public long currentId(String bizTag) {String key = ID_KEY + ":" + bizTag;String value = redisTemplate.opsForValue().get(key);return value != null ? Long.parseLong(value) : 0;}
}
优缺点
优点
- 实现极其简单,仅需一次Redis操作
- ID严格递增,适合作为数据库主键
- 支持多业务ID隔离
缺点
- Redis单点故障会导致ID生成服务不可用
- 主从切换可能导致ID重复
- 无法包含业务含义
适用场景
- 中小规模系统的自增主键生成
- 对ID连续性有要求的业务场景
- 单数据中心部署的应用
2. 基于Lua脚本的批量ID生成
原理
通过Lua脚本一次性获取一批ID,减少网络往返次数,客户端可在内存中顺序分配ID,显著提高性能。
代码实现
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.stereotype.Component;import java.util.Collections;
import java.util.List;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;@Component
public class RedisBatchIdGenerator {private final RedisTemplate<String, String> redisTemplate;private final String ID_KEY = "distributed:batch:id";private final DefaultRedisScript<Long> batchIncrScript;// 批量获取的大小private final int BATCH_SIZE = 1000;// 本地计数器和锁private AtomicLong currentId = new AtomicLong(0);private AtomicLong endId = new AtomicLong(0);private final Lock lock = new ReentrantLock();public RedisBatchIdGenerator(RedisTemplate<String, String> redisTemplate) {this.redisTemplate = redisTemplate;// 创建Lua脚本String scriptText = "local key = KEYS[1] " +"local step = tonumber(ARGV[1]) " +"local currentValue = redis.call('incrby', key, step) " +"return currentValue";this.batchIncrScript = new DefaultRedisScript<>();this.batchIncrScript.setScriptText(scriptText);this.batchIncrScript.setResultType(Long.class);}/*** 获取下一个ID*/public long nextId() {// 如果当前ID超过了分配范围,则重新获取一批if (currentId.get() >= endId.get()) {lock.lock();try {// 双重检查,防止多线程重复获取if (currentId.get() >= endId.get()) {// 执行Lua脚本获取一批IDLong newEndId = redisTemplate.execute(batchIncrScript, Collections.singletonList(ID_KEY),String.valueOf(BATCH_SIZE));if (newEndId == null) {throw new RuntimeException("Failed to generate batch ids");}// 设置新的ID范围endId.set(newEndId);currentId.set(newEndId - BATCH_SIZE);}} finally {lock.unlock();}}// 分配下一个IDreturn currentId.incrementAndGet();}/*** 为指定业务生成ID*/public long nextId(String bizTag) {// 实际项目中应该为每个业务标签维护独立的计数器和范围// 这里简化处理,仅使用不同的Redis keyString key = ID_KEY + ":" + bizTag;Long newEndId = redisTemplate.execute(batchIncrScript, Collections.singletonList(key),String.valueOf(1));return newEndId != null ? newEndId : -1;}
}
优缺点
优点
- 显著减少Redis网络请求次数
- 客户端缓存ID段,大幅提高性能
- 降低Redis服务器压力
- 支持突发流量处理
缺点
- 实现复杂度增加
- 服务重启可能导致ID段浪费
适用场景
- 高并发系统,需要极高ID生成性能的场景
- 对ID连续性要求不严格的业务
- 能容忍小部分ID浪费的场景
3. 基于Redis的分段式ID分配(号段模式)
原理
号段模式是一种优化的批量ID生成方案,通过预分配号段(ID范围)减少服务间竞争,同时引入双Buffer机制提高可用性。
代码实现
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.stereotype.Component;import java.util.Collections;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;@Component
public class RedisSegmentIdGenerator {private final RedisTemplate<String, String> redisTemplate;private final String SEGMENT_KEY = "distributed:segment:id";private final DefaultRedisScript<Long> segmentScript;// 号段大小private final int SEGMENT_STEP = 1000;// 加载因子,当前号段使用到这个百分比时就异步加载下一个号段private final double LOAD_FACTOR = 0.7;// 存储业务号段信息的Mapprivate final Map<String, SegmentBuffer> businessSegmentMap = new ConcurrentHashMap<>();public RedisSegmentIdGenerator(RedisTemplate<String, String> redisTemplate) {this.redisTemplate = redisTemplate;// 创建Lua脚本String scriptText = "local key = KEYS[1] " +"local step = tonumber(ARGV[1]) " +"local value = redis.call('incrby', key, step) " +"return value";this.segmentScript = new DefaultRedisScript<>();this.segmentScript.setScriptText(scriptText);this.segmentScript.setResultType(Long.class);}/*** 获取下一个ID* @param bizTag 业务标签* @return 唯一ID*/public long nextId(String bizTag) {// 获取或创建号段缓冲区SegmentBuffer buffer = businessSegmentMap.computeIfAbsent(bizTag, k -> new SegmentBuffer(bizTag));return buffer.nextId();}/*** 内部号段缓冲区类,实现双Buffer机制*/private class SegmentBuffer {private String bizTag;private Segment[] segments = new Segment[2]; // 双Bufferprivate volatile int currentPos = 0; // 当前使用的segment位置private