YOLOv8融合CPA-Enhancer【提高恶略天气的退化图像检测】
1.CPA介绍
CPA-Enhancer通过链式思考提示机制实现了对未知退化条件下图像的自适应增强,显著提升了物体检测性能。其插件式设计便于集成到现有检测框架中,并在物体检测及其他视觉任务中设立了新的性能标准,展现了广泛的应用潜力。
关于CPA-Enhancer的详细介绍可以看论文:[2403.11220v3] CPA-Enhancer: Chain-of-Thought Prompted Adaptive Enhancer for Object Detection under Unknown Degradations

Input Image│▼
[Conv + BN + ReLU](通用预处理)│├─► 分支1:多尺度卷积提取├─► 分支2:亮度补偿模块├─► 分支3:注意力增强机制(通道注意力+空间注意力)└─► 分支4:上下文结构感知(Transformer 模块等)│▼
[特征融合 + 残差连接]│▼
Enhanced Feature Map → YOLOv8 Backbone
CPA 处理图像的核心机制
1. 多尺度特征提取(Multi-Scale Extraction)
- 使用多个不同尺寸的卷积核(如 1x1, 3x3, 5x5)或金字塔结构提取局部+全局特征;
- 有效增强图像纹理信息和边缘结构;
- 防止小目标被弱特征淹没。
2. 亮度与对比度增强(Light & Contrast Enhancement)
- 模仿传统图像增强方法(如 CLAHE、Gamma 校正等)思想,但使用神经网络完成:
-
- 网络自动学习一套光照补偿策略;
- 增强图像暗部细节;
- 保留高光部分结构。
3. 上下文感知(Context-Aware Attention)
- 利用注意力机制(如 SE、CBAM、Transformer-style Attention)增强重要区域;
- 学习图像中哪些部分应该被重点关注(如前景物体、边缘);
- 抑制背景冗余信息。
4. 结构保留增强(Structure-Aware Enhancement)
- 保持图像结构(如边缘、角点)不被模糊化;
- 可能引入边缘检测或梯度引导模块,增强空间纹理信息;
- 可引入残差连接,减少特征漂移。
2.将CPA-Enhancer融合进YOLOv8
2.1 步骤一:放代码
首先找到如下的目录'ultralytics/nn',然后在这个目录下创建一个'Addmodules'文件夹,然后在这个目录下创建一个Enhancer.py文件,文件名字可以根据你自己的习惯起,然后将CPA-Enhancer的核心代码复制进去。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numbers
from einops import rearrange
from einops.layers.torch import Rearrange__all__ = ['CPA_arch']class RFAConv(nn.Module): # 基于Group Conv实现的RFAConvdef __init__(self, in_channel, out_channel, kernel_size=3, stride=1):super().__init__()self.kernel_size = kernel_sizeself.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1,groups=in_channel, bias=False))self.generate_feature = nn.Sequential(nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size, padding=kernel_size // 2,stride=stride, groups=in_channel, bias=False),nn.BatchNorm2d(in_channel * (kernel_size ** 2)),nn.ReLU())self.conv = nn.Sequential(nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size),nn.BatchNorm2d(out_channel),nn.ReLU())def forward(self, x):b, c = x.shape[0:2]weight = self.get_weight(x)h, w = weight.shape[2:]weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*kernel**2,h,w -> b c k**2 h wfeature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h,w) # b c*kernel**2,h,w -> b c k**2 h w 获得感受野空间特征weighted_data = feature * weightedconv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size,# b c k**2 h w -> b c h*k w*kn2=self.kernel_size)return self.conv(conv_data)class Downsample(nn.Module):def __init__(self, n_feat):super(Downsample, self).__init__()self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat // 2, kernel_size=3, stride=1, padding=1, bias=False),nn.PixelUnshuffle(2))def forward(self, x):return self.body(x)class Upsample(nn.Module):def __init__(self, n_feat):super(Upsample, self).__init__()self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat * 2, kernel_size=3, stride=1, padding=1, bias=False),nn.PixelShuffle(2))def forward(self, x): # (b,c,h,w)return self.body(x) # (b,c/2,h*2,w*2)class SpatialAttention(nn.Module):def __init__(self):super(SpatialAttention, self).__init__()self.sa = nn.Conv2d(2, 1, 7, padding=3, padding_mode='reflect', bias=True)def forward(self, x): # x:[b,c,h,w]x_avg = torch.mean(x, dim=1, keepdim=True) # (b,1,h,w)x_max, _ = torch.max(x, dim=1, keepdim=True) # (b,1,h,w)x2 = torch.concat([x_avg, x_max], dim=1) # (b,2,h,w)sattn = self.sa(x2) # 7x7conv (b,1,h,w)return sattn * xclass ChannelAttention(nn.Module):def __init__(self, dim, reduction=8):super(ChannelAttention, self).