【现代深度学习技术】循环神经网络05:循环神经网络的从零开始实现

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
- 一、独热编码
- 二、初始化模型参数
- 三、循环神经网络模型
- 四、预测
- 五、梯度截断
- 六、训练
- 小结
本节将根据循环神经网络中的描述, 从头开始基于循环神经网络实现字符级语言模型。 这样的模型将在H.G.Wells的时光机器数据集上训练。 和前面语言模型和数据集中介绍过的一样, 我们先读取数据集。
%matplotlib inline
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
一、独热编码
回想一下,在train_iter中,每个词元都表示为一个数字索引,将这些索引直接输入神经网络可能会使学习变得困难。我们通常将每个词元表示为更具表现力的特征向量。最简单的表示称为独热编码(one-hot encoding),它在softmax回归中介绍过。
简言之,将每个索引映射为相互不同的单位向量:假设词表中不同词元的数目为 N N N(即len(vocab)),词元索引的范围为 0 0 0到 N − 1 N-1 N−1。如果词元的索引是整数 i i i,那么我们将创建一个长度为 N N N的全 0 0 0向量,并将第 i i i处的元素设置为 1 1 1。此向量是原始词元的一个独热向量。索引为 0 0 0和 2 2 2的独热向量如下所示:
F.one_hot(torch.tensor([0, 2]), len(vocab))
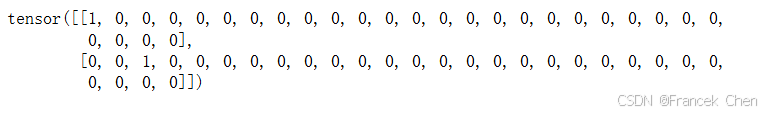
我们每次采样的小批量数据形状是二维张量:(批量大小,时间步数)。one_hot函数将这样一个小批量数据转换成三维张量,张量的最后一个维度等于词表大小(len(vocab))。我们经常转换输入的维度,以便获得形状为(时间步数,批量大小,词表大小)的输出。这将使我们能够更方便地通过最外层的维度,一步一步地更新小批量数据的隐状态。
X = torch.arange(10).reshape((2, 5))
F.one_hot(X.T, 28).shape
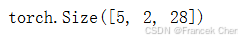
二、初始化模型参数
接下来,我们初始化循环神经网络模型的模型参数。隐藏单元数num_hiddens是一个可调的超参数。当训练语言模型时,输入和输出来自相同的词表。因此,它们具有相同的维度,即词表的大小。
def get_params(vocab_size, num_hiddens, device):num_inputs = num_outputs = vocab_sizedef normal(shape):return torch.randn(size=shape, device=device) * 0.01# 隐藏层参数W_xh = normal((num_inputs, num_hiddens))W_hh = normal((num_hiddens, num_hiddens))b_h = torch.zeros(num_hiddens, device=device)# 输出层参数W_hq = normal((num_hiddens, num_outputs))b_q = torch.zeros(num_outputs, device=device)# 附加梯度params = [W_xh, W_hh, b_h, W_hq, b_q]for param in params:param.requires_grad_(True)return params
三、循环神经网络模型
为了定义循环神经网络模型,我们首先需要一个init_rnn_state函数在初始化时返回隐状态。这个函数的返回是一个张量,张量全用0填充,形状为(批量大小,隐藏单元数)。在后面的章节中我们将会遇到隐状态包含多个变量的情况,而使用元组可以更容易地处理些。
def init_rnn_state(batch_size, num_hiddens, device):return (torch.zeros((batch_size, num_hiddens), device=device), )
下面的rnn函数定义了如何在一个时间步内计算隐状态和输出。循环神经网络模型通过inputs最外层的维度实现循环,以便逐时间步更新小批量数据的隐状态H。此外,这里使用 tanh \tanh tanh函数作为激活函数。如多层感知机概述所述,当元素在实数上满足均匀分布时, tanh \tanh tanh函数的平均值为0。
def rnn(inputs, state, params):# inputs的形状:(时间步数量,批量大小,词表大小)W_xh, W_hh, b_h, W_hq, b_q = paramsH, = stateoutputs = []# X的形状:(批量大小,词表大小)for X in inputs:H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)Y = torch.mm(H, W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=0), (H,)
定义了所有需要的函数之后,接下来我们创建一个类来包装这些函数,并存储从零开始实现的循环神经网络模型的参数。
