python爬虫复习
requests模块
-
爬虫的分类
- 通用爬虫:将一整张页面进行数据采集
- 聚焦爬虫:可以将页面中局部或指定的数据进行采集
- 聚焦爬虫是需要建立在通用的基础上来实现
- 功能爬虫:基于selenium实现的浏览器自动化的操作
- 分布式爬虫:使用分布式机群可以对一组资源进行联合且分布的爬取
- 增量式爬虫:监测网站数据更新的情况,以便爬取到网站最新更新出来的数据
-
反爬机制,反反爬策略
-
robots协议:君子协议。
-
requests模块是用来模拟浏览器发请求,因此可以基于requests模块实现爬虫的数据采集相关操作。
- 注意:如果爬虫程序采集不到我们想要的数据,唯一的原因:爬虫程序模拟浏览器的力度不够!
- 模拟力度重点体现在哪里?
- 请求头:
- User-Agent:请求载体的身份标识
- Cookie
- refere
- 其他
- 请求参数
- 重点关注动态变化的请求参数
- 如何检测请求参数是否动态变化的?
- 基于抓包工具多尝试抓取几次该数据包,检测不同时刻抓取数据包中的请求参数是否有变动。
- 如何检测请求参数是否动态变化的?
- 重点关注动态变化的请求参数
- 请求头:
- 模拟力度重点体现在哪里?
- 注意:如果爬虫程序采集不到我们想要的数据,唯一的原因:爬虫程序模拟浏览器的力度不够!
-
requests模块中常用的两个方法:
-
get:发起get请求
- 重要的方法参数:
- url:发起请求的url
- headers:请求头的伪装
- params:请求参数
- proxies:指定代理
- 重要的方法参数:
-
post:发起post请求
-
url
-
headers
-
data:请求参数。如果抓包工具中的请求参数为键值对,则使用data参数
-
name:deng password:123456
-
-
json:如果抓包工具中的请求参数为字符串形式的键值对,则使用json参数
-
"{'name':'deng','password':'123456'}"
-
-
proxies
-
-
-
动态加载数据
- 有哪些方式可以实现动态加载数据?
- 通过ajax请求生成动态加载的数据(常见)
- 通过js生成动态加载的数据
- 如何获取js生成的动态加载数据?(极为少见)
- 逆向。
- 如何获取js生成的动态加载数据?(极为少见)
- 在对一个陌生的网站进行数据爬取前,首先做什么?
- 检测你想要爬取的数据是否为动态加载数据?
- 如何检测?
- 基于抓包工具进行局部搜索,如果搜索不到则说明数据是动态加载的。
- 如何获取动态加载数据?
- 基于抓包工具进行全局搜索!
- 如何检测?
- 问题:如果基于抓包工具进行全局搜索,发现没有搜索到,说明说明?
- 说明该组数据被加密了。那就需要逆向操作。
- 检测你想要爬取的数据是否为动态加载数据?
- 有哪些方式可以实现动态加载数据?
数据解析
-
数据解析的作用是什么?
- 是为了实现聚焦爬虫!
-
如何实现数据解析呢?
- Bs4,xpath,正则
-
数据解析的通用原理是什么?
- 1.实现标签定位
- 2.提取定位到标签中的数据
-
bs4实现数据解析的流程:
-
1.实例化一个BeautifulSoup对象,然后把即将被解析的html页面加载到该对象中。
-
2.调用BeautifulSoup对象相关的属性和方法进行标签定位和数据提取
-
常见的属性或方法有哪些?
- find(属性定位),find_all(属性定位),select(选择器定位)
- text,string:获取定位到标签中的数据值
-
需求:想要将页面中的一组指定标签的html代码获取,如何实现?
-
<html><div>hello bobo</div> #如何可以解析到该一整行数据(包含标签的数据) </html> -
直接使用bs4定位到div标签,然后进行打印输出即可!
-
-
-
xpath实现数据解析的流程:
- xpath表达式进行标签定位和数据提取
- 注意:
- 如果xpath表达式中存在tbody标签,则无法实现标签定位和数据提取
- 直接将tbody从xpath表达式中删除即可
- //div/a/tbody/span/text()
- //div/a//span/text()
- 直接将tbody从xpath表达式中删除即可
- 可以在xpath表达式中使用|符号,来增加xpath表达式的通用性。
- //div | //span/div :|左右两侧的某一个xpath表达式生效,即可进行标签定位
- 如果xpath表达式中存在tbody标签,则无法实现标签定位和数据提取
requests高级
- cookie
- 处理cookie的方式
- 手动处理:将抓包工具中的cookie写在headers中即可
- 自动处理:使用session对象。该对象在进行请求发送的过程中,如果产生了cookie,则会自动将cookie存储到该对象中。
- 注意:Session对象处理cookie不是万能。
- 辅助方式:通过selenium实时获取cookie,然后将cookie写到requests程序的headers中(稳妥)
- 处理cookie的方式
- 代理:
- 代理服务器的作用:可以转发请求和响应。
- 可以使用get或者post方法的proxies实现代理操作。
- 注意:get(proxies={‘http’:‘ip:port’}) or get(proxies={‘http://’:‘ip:port’})
- 代理的类型:http和https
- 代理的匿名度:透明,匿名,高匿
- 验证码
- 将验证码下载到本地,基于相关的打码平台进行识别即可!
- 模拟登录
- 有些网站数据,是需要登录后在可以查看的,因此需要进行程序的模拟登录。
selenium
-
不同的浏览器是需要使用不同的驱动程序!!!
