【Python爬虫详解】第四篇:使用解析库提取网页数据——BeautifuSoup
在前一篇文章中,我们学习了如何编写第一个爬虫程序,成功获取了网页的HTML内容。然而,原始HTML通常包含大量我们不需要的信息,真正有价值的数据往往隐藏在HTML的标签和属性中。这一篇,我们将学习如何使用Python的解析库从HTML中提取出有用的数据。
一、网页解析库概述
Python提供了几个强大的库用于解析HTML,最常用的有:
- BeautifulSoup:最流行的HTML解析库,使用简单,功能强大
- lxml:基于C语言的高性能库,支持HTML和XML解析
- PyQuery:类似jQuery的Python实现,适合熟悉jQuery的开发者
本文将主要介绍BeautifulSoup,因为它对初学者最友好,同时功能也足够强大。
二、安装BeautifulSoup
首先,我们需要安装BeautifulSoup库和解析器:
pip install beautifulsoup4
pip install lxml # 推荐的解析器
BeautifulSoup本身只是一个解析器接口,需要搭配HTML解析器使用。lxml是目前速度最快的解析器,推荐使用。
三、BeautifulSoup基础
1. 创建BeautifulSoup对象
使用BeautifulSoup解析HTML的第一步是创建一个BeautifulSoup对象:
from bs4 import BeautifulSoup# 从HTML字符串创建BeautifulSoup对象
html_doc = """
<html><head><title>网页标题</title></head><body><h1>标题</h1><p class="content">这是一个<b>段落</b>。</p><p class="content">这是另一个段落。</p><div id="footer"><a href="https://www.example.com">链接</a></div></body>
</html>
"""soup = BeautifulSoup(html_doc, 'lxml') # 使用lxml解析器# 从文件创建BeautifulSoup对象
with open('example.html', 'r', encoding='utf-8') as f:soup = BeautifulSoup(f, 'lxml')
2. 基本导航方法
BeautifulSoup将HTML文档解析成树形结构,我们可以使用各种方法来导航和搜索这个树:
soup = BeautifulSoup(html_doc, 'lxml')# 获取标题
title = soup.title
print(f"标题标签: {title}")
print(f"标题文本: {title.string}")# 获取第一个段落
p = soup.p
print(f"第一个段落: {p}")# 获取所有段落
all_p = soup.find_all('p')
print(f"找到 {len(all_p)} 个段落")# 获取ID为footer的元素
footer = soup.find(id='footer')
print(f"页脚: {footer}")
3. 使用CSS选择器
BeautifulSoup支持使用CSS选择器来查找元素,这是一种强大而灵活的方法:
soup = BeautifulSoup(html_doc, 'lxml')# 使用CSS选择器查找元素
content_paragraphs = soup.select('p.content') # 查找class为content的p标签
print(f"内容段落数量: {len(content_paragraphs)}")# 查找ID为footer的元素内的所有链接
footer_links = soup.select('#footer a')
for link in footer_links:print(f"链接: {link['href']}")# 复杂的选择器
elements = soup.select('body > p.content') # 选择body直接子元素中class为content的p标签
CSS选择器语法说明:
tag:选择所有该类型的标签,如p选择所有段落#id:选择ID为指定值的元素,如#footer.class:选择具有指定class的元素,如.contentparent > child:选择parent的直接子元素中的child元素ancestor descendant:选择ancestor的后代元素中的descendant元素
四、提取数据
1. 提取文本内容
从元素中提取文本内容是最常见的操作之一:
soup = BeautifulSoup(html_doc, 'lxml')# 提取文本方法1:使用.string属性(只适用于没有子标签的元素)
title_text = soup.title.string
print(f"标题: {title_text}")# 提取文本方法2:使用.text属性(适用于任何元素,会提取所有子元素的文本)
p_text = soup.p.text
print(f"段落文本: {p_text}")# 提取文本方法3:使用.get_text()方法(可以指定分隔符)
body_text = soup.body.get_text(separator=' | ')
print(f"正文文本: {body_text}")
2. 提取属性
HTML元素的属性通常包含重要信息,如链接的URL:
soup = BeautifulSoup(html_doc, 'lxml')# 方法1:像字典一样访问属性
link = soup.find('a')
href = link['href']
print(f"链接地址: {href}")# 方法2:使用.get()方法(当属性不存在时不会抛出异常)
img = soup.find('img')
if img:src = img.get('src', '没有图片')print(f"图片地址: {src}")
else:print("没有找到图片标签")# 获取所有属性
if link:attrs = link.attrsprint(f"链接的所有属性: {attrs}")
3. 处理多个元素
通常,我们需要遍历和处理多个元素:
soup = BeautifulSoup(html_doc, 'lxml')# 查找所有段落
paragraphs = soup.find_all('p')# 遍历处理每个段落
for i, p in enumerate(paragraphs, 1):print(f"段落 {i}: {p.get_text().strip()}")# 使用CSS选择器查找多个元素
links = soup.select('a')
for link in links:print(f"链接地址: {link['href']}, 文本: {link.text.strip()}")
五、实际案例:解析百度热搜榜
在上一篇文章中,我们爬取了百度热搜榜的HTML内容并保存到了文件中。现在,让我们解析这个HTML并提取热搜数据:
from bs4 import BeautifulSoup
import logging# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')def parse_baidu_hot_search():"""解析百度热搜榜HTML"""try:# 从文件读取HTMLwith open("baidu_hot_search.html", "r", encoding="utf-8") as f:html_content = f.read()logging.info("开始解析百度热搜榜HTML...")# 创建BeautifulSoup对象soup = BeautifulSoup(html_content, 'lxml')# 找到热搜项元素# 注意:以下选择器是基于当前百度热搜页面的结构,如果页面结构变化,选择器可能需要更新hot_items = soup.select("div.category-wrap_iQLoo")if not hot_items:logging.warning("未找到热搜项,可能页面结构已变化,请检查HTML内容和选择器")return []logging.info(f"找到 {len(hot_items)} 个热搜项")# 提取每个热搜项的数据hot_search_list = []for index, item in enumerate(hot_items, 1):try:# 提取标题title_element = item.select_one("div.c-single-text-ellipsis")title = title_element.text.strip() if title_element else "未知标题"# 提取热度(如果有)hot_element = item.select_one("div.hot-index_1Bl1a")hot_value = hot_element.text.strip() if hot_element else "未知热度"# 提取排名rank = indexhot_search_list.append({"rank": rank,"title": title,"hot_value": hot_value})except Exception as e:logging.error(f"解析第 {index} 个热搜项时出错: {e}")logging.info(f"成功解析 {len(hot_search_list)} 个热搜项")return hot_search_listexcept Exception as e:logging.error(f"解析百度热搜榜时出错: {e}")return []def display_hot_search(hot_list):"""展示热搜榜数据"""if not hot_list:print("没有获取到热搜数据")returnprint("\n===== 百度热搜榜 =====")print("排名\t热度\t\t标题")print("-" * 50)for item in hot_list:print(f"{item['rank']}\t{item['hot_value']}\t{item['title']}")if __name__ == "__main__":hot_search_list = parse_baidu_hot_search()display_hot_search(hot_search_list)
注意:上面的选择器是基于编写时的百度热搜页面结构,如果页面结构发生变化,可能需要更新选择器。通常,我们需要先分析页面结构,找到包含目标数据的元素,然后编写相应的选择器。
六、如何找到正确的选择器?
在实际爬取过程中,找到正确的选择器是一个关键步骤。以下是一些实用技巧:
1. 使用浏览器开发者工具
- 在Chrome或Firefox中,右键点击要提取的元素,选择"检查"或"检查元素"
- 在元素面板中,右键点击对应的HTML代码,选择"Copy" > "Copy selector"获取CSS选择器
- 或者选择"Copy" > "Copy XPath"获取XPath表达式
2. 检查多个相似元素
当需要提取列表项(如热搜条目)时,检查多个相似元素,找出它们的共同特征:
- 检查第一个列表项,找到识别它的选择器
- 检查其他几个列表项,确认相同的选择器能够匹配所有项
- 尽量使用class、id等稳定属性,避免依赖位置或顺序
3. 从外到内逐层定位
对于复杂网页,可以采用从外到内的策略:
- 先定位包含所有目标数据的大容器(如列表容器)
- 再从容器中找出每个列表项
- 最后从每个列表项中提取所需的具体数据(标题、链接等)
# 从外到内逐层定位示例
container = soup.find('div', class_='list-container') # 先找到大容器
if container:list_items = container.find_all('div', class_='list-item') # 再找所有列表项for item in list_items:title = item.find('h3', class_='title').text.strip() # 从列表项中提取标题link = item.find('a')['href'] # 提取链接
七、常见问题与解决方案
1. 找不到元素
可能原因:
- 选择器不正确
- 页面结构与预期不同
- 内容是通过JavaScript动态加载的
解决方案:
- 检查HTML源码,确认元素是否存在
- 检查并调整选择器
- 如果内容是动态加载的,考虑使用Selenium等工具
2. 解析HTML出错
可能原因:
- HTML格式不规范
- 编码问题
解决方案:
- 使用更宽松的解析器,如html.parser
- 明确指定编码:
BeautifulSoup(html, 'lxml', from_encoding='utf-8')
3. 提取的文本包含多余内容
可能原因:
- 元素内包含子元素或多余空白
解决方案:
- 使用
.strip()去除多余空白 - 使用更精确的选择器定位具体文本节点
- 使用
.get_text(strip=True)获取清理后的文本
八、总结与最佳实践
通过本文,我们学习了如何使用BeautifulSoup从HTML中提取数据。以下是一些最佳实践:
-
选择合适的解析库:对于大多数情况,BeautifulSoup是一个很好的选择;对于更高性能需求,可以考虑直接使用lxml。
-
使用有意义的选择器:优先使用id、class等有语义的属性构建选择器,避免依赖元素位置。
-
健壮性处理:
- 总是检查元素是否存在再操作
- 使用try-except捕获可能的异常
- 使用
.get()方法获取属性,避免KeyError
-
文档和注释:由于网页结构可能变化,良好的文档和注释有助于维护。
-
定期检查:定期验证爬虫是否仍然有效,特别是在目标网站更新后。
在实际项目中,合理组合使用网页请求和数据提取技术,可以构建出强大而灵活的爬虫系统。
下一篇:【Python爬虫详解】第四篇:使用解析库提取网页数据——Xpath
相关文章:

【Python爬虫详解】第四篇:使用解析库提取网页数据——BeautifuSoup
在前一篇文章中,我们学习了如何编写第一个爬虫程序,成功获取了网页的HTML内容。然而,原始HTML通常包含大量我们不需要的信息,真正有价值的数据往往隐藏在HTML的标签和属性中。这一篇,我们将学习如何使用Python的解析库…...
《重塑AI应用架构》系列: Serverless与MCP融合创新,构建AI应用全新智能中枢
在人工智能飞速发展的今天,数据孤岛和工具碎片化问题一直是阻碍AI应用高效发展的两大难题。由于缺乏统一的标准,AI应用难以无缝地获取和充分利用数据价值。 为了解决这些问题,2024年AI领域提出了MCP(Model Context Protocol模型上…...

深度图可视化
import cv2# 1.读取一张深度图 depth_img cv2.imread("Dataset_depth/images/train/1112_0-rgb.png", cv2.IMREAD_UNCHANGED) print(depth_img.shape) cv2.imshow("depth", depth_img) # (960, 1280) print(depth_img)# 读取一张rgb的图片做对比 input_p…...

【调优】log日志海量数据分表后查询速度调优
原始实现 使用pagehelper实现分页 // 提取开始时间的年份和月份,拼装成表名List<String> timeBetween getTimeBetween(condition);List<String> fullTableName getFullTableName(Constants.LOG_TABLE_NAME, timeBetween);PageHelperUtil.startPage(c…...

hive默认的建表格式
在 Hive 中创建表时,默认的建表语法格式如下: CREATE TABLE table_name (column1_type,column2_type,... ) ROW FORMAT DELIMITED FIELDS TERMINATED BY , STORED AS TEXTFILE;在这个语法中: CREATE TABLE table_name:指定要创建…...

