分布式队列对消息语义的处理
1. 最多一次(At-Most-Once)
- 定义:消息可能丢失,但不会重复。
- 实现方式:消费者收到消息后立即标记为“已处理”(如更新偏移量),无需确认是否成功处理。若处理失败,消息不会重试。
- 优点:低延迟(无需重试或持久化状态)。
- 缺点:可能丢失消息,可靠性最低。
- 适用场景:实时性要求高但允许少量数据丢失的场景(如传感器数据、日志聚合)。
2. 最少一次(At-Least-Once)
- 定义:消息绝不会丢失,但可能重复处理。
- 实现方式:
- 消费者必须显式确认(ACK)消息处理成功。若未收到ACK,消息会被重新投递。
- 需业务逻辑处理幂等性(如数据库去重或业务去重)。
- 优点: 高可靠性(确保消息不丢失)。
- 缺点: 可能重复处理,需额外幂等设计。
- 适用场景:金融交易、订单支付等不允许丢失但可容忍重复的场景。
3. 精准一次(Exactly-Once)
- 定义:消息确保被处理且仅处理一次。
- 实现方式:
- 幂等性 + 事务:通过唯一ID去重(如Kafka的幂等生产者)或分布式事务(如两阶段提交)。
- 日志/状态快照:如Flink的检查点机制(Checkpoint)或事件溯源(Event Sourcing)。
- 优点:最高一致性(无丢失无重复)。
- 缺点: 实现复杂,性能开销大。
- 适用场景:严格要求的场景(如银行对账、计费系统)。
唯一id的设计
Exactly-Once 语义的实现设计
1. 幂等性设计 (Idempotency)
- 原理:使操作执行多次与执行一次效果相同
- 实现方式:
- 为每个操作分配唯一ID,处理前检查是否已执行
- 使用条件更新(如"update where version=X")
- 数据库唯一约束防止重复插入
2. 事务性处理 (Transactional Processing)
- 两阶段提交 (2PC):
- 准备阶段:协调者询问所有参与者是否可以提交
- 提交阶段:所有参与者确认后执行提交
- Saga模式:
- 将长事务分解为多个本地事务
- 每个本地事务有对应的补偿事务
- 失败时按相反顺序执行补偿事务
3. 日志与检查点 (Logging & Checkpointing)
- Write-Ahead Logging (WAL):
- 操作前先记录日志
- 崩溃恢复时重放日志
- 检查点机制:
- 定期保存系统状态快照
- 故障时从最近检查点恢复
4. 分布式流处理框架策略
- Apache Kafka:
- 生产者:启用幂等生产者和事务
- 消费者:使用事务性消费和read_committed隔离级别
- 存储偏移量与处理结果在同一事务中
- Apache Flink:
- Checkpoint机制保证状态一致性
- 两阶段提交Sink连接器
- 端到端精确一次保证
5. 去重表 (Deduplication Table)
- 存储已处理消息的唯一标识
- 处理前查询去重表检查是否已处理
- 可与TTL结合自动清理旧记录
6. 混合策略
- 幂等操作+事务性写入
- WAL+检查点+幂等消费者
- 去重表+Saga模式
问题
- 性能开销:Exactly-Once通常比At-Least-Once有更高延迟
- 实现复杂度:需要精心设计系统各组件
- 存储成本:去重表、日志等需要额外存储
Kafka 的 Exactly-Once 语义实现
Kafka 提供的 Exactly-Once 保障
- 生产者幂等性 (Idempotent Producer)
- 防止生产者重试导致的消息重复
- 通过 PID(Producer ID)和序列号(Sequence Number)实现
- 启用方式:设置 enable.idempotence=true
- 事务性生产 (Transactional Producer)
- 跨分区原子写入
- 使用事务协调器管理
- 启用方式:设置 transactional.id 并调用 initTransactions()
- 事务性消费 (Transactional Consumer)
- 确保"读取-处理-写入"的原子性
- 使用 isolation.level=read_committed
- 消费者只读取已提交的事务消息
实现原理
生产者端
消费者端
- 将消费位移(offset)和处理结果写入同一事务
- 要么全部成功,要么全部回滚
- 故障恢复后从正确位置重新消费
使用限制
- 范围限制:
- 仅保证 Kafka 内部的 Exactly-Once
- 如果处理逻辑涉及外部系统,需要额外措施(如幂等写入)
- 性能影响:
- 事务会降低吞吐量(约20-30%)
- 增加端到端延迟
- 配置要求:
- 需要集群版本 ≥ 0.11.0
- 要求 acks=all 和 min.insync.replicas≥1
代码实现
// 生产者配置
props.put("enable.idempotence", "true");