Lock lock = new ReentrantLock();private volatile boolean isLoadingNext = false; // 是否正在异步加载下一个号段public SegmentBuffer(String bizTag) {this.bizTag = bizTag;segments[0] = new Segment(0, 0);segments[1] = new Segment(0, 0);}/*** 获取下一个ID*/public long nextId() {// 获取当前号段Segment segment = segments[currentPos];// 如果当前号段为空或已用完,切换到另一个号段if (!segment.isInitialized() || segment.getValue() > segment.getMax()) {lock.lock();try {// 双重检查当前号段状态segment = segments[currentPos];if (!segment.isInitialized() || segment.getValue() > segment.getMax()) {// 切换到另一个号段currentPos = (currentPos + 1) % 2;segment = segments[currentPos];// 如果另一个号段也未初始化或已用完,则同步加载if (!segment.isInitialized() || segment.getValue() > segment.getMax()) {loadSegmentFromRedis(segment);}}} finally {lock.unlock();}}// 检查是否需要异步加载下一个号段long value = segment.incrementAndGet();if (value > segment.getMin() + (segment.getMax() - segment.getMin()) * LOAD_FACTOR&& !isLoadingNext) {isLoadingNext = true;// 异步加载下一个号段new Thread(() -> {Segment nextSegment = segments[(currentPos + 1) % 2];loadSegmentFromRedis(nextSegment);isLoadingNext = false;}).start();}return value;}/*** 从Redis加载号段*/private void loadSegmentFromRedis(Segment segment) {String key = SEGMENT_KEY + ":" + bizTag;// 执行Lua脚本获取号段最大值Long max = redisTemplate.execute(segmentScript, Collections.singletonList(key),String.valueOf(SEGMENT_STEP));if (max == null) {throw new RuntimeException("Failed to load segment from Redis");}// 设置号段范围long min = max - SEGMENT_STEP + 1;segment.setMax(max);segment.setMin(min);segment.setValue(min - 1); // 设置为min-1,第一次incrementAndGet返回minsegment.setInitialized(true);}}/*** 内部号段类,存储号段的范围信息*/private class Segment {private long min; // 最小值private long max; // 最大值private AtomicLong value; // 当前值private volatile boolean initialized; // 是否已初始化public Segment(long min, long max) {this.min = min;this.max = max;this.value = new AtomicLong(min);this.initialized = false;}public long getValue() {return value.get();}public void setValue(long value) {this.value.set(value);}public long incrementAndGet() {return value.incrementAndGet();}public long getMin() {return min;}public void setMin(long min) {this.min = min;}public long getMax() {return max;}public void setMax(long max) {this.max = max;}public boolean isInitialized() {return initialized;}public void setInitialized(boolean initialized) {this.initialized = initialized;}}
}
优缺点
优点
- 双Buffer设计,高可用性
- 异步加载下一个号段,性能更高
- 大幅降低Redis访问频率
- 即使Redis短暂不可用,仍可分配一段时间的ID
缺点
- 实现复杂,代码量大
- 多实例部署时,各实例获取的号段不连续
- 重启服务时号段内的ID可能浪费
- 需要在内存中维护状态
适用场景
- 对ID生成可用性要求高的业务
- 需要高性能且多服务器部署的分布式系统
4. 性能对比与选型建议
| 策略 | 性能 | 可用性 | ID长度 | 实现复杂度 | 单调递增 |
|---|---|---|---|---|---|
| INCR命令 | ★★★☆☆ | ★★☆☆☆ | 递增整数 | 低 | 严格递增 |
| Lua批量生成 | ★★★★★ | ★★★☆☆ | 递增整数 | 中 | 批次内递增 |
| 分段式ID | ★★★★★ | ★★★★☆ | 递增整数 | 高 | 段内递增 |
5. 实践优化技巧
1. Redis高可用配置
// 配置Redis哨兵模式,提高可用性
@Bean
public RedisConnectionFactory redisConnectionFactory() {RedisSentinelConfiguration sentinelConfig = new RedisSentinelConfiguration().master("mymaster").sentinel("127.0.0.1", 26379).sentinel("127.0.0.1", 26380).sentinel("127.0.0.1", 26381);return new LettuceConnectionFactory(sentinelConfig);
}
2. ID预热策略
// 系统启动时预热ID生成器
@PostConstruct
public void preWarmIdGenerator() {// 预先获取一批ID,确保系统启动后立即可用for (int i = 0; i < 10; i++) {try {segmentIdGenerator.nextId("order");segmentIdGenerator.nextId("user");segmentIdGenerator.nextId("payment");} catch (Exception e) {log.error("Failed to pre-warm ID generator", e);}}
}
3. 降级策略
// Redis不可用时的降级策略
public long nextIdWithFallback(String bizTag) {try {return segmentIdGenerator.nextId(bizTag);} catch (Exception e) {log.warn("Failed to get ID from Redis, using local fallback", e);// 使用本地UUID或其他替代方案return Math.abs(UUID.randomUUID().getMostSignificantBits());}
}
6. 结论
选择合适的分布式ID生成策略时,需要综合考虑系统规模、性能需求、可靠性要求和实现复杂度。无论选择哪种方案,都应注重高可用性设计,增加监控和预警机制,确保ID生成服务的稳定运行。
在实践中,可以基于业务需求对这些方案进行组合和优化,例如为不同业务选择不同策略,或者在ID中嵌入业务标识等,打造更适合自身系统的分布式ID生成解决方案。
相关文章:

