《AI大模型趣味实战》基于RAG向量数据库的知识库AI问答助手设计与实现
基于RAG向量数据库的知识库AI问答助手设计与实现
引言
随着大语言模型(LLM)技术的快速发展,构建本地知识库AI问答助手已成为许多企业级应用的需求。本研究报告将详细介绍如何基于FLASK开发一个使用本地OLLAMA大模型底座的知识库AI问答助手,该系统能够整合两部分知识语料:网站博客(存储在SQLite数据库中)和后台配置的知识博客URL链接内容(通过爬虫获取)。系统采用RAG(检索增强生成)技术,在用户提问时能够从两部分知识库中检索相关信息并生成高质量回答。
RAG技术概述
RAG(检索增强生成)是一种结合了检索系统和生成模型的技术,它首先从大型文档集合中检索相关信息,然后使用这些信息来生成最终答案。RAG的核心思想是"检索+生成":前者主要利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案[1]。
RAG架构通常使用转换器实现,包含编码器和解码器两部分。当用户提出问题时,输入文本被"编码"为捕获单词含义的向量,而向量被"解码"到我们的文档内容中[2]。

系统架构设计
整体架构
基于用户需求,我们设计了一个完整的AI问答助手系统架构,主要包含以下几个部分:
- 前端Web应用:基于FLASK开发,提供用户交互界面
- 向量数据库:使用Milvus存储和检索向量表示的知识
- 大模型底座:使用本地OLLAMA运行大模型
- 知识处理组件:处理SQLite数据库中的博客和URL链接内容
- RAG组件:实现检索和生成功能
整体技术细节为: - 嵌入模型使用Sentence Transformers
- 本地使用OLLAMA部署大模型
- 使用Milvus作为向量数据库
- 使用LangChain作为框架集成各组件
技术选型
Milvus向量数据库
Milvus是一个专为处理和搜索大量向量数据而设计的强大向量数据库。它以高性能和可扩展性著称,非常适合机器学习、深度学习、相似性搜索任务和推荐系统[5]。Milvus的主要功能包括:
- 高性能向量检索能力,支持百亿级别的向量索引
- 多种搜索方式(top-K & Range ANN搜索、稀疏和稠密向量搜索、多向量搜索、Grouping搜索)
- 提供元数据过滤功能
- 支持多租户架构
- 支持数据分区分片、数据持久化、增量数据摄取
- 支持标量向量混合查询和time travel功能
Milvus被广泛应用于智能客服、推荐系统、NLP服务、计算机视觉等领域,能够为大模型提供强大的知识库支持[6]。
Ollama本地大模型
Ollama是一个开源平台,可简化大型语言模型(LLM)的本地运行和定制。它提供了用户友好的无云体验,无需高级技术技能即可轻松实现模型部署[10]。Ollama的主要特点包括:
- 本地部署:不依赖云端服务,用户可以在自己的设备上运行模型
- 简化模型管理:提供便捷的模型管理功能
- 丰富的预建模型库:支持多种主流模型
- 跨平台支持:可在不同操作系统上运行
- 灵活的自定义选项:允许用户根据需求调整模型
Ollama通过提供便捷的模型管理、丰富的预建模型库、跨平台支持以及灵活的自定义选项,使得开发者和研究人员能够轻松使用大型语言模型[15]。
LangChain框架
LangChain是一个专门为LLM应用设计的框架,它允许开发人员将不同的组件像链一样串在一起,以围绕LLM创建更高级的应用。LangChain提供了一系列模块,这些模块是任何LLM应用的基础[49]。
LangChain的核心思想是开发人员可以将不同的组件像链一样串在一起,以围绕LLM创建更高级的示例。LangChain提供了一系列模块,这些模块是作为任何LLM应用的基础[49]。
系统流程设计
系统的主要流程包括:
- 知识库构建:
- 从SQLite数据库中读取博客内容
- 爬取后台配置的URL链接内容
- 使用文档加载器和拆分器处理文本内容
- 使用嵌入模型生成向量表示
- 将向量和元数据存储到Milvus数据库中
- 用户提问处理:
- 接收用户提问
- 使用相同的嵌入模型生成提问向量
- 从Milvus中检索相关知识
- 使用大模型和检索到的知识生成回答
- 大模型推理:
- 使用OLLAMA运行大模型
- 通过LangChain的ChatModel接口与大模型交互
- 生成最终回答
系统组件实现
知识库构建
1. 从SQLite数据库读取博客内容
首先需要从SQLite数据库中读取博客内容。可以使用Python的sqlite3模块来实现:
import sqlite3
from typing import List, Dict
def fetch_blog_content(db_path: str) -> List[Dict[str, str]]:"""从SQLite数据库中读取博客内容"""conn = sqlite3.connect(db_path)cursor = conn.cursor()# 假设博客表名为blogs,包含id、title、content等字段cursor.execute("SELECT id, title, content FROM blogs")rows = cursor.fetchall()blogs = []for row in rows:blog = {"id": row[0],"title": row[1],"content": row[2]}blogs.append(blog)conn.close()return blogs
2. 爬取后台配置的URL链接内容
需要爬取后台配置的URL链接内容。可以使用Python的requests和BeautifulSoup库来实现:
import requests
from bs4 import BeautifulSoup
from typing import List, Dict
def crawl_url_content(urls: List[str]) -> List[Dict[str, str]]:"""爬取指定URL的内容"""crawled_content = []for url in urls:try:response = requests.get(url)response.raise_for_status()soup = BeautifulSoup(response.text, 'html.parser')# 假设我们只关心正文内容content = soup.get_text()crawled_content.append({"url": url,"content": content})except Exception as e:print(f"Error crawling {url}: {e}")return crawled_content
3. 文档加载和拆分
使用LangChain的文档加载器和拆分器来处理文本内容。对于结构化数据(如博客),可以使用Pydantic加载器;对于非结构化数据(如网页内容),可以使用Text加载器。然后使用RecursiveCharacterTextSplitter将文本拆分为适当的块大小:
from langchain.document_loaders import Pydantic, Text
from langchain.text_splitter import RecursiveCharacterTextSplitter
from typing import List, Dict, Any
def process_documents(documents: List[Dict[str, str]]) -> List[Dict[str, Any]]:"""处理文档内容,包括加载和拆分"""processed_docs = []for doc in documents:# 根据文档类型选择合适的加载器if "blog" in doc: # 假设我们用"blog"标记博客内容loader = Pydantic(BlogDocument)else:loader = Text()# 加载文档loaded_doc = loader.load(doc)# 使用递归字符拆分器拆分文本text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200)splits = text_splitter.split_documents([loaded_doc])for split in splits:processed_docs.append({"content": split.page_content,"metadata": split.metadata})return processed_docs
