Hadoop+Spark 笔记 2025/4/21
读书笔记

定义
1. 大数据(Big Data)
- 指传统数据处理工具难以处理的海量、高速、多样的数据集合,通常具备3V特性(Volume体量大、Velocity速度快、Variety多样性)。扩展后还包括Veracity(真实性)和Value(价值)。
2. Hadoop
- 一个开源的分布式计算框架,用于存储和处理大规模数据集。核心组件包括HDFS(存储)和MapReduce(计算),具有高容错性和横向扩展能力。
3. HDFS(Hadoop Distributed File System)
- Hadoop的分布式文件系统,设计用于**廉价硬件集群**。特点:
- 分块存储(默认128MB/块)
- 多副本机制(默认3副本)
- 主从架构(NameNode管理元数据,DataNode存储实际数据)
4. MapReduce
- 一种批处理编程模型,分为两个阶段:
- Map阶段:将任务分割成更小任务交给每台服务器分别运行,也就是并行处理输入数据(映射)
- Reduce阶段:聚合Map结果(归约)
- 适合离线大规模数据处理,但磁盘I/O开销较大。
5. Spark
- 基于内存的分布式计算引擎,相比MapReduce优势:
- 内存计算(比Hadoop快10-100倍)
- 支持DAG(有向无环图)优化执行计划
- 提供SQL、流处理、图形处理、机器学习等统一API(Spark SQL/Streaming/GraphX/MLlib)
6. 机器学习(Machine Learning)
- 通过算法让计算机从数据中自动学习规律并做出预测/决策,主要分为:
- 监督学习(如分类、回归)
- 无监督学习(如聚类、降维)
- 强化学习(通过奖励机制学习)
关键区别:Hadoop基于磁盘批处理,Spark基于内存迭代计算,机器学习则是数据分析的高级应用方法。
安装Hadoop
1.虚拟机软件安装(搭建Hadoop cluster集群时需要很多台虚拟机)
2.安装Ubuntu操作系统(hadoop最主要在Linux操作系统环境下运行)
3.安装Hadoop Single Node Cluster(只以一台机器来建立Hadoop环境)
- 安装JDK(Hadoop是java开发的,必须先安装JDK)
- 设置SSH无密码登录(Hadoop必须通过SSH与本地计算机以及其他主机连接,所以必须设置SSH)
- 下载安装Hadoop(官网下载Hadoop,安装到Ubuntu中)
- 设置Hadoop环境变量(设置每次用户登录时必须要设置的环境变量)
- Hadoop配置文件的设置(在Hadoop的/usr/local/hadoop/etc/hadoop的目录下,有很多配置设置文件)
- 创建并格式化HDFS目录(HDFS目录是存储HDFS文件的地方,在启动Hadoop之前必须先创建并格式化HDFS目录)
- 启动Hadoop(全部设置完成后启动Hadoop,并查看Hadoop相关进程是否已经启动)
- 打开Hadoop Web界面(Hadoop界面可以查看当前Hadoop的状态:Node节点、应用程序、任务运行状态)
常用命令:
启动HDFS
start-dfs.sh启动YARN(启动Hadoop MapReduce框架YARN)
start-yarn.sh同时启动HDFS和YARN
start-all.sh使用jps查看已经启动的进程(查看NameNode、DataNode进程是否启动)
PS:因为只有一台服务器,所以所有功能都集中在一台服务器中,可以看到:
- HDFS功能:NameNode、Secondary NameNode、DataNode已经启动
- MapReduce2(YARN):Resource Manager、NodeManager已经启动
jps
监听端口上的网络服务:
打开Hadoop Resource-Manager Web界面
http://localhost:8088/NameNode HDFS Web界面
http://localhost:50070/
4.Hadoop Multi Node Cluster的安装(至少有四台服务器,才能发挥多台计算机并行的优势。不过我只有一个电脑,只能创建四台虚拟主机演练)
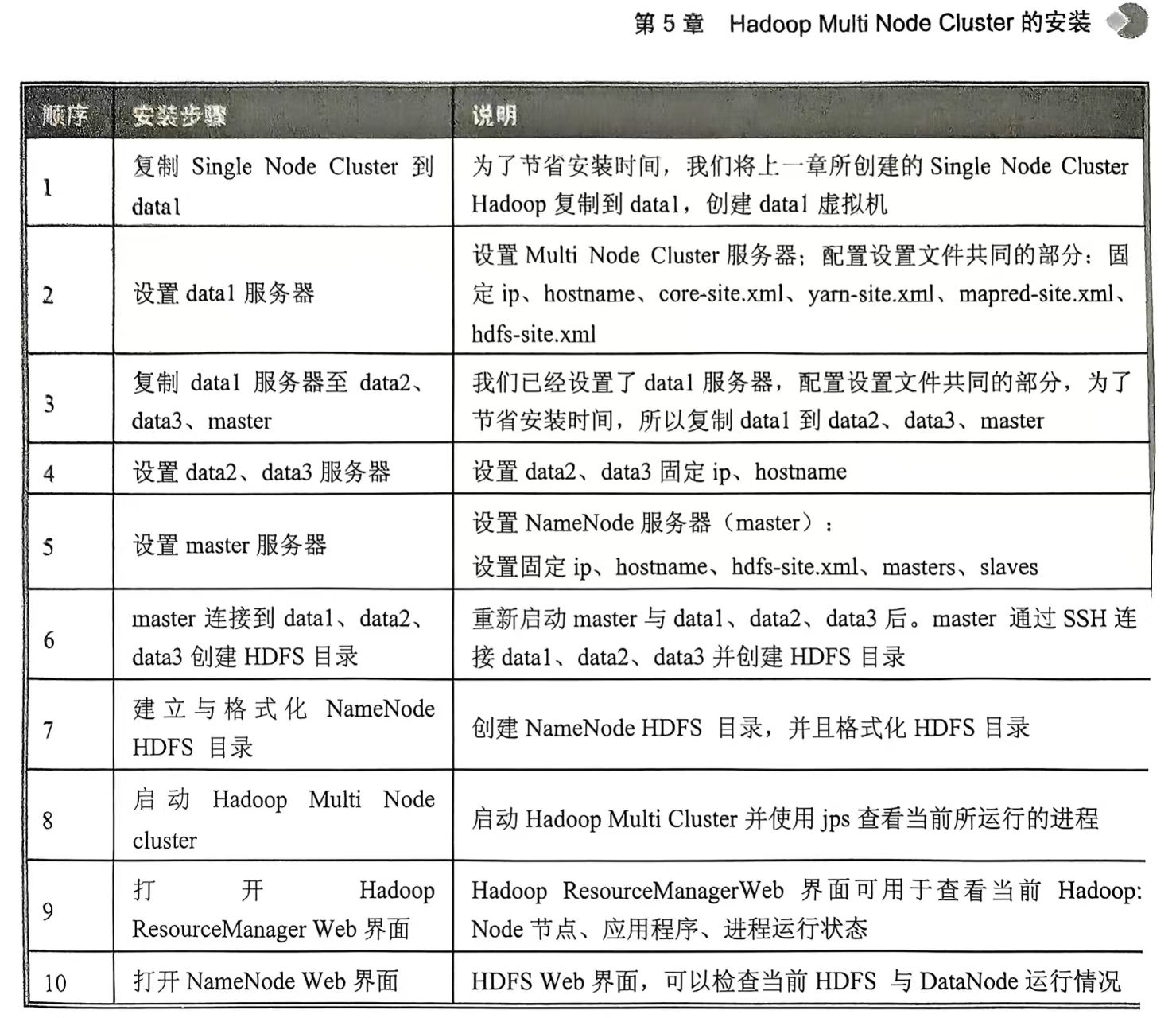
Hadoop的基本功能
1.HDFS
常用HDFS命令:

HDFS 常见命令 -CSDN博客
回头再写那些常用命令
2.MapReduce
以批处理为主。

首先使用Map将待处理的数据分割成很多的小份数据,由每台服务器分别运行。
再通过Reduce程序进行数据合并,最后汇总整理出结果。
单词计数

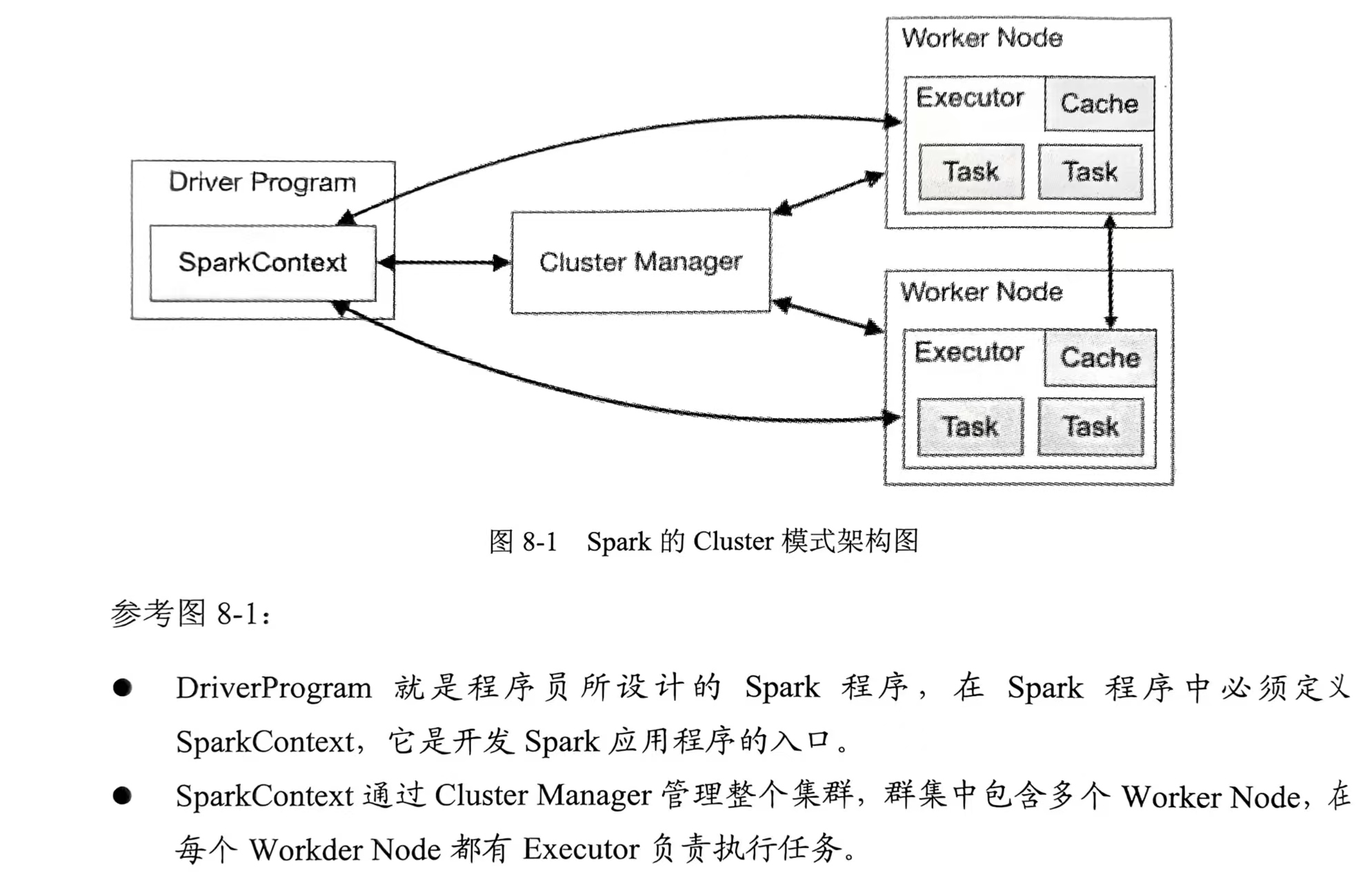
Spark
Spark的Cluster模式架构图👇
- 安装Spark
- 安装Scale
- 启动spark-shell交互界面
- 启动Hadoop(start-all.sh命令)
- 本地运行spark-shell(比如spark-shell --master local[4]->读取本地文件->读取HDFS文件)
- 在Hadoop YARN运行spark-shell(spark可以在Hadoop YARN上运行,让Yarn帮助它进行多台机器资源的管理。在Hadoop Yarn运行spark-shell->读取本地文件->读取HDFS文件->在Hadoop Web界面可以查看spark-shell APP,8080端口)
- 构建Spark Standalone Cluster执行环境(在master虚拟机设置spark-env.sh->复制spark程序到data1、data2、data3->在master虚拟机编辑slaves文件)
- 在Spark Standalone运行spark-shell(启动Spark Standalone Cluster也就是start-all.sh->在Spark Standalone运行Spark-shell->Spark Standalone Web UI界面->读取本地文件->读取HDFS文件->停止Spark stand alone cluster)
Spark本身是以Scala开发的,所以先安装Scala。试着安装在master虚拟机上。
安装:官网下载->解压缩并移动->配置环境变量->启动
PS:spark-shell默认显示很多信息,可以自己手动改,让它只显示警告信息。(cp复制log4j.properties.template模板到log4j.properties)👇
spark-shell --master local[4] 其中local[N]表示本地运行,使用N个线程,也就是说可以同时执行N个程序。
读取本地文件👇
读取HDFS文件👇


Spark的基本功能




1.RDD的特性
spark的核心是RDD(弹性分布式数据集),属于一种分布式的内存系统的数据集应用,RDD也是spark的主要优势。
RDD能与其他系统兼容,可以导入外部存储系统的数据集,如HDFS、Hbase或其他Hadoop数据源。