__init__()self.gap = nn.AdaptiveAvgPool2d(1)self.ca = nn.Sequential(nn.Conv2d(dim, dim // reduction, 1, padding=0, bias=True),nn.ReLU(inplace=True), # Relunn.Conv2d(dim // reduction, dim, 1, padding=0, bias=True),)def forward(self, x): # x:[b,c,h,w]x_gap = self.gap(x) # [b,c,1,1]cattn = self.ca(x_gap) # [b,c,1,1]return cattn * xclass Channel_Shuffle(nn.Module):def __init__(self, num_groups):super(Channel_Shuffle, self).__init__()self.num_groups = num_groupsdef forward(self, x):batch_size, chs, h, w = x.shapechs_per_group = chs // self.num_groupsx = torch.reshape(x, (batch_size, self.num_groups, chs_per_group, h, w))# (batch_size, num_groups, chs_per_group, h, w)x = x.transpose(1, 2) # dim_1 and dim_2out = torch.reshape(x, (batch_size, -1, h, w))return outclass TransformerBlock(nn.Module):def __init__(self, dim, num_heads, ffn_expansion_factor, bias, LayerNorm_type):super(TransformerBlock, self).__init__()self.norm1 = LayerNorm(dim, LayerNorm_type)self.attn = Attention(dim, num_heads, bias)self.norm2 = LayerNorm(dim, LayerNorm_type)self.ffn = FeedForward(dim, ffn_expansion_factor, bias)def forward(self, x):x = x + self.attn(self.norm1(x))x = x + self.ffn(self.norm2(x))return xdef to_3d(x):return rearrange(x, 'b c h w -> b (h w) c')def to_4d(x, h, w):return rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)class BiasFree_LayerNorm(nn.Module):def __init__(self, normalized_shape):super(BiasFree_LayerNorm, self).__init__()if isinstance(normalized_shape, numbers.Integral):normalized_shape = (normalized_shape,)normalized_shape = torch.Size(normalized_shape)assert len(normalized_shape) == 1self.weight = nn.Parameter(torch.ones(normalized_shape))self.normalized_shape = normalized_shapedef forward(self, x):sigma = x.var(-1, keepdim=True, unbiased=False)return x / torch.sqrt(sigma + 1e-5) * self.weightclass WithBias_LayerNorm(nn.Module):def __init__(self, normalized_shape):super(WithBias_LayerNorm, self).__init__()if isinstance(normalized_shape, numbers.Integral):normalized_shape = (normalized_shape,)normalized_shape = torch.Size(normalized_shape)assert len(normalized_shape) == 1self.weight = nn.Parameter(torch.ones(normalized_shape))self.bias = nn.Parameter(torch.zeros(normalized_shape))self.normalized_shape = normalized_shapedef forward(self, x):device = x.devicemu = x.mean(-1, keepdim=True)sigma = x.var(-1, keepdim=True, unbiased=False)result = (x - mu) / torch.sqrt(sigma + 1e-5) * self.weight.to(device) + self.bias.to(device)return resultclass LayerNorm(nn.Module):def __init__(self, dim, LayerNorm_type):super(LayerNorm, self).__init__()if LayerNorm_type == 'BiasFree':self.body = BiasFree_LayerNorm(dim)else:self.body = WithBias_LayerNorm(dim)def forward(self, x):h, w = x.shape[-2:]return to_4d(self.body(to_3d(x)), h, w)class FeedForward(nn.Module):def __init__(self, dim, ffn_expansion_factor, bias):super(FeedForward, self).__init__()hidden_features = int(dim * ffn_expansion_factor)self.project_in = nn.Conv2d(dim, hidden_features * 2, kernel_size=1, bias=bias)self.dwconv = nn.Conv2d(hidden_features * 2, hidden_features * 2, kernel_size=3, stride=1, padding=1,groups=hidden_features * 2, bias=bias)self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)def forward(self, x):device = x.deviceself.project_in = self.project_in.to(device)self.dwconv = self.dwconv.to(device)self.project_out = self.project_out.to(device)x = self.project_in(x)x1, x2 = self.dwconv(x).chunk(2, dim=1)x = F.gelu(x1) * x2x = self.project_out(x)return xclass Attention(nn.Module):def __init__(self, dim, num_heads, bias):super(Attention, self).