Kubeflow 快速入门实战(二) - Pipelines / Katib / KServer
承接前文博客 Kubeflow 快速入门实战(一)
Kubeflow 快速入门实战(一) - 简介 / Notebooks-CSDN博客文章浏览阅读441次,点赞19次,收藏6次。本文主要介绍了 Kubeflow 的主要功能和能力,适用场景,基本用法。以及Notebook,piplines,katib,KServer 的入门级示例https://blog.csdn.net/weixin_39403185/article/details/147337813?spm=1001.2014.3001.5502
4.2 Kubeflow piplines 示例
1) 生成 pipelines 配置文件
任意 python 环境都成
## 安装依赖
pip install kfp --upgrade准备流水线代码 simple_pipeline.py
# simple_pipeline.py
# 1. 导入 KFP 库
from kfp import dsl
from kfp import compiler# 2. 定义组件 (Component)
# - 使用 @dsl.component 装饰器
# - 指定基础镜像 (base_image),代码将在这个镜像的容器中运行
# - 使用 Python 类型提示 (Type Hinting) 定义输入和输出
@dsl.component(base_image='python:3.9')
def add_prefix(text: str) -> str:"""在输入文本前添加 'Hello, '"""# 组件的逻辑代码return f"Hello, {text}"@dsl.component(base_image='python:3.9')
def print_message(message: str):"""打印传入的消息"""# 组件的逻辑代码print(f"Received message: {message}")# 3. 定义流水线 (Pipeline)
# - 使用 @dsl.pipeline 装饰器
# - 提供名称 (name) 和描述 (description),会显示在 UI 上
@dsl.pipeline(name='simple-greeting-pipeline',description='一个简单的打印问候语的流水线示例'
)
def simple_pipeline(recipient: str = 'World'): # 定义流水线参数"""定义流水线的工作流程"""# 4. 在流水线函数内部,实例化组件来创建任务 (Task)# - 调用组件函数 (如 add_prefix()) 会创建一个任务节点add_prefix_task = add_prefix(text=recipient) # 将流水线参数传给组件# 5. 连接任务:将一个任务的输出作为另一个任务的输入# - 使用 .output 属性来引用上一个任务的返回值print_message_task = print_message(message=add_prefix_task.output)if __name__ == '__main__':compiler.Compiler().compile(pipeline_func=simple_pipeline,package_path='simple_pipeline.yaml')print("Pipeline compiled to simple_pipeline.yaml")## 生成 可供kubeflow识别的yaml文件
python simple_pipeline.py
2) UI 控制台 创建pipelines
开始在 UI 控制台上 创建流水线

