嵌入式面试高频考点深度解析:内存管理、指针操作与结构体实战指南
试题一:大小端系统中数据的内存表现形式
题目
short tmp = 0xaabb; 请分别写出大小端系统中,tmp 在内存中的表现形式。
分析
1. 什么是高位与低位?
对于一个数据而言,以十六进制数 0xaabb 为例,从左至右,数值权重更大的部分为 高位,权重更小的部分为 低位。这就好比十进制数 123,1 代表百位(权重为 102),是高位;3 代表个位(权重为 100),是低位。在十六进制 0xaabb 中,0xaa 的权重为 161,0xbb 的权重为 160,因此 0xaa 是高位字节,0xbb 是低位字节。若换成二进制视角,一个 16 位二进制数 1010101010111011(对应 0xaabb),左边的高位部分(如前 8 位 10101010)代表更高的数值权重,右边的低位部分(后 8 位 10111011)权重更低。
2. 什么是高地址与低地址?
内存是由一系列连续的存储单元组成,每个单元都有唯一的编号,这个编号就是 地址。地址值较小的称为 低地址,地址值较大的称为 高地址。可以将内存想象成一排抽屉,编号为 1、2、3…… 的抽屉,1 号抽屉就是低地址,3 号抽屉相对 1 号就是高地址(若抽屉连续排列)。在程序中,变量在内存中占据一定范围的地址,地址的大小关系就形成了高低地址的概念。
为了更清晰地理解高低地址,我们可以将内存想象成一栋多层的 “大楼”,每一层都有一个唯一的 “房间号”,这个 “房间号” 就是内存地址。地址数值较小的 “房间” 就是低地址,地址数值较大的 “房间” 就是高地址。例如,若有三个连续的内存单元,地址分别为 0x1000、0x1001、0x1002,那么 0x1000 是低地址(“房间号” 小),0x1002 是高地址(“房间号” 大)。
对于 short tmp = 0xaabb(占 2 字节),假设它从地址 0x2000 开始存储,那么它会占据两个连续的地址:0x2000 和 0x2001。此时,0x2000 是低地址(数值更小),0x2001 是高地址(数值更大)。
- 大端系统:高位字节
0xaa存放在低地址0x2000,低位字节0xbb存放在高地址0x2001,内存表现为[0x2000: 0xaa][0x2001: 0xbb]。 - 小端系统:低位字节
0xbb存放在低地址0x2000,高位字节0xaa存放在高地址0x2001,内存表现为[0x2000: 0xbb][0x2001: 0xaa]。
通过这个类比,我们可以更直观地理解:在连续的内存空间中,数值小的地址是低地址,数值大的地址是高地址。在大小端规则下,数据的高位或低位字节会根据规则被放置到对应的高低地址中。
3. 大小端系统与内存表现形式
- 大端系统(Big - endian):高位字节存放在低地址,低位字节存放在高地址。对于
0xaabb,先将高位字节0xaa存放在低地址,再将低位字节0xbb存放在高地址,内存表现为0xaa 0xbb(假设低地址在前,高地址在后)。 - 小端系统(Little - endian):低位字节存放在低地址,高位字节存放在高地址。即先将低位字节
0xbb存放在低地址,再将高位字节0xaa存放在高地址,内存表现为0xbb 0xaa。
知识点拓展
大小端模式的应用场景不同,例如网络传输常采用大端模式(如 IP 协议),而 x86 架构的机器多采用小端模式。我们可以通过一段程序判断当前系统的大小端模式:
#include <stdio.h>
int check_endian() { int i = 1; // 将整型变量 i 的地址强制转换为 char 指针(char 指针每次只能访问 1 字节),然后取值。 // 在小端系统中,低地址存放的是 1(0x01),所以 `*(char *)&i` 结果为 1; // 在大端系统中,低地址存放的是 0(高位字节为 0),所以结果为 0。 return (*(char *)&i == 1); // 返回 1 表示小端系统,返回 0 表示大端系统
}
int main() { if (check_endian()) { printf("当前系统是小端系统\n"); } else { printf("当前系统是大端系统\n"); } return 0;
}
常见易错点
新手容易混淆 “高位 / 低位” 与 “地址顺序”。需牢记:判断大小时,先明确数据本身的高位和低位(如 0xaabb 中 0xaa 是高位,0xbb 是低位),再根据大端小端规则确定在内存地址中的存放顺序,避免颠倒。例如,误将大端系统理解为 “低地址存低位”,这就与定义完全相反了。通过上述对高低位、高低地址的详细拆解,能更清晰地理解大小端系统中数据的存储逻辑,这对后续嵌入式开发中数据处理、通信协议设计等至关重要。
通过以上分析,可清晰理解大小端系统中数据的存储逻辑,这对后续嵌入式开发中数据处理、通信协议设计等至关重要。
试题二:PC 系统(4 字节对齐)中结构体成员地址计算
题目
typedef struct { unsigned char num[2]; float f;
} a;
a aa;
假设 aa 的地址为 0x20008500,请写出 aa.f 的地址。
分析
在嵌入式系统中,结构体的内存对齐是为了提高 CPU 对内存的访问效率。当访问未对齐的内存时,处理器可能需要多次访问,而对齐的内存访问只需一次,这是典型的 “用空间换时间” 策略。
对于 4 字节对齐规则,具体如下:
- 第一个成员的首地址:为结构体的起始地址,无需额外调整。
- 成员对齐:每个成员的首地址必须是其自身大小(若自身大小小于 4 字节)或 4 字节(若自身大小 ≥ 4 字节)的整数倍。
- 结构体总体补齐:结构体总大小必须是 4 的整数倍。
分析题目中的结构体 a:
unsigned char num[2]:unsigned char占 1 字节,num数组共占 2 字节。float f:float通常占 4 字节,其首地址需是 4 的整数倍。由于num占 2 字节,为满足对齐,需在num后填充 2 字节,使num部分总长度达 4 字节。
因此,aa.f 的地址为:0x20008500 + 4 = 0x20008504。
知识点拓展
内存对齐原则举例
- 例 1:
typedef struct { char c; int i;
} Example1;
-
char c占 1 字节,int i占 4 字节。 -
c后需填充 3 字节,使i首地址为 4 的整数倍。 -
结构体总大小:
1 + 3 + 4 = 8字节(8 是 4 的整数倍)。 -
例 2:
typedef struct { short s; char c1; char c2;
} Example2;
short s占 2 字节,char c1、char c2各占 1 字节。- 结构体最大成员大小为 2 字节(<4 字节),总大小为
2 + 1 + 1 = 4字节(4 是 2 的整数倍,也满足 4 字节对齐总体补齐规则)。
#pragma pack 指令
通过 #pragma pack(n) 可调整对齐方式(如 #pragma pack(1) 表示 1 字节对齐,成员紧密排列,无填充)。但不同编译器对该指令的支持略有差异。
常见易错点
- 忽略填充字节:直接按成员大小累加算偏移量。如本题中,若不考虑
