Apache Doris 使用指南:从入门到生产实践
目录
一、Doris 核心概念
1.1 架构组成
1.2 数据模型
二、Doris 部署方式
2.1 单机部署(测试环境)
2.2 集群部署(生产环境)
三、数据操作指南
3.1 数据库与表管理
3.2 数据导入方式
3.2.1 批量导入
3.2.2 实时导入
3.3 数据查询示例
四、性能优化实践
4.1 分区分桶策略
4.2 索引优化
4.3 查询优化技巧
Apache Doris 是一款高性能、实时的分析型数据库,广泛应用于大数据分析、实时报表等场景。本文将全面介绍 Doris 的核心概念、部署方式、数据操作及优化技巧。
下面附上官网地址:
Doris官网![]() https://doris.apache.org/zh-CN/docs/dev/gettingStarted/what-is-apache-doris
https://doris.apache.org/zh-CN/docs/dev/gettingStarted/what-is-apache-doris
一、Doris 核心概念
1.1 架构组成
- FE (Frontend):负责元数据管理、客户端连接和查询计划生成
- BE (Backend):负责数据存储和查询执行
- Broker:用于访问外部存储系统(如HDFS/S3)
1.2 数据模型
- 明细模型(Duplicate Key):适合原始数据存储
- 聚合模型(Aggregate Key):预聚合提高查询性能
- 主键模型(Unique Key):支持实时更新
- 更新模型(Merge-on-Write):2.0版本新增,更高性能更新
二、Doris 部署方式
2.1 单机部署(测试环境)
# 下载解压
wget https://apache-doris-releases.oss-accelerate.aliyuncs.com/doris-1.2.4-bin.tar.gz
tar -zxvf doris-1.2.4-bin.tar.gz# 启动FE
cd fe/bin/
./start_fe.sh --daemon# 启动BE
cd be/bin/
./start_be.sh --daemon2.2 集群部署(生产环境)
-- 在FE节点添加BE节点
ALTER SYSTEM ADD BACKEND "be1:9050";
ALTER SYSTEM ADD BACKEND "be2:9050";
ALTER SYSTEM ADD BACKEND "be3:9050";-- 查看节点状态
SHOW PROC '/backends';三、数据操作指南
3.1 数据库与表管理
-- 创建数据库
CREATE DATABASE demo_db;-- 创建明细表
CREATE TABLE demo_db.user_behavior (user_id LARGEINT NOT NULL,item_id LARGEINT NOT NULL,behavior_type VARCHAR(20),ts DATETIME NOT NULL
)
DUPLICATE KEY(user_id, item_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES ("replication_num" = "3","storage_medium" = "SSD"
);-- 创建聚合表
CREATE TABLE demo_db.sales_agg (dt DATE NOT NULL,product_id LARGEINT NOT NULL,user_region VARCHAR(50),SUM(sales_amount) BIGINT SUM,COUNT(sales_count) BIGINT COUNT
)
AGGREGATE KEY(dt, product_id, user_region)
DISTRIBUTED BY HASH(product_id) BUCKETS 10;3.2 数据导入方式
3.2.1 批量导入
-- 本地文件导入
LOAD LABEL demo_db.label_20231101
(DATA INFILE("hdfs://path/to/file.parquet")
INTO TABLE user_behavior
FORMAT AS "parquet")
WITH BROKER "hdfs_broker";-- Stream Load(HTTP API)
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-T data.csv \
http://fe_host:8030/api/demo_db/user_behavior/_stream_load3.2.2 实时导入
-- Kafka实时接入
CREATE ROUTINE LOAD demo_db.kafka_load ON user_behavior
COLUMNS(user_id, item_id, behavior_type, ts)
PROPERTIES ("desired_concurrent_number" = "3","max_batch_interval" = "20","max_batch_rows" = "300000"
)
FROM KAFKA ("kafka_broker_list" = "broker1:9092,broker2:9092","kafka_topic" = "user_events","property.group.id" = "doris_consumer"
);3.3 数据查询示例
-- 基础查询
SELECT user_region,SUM(sales_amount) AS total_sales
FROM sales_agg
WHERE dt BETWEEN '2023-10-01' AND '2023-10-31'
GROUP BY user_region
ORDER BY total_sales DESC
LIMIT 10;-- 窗口函数
SELECT user_id,ts,behavior_type,COUNT(*) OVER (PARTITION BY user_id ORDER BY ts RANGE INTERVAL 1 HOUR PRECEDING) AS hourly_actions
FROM user_behavior;-- 物化视图加速查询
CREATE MATERIALIZED VIEW mv_user_behavior_hourly
REFRESH EVERY INTERVAL 1 HOUR
AS
SELECT user_id,DATE_TRUNC('HOUR', ts) AS hour,COUNT(*) AS action_count,SUM(CASE WHEN behavior_type = 'buy' THEN 1 ELSE 0 END) AS buy_count
FROM user_behavior
GROUP BY user_id, DATE_TRUNC('HOUR', ts);四、性能优化实践
4.1 分区分桶策略
-- 按天分区+哈希分桶
CREATE TABLE time_series_data (ts DATETIME NOT NULL,device_id LARGEINT NOT NULL,metric_value DOUBLE
)
ENGINE=OLAP
DUPLICATE KEY(ts, device_id)
PARTITION BY RANGE(ts) (PARTITION p202301 VALUES LESS THAN ('2023-02-01'),PARTITION p202302 VALUES LESS THAN ('2023-03-01'),PARTITION p202303 VALUES LESS THAN ('2023-04-01')
)
DISTRIBUTED BY HASH(device_id) BUCKETS 32
PROPERTIES ("replication_num" = "3","storage_medium" = "SSD","storage_cooldown_time" = "7 days"
);4.2 索引优化
-- 添加倒排索引
ALTER TABLE user_behavior
ADD INDEX idx_behavior_type (behavior_type) USING INVERTED;-- 添加Bloom Filter索引
ALTER TABLE sales_agg
ADD INDEX bf_product_id (product_id) USING BLOOM_FILTER;4.3 查询优化技巧
-- 使用分区裁剪
SELECT * FROM time_series_data
WHERE ts BETWEEN '2023-03-15' AND '2023-03-20';-- 使用Bucket裁剪
SELECT * FROM user_behavior
WHERE user_id = 10086;-- 使用Colocate Group
CREATE TABLE colocate_table (user_id BIGINT,item_id BIGINT
)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES ("colocate_with" = "user_group"
);本文部分技术描述基于Apache Doris官方文档[1]及社区公认技术实践,相关SQL语法示例参考自开源项目文档。
[1] 官方文档链接:https://doris.apache.org/docs/
相关文章:
Apache Doris 使用指南:从入门到生产实践
目录 一、Doris 核心概念 1.1 架构组成 1.2 数据模型 二、Doris 部署方式 2.1 单机部署(测试环境) 2.2 集群部署(生产环境) 三、数据操作指南 3.1 数据库与表管理 3.2 数据导入方式 3.2.1 批量导入 3.2.2 实时导入 3.…...

