RunnerGo API性能测试实战与高并发调优
API 性能测试通过模拟不同负载场景,量化评估 API 的响应时间、吞吐量、稳定性、可扩展性等性能指标,关注其在正常、高峰甚至极限负载下的表现。这有助于确保 API 稳定高效地运行,为调用者提供优质服务。
接下来,我们借助 RunnerGo 全栈测试平台,深入探索 API 性能测试及实施细节。
一、API性能测试的重要性
API 是不同软件系统通信桥梁,广泛应用于现代软件架构。API 性能测试对保障应用稳定运行和良好用户体验起关键作用,主要体现在以下几点:
-
确保 API 接口稳定性 :验证接口在不同负载条件下是否能稳定工作,避免系统运行期间出现故障。
-
优化 API 接口响应速度 :通过性能测试找出影响接口响应速度的瓶颈环节,针对性优化,提升系统整体响应效率。
-
验证 API 接口可扩展性 :确定接口在业务增长时能否良好扩展,满足未来系统发展需求。
-
检测 API 接口安全性 :在性能测试过程中发现接口潜在安全漏洞,加固系统安全防线。
-
提供性能数据支持决策 :为系统架构设计、资源配置等决策提供数据支撑,助力企业合理规划资源。
二、使用RunnerGo进行API性能测试
RunnerGo 全栈测试平台功能强大、操作简便,适用于 API 测试、性能测试等场景。使用 RunnerGo 进行 API 性能测试的具体步骤如下:
创建性能测试计划
明确测试目标、范围和策略,开启性能测试之旅。
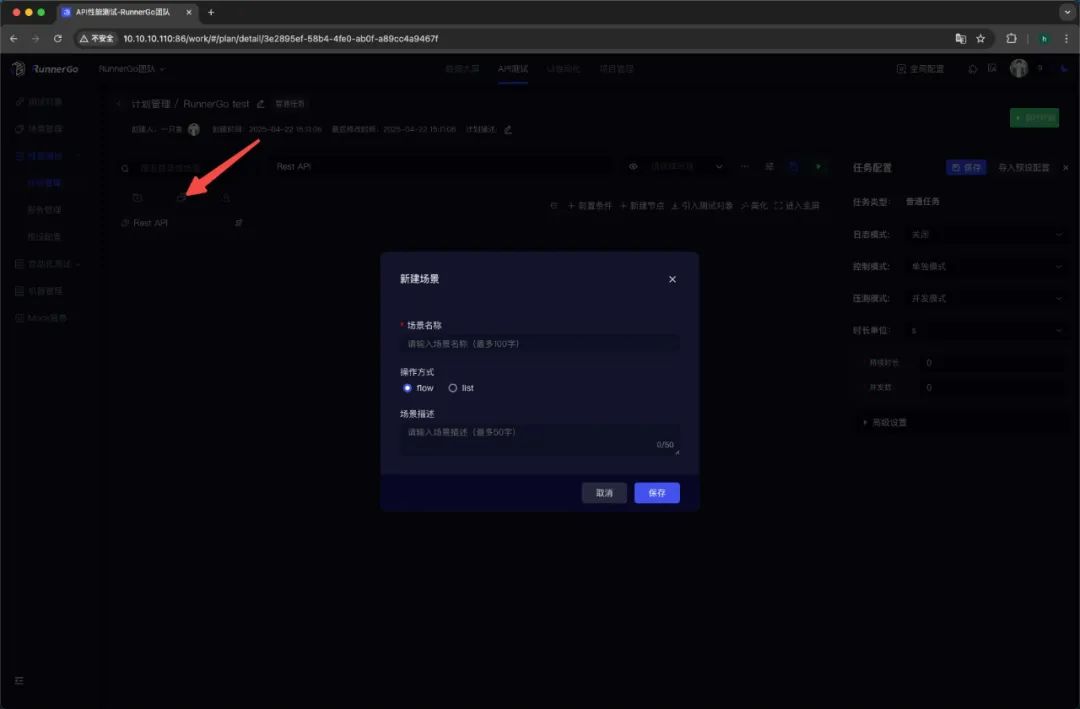
创建场景
在 RunnerGo 中,场景是性能测试基本单元,描述 API 请求执行顺序与逻辑关系。创建时可添加多个 API 请求,设置请求参数、headers、body 等内容,还能添加条件控制器、循环控制器等模拟复杂业务逻辑。
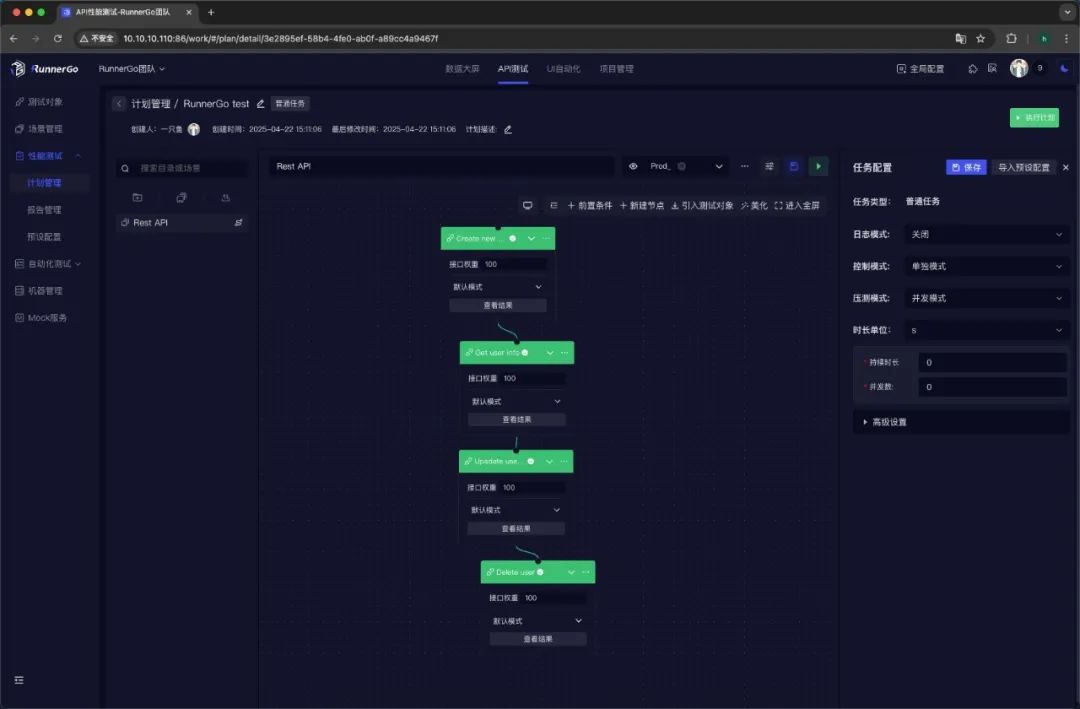
创建API请求
针对测试接口,设置请求方法、URL、Query 参数、Body 参数、Header 参数等,满足不同接口调用要求。场景分布支持 Flow 和 List 两种布局。
Flow:
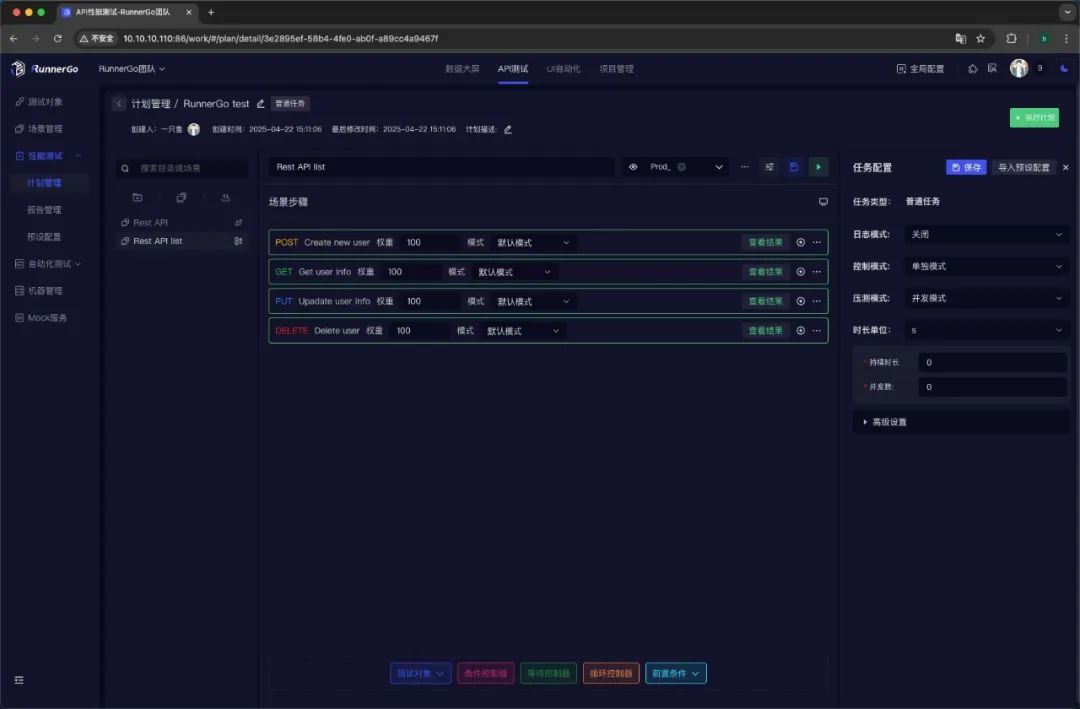
List:
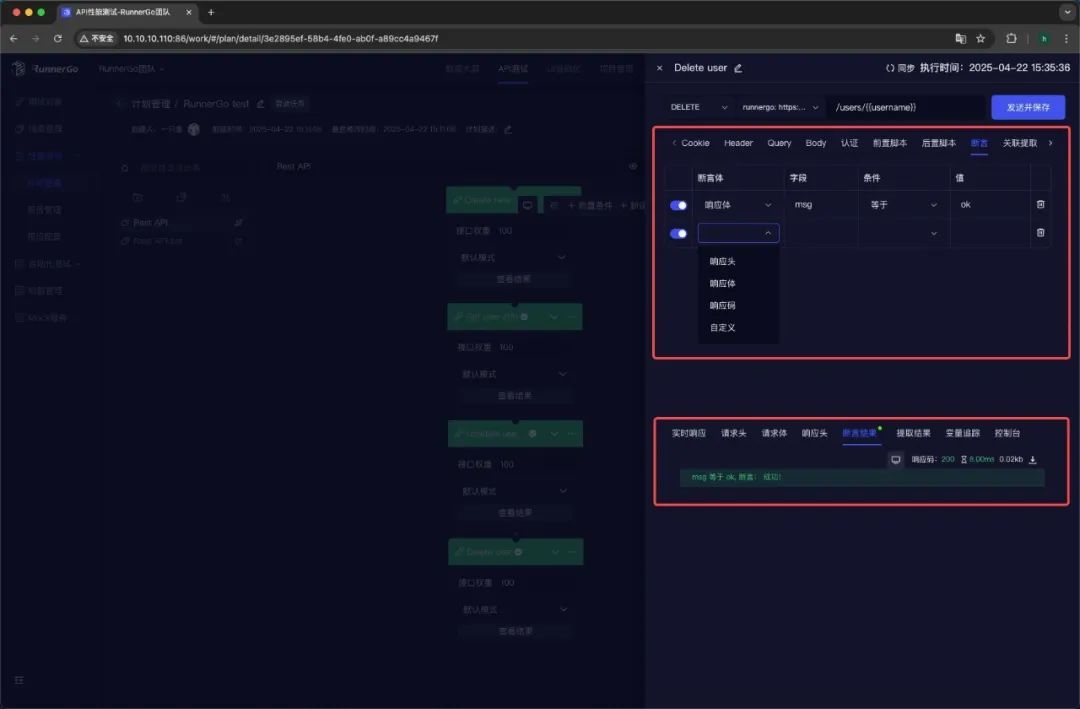
添加断言
对响应状态码、响应头、响应体等进行断言,确保接口返回正确结果,保障测试有效性。
设置性能测试参数
设置压测模式、并发数、持续时长、错误率阈值等关键参数,依业务需求和系统承受能力配置。
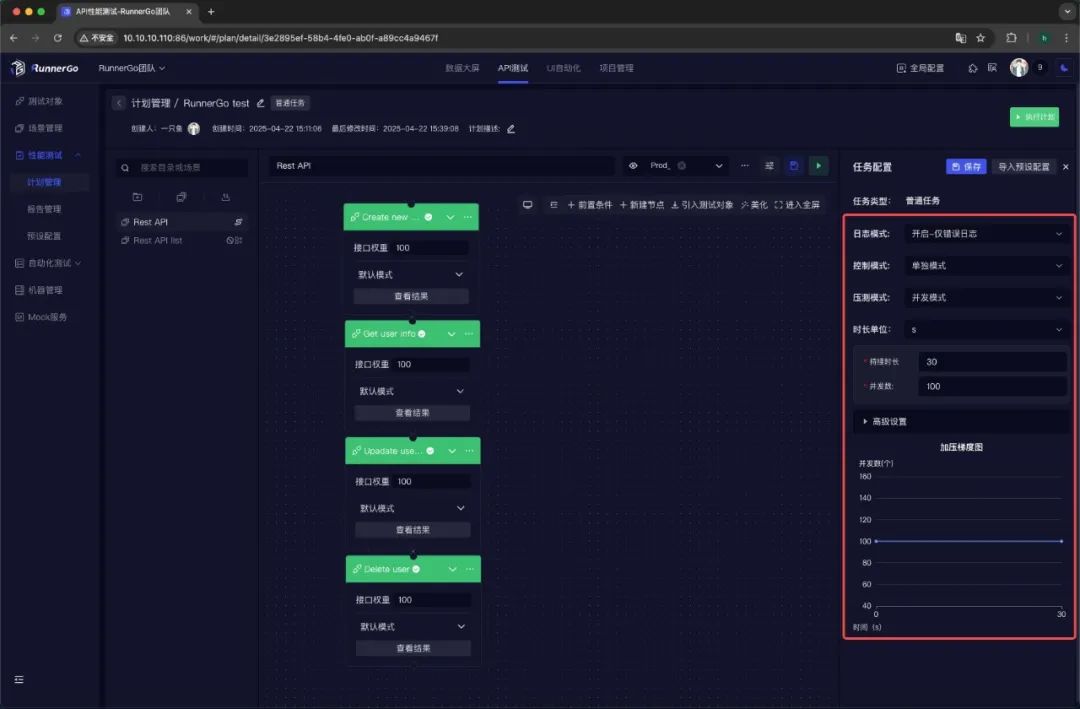
执行性能测试
完成性能测试计划创建后,执行性能测试。
启动性能测试
选择压测模式并配置参数,点击启动按钮,RunnerGo 向目标 API 接口发送大量请求,实时监控性能指标。
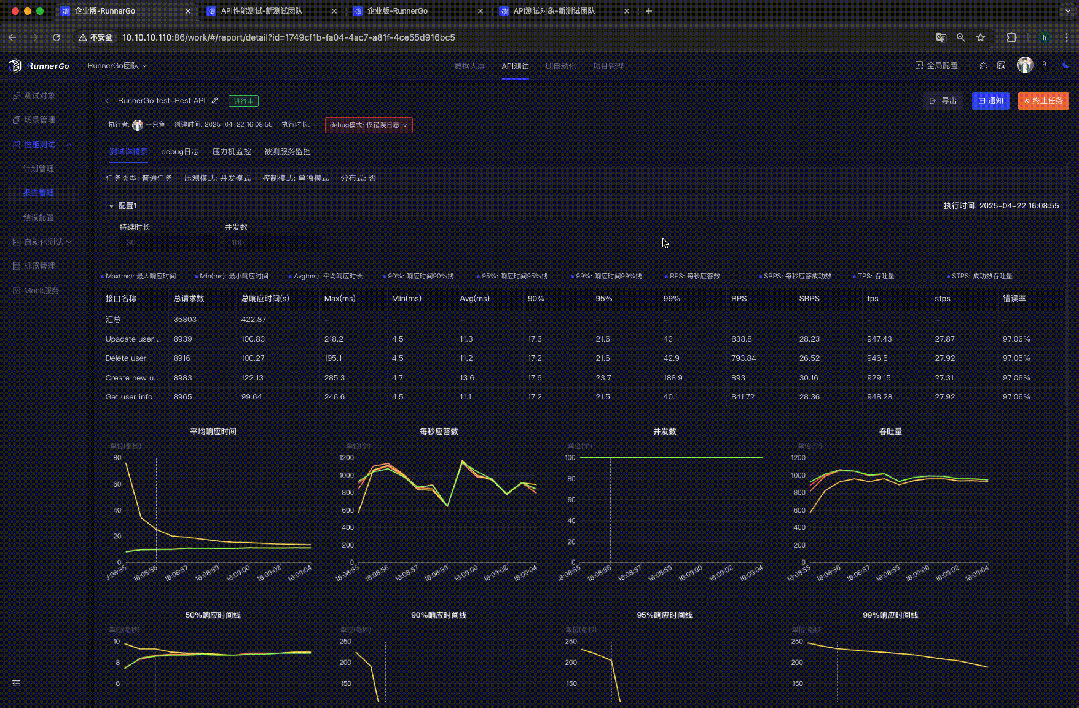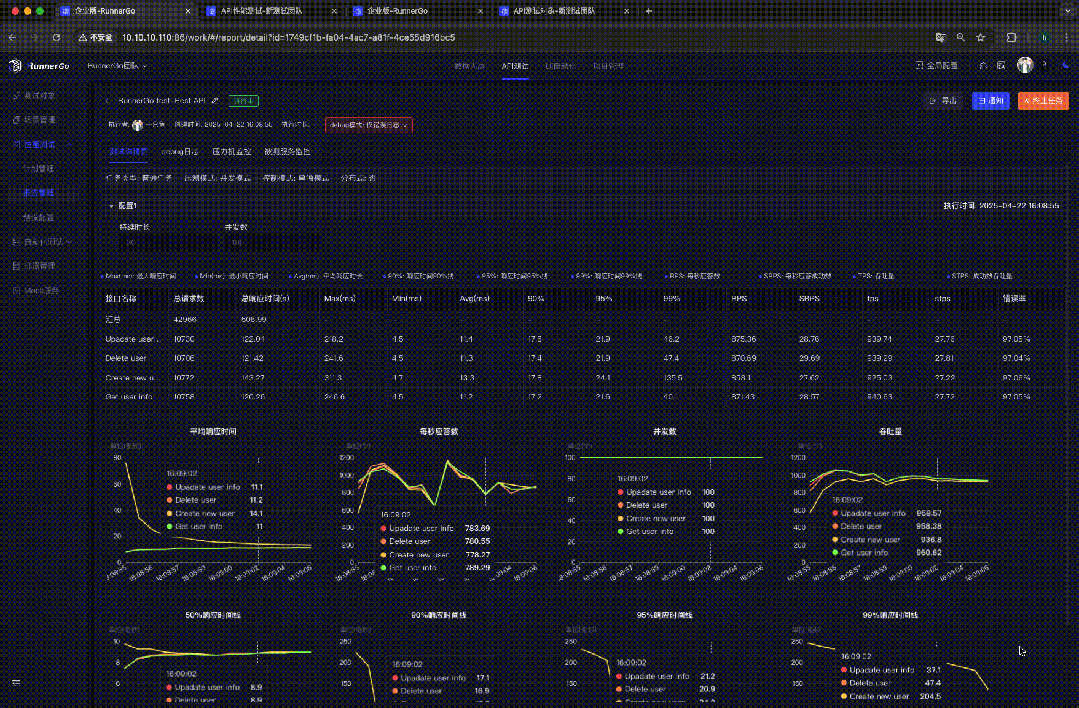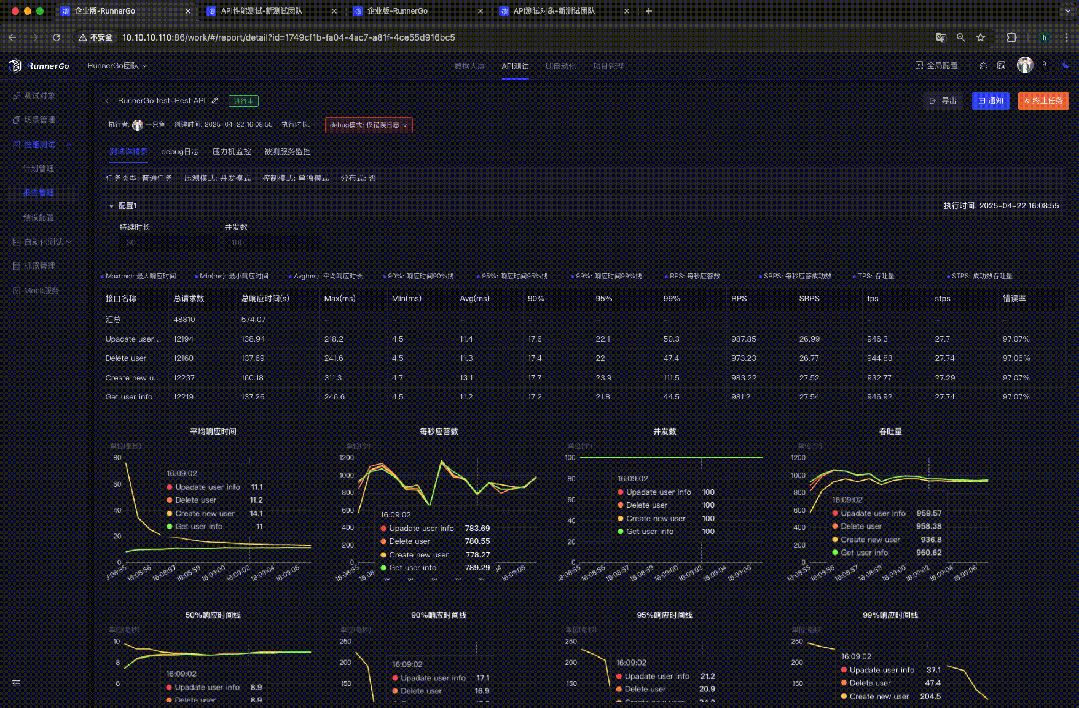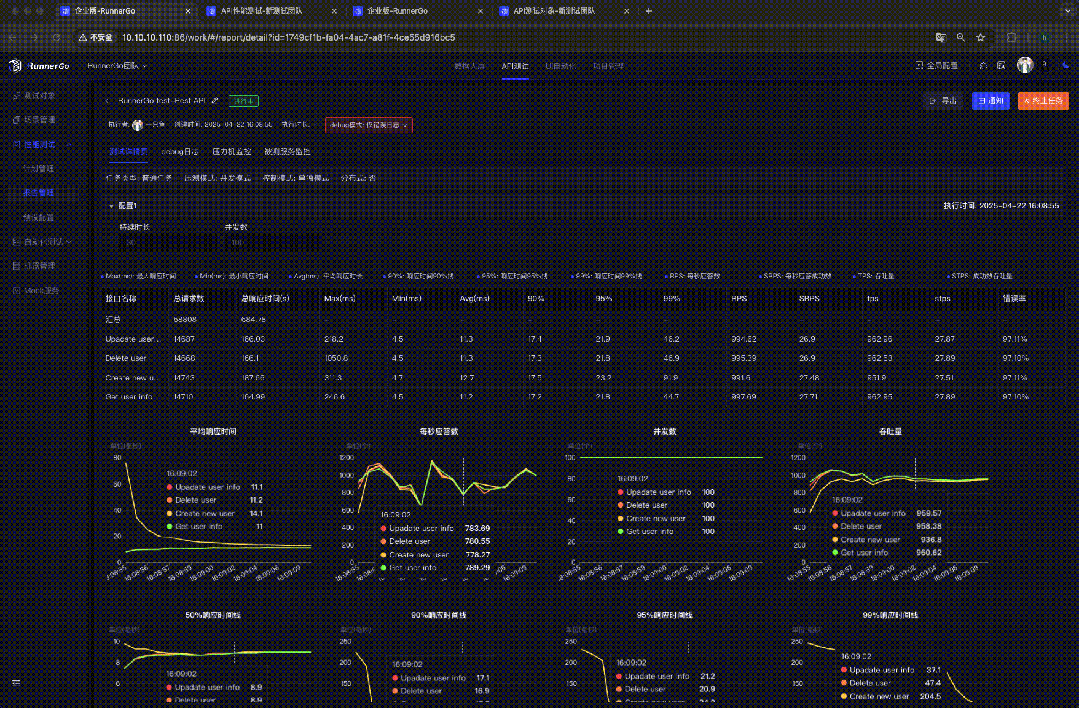
分析性能测试报告
性能测试执行完成后,RunnerGo 生成详细报告。
查看性能测试结果
直观查看性能指标数据和图表,了解 API 接口表现,发现性能瓶颈。
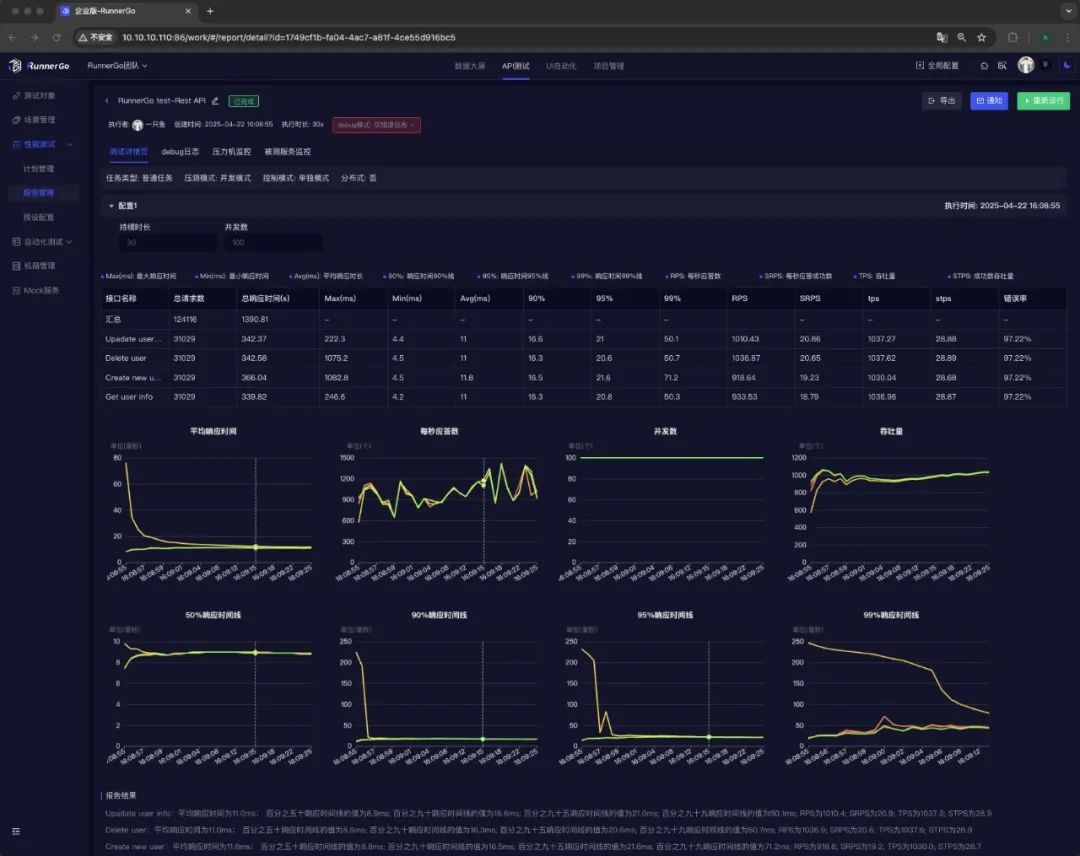
分析性能测试报告
深入分析数据,找出响应时间长的请求、评估系统负载能力和扩展性、发现稳定性问题等。
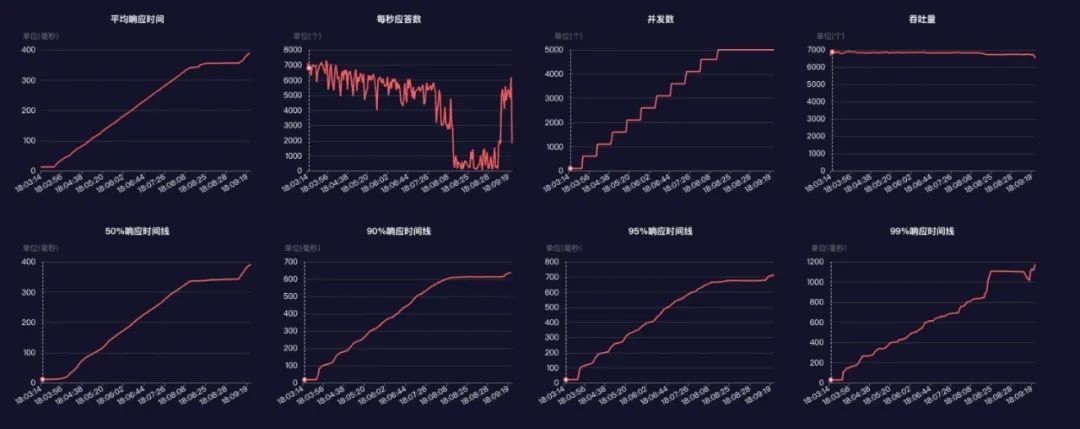
优化与改进
根据分析结果,针对性优化代码、数据库、服务器资源配置、网络等,再次执行测试,直至达到性能目标。
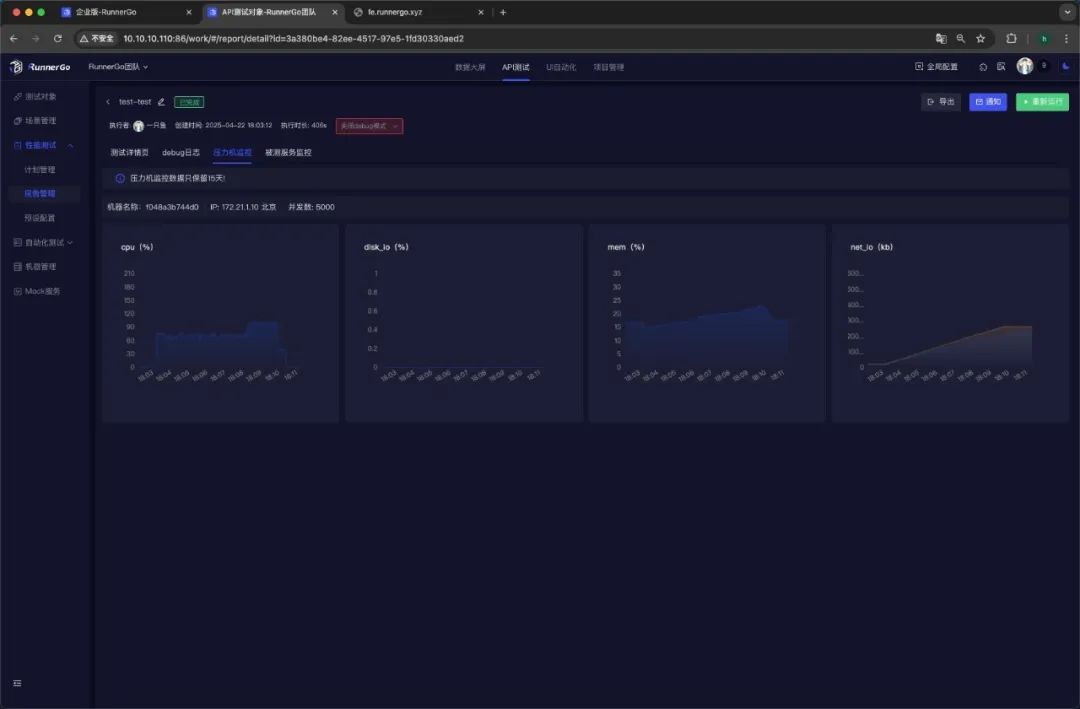
三、业务场景案例分析
为了更直观地展示RunnerGo在API性能测试中的实际应用,我们以电商平台的促销活动场景为例,详细分析如何使用RunnerGo进行性能测试。
业务场景背景
在电商平台的促销活动期间,如“618”“双11”等,用户访问量和交易量会呈现爆发式增长。大量的用户同时浏览商品、提交订单、支付等操作,对平台的API接口造成极大的压力。若API接口无法承受高并发负载,将导致页面加载缓慢、订单提交失败、支付超时等问题,严重影响用户体验和平台的销售额。
因此,提前对电商平台的API接口进行性能测试,确保其在促销活动期间能够稳定、高效地运行,是至关重要的。
