TDengine 集群高可用方案设计(二)
四、TDengine 集群高可用方案设计
4.1 硬件与网络架构设计
- 服务器选型:选择配置高、稳定性强的服务器,如戴尔 PowerEdge R740xd、华为 RH2288H V5 等。以戴尔 PowerEdge R740xd 为例,它配备英特尔至强可扩展处理器,具备高性能计算能力,能满足大量数据的快速处理需求;拥有大容量内存和高速存储接口,可确保数据的快速读写和存储。同时,服务器应具备良好的散热和冗余电源设计,以保证在长时间高负载运行下的稳定性。在实际应用中,根据业务规模和数据量来确定服务器的数量和配置,例如,对于数据量较大、读写频繁的物联网场景,可适当增加服务器内存和存储容量,以提高系统性能。
- 网络拓扑:采用万兆以太网作为集群内部网络,确保节点之间的高速通信。网络拓扑结构可选择树形或环形,树形拓扑结构易于扩展和管理,适合大规模集群;环形拓扑结构具有较高的可靠性,当某条链路出现故障时,数据可通过其他链路传输。为提高网络的可靠性,可采用冗余网络链路和网络设备,如双网卡绑定、冗余交换机等。在实际部署中,通过双网卡绑定技术,将服务器的两个网卡绑定在一起,实现链路冗余和负载均衡,当一个网卡出现故障时,另一个网卡可立即接管工作,确保网络通信的连续性。
- 存储方案:选用高速、可靠的存储设备,如 SSD 固态硬盘。SSD 具有读写速度快、延迟低的特点,能够显著提高数据的读写性能。对于大规模数据存储,可采用分布式存储系统,如 Ceph 等,实现存储资源的弹性扩展和数据的冗余备份。在实际应用中,Ceph 分布式存储系统可通过将数据分散存储在多个存储节点上,并采用多副本机制保证数据的可靠性,同时支持在线扩展存储容量,满足业务不断增长的数据存储需求。
4.2 软件配置与参数优化
- 安装部署步骤:以在 Linux 系统上部署 TDengine 集群为例,首先从 TDengine 官网下载相应版本的安装包,如TDengine-server-3.0.0.0-Linux-x64.tar.gz。下载完成后,解压安装包,进入解压后的目录,执行安装脚本./install.sh。安装过程中,根据提示进行相应配置,如设置服务器的 FQDN(Fully Qualified Domain Name)等。安装完成后,修改配置文件/etc/taos/taos.cfg,配置集群相关参数,如firstEp指定第一个节点的 Endpoint,fqdn指定当前节点的 FQDN 等 。然后启动第一个数据节点,执行命令systemctl start taosd,通过systemctl status taosd查看节点运行状态,确保节点处于 running 状态。接着在其他节点上重复上述安装步骤,并在第一个节点上使用create dnode命令将其他节点加入集群 。
- 关键配置参数及优化方法:
-
- 副本数配置:在创建数据库时,可通过replica参数设置副本数,如CREATE DATABASE demo replica 3;,合理设置副本数可提高数据的可靠性和系统的容错能力。根据业务对数据可靠性的要求和集群规模来确定副本数,对于对数据可靠性要求极高的金融行业,可将副本数设置为 3 或更多;对于数据量较小、对可靠性要求相对较低的测试环境,可将副本数设置为 2。
-
- Vnode 相关参数:maxVgroupsPerDb表示每个数据库中能够使用的最大 vnode 个数(单个副本),默认值为 0(自动配置,默认与 CPU 核数相同);minTablesPerVnode表示每个 vnode 中必须创建的最小表数,默认值为 1000;tablelncStepPerVnode表示每个 vnode 中超过最小表数后的递增步长,默认值为 1000 。在实际应用中,可根据业务需求和服务器资源情况调整这些参数,以优化数据分布和系统性能。例如,在测试表数量较少的数据库性能时,如果发现表分布不均匀,可适当调整minTablesPerVnode的值,使其更符合实际需求,从而实现表在 vnode 中的均匀分布,提高系统性能。
-
- 缓存参数:cache参数设定每个内存块的大小,默认值为 16M;blocks配置虚拟节点可以有几个内存块,默认值为 4 。根据服务器内存大小和业务数据量调整缓存参数,可提高数据的读取性能。如果服务器内存充足,且业务数据量较大、读写频繁,可适当增大cache和blocks的值,以增加缓存空间,减少磁盘 I/O 操作,提高数据读取速度。
4.3 故障检测与自动恢复机制
- 故障检测工具和脚本:TDengine 内置了故障检测机制,通过心跳机制来检测节点的健康状态。每个节点会定期向其他节点发送心跳消息,若某个节点在一定时间内未收到其他节点的心跳消息,则判定该节点出现故障。此外,还可以编写自定义的监控脚本,使用ping命令或telnet命令来检测节点的网络连通性和端口可用性。例如,编写一个简单的 Shell 脚本,使用ping命令定期检测节点的 IP 地址,若ping不通,则认为节点网络出现故障;使用telnet命令检测 TDengine 服务端口是否开放,若无法连接,则认为服务可能出现故障。同时,结合监控工具如 Prometheus 和 Grafana,实时监控集群的状态,当出现故障时及时发出警报。