4. 向量化和存储到Milvus
使用嵌入模型(如Sentence Transformers)将文本内容转换为向量,并存储到Milvus数据库中:
from sentence_transformers import SentenceTransformer
import numpy as np
from milvus import Milvus
def embed_and_store_to_milvus(documents: List[Dict[str, str]], milvus_host: str, milvus_port: int, collection_name: str):"""将文档内容嵌入向量并存储到Milvus"""# 加载嵌入模型model = SentenceTransformer('all-MiniLM-L6-v2')# 连接到Milvusmilvus = Milvus(host=milvus_host, port=milvus_port)# 检查集合是否存在,如果不存在则创建if collection_name not in milvus.list_collections():milvus.create_collection(collection_name, dim=model.get_sentence_embedding_dimension(),index_params={'index_type': 'IVF_FLAT','params': {'nlist': 100},'metric_type': 'L2'})# 准备向量和元数据embeddings = []metadatas = []for doc in documents:# 生成嵌入向量embedding = model.encode(doc["content"]).astype(np.float32).tolist()embeddings.append(embedding)# 准备元数据metadata = {"source": doc["source"], "chunk": doc["chunk"]}metadatas.append(metadata)# 插入到Milvusstatus, ids = milvus.insert(collection_name=collection_name,records=embeddings,metadatas=metadatas)if status.OK():print(f"Successfully inserted {len(ids)} documents into Milvus collection {collection_name}")else:print(f"Error inserting documents into Milvus: {status}")
用户提问处理
1. 提问向量化
使用相同的嵌入模型将用户提问转换为向量:
from sentence_transformers import SentenceTransformer
import numpy as np
def vectorize_query(query: str, model: SentenceTransformer) -> List[float]:"""将用户提问向量化"""query_vector = model.encode(query).astype(np.float32).tolist()return query_vector
2. 从Milvus中检索相关知识
使用Milvus从向量数据库中检索最相关的知识:
from milvus import Milvus
def retrieve_from_milvus(query_vector: List[float],milvus_host: str,milvus_port: int,collection_name: str,top_k: int = 5) -> List[Dict[str, Any]]:"""从Milvus中检索相关知识"""# 连接到Milvusmilvus = Milvus(host=milvus_host, port=milvus_port)# 检索status, results = milvus.search(collection_name=collection_name,query_records=[query_vector],top_k=top_k,params={'nprobe': 10})if status.OK():# 解析结果retrieved_docs = []for result in results[0]:doc = {"content": result.id, # 假设id存储了内容"score": result.distance,"metadata": result.metadata}retrieved_docs.append(doc)return retrieved_docselse:print(f"Error retrieving from Milvus: {status}")return []
3. 使用大模型生成回答
使用OLLAMA运行大模型,并使用检索到的知识生成回答:
import requests
from typing import Dict, Any
def query_ollama_model(query: str,context: str,model_name: str,ollama_host: str,ollama_port: int) -> str:"""使用OLLAMA查询大模型"""prompt = f"根据以下上下文回答问题:\n\n{context}\n\n问题:{query}\n\n回答:"endpoint = f"http://{ollama_host}:{ollama_port}/api/generate"payload = {"model": model_name,"prompt": prompt,"stream": False}response = requests.post(endpoint, json=payload)if response.status_code == 200:return response.json()["response"]else:print(f"Error querying Ollama model: {response.status_code} {response.text}")return "无法生成回答,请稍后再试。"
系统集成
将各个组件集成到一个完整的FLASK应用中:
from flask import Flask, request, jsonify
import sqlite3
import requests
from bs4 import BeautifulSoup
from sentence_transformers import SentenceTransformer
import numpy as np
from milvus import Milvus
app = Flask(__name__)
# 配置参数
SQLITE_DB_PATH = "path/to/blog.db"
MILVUS_HOST = "localhost"
MILVUS_PORT = 19530
MILVUS_COLLECTION_NAME = "knowledge_base"
OLLAMA_HOST = "localhost"
OLLAMA_PORT = 11434
MODEL_NAME = "deepseek"
# 初始化Milvus连接
milvus = Milvus(host=MILVUS_HOST, port=MILVUS_PORT)
# 初始化嵌入模型
model = SentenceTransformer('all-MiniLM-L6-v2')
@app.route("/build-kb", methods=["POST"])
