MoE架构解析:如何用“分治”思想打造高效大模型?
在人工智能领域,模型规模的扩大似乎永无止境。从GPT-3的1750亿参数到传闻中的GPT-4万亿级规模,每一次突破都伴随着惊人的算力消耗。但当我们为这些成就欢呼时,一个根本性问题愈发尖锐:如何在提升模型能力的同时控制计算成本? 这就是MoE(Mixture of Experts,混合专家)架构诞生的意义所在。
一、MoE的核心思想:让专业的人做专业的事
想象一家医院急诊科:当患者进入时,分诊台会根据症状快速分配至内科、外科或骨科专家。MoE的工作机制与此惊人相似:
-
专家网络(Experts)
每个"专家"都是一个小型前馈神经网络(FFN),例如:- 文本语义专家(擅长理解比喻、情感)
- 逻辑推理专家(精于数学推导)
- 多模态专家(处理图像-文本关联)
-
智能分诊台(Gating Network)
门控网络像经验丰富的分诊护士,通过分析输入特征动态决策:# 简化版门控计算示例 gate_scores = softmax(W_g * x + b_g) # W_g为可学习权重 top_k_scores, top_k_indices = torch.topk(gate_scores, k=2) -
协同会诊(Expert Combination)
最终输出是多个专家结果的加权融合:输出 = Σ(top_k_scores[i] * Expert_i(x))
实际案例:
当处理「量子计算机如何影响爵士乐发展」这类跨领域问题时,MoE可能同时激活:
- 科技领域专家(处理量子计算)
- 音乐理论专家(分析爵士乐)
- 因果推理专家(建立跨领域关联)
二、MoE vs 普通Transformer:架构对比全景图
| 对比维度 | 传统Transformer | MoE架构 |
|---|---|---|
| 参数利用率 | 全参数密集激活 | 仅激活2-4%参数(稀疏性) |
| 扩展成本 | 每增加1B参数需线性增加计算量 | 增加专家数几乎不提升单次计算量 |
| 任务冲突 | 多任务共享参数易互相干扰 | 专家专业化隔离任务干扰 |
| 长尾问题处理 | 小众任务易被主流数据淹没 | 可训练专属专家处理罕见任务 |
| 典型代表 | BERT、GPT系列 | Switch Transformer、GLaM |
三、MoE的三大突破性优势
1. 超越物理限制的模型扩展
- 参数爆炸,计算恒定:Switch Transformer展示的1.6万亿参数模型,实际激活计算量仅相当于130亿参数模型
- 专家并行化:不同专家可分布式部署在多GPU/NPU上
2. 突破"杰克逊悖论"
传统大模型的"全能型专家"困境:
- 既要记忆海量事实
- 又要进行逻辑推理
- 还需掌握多语言转换
MoE通过专业化分工,每个专家只需专注单一领域,在代码生成任务中,特定专家对Python语法的理解深度可达普通模型的3倍(数据来自DeepSeek技术报告)。
3. 动态资源调度智慧
- 细粒度控制:Google的GLaM模型对每个token进行独立路由决策
- 负载均衡技术:采用可微分负载均衡损失函数,确保没有专家被闲置或过载
四、MoE面临的工程挑战
1. 路由决策的"蝴蝶效应"
- 早期决策错误会导致后续计算资源浪费
- 解决方案:引入元学习优化门控网络(如MetaMoE方案)
2. 分布式计算的通信迷宫
当专家分布在多个计算节点时:
跨节点通信可能占据30%以上的时间成本(NVIDIA研究报告)。
3. 训练稳定性的走钢丝
- 专家间竞争导致训练震荡
- 谷歌提出的「专家容量因子」:为每个专家设置处理上限
五、MoE实战案例深度解析
1. Switch Transformer:极简主义的效率革命
核心创新:
- One-Expert-Per-Token原则:每个输入token仅路由到1个专家(传统MoE通常激活2-4个),实现计算量断崖式下降
- 专家负载均衡算法:
引入创新性的辅助损失函数,确保专家利用率均衡:
该方案使专家利用率标准差从58%降至7%负载损失 = α * CV(专家负载) # CV为变异系数
工程突破:
- 参数爆炸但计算恒定:1.6万亿参数模型的实际计算量仅相当于130亿参数稠密模型