-
基于浏览器自动化的模块。
-
常见操作:
- 请求操作:get
- 交互操作:
- click,send_keys…
- 标签定位操作
- find系列的函数
- 获取页面源码:page_source
- cookie:获取cookie
- 无头浏览器:没有可视化界面的浏览器
- 动作链:ActionChains
- 内部封装了很多比较复杂的动作。
- 规避检测的方法
- 较新的规避检测的方法去哪里找?
- GitHub,百度(效率低)
- 较新的规避检测的方法去哪里找?
-
在爬虫中,为什么需要使用selenium?(selenium和爬虫之间的关联是什么)
- selenium可以便捷的获取动态加载/加密数据(可见即可得)
- 实现便捷的模拟登录
- 缺点:效率较低,无法很好的使用异步操作。
异步操作
- 多线程
- 推荐大家使用线程池(Pool)
- 重要函数map:
- map(callback,alist):可以将alist列表中的每一个元素以此传递给callback这个回调函数的参数,然后会异步的调用callback函数完成相关任务操作。
- callback调用的次数完全取决于alist元素的个数。
- map(callback,alist):可以将alist列表中的每一个元素以此传递给callback这个回调函数的参数,然后会异步的调用callback函数完成相关任务操作。
- 协程(重点)
- 特殊的函数
- 被ascyc关键字修饰的函数定义,该函数就是一个特殊的函数
- 特殊之处:
- 该函数被调用会函数内部的函数体语句不会被立即执行
- 函数调用后会返回一个协程对象。
- 协程
- 协程对象 == 特殊的函数 == 一组指定形式的操作
- 协程对象 == 一组指定形式的操作
- 任务对象
- 高级的协程对象,高级之处就在于可以给任务对象绑定一个回调函数。
- 任务对象协程对象一组指定形式的操作
- 任务对象==一组指定形式的操作
- 绑定回调函数:
- 可以使用add_done_callback函数给任务对象绑定一个回调函数,记住:回调函数是在任务对象表示的这组操作执行完毕后,才可以执行回调函数的相关操作!
- 回调函数的重点:
- 回调函数只可以有一个参数,该参数表示的是就是当前的任务对象。
- 任务对象.result():result方法返回的就是特殊函数内部的返回值!
- 在爬虫中,一般情况下,任务对象的回调函数使用来进行数据解析或者持久化存储!
- 高级的协程对象,高级之处就在于可以给任务对象绑定一个回调函数。
- 事件循环
- loop这个事件循环对象,可以当做是一个容器,该容器内部存放一个或者多个任务对象。如果一个或者多个任务对象放置在了loop这个容器中,当loop启动,则其内部存放的任务对象就可以被异步的执行了!
- 注意:在特殊函数内部,不可以出现不支持异步模块的代码,否则会中断整个协程的异步效果。
- 因此在协程异步环节中,不可以使用requests,使用aiohttp这个支持异步的网络请求模块进行请求发送!
- req = aiohttp.ClinetSession() 创建请求对象
- response = req.get/post()进行请求发送
- response.text()返回字符串形式的响应数据,response.read()返回二进制形式的响应数据,response.json()返回json格式的响应数据。
- 因此在协程异步环节中,不可以使用requests,使用aiohttp这个支持异步的网络请求模块进行请求发送!
- 特殊的函数
scrapy
-
数据解析机制:
- 通常使用xpath进行数据解析,只不过,必须让xpath结合这extract()或者extract_first()进行联合解析!
-
持久化存储
- 基于终端指令的持久化存储
- 只可以将parse方法的返回值存储到指定后缀的文本文件中
- 指令:scrapy crawl spiderName -o filePath
- 基于管道的持久化存储
- 在爬虫文件中进行数据解析
- 将解析到的数据存储封装到item类型的对象中
- 将item对象通过yield关键字提交给管道
- 在管道中调用process_item进行item对象的接收,且可以将接收到的数据存储到任意的平台中。
- 在配置文件中开启管道机制。
- 注意:
- process_item方法调用次数取决于爬虫文件向管道提交item的次数。
- 如果将二进制形式的数据进行持久化存储如何操作?
- 基于ImagesPipeLine该管道类实现二进制数据的持久化存储!
- 在爬虫文件中,只需要将多媒体文件的路径和名字封装到item中,提交给ImagesPipeLine管道类即可。
- 基于ImagesPipeLine该管道类实现二进制数据的持久化存储!
