Kubernetes控制平面组件:APIServer 限流机制详解
云原生学习路线导航页(持续更新中)
- kubernetes学习系列快捷链接
- Kubernetes架构原则和对象设计(一)
- Kubernetes架构原则和对象设计(二)
- Kubernetes架构原则和对象设计(三)
- Kubernetes控制平面组件:etcd(一)
- Kubernetes控制平面组件:etcd(二)
- Kubernetes控制平面组件:etcd常用配置参数
- Kubernetes控制平面组件:etcd高可用集群搭建
- Kubernetes控制平面组件:etcd高可用解决方案
- Kubernetes控制平面组件:Kubernetes如何使用etcd
- Kubernetes控制平面组件:API Server详解(一)
本文主要对kubernetes的控制面组件API Server 的限流机制进行详细介绍,涵盖常见的限流算法:固定窗口、滑动窗口、漏斗算法、令牌桶算法,还详细介绍了API Server的基础限流机制和APF优先级限流机制
- 希望大家多多 点赞 关注 评论 收藏,作者会更有动力继续编写技术文章
1.常见限流算法
1.1.计数器固定窗口算法
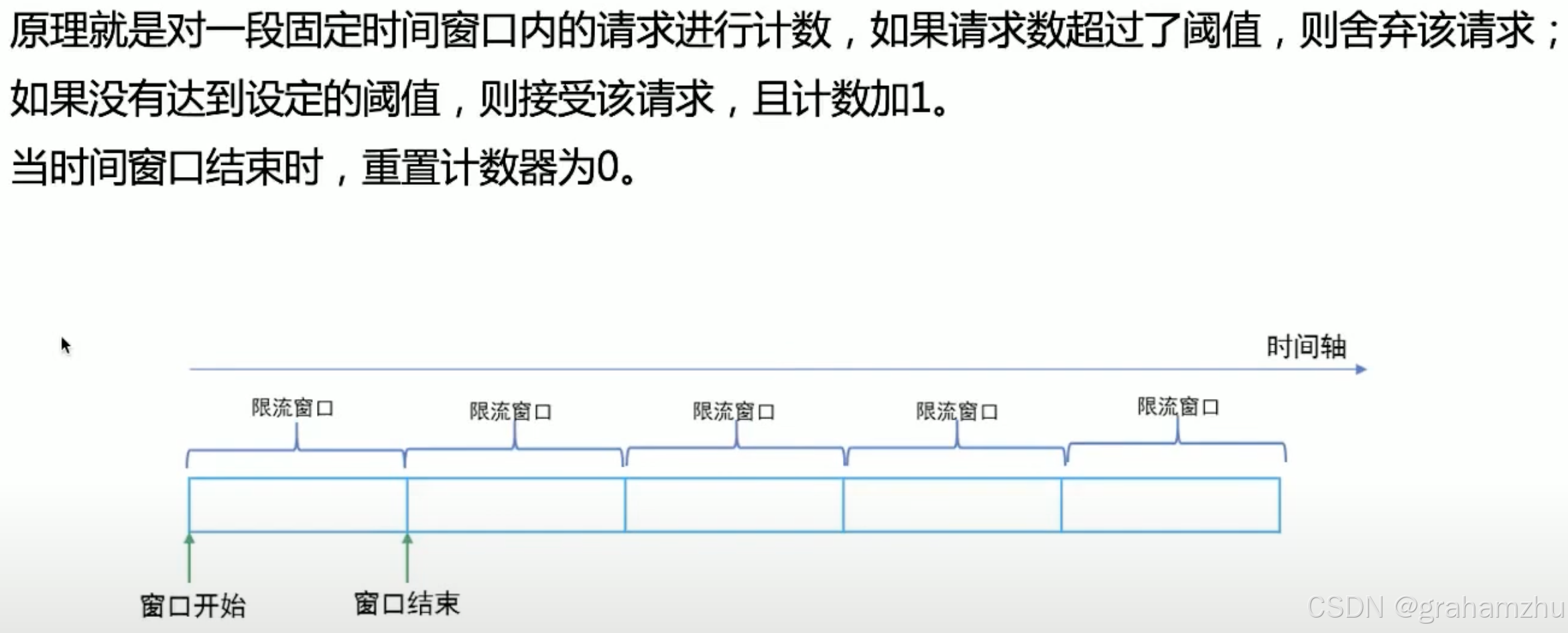
- 优点:实现简单
- 缺点:
- 场景一:可能在一段时间内接受超过服务能力的请求,导致服务挂掉。比如窗口1的最后1/10时间突增1000个请求,窗口2的最开始1/10时间突增1000个请求,那么相当于这2/10窗口期间,接收了2000个请求,可能就直接把服务打挂了
- 场景二:无法应对突增流量。比如在窗口1的时间刚开始1/10,来了一大波流量,直接就把请求数用尽了,那么窗口后续的9/10时间里,请求都将被拒绝
1.2.计数器滑动窗口算法

