Kafka 架构设计和组件介绍
什么是Apache Kafka?
Apache Kafka 是一个强大的开源分布式事件流平台。它最初由 LinkedIn 开发,最初是一个消息队列,后来发展成为处理各种场景数据流的工具。
Kafka 的分布式系统架构支持水平扩展,使消费者能够按照自己的节奏检索消息,并可以轻松地将 Kafka 节点(服务器)添加到集群中。
Kafka 旨在快速低延迟地处理大量数据。虽然它是用 Scala 和 Java 编写的,但它支持多种编程语言。
Apache Kafka 充当分布式日志收集器,将日志消息以键值对的形式存储在仅追加日志文件中,以实现持久的长期存储和检索。与 RabbitMQ 等传统消息队列(消息消费后即删除)不同,Kafka 会将消息保留一段可配置的时长,使其成为需要数据重放或事件溯源的用例的理想选择。
RabbitMQ 专注于实时消息传递,无需长期存储消息,而 Kafka 的保留策略则支持更复杂的数据驱动型应用程序。
Kafka 的常见用例包括应用程序跟踪、日志聚合和消息传递,但它缺乏查询和索引等传统数据库功能。它的优势在于处理实时数据流,这使其成为分布式系统和实时分析不可或缺的一部分。
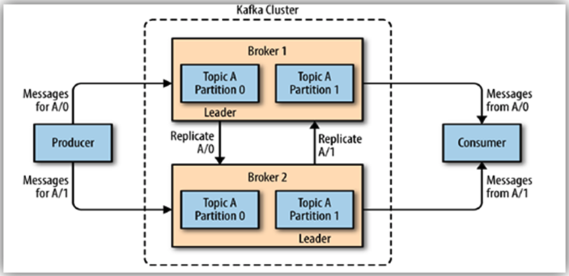
现在我们将讨论 Kafka 的架构和基本组件。下图是 Kafka 的架构示意图。
Kafka 有哪些特性?
Apache Kafka 是一个开源分布式流处理平台,广泛用于构建实时数据管道和流处理应用程序。它具有以下特性:
1. 高吞吐量
Kafka 能够处理海量数据。它旨在高效地从源客户端读取和写入数百 GB 的数据。
2. 分布式架构
Apache Kafka 采用以集群为中心的架构,并原生支持跨 Kafka 服务器的消息分区。这种设计还支持跨集群的消费者机器进行分布式消费,同时保持每个分区内消息的顺序。此外,Kafka 集群可以弹性透明地扩展,无需停机。
3. 支持各种客户端
Apache Kafka 支持集成来自不同平台的客户端,例如 .NET、JAVA、PHP 和 Python。
4. 实时消息
Kafka 生成实时消息,这些消息应该对消费者可见;这对于复杂的事件处理系统至关重要。
Kafka 与 RabbitMQ 有何不同?
Kafka 和 RabbitMQ 是两种流行的消息系统,在架构和使用方面有所不同。您可以比较一下它们在以下关键方面的差异:
1. 使用和设计
Kafka 旨在处理大规模数据流和实时管道,并针对高吞吐量和低延迟进行了优化。其基于日志的架构确保了数据的持久性,并允许数据重新处理,使其成为事件溯源和流处理等用例的理想选择。
RabbitMQ 是一个通用的消息代理,支持复杂的路由,通常用于微服务之间的消息传递或在工作器之间分配任务。它在可靠的消息传递、灵活的路由和服务间交互至关重要的环境中表现出色。
2. 架构
Kafka 将消息分类到主题中,主题又被划分为分区。每个分区可以由多个消费者处理,从而实现并行处理和扩展。数据存储在磁盘上,并具有可配置的保留期,确保了数据的持久性,并允许在需要时重新处理消息。
RabbitMQ 将消息发送到队列,由一个或多个消费者消费。它通过消息确认、重试和用于处理失败消息的死信交换来确保可靠的消息传递。该架构注重消息完整性和路由灵活性。
3. 性能和可扩展性
Kafka 通过添加更多代理和分区来实现水平可扩展性,使其每秒能够处理数百万条消息。其架构支持并行处理和高吞吐量,使其成为大规模数据流的理想选择。
RabbitMQ 可以扩展,但在处理海量数据时效率不如 Kafka。它适用于中高吞吐量场景,但并未针对 Kafka 在大规模流式应用中所能处理的极限吞吐量进行优化。
Kafka 和 RabbitMQ 都是强大的消息传递工具,但它们在不同的用例中表现出色。Kafka 非常适合需要大规模并行处理的高吞吐量、实时数据流和事件溯源应用程序。
RabbitMQ 非常适合可靠的消息传递、微服务架构中的任务分配以及复杂的消息路由。它在需要服务间松散耦合、异步处理和可靠性的场景中表现出色。
Kafka 的基本组件:
Broker
它是 Kafka 系统最基本的组件。在 Kafka 集群中运行的每个服务器/服务都称为 Broker。每个 Broker 都由一个由数字组成的 ID 标识。它们物理连接到安装它们的服务器,但 Broker 即使不在集群中,也能感知集群中的所有主题和分区。Broker 充当生产者和消费者的连接点。
Zookeeper
这是一个开源服务,具有分布式键值数据存储功能,已被许多开源项目(尤其是大数据项目)所使用。Kafka 的 Zookeeper 负责在集群中添加和删除 Broker,确定 Leader/Controller Broker,保存主题配置等。它负责集群管理。如今,Kafka 在新版本中已经不再使用 Zookeeper。但它在当前使用它的系统中也可用。
Topic
它是一种类似于 Kafka 数据库中队列或消息队列的结构,数据写入后所有 Broker 都可以访问。它们由用户命名。Kafka 集群中可以有数千个 Topic。
Partition
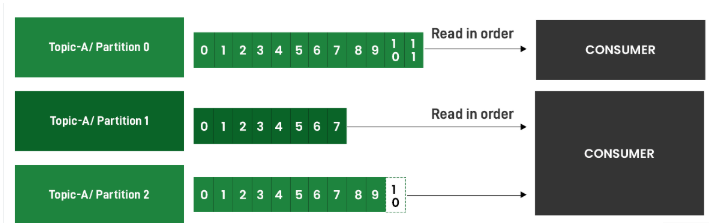
