Apache Parquet 文件组织结构
简要概述
Apache Parquet 是一个开源、列式存储文件格式,最初由 Twitter 与 Cloudera 联合开发,旨在提供高效的压缩与编码方案以支持大规模复杂数据的快速分析与处理。Parquet 文件采用分离式元数据设计 —— 在数据写入完成后,再追加文件级元数据(包括 Schema、Row Group 与 Column Chunk 的偏移信息等),使得写入过程只需一次顺序扫描,同时读取端只需先解析元数据即可随机访问任意列或任意 Row Group。其核心结构包括:
- Header(魔数“PAR1”)
- 若干 Row Group(行组)
- Footer(文件级元数据 + 魔数“PAR1”)
文件格式总体布局
1. Header(文件头)
- 文件以4字节的魔数
PAR1开始,标识这是一个 Parquet 文件格式。
2. Row Group(行组)
- Row Group 是水平切分的数据分片,每个 Row Group 包含表中若干行,通常大小在几十 MB 到几百 MB 之间,以兼顾并行处理与内存使用。
- 每个 Row Group 内部再按列拆分为若干 Column Chunk,支持对单个列或多个 Row Group 进行跳过式读取。
3. Column Chunk(列区块)
- Column Chunk 即某一列在某个 Row Group 中的数据块,它是 Parquet 最基本的物理存储单元之一。
- 每个 Column Chunk 中又分成多个Page,以便更细粒度地管理压缩与解压效率。
4. Page(页)
- Page 是 Column Chunk 中的最小读写单元,主要有三种类型:
- Dictionary Page:存放字典编码字典。
- Data Page:存放实际列数据(可进一步分为 Data Page V1/V2)。
- Index Page(可选):存放 Page-level 索引,加速定位。
- 通过 Page 级别的压缩与编码,Parquet 能够对不同类型的数据采用最优策略,极大提升 I/O 性能。
5. Footer(文件尾)
- 写入完全部 Row Group 后,接着写入File Metadata,其中包含:
- Schema 定义
- 每个 Row Group 的偏移及长度
- 每个 Column Chunk 的偏移、页信息、编码与压缩算法
- 最后再写入 4 字节魔数
PAR1,完整标识文件结束。
元数据管理
- Thrift 定义:Parquet 使用 Apache Thrift 描述元数据结构(Schema、Row Group 元信息、Column Chunk 元信息、Page Header 等),以保证跨语言支持。
- 单次写入:由于元数据紧跟数据之后写入,写入端无需回写或多次扫描,保证单次顺序写入效率。
- 快速读取:读端先读取文件末尾的 Footer,加载所有元数据后即可随机、并行地读取任意列与任意 Row Group,极大减少磁盘 I/O 与网络传输开销。
编码与压缩技术
字典编码(Dictionary Encoding)
- 针对低基数(unique values 较少)的列,自动开启字典编码,将原值映射到字典索引,从而显著减少存储量。
混合 RLE + Bit-Packing
- Parquet 对整数类型实现了混合 RLE(Run-Length Encoding)与Bit-Packing,根据数据分布动态选择最佳方案,例如对于长串相同值使用 RLE,对于小整数值使用 Bit-Packing。
其它压缩算法
- 支持 Snappy、Gzip、LZO、Brotli、ZSTD、LZ4 等多种压缩格式,可按列灵活选择。
写入过程原理
- Schema 序列化:将 DataFrame/表结构映射为 Thrift Schema。
- Row Group 切分:按预设行数或大小切分成多个 Row Group。
- Column Chunk 生成:对每个列分别收集数据,分 Page 编码与压缩。
- 顺序写入:先写 Header → 各 Row Group 的 Column Chunk(含 Page)→ Footer(含全部元数据)→ 终止魔数。
读取过程原理
- 读取 Footer:读取文件末尾 8 字节(4 字节元数据长度 + 4 字节魔数),定位并加载全部元数据。
- 筛选元数据:根据查询列与过滤条件,决定需要加载的 Column Chunk 与 Page 位置。
- 随机/并行读取:直接跳转到各 Column Chunk 的偏移位置,按需加载并解压 Page。
- 重建记录:将各列 Page 解码后重组成行,供上层引擎消费。
实践示例:使用 Python 创建并写入 Parquet
下面示例演示如何用 pandas+pyarrow 将一个简单表格写入 Parquet,并简要注释写入过程:
import pandas as pd# 1. 创建 DataFrame
df = pd.DataFrame({"user_id": [1001, 1002, 1003],"event": ["login", "purchase", "logout"],"timestamp": pd.to_datetime(["2025-04-20 10:00:00","2025-04-20 10:05:00","2025-04-20 10:10:00"])
})# 2. 写入 Parquet(默认 row_group_size=64MB,可通过 partition_cols 分区)
df.to_parquet("events.parquet", engine="pyarrow", compression="snappy")
- pandas 在内部将 DataFrame Schema 转为 Thrift Schema;
- 按列生成 Column Chunk 并分 Page 编码;
- 最后输出 Header、Column Chunk、Footer 以及魔数字段。
1. Row Group 的概念与分割原则
- Row Group 是 Parquet 中最小的水平切分单元,表示若干行的完整切片。一个 Parquet 文件由一个或多个 Row Group 依次组成,每个 Row Group 内部再按列拆分为若干 Column Chunk,支持列式读写与跳过式扫描。
- 选择合适的 Row Group 大小,是在I/O 效率(大块顺序读更快)和并行度/内存占用(小块更易并行、占用更少)间的权衡。
2. Row Group 的“大小”度量方式
Parquet 对 Row Group 的大小有两种常见度量:
- 未压缩字节数(uncompressed bytes)
- 行数(number of rows)
- 在 Parquet-Java(Hadoop/Spark 常用)中,
ParquetProperties.DEFAULT_ROW_GROUP_SIZE默认为 128 MiB(未压缩),并以字节为单位控制切分。 - 在 PyArrow(Python 生态)中,