def build_knowledge_base():"""构建知识库"""# 从SQLite中读取博客内容blogs = fetch_blog_content(SQLITE_DB_PATH)# 爬取URL内容urls = request.json.get("urls", [])url_content = crawl_url_content(urls)# 处理文档documents = process_documents(blogs + url_content)# 向量化并存储到Milvusembed_and_store_to_milvus(documents, MILVUS_HOST, MILVUS_PORT, MILVUS_COLLECTION_NAME)return jsonify({"status": "success", "message": "知识库构建完成"}), 200
@app.route("/query", methods=["POST"])
def query_knowledge_base():"""查询知识库"""query = request.json.get("query", "")if not query:return jsonify({"status": "error", "message": "查询不能为空"}), 400# 向量化查询query_vector = vectorize_query(query, model)# 从Milvus中检索retrieved_docs = retrieve_from_milvus(query_vector,MILVUS_HOST,MILVUS_PORT,MILVUS_COLLECTION_NAME,top_k=5)if not retrieved_docs:return jsonify({"status": "error", "message": "未找到相关知识"}), 404# 组合上下文context = "\n".join([doc["content"] for doc in retrieved_docs])# 使用大模型生成回答answer = query_ollama_model(query, context, MODEL_NAME, OLLAMA_HOST, OLLAMA_PORT)return jsonify({"status": "success","answer": answer,"sources": [doc["metadata"] for doc in retrieved_docs]}), 200
if __name__ == "__main__":app.run(debug=True)
系统部署方案
环境要求
- 硬件要求:
- CPU:支持AVX2指令集
- 内存:至少16GB RAM
- 存储:足够存储知识库和模型参数
- GPU:可选,用于加速大模型推理
- 软件要求:
- 操作系统:Linux/Windows/macOS(推荐Linux)
- Python:3.8或更高版本
- 依赖库:Milvus、OLLAMA、LangChain等
安装步骤
- 安装Milvus:
- 下载并安装Milvus:
curl -L https://github.com/milvus-io/milvus/releases/download/v2.5.1/milvus-2.5.1-linux-amd64.tar.gz | tar xz - 启动Milvus:
bin/milvus_server start
- 下载并安装Milvus:
- 安装OLLAMA:
- 下载并安装OLLAMA:
curl -L https://github.com/ollama/ollama/releases/download/v1.3.0/ollama_1.3.0_Linux_x86_64.tar.gz | tar xz - 启动OLLAMA:
./ollama serve
- 下载并安装OLLAMA:
- 安装Python依赖:
pip install flask requests beautifulsoup4 sentence-transformers numpy milvus-langchain-connector
配置步骤
- 配置Milvus:
- 确保Milvus服务已启动并监听在默认端口(19530)
- 创建知识库集合(如果尚不存在)
- 配置OLLAMA:
- 确保OLLAMA服务已启动并监听在默认端口(11434)
- 下载并加载所需模型:
ollama pull deepseek
- 配置FLASK应用:
- 设置SQLite数据库路径
- 设置Milvus连接参数
- 设置OLLAMA连接参数
- 设置默认模型名称
运行和测试
- 构建知识库:
- 从SQLite数据库中读取博客内容
- 爬取后台配置的URL链接内容
- 处理文档并存储到Milvus
- 进行问答测试:
- 发送用户提问
- 系统从Milvus中检索相关知识
- 使用大模型生成回答
系统优化与扩展
性能优化
- 向量索引优化:
- 调整IVF_FLAT索引的nlist参数
- 考虑使用更高效的索引类型,如HNSW
- 为不同类型的文档使用不同的索引策略
- 模型优化:
- 选择合适的嵌入模型(如all-MiniLM-L6-v2或更大模型)
- 调整大模型的参数(如temperature、top_p等)
- 考虑使用量化技术减少模型大小和推理时间
- 文档处理优化:
- 调整文本拆分的chunk_size和chunk_overlap
- 使用更智能的文档重要性评估方法
- 考虑使用多语言处理技术
功能扩展
- 支持更多知识源:
- 添加PDF、PPT、DOCX等文件格式的支持
- 集成企业内部知识管理系统
- 支持实时数据源的自动更新
- 增强用户体验:
- 提供更友好的Web界面
- 添加语音交互功能
- 实现多轮对话上下文记忆
- 监控和分析:
- 添加API调用日志记录
- 实现性能监控和分析
- 提供知识库使用统计报告
结论
本报告详细介绍了如何基于FLASK开发一个使用本地OLLAMA大模型底座的知识库AI问答助手。该系统通过RAG技术整合了两部分知识语料:网站博客(存储在SQLite数据库中)和后台配置的知识博客URL链接内容(通过爬虫获取)。系统主要由前端Web应用、向量数据库Milvus、本地大模型OLLAMA和知识处理组件组成,使用LangChain作为框架集成各组件。
通过本设计方案,企业可以构建一个高效、安全、可定制的AI问答系统,能够快速响应用户问题并提供基于本地知识库的支持。随着技术的不断发展,该系统可以通过多种方式进行优化和扩展,以满足更复杂的应用需求。
参考资料
[1] 一文读懂:大模型RAG(检索增强生成)含高级方法 - 知乎专栏. https://zhuanlan.zhihu.com/p/675509396.
[2] 15-检索增强生成(RAG) 和向量数据库 - 飞书文档. https://docs.feishu.cn/article/wiki/OinzwWLXGi2cQUkiNYjceAVunVg.
[5] 高性能向量数据库,为规模而构建 - Milvus. https://milvus.io/zh.
[6] 向量数据库Milvus_功能优势 - 金山云. https://www.ksyun.com/nv/product/Milvus.html.
[10] 使用Milvus 和Ollama 构建RAG. https://milvus.io/docs/zh/build_RAG_with_milvus_and_ollama.md.
[15] Ollama本地部署大模型及应用原创 - CSDN博客. https://blog.csdn.net/qq_43548590/article/details/142546580.
[49] 使用OpenAI、LangChain 和LlamaIndex 构建Knowledge. https://developer.aliyun.com/article/1394419.
相关文章:
《AI大模型趣味实战》基于RAG向量数据库的知识库AI问答助手设计与实现
基于RAG向量数据库的知识库AI问答助手设计与实现 引言 随着大语言模型(LLM)技术的快速发展,构建本地知识库AI问答助手已成为许多企业级应用的需求。本研究报告将详细介绍如何基于FLASK开发一个使用本地OLLAMA大模型底座的知识库AI问答助手&…...