Topic 被划分为多个分区。分区从 0 开始,并按递增顺序排列。在 Topic 中,可以创建单个分区,也可以根据场景创建一千个分区。数据一旦写入分区,就无法再次更改。
分区本身是连续的。但是,分区之间没有顺序。例如,有两个分区:分区 0 和分区 1。首先,消息 0 写入分区 0,然后消息 1 写入分区 1,最后消息 2 写入分区 0。在这种情况下,消息 0 总是先于消息 2 读取。但是,Kafka 不保证消息 1 会在消息 0 之前或之后读取。如果您不介意消息的读取顺序,可以使用不同的键生成消息。但是,如果您需要两条或更多消息按各自的顺序写入,则应使用相同的键生成这些消息。因为 Kafka 会将使用相同键生成的消息写入同一分区,从而确保消息的顺序。但是,如果您不介意消息的顺序,那么使用相同键发送所有消息会存在缺点。因为 Kafka 会将所有这些消息写入单个分区,从而导致负载无法分散。
复制
分布式系统的优势之一是即使其中一台服务器离线,系统也能持续维护。得益于 Kafka 中的副本,系统可以持续运行并防止数据丢失。通过复制,主题的每个分区都存储在多台服务器上。其中一台服务器是 Leader,其他服务器是称为 ISR(同步副本)的副本。ISR 是被动服务器,负责同步数据并保存副本。数据交换由 Leader 提供。Leader 和 ISR 由 Zookeeper 决定。创建主题时,使用复制因子 (replication-factor) 参数指定复制次数。如果领导者所在的服务器发生故障,ZooKeeper 会指定其中一个 ISR 作为领导者,系统将继续运行而不会中断。
偏移量
偏移量是分区特定的,在将数据写入每个分区时都会分配一个标识号。这样,数据可以按照写入分区的顺序读取,消费者在读取分区时可以记住自己所在的消息。偏移量从 0 开始,可以无限期地持续下去。每次写入一条消息时,都会为新消息分配下一个偏移量。Kafka 消息在读取后不会消失。它会在指定的保留时间内继续保留。消费者读取一条消息后,偏移量会递增 1,并从下一条消息继续读取。由于偏移量会保留一段时间,因此如果要再次读取之前读取的消息,可以通过重置偏移量来重复读取过程。
Kafka 生产者和消费者
生产者
生产者是客户端应用程序,它将事件消息写入 Kafka 集群中的主题。消息以键值对的形式存储在主题的分区中。正如前文中提到的,使用相同键生成的消息会写入同一个分区。在生产过程中发送键并非强制性要求。
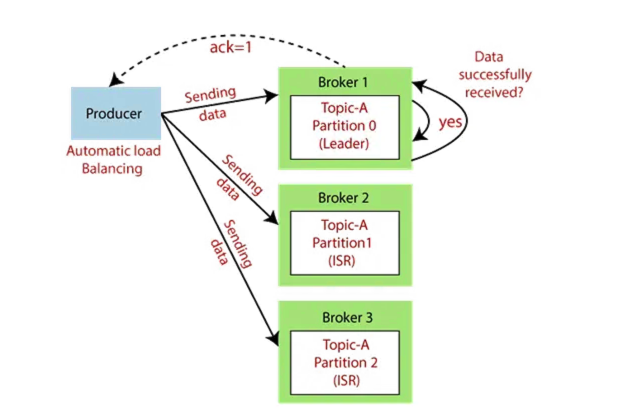
要从应用程序生成消息,首先需要编写生产者配置。生产者配置可能需要的一些配置如下。
- acks:acks 是指生产者接收发送到 Kafka 集群的消息时,必须收到来自 Broker 的最小确认数。它的值可以是“all”、“0”和“1”。all 表示生产者将等待 Leader 分区收到所有 Follower 已提交消息的确认。1 表示 Leader 分区足以写入其自己的提交日志。0 表示不需要确认。
- max.in.flight.requests.per.connection:客户端在阻塞之前在单个连接中可以发送的最大未批准请求数。默认值为 5。
- linger.ms:表示批量记录请求准备好发送之前的延迟时间。生产者会将两次请求之间收到的所有记录汇总到一个请求中。linger.ms 指定批处理的延迟上限。默认值为 0。这意味着不会有延迟,批处理将立即发送(即使批处理中只有 1 条消息)。在某些情况下,客户端可能会增加 linger.ms 以减少请求数量,即使在中等负载下也能提高吞吐量。只有这样,才能在内存中存储更多记录。
- batch.size:当多条记录发送到同一分区时,生产者会尝试将这些记录汇总在一起。通过这种方式,可以提高客户端和服务器的性能。batch.size 表示单个批处理的最大大小(以字节为单位)。较小的批处理大小会使批处理变得繁琐并降低效率;过大的批处理大小会浪费内存,因为通常会分配一个缓冲区来等待额外的记录。
生产者在向 Kafka 生成消息时需要序列化器。序列化器有很多种,但通常使用字符串、json 和 avro 序列化器。
消费者
消费者是从主题读取事件消息的客户端应用程序。您已经创建了主题,编写了生产器应用程序,数据正在流向 Kafka,现在是时候编写消费者应用程序了。您需要为消费者和生产器添加配置。有些配置与生产器通用,有些配置是消费者专用的。消费者配置可能需要的一些配置如下。
- auto.offset.reset:auto.offset.reset 参数用于确定消费者启动时从何处读取数据。如果设置为“earliest”,则从头开始重新读取主题中的数据。如果设置为“latest”,则从最后一个偏移量继续读取。如果设置为“none”,则表示起始偏移量需要手动确定。
