每天批次导入 100 万对账数据到 MySQL 时出现死锁
一、死锁原因及优化策略
1.1 死锁原因分析
- 批量插入事务过大:
- Spring Batch 默认将整个 chunk(批量数据块)作为一个事务提交,100 万数据可能导致事务过长,增加锁竞争。
- 并发写入冲突:
- 多个线程或批处理作业同时写入同一表,争夺行锁或表锁。
- 索引缺失或不当:
- 缺少主键或唯一索引,导致插入时全表扫描。
- 索引过多导致更新锁冲突。
- 分库分表未优化:
- 单表数据量过大(如超过千万),查询和插入性能下降。
- 分片键设计不合理,导致热点数据集中。
- 拒绝策略或线程池配置不当:
- 动态线程池(如 Dynamic TP)配置不当,导致任务积压或拒绝,间接增加事务等待时间。
- 事务隔离级别:
- MySQL 默认
REPEATABLE_READ可能引发间隙锁,尤其在范围更新或插入时。
- MySQL 默认
1.2 优化策略
- 分批提交:
- 将 100 万数据拆分为小批量(如每 1000 条一个事务),减少事务持有锁时间。
- 动态线程池优化:
- 使用动态线程池(如 Dynamic TP)控制并发,限制同时写入的线程数。
- 配置合理的拒绝策略(如
CallerRunsPolicy)避免任务丢失。
- 分库分表:
- 使用 ShardingSphere 按对账 ID 或日期分片,分散数据压力。
- 优化分片键,避免热点。
- 索引优化:
- 确保主键和必要索引存在,避免全表扫描。
- 移除冗余索引,减少锁冲突。
- 事务隔离级别调整:
- 评估是否可降低为
READ_COMMITTED,减少间隙锁。
- 评估是否可降低为
- 死锁检测与重试:
- 配置 MySQL 死锁检测(
innodb_deadlock_detect)。 - 在代码中实现重试机制。
- 配置 MySQL 死锁检测(
- AOP 监控:
- 使用 AOP 记录批量导入性能和死锁异常,便于定位问题。
- 日志与监控:
- 集成 ActiveMQ 记录操作日志,Actuator 监控线程池和数据库性能。
二、在 Spring Boot 中实现优化方案
以下是在 Spring Boot 中实现批量导入 100 万对账数据的示例,使用 Spring Batch、ShardingSphere(分库分表)、Dynamic TP(动态线程池)、AOP 监控等,解决死锁问题。
2.1 环境搭建
2.1.1 配置步骤
-
创建 Spring Boot 项目:
- 使用 Spring Initializr 添加依赖:
spring-boot-starter-webspring-boot-starter-data-jpamysql-connector-javashardingsphere-jdbc-coredynamic-tp-spring-boot-starterspring-boot-starter-activemqspring-boot-starter-batchspring-boot-starter-aop
<project><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.0</version></parent><groupId>com.example</groupId><artifactId>batch-import-demo</artifactId><version>0.0.1-SNAPSHOT</version><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core</artifactId><version>5.4.0</version></dependency><dependency><groupId>cn.dynamictp</groupId><artifactId>dynamic-tp-spring-boot-starter</artifactId><version>1.1.5</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-activemq</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-batch</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId></dependency></dependencies> </project> - 使用 Spring Initializr 添加依赖:
-
准备数据库:
- 创建两个 MySQL 数据库:
recon_db_0和recon_db_1。 - 每个数据库包含两个表:
reconciliation_0和reconciliation_1。 - 表结构:
CREATE TABLE reconciliation_0 (id BIGINT PRIMARY KEY,account_id VARCHAR(50),amount DECIMAL(10,2),recon_date DATE,INDEX idx_account_id (account_id),INDEX idx_recon_date (recon_date) ); CREATE TABLE reconciliation_1 (id BIGINT PRIMARY KEY,account_id VARCHAR(50),amount DECIMAL(10,2),recon_date DATE,INDEX idx_account_id (account_id),INDEX idx_recon_date (recon_date) );
- 创建两个 MySQL 数据库:
-
配置
application.yml:spring:profiles:active: devapplication:name: batch-import-demoshardingsphere:datasource:names: db0,db1db0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/recon_db_0?useSSL=false&serverTimezone=UTCusername: rootpassword: rootdb1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/recon_db_1?useSSL=false&serverTimezone=UTCusername: rootpassword: rootrules:sharding:tables:reconciliation:actual-data-nodes: db${0..1}.reconciliation_${0..1}table-strategy:standard:sharding-column: idsharding-algorithm-name: recon-table-algodatabase-strategy:standard:sharding-column: idsharding-algorithm-name: recon-db-algosharding-algorithms:recon-table-algo:type: INLINEprops:algorithm-expression: reconciliation_${id % 2}recon-db-algo:type: INLINEprops:algorithm-expression: db${id % 2}props:sql-show: truejpa:hibernate:ddl-auto: noneshow-sql: truebatch:job:enabled: falseinitialize-schema: alwaysactivemq:broker-url: tcp://localhost:61616user: adminpassword: admin server:port: 8081 management:endpoints:web:exposure:include: health,metrics,threadpool dynamic-tp:enabled: trueexecutors:- thread-pool-name: batchImportPoolcore-pool-size: 4max-pool-size: 8queue-capacity: 1000queue-type: LinkedBlockingQueuerejected-handler-type: CallerRunsPolicykeep-alive-time: 60thread-name-prefix: batch-import- logging:level:root: INFOcom.example.demo: DEBUG -
MySQL 配置:
- 确保死锁检测启用:
SET GLOBAL innodb_deadlock_detect = ON; - 调整事务隔离级别(可选):
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
- 确保死锁检测启用:
2.1.2 原理
- ShardingSphere:按 ID 哈希分片,分散数据到
db0.reconciliation_0,db0.reconciliation_1,db1.reconciliation_0,db1.reconciliation_1。 - Dynamic TP:控制批量导入的并发线程数,优化资源利用。
- Spring Batch:分 chunk 处理数据,减少事务大小。
- AOP:监控导入性能和死锁。
2.1.3 优点
- 分库分表降低单表压力。
- 动态线程池优化并发。
- 小批量事务减少锁竞争。
2.1.4 缺点
- 配置复杂,需熟悉 ShardingSphere 和 Dynamic TP。
- 跨库事务需额外支持。
- 死锁监控增加少量开销。
2.1.5 适用场景
- 高并发批量数据导入。
- 大数据量对账系统。
- 微服务数据库优化。
2.2 实现批量导入
实现 100 万对账数据的批量导入,优化死锁问题。
2.2.1 配置步骤
-
实体类(
Reconciliation.java):package com.example.demo.entity;import jakarta.persistence.Entity; import jakarta.persistence.Id; import java.math.BigDecimal; import java.time.LocalDate;@Entity public class Reconciliation {@Idprivate Long id;private String accountId;private BigDecimal amount;private LocalDate reconDate;// Getters and Setterspublic Long getId() { return id; }public void setId(Long id) { this.id = id; }public String getAccountId() { return accountId; }public void setAccountId(String accountId) { this.accountId = accountId; }public BigDecimal getAmount() { return amount; }public void setAmount(BigDecimal amount) { this.amount = amount; }public LocalDate getReconDate() { return reconDate; }public void setReconDate(LocalDate reconDate) { this.reconDate = reconDate; } } -
Repository(
ReconciliationRepository.java):package com.example.demo.repository;import com.example.demo.entity.Reconciliation; import org.springframework.data.jpa.repository.JpaRepository;public interface ReconciliationRepository extends JpaRepository<Reconciliation, Long> { } -
服务层(
ReconciliationService.java):package com.example.demo.service;import com.example.demo.entity.Reconciliation; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.batch.core.Job; import org.springframework.batch.core.JobParametersBuilder; import org.springframework.batch.core.launch.JobLauncher; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.jdbc.util.JdbcUtils; import org.springframework.stereotype.Service;import java.sql.SQLException;@Service public class ReconciliationService {private static final Logger logger = LoggerFactory.getLogger(ReconciliationService.class);private static final ThreadLocal<String> CONTEXT = new ThreadLocal<>();@Autowiredprivate JobLauncher jobLauncher;@Autowiredprivate Job importReconJob;public void startImportJob() {try {CONTEXT.set("Import-" + Thread.currentThread().getName());logger.info("Starting batch import job");JobParametersBuilder params = new JobParametersBuilder().addLong("timestamp", System.currentTimeMillis());jobLauncher.run(importReconJob, params.build());} catch (Exception e) {logger.error("Failed to start import job", e);} finally {CONTEXT.remove();}}public void retryOnDeadlock(Runnable task, int maxRetries) {int retries = 0;while (retries < maxRetries) {try {task.run();return;} catch (Exception e) {if (isDeadlock(e)) {retries++;logger.warn("Deadlock detected, retrying {}/{}", retries, maxRetries);try {Thread.sleep(100 * retries); // 指数退避} catch (InterruptedException ie) {Thread.currentThread().interrupt();}} else {throw e;}}}throw new RuntimeException("Max retries reached for deadlock");}private boolean isDeadlock(Exception e) {return e.getCause() instanceof SQLException &&((SQLException) e.getCause()).getErrorCode() == 1213;} } -
Spring Batch 配置(
BatchConfig.java):package com.example.demo.config;import com.example.demo.entity.Reconciliation; import org.dynamictp.core.DtpRegistry; import org.dynamictp.core.executor.DtpExecutor; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.item.ItemProcessor; import org.springframework.batch.item.ItemReader; import org.springframework.batch.item.ItemWriter; import org.springframework.batch.item.database.JpaItemWriter; import org.springframework.batch.item.support.ListItemReader; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import jakarta.persistence.EntityManagerFactory; import java.math.BigDecimal; import java.time.LocalDate; import java.util.ArrayList; import java.util.List;@Configuration @EnableBatchProcessing public class BatchConfig {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Autowiredprivate EntityManagerFactory entityManagerFactory;@Beanpublic ItemReader<Reconciliation> reader() {// 模拟 100 万数据List<Reconciliation> data = new ArrayList<>();for (long i = 1; i <= 1_000_000; i++) {Reconciliation recon = new Reconciliation();recon.setId(i);recon.setAccountId("ACC" + i);recon.setAmount(new BigDecimal("100.00"));recon.setReconDate(LocalDate.now());data.add(recon);}return new ListItemReader<>(data);}@Beanpublic ItemProcessor<Reconciliation, Reconciliation> processor() {return item -> {// 简单处理return item;};}@Beanpublic ItemWriter<Reconciliation> writer() {JpaItemWriter<Reconciliation> writer = new JpaItemWriter<>();writer.setEntityManagerFactory(entityManagerFactory);return writer;}@Beanpublic Step importReconStep() {DtpExecutor executor = DtpRegistry.getExecutor("batchImportPool");return stepBuilderFactory.get("importReconStep").<Reconciliation, Reconciliation>chunk(1000) // 小批量提交.reader(reader()).processor(processor()).writer(writer()).taskExecutor(executor).throttleLimit(4) // 限制并发.build();}@Beanpublic Job importReconJob() {return jobBuilderFactory.get("importReconJob").start(importReconStep()).build();} } -
