locust压力测试
安装
pip install locust
验证是否安装成功
locust -V
使用
网上的教程基本上是前几年的,
locust已经更新了好几个版本,有点过时了,在此做一个总结
启动
默认是使用浏览器进行设置的
# 使用浏览器
locust -f .\main.py
其他参数
Usage: locust [options] [UserClass ...]常用选项:-h, --help 显示帮助消息并退出-f <filename>, --locustfile <filename>包含测试的Python文件或模块,例如“my_test.py”。接受多个逗号分隔.py文件、包名/目录或指向的url远程locustfile。默认为“locustfile”。--config <filename> 从中读取其他配置的文件。-H <base url>, --host <base url>主机负载测试,格式如下:https://www.example.com-u <int>, --users <int>并发Locust用户的峰值数量。主要使用与无头或自动启动一起。可以是在测试期间通过键盘输入w、W(spawn1,10个用户)和s,S(停止1,10用户)-r <float>, --spawn-rate <float>生成用户的速率为(每秒用户数)。主要是与--headless或--autostart一起使用-t <time string>, --run-time <time string>在指定的时间量后停止,例如(300s,20m、3h、1h30m等)。仅与一起使用--headless 或 --autostart。默认为永远运行。-l, --list 显示可能的用户类列表并退出--config-users [CONFIG_USERS ...]用户配置为JSON字符串或文件。列表参数或JSON配置数组Web UI 选项:--web-host <ip> 将web界面绑定到的主机。默认为“*”(所有接口)--web-port <port number>, -P <port number>运行web主机的端口--headless 禁用web界面,然后立即开始测试。使用-u和-t来控制用户数量和运行时间--autostart 立即开始测试(比如--headless,但是不禁用web UI)--autoquit <seconds> 完全退出Locust,运行后X秒完成。仅与 --autostart一起使用。这个默认设置是保持Locust运行,直到您按下CTRL+C关闭它--web-login 使用登录页面保护web界面。--tls-cert <filename>用于提供服务的TLS证书的可选路径HTTPS--tls-key <filename> 用于提供服务的TLS私钥的可选路径HTTPS--class-picker 在web界面中启用选择框进行选择从所有可用的用户类和形状类主选项:
在分布式运行Locust时运行LocustMaster节点的选项。主节点需要连接到它的Worker节点,然后才能运行负载测试。--master 将locust作为主节点启动,工作节点连接到该节点。--master-bind-host <ip>主机监听的IP地址,例如'192.168.1.1'. 默认为*(全部可用接口)。--master-bind-port <port number>主机监听的端口。默认为5557。--expect-workers <int>延迟开始测试,直到达到此数量的workers(仅与结合使用 --headless/ --autostart)。--expect-workers-max-wait <int>master等待workers连接时间。默认为永远等待--enable-rebalancing 如果在测试运行期间添加或删除了新的worker,请重新分配用户。实验。Worker选项:
在分布式运行Locust时运行LocustWorker节点的选项。
通常只需要在workers上指定这些选项(和--locostfile),因为其他选项(-u、-r、-t、…)由主节点控制。--worker 将locust设置为以分布式模式运行,并将此进程设置为worker。可以与设置相结合--locustfile设置为“-”,以便从master下载。--processes <int> 分流 locust 进程的数量,以启用系统。结合--worker标志或让它自动设置--worker和--master标志,以实现一体化解决方案。在 Windows 上不可用。实验。--master-host <hostname>要连接的locust主节点的主机名。默认值127.0.0.1。--master-port <port number>主节点上要连接的端口。默认值为5557。标记选项:
Locust任务可以使用@tag装饰器进行标记。这些选项允许指定在测试期间包含或排除哪些任务。-T [<tag> ...], --tags [<tag> ...]测试中要包含的标签列表,只会执行至少有一个匹配标签的任务-E [<tag> ...], --exclude-tags [<tag> ...]要从测试中排除的标签列表,只会执行没有匹配标签的任务请求统计选项:--csv <filename> 将请求统计数据以CSV格式存储到文件中。设置此选项将生成三个文件:<filename>_stats.csv、<filename>_stats_history.csv和<filename>_failures.csv。前缀文件夹部分将自动创建--csv-full-history 将每个统计条目以CSV格式存储到_statshistory.csv文件。您还必须指定“--csv”参数来启用此功能。--print-stats 在UI运行中启用请求统计数据的定期打印--only-summary 禁用请求统计信息的定期打印--headless 运行--reset-stats 生成完成后重置统计信息。在分布式模式下运行时,应同时在master和worker上设置--html <filename> 将HTML报告存储到指定的文件路径--json 将JSON格式的最终统计数据打印到stdout。可用于解析其他程序/脚本中的结果。与--headless和--skip-log一起使用,仅用于json数据的输出。日志记录选项:--skip-log-setup 禁用Locust的日志记录设置。相反,配置是由Locust测试或Python默认值提供的。--loglevel <level>, -L <level>在DEBUG/INFO/WARNING/ERROR/CRITICAL之间进行选择。默认值为INFO。--logfile <filename> 日志文件的路径。如果未设置,日志将转到stderr其他选项:--show-task-ratio 打印用户类任务执行率表。如果某些类定义了非零的fixed_count属性,请将其与非零--user选项一起使用。--show-task-ratio-json打印User类任务执行率的json数据。如果某些类定义了非零的fixed_count属性,请将其与非零--user选项一起使用。--version, -V 显示程序的版本号并退出--exit-code-on-error <int>设置测试结果包含任何失败或错误时使用的进程退出代码。默认为1。-s <number>, --stop-timeout <number>退出前等待模拟用户完成所有执行任务的秒数。默认情况是立即终止。当运行分布式时,只需要在主服务器上指定。--equal-weights 使用均匀分布的任务权重,覆盖locostfile中指定的权重。User classes:<UserClass1 UserClass2>在命令行末尾,您可以列出要使用的User类(可用的User类可以用--list列出)。LOCUST_USER_CLASS环境变量也可用于指定USER类。默认设置是使用所有可用的用户类示例:locust -f my_test.py -H https://www.example.comlocust --headless -u 100 -t 20m --processes 4 MyHttpUser AnotherUser有关更多详细信息,包括如何使用文件或环境变量设置选项,请参阅文档:
https://docs.locust.io/en/stable/configuration.html参数介绍在其他文章上有有很多,这里不多赘述,下面主要介绍一下项目中的应用
TaskSet
新版的
locust使用的方式与旧版有点区别,写用例时需要继承TaskSet来实现
代码如下:
# coding: utf-8
from locust import TaskSet
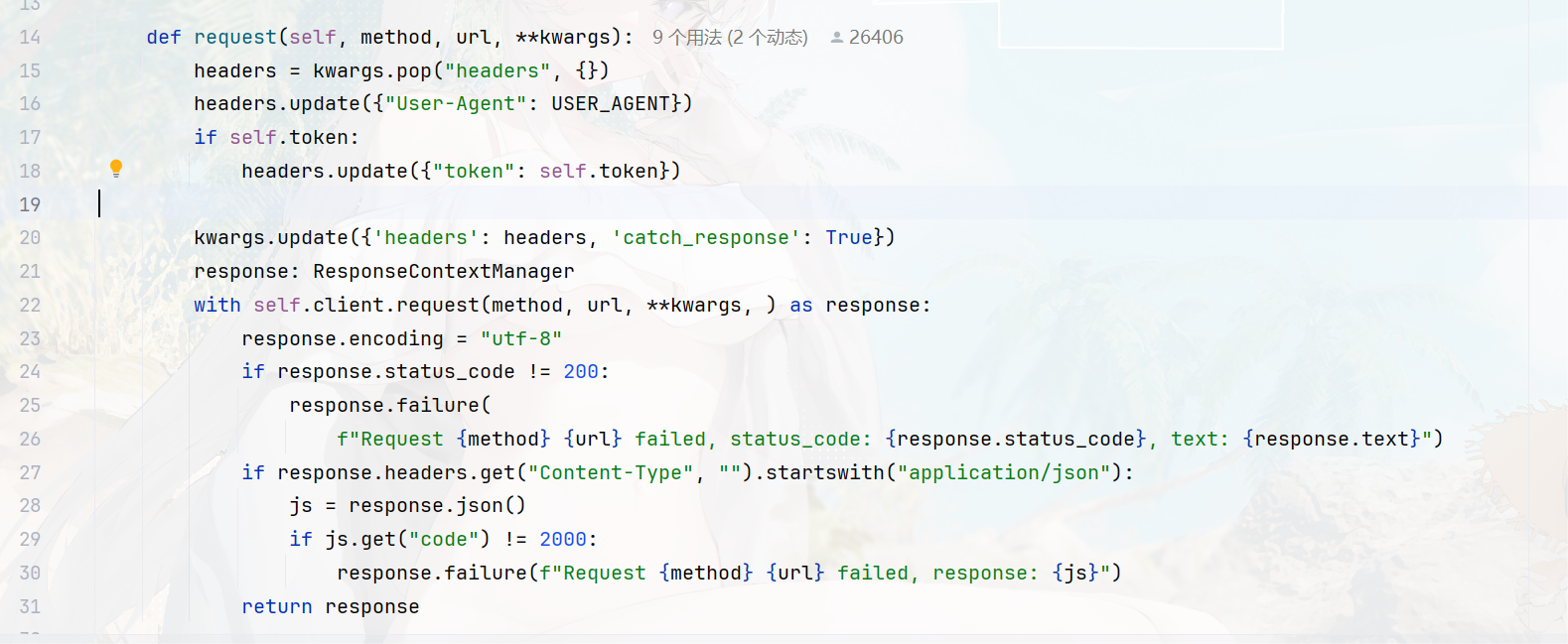
from locust.clients import ResponseContextManagerfrom .settings import USER_AGENTclass UserBehaviorBase(TaskSet):token = Nonedef setToken(self, token):self.token = tokendef request(self, method, url, **kwargs):headers = kwargs.pop("headers", {})headers.update({"User-Agent": USER_AGENT})if self.token:headers.update({"token": self.token})kwargs.update({'headers': headers, 'catch_response': True})response: ResponseContextManagerwith self.client.request(method, url, **kwargs, ) as response:response.encoding = "utf-8"if response.status_code != 200:response.failure(f"Request {method} {url} failed, status_code: {response.status_code}, text: {response.text}")if response.headers.get("Content-Type", "").startswith("application/json"):js = response.json()if js.get("code") != 2000:response.failure(f"Request {method} {url} failed, response: {js}")return responsedef get(self, url, **kwargs):return self.request("GET", url, **kwargs)def post(self, url, **kwargs):return self.request("POST", url, **kwargs)def