性能测试目标
在本案例中,我们设定以下性能测试目标:
-
确保API接口在高并发访问下的响应时间不超过1秒;
-
系统能够承受10,000并发用户的负载;
-
错误率控制在0.1%以内;
-
吞吐量达到每秒1000次请求以上。
RunnerGo性能测试策略
场景设计
根据电商平台促销活动的业务流程,我们设计了多个性能测试场景,覆盖用户浏览商品、加入购物车、提交订单、支付等关键业务环节。每个场景包含多个API请求,模拟用户的行为路径。
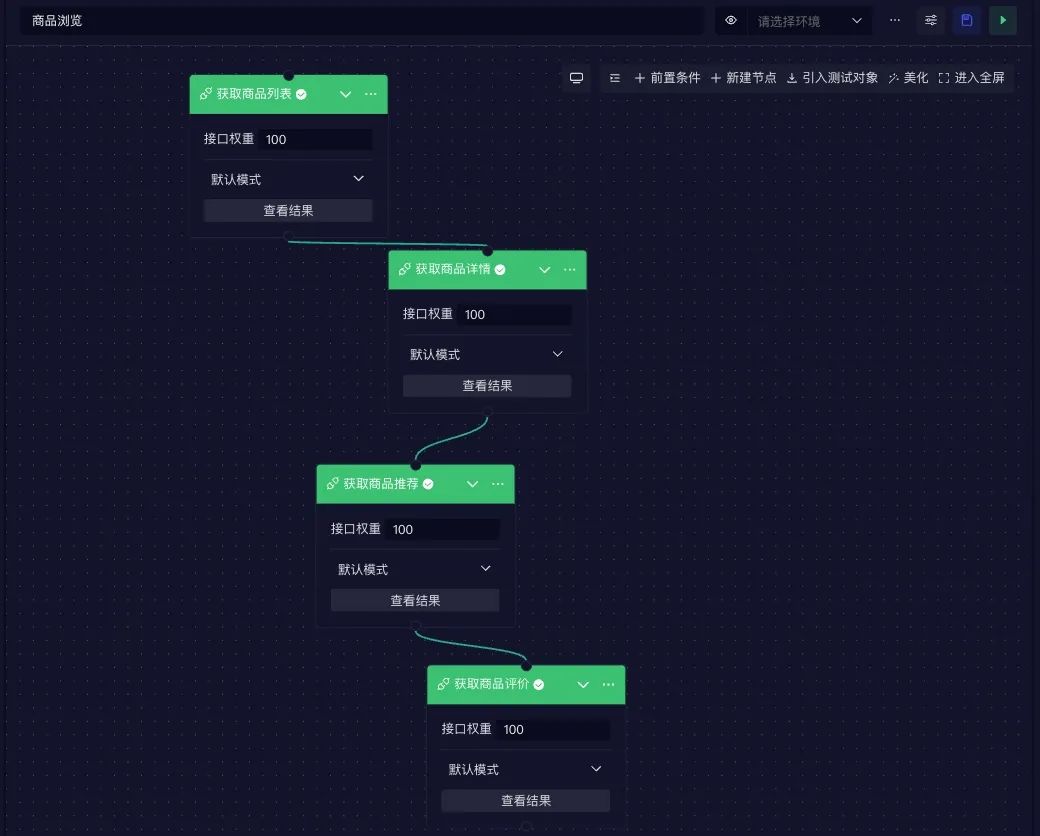
例如,在“商品浏览”场景中,包含以下API请求:
-
获取商品列表接口:模拟用户浏览商品列表页面;
-
获取商品详情接口:模拟用户点击商品查看详情;
-
获取商品推荐接口:模拟系统推荐相关商品;
-
获取商品评价接口:模拟用户查看商品评价。
压测模式选择
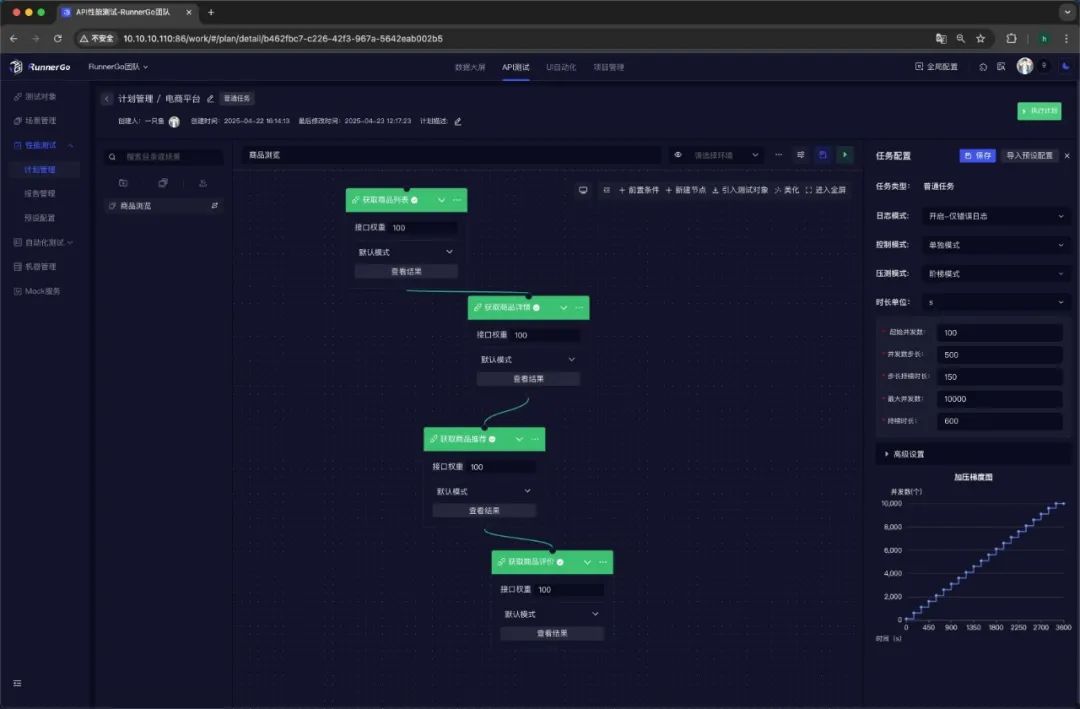
针对电商平台促销活动的特点,我们选择了阶梯模式作为压测模式。具体配置如下:
-
起始并发数:100;
-
并发数步长:500;
-
步长持续时长:150秒;
-
最大并发数:10,000;
-
持续时长:600秒。
通过阶梯模式,可以逐步增加并发用户数量,模拟促销活动期间用户流量逐渐增长的过程,观察系统在不同负载下的性能表现,找到系统的性能瓶颈和极限负载。
性能测试结果与分析
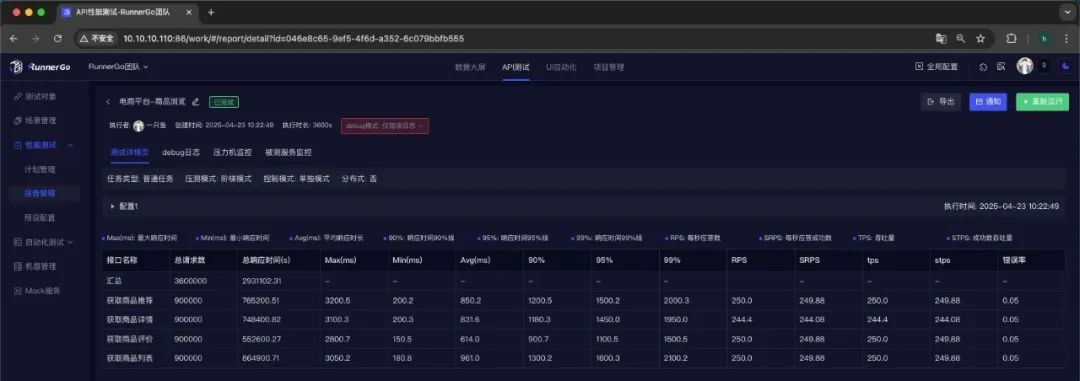
在执行性能测试后,我们获得了以下关键性能指标数据:
性能测试执行情况
-
最大并发用户数:10,000;
-
总请求数:3,600,000;
-
平均响应时间:850毫秒;
-
最大响应时间:3,200毫秒;
-
吞吐量:每秒980次请求;
-
错误率:0.05%。
数据分析与结论
从性能测试结果来看,系统在大部分情况下能够满足性能测试目标:
-
平均响应时间为850毫秒,低于目标值1秒,表明系统在一般负载下的响应速度较快;
-
吞吐量达到每秒980次请求,接近目标值每秒1,000次请求,说明系统具备较高的处理能力;
-
错误率为0.05%,远低于目标值0.1%,表明系统在高并发负载下的稳定性较好。
然而,也发现了一些问题和性能瓶颈:
-
当并发用户数达到8,000时,响应时间开始明显上升,部分请求的响应时间超过1秒,甚至有个别请求的响应时间达到3,200毫秒;
-
在订单提交和支付环节,错误率略有上升,主要表现为库存扣除接口和支付接口出现超时错误;
-
数据库连接池的利用率较高,在高并发时出现连接数耗尽的情况。
优化与改进措施
针对性能测试结果中发现的问题,我们采取了以下优化与改进措施:
优化代码和数据库查询
对响应时间较长的接口进行代码审查和优化,发现部分接口的数据库查询语句存在性能瓶颈,如缺少索引、查询条件不优化等。针对这些问题,我们添加了必要的数据库索引,优化了查询语句,降低了数据库查询的复杂度,从而提升了接口的响应速度。
以下是一个具体的示例代码,展示如何通过优化数据库查询语句来提升接口的响应速度:
优化前的代码示例(存在问题的代码)
-- 获取商品列表接口的数据库查询语句(优化前)SELECTg.*,c.category_nameFROMgoods gLEFT JOINcategory cONg.category_id = c.idWHEREg.name LIKE '%关键词%'ORDER BYg.idLIMIT0, 20;
// 获取商品列表接口的Java代码(优化前)List<HashMap> getGoodsList(String keyword) {String sql = "SELECT g.*, c.category_name FROM goods g LEFT JOIN category c ON g.category_id = c.id WHERE g.name LIKE ? ORDER BY g.id LIMIT ?, ?";return jdbcTemplate.query(sql, (rs, rowNum) -> {HashMap map = new HashMap();map.put("id", rs.getInt("id"));map.put("name", rs.getString("name"));map.put("price", rs.getDouble("price"));map.put("category_name", rs.getString("category_name"));return map;}, "%" + keyword + "%", 0, 20);}