row_group_size参数实际上是以行数为单位;若不指定(None),默认值已被调整为 1 Mi 行(绝对最大值仍为 64 Mi 行)。
3. 不同实现中的默认值与推荐配置
| 实现 / 场景 | 默认值 | 推荐范围 | 说明 |
|---|---|---|---|
| Parquet-Java | 128 MiB(未压缩) | 512 MiB – 1 GiB(未压缩) | 与 HDFS 块大小对齐,一般 HDFS 块也应设为 1 GiB,以便一组 Row Group 刚好填满一个块 |
| Spark/HDFS | spark.sql.files.maxPartitionBytes 默认 128 MiB | 同上 | Spark 会将每个 Row Group 当作一个分区,读写时以此并行 |
| PyArrow | 1 Mi 行 | 视数据表宽度换算成字节 | 若表宽为 10 列、每列单元假设 4 字节,1 Mi 行 ≈ 40 MiB(未压缩) |
| 其他工具(如 DuckDB/Polars) | 通常基于“每行最大允许字节数”来推算,默认约 1 Mi 行 | 需参考各自文档 | 如 Polars 中 row_group_size_bytes 默认 122 880 KiB(≈ 120 MiB) |
4. Row Group 在文件中的物理结构
一个 Row Group 在文件中的布局可以抽象为:
+--------------------------------------------+
| Row Group |
| ┌───────────────────────────────────────┐ |
| │ Column Chunk for Column 0 │ │
| │ ┌── Page 1 (Dictionary Page?) │ │
| │ │ - Page Header │ │
| │ │ - 字典或数据块 │ │
| │ └── Page 2 (Data Page v1/v2) │ │
| │ - Page Header │ │
| │ - 压缩/编码后的列数据 │ │
| │ … │ │
| └───────────────────────────────────────┘ │
| ┌───────────────────────────────────────┐ │
| │ Column Chunk for Column 1 │ │
| │ … │ │
| └───────────────────────────────────────┘ │
| ⋮ |
| ┌───────────────────────────────────────┐ │
| │ Column Chunk for Column N │ │
| │ … │ │
| └───────────────────────────────────────┘ │
+--------------------------------------------+
同时,文件末尾的 Footer 中包含了每个 Row Group 的元数据(Thrift 定义),主要字段有:
total_byte_size:该 Row Group 内所有 Column Chunk 未压缩数据总字节数num_rows:该 Row Group 包含的行数columns: list<ColumnChunk>:每个 ColumnChunk 的偏移、长度、编码、压缩算法、Page 统计等
读写时,写端按序将上述 Row Group 数据写入磁盘,待所有 Row Group 完成后再写 Footer 与尾部魔数;读端则先读 Footer,加载元数据后即可随机定位到任意 Row Group 和任意字段的 Column Chunk 进行解压与解码。
5. 举例说明
假设有一个表 10 列,每列单元平均占用 4 字节,我们若以 1 Mi 行为 Row Group(PyArrow 默认值),则:
- 未压缩 Row Group 大小 ≈ 1 Mi × 10 列 × 4 B ≈ 40 MiB。
- 压缩后:若使用 Snappy,通常可压缩到 1/2 – 1/4,大约 10 MiB – 20 MiB。
- 如果改为 Parquet-Java 默认 128 MiB(未压缩),则 Row Group 行数可按上述公式反算:128 MiB ÷ (10 × 4 B) ≈ 3.3 Mi 行。
小结
- Row Group 大小既可以用字节也可以用行数度量,具体含义取决于所用写入器与参数;
- Parquet-Java 默认 128 MiB(未压缩),官方推荐 512 MiB – 1 GiB;
- PyArrow 默认 1 Mi 行,且新版已调整绝对最大 64 Mi 行;
- 结构上,Row Group 包含多列的 Column Chunk,每个 Column Chunk 又由若干 Page 组成;
- 选取合适的 Row Group 大小,可在 顺序 I/O 性能 与 并行度/内存占用 之间取得平衡。
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq# 1. 创建示例 DataFrame
df = pd.DataFrame({"user_id": [1001, 1002, 1003, 1004],"event": ["login", "purchase", "logout", "login"],"timestamp": pd.to_datetime(["2025-04-20 10:00:00","2025-04-20 10:05:00","2025-04-20 10:10:00","2025-04-20 10:15:00"])
})# 2. 写入 Parquet(指定 row_group_size 为 2 行,以演示多个 Row Group)
pq.write_table(pa.Table.from_pandas(df), 'events.parquet', row_group_size=2)# 3. 读取 Parquet 元数据并提取 Row Group 信息
pq_file = pq.ParquetFile('events.parquet')
row_groups = []
for i in range(pq_file.num_row_groups):rg = pq_file.metadata.row_group(i)row_groups.append({"row_group_id": i,"num_rows": rg.num_rows,"total_byte_size": rg.total_byte_size})# 4. 展示 Row Group 元数据
rg_df = pd.DataFrame(row_groups)
import ace_tools as tools; tools.display_dataframe_to_user("Row Group Metadata", rg_df)相关文章:

