Spark与Hadoop之间的联系和对比
(一)Spark概述
Apache Spark 是一个快速、通用、可扩展的大数据处理分析引擎。它最初由加州大学伯克利分校 AMPLab 开发,后成为 Apache 软件基金会的顶级项目。Spark 以其内存计算的特性而闻名,能够在内存中对数据进行快速处理,相较于传统基于磁盘的计算框架,大大提高了数据处理的速度。
(二)Hadoop概述
Hadoop 是一个由 Apache 基金会开发的开源的分布式系统基础架构,旨在处理大规模数据的存储和处理。它最初由 Doug Cutting 和 Mike Cafarella 开发,灵感来自于 Google 的 MapReduce 和 Google File System(GFS)论文。Hadoop 为大数据处理提供了一个可靠、高效且可扩展的平台,被广泛应用于各种领域,如互联网公司、金融机构、科研单位等,用于处理海量的结构化、半结构化和非结构化数据。
(三)Hadoop 和 Spark 作为大数据处理领域的重要工具,它们之间存在着紧密的联系
- 存储层面:Spark 可以直接使用 Hadoop 分布式文件系统(HDFS)作为其数据存储后端。HDFS 为 Spark 提供了高可靠、可扩展的分布式存储能力,使得 Spark 能够处理存储在 HDFS 上的大规模数据。无论是批处理、流处理还是机器学习任务,Spark 都可以从 HDFS 中读取数据,并将处理结果写回到 HDFS 中。这样,Spark 可以充分利用 HDFS 的优点,如数据冗余、自动容错等,同时专注于数据的计算和处理。
- 计算层面:Spark 的计算模型与 Hadoop 的 MapReduce 有一定的相似性和互补性。虽然 Spark 的核心是基于内存的计算,采用了更先进的 DAG(有向无环图)执行引擎,能够更高效地处理复杂的计算任务,但它也可以借鉴 MapReduce 的一些思想。例如,Spark 中的 RDD(弹性分布式数据集)转换操作类似于 MapReduce 中的 Map 和 Reduce 操作,Spark 可以将一些复杂的计算任务分解为多个类似于 Map 和 Reduce 的阶段,进行分布式并行计算。此外,Spark 还可以与 Hadoop 的 YARN 资源管理器集成,利用 YARN 来管理集群资源,实现任务的调度和分配。这使得 Spark 能够在 Hadoop 集群上运行,充分利用 Hadoop 的资源管理和调度能力,同时发挥自身的计算优势。
- 生态系统层面:Hadoop 拥有庞大的生态系统,包括 Hive、Pig、HBase 等众多组件,而 Spark 也有自己的生态系统,如 Spark SQL、Spark Streaming、MLlib 等。Spark 可以与 Hadoop 生态系统中的其他组件进行无缝集成。例如,Spark SQL 可以与 Hive 集成,使用 Hive 的元数据和 SQL 解析器,实现对 Hive 表的查询和处理;Spark Streaming 可以与 Kafka 等消息队列集成,实现实时流数据的处理。通过这种集成,用户可以在一个统一的大数据平台上,结合 Hadoop 和 Spark 的各种组件,根据不同的业务需求选择合适的工具和技术,构建复杂的大数据处理和分析系统。
(三)Spark与Hadoop的区别
处理速度上
Hadoop:Hadoop MapReduce 基于磁盘进行数据处理,数据在 Map 和 Reduce 阶段会频繁地写入磁盘和读取磁盘,这使得数据处理速度相对较慢,尤其是在处理迭代式算法和交互式查询时,性能会受到较大影响。
Spark:Spark 基于内存进行计算,能将数据缓存在内存中,避免了频繁的磁盘 I/O。这使得 Spark 在处理大规模数据的迭代计算、交互式查询等场景时,速度比 Hadoop 快很多倍。例如,在机器学习和图计算等需要多次迭代的算法中,Spark 可以显著减少计算时间。
编程模型上
Hadoop:Hadoop 的 MapReduce 编程模型相对较为底层和复杂,开发人员需要编写大量的代码来实现数据处理逻辑,尤其是在处理复杂的数据转换和多阶段计算时,代码量会非常庞大,开发和维护成本较高。
Spark:Spark 提供了更加简洁、高层的编程模型,如 RDD(弹性分布式数据集)、DataFrame 和 Dataset 等。这些抽象使得开发人员可以用更简洁的代码来实现复杂的数据处理任务,同时 Spark 还支持多种编程语言,如 Scala、Java、Python 等,方便不同背景的开发人员使用。
实时性处理上
Hadoop:Hadoop 主要用于批处理任务,难以满足实时性要求较高的数据处理场景,如实时监控、实时推荐等。
Spark:Spark Streaming 提供了强大的实时数据处理能力,它可以将实时数据流分割成小的批次进行处理,实现准实时的数据分析。此外,Spark 还支持 Structured Streaming,提供了更高级的、基于 SQL 的实时流处理模型,使得实时数据处理更加容易和高效。
HadoopMR框架,从数据源获取数据,经过分析计算之后,将结果输出到指定位置,核心是一次计算,不适合迭代计算。
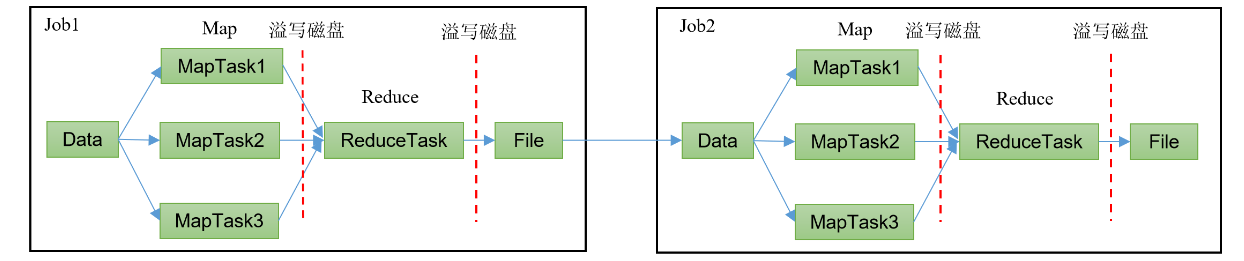
Spark框架,支持迭代式计算,图形计算