- enable.auto.commit:我们之前讨论过偏移量。消费者读取一条消息后,偏移量会加 1,以便另一个消费者或同一个消费者可以从下一条消息继续读取。必须提交该消息才能使偏移量加 1。如果此参数设置为 true,则消费者在读取消息后,如果任何情况下都没有发生故障,消息就会自动提交。如果设置为 false,则需要使用 commitSync() 方法手动提交。我举一个手动提交的例子。假设你从 Kafka 读取一条数据后有两个操作。第一个是将记录发送到数据库,第二个是向用户发送推送通知。这里对你来说,关键是要将记录写入数据库,并且不要重复执行。无论 pn 是否被清除,都可能存在问题。为此,请在将记录写入数据库后手动提交。这样,如果在此之后的任何步骤中出现错误,由于偏移量已经提前,因此不会出现重复记录。但是,如果使用自动提交机制,如果在发送 pn 时发生错误,由于偏移量不会增加,因此将再次处理同一条消息。
- fetch.min.bytes:此配置用于指定一次要获取的最小数据字节数。其默认值为 1。
- fetch.max.bytes:此配置用于指定一次要获取的最大数据字节数。默认值为 52428800(50MB)。
- max.poll.records:此配置用于指定一次要捕获的记录数。默认值为 500。
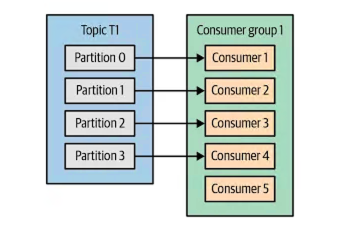
消费者组
与消费者相关的最重要的概念之一是消费者组。我想详细讨论它,因为必须完全建立消费者组逻辑才能编写高效的消费者应用程序。
一个主题通常包含多个分区。这些分区是 Kafka 消费者并行处理的成员。消费者通过消费分区而成为消费者组的一部分。一个主题可能有多个消费者组在消费。每个消费者组都有一个唯一的 ID。该 ID 由用户分配。
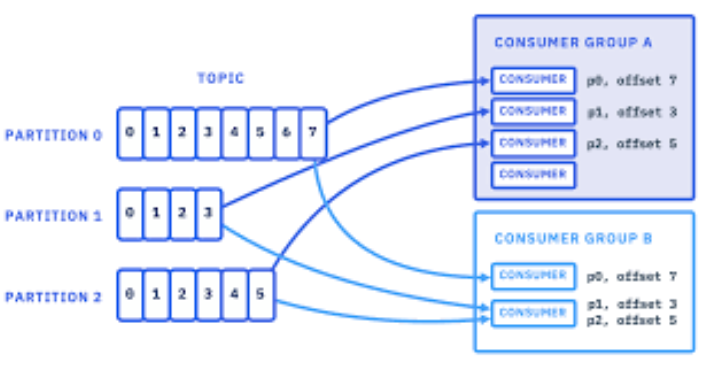
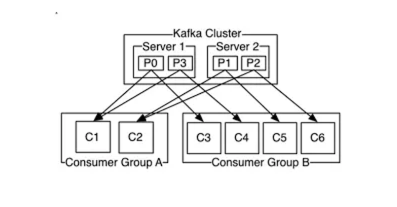
假设您有一个名为“user”的主题,该主题有 5 个分区。您编写了一个名为 Consumer1 的应用程序,并将消费者组 ID 设置为“userConsumerGroup”,该消费者组将消费用户主题。当您将应用程序部署为 3 个实例时,Kafka 的 GroupCoordinator 和 ConsumerCoordinator 会将 Consumer1 应用程序的 3 个实例分配给用户主题的 3 个分区。然后,您编写了一个名为 Consumer2 的新应用程序,并将其组 ID 设置为“userConsumerGroup”。当您将此应用程序部署为 3 个实例时,协调器会重新平衡消费者组,并将总共 6 个实例中的 5 个分配给用户主题的 5 个分区。1 个实例保持空闲状态,不执行任何消费操作。如果其中一个活动实例发生故障,则会再次进行重新平衡,并将空闲实例纳入游戏并分配到一个分区。我还必须说明,我给出的示例并非非常现实。通常,两个不同的应用程序不会包含在同一个消费者组中。如果同一主题中的消息将用于不同的目的,则需要分配不同的应用程序和不同的消费者组。
我们继续以单个应用程序为例。“用户”主题有 3 个分区,Consumer1 应用程序有 3 个实例。每个实例消费一个分区并继续运行。但是您的负载增加了,从每月 1000 个注册到该主题,到每天 100 万个注册。消息开始在您的分区中累积,应用程序难以使用它们。这里要做的第一件事是增加主题中的分区数量,并分发到达 Kafka 的消息。您将分区数增加到 12,消息开始跨分区分布。但是,由于应用程序中有 3 个实例,因此消费者组中有 3 个活跃成员,它们在时间 t 最多可以消费 3 个分区。因此,消息继续累积在 9 个分区中。这里有两种方法可供选择。第一种方法是将应用程序的实例数增加到 12。这样,每个实例将与一个分区配对,而在时间 t 时将消费 3 条消息,那么将消费 12 条消息,理论上速度将提高四倍。另一种方法是增加并发度。默认并发度为 1。如果您信任每个实例的来源,则可以增加并发度,并使一个实例消费多个分区。您可以将并发性视为一个线程。在这种情况下,如果将 3 个实例的并发度设置为 4,则可以并行消费总共 12 个分区。如果希望所有分区同时消费,则最大并发度为分区数 = 实例数 * 并发度。另外,我想指出的是,Kafka 每秒可以传输数百万条数据。但消费和处理数据的能力与您的应用程序和资源成正比。因此,Kafka 会说:“我可以传输大量数据给您,但您有能力处理吗?”
我想讨论最后一个关于消费者组的案例。人们通常会问这样的问题:“我在本地启动了测试应用程序,消息的偏移量正在增加,但我没有消费它。”原因如下。您的测试应用程序在 2 个实例中运行,它消费的主题有 2 个分区。如果您使用相同的消费者组 ID 在本地启动应用程序,由于没有空闲分区,您将无法消费。偏移量仍在增加,因为测试环境中的应用程序正在消费。解决方案是,如果您在本地运行应用程序时更改了消费者组 ID,则主题实例分发将在另一个组中进行,与测试环境无关。您仍然可以使用它。但这里有一点需要注意。如果在消费后,您可以保存到数据库、发送电子邮件、更新余额等。如果您正在进行交易,这些操作将是重复的。我建议针对这种情况添加本地检查。
相关文章:
Kafka 架构设计和组件介绍
什么是Apache Kafka? Apache Kafka 是一个强大的开源分布式事件流平台。它最初由 LinkedIn 开发,最初是一个消息队列,后来发展成为处理各种场景数据流的工具。 Kafka 的分布式系统架构支持水平扩展,使消费者能够按照自己的节奏检…...