props.put("transactional.id", "my-transactional-id");
KafkaProducer producer = new KafkaProducer(props);// 消费者配置
props.put("isolation.level", "read_committed");
KafkaConsumer consumer = new KafkaConsumer(props);// 事务处理流程
producer.initTransactions();
while(true) {ConsumerRecords records = consumer.poll(Duration.ofMillis(100));producer.beginTransaction();try {// 处理消息并生成新消息producer.send(new ProducerRecord(...));// 提交消费位移producer.sendOffsetsToTransaction(offsets, "consumer-group");producer.commitTransaction();} catch(Exception e) {producer.abortTransaction();}
}
RocketMQ 的 Exactly-Once 语义实现
RocketMQ 的 Exactly-Once 支持情况
1. 生产者幂等性 (4.4.0+ 版本支持)
- 实现原理:
- 每个消息携带唯一 UNIQ_KEY(业务标识符)
- Broker 端基于 UNIQ_KEY 进行重复检测
- 时间窗口默认为5分钟(可配置)
- 启用方式:
// 发送消息时设置UNIQ_KEY
Message msg = new Message("topic", "tag", "body".getBytes());
msg.setKeys("your_business_key"); // 设置幂等键
2. 事务消息 (半事务机制)
- 实现原理:
- 两阶段提交:预备消息 → 本地事务执行 → 提交/回滚
- 如果生产者崩溃,Broker 会回查事务状态
- 代码示例:
TransactionListener listener = new TransactionListenerImpl();
TransactionMQProducer producer = new TransactionMQProducer("group");
producer.setTransactionListener(listener);
// 发送事务消息
TransactionSendResult result = producer.sendMessageInTransaction(msg, null);
3. 消费者端 Exactly-Once
- 常见方案:
- 幂等消费:通过业务唯一键+去重表实现
- 事务性消费:将消息处理与存储更新放在同一事务中
- 手动位点管理:确保处理成功后再提交offset
与 Kafka Exactly-Once 的关键区别
| 特性 | RocketMQ | Kafka |
| 生产者幂等 | 基于业务键(UNIQ_KEY) | 基于PID+序列号 |
| 事务支持 | 半事务(需回查) | 完整两阶段提交 |
| 消费者Exactly-Once | 不原生支持 | 支持(事务性消费) |
| 性能影响 | 较小 | 较大(约20-30%吞吐下降) |
实现完整 Exactly-Once 的建议方案
- 生产者端:
- 启用事务消息
- 为每条消息设置唯一 UNIQ_KEY
- 消费者端:
// 伪代码示例:消费者幂等处理
consumer.registerMessageListener((msgs, context) -> {for (MessageExt msg : msgs) {String bizId = msg.getKeys(); // 获取业务唯一IDif (deduplicate(bizId)) { // 检查是否已处理continue;}// 处理消息(与数据库操作在同一个事务中)processInTransaction(msg);// 记录已处理(可异步)markAsProcessed(bizId); }
});
- 存储设计:
- 创建去重表:CREATE TABLE msg_dedup (biz_id VARCHAR PRIMARY KEY, processed_at TIMESTAMP)
- 使用TTL自动清理过期记录
总结
- RocketMQ 的事务消息不是严格的ACID事务,而是"最终一致"的
- 消息去重窗口期默认5分钟(fileReservedTime参数控制)
- 高并发场景下,去重检查可能成为性能瓶颈
- 跨系统场景仍需额外的一致性保障措施
相关文章:

分布式队列对消息语义的处理
在分布式系统中,消息的处理语义(Message Processing Semantics)是确保系统可靠性和一致性的关键。有三种语义: 在分布式系统中,消息的处理语义(Message Processing Semantics)是确保系统可靠性和…...

Servlet小结
视频链接:黑马servlet视频全套视频教程,快速入门servlet原理servlet实战 什么是Servlet? 菜鸟教程:Java Servlet servlet: server applet Servlet是一个运行在Web服务器(如Tomcat、Jetty)或应用…...

2025上海车展:光峰科技全球首发“灵境”智能车载光学系统
当AI为光赋予思想,汽车将会变成什么样?深圳光峰科技为您揭晓答案。 2025年4月23日,在刚刚开幕的“2025上海车展”上,全球领先的激光核心器件公司光峰科技举办了主题为“AI光影盛宴,智享未来出行”的媒体发布会&#x…...

BiliNote:开源的AI视频笔记生成工具,让知识提取与分享更高效——跨平台自动生成结构化笔记,实现从视频到Markdown的智能转化
引言:视频学习的痛点与BiliNote的解决方案 随着知识视频化趋势的加速,B站、YouTube等平台成为学习与信息获取的重要渠道,但手动记录笔记耗时低效、信息碎片化等问题依然突出。BiliNote的出现,通过AI驱动的自动化流程,将视频内容转化为结构清晰的Markdown笔记,支持截图插…...

docker 运行时权限和 Linux 能力了解
文档参考: https://docs.docker.com/engine/containers/run/#runtime-privilege-and-linux-capabilities https://docs.docker.com/reference/cli/docker/container/run/#privileged 本片主要了解容器在运行时如何赋予的格外的权限,默认情况下࿰…...

图纸安全防护管理:构建企业核心竞争力的关键屏障
在当今高度竞争的商业环境中,图纸作为企业核心技术的重要载体,其安全防护管理已成为企业知识产权保护体系中的关键环节。无论是建筑行业的施工蓝图、制造业的产品设计图,还是高科技企业的研发图纸,都承载着企业的核心竞争力和商业…...