RDD的三种基本运算:转换Transformation、动作Action、持久化Persistence
2.基本RDD“转换”运算
- 先进入spark-shell
- 创建intRDD
- 创建stringRDD
- map运算
- map字符串运算
- filter数字运算
- filter字符串运算
- distinct运算
- randomSplit运算
- groupBy运算
命令就不写了,下面也是
3.多个RDD“转换”运算
- 先创建3个RDD来示范
- union并集运算
- intersection交集运算
- subtract差集运算
- cartersian笛卡尔乘积运算
4.基本“动作”运算
- 读取元素
- 统计功能
5.RDD Key-Value基本“转换”运算
- 创建范例Key-Value RDD
- 列出keys值
- 列出values值
- 使用filter筛选key运算
- 使用filter筛选value运算
- mapValues运算
- sortByKey从小到大按照key排序
- sortByKey从大到小按照key排序
- reduceByKey(如(3,4)(3,5)(1,1)相同key进行合并(3,9)(1,1))
6.多个RDD Key-Value“转换”运算
- 创建Key-Value RDD范例
- Key-Value RDD join运算
- Key-Value leftOuterJoin运算
- Key-Value rightOuterJoin运算
- Key-Value subtractByKey运算
7.Key-Value“动作”运算
- Key-Value first运算
- 读取第一条数据的元素
- Key-Value countByKey运算
- Key-Value collectAsMap运算
- 使用对照表转换数据
8.Broadcast广播变量
9.accumulator累加器
共享变量包括:
- Broadcast广播变量
- accumulator累加器
10.RDD Persistence持久化
Spark RDD持久化机制,可以用于将需要重复运算的RDD存储在内存中,以便大幅提升运算效率。
使用方法:
- RDD.persist()——可指定存储等级
- RDD.unpersist()——取消持久化
11.用Spark创建WordCount
- 创建测试文件(mkdir -p ~workspace/WordCount/data,cd到刚刚创建的文件夹,编辑test.txt)
- 进入spark-shell(~workspace/WordCount/data下输入spark-shell)
- 执行WordCount spark命令