class RNNModelScratch: #@save"""从零开始实现的循环神经网络模型"""def __init__(self, vocab_size, num_hiddens, device, get_params, init_state, forward_fn):self.vocab_size, self.num_hiddens = vocab_size, num_hiddensself.params = get_params(vocab_size, num_hiddens, device)self.init_state, self.forward_fn = init_state, forward_fndef __call__(self, X, state):X = F.one_hot(X.T, self.vocab_size).type(torch.float32)return self.forward_fn(X, state, self.params)def begin_state(self, batch_size, device):return self.init_state(batch_size, self.num_hiddens, device)
让我们检查输出是否具有正确的形状。例如,隐状态的维数是否保持不变。
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params, init_rnn_state, rnn)
state = net.begin_state(X.shape[0], d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state)
Y.shape, len(new_state), new_state[0].shape
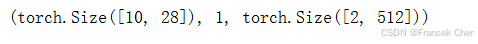
我们可以看到输出形状是(时间步数 × \times ×批量大小,词表大小),而隐状态形状保持不变,即(批量大小,隐藏单元数)。
四、预测
让我们首先定义预测函数来生成prefix之后的新字符,其中的prefix是一个用户提供的包含多个字符的字符串。在循环遍历prefix中的开始字符时,我们不断地将隐状态传递到下一个时间步,但是不生成任何输出。这被称为预热(warm-up)期,因为在此期间模型会自我更新(例如,更新隐状态),但不会进行预测。预热期结束后,隐状态的值通常比刚开始的初始值更适合预测,从而预测字符并输出它们。
def predict_ch8(prefix, num_preds, net, vocab, device): #@save"""在prefix后面生成新字符"""state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]]get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))for y in prefix[1:]: # 预热期_, state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds): # 预测num_preds步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idx_to_token[i] for i in outputs])
现在我们可以测试predict_ch8函数。我们将前缀指定为time traveller ,并基于这个前缀生成10个后续字符。鉴于我们还没有训练网络,它会生成荒谬的预测结果。
predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu())
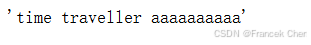
五、梯度截断
对于长度为 T T T的序列,我们在迭代中计算这 T T T个时间步上的梯度,将会在反向传播过程中产生长度为 O ( T ) \mathcal{O}(T) O(T)的矩阵乘法链。如数值稳定性和模型初始化所述,当 T T T较大时,它可能导致数值不稳定,例如可能导致梯度爆炸或梯度消失。因此,循环神经网络模型往往需要额外的方式来支持稳定训练。
一般来说,当解决优化问题时,我们对模型参数采用更新步骤。假定在向量形式的 x \mathbf{x} x中,或者在小批量数据的负梯度 g \mathbf{g} g方向上。例如,使用 η > 0 \eta > 0 η>0作为学习率时,在一次迭代中,我们将 x \mathbf{x} x更新为 x − η g \mathbf{x} - \eta \mathbf{g} x−ηg。如果我们进一步假设目标函数 f f f表现良好,即函数 f f f在常数 L L L下是利普希茨连续的(Lipschitz continuous)。也就是说,对于任意 x \mathbf{x} x和 y \mathbf{y} y我们有:
∣ f ( x ) − f ( y ) ∣ ≤ L ∥ x − y ∥ (1) |f(\mathbf{x}) - f(\mathbf{y})| \leq L \|\mathbf{x} - \mathbf{y}\| \tag{1} ∣f(x)−f(y)∣≤L∥x−y∥(1)
在这种情况下,我们可以安全地假设:如果我们通过 η g \eta \mathbf{g} ηg更新参数向量,则
∣ f ( x ) − f ( x − η g ) ∣ ≤ L η ∥ g ∥ (2) |f(\mathbf{x}) - f(\mathbf{x} - \eta\mathbf{g})| \leq L \eta\|\mathbf{g}\| \tag{2} ∣f(x)−f(x−ηg)∣≤Lη∥g∥(2)
这意味着我们不会观察到超过 L η ∥ g ∥ L \eta \|\mathbf{g}\| Lη∥g∥的变化。这既是坏事也是好事。坏的方面,它限制了取得进展的速度;好的方面,它限制了事情变糟的程度,尤其当我们朝着错误的方向前进时。
有时梯度可能很大,从而优化算法可能无法收敛。我们可以通过降低 η \eta η的学习率来解决这个问题。但是如果我们很少得到大的梯度呢?在这种情况下,这种做法似乎毫无道理。一个流行的替代方案是通过将梯度 g \mathbf{g} g投影回给定半径(例如 θ \theta θ)的球来截断梯度 g \mathbf{g} g。如下式:
g ← min ( 1 , θ ∥ g ∥ ) g (3) \mathbf{g} \leftarrow \min\left(1, \frac{\theta}{\|\mathbf{g}\|}\right) \mathbf{g} \tag{3} g←min(1,∥g∥θ)g(3)
通过这样做,我们知道梯度范数永远不会超过 θ \theta θ,并且更新后的梯度完全与 g \mathbf{g} g的原始方向对齐。它还有一个值得拥有的副作用,即限制任何给定的小批量数据(以及其中任何给定的样本)对参数向量的影响,这赋予了模型一定程度的稳定性。梯度截断提供了一个快速修复梯度爆炸的方法,虽然它并不能完全解决问题,但它是众多有效的技术之一。
下面我们定义一个函数来截断模型的梯度,模型是从零开始实现的模型或由高级API构建的模型。我们在此计算了所有模型参数的梯度的范数。
def grad_clipping(net, theta): #@save"""截断梯度"""if isinstance(net, nn.Module):params = [p for p in net.parameters() if p.requires_grad]else:params = net.paramsnorm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))if norm > theta:for param in params:param.grad[:] *= theta / norm
六、训练
在训练模型之前,让我们定义一个函数在一个迭代周期内训练模型。它与我们训练softmax回归的从零开始实现模型的方式有三个不同之处。
- 序列数据的不同采样方法(随机采样和顺序分区)将导致隐状态初始化的差异。
- 我们在更新模型参数之前截断梯度。这样的操作的目的是,即使训练过程中某个点上发生了梯度爆炸,也能保证模型不会发散。
- 我们用困惑度来评价模型。如循环神经网络所述,这样的度量确保了不同长度的序列具有可比性。
具体来说,当使用顺序分区时,我们只在每个迭代周期的开始位置初始化隐状态。由于下一个小批量数据中的第 i i i个子序列样本与当前第 i i i个子序列样本相邻,因此当前小批量数据最后一个样本的隐状态,将用于初始化下一个小批量数据第一个样本的隐状态。这样,存储在隐状态中的序列的历史信息可以在一个迭代周期内流经相邻的子序列。然而,在任何一点隐状态的计算,都依赖于同一迭代周期中前面所有的小批量数据,这使得梯度计算变得复杂。为了降低计算量,在处理任何一个小批量数据之前,我们先分离梯度,使得隐状态的梯度计算总是限制在一个小批量数据的时间步内。
当使用随机抽样时,因为每个样本都是在一个随机位置抽样的,因此需要为每个迭代周期重新初始化隐状态。与softmax回归的从零开始实现中的train_epoch_ch3函数相同,updater是更新模型参数的常用函数。它既可以是从头开始实现的d2l.sgd函数,也可以是深度学习框架中内置的优化函数。
#@save
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):"""训练网络一个迭代周期"""state, timer = None, d2l.Timer()metric = d2l.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)else:if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()y = Y.T.reshape(-1)X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)metric.add(l * y.numel(), y.numel())return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
循环神经网络模型的训练函数既支持从零开始实现,也可以使用高级API来实现。
#@save
def train_ch8(net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False):"""训练模型"""loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', ylabel='perplexity', legend=['train'], xlim=[10, num_epochs])# 初始化if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)# 训练和预测for epoch in range(num_epochs):ppl, speed = train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:print(predict('time traveller'))animator.add(epoch + 1, [ppl])print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')print(predict('time traveller'))print(predict('traveller'))
现在,我们训练循环神经网络模型。因为我们在数据集中只使用了10000个词元,所以模型需要更多的迭代周期来更好地收敛。
num_epochs, lr = 500, 1
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())

