专家系统的知识获取、检测与组织管理——基于《人工智能原理与方法》的深度解析
前文我们已经了解了专家系统的基本概念和一般结构,系统中有专业的知识才是专家系统的关键,接下来对专家系统中的知识是如何获取、检测、组织和管理的进行探讨。
1.专家系统的基本概念:专家系统的基本概念解析——基于《人工智能原理与方法》的深度拓展-CSDN博客
2.专家系统的一般结构:专家系统的一般结构解析——基于《人工智能原理与方法》的深度拓展-CSDN博客
一、知识获取(Knowledge Acquisition)
拥有知识是专家系统有别于其它计算机软件系统的重要标志,而知识的质量与数量又是决定专家系统性能的关键因素,但如何使专家系统获得高质量的知识呢?这正是知识获取要解决的问题。
(一)知识获取的任务
知识获取是将领域知识转化为专家系统可用形式的核心环节,王永庆在书中强调其本质是“解决知识从哪里来、如何转化、如何验证”的问题,包含四大核心任务:
1. 抽取知识(Knowledge Extraction)
目标:从专家经验、文献、数据中提取隐性 / 显性知识。
(1)隐性知识显性化:通过专家访谈(如“您如何判断变压器绕组故障?”)、协议分析(Protocol Analysis)记录决策过程。如:变压器专家指出“油色谱中H₂和CH₄浓度同时升高时,大概率是放电故障”,此经验需转化为规则前提“(H₂>100ppm)∧(CH₄>50ppm)”。
(2)显性知识结构化:整理教科书、手册中的公式、标准,如“正常白细胞计数为 (4-10)×10⁹/L”转化为框架槽值约束。
2. 知识的转换(Knowledge Transformation)
目标:将抽取的知识转化为系统支持的表示形式(规则、框架、逻辑等)。
(1)自然语言→形式化表示:
1)规则转换:“若患者发热且咳嗽,可能患感冒”→ IF (发热∧咳嗽) THEN 感冒 (CF=0.8)。
2)框架转换:“肺炎”概念转化为框架:
Frame: 肺炎
Slots:
症状 = {发热, 咳嗽, 胸痛}
诊断标准 =“胸片可见阴影”
治疗方案 =“抗生素治疗”
(2)多源知识融合:合并专家规则与数据挖掘结果,如将决策树生成的规则“体温> 39℃→重症肺炎”与专家规则加权融合。
3. 知识的输入(Knowledge Input)
目标:通过工具或接口将形式化知识录入知识库。
(1)人工输入工具:
专用知识编辑器(如Protege用于本体录入、CLIPS 的IDE用于规则编辑);
示例:在 Protege 中定义“疾病”类的子类“呼吸道疾病”,设置“症状”槽的取值范围。
(2)自动输入技术:
1)OCR识别技术:从纸质病历中提取“体温 38.5℃”转化为结构化数据;
2)NLP解析:将自由文本“患者咳嗽持续3周”解析为“咳嗽 (持续时间= 3周)”。
4. 知识的检测(Knowledge Validation)
目标:确保知识的一致性、完整性、无冗余(详见第二部分)。
示例:检测到两条规则:
R1: 体温>38℃→发热(CF=1.0)
R2: 体温>37.5℃→发热(CF=1.0)
发现R2完全包含R1的前提,存在冗余,需合并或标注优先级。
(二)知识获取方式
1. 非自动知识获取(Manual Knowledge Acquisition)
核心特征:依赖知识工程师与专家交互,耗时但精度高,适用于领域知识复杂且数据稀缺的场景。

流程示例(医疗诊断系统开发):
(1)专家访谈(持续 2 周):
记录呼吸科医生诊断肺炎的关键指标:“高热(>39℃)、咳嗽超过3周、痰涂片阳性”;
整理为规则模板:“IF [症状集合] THEN 肺炎(CF=0.95)”。
(2)知识建模(规则化):
将“高热”转换为“体温 > 39℃”,“咳嗽超过3周”转换为“咳嗽持续时间 > 21天”;
定义规则权重:痰涂片阳性对结论的贡献度为 0.4,高热为 0.3,咳嗽为 0.2。
(3)录入与初步检测:
使用 CLIPS 的 IDE 录入 100 + 规则,自动检测语法错误(如括号不匹配);
人工审查规则逻辑:确保“肺炎”规则不与“支气管炎”规则前提重叠。
局限性:知识工程师需兼具领域知识与AI技术,人力成本高(据统计占开发周期的60%-80%);专家可能因“知识默化”(Tacit Knowledge)难以清晰表达决策逻辑。
2. 自动知识获取(Automatic Knowledge Acquisition)
核心特征:通过机器学习、数据挖掘技术从数据中自动归纳知识,缓解人工瓶颈,适用于大数据场景。