基于Redis的3种分布式ID生成策略
在分布式系统设计中,全局唯一ID是一个基础而关键的组件。随着业务规模扩大和系统架构向微服务演进,传统的单机自增ID已无法满足需求。高并发、高可用的分布式ID生成方案成为构建可靠分布式系统的必要条件。 Redis具备高性能、原子操作及简单易用的特性&…...

OCR技术与视觉模型技术的区别、应用及展望
在计算机视觉技术飞速发展的当下,OCR技术与视觉模型技术成为推动各行业智能化变革的重要力量。它们在原理、应用等方面存在诸多差异,在自动化测试领域也展现出不同的表现与潜力,下面将为你详细剖析。 一、技术区别 (一ÿ…...
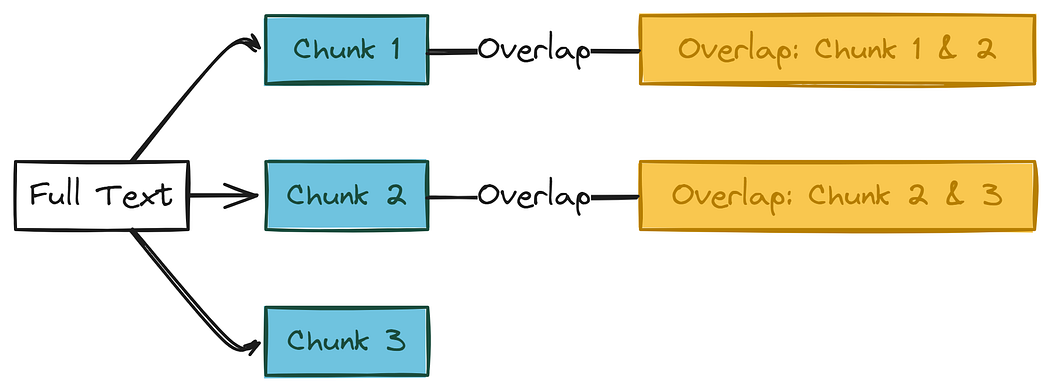
End-to-End从混沌到秩序:基于LLM的Pipeline将非结构化数据转化为知识图谱
摘要:本文介绍了一种将非结构化数据转换为知识图谱的端到端方法。通过使用大型语言模型(LLM)和一系列数据处理技术,我们能够从原始文本中自动提取结构化的知识。这一过程包括文本分块、LLM 提示设计、三元组提取、归一化与去重,最终利用 NetworkX 和 ipycytoscape 构建并可…...
