C++项目 —— 基于多设计模式下的同步异步日志系统(4)(双缓冲区异步任务处理器(AsyncLooper)设计)
C++项目 —— 基于多设计模式下的同步&异步日志系统(4)(双缓冲区异步任务处理器(AsyncLooper)设计)
- 异步线程
- 什么是异步线程?
- C++ 异步线程简单例子
- 代码解释
- 程序输出
- 关键点总结
- 扩展:使用 `std::thread` 实现异步线程
- 分辨同步异步线程
- 1. 看调用是否立即返回
- 同步线程(如排队买奶茶)
- 异步线程(如外卖下单)
- 2. 看是否有专门的工作线程
- 同步
- 异步
- 3. 看资源访问方式
- 同步
- 异步
- 4. 典型场景对比
- 代码示例对比
- 同步日志
- 异步日志
- 双缓冲区异步任务处理器
- 设计思想:异步线程 + 数据池
- 核心思想
- 任务池的设计:双缓冲区阻塞数据池
- 1. 双缓冲区的工作机制
- 2. 减少锁冲突
- 3. 内存管理优化
- 优势分析
- 1. 提高任务处理效率
- 2. 减少锁冲突
- 3. 降低内存分配开销
- 与其他设计方案的对比
- 1. 循环队列
- 2. 单缓冲区
- 3. 双缓冲区的优势
- 总结
- 缓冲区实现
- 总结
- loop.hpp中与线程有关的操作
- 1. 线程的创建与管理
- 2. 线程同步与通信
- 3. 线程入口函数
- 4. 数据生产与消费
- 5. 线程安全的设计
- 总结
- placeholders::_1
- 示例代码
- 说明
- 输出结果
- 具体作用
- 详细解释
- 为什么需要 `std::placeholders::_1`?
- 示例对比
- 不使用 `std::bind` 和占位符:
- 使用 `std::bind` 和占位符:
- 总结
我们上次把同步日志器的编写已经差不多完成了,如果还没有看过同步日志器编写的小伙伴可以点击这里:
https://blog.csdn.net/qq_67693066/article/details/147309275?spm=1011.2415.3001.5331
我们今天主要来编写异步任务处理器,但是在这之前我们得了解一下什么是异步线程:
异步线程
什么是异步线程?
异步线程指的是程序中的一种执行模式,其中某些任务可以在主线程或其他线程中并行运行,而不会阻塞主线程的执行。换句话说,异步线程允许我们在不等待某个操作完成的情况下继续执行其他任务。
在 C++ 中,异步线程可以通过标准库中的 <thread> 或 <future> 来实现。常见的异步编程工具包括:
std::thread:用于创建和管理线程。std::async:用于以异步方式执行任务,并返回结果。std::future和std::promise:用于在线程间传递数据。
C++ 异步线程简单例子
以下是一个使用 std::async 实现异步线程的简单例子:
#include <iostream>
#include <future> // std::async, std::future
#include <chrono> // std::this_thread::sleep_for
#include <thread> // std::this_thread// 模拟一个耗时的任务
int slowTask(int x) {std::cout << "Task started with input: " << x << std::endl;std::this_thread::sleep_for(std::chrono::seconds(2)); // 模拟耗时操作int result = x * x;std::cout << "Task completed. Result: " << result << std::endl;return result;
}int main() {// 使用 std::async 启动一个异步任务std::future<int> resultFuture = std::async(std::launch::async, slowTask, 5);// 主线程继续执行其他工作std::cout << "Main thread is doing other work..." << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟主线程的工作std::cout << "Main thread finished its work." << std::endl;// 获取异步任务的结果(如果任务未完成,会阻塞直到结果可用)int result = resultFuture.get();std::cout << "Final result from async task: " << result << std::endl;return 0;
}
代码解释
-
slowTask函数:- 这是一个模拟的耗时任务,接收一个整数参数
x,经过 2 秒的延迟后返回x * x的结果。
- 这是一个模拟的耗时任务,接收一个整数参数
-
std::async:std::async是一个函数模板,用于启动异步任务。- 参数
std::launch::async表示任务将在一个新线程中异步执行。 - 第二个参数是任务函数(
slowTask),后面的参数是传递给任务函数的参数(这里是5)。
-
主线程的行为:
- 在启动异步任务后,主线程继续执行自己的工作(例如打印消息或进行其他计算)。
- 当主线程需要获取异步任务的结果时,调用
resultFuture.get()。如果异步任务尚未完成,这一步会阻塞,直到结果可用。
-
std::future:std::future是一个模板类,用于存储异步任务的结果。- 调用
get()方法可以获取异步任务的返回值。
程序输出
运行上述代码,输出可能如下(顺序可能会因线程调度而略有不同):
Main thread is doing other work...
Task started with input: 5
Main thread finished its work.
Task completed. Result: 25
Final result from async task: 25
关键点总结
-
异步执行:
std::async允许我们异步地运行任务,而不会阻塞主线程。
-
线程管理:
- 使用
std::future可以方便地获取异步任务的结果。
- 使用
-
非阻塞与阻塞:
- 异步任务启动后,主线程可以继续执行其他任务。
- 调用
future.get()时,如果任务未完成,主线程会被阻塞,直到结果可用。
扩展:使用 std::thread 实现异步线程
如果你不想使用 std::async,也可以直接使用 std::thread 来实现类似的功能:
#include <iostream>
#include <thread>
#include <chrono>// 模拟一个耗时的任务
void slowTask(int x) {std::cout << "Task started with input: " << x << std::endl;std::this_thread::sleep_for(std::chrono::seconds(2));std::cout << "Task completed. Result: " << (x * x) << std::endl;
}int main() {// 创建一个线程执行异步任务std::thread t(slowTask, 5);// 主线程继续执行其他工作std::cout << "Main thread is doing other work..." << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));std::cout << "Main thread finished its work." << std::endl;// 等待线程完成t.join();return 0;
}
在这个版本中,std::thread 直接启动一个线程,主线程通过 t.join() 等待线程完成。

说直白的,就是主线程创建了一个子线程,本来是由主线程完成的,现在由这个子线程完成。
分辨同步异步线程
要判断一个线程模型是同步还是异步,可以从以下几个关键特征进行区分。我用最简单的比喻和代码示例来说明:
1. 看调用是否立即返回
同步线程(如排队买奶茶)
void syncLog(const std::string& msg) {std::ofstream file("log.txt");file << msg; // 必须等待文件写入完成// 调用者在这里阻塞等待
}
- 特征:函数执行完所有操作(包括I/O)后才返回
- 类比:就像在奶茶店排队,必须等到拿到奶茶才能离开
异步线程(如外卖下单)
void asyncLog(const std::string& msg) {_buffer.push(msg); // 只是把消息放入队列// 立即返回,后台线程会处理写入
}
- 特征:函数只把任务放入队列/缓冲区后立即返回
- 类比:像点外卖,下单后就可以做其他事情,外卖员会异步配送
2. 看是否有专门的工作线程
同步
// 没有额外线程,直接在当前线程处理
syncLog("error"); // 直接卡在这里写文件
异步
class AsyncLogger {std::thread _worker; // 关键:有专门的工作线程void workerThread() {while (true) { /* 处理队列中的任务 */ }}
};
3. 看资源访问方式
同步
void writeFile(const std::string& data) {// 直接访问资源(文件/网络)_file.write(data); // 同步I/O
}
异步
void asyncWrite(const std::string& data) {_queue.push(data); // 只是提交任务// 实际由其他线程从_queue取出数据后写文件
}
4. 典型场景对比
| 特征 | 同步 | 异步 |
|---|---|---|
| 调用阻塞 | 是 | 否 |
| 工作线程 | 无(当前线程处理) | 有专门线程 |
| 性能影响 | 受I/O速度限制 | 几乎不影响主线程 |
| 代码复杂度 | 简单 | 需要线程安全控制 |
| 适合场景 | 简单应用、低频操作 | 高性能服务、高频日志 |
代码示例对比
同步日志
// 当前线程直接写文件(阻塞)
void logSync(const std::string& msg) {std::lock_guard<std::mutex> lock(_mutex);_file << msg; // 同步写入,耗时操作!