26届秋招收割offer指南
26届暑期实习已经陆续启动,这也意味着对于26届的同学们来说,“找工作”已经提上了日程。为了帮助大家更好地准备暑期实习和秋招,本期主要从时间线、学习路线、核心知识点及投递几方面给大家介绍,希望能为大家提供一些实用的建议和…...
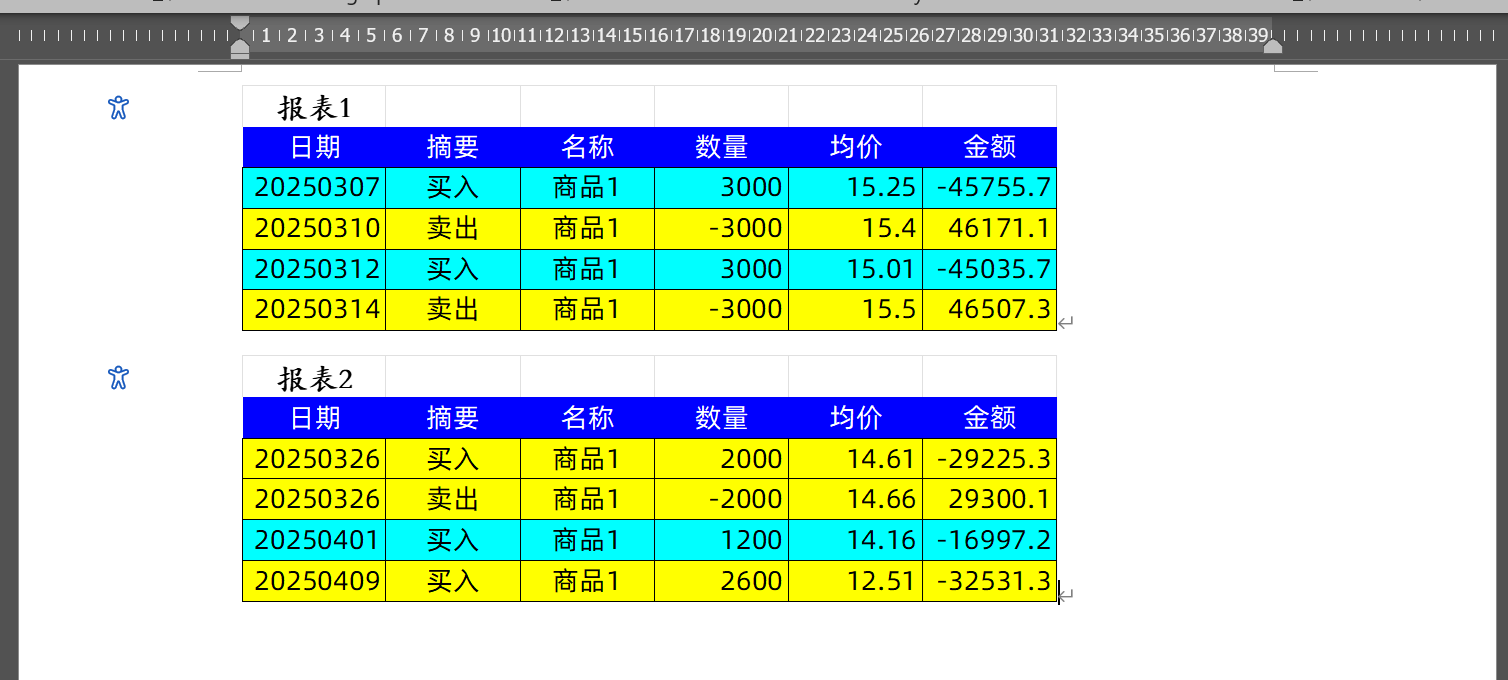
拷贝多个Excel单元格区域为图片并粘贴到Word
Excel工作表Sheet1中有两个报表,相应单元格区域分别定义名称为Report1和Report2,如下图所示。 现在需要将图片拷贝图片粘贴到新建的Word文档中。 示例代码如下。 Sub Demo()Dim oWordApp As ObjectDim ws As Worksheet: Set ws ThisWorkbook.Sheets(&…...

Kafka消息队列之 【消费者分组】 详解
消费者分组(Consumer Group)是 Kafka 提供的一种强大的消息消费机制,它允许多个消费者协同工作,共同消费一个或多个主题的消息,从而实现高吞吐量、可扩展性和容错性。 基本概念 消费者分组:一组消费者实例的集合,这些消费者实例共同订阅一个或多个主题,并通过分组来协调…...