Apache Parquet 文件组织结构
简要概述 Apache Parquet 是一个开源、列式存储文件格式,最初由 Twitter 与 Cloudera 联合开发,旨在提供高效的压缩与编码方案以支持大规模复杂数据的快速分析与处理。Parquet 文件采用分离式元数据设计 —— 在数据写入完成后,再追加文件级…...
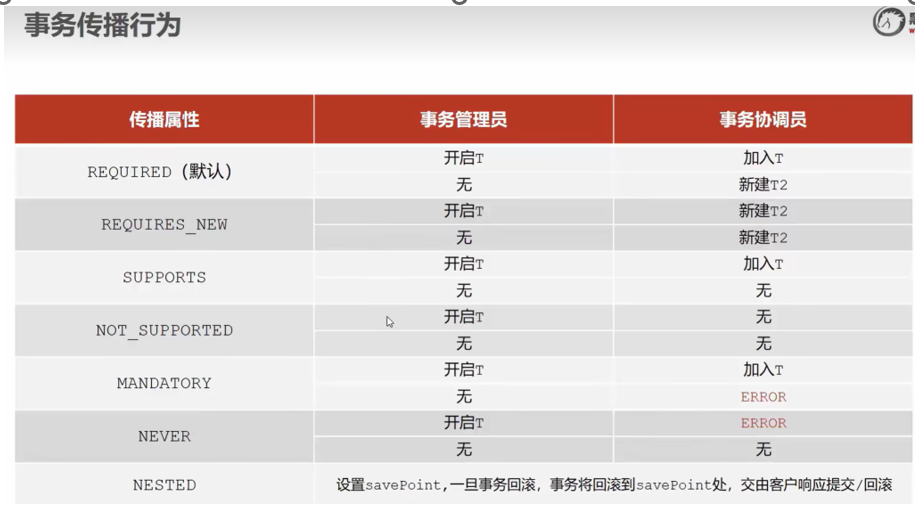
Spring 事务管理核心机制与传播行为应用
Spring 事务详解 一、Spring 事务简介 Spring 事务管理基于 AOP(面向切面编程)实现,通过 声明式事务(注解或 XML 配置)统一管理数据库操作,确保数据一致性。核心目标:保证多个数据库操作的原子…...