虚函数表的设计和多态的实现
虚函数表 1.包含虚函数的类会有对应的虚函数表,这个表在编译时就初始化好了 2.本质是一个函数指针数组,里面是虚函数的指针 3.该类实例化的对象共用一张虚函数表 4.子类的虚函数表会继承父类的虚函数,如果继承多个父类那就把父类的虚函数…...
【Node.js 】在Windows 下搭建适配 DPlayer 的轻量(简陋)级弹幕后端服务
一、引言 DPlayer官网:DPlayer 官方弹幕后端服务:DPlayer-node MoePlayer/DPlayer-node:使用 Docker for DPlayer Node.js 后端(https://github.com/DIYgod/DPlayer) 本来想直接使用官网提供的DPlayer-node直接搭建…...
OpenSSH配置连接远程服务器MS ODBC驱动与Navicat数据库管理
OpenSSH配置连接远程服务器MS ODBC驱动与Navicat数据库管理 目录 OpenSSH配置连接远程服务器MS ODBC驱动与Navicat数据库管理 一、MS ODBC驱动 1.1、安装到Windows后的表现形式 1.2、版本的互斥性 1.3、安装程序 1.4、配置后才可用 二、Navicat数据库管理工具 2.1、安…...

织梦dedecms调用会员详细字段信息
织梦如何调用会员详细信息: 在include/extend.func.php function GetMemberInfos($fields,$mid){ global $dsql; if($mid < 0){ $revalue "Error"; } else{ $row$dsql->GetOne("sele ct * fr…...