技术分类与示例:
(1)基于统计学习的方法:
1)决策树(如 C4.5):从10万份肺炎病历中归纳规则,如:
IF 体温>38.5℃∧淋巴细胞计数>40% THEN 病毒性肺炎(CF=0.88)
2)贝叶斯网络:构建“症状 - 疾病”概率图模型,计算 P(疾病|症状),公式为:
![]()
(2)基于深度学习的方法:
1)文本挖掘:使用BERT从医学文献中抽取实体关系,如“肺癌”与“吸烟”的因果关系;
2)图像识别:通过CNN分析胸片,自动生成“发现肺部阴影→建议进一步检查”的诊断规则。
流程示例(变压器故障诊断系统):
(1)数据预处理(3天):
收集5000组油色谱数据(H₂、CH₄、C₂H₂浓度)及对应的故障标签(放电、过热、绝缘老化);
归一化处理:将浓度值转换为 [0,1] 区间,便于模型训练。
(2)模型训练(使用随机森林):
输入特征:H₂、CH₄、C₂H₂浓度,输出:故障类型;
生成规则:“IF CH₄>80ppm ∧ C₂H₂<10ppm THEN 过热故障(置信度 = 0.92)”。
(3)规则转换与验证(1 周):
将模型决策边界转换为 IF-THEN 规则,匹配专家经验(如“过热故障通常CH₄升高,C₂H₂不显著”);
用1000组新数据测试,准确率达91%,高于人工规则的85%。
二、知识的检测与求精(Knowledge Validation and Refinement)
知识的一致性、完整性是影响专家系统性能的重要因素。
(一)知识的一致性与完整性问题
知识库的建立过程是知识经过一系列变换进人计算机系统的过程,在这个过程中存在着各种各样导致知识不健全的因素。例如:
(1)领域专家提供的知识中存在某些不一致、不完整、甚至错误的知识。由于专家系统是以专家知识为基础的,因而专家知识中的任何不一致、不完整必然影响到知识库的一致性与完整性。
(2)知识工程师未能准确、全面地理解领域专家的意图,使得所形成的知识条款隐含着种种错误,影响到知识的一致性及完整性。
(3)采用的知识表示模式不适当,不能把领域知识准确地表示出来。
(4)对知识库进行增、删、改时没有充分考虑到可能产生的影响,以致在进行了这些操作之后使得知识库出现了不完备的情况。特别是在知识库建成之后,由于知识间存在着千丝万缕的复杂联系,因而对它的任何改动都可能产生意想不到的后果。
知识缺陷会导致推理错误,王永庆将其归纳为五大类,需通过形式化方法检测:
1. 知识冗余(Redundancy)
定义:两条或多条规则前提等价且结论相同,或一条规则前提包含另一条(子集冗余)。
示例:
R1: 体温>39℃ ∧ 咳嗽→肺炎(CF=0.9)
R2: 高热 ∧ 咳嗽→肺炎(CF=0.9)
其中“高热”等价于“体温 > 39℃”,R1与R2冗余。
2. 矛盾(Contradiction)
定义:规则前提一致但结论互斥,或置信度冲突。
示例:
R1: 白细胞升高→感染(CF=0.8)
R2: 白细胞升高→非感染(CF=0.7)
前提相同但结论矛盾,需通过优先级或证据权重解决。
3. 从属(Subsumption)
定义:一条规则的前提是另一条的子集,且结论相同(父规则包含子规则)。
示例:
R1: 体温>38℃→发热(CF=1.0)
R2: 体温>39℃→发热(CF=1.0)
R2的前提是R1的子集,R1从属 R2,可删除R1或标注“R2优先级更高”。
4. 环路(Cycle)
定义:规则链形成循环依赖,导致推理死锁。
示例:
R1: A→B,R2: B→C,R3: C→A
形成 A→B→C→A的环路,无法终止推理。
5. 不完整(Incompleteness)
定义:对合法输入无匹配规则,导致推理失败。
示例:知识库中无“体温 = 37.5℃”的处理规则,当输入该值时系统无法判断是否为发热。
(二)基于经典逻辑的检测方法
利用一阶谓词逻辑的形式化表达,检测知识缺陷:
1. 逻辑表达式等价性检测
方法:验证两条规则的前提是否逻辑等价(P_1 ↔ P_2)。
算法:将规则前提转换为合取范式(CNF)或析取范式(DNF);
比较范式结构,如 (A∧B)∨C与 (A∨C)∧(B∨C) 等价。
2. 冗余检测
子集冗余:若 P_1 ⊆ P_2 且结论相同,则R2冗余(如 R1: A∧B→C,R2: A→C,当 A→A∧B 不成立时,R2非冗余)。
公式:若 ∀x (P_1(x) → P_2(x)) 且 结论相同,则R2冗余。
3. 矛盾规则检测
(1)直接矛盾:前提相同但结论互斥(C_1 = ¬ C_2)。
(2)置信度矛盾:前提相同但 CF_1 + CF_2 > 1(如 CF1=0.8,CF2=0.7,总和 1.5>1)。
4. 从属规则检测
方法:检查 P_1 ⊆ P_2 是否成立,即 P_1 → P_2 永真。
示例:R1前提“体温> 39℃”是R2前提“体温 > 38℃”的子集,故R1从属于R2。
5. 环路检测
图论方法:将规则视为有向边(前提→结论),构建知识依赖图,检测是否存在环。
算法:深度优先搜索(DFS),若访问到已访问节点且非父节点,则存在环路。
(三)基于Petri网的检测方法
Petri网通过“库所(Place)- 变迁(Transition)”模型表示知识流动,适合检测复杂依赖:
1. 冗余检测
原理:若两个变迁(规则)的输入库所(前提)相同,输出库所(结论)相同,则冗余。
示例:变迁T1和T2均以“体温> 39℃”“咳嗽”为输入,输出“肺炎”,则T1与T2冗余。
2. 矛盾、从属及环路检测
矛盾:两个变迁输入相同,输出库所为互斥节点(如“感染”与“非感染”)。
从属:变迁T1的输入库所是T2输入库所的子集,且输出相同。
环路:库所与变迁形成环(如 P1→T1→P2→T2→P1)。