- 基于终端指令的持久化存储
-
手动请求发送:
- 可以将url放置在start_urls这个列表中,该列表会对其内部的url发起get请求
- 手动发起请求:
- yield scrapy.Request():发起get请求
- yield scrapy.FormRequest():发起post请求
-
请求传参:
- 作用:可以实现深度爬取(爬取的数据没有存在于同一张页面中)
- 如何实现:
- Yield scrapy.Request(url,callback,meta):meta是一个字典,meta可以将自身传递给callback这个回调函数。
- 在回调函数中,可以通过response.meta获取传递过来的meta字典
-
中间件:
- 作用:拦截到所有的请求和响应
- 常用的功能:
- 设置请求代理(常用)
- cookie设置
-
全站数据爬取(将所有页码对应页面的数据进行爬取)
- CrawlSpider技术
- 可以创建一个基于CrawlSpider的爬虫类
- scrapy genspider -t crawl spiderName www.xxx.com
- 链接提取器LinkExtractor(rule=‘正则’):
- 可以根据正则匹配的要求在页面中提取指定的链接(url)
- 规则解析器Rule(link,callback,follow=True):
- Rule可以将链接提取器提取到的链接进行请求发送,然后根据指定规则(callback)对请求到的数据进行数据解析
- 发现:链接提取器提取到链接的个数就是callback这个回调函数调用的次数。
- 可以创建一个基于CrawlSpider的爬虫类
- CrawlSpider技术
-
分布式:
- 编码流程:
- 导包:在爬虫文件中导入RedisCrawlSpider
- 将爬虫类的父类修改为RedisCrawlSpider
- 将start_urls替换成redis_key属性(调度器队列的名称)
- 数据解析解析和item提交管道操作
- settings中配置可以被共享的管道类和调度器类即可
- settings配置redis数据库的访问接口
- 配置redis数据库的配置文件(redis.window.conf)
- 取消127.0.0.1的默认绑定
- 取消保护模式:protected mode = no
- 启动redis的服务端和客户端
- 启动scrapy的分布式项目
- 将起始的url扔入到redis-key表示的调度器队列中即可
- 编码流程:
-
增量式
- 核心:去重
- 如何去重?
- 使用一个记录表
- 记录表需要具备两个功能:1.可以去重 2.可以持久化存储
- 因此使用redis的set充当记录表
- 使用一个记录表
- 如何去重?
- 数据指纹:
- 记录表中通常存储的是数据指纹
- 数据指纹:爬取到的数据的唯一标识
- 使用数据的md5值
- 详情页的url
- 核心:去重
web逆向
- 什么叫做逆向?
- 将js代码改写成python代码,这个过程就是逆向。
- 为什么要把js代码改写成python代码?
- 网站中,有些数据是通过js代码生成的,因此,需要将生成该数据的js代码运行,获取运行结果,该结果就是我们要爬取的数据。
- 如何将js代码改写成python代码?
- 手动改写:不选择
- 自动改写:PyExceJs模块实现基于python代码执行js代码
- 逆向通产用来处理什么样的问题?
- 处理动态变化的请求参数
- 破解加密的响应数据
- 处理动态变化的cookie值(终极武器)
相关文章:

python爬虫复习
requests模块 爬虫的分类 通用爬虫:将一整张页面进行数据采集聚焦爬虫:可以将页面中局部或指定的数据进行采集 聚焦爬虫是需要建立在通用的基础上来实现 功能爬虫:基于selenium实现的浏览器自动化的操作分布式爬虫:使用分布式机群…...

kotlin知识体系(五) :Android 协程全解析,从作用域到异常处理的全面指南
1. 什么是协程 协程(Coroutine)是轻量级的线程,支持挂起和恢复,从而避免阻塞线程。 2. 协程的优势 协程通过结构化并发和简洁的语法,显著提升了异步编程的效率与代码质量。 2.1 资源占用低(一个线程可运行多个协程)…...
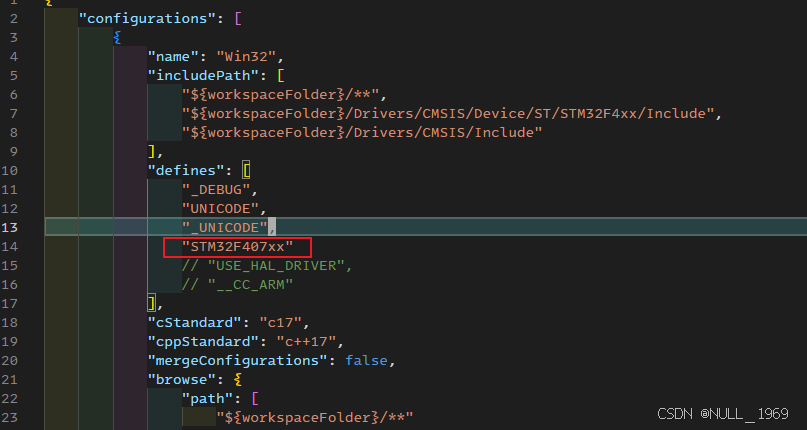
vscode stm32 variable uint32_t is not a type name 问题修复
问题 在使用vscodekeil开发stm32程序时,发现有时候vscode的自动补全功能失效,且problem窗口一直在报错。variable “uint32_t” is not a type name uint32_t 定义位置 uint32_t 实际是在D:/Keil_v5/ARM/ARMCC/include/stdint.h中定义的。将D:/Keil_v5…...
Formality:Bug记录
相关阅读 Formalityhttps://blog.csdn.net/weixin_45791458/category_12841971.html?spm1001.2014.3001.5482 本文记录博主在使用Synopsys的形式验证工具Formality中遇到的一个Bug。 Bug复现 情况一 // 例1 module dff (input clk, input d_in, output d_out …...

在ubuntu20.04+系统部署VUE及Django项目的过程记录——以腾讯云为例
目录 1. 需求2. 项目准备3. VUE CLI项目部署3.1 部署前的准备3.1.1 后端通信路由修改3.1.2 导航修改 3.2 构建项目3.3 配置nginx代理 4. 后端配置4.1 其他依赖项4.2 单次执行测试4.3 创建Systemd 服务文件4.4 配置 Nginx 作为反向代理 5. 其他注意事项 1. 需求 近期做一些简单…...

回归,git 分支开发操作命令
核心分支说明 主分支(master/production)存放随时可部署到生产环境的稳定代码,仅接受通过测试的合并请求。 开发分支(develop)集成所有功能开发的稳定版本,日常开发的基础分支,从该分支创建特性…...