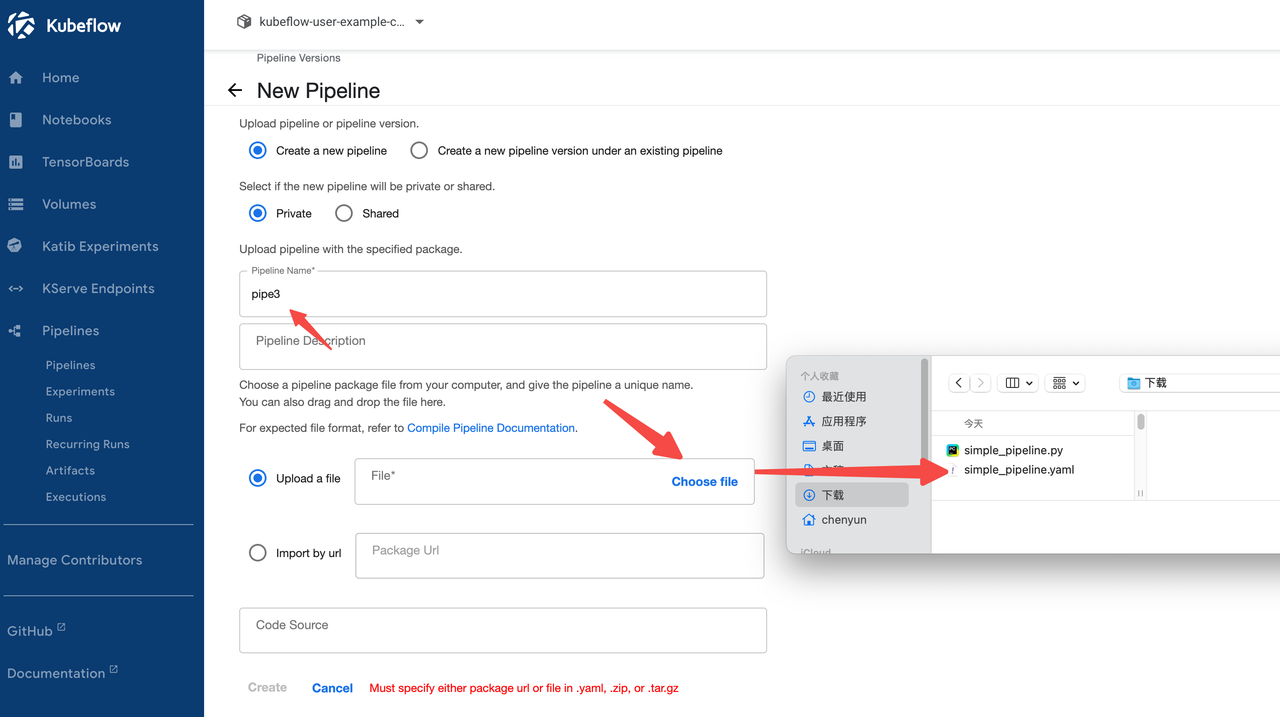
3) UI 控制台 运行pipelines
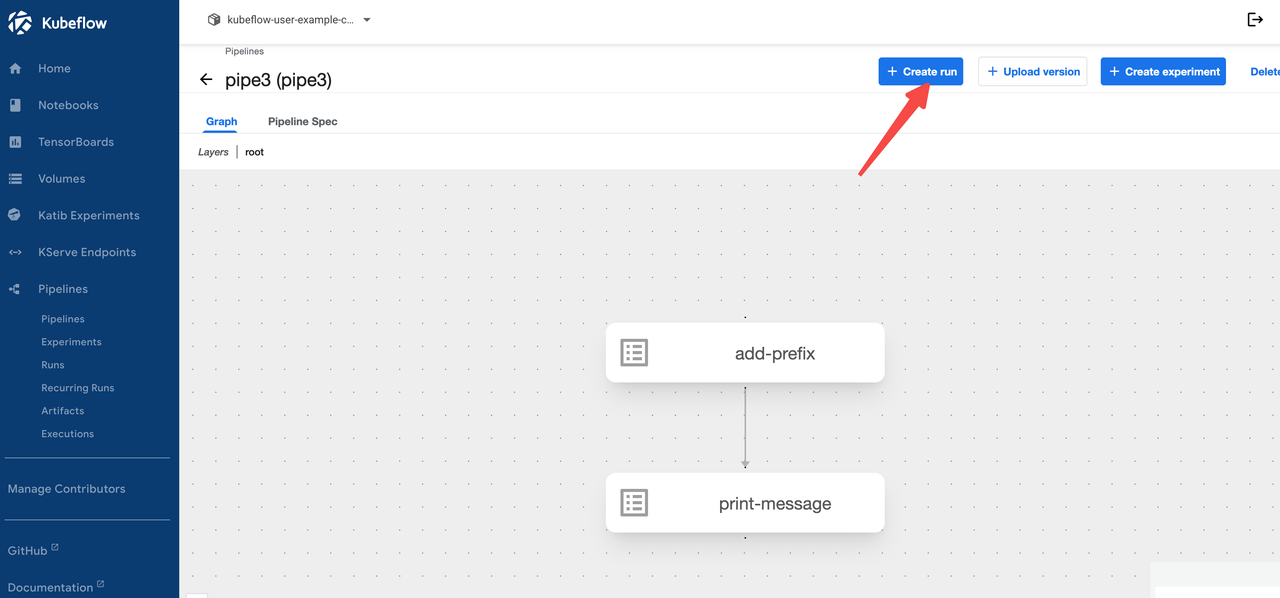
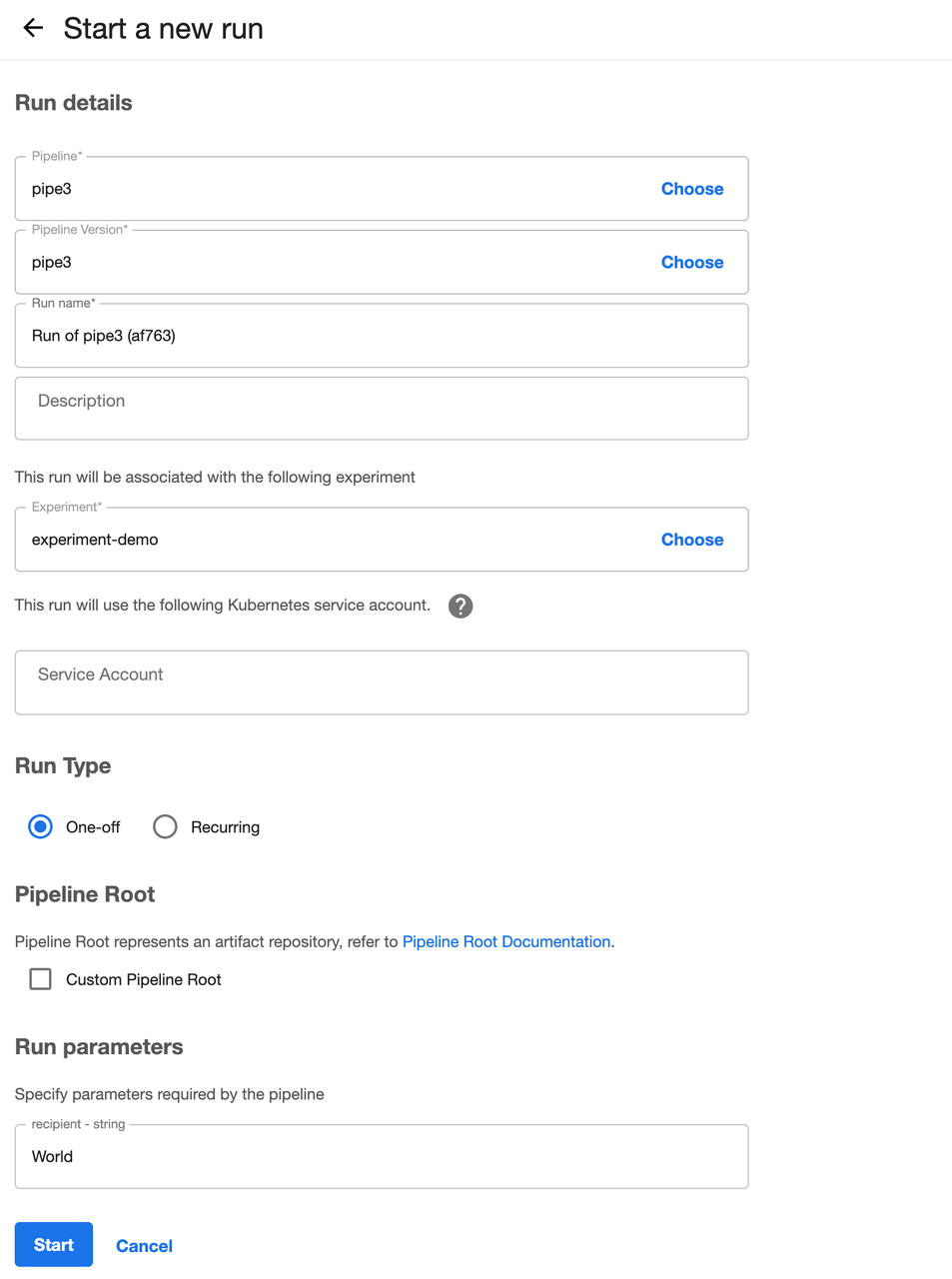
3) UI 控制台 查看pipelines结果
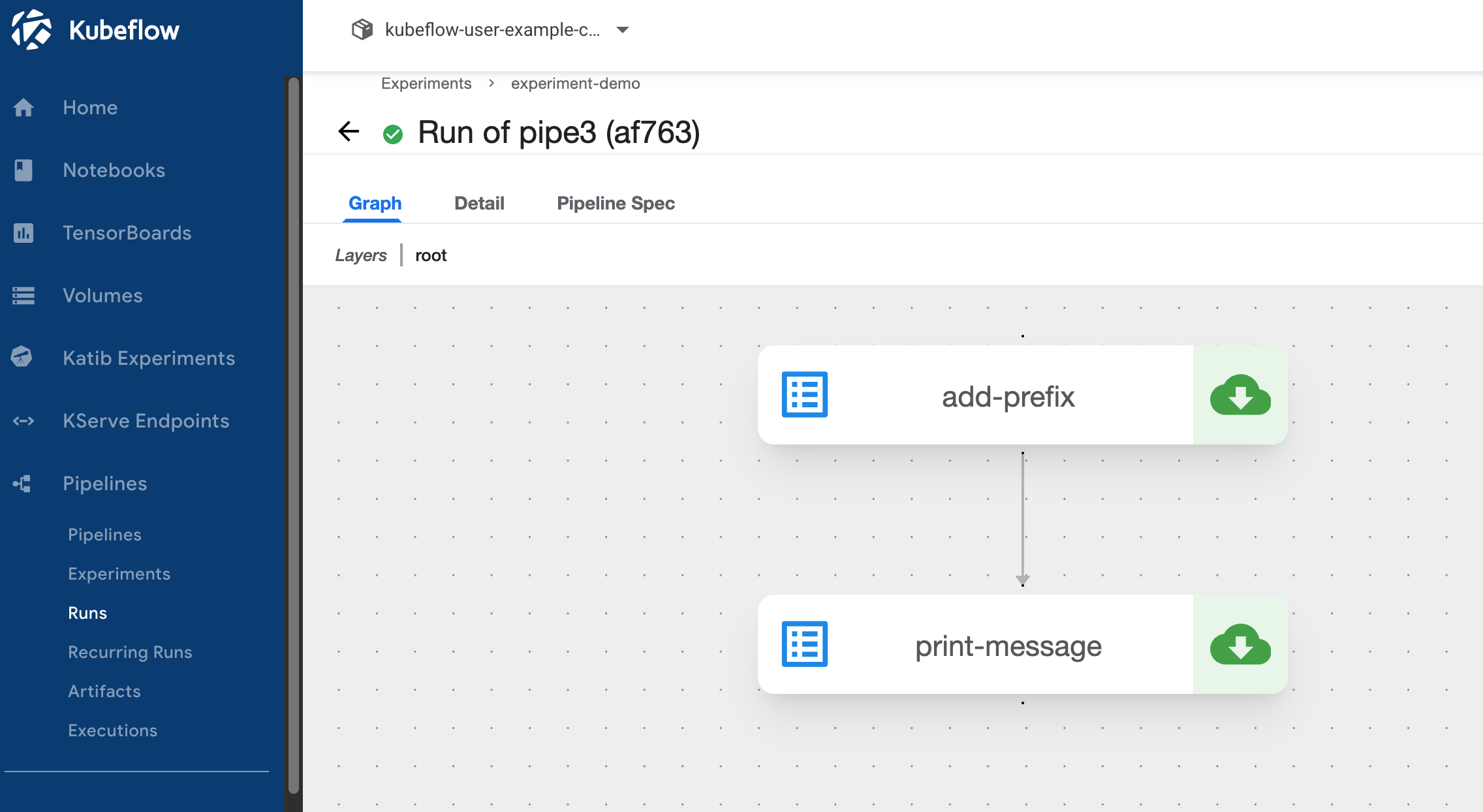
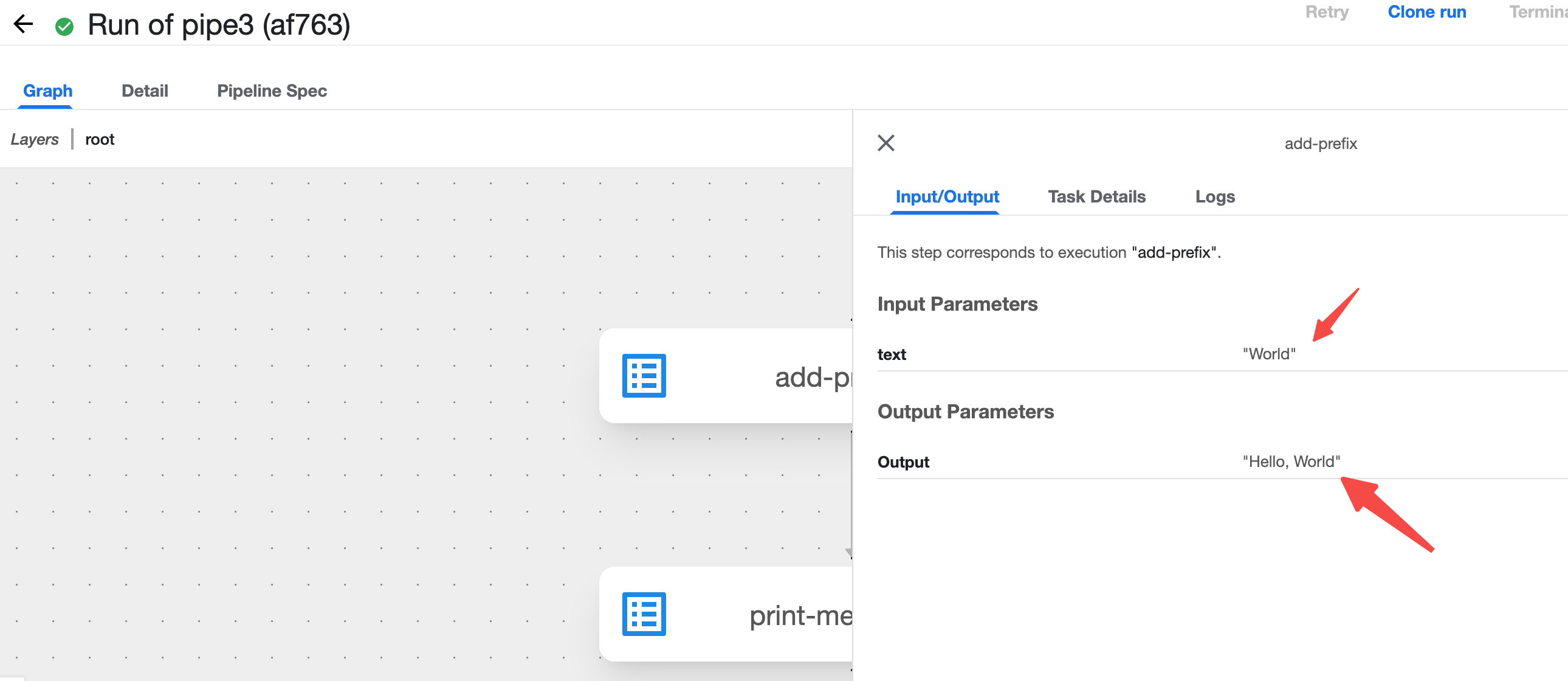