float的 4 字节对齐,误算aa.f地址为0x20008500 + 2 = 0x20008502,则结果错误。 - 对齐规则混淆:处理复杂结构体(如嵌套结构体)时,易混淆各成员对齐要求与填充规则。
通过对内存对齐规则的解析、举例及易错点提醒,新手可全面掌握结构体成员地址计算,这对嵌入式开发中的内存管理与性能优化至关重要。
试题三:指针操作在数组中的应用
题目
int main() { int a[5] = {1, 2, 3, 4, 5}; int *ptr = (int*)(&a + 1); printf("%d, %d\n", *(a + 1), *(ptr - 1));
}
要求:分析程序输出结果,并解释指针操作的核心逻辑。
分析(分步骤解析)
步骤 1:理解数组名a与数组指针&a的本质区别
-
数组名
a:- 类型为
int*(指向单个元素的指针),表示数组首元素a[0]的地址。 a + 1表示向后偏移 1 个int类型的长度(4 字节,假设 32 位系统),指向a[1]。
- 类型为
-
数组指针
&a:- 类型为
int(*)[5](指向包含 5 个int元素的数组的指针),表示整个数组的地址。 &a + 1表示向后偏移 1 个完整数组的长度(5 * sizeof(int) = 20字节),指向数组a之后的内存区域。
- 类型为
步骤 2:指针类型转换与地址计算
int *ptr = (int*)(&a + 1):- 将数组指针
&a + 1(类型为int(*)[5])强制转换为普通int*指针。 - 转换后,
ptr指向a[5]的下一个位置(即原数组末尾地址&a[4] + 4之后的地址)。
- 将数组指针
步骤 3:计算*(a + 1)和*(ptr - 1)的值
*(a + 1):等价于a[1],值为2。ptr - 1:由于ptr指向数组末尾之后的地址,向前偏移 1 个int长度,回到a[4]的地址,因此*(ptr - 1)的值为5。
最终输出:2, 5
知识点拓展(核心概念详解)
1. 数组名与指针的本质区别
| 概念 | 类型 | 含义 | 偏移量计算 |
|---|---|---|---|
数组名a | int* | 指向首元素a[0]的地址 | a + n:偏移 n 个int长度 |
数组指针&a | int(*)[5] | 指向整个数组的地址 | &a + n:偏移 n 个数组长度 |
示例:
int a[5];
printf("a的地址:%p\n", a); // 输出首元素地址(如0x7fff5fbff7a0)
printf("&a的地址:%p\n", &a); // 地址值与a相同,但类型不同
printf("a+1的地址:%p\n", a+1); // 0x7fff5fbff7a4(+4字节)
printf("&a+1的地址:%p\n", &a+1); // 0x7fff5fbff7b4(+20字节,5*4)
2. 指针运算的核心规则
-
指针偏移量 = 偏移个数 × 指针指向类型的大小
- 例如:
int*指针偏移 1,实际移动sizeof(int)字节(4 字节);char*指针偏移 1,移动 1 字节。
- 例如:
-
强制类型转换改变指针解析方式
int (*arr_ptr)[5] = &a; // 数组指针,每次偏移20字节 int *ptr = (int*)arr_ptr; // 转换为普通指针,每次偏移4字节
3. 指针与数组的常见操作场景
-
通过指针访问数组元素:
int a[5] = {1,2,3,4,5}; int *p = a; printf("%d\n", *(p + 2)); // 输出3(等价于a[2]) -
处理多维数组:
int b[2][3] = {{1,2,3}, {4,5,6}}; int (*ptr2d)[3] = b; // 二维数组本质是数组的数组,ptr2d指向第一行 printf("%d\n", *( *(ptr2d + 1) + 2 )); // 输出6(等价于b[1][2])
常见易错点
1. 混淆数组名与数组指针的类型
- 错误认知:认为
a和&a是同一类型,导致偏移量计算错误。 - 正确理解:
a是元素指针(int*),&a是数组指针(int(*)[n]),两者偏移量相差数组长度倍。
2. 忽略指针类型转换对地址解析的影响
- 错误示例:
int a[5]; char *ch_ptr = (char*)&a; // ch_ptr指向数组首地址 printf("%p\n", ch_ptr + 1); // 正确偏移1字节(char类型)
若误将ch_ptr当作int*使用,会导致访问越界。
3. 指针运算时未考虑数据类型大小
- 正确做法:始终明确指针指向的类型,例如
double*指针每次偏移sizeof(double)(8 字节)。
实战练习(举一反三)
题目 1:
int main() { char str[] = "abcd"; char *p = str; printf("%c, %c\n", *(p + 1), *( (char*)(&str + 1) - 1 ));
}
分析:
&str + 1:指向整个字符数组之后的地址(偏移 4 字节,str长度为 4)。(char*)(&str + 1) - 1:向前偏移 1 字节,指向最后一个字符'd'。
输出:b, d
题目 2:
int main() { int arr[3][2] = {{1,2}, {3,4}, {5,6}}; int *ptr = (int*)(&arr + 1); printf("%d\n", *(ptr - 1));
}
分析:
&arr是指向二维数组的指针,&arr + 1偏移3*2*4=24字节。ptr - 1回到最后一个元素arr[2][1](值为 6)。
输出:6
通过以上解析,新手可深入理解指针与数组的关系,掌握不同指针类型的偏移量计算方法。关键在于明确指针类型、牢记偏移规则,并通过大量实例练习避免常见错误。
试题四:联合体与结构体大小计算(32 位系统)
题目
typedef union { long i; int k[5]; char c;
} DATE;
struct data { int cat; DATE cow; double dog;
} too;
DATE max;
printf("%d,%d", sizeof(too), sizeof(max));
要求:计算并解释sizeof(too)和sizeof(max)的结果,涉及联合体与结构体的内存布局规则。
分析(分步骤解析)
步骤 1:理解联合体(Union)的内存布局规则
- 核心特性:联合体所有成员共享同一段内存空间,其大小由最大成员的大小决定,且需满足成员对齐要求。
- 对齐规则:联合体的大小必须是其最大成员类型大小的整数倍(32 位系统中,基本类型对齐规则如下):
类型 大小(字节) 对齐字节数 char1 1 int/long4 4 double8 8
分析联合体DATE:
long i:占 4 字节,对齐 4 字节。int k[5]:占5×4=20字节,对齐 4 字节(int类型对齐 4 字节)。char c:占 1 字节,对齐 1 字节。- 最大成员:
int k[5](20 字节),且 20 是 4 的整数倍(满足对齐)。 - 结论:
sizeof(DATE) = 20,即sizeof(max) = 20。
步骤 2:解析结构体(Struct)的内存对齐规则
结构体的大小计算需遵循以下原则(以 32 位系统、默认 4 字节对齐为例):