Lua 第8部分 补充知识
8.1 局部变量和代码块 Lua 语言中的变量在默认情况下是全局变量 ,所有的局部变量在使用前必须声明 。 与全局变量不同,局部变量的生效范围仅限于声明它的代码块。一个代码块( block )是一个控制结构的主体,或是一个函…...

正则表达式三剑客之——awk命令
目录 一.什么是awk 二.awk的语法格式 1.选项 2. 模式(Pattern) 3. 操作(Action) 4. 输入文件(file) 5.总结 三.awk的工作原理 1. 逐行扫描输入 2. 匹配模式 1.正则表达式: 2.逻辑…...

BeeWorks Meet:私有化部署视频会议的高效选择
在数字化时代,视频会议已成为企业沟通协作的重要工具。然而,对于金融、政务、医疗等对数据安全和隐私保护要求极高的行业来说,传统的公有云视频会议解决方案往往难以满足其严格的安全标准。此时,BeeWorks Meet 私有化部署视频会议…...

[Mybatis-plus]
简介 MyBatis-Plus (简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变。Mybatis-plus官网地址 注意,在引入了mybatis-plus之后,不要再额外引入mybatis和mybatis-spring,避免因为版本…...
IPv6 技术细节 | 源 IP 地址选择 / Anycast / 地址自动配置 / 地址聚类分配
注:本文为 “IPv6 技术细节” 相关文章合集。 部分文章中提到的其他文章,一并引入。 略作重排,未整理去重。 如有内容异常,请看原文。 闲谈 IPv6 - 典型特征的一些技术细节 iteye_21199 于 2012-11-10 20:54:00 发布 0. 巨大的…...

【高频考点精讲】ES6 String的新增方法,处理字符串更方便了
ES6 String的新增方法:处理字符串从未如此优雅 【初级】前端开发工程师面试100题(一) 【初级】前端开发工程师面试100题(二) 【初级】前端开发工程师的面试100题(速记版) 作为天天和字符串打交道的码农,谁还没被indexOf和substring折磨过?ES6给String对象新增的几个方…...
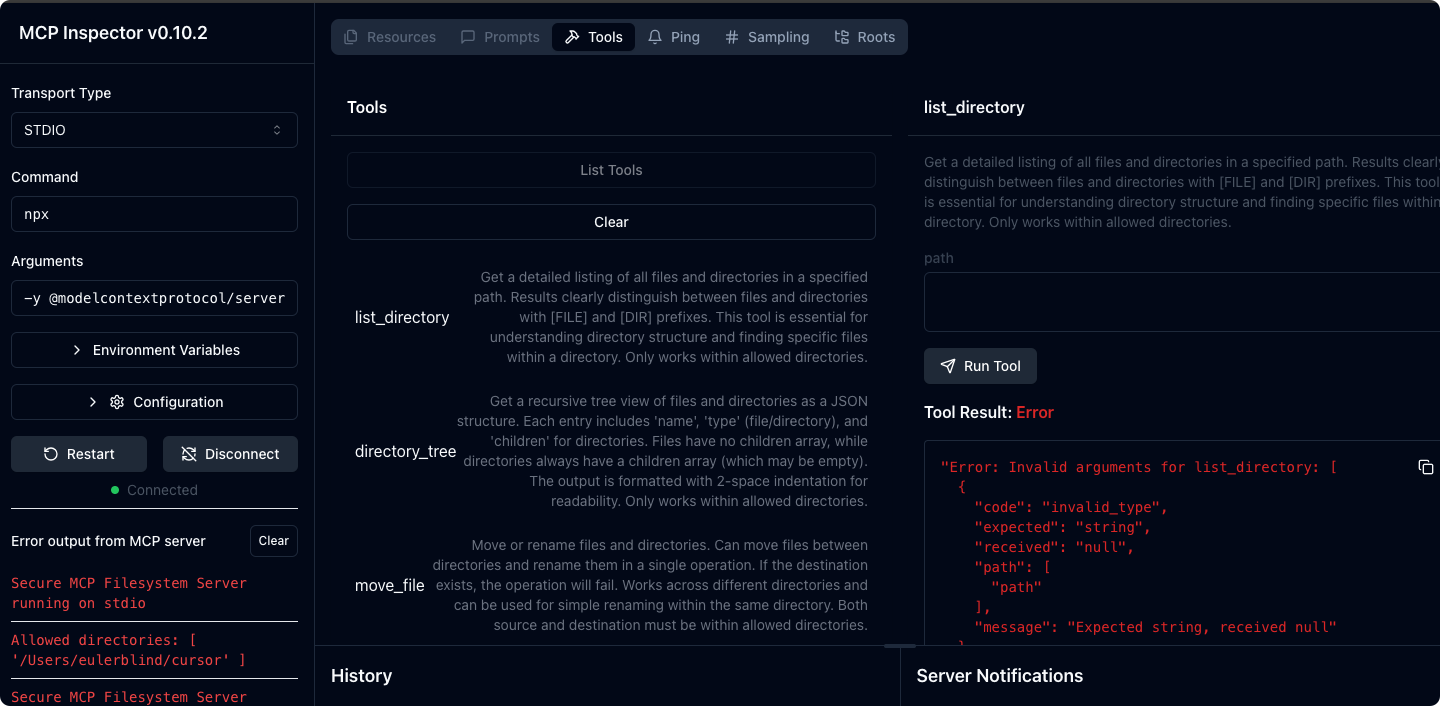
【工具】使用 MCP Inspector 调试服务的完全指南
Model Context Protocol (MCP) Inspector 是一个交互式开发工具,专为测试和调试 MCP 服务器而设计。本文将详细介绍如何使用 Inspector 工具有效地调试和测试 MCP 服务。 1. MCP Inspector 简介 MCP Inspector 提供了直观的界面,让开发者能够ÿ…...