代码分析
上述代码存在以下性能瓶颈:
-
查询语句中使用了g.name LIKE '%关键词%',这种模糊查询会导致数据库无法有效利用索引,只能进行全表扫描,查询效率低下。
-
查询结果中新商品会优先展示,但查询语句按g.id排序,未对id字段创建索引,导致排序操作耗时较长。
-
查询语句中包含*,查询了商品表中的所有字段,增加了数据传输量和查询复杂度。
优化后的代码示例:
-- 获取商品列表接口的数据库查询语句(优化后)SELECTg.id,g.name,g.price,c.category_nameFROMgoods gLEFT JOINcategory cONg.category_id = c.idWHEREg.name LIKE CONCAT('%', ?, '%')ORDER BYg.idLIMIT?, ?;-- 为goods表的name字段创建索引CREATE INDEX idx_goods_name ON goods(name);-- 为goods表的id字段创建索引CREATE INDEX idx_goods_id ON goods(id);// 获取商品列表接口的Java代码(优化后)List<HashMap> getGoodsList(String keyword, int offset, int limit) {String sql = "SELECT g.id, g.name, g.price, c.category_name FROM goods g LEFT JOIN category c ON g.category_id = c.id WHERE g.name LIKE CONCAT('%', ? , '%') ORDER BY g.id LIMIT ?, ?";return jdbcTemplate.query(sql, (rs, rowNum) -> {HashMap map = new HashMap();map.put("id", rs.getInt("id"));map.put("name", rs.getString("name"));map.put("price", rs.getDouble("price"));map.put("category_name", rs.getString("category_name"));return map;}, keyword, offset, limit);}
扩容数据库连接池
针对数据库连接池耗尽的问题,我们对数据库连接池的配置进行了调整,增加了最大连接数,并优化了连接的释放策略,确保在高并发时能够有足够的数据库连接可用。
针对数据库连接池耗尽的问题,可以通过以下具体措施进行优化:
增加最大连接数
根据数据库服务器的承载能力和应用程序的需求,合理增加数据库连接池的最大连接数。例如,将最大连接数从默认的 100 增加到 200 或更高。具体配置因使用的数据库连接池实现而异,以下是一些常见数据库连接池的配置示例:
// HikariCP 数据库连接池配置示例(Java)HikariConfig config = new HikariConfig();config.setMaximumPoolSize(200); // 设置最大连接数为 200config.setMinimumIdle(20); // 设置最小空闲连接数为 20config.setIdleTimeout(30000); // 设置空闲超时时间为 30 秒config.setConnectionTimeout(5000); // 设置连接超时时间为 5 秒
优化连接释放策略
确保应用程序在使用完数据库连接后及时将其释放回连接池。可以通过以下方式优化连接释放策略:
-
确保及时关闭连接:在代码中,确保在使用完数据库连接后及时调用 close 方法将其释放回连接池。
// Java 示例代码Connection conn = null;try {conn = dataSource.getConnection();// 执行数据库操作} finally {if (conn != null) {conn.close(); // 确保连接被关闭,释放回连接池}}
-
设置合理的空闲超时时间:将连接池中连接的空闲超时时间设置得稍微短一些,以便及时释放长时间未使用的连接。
config.setIdleTimeout(30000); // 设置空闲超时时间为 30 秒-
设置合理的最大等待时间:当连接池中的所有连接都在使用中时,请求新连接的线程将等待一定的时间。如果在这个时间内仍然无法获取连接,则抛出异常。可以适当增加最大等待时间,但不宜过长。