(四)知识求精(Knowledge Refinement)
当检测到知识缺陷时,需通过求精提升知识库质量:
1. KBRS(Knowledge-Based Reasoning System)的知识表示
求精对象:规则、框架、逻辑公式等,需明确表示形式的语法和语义。
示例:对规则 R: P → C (CF),求精涉及调整 P(前提)、C(结论)、CF(置信度)。
2. 求精策略
基于错误分析的回溯求精:
(1)错误分类:
漏判错误(False Negative):实际为真但系统未推导(如符合肺炎规则但未触发);
误判错误(False Positive):实际为假但系统推导为真(如普通感冒被诊断为肺炎)。
(2)回溯定位:
漏判:检查是否因前提过严(如要求“痰涂片阳性”而患者未做检查);
误判:检查是否因前提过松(如“咳嗽”单独触发规则,而实际需结合发热)。
(3)修正规则:
放宽前提:将“痰涂片阳性”改为“痰涂片阳性或 PCR 检测阳性”;
增加约束:在“咳嗽”规则中添加“持续时间 > 7 天”条件。
示例(变压器故障知识库求精):
问题:系统将“CH₄=60ppm,H₂=150ppm”误判为放电故障(实际为过热故障);
分析:现有规则“(H₂>100ppm)∧(CH₄>50ppm)→放电故障”未考虑C₂H₂浓度(放电故障通常C₂H₂>20ppm);
修正:添加前提“C₂H₂>20ppm”,规则变为:
(H₂>100ppm)∧(CH₄>50ppm)∧(C₂H₂>20ppm)→放电故障 (CF=0.95)
三、知识的组织与管理(Knowledge Organization and Management)
(一)知识的组织
知识组织需兼顾推理效率与可维护性,常见方法:
1. 按知识类型组织
(1)规则库:将规则按主题分组(如医疗系统分为“症状判断”“疾病诊断”“治疗建议”);
(2)框架库:构建层次结构(如“疾病”→“呼吸道疾病”→“肺炎”),支持继承(子类继承父类的症状槽);
(3)案例库:按案例特征索引(如“肺炎案例”按“年龄”“并发症”分类)。
2. 按推理策略组织
(1)正向链规则:按数据获取顺序排序(如先匹配“体温”规则,再匹配“白细胞”规则);
(2)反向链规则:按目标优先级排序(如“危及生命疾病”规则优先于普通疾病)。
3. 示例(电力系统故障知识库组织)
层次结构:
电力系统故障
├─ 发电故障
│ ├─ 发电机绕组故障
│ └─ 励磁系统故障
├─ 输电故障
│ ├─ 线路短路(按电压等级:110kV, 220kV)
│ └─ 绝缘子老化
└─ 变电故障
├─ 变压器过热
└─ 套管放电
索引机制:为每个故障类型建立关键词索引(如“变压器过热”关联“油色谱”“温度传感器”),加速规则匹配。
(二)知识的管理
知识管理涵盖存储、检索、更新、版本控制等,需借助专用工具或系统:
1. 存储技术
(1)文件存储:早期系统用文本文件(如CLIPS的*.clp文件),适合小规模知识库;
(2)数据库存储:关系型数据库(如MySQL)存储规则表(前提、结论、CF)、框架表(类、槽、值);
(3)图数据库:如Neo4j 存储语义网络,支持高效的关系查询(如“查找所有与‘肺炎’相关的症状”)。
2. 检索与推理优化
(1)Rete算法:将规则编译为数据流网络,增量式匹配事实,提升正向链效率;
(2)索引技术:为规则前提建立B +树索引(如对“体温”“白细胞计数”字段索引),减少匹配时间。
3. 更新与版本控制
增量更新:新增规则时检测与现有知识的兼容性(如是否引入矛盾或冗余);
版本管理:记录知识变更历史(如Git-like系统,保存每个版本的规则差异),支持回滚。
示例(医疗知识库更新流程):
提议变更:医生发现“奥密克戎感染”需新增规则,提交至知识管理系统;
自动检测:系统验证新规则与现有规则无矛盾,且不产生冗余;
人工审核:知识工程师确认规则逻辑正确(如前提“核酸阳性”→结论“新冠感染”);
版本发布:生成新版本(v2.1),记录变更日志(新增规则 ID=501-505)。
4. 可视化管理工具
(1)Protege:支持本体可视化,通过图形界面编辑框架、槽、继承关系;
(2)Gensim:用于案例库的相似性检索,如通过TF-IDF计算新案例与历史案例的相似度。
四、总结与前沿趋势
(一)核心价值
知识获取、检测与组织管理是专家系统的“知识工程三要素”:
(1)获取解决知识“从无到有”,依赖人机协作与数据驱动技术;
(2)检测解决知识“从有到准”,通过逻辑与图论方法保障质量;
(3)组织管理解决知识“从准到优”,通过结构化存储提升效率。
(二)前沿趋势
(1)自动化知识获取:结合大语言模型(如GPT-4)自动抽取文献知识,减少人工干预;
(2)动态知识检测:在推理过程中实时检测知识缺陷,如通过在线学习修正置信度;
(3)知识图谱集成:将专家系统知识库与知识图谱融合,支持更复杂的语义推理(如“疾病 - 药物 - 副作用”关系网络)。
(三)数学化表达总结
(1)知识冗余检测:P_1 ⊆ P_2∧C_1 = C_2
(2)矛盾规则检测:P_1 = P_2∧C_1 = ¬ C_2
(3)置信度合成:![]() (适用于同向证据)
(适用于同向证据)
通过系统化的知识工程方法,专家系统得以在医疗、工业等领域实现可靠决策,而随着机器学习与知识表示技术的进步,其知识处理能力将迈向更高智能化水平。
相关文章:
专家系统的知识获取、检测与组织管理——基于《人工智能原理与方法》的深度解析
前文我们已经了解了专家系统的基本概念和一般结构,系统中有专业的知识才是专家系统的关键,接下来对专家系统中的知识是如何获取、检测、组织和管理的进行探讨。 1.专家系统的基本概念:专家系统的基本概念解析——基于《人工智能原理与方法》…...