从零开始解剖Spring Boot启动流程:一个Java小白的奇幻冒险之旅
大家好呀!今天我们要一起探索一个神奇的话题——Spring Boot的启动流程。我知道很多小伙伴一听到"启动流程"四个字就开始头疼,别担心!我会用最通俗易懂的方式,带你从main()方法开始,一步步揭开Spring Boot的…...

集合框架(重点)
1. 什么是集合框架 List有序插入对象,对象可重复 Set无序插入对象,对象不可重复(重复对象插入只会算一个) Map无序插入键值对象,键只唯一,值可多样 (这里的有序无序指的是下标,可…...
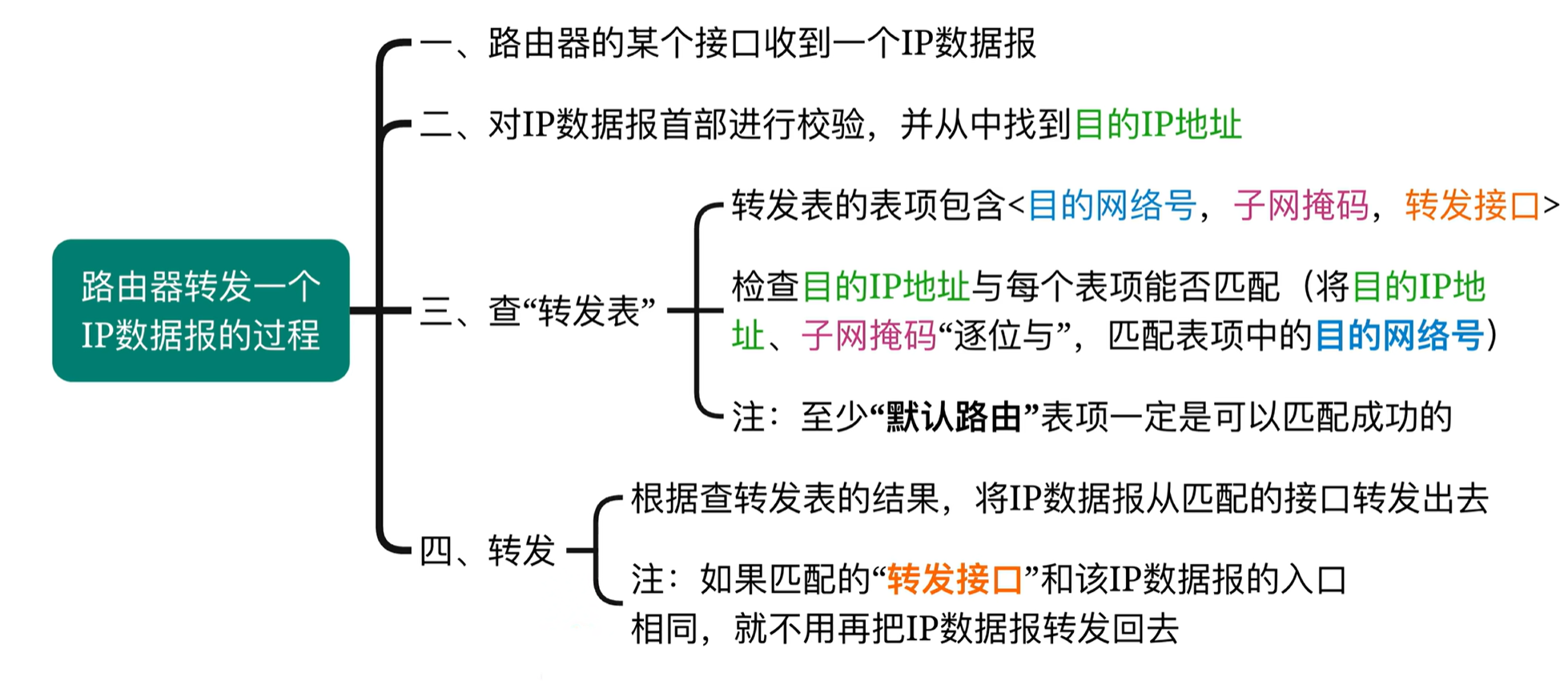
IPv4地址分类与常用网络地址详解
常见的 IPv4 地址分类: 1. A 类地址(Class A) 范围:0.0.0.0 到 127.255.255.255 默认子网掩码:255.0.0.0 或 /8 用途:通常用于大型网络,例如大型公司、组织。 特点: 网络地址范围…...
模拟实现memmove,memcpy,memset
目录 前言 一、模拟实现memmove 代码演示: 二、模拟实现memcpy 代码演示: 三、模拟实现memset 代码演示: 总结 前言 这篇文章主要讲解了库函数的模拟实现,包含memmove,memcpy,memset 一、模拟实现m…...
等权限,未同步告知权限申请的使用目的,不符合相关法律法规要求)
uni-app 开发安卓 您的应用在运行时,向用户索取(定位、相机、存储)等权限,未同步告知权限申请的使用目的,不符合相关法律法规要求
您的应用在运行时,向用户索取(定位、相机、存储)等权限,未同步告知权限申请的使用目的,不符合相关法律法规要求。 测试步骤:1、 工作台 -打卡,申请定位权限;2、工作台-设置-编辑资料-更换头像,申请相机、存 储权限。 修改建议:APP在申请敏感权限时,应同步说明权限申…...