如何用WordPress AI插件自动生成SEO文章,提升网站流量?
1. 为什么你需要一个WordPress AI文章生成插件? 每天手动写文章太耗时?SEO优化总是不达标?WordPress AI插件能帮你24小时自动生成原创内容,从关键词挖掘到智能排版,全程无需人工干预。 痛点:手动写作效率低…...
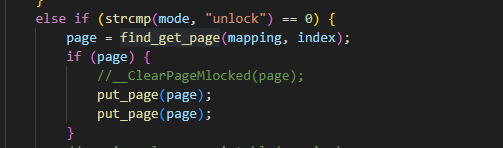
借助内核逻辑锁pagecache到内存
一、背景 内存管理是一个永恒的主题,尤其在内存紧张触发内存回收的时候。系统在通过磁盘获取磁盘上的文件的内容时,若不开启O_DIRECT方式进行读写,磁盘上的任何东西都会被缓存到系统里,我们称之为page cache。可以想象࿰…...
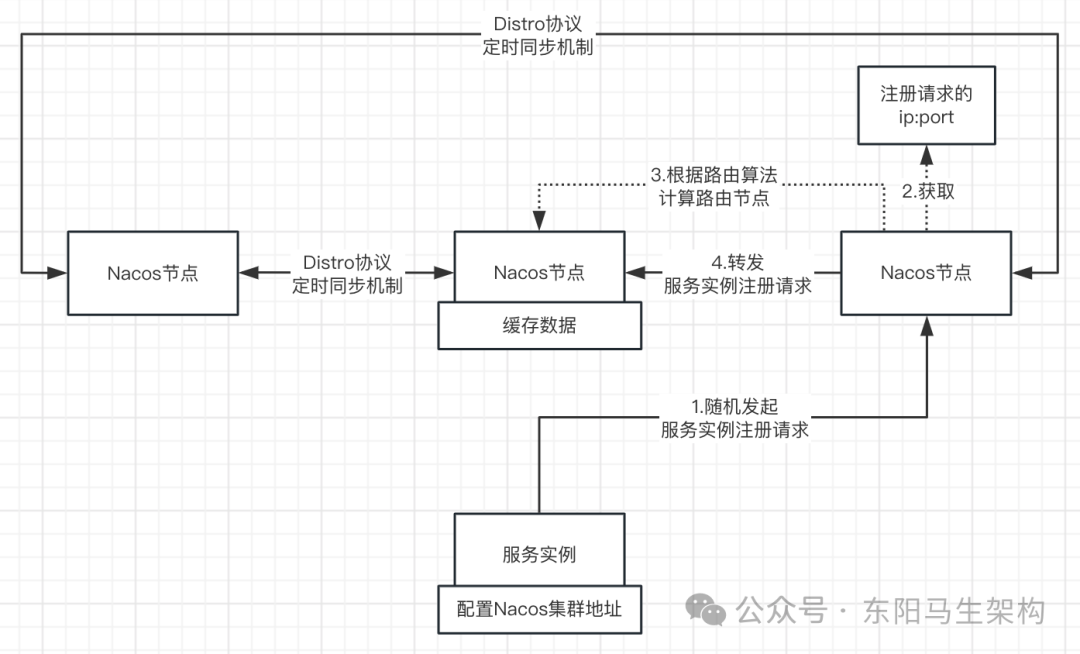
Nacos简介—2.Nacos的原理简介
大纲 1.Nacos集群模式的数据写入存储与读取问题 2.基于Distro协议在启动后的运行规则 3.基于Distro协议在处理服务实例注册时的写路由 4.由于写路由造成的数据分片以及随机读问题 5.写路由 数据分区 读路由的CP方案分析 6.基于Distro协议的定时同步机制 7.基于Distro协…...
)
【信息系统项目管理师】高分论文:论人力资源管理与成本管理(医院信息系统)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 论文一、规划人力资源管理二、组建项目团队三、建设项目团队四、管理项目团队论文 一个完善的医院信息系统通常由上百个子系统构成,而这些系统随着医院发展需求逐步建设的,他们来源于不同厂家,基于不同的技…...
区别)
Docker Compose和 Kubernetes(k8s)区别
Docker Compose 和 Kubernetes(k8s)是两种不同层次的容器编排工具,主要区别体现在设计目标、使用场景和功能特性上。以下是它们的核心对比: 1. 设计目标 Docker Compose 单机编排:专注于在单个主机上定义和运行多容器应…...

IP查询专业版:支持IPv4/IPv6自动识别并切换解析的API接口使用指南
以下是根据您提供的网页内容编辑的符合CSDN内容发布要求的Markdown格式文本: 一、API概述 在开发过程中,我们常常需要对IP地址进行查询,以获取其详细信息,如地理位置、运营商等。万维易源的“IP查询专业版”API接口能够提供丰富…...

Spring Boot中的监视器:Actuator的原理、功能与应用
在 Spring Boot 应用中,监视器通常指 Spring Boot Actuator,一个内置的生产就绪工具,用于监控和管理运行中的应用。Actuator 提供了一系列 RESTful 端点,暴露应用的运行时信息,如健康状态、性能指标、日志配置和环境变…...

