增强学习(Reinforcement Learning)简介
增强学习(Reinforcement Learning)简介
增强学习是机器学习的一种范式,其核心目标是让智能体(Agent)通过与环境的交互,基于试错机制和延迟奖励反馈,学习如何选择最优动作以最大化长期累积回报。其核心要素包括:
• 状态(State):描述环境的当前信息(如棋盘布局、机器人传感器数据)。
• 动作(Action):智能体在特定状态下可执行的操作(如移动、下棋)。
• 奖励(Reward):环境对动作的即时反馈信号(如得分增加或惩罚)。
• 策略(Policy):从状态到动作的映射规则(如基于Q值选择动作)。
• 价值函数(Value Function):预测某状态或动作的长期回报(如Q-Learning中的Q表)。
与监督学习不同,增强学习无需标注数据,而是通过探索-利用权衡(Exploration vs Exploitation)自主学习。
使用PyTorch实现深度Q网络(DQN)演示
以下以CartPole-v0(平衡杆环境)为例,展示完整代码及解释:
- 环境与依赖库
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from collections import deque
import random# 初始化环境
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
- 定义DQN网络
class DQN(nn.Module):def __init__(self, state_dim, action_dim):super(DQN, self).__init__()self.fc = nn.Sequential(nn.Linear(state_dim, 128),nn.ReLU(),nn.Linear(128, 64),nn.ReLU(),nn.Linear(64, action_dim))def forward(self, x):return self.fc(x)
- 经验回放缓冲区(Replay Buffer)
class ReplayBuffer:def __init__(self, capacity):self.buffer = deque(maxlen=capacity)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, batch_size):batch = random.sample(self.buffer, batch_size)states, actions, rewards, next_states, dones = zip(*batch)return (torch.FloatTensor(states),torch.LongTensor(actions),torch.FloatTensor(rewards),torch.FloatTensor(next_states),torch.FloatTensor(dones))
- 训练参数与初始化
# 超参数
batch_size = 64
gamma = 0.99 # 折扣因子
epsilon_start = 1.0
epsilon_decay = 0.995
epsilon_min = 0.01
target_update = 10 # 目标网络更新频率# 初始化网络与优化器
policy_net = DQN(state_dim, action_dim)
target_net = DQN(state_dim, action_dim)
target_net.load_state_dict(policy_net.state_dict())
optimizer = optim.Adam(policy_net.parameters(), lr=0.001)
buffer = ReplayBuffer(10000)
epsilon = epsilon_start
- 训练循环
num_episodes = 500
for episode in range(num_episodes):state = env.reset()total_reward = 0while True:# ε-贪婪策略选择动作if random.random() < epsilon:action = env.action_space.sample()else:with torch.no_grad():q_values = policy_net(torch.FloatTensor(state))action = q_values.argmax().item()# 执行动作并存储经验next_state, reward, done, _ = env.step(action)buffer.push(state, action, reward, next_state, done)state = next_statetotal_reward += reward# 经验回放与网络更新if len(buffer.buffer) >= batch_size:states, actions, rewards, next_states, dones = buffer.sample(batch_size)# 计算目标Q值with torch.no_grad():next_q = target_net(next_states).max(1)[0]target_q = rewards + gamma * next_q * (1 - dones)# 计算当前Q值current_q = policy_net(states).gather(1, actions.unsqueeze(1))# 均方误差损失loss = nn.MSELoss()(current_q, target_q.unsqueeze(1))# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()if done:break# 更新目标网络与εif episode % target_update == 0:target_net.load_state_dict(policy_net.state_dict())epsilon = max(epsilon_min, epsilon * epsilon_decay)print(f"Episode {episode}, Reward: {total_reward}, Epsilon: {epsilon:.2f}")
关键点解释
- 经验回放(Replay Buffer):通过存储历史经验并随机采样,打破数据相关性,提升训练稳定性。
- 目标网络(Target Network):固定目标Q值计算网络,缓解训练震荡问题。
- ε-贪婪策略:平衡探索(随机动作)与利用(最优动作),逐步降低探索率。
结果与优化方向
• 预期效果:经过约200轮训练,智能体可稳定保持平衡超过195步(CartPole-v1的胜利条件)。
• 优化方法:
• 使用Double DQN或Dueling DQN改进Q值估计。
• 调整网络结构(如增加卷积层处理图像输入)。
• 引入优先级经验回放(Prioritized Experience Replay)。
完整代码及更多改进可参考PyTorch官方文档或强化学习框架(如Stable Baselines3)。
相关文章:
简介)
增强学习(Reinforcement Learning)简介
增强学习(Reinforcement Learning)简介 增强学习是机器学习的一种范式,其核心目标是让智能体(Agent)通过与环境的交互,基于试错机制和延迟奖励反馈,学习如何选择最优动作以最大化长期累积回报。…...
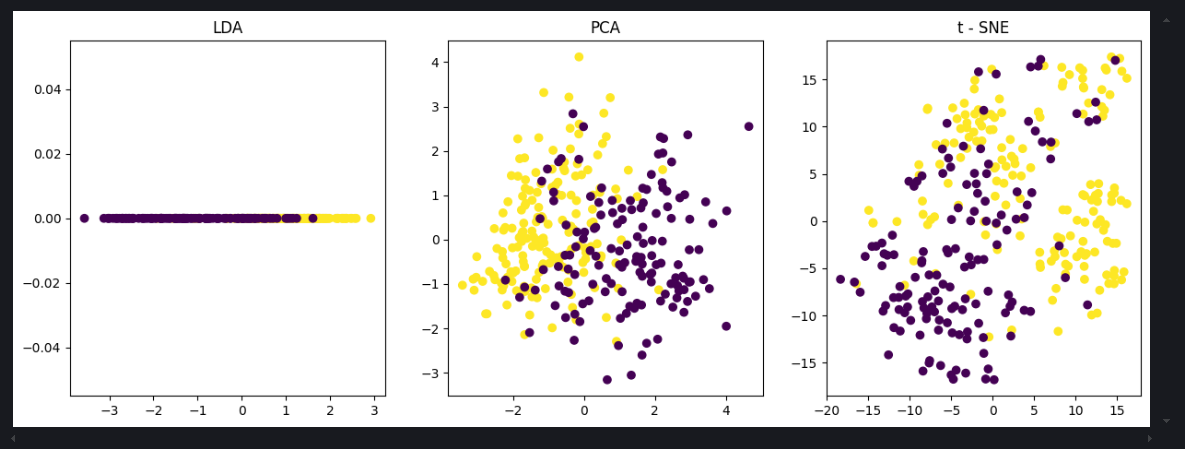
常见降维算法分析
一、常见的降维算法 LDA线性判别PCA主成分分析t-sne降维 二、降维算法原理 2.1 LDA 线性判别 原理 :LDA(Linear Discriminant Analysis)线性判别分析是一种有监督的降维方法。它的目标是找到一个投影方向,使得不同类别的数据在…...