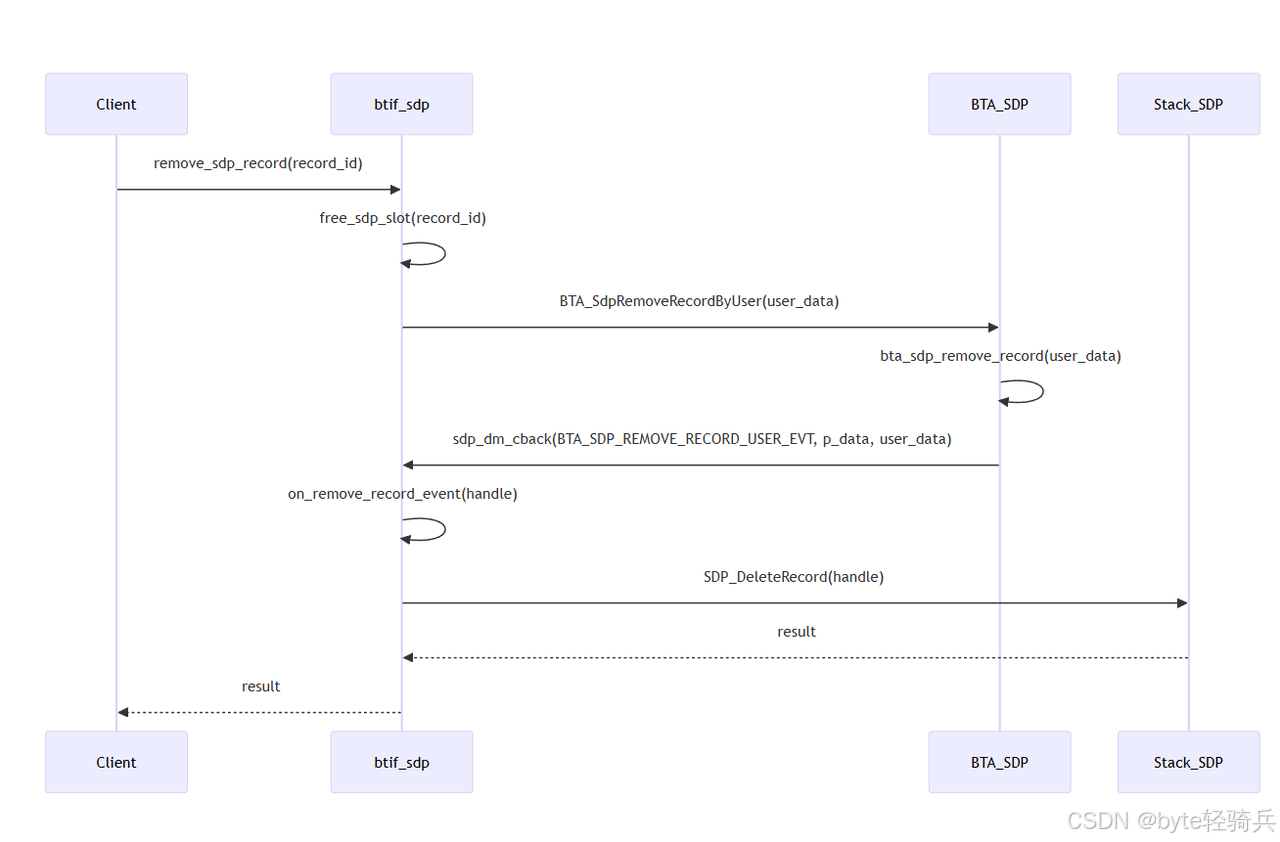
【Bluedroid】蓝牙 SDP(服务发现协议)模块代码解析与流程梳理
本文深入剖析Bluedroid蓝牙协议栈中 SDP(服务发现协议)服务记录的全生命周期管理流程,涵盖初始化、记录创建、服务搜索、记录删除等核心环节。通过解析代码逻辑与数据结构,揭示各模块间的协作机制,包括线程安全设计、回…...

中国自动驾驶研发解决方案,第一!
4月28日,IDC《中国汽车云市场(2024下半年)跟踪》报告发布,2024下半年中国汽车云市场整体规模达到65.1亿元人民币,同比增长27.4%。IDC认为,自动驾驶技术深化与生成式AI的发展将为汽车云打开新的成长天花板,推动云计算在…...
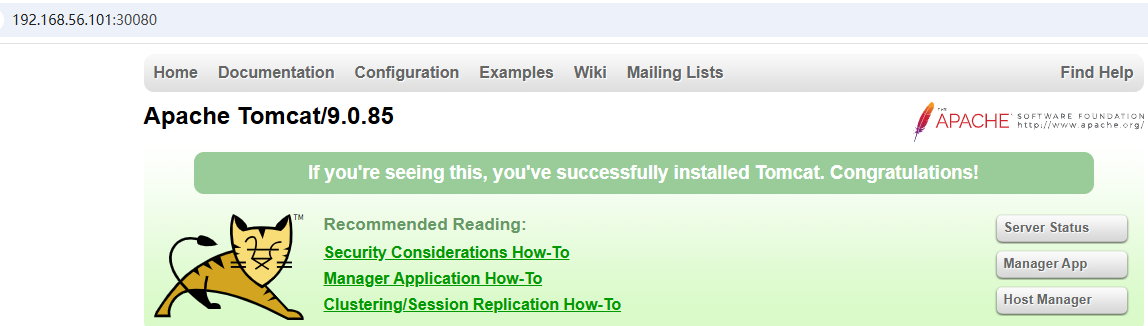
Kubernetes(k8s)学习笔记(四)--入门基本操作
本文通过kubernetes部署tomcat集群,来学习和掌握kubernetes的一些入门基本操作 前提条件 1.各个节点处于Ready状态; 2.配置好docker镜像库(否则会出现ImagePullBackOff等一些问题); 3.网络配置正常(否则即使应用发布没问题,浏…...

【项目篇之统一硬盘操作】仿照RabbitMQ模拟实现消息队列
统一硬盘操作 创建出实例封装交换机的操作封装队列的操作封装绑定的操作封装消息的操作总的完整代码: 我们之前已经使用了数据库去管理交换机,绑定,队列 还使用了数据文件去管理消息 此时我们就搞一个类去把上述两个部分都整合在一起&#…...