- 自动恢复机制原理及实现方式:当检测到节点故障时,TDengine 利用 RAFT 算法进行自动恢复。以 vnode group 为例,当 Leader vnode 出现故障时,Follower vnode 会在选举超时时间内没有收到 Leader vnode 的心跳后,变成 Candidate vnode 并发起选举请求。其他 vnode 会根据一定的选举规则(如日志的完整性、节点的 ID 等)进行投票,获得半数以上投票的 Candidate vnode 将成为新的 Leader vnode,从而保证集群的正常运行。在数据恢复方面,TDengine 通过多副本机制和日志复制来确保数据的一致性和完整性。当某个节点故障恢复后,它会从其他正常节点同步缺失的数据,通过日志来恢复到故障前的状态,确保数据的正确性。例如,在一个包含三个 vnode 的 vnode group 中,当 Leader vnode 故障后,另外两个 Follower vnode 中的一个会被选举为新的 Leader vnode,继续提供服务。故障恢复的 vnode 会向新的 Leader vnode 和其他正常 vnode 请求同步数据,通过日志重放等方式,将数据恢复到与其他节点一致的状态。
4.4 负载均衡策略
- 常见负载均衡算法:常见的负载均衡算法有轮询(Round Robin)、随机(Random)、最少连接(Least Connections)、Hash 等。轮询算法按照顺序依次将请求分配到后端服务器,实现简单,但未考虑服务器的性能差异;随机算法随机选择后端服务器,具有一定的随机性;最少连接算法将请求分配到当前连接数最少的服务器,能较好地均衡服务器负载;Hash 算法根据请求的某些特征(如 IP 地址、请求 URL 等)计算 Hash 值,将请求分配到对应的服务器,具有较好的一致性。
- TDengine 集群负载均衡策略及实现方法:TDengine 采用 Hash 一致性算法将一个数据库中的所有表和子表的数据均衡分散在属于该数据库的所有 vgroup 中,每张表或子表只能由一个 vgroup 处理,一个 vgroup 可能负责处理多个表或子表 。在创建数据库时,可以通过vgroups参数指定其中的 vgroup 数量,如create database db0 vgroups 16; 。合适的 vgroup 数量取决于系统资源,原则上可用的 CPU 和 Memory 越多,可建立的 vgroup 也越多,但也要考虑磁盘性能,过多的 vgroup 在磁盘性能达到上限后反而会拖累整个系统的性能。在实际应用中,首先根据系统资源配置选择一个初始的 vgroup 数量,比如 CPU 总核数的 2 倍,以此为起点通过测试找到最佳的 vgroup 数量配置。对于任意数据库的 vgroup,TDengine 都是尽可能将其均衡分散在多个 dnode 上,在多副本情况下(replica>1),这种均衡分布尤其复杂,TDengine 的分布策略会尽量避免任意一个 dnode 成为写入的瓶颈,从而最大限度地在整个 TDengine 集群中实现负载均衡,提升系统总的数据处理能力 。
五、案例分析与实践
5.1 实际应用场景介绍
以某大型智能工厂的生产监控系统为例,该工厂拥有数千台生产设备,每台设备都配备了多个传感器,用于实时采集设备的运行状态数据,如温度、压力、转速、振动等。这些数据以秒级频率产生,每天产生的数据量高达数 TB。生产监控系统需要对这些数据进行实时存储、分析和展示,以便及时发现设备故障和生产异常,保障生产的连续性和产品质量。
在这个场景中,对 TDengine 集群高可用方案的应用需求十分明确。首先,由于数据量巨大且写入频率高,需要一个高性能、可扩展的数据库系统来存储和处理这些数据。TDengine 的分布式架构和高效的写入性能能够满足这一需求,通过水平扩展集群节点,可以轻松应对不断增长的数据量。其次,生产监控系统对数据的可靠性和实时性要求极高,任何数据丢失或延迟都可能导致严重的生产事故。TDengine 的多副本机制和快速的数据同步能力,能够保证数据的可靠性和实时性,确保在节点故障时数据不会丢失,并且能够及时提供给分析和展示模块。
然而,在实际应用中也面临着一些挑战。例如,智能工厂的网络环境复杂,存在网络波动和延迟的情况,这可能会影响 TDengine 集群节点之间的通信和数据同步。此外,生产设备的多样性和复杂性导致数据格式和采集频率存在差异,需要 TDengine 能够灵活适应不同的数据类型和采集策略。同时,随着工厂业务的不断发展,未来可能需要接入更多的设备和传感器,这就要求 TDengine 集群具有良好的扩展性,能够方便地进行动态扩容。
5.2 方案实施过程与步骤
在该智能工厂中实施 TDengine 集群高可用方案,主要包括以下步骤:
- 前期准备:对工厂的业务需求和现有基础设施进行详细调研,确定 TDengine 集群的规模和配置。根据数据量和读写性能要求,选择了 6 台高性能服务器作为集群节点,每台服务器配备 2 颗英特尔至强金牌 6248 处理器、128GB 内存、2 块 1TB SSD 硬盘,并采用万兆以太网进行网络连接。同时,制定了详细的项目计划和风险预案,确保实施过程的顺利进行。