RHCSA Linux 系统文件内容显示2
6. 过滤文件内容显示 grep (1)功能:在指定普通文件中查找并显示含指定字符串的行,也可与管道符连用。 (2)格式:grep 选项... 关键字字符串 文件名... (3)常用选项及说…...

C语言状态字与库函数详解:概念辨析与应用实践
C语言状态字与库函数详解:概念辨析与应用实践 一、状态字与库函数的核心概念区分 在C语言系统编程中,"状态字"和"库函数"是两个经常被混淆但本质完全不同的概念,理解它们的区别是掌握系统编程的基础。 1. 状态字&…...
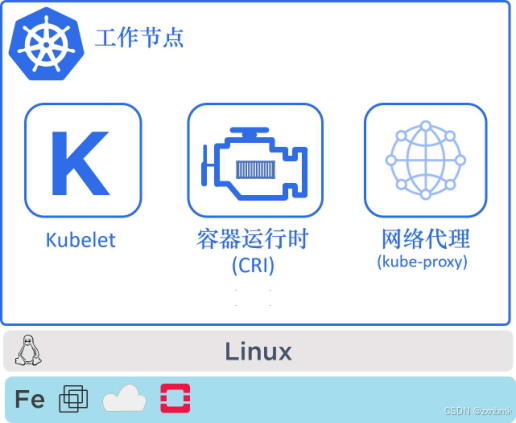
【2】Kubernetes 架构总览
Kubernetes 架构总览 主节点与工作节点 主节点 Kubernetes 的主节点(Master)是组成集群控制平面的关键部分,负责整个集群的调度、状态管理和决策。控制平面由多个核心组件构成,包括: kube-apiserver:集…...

Redis下载
目录 安装包 1、使用.msi方式安装 2.使用zip方式安装【推荐方式】 添加环境变量 配置后台运行 启动: 1.startup.cmd的文件 2.cmd窗口运行 3.linux源码安装 (1)准备安装环境 (2)上传安装文件 (3&…...

React 文章 分页
删除功能 携带路由参数跳转到新的路由项 const navigate useNavigate() 根据文章ID条件渲染...
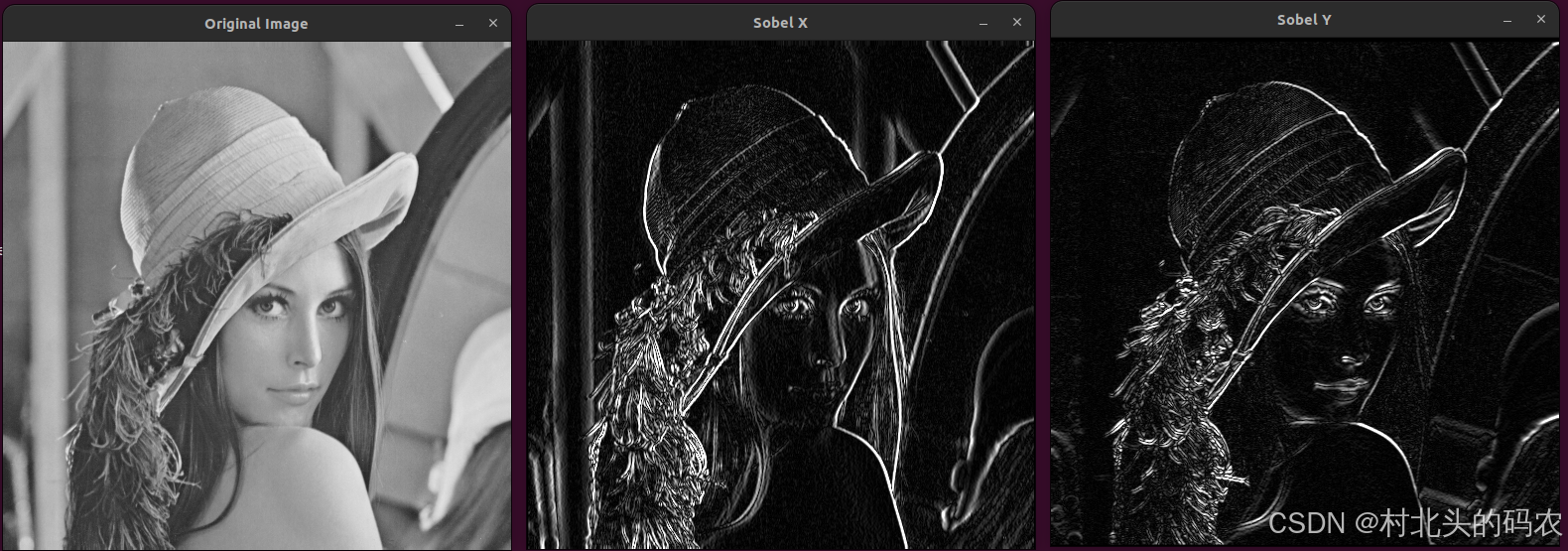
OpenCV 图形API(39)图像滤波----同时计算图像在 X 和 Y 方向上的一阶导数函数SobelXY()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::gapi::SobelXY 函数是 OpenCV 的 G-API 模块中用于同时计算图像在 X 和 Y 方向上的一阶导数(即 Sobel 边缘检测)的一…...