- 查看data目录(ll)
- 查看output目录(cd output,ll,因为结果保存在/data/output)
- 查看part-00000输出文件(cat part-00000)
Spark的集成开发环境
使用eclipse集成开发环境(IDE)开发Spark应用程序。
- 下载与安装eclipse Scala IDE,安在master服务器上
- 下载项目所需要的Library
- 启动eclipse
- 创建新的Spark项目(要添加外部Jar或者创建后像第五步一样添加,设置scala library版本)
- 设置项目链接库
- 新建scala程序
- 创建WordCount测试文本文件
- 创建WordCount.scala
- 编译WordCount.scala程序
- 运行Word.scala程序
- 导出jar文件
- spark-submit介绍
- 在本地local模式运行WordCount程序(记得删除之前的/data/output目录,切换到WordCount目录,本地运行WordCount——spark-submit...代码巴拉巴拉,查看结果/data/output里)
- 在Hadoop yarn-client运行WordCount程序(介绍如何用spark-submit,在Hadoop YARN上运行WordCount Spark程序:启动集群start-all.sh->在HDFS创建data目录,复制LICENSE.txt文件到HDFS,查看HDFS->修改环境配置文件bashrc并使其生效->切换到WordCount项目目录,在Hadoop YARN上运行WordCount(spark-submit),查看HDFS产生的目录和文件,看完删除,因为一会还要测试)
- 在Spark Standalone Cluster上运行WordCount程序(仍然是启动Standalone Cluster->运行程序->看结果)
机器学习(推荐引擎)
几个概念和目录,实战。简写,主播也第一次学
- 推荐算法是啥
- 推荐引擎在大数据分析的几个使用场景:电影推荐
- ALS推荐算法
- ml-100k推荐数据(一个数据集)的下载
- 使用spark-shell导入ml-100k数据
- 查看导入的数据
- 使用ALS.train训练(ALS.train命令)
- 使用模型进行推荐
- 显示推荐电影名
- 创建Recommend项目(刚刚是用spark-shell学习的,它的缺点是无法重复使用,这次启动eclipse演示:启动eclipse->创建Recommend项目->创建Recommend.scala文件->起个名字吧->创建完成的Scala程序,接下来开始输入程序代码)
- Recommend.scala程序代码(Import导入链接库->main主函数代码(数据准备、训练、推荐)->SetLogger可设置不显示log信息)
- 创建PrepareData()数据准备(创建PrepareData()函数->创建用户评分数据->创建电影ID与名称对照表->显示数据记录数)
- recommend()推荐程序代码(recommend()推荐程序代码、RecommendMovies()针对此用户推荐电影)
- 运行Recommend.scala
- 创建AIsEvaluation.scala调校推荐引擎参数(前面使用的ALS.train命令训练,会返回model训练完成的模型,其中rank、Iterations、lambda这些参数值的设置会影响结果的准确度,以及训练所需的时间。接下来将进行调校找出最佳的参数组合)
- 创建PrepareData()数据准备(共有4步,前3部与Recommend.scala完全相同:1.创建用户评分数据;2.创建电影ID与名称对照表;3.显示数据记录数;4.以随机方式将数据分为3个部分并且返回(以8:1:1比例分成训练数据、验证数据、测试数据))
- 进行训练评估(1.train Validation训练评估:评估rank参数、评估numIterations参数、评估lambda参数、所有参数交叉评估。2.evaluateParamter评估单个参数。3.Chart.plotBarLineChart绘制出柱形图与折线图。4.trainModel训练模型。5.计算RMSE,表示预测与实际的误差平均值,通常RMSE越小误差越小。6.evaluateAllParameter程序将三个参数交叉评估找出最好的参数组合)
- 运行AlsEvaluation(运行AlsEvaluation,评估rank参数,评估lambda参数、所有参数交叉评估找出最好的参数组合)
- 修改Recommend.scala为最佳参数组合(刚刚我们已经找出了最佳参数组合)
机器学习(二元分类)

机器学习(多元分类)

机器学习(回归分析)

数据可视化

使用Apache Zeppelin数据可视化。
相关文章:
Hadoop+Spark 笔记 2025/4/21
读书笔记 定义 1. 大数据(Big Data) - 指传统数据处理工具难以处理的海量、高速、多样的数据集合,通常具备3V特性(Volume体量大、Velocity速度快、Variety多样性)。扩展后还包括Veracity(真实性&#x…...