【音视频】AVIO输入模式
内存IO模式 AVIOContext *avio_alloc_context( unsigned char *buffer, int buffer_size, int write_flag, void *opaque, int (*read_packet)(void *opaque, uint8_t *buf, int buf_size), int (*write_packet)(void *opaque, uint8_t *buf, int buf_size), int64_t (*seek)(…...

AI与思维模型【76】——SWOT思维模型
一、定义 SWOT思维模型是一种用于分析事物内部和外部因素的战略规划工具。其中,S代表优势(Strengths),是指事物自身所具备的独特能力、资源或特点,这些因素有助于其在竞争中取得优势;W代表劣势(…...

大模型提示词如何编写
一、提示词的核心三要素 明确目标(What) 告诉 AI「你要它做什么」,越具体越好。 ❌ 模糊:写一篇文章 ✅ 清晰:写一篇 800 字的高考作文,主题 “坚持与创新”,结构分引言、三个论点(…...

python如何取消word中的缩进
在python-docx中,取消缩进可以通过将相应的缩进属性设置为None或0来实现。以下是取消不同类型缩进的方法: 取消左缩进 from docx import Documentdoc Document(existing_document.docx)for paragraph in doc.paragraphs:# 取消左缩进paragraph.paragr…...

DDL小练习
1.创建一张t_user表 要求属性有id(INT),name(VARCHAR),sex(VARCHAR),birthday(DATE) 其中id和name不能为空,添加数据并测试。 创建数据库 create database spt2503; 创建数据库中的t_user表 create table t_user (id int not null, name varchar(20) not…...
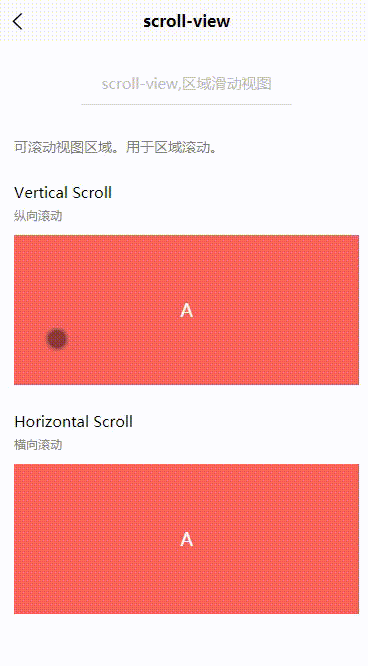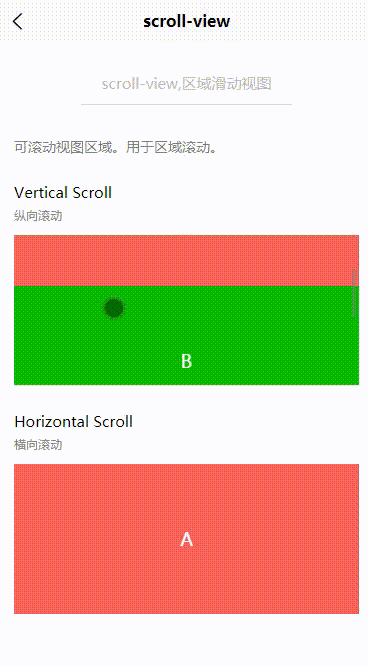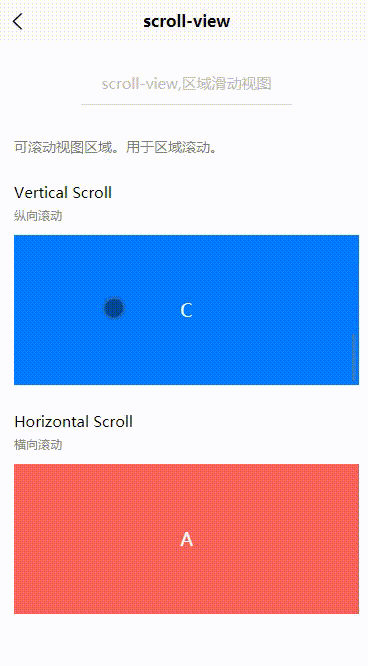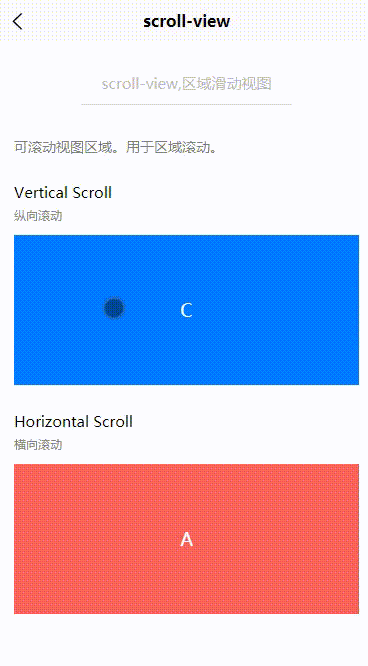
Uniapp:scroll-view(区域滑动视图)
目录 一、基本概述二、属性说明三、基本使用3.1 纵向滚动3.2 横向滚动一、基本概述 scroll-view,可滚动视图区域。用于区域滚动。 二、属性说明 属性名类型默认值说明平台差异说明scroll-xBooleanfalse允许横向滚动scroll-yBooleanfalse允许纵向滚动三、基本使用 3.1 纵向滚…...