传导发射测试(CE)和传导骚扰抗扰度测试(CS)
传导发射测试(CE): 测量接收机: 是EMI测试中最常用的基本测试仪器,仪器类型包括准峰值测量接收机、峰值测量接收机、平均值测量接收机和均方根值测量接收机。测量接收机的几个重要指标分别是:6dB处的带宽、充电时间常数、放电时…...

ubuntu 查看现在服务使用的端口
1. 使用netstat命令 netstat是一个常用的网络工具,可以显示网络连接、路由表、接口统计等信息。虽然在较新的系统中netstat可能被ss命令替代,但仍然可以通过安装net-tools包来使用它。 安装net-tools: sudo apt-get install net-tools 查看…...
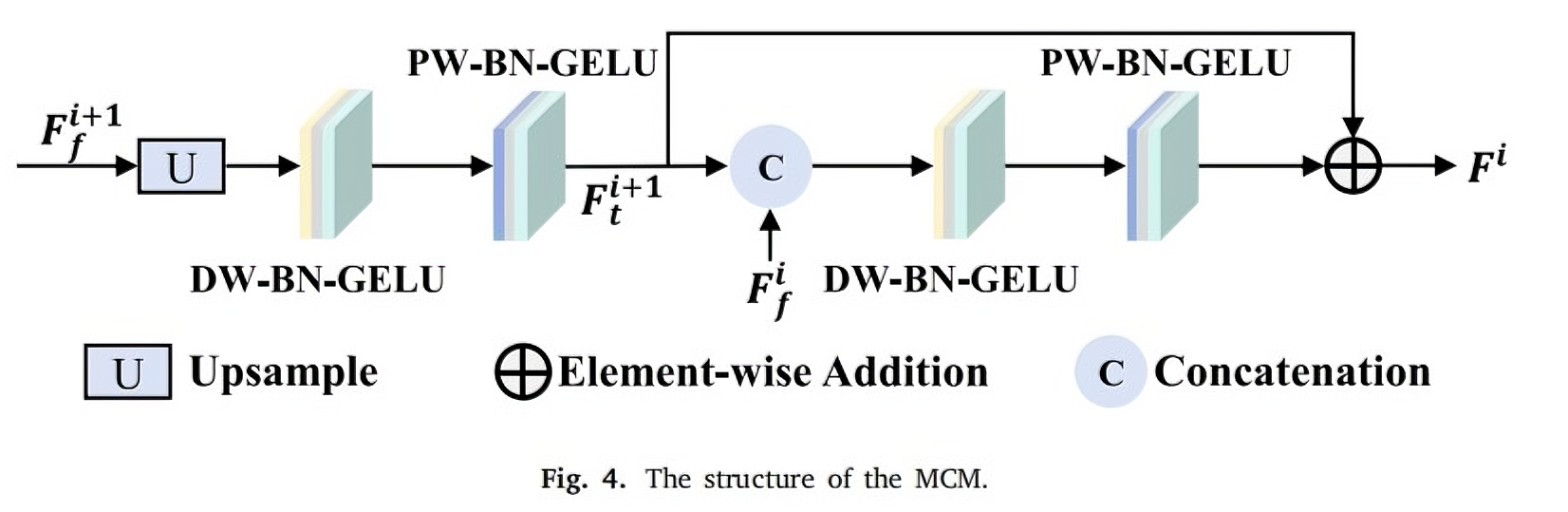
即插即用模块(1) -MAFM特征融合
(即插即用模块-特征处理部分) 一、(2024) MAFM&MCM 特征融合特征解码 paper:MAGNet: Multi-scale Awareness and Global fusion Network for RGB-D salient object detection 1. 多尺度感知融合模块 (MAFM) 多尺度感知融合模块 (MAFM) 旨在高效融合 RGB 和深度…...
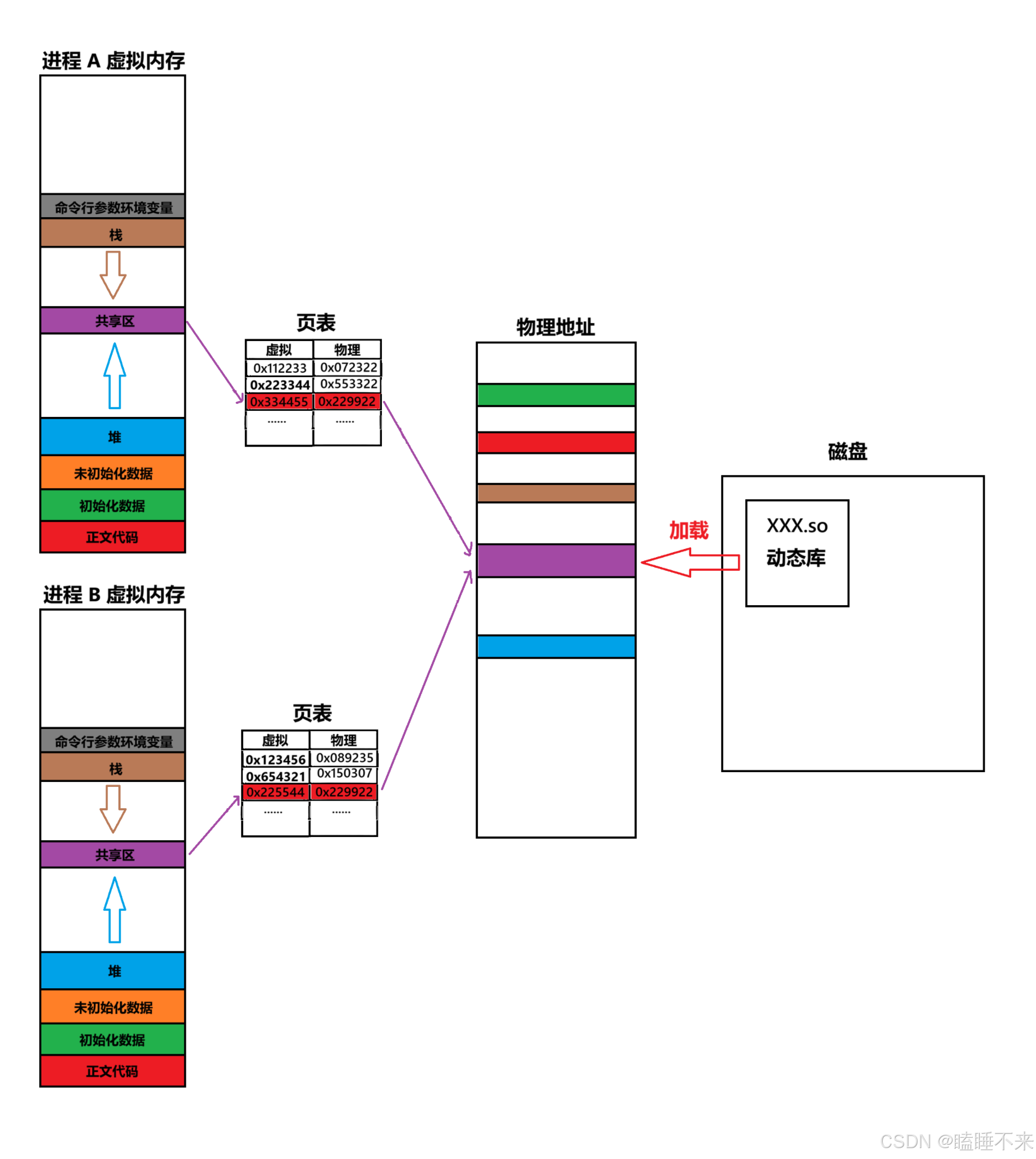
(学习总结34)Linux 库制作与原理
Linux 库制作与原理 库的概念静态库操作归档文件命令 ar静态库制作静态库使用 动态库动态库制作动态库使用与运行搜索路径问题解决方案方案2:建立同名软链接方案3:使用环境变量 LD_LIBRARY_PATH方案4:ldconfig 方案 使用外部库目标文件ELF 文…...
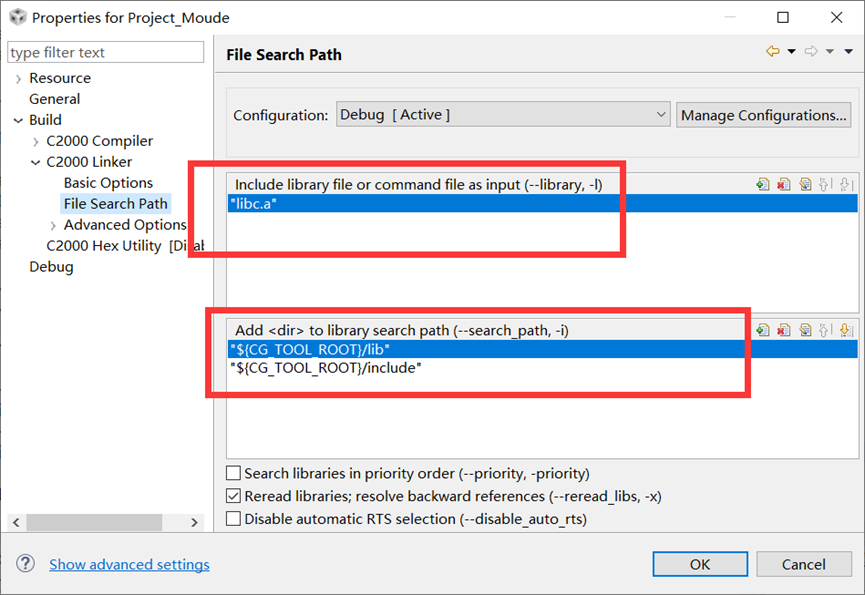
DSP28335入门学习——第一节:工程项目创建
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.20 DSP28335开发板学习——第一节:工程项目创建 前言开发板说明引用解答…...

