【数学建模】孤立森林算法:异常检测的高效利器
孤立森林算法:异常检测的高效利器
文章目录
- 孤立森林算法:异常检测的高效利器
- 1 引言
- 2 孤立森林算法原理
- 2.1 核心思想
- 2.2 算法流程
- 步骤一:构建孤立树(iTree)
- 步骤二:构建孤立森林(iForest)
- 步骤三:计算异常分数
- 3 代码实现
- 算法优势
- 应用场景
- 算法参数调优
- 局限性与改进
- 结论
- 参考资料
1 引言
在数据挖掘和机器学习领域,异常检测是一个重要的研究方向。异常检测的目标是从数据集中找出与大多数数据显著不同的异常点。这些异常点可能代表系统故障、欺诈行为、网络入侵等异常情况。本文将介绍一种高效的异常检测算法——孤立森林(Isolation Forest),它以其简单高效的特点在异常检测领域备受关注。
2 孤立森林算法原理
2.1 核心思想
孤立森林算法的核心思想非常直观:异常点更容易被孤立。如下图所示,B点所表示的数据很可能是一个异常值。

与传统的基于密度或距离的异常检测方法不同,孤立森林采用了一种全新的视角:通过随机构建决策树来孤立数据点。算法假设异常点具有以下两个关键特性:
- 数量少
- 特征值与正常点显著不同
基于这两个特性,异常点通常更容易在决策树的早期被孤立出来,即到达叶子节点所需的决策路径更短。
2.2 算法流程
孤立森林(Isolation Forest)是一种无监督学习算法,主要用于异常检测,以下是它的主要步骤和相关公式(参考资料:孤立森林(isolation):一个最频繁使用的异常检测算法 。):
步骤一:构建孤立树(iTree)
- 随机选择数据集的子样本
- 随机选择一个特征维度 q
- 随机选择一个分割值 p (在特征 q 的最大值和最小值之间)
- 根据特征 q 和分割值 p 将数据分为左右两部分
- 递归重复上述过程,直到:
- 节点中只包含一个样本
- 达到预定义的最大树高度 (通常为 log₂(子样本大小))
- 所有样本具有相同的特征值

步骤二:构建孤立森林(iForest)
- 重复构建多棵孤立树(通常为50-100棵)
步骤三:计算异常分数
- 对于每个样本,计算在每棵树中的路径长度(从根节点到终止节点的边数)
- 取这个样本在所有树中的平均路径长度作为该样本的最终路径长度
异常分数 s 的计算公式为:
s ( x , n ) = 2 − E ( h ( x ) ) c ( n ) s(x, n) = 2^{-\frac{E(h(x))}{c(n)}} s(x,n)=2−c(n)E(h(x))
其中:
- h ( x ) h(x) h(x) 是样本 x x x 的平均路径长度
- E ( h ( x ) ) E(h(x)) E(h(x)) 是 h ( x ) h(x) h(x) 的期望值
- c ( n ) c(n) c(n) 是样本数为 n 的二叉搜索树的平均路径长度的归一化因子
归一化因子 c ( n ) c(n) c(n) 的计算公式:
c ( n ) = 2 H ( n − 1 ) − 2 ( n − 1 ) n c(n) = 2H(n-1) - \frac{2(n-1)}{n} c(n)=2H(n−1)−n2(n−1)
其中 H ( i ) H(i) H(i) 是第 i 个调和数:
H ( i ) = ln ( i ) + 0.5772156649 H(i) = \ln(i) + 0.5772156649 H(i)=ln(i)+0.5772156649
- 当 s s s 接近 1 时,样本更可能是异常点
- 当 s s s 接近 0.5 时,样本更可能是正常点
- 当 s s s 明显小于 0.5 时,样本可能在一个密集区域
通常我们设置一个阈值(如0.6)来判断异常点。
3 代码实现
下面是使用Python和scikit-learn库实现孤立森林算法的示例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
from sklearn.datasets import make_blobs# 生成示例数据:正常点和异常点
n_samples = 300
n_outliers = 15
X, _ = make_blobs(n_samples=n_samples-n_outliers, centers=1, cluster_std=0.5, random_state=42)# 添加一些异常点
rng = np.random.RandomState(42)
X = np.vstack([X, rng.uniform(low=-4, high=4, size=(n_outliers, 2))])# 训练孤立森林模型
clf = IsolationForest(n_estimators=100, max_samples='auto', contamination=float(n_outliers) / n_samples,random_state=42)
clf.fit(X)# 预测结果
y_pred = clf.predict(X) # 1表示正常点,-1表示异常点
scores = clf.decision_function(X) # 异常分数# 可视化结果
plt.figure(figsize=(10, 7))
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis', s=50)
plt.colorbar(label='预测结果:1为正常,-1为异常')
plt.title('孤立森林异常检测结果')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.show()
算法优势
孤立森林算法相比传统异常检测方法具有以下优势:
- 高效性:时间复杂度为O(n log n),适用于大规模数据集
- 无需密度估计:不需要计算点与点之间的距离或密度,减少了计算开销
- 适应高维数据:不受维度灾难的影响,在高维空间中表现良好
- 无需假设数据分布:不需要对数据分布做任何假设
- 易于实现和使用:算法简单,参数较少
应用场景
孤立森林算法在多个领域有广泛应用:
- 金融欺诈检测:识别异常交易行为
- 网络安全:检测网络入侵和异常流量
- 工业监控:发现设备异常运行状态
- 医疗健康:识别异常生理指标
- 质量控制:检测生产过程中的异常产品
算法参数调优
在使用孤立森林算法时,以下参数需要特别关注:
- n_estimators:森林中树的数量,通常100~200棵树已经足够
- max_samples:每棵树的样本数量,默认为’auto’(256)
- contamination:数据集中预期的异常比例
- max_features:每次分割考虑的特征数量
- bootstrap:是否使用有放回抽样
局限性与改进
尽管孤立森林算法表现优秀,但它也存在一些局限性:
- 对于具有不同密度区域的数据集,可能会将低密度正常区域误判为异常
- 在处理包含大量不相关特征的数据时效果可能下降
针对这些问题,研究人员提出了一些改进版本,如Extended Isolation Forest和SCiForest等。
结论
孤立森林算法凭借其简单、高效、可扩展的特点,已成为异常检测领域的重要工具。它不仅在理论上具有坚实基础,在实际应用中也展现出了强大的性能。对于需要进行异常检测的数据科学家和工程师来说,孤立森林无疑是一个值得掌握的算法。
在实际应用中,建议将孤立森林与其他异常检测方法结合使用,以获得更加稳健的检测结果。同时,针对特定领域的数据特点进行参数调优,也能显著提升算法性能。
参考资料
- Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008). Isolation forest. In 2008 Eighth IEEE International Conference on Data Mining (pp. 413-422). IEEE.
- Scikit-learn官方文档:Isolation Forest
- 周志华. (2016). 机器学习. 清华大学出版社.
本文介绍了孤立森林算法的基本原理、实现方法、优势特点及应用场景,希望能对读者理解和应用这一算法有所帮助。如有问题,欢迎在评论区讨论交流!
相关文章:
【数学建模】孤立森林算法:异常检测的高效利器
孤立森林算法:异常检测的高效利器 文章目录 孤立森林算法:异常检测的高效利器1 引言2 孤立森林算法原理2.1 核心思想2.2 算法流程步骤一:构建孤立树(iTree)步骤二:构建孤立森林(iForest)步骤三:计算异常分数 3 代码实现…...