}
异步日志
// 只是提交任务到队列
void logAsync(const std::string& msg) {std::lock_guard<std::mutex> lock(_mutex);_queue.push(msg); // 内存操作,极快_cond.notify_one(); // 通知工作线程
}// 工作线程
void workerThread() {while (true) {std::string msg = _queue.pop(); // 从队列取任务_file << msg; // 实际耗时操作在这里}
}
只要记住:异步=把任务丢给别人处理,自己不等结果,就能轻松区分了!
双缓冲区异步任务处理器
设计思想:异步线程 + 数据池
核心思想
通过引入异步线程和双缓冲区数据池,将任务的生产和消费分离。生产者负责生成任务并将其放入任务池,而消费者(异步线程)从任务池中取出任务并执行。这种设计的目标是提高任务处理效率,减少锁冲突,并降低内存分配和释放的开销。
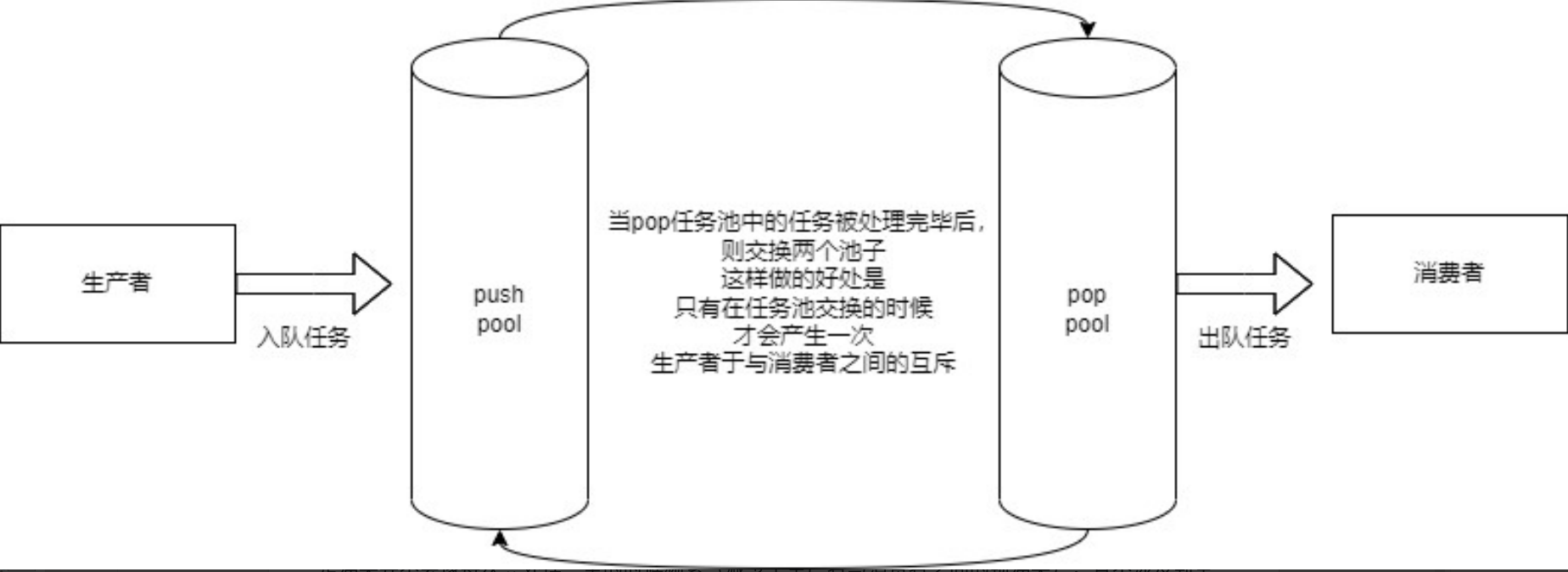
任务池的设计:双缓冲区阻塞数据池
1. 双缓冲区的工作机制
- 两个缓冲区:任务池由两个独立的缓冲区组成,分别称为主缓冲区和备用缓冲区。
- 主缓冲区:用于存放生产者提交的任务。
- 备用缓冲区:在主缓冲区被消费者完全处理后,与主缓冲区交换角色。
- 交换机制:
- 当主缓冲区中的所有任务被消费者处理完毕后,主缓冲区和备用缓冲区的角色互换。
- 这样,消费者可以立即开始处理新的任务,而生产者可以继续向新的主缓冲区添加任务。
2. 减少锁冲突
- 在传统的单缓冲区或循环队列中,每次任务的添加或取出都需要加锁,导致生产者和消费者之间的锁冲突频繁发生。
- 而双缓冲区通过批量处理的方式减少了锁冲突的概率:
- 生产者只需要在向主缓冲区添加任务时加锁,消费者只需要在处理完主缓冲区的所有任务后进行一次锁操作来交换缓冲区。
- 这种方式大大减少了锁的使用频率,降低了线程间的竞争。
3. 内存管理优化
- 双缓冲区的设计避免了频繁申请和释放内存空间。
- 缓冲区的大小通常是固定的,生产者和消费者只需在缓冲区内操作,无需动态分配或释放内存。
- 这不仅提高了性能,还减少了内存碎片化的风险。
优势分析
1. 提高任务处理效率
- 消费者可以一次性处理主缓冲区中的所有任务,而不是逐条处理。这种方式减少了任务调度的开销,提升了整体效率。
2. 减少锁冲突
- 由于锁操作只发生在缓冲区交换时,而非每次任务的添加或取出,锁冲突的概率显著降低。
- 生产者和消费者之间的交互更加高效,尤其在高并发场景下表现尤为明显。
3. 降低内存分配开销
- 固定大小的缓冲区避免了频繁的内存申请和释放操作,减少了系统资源的消耗。
- 同时,固定大小的设计也使得内存管理更加可控,避免了因动态内存分配引发的问题。
与其他设计方案的对比
1. 循环队列
- 循环队列是一种常见的任务池实现方式,但其每次任务的添加或取出都需要加锁,容易引发生产者和消费者之间的锁冲突。
- 此外,循环队列通常需要动态调整大小,这会增加内存管理的复杂性。
2. 单缓冲区
- 单缓冲区的设计简单,但在高并发场景下,锁冲突问题尤为突出。
- 生产者和消费者需要频繁地争夺缓冲区的访问权,导致性能下降。
3. 双缓冲区的优势
- 相比循环队列和单缓冲区,双缓冲区通过批量处理和缓冲区交换机制,减少了锁冲突和内存管理的开销。
- 它在保证高效的同时,提供了一种简单且可靠的解决方案。
总结
双缓冲区阻塞数据池的设计思想旨在通过批量处理和缓冲区交换,减少锁冲突和内存分配的开销,从而提高任务处理效率。它特别适用于高并发场景下的任务池设计,能够有效平衡生产者和消费者之间的关系,提升系统的整体性能。
不过在这之前,我们得要实现一下缓冲区:
缓冲区实现
创建一个头文件,用来专门实现缓冲区:
buffer.hpp
#ifndef __M_BUFFER_H__
#define __M_BUFFER_H__
#include "utils.hpp"
#include <vector>
#include <cassert>namespace logs
{#define DEFAULT_BUFFER_SIZE (1 * 1024 * 1024)#define THRESHOLD_BUFFER_SIZE (8 * 1024 * 1024)#define INCREAMENT_BUFFER_SIZE (1 * 1024 * 1024)class Buffer{public:Buffer(): _buffer(DEFAULT_BUFFER_SIZE), _writer_idx(0), _read_idx(0){}// 1、写入操作void push(const char *data, size_t len){// 1.首先判断是否需要扩容ensureEnoughSize(len);std::copy(data, data + len, &_buffer[_writer_idx]);moveWriter(len);}//返回可读数据的起始地址const char* begin(){return &_buffer[_read_idx];}size_t writeAbleSize(){return (_buffer.size() - _writer_idx);}size_t readAbleSize(){return (_writer_idx - _read_idx);}void reset(){_read_idx = 0; // 缓冲区所有空间都是空闲的_writer_idx = 0; // 与_writer_idx相等表示没有数据可读}// 对一个buffer进行一个交换void swap(Buffer &buffer){_buffer.swap(buffer._buffer);// 交换指针std::swap(_read_idx, buffer._read_idx);std::swap(_writer_idx, buffer._writer_idx);}void moveReader(size_t len){assert(len <= readAbleSize());_read_idx += len;}// 判断缓冲区是否为空bool empty(){return (_read_idx == _writer_idx);}private:// 扩容操作void ensureEnoughSize(size_t len){if (len <= writeAbleSize()){return;}size_t new_size = 0;if (_buffer.size() < THRESHOLD_BUFFER_SIZE){new_size = _buffer.size() * 2;}else{new_size = _buffer.size() + INCREAMENT_BUFFER_SIZE;}_buffer.resize(new_size);}// 对读写指针进行向后偏移操作void moveWriter(size_t len){assert(len + _writer_idx <= _buffer.size());_writer_idx += len;}std::vector<char> _buffer; // 缓冲区size_t _writer_idx; // 写指针size_t _read_idx; // 读指针};
}#endif
这是一个缓冲区的定义,我们要的是一个双缓冲区,所以我们再建一个头文件:
loop.hpp
#ifndef __M_LOOP_H__
#define __M_LOOP_H__#include "utils.hpp"
#include <condition_variable>
#include <thread>
#include <mutex>
#include <functional>
#include <atomic>
#include "message.hpp"
#include "buffer.hpp"
#include "loop.hpp"// 命名空间
namespace logs