sass 变量
基本使用 如果分配给变量的值后面添加了 !default 标志 ,这意味着该变量如果已经赋值,那么它不会被重新赋值,但是,如果它尚未赋值,那么它会被赋予新的给定值。 如果在此之前变量已经赋值,那就不使用默认值…...
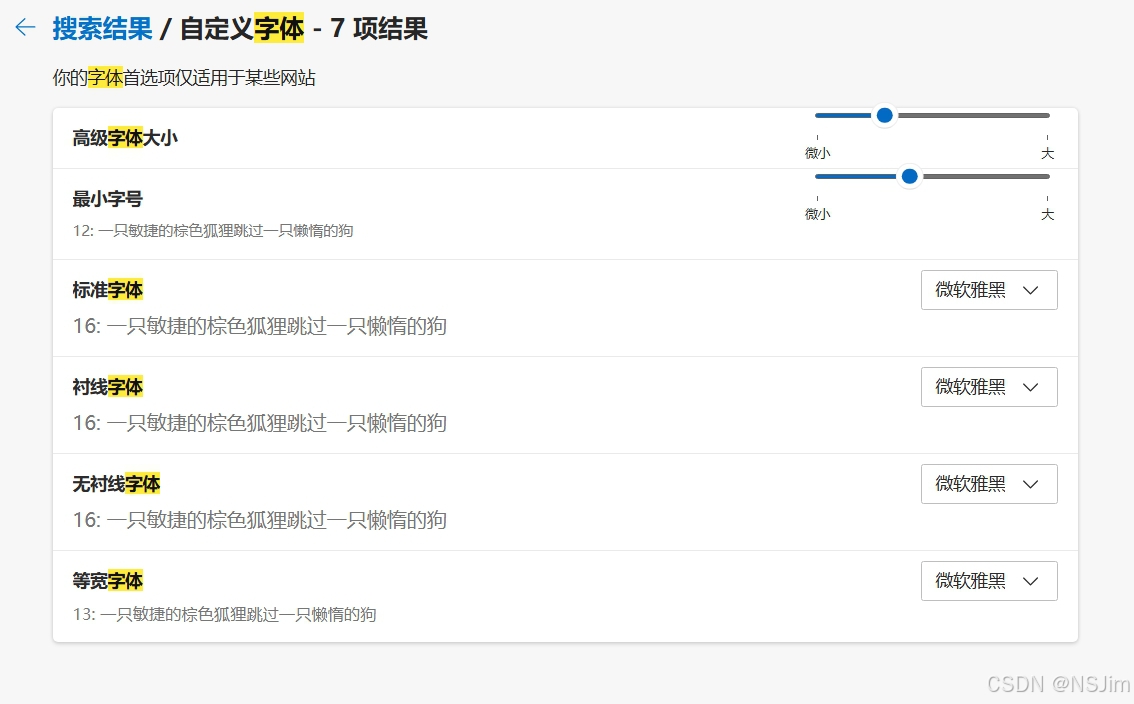
微软Edge浏览器字体设置
前言 时间:2025年4月 自2025年4月起,微软Edge浏览器的默认字体被微软从微软雅黑替换成了Noto Sans,如下图。Noto Sans字体与微软雅黑风格差不多,但在4K以下分辨率的显示器上较微软雅黑更模糊,因此低分辨率的显示器建议…...
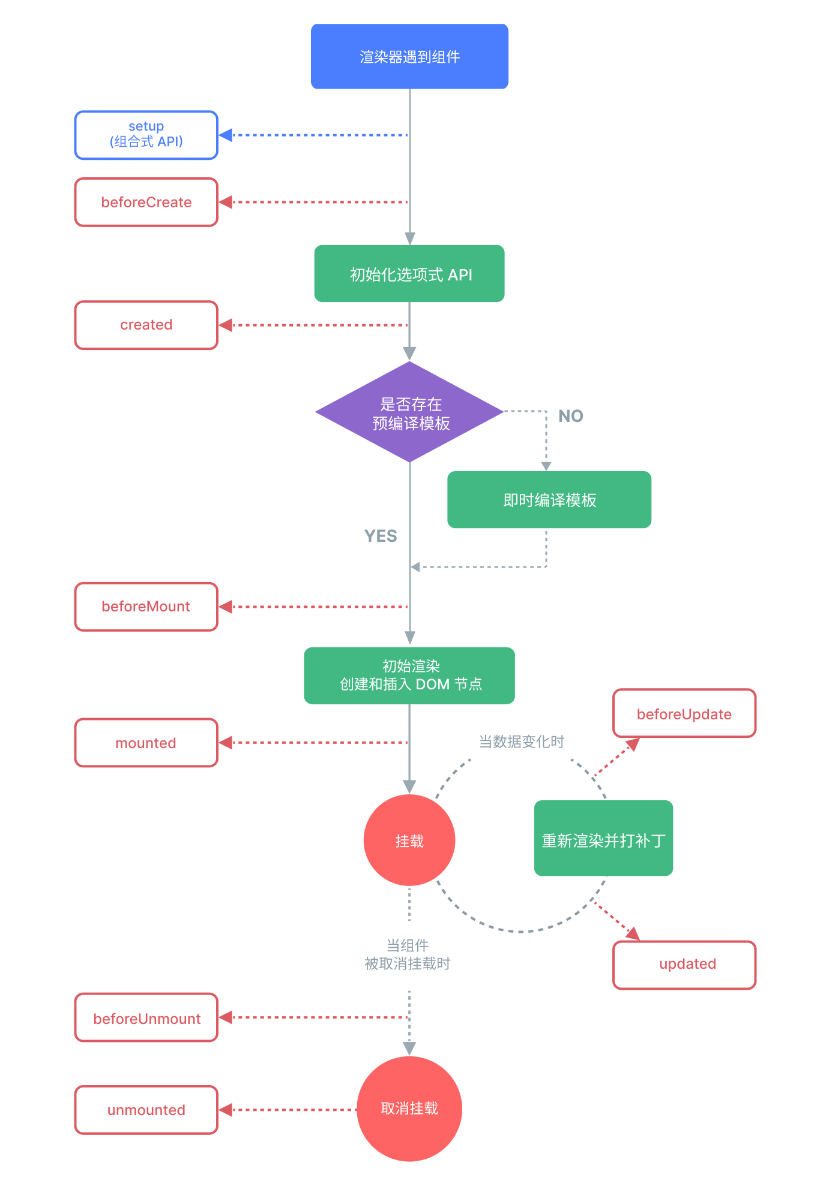
Vue生命周期详细解析
前言 Vue.js作为当前最流行的前端框架之一,其生命周期钩子函数是每个Vue开发者必须掌握的核心概念。本文将全面解析Vue的生命周期,帮助开发者更好地理解Vue实例的创建、更新和销毁过程。 一、Vue生命周期概述 Vue实例从创建到销毁的整个过程被称为Vue…...
基于c#,wpf,ef框架,sql server数据库,音乐播放器
详细视频: 【基于c#,wpf,ef框架,sql server数据库,音乐播放器。-哔哩哔哩】 https://b23.tv/ZqmOKJ5...
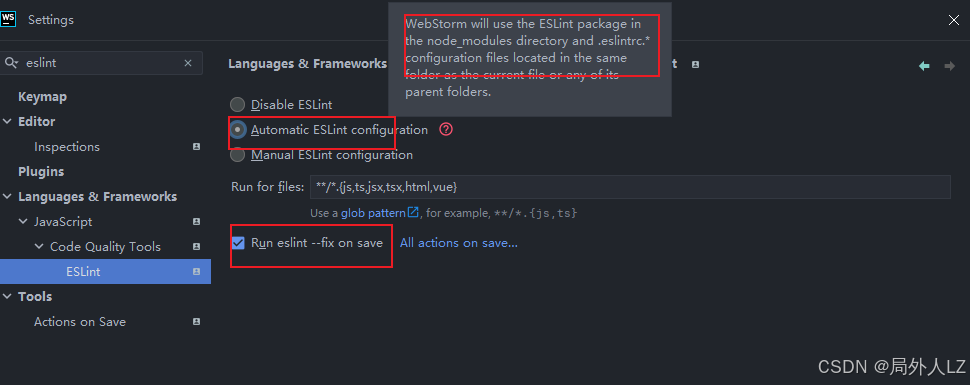
前端项目搭建集锦:vite、vue、react、antd、vant、ts、sass、eslint、prettier、浏览器扩展,开箱即用,附带项目搭建教程