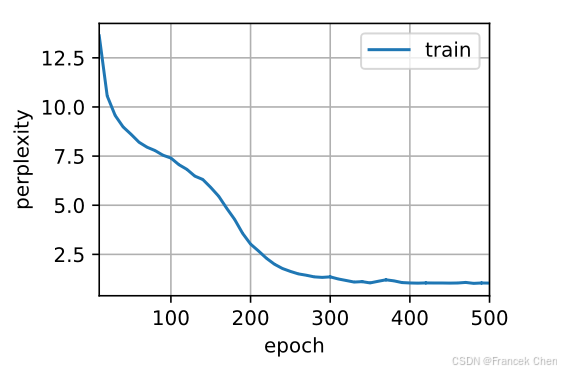
最后,让我们检查一下使用随机抽样方法的结果。
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params, init_rnn_state, rnn)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(), use_random_iter=True)

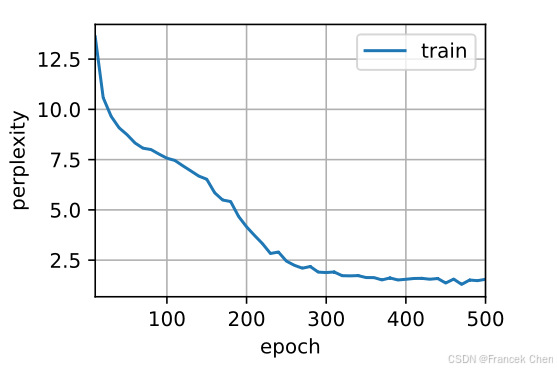
从零开始实现上述循环神经网络模型,虽然有指导意义,但是并不方便。在下一节中,我们将学习如何改进循环神经网络模型。例如,如何使其实现地更容易,且运行速度更快。
小结
- 我们可以训练一个基于循环神经网络的字符级语言模型,根据用户提供的文本的前缀生成后续文本。
- 一个简单的循环神经网络语言模型包括输入编码、循环神经网络模型和输出生成。
- 循环神经网络模型在训练以前需要初始化状态,不过随机抽样和顺序划分使用初始化方法不同。
- 当使用顺序划分时,我们需要分离梯度以减少计算量。
- 在进行任何预测之前,模型通过预热期进行自我更新(例如,获得比初始值更好的隐状态)。
- 梯度截断可以防止梯度爆炸,但不能应对梯度消失。
相关文章:
【现代深度学习技术】循环神经网络05:循环神经网络的从零开始实现
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...
Python实现技能记录系统
Python实现技能记录系统 来自网络,有改进。 技能记录系统界面如下: 具有保存图片和显示功能——允许用户选择图片保存,选择历史记录时若有图片可预览图片。 这个程序的数据保存在数据库skills2.db中,此数据库由用Python 自带的…...
—过滤器》)
前端基础之《Vue(10)—过滤器》
一、过滤器 1、作用 用于数据处理。 2、全局过滤器 使用Vue.filter(名称, val>{return newVal})定义。 在任何组件中都可以直接使用。 3、局部过滤器 使用选项,filters: {}定义,只能在当前组件中使用。 4、过滤器在Vue 3.0中已经淘汰了 5、过滤器…...
Linux常见指令介绍下(入门级)
1. head head就和他的名字一样,是显示一个文件头部的内容(会自动排序),默认是打印前10行。 语法:head [参数] [文件] 选项: -n [x] 显示前x行。 2. tail tail 命令从指定点开始将文件写到标准输出.使用t…...