{using Functor = std::function<void(Buffer &)>;class AsyncLooper{public:using ptr = std::shared_ptr<AsyncLooper>;enum class AsyncType{ASYNC_SAFE, // 安全模式,对空间索取有限制ASYNC_UNSAFE // 非安全模式,对空间索取无限制};AsyncLooper(const Functor &cb, AsyncType looper_type = AsyncType::ASYNC_SAFE): _stop(false), _thread(std::thread(&AsyncLooper::threadEntry, this)), _callback(cb), _looper_type(_looper_type){}~AsyncLooper(){stop();}void stop(){_stop = true;_cond_con.notify_all(); // 唤醒所有工作线程_thread.join();}void push(const char *data, size_t len){// 无限扩容或固定大小std::unique_lock<std::mutex> lock(_mutex);// 条件变量空值,如缓冲区空间大小大于数据长度,则可以添加数据if (_looper_type == AsyncType::ASYNC_SAFE)_cond_pro.wait(lock, [&](){ return _pron_buf.writeAbleSize() >= len; });// 如果走下来,可以向缓冲区添加数据_pron_buf.push(data, len);// 唤醒消费者对缓冲区的数据进行处理_cond_con.notify_one();}private:// 线程入口函数void threadEntry(){while (1){// 1.判断生产缓冲区有没有数据,有则交换,无则阻塞std::unique_lock<std::mutex> lock(_mutex);// 若是当前是退出前被唤醒,或者有数据被唤醒,则返回真,继续向下运行,否则重新进入休眠_cond_con.wait(lock, [&](){ return _stop || !_pron_buf.empty(); });退出标志被设置,且生产缓冲区无数据if (_stop && _pron_buf.empty()){break;}_con_buf.swap(_pron_buf);// 2.唤醒生产者_cond_pro.notify_all();}// 3.被唤醒后,对消费缓冲区进行数据处理_callback(_con_buf);// 4.初始化消费缓冲区_con_buf.reset();}Functor _callback; // 具体对缓冲区进行处理的回调函数,由异步工作器使用者传入private:AsyncType _looper_type; // 异步日志器类型std::atomic<bool> _stop; // 停止标志位Buffer _pron_buf; // 生产缓冲区Buffer _con_buf; // 消费缓冲区std::mutex _mutex;std::condition_variable _cond_pro; // 生产条件变量std::condition_variable _cond_con; // 消费者条件变量std::thread _thread; // 异步工作器对应的工作线程};
} // namespace logs#endif
这里的_pron_buf 和 _con_buf就是两个缓冲区,当_pron_buf缓冲区充满数据之后,就会和_con_buf进行交换,_pron_buf里面的数据就会到_con_buf里面去,这个时候工作线程就会从_con_buf中拿出数据进行工作。
异步任务处理器的构建是基于以上两个文件的,这个时候回到我们之前定义logger的头文件里面去:
#ifndef __M_LOGGER_H__
#define __M_LOGGER_H__
#include "utils.hpp"
#include "message.hpp"
#include "utils.hpp"
#include "level.hpp"
#include "sink.hpp"
#include <atomic>
#include <mutex>
#include <iostream>
#include <memory>
#include <ctime>
#include <vector>
#include <cassert>
#include <sstream>
#include <stdarg.h>
#include "loop.hpp"namespace logs
{class BaseLogger{public:using ptr = std::shared_ptr<BaseLogger>;BaseLogger(const std::string &logger_name,Loglevel::value limt_level,Formetter::ptr &formetter,std::vector<BaseSink::ptr> &sinks): _logger_name(logger_name), _limt_level(limt_level), _formetter(formetter), _sinks(sinks.begin(), sinks.end()){}const std::string &get_logger_name(){return _logger_name;}/*完成构造日志消息对象过程并进行格式化,得到格式化后的日志消息字符串---然后进行输出*/void debug(const std::string &file, size_t line, const std::string fmt, ...){// 如果限制输出的日志等级比debug高,则直接返回if (Loglevel::value::DEBUG < _limt_level){return;}// 声明参数列表变量va_list ap;va_start(ap, fmt); // 初始化fmt是最后一个固定的参数char *res; // 声明缓冲区int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放参数列表变量serialize(Loglevel::value::DEBUG, file, line, res);free(res);}void info(const std::string &file, size_t line, const std::string fmt, ...){// 如果限制输出的日志等级比debug高,则直接返回if (Loglevel::value::INFO < _limt_level){return;}// 声明参数列表变量va_list ap;va_start(ap, fmt); // 初始化fmt是最后一个固定的参数char *res; // 声明缓冲区int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放参数列表变量serialize(Loglevel::value::INFO, file, line, res);free(res);}void warn(const std::string &file, size_t line, const std::string fmt, ...){// 如果限制输出的日志等级比debug高,则直接返回if (Loglevel::value::WARN < _limt_level){return;}// 声明参数列表变量va_list ap;va_start(ap, fmt); // 初始化fmt是最后一个固定的参数char *res; // 声明缓冲区int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放参数列表变量serialize(Loglevel::value::WARN, file, line, res);free(res);}void error(const std::string &file, size_t line, const std::string &fmt, ...){// 1.通过传入的参数构造一个日志对象,进行日志的格式化,最终落地if (Loglevel::value::ERROR < _limt_level){return;}// 2.