put(self, url, **kwargs):return self.request("PUT", url, **kwargs)def delete(self, url, **kwargs):return self.request("DELETE", url, **kwargs)def options(self, url, **kwargs):return self.request("OPTIONS", url, **kwargs)def head(self, url, **kwargs):return self.request("HEAD", url, **kwargs)def patch(self, url, **kwargs):return self.request("PATCH", url, **kwargs)自定义错误
在
locust中assert函数只能抛出错误只能在Exceptions中查看,这是错误,但是用例还是成功的
如果标记失败需要在
ResponseContextManager中进行指定,在locust中用例状态只有两种,成功,失败
自定义失败需要在ResponseContextManager中指定一个参数catch_response= True
例:
若不指定
failure,默认用例是成功的,locust中status_code小于400就是成功的用例,不满足需求常常是自定义的
task
项目中一个
task便是一个用例,用例必须要有task装饰器
task有个weight参数,若weight=2,可以简单的理解为,不指定参数的运行一次,指定参数的运行两次
例:
# coding: utf-8
from locust import taskfrom common import UserBehaviorBase, operationToken, USER_MANAGEclass InsuranceUser(UserBehaviorBase):"""保险端用户"""# def on_start(self):# insurance = Login.login(USER_MANAGE['operation'])# token = operation.get('result', {}).get('token')# self.setToken(token)def on_start(self) -> None:self.setToken(operationToken)@taskdef test01(self):"""承保管理 - 询价申请"""url = '/gateway/spli/insurance/apply/page'payload = {"param": {},"page": {"current": 1,"size": 10}}self.post(url, json=payload)
on_start/on_stop
类运行前、后的函数,只运行一次,通常用于登录、清理内存
执行程序
这里只说一下单使用
locust自己写的用例运行。项目中经常需要在多个文件中写用例,官方文档中并没有明确说该怎么运行多个文件的用例。
其实也比较简单
例:
# coding: utf-8
from locust import HttpUser, between, run_single_userfrom common import HOST
# 从其他文件中引入类
from tasks import *class WebSite(HttpUser):# 将用例类添加到任务重tasks = [RegulatoryUser, CustomerUser, ProjectUser, InsuranceUser]# tasks = [InsuranceUser]host = HOSTwait_time = between(0.5, 2)if __name__ == '__main__':# 调试模式下,只运行一个用户run_single_user(WebSite)参数解析
class WebSite(HttpUser):host = '' # 需要测试的主机地址 eg: http://127.0.0.1:1234tasks: list[TaskSet | Callable] = [] # 任务列表min_wait= 1 # 最小等待时间,已弃用,使用wait_timemax_wait = 2 # 最大等待时间,已弃用 使用 wait_timewait_time=between(3, 25) # 等待时间,这个例子是在2-25秒中随机选择一个wait_function=None # 自定义等待函数,已弃用weight: float = 1 # 与`task`中相同fixed_count: int = 0 # 如果值为> 0,则权重属性将被忽略,并且将生成'fixed_count'-实例。首先生成这些用户。如果总目标计数(由——users参数指定)不足以生成具有已定义属性的每个User类的所有实例,则每个User的最终计数是未定义的。abstract: bool = True # 如果abstract为True,则该类将被子类化,并且在测试期间不会生成该类的用户
相关文章:
locust压力测试
安装 pip install locust验证是否安装成功 locust -V使用 网上的教程基本上是前几年的,locust已经更新了好几个版本,有点过时了,在此做一个总结 启动 默认是使用浏览器进行设置的 # 使用浏览器 locust -f .\main.py其他参数 Usage: locust […...