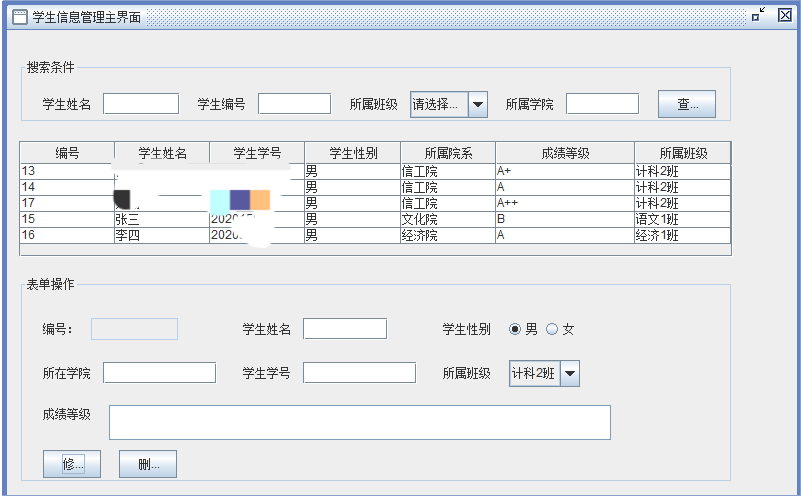
【java+Mysql】学生信息管理系统
学生信息管理系统是一种用于管理学生信息的软件系统,旨在提高学校管理效率和服务质量。本课程设计报告旨在介绍设计和实现学生信息管理系统的过程。报告首先分析了系统的需求,包括学生基本信息管理、成绩管理等功能。接着介绍了系统的设计方案࿰…...

小白从0学习网站搭建的关键事项和避坑指南(2)
以下是针对小白从零学习网站搭建的 进阶注意事项和避坑指南(第二期),覆盖开发中的高阶技巧、常见陷阱及解决方案,帮助你在实战中提升效率和质量: 一、进阶技术选型避坑 1. 前端框架选择 误区:盲目追求最新…...
Windows 10 上安装 Spring Boot CLI详细步骤
在 Windows 10 上安装 Spring Boot CLI 可以通过以下几种方式完成。以下是详细的步骤说明: 1. 手动安装(推荐) 步骤 1:下载 Spring Boot CLI 访问 Spring Boot CLI 官方发布页面。下载最新版本的 .zip 文件(例如 sp…...

spring boot -- 配置文件application.properties 换成 application.yml
在Spring Boot项目中,application.properties和application.yml是两种常用的配置文件格式,它们各自具有不同的特点和适用场景2。以下是它们之间的主要差异2: 性能差异 4: 加载机制 2: application.properties文件会被加载到内存中,并且只加载一次,之后直接从内存中读取…...

Spring Boot实战:基于策略模式+代理模式手写幂等性注解组件
一、为什么需要幂等性? 核心定义:在分布式系统中,一个操作无论执行一次还是多次,最终结果都保持一致。 典型场景: 用户重复点击提交按钮网络抖动导致的请求重试消息队列的重复消费支付系统的回调通知 不处理幂等的风…...

【Rust 精进之路之第14篇-结构体 Struct】定义、实例化与方法:封装数据与行为
系列: Rust 精进之路:构建可靠、高效软件的底层逻辑 作者: 码觉客 发布日期: 2025-04-20 引言:超越元组,给数据赋予意义 在之前的学习中,我们了解了 Rust 的基本数据类型(标量)以及两种基础的复合类型:元组 (Tuple) 和数组 (Array)。元组允许我们将不同类型的值组合…...

postgres 数据库信息解读 与 sqlshell常用指令介绍
数据库信息: sqlshell Server [localhost]: 192.168.30.101 Database [postgres]: Port [5432]: 5432 Username [postgres]: 用户 postgres 的口令: psql (15.12, 服务器 16.8 (Debian 16.8-1.pgdg120+1)) 警告:psql 主版本15,服务器主版本为16.一些psql功能可能无法正常使…...

论文阅读:2024 arxiv DeepInception: Hypnotize Large Language Model to Be Jailbreaker
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 DeepInception: Hypnotize Large Language Model to Be Jailbreaker DeepInception:催眠大型语言模型,助你成为越狱者 https://arxiv.org/pdf/2311.0…...