千问2.5-VL-7B的推理、微调、部署_笔记2
接上篇:部署千问2.5-VL-7B_笔记1-CSDN博客 这里主要记录微调过程 一、模型微调 这里也使用ms-swift对qwen2.5和qwen2-vl进行自我认知微调和图像OCR微调,并对微调后的模型进行推理。ms-swift是魔搭社区官方提供的LLM工具箱,支持300大语言模…...
Redis从入门到实战基础篇
前言:Redis的安装包含在Redis从入门到实战先导篇中,需要的可移步至此节 目录 1.Redis简单介绍 2.初始Redis 2.1.认识NoSQL 2.2.认识Redis 2.3.安装Redis 3.Redis常见命令 3.1 Redis数据结构 3.2 通用命令 3.3 String命令 3.4 Key的层级结构 3…...

【Docker】在Ubuntu平台上的安装部署
写在前面 docker作为一种部署项目的辅助工具,真是太好用了需要魔法,不然无法正常运行笔者环境:ubuntu22.04 具体步骤 更新系统包索引 sudo apt update安装必要依赖包 sudo apt install -y apt-transport-https ca-certificates curl softwa…...
Java虚拟机(JVM)家族发展史及版本对比
Java虚拟机(JVM)家族发展史及版本对比 一、JVM家族发展史 1. 早期阶段(1996-2000) Classic VM(Java 1.0-1.1): 厂商:Sun Microsystems(Oracle前身)。特点&…...

【学习笔记】Cadence电子设计全流程(三)Capture CIS 原理图绘制(下)
【学习笔记】Cadence电子设计全流程(三)Capture CIS 原理图绘制(下) 3.16 原理图中元件的编辑与更新3.17 原理图元件跳转与查找3.18 原理图常见错误设置于编译检查3.19 低版本原理图文件输出3.20 原理图文件的锁定与解锁3.21 Orca…...

数据库对象与权限管理-Oracle数据字典详解
1. 数据字典概念讲解 Oracle数据字典是数据库的核心组件,它存储了关于数据库结构、用户信息、权限设置和系统性能等重要的元数据信息。这些信息对于数据库的日常管理和维护至关重要。数据字典在数据库创建时自动生成,并随着数据库的运行不断更新。 数据…...

计算机图形学实践:结合Qt和OpenGL实现绘制彩色三角形
在Qt项目中结合OpenGL与CMake需要配置正确的依赖关系、链接库以及代码结构设计。以下是具体实现步骤和关键要点: 一、环境准备 安装Qt 确保安装包含OpenGL模块的Qt版本(如Qt OpenGL、Qt OpenGLWidgets组件)。安装CMake 使用3.10及以上版本&a…...

OpenCV 图形API(54)颜色空间转换-----将图像从 RGB 色彩空间转换到 HSV色彩空间RGB2HSV()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将图像从 RGB 色彩空间转换为 HSV。该函数将输入图像从 RGB 色彩空间转换到 HSV。R、G 和 B 通道值的常规范围是 0 到 255。 输出图像必须是 8 位…...

SpringBoot 封装统一API返回格式对象 标准化开发 请求封装 统一格式处理
统一HTTP请求代码 public class HttpCode {/*** 操作成功*/public static final int SUCCESS 200;/*** 对象创建成功*/public static final int CREATED 201;/*** 请求已经被接受*/public static final int ACCEPTED 202;/*** 操作已经执行成功,但是没有返回数据…...
 but expected ‘xxx‘)
#git pull 问题:cannot lock ref ‘xxx‘: ref xxx is at (commitID) but expected ‘xxx‘
问题描述:git在拉取远程代码时出现该提示,拉取失败,导致该问题可能是远程有本地没有跟踪过的(小写大写不同)重名的分支,git是不区分大小写的,所以比如有一个的分支原先是example1.0,…...
JavaWeb学习打卡-Day1-分层解耦、Spring IOC、DI
三层架构 Controller(控制层):接收前端发送的请求,对请求进行处理,并响应数据。Service(业务逻辑层):处理具体的业务逻辑。DAO(数据访问层/持久层)ÿ…...

PostgesSQL外部数据封装FDW
PostgesSQL外部数据封装FDW 1. FDW外部数据配置(单表)1.1 远端数据库创建测试表1.2 安装扩展postges\_fdw1.3 创建外部服务SERVER1.4 创建用户映射USER MAPPING1.5 创建远程表FOREIGN TABLE1.6 数据库更新测试 2. FDW外部数据配置(用户&#…...

redis相关问题整理
Redis 支持多种数据类型: 字符串 示例:存储用户信息 // 假设我们使用 redis-plus-plus 客户端库 auto redis Redis("tcp://127.0.0.1:6379"); redis.set("user:1000", "{name: John Doe, email: john.doeexample.com}"…...