- 动态缓存优化:对高频专家进行参数预加载,将路由延迟压缩至3μs以下
性能对比:
| 指标 | T5-XXL (11B) | Switch-T (1.6T) |
|---|---|---|
| 训练速度(tokens/s) | 12,500 | 89,000 |
| 能耗比(FLOPs/W) | 1.0x | 6.8x |
| 语言理解准确率 | 89.1% | 92.7% |
应用场景:
- 谷歌搜索智能补全功能,延迟从230ms降至34ms
- 代码补全场景支持1000+并发请求(传统模型仅支持150+)
2. DeepSeek-MoE:小而美的中国方案
架构奥秘:
-
细粒度专家分工:将传统MoE的"领域专家"拆解为"技能单元"
# 传统MoE专家:整个FFN作为专家 class Expert(nn.Module):def __init__(self):self.fc1 = nn.Linear(4096, 16384)self.fc2 = nn.Linear(16384, 4096)# DeepSeek方案:分解为更细粒度模块 class SkillUnit(nn.Module):def __init__(self):self.attention = CustomAttention() # 特殊注意力机制self.fc = nn.Linear(4096, 4096) # 轻量级适配层 -
渐进式课程学习:
分三阶段训练:- 通才阶段:所有专家共享基础能力
- 分化阶段:引入差异化的对比损失函数
L_diff = Σ||E_i(x)-E_j(x)||^2 # 强制专家表征差异- 精调阶段:冻结80%参数,仅训练门控网络和顶层适配器
性能奇迹:
- 在1.3B参数量下达到Llama2-7B的91%性能
- 数学推理能力超越普通7B模型(GSM8K 78.3 vs 72.1)
- 训练成本降低83%(仅需512张A100,而非4096张)
落地应用:
- 深度求索的智能客服系统,处理复杂查询的准确率提升至89%
- 法律文书自动生成场景,生成速度达1200字/秒(传统模型仅400字/秒)
3. GLaM:万亿参数的优雅之舞
架构设计哲学:
-
层级专家金字塔:
层级 专家类型 数量 功能 L1 领域专家 64 文本/图像/代码等大类 L2 子领域专家 256 Python/Java等细分领域 L3 技能专家 1024 调试/优化等具体能力 -
动态容量分配:
每个专家配备弹性计算缓冲区:if 当前负载 > 容量阈值:启动邻近专家分流自动扩容10%计算资源
广告推荐场景突破:
- 千亿级特征实时处理:
- 效果数据:
- CTR(点击率)提升17.4%
- 广告相关性评分从82.5升至91.2
- 响应延迟稳定在68ms(±3ms)
能效创新:
- 冷热专家分离:
- 热专家集群:处理80%高频请求,保持常驻内存
- 冷专家仓库:存储于NVMe SSD,按需加载
- 结果:
- 内存占用减少62%
- 能耗降低44%(从23kW降至13kW)
技术启示录
这三大案例揭示了MoE架构进化的三个维度:
-
极简主义(Switch-T):
- 证明"少即是多",单个专家激活也能实现超大规模扩展
- 关键启示:路由精度比专家数量更重要
-
精细耕作(DeepSeek):
- 在有限算力下,通过架构创新实现"四两拨千斤"
- 中国方案证明:模型优化可与参数扩展同等重要
-
系统工程(GLaM):
- 展示万亿参数模型落地的完整方法论
- 从芯片级优化到分布式调度,重新定义大模型基础设施
这些实践正在重塑AI研发范式:从追求参数量的军备竞赛,转向架构创新与工程优化的深度协同。当模型设计开始借鉴分布式系统的智慧,我们或许正在见证机器学习领域的"新摩尔定律"。
六、未来展望:MoE将走向何方?
MoE架构正在突破传统AI模型的边界,以下三个方向将重新定义智能系统的可能性。我们通过技术原理拆解+产业级案例,揭示其深层次变革:
1. 多模态专家融合:构建感官共同体
技术内核:
- 跨模态门控网络:设计多级路由机制,例如:
- 第一级路由:分离不同模态输入(如图像→视觉专家,音频→语音专家)