P12167 [蓝桥杯 2025 省 C/Python A] 倒水
P12167 [蓝桥杯 2025 省 C/Python A] 倒水 题目描述 小蓝有 n n n 个装了水的瓶子,从左到右摆放,第 i i i 个瓶子里装有 a i a_i ai 单位的水。为了美观,小蓝将水循环染成了 k k k 种颜色,也就是说,第 i i i …...
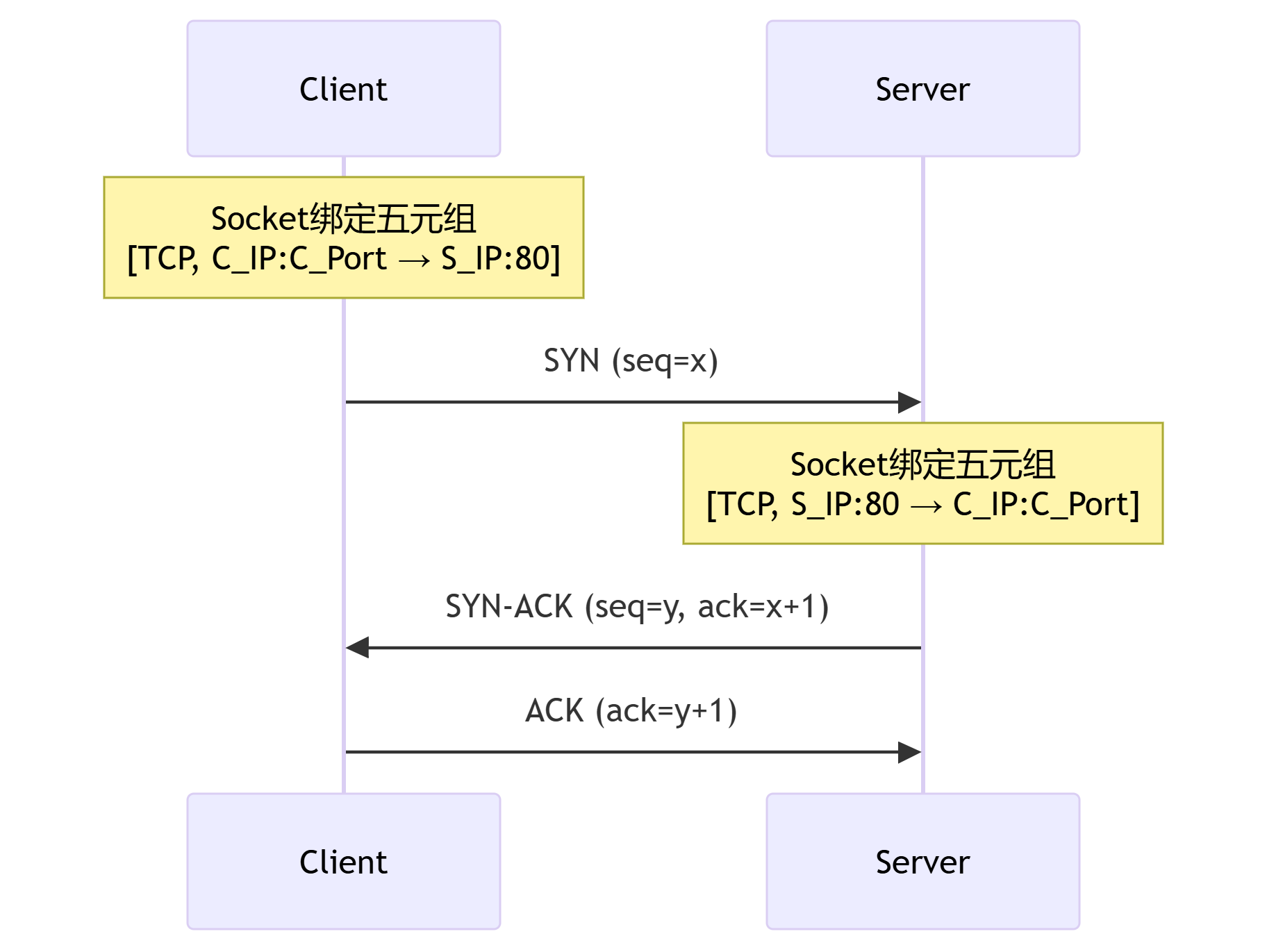
TCP协议理解
文章目录 TCP协议理解理论基础TCP首部结构图示字段逐项解析 TCP是面向连接(Connection-Oriented)面向连接的核心表现TCP 面向连接的核心特性TCP 与UDP对比 TCP是一个可靠的(reliable)序号与确认机制(Sequencing & Acknowledgment…...