__init__()self.num_heads = num_headsself.temperature = nn.Parameter(torch.ones(num_heads, 1, 1, dtype=torch.float32), requires_grad=True)self.qkv = nn.Conv2d(dim, dim * 3, kernel_size=1, bias=bias)self.qkv_dwconv = nn.Conv2d(dim * 3, dim * 3, kernel_size=3, stride=1, padding=1, groups=dim * 3,bias=bias)self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)def forward(self, x):b, c, h, w = x.shapedevice = x.deviceself.qkv = self.qkv.to(device)self.qkv_dwconv = self.qkv_dwconv.to(device)self.project_out = self.project_out.to(device)qkv = self.qkv(x)qkv = self.qkv_dwconv(qkv)q, k, v = qkv.chunk(3, dim=1)q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)q = torch.nn.functional.normalize(q, dim=-1)k = torch.nn.functional.normalize(k, dim=-1)attn = (q @ k.transpose(-2, -1)) * self.temperature.to(device)attn = attn.softmax(dim=-1)out = (attn @ v)out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)out = self.project_out(out)return outclass resblock(nn.Module):def __init__(self, dim):super(resblock, self).__init__()# self.norm = LayerNorm(dim, LayerNorm_type='BiasFree')self.body = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, bias=False),nn.PReLU(),nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, bias=False))def forward(self, x):res = self.body((x))res += xreturn res#########################################################################
# Chain-of-Thought Prompt Generation Module (CGM)
class CotPromptParaGen(nn.Module):def __init__(self,prompt_inch,prompt_size, num_path=3):super(CotPromptParaGen, self).__init__()# (128,32,32)->(64,64,64)->(32,128,128)self.chain_prompts=nn.ModuleList([nn.ConvTranspose2d(in_channels=prompt_inch if idx==0 else prompt_inch//(2**idx),out_channels=prompt_inch//(2**(idx+1)),kernel_size=3, stride=2, padding=1) for idx in range(num_path)])def forward(self,x):prompt_params = []prompt_params.append(x)for pe in self.chain_prompts:x=pe(x)prompt_params.append(x)return prompt_params#########################################################################
# Content-driven Prompt Block (CPB)
class ContentDrivenPromptBlock(nn.Module):def __init__(self, dim, prompt_dim, reduction=8, num_splits=4):super(ContentDrivenPromptBlock, self).__init__()self.dim = dimself.num_splits = num_splitsself.pa2 = nn.Conv2d(2 * dim, dim, 7, padding=3, padding_mode='reflect', groups=dim, bias=True)self.sigmoid = nn.Sigmoid()self.conv3x3 = nn.Conv2d(prompt_dim, prompt_dim, kernel_size=3, stride=1, padding=1, bias=False)self.conv1x1 = nn.Conv2d(dim, prompt_dim, kernel_size=1, stride=1, bias=False)self.sa = SpatialAttention()self.ca = ChannelAttention(dim, reduction)self.myshuffle = Channel_Shuffle(2)self.out_conv1 = nn.Conv2d(prompt_dim + dim, dim, kernel_size=1, stride=1, bias=False)self.transformer_block = [TransformerBlock(dim=dim // num_splits, num_heads=1, ffn_expansion_factor=2.66, bias=False,LayerNorm_type='WithBias') for _ in range(num_splits)]def forward(self, x, prompt_param):# latent: (b,dim*8,h/8,w/8) prompt_param3: (1, 256, 16, 16)x_ = xB, C, H, W = x.shapecattn = self.ca(x) # channel-wise attnsattn = self.sa(x) # spatial-wise attnpattn1 = sattn + cattnpattn1 = pattn1.unsqueeze(dim=2) # [b,c,1,h,w]x = x.unsqueeze(dim=2) # [b,c,1,h,w]x2 = torch.cat([x, pattn1], dim=2) # [b,c,2,h,w]x2 = Rearrange('b c t h w -> b (c t) h w')(x2) # [b,c*2,h,w]x2 = self.myshuffle(x2) # [c1,c1_att,c2,c2_att,...]pattn2 = self.pa2(x2)pattn2 = self.conv1x1(pattn2) # [b,prompt_dim,h,w]prompt_weight = self.sigmoid(pattn2) # Sigmodprompt_param = F.interpolate(prompt_param, (H, W), mode="bilinear")# (b,prompt_dim,prompt_size,prompt_size) -> (b,prompt_dim,h,w)prompt = prompt_weight * prompt_paramprompt = self.conv3x3(prompt) # (b,prompt_dim,h,w)inter_x = torch.cat([x_, prompt], dim=1) # (b,prompt_dim+dim,h,w)inter_x = self.out_conv1(inter_x) # (b,dim,h,w) dim=64splits = torch.split(inter_x, self.dim // self.num_splits, dim=1)transformered_splits = []for i, split in enumerate(splits):transformered_split = self.transformer_block[i](split)transformered_splits.append(transformered_split)result = torch.cat(transformered_splits, dim=1)return result#########################################################################
# CPA_Enhancer
class CPA_arch(nn.Module):def __init__(self, c_in=3, c_out=3, dim=4, prompt_inch=128, prompt_size=32):super(CPA_arch, self).__init__()self.conv0 = RFAConv(c_in, dim)self.conv1 = RFAConv(dim, dim)self.conv2 = RFAConv(dim * 2, dim * 2)self.conv3 = RFAConv(dim * 4, dim * 4)self.conv4 = RFAConv(dim * 8, dim * 8)self.conv5 = RFAConv(dim * 8, dim * 4)self.conv6 = RFAConv(dim * 4, dim * 2)self.conv7 = RFAConv(dim * 2, c_out)self.down1 = Downsample(dim)self.down2 = Downsample(dim * 2)self.down3 = Downsample(dim * 4)self.prompt_param_ini = nn.Parameter(torch.rand(1, prompt_inch, prompt_size, prompt_size)) # (b,c,h,w)self.myPromptParamGen = CotPromptParaGen(prompt_inch=prompt_inch,prompt_size=prompt_size)self.prompt1 = ContentDrivenPromptBlock(dim=dim * 2 ** 1, prompt_dim=prompt_inch // 4, reduction=8) # !!!!self.prompt2 = ContentDrivenPromptBlock(dim=dim * 2 ** 2, prompt_dim=prompt_inch // 2, reduction=8)self.prompt3 = ContentDrivenPromptBlock(dim=dim * 2 ** 3, prompt_dim=prompt_inch , reduction=8)self.up3 = Upsample(dim * 8)self.up2 = Upsample(dim * 4)self.up1 = Upsample(dim * 2)def forward(self, x): # (b,c_in,h,w)prompt_params = self.myPromptParamGen(self.prompt_param_ini)prompt_param1 = prompt_params[2] # [1, 64, 64, 64]prompt_param2 = prompt_params[1] # [1, 128, 32, 32]prompt_param3 = prompt_params[0] # [1, 256, 16, 16]x0 = self.conv0(x) # (b,dim,h,w)x1 = self.conv1(x0) # (b,dim,h,w)x1_down = self.down1(x1) # (b,dim,h/2,w/2)x2 = self.conv2(x1_down) # (b,dim,h/2,w/2)x2_down = self.down2(x2)x3 = self.conv3(x2_down)x3_down = self.down3(x3)x4 = self.conv4(x3_down)device = x4.deviceself.prompt1 = self.prompt1.to(device)self.prompt2 = self.prompt2.to(device)self.prompt3 = self.prompt3.to(device)x4_prompt = self.prompt3(x4, prompt_param3)x3_up = self.up3(x4_prompt)x5 = self.conv5(torch.cat([x3_up, x3], 1))x5_prompt = self.prompt2(x5, prompt_param2)x2_up = self.up2(x5_prompt)x2_cat = torch.cat([x2_up, x2], 1)x6 = self.conv6(x2_cat)x6_prompt = self.prompt1(x6, prompt_param1)x1_up = self.up1(x6_prompt)x7 = self.conv7(torch.cat([x1_up, x1], 1))return x7if __name__ == "__main__":# Generating Sample imageimage_size = (1, 3, 640, 640)image = torch.rand(*image_size)out = CPA_arch(3, 3, 4)out = out(image)print(out.size())2.2 步骤二:告诉 YOLOv8 有新东西
在Addmodules下创建一个新的py文件名字为'__init__.py',然后在其内部添加如下代码