【基础复习笔记】计算机视觉
目录 一、计算机视觉基础 1. 卷积神经网络原理 2. 目标检测系列 二、算法与模型实现 1. 在PyTorch/TensorFlow中实现自定义损失函数或网络层的步骤是什么? 2. 如何设计一个轻量级模型用于移动端的人脸识别? 3. 描述使用过的一种注意力机制&#…...
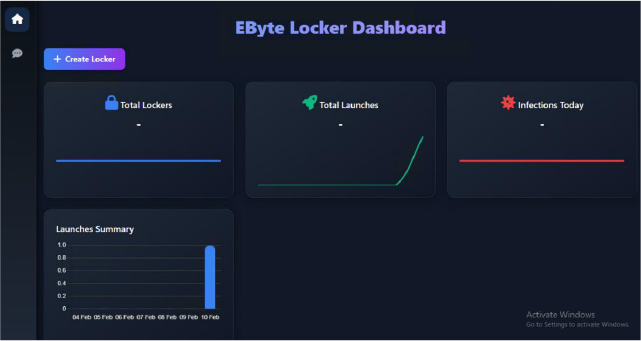
基于 GO 语言的 Ebyte 勒索软件——简要分析
一种新的勒索软件变种,采用Go 语言编写,使用ChaCha20进行加密,并使用ECIES进行安全密钥传输,加密用户数据并修改系统壁纸。其开发者EvilByteCode曾开发过多种攻击性安全工具,现已在 GitHub 上公开 EByte 勒索软件。尽管该勒索软件声称仅用于教育目的,但滥用可能会导致严重…...
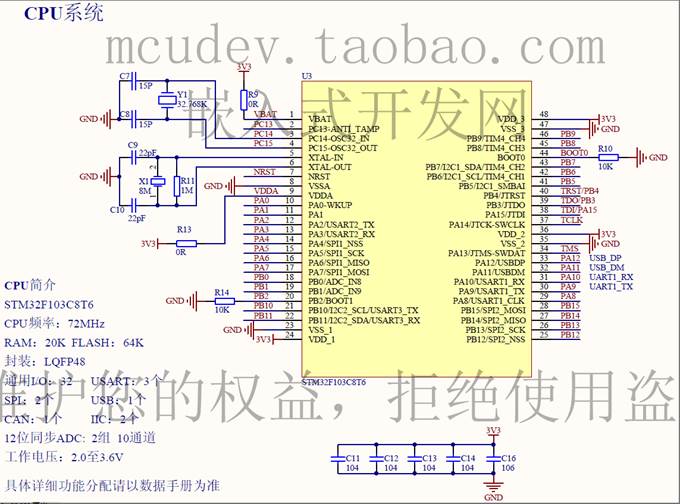
0基础 | STM32 | STM32F103C8T6开发板 | 项目开发
注:本专题系列基于该开发板进行,会分享源代码 F103C8T6核心板链接: https://pan.baidu.com/s/1EJOlrTcProNQQhdTT_ayUQ 提取码:8c1w 图 STM32F103C8T6开发板 1、黑色制版工艺、漂亮、高品质 2、入门级配置STM32芯片(SEM32F103…...

南京大学OpenHarmony技术俱乐部正式揭牌 仓颉编程语言引领生态创新
2025年4月24日,由OpenAtom OpenHarmony(以下简称“OpenHarmony”)项目群技术指导委员会与南京大学软件学院共同举办的“南京大学OpenHarmony技术俱乐部成立大会暨基础软件与生态应用论坛”在南京大学仙林校区召开。 大会聚焦国产自主编程语言…...
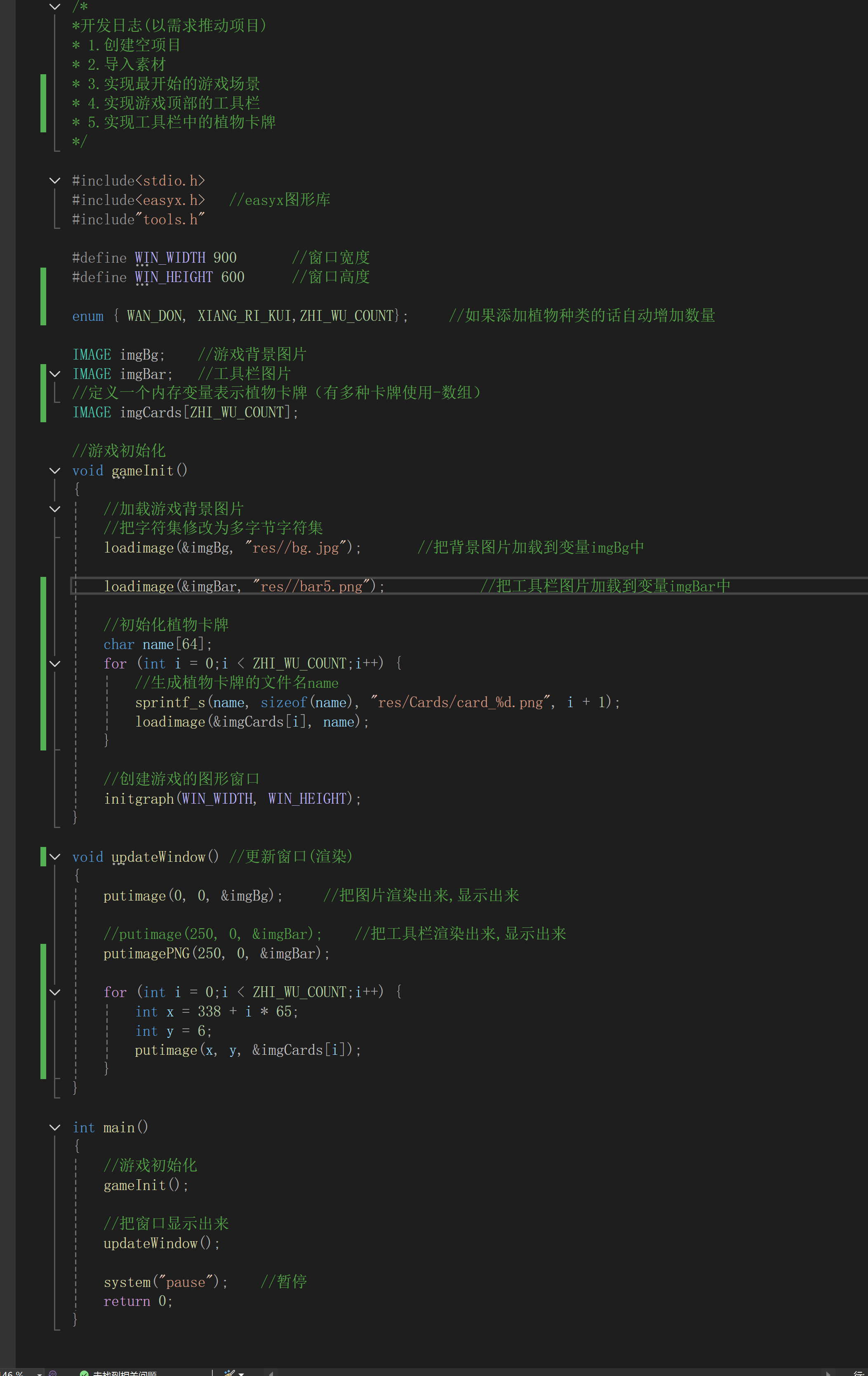
主场景 工具栏 植物卡牌的渲染
前置知识:使用easyx图形库 1.IMAGE内存变量存储的是一张位图(图像),存储了像素数据(颜色,尺寸等) 2.loadimage(&变量名,"加载的文件路径")表示从文件中加载图像到变量中 3. saveimage("文件路径", &变…...

