RAGFlow:构建高效检索增强生成流程的技术解析
引言
在当今信息爆炸的时代,如何从海量数据中快速准确地获取所需信息并生成高质量内容已成为人工智能领域的重要挑战。检索增强生成(Retrieval-Augmented Generation, RAG)技术应运而生,它将信息检索与大型语言模型(LLM)的强大生成能力相结合,显著提升了生成内容的准确性和可靠性。而RAGFlow作为这一领域的新兴框架,通过系统化的流程设计和优化,为开发者提供了构建高效RAG系统的完整解决方案。
本文将深入探讨RAGFlow的技术架构、核心组件、实现细节以及优化策略,帮助开发者全面理解并有效应用这一技术。
github地址:https://github.com/infiniflow/ragflow
一、RAG技术概述
1.1 RAG的基本原理
检索增强生成(RAG)是一种将信息检索与文本生成相结合的技术范式。与传统生成模型不同,RAG在生成答案前会先从知识库中检索相关文档片段,然后将这些检索结果与原始问题一起输入生成模型,从而产生基于事实的准确回答。
RAG的核心优势在于:
- 事实准确性:基于检索到的真实信息生成内容,减少幻觉现象
- 知识更新便捷:只需更新检索库而无需重新训练模型
- 可解释性:可以追溯生成内容的来源依据
1.2 RAG的发展历程
RAG技术自2020年由Facebook AI Research首次提出后迅速发展:
- 原始RAG:使用DPR检索器+Seq2Seq生成器
- 改进版本:引入更高效的检索器和更大规模的生成模型
- 现代RAG系统:结合稠密检索、重排序、多跳推理等高级技术
1.3 RAG面临的挑战
尽管RAG优势明显,但在实际应用中仍面临诸多挑战:
- 检索质量:如何从海量数据中精准定位相关信息
- 上下文长度:LLM的上下文窗口限制影响信息利用
- 延迟问题:检索+生成的双阶段流程导致响应时间增加
- 连贯性:如何确保生成内容与检索信息自然融合
RAGFlow正是针对这些挑战提出的系统化解决方案。
二、RAGFlow架构设计
2.1 整体架构
RAGFlow采用模块化设计,将整个流程划分为五个核心组件:
- 文档处理管道:负责原始知识的提取、分块和向量化
- 检索引擎:实现高效相似性搜索和多模态检索
- 生成引擎:集成现代LLM并优化提示工程
- 评估模块:质量监控和持续改进
- 服务接口:提供统一的API和部署方案
2.2 核心创新点
RAGFlow相较于传统RAG实现有以下创新:
- 动态分块策略:根据文档类型和内容自动优化分块大小和重叠
- 混合检索:结合稠密向量、稀疏向量和关键词的多路检索
- 渐进式生成:分阶段生成和验证机制
- 反馈学习:基于用户反馈持续优化检索和生成
三、关键技术实现
3.1 文档处理优化
文档处理是RAG流程的第一步,也是影响后续效果的关键环节。
3.1.1 智能分块算法
RAGFlow实现了自适应的文档分块策略:
def adaptive_chunking(text, min_size=256, max_size=1024, overlap=0.2):# 基于语义分割的初步分块paragraphs = text.split('\n\n')chunks = []current_chunk = ""for para in paragraphs:if len(current_chunk) + len(para) > max_size:if current_chunk:chunks.append(current_chunk)current_chunk = para[-int(len(para)*overlap):] + " "else:chunks.append(para[:max_size])current_chunk = para[max_size-int(len(para)*overlap):] + " "else:current_chunk += para + " "if current_chunk:chunks.append(current_chunk)# 后处理:合并过小的块merged_chunks = []for chunk in chunks:if len(chunk) < min_size and merged_chunks:merged_chunks[-1] += " " + chunkelse:merged_chunks.append(chunk)return merged_chunks
3.1.2 多模态支持
RAGFlow扩展了传统文本处理能力,支持:
- PDF/Word/Excel等格式解析
- 表格数据提取和结构化
- 图像OCR文本识别
- 音频转录处理
3.2 高效检索实现
3.2.1 混合检索策略
RAGFlow采用三阶段检索流程:
- 初步筛选:使用BM25等稀疏检索快速缩小范围
- 精确检索:应用稠密向量相似度计算