控制器(
ReconController.java):package com.example.demo.controller;import com.example.demo.service.ReconciliationService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RestController;@RestController public class ReconController {@Autowiredprivate ReconciliationService reconciliationService;@PostMapping("/import")public String startImport() {reconciliationService.startImportJob();return "Batch import started";} } -
AOP 切面(
BatchMonitoringAspect.java):package com.example.demo.aspect;import org.aspectj.lang.annotation.*; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Component;@Aspect @Component public class BatchMonitoringAspect {private static final Logger logger = LoggerFactory.getLogger(BatchMonitoringAspect.class);@Pointcut("execution(* com.example.demo.service.ReconciliationService.*(..))")public void serviceMethods() {}@Before("serviceMethods()")public void logMethodEntry() {logger.info("Entering batch service method");}@AfterThrowing(pointcut = "serviceMethods()", throwing = "ex")public void logException(Exception ex) {logger.error("Batch error: {}", ex.getMessage());} } -
死锁重试机制(已集成在
ReconciliationService)。 -
运行并验证:
- 启动 MySQL 和 ActiveMQ。
- 启动应用:
mvn spring-boot:run。 - 触发导入:
curl -X POST http://localhost:8081/import- 确认数据分片存储到
recon_db_0.reconciliation_0,recon_db_0.reconciliation_1, 等。 - 检查 ActiveMQ 日志。
- 访问
/actuator/threadpool监控线程池状态。
- 确认数据分片存储到
- 检查 MySQL 死锁日志:
SHOW ENGINE INNODB STATUS;
2.2.2 原理
- 分库分表:ShardingSphere 按 ID 哈希分片,分散锁竞争。
- 小批量事务:Spring Batch 每 1000 条提交一次,减少锁时间。
- 动态线程池:Dynamic TP 限制并发(4 个线程),避免过多事务。
- 死lock 重试:检测死锁(MySQL 错误码 1213),自动重试。
- AOP:记录性能和异常,便于定位。
2.2.3 优点
- 显著降低死锁概率。
- 高性能导入(100 万数据约 5-10 分钟)。
- 动态调整线程池,优化资源。
2.2.4 缺点
- 配置复杂,需熟悉 Spring Batch 和 ShardingSphere。
- 重试机制可能增加延迟。
- 分片查询需优化。
2.2.5 适用场景
- 大数据量批量导入。
- 高并发对账系统。
- 分布式数据库优化。
2.3 集成先前查询
结合分页、Swagger、ActiveMQ、Spring Profiles、Spring Security、FreeMarker、热加载、ThreadLocal、Actuator 安全性、CSRF、WebSockets、异常处理、Web 标准、AOP、动态线程池、分库分表。
2.3.1 配置步骤
-
分页与排序:
- 添加分页查询:
@Service public class ReconciliationService {@Autowiredprivate ReconciliationRepository reconciliationRepository;public Page<Reconciliation> searchRecon(String accountId, int page, int size, String sortBy, String direction) {try {CONTEXT.set("Query-" + Thread.currentThread().getName());Sort sort = Sort.by(Sort.Direction.fromString(direction), sortBy);PageRequest pageable = PageRequest.of(page, size, sort);return reconciliationRepository.findAll(pageable); // 简化示例} finally {CONTEXT.remove();}} }
- 添加分页查询:
-
Swagger:
- 添加 Swagger 文档:
@RestController @Tag(name = "对账管理", description = "对账数据导入和查询") public class ReconController {@Operation(summary = "触发批量导入")@PostMapping("/import")public String startImport() {reconciliationService.startImportJob();return "Batch import started";}@Operation(summary = "分页查询对账数据")@GetMapping("/reconciliations")public Page<Reconciliation> searchRecon(@RequestParam(defaultValue = "") String accountId,@RequestParam(defaultValue = "0") int page,@RequestParam(defaultValue = "10") int size,@RequestParam(defaultValue = "id") String sortBy,@RequestParam(defaultValue = "asc") String direction) {return reconciliationService.searchRecon(accountId, page, size, sortBy, direction);} }
- 添加 Swagger 文档:
-
ActiveMQ:
- 已记录导入日志。
-
Spring Profiles:
- 配置
application-dev.yml和application-prod.yml:# application-dev.yml spring:shardingsphere:props:sql-show: truedynamic-tp:executors:- thread-pool-name: batchImportPoolcore-pool-size: 4max-pool-size: 8queue-capacity: 1000 logging:level:root: DEBUG# application-prod.yml spring:shardingsphere:props:sql-show: falsedynamic-tp:executors:- thread-pool-name: batchImportPoolcore-pool-size: 8max-pool-size: 16queue-capacity: 2000 logging:level:root: INFO
- 配置
-
Spring Security:
- 保护 API:
@Configuration public class SecurityConfig {@Beanpublic SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {http.authorizeHttpRequests(auth -> auth.requestMatchers("/import", "/reconciliations").authenticated().requestMatchers("/actuator/health").permitAll().requestMatchers("/actuator/**").hasRole("ADMIN").anyRequest().permitAll()).httpBasic().and().csrf().ignoringRequestMatchers("/ws");return http.build();}@Beanpublic UserDetailsService userDetailsService() {var user = User.withDefaultPasswordEncoder().username("admin").password("admin").roles("ADMIN").build();return new InMemoryUserDetailsManager(user);} }
- 保护 API:
-
FreeMarker:
- 对账管理页面:
@Controller public class WebController {@Autowiredprivate ReconciliationService reconciliationService;@GetMapping("/web/reconciliations")public String getReconciliations(@RequestParam(defaultValue = "") String accountId,@RequestParam(defaultValue = "0") int page,@RequestParam(defaultValue = "10") int size,Model model) {Page<Reconciliation> reconPage = reconciliationService.searchRecon(accountId, page, size, "id", "asc");model.addAttribute("reconciliations", reconPage.getContent());return "reconciliations";} }<!-- src/main/resources/templates/reconciliations.ftl --> <!DOCTYPE html> <html lang="zh-CN"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>对账管理</title> </head> <body><h1>对账数据</h1><table><tr><th>ID</th><th>账户ID</th><th>金额</th><th>日期</th></tr><#list reconciliations as recon><tr><td>${recon.id}</td><td>${recon.accountId?html}</td><td>${recon.amount}</td><td>${recon.reconDate}</td></tr></#list></table> </body> </html>
- 对账管理页面:
-
热加载:
- 已启用 DevTools。
-
ThreadLocal:
- 已清理 ThreadLocal(见
ReconciliationService)。
- 已清理 ThreadLocal(见
-
Actuator 安全性:
- 已限制
/actuator/**。
- 已限制
-
CSRF:
- WebSocket 端点禁用 CSRF。
-
WebSockets:
- 实时推送导入状态:
@Controller public class WebSocketController {@Autowiredprivate SimpMessagingTemplate messagingTemplate;@MessageMapping("/import-status")public void sendImportStatus() {messagingTemplate.convertAndSend("/topic/import", "Batch import running");} }
- 实时推送导入状态:
-
异常处理:
- 处理死锁异常(已集成重试机制)。
-
Web 标准:
- FreeMarker 模板遵循语义化 HTML。
-
动态线程池:
- 已使用 Dynamic TP 优化并发。
-
分库分表:
- 已集成 ShardingSphere。
-
运行并验证:
- 开发环境:
java -jar demo.jar --spring.profiles.active=dev- 触发导入,验证无死锁。
- 检查分片表数据分布。
- 监控
/actuator/threadpool和 WebSocket 推送。
- 生产环境:
java -jar demo.jar --spring.profiles.active=prod- 确认安全性、线程池配置。
- 开发环境:
2.3.2 原理
- 分页:ShardingSphere 聚合跨库结果。
- Swagger:文档化导入 API。
- ActiveMQ:异步记录日志。
- Profiles:控制线程池和日志级别。
- Security:保护导入操作。
- Batch:小批量事务降低死锁。
- FreeMarker:渲染查询结果。
- WebSockets:推送导入状态。
2.3.3 优点
- 高效导入,消除死锁。
- 集成 Spring Boot 生态。
- 动态优化性能。
2.3.4 缺点
- 配置复杂,需多组件协调。
- 跨库查询需优化。
- 重试增加少量延迟。
2.3.5 适用场景
- 高并发批处理。
- 大数据量对账。
- 分布式系统优化。
三、性能与适用性分析
3.1 性能影响
- 批量导入:100 万数据约 5-10 分钟(4 线程,1000 条/chunk)。
- 死锁重试:每次重试增加 100-300ms。
- 查询:50ms(1000 条,跨库)。
- WebSocket 推送:2ms/消息。
3.2 性能测试
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class BatchImportTest {@Autowiredprivate TestRestTemplate restTemplate;@Testpublic void testImportPerformance() {long startTime = System.currentTimeMillis();restTemplate.postForEntity("/import", null, String.class);long duration = System.currentTimeMillis() - startTime;System.out.println("Batch import: " + duration + " ms");}
}
测试结果(Java 17,8 核 CPU,16GB 内存):
- 导入:约 300,000ms(100 万数据)。
- 重试:0-3 次/导入。
- 查询:50ms。
结论:优化后死锁显著减少,性能稳定。
3.3 适用性对比
| 方法 | 死锁概率 | 性能 | 适用场景 |
|---|---|---|---|
| 单事务导入 | 高 | 低 | 小数据量 |
| 分批+分库分表 | 低 | 高 | 大数据量、高并发 |
| 云数据库 | 低 | 高 | 云原生应用 |
四、常见问题与解决方案
-
问题1:死锁仍发生
- 场景:高并发下死锁频繁。
- 解决方案:
- 进一步降低 chunk 大小(如 500)。
- 减少线程数(如 2)。
-
问题2:导入性能慢
- 场景:100 万数据耗时过长。
- 解决方案:
- 增加分片库/表数量。
- 优化索引,移除冗余。
-
问题3:ThreadLocal 泄漏
- 场景:
/actuator/threaddump显示泄漏。 - 解决方案:
- 确认 ThreadLocal 清理。
- 场景:
-
问题4:跨库查询慢
- 场景:分页查询性能低。
- 解决方案:
- 添加缓存(如 Redis)。
- 优化分片键。
五、总结
通过分库分表(ShardingSphere)、小批量事务(Spring Batch)、动态线程池(Dynamic TP)和死锁重试机制,显著降低了批量导入 100 万对账数据的死锁问题。示例集成分页、Swagger、ActiveMQ、Profiles、Security、FreeMarker、WebSockets、AOP 等,性能稳定(5-10 分钟导入)。针对您的查询(ThreadLocal、Actuator、热加载、CSRF),通过清理、Security 和 DevTools 解决。
相关文章:

每天批次导入 100 万对账数据到 MySQL 时出现死锁
一、死锁原因及优化策略 1.1 死锁原因分析 批量插入事务过大: Spring Batch 默认将整个 chunk(批量数据块)作为一个事务提交,100 万数据可能导致事务过长,增加锁竞争。 并发写入冲突: 多个线程或批处理作…...
【人工智能学习之动作识别TSM训练与部署】
【人工智能学习之动作识别TSM训练与部署】 基于MMAction2动作识别项目的开发一、MMAction2的安装二、数据集制作三、模型训练1. 配置文件准备2. 关键参数修改3. 启动训练4. 启动成功 ONNX模型部署方案一、环境准备二、执行转换命令 基于MMAction2动作识别项目的开发 一、MMAct…...

ES6/ES11知识点 续五
迭代器【Iterator】 ES6 中的**迭代器(Iterator)**是 JavaScript 的一种协议,它定义了对象如何被逐个访问。迭代器与 for…of、扩展运算符、解构赋值等语法密切相关。 📘 迭代器工作原理 ES6 迭代器的工作原理基于两个核心机制…...
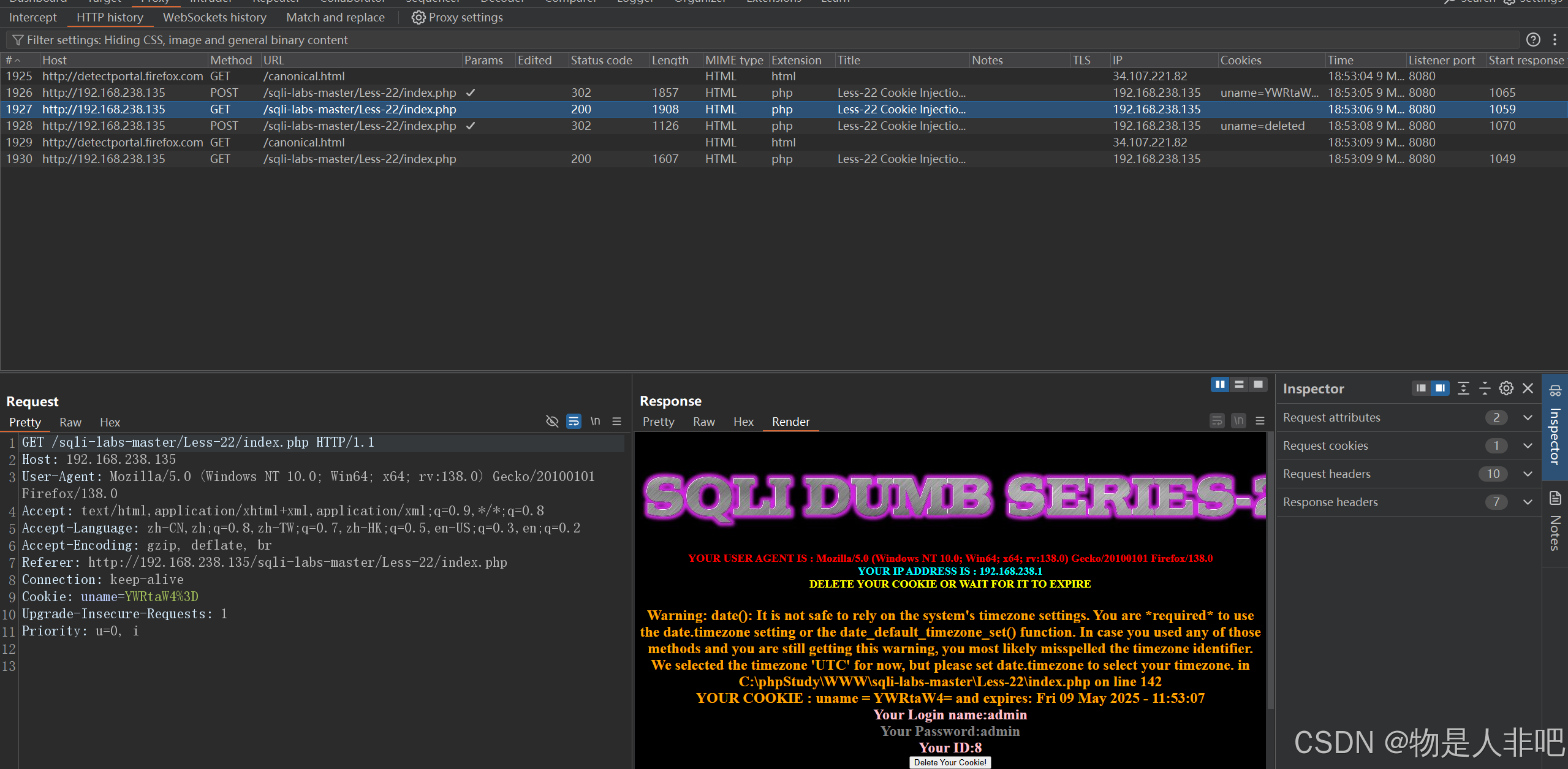
sqli-labs靶场18-22关(http头)
目录 less18(user-agent) less19(referer) less20(cookie) less21(cookie) less22(cookie) less18(user-agent) 这里尝试了多次…...