对fmt格式化字符串和不定参进行字符串组织,得到日志消息字符串va_list ap;va_start(ap, fmt);char *res;int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap);serialize(Loglevel::value::ERROR, file, line, res);free(res);}void fatal(const std::string &file, size_t line, const std::string &fmt, ...){// 1.通过传入的参数构造一个日志对象,进行日志的格式化,最终落地if (Loglevel::value::FATAL < _limt_level){return;}// 2.对fmt格式化字符串和不定参进行字符串组织,得到日志消息字符串va_list ap;va_start(ap, fmt);char *res;int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap);serialize(Loglevel::value::FATAL, file, line, res);free(res);}protected:void serialize(Loglevel::value level, const std::string &file_name,size_t line, char *str){// 1.构造msg对象logs::logMsg msg(level, file_name, line, _logger_name, str);// 2.利用Formetter进行消息格式化std::stringstream ss;_formetter->format(ss, msg);// 3.落地方向的输出log(ss.str().c_str(), ss.str().size());}/*抽象接口完成实际的落地输出---不同的日志器会有不同的落地方式*/virtual void log(const char *data, size_t len) = 0;protected:std::mutex _mutex; // 锁std::string _logger_name; // 日志器名称std::atomic<Loglevel::value> _limt_level; // 日志等级Formetter::ptr _formetter; // 格式化消息指针std::vector<BaseSink::ptr> _sinks; // 落地方向};class SyncLogger : public BaseLogger{public:SyncLogger(const std::string &logger_name,Loglevel::value limt_level,Formetter::ptr &formetter,std::vector<BaseSink::ptr> &sinks): BaseLogger(logger_name, limt_level, formetter, sinks) {}protected:void log(const char *data, size_t len){// 1.上锁std::unique_lock<std::mutex> _lock(std::mutex);if (_sinks.empty())return;for (auto &sink : _sinks){sink->log(data, len);}}};enum class loggerType{LOGGER_SYNC,LOGGER_ASYNC};class AsyncLogger : public BaseLogger{public:AsyncLogger(const std::string &logger_name, Loglevel::value level,Formetter::ptr &formatter,std::vector<BaseSink::ptr> &sinks,logs::AsyncLooper::AsyncType looper_type): BaseLogger(logger_name, level, formatter, sinks), _looper(std::make_shared<AsyncLooper>(std::bind(&AsyncLogger::realLog, this, std::placeholders::_1), looper_type)){}void log(const char *data, size_t len){_looper->push(data,len);}void realLog(Buffer& buffer){if (_sinks.empty())return;for (auto &sink : _sinks){sink->log(buffer.begin(), buffer.readAbleSize());}}private:AsyncLooper::ptr _looper;};
}#endif
我们可以来测试一下:
#include "utils.hpp"
#include "level.hpp"
#include "message.hpp"
#include "fometter.hpp"
#include "sink.hpp"
#include "logger.hpp"int main()
{logs::Formetter formatter("abc[%d{%H:%M:%S}][%c]%T%m%n");logs::Formetter::ptr fmt_ptr = std::make_shared<logs::Formetter>(formatter);auto st1 = logs::SinkFactory::create<logs::StdoutSink>();std::vector<logs::BaseSink::ptr> sinks = {st1};std::string logger_name = "asynclogger";logs::BaseLogger::ptr logger(new logs::AsyncLogger(logger_name, logs::Loglevel::value::DEBUG, fmt_ptr, sinks,logs::AsyncLooper::AsyncType::ASYNC_SAFE));logger->debug("main.cc", 53, "%s","格式化功能测试....");// 5. 确保异步日志线程有足够时间处理std::this_thread::sleep_for(std::chrono::milliseconds(100)); }

总结
loop.hpp中与线程有关的操作
在这段代码中,与线程相关的操作和函数主要包括以下几个方面:
1. 线程的创建与管理
-
线程的创建:
- 在
AsyncLooper构造函数中,通过std::thread创建一个新的线程_thread,并将其绑定到成员函数threadEntry。
这个线程是异步工作器的核心,负责处理缓冲区中的数据。_thread(std::thread(&AsyncLooper::threadEntry, this))
- 在
-
线程的销毁:
- 在析构函数
~AsyncLooper()中调用stop()函数,确保线程安全退出。~AsyncLooper() {stop(); }
- 在析构函数
-
线程的停止:
stop()函数用于优雅地停止线程:- 设置
_stop标志位为true,通知线程准备退出。 - 调用
_cond_con.notify_all()唤醒所有等待的线程。 - 使用
_thread.join()等待线程执行完毕后回收资源。void stop() {_stop = true;_cond_con.notify_all(); // 唤醒所有工作线程_thread.join(); }
- 设置
2. 线程同步与通信
为了确保线程之间的安全协作,使用了互斥锁(std::mutex)和条件变量(std::condition_variable)。
-
互斥锁 (
std::mutex):_mutex用于保护共享资源(如生产缓冲区_pron_buf和消费缓冲区_con_buf),防止多个线程同时访问导致数据竞争。- 在
push()和threadEntry()中使用std::unique_lock<std::mutex>对_mutex加锁。
-
条件变量 (
std::condition_variable):-
生产者条件变量
_cond_pro:- 用于控制生产者的阻塞和唤醒。