相关文章:
Spark与Hadoop之间的联系和对比
(一)Spark概述 Apache Spark 是一个快速、通用、可扩展的大数据处理分析引擎。它最初由加州大学伯克利分校 AMPLab 开发,后成为 Apache 软件基金会的顶级项目。Spark 以其内存计算的特性而闻名,能够在内存中对数据进行快速处理&am…...
——STL之删除算法)
C++学习笔记(三十九)——STL之删除算法
STL 算法分类: 类别常见算法作用排序sort、stable_sort、partial_sort、nth_element等排序搜索find、find_if、count、count_if、binary_search等查找元素修改copy、replace、replace_if、swap、fill等修改容器内容删除remove、remove_if、unique等删除元素归约for…...

C++——Lambda表达式
在C中,Lambda表达式是一种匿名函数对象,它允许你在代码中直接定义一个函数,而不需要提前声明一个单独的函数。Lambda表达式是从C11标准开始引入的,它极大地增强了C语言的灵活性和表达能力,尤其在处理函数对象、回调函数…...
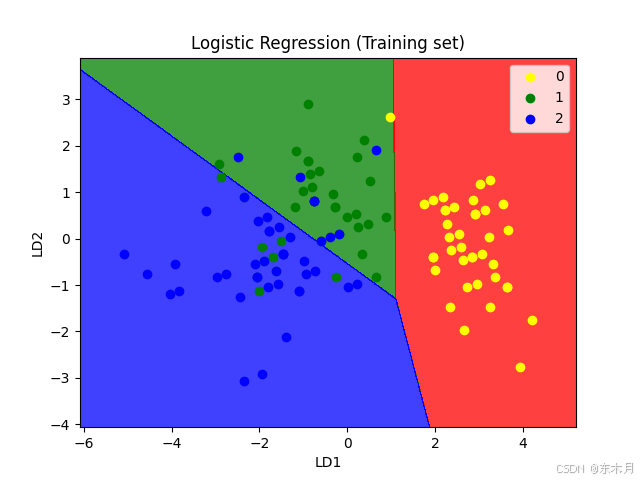
基于线性LDA算法对鸢尾花数据集进行分类
基于线性LDA算法对鸢尾花数据集进行分类 1、效果 2、流程 1、加载数据集 2、划分训练集、测试集 3、创建模型 4、训练模型 5、使用LDA算法 6、画图3、示例代码 # 基于线性LDA算法对鸢尾花数据集进行分类# 基于线性LDA算法对鸢尾花数据集进行分类 import numpy as np import …...