基于 Electron、Vue3 和 TypeScript 的辅助创作工具全链路开发方案:涵盖画布系统到数据持久化的完整实现
基于 Electron、Vue3 和 TypeScript 的辅助创作工具全链路开发方案:涵盖画布系统到数据持久化的完整实现 引言 在数字内容创作领域,高效的辅助工具是连接创意与实现的关键桥梁。创作者需要一款集可视化画布、节点关系管理、数据持久化于一体的专业工具&…...
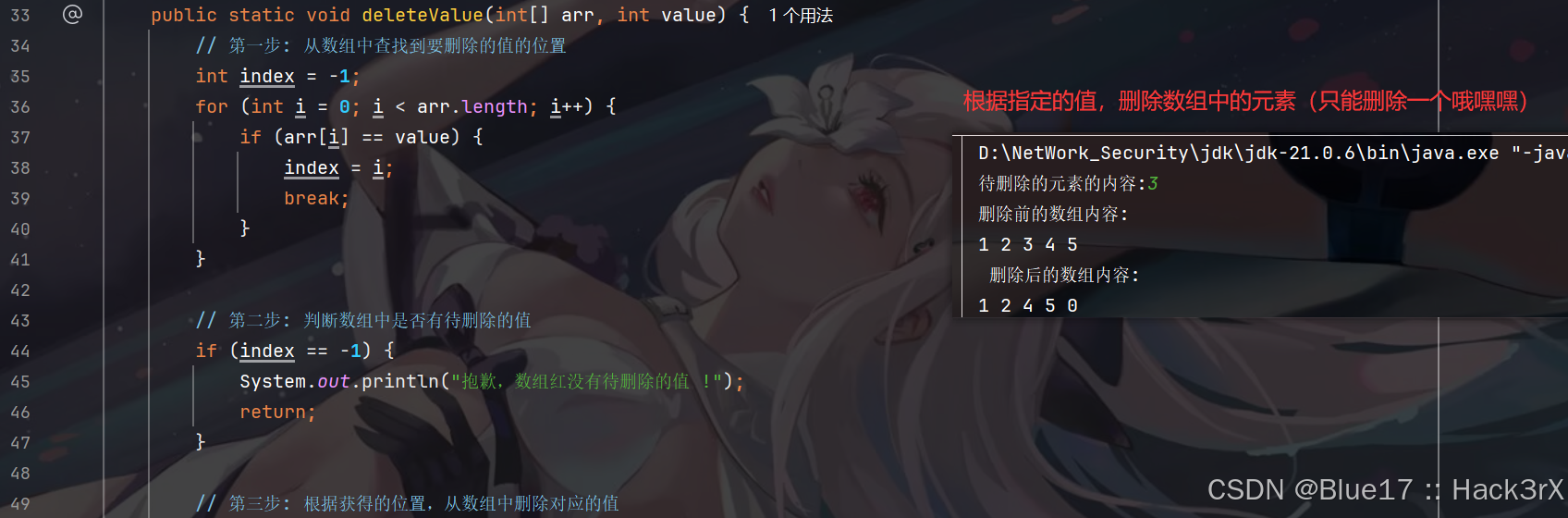
[Java · 铢积寸累] 数据结构 — 数组类型 - 增 删 改 查
🌟 想系统化学习 Java 编程?看看这个:[编程基础] Java 学习手册 在上一章中我们介绍了如何声明与创建数组,还介绍了数组的基本使用方式。本章我们将在上一章的基础上,拓展数组的使用方式(可能会涉及一些思…...

前端笔记-Axios
Axios学习目标 Axios与API交互1、Axios配置与使用2、请求/响应拦截器3、API设计模式(了解RESTful风格即可) 学习参考:起步 | Axios中文文档 | Axios中文网 什么是Axios Axios 是一个基于 Promise 的现代化 HTTP 客户端库,专…...

vue3数据响应式丢失的情况有哪些
在 Vue 3 中,响应式系统使用的是 Proxy 实现,相比 Vue 2 提升很大,很多 Vue 2 中的数据响应式陷阱都被解决了(比如数组索引、新增属性等),但依然存在一些可能导致“响应式丢失”的情况。 🚨 Vue…...
:特别数的和)
每日一练(4~23):特别数的和
算法:枚举 题目 题目描述 小明对数位中含有 2、0、1、9 的数字很感兴趣(不包括前导 0),在 1 到 40 中这样的数包括 1、2、9、10 至 32、39 和 40,共 28 个,他们的和是 574。 请问,在 1 到 n…...