2.3 步骤三:让 YOLOv8 认识新工具
在task.py进行导入
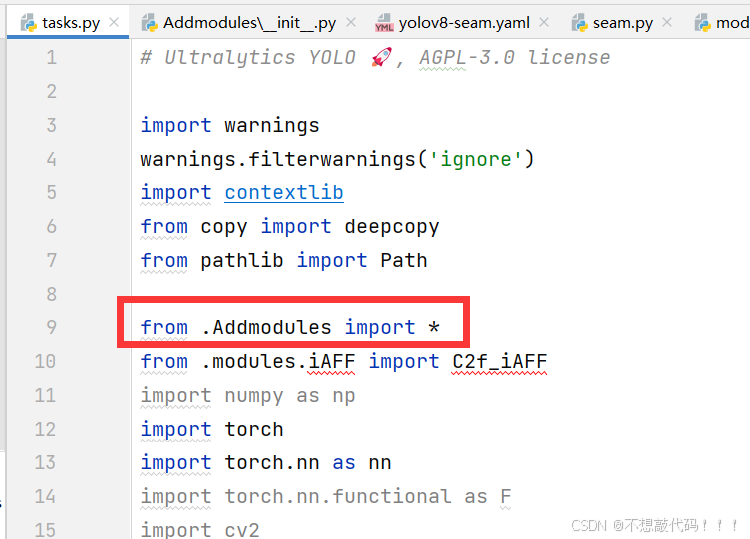
到此注册成功
2.4 步骤四:改 YOLOv8 的“说明书”
复制后面的yaml文件直接运行即可
yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, CPA_arch, []] # 0-P1/2- [-1, 1, Conv, [64, 3, 2]] # 1-P1/2- [-1, 1, Conv, [128, 3, 2]] # 2-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 4-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 6-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 8-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 10# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 7], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 5], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)相关文章:
YOLOv8融合CPA-Enhancer【提高恶略天气的退化图像检测】
1.CPA介绍 CPA-Enhancer通过链式思考提示机制实现了对未知退化条件下图像的自适应增强,显著提升了物体检测性能。其插件式设计便于集成到现有检测框架中,并在物体检测及其他视觉任务中设立了新的性能标准,展现了广泛的应用潜力。 关于CPA-E…...
Python 项目环境配置与 Vanna 安装避坑指南 (PyCharm + venv)
在进行 Python 项目开发时,一个干净、隔离且配置正确的开发环境至关重要。尤其是在使用像 PyCharm 这样的集成开发环境 (IDE) 时,正确理解和配置虚拟环境 (Virtual Environment) 是避免许多常见问题的关键。本文结合之前安装 Vanna 库时遇到的问题&#…...