用 LangChain 手搓 RAG 系统:从原理到实战
一、RAG 系统简介 在当今信息爆炸的时代,如何高效地从海量数据中获取有价值的信息并生成准确、自然的回答,成为了人工智能领域的重要课题。检索增强生成(Retrieval-Augmented Generation,RAG)系统应运而生,…...

联合体和枚举类型
1.联合体类型 1.1:联合体类型变量的创建 与结构体类型一样,联合体类型 (关键字:union) 也是由⼀个或者多个成员变量构成,这些成员变量既可以是不同的类型,也可以是相同的类型。但是编译器只为最⼤的成员变量分配⾜够的内存空间。联合体的特…...

一种企业信息查询系统设计和实现:xujian.tech/cs
一种企业信息查询系统设计和实现:xujian.tech/cs 背景与定位 企业在对外合作、风控审查或市场调研时,常需快速获取公开的工商信息。本文介绍一个企业信息搜索引擎,面向普通用户与开发者,帮助快速定位企业名称、统一社会信用代码…...
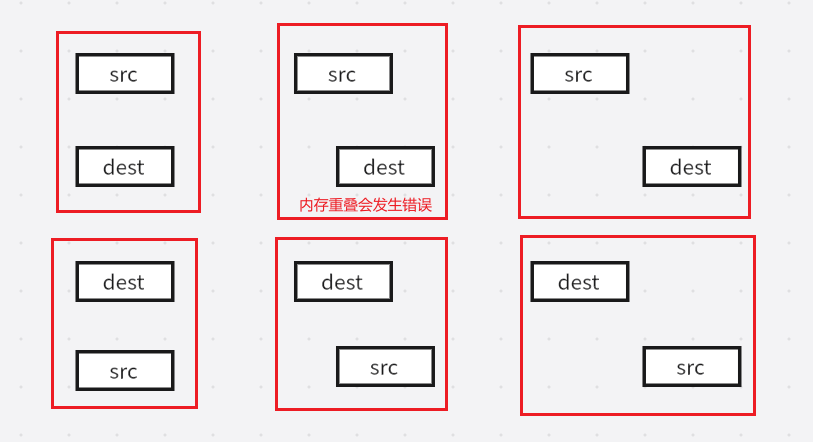
C语言指针5
1.void*概述 void称为无类型,void*称为无类型指针,void不可以单独定义变量,却可以定义无类型的指针,而且所定义的指针称为泛型指针,所谓泛型指针,其含义是void*类型的指针可以接收一切类型变量的地址 struc…...

[4A/OP]
2.2 安装程序 2.2.1 解压缩.tar.gz文件 调用UNIX命令tar会在当前目录下创建4A/OP子例程主目录4AOP-1.5/,包括所有必要的子目录。只需键入以下命令即可解压缩和“untar”4AOP-1.5.tar.gz: tar -xzvf 4AOP-1.5.tar.gz4AOP-1.5/目录现在应该已经创建&…...

来云台跑腿配送平台:用户体验至上的服务理念
来云台跑腿配送平台始终秉持用户体验至上的服务理念,从下单到收货的每一个环节,都致力于为用户提供优质、便捷的服务。 简洁的下单流程是良好体验的开端。用户通过 APP 或小程序,只需几步操作就能完成下单。清晰的服务分类、自动定位功能和…...

本地部署 Dify + Ollama 到 D盘,并挂载本地大模型 的完整教程,结合 Docker 运行环境
一、环境准备 1. 软件与硬件要求 • 操作系统:Windows 10/11 专业版(需开启 Hyper-V) • 硬件配置: • CPU ≥ 4核(推荐 Intel i5 及以上) • 内存 ≥ 16GB(大模型运行需预留 8GB 以上&#…...

文档构建:Sphinx全面使用指南 — 强化篇
文档构建:Sphinx全面使用指南 — 强化篇 Sphinx 是一款强大的文档生成工具,使用 reStructuredText 作为标记语言,通过扩展兼容 Markdown,支持 HTML、PDF、EPUB 等多种输出格式。它具备自动索引、代码高亮、跨语言支持等功能&#…...