计算机二级(C语言)已过
非线性结构:树、图 链表和队列的结构特性不一样,链表可以在任何位置插入、删除,而队列只能在队尾入队、队头出队 对长度为n的线性表排序、在最坏情况下时间复杂度,二分查找为O(log2n),顺序查找为O(n),哈希查…...

2025年3月,韩先超对国网宁夏进行Python线下培训
大家好,我是韩先超!在2025年3月3号和4号,为 宁夏国网 的运维团队进行了一场两天的 Python培训 ,培训目标不仅是让大家学会Python编程,更是希望大家能够通过这门技术解决实际工作中的问题,提升工作效率。 对…...

ATH12K驱动框架架构图
ATH12K驱动框架架构图 ATH12K驱动框架架构图(分层描述)I. 顶层架构II. 核心数据结构层次关系III. 主要模块详解1. 核心模块 (Core)2. 硬件抽象层 (HAL)3. 无线管理接口 (WMI)4. 主机目标通信 (HTC)5. 复制引擎 (CE)6. MAC层7. 数据路径 (DP)IV. 关键数据流路径1. 发送数据流 …...

pcb样板打样厂家哪家好?
国内在PCB样板加工领域具有较强竞争力的企业主要包括以下几家,综合技术实力、市场份额、客户评价及行业认可度进行推荐: 1. 兴森科技 行业地位:国内最大的PCB样板生产商,细分领域龙头企业,月订单品种数可达25,000种&…...
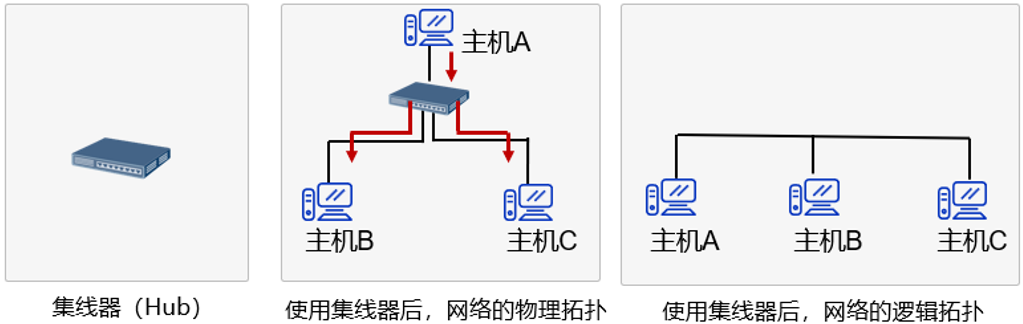
[计算机网络]物理层
文章目录 物理层的概述与功能传输介质双绞线:分类:应用领域: 同轴电缆:分类: 光纤:分类: 无线传输介质:无线电波微波:红外线:激光: 物理层设备中继器(Repeater):放大器:集线器(Hub)&…...
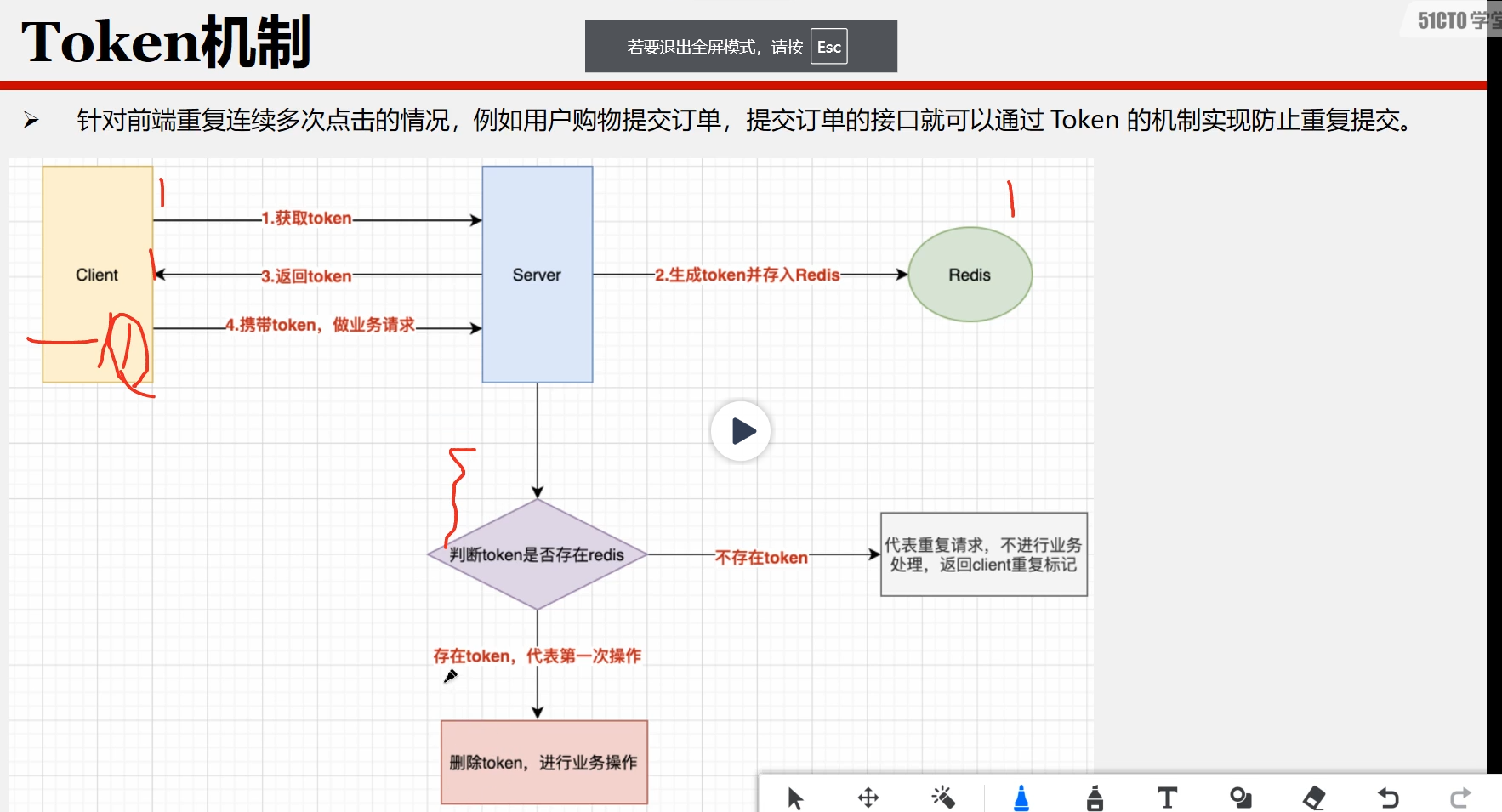
幂等操作及处理措施
利用token模式去避免幂等操作 按以上图所示,除了token,应该也可以把传入的参数用MD5加密,当成key放入redis里面,业务执行完后再删除这个key.如还没有执行完,则请不要重复操作。纯属个人理解...