MySQL 8.0 忘记登录密码 mysqld --init-file重置
看到了很多跳过授权表的办法,这里通过mysqld --init-file办法。 适用情况: 服务器可以启动但无法登录/忘记登录密码。 一、首先停止 MySQL 服务: 按下 Win R 组合键,输入 services.msc 并点击“确定”,打开“服务”…...
)
Python 学习路线与笔记跳转(持续更新笔记链接)
这里写目录标题 Python 学习路线与笔记Python 简介学习路线第一阶段:Python 基础第二阶段:Python 进阶第三阶段:实用库与框架第四阶段:DevOps 与 Python第五阶段:最佳实践与高级技巧 学习资源官方资源在线学习平台书籍…...

操作系统:计算机世界的基石与演进
一、操作系统的本质与核心功能 操作系统如同计算机系统的"总管家",在硬件与应用之间架起关键桥梁。从不同视角观察,其核心功能呈现多维价值: 硬件视角的双重使命: 硬件管理者:通过内存管理、进程调度和设…...

Codeium 免费的AI编程助手
Codeium 由 Exafunction 团队(主要也是美国华人)开发的一款免费AI编程助手,是一个建立在顶尖AI技术上的代码加速工具,其背后的老板非常厉害,据说投资过马斯克的SpaceX。Codeium 本身具有颇多的亮点,支持70种…...
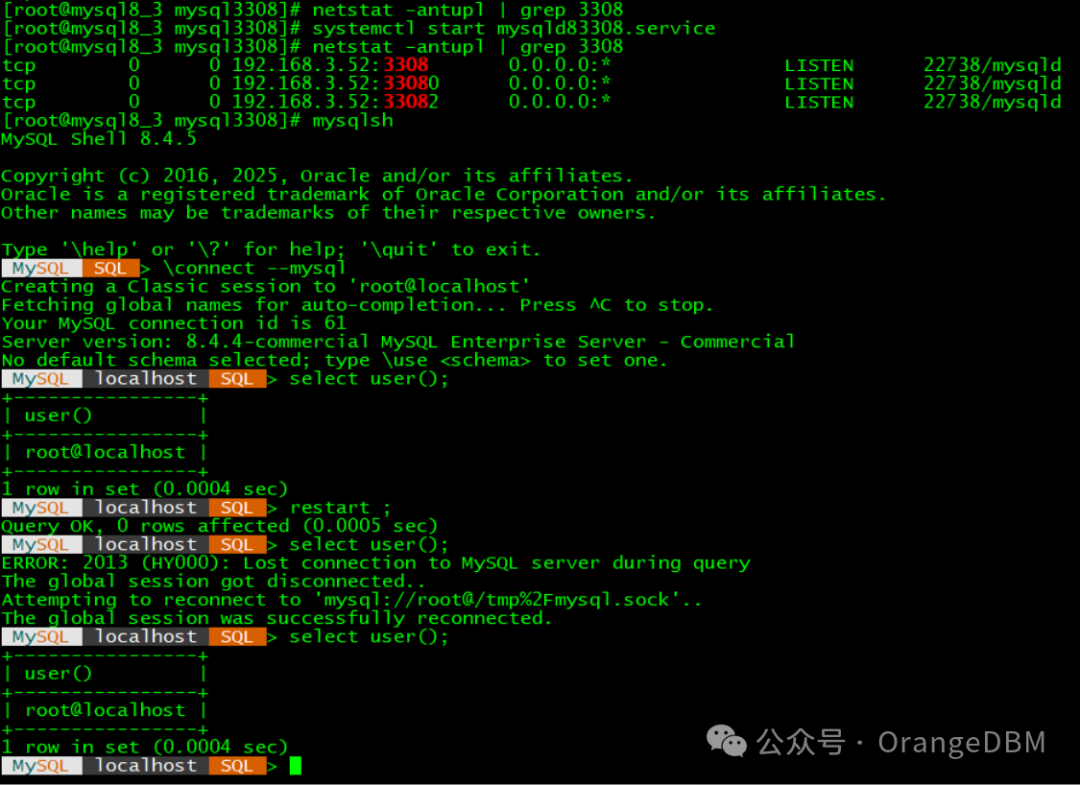
在MySQL Shell里 重启MySQL 8.4实例
前一段时间看到MySQL官方视频的Oracle工程师在mysql shell里面重启mysql实例,感觉这个操作很方便,所以来试试,下面为该工程师的操作截图 1.MySQL Shell 通过root用户连上mysql,shutdown mysql实例 [rootmysql8_3 bin]# mysqlshMy…...
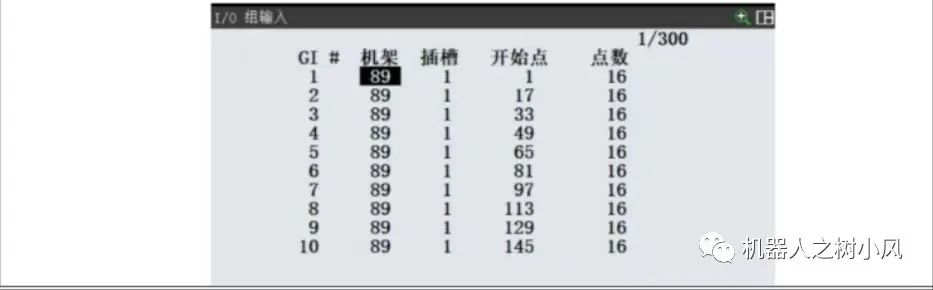
FANUC机器人GI与GO位置数据传输设置
FANUC机器人GI与GO位置数据传输设置(整数小数分开发) 一、概述 在 Fanuc 机器人应用中,如果 IO 点位足够,可以利用机器人 IO 传输位置数据及偏移位置数据等。 二、操作步骤 1、确认通讯软件安装 首先确认机器人控制柜已经安装…...
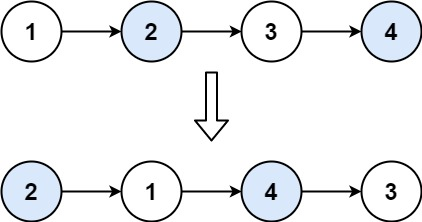
LeetCode 24 两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1: 输入:head [1,2,3,4] 输出:[2,1…...
低代码平台开发手机USB-HID调试助手
项目介绍 USB-HID调试助手是一种专门用于调试和测试USB-HID设备的软件工具。USB-HID设备是一类通过USB接口与计算机通信的设备,常见的HID设备包括键盘、鼠标、游戏控制器、以及一些专用的工业控制设备等。 主要功能包括: 数据监控:实时监控和…...