AR行业应用案例与NXP架构的结合
1. 工业巡检AR头盔 场景示例:宁德核电基地使用AR智能头盔进行设备巡检,通过实时数据叠加和远程指导,将工作效率提升35%。头盔需处理传感器数据、图像渲染和低延迟通信1。 NXP架构支持: 协处理器角色:NXP i.MX RT系列M…...
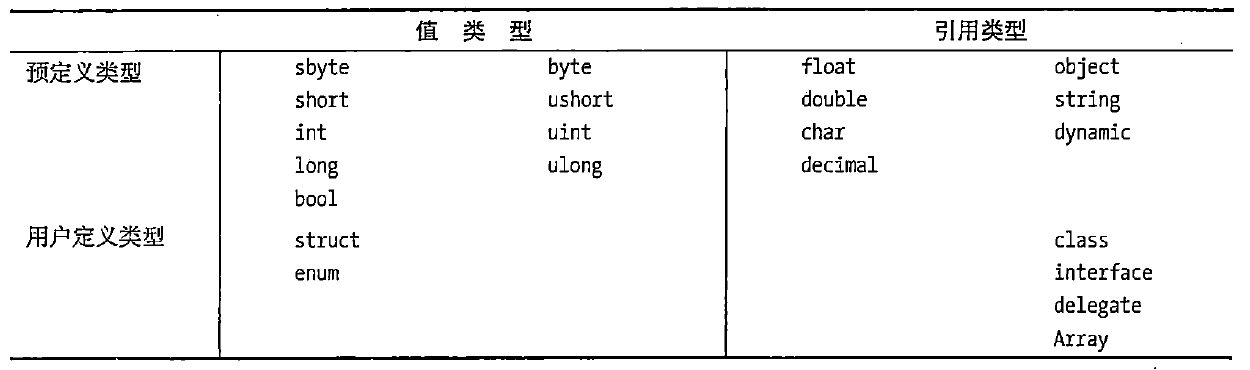
C# 类型、存储和变量(值类型引用类型)
本章内容 C#程序是一组类型声明 类型是一种模板 实例化类型 数据成员和函数成员 预定义类型 用户定义类型 栈和堆 值类型和引用类型 变量 静态类型和dynamic关键字 可空类型 值类型引用类型 数据项的类型定义了存储数据需要的内存大小及组成该类型的数据成员。类型还决定了对象…...
智慧校园从配电开始:AISD300为校园安全加上智能防护罩
安科瑞刘鸿鹏 摘要 随着校园用电需求不断上升及其安全保障要求的提高,传统低压配电系统已逐渐难以满足现代校园的安全与智能化管理需求。本文基于安科瑞电气推出的AISD300系列三相智能安全配电装置,探讨其在校园电力系统中的应用优势及关键技术特性。…...

如何创建极狐GitLab 议题?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 创建议题 (BASIC ALL) 创建议题时,系统会提示您输入议题的字段。 如果您知道要分配给议题的值,则可…...