- 把一个大窗口切割成多个小窗口,总窗口的request数量小于最大并发量即可
- 优点:对固定窗口算法进行了优化,让请求流量变得更平滑
- 缺点:还是没有解决固定窗口算法存在的问题
1.3.漏斗算法
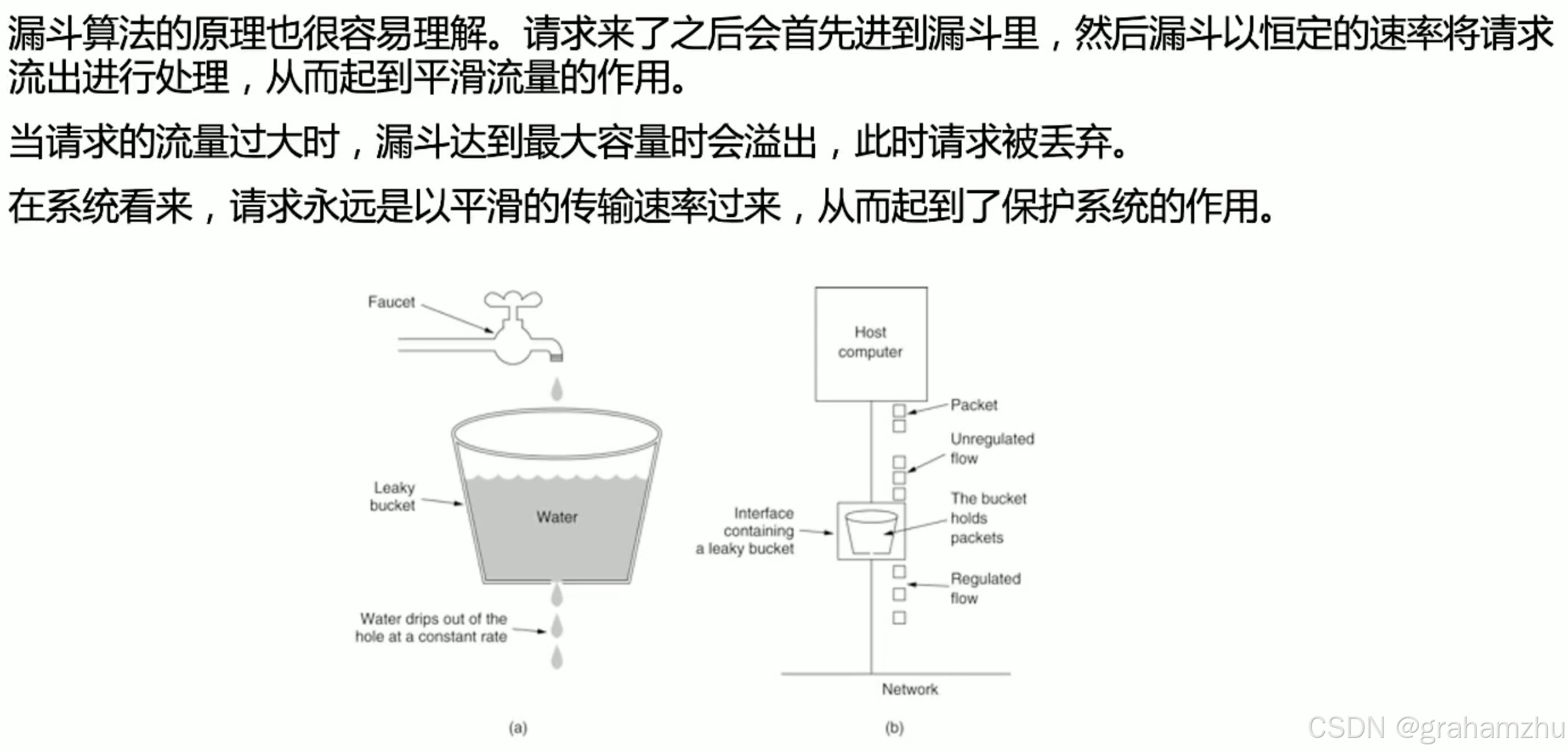
- 优点:控制了请求从漏斗出的速率,永远保证请求匀速进入系统,保护了系统
- 缺点:难以应对高峰请求,请求处理的慢,就要求请求进入的也要慢,否则漏斗满了请求就会被丢弃
1.4.令牌桶算法
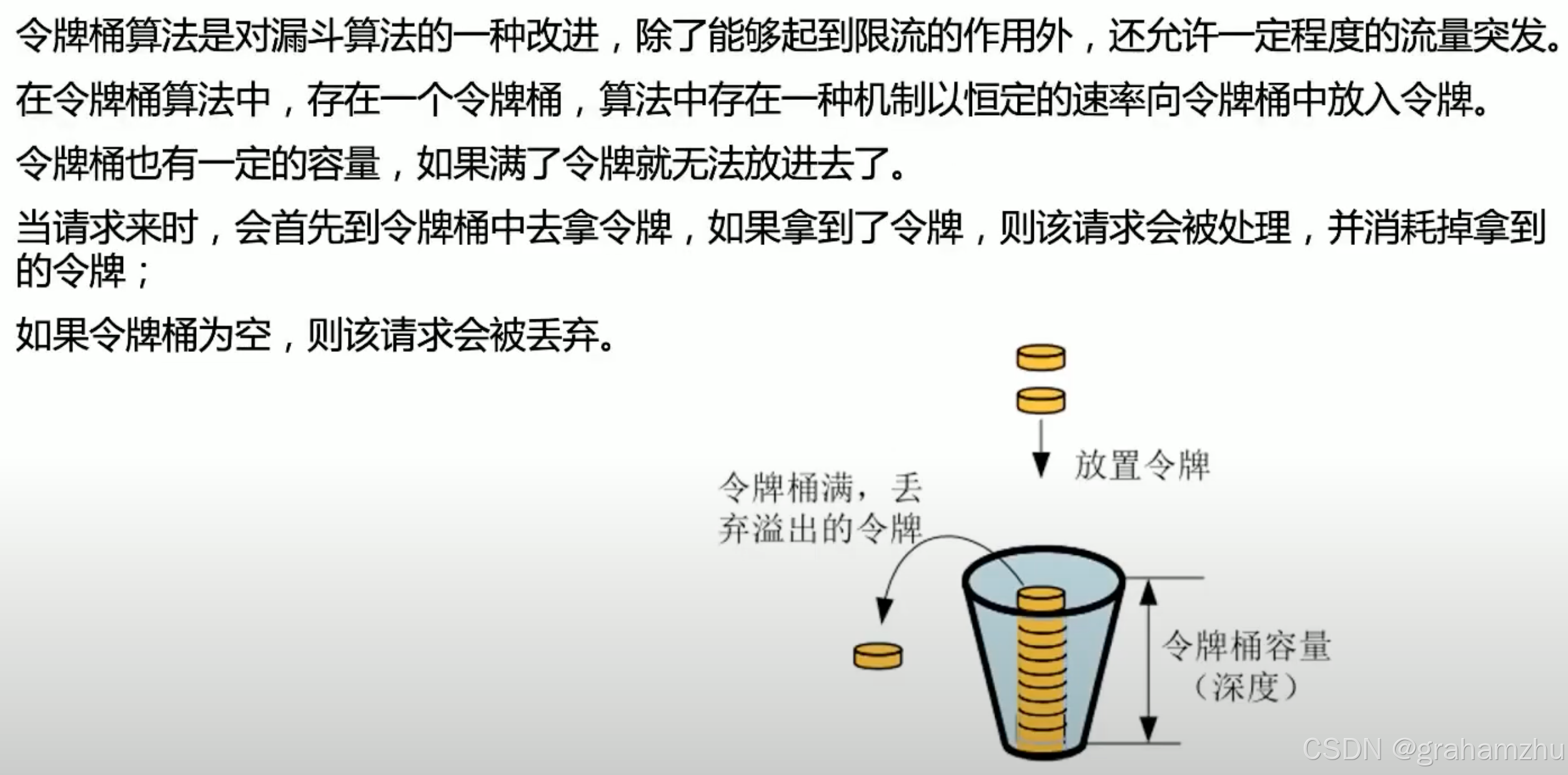
- 与漏斗算法相比,令牌桶算法不限制请求出桶的速率,而是限制请求进桶的速率
- 如果请求来了,发现桶里有令牌,则直接可以拿到令牌进入系统
- 如果请求来了,发现桶里没有令牌,则会等待,直到桶里生成令牌 或 请求超时
- 优点:可以应对高峰流量
- 生成令牌的线程会匀速生成令牌,即使当前没有那么多请求,也会不断的生成,直到把桶填满
- 如果突然来了一波高峰流量,桶里就事先生成了大量令牌供请求获取,这些请求都可以被处理
- 如果高峰之后,用户不活跃了,则桶里令牌又开始积累,可以应对下一次高峰
2.APIServer的限流
2.1.APIServer的基础限流参数
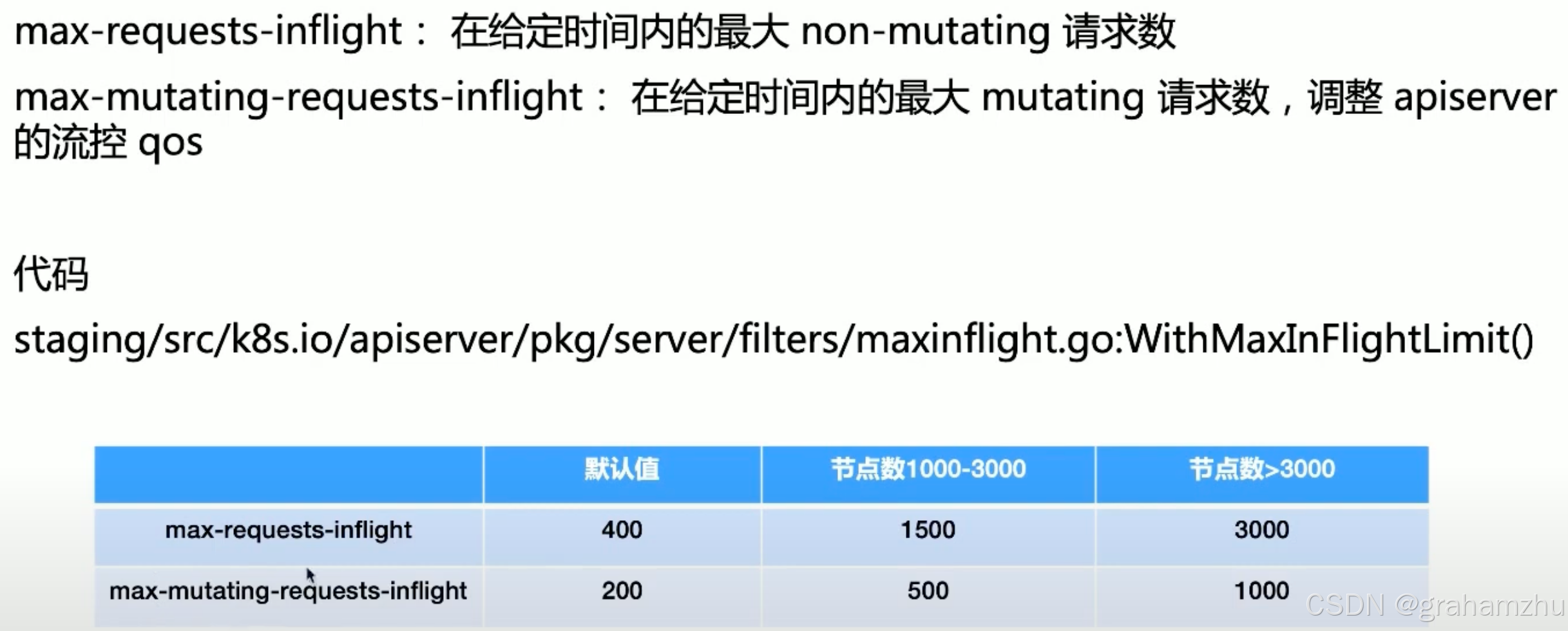
- 并发请求数,即为正在处理尚未结束的请求。因为一个请求的处理要经过认证、鉴权、准入等一系列操作,还是比较耗时的
- 给定时间,并非一个固定时间,而是apiserver能够承受的最大处理请求数量,如果400个请求不结束,那么就一直无法接收新请求
2.1.1.限流参数详解
-
max-requests-inflight- 定义:限制 API Server 非变更类请求(如
GET、LIST、WATCH)的并发处理数量。 - 默认值:400。
- 适用场景:保护查询类请求的稳定性,例如大规模集群中频繁的监控数据拉取或资源列表查询。
- 定义:限制 API Server 非变更类请求(如
-
max-mutating-requests-inflight- 定义:限制 API Server 变更类请求(如
CREATE、UPDATE、DELETE、PATCH)的并发处理数量。 - 默认值:200。
- 适用场景:防止资源修改操作(如 Pod 创建或配置更新)导致 API Server 过载。
- 定义:限制 API Server 变更类请求(如
2.1.2.参数对比
| 维度 | max-requests-inflight | max-mutating-requests-inflight |
