Mysql常用函数解析
字符串函数
CONCAT(str1, str2, …)
将多个字符串连接成一个字符串。
SELECT CONCAT('Hello', ' ', 'World'); -- 输出: Hello World
SUBSTRING(str, start, length)
截取字符串的子串(起始位置从1开始)。
SELECT SUBSTRING('MySQL', 3, 2); -- 输出: 'SQ'
LENGTH(str)
返回字符串的字节数(注意字符集影响)。
SELECT LENGTH('数据库'); -- UTF-8下输出: 9(每个中文3字节)
CHAR_LENGTH(str)
返回字符串的字符数(忽略字节)。
SELECT CHAR_LENGTH('数据库'); -- 输出: 3
TRIM([LEADING|TRAILING|BOTH] ‘char’ FROM str)
去除字符串两端(或指定方向)的指定字符。
SELECT TRIM(' MySQL '); -- 输出: 'MySQL'
数值函数
ROUND(num, decimals)
四舍五入到指定小数位数。
SELECT ROUND(3.1415, 2); -- 输出: 3.14
CEIL(num) 和 FLOOR(num)
向上取整和向下取整。
SELECT CEIL(3.2), FLOOR(3.8); -- 输出: 4, 3
RAND()
生成0到1之间的随机浮点数。
SELECT FLOOR(RAND() * 100); -- 生成0-99的随机整数
ABS(num)
返回绝对值。
SELECT ABS(-10); -- 输出: 10
日期时间函数
NOW()
返回当前日期和时间(格式:YYYY-MM-DD HH:MM:SS)。
SELECT NOW(); -- 输出: 2023-10-01 14:30:00
DATE_FORMAT(date, format)
格式化日期时间。
SELECT DATE_FORMAT(NOW(), '%Y年%m月%d日'); -- 输出: 2023年10月01日
DATEDIFF(date1, date2)
计算两个日期之间的天数差。
SELECT DATEDIFF('2023-10-10', '2023-10-01'); -- 输出: 9
TIMESTAMPDIFF(unit, start, end)
计算两个日期的时间差(单位:DAY/MONTH/YEAR等)。
SELECT TIMESTAMPDIFF(MONTH, '2023-01-01', '2023-10-01'); -- 输出: 9
-- 若 end_time 早于 start_time,结果为负数。
支持的 unit 参数值:
| 单位 | 说明 | 示例 |
|---|---|---|
| MICROSECOND | 微秒差(1秒=1,000,000微秒) | TIMESTAMPDIFF(MICROSECOND, ‘08:00:00’, ‘08:00:00.123456’) → 123456 |
| SECOND | 整数秒差(忽略微秒部分) | TIMESTAMPDIFF(SECOND, ‘08:00:00’, ‘08:01:30’) → 90 |
| MINUTE | 整数分钟差(基于秒差向下取整) | TIMESTAMPDIFF(MINUTE, ‘08:00:00’, ‘08:01:30’) → 1 |
| HOUR | 整数小时差(基于分钟差向下取整) | TIMESTAMPDIFF(HOUR, ‘08:15:00’, ‘12:30:00’) → 4 |
| DAY | 整数天数差(基于时间差计算完整天数) | TIMESTAMPDIFF(DAY, ‘2023-10-01’, ‘2023-10-05’) → 4 |
| WEEK | 整数周差(等同于 FLOOR(TIMESTAMPDIFF(DAY, …) / 7)) | TIMESTAMPDIFF(WEEK, ‘2023-10-01’, ‘2023-10-15’) → 2 |
| MONTH | 整数月差(基于日历月,忽略天数差异) | TIMESTAMPDIFF(MONTH, ‘2023-01-15’, ‘2023-03-10’) → 2 |
| QUARTER | 整数季度差(1季度=3个月) | TIMESTAMPDIFF(QUARTER, ‘2023-01-01’, ‘2023-10-01’) → 3 |
| YEAR | 整数年差(基于日历年,忽略月内天数) | TIMESTAMPDIFF(YEAR, ‘2020-02-29’, ‘2023-02-28’) → 3 |
流程控制函数
IF(condition, value_if_true, value_if_false)
简单条件判断。
SELECT IF(score >= 60, '及格', '不及格') AS result FROM students;
CASE WHEN
多条件分支处理。
SELECT CASE WHEN salary > 10000 THEN '高薪'WHEN salary > 5000 THEN '中薪'ELSE '低薪'END AS level
FROM employees;
聚合函数
SUM(column)
计算某列的总和。
SELECT SUM(salary) FROM employees;
AVG(column)
计算平均值。
SELECT AVG(score) FROM exams;
COUNT(column)
统计行数(注意:COUNT(*)包含NULL,COUNT(column)忽略NULL)。
SELECT COUNT(*) FROM users; -- 统计所有行数
GROUP_CONCAT(column SEPARATOR ‘sep’)
将分组后的多行数据合并为一个字符串。
SELECT department, GROUP_CONCAT(name SEPARATOR ', ')
FROM employees
GROUP BY department;
空值函数
COALESCE(value1, value2, …)
返回第一个非NULL的值。
SELECT COALESCE(NULL, '备用值'); -- 输出: '备用值'
IFNULL(value, default)
如果值为NULL,返回默认值。
SELECT IFNULL(email, '未填写') FROM users;
JSON操作函数
JSON 路径语法
$ 表示根节点。
$.key 访问对象的键。
$[index] 访问数组元素(索引从 0 开始)。
$.* 匹配所有成员。
$.a.b 嵌套访问。
JSON 创建与修改
JSON_ARRAY([value1, value2, …])
创建 JSON 数组。
SELECT JSON_ARRAY('a', 1, TRUE, NULL);
-- 输出: ["a", 1, true, null]
JSON_OBJECT([key1, value1, key2, value2, …])
创建 JSON 对象。
SELECT JSON_OBJECT('name', 'Alice', 'age', 25);
-- 输出: {"name": "Alice", "age": 25}
JSON_SET(json_doc, path, val [, path, val]…)
插入或更新 JSON 中的字段(若路径存在则更新,不存在则插入)。
SELECT JSON_SET('{"a": 1}', '$.b', 2);
-- 输出: {"a": 1, "b": 2}
JSON_INSERT(json_doc, path, val [, path, val]…)
仅在路径不存在时插入新字段。
SELECT JSON_INSERT('{"a": 1}', '$.a', 100, '$.b', 2);
-- 输出: {"a": 1, "b": 2} (仅插入不存在的路径)
JSON_REPLACE(json_doc, path, val [, path, val]…)
仅更新已存在的路径。
SELECT JSON_REPLACE('{"a": 1, "b": 2}', '$.a', 100, '$.c', 3);
-- 输出: {"a": 100, "b": 2} (仅更新存在的路径)
JSON_REMOVE(json_doc, path [, path]…)
删除 JSON 中的指定路径。
SELECT JSON_REMOVE('{"a": 1, "b": 2}', '$.a');
-- 输出: {"b": 2}