- 安装部署:在 6 台服务器上分别安装 TDengine 服务端软件,按照前文所述的安装部署步骤进行操作。安装完成后,对配置文件进行优化,根据数据特点和业务需求,设置合适的副本数为 3,调整 vnode 相关参数,如maxVgroupsPerDb设置为 128,minTablesPerVnode设置为 2000,tablelncStepPerVnode设置为 1000,以实现数据的均匀分布和高效存储。同时,优化缓存参数,cache设置为 32M,blocks设置为 8,以提高数据读取性能。
- 集群配置与测试:在第一台服务器上启动 TDengine 服务,通过create dnode命令将其他 5 台服务器加入集群,形成一个 6 节点的 TDengine 集群。使用show dnodes命令查看集群节点状态,确保所有节点都正常运行。然后,创建测试数据库和表,进行数据写入和查询测试,验证集群的基本功能是否正常。通过向测试表中插入大量模拟的设备运行数据,测试集群的写入性能,结果显示集群能够轻松应对每秒数千次的写入请求,写入延迟控制在毫秒级。同时,进行复杂的查询测试,如按照时间范围查询、多表关联查询等,查询响应时间也在可接受范围内,满足了生产监控系统对实时性的要求。
- 故障检测与自动恢复机制配置:配置故障检测工具和脚本,利用 TDengine 内置的心跳机制结合自定义的监控脚本,实时监测集群节点的健康状态。自定义脚本使用ping命令和telnet命令定期检测节点的网络连通性和 TDengine 服务端口可用性,一旦发现节点故障,立即发出警报。同时,配置自动恢复机制,确保在节点故障时能够快速恢复服务。当某个节点出现故障时,TDengine 利用 RAFT 算法进行自动选主和数据同步,确保集群的正常运行。在测试过程中,故意模拟节点故障,观察集群的恢复情况,结果显示集群能够在数秒内完成故障节点的检测和新主节点的选举,数据同步也能在短时间内完成,对业务的影响极小。
- 负载均衡配置:采用 Hash 一致性算法实现负载均衡,将不同设备的数据均匀分布到各个 vgroup 中。在创建数据库时,通过vgroups参数指定 vgroup 数量为 64,根据服务器的 CPU、内存和磁盘性能,经过多次测试和优化,确定这个 vgroup 数量能够在保证数据均衡分布的同时,充分利用系统资源,避免出现写入瓶颈。通过监控工具实时监测集群中各个节点的负载情况,确保负载均衡效果良好。在实际运行中,各个节点的 CPU 使用率、内存使用率和磁盘 I/O 负载都保持在合理范围内,没有出现明显的负载不均衡现象。
5.3 效果评估与经验总结
实施 TDengine 集群高可用方案后,通过一系列性能指标的监测和分析,评估方案的实施效果。在写入性能方面,集群能够稳定地处理每秒 5000 次以上的写入请求,平均写入延迟小于 5 毫秒,相比之前使用的传统数据库,写入性能提升了 10 倍以上,能够轻松应对智能工厂中大量设备数据的高频写入需求。在查询性能方面,对于常见的时间范围查询和聚合查询,响应时间平均在 100 毫秒以内,大大提高了数据分析和展示的实时性,为生产监控和故障预警提供了有力支持。在可靠性方面,经过多次模拟节点故障测试,集群能够在 5 秒内完成故障检测和自动恢复,数据无丢失,保证了系统的高可用性,有效降低了因节点故障导致的生产中断风险。
通过这个项目实践,总结出以下经验教训:在方案设计阶段,充分的前期调研和需求分析至关重要,要深入了解业务特点和数据规模,以便选择合适的硬件配置和软件参数。在实施过程中,严格按照安装部署步骤和配置指南进行操作,确保每个环节的正确性。同时,要注重测试工作,全面测试集群的各项功能和性能指标,及时发现并解决问题。此外,故障检测和自动恢复机制的配置要合理,确保在节点故障时能够快速、准确地进行恢复,减少对业务的影响。在负载均衡方面,要根据系统资源和数据特点,经过多次测试和优化,选择合适的 vgroup 数量和负载均衡算法,以实现集群的高效运行。未来,随着业务的发展和数据量的进一步增长,可以考虑增加集群节点或采用更高级的负载均衡策略,以满足不断提高的性能需求 。
六、常见问题与解决方案
6.1 常见故障及排查方法
在 TDengine 集群运行过程中,可能会出现各种故障,以下是一些常见故障及排查方法:
- 节点失联:当某个节点失联时,首先检查节点的网络连接是否正常,使用ping命令测试节点的 IP 地址或 FQDN 是否可达。若网络连接正常,查看节点的 TDengine 服务是否正常运行,通过systemctl status taosd命令查看服务状态。若服务未运行,检查日志文件/var/log/taos/taosdlog.0(或taosdlog.1等),查看是否有相关错误信息,如端口被占用、配置文件错误等 。此外,还需检查节点的硬件是否出现故障,如硬盘损坏、内存不足等。
- 数据不一致:如果发现数据不一致问题,首先检查集群的配置参数,特别是副本数、数据同步相关参数是否正确。查看 TDengine 的日志文件,了解数据同步过程中是否出现错误。对于 RAFT 组,检查 Leader 节点的选举和日志同步情况,确保数据变更操作在各个副本之间正确同步。可以通过执行一些数据一致性检查工具或脚本来验证数据的一致性,如对比不同副本上的数据记录、检查数据的完整性等。