|---|---|---|
| 请求类型 | 非变更类(只读) | 变更类(写操作) |
| 资源消耗 | 较低(仅数据读取) | 较高(涉及资源修改和状态同步) |
| 默认配额 | 400 | 200 |
| 优先级 | 通常优先级较低(APF 启用后由 FlowSchema 控制) | 通常优先级较高(如内置 workload-high 优先级) |
- 联系:
- 共同目标:防止 API Server 因突发流量过载,保障集群稳定性。
- 总和限制:当启用 APF(API 优先级和公平性)时,两者之和决定 API Server 的总并发处理能力(如
400+200=600)。
2.1.3.实现原理
- 计数器机制
- 每个参数维护一个独立的 并发请求计数器,请求处理前递增,完成后递减。
- 若计数器超过阈值,新请求会被拒绝(返回 HTTP 429 状态码)。
- 请求分类逻辑
- 非变更类请求:通过 HTTP 方法(如
GET)或 Kubernetes 资源操作(如list)识别。 - 变更类请求:通过 HTTP 方法(如
POST)或资源操作(如create)识别。
- APF 整合(Kubernetes 1.18+)
- 当启用
--enable-priority-and-fairness=true(默认开启),APF 接管限流逻辑:- 总并发数 =
max-requests-inflight + max-mutating-requests-inflight。 - 请求通过
FlowSchema分类并分配至PriorityLevelConfiguration队列,按优先级处理。
- 总并发数 =
2.1.4.配置与优化
1.参数设置方法
- 启动参数配置:
kube-apiserver \--max-requests-inflight=1000 \--max-mutating-requests-inflight=500 - 高可用集群建议:
- 三节点集群总并发数建议 3000(单节点 1000)。
- 大规模集群(如 5000 节点)总并发数可提升至 5000。
2.监控与调优
- 关键指标:
apiserver_current_inflight_requests:当前并发请求数。apiserver_request_duration_seconds:请求延迟分布。
- 调优策略:
- 逐步增加并发数,观察 API Server 内存和 CPU 使用率。
- 结合 APF 配置优先级,优先保障核心组件(如
kube-controller-manager)的请求。
2.1.5.基础限流参数的局限性