- 重排序:基于交叉编码器对Top结果精细排序
class HybridRetriever:def __init__(self, sparse_index, dense_index, reranker):self.sparse_index = sparse_index # BM25/ElasticSearchself.dense_index = dense_index # FAISS/Milvusself.reranker = reranker # Cross-Encoderdef search(self, query, top_k=10):# 第一阶段:稀疏检索sparse_results = self.sparse_index.search(query, top_k=top_k*3)# 第二阶段:稠密检索dense_results = self.dense_index.search(query, top_k=top_k*3)# 结果合并与去重combined = self.merge_results(sparse_results, dense_results)# 第三阶段:重排序reranked = self.reranker.rerank(query, combined[:top_k*2])return reranked[:top_k]
3.2.2 元数据过滤
RAGFlow支持基于文档元数据的过滤检索:
- 时间范围
- 作者/来源
- 文档类型
- 置信度评分
3.3 生成优化技术
3.3.1 动态提示工程
RAGFlow根据检索结果动态构建提示模板:
你是一位专业助手,请基于以下上下文回答问题。
上下文可能包含多个来源,请注意区分。问题:{query}上下文:
1. [来源:{source1}] {text1}
2. [来源:{source2}] {text2}
...
N. [来源:{sourceN}] {textN}请综合以上信息,给出准确、简洁的回答。如果上下文不足以回答问题,请明确说明。
3.3.2 渐进式生成
对于复杂问题,RAGFlow采用分步生成策略:
- 问题分解
- 分步检索
- 中间答案生成
- 最终综合
3.4 评估与优化
RAGFlow内置多维评估体系:
| 评估维度 | 指标 | 测量方法 |
|---|---|---|
| 检索质量 | 召回率@K | 人工标注相关文档 |
| 精确率@K | 人工标注相关文档 | |
| 生成质量 | 事实准确性 | 基于来源验证 |
| 流畅度 | 语言模型评分 | |
| 相关性 | 与问题的语义相似度 | |
| 系统性能 | 延迟 | 端到端响应时间 |
| 吞吐量 | QPS |
四、部署实践
4.1 系统要求
- 硬件:推荐GPU服务器(至少16GB显存)
- 软件:Python 3.8+, Docker
- 向量数据库:Milvus/FAISS/Pinecone
- LLM服务:本地部署或API接入
4.2 典型部署架构
用户请求 → 负载均衡 → [RAGFlow实例1][RAGFlow实例2] → 缓存层 → 向量数据库集群[RAGFlow实例3] → 文档存储
4.3 性能优化技巧
-
检索优化:
- 量化向量(FP16/INT8)
- 分层导航小世界图(HNSW)索引
- 批量检索
-
生成优化:
- 模型量化
- 推测解码
- 缓存常见问题回答
-
系统优化:
- 异步处理
- 结果缓存
- 预计算热点查询
五、应用案例
5.1 企业知识问答
某科技公司使用RAGFlow构建内部知识库系统:
- 索引文档:15万+(技术文档、会议记录、产品手册)
- 日均查询:3000+
- 回答准确率:从基线65%提升至89%
5.2 学术研究助手
研究机构部署的文献分析系统:
- 处理PDF论文:50万+
- 支持复杂多跳查询
- 生成文献综述效率提升3倍
5.3 客户服务自动化
电商平台客服机器人:
- 整合产品数据库和客服记录
- 自动生成个性化回复
- 客服效率提升40%
六、未来展望
RAGFlow技术仍在快速发展中,未来可能的方向包括:
- 多模态扩展:支持图像、视频等非文本信息的检索与生成
- 实时更新:流式数据处理和近实时索引
- 自我优化:基于用户反馈的自动调优
- 复杂推理:结合符号推理和逻辑验证
- 个性化:用户画像引导的检索和生成
结论
RAGFlow通过系统化的流程设计和多项技术创新,有效解决了传统RAG系统的诸多痛点,为构建高效、可靠的检索增强生成应用提供了强大支持。随着技术的不断演进,RAGFlow有望成为连接海量数据与智能生成的关键基础设施,推动知识密集型应用的快速发展。
对于开发者而言,掌握RAGFlow不仅能够构建更强大的AI应用,还能深入理解现代信息检索与生成模型协同工作的前沿技术。建议从官方示例入手,逐步探索适合特定场景的定制方案,充分发挥这一技术的潜力。
相关文章:

RAGFlow:构建高效检索增强生成流程的技术解析
引言 在当今信息爆炸的时代,如何从海量数据中快速准确地获取所需信息并生成高质量内容已成为人工智能领域的重要挑战。检索增强生成(Retrieval-Augmented Generation, RAG)技术应运而生,它将信息检索与大型语言模型(L…...
STM32提高篇: 蓝牙通讯
STM32提高篇: 蓝牙通讯 一.蓝牙通讯介绍1.蓝牙技术类型 二.蓝牙协议栈1.蓝牙芯片架构2.BLE低功耗蓝牙协议栈框架 三.ESP32-C3中的蓝牙功能1.广播2.扫描3.通讯 四.发送和接收 一.蓝牙通讯介绍 蓝牙,是一种利用低功率无线电,支持设备短距离通信的无线电技…...

SpringMVC处理请求映射路径和接收参数
目录 springmvc处理请求映射路径 案例:访问 OrderController类的pirntUser方法报错:java.lang.IllegalStateException:映射不明确 核心错误信息 springmvc接收参数 一 ,常见的字符串和数字类型的参数接收方式 1.1 请求路径的…...

高质量学术引言如何妙用ChatGPT?如何写提示词
目录 1、引言究竟是什么? 2、引言如何构建?? 在学术写作领域,巧妙利用人工智能来构建文章的引言和理论框架是一个尚待探索的领域。小编在这篇文章中探讨一种独特的方法,即利用 ChatGPT 作为工具来构建引言和理论框架…...

【程序员 NLP 入门】词嵌入 - 上下文中的窗口大小是什么意思? (★小白必会版★)
🌟 嗨,你好,我是 青松 ! 🌈 希望用我的经验,让“程序猿”的AI学习之路走的更容易些,若我的经验能为你前行的道路增添一丝轻松,我将倍感荣幸!共勉~ 【程序员 NLP 入门】词…...

从物理到预测:数据驱动的深度学习的结构化探索及AI推理
在当今科学探索的时代,理解的前沿不再仅仅存在于我们书写的方程式中,也存在于我们收集的数据和构建的模型中。在物理学和机器学习的交汇处,一个快速发展的领域正在兴起,它不仅观察宇宙,更是在学习宇宙。 AI推理 我们…...

各种各样的bug合集
一、连不上数据库db 1.可能是密码一大包东西不对; 2.可能是里面某个port和数据库不一样(针对于修改了数据库但是连不上的情况); 3.可能是git代码没拉对,再拉一下代码。❤ 二、没有这个包 可能是可以#注释掉。❤ …...

大模型AI的“双刃剑“:数据安全与可靠性挑战与破局之道
在数字经济蓬勃发展的浪潮中,数据要素已然成为驱动经济社会创新发展的核心引擎。从智能制造到智慧城市,从电子商务到金融科技,数据要素的深度融合与广泛应用,正以前所未有的力量重塑着产业格局与经济形态。 然而,随着…...

如何使用 CompletableFuture、Function 和 Optional 优雅地处理异步编程?
当异步遇上函数式编程,代码变得更优雅 在日常开发中,很多时候我们需要处理异步任务、函数转换和空值检查。传统的回调方式和空值判断常常让代码看起来繁琐而难以维护。幸运的是,Java 提供了 CompletableFuture、Function 和 Optional&#x…...