JSON 查询与提取
JSON_EXTRACT(json_doc, path) 或 -> 操作符
提取 JSON 中的值(支持路径表达式)。
SELECT JSON_EXTRACT('{"user": {"name": "Alice", "age": 25}}', '$.user.name');
-- 输出: "Alice"-- 等效写法(MySQL 5.7+):
SELECT data->'$.user.age' FROM users;
JSON_UNQUOTE(json_val)
去除 JSON 字符串的引号。
SELECT JSON_UNQUOTE(JSON_EXTRACT('{"name": "Alice"}', '$.name'));
-- 输出: Alice
JSON_CONTAINS(json_doc, val [, path])
检查 JSON 中是否包含指定值。
SELECT JSON_CONTAINS('{"a": [1, 2, 3]}', '2', '$.a');
-- 输出: 1 (true)
JSON_SEARCH(json_doc, ‘one|all’, search_str)
查找包含指定字符串的路径。
SELECT JSON_SEARCH('{"user": {"name": "Alice"}}', 'one', 'Alice');
-- 输出: "$.user.name"
JSON 聚合与转换
JSON_ARRAYAGG(expr)
将多行数据聚合为 JSON 数组。
SELECT JSON_ARRAYAGG(name) FROM users;
-- 输出: ["Alice", "Bob", "Charlie"]
JSON_OBJECTAGG(key, value)
将键值对聚合为 JSON 对象。
SELECT JSON_OBJECTAGG(id, name) FROM users;
-- 输出: {"1": "Alice", "2": "Bob"}
JSON_TYPE(json_val)
返回 JSON 值的类型(如 OBJECT, ARRAY, STRING, INTEGER)。
SELECT JSON_TYPE(JSON_EXTRACT('{"a": [1, "b"]}', '$.a'));
-- 输出: ARRAY
子查询
子查询类型
标量子查询(Scalar Subquery)
返回单个值(一行一列)。
常用在 SELECT、WHERE 或 HAVING 中。
-- 示例:查询工资高于平均工资的员工
SELECT name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
行子查询(Row Subquery)
返回单行多列。
-- 示例:查询工资高于平均工资的员工
-- 示例:查询与指定员工部门和职位相同的其他员工
SELECT name
FROM employees
WHERE (department, job_title) = (SELECT department, job_title FROM employees WHERE name = 'Alice'
);
列子查询(Column Subquery)
返回多行单列。
常与 IN、ANY、ALL 等操作符搭配使用。
-- 示例:查询所有在销售部或技术部的员工
SELECT name
FROM employees
WHERE department IN (SELECT department FROM departments WHERE location = 'New York'
);
表子查询(Table Subquery)
返回多行多列。
通常作为派生表(Derived Table)出现在 FROM 子句。
-- 示例:查询每个部门的平均工资,并与公司平均工资比较
SELECT department, AVG(salary) AS dept_avg,(SELECT AVG(salary) FROM employees) AS company_avg
FROM employees
GROUP BY department;
子查询与操作符
IN / NOT IN
-- 示例:查询购买了某产品的客户
SELECT customer_name
FROM customers
WHERE customer_id IN (SELECT customer_id FROM orders WHERE product_id = 1001
);
ANY / SOME
与比较符(>、<、= 等)搭配,表示满足任一结果。
-- 示例:查询工资高于技术部任一员工的员工
SELECT name
FROM employees
WHERE salary > ANY (SELECT salary FROM employees WHERE department = '技术部'
);
ALL
表示满足所有结果。
-- 示例:查询工资高于所有技术部员工的员工
SELECT name
FROM employees
WHERE salary > ALL (SELECT salary FROM employees WHERE department = '技术部'
);
EXISTS / NOT EXISTS
检查子查询是否返回结果(更高效,常用于关联子查询)。
-- 示例:查询至少有一个订单的客户
SELECT customer_name
FROM customers c
WHERE EXISTS (SELECT 1 FROM orders o WHERE o.customer_id = c.customer_id
);
类型转换函数
CAST(expr AS type)
功能:将表达式转换为指定类型。
支持类型:
BINARY(二进制)
CHAR(字符串)
DATE、DATETIME、TIME
DECIMAL
SIGNED(有符号整数)、UNSIGNED(无符号整数)
-- 字符串转整数
SELECT CAST('123' AS SIGNED); -- 输出: 123-- 浮点数转 DECIMAL(控制精度)
SELECT CAST(3.1415 AS DECIMAL(5,2)); -- 输出: 3.14 (总位数 5,小数位 2)-- 时间戳转日期
SELECT CAST(NOW() AS DATE); -- 输出: 2023-10-01
CONVERT(expr, type) 或 CONVERT(expr USING charset)
功能:
转换数据类型(同 CAST)。
转换字符集(如 utf8mb4 转 latin1)。
-- 字符串转整数
SELECT CONVERT('456', SIGNED); -- 输出: 456-- 转换字符集
SELECT CONVERT('你好' USING latin1); -- 输出可能为乱码(如字符集不支持)
with as 子句
WITH dept_avg AS (SELECT department, AVG(salary) AS avg_salary FROM employees GROUP BY department
)
SELECT * FROM dept_avg WHERE avg_salary > 10000;
union
SELECT column1, column2 FROM table1
UNION [ALL | DISTINCT]
SELECT column1, column2 FROM table2
[ORDER BY column1]
[LIMIT N];
UNION DISTINCT:默认行为,合并结果并去重。
UNION ALL:保留所有重复行。
ORDER BY 和 LIMIT:对整个合并后的结果集生效(非单个查询)。
group by having
对分组后的结果进行过滤(类似于 WHERE,但作用于分组后的数据)。
SELECT column1, aggregate_function(column2)
FROM table
GROUP BY column1
HAVING condition;
GROUP BY 与 WHERE 的区别:
WHERE:在分组前过滤数据(作用于原始数据行)。
HAVING:在分组后过滤数据(作用于聚合结果)。
SELECT employee_id, COUNT(*) AS order_count
FROM orders
WHERE department = '销售部' -- 先过滤部门
GROUP BY employee_id
HAVING order_count > 50; -- 再过滤分组结果
相关文章:

Mysql常用函数解析
字符串函数 CONCAT(str1, str2, …) 将多个字符串连接成一个字符串。 SELECT CONCAT(Hello, , World); -- 输出: Hello WorldSUBSTRING(str, start, length) 截取字符串的子串(起始位置从1开始)。 SELECT SUBSTRING(MySQL, 3, 2); -- 输出: SQ…...

llamafactory-cli webui启动报错TypeError: argument of type ‘bool‘ is not iterable
一、问题 在阿里云NoteBook上启动llamafactory-cli webui报错TypeError: argument of type ‘bool’ is not iterable This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run gradio deploy from the terminal in the working directory t…...

智能电子白板的设计与实现:从硬件选型到软件编程
摘要:本文围绕智能电子白板展开,详述其从硬件芯片与模块选型、接线布局,到软件流程图规划及关键代码编写等方面的设计与实现过程,旨在打造满足现代教育与商务会议需求的多功能智能设备。 注:有想法可在评论区或者看我个人简介。 一、引言 在现代教育与商务场景中,智能…...

机器学习——特征选择
特征选择算法总结应用 特征选择概述 注:关于详细的特征选择算法介绍详见收藏夹。...
Spring - 简单实现一个 Spring 应用
一、为什么需要学习Spring框架? 1.企业级开发标配 超过60%的Java项目都使用Spring生态(数据来源:JetBrains开发者报告)。 2.简化复杂问题 通过IoC和DI,告别new关键字满天飞的代码。 3.职业竞争力 几乎所有Java岗…...