- 成员对齐:每个成员的起始地址必须是其自身类型大小的整数倍(若类型大小≤4 字节,按实际大小对齐;若>4 字节,按 4 字节对齐)。
- 整体补齐:结构体总大小必须是最大成员类型大小的整数倍(若最大成员≤4 字节,按 4 字节对齐;若最大成员为
double等 8 字节类型,按 8 字节对齐)。
分析结构体struct data:
- 成员 1:
int cat- 占 4 字节,对齐 4 字节,起始地址为结构体起始地址(假设为
0x00),无填充。
- 占 4 字节,对齐 4 字节,起始地址为结构体起始地址(假设为
- 成员 2:
DATE cowDATE联合体大小为 20 字节,成员最大类型为int(4 字节),因此DATE自身按 4 字节对齐。cat占 4 字节,下一个地址为0x04,0x04是 4 的整数倍(满足DATE对齐要求),直接存储 20 字节,结束地址为0x04 + 20 = 0x18。
- 成员 3:
double dog- 占 8 字节,对齐 8 字节(
double在 32 位系统中通常按 8 字节对齐)。 - 当前地址为
0x18,需判断是否为 8 的整数倍:0x18 ÷ 8 = 2.25,不满足,需填充8 - (0x18 % 8) = 8 - 2 = 6字节,使起始地址为0x20(8 的整数倍)。 dog存储从0x20到0x27,占 8 字节。
- 占 8 字节,对齐 8 字节(
- 整体补齐:结构体总大小需是最大成员大小的整数倍。最大成员为
double(8 字节),当前总长度为0x20(填充后起始地址) + 8 = 0x28字节,0x28是 8 的整数倍(0x28 ÷ 8 = 5.5?不,0x28等于 40 字节?此处需注意:实际计算应为4(cat) + 20(cow) + 6(填充) + 8(dog) = 38字节,但 38 不是 8 的整数倍,需补至 40 字节(8×5=40)。- 修正计算:成员地址分布如下:
cat:0x00~0x03(4 字节)cow:0x04~0x17(20 字节,0x04+20=0x18)- 填充:
0x18~0x1F(6 字节,使下一个地址0x20为 8 的倍数) dog:0x20~0x27(8 字节)- 总大小:
0x28(即 40 字节),是 8 的整数倍。
- 修正计算:成员地址分布如下:
结论:sizeof(too) = 40,sizeof(max) = 20。
知识点拓展(核心概念详解)
1. 联合体与结构体的本质区别
| 概念 | 内存分配方式 | 大小决定因素 | 典型应用场景 |
|---|---|---|---|
| 联合体 | 所有成员共享同一段内存 | 最大成员大小 + 对齐要求 | 节省内存,如协议字段解析 |
| 结构体 | 成员按顺序占用独立内存 | 各成员大小 + 填充字节 + 整体补齐 | 存储多类型关联数据 |
2. 对齐规则的深层原理
- CPU 访问效率:现代 CPU 对对齐内存的访问速度更快(如 32 位 CPU 一次读取 4 字节,若数据从 4 的倍数地址开始,可一次读取;否则需两次读取并拼接)。
- 编译器控制:可通过
#pragma pack(n)指令修改默认对齐字节数(如#pragma pack(1)表示 1 字节对齐,关闭填充)。#pragma pack(1) struct packed { char c; int i; }; // sizeof(packed) = 1 + 4 = 5(无填充) #pragma pack() // 恢复默认对齐
3. 嵌套结构体 / 联合体的处理方式
若结构体成员为其他结构体 / 联合体,其对齐规则以成员自身的最大对齐要求为准。
typedef struct { double d; // 对齐8字节 int i; // 对齐4字节
} SubStruct; // sizeof(SubStruct) = 8(d) + 4(i) = 12?不,需补至16字节(8的整数倍) struct MainStruct { char c; // 对齐1字节 SubStruct sub; // 对齐8字节(SubStruct中最大成员为double)
};
// c占1字节,下一个地址需是8的倍数,填充7字节,sub占16字节,总大小:1+7+16=24字节(24是8的整数倍)
4. 常见数据类型对齐规则(32 位系统)
| 类型 | 大小(字节) | 对齐字节数(默认) |
|---|---|---|
char | 1 | 1 |
short | 2 | 2 |
int/long | 4 | 4 |
float | 4 | 4 |
double | 8 | 8 |
指针(int*) | 4 | 4 |
常见易错点
1. 忽略联合体的对齐要求
- 错误示例:认为联合体大小仅等于最大成员大小,不考虑对齐。
c
union U { short s; // 2字节,对齐2字节 int i; // 4字节,对齐4字节 }; // 最大成员为int(4字节),且4是2的整数倍,sizeof(U)=4(正确) // 若误算为2(仅取s的大小),则错误
2. 结构体整体补齐时误判最大成员
- 错误示例:结构体包含
double(8 字节)和int(4 字节),整体补齐时按 4 字节计算。struct S { int i; // 4字节 double d; // 8字节(最大成员) }; // 总大小:4(i) + 4(填充,使d对齐8字节) + 8(d) = 16字节(正确,16是8的整数倍) // 若按4字节补齐,误算为12字节,则错误
3. 嵌套结构体内存对齐计算错误
- 正确做法:先计算嵌套结构体自身的大小和对齐要求,再按外层结构体规则处理。
实战练习(举一反三)
题目 1:
union U1 { char c[5]; int i;
};
struct S1 { union U1 u; short s;
};
printf("%d, %d\n", sizeof(union U1), sizeof(struct S1));
分析:
union U1:最大成员char c[5](5 字节),对齐 4 字节(int的对齐要求),需补至 8 字节(5 不是 4 的倍数,补 3 字节,总大小 8)。struct S1:u占 8 字节(对齐 4 字节),s占 2 字节(对齐 2 字节),8是 2 的倍数,总大小8+2=10,但需按最大成员(u的对齐 4 字节)补齐至 12 字节。
输出:8, 12
题目 2:
#pragma pack(2)
struct S2 { char c; double d;
};
#pragma pack()
printf("%d\n", sizeof(struct S2));
分析:
- 设定 2 字节对齐,
char c(1 字节)后需填充 1 字节,使d(8 字节)对齐 2 字节(8 是 2 的倍数,无需额外填充)。 - 总大小:
1+1+8=10字节(10 是 2 的整数倍)。
输出:10
通过以上解析,新手可系统掌握联合体与结构体的大小计算规则,关键在于明确对齐要求、分步计算成员偏移量,并注意整体补齐规则。建议通过大量实例练习,结合编译器的offsetof宏(需包含stddef.h,如offsetof(struct data, dog)获取成员偏移量)验证计算结果,加深理解。
通过以上题目,深入理解大小端、内存对齐、指针操作、联合体和结构体大小计算,这些是嵌入式面试的高频考点。新手需多动手练习,结合实例掌握原理,避免常见错误。
相关文章:

嵌入式面试高频考点深度解析:内存管理、指针操作与结构体实战指南
试题一:大小端系统中数据的内存表现形式 题目 short tmp 0xaabb; 请分别写出大小端系统中,tmp 在内存中的表现形式。 分析 1. 什么是高位与低位? 对于一个数据而言,以十六进制数 0xaabb 为例,从左至右࿰…...

ApplicationRunner的run方法与@PostConstruct注解
ApplicationRunner 的 run 方法与 PostConstruct 注解在 Spring Boot 中均用于初始化逻辑,但二者的 执行时机、作用范围 和 功能特性 存在显著差异。以下是详细对比分析: 一、核心差异对比 维度PostConstructApplicationRunner.run()触发时机Bean 实例化…...
今日行情明日机会——20250425
指数依然在震荡,等待方向选择,整体量能不搞但个股红多绿少。 2025年4月25日涨停板行业方向分析如下: 一、核心行业方向及驱动逻辑 一季报增长(17家涨停) 核心个股:惠而浦、鸿博股份、卫星化学驱动逻辑&am…...
一道MySQL索引题
复合索引基础 MySQL中的复合索引(Composite Index)是指由多个列组成的索引。与单列索引不同、复合索引的结构更为复杂,但使用得当可以大幅提升查询性能。 复合索引的工作原理 复合索引的本质是一种有序的数据结、每个列是建立在那个索引前一列存在的情况下、那一…...
)
Python 读取 txt 文件详解 with ... open()
文章目录 1 概述1.1 注意事项1.2 模式说明1.3 文件准备 2 读文件2.1 读取整个文件2.2 逐行读取2.3 读取所有行到列表 3 写文件3.1 覆盖写入3.2 追加写入3.3 写入多行 4 实用技巧4.1 检查文件是否存在4.2 异常处理 1 概述 1.1 注意事项 文件编码:建议指定编码&…...
【linux】设置邮件发送告警功能
当服务器内存不足或者其他故障时,可以通过自动发送故障到邮箱进行提醒。 步骤: 以qq邮箱为例: 登录qq邮箱点击设置 点击账号后,往下翻 找到POP3/IMAP...开启服务 复制授权码 安装邮箱功能 编辑/etc/s-nail.rc 验证 …...
【手机】vivo手机应用声音分离方案
文章目录 前言方案 前言 尝试分离vivo手机音乐与其他应用的声音 方案 最佳方案:网易云音乐设置内关闭音量均衡 上传不同的白噪音,成功 goodlock,主要适用于三星手机,vivo不一定适用 app volume control ,可行...
关于Safari浏览器在ios<16.3版本不支持正则表达式零宽断言的解决办法
异常原因 今天在升级Dify版本的时候发现低版本的ios手机出现了以下报错: SyntaxError: Invalid regular expression: invalid group specifier nameError: Invalid regular expression: invalid group specifier name Call Stack 46 eval [native code] (0:0) ./n…...