- 在
push()中,当缓冲区空间不足时,生产者会调用_cond_pro.wait()阻塞,直到消费者释放空间。_cond_pro.wait(lock, [&]() { return _pron_buf.writeAbleSize() >= len; }); - 消费者在处理完数据后,调用
_cond_pro.notify_all()唤醒所有等待的生产者。_cond_pro.notify_all();
-
消费者条件变量
_cond_con:- 用于控制消费者的阻塞和唤醒。
- 在
threadEntry()中,当生产缓冲区为空时,消费者会调用_cond_con.wait()阻塞,直到有新数据可用。_cond_con.wait(lock, [&]() { return _stop || !_pron_buf.empty(); }); - 生产者在向缓冲区添加数据后,调用
_cond_con.notify_one()唤醒一个消费者。_cond_con.notify_one();
-
3. 线程入口函数
threadEntry():- 这是线程的主要执行逻辑,负责从生产缓冲区
_pron_buf中读取数据并处理。 - 主要流程:
- 判断生产缓冲区是否有数据。如果有,则交换生产缓冲区和消费缓冲区;如果没有,则阻塞等待。
- 如果退出标志
_stop被设置且生产缓冲区为空,则线程退出。 - 调用回调函数
_callback(_con_buf)处理消费缓冲区中的数据。 - 初始化消费缓冲区
_con_buf,以便下一次使用。
void threadEntry() {while (1){std::unique_lock<std::mutex> lock(_mutex);_cond_con.wait(lock, [&]() { return _stop || !_pron_buf.empty(); });if (_stop && _pron_buf.empty()){break;}_con_buf.swap(_pron_buf);_cond_pro.notify_all();}_callback(_con_buf);_con_buf.reset(); }
- 这是线程的主要执行逻辑,负责从生产缓冲区
4. 数据生产与消费
-
生产数据:
push(const char *data, size_t len)是生产者接口,用于向生产缓冲区_pron_buf添加数据。- 在安全模式下(
ASYNC_SAFE),如果缓冲区空间不足,生产者会阻塞等待。if (_looper_type == AsyncType::ASYNC_SAFE)_cond_pro.wait(lock, [&]() { return _pron_buf.writeAbleSize() >= len; });
-
消费数据:
- 消费者线程通过
threadEntry()不断从生产缓冲区中获取数据,并调用用户提供的回调函数_callback进行处理。
- 消费者线程通过
5. 线程安全的设计
-
原子变量
_stop:- 使用
std::atomic<bool>类型的_stop标志位,确保多线程环境下的安全读写。std::atomic<bool> _stop;
- 使用
-
双重检查机制:
- 在
threadEntry()中,使用_stop && _pron_buf.empty()来判断是否需要退出线程,避免误退出或死锁。
- 在
总结
这段代码通过多线程技术实现了生产者-消费者模型,核心线程相关的操作包括:
- 线程的创建、管理和销毁。
- 使用互斥锁和条件变量实现线程同步与通信。
- 提供生产者接口
push()和消费者逻辑threadEntry()。 - 通过原子变量和双重检查机制确保线程安全。
这种设计适用于异步日志记录等场景,能够高效地处理大量并发数据。
placeholders::_1
下面是一个简单的例子来展示 std::bind 和 std::placeholders::_1 的使用方法。这个例子定义了一个类 Calculator,其中包含一个成员函数 add,该函数接受两个参数:一个整数和另一个整数引用。我们将通过 std::bind 将这个成员函数绑定到一个对象实例,并使用占位符 _1 来预留第二个参数的位置。
示例代码
#include <iostream>
#include <functional> // 包含 std::bind 和 std::placeholdersclass Calculator {
public:// 成员函数 add 接受一个整数 n 和一个整数引用 mvoid add(int n, int& m) {m += n;std::cout << "After adding " << n << ", m = " << m << std::endl;}
};int main() {Calculator calc; // 创建 Calculator 类的实例int value = 10;// 使用 std::bind 绑定成员函数 add 到 calc 实例,并预留第二个参数的位置auto boundFunc = std::bind(&Calculator::add, &calc, 5, std::placeholders::_1);// 调用绑定后的函数对象,传递 value 变量作为第二个参数boundFunc(value);return 0;
}
说明
-
Calculator::add:- 这个成员函数接收两个参数:一个整数
n和一个整数引用m。它将n加到m上,并输出结果。
- 这个成员函数接收两个参数:一个整数
-
std::bind:- 我们使用
std::bind函数将Calculator::add成员函数绑定到calc对象实例上,并固定第一个参数为5(即每次调用都会加上5),同时使用std::placeholders::_1占位符表示第二个参数将在实际调用时传入。
- 我们使用
-
boundFunc:boundFunc是一个可调用对象,当调用它并传入一个整数引用时,实际上会调用calc.add(5, /*传入的值*/)。
-
boundFunc(value);:- 在这里,我们调用了
boundFunc并传入了value变量作为第二个参数。这将导致Calculator::add函数被调用,执行value += 5操作,并打印出更新后的value值。
- 在这里,我们调用了
输出结果
当你运行上述代码时,程序将输出:
After adding 5, m = 15
这表明原始的 value 变量从 10 变为了 15,因为 5 被加到了 value 上。通过这种方式,我们可以看到如何使用 std::bind 和 std::placeholders::_1 来创建一个绑定特定参数的函数对象,并在调用时动态地提供剩余的参数。
放到代码中:
具体作用
在这段代码中:
_looper(std::make_shared<AsyncLooper>(std::bind(&AsyncLogger::realLog, this, std::placeholders::_1), looper_type))
std::bind用于将成员函数AsyncLogger::realLog绑定到一个可调用对象。this表示当前对象(即AsyncLogger的实例),作为成员函数的第一个隐式参数。std::placeholders::_1是一个占位符,表示这个绑定的函数对象在调用时需要接收一个参数,并将该参数传递给AsyncLogger::realLog的第一个显式参数。
换句话说,std::placeholders::_1 在这里的作用是预留一个位置,使得 AsyncLooper 的回调函数可以在运行时动态地传入一个参数(比如 Buffer & 类型的数据)。
详细解释
假设 AsyncLogger::realLog 的定义如下:
void AsyncLogger::realLog(Buffer &buffer);
通过 std::bind 和 std::placeholders::_1,我们创建了一个函数对象,其行为等价于:
void callback(Buffer &buffer) {this->realLog(buffer);
}
这个函数对象会被传递给 AsyncLooper 的构造函数,作为 _callback 回调函数。当 AsyncLooper 调用 _callback 时,它会将一个 Buffer 对象作为参数传递给 realLog。
为什么需要 std::placeholders::_1?