css 数字从0开始增加的动画效果
项目场景: 提示:这里简述项目相关背景: 在有些时候比如在做C端项目的时候,页面一般需要一些炫酷效果,比如数字会从小值自动加到数据返回的值 css 数字从0开始增加的动画效果 分析: 提示:这里填…...
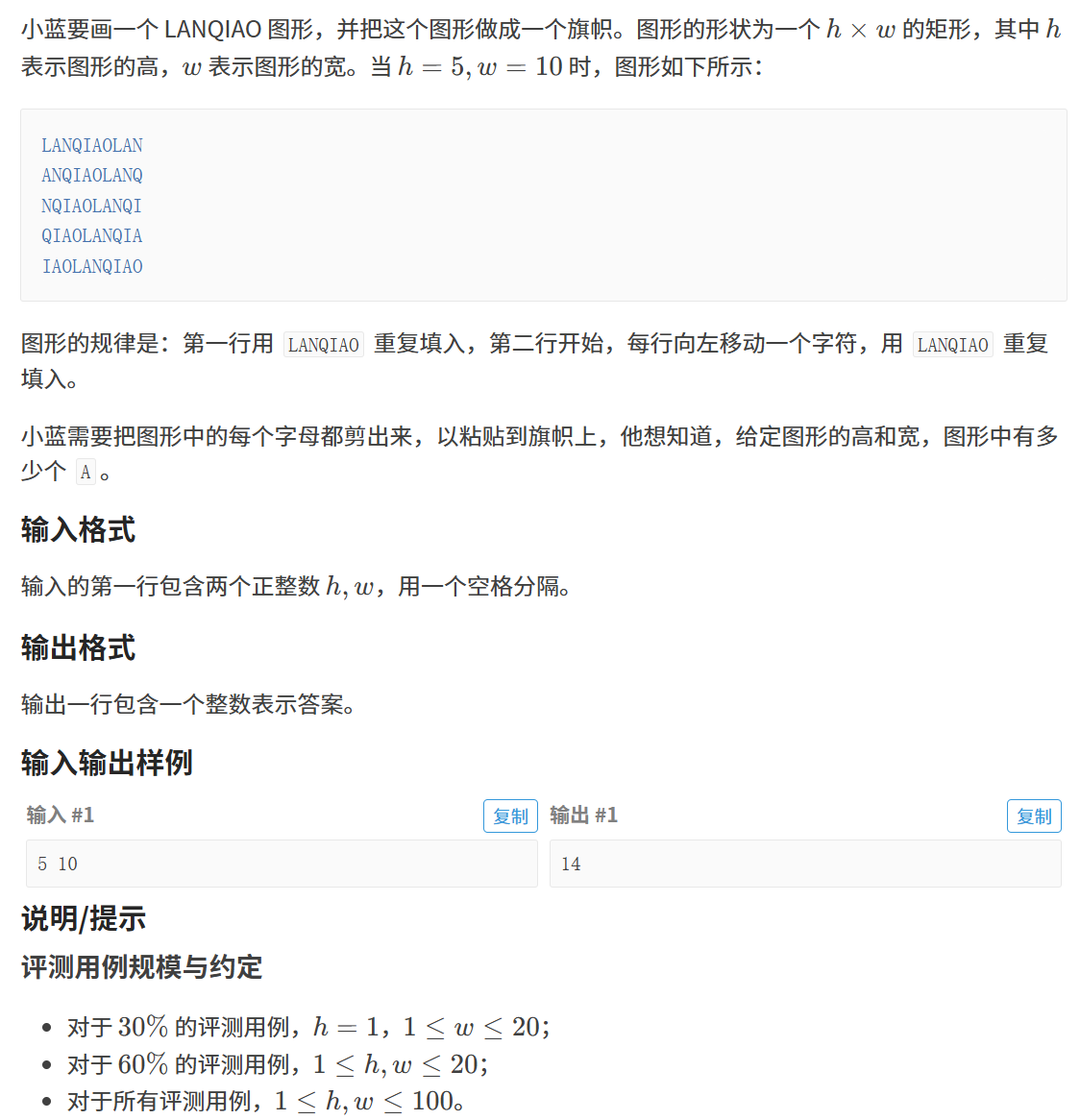
第十六届蓝桥杯 2025 C/C++组 旗帜
目录 题目: 题目描述: 题目链接: 思路: 思路详解: 代码: 代码详解: 题目: 题目描述: 题目链接: P12340 [蓝桥杯 2025 省 AB/Python B 第二场] 旗帜 -…...
利用无事务方式插入数据库解决并发插入问题
一、背景 由于项目中同一个网元,可能会被多个不同用户操作,而且操作大部分都是以异步子任务形式进行执行,这样就会带来并发写数据问题,本文通过利用无事务方式插入数据库解决并发插入问题,算是解决问题的一种思路&…...

云计算市场的重新分类研究
云计算市场传统分类方式,比如按服务类型分为IaaS、PaaS、SaaS,或者按部署模式分为公有云、私有云、混合云。主要提供计算资源、存储和网络等基础设施。 但随着AI大模型的出现,云计算市场可以分为计算云和智算云,智算云主要是AI模…...

【C语言练习】014. 使用数组作为函数参数
014. 使用数组作为函数参数 014. 使用数组作为函数参数示例1:使用数组作为函数参数并修改数组元素函数定义输出结果 示例2:使用数组作为函数参数并计算数组的平均值函数定义输出结果 示例3:使用二维数组作为函数参数函数定义输出结果 示例4&a…...