基于大模型的结肠癌全病程预测与诊疗方案研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与创新点 二、结肠癌概述 2.1 流行病学特征 2.2 发病机制与危险因素 2.3 临床症状与诊断方法 三、大模型技术原理与应用现状 3.1 大模型的基本原理 3.2 在医疗领域的应用情况 3.3 在结肠癌预测中的潜力分析 四、术前…...
操作系统概述与安装
主流操作系统概述 信创平台概述 虚拟机软件介绍与安装 windows server 安装 centos7 安装 银河麒麟V10 安装 一:主流服务器操作系统 (1)Windows Server 发展历程: 1993年推出第一代 WindowsNT(企业级内核&am…...
)
算法设计与分析(基础)
问题列表 一、 算法的定义与特征,算法设计的基本步骤二、 算法分析的目的是什么?如何评价算法,如何度量算法的复杂性?三、 递归算法、分治法、贪婪法、动态规划法、回溯法的基本思想方法。四、 同一个问题,如TSP&#…...
)
多线程(线程安全)
一、线程安全的风险来源 1.1 后厨的「订单撞单」现象 场景:两服务员同时录入客人点单到同一个菜单本 问题: 订单可能被覆盖菜品数量统计错误 Java中的表现: public class OrderServlet extends HttpServlet {private int totalOrders 0…...
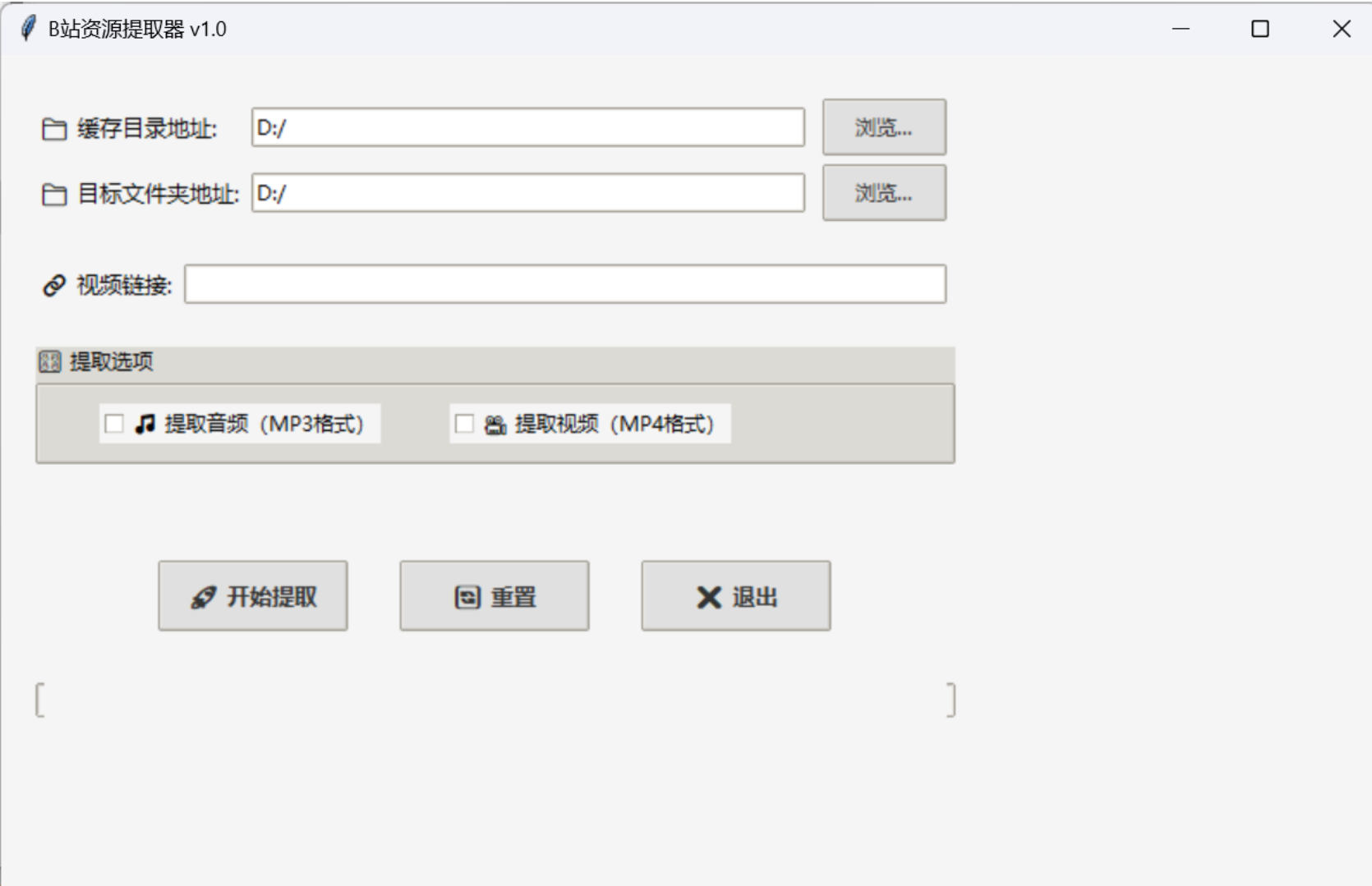
开发了一个b站视频音频提取器
B站资源提取器-说明书 一、功能说明 本程序可自动解密并提取B站客户端缓存的视频资源,支持以下功能: - 自动识别视频缓存目录 - 将加密的.m4s音频文件转换为标准MP3格式 - 将加密的.m4s视频文件转换为标准MP4格式(合并音视频流)…...
基于javaweb的SpringBoot校园服务平台系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