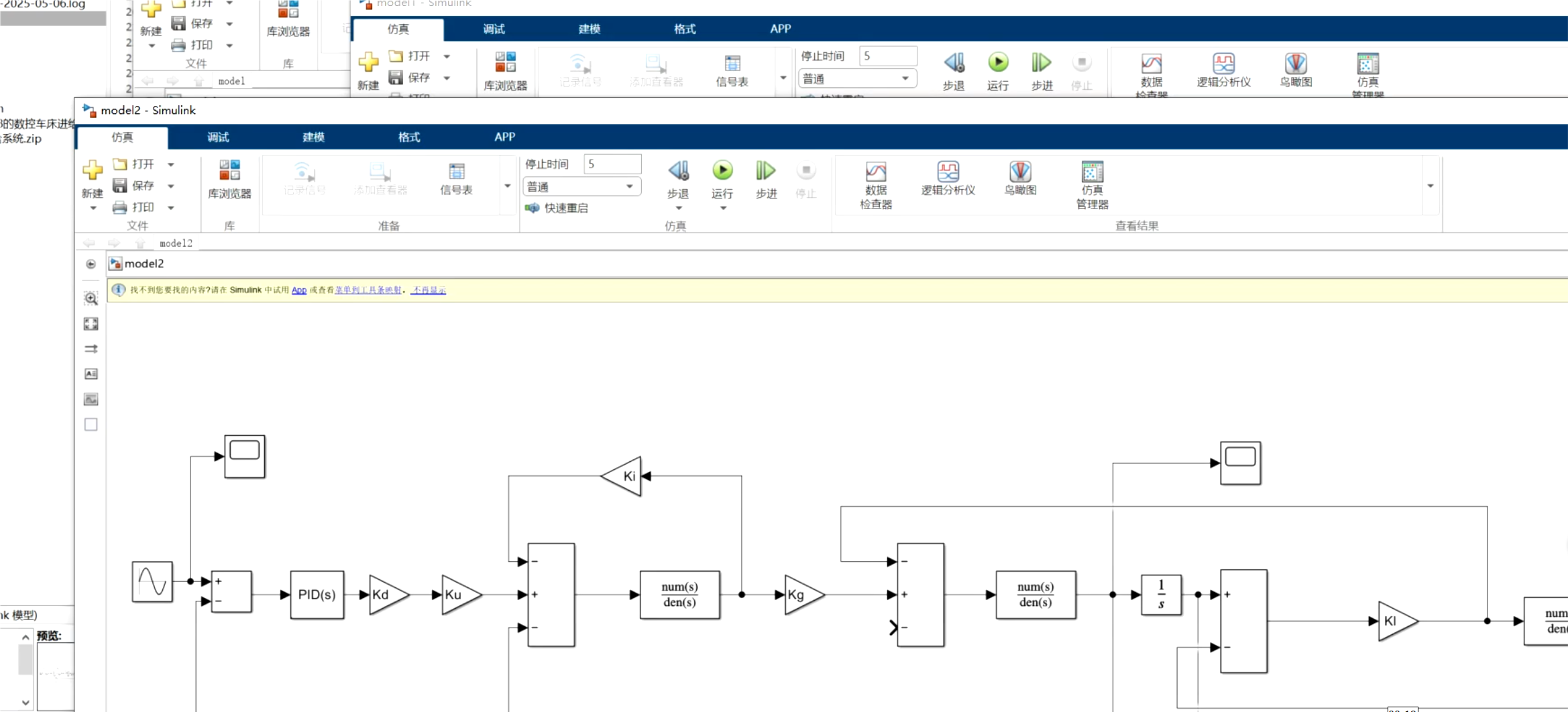
Matlab 数控车床进给系统的建模与仿真
1、内容简介 Matlab217-数控车床进给系统的建模与仿真 可以交流、咨询、答疑 2、内容说明 略 摘 要:为提高数控车床的加工精度,对数控 车床进给系统中影响加工精度的主要因素进行了仿真分析研 动系统的数学模型,利用MATLAB软件中的动态仿真工具 究:依据机械动力学原理建立了…...
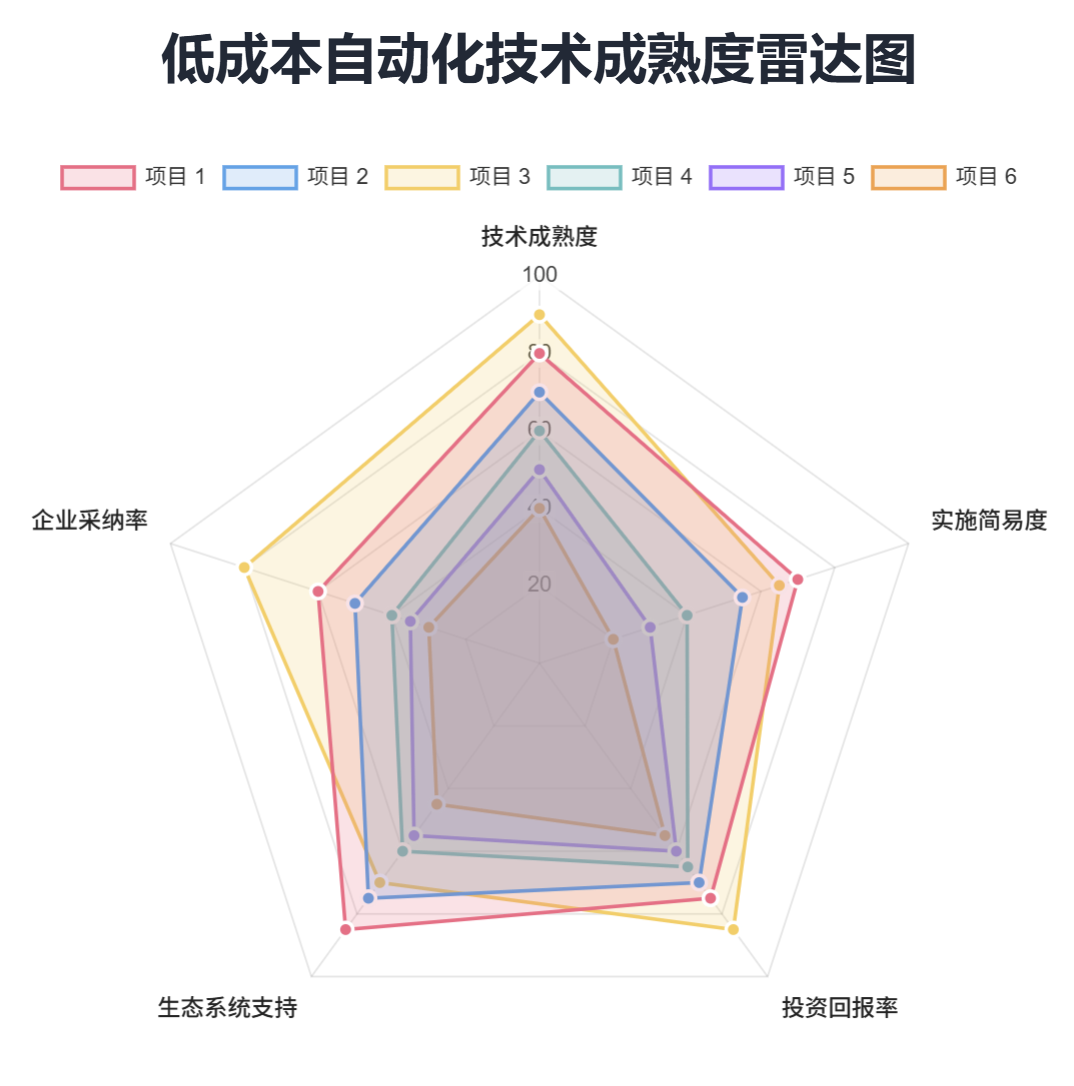
低成本自动化改造的18个技术锚点深度解析
执行摘要 本文旨在深入剖析四项关键的低成本自动化技术,这些技术为工业转型提供了显著的运营和经济效益。文章将提供实用且深入的指导,涵盖老旧设备联网、AGV车队优化、空压机系统智能能耗管控以及此类项目投资回报率(ROI)的严谨…...