python 线程池顺序执行
在Python中,线程池(ThreadPoolExecutor)默认是并发执行任务的,但若需要实现任务的顺序执行(按提交顺序执行或按结果顺序处理),可以通过以下方案实现: 方案一:强制单线程&…...

第十二届蓝桥杯 2021 C/C++组 空间
目录 题目: 题目描述: 题目链接: 思路: 思路详解: 代码: 代码详解: 题目: 题目描述: 题目链接: 空间 - 蓝桥云课 思路: 思路详解&#…...

以太网的mac帧格式
一.以太网的mac帧 帧的要求 1.长度 2.物理层...

前端如何使用Mock模拟数据实现前后端并行开发,提升项目整体效率
1. 安装 Mock.js npm install mockjs --save-dev # 或使用 CDN <script src"https://cdn.bootcdn.net/ajax/libs/Mock.js/1.0.0/mock-min.js"></script>2. 创建 Mock 数据文件 在项目中新建 mock 目录,创建 mock.js 文件: // m…...

【hadoop】HBase shell 操作
1.创建course表 hbase(main):002:0> create course,cf 2.查看HBase所有表 hbase(main):003:0> list 3.查看course表结构 hbase(main):004:0> describe course 4.向course表插入数据 hbase(main):005:0> put course,001,cf:cname,hbase hbase(main):006:0> …...

如何使用 Redis 缓存验证码
目录 🧠 Redis 缓存验证码的工作原理 🧰 实现流程 1. 安装 Redis 和 Python 客户端 2. 生成并缓存验证码 示例代码:生成并存储验证码 3. 发送验证码(以短信为例) 4. 校验验证码 示例代码:校验验证码…...