4.3 Kubeflow katib 示例
a) 脚本yaml准备
simple-function-tuning-v2.yaml
apiVersion: "kubeflow.org/v1beta1"
kind: Experiment
metadata:namespace: kubeflow-user-example-com name: simple-function-tuning-v2
spec:objective:type: maximizegoal: 99.9objectiveMetricName: Metricalgorithm:algorithmName: randomparallelTrialCount: 3maxTrialCount: 12maxFailedTrialCount: 3parameters:- name: "x"parameterType: doublefeasibleSpace:min: "-5.0"max: "5.0"- name: "y"parameterType: doublefeasibleSpace:min: "-5.0"max: "5.0"trialTemplate:trialParameters:- name: "paramX"description: Parameter X for the functionreference: "x"- name: "paramY"description: Parameter Y for the functionreference: "y"trialSpec:apiVersion: batch/v1kind: Jobspec:template:metadata:annotations:sidecar.istio.io/inject: "false"spec:containers:- name: trial-containerimage: ubuntu:22.04resources:requests:memory: "64Mi"cpu: "100m"limits:memory: "128Mi"cpu: "500m"command:- /bin/bash- -c- |set -eecho "--- Starting Trial ---"echo "Updating package lists..."apt-get update > /dev/null && apt-get upgrade -y > /dev/null && apt-get install -y bc > /dev/nullecho "Packages installed successfully."X="${trialParameters.paramX}"Y="${trialParameters.paramY}"echo "Parameters received: X=$X, Y=$Y"echo "Calculating metric..."RESULT=$(echo "scale=4; 100 - ($X-3)^2 - ($Y-5)^2" | bc)echo "Calculation result: RESULT=$RESULT"echo "Reporting metric..."echo "Metric=${RESULT}" > /var/log/katib/metrics.log \restartPolicy: NeverprimaryContainerName: trial-containermetricsCollectorSpec:collector:kind: Filesource:fileSystem:path: /var/log/katib/metrics.log filter:metricNameRegex: '^Metric$'metricValueRegex: '([+-]?\d*\.?\d+([eE][+-]?\d+)?)'b) 脚本部署并运行
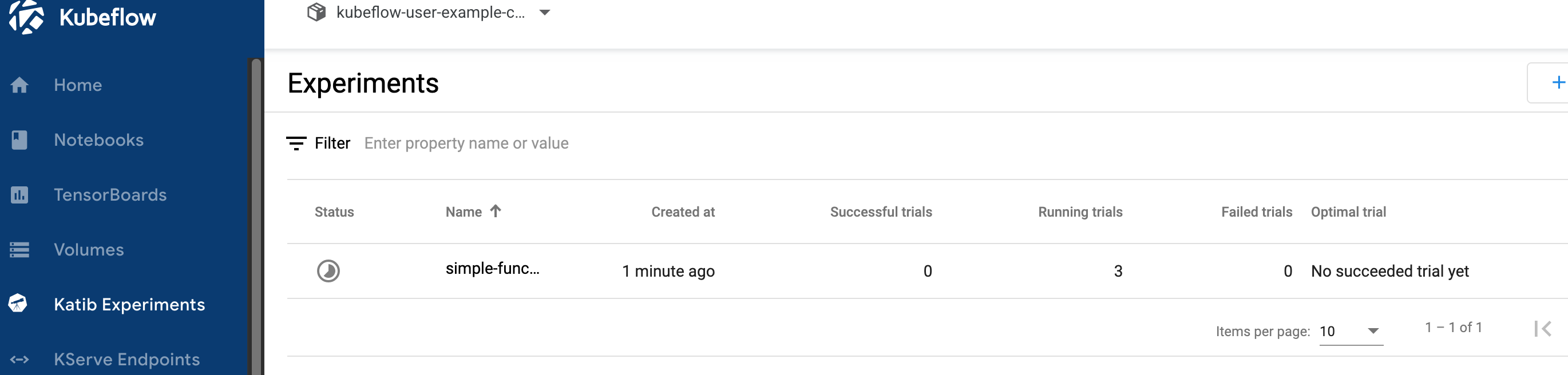
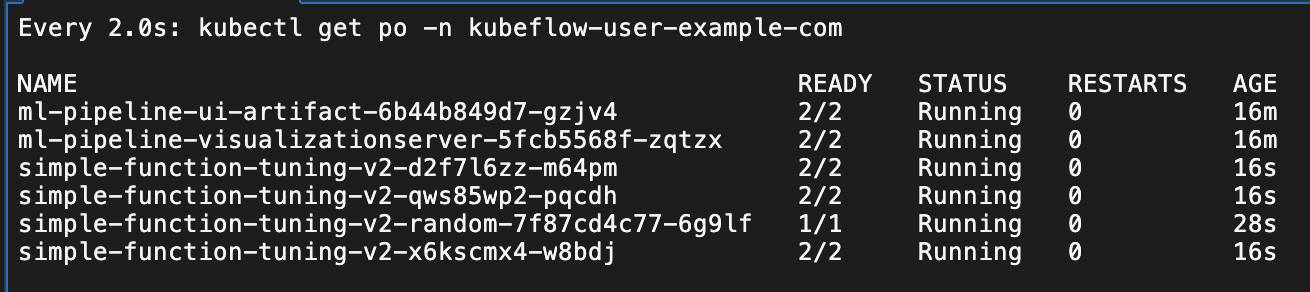
c) 运行结果查看
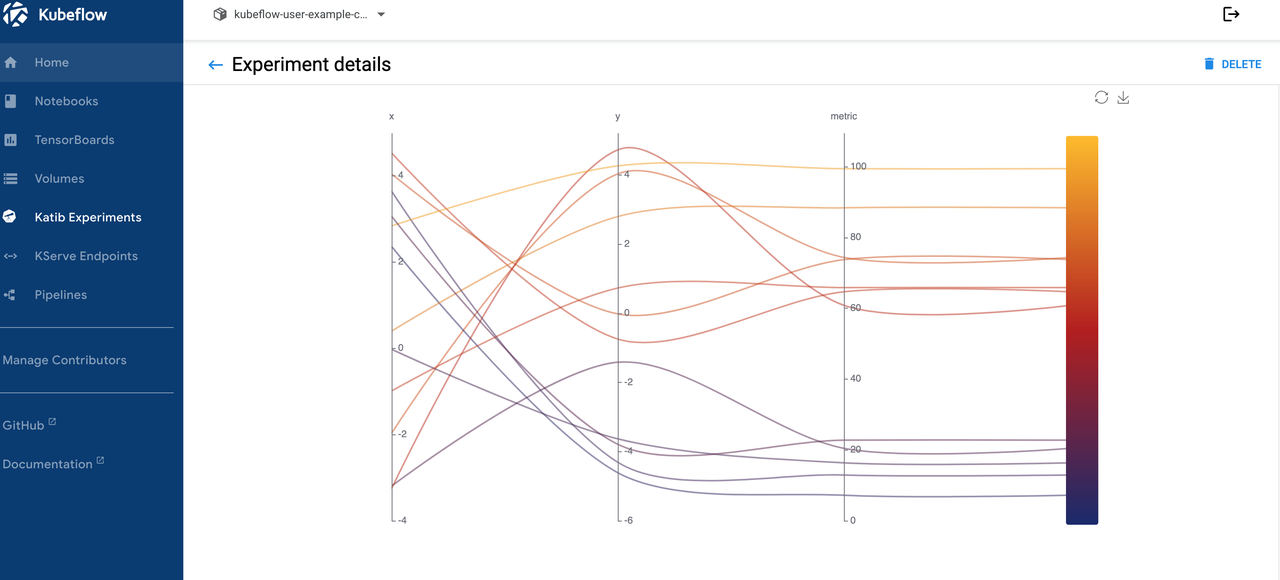
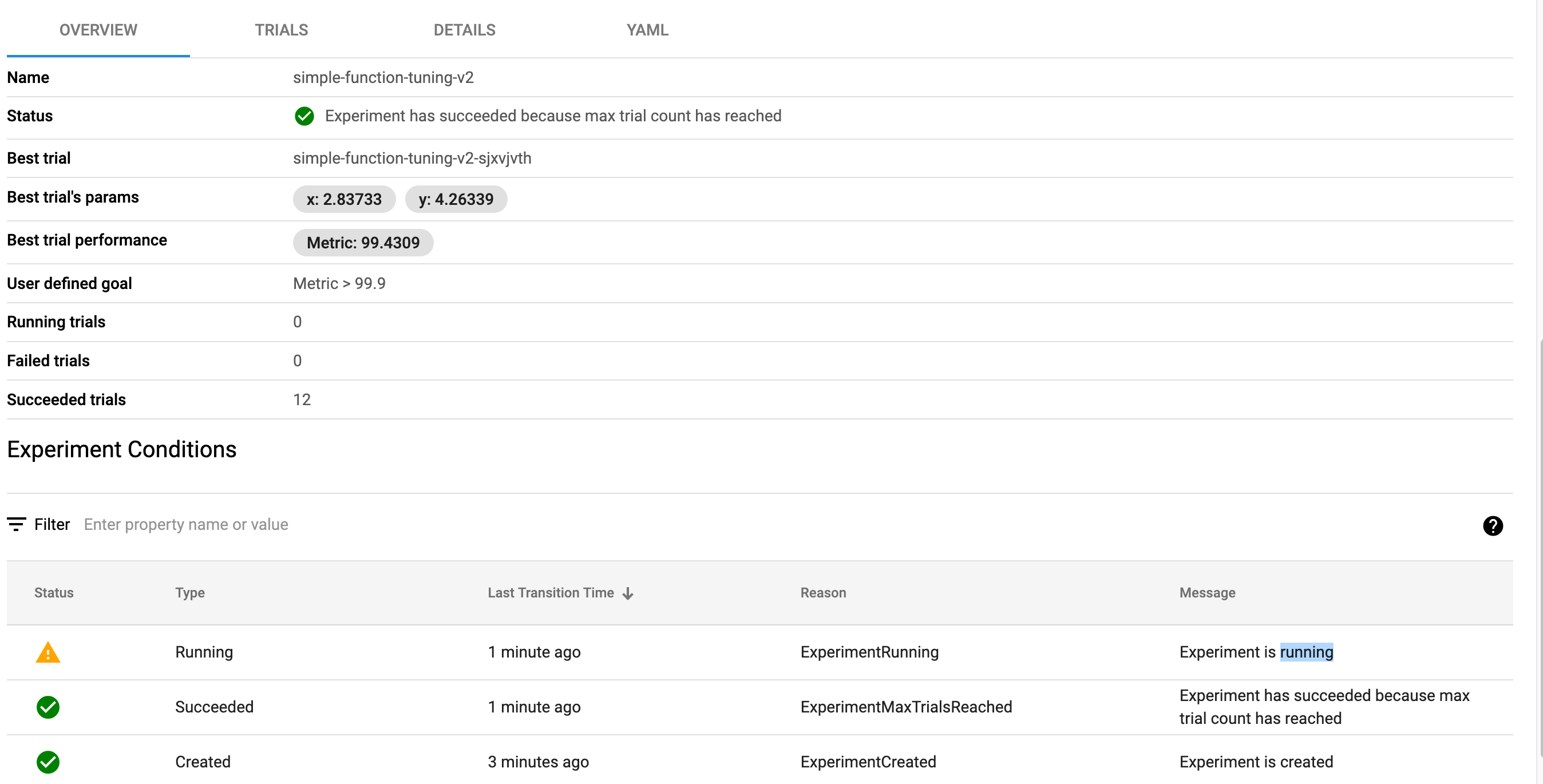
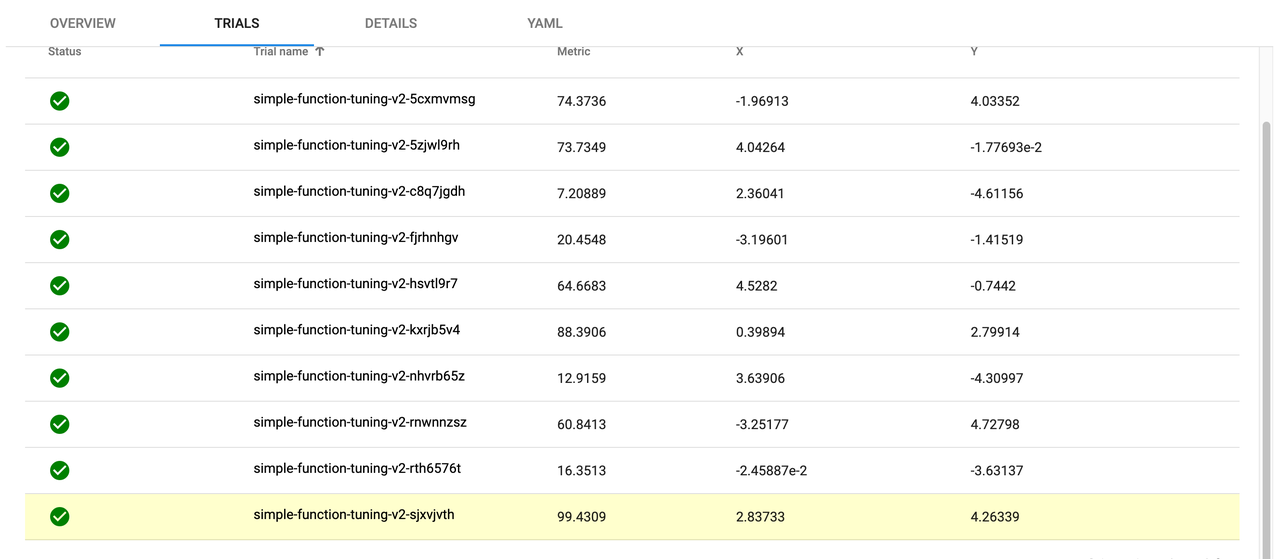
4.4 Kubeflow KServer 示例
这个模块就很复杂了 涉及到的元素特别多。画了一个简易的逻辑架构图
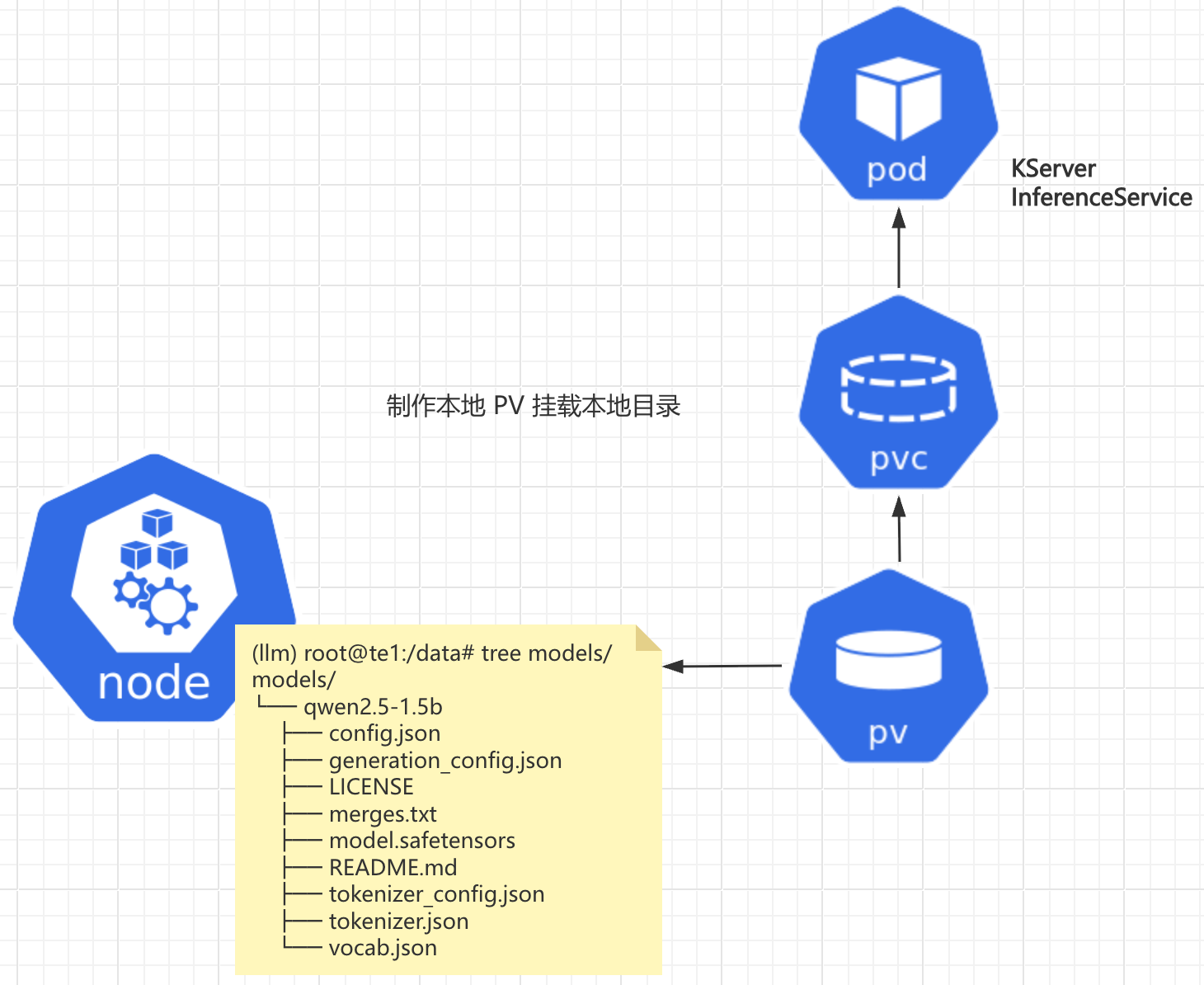
a) 基础环境准备 conda python
mkdir -p /data/modelswget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /data/Miniconda3.sh
bash /data/Miniconda3.sh -b -p /data/miniconda3echo 'export PATH="/data/miniconda3/bin:$PATH"' >> ~/.bashrc
source /data/miniconda3/bin/activateconda create -n llm python=3.10 -y
conda activate llm
echo 'conda activate llm' >> ~/.bashrc
source ~/.bashrcpip install huggingface_hub
huggingface-cli download Qwen/Qwen2.5-1.5B --resume-download --local-dir /data/models/qwen2.5-1.5bb) 镜像准备
可以白嫖一下阿里云的个人版私有仓库
model_server.py
import os
from fastapi import FastAPI, Request
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer# 模型加载路径,对应 PV 挂载点
MODEL_DIR = "/data/models/qwen2.5-1.5b" # 这个路径必须和 InferenceService 中 volumeMounts 的 mountPath 一致
MODEL_NAME = "Qwen/Qwen2-1.5B-Instruct" # 可以从环境变量读取或硬编码# 检查是否有可用的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")# 加载模型和 Tokenizer
print(f"Loading tokenizer from {MODEL_DIR}...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR, trust_remote_code=True)
print(f"Loading model from {MODEL_DIR}...")
model = AutoModelForCausalLM.from_pretrained(MODEL_DIR,torch_dtype="auto", # 或者 torch.float16 节省显存device_map="auto", # 自动将模型分片到可用设备 (GPU)trust_remote_code=True
)
# model.to(device) # 如果 device_map="auto" 不起作用或想强制指定,可以用这个
model.eval() # 设置为评估模式
print("Model loaded successfully.")# 创建 FastAPI 应用
app = FastAPI()@app.get('/')
def read_root():return {"message": "Qwen Model Server is running"}# KServe V1 Predict Protocol (可以简化为自定义 /predict 接口)