【大数据】服务器上部署Apache Paimon
1. 环境准备 在开始部署之前,请确保服务器满足以下基本要求: 操作系统: 推荐使用 Linux(如 Ubuntu、CentOS)。 Java 环境: Paimon 依赖 Java,推荐安装 JDK 8 或更高版本。 Flink 环境: Paimon 是基于 Apache Flink 的…...
我国脑机接口市场规模将破38亿元,医疗领域成关键突破口
当人类仅凭"意念"就能操控无人机编队飞行,当瘫痪患者通过"脑控"重新站立行走,这些曾只存在于科幻电影的场景,如今正通过脑机接口技术变为现实。作为"十四五"规划中重点发展的前沿科技,我国脑机接口…...
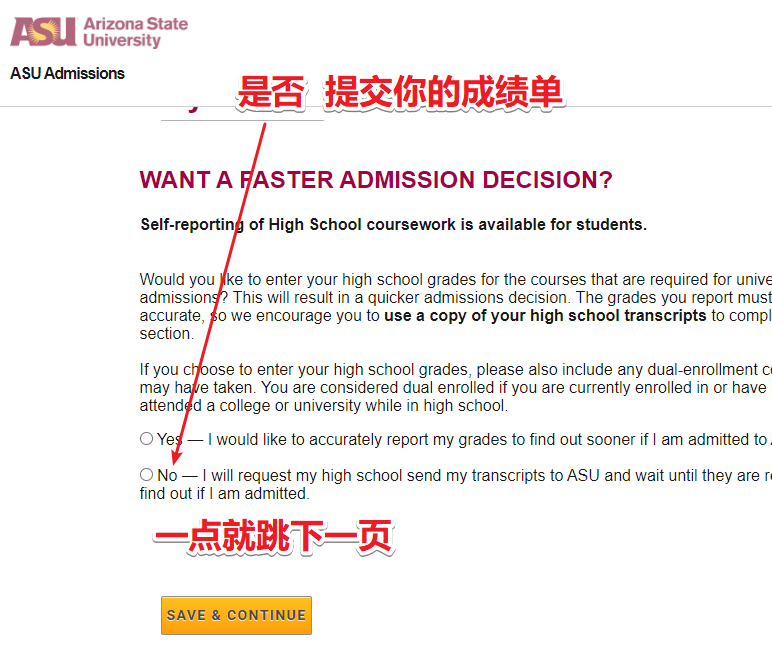
Edu教育邮箱申请成功下号
这里是第2部分 如你所见,我根本就没有考虑流量的问题, 如果你有幸看到前面的内容,相信你能自己找到这个后续。...