<项目代码>YOLO小船识别<目标检测>
项目代码下载链接 YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN)࿰…...

Crawl4AI:打破数据孤岛,开启大语言模型的实时智能新时代
当大语言模型遇见数据饥渴症 在人工智能的竞技场上,大语言模型(LLMs)正以惊人的速度进化,但其认知能力的跃升始终面临一个根本性挑战——如何持续获取新鲜、结构化、高相关性的数据。传统数据供给方式如同输血式营养支持ÿ…...

AI 技术发展:从起源到未来的深度剖析
一、AI 的起源与早期发展 人工智能(AI)作为计算机科学的重要分支,其诞生可以追溯到 20 世纪中叶。1943 年,艾伦・图灵提出图灵机的概念,为计算机科学和 AI 理论奠定了基础。1950 年,图灵又提出著名的图灵…...

jsconfig.json文件的作用
jsconfig.json文件的作用 为什么今天会谈到这个呢?有这么一个场景:我们每次开发项目时都会给路径配置别名,配完别名之后可以简化我们的开发,但是随之而来的就有一个问题,一般来说,当我们使用相对路径时…...

nodejs的包管理工具介绍,npm的介绍和安装,npm的初始化包 ,搜索包,下载安装包
nodejs的包管理工具介绍,npm的介绍和安装,npm的初始化包 ,搜索包,下载安装包 🧰 一、Node.js 的包管理工具有哪些? 工具简介是否默认特点npmNode.js 官方的包管理工具(Node Package Manager&am…...

常见的raid有哪些,使用场景是什么?
RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)是一种将多个物理硬盘组合成一个逻辑硬盘的技术,目的是通过数据冗余和/或并行访问提高性能、容错能力和存储容量。不同的 RAID 级别有不同的实现方式和应用场景。以下…...