- 集群无法启动:若集群无法启动,检查所有节点的配置文件taos.cfg是否正确,特别是firstEp、fqdn、serverPort等关键参数 。确保节点的网络配置正确,防火墙已关闭或相关端口已开放(TDengine 默认使用 6030 - 6042 端口)。检查节点的磁盘空间是否充足,若磁盘空间不足可能导致服务无法启动。同时,查看日志文件,分析是否有其他错误信息,如依赖包缺失、权限不足等。
6.2 性能优化建议
针对 TDengine 集群的性能问题,可采取以下优化建议和措施:
- 查询慢:当出现查询慢的问题时,首先优化查询语句,避免使用复杂的子查询和全表扫描。合理使用索引,根据查询条件创建合适的索引,提高查询效率。调整缓存参数,适当增大cache和blocks的值,增加缓存空间,减少磁盘 I/O 操作 。此外,检查集群的负载均衡情况,确保查询请求均匀分布在各个节点上,避免单个节点负载过高。
- 写入卡顿:若写入出现卡顿,优化写入数据的格式和批量大小,尽量使用批量写入方式,减少写入次数。调整 TDengine 的配置参数,如maxVgroupsPerDb、minTablesPerVnode、tablelncStepPerVnode等,优化数据分布 。检查磁盘 I/O 性能,若磁盘读写速度较慢,可考虑更换高速磁盘或优化磁盘阵列配置。同时,确保集群的网络带宽充足,避免因网络瓶颈导致写入卡顿。
- 资源利用率低:如果集群的 CPU、内存等资源利用率较低,可能是配置参数不合理或负载不均衡导致。根据实际业务需求,调整集群的配置参数,如增加 vgroup 数量,充分利用系统资源。优化负载均衡策略,确保各个节点的负载均衡,提高资源利用率。此外,还可以考虑对业务进行优化,合理分配数据读写任务,避免资源浪费。
6.3 与其他系统集成时的问题及解决
在与其他系统集成时,TDengine 可能会遇到以下问题及相应解决方法:
- 兼容性问题:与其他系统集成时,可能存在版本兼容性问题。在集成前,仔细查看 TDengine 和其他系统的官方文档,了解其兼容性要求和支持的版本范围。例如,在与某监控系统集成时,发现该监控系统只支持特定版本范围内的 TDengine,此时需要根据监控系统的要求,选择合适的 TDengine 版本进行部署。同时,关注 TDengine 和其他系统的更新情况,及时进行版本升级和兼容性测试,确保系统的稳定运行。
- 接口问题:不同系统之间的接口可能存在差异,导致数据传输和交互出现问题。在集成过程中,详细了解 TDengine 和其他系统的接口规范和数据格式,确保接口参数的一致性和数据的正确解析。例如,在与某数据分析平台集成时,需要根据数据分析平台的接口要求,对 TDengine 返回的数据进行格式转换和处理,使其符合数据分析平台的输入要求。可以编写数据转换脚本或使用中间件来实现接口的适配,确保数据能够准确无误地在不同系统之间传输和交互。
七、总结与展望
本文深入探讨了 TDengine 集群高可用方案的设计与实现,涵盖了从基础概念到实际应用的各个方面。通过多副本机制和 RAFT 算法,TDengine 集群能够有效保障数据的可靠性和一致性,确保在节点故障的情况下仍能稳定运行。在硬件与网络架构设计、软件配置与参数优化、故障检测与自动恢复机制以及负载均衡策略等方面的精心设计,使得 TDengine 集群具备了高性能、高可靠和高可用的特性,能够满足各种复杂业务场景的需求。
实际案例分析表明,TDengine 集群高可用方案在智能工厂等场景中取得了显著的成效,大幅提升了数据处理能力和系统的稳定性。然而,随着物联网、大数据和人工智能技术的不断发展,未来对 TDengine 集群的性能和功能将提出更高的要求。
展望未来,TDengine 有望在以下几个方向实现进一步发展:一是在性能优化方面,持续改进存储引擎和查询算法,进一步提升数据读写性能,以应对日益增长的数据量和复杂的查询需求;二是在功能扩展上,加强对更多数据类型和分析场景的支持,如机器学习算法与 TDengine 的深度融合,实现更智能化的数据分析和预测;三是在生态建设方面,积极与更多的开源项目和企业进行合作,完善周边工具和生态系统,提高 TDengine 的易用性和可扩展性。相信在不断的创新和发展中,TDengine 将在时序数据处理领域发挥更加重要的作用,为各行业的数字化转型提供更强大的支持。
相关文章:
)
TDengine 集群高可用方案设计(二)
四、TDengine 集群高可用方案设计 4.1 硬件与网络架构设计 服务器选型:选择配置高、稳定性强的服务器,如戴尔 PowerEdge R740xd、华为 RH2288H V5 等。以戴尔 PowerEdge R740xd 为例,它配备英特尔至强可扩展处理器,具备高性能计…...
【Langchain】RAG 优化:提高语义完整性、向量相关性、召回率--从字符分割到语义分块 (SemanticChunker)
RAG 优化:提高语义完整性、向量相关性、召回率–从字符分割到语义分块 (SemanticChunker) 背景:提升 RAG 检索质量 在构建基于知识库的问答系统(RAG)时,如何有效地将原始文档分割成合适的文本块(Chunks&a…...