contenthash 持久化缓存
以下是关于持久化缓存(contenthash)的深度技术解析,涵盖原理、配置策略及最佳实践,帮助我们构建高性能前端应用的缓存体系: 一、缓存机制核心原理 1. 浏览器缓存决策矩阵 触发条件缓存行为对应场景URL 未变化 + 强缓存有效直接读取磁盘/内存缓存未修改的静态资源URL 变化…...
让Editplus支持squirrel语言
用EditPlus配置完实现关键字、函数、高光代码、自动完成、代码调试。先看看效果: 主要是由 nut.stx (语法文件)和 nut.acp (自动完成)两个文件 实现 Nut.stx文件内容: ---------------------------------…...

Arm GICv3中断处理模型解析
1. Targeted Distribution Model(目标分发模型) 中断会被发送到软件指定的目标PE,且仅由该PE处理。 2. Targeted List Model(目标列表模型) 主要针对于SGIs(Software Generated Interrupts,软件生成中断)中断。 多个PE可以独立接收同一个中断。 当一个PE确认(ackn…...

Leetcode 2845 题解
还是要把自己做题的思路写出来的,但是结果可能还是得去观摩一下题解,无论是大佬写的题解还是leetcode官方写的题解,看完题解后再去反思才能有收获,即使下次遇见一样的题不见得能写出来,但有思路比没思路更重要。 今天写…...
【爬虫】DrissionPage-获取douyim用户下的视频
之前看过DrissionPage,觉得很厉害,比selenium简单,适合新手。因为盲目跟风逆向,今天看了一个DrissionPage案例直播,学习一下,真香哈。 DrissionPage官网:🛰️ 概述 | DrissionPage官…...

【Python爬虫基础篇】--3.cookie和session
目录 1.cookie 1.1.定义 1.2.参数 1.3.分类 2.session 3.使用cookie登录微博 4.使用session登录 1.cookie 由于http是一个无状态的协议,请求与请求之间无法相互传递或者记录一些信息,cookie和session正是为了解决这个问题而产生。 例子࿱…...