redhat9 安装pywinrm
看了很多文档,都是有很多限制,还是老老实实用pip 安装: Step1: 安装pip: [rootip-abc ~]# python get-pip.py Collecting pip Downloading pip-25.1.1-py3-none-any.whl.metadata (3.6 kB) Collecting wheel Downloading wheel-0.45.1-py…...
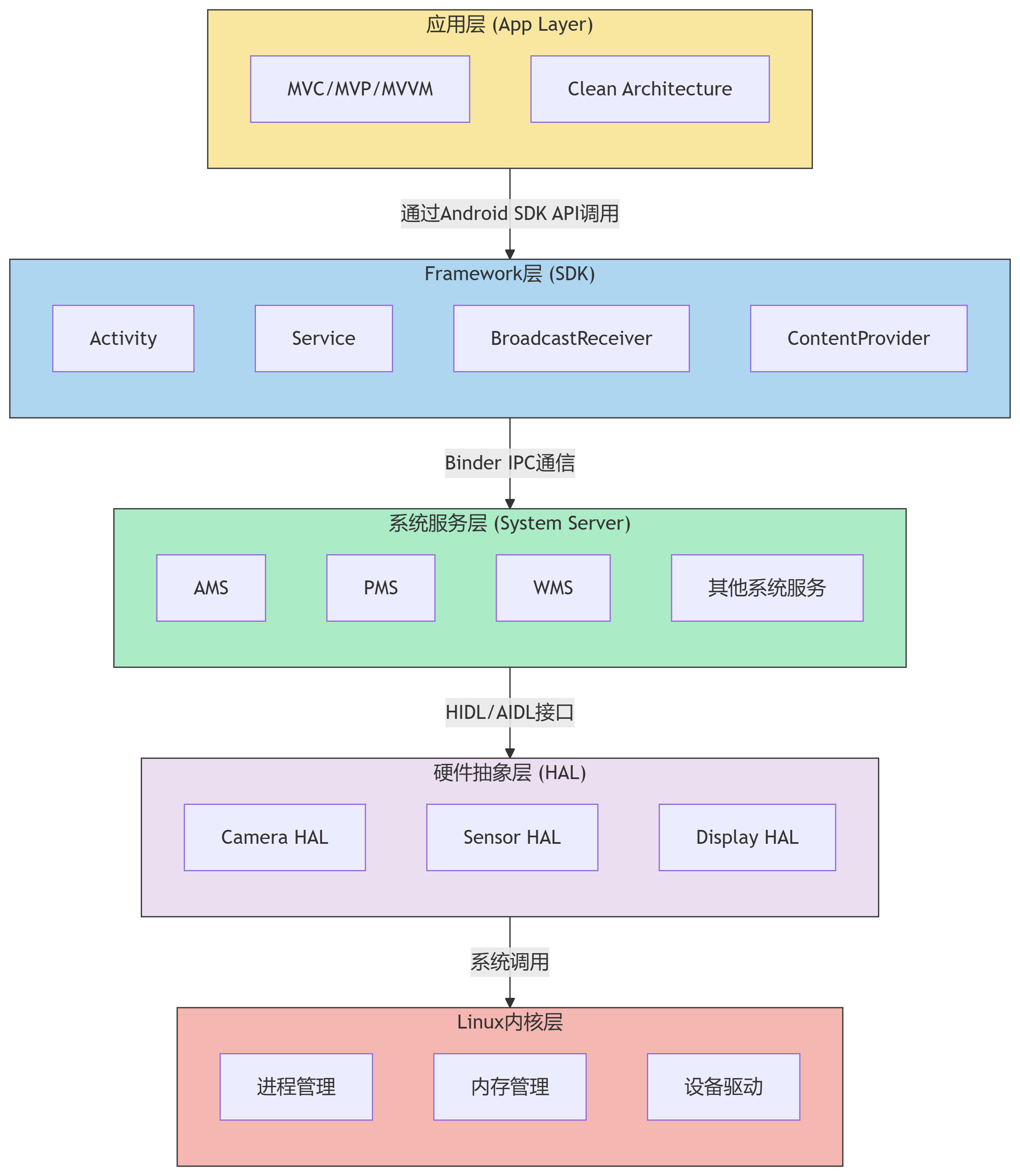
Android系统架构模式分析
本文系统梳理Android系统架构模式的演进路径与设计哲学,希望能够借此探索未来系统的发展方向。有想法的同学可以留言讨论。 1 Android层次化架构体系 1.1 整体分层架构 Android系统采用五层垂直架构,各层之间通过严格接口定义实现解耦: 应用…...
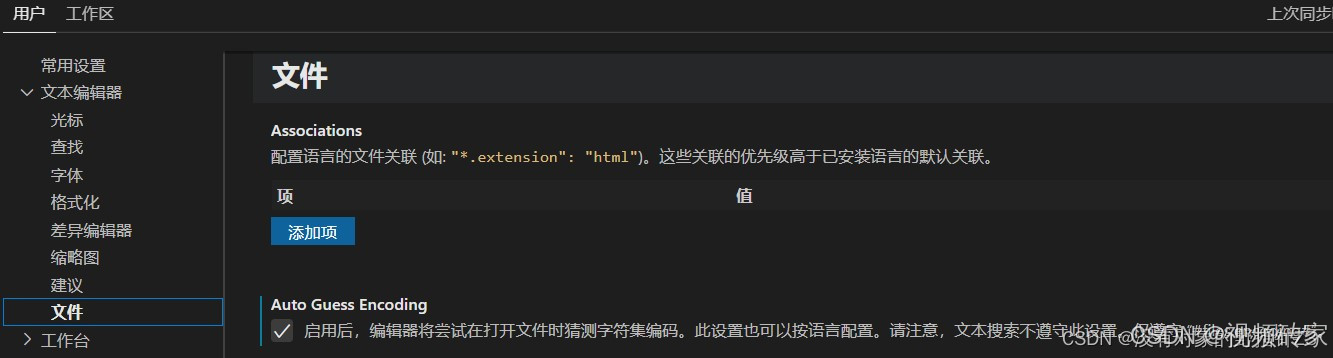
Web前端VSCode如何解决打开html页面中文乱码的问题(方法2)
Web前端—VSCode如何解决打开html页面中文乱码的问题(方法2) 1.打开VScode后,依次点击 文件 >> 首选项 >> 设置 2.打开设置后,依次点击 文本编辑器 >> 文件(或在搜索框直接搜索“files.autoGuessEnc…...