第52讲:农业AI + 区块链——迈向可信、智能、透明的未来农业
目录 一、为什么农业需要“AI+区块链”? 二、核心应用场景解读 1. 农产品溯源系统 2. 农业信贷与保险精准评估 3. 农业碳足迹追踪与碳汇交易 三、案例实战分享:智能溯源 + 区块链合约 四、面临挑战与展望 五、总结 在数字农业时代,“AI” 和 “区块链” 是两股不容忽…...
)
模板偏特化 (Partial Specialization)
C 模板偏特化 (Partial Specialization) 模板偏特化允许为模板的部分参数或特定类型模式提供定制实现,是 静态多态(Static Polymorphism) 的核心机制之一。以下通过代码示例和底层原理,全面解析模板偏特化的实现规则、匹配优先级…...

【防火墙 pfsense】1简介
(1) pfSense 有以下可能的用途: 边界防火墙 路由器 交换机 无线路由器 / 无线接入点 (2)边界防火墙 ->要充当边界防火墙,pfSense 系统至少需要两个接口:一个广域网(WAN࿰…...

Qt UDP组播实现与调试指南
在Qt中使用UDP组播(Multicast)可以实现高效的一对多网络通信。以下是关键步骤和示例代码: 一、UDP组播核心机制 组播地址:使用D类地址(224.0.0.0 - 239.255.255.255)TTL设置:控制数据包传播范围(默认1,同一网段)网络接口:指定发送/接收的物理接口二、发送端实现 /…...
线上助农产品商城小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的线上助农产品商城小程序源码,旨在为农产品销售搭建一个高效、便捷的线上平台,助力乡村振兴。 一、技术架构 该小程序源码采用了ThinkPHP作为后端框架,FastAdmin作为快速开发框架,UniApp作为跨…...

【maven-7.1】POM文件中的属性管理:提升构建灵活性与可维护性
在Maven项目中,POM (Project Object Model) 文件是核心配置文件,而属性管理则是POM中一个强大但常被低估的特性。良好的属性管理可以显著提升项目的可维护性、减少重复配置,并使构建过程更加灵活。本文将深入探讨Maven中的属性管理机制。 1.…...

基于Matlab的车牌识别系统
1.程序简介 本模型基于MATLAB,通过编程创建GUI界面,基于Matlab的数字图像处理,对静止的车牌图像进行分割并识别,通过编写matlab程序对图像进行灰度处理、二值化、腐蚀膨胀和边缘化处理等,并定位车牌的文字,实现字符的…...

three.js精灵及精灵材质、Shader源码分析
在Three.js中,Sprite(精灵)用于创建始终面向相机的2D元素,适用于标签、图标或粒子效果。本文将分析其源码及Shader实现。 1. sprite的基本使用方法 创建精灵材质: 精灵材质有个特殊的参数rotation,可以让其旋转一定的角度。 const material = new THREE.SpriteMateria…...

Kubernetes Docker 部署达梦8数据库
Kubernetes & Docker 部署达梦8数据库 一、达梦镜像获取 目前达梦官方暂未在公共镜像仓库提供Docker镜像,需通过达梦官网联系获取官方镜像包。 二、Kubernetes部署方案 部署配置文件示例 apiVersion: apps/v1 kind: Deployment metadata:labels:app: dm8na…...
探索 CameraCtrl模型:视频生成中的精确摄像机控制技术
在当今的视频生成领域,精确控制摄像机轨迹一直是一个具有挑战性的目标。许多现有的模型在处理摄像机姿态时往往忽略了精准控制的重要性,导致生成的视频在摄像机运动方面不够理想。为了解决这一问题,一种名为 CameraCtrl 的创新文本到视频模型…...

Streamlit从入门到精通:构建数据应用的利器
在数据科学与机器学习日益普及的今天,如何快速将模型部署为可交互的应用成为了许多数据科学家的重要任务。Streamlit,作为一个开源的Python库,专为数据科学家设计,能够帮助我们轻松构建美观且直观的Web应用。本文将从入门到精通&a…...