React 文件链条
在 React 项目中,首次展示在前台的是以下文件组合作用的结果: --- ### **核心文件链条** 1. **public/index.html** - 这是浏览器实际加载的入口文件 - 包含一个 <div id"root"></div> 容器 - 通过 <script> 标…...

分数线降低,25西电马克思主义学院(考研录取情况)
1、马克思主义学院各个方向 2、马克思主义学院近三年复试分数线对比 学长、学姐分析 由表可看出: 1、马克思主义理论25年相较于24年下降10分,为355分 3、25vs24推免/统招人数对比 学长、学姐分析 由表可看出: 1、 马克思主义学院25年共接…...

微信、抖音、小红书emoji符号大全
1、Emoji 日常符号 👣👀👁️👄💋👂🦻👃👅🧠🫀🫁🦷🦴💪🦾🦿🦵&a…...
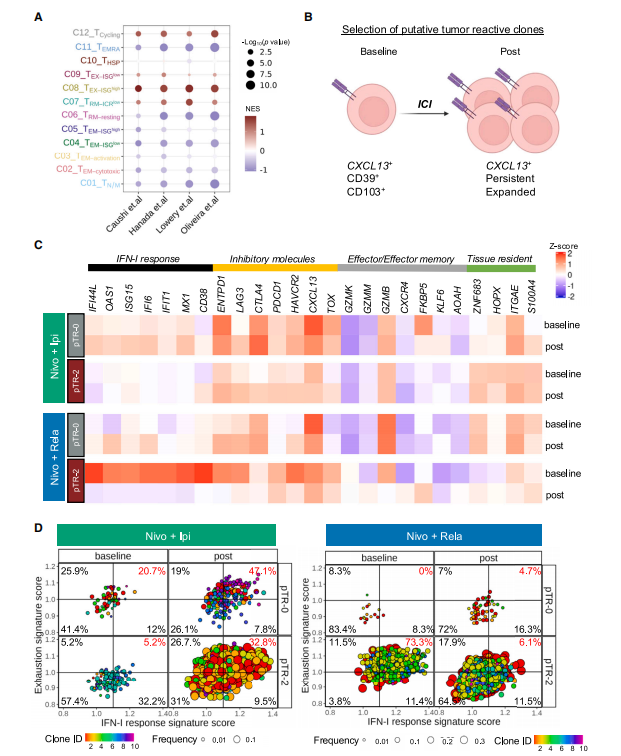
Cancer Cell|scRNA-seq + scTCR + 空间多组学整合分析,揭示CD8⁺ T细胞在免疫治疗中的“双路径” | 临床问题的组学解答
Cancer Cell|scRNA-seq scTCR 空间多组学整合分析,揭示CD8⁺ T细胞在免疫治疗中的“双路径” 👋 欢迎关注我的生信学习专栏~ 如果觉得文章有帮助,别忘了点赞、关注、评论,一起学习 近日,《Cancer Cell》…...
:ubuntu系统多版本conda和多版本cuda共存)
ubuntu(28):ubuntu系统多版本conda和多版本cuda共存
0. cuda(包括cudnn)、conda安装照常 注意: (1)多个conda不要安装到一个目录了,可以见下面的示例目录; (2)cuda(包括cudnn)不用纠结是否添加超链接 1. 需要修改环境配置…...
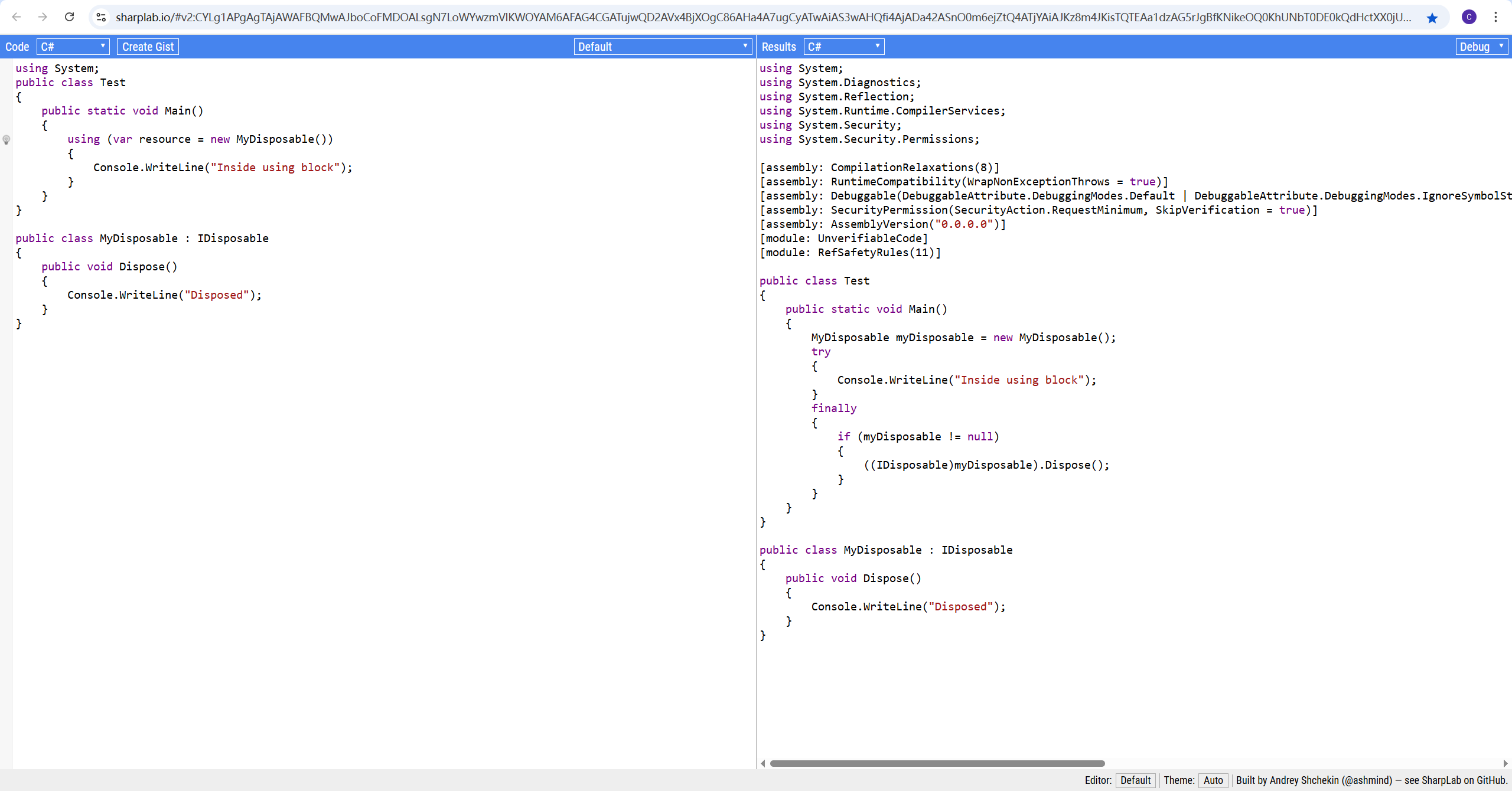
C# 下 using 块的作用 + VS2022 下 using 语法糖怎样工作
🔍 using 的本意是什么? using 是 C# 中用于 自动释放资源 的语法糖,适用于实现了 IDisposable 接口的对象(比如数据库连接、文件、网络流等)。 🧐 首先看下SqlSugarClient类部分源码: SqlSug…...