计算机网络:深入分析三层交换机硬件转发表生成过程
三层交换机的MAC地址转发表生成过程结合了二层交换和三层路由的特性,具体可分为以下步骤: 一、二层MAC地址表学习(基础转发层) 初始状态 交换机启动时,MAC地址表为空,处于学习阶段。 数据帧接收与源MAC学习 当主机A发送数据帧到主机B时,交换机会检查数据帧的源MAC地址。…...
Java三大基本特征之多态
多态(Polymorphism)是面向对象编程(OOP)的三大特性之一(另外两个是 封装 和 继承),它允许 同一个行为具有不同的表现形式。在 Java 中,多态主要通过 方法重写(Override&a…...

OpenCV 基于生物视觉模型的工具------模拟人眼视网膜的生物视觉机制类cv::bioinspired::Retina
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::bioinspired::Retina 是 OpenCV 中用于仿生视觉处理的一个类,它基于生物视觉模型进行图像预处理。该算法特别适用于动态范围调整…...
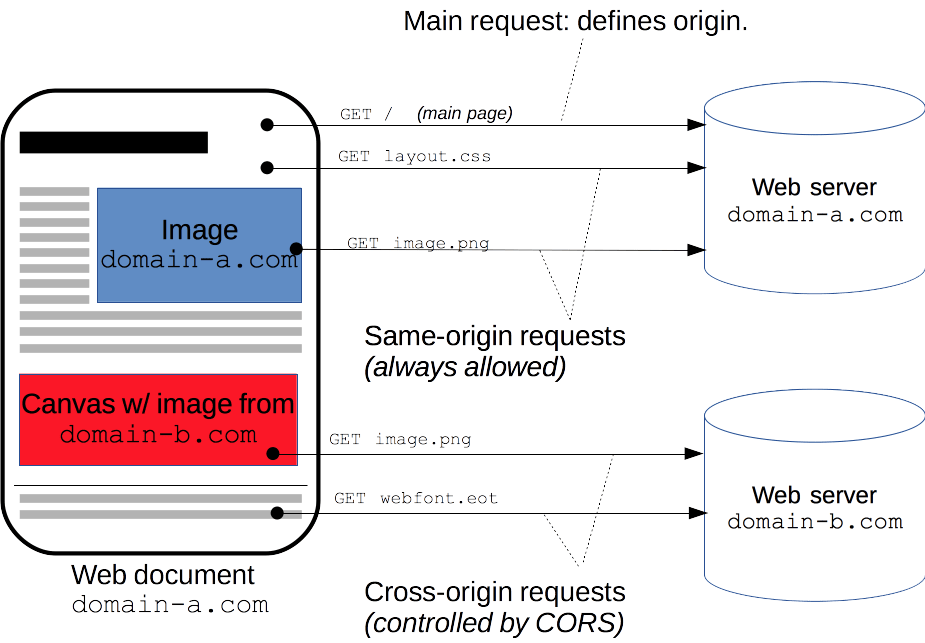
前端跨域问题怎么在后端解决
目录 简单的解决方法: 添加配置类: 为什么会跨域 1. 什么是源 2. URL结构 3. 同源不同源举🌰 同源例子 不同源例子 4. 浏览器为什么需要同源策略 5. 常规前端请求跨域 简单的解决方法: 添加配置类: packag…...
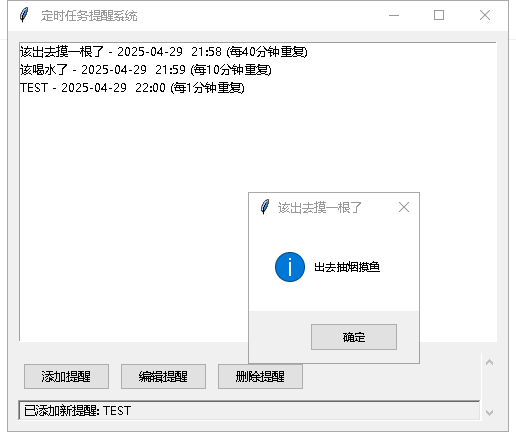
Python小程序:上班该做点摸鱼的事情
系统提醒 上班会忘记一些自己的事,所以你需要在上班的的时候突然给你弹窗,你就知道要做啥了 源码 这里有一个智能家居项目可以看看(开源) # -*- coding:utf-8 -*- """ 作者:YTQ 日期: 2025年04日29 21:51:24 """ impor…...