深度理解C语言函数之strlen()的模拟实现
文章目录 前言一、strlen的模拟实现二、模拟实现代码及思路2.1 计数法2.2 指针相减法三、递归计数法 总结 前言 我写这篇文章的目的主要是帮助理解C语言中重要函数的用法,后面也会总结C相关的函数的模拟实现,这里的算法不一定是最好的,因为只…...

0基础 | Proteus仿真 | 51单片机 | 继电器
继电器---RELAY 本次选择一款5v一路继电器进行讲解 信号输入 IN1输入高电平,三极管导通,LED1点亮,电磁铁12接通吸引3向下与4接通,J1A的12接通 IN1输入低电平,则J1A的23接通 产品引脚定义及功能 序号 引脚符号 引脚…...

Python解析地址中省市区街道
Python解析地址中省市区街道 1、效果 输入:海珠区沙园街道西基村 输出: 2、导入库 pip install jionlp3、示例代码 import jionlp as jiotext 海珠区沙园街道西基村 res jio.parse_location(text, town_villageTrue) print(res)...

在vscode终端中运行npm命令报错
解决方案 这个错误信息表明,你的系统(可能是 Windows)阻止了 PowerShell 执行脚本,这是由于 PowerShell 的执行策略导致的。PowerShell 的执行策略控制着在系统上运行哪些 PowerShell 脚本。默认情况下,Windows 可能…...