kotlin中枚举带参数和不带参数的区别
一 ✅ 代码对比总结 第一段(带参数 工具方法) enum class SeatPosition(val position: Int) {DRIVER_LEFT(0),DRIVER_RIGHT(1),SECOND_LEFT(2),SECOND_RIGHT(3);companion object {fun fromPosition(position: Int): SeatPosition? {return SeatPosi…...
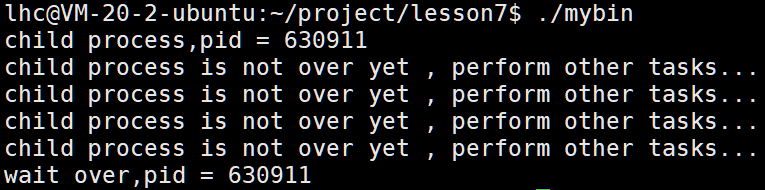
【Linux进程控制一】进程的终止和等待
【Linux进程控制一】进程的终止和等待 一、进程终止1.main函数的return2.strerror函数3.库函数exit4.系统调用_exit和库函数exit的区别5.异常信号6.变量errno 二、进程等待1.什么是进程等待?2.wait接口3.status4.waitpid接口 一、进程终止 1.main函数的return 写C…...

修改docker为国内源
一、编辑docker配置文件 vi /etc/docker/daemon.json二、配置国内源和修改docker数据目录 {"registry-mirrors":["http://hub-mirror.c.163.com","https://mirrors.tuna.tsinghua.edu.cn","http://mirrors.sohu.com","https://u…...