【Deepseek基础篇】--v3基本架构
目录 MOE参数 1.基本架构 1.1. Multi-Head Latent Attention多头潜在注意力 1.2.无辅助损失负载均衡的 DeepSeekMoE 2.多标记预测 2.1. MTP 模块 论文地址:https://arxiv.org/pdf/2412.19437 DeepSeek-V3 是一款采用 Mixture-of-Experts(MoE&…...

从爬楼梯到算法世界:动态规划与斐波那契的奇妙邂逅
从爬楼梯到算法世界:动态规划与斐波那契的奇妙邂逅 在算法学习的旅程中,总有一些经典问题让人印象深刻。“爬楼梯问题”就是其中之一,看似简单的题目,却蕴藏了动态规划与斐波那契数列的深刻联系。今天,我就以这个问题…...

centos7使用yum快速安装最新版本Jenkins-2.462.3
Jenkins支持多种安装方式:yum安装、war包安装、Docker安装等。 官方下载地址:https://www.jenkins.io/zh/download 本次实验使用yum方式安装Jenkins LTS长期支持版,版本为 2.462.3。 一、Jenkins基础环境的安装与配置 1.1:基本…...
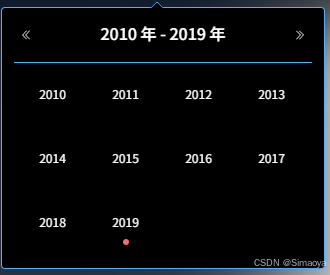
【vue】【element-plus】 el-date-picker使用cell-class-name进行标记,type=year不生效解决方法
typedete,自定义cell-class-name打标记效果如下: 相关代码: <el-date-pickerv-model"date":clearable"false":editable"false":cell-class-name"cellClassName"type"date"format&quo…...
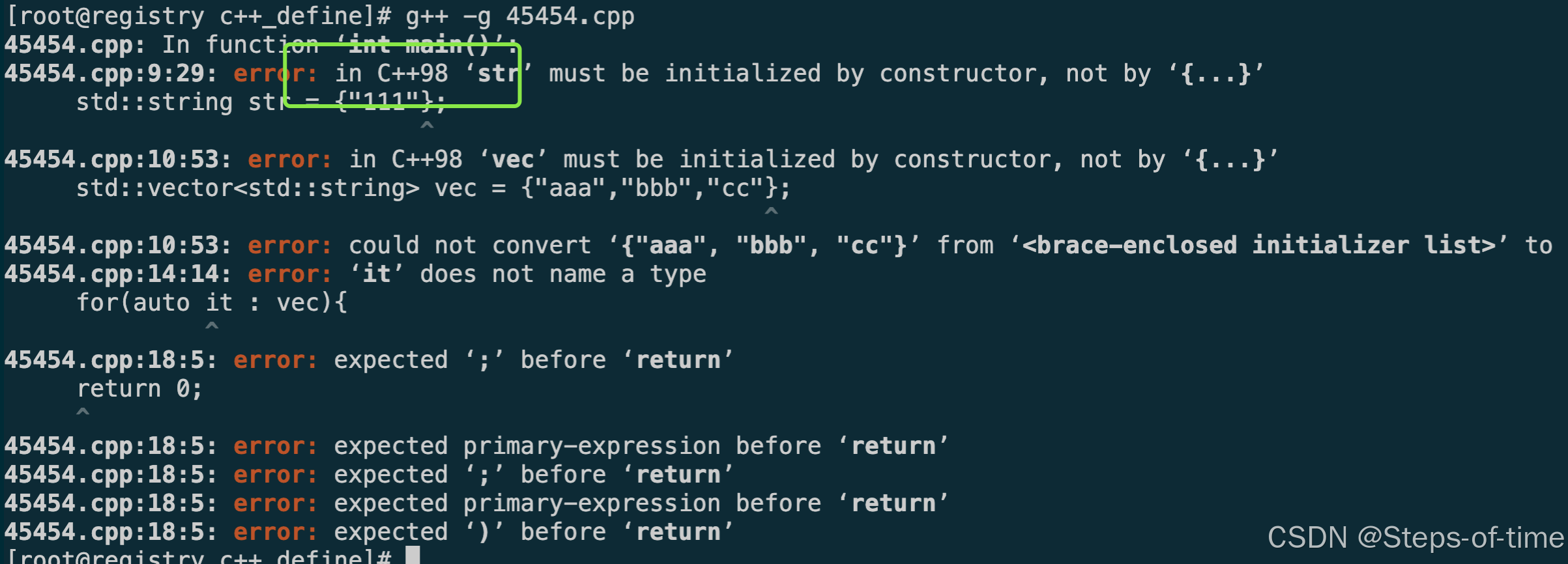
c++11新特性随笔
1.统一初始化特性 c98中不支持花括号进行初始化,编译时会报错,在11当中初始化可以通过{}括号进行统一初始化。 c98编译报错 c11: #include <iostream> #include <set> #include <string> #include <vector>int main() {std:…...