管理+技术”双轮驱动工业企业能源绿色转型
00序言 在“3060双碳”政策目标下,工业领域作为碳排放的主要来源(占比约70%),国家出台《工业领域碳达峰实施方案》《加快推动制造业绿色化发展的指导意见》等文件,明确行业碳达峰时间表和重点任务,完善碳市…...

每天学一个 Linux 命令(30):cut
可访问网站查看,视觉品味拉满: http://www.616vip.cn/30/index.html cut 命令用于从文件或输入流中提取文本的特定部分(如列、字符或字节位置)。它常用于处理结构化数据(如 CSV、TSV)或按固定格式分割的文本。以下是详细说明和示例: 命令格式 cut [选项] [文件...]…...
智慧养老综合实训室规划与实施:产教融合的智慧养老实践
智慧养老综合实训室作为智慧养老、智慧康养产业发展的关键支撑,深度融合物联网、大数据、人工智能等前沿技术,搭建虚实结合的教学场景,依托DeepSeek知识库模型实现知识的高效转化与创新,旨在打造产教融合的实践平台,为…...

华为设备命令部分精简分类汇总示例
华为网络设备的命令体系庞大且复杂,不同设备系列(如交换机、路由器、防火墙)和不同操作系统版本(如VRP5、VRP8)的命令可能存在差异。以下是一个 精简分类汇总,涵盖常用配置场景和命令示例: 一、…...

JAVA | 聚焦 OutOfMemoryError 异常
个人主页 文章专栏 在正文开始前,我想多说几句,也就是吐苦水吧…最近这段时间一直想写点东西,停下来反思思考一下。 心中万言,真正执笔时又不知先写些什么。通常这个时候,我都会随便写写,文风极像散文&…...

Operating System 实验二 内存管理实验
目录 实验目标: 实验设备: 实验内容: (1)验证FIFO和Stack LRU页面置换算法 【代码(注释率不低于30%)】 【实验过程(截图)】 【结论】 (2)分别用FIFO和Stack LRU页置换算法,自己设定一个页面引用序列,绘制页错误次数和可用页帧总数的曲线并对比(可用Excel绘…...
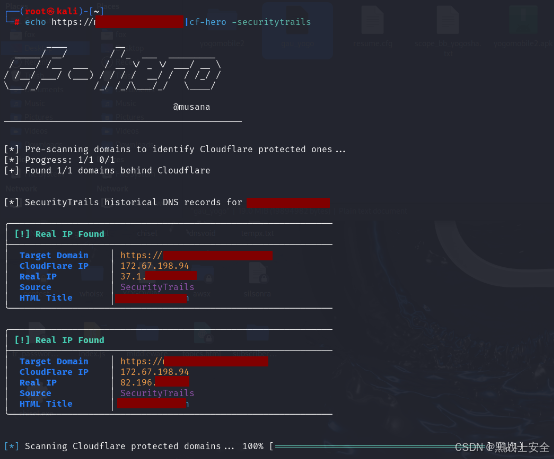
CF-Hero:自动绕过CDN找真实ip地址
CF-Hero:自动绕过CDN找真实ip地址 CF-Hero 是一个全面的侦察工具,用于发现受 Cloudflare 保护的 Web 应用程序的真实 IP 地址。它通过各种方法执行多源情报收集。目前仅支持Cloudflare的cdn服务查找真实ip,但从原理上来说查找方法都是通用的…...
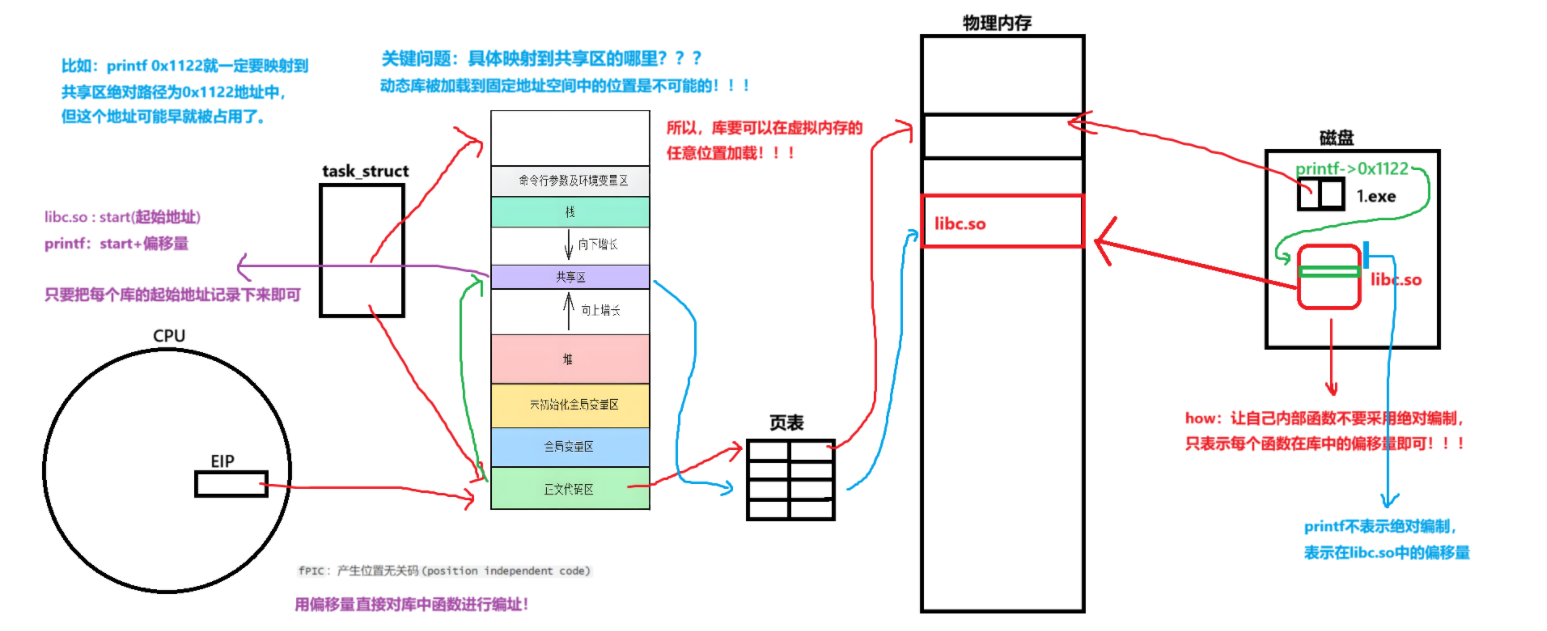
Linux基础IO(十一)之动态库(基础IO的最后一篇啦!)
文章目录 动态库生成动态库使用动态库现象事实使用外部库动态库怎么被加载的进程地址空间的第二讲关于地址1.程序没有加载前的地址(程序)2.程序加载后的地址(进程)3.动态库的地址 动态库 生成动态库 shared: 表示生成共享库格式…...
)
【版本控制】SVN + TortoiseSVN版本管理实用教程(附安装+开发常用操作)
摘要: 本文将带你从零开始掌握 SVN 版本控制系统,结合 TortoiseSVN 图形客户端工具,深入学习包括安装、检出、提交、更新、回滚、冲突解决等常用开发操作,快速上手团队协作! 🧩 什么是 SVN? SV…...