【Spring Boot】MyBatis多表查询的操作:注解和XML实现SQL语句
1.准备工作 1.1创建数据库 (1)创建数据库: CREATE DATABASE mybatis_test DEFAULT CHARACTER SET utf8mb4;(2)使用数据库 -- 使⽤数据数据 USE mybatis_test;1.2 创建用户表和实体类 创建用户表 -- 创建表[⽤⼾表…...
个人学习笔记(12):网络爬虫)
金融数据分析(Python)个人学习笔记(12):网络爬虫
一、导入模块和函数 from bs4 import BeautifulSoup from urllib.request import urlopen import re from urllib.error import HTTPError from time import timebs4:用于解析HTML和XML文档的Python库。 BeautifulSoup:方便地从网页内容中提取和处理数据…...
[Android]豆包爱学v4.5.0小学到研究生 题目Ai解析
拍照解析答案 【应用名称】豆包爱学 【应用版本】4.5.0 【软件大小】95mb 【适用平台】安卓 【应用简介】豆包爱学,一般又称河马爱学教育平台app,河马爱学。 关于学习,你可能也需要一个“豆包爱学”这样的AI伙伴,它将为你提供全方位的学习帮助…...
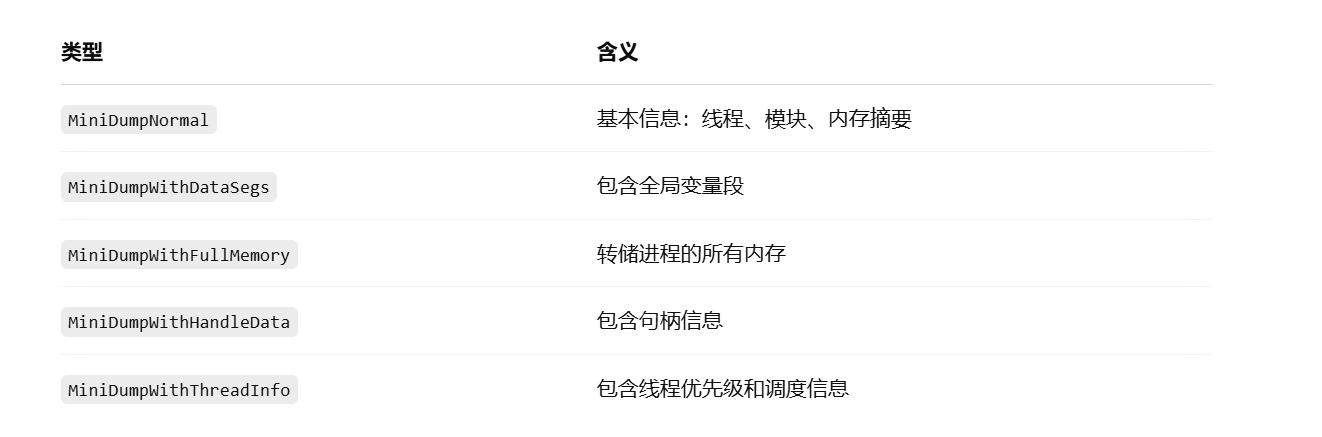
Qt开发:软件崩溃时,如何生成dump文件
文章目录 一、程序崩溃时如何自动生成 Dump 文件二、支持多线程中的异常捕获三、在 DLL 中使用 Dump 捕获四、封装成可复用类五、MiniDumpWriteDump函数详解 一、程序崩溃时如何自动生成 Dump 文件 步骤一:包含必要的头文件 #include <Windows.h> #include …...

普罗米修斯Prometheus监控安装(mac)
普罗米修斯是后端数据监控平台,通过Node_exporter/mysql_exporter等收集数据,Grafana将数据用图形的方式展示出来 官网各平台下载 Prometheus安装(mac) (1)通过brew安装 brew install prometheus &…...

Python SQL 工具包:SQLAlchemy介绍
SQLAlchemy 是一个功能强大且灵活的 Python SQL 工具包和对象关系映射(ORM)库。它被广泛用于与关系型数据库进行交互,提供了从低级 SQL 表达式到高级 ORM 的完整工具链。SQLAlchemy 的设计目标是让开发者能够以 Pythonic 的方式操作数据库&am…...

Shader属性讲解+Cg语言讲解
CPU调用GPU传递数据 修改Render组件的material属性 在脚本中更改游戏物体材质颜色代码示例: using System.Collections; using System.Collections.Generic; using UnityEngine;public class TestFixedColor : MonoBehaviour {void Start(){//创建预制体GameObjec…...
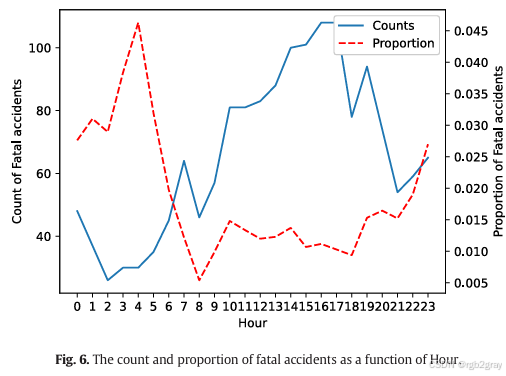
基于LightGBM-TPE算法对交通事故严重程度的分析与可视化
基于LightGBM-TPE算法对交通事故严重程度的分析与可视化 原文: Analysis and visualization of accidents severity based on LightGBM-TPE 1. 引言部分 文章开篇强调了道路交通事故作为意外死亡的主要原因,引起了多学科领域的关注。分析事故严重性特…...

什么是CRM系统,它的作用是什么?CRM全面指南
CRM(Customer Relationship Management,客户关系管理)系统是一种专门用于集中管理客户信息、优化销售流程、提升客户满意度、支持精准营销、驱动数据分析决策、加强跨部门协同、提升客户生命周期价值的业务系统工具。其中,优化销售…...