【前端】【面试】在前端开发中,如何实现图片的渐进式加载,以及这样做的好处是什么?
题目:在前端开发中,如何实现图片的渐进式加载,以及这样做的好处是什么? 在浏览器端实现图片的“渐进式加载”(Progressive Image Loading)常用的三种方式 方法思路典型实现要点适用场景优缺点简述1. 使…...
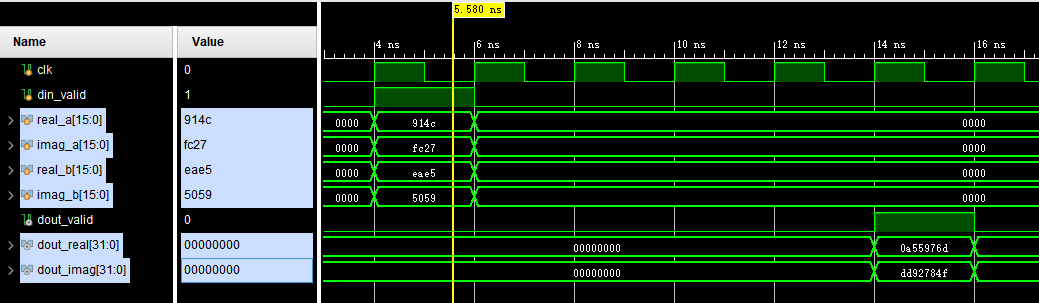
单精度浮点运算/定点运算下 MATLAB (VS) VIVADO
VIVADO中单精度浮点数IP核计算结果与MATLAB单精度浮点数计算结果的对比 MATLAB定点运算仿真,对比VIVADO计算的结果 目录 前言 一、VIVADO与MATLAB单精度浮点数运算结果对比 二、MATLAB定点运算仿真 总结 前言 本文介绍了怎么在MATLAB中使用单精度浮点数进行运算…...

基于大模型对先天性巨结肠全流程预测及医疗方案研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与创新点 二、大模型在先天性巨结肠预测中的理论基础 2.1 大模型概述 2.2 大模型预测先天性巨结肠的可行性分析 三、术前预测与准备方案 3.1 大模型对术前病情的预测 3.1.1 疾病确诊预测 3.1.2 病情严重程度评估 3.2 …...