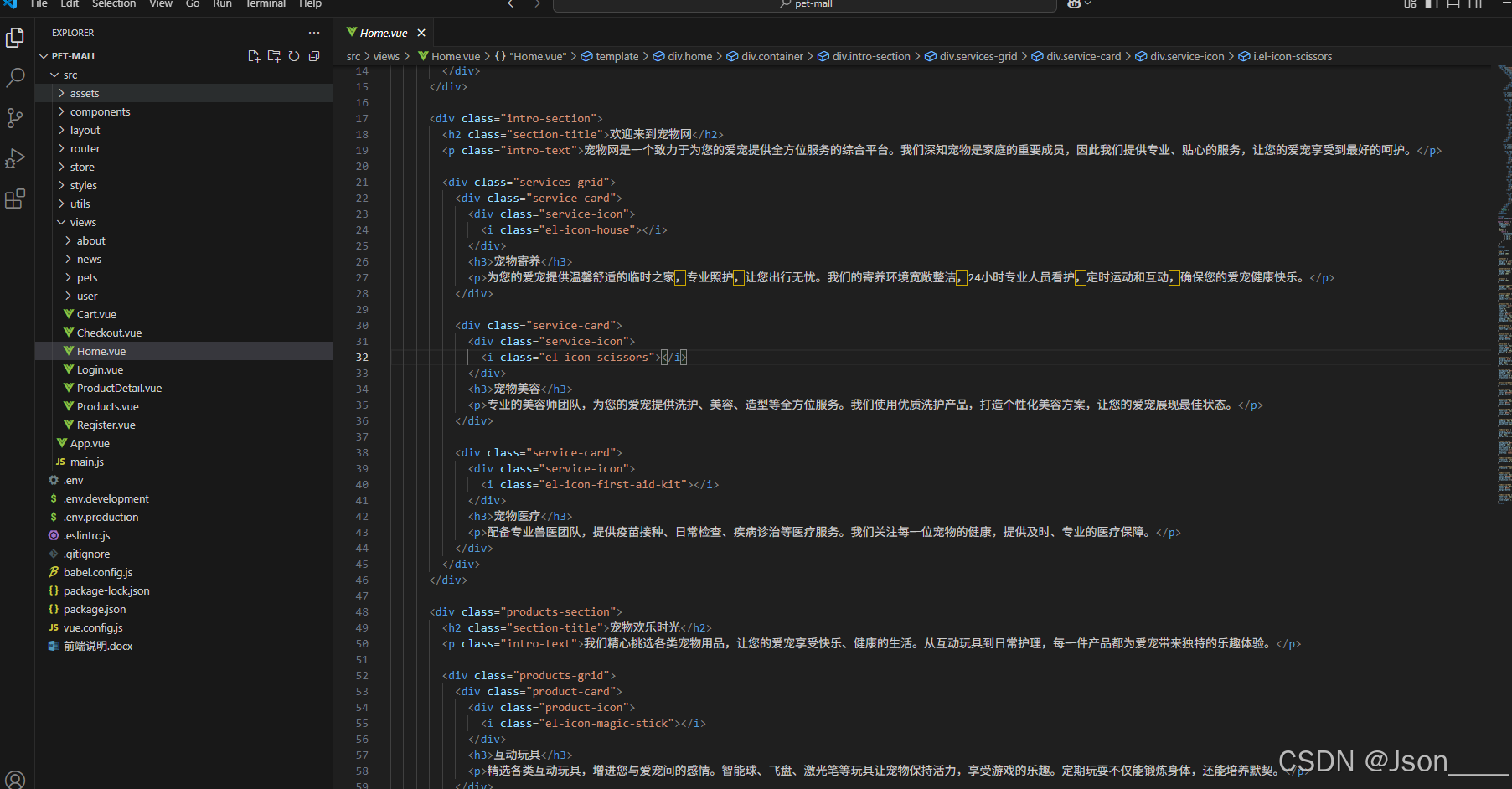
vue2技术练习-开发了一个宠物相关的前端静态商城网站-宠物商城网站
为了尽快学习掌握相关的前端技术,最近又实用 vue2做了一个宠物行业的前端静态网站商城。还是先给大家看一下相关的网站效果: 所以大家如果想快速的学习或者掌握一门编程语言,最好的方案就是通过学习了基础编程知识后,就开始利用…...
嵌入式学习——远程终端登录和桌面访问
目录 通过桥接模式连接虚拟机和Windows系统 1、桥接模式 2、虚拟机和Windows连接(1) 3、虚拟机和Windows连接(2) 在Linux虚拟机中创建新用户 Windows系统环境下对Linux系统虚拟机操作 远程登录虚拟机(1ÿ…...

wpf stylet框架 关于View与viewmodel自动关联绑定的问题
1.1 命名规则 Aview 对应 AVIewModel, 文件夹 views 和 viewmodels 1.2 需要注册服务 //RootViewModel是主窗口 public class Bootstrapper : Bootstrapper<RootViewModel>{/// <summary>/// 配置IoC容器。为数据共享创建服务/// </summary…...
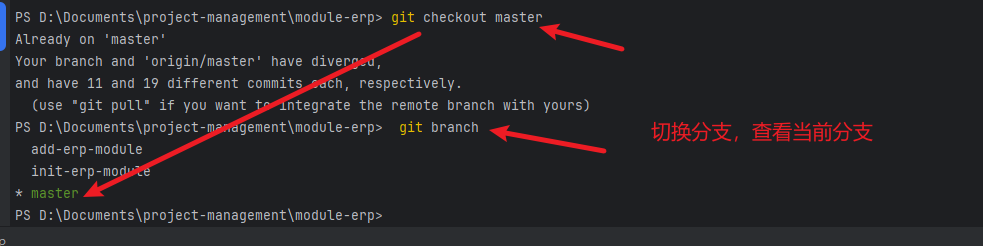
如何新建一个空分支(不继承 master 或任何提交)
一、需求分析: 在 Git 中,我们通常通过 git branch 来新建分支,这些分支默认都会继承当前所在分支的提交记录。但有时候我们希望新建一个“完全干净”的分支 —— 没有任何提交,不继承 master 或任何已有内容,这该怎么…...

HarmonyOS-ArkUI-动画分类简介
本文的目的是,了解一下HarmonyOS动画体系中的分类。有个大致的了解即可。 动效与动画简介 动画,是客户端提升界面交互用户体验的一个重要的方式。可以使应用程序更加生动灵越,提高用户体验。 HarmonyOS对于界面的交互方面,围绕回归本源的设计理念,打造自然,流畅品质一提…...