Linux字符设备驱动开发的详细步骤
1. 确定主设备号 手动指定:明确设备号时,使用register_chrdev_region()静态申请(需确保未被占用)。动态分配:通过alloc_chrdev_region()由内核自动分配主设备号(更灵活,推…...

Nginx 二进制部署与 Docker 部署深度对比
一、核心概念解析 1. 二进制部署 通过包管理器(如 apt/yum)或源码编译安装 Nginx,直接运行在宿主机上。其特点包括: 直接性:与操作系统深度绑定,直接使用系统库和内核功能 。定制化:支持通过编译参数(如 --with-http_ssl_module)启用或禁用模块,满足特定性能需求 。…...

C++23 中 constexpr 的重要改动
文章目录 1. constexpr 函数中使用非字面量变量、标号和 goto (P2242R3)示例代码 2. 允许 constexpr 函数中的常量表达式中使用 static 和 thread_local 变量 (P2647R1)示例代码 3. constexpr 函数的返回类型和形参类型不必为字面类型 (P2448R2)示例代码 4. 不存在满足核心常量…...

CMake ctest
CMake学习–ctest全面介绍 1. 环境准备 确保已安装 cmake 和编译工具: sudo apt update sudo apt install cmake build-essential2. 创建示例项目 假设我们要测试一个简单的数学函数 add(),项目结构如下: math_project/ ├── CMakeList…...