VIC-3D非接触全场应变测量系统用于小尺寸测量之电子元器件篇—研索仪器DIC数字图像相关技术
在5G通信、新能源汽车电子、高密度集成电路快速迭代的今天,电子元件的尺寸及连接工艺已进入亚毫米级竞争阶段,这种小尺寸下的力学性能评估对测量方式的精度有更高的要求,但传统应变测量手段常因空间尺寸限制及分辨率不足难以捕捉真实形变场。…...

字典与集合——测试界的黑话宝典与BUG追捕术
主题:“字典是测试工程师的暗号手册,集合是BUG的照妖镜” 一、今日目标 ✅ 掌握字典的「键值对暗号体系」与集合的「去重妖法」✅ 开发《测试工程师黑话词典》,让新人秒变老司机✅ 统计自动化测试结果中的高频BUG类型(附赠甩锅指…...
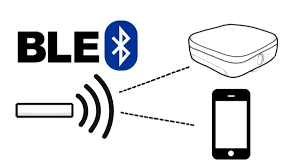
下篇:深入剖析 BLE GATT / GAP / SMP 与应用层(约5000字)
引言 在 BLE 协议栈的最上层,GAP 定义设备角色与连接管理,GATT 构建服务与特征,SMP 负责安全保障,应用层则承载具体业务逻辑与 Profile。掌握这一层,可实现安全可靠的设备发现、配对、服务交互和定制化业务。本文将详解 GAP、GATT、SMP 三大模块,并通过示例、PlantUML 时…...

事务详细介绍
一、简介 1、什么是事务 事务是指一组操作,这些操作要么全部成功执行,要么全部不执行,保证数据的完整性和一致性。事务广泛应用于数据库管理系统、分布式系统和企业级应用中; 2、事务的特性 事务具有四个基本特性,…...

PostgreSQL 中的权限视图
PostgreSQL 中的权限视图 PostgreSQL 提供了多个系统视图来查询权限信息,虽然不像 Oracle 的 DBA_SYS_PRIVS 那样集中在一个视图中,但可以通过组合以下视图获取完整的系统权限信息。 一 主要权限相关视图 Oracle 视图PostgreSQL 对应视图描述DBA_SYS_…...

Python-36:饭馆菜品选择问题
问题描述 小C来到了一家饭馆,这里共有 nn 道菜,第 ii 道菜的价格为 a_i。其中一些菜中含有蘑菇,s_i 代表第 ii 道菜是否含有蘑菇。如果 s_i 1,那么第 ii 道菜含有蘑菇,否则没有。 小C希望点 kk 道菜,且希…...

27、Session有什么重⼤BUG?微软提出了什么⽅法加以解决?
Session的重大BUG 1、进程回收导致Session丢失 原理: IIS的进程回收机制会在系统繁忙、达到特定内存阈值等情况下,自动回收工作进程(w3wp.exe)。由于Session数据默认存储在进程内存中,进程回收时这些数据会被清除。 …...

图论---Bellman-Ford算法
适用场景:有边数限制 ->(有负环也就没影响了),存在负权边,O( n * m ); 有负权回路时有的点距离会是负无穷,因此最短路存在的话就说明没有负权回路。 从1号点经过不超过k条边到每个点的距离…...

复杂性决策-思维训练
思维训练 1.模式识别 观察、复杂、不确定、波动、模糊 –找出必要和非必要因素 –识别重大威胁和机遇 2.系统分析 为复杂情景构建系统心智模型 利用模型识别模式做出预测,指定有效策略 3.心智敏锐度 利用不同层次的分析探索挑战的能力,对其他利益相关方在…...

云智融合普惠大模型AI,政务服务重构数智化路径
2025年是“十四五”收官之年,数字政府和政务数智化作为“数字中国”建设的重点,已经取得了显著成效。根据《联合国电子政务调查报告2024》,我国电子政务发展指数全球排名第35位,与2022年相比提升8个名次;其中ÿ…...