实体店的小程序转型之路:拥抱新零售的密码-中小企实战运营和营销工作室博客
实体店的小程序转型之路:拥抱新零售的密码-中小企实战运营和营销工作室博客 在当今数字化浪潮的冲击下,实体店面临着前所未有的挑战,但小程序的出现为实体店转型新零售带来了新的曙光。先来看一组惊人的数据,据相关统计ÿ…...
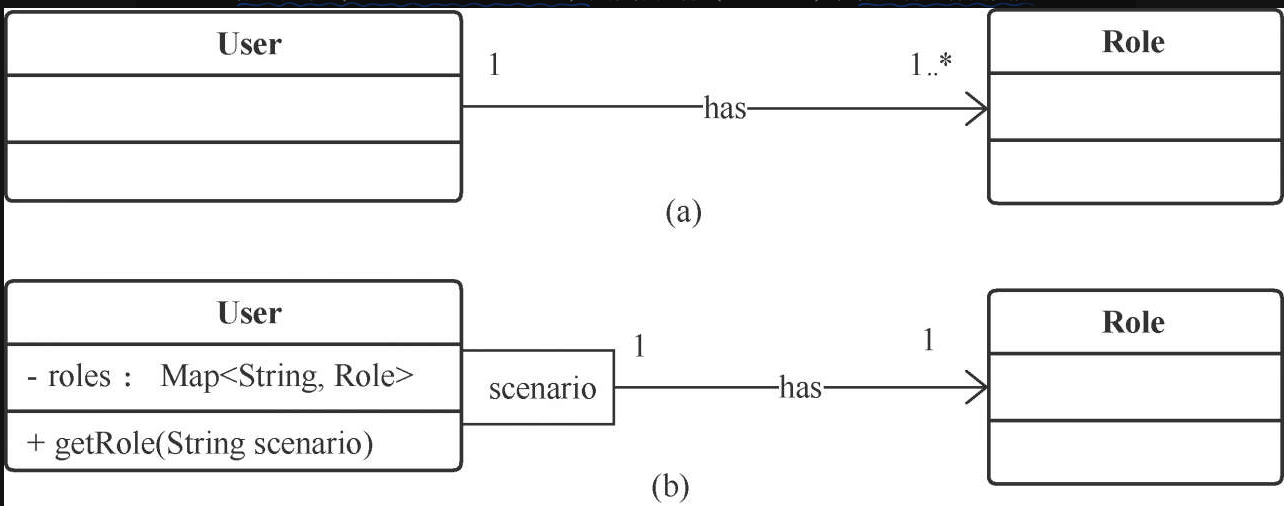
UML 类图基础和类关系辨析
UML 类图 目录 1 概述 2 类图MerMaid基本表示法 3 类关系详解 3.1 实现和继承 3.1.1 实现(Realization)3.1.2 继承/泛化(Inheritance/Generalization) 3.2 聚合和组合 3.2.1 组合(Composition)3.2.2 聚…...