-
适配函数签名:
AsyncLooper的构造函数期望一个std::function<void(Buffer &)>类型的回调函数。AsyncLogger::realLog是一个成员函数,需要绑定到某个对象(this)才能调用。- 使用
std::placeholders::_1可以确保绑定后的函数对象能够接受一个参数,并将其正确传递给realLog。
-
灵活性:
- 占位符允许我们灵活地控制参数的传递顺序和数量。例如,如果有多个参数,可以使用
_1,_2,_3等分别表示不同的参数位置。
- 占位符允许我们灵活地控制参数的传递顺序和数量。例如,如果有多个参数,可以使用
示例对比
不使用 std::bind 和占位符:
如果直接传递成员函数指针,编译器会报错,因为成员函数需要绑定到一个对象:
_looper(std::make_shared<AsyncLooper>(&AsyncLogger::realLog, looper_type));
// 错误:无法直接传递成员函数指针
使用 std::bind 和占位符:
通过 std::bind,我们可以将成员函数绑定到当前对象,并预留参数位置:
_looper(std::make_shared<AsyncLooper>(std::bind(&AsyncLogger::realLog, this, std::placeholders::_1), looper_type));
// 正确:绑定后的函数对象符合 std::function<void(Buffer &)> 的要求
总结
std::placeholders::_1 的作用是为绑定的函数对象预留一个参数位置,使得 AsyncLogger::realLog 可以在运行时接受一个参数(如 Buffer &)。这种机制让 std::bind 更加灵活,能够适配不同函数签名的需求。
相关文章:
C++项目 —— 基于多设计模式下的同步异步日志系统(4)(双缓冲区异步任务处理器(AsyncLooper)设计)
C项目 —— 基于多设计模式下的同步&异步日志系统(4)(双缓冲区异步任务处理器(AsyncLooper)设计) 异步线程什么是异步线程?C 异步线程简单例子代码解释程序输出关键点总结扩展:使…...

Vue el-checkbox 虚拟滚动解决多选框全选卡顿问题 - 高性能处理大数据量选项列表
一、背景 在我们开发项目中,经常会遇到需要展示大量选项的多选框场景,比如权限配置、数据筛选等。当选项数量达到几百甚至上千条时,传统的渲染方式全选时会非常卡顿,导致性能问题。本篇文章,记录我使用通过虚拟滚动实现…...

案例速成k8s,个人笔记快速入门
更多个人笔记见github个人笔记仓库 个人学习,学习过程中还会不断补充~ (后续会更新在github上) 案例代码仓库:k8s学习代码 每一步重要的我都commit了,可以通过可视化软件比如github desktop 查看 简述 接…...
声音识别(声纹识别)和语音识别的区别
目录 引言一、语音识别1.声学模型2.语言模型3.词典 二、声音识别(声纹识别)三、语音识别、声音识别、语义识别的区别四、总结 引言 咋一看这个标题是不是很多小伙伴都迷糊了,哇哈,这两个不是一样的吗? 结论是&#x…...
使用Mybaitis-plus提供的各种的免写SQL的Wrapper的使用方式
文章目录 内连接JoinWrappers.lambda和 new MPJLambdaWrapper 生成的MPJLambdaWrapper对象有啥区别?LambdaQueryWrapper 和 QueryWrapper的区别?LambdaQueryWrapper和MPJLambdaQueryWrapper的区别?在作单表更新时建议使用:LambdaU…...

springboot-基于Web企业短信息发送系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 当今社会已经步入了科学技术进步和经济社会快速发展的新时期,国际信息和学术交流也不断加强,计算机技术对经济社会发展和人民生活改善的影响也日益突出,人类的生存和思考方式也产生了变化。本系统采用B/S架构,数据库是MySQL…...
秀丸编辑器 使用技巧
参考资料 第II部〜知っていると便利な秀丸の機能 検索テキストファイルの16進表示について秀丸エディタヘルプ目次秀丸エディタQ&A集(第9.6版)(HTML 形式)テンプレート(Ver9.43対応版) 目录 零…...

什么是量子计算?它能做什么?
抛一枚硬币。要么正面朝上,要么反面朝上,对吧?当然,那是在我们看到硬币落地的结果之后。但当硬币还在空中旋转时,它既不是正面也不是反面,而是正面和反面都有一定的可能性。 这个灰色地带就是量子计算的简…...

Python Web开发常用框架介绍
Python Web开发常用框架介绍 Python 是一种简洁、易于学习且功能强大的编程语言,广泛应用于 Web 开发、数据分析、人工智能等领域。Python 的 Web 开发框架能帮助开发者更高效地创建和管理 Web 应用。本文将介绍几种常用的 Python Web 开发框架,帮助你选…...
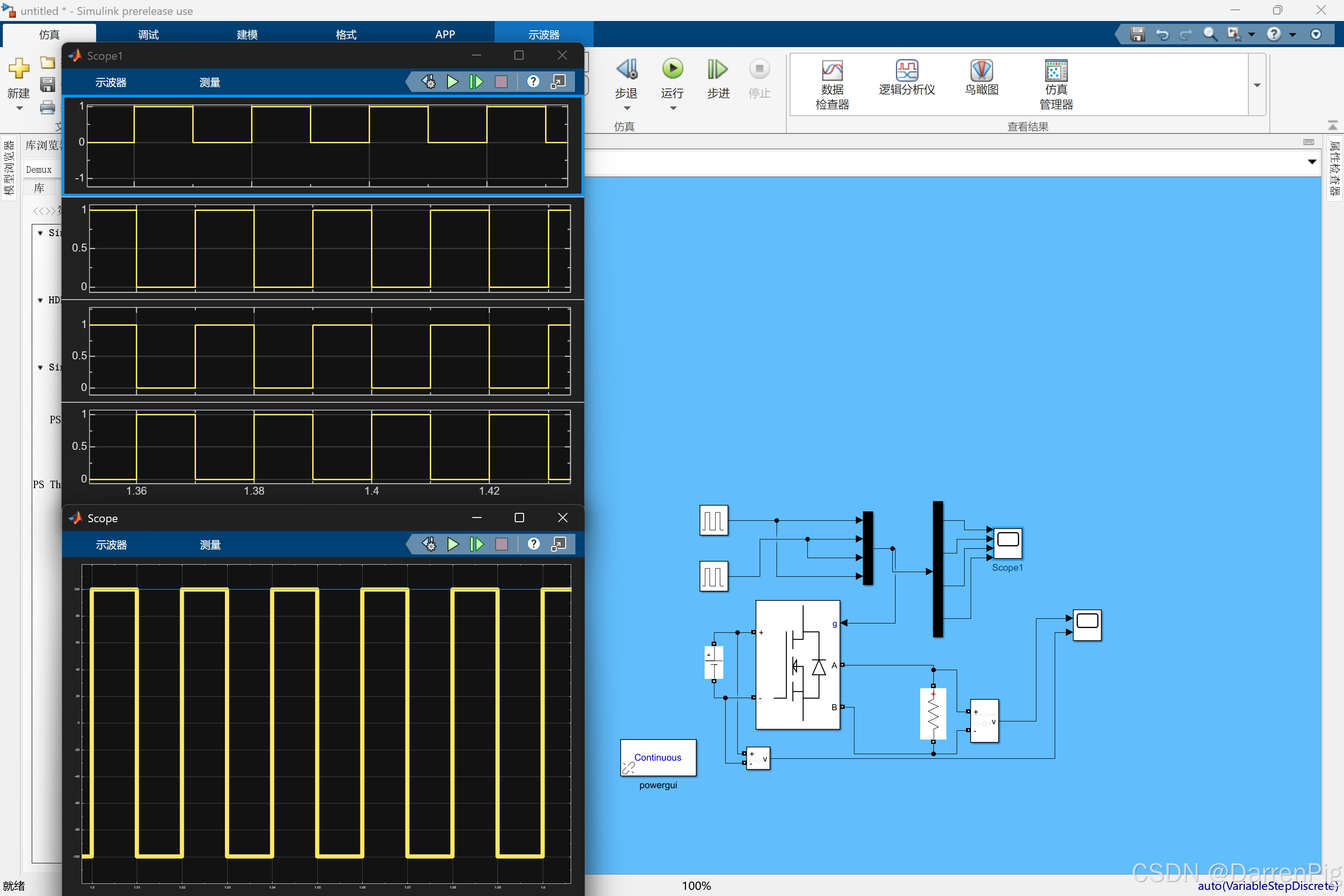
【新能源科学与技术】MATALB/Simulink小白教程(一)实验文档【新能源电力转换与控制仿真】
DP读书:新能源科学与工程——专业课「新能源发电系统」 2025a 版本 MATLAB下面进入正题 仿真一:Buck 电路一、仿真目的二、仿真内容(一)Buck电路基本构成及工作原理(二)Buck电路仿真模型及元件连接…...