深入剖析扣子智能体的工作流与实战案例
前面我们已经初步带大家体验过扣子工作流,工作流程是 Coze 最为强大的功能之一,它如同扣子中蕴含的奇妙魔法工具,赋予我们的机器人处理极其复杂问题逻辑的能力。 这篇文章会带你更加深入地去理解并运用工作流解决实际问题 目录 一、工作流…...

C++----模拟实现string
模拟实现string,首先我们要知道成员变量有哪些: class _string{private:char* _str;size_t capacity;//空间有多大size_t size;//有效字符多少const static size_t npos;};const size_t _string::npos-1;//static在外面定义不需要带static,np…...

CodeMeter Runtime 安装失败排查与解决指南
CodeMeter Runtime 是威步提供的核心运行服务组件,用于加密授权的识别与管理。如果安装过程中出现异常或中断,常见原因包括系统冲突程序、数字签名校验失败、安全软件干扰或权限不足。 以下为推荐的完整排查步骤: 1. 检查并清理冲突程序或驱动…...

基于K8s日志审计实现攻击行为检测
K8s日志审计以一种事件溯源的方式完整记录了所有API Server的交互请求。当K8s集群遭受入侵时,安全管理员可以通过审计日志进行攻击溯源,通过分析攻击痕迹,找到攻击者的入侵行为并还原攻击者的攻击路径,修复安全问题。 在本篇文章中…...
【Linux网络编程】应用层协议HTTP(实现一个简单的http服务)
目录 前言 一,HTTP协议 1,认识URL 2,urlencode和urldecode 3,HTTP协议请求与响应格式 二,myhttp服务器端代码的编写 HTTP请求报文示例 HTTP应答报文示例 代码编写 网络通信模块 处理请求和发送应答模块 结…...