前端项目搭建集锦:vite、vue、react、antd、vant、ts、sass、eslint、prettier、浏览器扩展,开箱即用,附带项目搭建教程 前言:一、Vue项目下载快速通道二、React项目下载快速通道三、BrowserPlugins项目下载快速通道四、项目搭建教…...
——统计学解构材质与光影)
【C++游戏引擎开发】第21篇:基于物理渲染(PBR)——统计学解构材质与光影
引言 宏观现象:人眼观察到的材质表面特性(如金属的高光锐利、石膏的漫反射柔和),本质上是微观结构对光线的统计平均结果。 微观真相:任何看似平整的表面在放大后都呈现崎岖的微观几何。每个微表面(Microfacet)均为完美镜面,但大量微表面以不同朝向分布时,宏观上会表…...
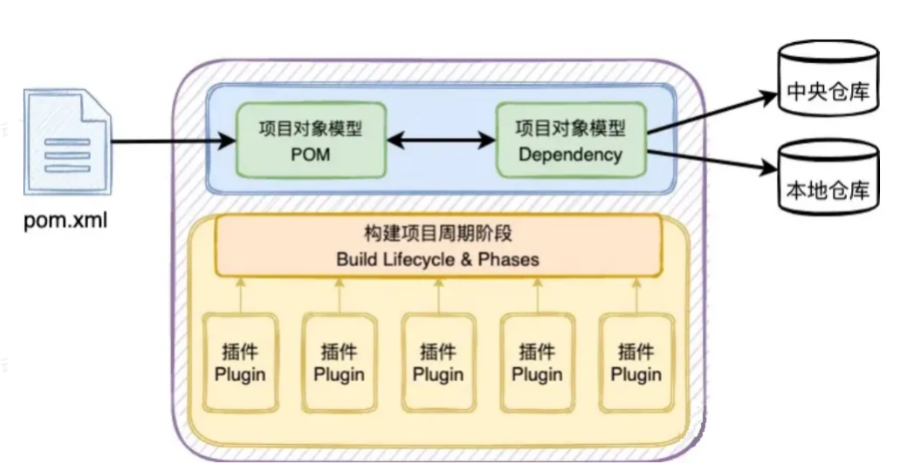
什么是Maven
Maven的概念 Maven是一个一键式的自动化的构建工具。Maven 是 Apache 软件基金会组织维护的一款自动化构建工具,专注服务于Java 平台的项目构建和依赖管理。Maven 这个单词的本意是:专家,内行。Maven 是目前最流行的自动化构建工具࿰…...
(动手学也有))
强化学习复习,价值函数的推导——北大pdf p41(ppt75)(动手学也有)
我们经常看到强化学习中有求汇报期望 E E E,转化为价值函数(value function) V V V,策略的状态价值函数(State-Value function) V π V_π Vπ和动作价值函数(action-value function) Q π Q_π Qπ。还有提到通过将期望将消除…...