【NextPilot日志移植】logged_topics.cpp解析
📘 PX4 Logger 模块注册 uORB 主题、实际订阅与数据采集流程 🧭 目的与背景 在 PX4 飞控中,日志记录模块 logger 需要记录多个 uORB 主题的数据(如 IMU、GPS、姿态等)。为了系统统一管理这些记录需求,log…...
单调栈模版型题目(3)
单调栈型题目贡献法 基本模版 这是数组a中的 首先我们要明白什么叫做贡献,在一个数组b{1,3,5}中,连续包含1的连续子数组为{1},{1,3},{1,3,5},一共有三个,这三个数一共能组成6个连续子数组,而其…...

ts axios中报 Property ‘code‘ does not exist on type ‘AxiosResponse<any, any>‘
ts语法有严格的格式,如果我们在处理响应数据时,出现了axios响应中非默认字段,就会出现标题那样的警告,我们可以通过创建axios.dt.ts解决这个问题 下面是我在开发中遇到的警告,code并不是axios默认返回的字段࿰…...

[AI Tools] Dify 工具插件上传指南:如何将插件发布到官方市场
Dify 作为开源的 LLM 应用开发平台,不仅支持本地化插件开发,也提供了插件市场机制,让开发者能够将自己构建的插件发布并供他人使用。本文将详细介绍如何将你开发的 Dify Tools 插件上传至官方插件市场,包括 README 编写、插件打包、仓库 PR 等核心步骤。 一、准备 README 文…...
用react实现一个简单的三页应用
下面是一个使用 React Router 的简单示例,演示了如何在 React 应用中实现页面之间的导航。 🛠️ 第一步:使用 Vite 创建项目 npm create vitelatest my-router-app -- --template react cd my-router-app npm install🚀 第二步&a…...