@app.post('/v1/models/{model_name}:predict')
async def predict(model_name: str, request: Request):"""接收 KServe V1 协议的请求或自定义请求预期 JSON: {"instances": [{"text": "your prompt"}]}或者简化: {"text": "your prompt"}"""body = await request.json()print(f"Received request body: {body}")# 兼容 KServe V1 和自定义格式if "instances" in body and isinstance(body["instances"], list) and "text" in body["instances"][0]:prompt_text = body["instances"][0]["text"]elif "text" in body:prompt_text = body["text"]else:return {"error": "Invalid input format. Expecting {'instances': [{'text': '...'}]} or {'text': '...'}"}, 400print(f"Generating text for prompt: {prompt_text}")try:# 构建 Qwen 需要的 messages 格式messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt_text}]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512, # 控制最大生成长度do_sample=True, # 启用采样策略,而不是贪婪解码temperature=0.7, # 控制随机性,稍小于 1.0 使输出更集中但仍有变化top_p=0.9, # Nucleus sampling,只考虑概率累积到 0.9 的词repetition_penalty=1.1 # 轻微惩罚重复 token,大于 1.0 即可,不要设置过高)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(f"Generated response: {response}")# 返回 KServe V1 兼容格式return {"predictions": [response]}except Exception as e:print(f"Error during inference: {e}")return {"error": str(e)}, 500# KServe 要求健康检查端点 (可选,但推荐)
@app.get('/healthz')
def healthz():return {"status": "ok"}requirements.txt
fastapi>=0.100.0
uvicorn>=0.20.0
torch>=2.1.0 --index-url https://download.pytorch.org/whl/cu121
transformers>=4.38.0
accelerate>=0.25.0
sentencepiece
tiktoken
einops
protobufdockerfile
FROM pytorch/pytorch:2.1.2-cuda12.1-cudnn8-runtime
WORKDIR /appCOPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt# 复制模型服务代码
COPY model_server.py .# 暴露端口 (KServe 默认希望容器监听 8080)
EXPOSE 8080# 设置时区 (可选, 但有助于日志时间戳统一)
ENV TZ=Asia/Shanghai
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone# 设置入口点,启动 FastAPI 服务
# 使用 uvicorn 运行 FastAPI 应用
CMD ["uvicorn", "model_server:app", "--host", "0.0.0.0", "--port", "8080"]## 制作镜像
docker build -t registry.ap-southeast-5.aliyuncs.com/xxx/qwen-kserve:0.5b-cu121 .
## 登录阿里云的私有仓库 免费的
docker login
##推送过去
docker push registry.ap-southeast-5.aliyuncs.com/xxx/qwen-kserve:0.5b-cu121 c) 模型准备
huggingface-cli download Qwen/Qwen2.5-1.5B --resume-download --local-dir /data/models/qwen2.5-1.5b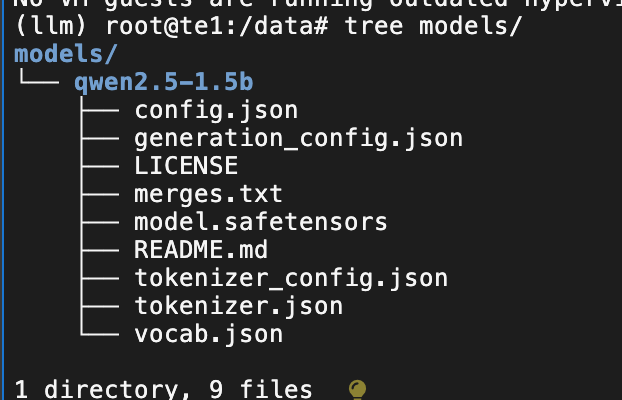
qwen-model-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:name: qwen-model-pvnamespace: kubeflow-user-example-com
spec:capacity:storage: 10Gi volumeMode: FilesystemaccessModes:- ReadWriteOncepersistentVolumeReclaimPolicy: Retain storageClassName: manual hostPath:path: "/data/models" qwen-model-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: qwen-model-pvcnamespace: kubeflow-user-example-com
spec:accessModes:- ReadWriteOncevolumeMode: Filesystemresources:requests:storage: 10Gi storageClassName: manual## 部署pv pvc
kubectl apply -f qwen-model-pv.yaml
kubectl apply -f qwen-model-pvc.yaml
d) InferenceService部署
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:name: "qwen25-15b-instruct" namespace: kubeflow-user-example-com
spec:predictor:containers:- name: kserve-containerimage: registry.ap-southeast-5.aliyuncs.com/xxxxx/qwen-kserve:0.5b-cu121imagePullPolicy: IfNotPresentresources:requests:cpu: "2"memory: "8Gi"nvidia.com/gpu: "1"limits:cpu: "4"memory: "16Gi"nvidia.com/gpu: "1"ports:- containerPort: 8080protocol: TCPvolumeMounts:- name: model-storagemountPath: /data/modelsreadOnly: truevolumes:- name: model-storagepersistentVolumeClaim:claimName: qwen-model-pvc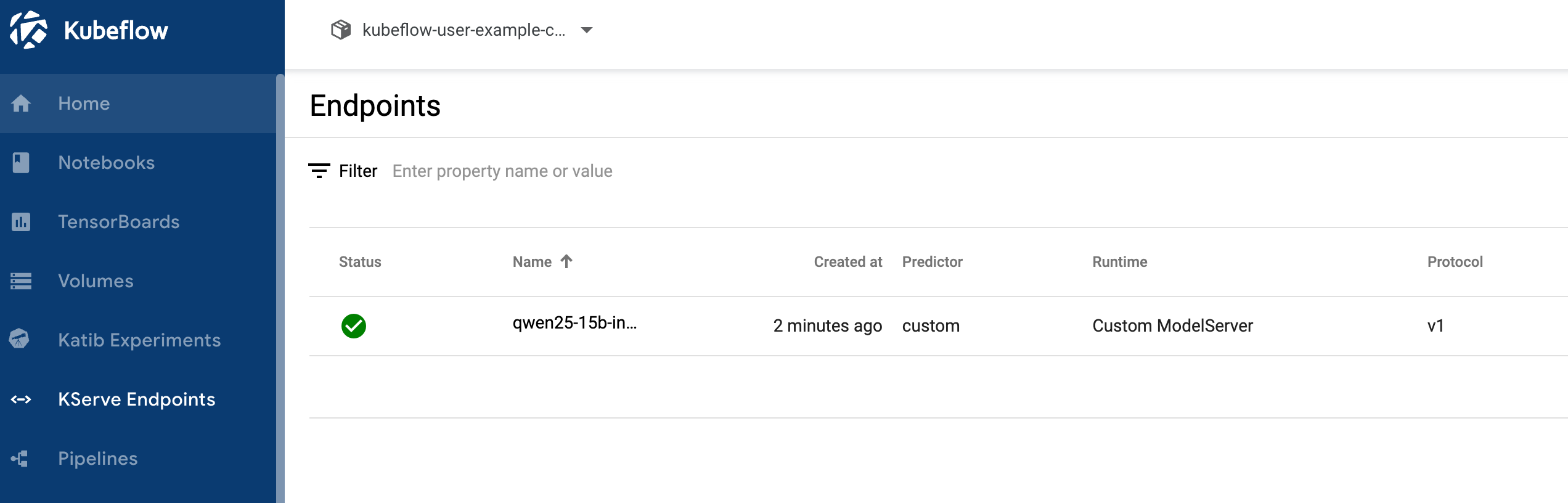
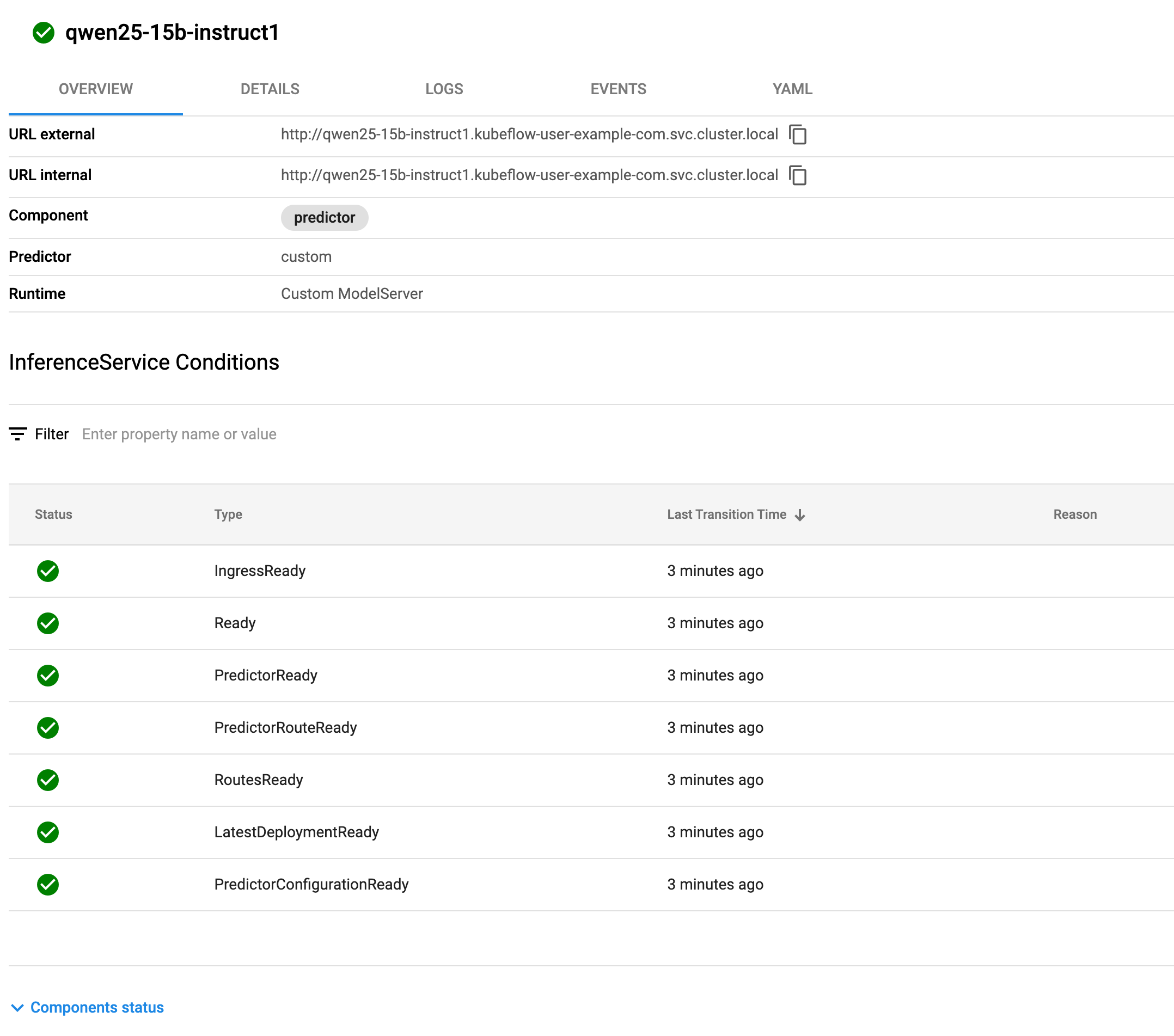
e) 测试