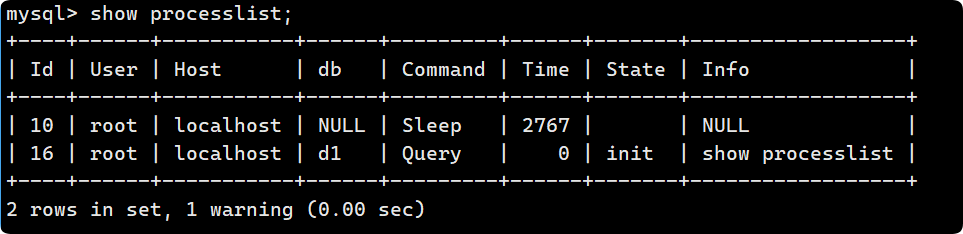
MySQL 启动报错:InnoDB 表空间丢失问题及解决方法
MySQL 启动报错:InnoDB 表空间丢失问题及解决方法 在启动 MySQL 时,遇到了如下错误: 2025-01-16T12:43:28.341240Z 0 [ERROR] InnoDB: Tablespace 5975 was not found at ./my_jspt/sw_rtu_message_202408.ibd. 2025-01-16T12:43:28.341244…...
MYSQL之库的操作
创建数据库 语法很简单, 主要是看看选项(与编码相关的): CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...] create_specification: [DEFAULT] CHARACTER SET charset_name [DEFAULT] COLLATE collation_name 1. 语句中大写的是…...

笔记本电脑研发笔记:BIOS,Driver,Preloader详记
在笔记本电脑的研发过程中,Driver(驱动程序)、BIOS(基本输入输出系统)和 Preloader(预加载程序)之间存在着密切的相互关系和影响,具体如下: 相互关系 BIOS 与 Preload…...

同样的html标记,不同语言的文本,显示的字体和粗细会不一样吗