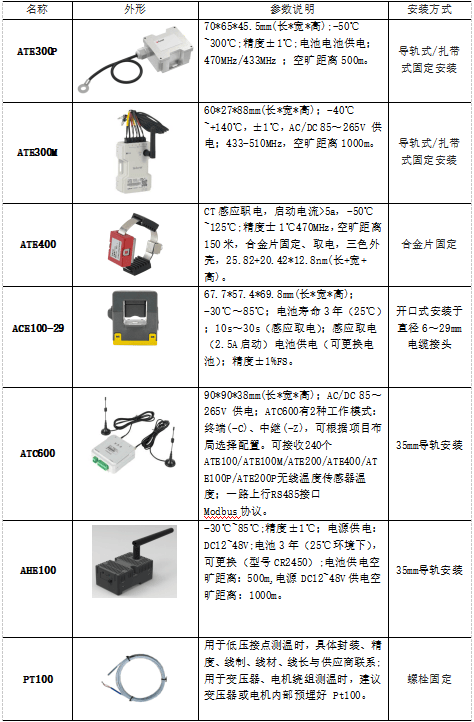
提升变电站运维效率:安科瑞无线测温系统创新应用
一、引言 变电站作为电力系统的关键枢纽,承担着变换电压、分配电能以及控制电力流向等重要任务。在变电站的运行过程中,电气设备的接点温度监测至关重要。过热问题可能由多种因素引发,如电阻过大、接头质量欠佳、衔接不紧密、物理老化等&…...
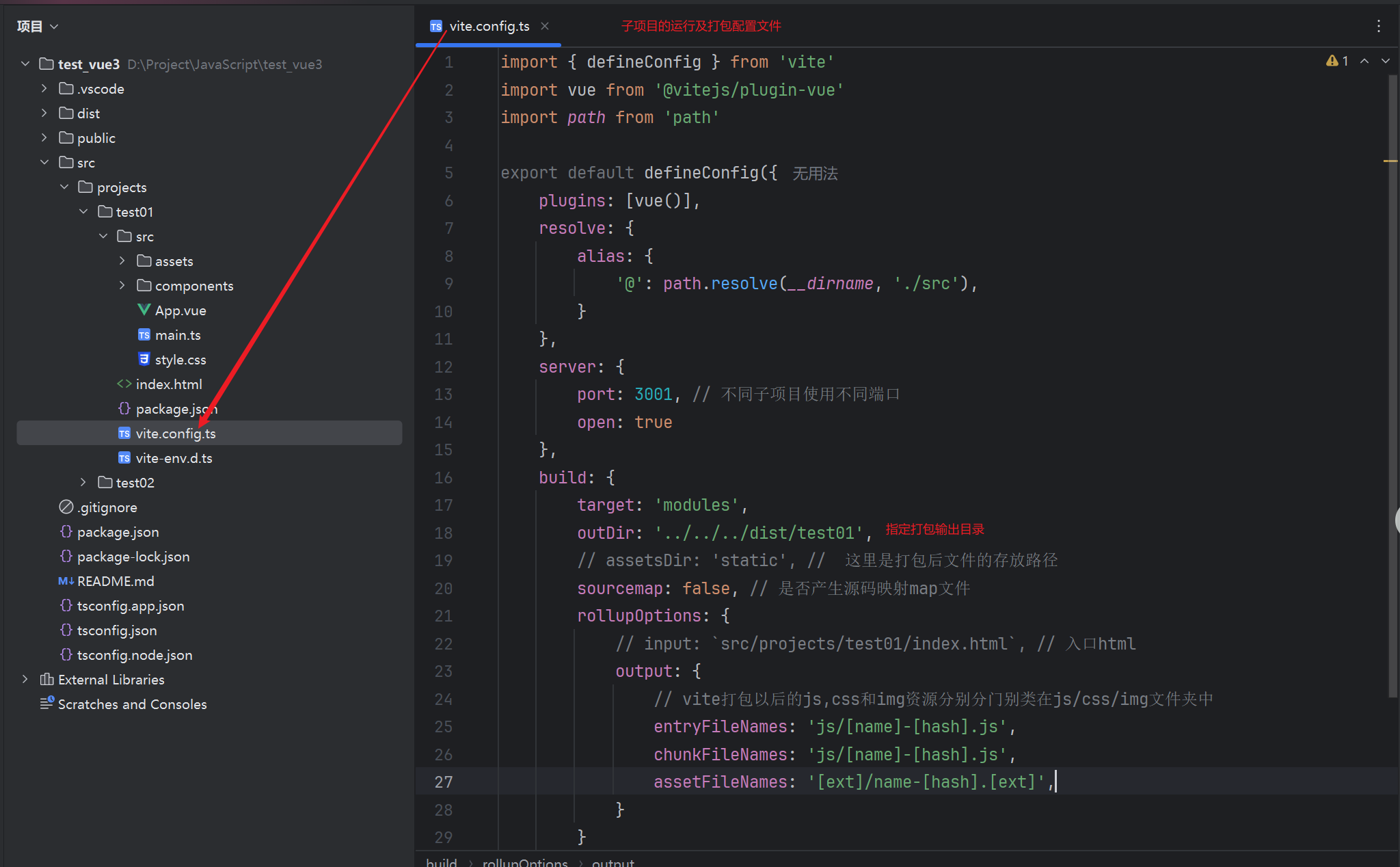
vue3 使用 vite 管理多个项目,实现各子项目独立运行,独立打包
场景: 之前写过一篇 vite vue2 的配置,但是现在项目使用 vue3 较多,再更新一下 vue脚手架初始化之后的项目,每个项目都是独立的,导致项目多了之后,node依赖包过多,占用内存较多。想实现的效果…...
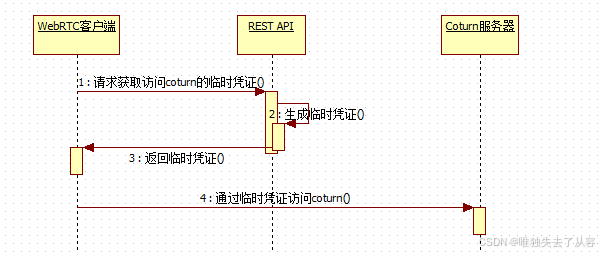
WebRTC服务器Coturn服务器用户管理和安全性
1、概述 Coturn服务器对用户管理和安全方面也做了很多的措施,以下会介绍到用户方面的设置 1.1、相关术语 1.1.1 realm 在 coturn 服务器中,域(realm)是一种逻辑上的分组概念,用于对不同的用户群体、应用或者服务进行区…...