Java 深度与实战 · 每日一读 :高频面试真题解析 · ReentrantLock / CAS / AQS 篇
ReentrantLock 深层分析:CAS、AQS原理全揭秘 此文为「Java 深度与实战每日一读」系列第1篇,原创专栏,全篇不含水分,该系列整个面向:初学、进阶、面试、原理、实战,全综合型导向。 目标:让任何级…...
和 channel(管道) 案例解析)
golang goroutine(协程)和 channel(管道) 案例解析
文章目录 goroutine和channel概念开启线程与channel简单通信流程多个工作协程并发执行流程 goroutine和channel概念 goroutine(协程),一般我们常见的是进程,线程,进程可以理解为一个软件在运行执行的过程,线程跟协程比较类似&…...
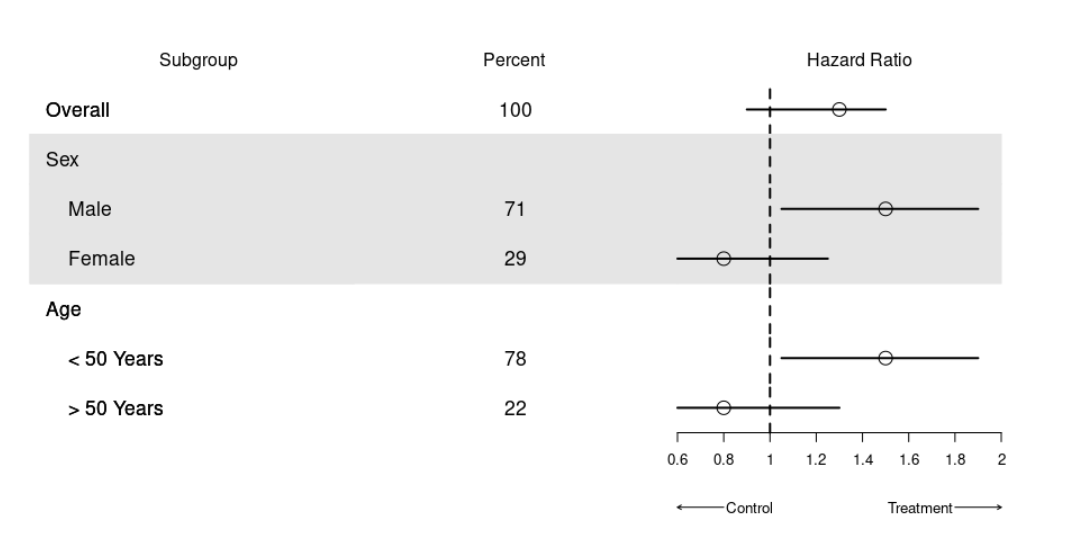
亚组风险比分析与可视化
1. 结果解读 1.1 风险比概述 1.1.1 风险比基本概念 风险比(Hazard Ratio)用于衡量治疗组与对照组事件发生的风险差异。 风险比为1,表示两组风险相同;小于1,治疗组风险低;大于1,治疗组风险高。 1.1.2 性别亚组分析 A性风险比小于1,表明治疗对A性有积极效果,风险降低。…...
)
计算机网络核心知识点全解析(面试通关版)
一、网络体系结构:从OSI到TCP/IP的分层设计 1.1 七层模型与四层模型对比 OSI七层模型核心功能TCP/IP四层对应典型协议生活类比应用层为应用程序提供服务(如文件传输、邮件、Web浏览)应用层HTTP、FTP、SMTP、DNS快递面单信息(收件…...