同样的 HTML 标记,在不同语言的文本下,显示出来的字体和粗细确实可能会不一样,原因如下: 🌍 不同语言默认字体不同 浏览器字体回退机制 CSS 里写的字体如果当前系统不支持,就会回退到下一个,比如…...
)
JavaScript 笔记 --- part 5 --- Web API (part 3)
(webAPI part3) BOM 操作 JS 执行机制 javascript 是单线程的, 也就是说, 只能同时执行一个任务。 为了解决这个问题, 利用多核 CPU 的计算能力, HTML5 提出 Web Worker API, 允许 JavaScript 脚本创建多个线程, 并将任务分配给这些线程。 于是, JS 出现了同步和异步的概念。…...
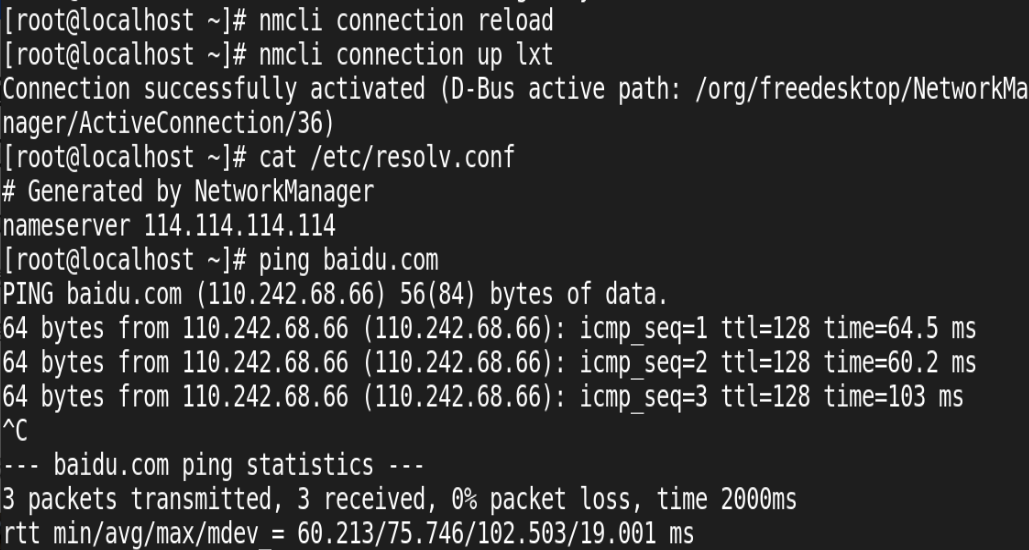
Linux 下的网络管理(附加详细实验案例)
一、简单了解 NM(NetworkManager) 在 Linux 中,NM 是 NetworkManager 的缩写。它是一个用于管理网络连接的守护进程和工具集。 在 RHEL9 上,使用 NM 进行网络配置,ifcfg (也称为文件)将不再…...
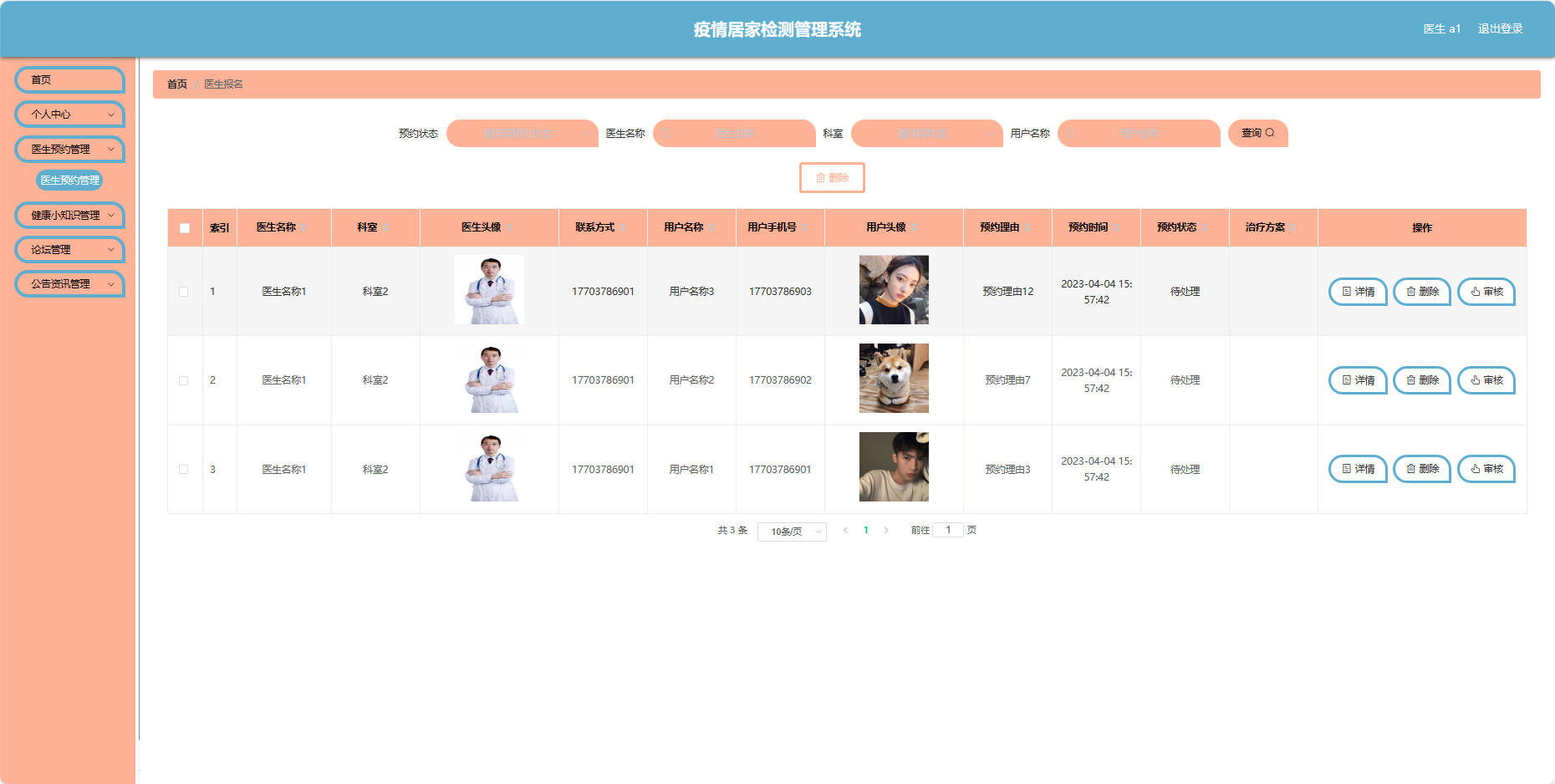
基于SpringBoot的疫情居家检测管理系统(源码+数据库)
514基于SpringBoot的疫情居家检测管理系统,系统包含三种角色:管理员、用户、医生,主要功能如下。 【用户功能】 1. 首页:获取系统信息。 2. 论坛:参与居民讨论和分享信息。 3. 公告:查看社区发布的各类公告…...