Qt编写推流程序/支持webrtc265/从此不用再转码/打开新世界的大门
一、前言 在推流领域,尤其是监控行业,现在主流设备基本上都是265格式的视频流,想要在网页上直接显示监控流,之前的方案是,要么转成hls,要么魔改支持265格式的flv,要么265转成264,如…...

[第十六届蓝桥杯 JavaB 组] 真题 + 经验分享
A:逃离高塔(AC) 这题就是简单的签到题,按照题意枚举即可。需要注意的是不要忘记用long,用int的话会爆。 📖 代码示例: import java.io.*; import java.util.*; public class Main {public static PrintWriter pr ne…...
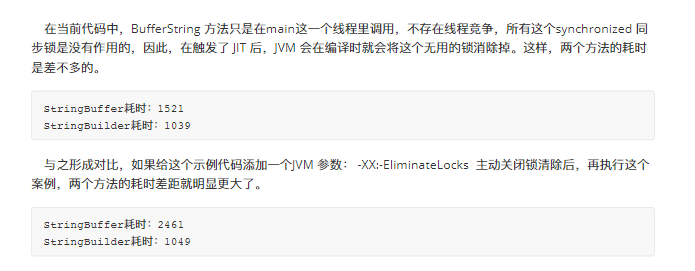
深⼊理解 JVM 执⾏引擎
深⼊理解 JVM 执⾏引擎 其中前端编译是在 JVM 虚拟机之外执⾏,所以与 JVM 虚拟机没有太⼤的关系。任何编程语⾔,只要能够编译出 满⾜ JVM 规范的 Class ⽂件,就可以提交到 JVM 虚拟机执⾏。⾄于编译的过程,如果你不是想要专⻔去研…...
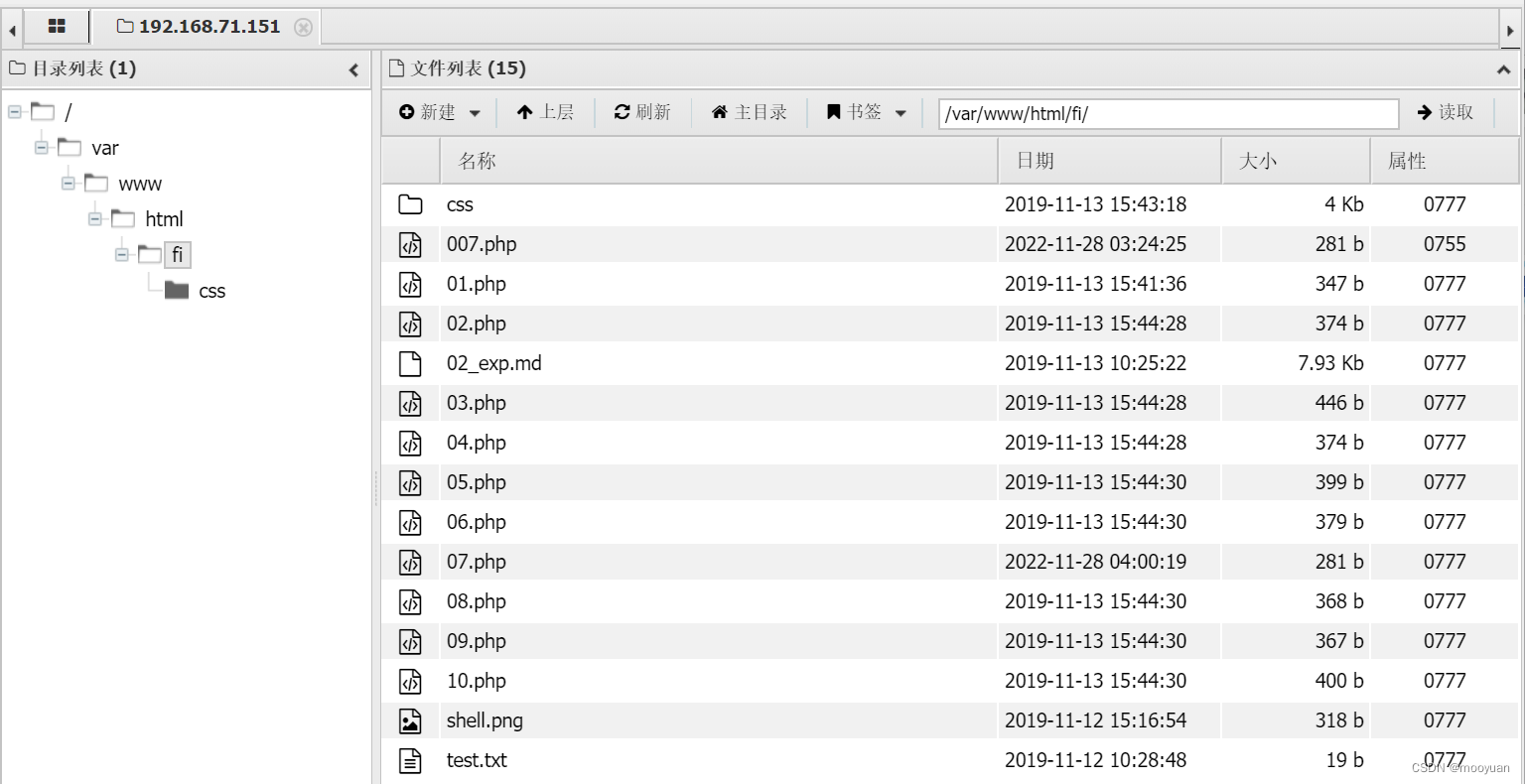
iwebsec靶场 文件包含关卡通关笔记11-ssh日志文件包含
目录 日志包含 1.构造恶意ssh登录命令 2.配置ssh日志开启 (1)配置sshd (2)配置rsyslog (3)重启服务 3.写入webshell木马 4.获取php信息渗透 5.蚁剑连接 日志包含 1.构造恶意ssh登录命令 ssh服务…...
kafka菜鸟教程
一、kafka原理 1、kafka是一个高性能的消息队列系统,能够处理大规模的数据流,并提供低延迟的数据传输,它能够以每秒数十万条消息的速度进行读写操作。 二、kafka优点 1、服务解耦 (1)提高系统的可维护性 通过服务…...