15.三数之和(LeetCode)java
个人理解: 1.使用双指针做法,首先对数组进行排序 第一重for循环控制第一个数,对数组进行遍历。双指针初始化为lefti1, rigthnums.length-1。然后使用while循环移动双指针寻找合适的数。因为返回的是数,不是下标,数不能…...

Spark读取Apollo配置
--conf spark.driver.extraJavaOptions-Dapp.idapollo的app.id -Denvfat -Dapollo.clusterfat -Dfat_metaapollo的meta地址 --conf spark.executor.extraJavaOptions-Dapp.idapollo的app.id -Denvfat -Dapollo.clusterfat -Dfat_metaapollo的meta地址 在spark的提交命令中&…...
如何通过 Websoft9 应用自托管平台一键安装任意版本 Odoo?
手工安装 Odoo 的复杂流程 环境准备阶段:安装 Docker 需熟悉 Linux 系统操作,需配置软件源、解决依赖冲突; 镜像获取阶段:从 Docker Hub 拉取官方镜像时可能因网络问题失败,且需自行验证版本兼容性; 容器…...

Anaconda3使用conda进行包管理
一、基础包管理操作 安装包 使用 conda install <包名> 安装指定包,支持多包批量安装和版本指定: conda install numpy # 安装单个包 conda install numpy scipy pandas # 批量安装多个包 conda install numpy1.21 # 指定版本 conda instal…...

exec和spawn
前言 需求:做一个electron应用,用node打开exe软件,打开后返回成功与否,打开的软件不会随electron应用的关闭而关闭 exec exec 第一个参数为要运行的command命令,参数以空格分隔。 child_process.exec(command[, opti…...

整平机:精密制造的“隐形守护者”
在金属加工车间里,一块表面凹凸不平的钢板经过一组高速旋转的辊轮后,神奇地变得如镜面般平整——这看似简单的场景背后,隐藏着现代工业对材料精度近乎苛刻的追求。整平机,这个常被忽视的工业设备,实则是高端制造业的基…...

Lesar: 面向 Lustre/Scade 语言的形式化模型检测工具
在《同步反应式系统》的第一课中,介绍了同步数据流语言 Lustre 生态中的形式化模型检查器 Lesar 的用法。Lesar 可对 lustre v4 语言以及 Scade 语言中部分数据流核心特性进行模型检查。 Lesar 介绍 Lesar 是 Verimag 研发维护的形式化方法模型检查工具。该工具的理…...