【AI插件开发】Notepad++ AI插件开发1.0发布和使用说明
一、产品简介 AiCoder是一款为Notepad设计的轻量级AI辅助插件,提供以下核心功能: 嵌入式提问:对选中的文本内容进行AI分析,通过侧边栏聊天界面与AI交互,实现多轮对话、问题解答或代码生成。对话式提问:独…...
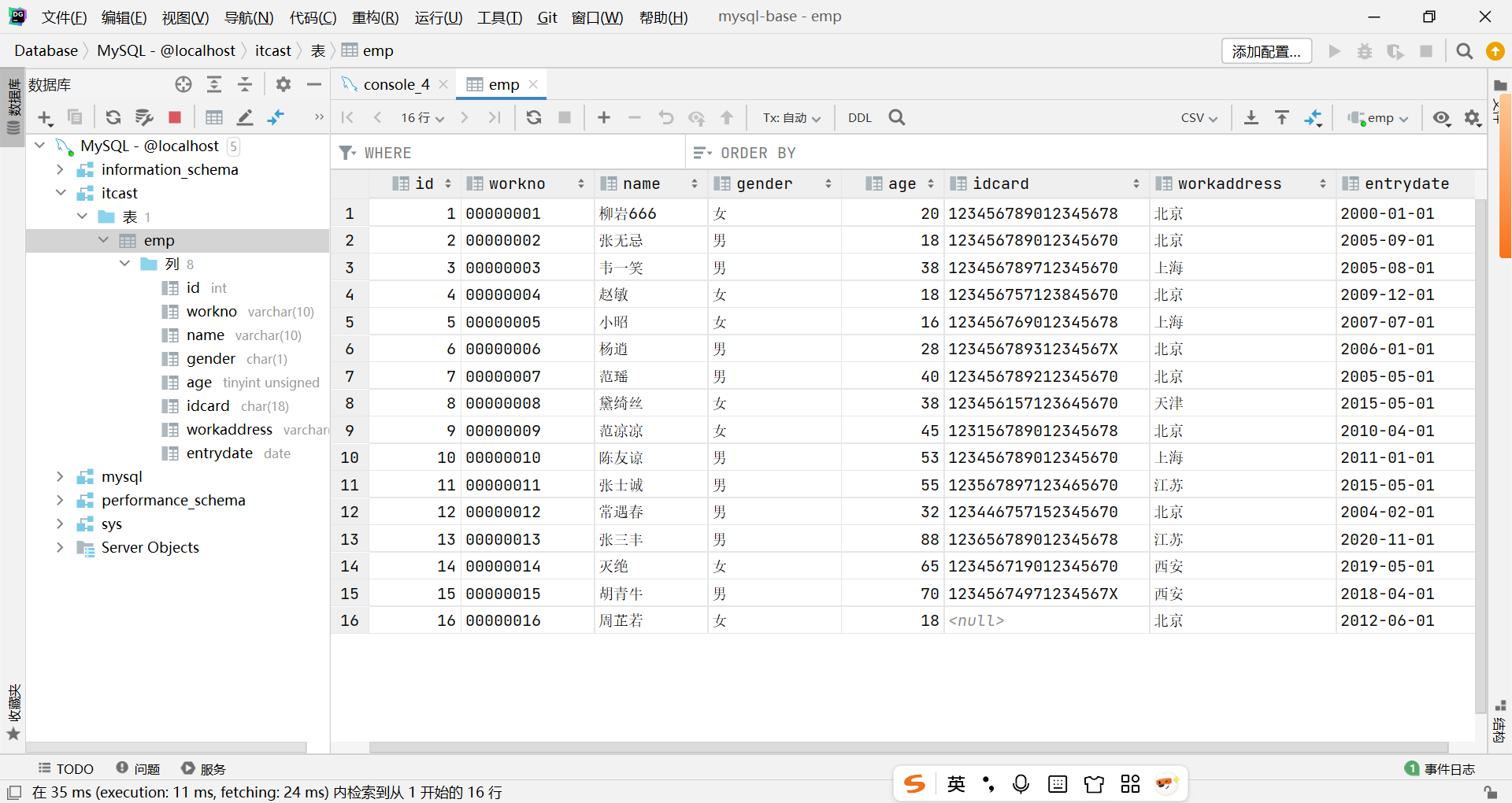
【MySQL数据库入门到精通-07 函数-字符串函数、数值函数、日期函数和流程函数】
文章目录 一、字符串函数1. MySQL中的函数主要分为以下四类: 字符串函数、数值函数、日期函数、流程函数。下面是字符串函数常见的函数,见下表。2.具体代码实现3.结果 二、数值函数1.知识点2.具体代码实现3.结果 三、日期函数1.知识点2.具体代码实现3.结…...