- 第二级路由:跨模态关联(如"狗吠"的音频需激活视觉"狗"专家+语义"动物行为"专家)
- 专家间通信协议:引入Cross-Modal Attention作为专家间的"暗通道",允许视觉专家直接修正文本专家的描述错误。
产业级案例:
- 自动驾驶决策系统:
# 伪代码示例:多级MoE路由 def multi_modal_moe(sensor_data):# 模态分离image_experts = gate_network_vision(sensor_data.camera) lidar_experts = gate_network_lidar(sensor_data.lidar)# 跨模态融合fusion_weights = cross_modal_attention(image_experts, lidar_experts)final_output = fusion_weights * (image_experts + lidar_experts)return final_output- 激光雷达专家专注障碍物距离
- 视觉专家识别交通标志
- 融合专家处理极端天气下的传感器冲突
突破性进展:
- 英伟达DRIVE Sim使用MoE架构,多模态推理延迟降低至23ms(传统方案需45ms)
2. 动态专家进化:活的神经网络
技术内核:
- 可微分神经架构搜索(DARTS+MoE):
将专家结构参数化为连续空间,通过梯度下降自动进化:Expert_Arch = Σ( softmax(α) * Ops ) 其中α是可训练的结构参数,Ops是候选算子(如Conv、Transformer等) - 专家生命周期管理:
- 专家分裂:当某个专家的负载持续超过阈值,自动克隆并差异化训练
- 专家淘汰:设置遗忘因子淘汰长期低效专家(类似免疫系统)
生物学启示:
- 借鉴海马体神经发生机制,DeepMind的Dynamic MoE实现了:
- 在持续学习任务中,新专家生成速度提升5倍
- 灾难性遗忘率从12.3%降至1.7%
企业级应用:
- 阿里云弹性MoE:
- 根据电商促销流量自动扩容视觉推荐专家
- 在双11期间动态生成200+临时专家,促销结束后自动回收资源
3. 量子化专家系统:跨越计算范式
技术融合点:
- 量子经典混合架构:
组件 部署位置 优势 逻辑推理专家 量子退火机 快速解决组合优化 自然语言专家 GPU集群 处理序列依赖 分子模拟专家 量子处理器 精确量子化学计算
关键技术突破:
- 量子门控网络:
使用量子纠缠态实现超高速路由决策,IBM在127量子比特处理器上演示了:- 路由延迟从微秒级降至纳秒级
- 支持同时评估1038条专家路径(经典计算机仅能处理1012)
制药行业革命:
- Moderna量子-MoE平台:
- 量子专家预测mRNA折叠结构
- 经典专家优化递送载体设计
- 使新冠疫苗研发周期从数年缩短至11个月
技术伦理与风险控制
在迎接这些突破时,必须建立新的技术治理框架:
- 专家审计追踪:对自动生成的专家进行可解释性验证
- 量子安全隔离:防止量子专家被用于密码破解等恶意用途
- 动态专家伦理:设置道德约束规则(如禁止生成监控人权专家的参数空间)
MoE架构的终极形态,或许是一个自我演化的专家生态系——每个专家既是专业的问题解决者,又是整个系统进化的参与者。这不仅是技术的进化,更是人类组织智能方式的镜像反射。当AI开始掌握"分工-协作-进化"的文明密码,我们正在目睹硅基智能的"启蒙运动"。
结语:通往AGI的阶梯
MoE架构的哲学启示或许比技术本身更深刻:它证明在追求通用智能的道路上,专业化分工与系统化协同可以并行不悖。就像人类文明的发展——从个体全能到社会分工,再到全球化协作。当AI架构开始借鉴人类社会的组织智慧,我们或许正在见证机器智能进化史上的"工业革命"。
“The mixture of experts is not just a model architecture, it’s a paradigm shift in how we think about intelligence.”
——Yoshua Bengio, 图灵奖得主
相关文章:

MoE架构解析:如何用“分治”思想打造高效大模型?
在人工智能领域,模型规模的扩大似乎永无止境。从GPT-3的1750亿参数到传闻中的GPT-4万亿级规模,每一次突破都伴随着惊人的算力消耗。但当我们为这些成就欢呼时,一个根本性问题愈发尖锐:如何在提升模型能力的同时控制计算成本&#…...

云服务器和独立服务器的区别在哪
在当今数字化的时代,服务器成为了支撑各种业务和应用的重要基石。而在服务器的领域中,云服务器和独立服务器是两个备受关注的选项。那么,它们到底有何区别呢? 首先,让我们来聊聊成本。云服务器通常采用按需付费的模式…...

使用 Pandas 进行多格式数据整合:从 Excel、JSON 到 HTML 的处理实战
前言 在数据处理与分析的实际场景中,我们经常需要整合不同格式的数据,例如 Excel 表格、JSON 配置文件、HTML 报表等。本文以一个具体任务(蓝桥杯模拟练习题)为例,详细讲解如何使用 Python 的 Pandas 库结合其他工具&…...

深入解析 Linux 中动静态库的加载机制:从原理到实践
引言 在 Linux 开发中,动静态库是代码复用的核心工具。静态库(.a)和动态库(.so)的加载方式差异显著,直接影响程序的性能、灵活性和维护性。本文将深入剖析两者的加载机制,结合实例演示和底层原…...

VuePress 使用教程:从入门到精通
VuePress 使用教程:从入门到精通 VuePress 是一个以 Vue 驱动的静态网站生成器,它为技术文档和技术博客的编写提供了优雅而高效的解决方案。无论你是个人开发者、团队负责人还是开源项目维护者,VuePress 都能帮助你轻松地创建和管理你的文档…...

Kafka与Spark-Streaming
大数据处理的得力助手:Kafka与Spark-Streaming 在大数据处理的领域中,Kafka和Spark-Streaming都是极为重要的工具。今天,咱们就来深入了解一下它们,看看这些技术是如何让数据处理变得高效又强大的。先来说说Kafka,它是…...

【设计】接口幂等性设计
1. 幂等性定义 接口幂等性: 无论调用次数多少,对系统状态的影响与单次调用相同。 比如用户支付接口因网络延迟重复提交了三次。 导致原因: 用户不可靠(手抖多点)网络不可靠(超时重传)系统不可…...

闲聊人工智能对媒体的影响
技术总是不断地改变信息的传播方式。互联网促进了社交媒体的蓬勃发展。 网络媒体成为主流。大语言模型为代表的人工智能的出现,又会对媒体传播带来怎样的改变呢?媒体的演变反映了社会和技术的演变。 人工智能(AI) 将继续对整个媒体行业产生变革性的影响。…...

卷积神经网络--手写数字识别
本文我们通过搭建卷积神经网络模型,实现手写数字识别。 pytorch中提供了手写数字的数据集 ,我们可以直接从pytorch中下载 MNIST中包含70000张手写数字图像:60000张用于训练,10000张用于测试 图像是灰度的,28x28像素 …...