Java关键字解析
Java关键字是编程语言中具有特殊含义的保留字,不能用作标识符(如变量名、类名等)。Java共有50多个关键字(不同版本略有差异),下面我将分类详细介绍这些关键字及其使用方式。 一、数据类型相关关键字 1. 基…...
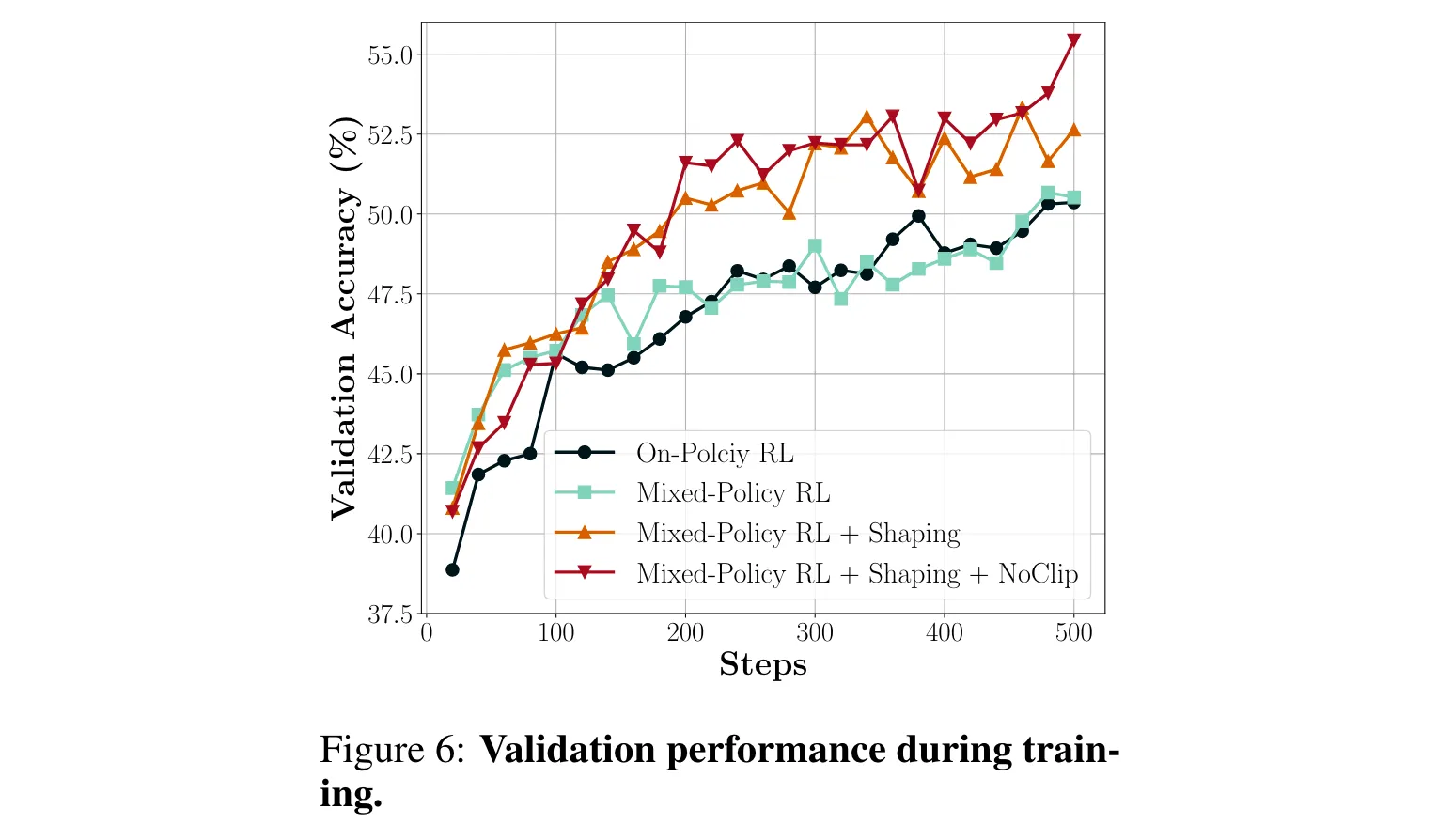
突破zero-RL 困境!LUFFY 如何借离线策略指引提升推理能力?
在大模型推理能力不断取得突破的今天,强化学习成为提升模型能力的关键手段。然而,现有zero-RL方法存在局限。论文提出的LUFFY框架,创新性地融合离线策略推理轨迹,在多个数学基准测试中表现卓越,为训练通用推理模型开辟…...

React Native本地存储方案总结
1. AsyncStorage(键值对存储) 适用场景:简单键值对存储(如用户配置、Token、缓存数据)。特点:异步、轻量、API 简单,但性能一般,不推荐存储大量数据。安装:npm install …...

基于Redis实现-附近商铺查询
基于Redis实现-附近查询 这个功能将使用到Redis中的GEO这种数据结构来实现。 1.GEO相关命令 GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入到了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据&#…...
【java WEB】恢复补充说明
Server 出现javax.servlet.http.HttpServlet", according to the project’s Dynamic Web Module facet version (3.0), was not found on the Java Build Path. 右键项目 > Properties > Project Facets。Dynamic Web Module facet version选4.0即可 还需要在serv…...

安川机器人常见故障报警及解决办法
机器人权限设置 操作权限设置(如果密码不对,就证明密码被人修改) 编辑模式密码:无(一把钥匙,默认) 管理模式密码:999999999(9个9,二把钥匙) 安全模式密码:555555555(9个5,三把钥匙,权限最高,有的型号机器人,没有此模式,但最高密码为安全模式密码) 示教器…...