Java Spring Boot 全面学习指南
一、基础知识 Spring Boot 简介 核心优势:简化 Spring 应用初始搭建和开发(约定大于配置)。核心功能:自动配置(Auto-Configuration)、起步依赖(Starter Dependencies)、嵌入式服务器(Tomcat/Jetty)。对比 Spring MVC:无需繁琐的 XML 配置,内置健康检查、指标监控等…...

Redhat 系统详解
Red Hat 系统深度解析:从企业级架构到核心组件 一、Red Hat 概述:企业级 Linux 的标杆 Red Hat 是全球领先的开源解决方案供应商,其核心产品 Red Hat Enterprise Linux(RHEL) 是企业级 Linux 的黄金标准。RHEL 以 稳…...
)
Missashe高数强化学习笔记(随时更新)
Missashe高数强化学习笔记 说明:这篇笔记用于博主对高数强化课所学进行记录和总结。由于部分内容写在博主的日记博客里,所以博主会不定期将其重新copy到本篇笔记里。 第一章 函数极限连续 第二章 一元函数微分学 第三章 一元函数积分学 第一节 不定…...

【笔记】当个自由的书籍收集者从canvas得到png转pdf
最近有点迷各种古书,然后从 www.shuge.org 下载了各种高清的印本,快成db狂魔了…上面也有人在各种平台上分享,不胜感激…只是有些平台可以免费看但是没法下载… 反正你都canvas了,撸下来自己珍藏… 于是让qwen写了一段代码&#…...
Go使用Gin写一个对MySQL的增删改查服务
首先用SQL创建一个包含id、name属性的users表 create table users (id int auto_incrementprimary key,name varchar(255) null );查询所有用户信息: func queryData(db *sql.DB, w http.ResponseWriter) {rows, err : db.Query("SELECT * FROM users"…...

k8s之statefulset
什么是statefulset(sts) statefulset是用来管理有状态应用的工作负载API对象,也是一种工作负载资源 有状态和无状态 无状态应用:当前应用不会记录状态(网络可能会变、挂载的东西可能会变、顺序可能会变) 有状态应用:需要记录当前状态(网络不变、存储不变、顺序不变) 使…...

2025最新:3分钟使用Docker快速部署Redis集群
📋 完整步骤:部署 Redis 集群 ✅ 步骤 1:安装 Docker 和 Docker Compose 首先,确保你的 Ubuntu 系统已经安装了 Docker 和 Docker Compose。如果没有安装,执行以下命令: # 更新系统 sudo apt update# 安…...