企业级AI革命!私有化部署开源大模型:数据安全+自主可控,打造专属智能引擎
AI大模型浪潮席卷全球,但企业面临两大痛点:数据隐私风险高、公有云服务难定制! 如何既享受大模型的强大能力,又能保障核心数据安全?私有化部署开源大模型强势破局——将顶尖AI能力“装进”企业内网,数据0外…...
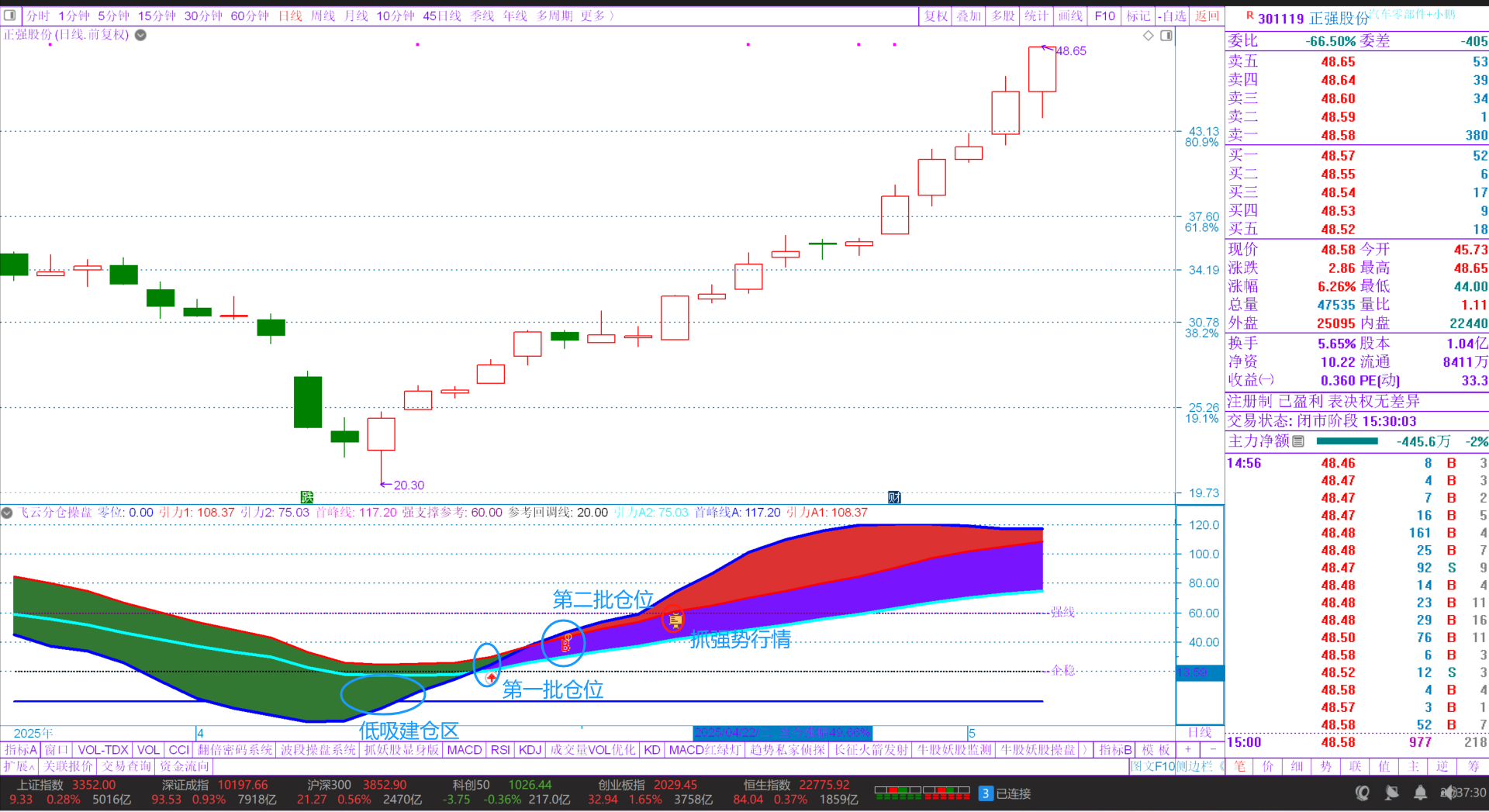
飞云分仓操盘副图指标操作技术图文分解
如上图,副图指标-飞云分仓操盘指标,指标三条线蓝色“首峰线”,红色“引力1”,青色“引力2”,多头行情时“首峰线”和“引力1”之间显示为红色,“引力1”和“引力2”多头是区间颜色显示为紫色。 如上图图标信…...