全面解析React内存泄漏:原因、解决方案与最佳实践
在开发React应用时,内存泄漏是一个常见但容易被忽视的问题。如果处理不当,它会导致应用性能下降、卡顿甚至崩溃。由于React的组件化特性,许多开发者可能没有意识到某些操作(如事件监听、异步请求、定时器等)在组件卸载…...
)
JavaScript学习教程,从入门到精通,Ajax数据交换格式与跨域处理(26)
Ajax数据交换格式与跨域处理 一、Ajax数据交换格式 1. XML (eXtensible Markup Language) XML是一种标记语言,类似于HTML但更加灵活,允许用户自定义标签。 特点: 可扩展性强结构清晰数据与表现分离文件体积相对较大 示例代码࿱…...
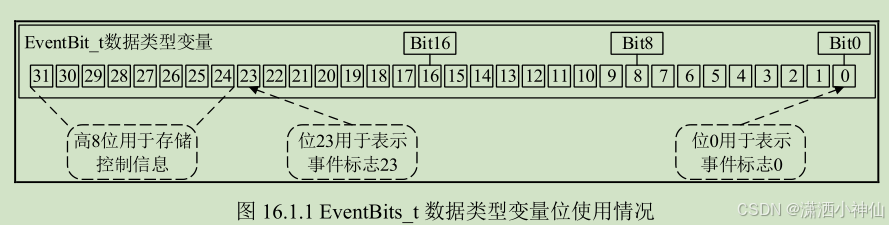
【FreeRTOS】事件标志组
文章目录 1 简介1.1事件标志1.2事件组 2事件标志组API2.1创建动态创建静态创建 2.2 删除事件标志组2.3 等待事件标志位2.4 设置事件标志位在任务中在中断中 2.5 清除事件标志位在任务中在中断中 2.6 获取事件组中的事件标志位在任务中在中断中 2.7 函数xEventGroupSync 3 事件标…...
超级扩音器手机版:随时随地,大声说话
在日常生活中,我们常常会遇到手机音量太小的问题,尤其是在嘈杂的环境中,如KTV、派对或户外活动时,手机自带的音量往往难以满足需求。今天,我们要介绍的 超级扩音器手机版,就是这样一款由上海聚告德业文化发…...
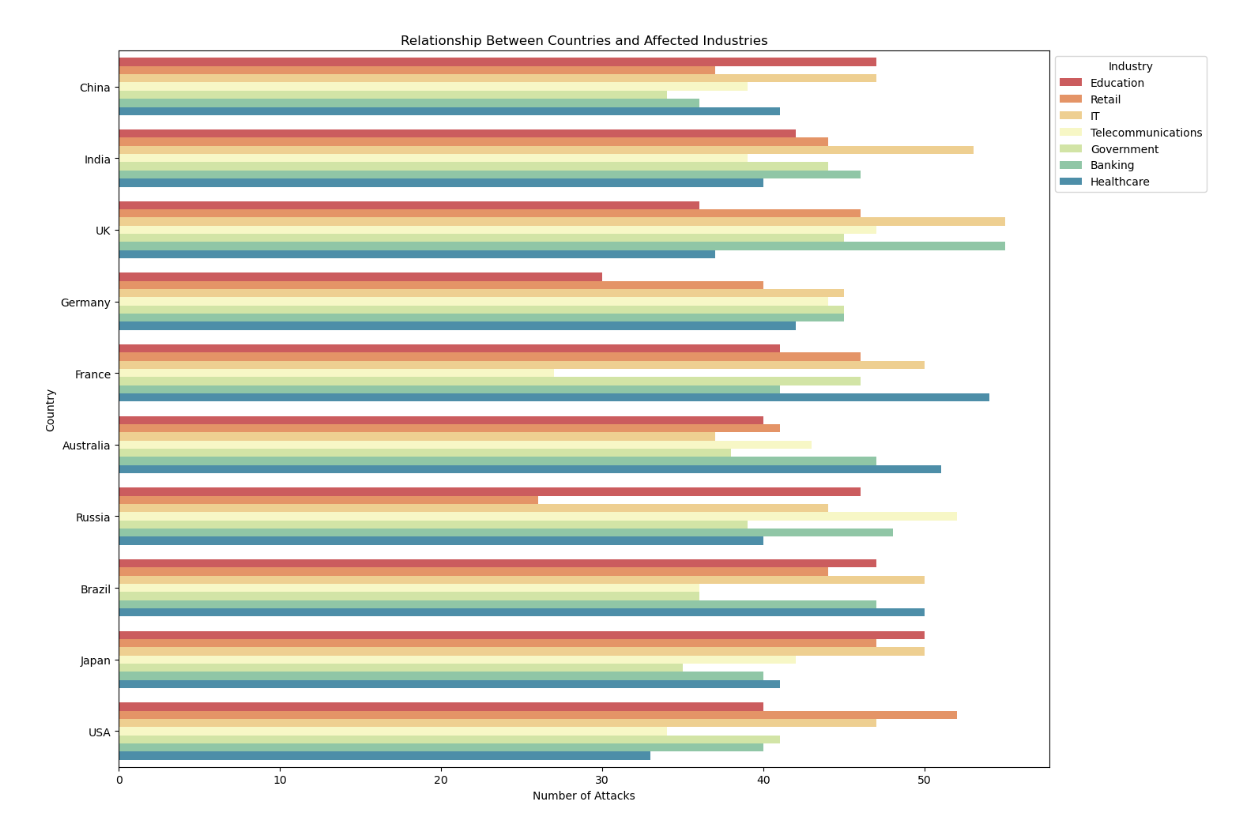
【数据可视化-27】全球网络安全威胁数据可视化分析(2015-2024)
🧑 博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN…...
【6G 开发】NV NGC
配置 生成密钥 API Keys 生成您自己的 API 密钥,以便通过 Docker 客户端或通过 NGC CLI 使用 Secrets Manager、NGC Catalog 和 Private Registry 的 NGC 服务 以下个人 API 密钥已成功生成,可供此组织使用。这是唯一一次显示您的密钥。 请妥善保管您的…...

计算机视觉各类任务评价指标详解
文章目录 计算机视觉各类任务评价指标详解一、图像分类(Image Classification)常用指标1. 准确率(Accuracy)2. Top-k Accuracy3. 精确率(Precision)、召回率(Recall)、F1 分数&#…...

SIEMENS PLC程序解读 -Serialize(序列化)SCATTER_BLK(数据分散)
1、程序数据 第12个字节 PI 2、程序数据 第16个字节 PI 3、程序数据 第76个字节 PO 4、程序代码 2、程序解读 图中代码为 PLC 梯形图,主要包含以下指令及功能: Serialize(序列化): 将 SRC_VARIABLEÿ…...
宁德时代25年时代长安动力电池社招入职测评SHL题库Verify测评语言理解数字推理真题
测试分为语言和数字两部分,测试时间各为17分钟,测试正式开始后不能中断或暂停...

python源码打包为可执行的exe文件
文章目录 简单的方式(PyInstaller)特点步骤安装 PyInstaller打包脚本得到.exe文件 简单的方式(PyInstaller) 特点 支持 Python 3.6打包为单文件(–onefile)或文件夹形式自动处理依赖项 步骤 安装 PyIns…...