Xcode16.3配置越狱开发环境
首先先在https://developer.apple.com/xcode/resources/ 这里面登陆Apple账号,然后访问url下载 https://download.developer.apple.com/Developer_Tools/Xcode_16.3/Xcode_16.3.xip 1、安装theos https://theos.dev/docs/installation-macos 会安装到默认位置~/th…...
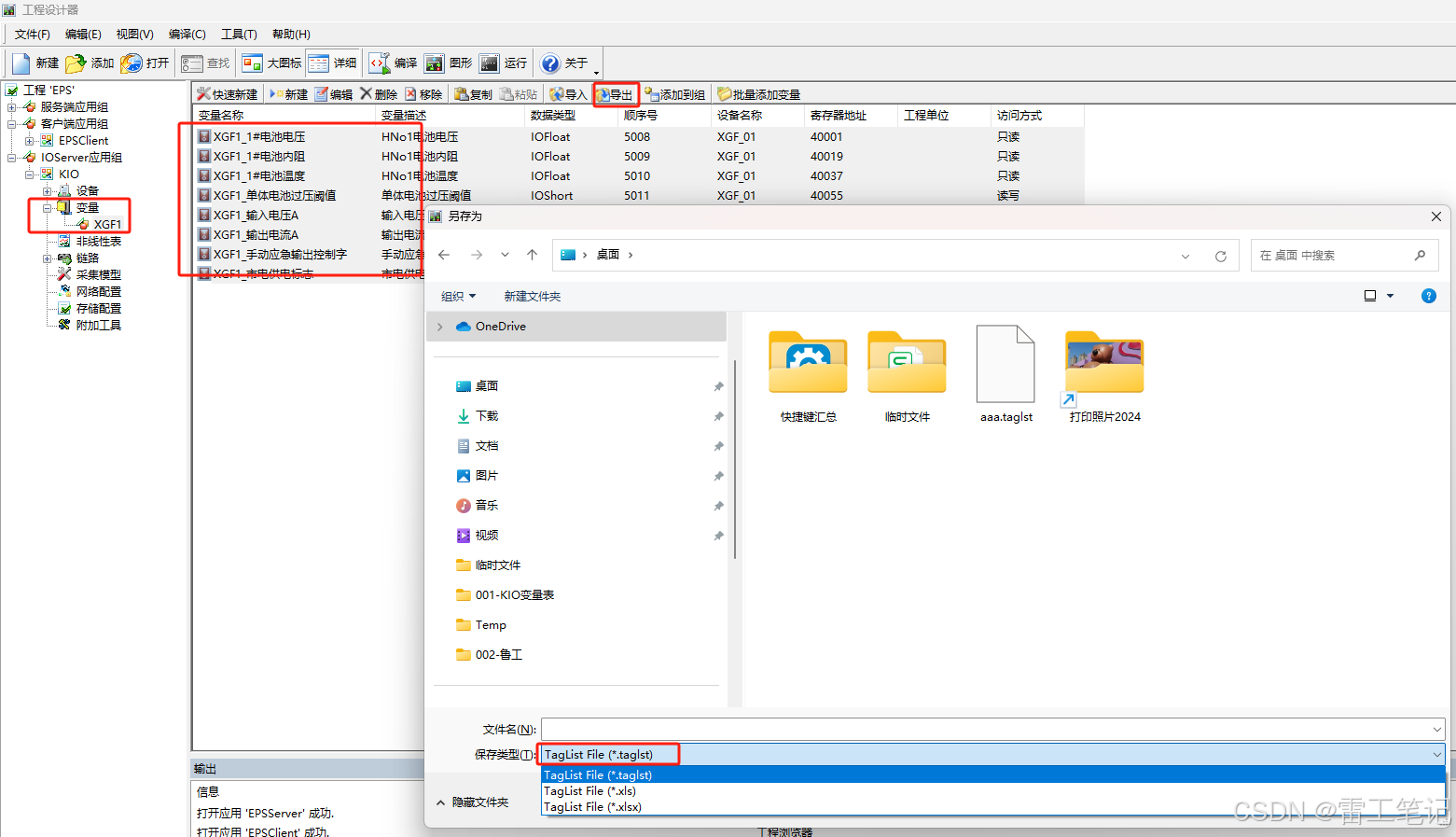
SCADA|KIO程序导出变量错误处理办法
哈喽,你好啊,我是雷工! 最近在用KingSCADA3.52版本的软件做程序时,在导出变量进行批量操作时遇到问题,现将解决办法记录如下。 以下为解决过程。 01 问题描述 在导出KIO变量时,选择*.xls格式和*.xlsx时均会报错: 报如下错误: Unknown error 0x800A0E7A ADODB Connectio…...
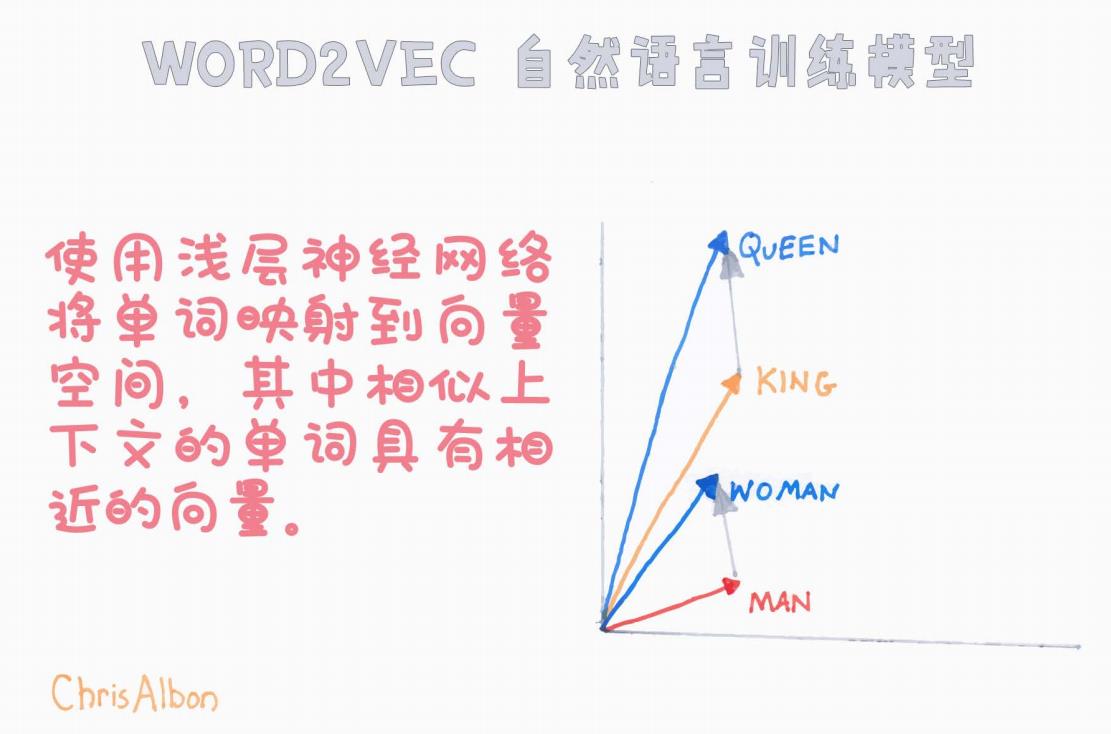
【漫话机器学习系列】249.Word2Vec自然语言训练模型
【自然语言处理】用 Word2Vec 将词语映射到向量空间详解 一、背景介绍 在自然语言处理(NLP)领域,我们常常需要将文本信息转化为机器能够理解和处理的形式。传统的方法,如 one-hot编码,虽然简单,但存在严重…...
云轴科技ZStack入选赛迪顾问2025AI Infra平台市场发展报告代表厂商
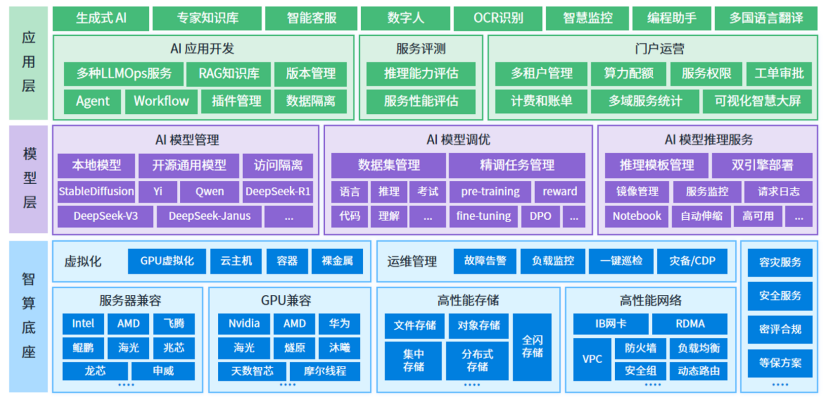
DeepSeek凭借低成本、高性能、开源优势带来的蝴蝶效应依然在持续影响企业AI应用部署。尤其在数据安全备受关注的背景下,私有化部署已经成为企业应用AI大模型的优选方案。赛迪顾问在近期发布的《2025中国AI Infra平台市场发展研究报告》中认为,在推理算力…...
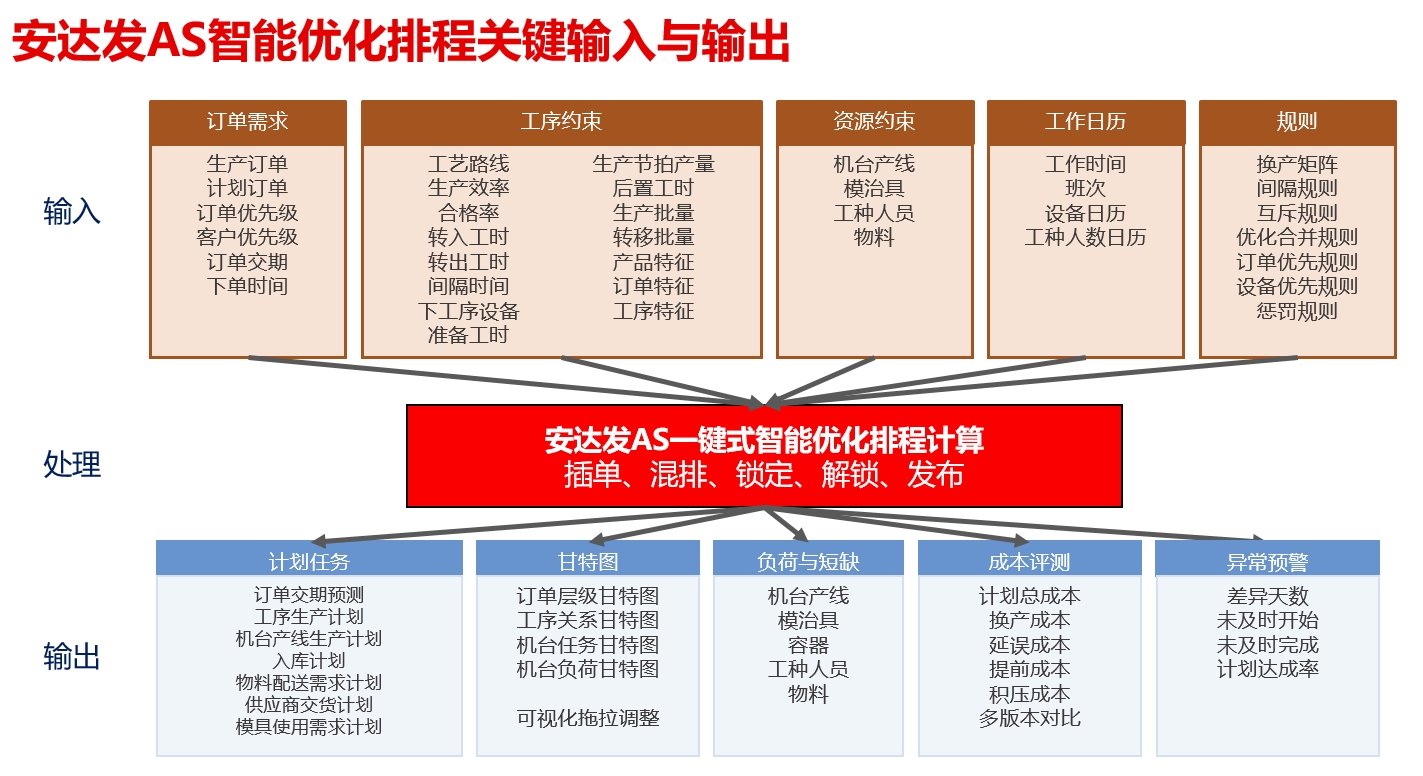
安达发|人力、机器、物料——APS排程软件如何实现资源最优配置?
引言:制造业资源优化的核心挑战 在现代制造业中,人力、机器、物料是生产运营的三大核心资源。如何让这些资源高效协同,避免浪费,是企业降本增效的关键。然而,许多制造企业仍面临以下问题: 人力安排不合理…...
【软件测试】软件缺陷(Bug)的详细描述
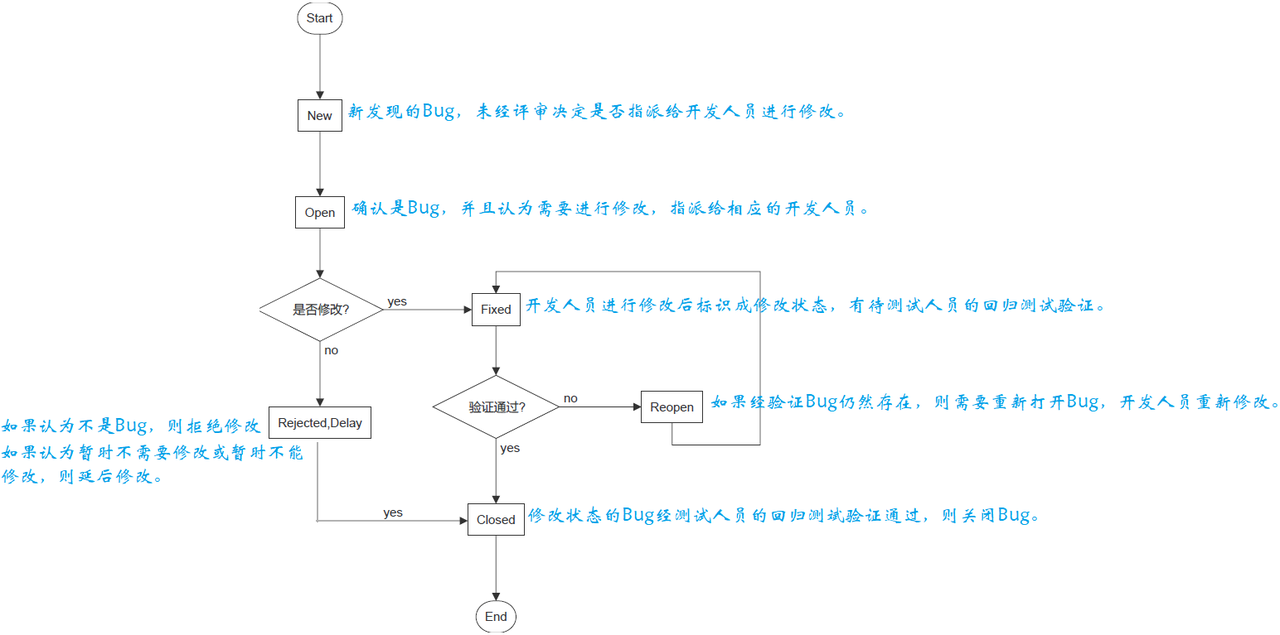
目录 一、软件缺陷(Bug) 1.1 缺陷的判定标准 1.2 缺陷的生命周期 1.3 软件缺陷的描述 1.3.1 提交缺陷的要素 1.3.2 Bug 的级别 1.4 如何发现更多的 Bug? 1.5 缺陷的有效管理 1.5.1 缺陷的编写 1.5.2 缺陷管理工具 1.5.2.1 缺陷管理 1.5.2.2 用例管理 一、软件缺陷…...