非序列实现MEMS聚焦功能
zemax非序列模式下有MEMS,但是没有对应的代码。无法修改成自己需要的功能 以下是实现MEMS聚焦功能: #include <windows.h> #include <cmath> #include <stdio.h> #include <string.h> #include <algorithm> #undef max #undef min#define D…...

【前端】CSS 基础
> 作者:დ旧言~ > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:了解 CSS 基础语法。 > 毒鸡汤:有些事情,总是不明白,所以我不会坚持。早安! > 专栏选自:前端基础…...

【金仓数据库征文】——选择金仓,选择胜利
目录 第一部分:金仓数据库——开创数据库技术的新时代 1.1 金仓数据库的技术底蕴 1.2 高可用架构与灾备能力 1.3 分布式架构与弹性扩展能力 第二部分:金仓数据库助力行业数字化转型 2.1 电信行业:核心系统国产化替代 2.2 医疗行业&…...
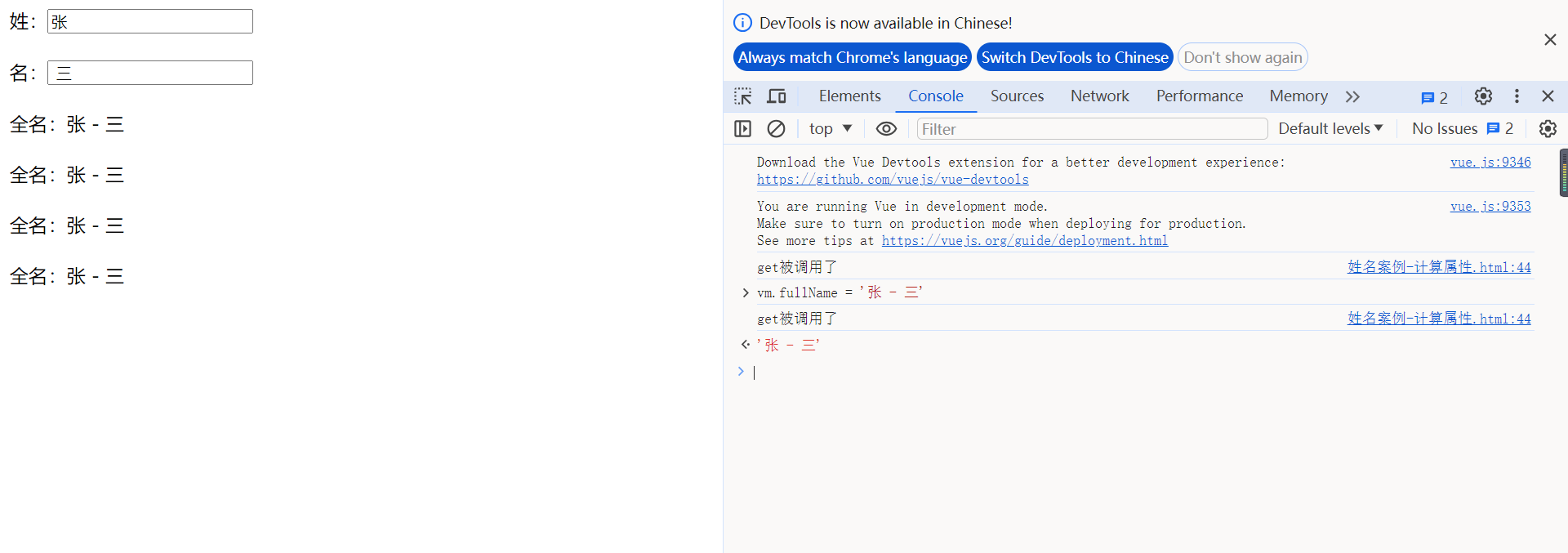
跟着尚硅谷学vue-day5
计算属性和watch监视 一.姓名案例 1.姓名案例-插值语法 <div id"root">姓:<input type"text" value"张" v-model"firstname"><br/><br/>名:<input type"text" value&q…...