)
比特币的跨输入签名聚合(Cross-Input Signature Aggregation,CISA)
1. 引言 2024 年,人权基金会(Human Rights Foundation,简称 HRF)启动了一项研究奖学金计划,旨在探讨“跨输入签名聚合”(Cross-Input Signature Aggregation,简称 CISA)的潜在影响。…...
)
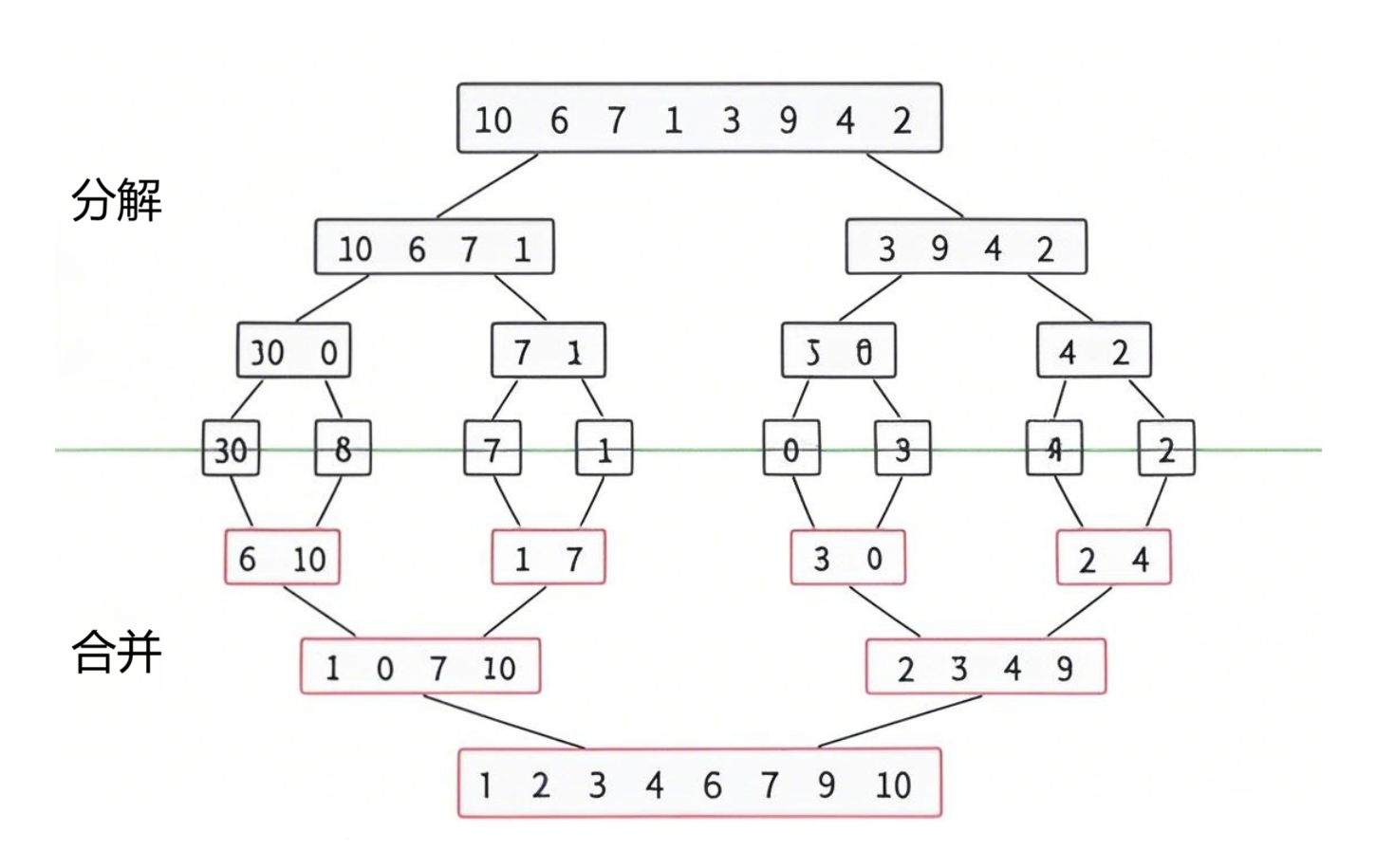
洛谷P1177【模板】排序:十种排序算法全解(2)
我们接着上一篇继续讲【洛谷P1177【模板】排序:十种排序算法全解(1)】 三、计数排序(Counting Sort) 仅适用于数据范围较小的情况 // Java import java.io.*; public class Main {static final int OFFSET 100000;public static void…...
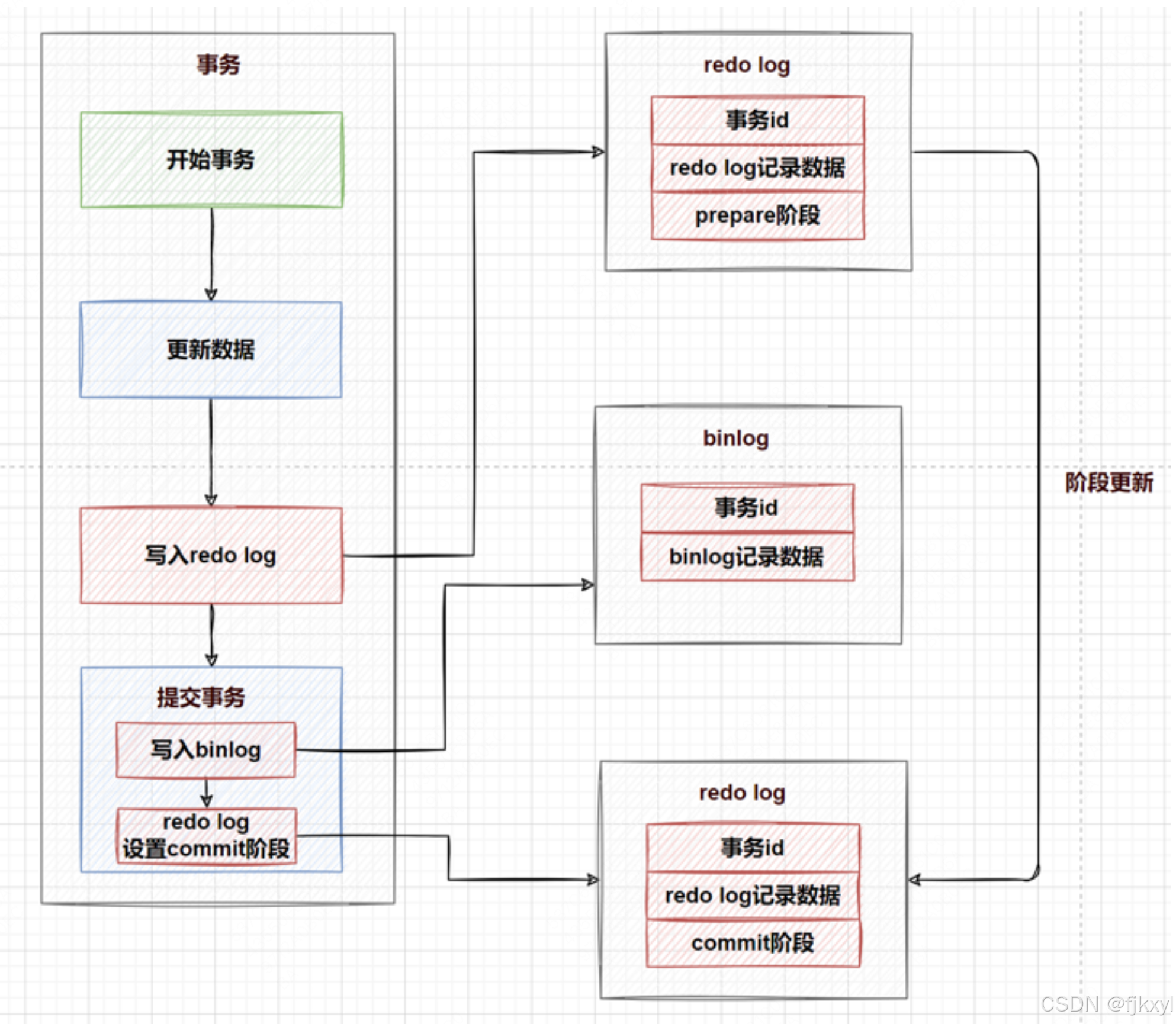
MySql 三大日志(redolog、undolog、binlog)详解