Python图像处理——基于Retinex算法的低光照图像增强系统
1.项目内容 (1)算法介绍 ①MSRCR (Multi-Scale Retinex with Color Restoration) MSRCR 是多尺度 Retinex 算法(MSR)的扩展版,引入了色彩恢复机制以进一步提升图像增强质量。MSR 能有效地压缩图像动态范围ÿ…...
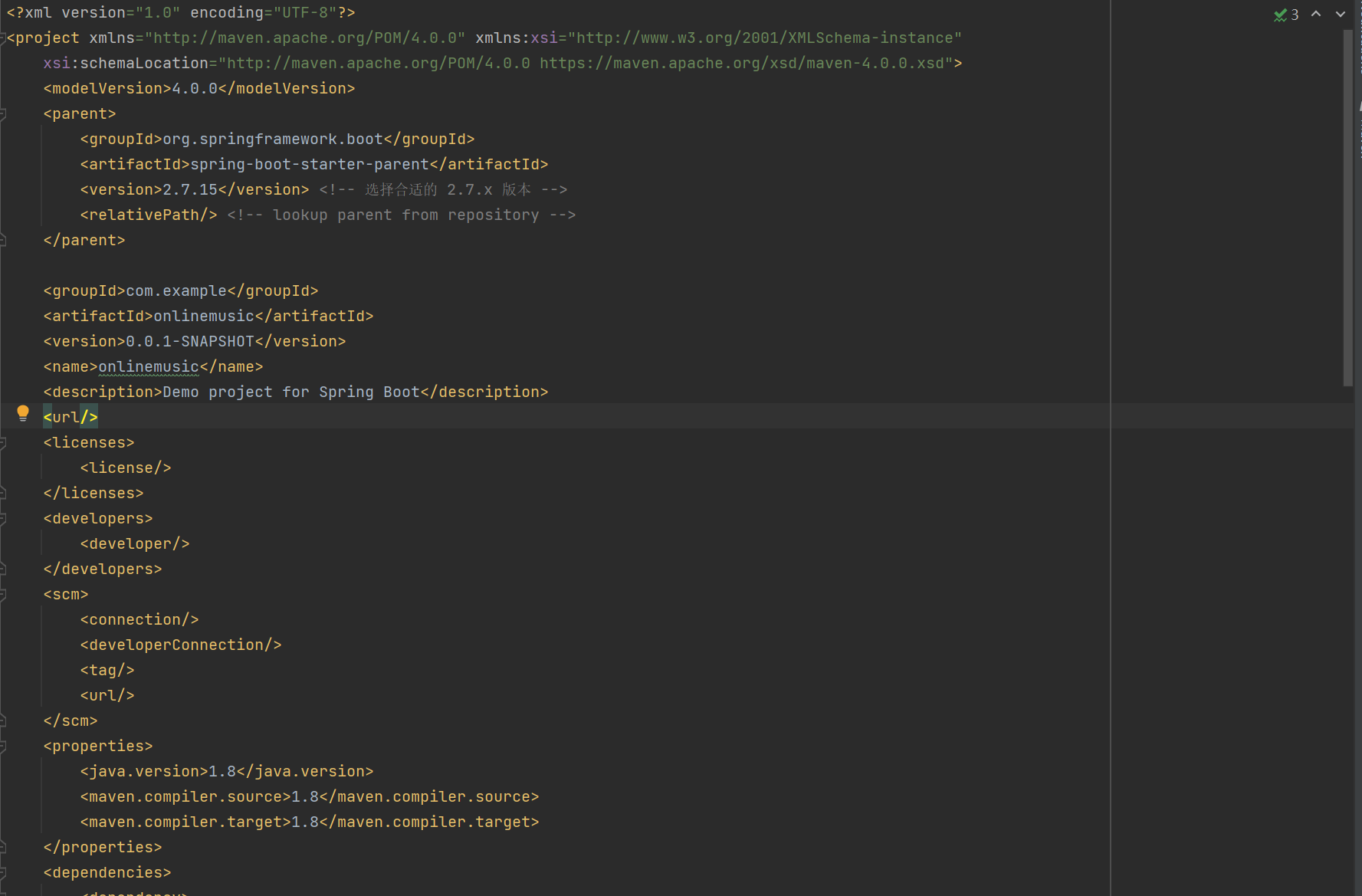
如何在JDK17项目中改成1.8
1.调整 Spring Boot 版本 由于 Spring Boot 3.x 最低要求 JDK 17,所以如果要使用 JDK 8,需要把 spring-boot-starter-parent 的版本降低到 2.7.x 系列,这个系列是支持 JDK 8 的。示例如下: <parent><groupId>org.sp…...
【不同名字的yolo的yaml文件名是什么意思】
以下是这些 YOLO 系列配置文件的详细解析,按版本和功能分类说明: 一、YOLOv3 系列 文件名核心特性适用场景yolov3.yaml原始 YOLOv3 结构,3 尺度预测(13x13,26x26,52x52)通用目标检测yolov3-spp.yaml增加 SPPÿ…...
Zephyr kernel Build System (CMake)介绍
目录 概述 1. 结构介绍 2 构建和配置阶段 2.1 配置阶段 2.2 Cmake编译 3 Zephy项目目录结构 3.1 文件架构 3.2 文件content 概述 本文主要介绍Zephyr kernel Build System CMake的功能,以及使用该工具构建项目,并详细介绍了每个目录以及目录下文…...
相对论大师-记录型正负性质BFS/图论-链表/数据结构
看到这一题我的第一个思路就是双向bfs 起点是a,终点还是a,但是flag是相反的(“越”的方向) tip1.可以用字典vis来存储flag 刚开始初始化时vissta,visend一个对应0、1 要求两个队列相…...

研发内控新规下的合规之道:维拉工时助力企业穿越IPO审查雷区
📌 背景 | 全面注册制下,研发内控成“必修课” 在全面注册制背景下,证监会发布的《监管规则适用指引——发行类第9号:研发人员及研发投入》(简称“发行类9号”),对企业的研发费用归集、研发工时…...
Jenkins流水线管理工具
文章目录 前言: DevOps时代的自动化核心 —Jenkins一、Jenkins是什么?二、Linux安装Jenkinswar包方式安装依赖环境下载 Jenkins WAR 包启动 Jenkins 服务启动日志验证配置插件镜像源 docker镜像方式安装依赖环境拉取 Jenkins 镜像运行 Jenkins 容器获取初…...

嵌入式开发:基础知识介绍
一、嵌入式系统 1、介绍 以提高对象体系智能性、控制力和人机交互能力为目的,通过相互作用和内在指标评价的,嵌入到对象体系中的专用计算机系统。 2、分类 按其形态的差异,一般可将嵌入式系统分为:芯片级(MCU、SoC&am…...
el-table中el-input的autofocus无法自动聚焦的解决方案
需求 有一个表格展示了一些进度信息,进度信息可以修改,需要点击进度信息旁边的编辑按钮时,把进度变为输入框且自动聚焦,当鼠标失去焦点时自动请求更新接口。 注:本例以vue2 element UI为例 分析 这个需求看着挺简单…...
一文了解智慧教育顶刊TLT的研究热点
本文聚焦于IEEE Transactions on Learning Technologies(TLT)期刊,通过图文结合的方式,梳理了2025年第18卷的研究热点,帮助读者把握教育技术与人工智能交叉领域的研究进展,深入了解智能学习系统、自适应学习…...

统计术语学习
基期、现期 作为对比参照的时期称为基期,而相对于基期的称为现期。 描述具体数值时我们称之为基期量和现期量。 【例 1】2017 年比 2016 年第三产业 GDP 增长 6.8%, (2016)为基期,(2017) 为现…...