tiktok web X-Bogus X-Gnarly 分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 逆向过程 部分python代码 import req…...
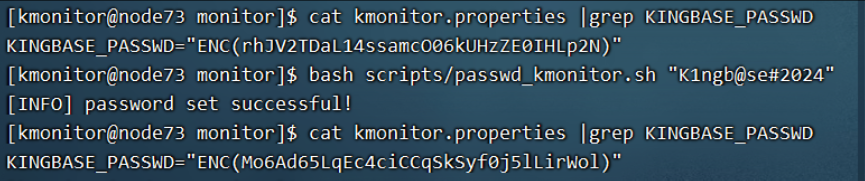
kes监控组件安装
环境准备 创建监控用户 useradd -m -s /bin/bash -d /home/kmonitor kmonitor passwd k_monitor usermod –a –G kingbase kmonitor 检查java版本 java –version [kmonitorkingbase node_exporter]$ java -version java version "1.8.0_341" Java(TM) SE …...
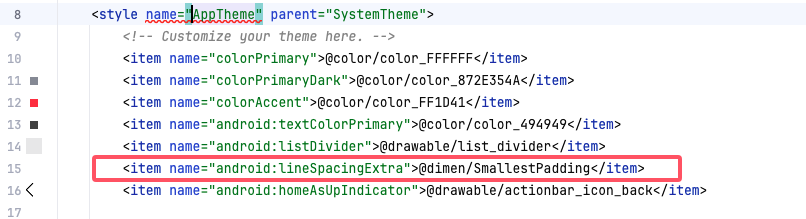
React-Native Android 多行被截断
1. 问题描述: 如图所示: 2. 问题解决灵感: 使用相同的react-native代码,运行在两个APP(demo 和 project)上。demo 展示正常,project 展示不正常。 对两个页面截图,对比如下。 得出…...
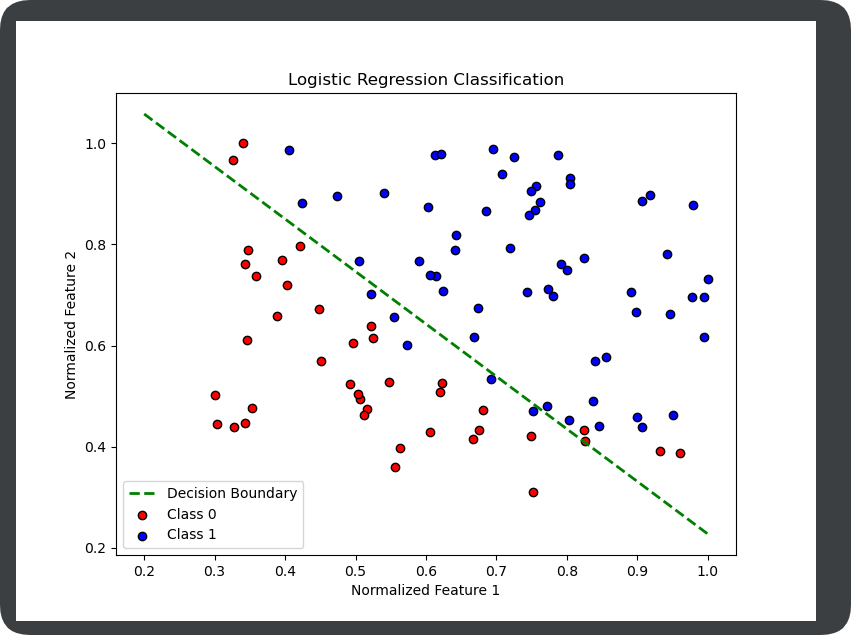
深度学习【Logistic回归模型】
回归和分类 回归问题得到的结果都是连续的,比如通过学习时间预测成绩 分类问题是将数据分成几类,比如根据邮件信息将邮件分成垃圾邮件和有效邮件两类。 相比于基础的线性回归其实就是增加了一个sigmod函数。 代码 import matplotlib.pyplot as plt i…...
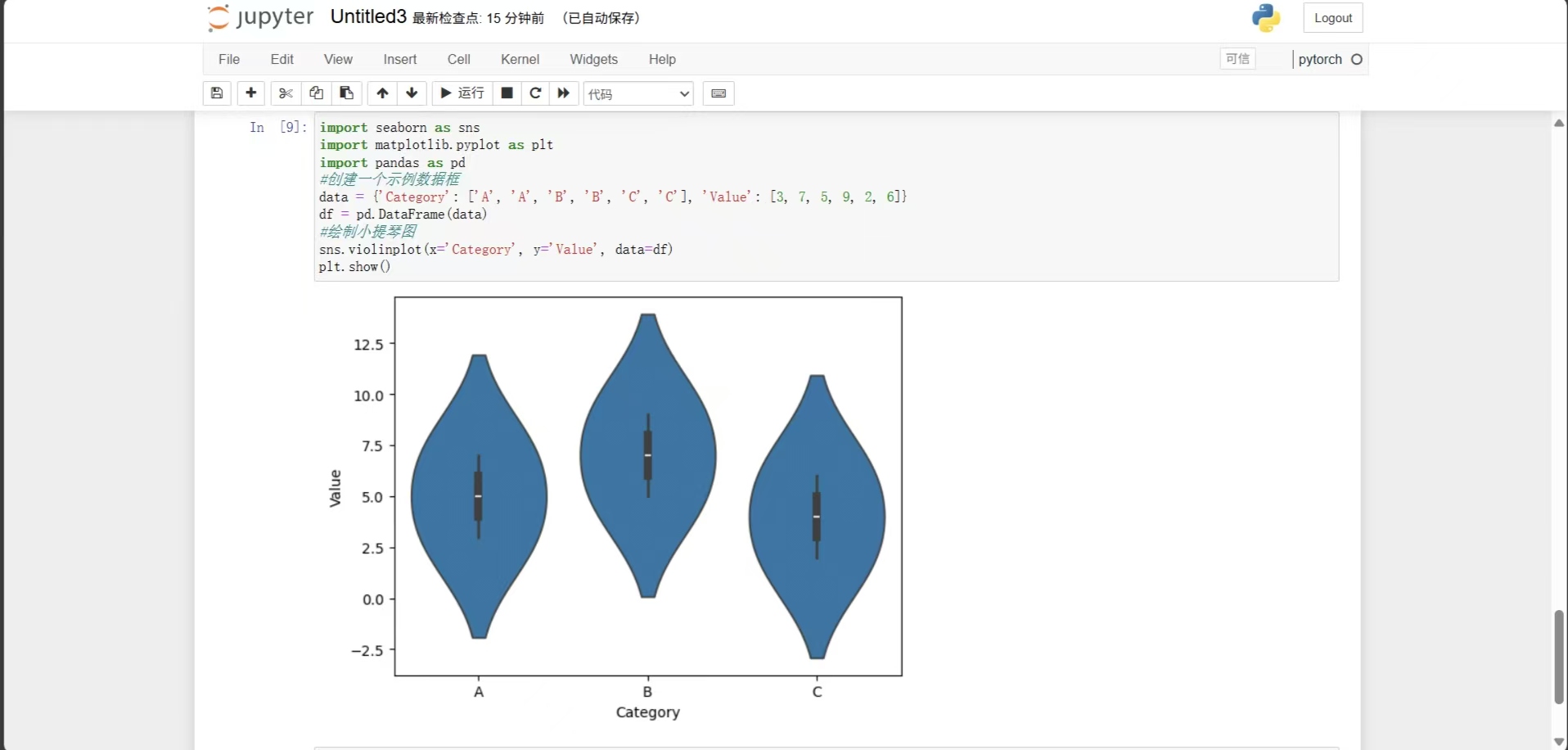
数据科学与计算
1.设计目标与安装 Seaborn 是一个建立在 Matplotlib 基础之上的 Python 数据可视化库,专注于绘制各种统计图形,以便更轻松地呈现和理解数据。Seaborn 的设计目标是简化统计数据可视化的过程,提供高级接口和美观的默认主题,使得用…...