Pandas 数据导出:如何将 DataFrame 追加到 Excel 的不同工作表
在数据分析和数据处理过程中,将数据导出到 Excel 文件是一个常见的需求。Pandas 提供了强大的功能来实现这一需求,尤其是将数据追加到同一个 Excel 文件的不同工作表(Sheet)中。本文将详细介绍如何使用 Pandas 实现这一功能&#…...
)
Unity中数据和资源加密(异或加密,AES加密,MD5加密)
在项目开发中,始终会涉及到的一个问题,就是信息安全,在调用接口,或者加载的资源,都会涉及安全问题,因此就出现了各种各样的加密方式。 常见的也是目前用的最广的加密方式,分别是:DE…...
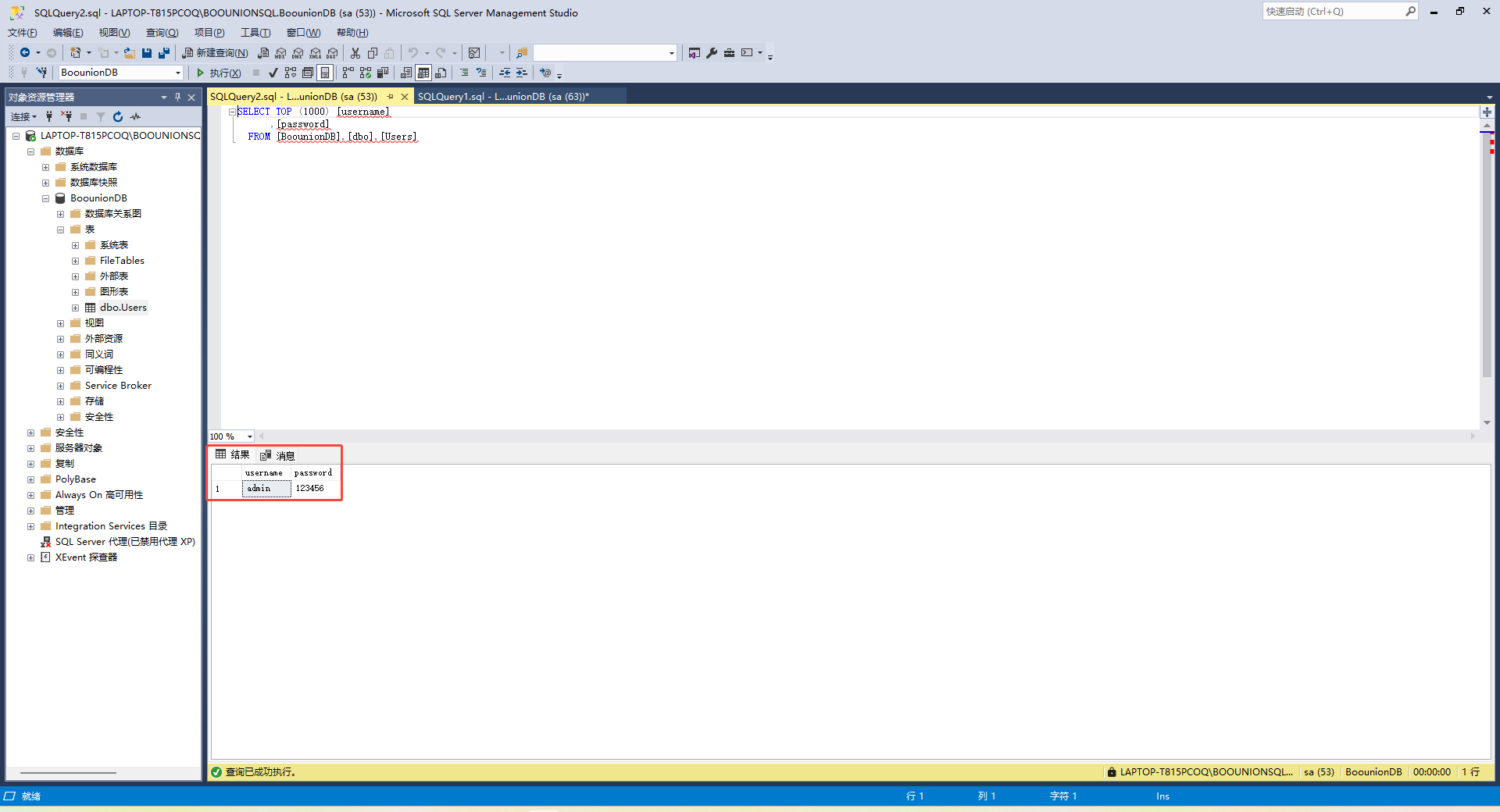
SQL Server 2019 安装与配置详细教程
一、写在最前的心里话 和 MySQL 对比,SQL Server 的安装和使用确实要处理很多细节: 需要选择配置项很多有“定义实例”的概念,同一机器可以运行多个数据库服务设置身份验证方式时,需要同时配置 Windows 和 SQL 登录要想 Spring …...