使用 Frida 绕过 iOS 应用程序中的越狱检测
在这篇博文中,我们将介绍**Frida**,它是用于移动应用程序安全分析的真正有趣的工具之一。 我们在高级 Android 和 iOS 漏洞利用培训中也深入讲解了这一点,您可以在这里注册 -培训链接 即使您从未使用过 Frida,本文也将作为指南,帮助您进入 Frida 的世界,进行移动应用程…...

【博客系统】博客系统第一弹:博客系统项目配置、MyBatis-Plus 实现 Mapper 接口、处理项目公共模块:统一返回结果、统一异常处理
案例综合练习 - 博客系统 本节目标 从 0 到 1 完成博客系统后端项目的开发。 前言 通过前面课程的学习,我们掌握了 Spring 框架和 MyBatis 的基本使用,并完成了图书管理系统的常规功能开发。接下来我们系统地从 0 到 1 完成一个项目的开发。 项目介绍 …...

如何通过挖掘需求、SEO优化及流量变现成功出海?探索互联网产品的盈利之道
挖掘需求,优化流量,实现变现:互联网出海产品的成功之路 在当今全球化的数字时代,越来越多的企业和个人选择将业务扩展到国际市场。这一趋势不仅为企业带来了新的增长机会,也为个人提供了通过互联网产品实现盈利的途径…...

车载功能测试-车载域控/BCM控制器测试用例开发流程【用例导出方法+优先级划分原则】
目录 1 摘要2 位置灯手动控制简述2.1 位置灯手动控制需求简述2.2 位置灯手动控制逻辑交互图 3 用例导出方法以及优先级原则3.1 用例导出方法3.1.1 用例导出方法介绍3.1.2 用例导出方法关键差异分析 3.2 优先级规则3.2.1 优先级划分的核心原则3.2.2 具体等级定义与判定标准 3.3 …...
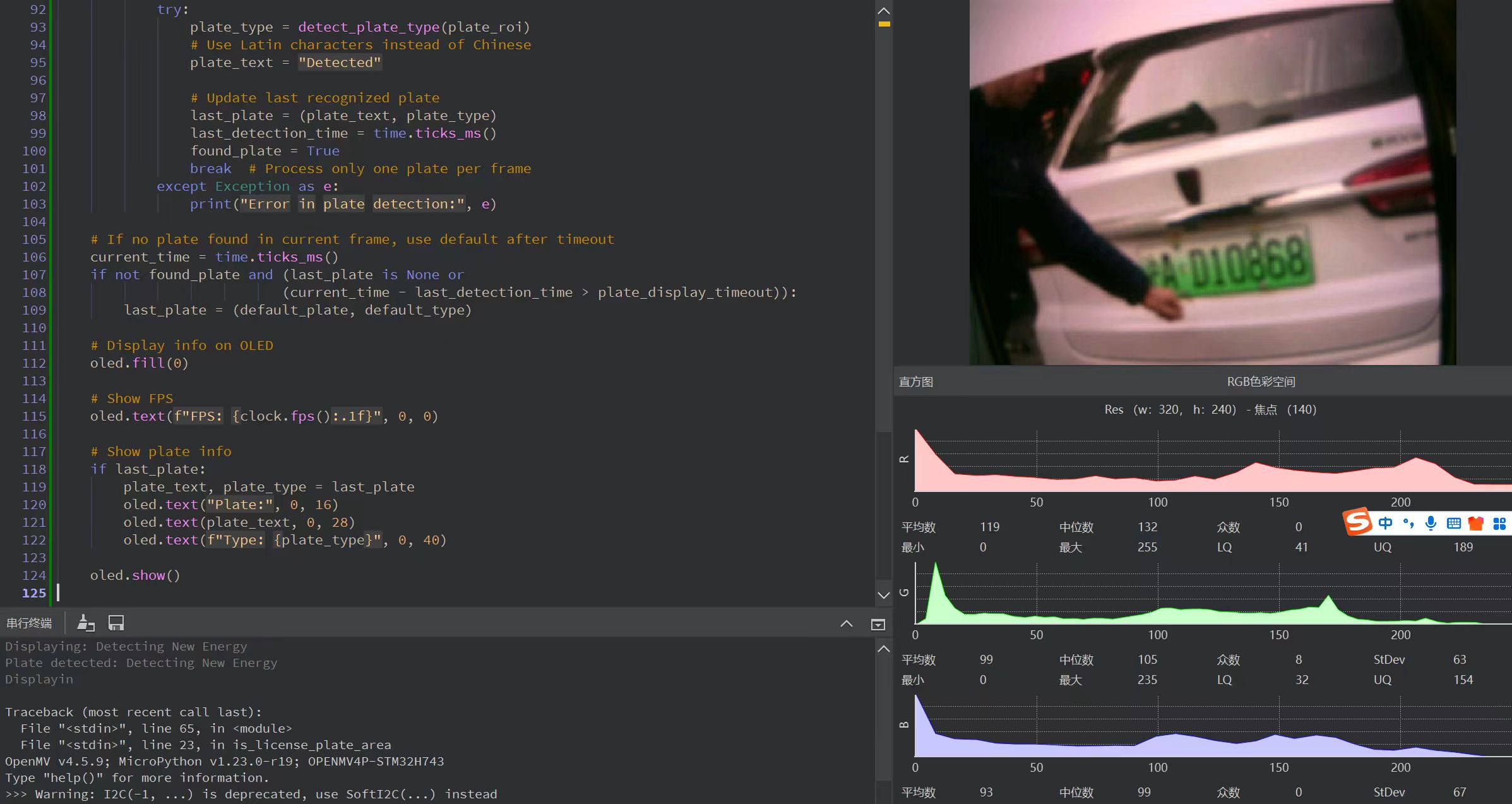
基于OpenMV+STM32+OLED与YOLOv11+PaddleOCR的嵌入式车牌识别系统开发笔记
基于OpenMV、STM32与OLED的嵌入式车牌识别系统开发笔记 基于OpenMV、STM32与OLED的嵌入式车牌识别系统开发笔记系统架构全景 一、实物演示二、OpenMV端设计要点1. 硬件配置优化2. 智能帧率控制算法3. 数据传输协议设计 三、PyTorch后端核心实现:YOLOv11与PaddleOCR的…...