config.setConnectionTimeout(10000); // 设置连接超时时间为 10 秒监控和调整
-
监控连接池状态:定期监控数据库连接池的使用情况,包括活动连接数、空闲连接数、连接的等待时间等指标。
-
根据监控结果调整参数:根据监控数据,动态调整最大连接数、空闲超时时间等参数,以达到最佳的性能和资源利用率。
-
使用连接泄漏检测:一些数据库连接池(如 HikariCP)提供了连接泄漏检测功能,可以检测到未及时释放的连接并发出警报。
config.setLeakDetectionThreshold(2000); // 设置连接泄漏检测阈值为 2000 毫秒示例:HikariCP 数据库连接池配置
HikariConfig config = new HikariConfig();config.setJdbcUrl("jdbc:mysql://localhost:3306/mydatabase");config.setUsername("username");config.setPassword("password");config.setMaximumPoolSize(200); // 增加最大连接数config.setMinimumIdle(20); // 设置最小空闲连接数config.setIdleTimeout(30000); // 设置空闲超时时间为 30 秒config.setConnectionTimeout(10000); // 设置连接超时时间为 10 秒config.setLeakDetectionThreshold(2000); // 设置连接泄漏检测阈值为 2000 毫秒HikariDataSource dataSource = new HikariDataSource(config);
通过以上措施,可以有效扩容数据库连接池,并优化连接的释放策略,确保在高并发场景下有足够的数据库连接可用,从而提高系统的性能和稳定性。
优化服务器资源配置
根据性能测试结果,我们对服务器资源进行了评估和调整。增加了服务器的内存和CPU资源,优化了负载均衡策略,确保系统的计算和存储能力能够满足高并发负载的需求。
实施缓存策略
为了进一步提升系统的响应速度和减轻数据库压力,我们在API接口层面实施了缓存策略。对于一些频繁访问且数据变化不频繁的接口,如商品列表、商品详情等,采用Redis缓存数据,减少对数据库的直接访问,提高数据读取效率。
优化网络配置
对服务器的网络配置进行了优化,调整了网络带宽和连接超时时间等参数,以减少网络延迟和丢包率,确保请求和响应在网络传输过程中更加高效和稳定。
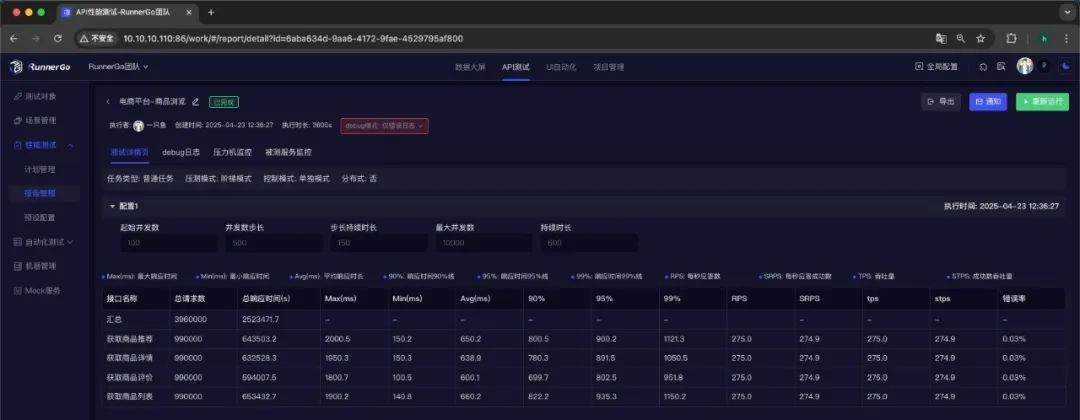
在实施上述优化和改进措施后,我们再次执行了性能测试。结果显示,系统的平均响应时间降低到了650毫秒,最大响应时间降低到了2,000毫秒,吞吐量提升到了每秒1,100次请求,错误率降低到了0.03%。系统在10,000并发用户数下的性能表现更加稳定和可靠,成功满足了促销活动期间的性能需求。
四、总结
以上是如何借助 全栈测试平台RunnerGo 高效开展 API 性能测试的全流程方法,然而,API 性能测试并非一劳永逸,它需要随着业务的不断拓展、系统架构的持续演进以及用户需求的日益增长而持续关注与优化。希望广大测试工程师与从业者能够深入学习、熟练掌握 API 性能测试技能,充分利用各类先进的测试工具与方法,持续提升系统的性能表现,为用户打造更加卓越的数字化体验。
相关文章:
RunnerGo API性能测试实战与高并发调优
API 性能测试通过模拟不同负载场景,量化评估 API 的响应时间、吞吐量、稳定性、可扩展性等性能指标,关注其在正常、高峰甚至极限负载下的表现。这有助于确保 API 稳定高效地运行,为调用者提供优质服务。 接下来,我们借助 RunnerG…...
STM32——相关软件安装
本文是根据江协科技提供的教学视频所写,旨在便于日后复习,同时供学习嵌入式的朋友们参考,文中涉及到的所有资料也均来源于江协科技(资料下载)。 Keil5 MDK安装 1.安装Keil5 MDK2.安装器件支持包方法一:离线…...
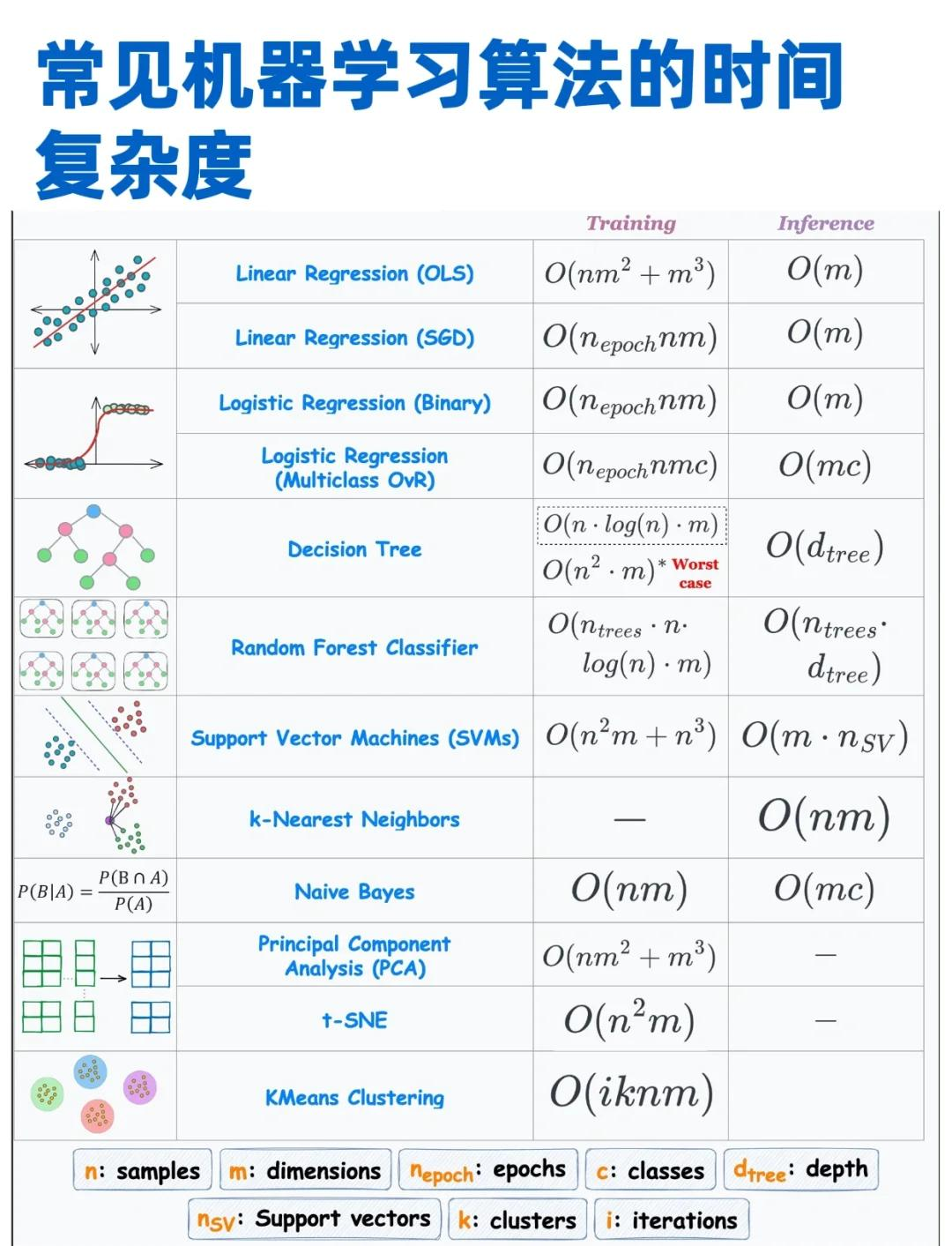
数据结构入门【算法复杂度】超详解深度解析
🌟 复杂度分析的底层逻辑 复杂度是算法的"DNA",它揭示了两个核心问题: 数据规模(n)增长时,资源消耗如何变化? 不同算法在极端情况下的性能差异有多大? 数学本质解析 复杂度函数 T(n)O(f(n))…...