短视频+直播商城系统源码全解析:音视频流、商品组件逻辑剖析
时下,无论是依托私域流量运营的品牌方,还是追求用户粘性与转化率的内容创作者,搭建一套完整的短视频直播商城系统源码,已成为提升用户体验、增加商业变现能力的关键。本文将围绕三大核心模块——音视频流技术架构、商品组件设计、…...
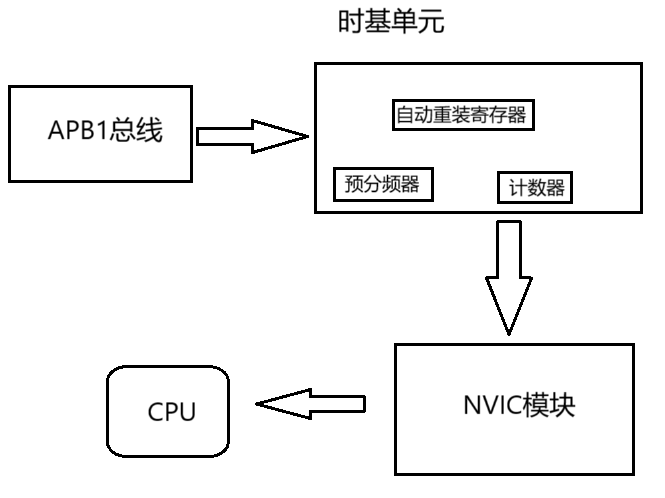
STM32定时器---基本定时器
目录 一、定时器的概述 二、时基单元 三、基本定时器的的时序 (1)预分频器时序 (2)计数器时序 四、基本定时器的使用 一、定时器的概述 在没有定时器的时候,我们想要延时往往都是写一个Delay函数,里面…...

mysql快速在不同库中执行相同的sql
目录 背景 解决方案 方式一:利用变量拼接好sql,复制出来执行(简单,推荐) 方式二:使用存储过程和游标实现(比较复杂,脚本需要拼接一个完整的,也比较麻烦,不…...
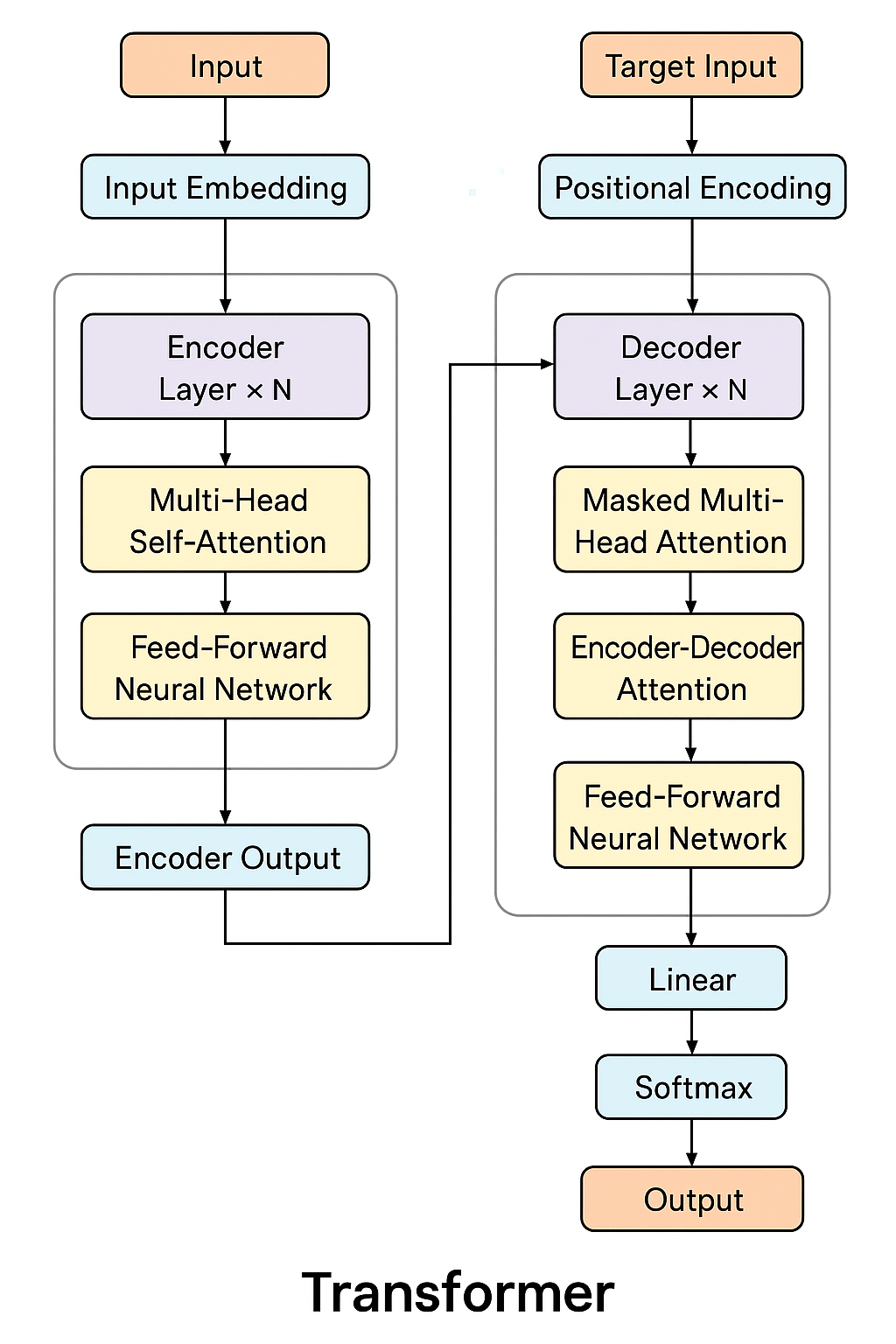
大模型微调 - transformer架构
什么是Transformer Transformer 架构是由 Vaswani 等人在 2017 年提出的一种深度学习模型架构,首次发表于论文《Attention is All You Need》中 Transformer 的结构 Transformer 编码器(Encoder) 解码器(Decoder) …...