【C到Java的深度跃迁:从指针到对象,从过程到生态】第四模块·Java特性专精 —— 第十三章 异常处理:超越C错误码的文明时代
一、错误处理的范式革命 1.1 C错误处理的黑暗时代 C语言通过返回值传递错误状态,存在系统性缺陷: 典型错误处理模式: FILE* open_file(const char* path) { FILE* f fopen(path, "r"); if (!f) { return NULL; // 错误信息…...

运维打铁:Centos 7 使用yum安装 mysql5.7
文章目录 一、安装前信息说明二、安装步骤1. 下载并安装官网 RPM 安装包2. 修改配置文件 /etc/my.cnf3. 创建 MySQL 数据相关目录并授权4. 启动 MySQL 服务 三、修改数据库访问密码1. 修改配置文件 /etc/my.cnf2. 重启 MySQL 服务3. 登录数据库并修改密码4. 恢复配置文件并重启…...

网络原理初始
基础概念 组建局域网方式:路由器或者交换机。 IP确定主机,端口号确定使用的应用程序。 端口号:每个程序在进行网络通信中,都需要一个端口号。 协议:通信过程中的约定。 TCP/IP五层网络协议 从上到下 1、应用层&a…...
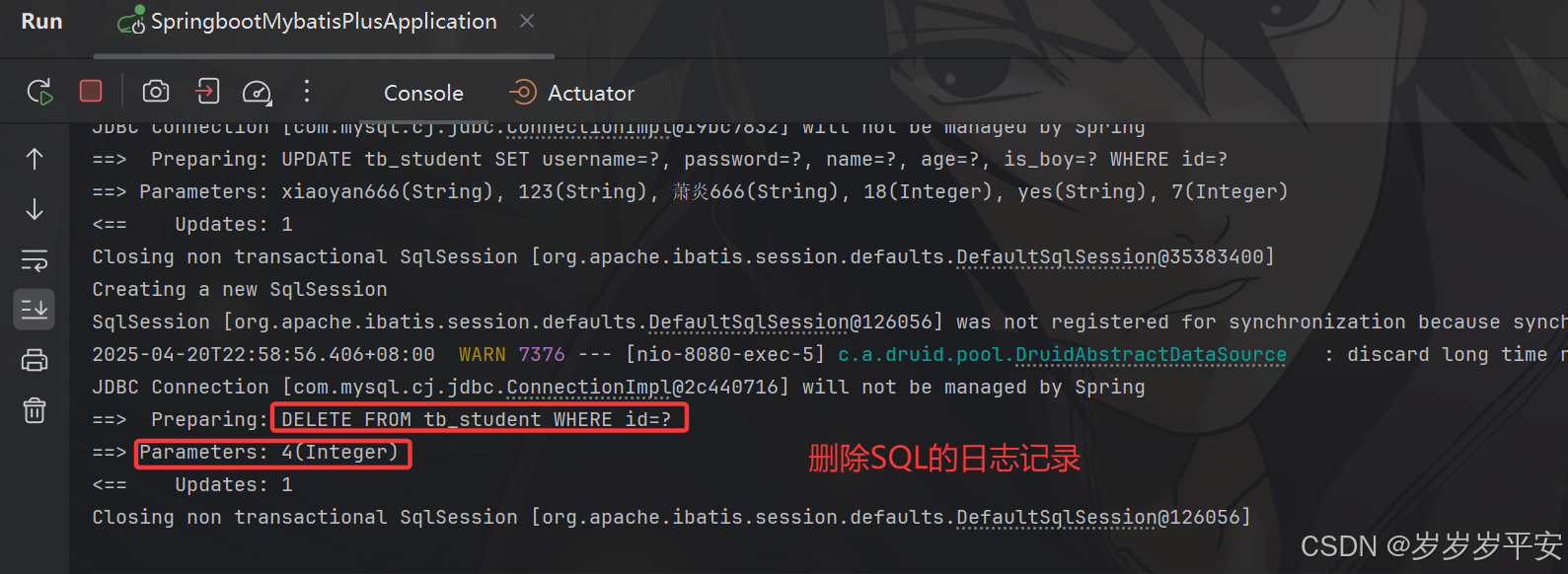
基于SpringBoot3实现MyBatis-Plus(SSMP)整合快速入门CURD(增删改查)
目录 一、快速搭建SpringBoot-Web工程脚手架。 1.1 Spring Initializr 初始化工程。(官方提供) 1.2 工程脚手架初始化详细步骤。(IDEA2024.1.1) 二、MyBatis-Plus的特性与快速上手。 2.1 官网地址与基本特性。 2.2 快速上手技术栈基础。 2.3 Spring Boot2 的 MyBatis-Plus Star…...

主题模型三大基石:Unigram、LSA、PLSA详解与对比
🌟 主题模型演进图谱 文本建模三阶段: 词袋模型 → 潜在语义 → 概率生成 Unigram → LSA → PLSA → LDA 📦 基础模型:Unigram模型 核心假设 文档中每个词独立生成(词袋假设) 忽略词语顺序和语义关联 …...