java多线程(7.0)
目录 编辑 定时器 定时器的使用 三.定时器的实现 MyTimer 3.1 分析思路 1. 创建执行任务的类。 2. 管理任务 3. 执行任务 3.2 线程安全问题 定时器 定时器是软件开发中的一个重要组件. 类似于一个 "闹钟". 达到一个设定的时间之后, 就执行某个指定好的…...
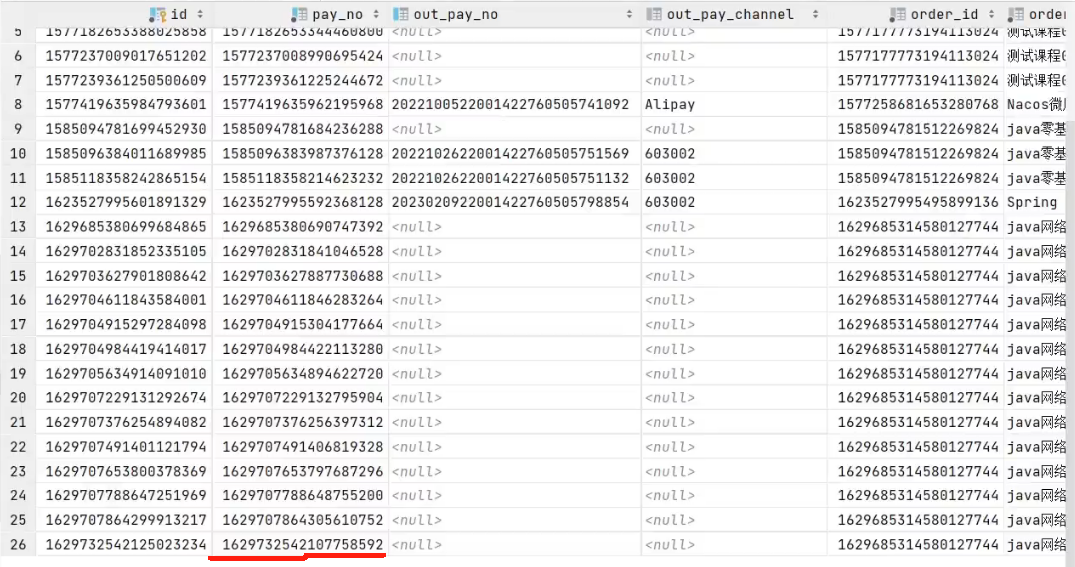
Long类型封装Json传输时精度丢失问题
在信息做传输时,经常会使用到类型转换,这个时候因为一些问题会导致精度的丢失。在支付业务中这种问题更为致命。 这里我主动生成一个支付订单并将相关信息使用base64编码为一个二维码返回给前端进行支付,前端进行支付时我通过回调方法发现回调…...