- 如果一个用户对apiserver操作不规范,可能会影响到整个系统。比如一个应用没有使用长连接watch,而是在不停的 list pods,就有可能把apiserver打挂
- 重要请求如node心跳、controller-leaderselection等,都不应该被限流
2.2.APF(API Priority and Fairness)
其实和 linux kernel 的网络保持思想是一致的,好的设计是到处应用的
2.2.1.APF是什么

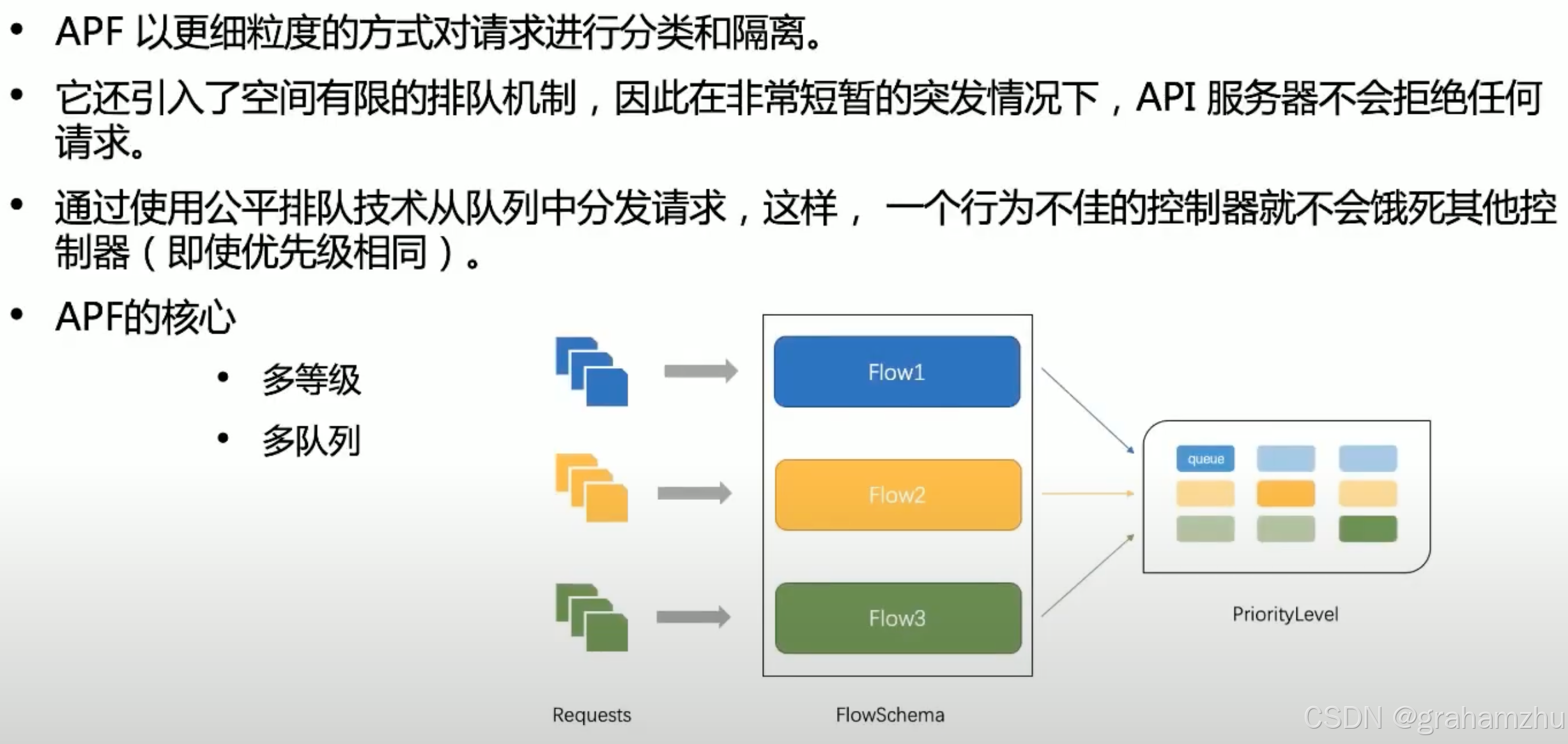
- 总的来说,APF是一种 兼顾优先级和公平性 的限流解决方案
- 支持版本:kubernetes 1.18引入,1.20默认开启
2.2.2.APF的具体实现

- APF机制中,有两种资源非常重要:FlowSchema、PriorityLevelConfiguration
- FlowSchema(FS):定义 请求流模板,一个FS会绑定一个唯一的PL,所以只要一个请求被判定为属于这个FS,那么这个请求的PL优先级也就确定了
- PriorityLevelConfiguration(PLC):定义 优先级 的配置,声明一个优先级PL的具体行为配置。一个PL可以被多个FS绑定
- 因此 FS --> PL 是 多对1 的关系
- APF 几个规则
- 一个FlowSchema对应一个优先级PL,一个PL包含多个queue队列
- 一个FlowSchema可以把请求划分为 不同的Flow,每个Flow又可以映射到不同的queue
- 一个具体的请求如何处理?
- 一个具体请求,在FlowSchema列表中,从优先级从高到低进行rules匹配,找到第一个匹配上的FlowSchema
- 然后FlowSchema会通过绑定的PL确定请求的优先级,并通过
distinguisherMethod.type的值,将请求划分到具体的Flow中 - 一个PL优先级会对应一个QueueSet(包含好多个队列),不同Flow会通过shuffle sharding算法 映射到不同的queue,就实现了 用户级别/ns级别 的请求隔离。
- 因为不同 用户/ns 的请求,都没有放在同一个queue
- 如此一个请求就被放入了一个queue,等待执行
- 执行的时候,该PL的执行器会通过 fair公平性算法 从QueueSet中选出一个queue,并挑选queue中最老的请求进行执行
- 由于不同Flow对应不同的queue,所以不同Flow请求被执行到的概率也是公平的,不会出现一个Flow一直执行,其他Flow饿死的情况

- 由于不同Flow对应不同的queue,所以不同Flow请求被执行到的概率也是公平的,不会出现一个Flow一直执行,其他Flow饿死的情况
2.2.3.FlowSchema结构
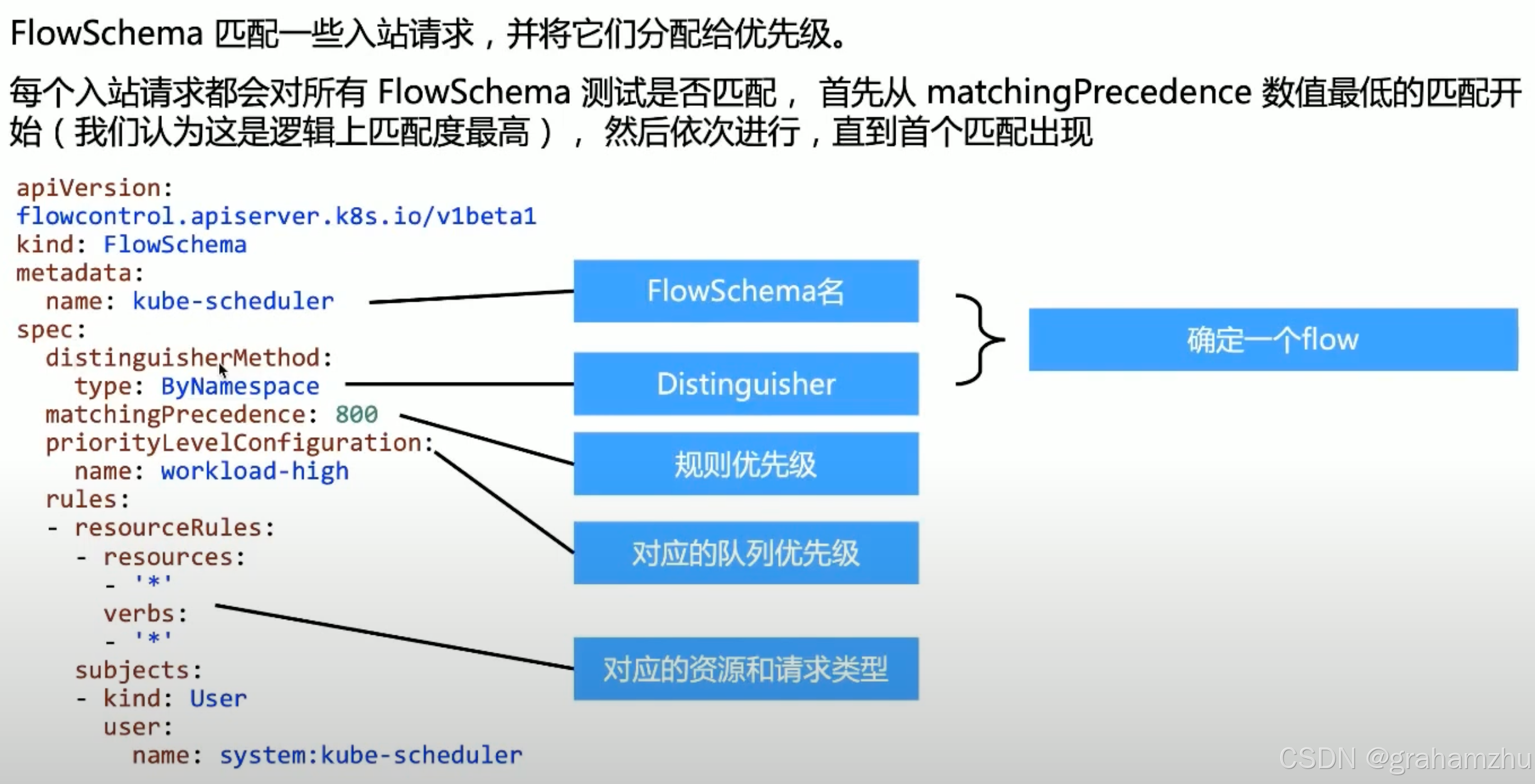
- FlowSchema 的 matchingPrecedence数值表示规则的优先级,取值范围:1-10000。值越小,优先级越高。比如:
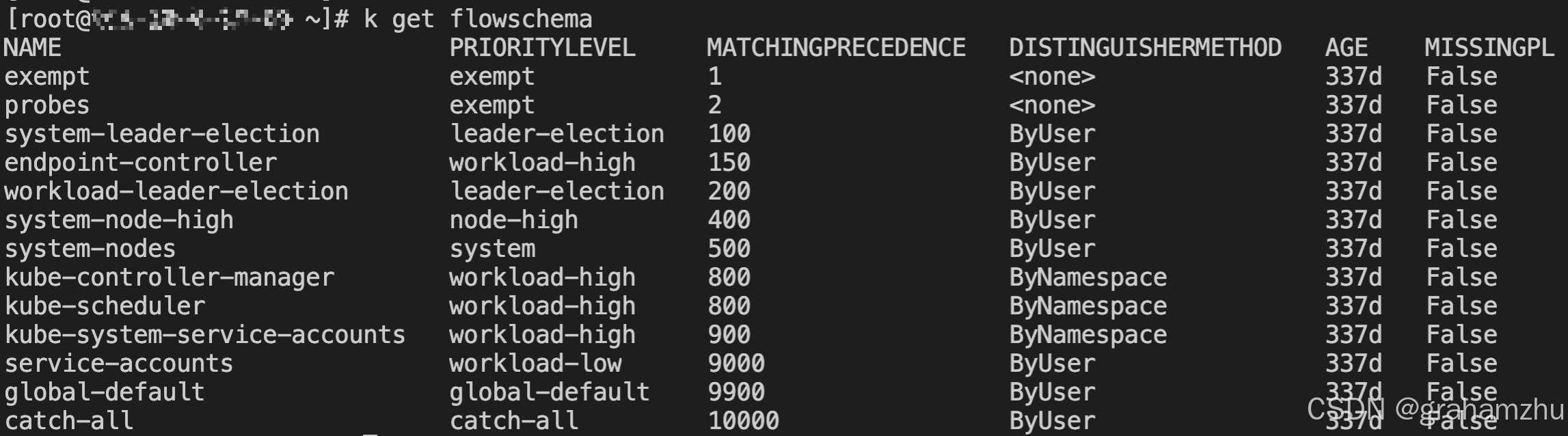
- exempt:豁免,该flowschema的请求不作限流,所有请求都会被执行
- catch-all:如果上面的FlowSchema 都没有被匹配到,就会放入这个flowschema
2.2.4.PriorityLevelConfiguration结构
- 从上面描述可知,一个PL对应一个QueueSet,包含好多个queue,那么queue的具体数量、具体配置在哪里配置?
- 就是对应的PriorityLevelConfiguration