数据加密技术:从对称加密到量子密码的原理与实战
数据加密技术:从对称加密到量子密码的原理与实战 在网络安全体系中,数据加密是保护信息机密性、完整性的核心技术。从古代的凯撒密码到现代的量子加密,加密技术始终是攻防博弈的关键战场。本文将深入解析对称加密、非对称加密、哈希函数的核…...

高性能的开源网络入侵检测和防御引擎:Suricata介绍
一、Debian下使用Suricata 相较于Windows,Linux环境对Suricata的支持更加完善,操作也更为便捷。 1. 安装 Suricata 在Debian系统上,你可以通过包管理器 apt 轻松安装 Suricata。 更新软件包列表: sudo apt update安装 Suricata: sudo apt …...

【硬核解析:基于Python与SAE J1939-71协议的重型汽车CAN报文解析工具开发实战】
引言:重型汽车CAN总线的数据价值与挑战 随着汽车电子化程度的提升,控制器局域网(CAN总线)已成为重型汽车的核心通信网络。不同控制单元(ECU)通过CAN总线实时交互海量报文数据,这些数据隐藏着车…...

React类组件与React Hooks写法对比
React 类组件 vs Hooks 写法对比 分类类组件(Class Components)函数组件 Hooks组件定义class Component extends React.Componentconst Component () > {}状态管理this.state this.setState()useState()生命周期componentDidMount, componentDidU…...
Uniapp 自定义 Tabbar 实现教程
Uniapp 自定义 Tabbar 实现教程 1. 简介2. 实现步骤2.1 创建自定义 Tabbar 组件2.2 配置 pages.json2.3 在 App.vue 中引入组件 3. 实现过程中的关键点3.1 路由映射3.2 样式设计3.3 图标处理 4. 常见问题及解决方案4.1 页面跳转问题4.2 样式适配问题4.3 性能优化 5. 扩展功能5.…...
记录一次使用面向对象的C语言封装步进电机驱动
简介 (2025/4/21) 本库对目前仅针对TB6600驱动下的42步进电机的基础功能进行了一定的封装, 也是我初次尝试以面向对象的思想去编写嵌入式代码, 和直流电机的驱动步骤相似在调用stepmotor_attach()函数和stepmotor_init()函数之后仅通过结构体数组stepm然后指定枚举变量中的id即…...
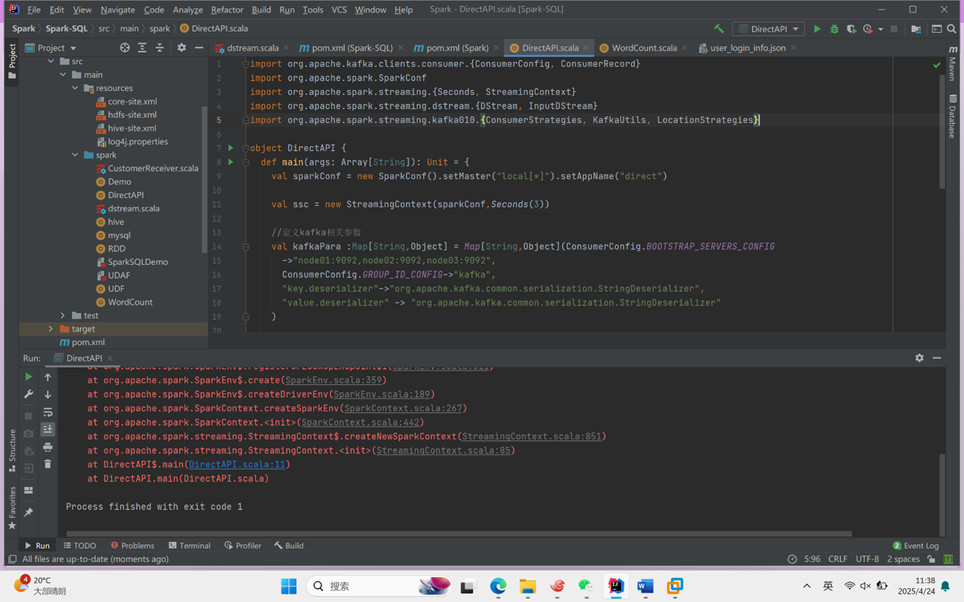
Spark-streaming核心编程
1.导入依赖: <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.12</artifactId> <version>3.0.0</version> </dependency> 2.编写代码: 创建Sp…...