应用镜像是什么?轻量应用服务器的镜像大全
应用镜像是轻量应用服务器专属的,镜像就是轻量应用服务器的装机盘,应用镜像在原有的纯净版操作系统上集成了应用程序,例如WordPress应用镜像、宝塔面板应用镜像、WooCommerce等应用,阿里云服务器网aliyunfuwuqi.com整理什么是轻量…...
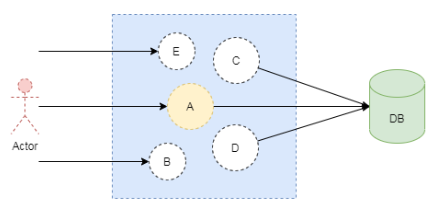
深入理解分布式缓存 以及Redis 实现缓存更新通知方案
一、分布式缓存简介 1. 什么是分布式缓存 分布式缓存:指将应用系统和缓存组件进行分离的缓存机制,这样多个应用系统就可以共享一套缓存数据了,它的特点是共享缓存服务和可集群部署,为缓存系统提供了高可用的运行环境,…...
Spring Boot 中的自动配置原理
2025/4/6 向全栈工程师迈进! 一、自动配置 所谓的自动配置原理就是遵循约定大约配置的原则,在boot工程程序启动后,起步依赖中的一些bean对象会自动的注入到IOC容器中。 在讲解Spring Boot 中bean对象的管理的时候,我们注入bean对…...
)
软考高级-系统架构设计师 论文范文参考(一)
文章目录 论SOA技术的应用论SOA在企业信息化中的应用论UP(统一过程方法)的应用论分布式数据库的设计与实现论改进Web服务器性能的有关技术论基于UML的需求分析论基于构件的软件开发论基于构件的软件开发(二) 论SOA技术的应用 摘要: 本人于…...
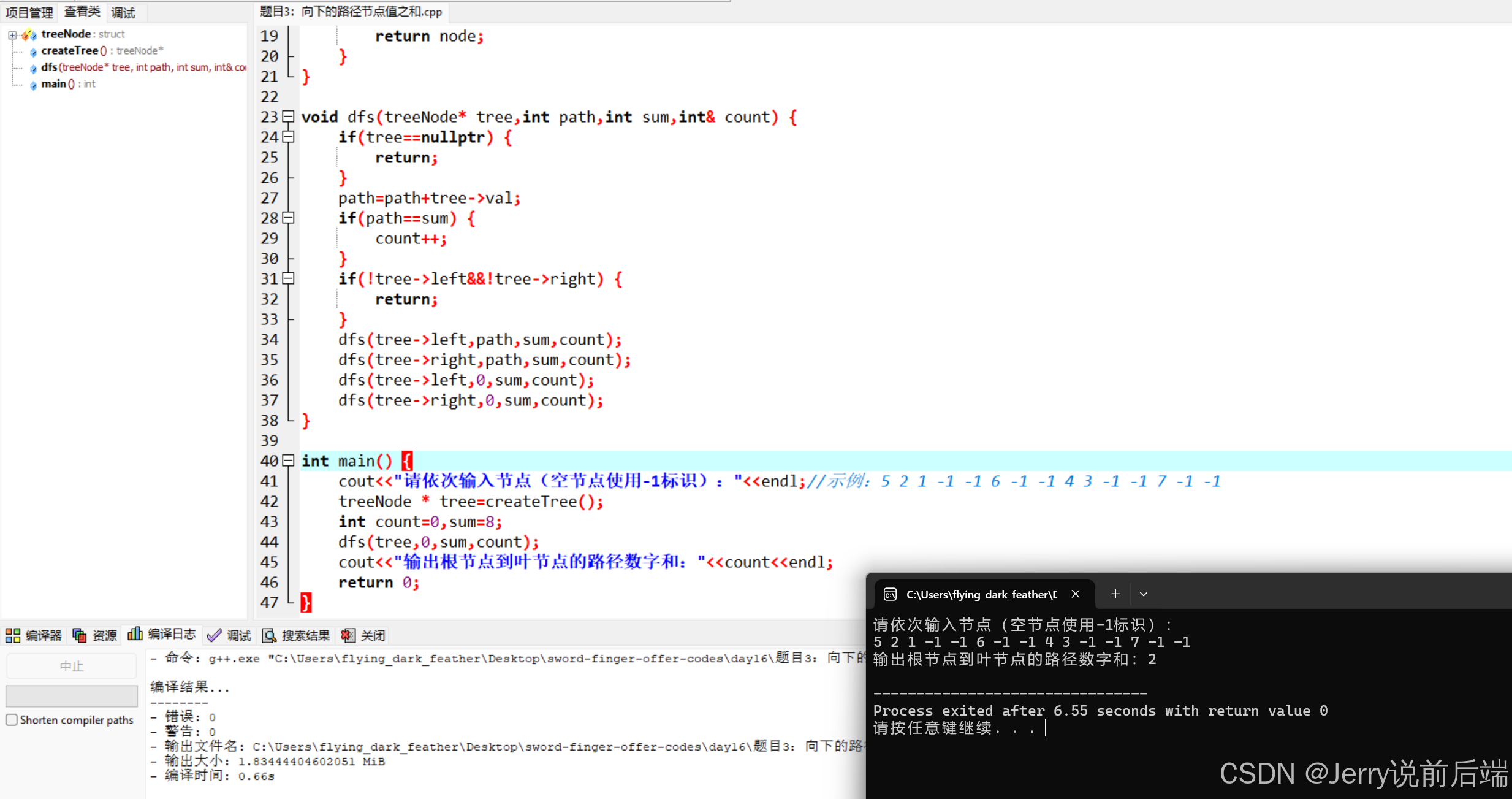
剑指Offer(数据结构与算法面试题精讲)C++版——day16
剑指Offer(数据结构与算法面试题精讲)C版——day16 题目一:序列化和反序列化二叉树题目二:从根节点到叶节点的路径数字之和题目三:向下的路径节点值之和附录:源码gitee仓库 题目一:序列化和反序…...