curl -X POST -H "Content-Type: application/json" \
http://127.0.0.1:8080/v1/models/qwen:predict \
-d '{"instances": [{"text": "你好,请简单介绍一下阿里云ECS?"}]
}' | jq .
参考:
Kubeflow Pipelines介绍与实例-CSDN博客文章浏览阅读2.5k次,点赞2次,收藏8次。kubeflow/kubeflow 是一个胶水项目,。pipelines 是基于 kubeflow 实现的工作流系统,它的目标是借助 kubeflow 的底层支持,实现出一套工作流,支持数据准备,模型训练,模型部署,可以通过代码提交等等方式触发。_kubeflow pipelinehttps://blog.csdn.net/qq_45808700/article/details/132188234?spm=1001.2101.3001.6650.4&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7ERate-4-132188234-blog-147349105.235%5Ev43%5Epc_blog_bottom_relevance_base3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7ERate-4-132188234-blog-147349105.235%5Ev43%5Epc_blog_bottom_relevance_base3&utm_relevant_index=5
相关文章:
Kubeflow 快速入门实战(二) - Pipelines / Katib / KServer
承接前文博客 Kubeflow 快速入门实战(一) Kubeflow 快速入门实战(一) - 简介 / Notebooks-CSDN博客文章浏览阅读441次,点赞19次,收藏6次。本文主要介绍了 Kubeflow 的主要功能和能力,适用场景,基本用法。以及Notebook,…...