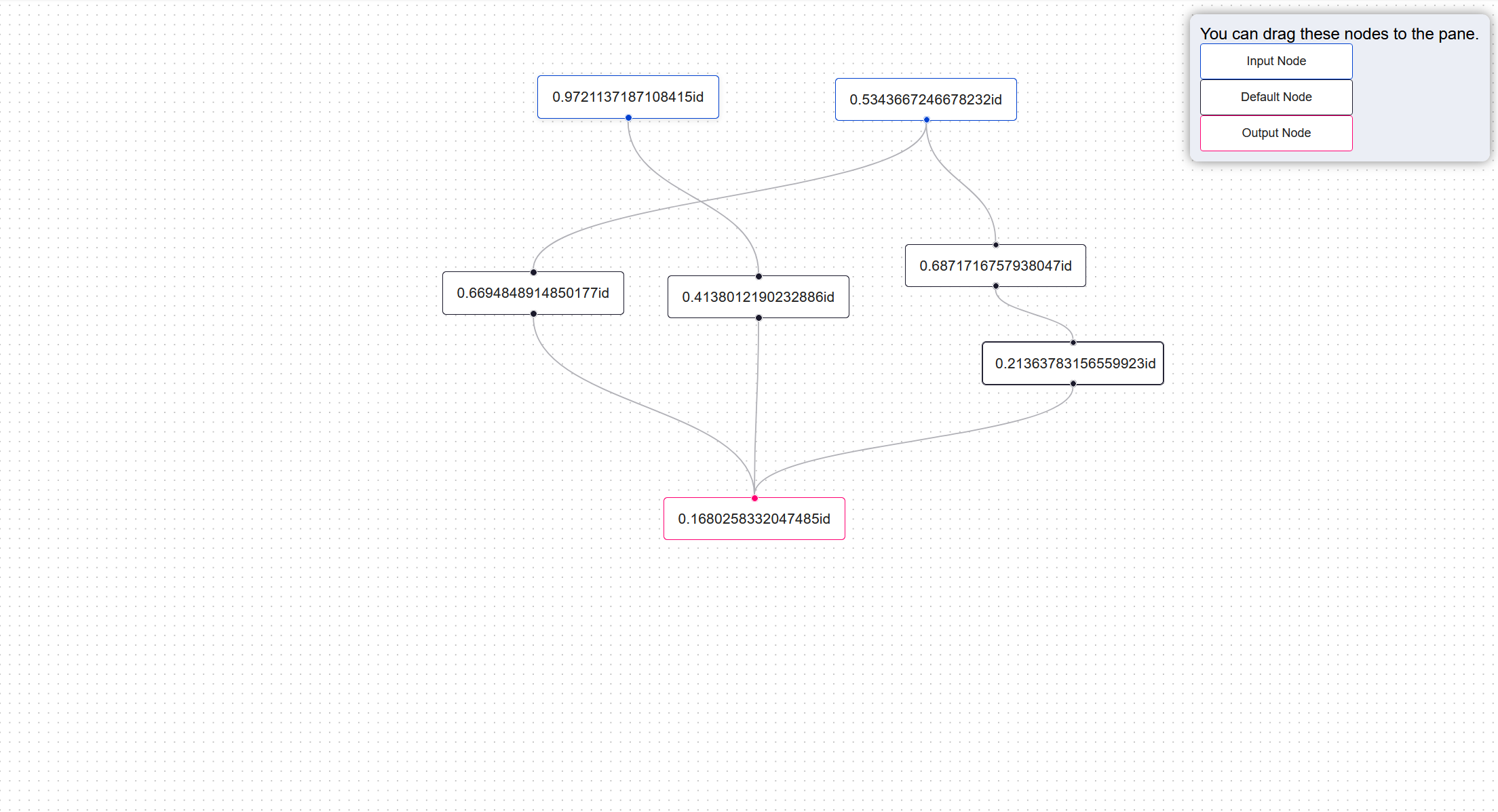
基于vueflow可拖拽元素的示例(基于官网示例的单文件示例)
效果图 代码 <template><div style"width: 100%;height: calc(100vh - 84px)"><VueFlow :nodes"nodes" :edges"edges" drop"onDrop" dragover"onDragOver" dragleave"onDragLeave"><div cl…...
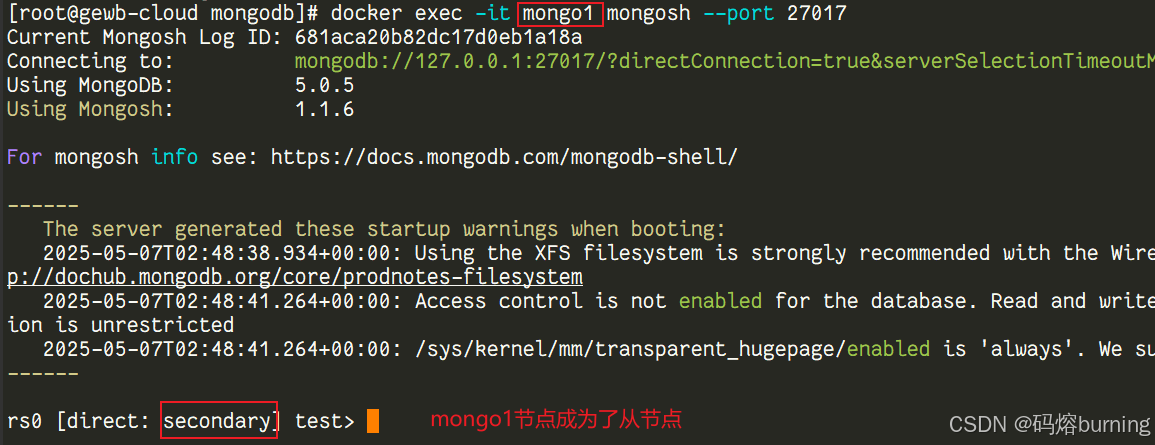
【MongoDB篇】MongoDB的副本集操作!
目录 引言第一节:副本集的核心概念:它是什么?为什么需要它?🤔🧠第二节:副本集的“骨架”:成员与数据同步机制 👑🔄❤️🔥第三节:生死…...
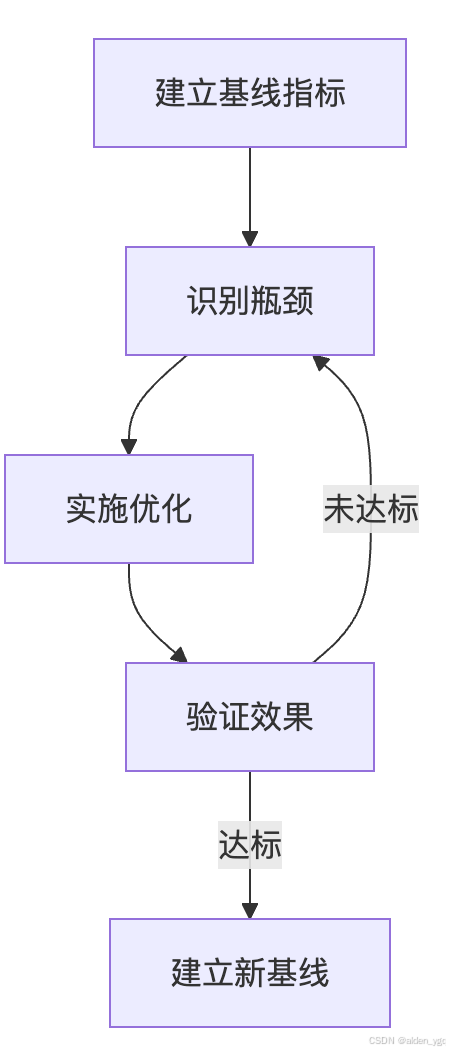
Kubernetes 集群优化实战手册:从零到生产级性能调优
一、硬件资源优化策略 1. 节点选型黄金法则 # 生产环境常见节点规格(AWS示例) - 常规计算型:m5.xlarge (4vCPU 16GB) - 内存优化型:r5.2xlarge (8vCPU 64GB) - GPU加速型:p3.2xlarge (8vCPU V100 GPU)2. 自动扩缩容…...