MCP实战-本地MCP Server + Client实战
概述 本文开发一个MCP的Client和Server。然后通过本地模式来运行,并获取到server的结果。 MCP Server开发 import anyio import click import mcp.types as types from mcp.server.lowlevel import Server from pydantic import FileUrlSAMPLE_RESOURCES {"…...

w~嵌入式C语言~合集4
我自己的原文哦~ https://blog.51cto.com/whaosoft/13870376 一、STM32怎么选型 什么是 STM32 STM32,从字面上来理解,ST是意法半导体,M是Microelectronics的缩写,32表示32位,合起来理解,STM32就是指S…...

lightrag : from lightrag.utils import EmbeddingFunc 报错
原因: 1. 同时安装了lightrag与lightrag-hku 解决方法: 卸载原有的lightrag与lightrag-hku,只安装lightrag-hku pip install lightrag-hku...

ppt流程图怎么?ppt流程图模板大全
ppt流程图怎么?ppt流程图剪头模板,ppt流程图模板大全: ppt流程图_模板素材_PPT模板_ppt素材_免抠图片_AiPPTer...

AWS中国区ICP备案全攻略:流程、注意事项与最佳实践
导语 在中国大陆地区开展互联网业务时,所有通过域名提供服务的网站和应用必须完成ICP备案(互联网内容提供商备案)。对于选择使用AWS中国区(北京/宁夏区域)资源的用户,备案流程因云服务商的特殊运营模式而有所不同。本文将详细解析AWS中国区备案的核心规则、操作步骤及避坑…...
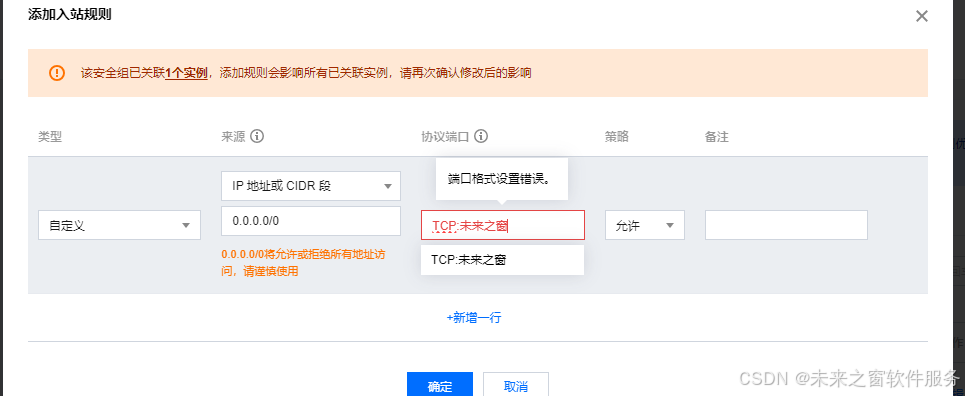
腾讯云服务器安全——服务防火墙端口放行
点击服务进入安全策略 添加规则...

对局匹配--stl+模拟
1.模拟,先找匹配对数,然后减 2.特殊情况,k0 3.stl容器使用,lower_bound https://www.luogu.com.cn/problem/P8656 #include<bits/stdc.h> using namespace std; #define N 100011 typedef long long ll; typedef pair&…...

K8S安全认证
一。用户认证的基本框架 在K8S集群中,客户端通常有两类: 1.User Account:一般独立于K8S之外的其他服务管理的用过户账号 2.Service Account:K8S管理的账号,用于为Pod中的服务进程在访问K8S提供身份标识 ApiServer是…...