【JavaEE初阶】多线程重点知识以及常考的面试题-多线程进阶(一)
本篇博客给大家带来的是多线程中常见的所策略和CAS知识点. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅🚀 要开心要快…...

ECA 注意力机制:让你的卷积神经网络更上一层楼
ECA 注意力机制:让你的卷积神经网络更上一层楼 在深度学习领域,注意力机制已经成为提升模型性能的重要手段。从自注意力(Self-Attention)到各种变体,研究人员不断探索更高效、更有效的注意方法。今天我们要介绍一种轻…...
)
基于定时器查询模式的LED闪烁(STC89C52单片机)
#include <reg52.h> sbit LED P0^0; sbit ADDR0 P1^0; sbit ADDR1 P1^1; sbit ADDR2 P1^2; sbit ADDR3 P1^3; sbit ENLED P1^4; void main() { unsigned char cnt 0; //定义一个计数变量,记录T0溢出次数 ENLED 0; //使能U3,选择…...
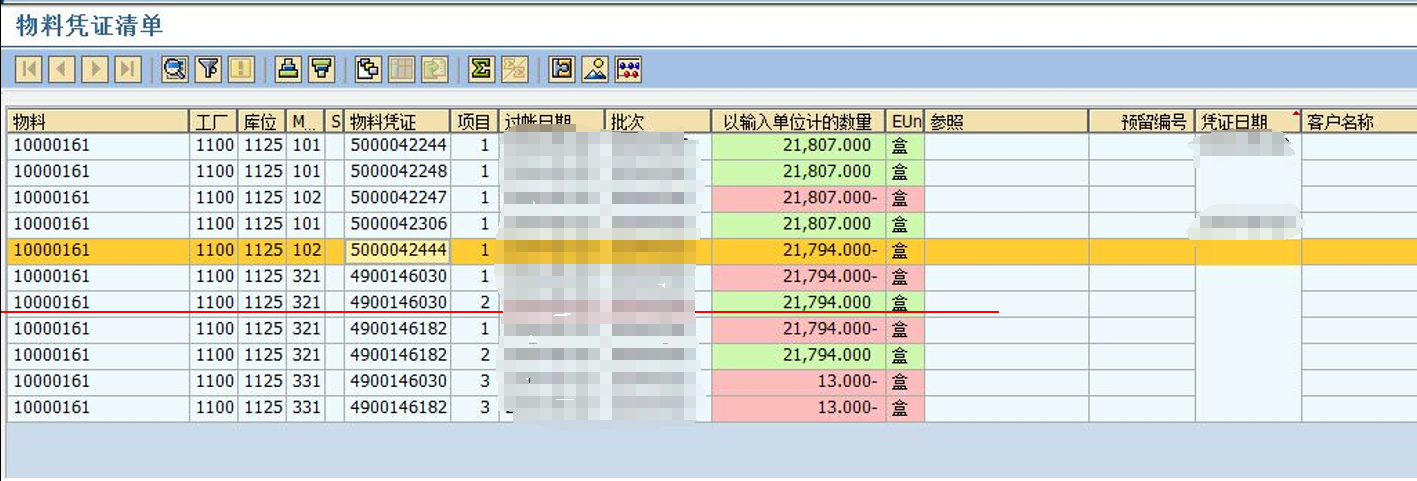
SAP系统生产跟踪报表入库数异常
生产跟踪报表入库数异常 交库21820,入库43588是不可能的 原因排查: 报表的入库数取值,是取移动类型321 (即系检验合格后过账到非限制使用)的数. 查凭证,101过账2次21807,321过账了2次21794,然后用102退1次21794.就是说这批物料重复交库了. 解决: 方案一:开发增强设…...
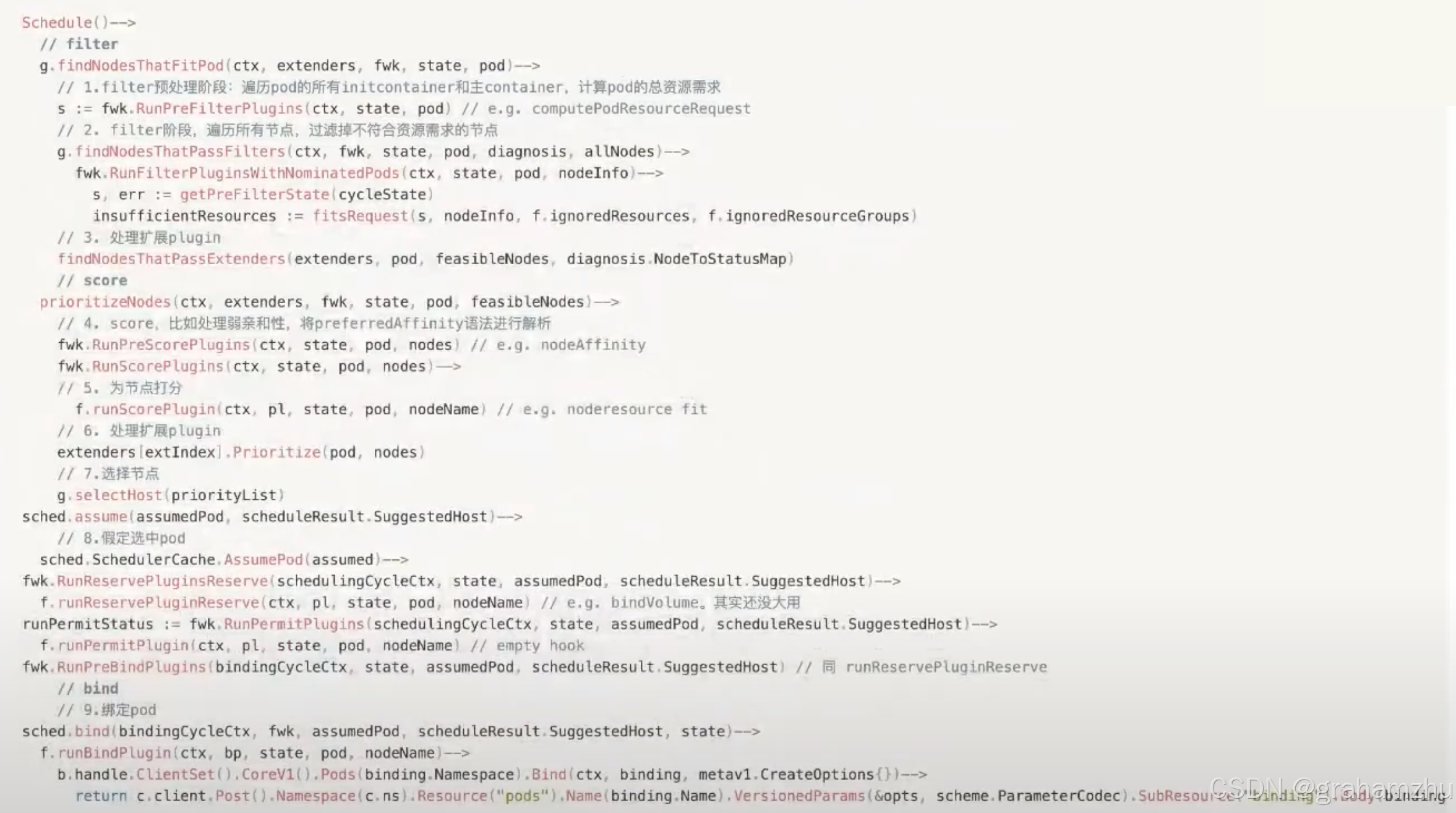
Kubernetes控制平面组件:调度器Scheduler(一)
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...
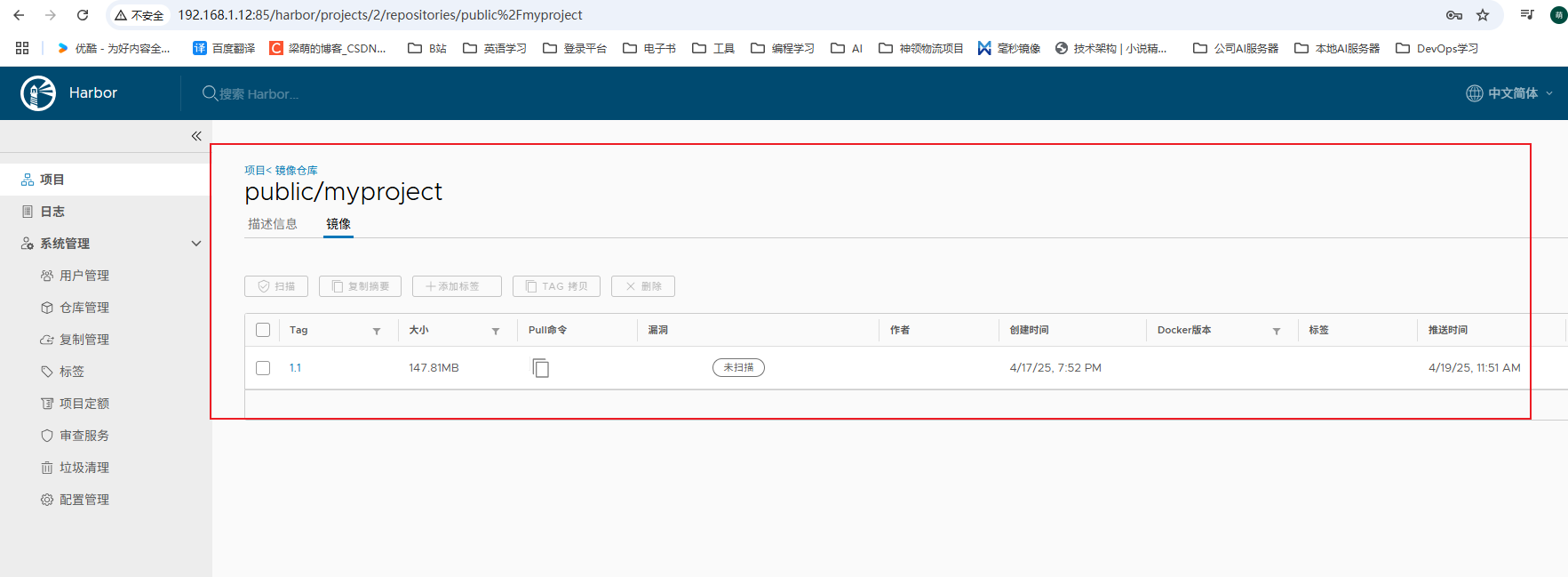
08-DevOps-向Harbor上传自定义镜像
harbor创建完成,往harbor镜像仓库中上传自定义的镜像,包括新建项目、docker配置镜像地址、镜像重命名、登录harbor、推送镜像这几个步骤,具体操作如下: harbor中新建项目 访问级别公开,代表任何人都可以拉取仓库中的镜…...