【计算机视觉】CV实战项目- 深度解析FaceAI:一款全能的人脸检测与图像处理工具库
深度解析FaceAI:一款全能的人脸检测与图像处理工具库 项目概述核心功能与技术实现1. 人脸检测与识别2. 数字化妆与轮廓标识3. 性别与表情识别4. 高级图像处理 实战指南:项目运行与开发环境配置典型应用示例常见问题与解决方案 学术背景与相关研究项目扩展…...

快速上手GO的net/http包,个人学习笔记
更多个人笔记:(仅供参考,非盈利) gitee: https://gitee.com/harryhack/it_note github: https://github.com/ZHLOVEYY/IT_note 针对GO中net/http包的学习笔记 基础快速了解 创建简单的GOHTTP服务 func …...

达梦DMDSC初研
1.文件系统 1.1文件系统DMASM DMASM是一个分布式文件系统,用来管理块设备的磁盘和文件,DMASMCMD将物理磁盘格式化后,变成可识别、可管理的 ASM磁盘,再通过 ASM磁盘组将一个或者多个 ASM磁盘整合成一个整体提供文件服务。ASM磁盘…...

Cephalon端脑云:神经形态计算+边缘AI·重定义云端算力
前引:当算力不再是“奢侈品” ,在人工智能、3D渲染、科学计算等领域,算力一直是横亘在个人与企业面前的“高墙”。高性能服务器价格动辄数十万元,专业设备维护成本高,普通人大多是望而却步。然而,Cephalon算…...

深度解析 Kubernetes 配置管理:如何安全使用 ConfigMap 和 Secret
目录 深度解析 Kubernetes 配置管理:如何安全使用 ConfigMap 和 Secret一、目录结构二、ConfigMap 和 Secret 的创建1. 创建 ConfigMapconfig/app-config.yaml:config/db-config.yaml: 2. 创建 Secretsecrets/db-credentials.yaml:…...
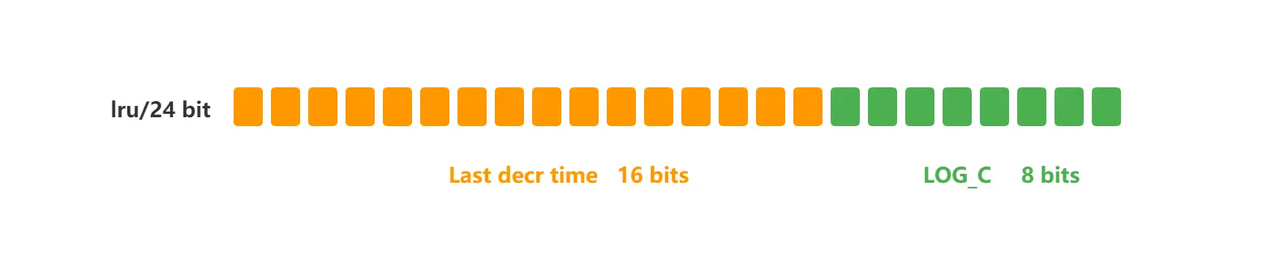
Redis的过期删除策略和内存淘汰策略
🤔 过期删除和内存淘汰乍一看很像,都是做删除操作的,这么分有什么意思? 首先,设置过期时间我们很熟悉,过期时间到了,我么的键就会被删除掉,这就是我们常认识的过期删除,…...
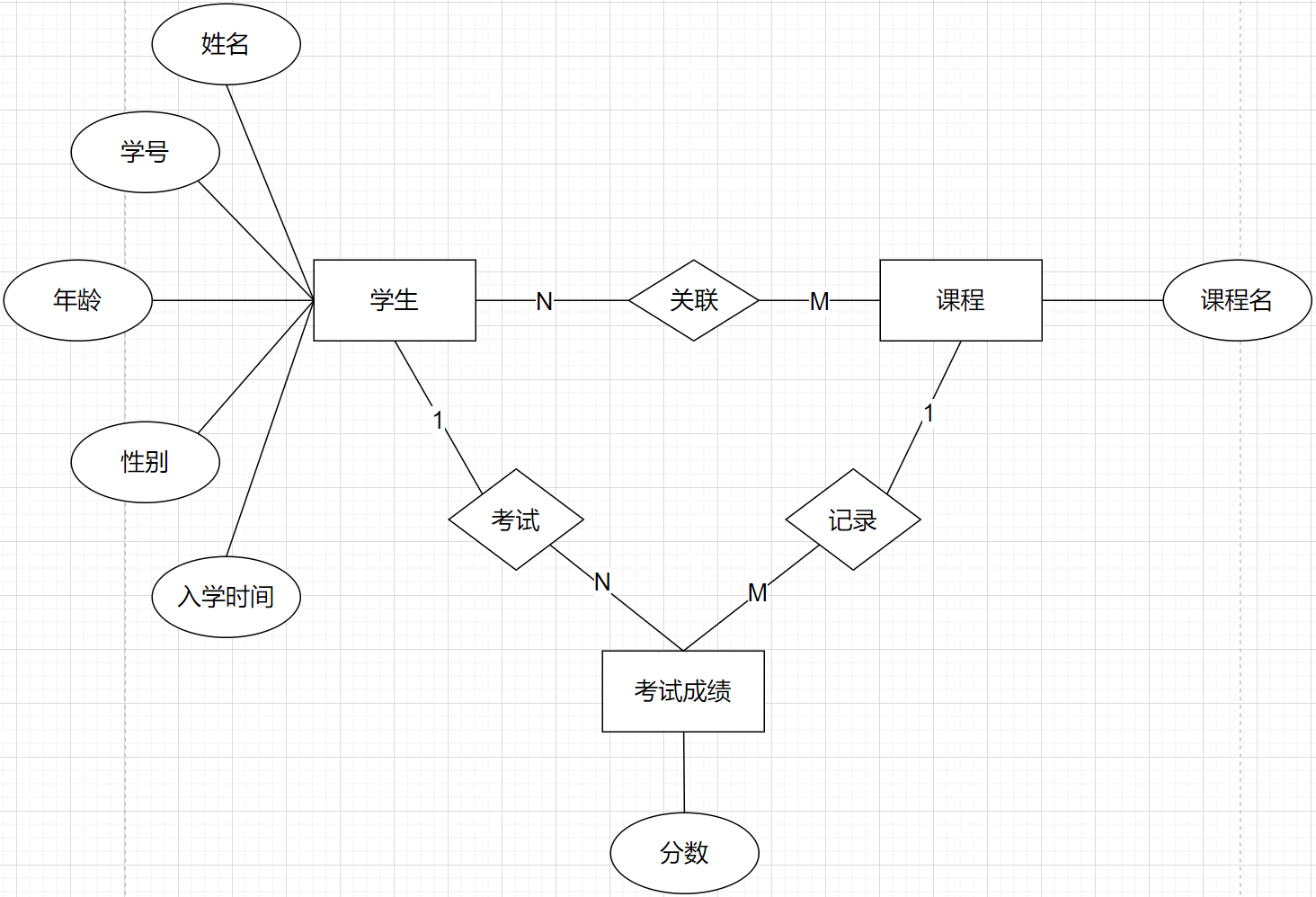
MySQL:数据库设计
目录 一、范式 二、第一范式 二、第二范式 三、第三范式 四、设计 (1)一对一关系 (2)一对多关系 (3)多对多关系 一、范式 数据库的范式是一种规则(规范),如果我们…...