Swift与iOS内存管理机制深度剖析
前言 内存管理是每一位 iOS 开发者都绕不开的话题。虽然 Swift 的 ARC(自动引用计数)极大简化了开发者的工作,但只有深入理解其底层实现,才能写出高效、健壮的代码,避免各种隐蔽的内存问题。本文将从底层原理出发&…...
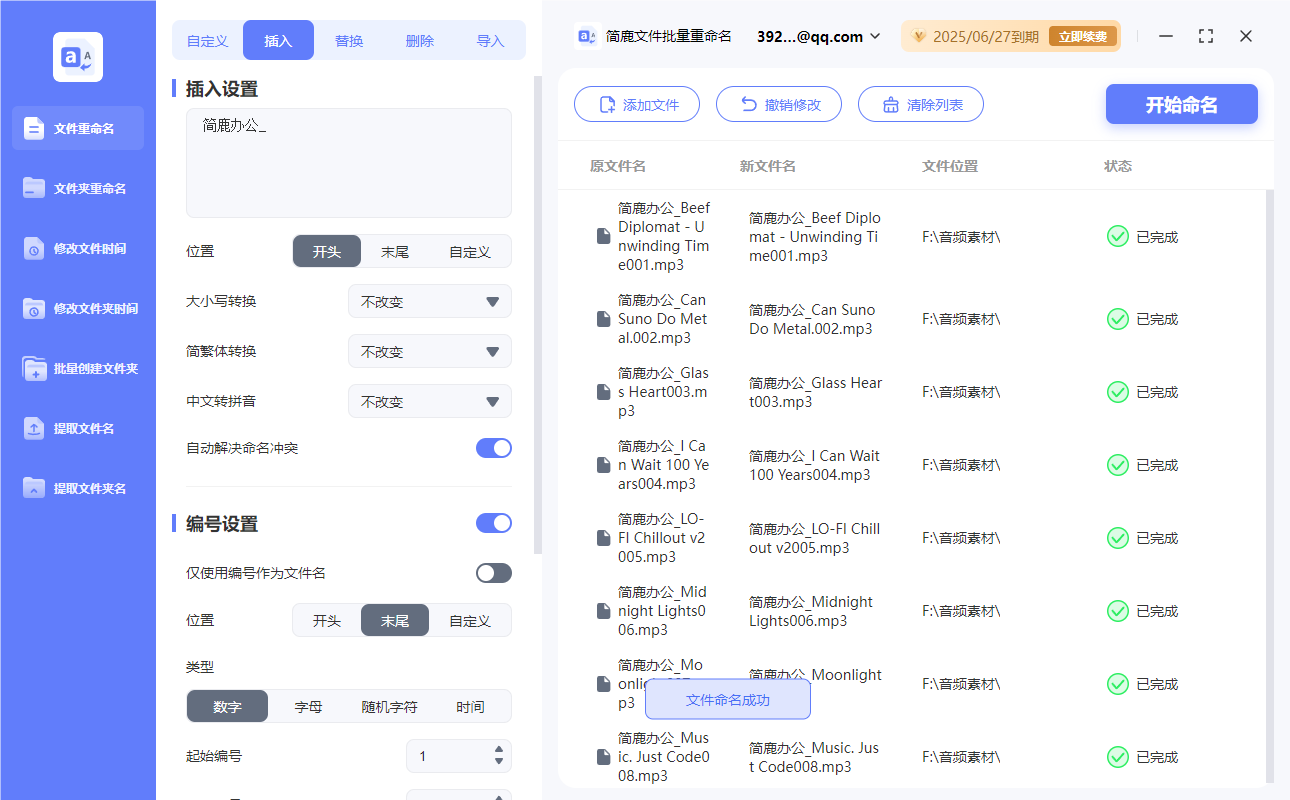
怎样给MP3音频重命名?是时候管理下电脑中的音频文件名了
在处理大量音频文件时,给这些文件起一个有意义的名字可以帮助我们更高效地管理和查找所需的内容。通过使用专业的文件重命名工具如简鹿文件批量重命名工具,可以极大地简化这一过程。本文将详细介绍如何利用该工具对 MP3 音频文件进行重命名。 步骤一&am…...