Vue v-for 循环DOM 指定dom个数展示一行
在Vue.js中,如果想根据v-for循环的结果来控制哪些元素应该在一行中展示,你可以通过计算属性或者方法来实现。这里使用CSS改变样式和js脚本两种方式做到这一点,根据你的具体需求选择适合的方法。 方法1:使用计算属性 如果你想要基…...

mysql控制单表数据存储及单实例表创建
1. 单表数据存储不要过大 主流建议 保守建议。100万以内保持最佳性能其他。不超过2000万 理论依据。 B树层级可能变多。从3增加到4。导致索引查询路径边长,增加IO开销 优化 加索引。对高频查询字段增加索引。避免全表扫描低频历史数据通过分区表或归档隔离。足够的…...

极验4滑块笔记:整理思路--填坑各种问题
最近在研究某验4逆向分析,以前没弄过这种,所以爬了很多坑,就是把分享给大家~ 1.这个gcaptcha4.js需要逆向,我的方法很笨就是将_ᕶᕴᕹᕶ()这个蝌蚪文打印处来,全局替换一下,然后Unicode这种代码࿰…...
LX3-初识是单片机
初识单片机 一 什么是单片机 单片机:单片微型计算机单片机的组成:CPU,RAM(内存),flash(硬盘),总线,时钟,外设…… 二 Coretex-M系列介绍 了解ARM公司与ST公司ARM内核系列: A 高性能应用,如手机,电脑…R 实时性强,如汽车电子,军工…M 超低功耗,如消费电子,家电,医疗器械 三…...

2025年渗透测试面试题总结-拷打题库10(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 2025年渗透测试面试题总结-拷打题库10 1. CSRF成因及防御措施 | 非Token防御 2. XSS Worm原理 3. Co…...

Linux系统下docker 安装 MySQL
踩坑解决: 1、docker安装mysql,不需要执行search 2、pull时,需要指定版本号 3、连接Navicat需要看阿里云端口号是否开启 在拉取镜像的时候,如果不使用代理服务器,docker search mysql不需要执行 本人在未使用代理服…...

配置 VS Code 使用 ESLint 格式化
1、在设置里面搜索Default Formatter,下拉框里选择eslint 2、并勾选Enables ESlint as a formatter 3、再在settings.json文件中添加配置代码,如下所示: 1) 、打开 VS Code 设置 快捷键:Ctrl ,(Mac: ⌘ ,…...

从代码实现理解Vision Permutator:WeightedPermuteMLP模型解析
从代码实现理解Vision Permutator:WeightedPermuteMLP模型解析 随着人工智能的快速发展,视觉识别任务变得越来越重要。最近提出的Vision Permutator架构为这一领域带来了新的思路,它通过可学习的排列操作重新定义了特征交互的方式。 今天我…...
Web开发:ABP框架10——使用数据库存储文件,完成文件的下载和上传
一、简要介绍 字节数组:字节数组是存储数据的字节序列,常用于二进制数据(如图片、音视频、文档等)的表示。 文件和字节的关系:文件是由字节构成,字节是文件内容的基本单位。 文件以字节形式存储在服务器数…...

SystemVerilog语法之内建数据类型
简介:SystemVerilog引进了一些新的数据类型,具有以下的优点:(1)双状态数据类型,更好的性能,更低的内存消耗;(2)队列、动态和关联数组,减少内存消耗…...

NestJS-Knife4j
文章目录 前言✅ 一、什么是 Knife4j?✅ 二、Knife4j 与 Swagger 对比✅ 三、NestJS-Knife4j 集成1. 安装依赖2. 配置 Swagger 与 Knife4j3. 启动应用并访问接口文档 ✅ 四、功能增强1. **接口分组**2. **请求/响应示例**3. **接口文档的美化** ✅ 五、总结 前言 N…...
【项目管理】成本类计算 笔记
项目管理-相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应&…...

手机投屏到电视方法
一、投屏软件 比如乐播投屏 二、视频软件 腾讯视频、爱奇艺 三、手机无线投屏功能 四、有线投屏 五、投屏器...
安卓开发中的MVP模式详解)
(三十)安卓开发中的MVP模式详解
在安卓开发中,MVP(Model-View-Presenter) 是一种常见的软件架构模式,它通过将应用程序的逻辑与用户界面分离,使得代码更加模块化、易于维护和测试。本文将详细讲解MVP模式的组成部分、工作流程、优点,并结合…...

基于MuJoCo物理引擎的机器人学习仿真框架robosuite
Robosuite 基于 MuJoCo 物理引擎,能支持多种机器人模型,提供丰富多样的任务场景,像基础的抓取、推物,精细的开门、拧瓶盖等操作。它可灵活配置多种传感器,提供本体、视觉、力 / 触觉等感知数据。因其对强化学习友好&am…...