Docker使用、容器迁移
Docker 简介 Docker 是一个开源的容器化平台,用于打包、部署和运行应用程序及其依赖环境。Docker 容器是轻量级的虚拟化单元,运行在宿主机操作系统上,通过隔离机制(如命名空间和控制组)确保应用运行环境的一致性和可移…...
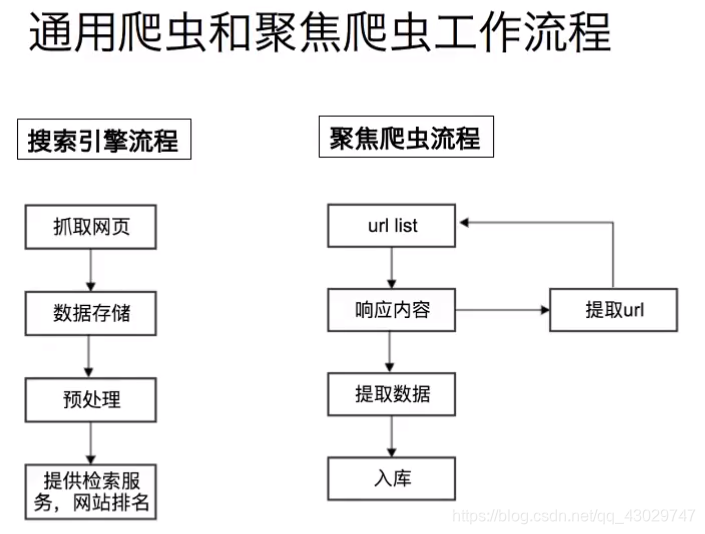
HTTP:九.WEB机器人
概念 Web机器人是能够在无需人类干预的情况下自动进行一系列Web事务处理的软件程序。人们根据这些机器人探查web站点的方式,形象的给它们取了一个饱含特色的名字,比如“爬虫”、“蜘蛛”、“蠕虫”以及“机器人”等!爬虫概述 网络爬虫(英语:web crawler),也叫网络蜘蛛(…...
2025妈妈杯数学建模C题完整分析论文(共36页)(含模型建立、可运行代码、数据)
2025 年第十五届 MathorCup 数学建模C题完整分析论文 目录 摘 要 一、问题分析 二、问题重述 三、模型假设 四、 模型建立与求解 4.1问题1 4.1.1问题1思路分析 4.1.2问题1模型建立 4.1.3问题1代码(仅供参考) 4.1.4问题1求解结果(仅…...
数据结构排序算法全解析:从基础原理到实战应用
在计算机科学领域,排序算法是数据处理的核心技术之一。无论是小规模数据的简单整理,还是大规模数据的高效处理,选择合适的排序算法直接影响着程序的性能。本文将深入解析常见排序算法的核心思想、实现细节、特性对比及适用场景,帮…...