【器件专题1——IGBT第1讲】IGBT:电力电子领域的 “万能开关”,如何撑起新能源时代?
一、IGBT 是什么?重新认识这个 “低调的电力心脏” 你可能没听过 IGBT,但一定用过它驱动的设备:家里的变频空调、路上的电动汽车、屋顶的光伏逆变器,甚至高铁和电网的核心部件里,都藏着这个 “电力电子开关的瑞士军刀”…...
)
文件IO(Java)
注:此博文为本人学习过程中的笔记 1.概念 狭义上的文件是指保存在硬盘上的文件,广义上指操作系统进行资源管理的一种机制,很多软件/硬件资源都可以抽象成文件,这里我们针对的是狭义上的文件。 在硬盘里还有文件夹,这…...
的区别与实现)
常见缓存淘汰算法(LRU、LFU、FIFO)的区别与实现
一、前言 缓存淘汰算法主要用于在内存资源有限的情况下,优化缓存空间的使用效率。以确保缓存系统在容量不足时能够智能地选择需要移除的数据。 二、LRU(Least Recently Used) 核心思想:淘汰最久未被访问的数据。实现方式&#x…...

Sentinel数据S2_SR_HARMONIZED连续云掩膜+中位数合成
在GEE中实现时,发现简单的QA60是无法去云的,最近S2地表反射率数据集又进行了更新,原有的属性集也进行了变化,现在的SR数据集名称是“S2_SR_HARMONIZED”。那么: 要想得到研究区无云的图像,可以参考执行以下…...
HTMLCSS模板实现水滴动画效果
.container 类:定义了页面的容器样式。 display: flex:使容器成为弹性容器,方便对其子元素进行布局。justify-content: center 和 align-items: center:分别使子元素在水平和垂直方向上居中对齐。min-height: 100vh:设…...

Cesium实现地形可视域分析
Cesium实现可视化分析 一、地形可视域主要实现技术(Ray + 地形碰撞检测) Cesium 本身的 Ray 类可以用来执行非常精确的射线检测,我们可以结合地形高度(sample)来逐点检测光线是否与 terrain 相交,从而判断是否可见。 1.1 优势 实时判断每条射线是否被 terrain 遮挡地形…...

前端如何获取文件的 Hash 值?多种方式详解、对比与实践指南
文章目录 前言一、Hash 值为何重要?二、Hash 值基础知识2.1 什么是 Hash?2.2 Hash 在前端的应用场景2.3 常见的 Hash 算法(MD5、SHA 系列) 三、前端获取文件 Hash 的常用方式3.1 使用 SparkMD5 计算 MD5 值3.2 使用 Web Crypto AP…...