配置管理CM
以下是关于项目管理中 配置管理 的详细解析,结合高项(如软考高级信息系统项目管理师)教材内容,从理论到实践进行系统阐述: 一、配置管理的基本概念 1. 定义 配置管理(Configuration Management, CM)是识别、记录、控制项目成果(产品、服务或过程)的物理和功能特征,…...
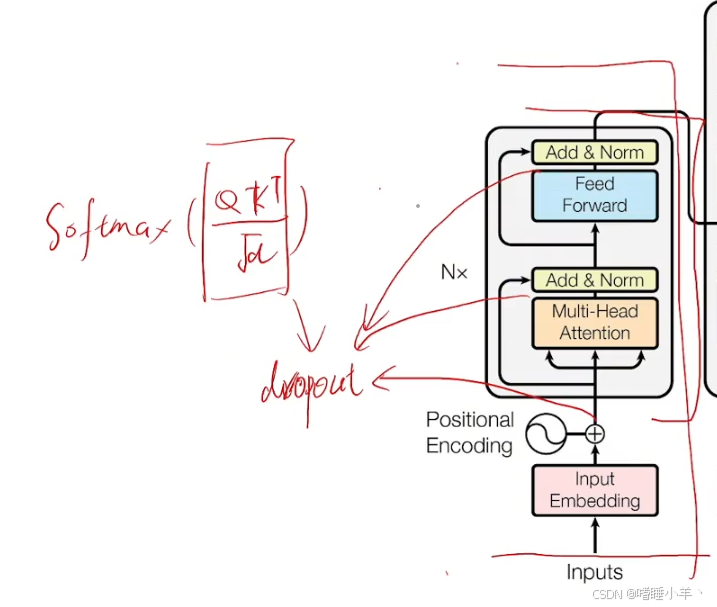
13.编码器的结构
从入门AI到手写Transformer-13.编码器的结构 13.编码器的结构代码 整理自视频 老袁不说话 。 13.编码器的结构 T r a n s f o r m e r E n c o d e r : 输入 [ b , n ] TransformerEncoder:输入[b,n] TransformerEncoder:输入[b,n] E m b e d d i n g : − > [ b , n , d ]…...
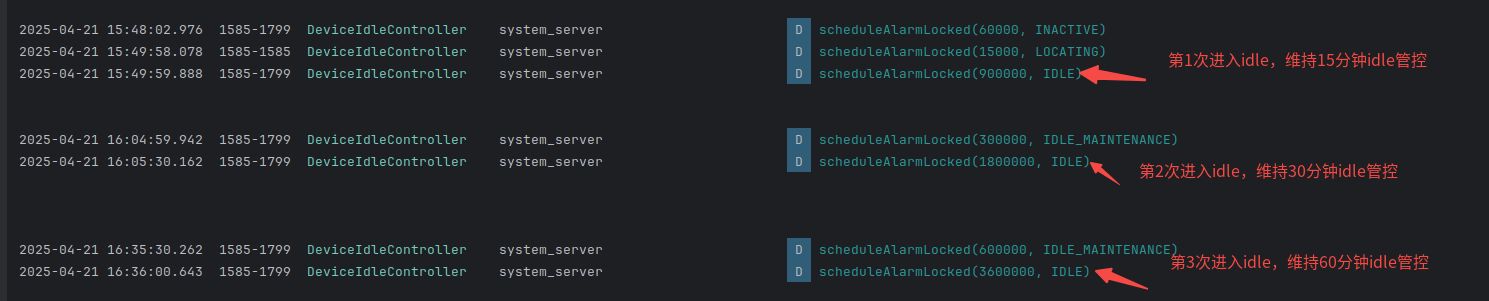
[原理分析]安卓15系统大升级:Doze打盹模式提速50%,续航大幅增强,省电提升率5%
技术原理:借鉴中国友商思路缩短进入Doze的时序 开发者米沙尔・拉赫曼(Mishaal Rahman)在其博文中透露,谷歌对安卓15系统进行了显著优化,使得设备进入“打盹模式”(Doze Mode)的速度提升了50%,并且部分机型的待机时间因此得以延长三小时。设备…...
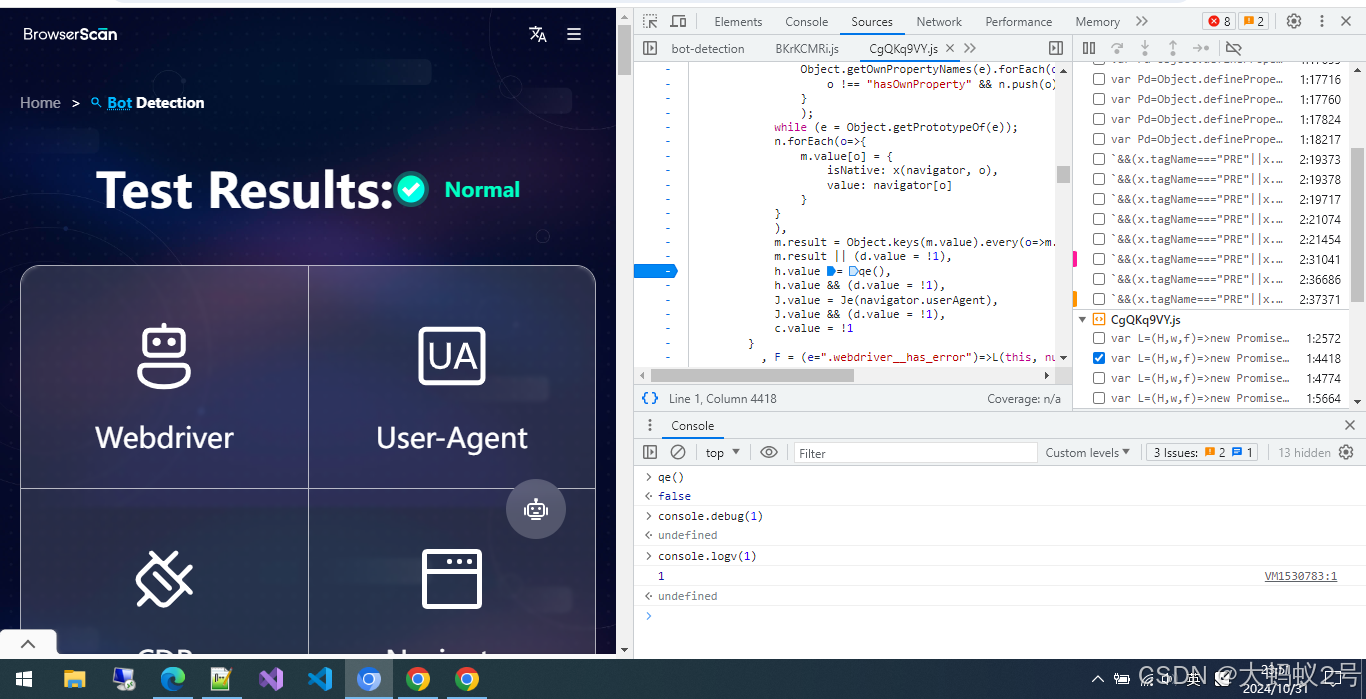
cdp-(Chrome DevTools Protocol) browserscan检测原理逆向分析
https://www.browserscan.net/zh/bot-detection 首先,打开devtools后访问网址,检测结果网页显示红色Robot,标签插入位置,确定断点位置可以hook该方法,也可以使用插件等方式找到这个位置,本篇不讨论. Robot标签是通过insertBefore插入的. 再往上追栈可以发现一个32长度数组,里面…...
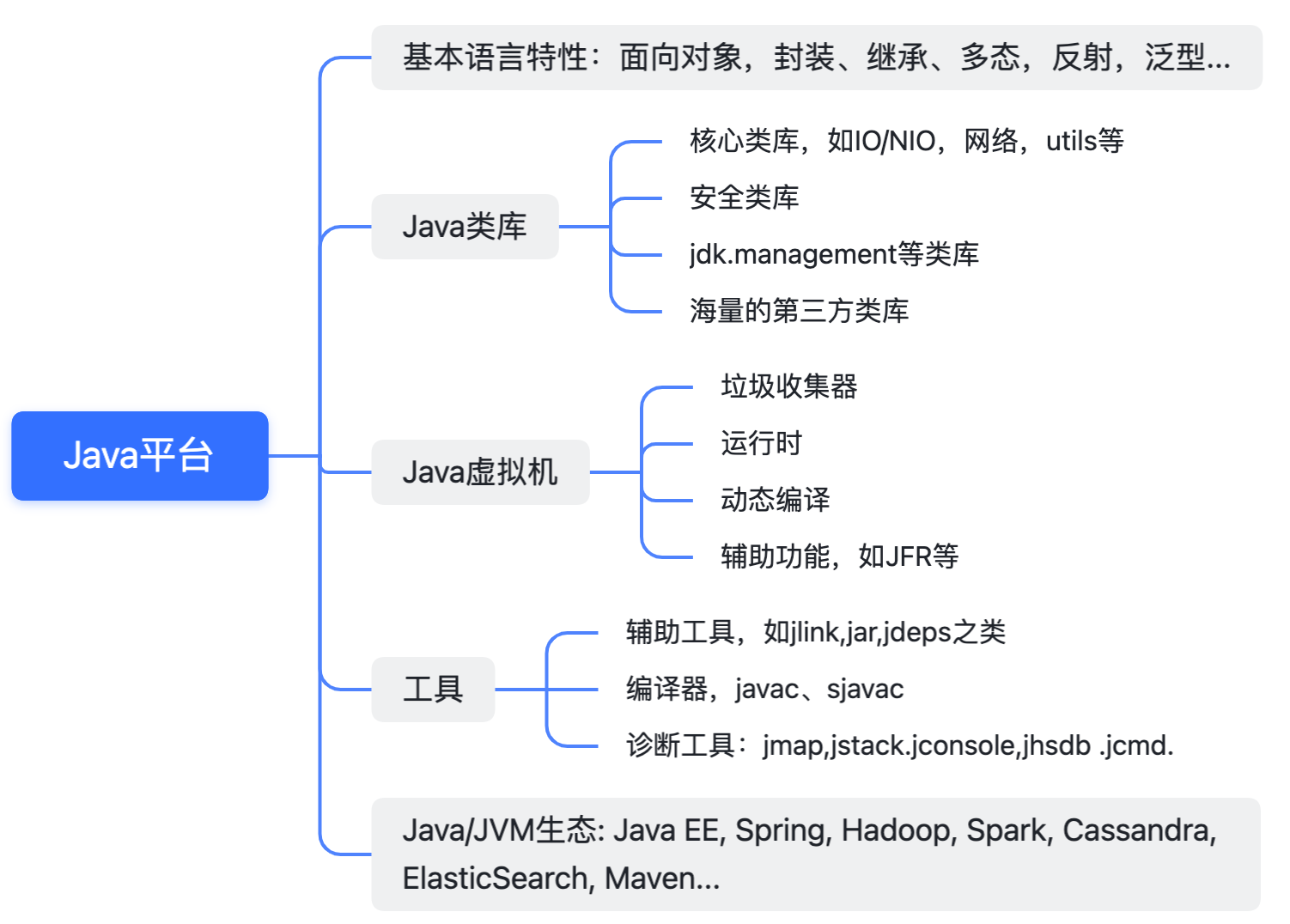
【Java面试笔记:基础】1.谈谈你对Java平台的理解?
前言 Java 是历史悠久且主流的编程语言,拥有庞大的开发者群体和广泛的应用领域。通过系统学习和实践,构建扎实的 Java 知识体系,提升面试成功率 笔记核心内容 1. Java 平台的核心特性 跨平台特性:Java 的核心特性之一是“Writ…...

Containerd与Docker的相爱相杀:容器运行时选型指南
容器运行时(Container Runtime)作为云原生基础设施的底层引擎,正从Docker一家独大走向多元化竞争。本文将深入剖析Containerd与Docker的技术血缘、性能差异及选型策略,揭示如何根据场景需求选择最优解。 一、技术血缘:…...
Java第五节:继承thread类创建线程
1、创建类Thread01 创建类Thread01然后继承thread类 2、重写run函数 3、运行线程 在主函数创建两个线程,并执行。...

vite安装及使用
没特殊要求的项目,还是怎么简单怎么来╮(╯▽╰)╭ 一、Vite 基础知识 1. 什么是 Vite? Vite 是一个前端构建工具,专注于开发服务器速度和优化构建过程。特点: 快速冷启动:利用 ES 模块的原生支持,实现快速的开发服务器启动。即时热更新:在开发过程中,修改代码后可以…...