neo4j中节点内的名称显示不全解决办法(如何让label在节点上自动换行)
因为节点过多而且想让节点中所有文字都显示出来而放大节点尺寸 从neo4j中导出png,再转成PDF来查看时,要看清节点里面的文字就得放大5倍才行 在网上看了很多让里面文字换行的办法都不行 然后找到一个比较靠谱的办法是在要显示的标签内加换行符 但是我的节点上显示的是…...

day 32 学习笔记
文章目录 前言一、模版匹配的概念二、模版匹配方法 前言 通过今天的学习,我掌握了OpenCV中有关模版匹配和模版匹配方法的相关原理和操作 一、模版匹配的概念 模板匹配就是用模板图(通常是一个小图)在目标图像(通常是一个比模板图…...

【GIT】github中的仓库如何删除?
你可以按照以下步骤删除 GitHub 上的仓库(repository): 🚨 注意事项: ❗️删除仓库是不可恢复的操作,所有代码、issue、pull request、release 等内容都会被永久删除。 🧭 删除 GitHub 仓库步骤…...

使用Python将YOLO的XML标注文件转换为TXT文件格式
使用Python将YOLO的XML标注文件转换为TXT文件格式,并划分数据集 import xml.etree.ElementTree as ET import os from os import listdir, getcwd from os.path import join import random from shutil import copyfile from PIL import Image# 只要改下面的CLASSE…...

docker容器监控自动恢复
关于实现对docker容器监控以及自动恢复,这里介绍两种实现方案。 方案1: 实现思路: 找到(根据正则表达式)所有待监控的docker容器,此处筛选逻辑根据docker运行状态找到已停止(Exit)类…...