关于系统架构思考,如何设计实现系统的高可用?
绪论、系统高可用的必要性 系统高可用为了保持业务连续性保障,以及停机成本量化,比如在以前的双十一当天如果出现宕机,那将会损失多少钱?比如最近几年Amazon 2021年30分钟宕机损失$5.6M。当然也有成功的案例,比如异地…...
MATLAB 控制系统设计与仿真 - 35
MATLAB鲁棒控制器分析 所谓鲁棒性是指控制系统在一定(结构,大小)的参数扰动下,维持某些性能的特征。 根据对性能的不同定义,可分为稳定鲁棒性(Robust stability)和性能鲁棒性(Robust performance)。 以闭环系统的鲁棒性作为目标设计得到的…...
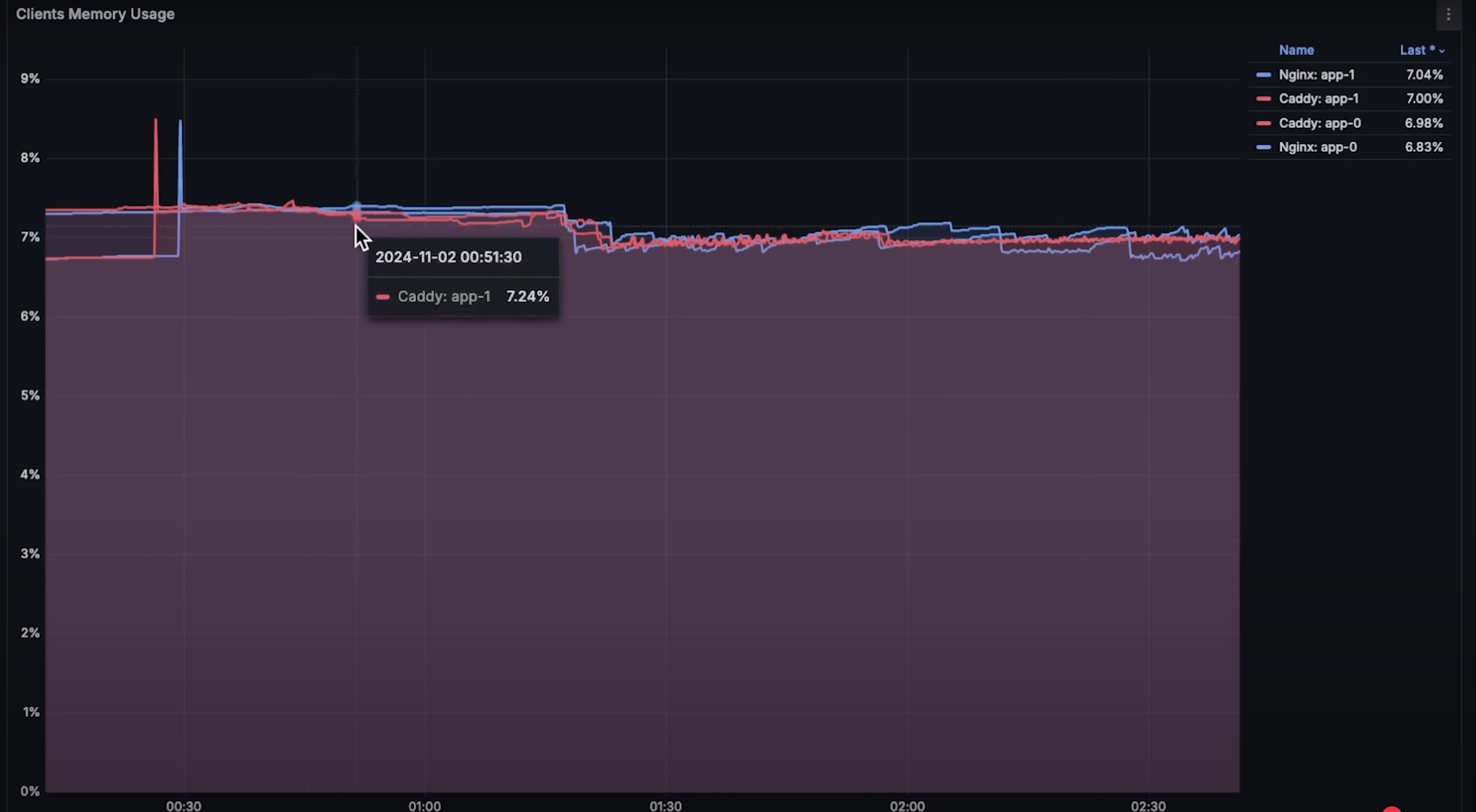
性能比拼: Nginx vs Caddy
本内容是对知名性能评测博主 Anton Putra Nginx vs Caddy Performance 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 