- 就是对应的PriorityLevelConfiguration
- assuredConcurrencyShares:定义当前优先级PL所允许的最大并发请求数量
- 对不同优先级配置不同的 并发量,可以保证高优先级一定能执行,低优先级尽量执行
- queuing.queues:表示当前PL下队列总数
- queuing.queueLengthLimit:队列长度
- queuing.handSize:表示一个flow会占用多少个队列,是shuffle sharding的取模数量
2.2.5.其他设计点
2.2.5.1.基础限流参数 与 APF 的关系

- 当启用
--enable-priority-and-fairness=true(默认开启),APF 接管限流逻辑:- apiserver总并发数 =
max-requests-inflight + max-mutating-requests-inflight。 - 总并发数通过
FlowSchema分类并分配至PriorityLevelConfiguration队列,按优先级处理。每个优先级就具备了自己的并发限制。可以保证高优先级一定能执行,低优先级尽量执行
- apiserver总并发数 =
2.2.5.2.同一PL下的排队算法

2.2.5.3.豁免请求

- 系统内置的一些flowschema
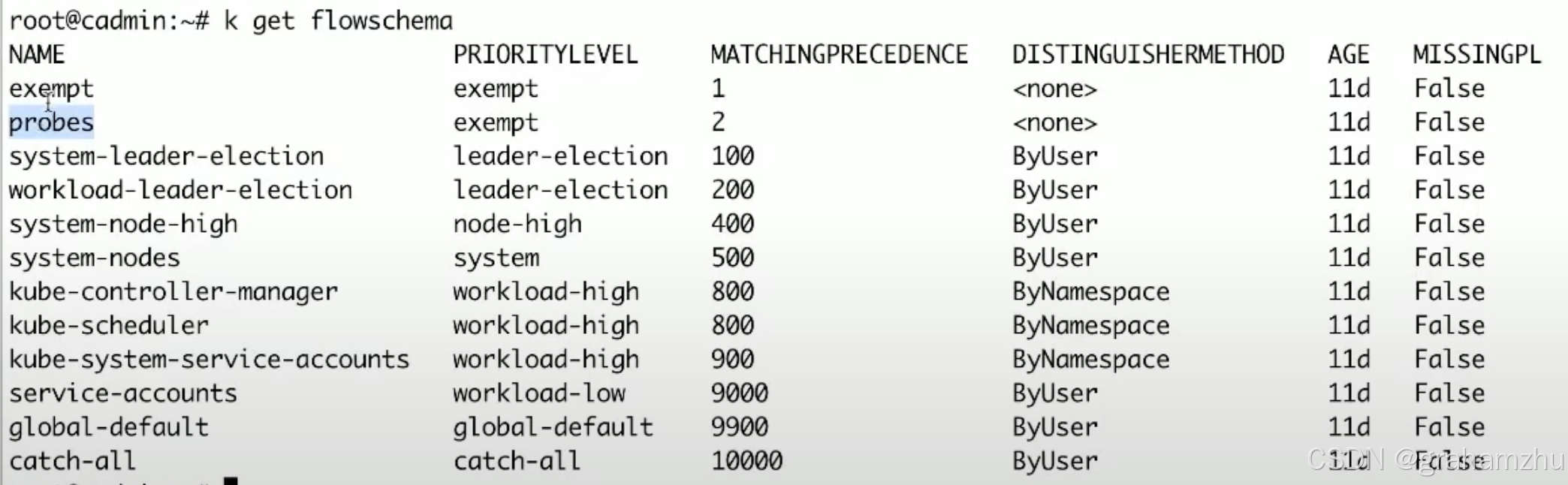
- 其中 exempt、健康检查probes的两个flowschema,都对应 exempt豁免PL,即都会被豁免
- 可以看到,来自 system:masters 用户组下的所有请求,或url为
/healthz、/readyz、/livez都会被豁免,不会被限流
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:annotations:apf.kubernetes.io/autoupdate-spec: "true"creationTimestamp: "2024-05-11T05:25:46Z"generation: 1name: exemptresourceVersion: "75"uid: 3366d878-6d31-4cb8-9570-44b072839d49
spec:matchingPrecedence: 1priorityLevelConfiguration:name: exemptrules:- nonResourceRules:- nonResourceURLs:- '*'verbs:- '*'resourceRules:- apiGroups:- '*'clusterScope: truenamespaces:- '*'resources:- '*'verbs:- '*'subjects:- group:name: system:masterskind: Group
status:conditions:- lastTransitionTime: "2024-05-11T05:25:46Z"message: This FlowSchema references the PriorityLevelConfiguration object named"exempt" and it existsreason: Foundstatus: "False"type: Dangling---apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:annotations:apf.kubernetes.io/autoupdate-spec: "true"creationTimestamp: "2024-05-11T05:25:46Z"generation: 1name: probesresourceVersion: "69"uid: 6a73e8ae-4190-443d-92d0-58bc1e2dd691
spec:matchingPrecedence: 2priorityLevelConfiguration:name: exemptrules:- nonResourceRules:- nonResourceURLs:- /healthz- /readyz- /livezverbs:- getsubjects:- group:name: system:unauthenticatedkind: Group- group:name: system:authenticatedkind: Group
status:conditions:- lastTransitionTime: "2024-05-11T05:25:46Z"message: This FlowSchema references the PriorityLevelConfiguration object named"exempt" and it existsreason: Foundstatus: "False"type: Dangling---apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: PriorityLevelConfiguration
metadata:annotations:apf.kubernetes.io/autoupdate-spec: "true"creationTimestamp: "2024-05-11T05:25:46Z"generation: 1name: exemptresourceVersion: "64"uid: 91deb647-6513-45f4-8c2b-a5d218cda4ac
spec:type: Exempt
status: {}
2.2.6.APF的调试手段