[Unity]ColdKD树 冷处理解决含有删除操作的最近邻问题
在 Unity 开发中,最近邻问题是一个常见的需求场景。例如,在游戏中的寻路系统、物体之间的交互检测、资源分配等场景中,都需要快速准确地找到某个点或物体的最近邻。然而,传统的暴力遍历方法在处理这类问题时,往往会暴露…...
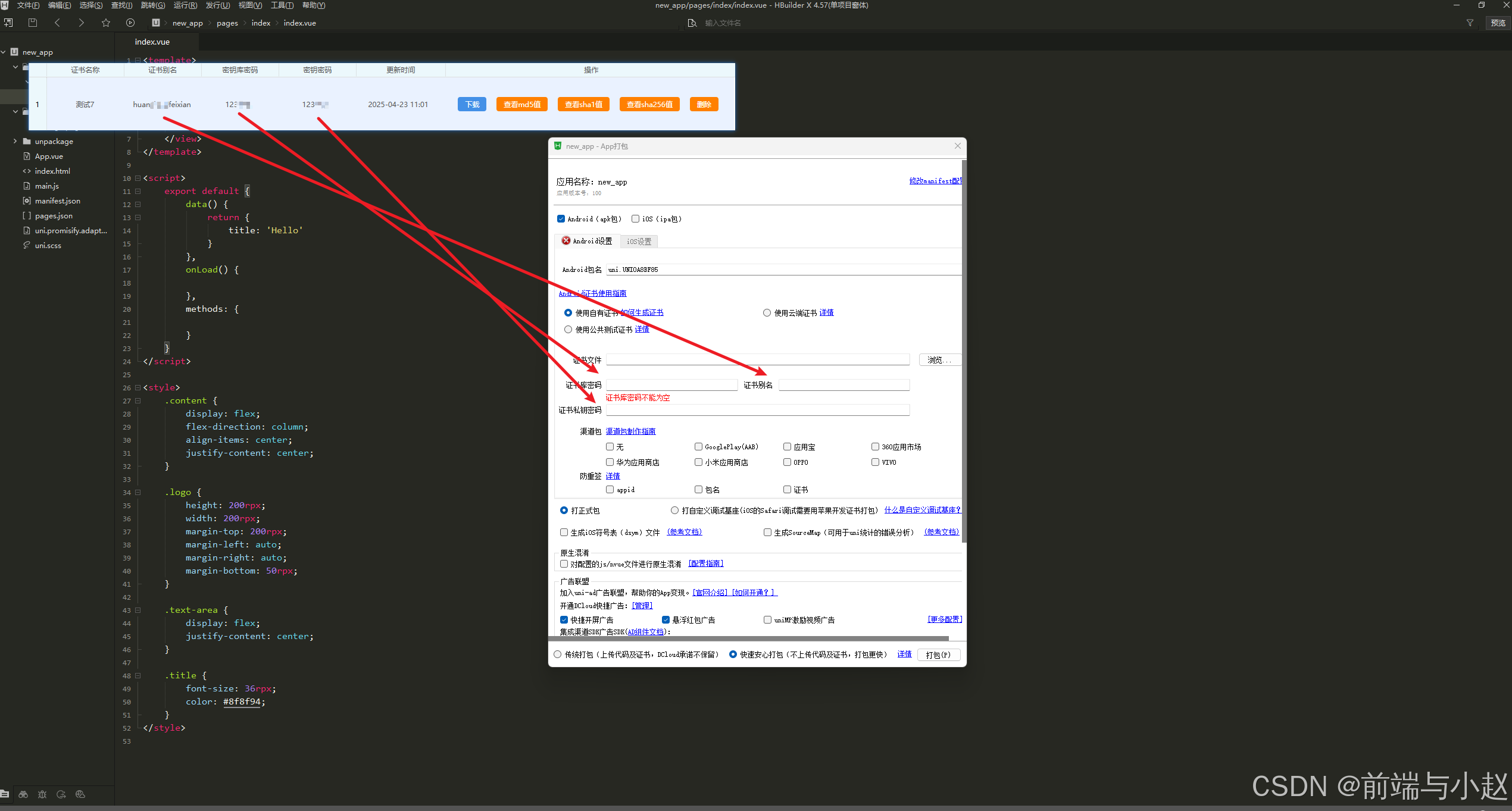
快速生成安卓证书并打包生成安卓apk(保姆教程)
一.生成安卓证书 目前市面上生成可以快速生成安卓证书的网站有很多个人推荐香蕉云编以下是网站链接 香蕉云编-app打包上架工具类平台 1.进入网站如下图 2.点击生成签名证书 3.点击立即创建证书 4.点击创建安卓证书 5.按照指引完成创建 6.点击下载就可使用 二.打包安卓apk …...
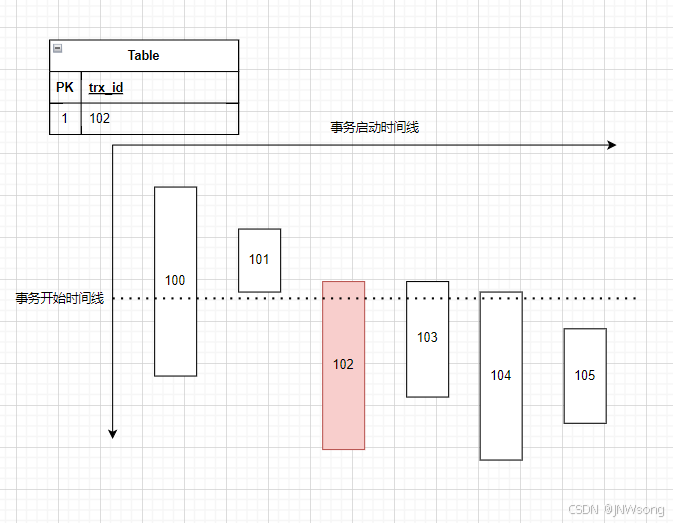
mysql mvvc 实现方案
Mysql 事务隔离级别 并发问题 mysql中事务并发时,会产生的问题如下 脏读: 读到了其他事务中,暂未提交的数据 脏读 (Dirty Read) 是数据库事务隔离级别中最低的一种隔离级别 (READ UNCOMMITTED) 下可能出现的一种并发问题。 它指的是一个事务读取了另…...