当AI浏览器和AI搜索替代掉传统搜索份额时,老牌的搜索引擎市场何去何从。
AI搜索与传统搜索优劣势分析 AI搜索优势 理解和处理查询方式更智能:利用自然语言处理(NLP)和机器学习技术,能够更好地理解用户的意图和上下文,处理复杂的问答、长尾问题以及多轮对话,提供更为精准和相关的…...
快速上手非关系型数据库-MongoDB
简介 MongoDB 是一个基于文档的 NoSQL 数据库,由 MongoDB Inc. 开发。 NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。 MongoDB 的设计理念是为了应对大数据量、…...
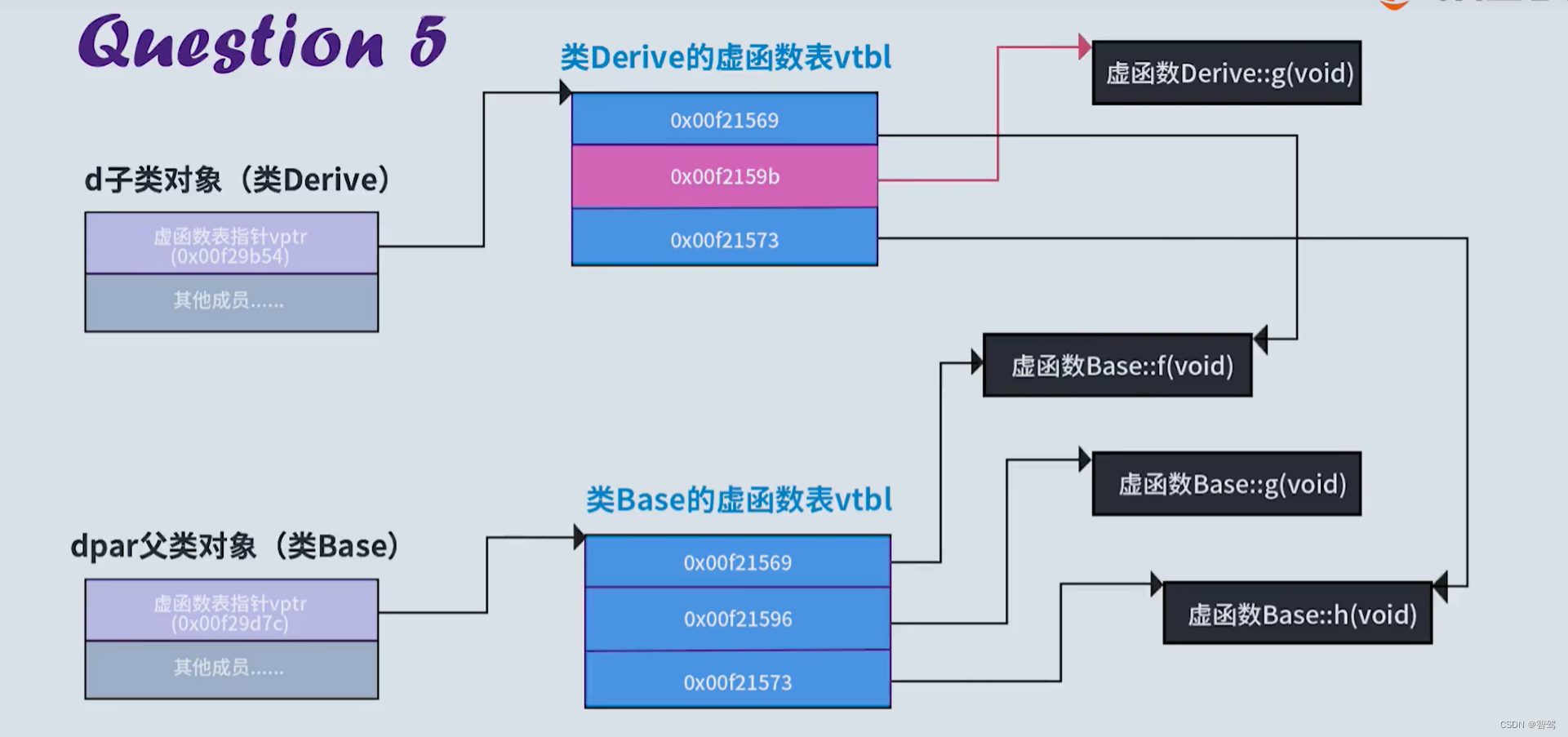
【C++学习笔记】深入理解虚函数和多态
文章目录 1. 基本概念1.1 虚函数1.2 虚函数表1.3 虚函数表指针1.4 虚函数表在支持多态方面的工作原理 2. 类对象在内存中的布局参考 1. 基本概念 1.1 虚函数 类的成员函数,并不占用类对象的内存空间。 类中有虚函数,编译器会向类中插入一个看不见的成…...

STM32F103C8T6信息
STM32F103C8T6 完整参数列表 一、核心参数 内核架构 ARM Cortex-M3 32位RISC处理器 最大主频:72 MHz(基于APB总线时钟) 运算性能:1.25 DMIPS/MHz(Dhrystone 2.1基准) 总线与存储 总线宽度ÿ…...

用手机相册教我数组概念——照片分类术[特殊字符][特殊字符]
目录 前言一、现实场景1.1 手机相册的照片管理1.2 照片分类的需求 二、技术映射2.1 数组与照片分类的对应关系2.2 数组索引与照片标签的类比 三、知识点呈现3.1 数组的基本概念3.2 数组在编程中的重要性3.3 数组的定义与初始化3.4 数组的常见操作(增删改查ÿ…...

Node.js CSRF 保护指南:示例及启用方法
解释 CSRF 跨站请求伪造 (CSRF/XSRF) 是一种利用用户权限劫持会话的攻击。这种攻击策略允许攻击者通过诱骗用户以攻击者的名义提交恶意请求,从而绕过我们的安全措施。 CSRF 攻击之所以可能发生,是因为两个原因。首先,CSRF 攻击利用了用户无法辨别看似合法的 HTML 元素是否…...
【Linux】VSCode用法
描述 部分图片和经验来源于网络,若有侵权麻烦联系我删除,主要是做笔记的时候忘记写来源了,做完笔记很久才写博客。 专栏目录:记录自己的嵌入式学习之路-CSDN博客 目录 1 安装环境及运行C/C 1.1 安装及配置步骤 1.2 运…...