北京SMT贴片加工工艺优化要点
内容概要 在北京地区SMT贴片加工领域,工艺优化是实现高可靠电子组装的系统性工程。本文以精密化生产需求为导向,围绕制程关键节点展开技术剖析,从钢网印刷的锡膏成型控制到贴装环节的视觉定位精度,逐步构建全流程优化模型。通过分…...
PHYBench:首个大规模物理场景下的复杂推理能力评估基准
2025-04-23, 由北京大学物理学院和人工智能研究所等机构共同创建的 PHYBench 数据集,这是一个专门用于评估大型语言模型在物理场景下的复杂推理能力的高质量基准。该数据集包含 500 道精心策划的物理问题,覆盖力学、电磁学、热力学、光学、现代物理和高级…...

将输入帧上下文打包到下一个帧的预测模型中用于视频生成
Paper Title: Packing Input Frame Context in Next-Frame Prediction Models for Video Generation 论文发布于2025年4月17日 Abstract部分 在这篇论文中,FramePack是一种新提出的网络结构,旨在解决视频生成中的两个主要问题:遗忘和漂移。 具体来说,遗忘指的是在生成视…...

使用localStorage的方式存储数据,刷新之后,无用户消息,需要重新登录,,localStorage 与 sessionStorage 的区别
1 localStorage 与 sessionStorage 的区别: 特性localStoragesessionStorage存储时长永久存储,除非手动删除或者清空浏览器缓存会话存储,浏览器关闭后数据丢失数据生命周期持久存在,直到被明确删除(即使关闭浏览器也不会消失)当前会话结束后数据自动清空(关闭标签页或浏…...

第15章:MCP服务端项目开发实战:性能优化
第15章:MCP服务端项目开发实战:性能优化 在构建和部署 MCP(Memory, Context, Planning)驱动的 AI Agent 系统时,性能和可扩展性是关键的考量因素。随着用户量、数据量和交互复杂度的增加,系统需要能够高效地处理请求,并能够平滑地扩展以应对更高的负载。本章将探讨 MCP…...
MOA Transformer:一种基于多尺度自注意力机制的图像分类网络
MOA Transformer:一种基于多尺度自注意力机制的图像分类网络 引言 近年来,Transformer 架构在自然语言处理领域取得了巨大的成功,并逐渐扩展到计算机视觉领域。Swin Transformer 就是其中一个典型的成功案例。它通过引入“无卷积”架构&…...

Red:1靶场环境部署及其渗透测试笔记(Vulnhub )
环境介绍: 靶机下载: https://download.vulnhub.com/red/Red.ova 本次实验的环境需要用到VirtualBox(桥接网卡),VMware(桥接网卡)两台虚拟机(网段都在192.168.152.0/24࿰…...

从 Java 到 Kotlin:在现有项目中迁移的最佳实践!
全文目录: 开篇语 1. 为什么选择 Kotlin?1.1 Kotlin 与 Java 的兼容性1.2 Kotlin 的优势1.3 Kotlin 的挑战 2. Kotlin 迁移最佳实践2.1 渐进式迁移2.1.1 步骤一:将 Kotlin 集成到现有的构建工具中2.1.2 步骤二:逐步迁移2.1.3 步骤…...

Java Collections工具类指南
一、Collections工具类概述 java.util.Collections是Java集合框架中提供的工具类,包含大量静态方法用于操作和返回集合。这些方法主要分为以下几类: 排序操作查找和替换同步控制不可变集合特殊集合视图其他实用方法 二、排序操作 1. 自然排序 List&…...

深入详解人工智能数学基础——概率论中的KL散度在变分自编码器中的应用
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用…...

测试模版x
本篇技术博文摘要 🌟 引言 📘 在这个变幻莫测、快速发展的技术时代,与时俱进是每个IT工程师的必修课。我是盛透侧视攻城狮,一名什么都会一丢丢的网络安全工程师,也是众多技术社区的活跃成员以及多家大厂官方认可人员&a…...