校园外卖服务系统的设计与实现(代码+数据库+LW)
摘 要 传统信息的管理大部分依赖于管理人员的手工登记与管理,然而,随着近些年信息技术的迅猛发展,让许多比较老套的信息管理模式进行了更新迭代,外卖信息因为其管理内容繁杂,管理数量繁多导致手工进行处理不能满足广…...
纷析云:开源财务管理软件的创新与价值
在企业数字化转型中,纷析云作为一款优秀的开源财务管理软件,正为企业财务管理带来新变革,以下是其核心要点。 一、产品概述与技术架构 纷析云采用微服务架构,功能组件高内聚低耦合,可灵活扩展和定制。前端基于现代框…...
Centos安装Dockers+Postgresql13+Postgis3.1
centos8安装docker步骤 1、# 强制卸载 podman 和 buildah 执行命令: yum erase podman buildah 2、# 添加阿里云仓库 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo 3、# 安装基础依赖包 yum install…...
【计算机网络 | 第二篇】常见的通信协议(一)
HTTP和HTTPS有什么区别? 端口号:HTTP默认是80端口,HTTPS默认是443。 URL前缀:HTTPHTTP 的 URL 前缀是 http://,HTTPS 的 URL 前缀是 https://。 安全性和资源消耗:HTTP协议运行在TCP上,都是明…...
集群控制与调度方案问题)
基于Java与MAVLink协议的多无人机(Cube飞控)集群控制与调度方案问题
基于Java与MAVLink协议的多无人机(Cube飞控)集群控制与调度方案问题 背景需求: 我们目前有一个基于Cube飞控的无人机系统,需实现以下核心功能: 多机通信:通过MAVLink协议同时连接并控制多架无人机&#x…...
单片机——使用printf调试
配置printf()输出函数 1、来自于<stdio.h> 2、运行C语言时,输出到终端 3、单片机没有终端,需要使用串口,将要输出的内容传到电脑(串口调试助手)上 例子如下 #include <stdio.h> #include &qu…...
4.23晚间工作总结
主要工作:将ClassicDetail界面拆分成utils,apis,stores,css,vue多个文件,方便后续重用 具体代码截图:...

Spring 用到了哪些设计模式?
Spring 框架使用了多种设计模式,这些模式帮助其实现松耦合、高内聚和可扩展性。以下是 Spring 中常见的设计模式及其应用场景: 1. 工厂模式(Factory Pattern) 应用场景:Spring 的 BeanFactory 和 ApplicationContext 是…...

JavaEE学习笔记(第二课)
1、好用的AI代码工具cursor 2、Java框架:Spring(高级框架)、Servelt、Struts、EJB 3、Spring有两层含义: ①Spring Framework(原始框架) ②Spring家族 4、Spring Boot(为了使Spring简化) 5、创建Spring Boot 项目 ① ② ③…...
约束constraint
创建表时,可以给表的字段添加约束,可以保证数据的完整性、有效性。比如大家上网注册用户时常见的:用户名不能为空。对不起,用户名已存在。等提示信息。 约束通常包括: 非空约束:not null检查约束…...
)
【Qwen2.5-VL 踩坑记录】本地 + 海外账号和国内账号的 API 调用区别(阿里云百炼平台)
API 调用 阿里云百炼平台的海内外 API 的区别: 海外版:需要进行 API 基础 URL 设置国内版:无需设置。 本人的服务器在香港,采用海外版的 API 时,需要进行如下API端点配置 / API基础URL设置 / API客户端配置…...

解锁现代生活健康密码,开启养生新方式
在科技飞速发展的当下,我们享受着便捷生活,却也面临诸多健康隐患。想要维持良好状态,不妨从这些细节入手,解锁科学养生之道。 肠道是人体重要的消化器官,也是最大的免疫器官,养护肠道至关重要。日常可多…...
在kali中安装AntSword(蚁剑)
步骤一、下载压缩包 源码:https://github.com/AntSwordProject/antSword,下载压缩包。 加载器:https://github.com/AntSwordProject/AntSword-Loader,根据系统选择压缩包(kali选择AntSword-Loader-v4.0.3-linux-x64&…...
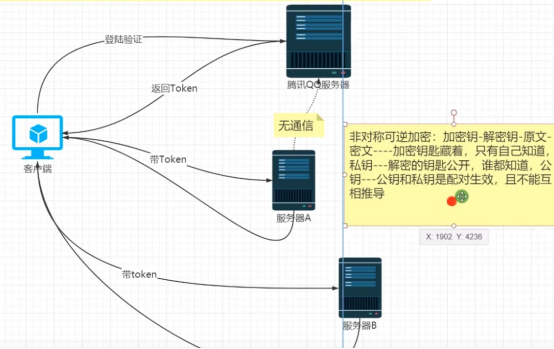
GateWay与Consul知识点
这是一个涵盖客户端访问、网关处理、服务注册发现、业务服务及鉴权授权的系统架构图,各部分解析如下: 客户端层 App 端、Web 端:代表不同类型的客户端,涵盖手机 App、电脑 Web 页面等。用户通过这些客户端发起请求,访…...

安宝特科技 | Vuzix Z100智能眼镜+AugmentOS:重新定义AI可穿戴设备的未来——从操作系统到硬件生态,如何掀起无感智能革命?
一、AugmentOS:AI可穿戴的“操作系统革命” 2025年2月3日,Vuzix与AI人机交互团队Mentra联合推出的AugmentOS,被业内视为智能眼镜领域的“iOS时刻”。这款全球首个专为智能眼镜设计的通用操作系统,通过三大突破重新定义了AI可穿戴…...

【数据结构和算法】1. 数据结构和算法简介、二分搜索
本文根据 数据结构和算法入门 视频记录 文章目录 1. 数据结构和算法简介1.1 什么是数据结构?什么是算法?1.2 数据结构和算法之间的关系1.3 “数据结构和算法”有那么重要吗? 2. 二分搜索(Binary Search)2.1 算法概念2…...

SpringBoot3设置maven package直接打包成二进制可执行文件
注意事项 SpringBoot普通native打包顺序clean compile spring-boot:process-aot native:compile 使用以下配置只会的打包顺序clean package(注意:使用此配置以后打包会有编译后的class文件、jar包、original源文件、二进制可执行文件【Linux是无后缀的包…...