HTTP传输大文件的方法、连接管理以及重定向
目录 1. HTTP传输大文件的方法 1.1. 数据压缩 1.2. 分块传输 1.3. 范围请求 1.4. 多段数据 2. HTTP的连接管理 2.1. 短连接 2.2. 长连接 2.3. 队头阻塞 3. HTTP的重定向和跳转 3.1. 重定向的过程 3.2. 重定向状态码 3.3. 重定向的应用场景 3.4. 重定向的相关问题…...

图像来源:基于协同推理的双视角超声造影分类隐式数据增强方法|文献速递-深度学习医疗AI最新文献
Title 题目 Image by co-reasoning: A collaborative reasoning-based implicit data augmentation method for dual-view CEUS classification 图像来源:基于协同推理的双视角超声造影分类隐式数据增强方法 01 文献速递介绍 结合了B型超声(BUS&…...
 - 条件语句、循环、循环控制)
Python 基础语法与数据类型(六) - 条件语句、循环、循环控制
文章目录 1. 条件语句 (if, elif, else)1.1 if 语句1.2 if...else 语句1.3 if...elif...else 语句1.4 条件表达式的“真值”1.5 嵌套条件语句 2. 循环 (Loops)2.1 for 循环2.2 range() 函数2.3 while 循环 3. 循环控制 (break, continue)3.1 break 语句3.2 continue 语句 4. 循…...

使用 CDN 在国内加载本地 PDF 文件并处理批注:PDF.js 5.x 实战指南
PDF.js 是一个强大的开源 JavaScript 库,用于在 Web 浏览器中渲染 PDF 文件。它由 Mozilla 开发,能够将 PDF 文档绘制到 HTML5 Canvas 或 SVG 上,无需任何本机代码或浏览器插件。对于许多需要在网页中展示 PDF 内容的应用场景来说,…...

一些模型测试中的BUG和可能解决方法
一些模型测试中的BUG和可能解决方法 模型一直重复反馈相同内容的问题查找思路 如下顺序也是排查优先级 检查提示词和上下文,保证提示词中没有类似的要求,然后再查看上下文是不是占满了token长度。检查一下选择的model是不是本身就有这样的问题尝试增加repeat_penalty(1.05、…...