《从GPT崛起,看AI重塑世界》
《从GPT崛起,看AI重塑世界》 GPT 诞生:AI 领域的震撼弹 2022 年 11 月 30 日,OpenAI 发布了一款名为 ChatGPT 的人工智能聊天机器人程序,宛如一颗重磅炸弹投入了平静的湖面,迅速在全球范围内引发了轩然大波,成为了科技领域乃至大众舆论场中最热门的话题之一。一时间,无…...
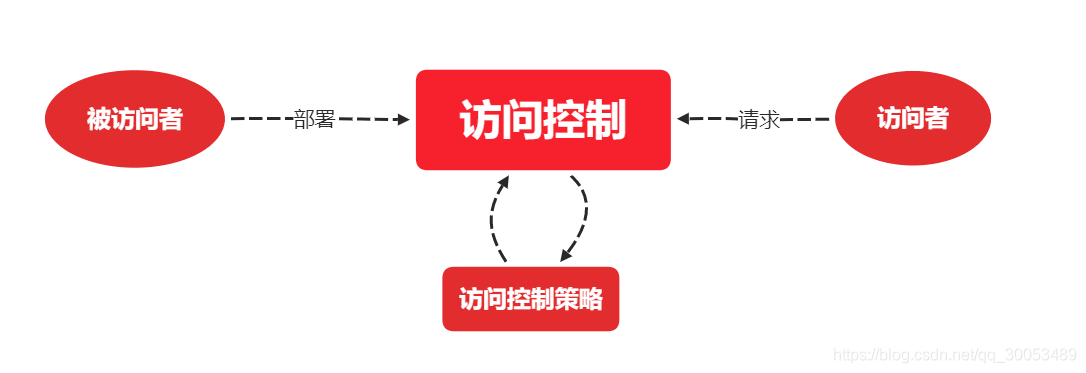
系统架构-安全架构设计
概述 对于信息系统来说,威胁有:物理环境(最基础)、通信链路、网络系统、操作系统、应用系统、管理系统 物理安全:系统所用设备的威胁,如自然灾害、电源故障通信链路安全:在传输线路上安装窃听…...