【数据可视化艺术·应用篇】三维管线分析如何重构城市“生命线“管理?
在智慧城市、能源管理、工业4.0等领域的快速发展中,地下管线、工业管道、电力通信网络等“城市血管”的复杂性呈指数级增长。传统二维管理模式已难以应对跨层级、多维度、动态变化的管线管理需求。三维管线分析技术应运而生,成为破解这一难题的核心工具。…...

蓝桥杯 16.对局匹配
对局匹配 原题目链接 题目描述 小明喜欢在一个围棋网站上找别人在线对弈。这个网站上所有注册用户都有一个积分,代表他的围棋水平。 小明发现,网站的自动对局系统在匹配对手时,只会将积分差恰好是 K 的两名用户匹配在一起。如果两人分差小…...
【MinerU】:一款将PDF转化为机器可读格式的工具——RAG加强(Docker版本)
目录 创建容器 安装miniconda 安装mineru CPU运行 GPU加速 多卡问题 创建容器 构建Dockerfile文件 开启ssh服务,设置密码为1234等操作 # 使用官方 Ubuntu 24.04 镜像 FROM ubuntu:24.04# 安装基础工具和SSH服务 RUN apt-get update && \apt-get ins…...

DeepSeek回答过于笼统,提示词如何优化
针对DeepSeek回答过于笼统的问题,可通过以下方法优化,使输出更具体、详细: 一、优化提示词设计 明确具体要求 在提问中嵌入「背景限制示例」,例如: “作为跨境电商运营新手,请详细说明如何优化亚马逊产品标…...

C语言实现贪心算法
一、贪心算法核心思想 特征:在每一步选择中都采取当前状态下最优(局部最优)的选择,从而希望导致全局最优解 适用场景:需要满足贪心选择性质和最优子结构性质 二、经典贪心算法示例 1. 活动选择问题 目标:…...
)
全球碳化硅晶片市场深度解析:技术迭代、产业重构与未来赛道争夺战(2025-2031)
一、行业全景:从“材料突破”到“能源革命”的核心引擎 碳化硅(SiC)作为第三代半导体材料的代表,凭借其宽禁带(3.26eV)、高临界击穿场强(3MV/cm)、高热导率(4.9W/cmK&…...

FreeRTOS学习笔记【10】-----任务上下文切换
1 概念性内容 开机到调度需要经历的步骤有: 系统初始化任务创建启动调度器上下文切换时间分片任务执行 1.1 任务本质 FreeRTOS 的 任务(Task)本质上就是一个运行在任务自己的栈区中无限循环的函数 一段上下文(context&#x…...
Appium自动化开发环境搭建
自动化 文章目录 自动化前言 前言 Appium是一款开源工具,用于自动化iOS、Android和Windows桌面平台上的本地、移动web和混合应用程序。原生应用是指那些使用iOS、Android或Windows sdk编写的应用。移动网页应用是通过移动浏览器访问的网页应用(appum支持iOS和Chrom…...
C++学习-入门到精通-【1】C++编程入门,输入/输出和运算符
C学习-入门到精通-【1】C编程入门,输入/输出和运算符 C编程入门,输入/输出和运算符 C学习-入门到精通-【1】C编程入门,输入/输出和运算符第一个C程序:输出一行文本算术运算 第一个C程序:输出一行文本 // 文本打印程序…...

UOJ 228 基础数据结构练习题 Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),有 m m m 个操作分三种: add ( l , r , k ) \operatorname{add}(l,r,k) add(l,r,k):对每个 i ∈ [ l , r ] i\in[l,r] i∈[l,r] 执行 …...

面向高性能运动控制的MCU:架构创新、算法优化与应用分析
摘要:现代工业自动化、汽车电子以及商业航天等领域对运动控制MCU的性能要求不断提升。本文以国科安芯的MCU芯片AS32A601为例,从架构创新、算法优化到实际应用案例,全方位展示其在高性能运动控制领域的优势与潜力。该MCU以32位RISC-V指令集为基…...
某地农产品交易中心钢网架自动化监测项目
1. 项目简介 本项目规划建设现代物流产业园,新建6万平方米仓库,具体为新建3栋钢构仓库2万平方米,2栋砖混结构仓库1万平方米,3栋交易中心2万平方米,改造现有3栋3层砖混结构仓库1万平方米,配备智能化仓库物流…...