MDG 实现后端主数据变更后快照自动刷新的相关设置
文章目录 前言实现过程BGRFC期初配置(可选)设置 MDG快照 BGRFC维护BP出站功能模块 监控 前言 众所周知,在MDG变更请求创建的同时,所有reuse模型实体对应的快照snapshot数据都会记录下来。随后在CR中,用户可以修改这些…...

基于瑞芯微RK3562 的四核 AR M Cortex-A53 + 单核 ARM Cortex-M0——MQTT通信方案
前 言 本文主要介绍创龙科技TL3562-MiniEVM评估板基于MQTT通信协议的开发案例,适用开发...

Java 实体类链式操作
目录 1. 使用返回 this 的 setter 方法 2. 使用 Lombok 的 Accessors 注解 3. 建造者模式 (Builder Pattern) 比较 链式设置参数(也称为链式调用或方法链)是一种编程风格,可以让代码更加简洁易读。在 Java 实体类中实现链式设置参数通常有…...
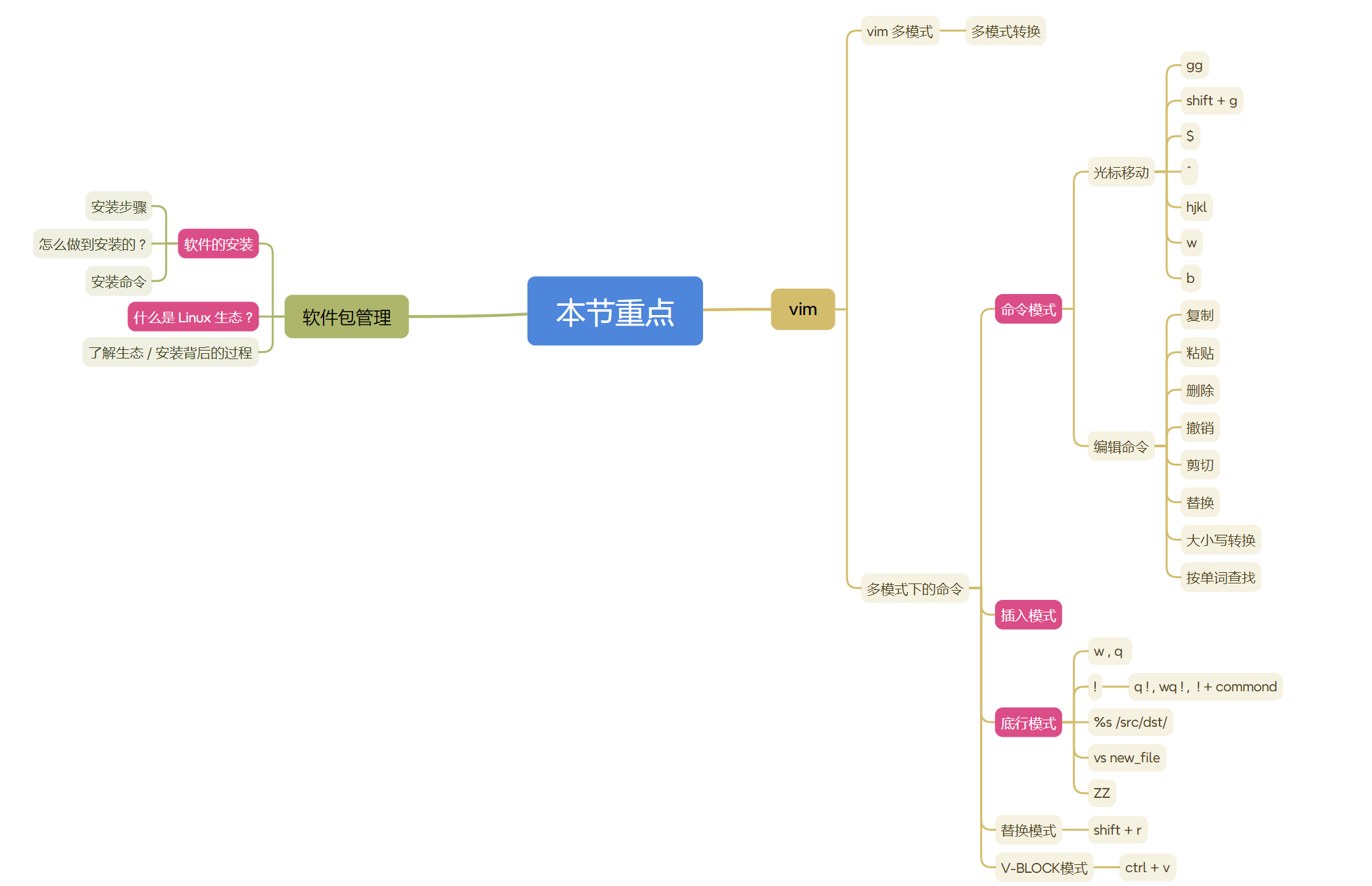
【Linux】Linux 操作系统 - 05 , 软件包管理器和 vim 编辑器的使用 !
文章目录 前言一、软件包管理器1 . 软件安装2 . 包管理器3 . Linux 生态 二、软件安装 、卸载三、vim 的使用1 . 什么是 vim ?2 . vim 多模式3 . 命令模式 - 命令4 . 底行模式 - 命令5. 插入模式6 . 替换模式7 . V-BLOCK 模式8 . 技巧补充 总结 前言 本篇笔者将会对软件包管理…...
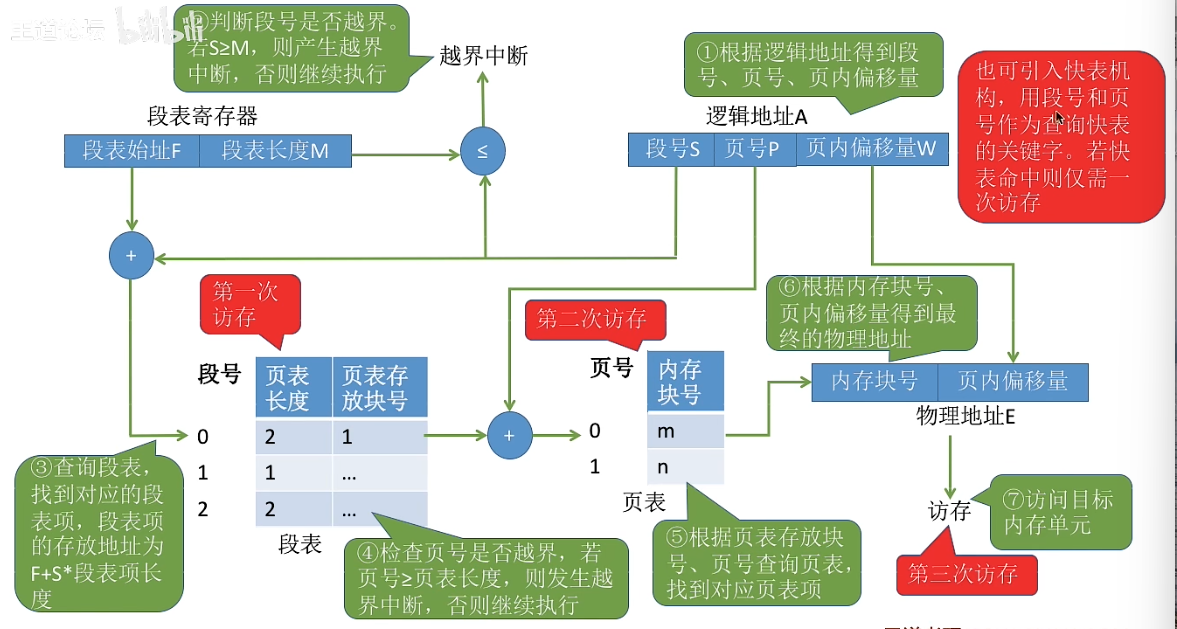
【操作系统原理05】存储器管理
大纲 文章目录 大纲一. 内存基础知识0.大纲1.什么是内存2.进程运行基本原理2.1 指令工作原理2.2逻辑地址VS物理地址2.3 从写程序到程序运行完整运行三种链接方式 二.内存管理0.大纲1.操作系统进行内存管理 三.覆盖与交换0.大纲1.覆盖技术2.交换技术 四.连续分配管理方式0.大纲1…...