深度学习---框架流程
核心六步 一、数据准备 二、模型构建 三、模型训练 四、模型验证 五、模型优化 六、模型推理 一、数据准备:深度学习的基石 数据是模型的“燃料”,其质量直接决定模型上限。核心步骤包括: 1. 数据收集与标注 来源:公开数据集…...
业绩回暖、股价承压,三只松鼠赴港上市能否重构价值锚点?
在营收重返百亿俱乐部后,三只松鼠再度向资本市场发起冲击。 4月25日,这家坚果零食巨头正式向港交所递交上市申请书,若成功登陆港股,将成为国内首个实现“AH”双上市的零食品牌。 其赴港背后的支撑力,显然来自近期披露…...

JAVA-StringBuilder使用方法
JAVA-StringBuilder使用方法 常用方法 append(Object obj) 追加内容到末尾 sb.append(" World"); insert(int offset, Object obj) 在指定位置插入内容 sb.insert(5, “Java”); delete(int start, int end) 删除指定范围的字符 sb.delete(0, 5); replace(int start…...

【Python】Matplotlib:立体永生花绘制
本文代码部分实现参考自CSDN博客:https://blog.csdn.net/ak_bingbing/article/details/135852038 一、引言 Matplotlib作为Python生态中最著名的可视化库,其三维绘图功能可以创造出令人惊叹的数学艺术。本文将通过一个独特的参数方程,结合极…...
Unity AI-使用Ollama本地大语言模型运行框架运行本地Deepseek等模型实现聊天对话(一)
一、Ollama介绍 官方网页:Ollama官方网址 中文文档参考:Ollama中文文档 相关教程:Ollama教程 Ollama 是一个开源的工具,旨在简化大型语言模型(LLM)在本地计算机上的运行和管理。它允许用户无需复杂的配置…...

terraform使用vault动态管多理云账号AK/SK
为了使用 Terraform 和 HashiCorp Vault 动态管理多个云账号的 Access Key (AK) 和 Secret Key (SK),可以按照以下步骤实现安全、自动化的凭证管理: 一、架构概述 核心组件: Vault:存储或动态生成云账号的 AK/SK,提供…...
SAP /SDF/SMON配置错误会导致HANA OOM以及Disk Full的情况
一般来说,为了保障每日信息收集,每个企业都会配置/SDF/SMON的监控。这样在出现性能问题时,可以通过收集到的snapshot进行分析检查。如果/SDF/SMON在配置时选取了过多的记录项,或者选择了过低的时间间隔[Interval in seconds],那显…...

CMU和苹果公司合作研究机器人长序列操作任务,提出ManipGen
我们今天来介绍一项完成Long-horizon任务的一项新的技术:ManipGen。 什么叫Long-horizon?就是任务比较长。说到底,也是任务比较复杂。 那么这个技术就给我们提供了一个非常好的解决这类问题的思路,同时,也取得了不错的…...
大模型(LLMs)强化学习—— PPO
一、大语言模型RLHF中的PPO主要分哪些步骤? 二、举例描述一下 大语言模型的RLHF? 三、大语言模型RLHF 采样篇 什么是 PPO 中 采样过程?介绍一下 PPO 中 采样策略?PPO 中 采样策略中,如何评估“收益”? …...
)
[Python开发] 如何用 VSCode 编写和管理 Python 项目(从 PyCharm 转向)
在 Python 开发领域,PyCharm 一直是广受欢迎的 IDE,但其远程开发功能(如远程 SSH 调试)仅在付费版中提供。为了适应服务器部署需求,很多开发者开始将目光转向更加轻量、灵活且免费扩展能力强的 VSCode。本篇文章将详细介绍,从 PyCharm 转向 VSCode 后,如何高效搭建和管理…...

Maven多模块工程版本管理:flatten-maven-plugin扁平化POM
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...
视频汇聚平台EasyCVR赋能高清网络摄像机:打造高性价比视频监控系统
在现代视频监控系统中,高清网络摄像机作为核心设备,其性能和配置直接影响监控效果和整体系统的价值。本文将结合EasyCVR视频监控的功能,探讨如何在满足使用需求的同时,优化监控系统的设计,降低项目成本,并提…...