引言 在本期视频中,我们将对比 Nginx 和 Caddy---一个用 Go 编写的 Web 服务器和反向代理。 在第一个测试中,我们会使用…...
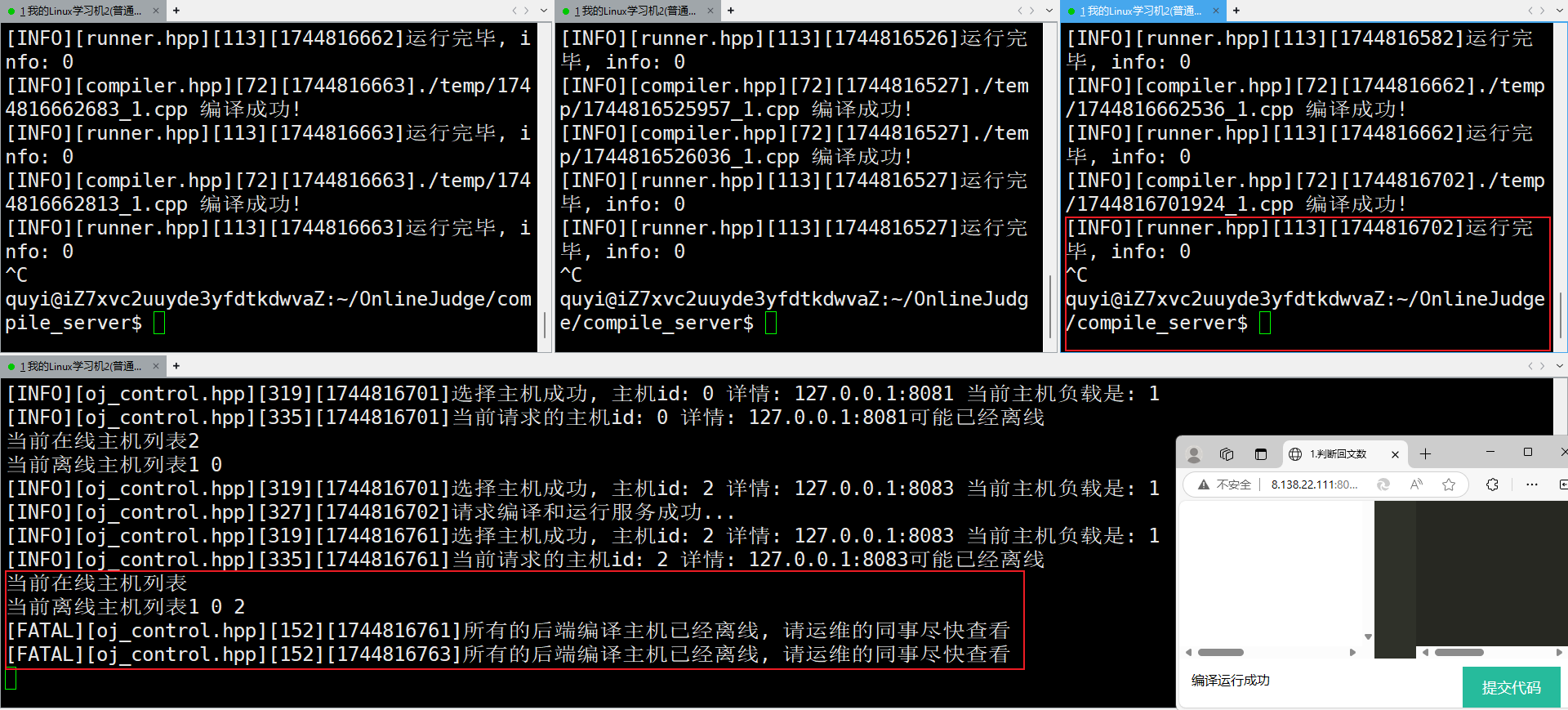
C++项目-衡码云判项目演示
衡码云判项目是什么呢?简单来说就是这是一个类似于牛客、力扣等在线OJ系统,用户在网页编写代码,点击提交后传递给后端云服务器,云服务器将用户的代码和测试用例进行合并编译,返回结果到网页。 项目最大的两个亮点&…...
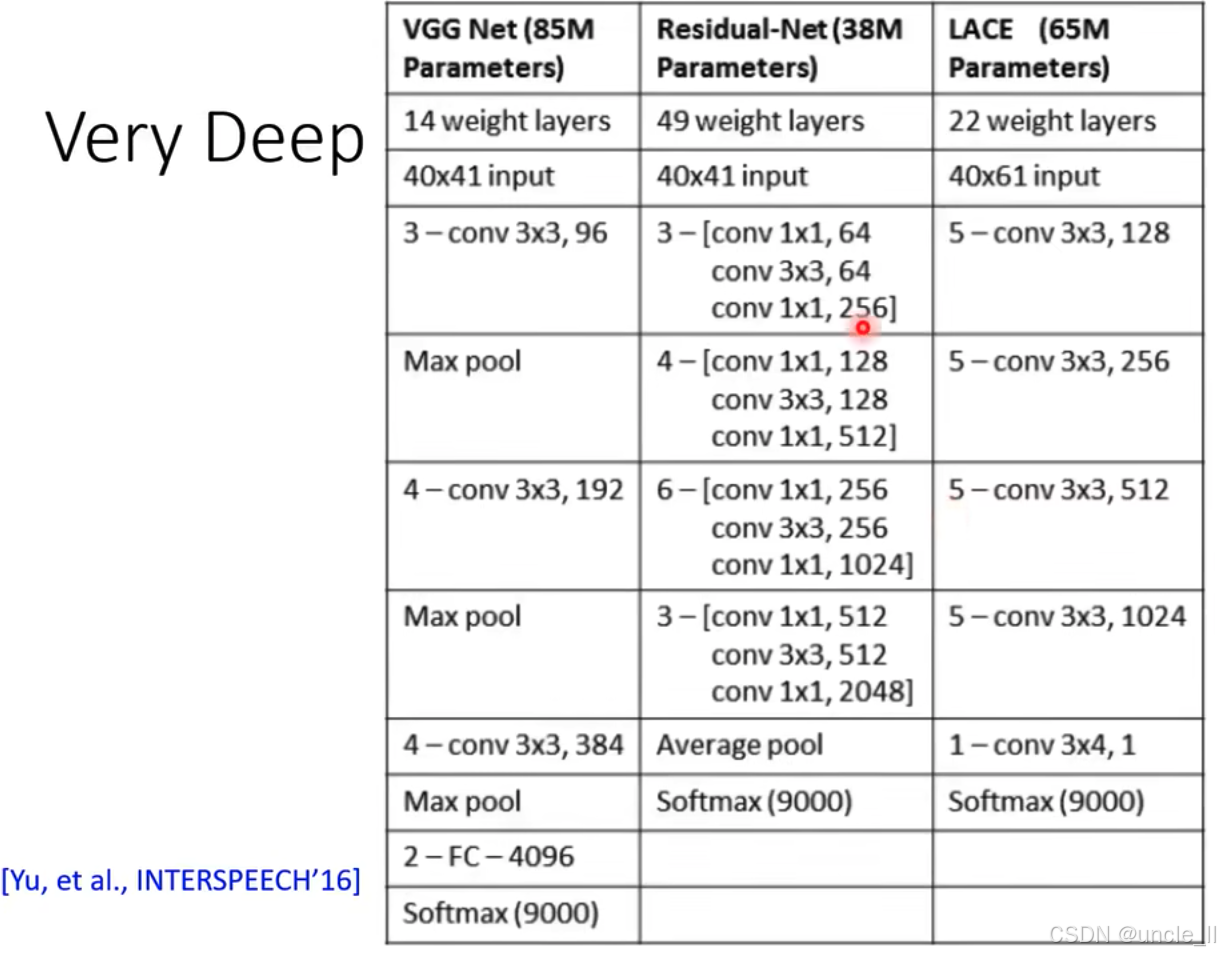
李宏毅NLP-6-seq2seqHMM
比较seq2seq和HMM Hidden Markov Model(HMM) 隐马尔可夫模型(HMM)在语音识别中的应用,具体内容如下: 整体流程: 左侧为语音信号(标记为 “speech”),其特征表示为 X X X。中间蓝色模…...