Java反射 八股版
目录 一、核心概念阐释 1. Class类 2. Constructor类 3. Method类 4. Field类 二、典型应用场景 1. 框架开发 2. 单元测试 3. JSON序列化/反序列化 三、性能考量 四、安全与访问控制 1. 安全管理器限制 2. 打破封装性 3. 安全风险 五、版本兼容性问题 六、最佳…...
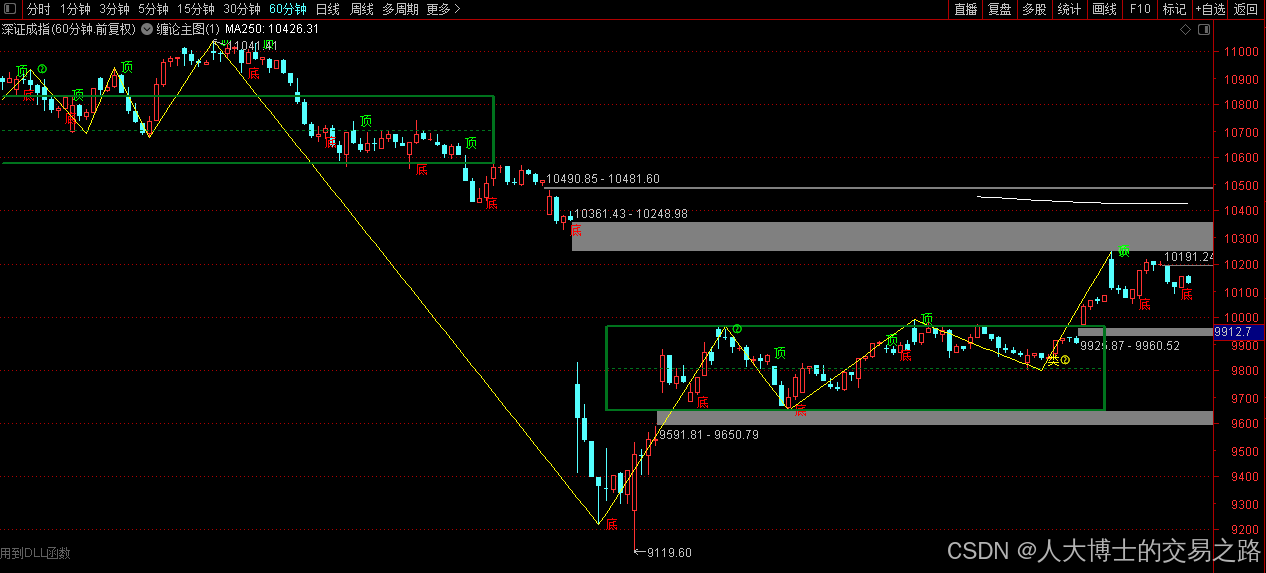
今日行情明日机会——20250509
上证指数今天缩量,整体跌多涨少,走势处于日线短期的高位~ 深证指数今天缩量小级别震荡,大盘股表现更好~ 2025年5月9日涨停股主要行业方向分析 一、核心主线方向 服装家纺(消费复苏出口链驱动) • 涨停家数…...
单片机-STM32部分:10、串口UART
飞书文档https://x509p6c8to.feishu.cn/wiki/W7ZGwKJCeiGjqmkvTpJcjT2HnNf 串口说明 电平标准是数据1和数据0的表达方式,是传输线缆中人为规定的电压与数据的对应关系,串口常用的电平标准有如下三种: TTL电平:3.3V或5V表示1&am…...

RabittMQ-高级特性2-应用问题
文章目录 前言延迟队列介绍ttl死信队列存在问题延迟队列插件安装延迟插件使用事务消息分发概念介绍限流非公平分发(负载均衡) 限流负载均衡RabbitMQ应用问题-幂等性保障顺序性保障介绍1顺序性保障介绍2消息积压总结 前言 延迟队列介绍 延迟队列(Delaye…...
React 播客专栏 Vol.5|从“显示”到“消失”:打造你的第一个交互式 Alert 组件!
👋 欢迎回到《前端达人 播客书单》第 5 期(正文内容为学习笔记摘要,音频内容是详细的解读,方便你理解),请点击下方收听 📌 今天我们不再停留在看代码,而是动手实现一个真正的 React…...