反爬系列 IP 限制与频率封禁应对指南
在数据采集领域,IP 限制与频率封禁是反爬机制中最常见的防御手段。随着网站安全策略的升级,单靠传统爬虫技术已难以应对高强度的检测。本文将从反爬机制解析、实战应对策略两个维度,系统讲解如何突破 IP 限制与频率封禁。 一、反爬机制解析 …...

Redis Cluster 使用 CRC16 算法实现 Slot 槽位分片的核心细节
一、CRC16 算法作用原理 哈希计算流程 对键值(Key)执行 CRC16 算法,生成 16 位校验值(0~65535)。 将校验值 对 16384 取模(公式:slot CRC16(key) % 16384),…...

Java基础集合 面试经典八股总结 [连载ing]
序言 八股,怎么说呢。我之前系统学习的内容,进行梳理。通过问题的方式,表达出得当的内容,这件事本身就很难。面试时心态、状态、掌握知识的情况等。关于八股文,我不想有太多死记硬背的内容,更多的是希望自我…...

如何将极狐GitLab 议题导出为 CSV?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 导出议题到 CSV (BASIC ALL) 您可以将问题从极狐GitLab 导出为 CSV 文件,这些文件将作为附件发送到您的默认通知…...
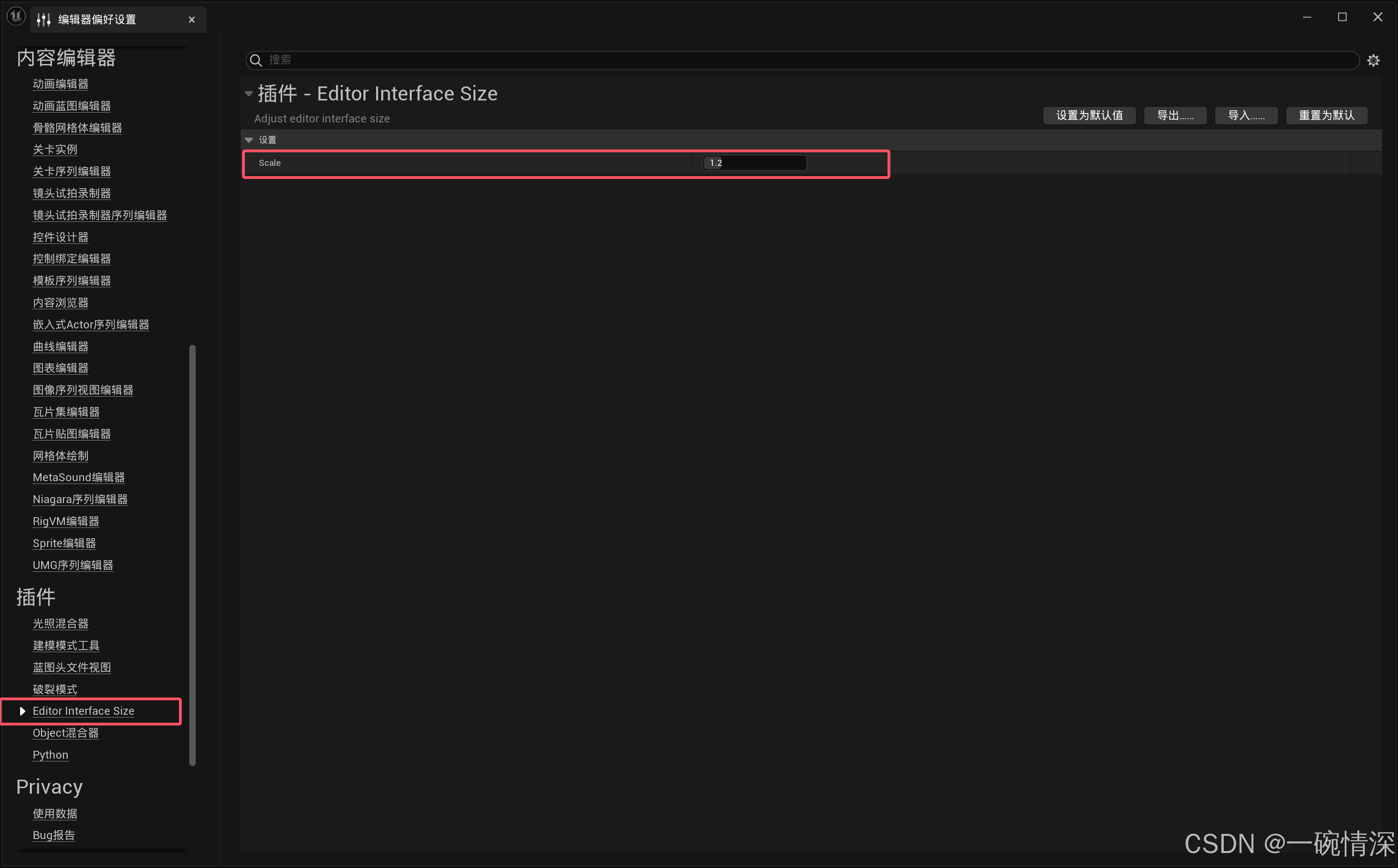
UE5 调整字体、界面大小
文章目录 方案一 5.4 版本及以上(推荐)方案二 5.3 版本及以下(推荐)方案三 使用插件(不推荐) 方案一 5.4 版本及以上(推荐) 进入 编辑 > 编辑器偏好设置,如下图所示&…...
)
Android Cordova 开发 - Cordova 快速入门(Cordova 环境配置、Cordova 第一个应用程序)
一、Cordova 1、Cordova 概述 Cordova 是使用 HTML,CSS 和 JavaScript 构建混合移动应用程序的平台 2、Cordova 特征 (1)命令行界面(Cordova CLI) 这是可用于启动项目,构建不同平台的进程,…...
区别)
Docker Compose 和 Kubernetes(k8s)区别
前言:Docker Compose 和 Kubernetes(k8s)是容器化技术中两个常用的工具,但它们的定位、功能和适用场景有显著区别。以下是两者的核心对比: 1. 定位与目标 特性 Docker Compose Kubernet…...
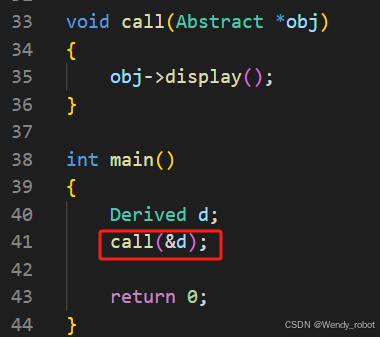
抽象类相关
抽象类的定义 抽象类 是一种特殊的类,它不能被实例化,只能作为基类来派生出具体类。抽象类至少包含一个纯虚函数 。纯虚函数是在函数原型前加上 0 的虚函数,表示该函数没有具体实现,必须由派生类来实现。 抽象类的作用 提供统…...