Openharmony 和 HarmonyOS 区别?
文章目录 OpenHarmony 与 HarmonyOS 的区别:开源生态与商业发行版的定位差异一、定义与定位二、技术架构对比1. OpenHarmony2. HarmonyOS 三、应用场景差异四、开发主体与生态支持五、关键区别总结六、如何选择?未来展望 OpenHarmony 与 HarmonyOS 的区别…...

uniapp 仿小红书轮播图效果
通过对小红书的轮播图分析,可得出以下总结: 1.单张图片时容器根据图片像素定高 2.多图时轮播图容器高度以首图为锚点 3.比首图长则固高左右留白 4.比首图短则固宽上下留白 代码如下: <template><view> <!--轮播--><s…...

让Docker端口映射受Firewall管理而非iptables
要让Docker容器的端口映射受系统防火墙(如firewalld或ufw)管理,而不是直接通过iptables,可以按照以下步骤配置: 方法一:禁用Docker的iptables规则 (1)编辑Docker配置文件: vi /etc/docker/da…...
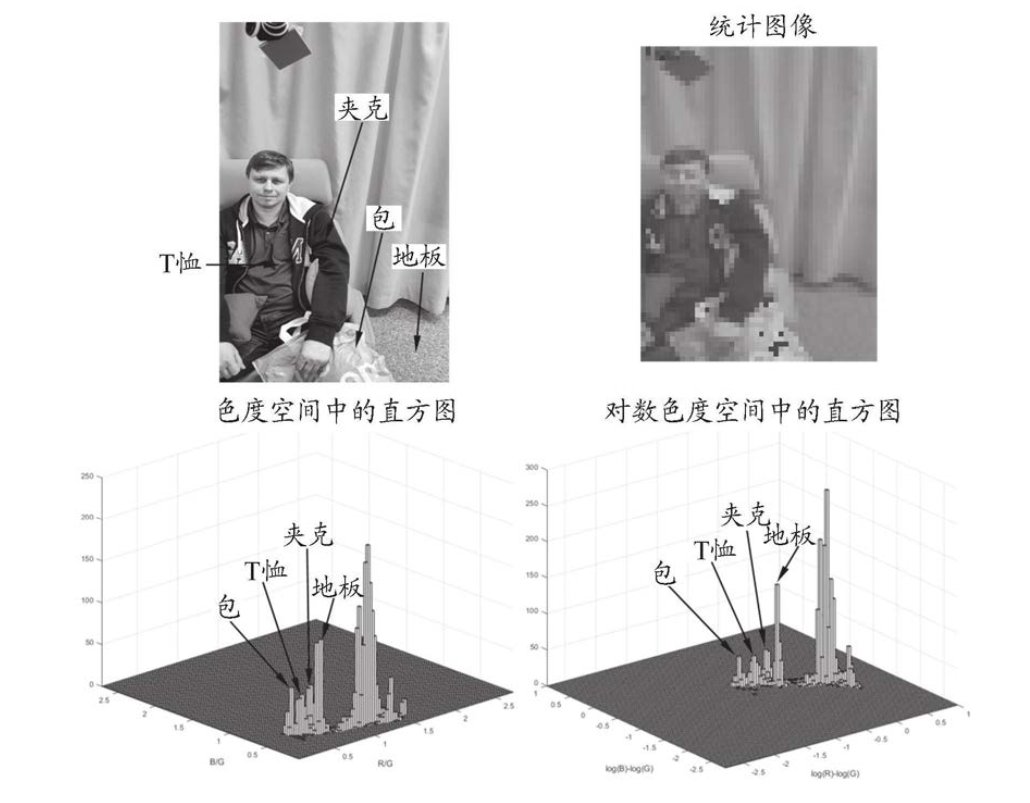
R/G-B/G色温坐标系下对横纵坐标取对数的优势
有些白平衡色温坐标系会分别对横纵坐标取对数运算。 这样做有什么优势呢? 我们知道对数函数对0-1之间的因变量值具有扩展作用。即自变量x变化比较小时,经过对数函数作用后可以把因变量扩展到较大范围内,即x变化较小时,y变化较大,增加了识别数据的识别性。 由于Raw数据中的…...