【农气项目】基于适宜度的产量预报
直接上干货(复制到开发工具即可运行的代码) 1. 适宜度模型及作物適宜度计算方法 2. 产量分离 3. 基于适宜度计算产量预报 1. 适宜度模型及作物適宜度计算方法 // 三基点温度配置private final double tempMin;private final double tempOpt;private f…...

1、AI及LLM基础:Python语法入门教程
Python语法入门教程 这是一份全面的Python语法入门教程,涵盖了注释、变量类型与操作符、逻辑运算、list和字符串、变量与集合、控制流和迭代、模块、类、继承、进阶等内容,通过详细的代码示例和解释,帮助大家快速熟悉Python语法。 文章目录 Python语法入门教程一、注释二…...
3台CentOS虚拟机部署 StarRocks 1 FE+ 3 BE集群
背景:公司最近业务数据量上去了,需要做一个漏斗分析功能,实时性要求较高,mysql已经已经不在适用,做了个大数据技术栈选型调研后,决定使用StarRocks StarRocks官网:StarRocks | A High-Performa…...

服务器上安装node
1.安装 下载安装包 https://nodejs.org/en/download 解压安装包 将安装包上传到/opt/software目录下 cd /opt/software tar -xzvf node-v16.14.2-linux-x64.tar.gz 将解压的文件夹移动到安装目录(/opt/nodejs)下 mv /opt/software/node-v16.14.2-linux-x64 /opt/nodejs …...
:解析经典数据分析框架,助力创业增长)
精益数据分析(20/126):解析经典数据分析框架,助力创业增长
精益数据分析(20/126):解析经典数据分析框架,助力创业增长 在创业和数据分析的学习道路上,每一次深入探索都可能为我们带来新的启发。今天,依旧带着和大家共同进步的想法,我们一起深入研读《精…...

9.策略模式:思考与解读
原文地址:策略模式:思考与解读 更多内容请关注:7.深入思考与解读设计模式 引言 你是否曾遇到过这样的情况:在一个系统中,有许多算法或策略,每种策略的实现逻辑相似,但在某些情况下需要进行替换和扩展&am…...
【HCIA】简易的两个VLAN分别使用DHCP分配IP
前言 之前我们通过 静态ip地址实现了Vlan间通信 ,现在我们添加一个常用的DHCP功能。 文章目录 前言1. 配置交换机2. 接口模式3. 全局模式后记修改记录 1. 配置交换机 首先,使用DHCP,需要先启动DHCP服务: [Huawei]dhcp enable I…...

【设计模式-4】深入理解设计模式:工厂模式详解
在软件开发中,对象的创建是一个基础但至关重要的环节。随着系统复杂度的增加,直接使用new关键字实例化对象会带来诸多问题,如代码耦合度高、难以扩展和维护等。工厂模式(Factory Pattern)作为一种创建型设计模式&#…...

Spring Boot 整合 JavaFX 核心知识点详解
1. 架构设计与集成模式 1.1 Spring Boot 与 JavaFX 的分层架构设计 Spring Boot 与 JavaFX 的整合需要精心设计的分层架构,以充分利用两个框架的优势。 标准分层架构 ┌────────────────────────────────────────────────…...

Spring MVC DispatcherServlet 的作用是什么? 它在整个请求处理流程中扮演了什么角色?为什么它是核心?
DispatcherServlet 是 Spring MVC 框架的绝对核心和灵魂。它扮演着前端控制器(Front Controller)的角色,是所有进入 Spring MVC 应用程序的 HTTP 请求的统一入口点和中央调度枢纽。 一、 DispatcherServlet 的核心作用和职责: 请…...

亚马逊英国站FBA费用重构:轻小商品迎红利期,跨境卖家如何抢占先机?
一、政策背景:成本优化成平台与卖家共同诉求 2024年4月,亚马逊英国站(Amazon.co.uk)发布近三年来力度最大的FBA费用调整方案,标志着英国电商市场正式进入精细化成本管理时代。这一决策背后,是多重因素的叠…...

Redis在.NET平台中的各种应用场景
关键点总结 连接管理:所有示例都使用ConnectionMultiplexer来管理Redis连接,它是线程安全的,应该在整个应用程序中重用。 键设计:良好的键命名规范很重要,通常使用冒号分隔的层次结构(如page:home:pv)。 数据序列化&…...