学习笔记—C++—string(练习题)
练习题 仅仅反转字母 917. 仅仅反转字母 - 力扣(LeetCode) 题目 给你一个字符串 s ,根据下述规则反转字符串: 所有非英文字母保留在原有位置。所有英文字母(小写或大写)位置反转。 返回反转后的 s 。…...
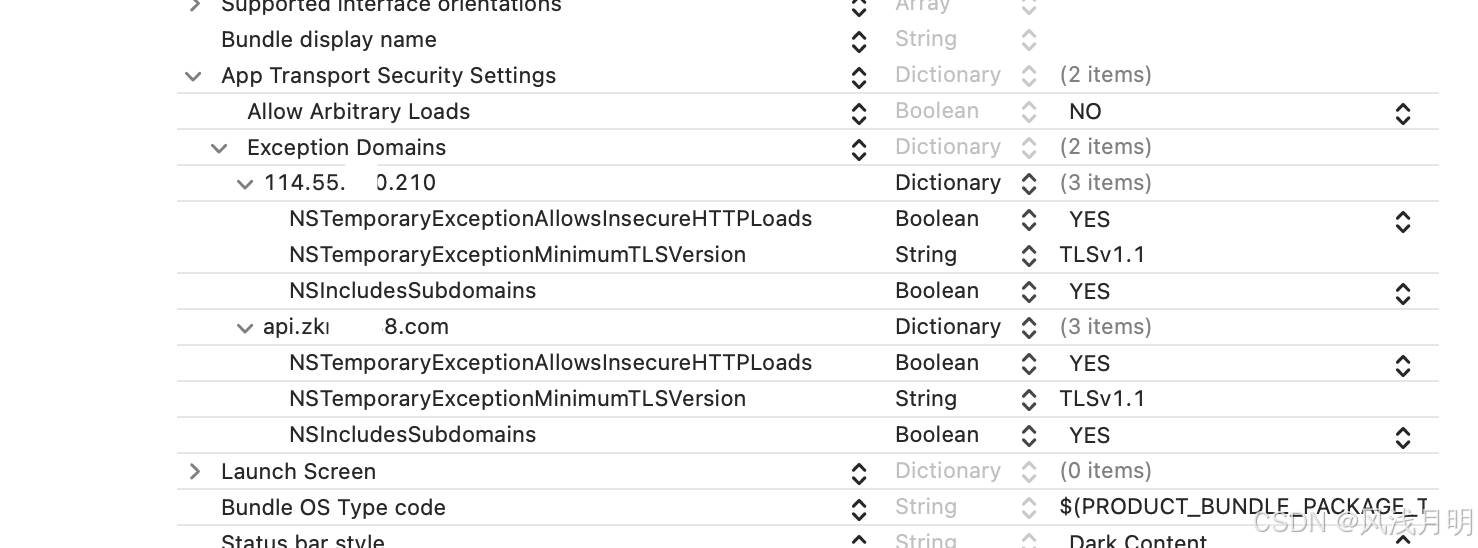
[Swift]Xcode模拟器无法请求http接口问题
1.以前偷懒一直是这样设置 <key>NSAppTransportSecurity</key> <dict><key>NSAllowsArbitraryLoads</key><true/><key>NSAllowsArbitraryLoadsInWebContent</key><true/> </dict> 现在我在Xcode16.3上ÿ…...
返回之术:用 navigate(-1) 闯荡前端江湖
前言 在前端这片江湖,页面跳转宛如轻功水上漂,来去无踪,飘忽不定。但其中有一门绝学,专治“回头是岸”之需求,那便是 React Router 中的 navigate(-1) 身法。 昔日我闯荡项目林,误入“下一页”禁地,一脚踏空,身陷页面迷阵。正当我焦头烂额之际,师父袖袍一挥,口吐一…...

《Operating System Concepts》阅读笔记:p748-p748
《Operating System Concepts》学习第 64 天,p748-p748 总结,总计 1 页。 一、技术总结 1.Transmission Control Protocol(TCP) 重点是要自己能画出其过程,这里就不赘述了。 二、英语总结(生词:3) transfer, transport, tran…...

基于深度学习的线性预测:创新应用与挑战
一、引言 1.1 研究背景 深度学习作为人工智能领域的重要分支,近年来在各个领域都取得了显著的进展。在线性预测领域,深度学习也逐渐兴起并展现出强大的潜力。传统的线性预测方法在处理复杂数据和动态变化的情况时往往存在一定的局限性。而深度学习凭借…...
网络编程3
day3 一、服务器模型 1.循环服务器模型 同一个时刻只能响应一个客户端的请求 2.并发服务器模型 2.1含义 同一个时刻可以响应多个客户端的请求,常用的模型有多进程模型/多线程模型/IO多路复用模型。 2.2多进程模型 每来一个客户端连接,开一个子进程来专门…...

数字化时代下的工业物联网智能体开发平台策略
1. 引言 1.1 工业物联网智能体的发展背景 随着工业4.0的兴起和数字化转型的不断深入,工业物联网(IIoT)已成为推动制造业创新发展的关键技术之一。智能体作为工业物联网的核心组成部分,其开发平台的建设与应用对于实现智能化升级、提升生产效率、降低…...