百度暑期实习岗位超3000个,AI相关岗位占比87%,近屿智能携AIGC课程加速人才输出
今年3月,百度重磅发布3000暑期实习岗位,聚焦大模型、机器学习、自动驾驶等AI方向的岗位比例高达87%。此次实习岗位涉及技术研发、产品策划、专业服务、管理支持、政企解决方案等四大类别,覆盖超300个岗位细分方向。值得一提的是,百…...
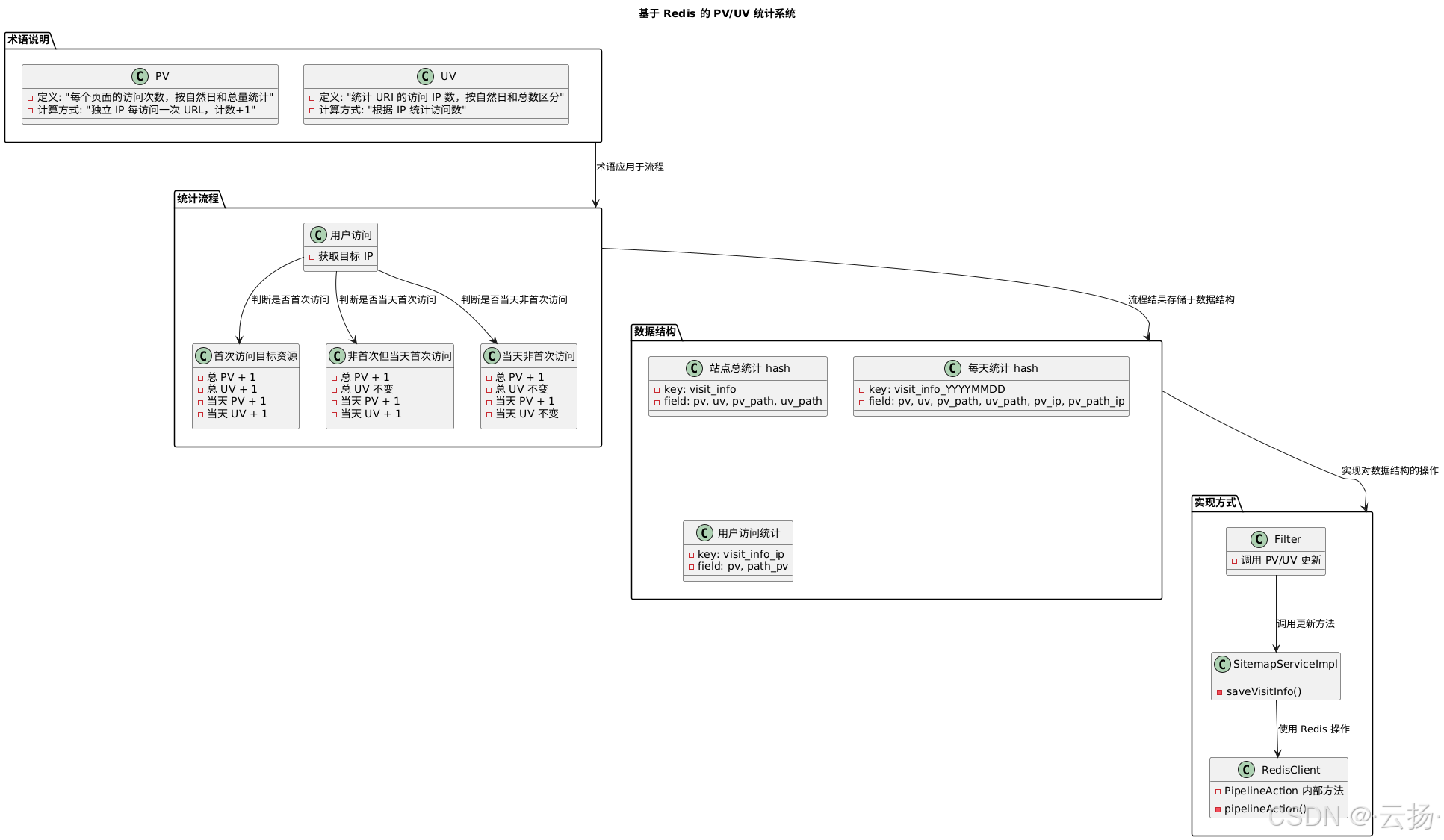
【技术派后端篇】基于 Redis 实现网站 PV/UV 数据统计
在网站的数据分析中,PV(Page View,页面浏览量)和 UV(Unique Visitor,独立访客数)是两个重要的指标,几乎每个网站都需要对其进行统计。市面上有很多成熟的统计产品,例如百…...