Android Kotlin AIDL 完整实现与优化指南
本文将详细介绍如何在Android中使用Kotlin实现AIDL(Android Interface Definition Language),并提供多种优化方案。 一、基础实现 1. 创建AIDL文件 在src/main/aidl/com/example/myapplication/目录下创建: IMyAidlInterface.…...

synchronized关键字的实现
Java对象结构 synchronized锁升级过程 为了优化synchronized锁的效率,在JDK6中,HotSpot虚拟机开发团队提出了锁升级的概念,包括偏向锁、轻量级锁、重量级锁等,锁升级指的就是“无锁 --> 偏向锁 --> 轻量级锁 --> 重量级…...

Ubuntu K8s集群安全加固方案
Ubuntu K8s集群安全加固方案 在Ubuntu系统上部署Kubernetes集群时,若服务器拥有外网IP,需采取多层次安全防护措施以确保集群安全。本方案通过系统防火墙配置、TLS通信启用、网络策略实施和RBAC权限控制四个核心层面,构建安全的Kubernetes环境…...

如何在spark里搭建local模式
在Spark里搭建local模式较为简单,下面详细介绍在不同环境下搭建local模式的步骤。 ### 环境准备 - **Java**: Spark是基于Java虚拟机(JVM)运行的,所以要安装Java 8及以上版本。 - **Spark**: 可从[Apache…...
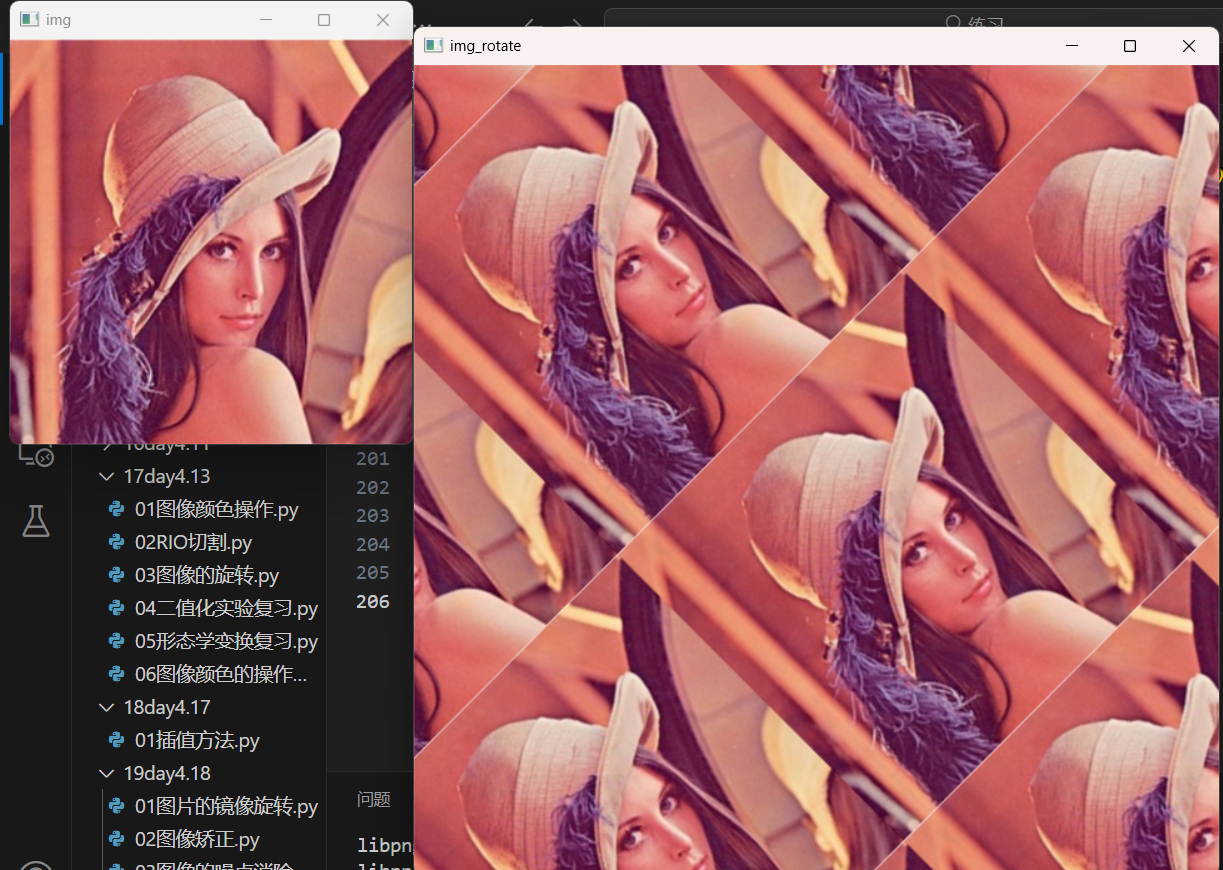
opencv 图像的旋转
图像的旋转 1 单点旋转2. 图片旋转(cv2.getRotationMatrix2D)3. 插值方法3.1 最近邻插值(cv2.INTER_NEAREST)3.2 双线性插值(cv2.INTER_LINEAR)3.3 像素区域插值(cv2.INTER_AREA)3.4 双三次插值(cv2.INTER_CUBIC&#…...

【DNS】BIND 9的配置
该文档围绕BIND 9的配置与区域文件展开,介绍了BIND 9配置文件及区域文件的相关知识,以及权威名称服务器、解析器的相关内容,还阐述了负载均衡和区域文件的详细知识,具体如下: 基础配置文件: named.conf&am…...

Spring Boot常用注解详解:实例与核心概念
Spring Boot常用注解详解:实例与核心概念 前言 Spring Boot作为Java领域最受欢迎的快速开发框架,其核心特性之一是通过注解(Annotation)简化配置,提高开发效率。注解驱动开发模式让开发者告别繁琐的XML配置ÿ…...

【多线程】线程互斥 互斥量操作 守卫锁 重入与线程安全
文章目录 Ⅰ. 线程互斥概念Ⅱ. 互斥锁的概念Ⅲ. 互斥锁的接口一、互斥锁的定义二、初始化互斥锁三、销毁互斥锁四、互斥量的加锁和解锁① 加锁接口② 解锁接口五、改进买票系统💥注意事项Ⅳ. 互斥锁的实现原理一、问题引入二、复习知识三、实现原理Ⅴ. 封装锁对象 &&…...
:[macOS 64bit App开发]:如何使用NSString类型字符串?)
[原创](现代Delphi 12指南):[macOS 64bit App开发]:如何使用NSString类型字符串?
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...

Python协程详解:从基础到实战
协程是Python中实现并发编程的重要方式之一,它比线程更轻量级,能够高效处理I/O密集型任务。本文将全面介绍协程的概念、原理、实现方式以及与线程、进程的对比,包含完整的效率对比代码和详细说明,帮助Python开发者深入理解并掌握协…...