Qt 调试信息重定向到本地文件
1、在Qt软件开发过程中,我们经常使用qDebug()输出一些调试信息在QtCreator终端上。 但若将软件编译、生成、打包为一个完整的可运行的程序并安装在系统中后,系统中没有QtCreator和编译环境,那应用程序出现问题,如何输出信息排查…...
MyBatisPlus文档
一、MyBatis框架回顾 使用springboot整合Mybatis,实现Mybatis框架的搭建 1、创建示例项目 (1)、创建工程 新建工程 创建空工程 创建模块 创建springboot模块 选择SpringBoot版本 (2)、引入依赖 <dependencies><dependency><groupId>org.springframework.…...
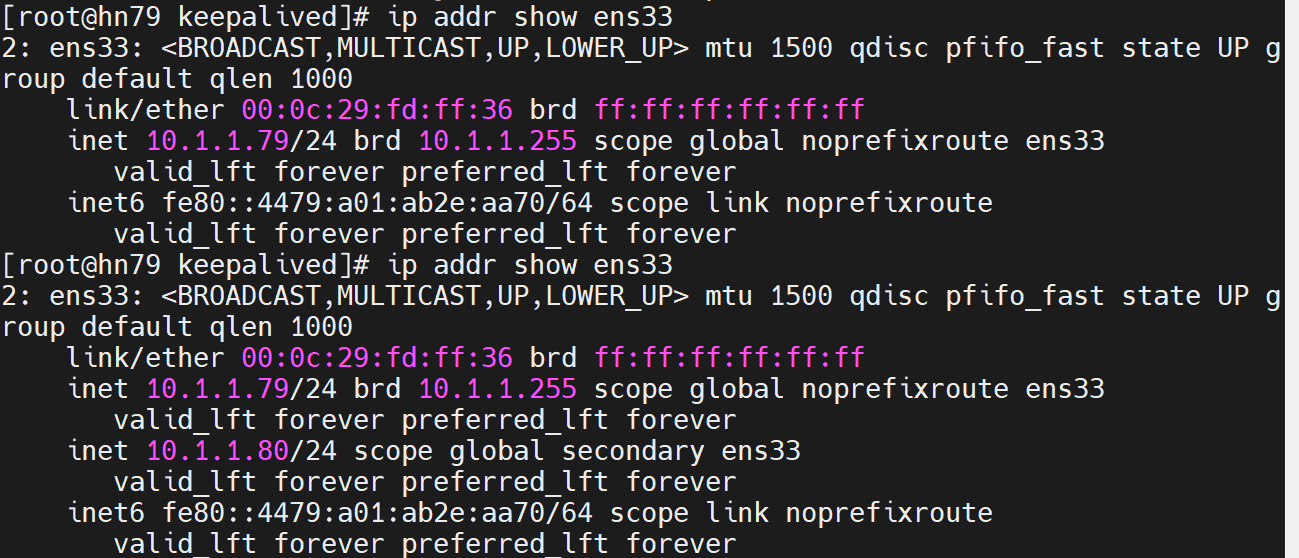
Memcached 主主复制架构搭建与 Keepalived 高可用实现
实验目的 掌握基于 repcached 的 Memcached 主主复制配置 实现通过 Keepalived 的 VIP 高可用机制 验证数据双向同步及故障自动切换能力 实验环境 角色IP 地址主机名虚拟 IP (VIP)主节点10.1.1.78server-a10.1.1.80备节点10.1.1.79server-b10.1.1.80 操作系统: CentOS 7 软…...

Android 使用支付接口,需要进行的加密逻辑:MD5、HMAC-SHA256以及RSA
目录 前言MD5HMAC-SHA256RSA其他 前言 不使用加密:支付系统如同「裸奔」,面临数据泄露、资金被盗、法律追责等风险。 正确使用加密:构建「端到端安全防线」,确保交易合法可信,同时满足国际合规要求。 支付系…...