Redis 热 key 和大 key 问题
一、什么是 Redis 热 key? 热 key(Hot Key)定义: 在单位时间内被**频繁访问(读/写)**的 key,导致其访问集中、压力过大。 热 key 常见表现: QPS 极高(某 key 每秒被访问…...
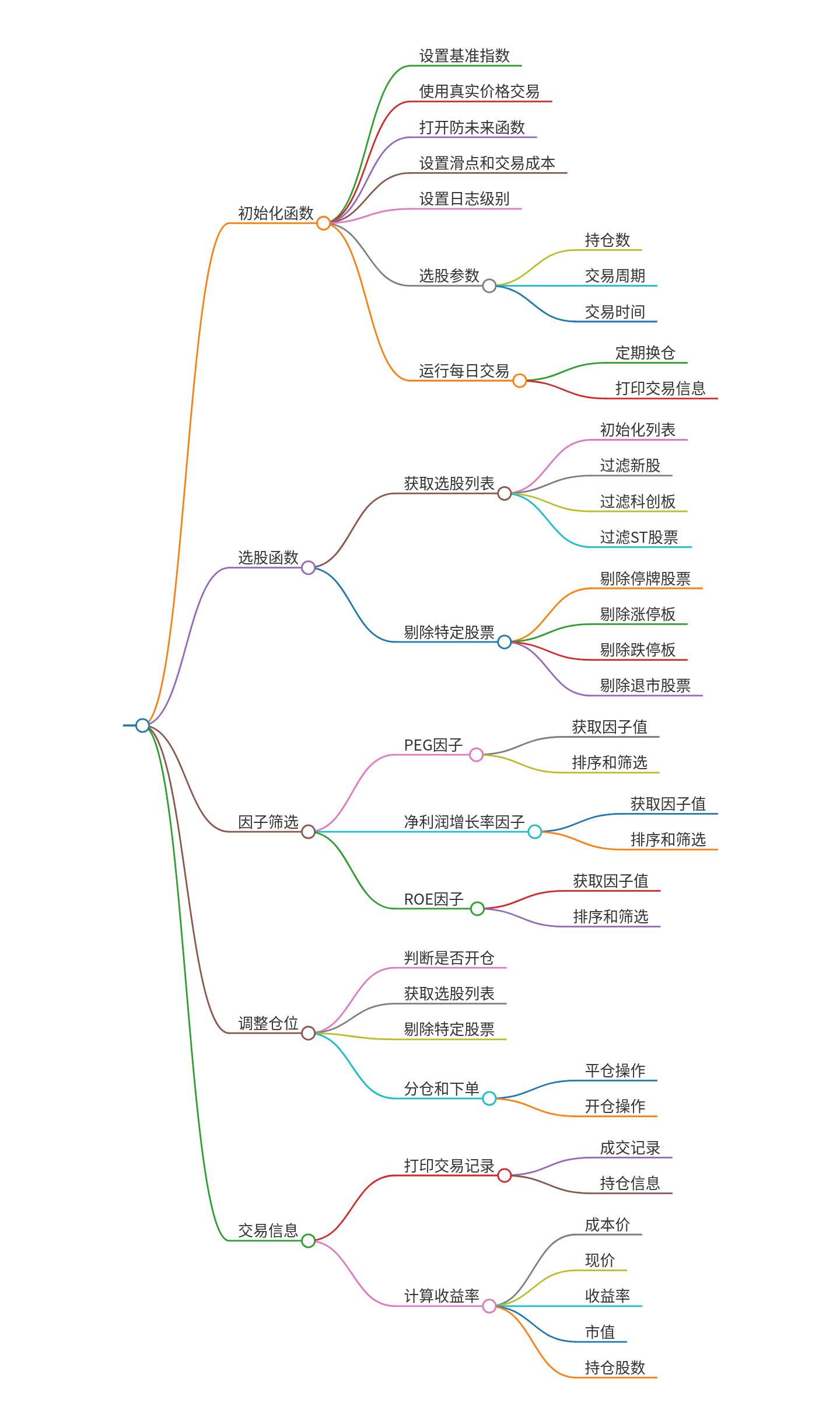
基准指数选股策略思路
一种基于Python和聚宽平台的量化交易策略,主要包含以下内容: 1. 导入必要的库 - 导入jqdata和jqfactor库用于数据获取和因子计算。 - 导入numpy和pandas库用于数据处理。 2. 初始化函数 - 设置基准指数为沪深300指数。 - 配置交易参数,如使用…...
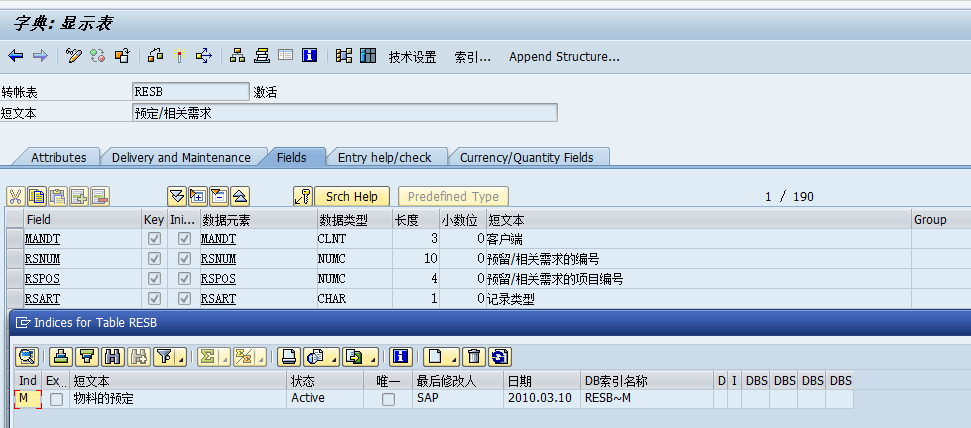
SAP接口超时:对 FOR ALL ENTRIES IN 的优化
SAP接口超时 经分析要10多分钟以上才出结果,且是这个语句耗时较长: SELECTaufnrmatnrbdmnglgortmeinschargFROM resbINTO CORRESPONDING FIELDS OF TABLE lt_lylcddxhFOR ALL ENTRIES IN lt_lylcddWHERE aufnr IN r_aufnr发现RESB有420万条记录…...

如何成功防护T级超大流量的DDoS攻击
防护T级超大流量的DDoS攻击需要综合技术、架构与运营策略的多层次防御体系。以下是基于最新技术实践和行业案例总结的关键防护策略: 一、流量清洗与分布式处理 部署流量清洗中心 T级攻击的核心防御依赖于专业的流量清洗技术。通过部署分布式流量清洗集群,…...