解决 MySQL 数据库无法远程连接的问题
在使用 MySQL 数据库时,遇到这样的问题: 本地可以连接 MySQL,但远程机器连接时,总是报错 Host ... is not allowed to connect to this MySQL server。 这通常是因为 MySQL 的用户权限或配置限制了远程访问。 1. 登录 MySQL 数据…...

互联网大厂Java求职面试:基于RAG的智能问答系统设计与实现
互联网大厂Java求职面试:基于RAG的智能问答系统设计与实现 场景背景 在某互联网大厂的技术面试中,技术总监张总正在面试一位名为郑薪苦的求职者。郑薪苦虽然对技术充满热情,但回答问题时总是带着幽默感,有时甚至让人哭笑不得。 …...

解密火星文:LeetCode 269 题详解与 Swift 实现
文章目录 摘要描述题解答案题解代码分析构建图(Graph)拓扑排序(Topological Sort) 示例测试及结果时间复杂度空间复杂度实际场景类比总结 摘要 这篇文章我们来聊聊 LeetCode 269 题:火星词典(Alien Dictio…...
动态规划-62.不同路径-力扣(LeetCode)
一、题目解析 机器人只能向下或向左,要从Start位置到Finish位置。 二、算法原理 1.状态表示 我们要求到Finish位置一共有多少种方法,记Finish为[i,j],此时dp[i,j]表示:到[i,j]位置时,一共有多少种方法,满…...

5月9号.
v-for: v-bind: v-if&v-show: v-model: v-on: Ajax: Axios: async&await: Vue生命周期: Maven: Maven坐标:...
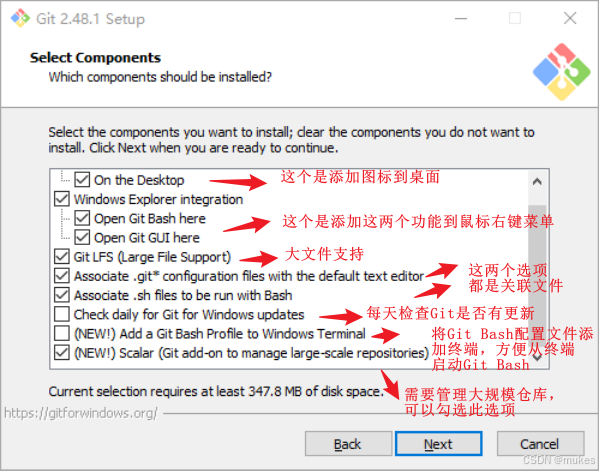
从 Git 到 GitHub - 使用 Git 进行版本控制 - Git 常用命令
希望本贴能从零开始带您一起学习如何使用 Git 进行版本控制,并结合远程仓库 GitHub。这会是一个循序渐进的指南,我们开始吧! 学习 Git 和 GitHub 的路线图: 理解核心概念:什么是版本控制?Git 是什么&…...
)
何时需要import css文件?怎么知道需要导入哪些css文件?为什么webpack不提示CSS导入?(导入css导入规则、css导入规范)
文章目录 何时需要import css文件?**1. 使用模块化工具(如 Webpack、Vite、Rollup 等)****适用场景:****示例:****优点:** **2. 动态加载 CSS(按需加载)****适用场景:***…...

双指针算法详解(含力扣和蓝桥杯例题)
目录 一、双指针算法核心概念 二、常用的双指针类型: 2.1 对撞指针 例题1:盛最多水的容器 例题2:神奇的数组 2.2 快慢指针: 例题1:移动零 例题2:美丽的区间(蓝桥OJ1372) 3.总…...

【网络编程】二、UDP网络套接字编程详解
文章目录 前言Ⅰ. UDP服务端一、服务器创建流程二、创建套接字 -- socketsocket 属于什么类型的接口❓❓❓socket 是被谁调用的❓❓❓socket 底层做了什么❓❓❓和其函数返回值有没有什么关系❓❓❓ 三、绑定对应端口号、IP地址到套接字 -- bind四、数据的发送和接收 -- sendto…...