十分钟恢复服务器攻击——群联AI云防护系统实战
场景描述 服务器遭遇大规模DDoS攻击,导致服务不可用。通过群联AI云防护系统的分布式节点和智能调度功能,快速切换流量至安全节点,清洗恶意流量,10分钟内恢复业务。 技术实现步骤 1. 启用智能调度API触发节点切换 群联系统提供RE…...
)
鸿蒙NEXT开发网络相关工具类(ArkTs)
import { connection } from kit.NetworkKit; import { BusinessError, Callback } from kit.BasicServicesKit; import { wifiManager } from kit.ConnectivityKit; import { LogUtil } from ./LogUtil; import { data, radio, sim } from kit.TelephonyKit;// 网络类型枚举 e…...

【上位机——MFC】MFC入门
MFC库中相关类简介 CObject MFC类库中绝大部分类的父类,提供了MFC类库中一些基本的机制。 对运行时类信息的支持。对动态创建的支持。对序列化的支持。 CWinApp 应用程序类,封装了应用程序、线程等信息。 CDocument 文档类,管理数据 F…...

全面介绍AVFilter 的添加和使用
author: hjjdebug date: 2025年 04月 22日 星期二 13:48:19 CST description: 全面介绍AVFilter 的添加和使用 文章目录 1.两个重要的编码思想1. 写代码不再是我们调用别人,而是别人调用我们!2. 面向对象的编程方法. 2. AVFilter 开发流程2.1 编写AVFilter 文件2.1.…...