Unity 接入阿里的全模态大模型Qwen2.5-Omni
1 参考 根据B站up主阴沉的怪咖 开源的项目的基础上修改接入 AI二次元老婆开源项目地址(unity-AI-Chat-Toolkit): Github地址:https://github.com/zhangliwei7758/unity-AI-Chat-Toolkit Gitee地址:https://gitee.com/DammonSpace/unity-ai-chat-too…...
Nginx知识点
Nginx发展历史 Nginx 是由俄罗斯程序员 Igor Sysoev 开发的高性能开源 Web 服务器、反向代理服务器和负载均衡器 ,其历史如下: 起源与早期开发(2002 - 2004 年) 2002 年,当时 Igor Sysoev 在为俄罗斯门户网站 Rambl…...
——DeepSeek系列概览与发展背景)
NLP高频面试题(五十五)——DeepSeek系列概览与发展背景
大型模型浪潮背景 近年来,大型语言模型(Large Language Model, LLM)领域发展迅猛,从GPT-3等超大规模模型的崛起到ChatGPT的横空出世,再到GPT-4的问世,模型参数规模和训练数据量呈指数级增长。以GPT-3为例,参数高达1750亿,在570GB文本数据上训练,显示出模型规模、数据…...
)
详解 Unreal Engine(虚幻引擎)
详解 Unreal Engine(虚幻引擎) Unreal Engine(简称 UE)是由 Epic Games 开发的一款全球领先的实时渲染引擎,自 1998 年随首款游戏《Unreal》问世以来,已发展成为覆盖 游戏开发、影视制作、建筑可视化、汽车…...

Mysql从入门到精通day6————时间和日期函数精讲
关于Mysql的日期和时间计算函数种类非常繁多,此处我们对常用的一些函数的用法通过实例演示让读者体会他们的用法,文章末尾也给出了时间和日期计算的全部函数 函数1:curdate()和current_date()函数 作用:获取当前日期 select curdate(),current_date();运行效果:...
逻辑漏洞安全
逻辑漏洞是指由于程序逻辑不严导致一些逻辑分支处理错误造成的漏洞。 在实际开发中,因为开发者水平不一没有安全意识,而且业务发展迅速内部测试没有及时到位,所以常常会出现类似的漏洞。 由于开发者/设计者在开发过程中,由于代码…...

Github 热点项目 rowboat 一句话生成多AI智能体!5分钟搭建企业级智能工作流系统
今日高星项目推荐:rowboat凭借1705总星数成为智能协作工具黑马!亮点速递:①自然语言秒变AI流水线——只需告诉它“帮外卖公司处理配送异常”,立刻生成多角色协作方案;②企业工具库即插即用,Python包HTTP接口…...

(26)VTK C++开发示例 ---将点坐标写入PLY文件
文章目录 1. 概述2. CMake链接VTK3. main.cpp文件4. 演示效果 更多精彩内容👉内容导航 👈👉VTK开发 👈 1. 概述 本示例演示了将球体数据写入ply文件,并从ply文件读取显示; PLY 文件(Polygon Fil…...

32BIT的SPI主机控制
SPI传输位数可参数化配置。 SPI_MASTER: timescale 1ns / 1ps module SPI_Master #(parameter CLK_FREQ 50,parameter SPI_CLK 1000,parameter CPOL 0,parameter CPHA 0 )(input clk,input rst_n,input WrRdReq, //读/写数据请求output …...
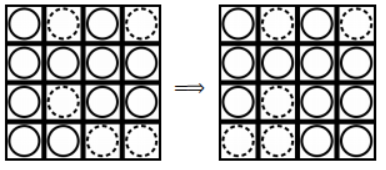
2025蓝桥省赛c++B组第二场题解
前言 这场的题目非常的简单啊,至于为什么有第二场,因为当时河北正在刮大风被迫停止了QwQ,个人感觉是历年来最简单的一场,如果有什么不足之处,还望补充。 试题 A: 密密摆放 【问题描述】 小蓝有一个大箱子࿰…...

vue3 vite打包后动态修改打包后的请求路径,无需打多个包给后端
整体思路和需求 部署多个服务器环境的时候,需要多次打包很麻烦,所以需要打包之后动态的修改 1.创建一个webconfig文件夹 2.在自己封装的接口文件中 判断是否在生产环境,然后将数据保存到vuex 中 代码: // 创建axios服务的函数 …...