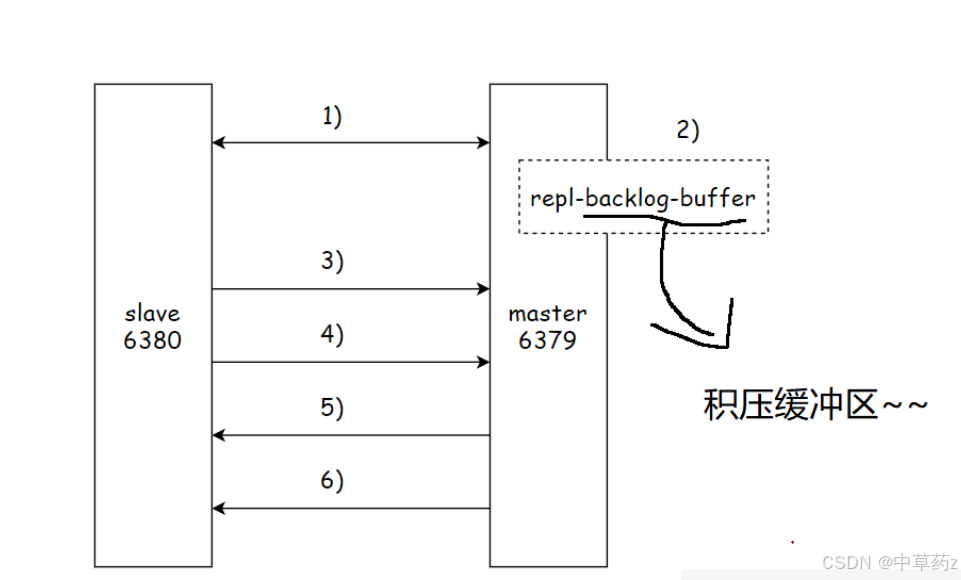
【Redis分布式】主从复制
🔥个人主页: 中草药 🔥专栏:【中间件】企业级中间件剖析 一、主从复制 在分布式系统之中为了解决单点问题(1、可用性问题,该机器挂掉服务会停止2、性能支持的并发量是有限的)通常会把数据复制多…...

用递归实现各种排列
为了满足字典序的输出,我采用了逐位递归的方法(每一位的所能取到的最小值都大于前一位) 1,指数型排列 #include<bits/stdc.h> using ll long long int; using namespace std; int a[10];void printp(int m) {for (int h …...
测试用例介绍
文章目录 一、测试用例基本概念1.1 测试用例基本要素 二、测试用例的设计方法2.1 基于需求的设计方法2.2 等价类2.3 边界值2.4 错误猜测法2.6 场景设计法2.7 因果图2.5 正交排列 三、综合:根据某个场景去设计测试用例(万能公式)四、如何使用F…...
phpstudy升级新版apache
1.首先下载要升级到的apache版本,这里apache版本为Apache 2.4.63-250207 Win64下载地址:Apache VS17 binaries and modules download 2.将phpstudy中原始apache复制备份Apache2.4.39_origin 3.将1中下载apache解压, 将Apache24复制一份到ph…...

在一台服务器上通过 Nginx 配置实现不同子域名访问静态文件和后端服务
一、域名解析配置 要实现通过不同子域名访问静态文件和后端服务,首先需要进行域名解析。在域名注册商或 DNS 服务商处,为你的两个子域名 blog.xxx.com 和 api.xxx.com 配置 A 记录或 CNAME 记录。将它们的 A 记录都指向你服务器的 IP 地址。例如&#x…...
React Native基础环境配置
React Native基础环境配置 1.引言2.React-Native简介3.项目基础环境搭建1.引言 感觉自己掌握的知识面还是有点太窄了,于是决定看看移动端的框架,搞个react搭一个后端管理项目,然后拿react-native写个小的软件,试着找个三方上架一下应用市场玩玩。毕竟不可能一直在简历上挂一…...
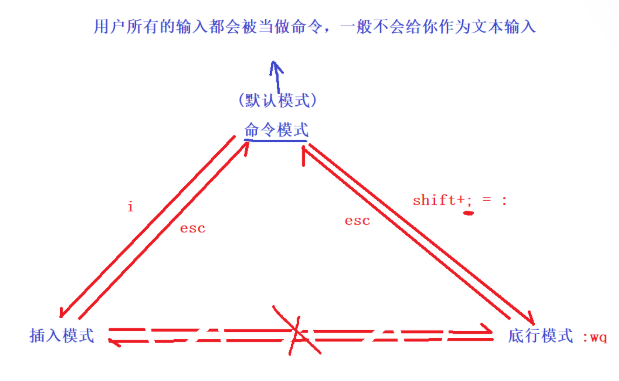
【Linux修炼手册】Linux开发工具的使用(一):yum与vim
文章目录 一、Linux 软件包管理器——yum安装与卸载的使用方法查看软件包 二、Linux编辑器——vimvim命名模式常用指令底行模式常用指令 一、Linux 软件包管理器——yum Linux安装软件的方式有3种: 源代码安装——成本极高rmp安装——具有安装依赖、安装源、安装版…...