【UVM项目实战】异步fifo—uvm项目结构以及uvm环境搭建
本文章同步到我的个人博客网站:ElemenX-King:【UVM项目实战】异步fifo—uvm项目结构以及uvm环境搭建 希望大家能使用此网站来进行浏览效果更佳!!! 目录 一、异步FIFO1.1 异步FIFO的定义1.2 亚稳态1.3 异步FIFO关键技术…...
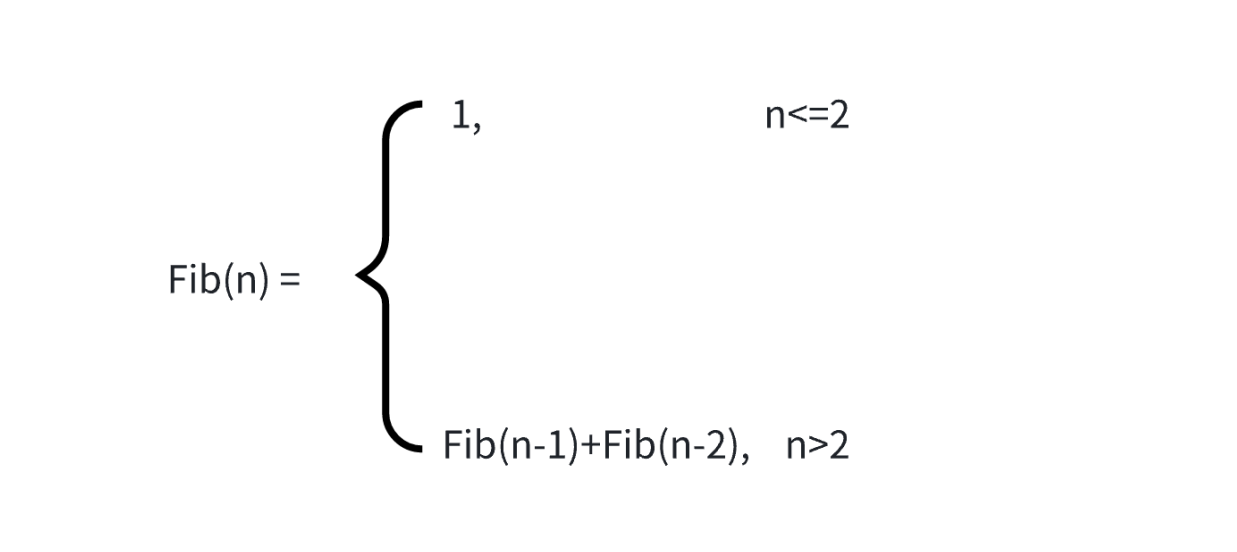
【通关函数的递归】--递归思想的形成与应用
目录 一.递归的概念与思想 1.定义 2.递归的思想 3.递归的限制条件 二.递归举例 1.求n的阶乘 2.顺序打印一个整数的每一位 三.递归与迭代 前言:上篇博文分享了扫雷游戏的实现,这篇文章将会继续分享函数的递归相关知识点,让大家了解并掌握递归的思…...

AI日报 - 2025年04月25日
🌟 今日概览(60秒速览) ▎🤖 AGI突破 | OpenAI o3模型展现行动能力,英国发布RepliBench评估AI自主复制风险,DeepMind CEO担忧AGI协调挑战。 模型能力向行动和自主性演进,安全与协调成为焦点。 ▎💼 商业动向…...

【FAQ】针对于消费级NVIDIA GPU的说明
概述 本文概述 HP Anyware 在配备消费级 NVIDIA GPU 的物理工作站上的关键组件、安装说明和重要注意事项。 注意:本文档适用于 NVIDIA 消费级 GPU。NVIDIA Quadro 和 Tesla GPU 也支持 HP Anyware 在公有云、虚拟化或物理工作站环境中运行。请参阅PCoIP Graphi…...