- kubernetes提供了一些调试的uri,供我们查看当前系统的一些状态
- 比如
k get --raw /debug/api_priority_and_fairness/dump_priority_levels
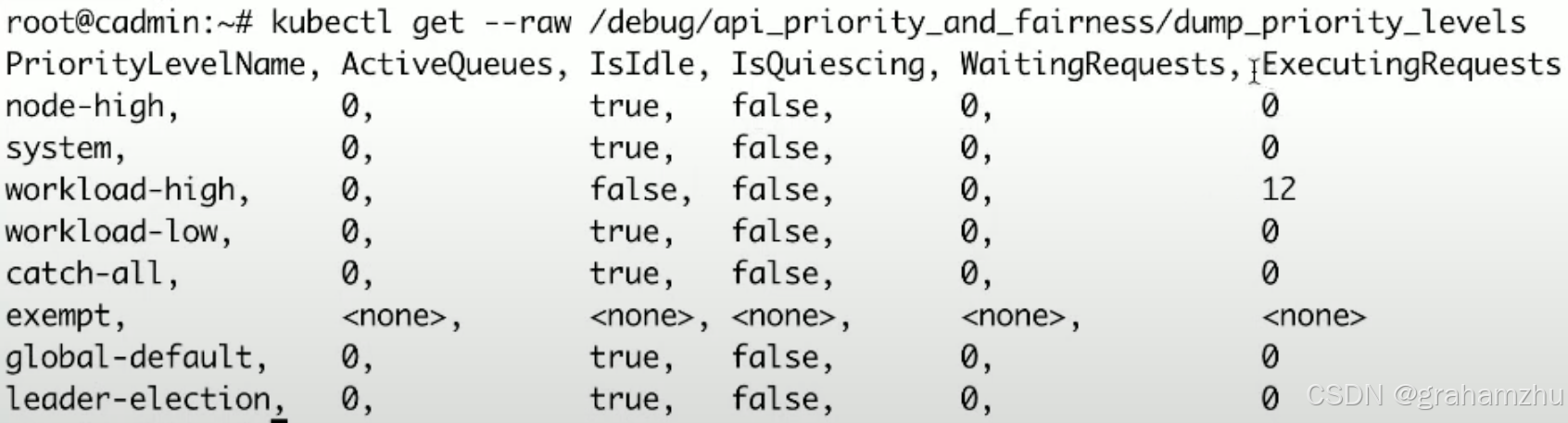
- 比如
相关文章:
Kubernetes控制平面组件:APIServer 限流机制详解
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

springboot全局异常捕获处理
一、需求 实际项目中,经常抛出各种异常,不能直接抛出异常给前端,这样用户体验相当不好,用户看不懂你的Exception,对于一些sql异常,直接抛到页面上也不安全。所以有没有好的办法解决这些问题呢,当然有了&am…...
: 在windows系统上部署项目1)
Flask(1): 在windows系统上部署项目1
1 前言 学习python也有段时间了,最近一个小项目要部署,正好把过程写下来。 在程序的结构上我选择了w/s模式,相比于c/s模式,无需考虑客户端的升级;框架我选择了flask,就是冲着轻量级去的,就是插件…...
【文献阅读】EndoNet A Deep Architecture for Recognition Tasks on Laparoscopic Videos
关于数据集的整理 Cholec80 胆囊切除手术视频数据集介绍 https://zhuanlan.zhihu.com/p/700024359 数据集信息 Cholec80 数据集 是一个针对内窥镜引导 下的胆囊切除手术视频流程识别数据集。数据集提供了每段视频中总共7种手术动作及总共7种手术工具的标注,标…...
基于springboot的个人财务管理系统的设计与实现
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...
Linux系统编程---孤儿进程与僵尸进程
1、前言 在上一篇博客文章已经对Linux系统编程内容进行了较为详细的梳理,本文将在上一篇的基础上,继续梳理Linux系统编程中关于孤儿进程和僵尸进程的知识脉络。如有疑问的博客朋友可以通过下面的博文链接进行参考学习。 Linux系统编程---多进程-CSDN博客…...
简单使用MCP
简单使用MCP 1 简介 模型上下文协议(Model Context Protocol,MCP)是由Anthropic(产品是Claude)推出的开放协议,它规范了应用程序如何向LLM提供上下文。MCP可帮助你在LLM之上构建代理和复杂的工作流。 从…...

Semaphore的核心机制
在 Java 中,Semaphore 通过 许可计数器 和 同步队列 的机制实现并发线程数的限制。以下是其核心实现原理和步骤的详细分析: 一、核心机制 许可计数器(Permits) • 初始化时指定的许可数(如 new Semaphore(3)࿰…...

计算机视觉与深度学习 | RNN原理,公式,代码,应用
RNN(循环神经网络)详解 一、原理 RNN(Recurrent Neural Network)是一种处理序列数据的神经网络,其核心思想是通过循环连接(隐藏状态)捕捉序列中的时序信息。每个时间步的隐藏状态 ( h_t ) 不仅依赖当前输入 ( x_t ),还依赖前一时间步的隐藏状态 ( h_{t-1} ),从而实现…...

Keil MDK 编译问题:last line of file ends without a newline
问题与处理策略 问题描述 ..\..\User\main.c(38): warning: #1-D: last line of file ends without a newline} ..\..\User\main.c: 1 warning, 0 errors问题原因 这是文件末尾缺少换行符警告 处理策略 在文件(main.c)的最后一行按回车键添加一个空…...

MySQL:9.表的内连和外连
9.表的内连和外连 表的连接分为内连和外连 9.1 内连接 内连接实际上就是利用where子句对两种表形成的笛卡儿积进行筛选,之前查询都是内连 接,也是在开发过程中使用的最多的连接查询。 语法: select 字段 from 表1 inner join 表2 on 连接…...