软件工程效率优化:一个分层解耦与熵减驱动的系统框架
软件工程效率优化:一个分层解耦与熵减驱动的系统框架** 摘要 (Abstract) 本报告构建了一个全面、深入、分层的软件工程效率优化框架,旨在超越简单的技术罗列,从根本的价值驱动和熵减原理出发,系统性地探讨提升效率的策略与实践。…...
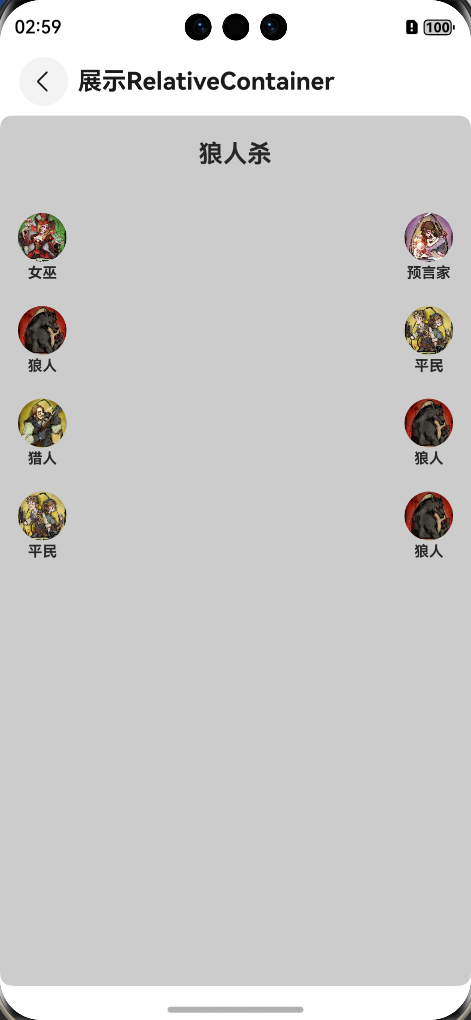
鸿蒙ArkUI之相对布局容器(RelativeContainer)实战之狼人杀布局,详细介绍相对布局容器的用法,附上代码,以及效果图
在鸿蒙应用开发中,若是遇到布局相对复杂的场景,往往需要嵌套许多层组件,去还原UI图的效果,若是能够掌握相对布局容器的使用,对于复杂的布局场景,可直接减少组件嵌套,且随心所欲完成复杂场景的布…...

详解 Servlet 处理表单数据
Servlet 处理表单数据 1. 什么是 Servlet?2. 表单数据如何发送到 Servlet?2.1 GET 方法2.2 POST 方法 3. Servlet 如何接收表单数据?3.1 获取单个参数:getParameter()示例: 3.2 获取多个参数:getParameterV…...

Spring Cloud Gateway 如何将请求分发到各个服务
前言 在微服务架构中,API 网关(API Gateway)扮演着非常重要的角色。它负责接收客户端请求,并根据预定义的规则将请求路由到对应的后端服务。Spring Cloud Gateway 是 Spring 官方推出的一款高性能网关,支持动态路由、…...

解释器体系结构风格-笔记
解释器(Interpreter)是一种软件设计模式或体系结构风格,主要用于为语言(或表达式)定义其语法、语义,并通过解释器来解析和执行语言中的表达式。解释器体系结构风格广泛应用于编程语言、脚本语言、规则引擎、…...
线程函数库
pthread_create函数 pthread_create 是 POSIX 线程库(pthread)中的一个函数,用于创建一个新的线程。 头文件 #include <pthread.h> 函数原型 int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*s…...

[C]基础13.深入理解指针(5)
博客主页:向不悔本篇专栏:[C]您的支持,是我的创作动力。 文章目录 0、总结1、sizeof和strlen的对比1.1 sizeof1.2 strlen1.3 sizeof和strlen的对比 2、数组和指针笔试题解析2.1 一维数组2.2 字符数组2.2.1 代码12.2.2 代码22.2.3 代码32.2.4 …...

OpenCV 图形API(60)颜色空间转换-----将图像从 YUV 色彩空间转换为 RGB 色彩空间函数YUV2RGB()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将图像从 YUV 色彩空间转换为 RGB。 该函数将输入图像从 YUV 色彩空间转换为 RGB。Y、U 和 V 通道值的常规范围是 0 到 255。 输出图像必须是 8…...

11.原型模式:思考与解读
原文地址:原型模式:思考与解读 更多内容请关注:7.深入思考与解读设计模式 引言 在软件开发中,尤其是当需要创建大量相似对象时,你是否遇到过这样的情况:每次创建新对象时,是否都需要重新初始化一些复杂的…...