C++中的vector和list的区别与适用场景
区别 特性vectorlist底层实现动态数组双向链表内存分配连续内存块非连续内存块随机访问支持,通过索引访问,时间复杂度O(1)不支持,需遍历,时间复杂度O(n)插入/删除末尾操作效率高,时间复杂度O(1)任意位置操作效率高&am…...
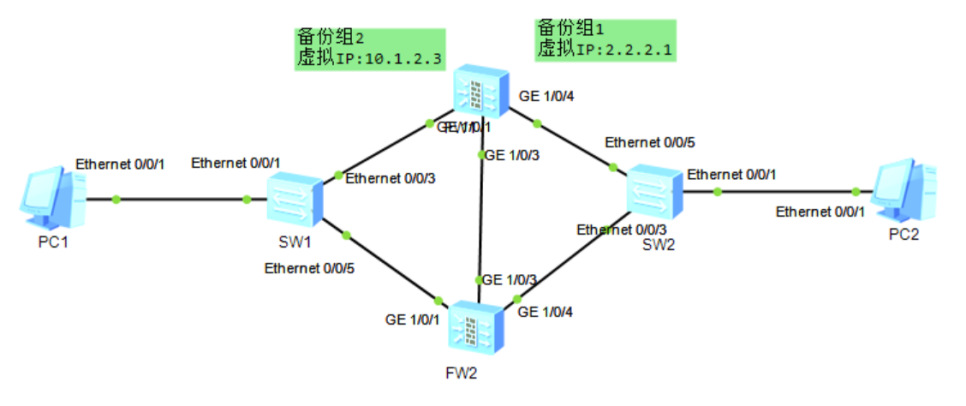
VRRP与防火墙双机热备实验
目录 实验一:VRRP负载均衡与故障切换 实验拓扑编辑一、实验配置步骤 1. 基础网络配置 2. VRRP双组配置 二、关键验证命令 1. 查看VRRP状态 2. 路由表验证 三、流量分析 正常负载均衡场景: 故障切换验证: 实验二:防火…...
win11什么都不动之后一段时间黑屏桌面无法显示,但鼠标仍可移动,得要熄屏之后才能进入的四种解决方法
现象: 1. 当时新建运行的资源管理器的任务卡了或者原本资源管理器卡了 比如:当时在文本框中输入explorer 注:explorer.exe是Windows的文件资源管理器,它用于管理Windows的图形外壳,包括桌面和文件管理 按住CtrlAltEs…...
的性能,特别是在处理复杂图形和动画时)
【前端】【业务场景】【面试】在前端开发中,如何优化 SVG(可缩放矢量图形)的性能,特别是在处理复杂图形和动画时
SVG 性能优化:循序渐进 4 步法 目标:先减负 → 再复用 → 后加速 → 最后按场景微调 ① 精简—把包袱先丢掉 删除无用元素 隐藏/被遮挡的 <path>、未引用的 <defs> 里渐变、滤镜。 合并路径 同填充色或描边的路径 ⇒ SVGO / SVGOMG「Mer…...
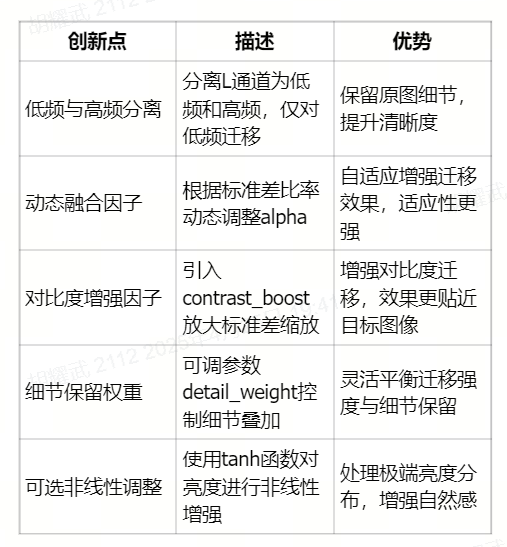
基于LAB颜色空间的增强型颜色迁移算法
本文算法使用Grok完成所有内容,包含算法改进和代码编写,可大大提升代码编写速度,算法改进速度,提供相关idea,提升效率; 概述 本文档描述了一种基于LAB颜色空间的颜色迁移算法,用于将缩略图D的…...
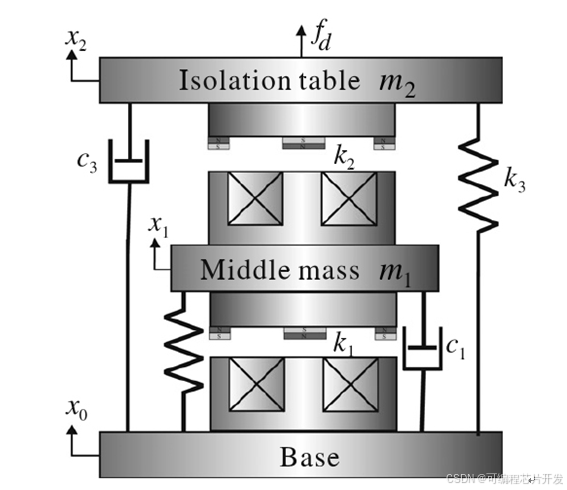
基于SIMMECHANICS的单自由度磁悬浮隔振器PID控制系统simulink建模与仿真
目录 1.课题概述 2.系统仿真结果 3.核心程序与模型 4.系统原理简介 4.1 单自由度磁悬浮减振器工作原理简介 4.2 SIMMECHANICS工具箱 5.完整工程文件 1.课题概述 基于SIMMECHANICS的单自由度磁悬浮隔振器PID控制系统simulink建模与仿真。其中,SIMMECHANICS是M…...

河北省大数据应用创新大赛样题
** 河北省大数据应用创新大赛样题 ** 1. 在Linux下安装Java并搭建完全分布式Hadoop集群。在Linux终端执行命令“initnetwork”,或双击桌面上名称为“初始化网络”的图标,初始化实训平台网络。 【数据获取】 使用wget命令获取JDK安装包: “w…...

RabbitMQ 的专业术语
术语定义示例/说明生产者(Producer)发送消息到 RabbitMQ 的客户端应用程序。日志系统将错误信息发送到 RabbitMQ。消费者(Consumer)从 RabbitMQ 队列中接收并处理消息的客户端应用程序。一个订单处理服务从队列中读取消息并更新数…...