C++栈操作集合
数组 #include <bits/stdc.h> using namespace std;class sss{ private:int a[1000];int curr -1; public:void push(int);void pop();int top();bool empyt();int size(); };int main() {sss n;while(true){int a;cout<<"1.添加\n2.删除-\n3.显示栈顶\n4.储…...
在阿里云和树莓派上编写一个守护进程程序
目录 一、阿里云邮件守护进程 1. 安装必要库 2. 创建邮件发送脚本 mail_daemon.py 3. 设置后台运行 二、树莓派串口守护进程 1. 启用树莓派串口 2. 安装依赖库 3. 创建串口输出脚本 serial_daemon.py 4. 设置开机自启 5. 使用串口助手接收 一、阿里云邮件守护进程 1.…...

每日一题——最小测试用例集覆盖问题
最小测试用例集覆盖问题(C语言实现) 问题描述 假设我们有一系列测试用例,每个测试用例会覆盖若干个代码模块。 我们使用一个二维数组来表示这些测试用例的覆盖情况: 如果某个测试用例 i 能覆盖代码模块 j,则数组中…...

LangChain 单智能体模式示例【纯代码】
# LangChain 单智能体模式示例import os from typing import Anyfrom langchain.agents import AgentType, initialize_agent, Tool from langchain_openai import ChatOpenAI from langchain.tools import BaseTool from langchain_experimental.tools.python.tool import Pyt…...

基于前端技术的QR码API开发实战:从原理到部署
前言 QR码(Quick Response Code)是一种二维码,于1994年开发。它能快速存储和识别数据,包含黑白方块图案,常用于扫描获取信息。QR码具有高容错性和快速读取的优点,广泛应用于广告、支付、物流等领域。通过扫…...
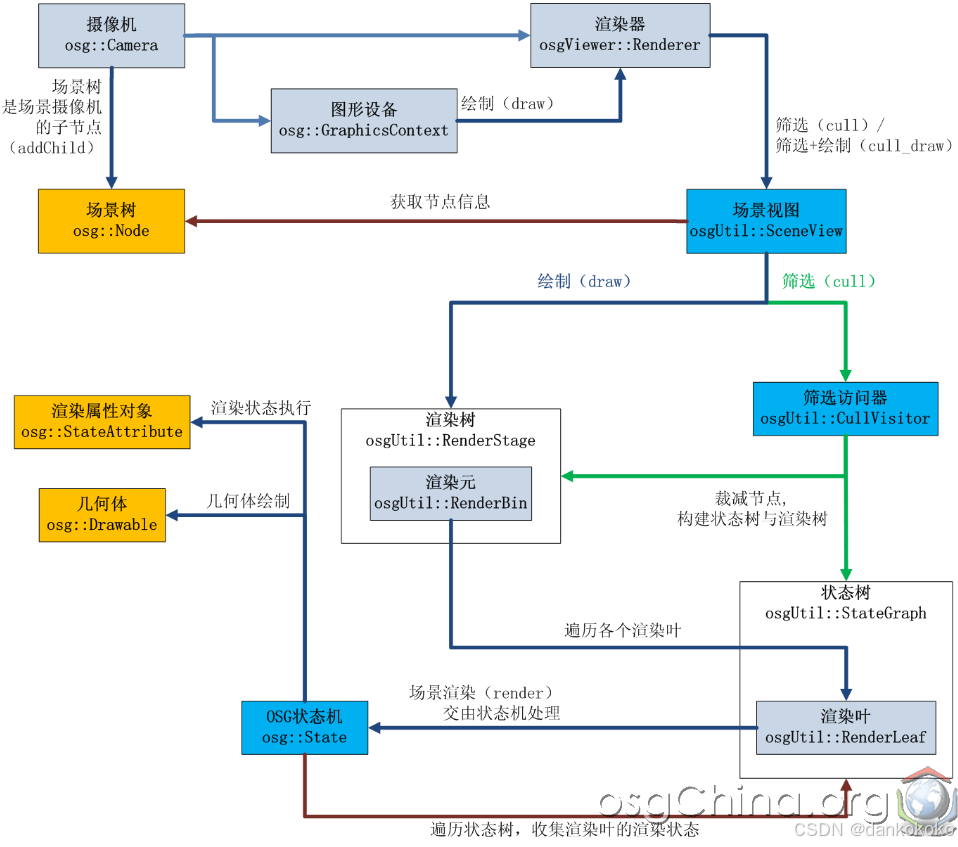
RenderStage::drawInner
文章目录 RenderStage::drawInnerOSG渲染后台关系图OSG的渲染流程RenderBin::draw(renderInfo,previous)RenderBin::drawImplementationRenderLeaf::renderosg::State::apply(const StateSet*)Drawable::draw(RenderInfo& renderInfo)Drawable::drawInner(RenderInfo& …...

C++初阶-类和对象(中)
目录 1.类的默认成员函数 2.构造函数(难度较高) 编辑 编辑 编辑 3.析构函数 4.拷贝构造函数 5.赋值运算符重载 5.1运算符重载 5.2赋值运算符重载 6.取地址运算符重载 6.1const成员函数 6.2取地址运算符重载 7.总结 1.类的默认成员函数…...
智谱开源新一代GLM模型,全面布局AI智能体生态
2024年4月15日,智谱在中关村论坛上正式发布了全球首个集深度研究与实际操作能力于一体的AI智能体——AutoGLM沉思。这一革命性技术的发布标志着智谱在AGI(通用人工智能)领域的又一次重要突破。智谱的最新模型不仅推动了AI智能体技术的升级&am…...

Vue3中provide和inject的用法示例
在 Vue3 中,provide 和 inject 用于实现跨层级组件通信。以下是一个简单的示例: 1. 父组件 (祖先组件) - 提供数据 javascript 复制 // ParentComponent.vue import { provide, ref, reactive } from vue;export default {setup() {// 提供静态数据p…...