基于大语言模型的AI智能体开发:构建具备工具使用能力的智能助手
本文将结合大语言模型(LLM)与工具调用能力,构建新一代AI智能体系统。通过ReAct框架实现智能思考-行动循环,集成网络搜索、计算器、API调用等外部工具,并基于LangChain实现可扩展的智能体架构。 一、新一代AI智能体技术…...
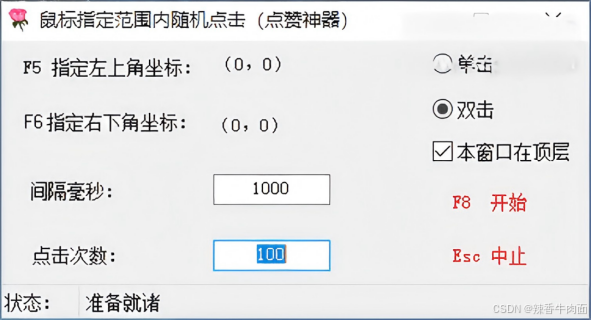
鼠标指定范围内随机点击
鼠标指定范围内随机点击 点赞神器 将鼠标移动到相应位置后按F5 F6键,设置点击范围, F8开始,ESC中止。 有些直播有点赞限制,例如某音,每小时限制3千次,可以设置1200毫秒,3000次。 软件截图&#…...