UMG:ListView
1.创建WBP_ListView,添加Border和ListView。 2.创建Object,命名为Item(数据载体,可以是其他类型)。新增变量name。 3.创建User Widget,命名为Entry(循环使用的UI载体).添加Border和Text。 4.设置Entry继承UserObjectListEntry接口。 5.Entry中对象生成时…...

每天学一个 Linux 命令(18):mv
可访问网站查看,视觉品味拉满: http://www.616vip.cn/18/index.html 每天学一个 Linux 命令(18):mv 命令功能 mv(全称:move)用于移动文件/目录或重命名文件/目录,是…...
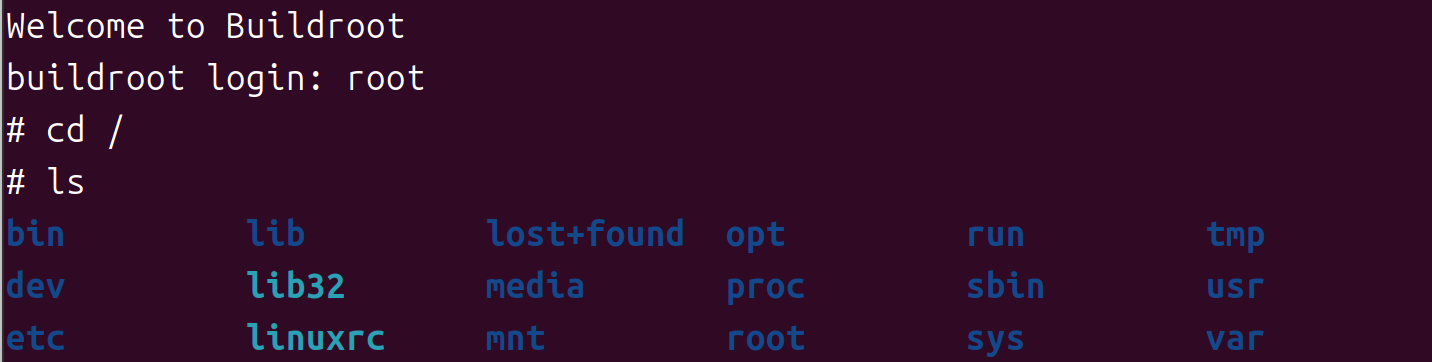
ubuntu24.04上使用qemu和buildroot模拟vexpress-ca9开发板构建嵌入式arm linux环境
1 准备工作 1.1 安装qemu 在ubuntu系统中使用以下命令安装qemu。 sudo apt install qemu-system-arm 安装完毕后,在终端输入: qemu- 后按TAB键,弹出下列命令证明安装成功。 1.2 安装arm交叉编译工具链 sudo apt install gcc-arm-linux-gnueabihf 安装之…...
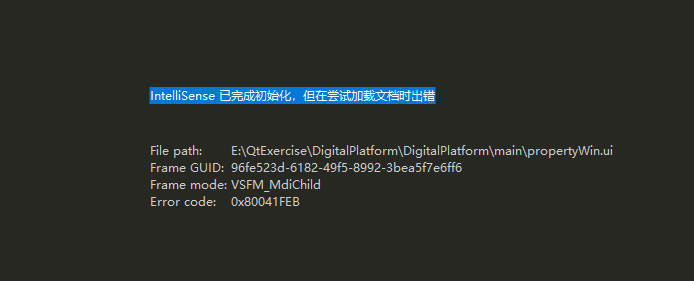
IntelliSense 已完成初始化,但在尝试加载文档时出错
系列文章目录 文章目录 系列文章目录前言一、原因二、使用步骤 前言 IntelliSense 已完成初始化,但在尝试加载文档时出错 File path: E:\QtExercise\DigitalPlatform\DigitalPlatform\main\propertyWin.ui Frame GUID:96fe523d-6182-49f5-8992-3bea5f7e6ff6 Frame …...