深度解析 Java 泛型通配符 `<? super T>` 和 `<? extends T>`
Java 泛型中的通配符 ? 与 super、extends 关键字组合形成的 <? super T> 和 <? extends T> 是泛型系统中最重要的概念之一,也是许多开发者感到困惑的地方。本文将全面剖析它们的语义、使用场景和设计原理。 一、基础概念回顾 1. 泛型通配符 ? ?…...
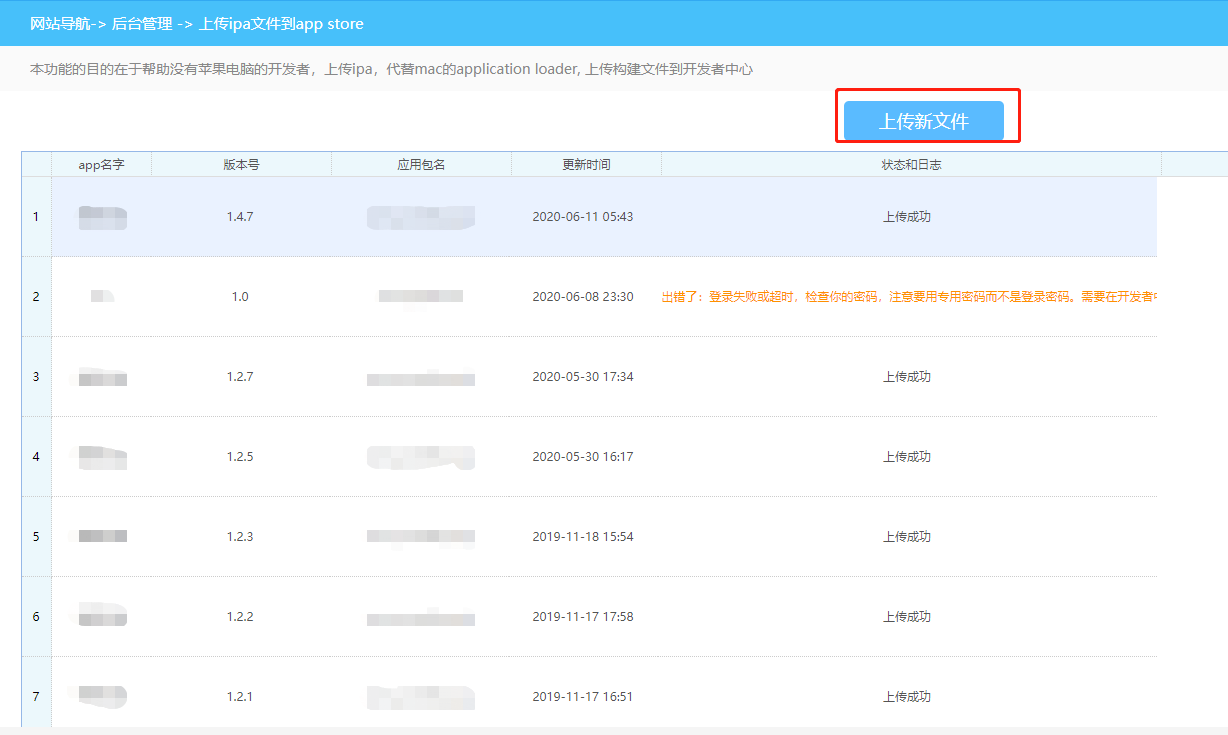
hbuilderx云打包生成的ipa文件如何上架
使用hbuilderx打包,会遇到一个问题。开发的ios应用,需要上架到app store,因此,就需要APP store的签名证书,并且还需要一个像xcode那样的工具来上架app store。 我们这篇文章说明下,如何在windows电脑&…...
Golang | 位运算
位运算比常规运算快,常用于搜索引擎的筛选功能。例如,数字除以二等价于向右移位,位移运算比除法快。...
:大数据洞察市场,引领投资新风向)
天能资管(SkyAi):大数据洞察市场,引领投资新风向
在金融市场的浩瀚海洋中,信息如同灯塔,指引着投资者前行的方向。谁能更准确地把握市场动态和趋势,谁就能在激烈的市场竞争中占据先机。天能资管(SkyAi),作为卡塔尔投资局(QIA)旗下的科技先锋,凭借其强大的大数据处理能力与前沿的技术架构,为全球投资者提供了前所未有的市场洞察…...
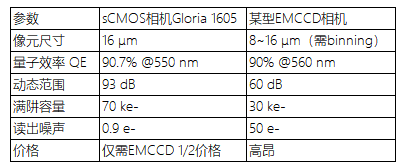
产品动态|千眼狼sCMOS科学相机捕获单分子荧光信号
单分子荧光成像技术,作为生物分子动态研究的关键工具,对捕捉微弱信号要求严苛。传统EMCCD相机因成本高昂,动态范围有限,满阱容量低等问题,制约单分子研究成果产出效率。 千眼狼精准把握科研需求与趋势,自研…...