分治-快排-75.颜色分类-力扣(LeetCode)
一、题目解析 给定一个数组将其元素按照0,1,,2三段式排序,并且在原地进行排序。 二、算法原理 解法:三指针 用cur遍历数组,left记录0的最左侧,right记录2的最右侧。 left初始值为-1,right的初…...
铅酸电池充电器方案EG1253+EG4321
参考: 基于EG1253EG4321铅酸电池(48V20AH)三段式充电器 屹晶微高性价比的电瓶车充电器方案——EG1253 电瓶电压 48V电瓶锂电池,其充满约为55V~56V,因此充电器输出电压为55V~56V; 若是48V铅酸电池,标称电压为48V&…...
)
Spring Boot 实现 Excel 导出功能(支持前端下载 + 文件流)
🧠 一、为什么用 EasyExcel? 在 Java 开发中,操作 Excel 的框架主要有: Apache POI(经典但慢、内存占用大) JXL(老旧不维护) Alibaba EasyExcel(阿里出品,…...
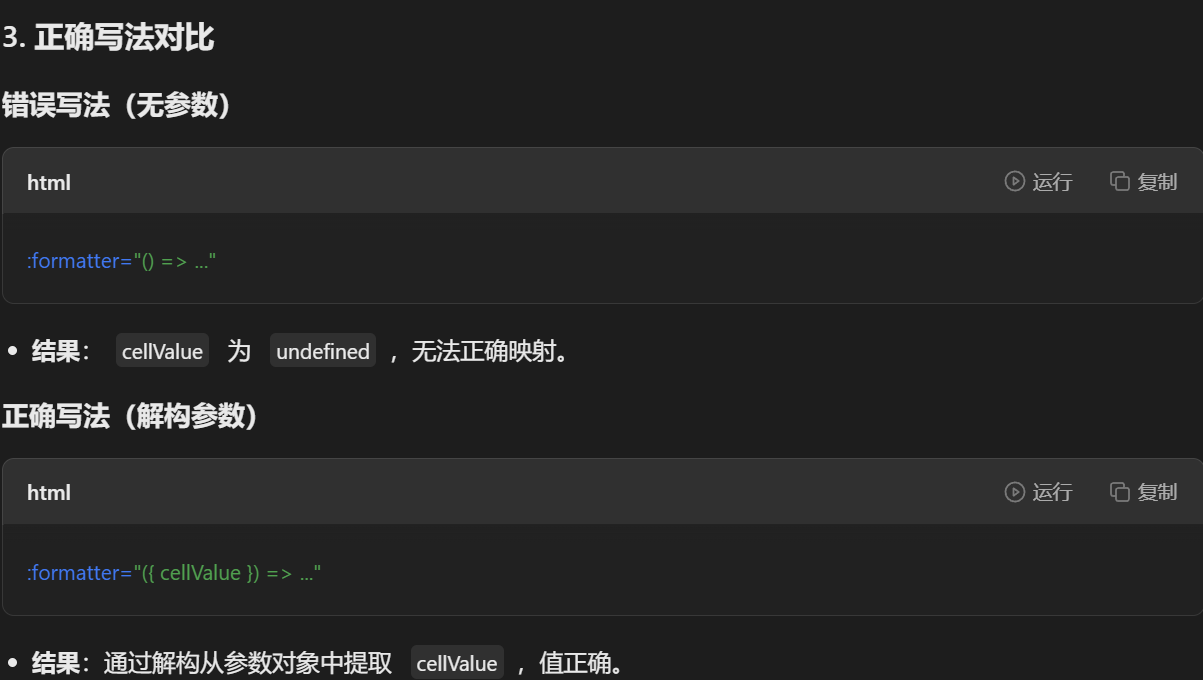
vue 中formatter
:formatter 是前端表格组件(如 Element UI、Vxe-Table 等)中用于 自定义单元格内容显示格式 的属性。它的核心作用是:将后端返回的原始数据(如编码、状态值等)转换为更友好、更易读的文本。 这段代码 :forma…...

协程?协程与线程的区别?Java是否支持协程?
一、前言 协程(Coroutine) 是一种轻量级的并发编程模型,允许在单线程内通过协作式多任务调度实现并发。由用户代码显式控制(用户态调度而非操作系统内核调度),避免了线程上下文切换的开销,适合…...
)
jsch(shell终端Java版)
学习笔记 Java SSH库使用简介:Apache sshd和JSch(Java Secure Channel) github - fork of the popular jsch library JSch学习笔记 web-shell - gitee代码 - 纯Java实现一个web shell登录Linux远程主机,技术选型 SpringBoot …...

Muduo网络库实现 [十六] - HttpServer模块
目录 设计思路 类的设计 模块的实现 公有接口 私有接口 疑问点 设计思路 本模块就是设计一个HttpServer模块,提供便携的搭建http协议的服务器的方法。那么这个模块需要如何设计呢? 这还需要从Http请求说起。 首先从http请求的请求行开始分析&…...
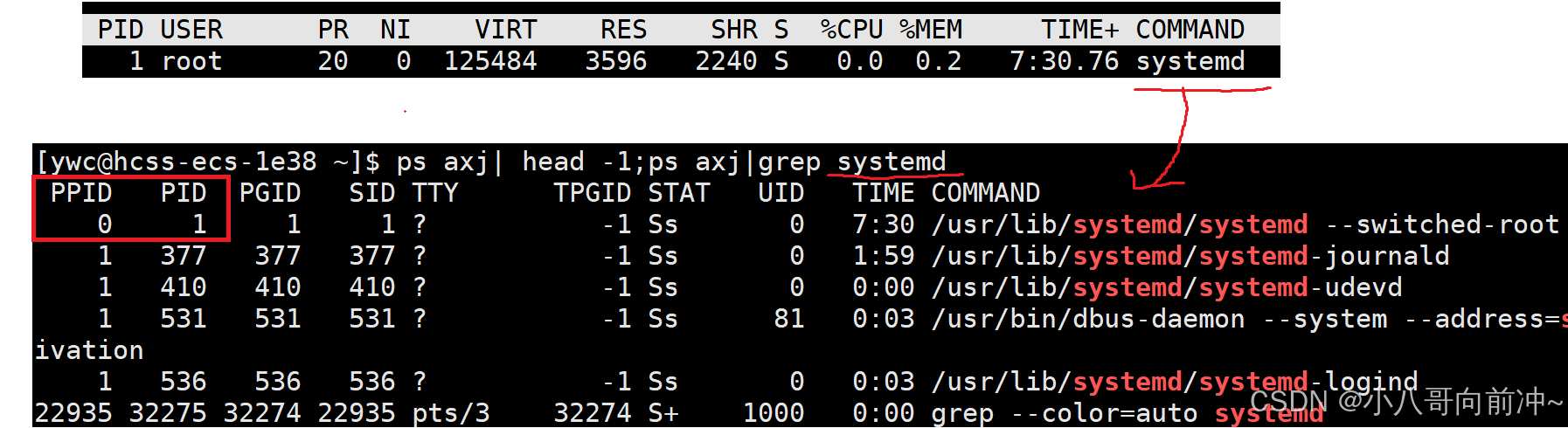
关于进程状态
目录 进程的各种状态 运行状态 阻塞状态 挂起状态 linux中的进程状态、 进程状态查看 S状态(浅睡眠) t 状态(追踪状态) T状态(暂停状态) 编辑 kill命令手册 D状态(深度睡眠&#…...

【MySQL】Read view存储的机制,记录可见分析
read view核心组成 1.1 事务id相关 creator_trx_id: 创建该read view的事务id 每开启一个事务都会生成一个 ReadView,而 creator_trx_id 就是这个开启的事务的 id。 m_ids: 创建read view时系统的活跃事务(未提交的事务)id集合 当前有哪些事…...
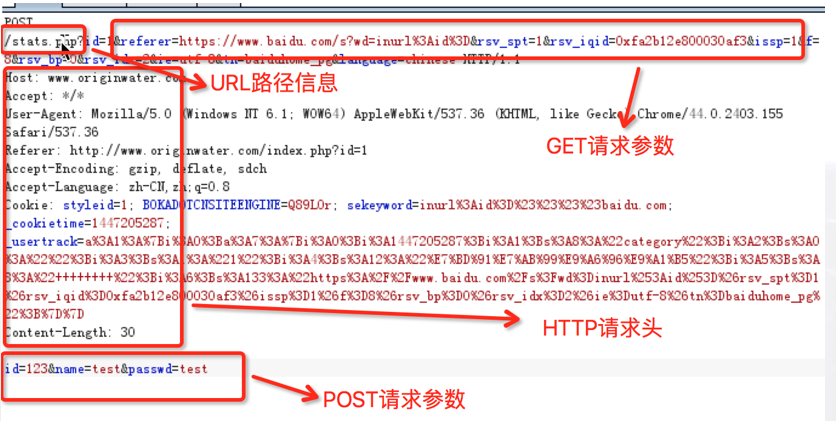
SQL注入 01
0x01 用户、脚本、数据库之间的关系 首先客户端发出了ID36的请求,脚本引擎收到后将ID36的请求先代入脚本的sql查询语句Select * from A where id 36 , 然后将此代入到数据库中进行查询,查到后将返回查询到的所有记录给脚本引擎,接…...