dumpsys--音频服务状态信息
Audio相关的信息获取指令: dumpsys media.audio_flinger dumpsys media.audio_policy dumpsys audio media.audio_flinger dumpsys media.audio_flinger 用于获取 AudioFlinger 服务的详细状态信息。 1. 命令作用 该命令输出当前系统的 音频设备状态、活跃音频流…...
【更新完毕】2025泰迪杯数据挖掘竞赛A题数学建模思路代码文章教学:竞赛论文初步筛选系统
完整内容请看文末最后的推广群 基于自然语言处理的竞赛论文初步筛选系统 基于多模态分析的竞赛论文自动筛选与重复检测模型 摘要 随着大学生竞赛规模的不断扩大,参赛论文的数量激增,传统的人工筛选方法面临着工作量大、效率低且容易出错的问题。因此&…...

服务器内存规格详解
服务器内存规格详解 一、内存安装原则与配置规范 1. 内存槽位安装规则 规则描述CPU1对应的内存槽位至少需配置一根内存禁止混用不同规格(容量/位宽/rank/高度)内存条,需保持相同Part No.推荐完全平衡的内存配置,避免通道/处理器…...

kafka集群认证
1、安装Kerberos(10.10.10.168) yum install krb5-server krb5-workstation krb5-libs -y 查看版本 klist -V Kerberos 5 version 1.20.1 编辑/etc/hosts 10.10.10.168 ms1 10.10.10.150 ms2 10.10.10.110 ms3 vim /etc/krb5.conf # Configuration snippets ma…...