如何将极狐GitLab 合并请求导出为 CSV?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 导出合并请求为 CSV (BASIC ALL) 将从项目的合并请求中收集的所有数据导出到逗号分隔值(CSV)文件中。…...
一 、环境的安装 Anaconda + Pycharm + PaddlePaddle
《从零到一实践:系统性学习生成式 AI(NLP)》 一 、环境的安装 Anaconda Pycharm PaddlePaddle 1. Anaconda 软件安装 Anaconda 软件安装有大量的教程,此处不在说明,安装完成之后界面如下: 2. 创建 Anaconda 虚拟环境 Paddl…...
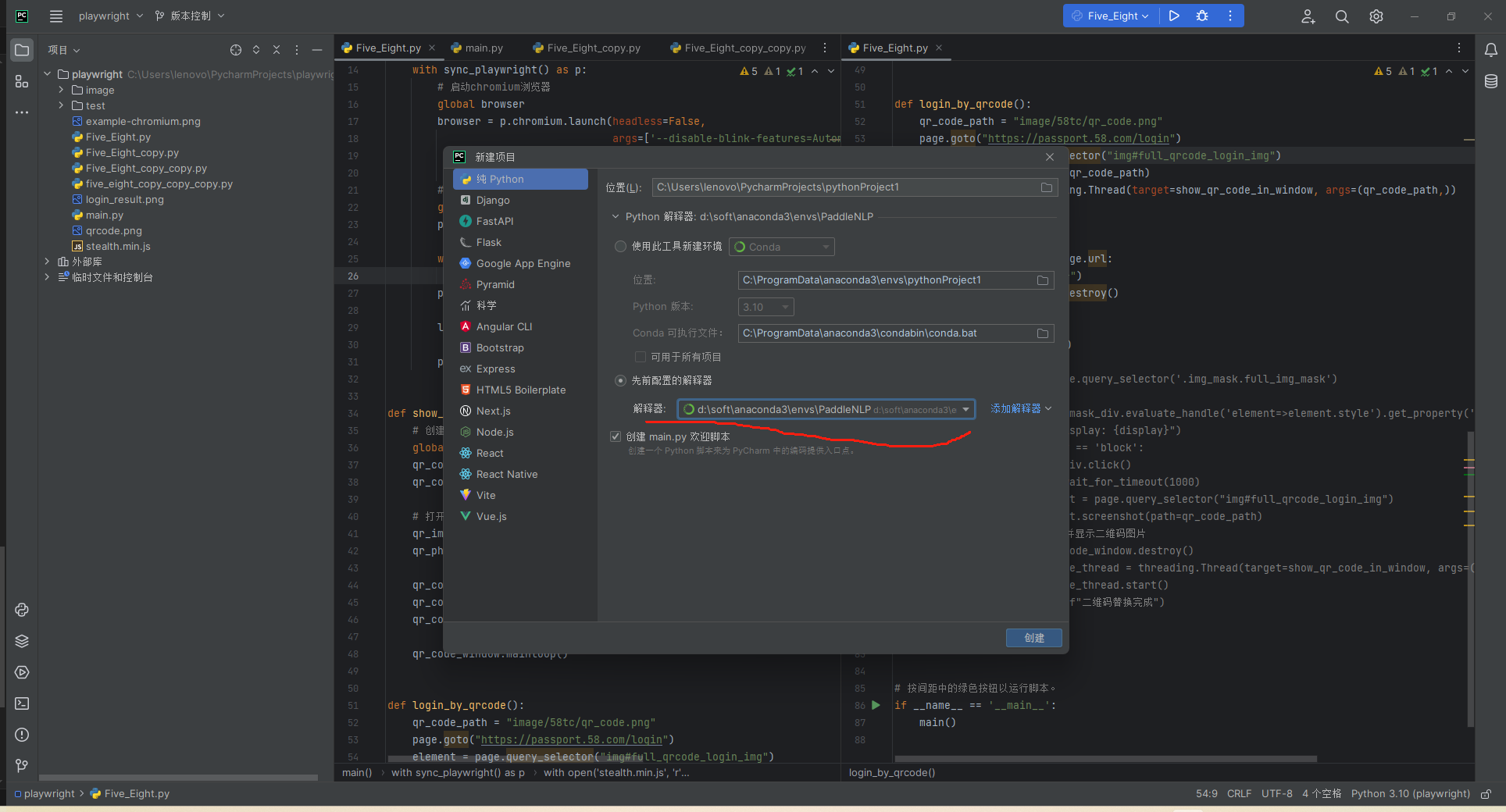
十倍开发效率 - IDEA插件之 Maven Helper
0X00 先看效果 第一个选项表示存在冲突的依赖,可以看到图片中 mysql 的连接依赖发生了冲突,在低版本的上面直接右键选择 Exclude,冲突的依赖就被解决掉了。 0X01 安装 在 Plugins 中直接搜索 Maven Helper,选择第一个进行安装&am…...

Go语言和Python 3的协程对比
Go语言和Python 3都支持协程(concurrent coroutines),但它们的实现机制、使用方式、调度方式和性能表现差异很大。下面是对比分析: 一、基本概念对比 特性Go 协程(goroutine)Python3 协程(asyn…...

人机共跑,马拉松人型机器人同跑
马拉松比赛对人形机器人来说,是一场对硬件极限的测试,涉及机械、传感器、能源管理等多个方面。用户问的是硬件方面的考察和改进,这意味着我的回答需要聚焦于硬件性能,而不是算法或软件的优化。 对人形机器人硬件的考研 机械结构与…...
策略模式:动态切换算法的设计智慧
策略模式:动态切换算法的设计智慧 一、模式核心:定义一系列算法并可相互替换 在软件开发中,常常会遇到需要根据不同情况选择不同算法的场景。例如,在电商系统中,根据不同的促销活动(如满减、折扣、赠品&a…...
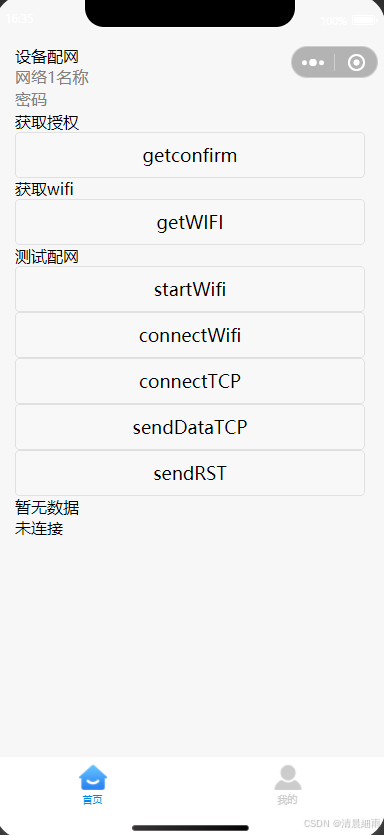
uniapp微信小程序:WIFI设备配网之TCP/UDP开发AP配网
一、AP配网技术原理 1.1 配网模式选择 AP配网(SoftAP模式)是IoT设备配网成功率最高的方案之一 1、其核心原理: 设备端:启动AP模式(如SSID格式YC3000_XXXX,默认IP192.168.4.1)手…...