HashSet 概述
1. HashSet 概述 HashSet 是 Java 集合框架中 Set 接口的一个实现类,它存储唯一元素,即集合中不会有重复的元素。HashSet 基于哈希表(实际上是 HashMap 实例)来实现,不保证元素的顺序,并且允许存储 null 元…...

遥测终端机,推动灌区流量监测向数据驱动跃迁
灌区范围那么大,每一滴水怎么流都关系到粮食够不够吃,还有生态能不能平衡。过去靠人工巡查、测量,就像拿着算盘想算明白大数据,根本满足不了现在水利管理的高要求。遥测终端机一出现,就像给灌区流量监测安上了智能感知…...

蓝耘平台介绍:算力赋能AI创新的智算云平台
一、蓝耘平台是什么 蓝耘智算云(LY Cloud)是蓝耘科技打造的现代化GPU算力云服务平台,深度整合自研DS满血版大模型技术与分布式算力调度能力,形成"模型算力"双轮驱动的技术生态。平台核心优势如下: 平台定位…...

QtDesigner中Button控件详解
一:Button控件 关于Button控件的主要作用就是作为触发开关,通过点击事件(click)执行代码逻辑,或者作为功能入口,跳转到其他界面或模块。 二:常见属性与配置 ①Button的enabled,大…...
Flink 源码编译
打包命令 打包整个项目 mvn clean package -DskipTests -Drat.skiptrue打包单个模块 mvn clean package -DskipTests -Drat.skiptrue -pl flink-dist如果该模块依赖其他模块,可能需要先将其他模块 install 到本地,如果依赖的模块的源代码有修改&#…...
docker的安装和简单使用(ubuntu环境)
环境准备 这里用的是linux的环境,如果没有云服务器的话,就是用虚拟环境吧。 虚拟环境的安装参考:vmware17的安装 linux镜像的安装 docker安装 我使用的是ubuntu,使用以下命令: 更新本地软件包索引 sudo apt u…...

mongo客户端操作mongodb记录
背景: 长时间不操作mongodb数据库,已经遗忘了命令,今天正好用到,温习一下 直接上命令 #进入mongodb数据库安装bin目录cd /opt/mongodb/bin#连接mongodb ./mongo #查看所有的数据库 show dbs; #选择数据库 use xx; #查看表 show …...

Flink 数据清洗与字段标准化最佳实践
—— 构建可配置、可扩展的实时标准化清洗链路 本文是「Flink Kafka 构建实时数仓实战」专栏的第 4 篇,将围绕字段标准化这一核心问题,从业务痛点、技术架构、配置设计到完整代码工程,系统讲透标准化实践。 📌 一、为什么实时字段…...

哈工大李治军《操作系统》进程同步与信号量笔记
1.什么是信号量? 定义:记录一些信息(即量),并根据这个信息决定睡眠还是唤醒(即信号)。睡眠和唤醒只是一个信号(相当于0和1)。 2.问题:一种资源的数量是8&am…...
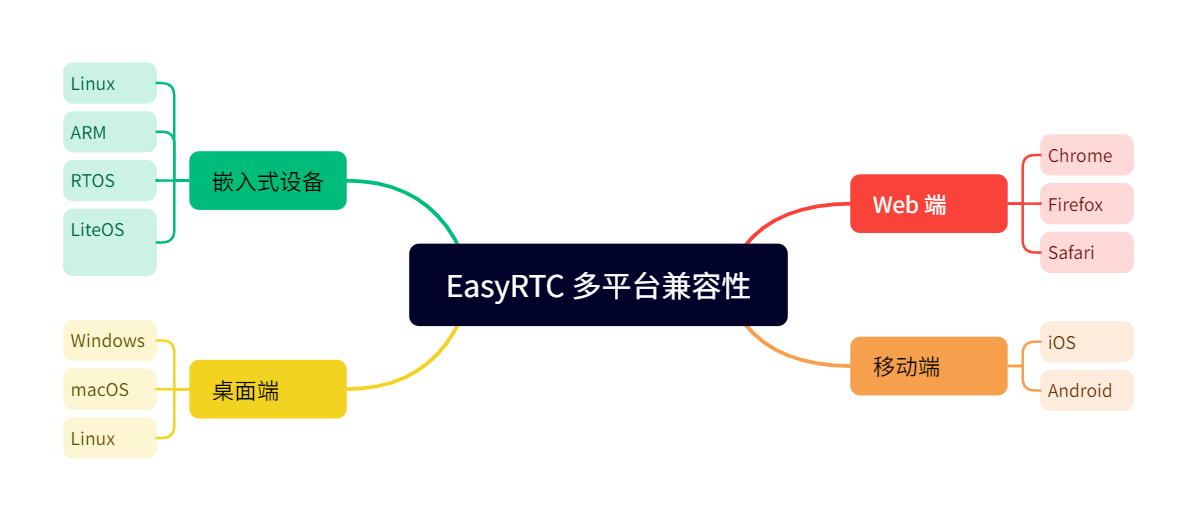
EasyRTC音视频实时通话在线教育解决方案:打造沉浸式互动教学新体验
一、方案概述 EasyRTC是一款基于WebRTC技术的实时音视频通信平台,为在线教育行业提供了高效、稳定、低延迟的互动教学解决方案。本方案将EasyRTC技术深度整合到在线教育场景中,实现师生间的实时音视频互动等核心功能,打造沉浸式的远程学习体…...
:DDoS攻击——分类、攻击机制及企业级防御策略)
常见网络安全攻击类型深度剖析(三):DDoS攻击——分类、攻击机制及企业级防御策略
常见网络安全攻击类型深度剖析(三):DDoS攻击——分类、攻击机制及企业级防御策略 在网络安全威胁中,分布式拒绝服务攻击(Distributed Denial of Service, DDoS)堪称“网络流量炸弹”。攻击者通过控制成百上…...

【分布式系统中的“瑞士军刀”_ Zookeeper】一、Zookeeper 快速入门和核心概念
在分布式系统的复杂世界里,协调与同步是确保系统稳定运行的关键所在。Zookeeper 作为分布式协调服务的 “瑞士军刀”,为众多分布式项目提供了高效、可靠的协调解决方案。无论是在分布式锁的实现、配置管理,还是在服务注册与发现等场景中&…...

Libconfig 修改配置文件里的某个节点
THCommandStatus ( { Status "1"; index 5; }, { Status "2"; index 8; }, { Status "3"; index 7; }, { Status "4"; index 0; } ); 比如这是配置文件的内容ÿ…...

从FP32到BF16,再到混合精度的全景解析
笔者做过目标检测模型、超分模型以及扩散生成模型。其中最常使用的是单精度FP32、半精度FP16、BF16。 双精度"FP64"就不说了,不太会用到。 #1. 单精度、半精度和混合精度 单精度(FP32)、半精度(FP16)和混合…...

Electron从入门到入门
项目说明 项目地址 项目地址:https://gitee.com/ruirui-study/electron-demo 本项目为示例项目,代码注释非常清晰,给大家当做入门项目吧。 其实很多东西都可以在我这基础上添加或修改、市面上有些已开源的项目,但是太臃肿了&am…...
优化提示词方面可以使用的数学方法理论:信息熵,概率论 ,最优化理论
优化提示词方面可以使用的数学方法理论:信息熵,概率论 ,最优化理论 目录 优化提示词方面可以使用的数学方法理论:信息熵,概率论 ,最优化理论信息论信息熵明确问题主题提供具体细节限定回答方向规范语言表达概率论最优化理论信息论 原理:信息论中的熵可以衡量信息的不确定性。…...

腾讯一面面经:总结一下
1. Java 中的 和 equals 有什么区别?比较对象时使用哪一个 1. 操作符: 用于比较对象的内存地址(引用是否相同)。 对于基本数据类型、 比较的是值。(8种基本数据类型)对于引用数据类型、 比较的是两个引…...
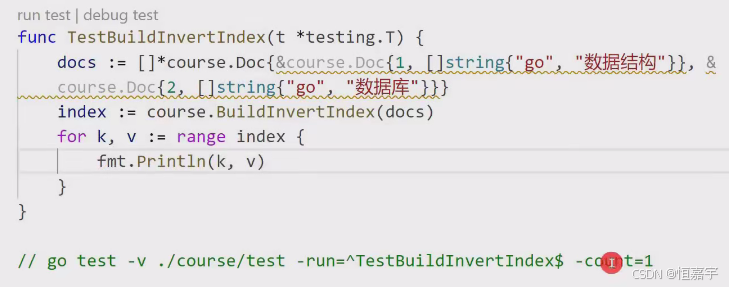
Golang | 倒排索引
文章目录 倒排索引的设计倒排索引v0版实现 倒排索引的设计 通用搜索引擎 v.s. 垂直搜索引擎: 通用搜索引擎:什么都可以搜索,更加智能化垂直搜索引擎:只能搜自家数据库里面的内容,一般都带着搜索条件,搜索一…...

大模型驱动智能服务变革:从全流程赋能到行业纵深落地
大模型技术的快速发展,正深刻改变着人工智能的研发与应用模式。作为"软硬协同、开箱即用"的智能化基础设施,大模型一体机通过整合计算硬件、部署平台和预置模型,重构了传统AI部署方式,成为推动AI普惠化和行业落地的重要…...
、f-string 对比与最佳实践)
【Python-Day 5】Python 格式化输出实战:%、format()、f-string 对比与最佳实践
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

【初识Trae】字节跳动推出的下一代AI原生IDE,重新定义智能编程
初识官网文档 从官网可以看到有两个大标签页,即Trae IDE CN和Trae插件,这就说明Trae在发布Trae IDE的同时考虑到对主流IDE的插件支持,这一点非常有心,但是我估测Trae IDE的体验更好(就是AI IDE出生,毕…...