数据要素市场化核心概念解析与产业实践路径
在数字经济成为全球经济增长新引擎的背景下,数据要素市场化配置改革正推动着生产关系的深刻变革。本文基于数据要素价值化全生命周期,系统梳理关键概念体系,为数据资产化实践提供方法论支撑。 一、数据资源的价值演进路径 1.基础资源层 原…...
Vue3+Vite+TypeScript+Element Plus开发-22.客制Table组件
系列文档目录 Vue3ViteTypeScript安装 Element Plus安装与配置 主页设计与router配置 静态菜单设计 Pinia引入 Header响应式菜单缩展 Mockjs引用与Axios封装 登录设计 登录成功跳转主页 多用户动态加载菜单 Pinia持久化 动态路由 -动态增加路由 动态路由-动态删除…...

QT 文件和文件夹操作
文件操作 1. 文件读写 QFile - 基本文件操作 // 只写模式创建文件(如果文件已存在会清空内容) file.open(QIODevice::WriteOnly);// 读写模式创建文件 file.open(QIODevice::ReadWrite);// 追加模式(如果文件不存在则创建) fil…...

confluent-kafka入门教程
文章目录 官方文档与kafka-python的对比配置文档配置项 Producer代码示例Consumer代码示例 官方文档 confluent_kafka API — confluent-kafka 2.8.0 documentation Quick Start for Confluent Cloud | Confluent Documentation 与kafka-python的对比 对比维度confluent-ka…...

江苏广电HC2910-创维代工-Hi3798cv200-2+8G-海美迪安卓7.0-强刷包
江苏广电HC2910-创维代工-Hi3798cv200-28G-海美迪安卓7.0-强刷包 说明 1、由于原机的融合网关路由不能设置,原网口无法使用,需要用usb2.0的RJ45usb网卡接入。 通过usb接口网卡联网可以实现百兆网口连接。原机usb3.0的接口可以以接入硬盘,播放…...

如何提高前端应用的性能?
如何提高前端应用的性能? 提高前端应用性能的方法可以从以下几个方面入手: 1. **代码优化** - 使用代码分割(Code Splitting)按需加载资源 - 减少DOM操作,使用虚拟DOM技术 - 避免深层嵌套的数据结构 - 使用Web Worker…...

python 库 下载 ,整合在一个小程序 UIUIUI
上图 import os import time import threading import requests import subprocess import importlib import tkinter as tk from tkinter import ttk, messagebox, scrolledtext from concurrent.futures import ThreadPoolExecutor, as_completed from urllib.parse import…...

Python爬虫-爬取猫眼演出数据
前言 本文是该专栏的第53篇,后面会持续分享python爬虫干货知识,记得关注。 猫眼平台除了有影院信息之外,它还涵盖了演出信息,比如说“演唱会,音乐节,话剧音乐剧,脱口秀,音乐会,戏曲艺术,相声”等等各种演出相关信息。 而本文,笔者将以猫眼平台为例,基于Python爬虫…...
nvm切换node版本后,解决npm找不到的问题
解决方法如下 命令行查看node版本 node -v找到node版本所对应的npm版本 点击进入node版本 npm对应版本下载 点击进入npm版本 下载Windows 压缩包 下载完成后,解压,文件改名为npm 复制到你nvm对应版本的node_modules 下面 将下载的npm /bin 目录…...

Windows系统安装MySQL安装实战分享
以下是在 Windows 系统上安装 MySQL 的详细实战步骤,涵盖下载、安装、配置及常见问题处理。 一、准备工作 下载 MySQL 安装包 访问 MySQL 官网。选择 MySQL Community Server(免费版本)。根据系统位数(32/64位)下载 …...

Vue 人看 React useRef:它不只是替代 ref
如果你是从 Vue 转到 React 的开发者,初见 useRef 可能会想:这不就是 React 版的 ref 吗?但真相是 —— 它能做的,比你想象得多得多。 👀 Vue 人初见 useRef 在 Vue 中,ref 是我们访问 DOM 或响应式数据的…...

零成本自建企业级SD-WAN!用Panabit手搓iWAN实战
我们前面提到过,最开始了解到Panabit,是因为他的SD-WAN产品(误以为是外国货?这家国产SD-WAN神器竟能免费白嫖,附Panabit免费版体验全记录);现在发现,其SD-WAN的技术基础是iWAN&#…...