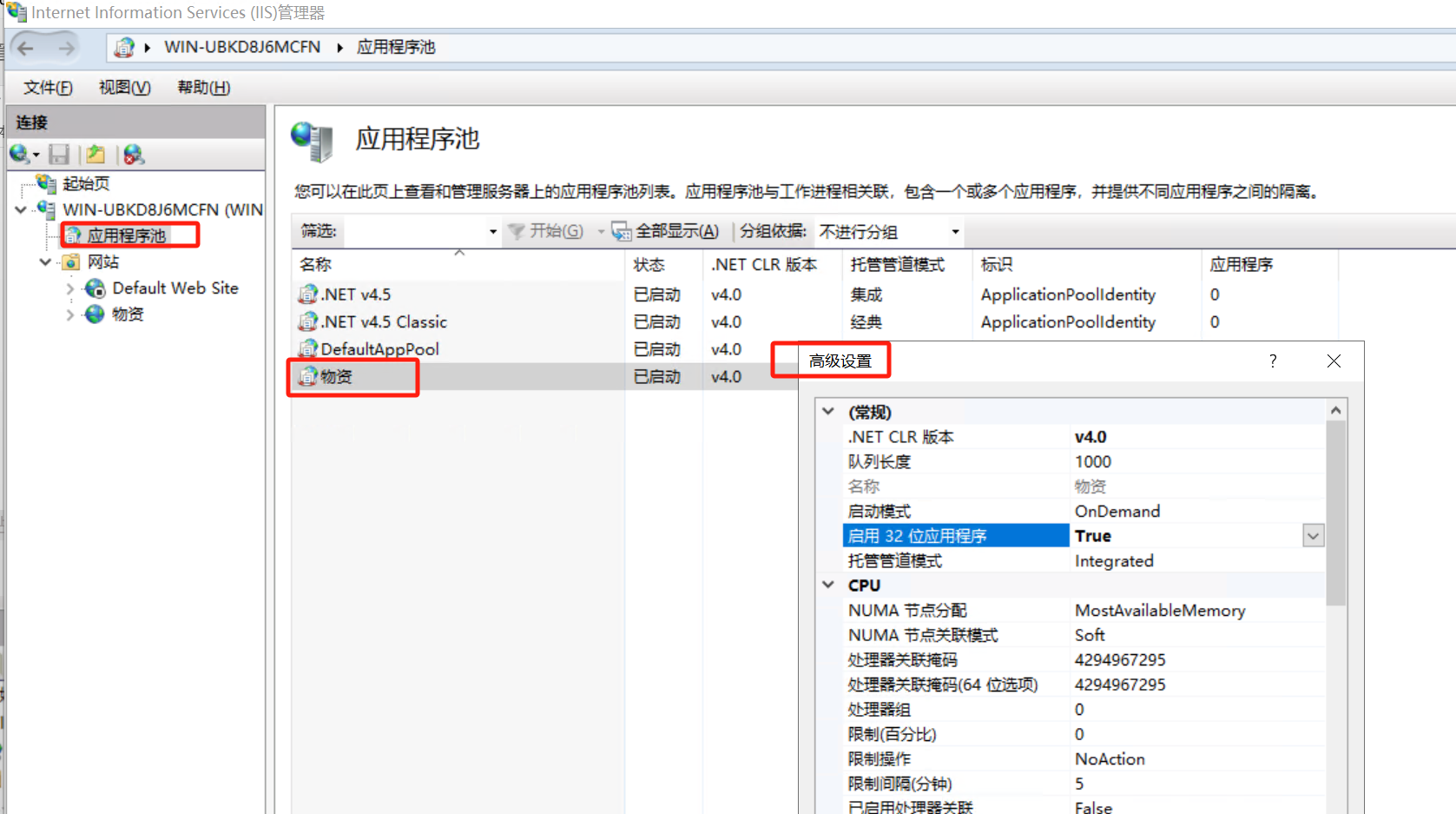
windows server C# IIS部署
1、添加IIS功能 windows server 2012、windows server 2016、windows server 2019 说明:自带的是.net 4.5 不需要安装.net 3.5 尽量使用 windows server 2019、2016高版本,低版本会出现需要打补丁的问题 2、打开IIS 3、打开iis应用池 .net 4.5 4、添…...