当当网Top500书籍信息爬取与分析
爬取当当网的Top500书籍信息,并对书籍的评价数量进行排序,然后绘制前十名的条形图,然后对各个出版社出版的书籍数量进行排序,绘制百分比的饼图
# 导入所需的模块
import re # 正则表达式模块,用于提取文本中的特定模式
from time import sleep # 用于在循环中添加延迟,避免请求过于频繁
import csv # 用于读写CSV文件
import requests # 用于发送HTTP请求,获取网页内容
import pandas as pd # 用于数据处理和分析
import matplotlib.pyplot as plt # 用于绘制图表
import numpy as np # 用于数值计算# 设置请求头,模拟浏览器访问,避免被网站识别为爬虫
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}# 定义函数,从网页获取特定页面的内容,并以列表形式返回
def getInfo(page):page = str(page) # 将页码转换为字符串# 构造目标网页的URL,这里使用了一个无效的网页地址,需要替换成有效的当当网图书排行榜页面URLurl = '<url id="d0f0ofd96bk4h4b9797g" type="url" status="parsed" title="对不起,您要访问的页面暂时没有找到。" wc="658">http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-</url> ' + page# 发送GET请求,获取网页内容response = requests.get(url=url, headers=headers).text# 使用正则表达式提取网页中的<li>标签内容ex = '(?<=<li>\\s)[\\w\\W]*?(?=</li>)'p = re.findall(ex, response) # 在网页内容中查找所有匹配的模式del p[0:3] # 删除前三个无用的元素(假设前三个元素不是书籍信息)return p # 返回提取到的书籍信息列表# 定义函数,从字符串中提取书籍的序号
def getIndex(str):ex = 'list_num.*?>(.*?)<' # 匹配序号的正则表达式p = re.findall(ex, str)return p[0] # 返回提取到的序号# 定义函数,从字符串中提取书籍的名称
def getName(str):ex = 'title="(.*?)"\\/' # 匹配书名的正则表达式p = re.findall(ex, str)return p[0] # 返回提取到的书名# 定义函数,从字符串中提取书籍的评论数量
def getCommentCount(str):ex = '_blank">([\d]+.*?)<' # 匹配评论数量的正则表达式p = re.findall(ex, str)return p[0] # 返回提取到的评论数量# 定义函数,从字符串中提取书籍的作者
def getWriter(str):ex = 'title="(.*?)"' # 匹配作者的正则表达式p = re.findall(ex, str)try:return p[2] # 尝试返回第三个匹配结果(假设作者信息是第三个匹配项)except:return "暂未找到" # 如果匹配失败,返回默认值# 定义函数,从字符串中提取书籍的出版时间
def getTime(str):ex = '<span>(.*?)<' # 匹配出版时间的正则表达式p = re.findall(ex, str)return p[0] # 返回提取到的出版时间# 定义函数,从字符串中提取书籍的出版社
def getPub(str):ex = 'key=(.*?)"' # 匹配出版社的正则表达式p = re.findall(ex, str)return p[-1] # 返回最后一个匹配结果(假设出版社信息是最后一个匹配项)# 定义函数,从字符串中提取书籍的原价
def getPriceFir(str):ex = 'price_r">.*?;(.*)<' # 匹配原价的正则表达式p = re.findall(ex, str)return p[0] # 返回提取到的原价# 定义函数,从字符串中提取书籍的促销价格
def getPriceNow(str):ex = 'price_n">.*?;(.*)<' # 匹配促销价的正则表达式p = re.findall(ex, str)return p[0] # 返回提取到的促销价# 定义主函数,用于爬取多页数据并保存到CSV文件
def main():for page in range(1, 26): # 循环遍历1到25页book_list = getInfo(page) # 获取当前页的书籍列表with open('book.csv', 'a', encoding='UTF-8', newline='') as f: # 打开或创建CSV文件,追加模式writer = csv.writer(f) # 创建CSV写入对象# 如果文件是新建的(指针位置为0),则写入表头if f.tell() == 0:writer.writerow(["序号", "书名", "作者", "出版时间", "出版社", "原价", "促销价","评价量"])for info in book_list: # 遍历每本书的信息index = getIndex(info) # 提取序号name = getName(info) # 提取书名priceFir = getPriceFir(info) # 提取原价priceNow = getPriceNow(info) # 提取促销价try:# 提取评论数量,并移除"条评论"字样commentCount = getCommentCount(info).replace("条评论", "")except Exception as e:commentCount = 0 # 如果提取失败,设置默认值为0writer_name = getWriter(info) # 提取作者pub_time = getTime(info) # 提取出版时间pub = getPub(info) # 提取出版社# 将提取到的信息写入CSV文件writer.writerow([index, name, writer_name, pub_time, pub, priceFir, priceNow, commentCount])sleep(0.5) # 每次请求后暂停0.5秒,避免请求过于频繁# 执行主函数,开始爬取数据
main()# 读取保存的CSV文件,准备数据分析和可视化
df = pd.read_csv('book.csv', encoding='utf-8')# 按评价数量降序排序,并取前十名书籍
top_books = df.sort_values(by='评价量', ascending=False).head(10)# 处理书名,使其每20个字符换一行,便于在图表中显示
top_books['书名'] = top_books['书名'].apply(lambda x: '\n'.join([x[i:i+20] for i in range(0, len(x), 20)]))# 设置字体,确保正确显示中文和负号
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False# 创建一个新的图形,设置大小为12x8英寸
plt.figure(figsize=(12, 8))# 绘制评价数量前十名的书籍的水平条形图
bars = plt.barh(top_books['书名'], top_books['评价量'], color='skyblue')# 为每个条形添加数据标签
for bar in bars:width = bar.get_width()plt.text(width - 210000, bar.get_y() + bar.get_height()/2, f'{int(width):,}', va='center')# 再次绘制条形图以确保标签正确显示
plt.barh(top_books['书名'], top_books['评价量'], color='skyblue')# 添加坐标轴标签和图表标题
plt.xlabel('评价数量')
plt.title('评价数量前十名的书籍')# 反转Y轴,使评价最多的书籍显示在顶部
plt.gca().invert_yaxis()# 调整布局,确保所有元素都能正确显示
plt.tight_layout()# 显示图表
plt.show()# 统计各出版社出版的书籍数量
publisher_counts = df['出版社'].value_counts()# 将数量小于等于2的出版社和空白出版社归类为“其他”
threshold = 3
other = publisher_counts[publisher_counts <= threshold].sum() + publisher_counts.get('', 0)
publisher_counts = publisher_counts[publisher_counts > threshold]
publisher_counts = publisher_counts.drop('', errors='ignore') # 删除空白出版社
publisher_counts['其他'] = other # 添加“其他”类别# 绘制出版社百分比饼图
plt.figure(figsize=(10, 10))
patches, texts, autotexts = plt.pie(publisher_counts, autopct='%1.1f%%', startangle=140)# 添加图例
plt.legend(patches, publisher_counts.index, loc='lower center', bbox_to_anchor=(0.5, -0.2), ncol=5)# 添加图表标题
plt.title('各出版社出版书籍数量百分比')# 调整布局并显示图表
plt.tight_layout()
plt.show()
相关文章:

当当网Top500书籍信息爬取与分析
爬取当当网的Top500书籍信息,并对书籍的评价数量进行排序,然后绘制前十名的条形图,然后对各个出版社出版的书籍数量进行排序,绘制百分比的饼图 # 导入所需的模块 import re # 正则表达式模块,用于提取文本中的特定模…...

Android Framework 记录之二
23、services目录 文件描述class AlarmManagerService extends IAlarmManager.Stub {//定时管理服务public class AppOpsService extends IAppOpsService.Stub { // 程序选项服务public class AppsLaunchFailureReceiver extends BroadcastReceiver { //app启动失败广播class A…...

RabbitMQ 幂等性与消息可靠性保障
一、引言 RabbitMQ 是一个广泛应用于软件开发、数据传输、微服务等领域的高效、可靠的开源消息队列系统1。在分布式系统中,保证消息的可靠传递和幂等性是至关重要的,它能够确保系统在各种复杂情况下的稳定性和数据的准确性。 二、消息可靠性保障 &…...

neo4j图数据库基本概念和向量使用
一.节点 1.新建节点 create (n:GroupProduct {name:都邦高保额团意险,description: "保险产品名称"} ) return n CREATE:Neo4j 的关键字,用于创建新节点或关系。 (n:GroupProduct): n 是节点的临时别名(变量名&#…...

修复笔记:获取 torch._dynamo 的详细日志信息
一、问题描述 在运行项目时,遇到与 torch._dynamo 相关的报错,并且希望获取更详细的日志信息以便于进一步诊断问题。 二、相关环境变量设置 通过设置环境变量,可以获得更详细的日志信息: set TORCH_LOGSdynamo set TORCHDYNAM…...

Windows平台下的Qt发布版程序打包成exe可执行文件(带图标)|Qt|C++
首先先找一个可执行文件的图标 可以去阿里的矢量图库里找 iconfont-阿里巴巴矢量图标库 找到想要的图标下载下来 此时的图标是png格式的,我们要转到icon格式的文件 要使用到一个工具Drop Icons_2.1.1.rar - 蓝奏云 生成icon文件后把icon文件放到你项目的根目录下…...

PDF解析新范式:Free2AI工具实测
在数字化浪潮中,PDF文件已成为企业、政府及个人存储与传递信息的核心载体。然而,PDF内容的提取与处理始终是行业痛点——无论是合同解析、研究报告整理,还是大规模知识库构建,传统方法常面临效率低、成本高、准确率不足等问题。Free2AI基于智能体技术与大模型算力,为PDF内…...

CSS--图片链接垂直居中展示的方法
原文网址:CSS--图片链接垂直居中展示的方法-CSDN博客 简介 本文介绍CSS图片链接垂直居中展示的方法。 图片链接 问题复现 源码 <html xml:lang"cn" lang"cn"><head><meta http-equiv"Content-Type" content&quo…...

聊聊Spring AI autoconfigure模块的拆分
序 本文主要研究一下Spring AI autoconfigure模块的拆分 v1.0.0-M6版本 (base) ➜ spring-ai-spring-boot-autoconfigure git:(v1.0.0-M6) tree -L 9 . ├── pom.xml ├── src │ ├── main │ │ ├── java │ │ │ └── org │ │ │ └…...

【Elastsearch】如何获取已创建的api keys
『这种方法其实无法获取秘钥,只是获取了秘钥的名字等信息』 在Elasticsearch中,可以通过API获取已创建的API密钥(API keys)。以下是具体步骤和示例: 1.使用GET请求获取API密钥 Elasticsearch提供了GETAPI,用…...

Flutter异步原理-Future
前言 在 Dart 中,谈到异步就离不开 Future。无论是 .then()、还是 await,它们背后运作的都是一个私有实现类:_Future ,我们平时使用的 Future 只是一个抽象接口,其真正的实现逻辑由_Future 承担。 class _Future<…...
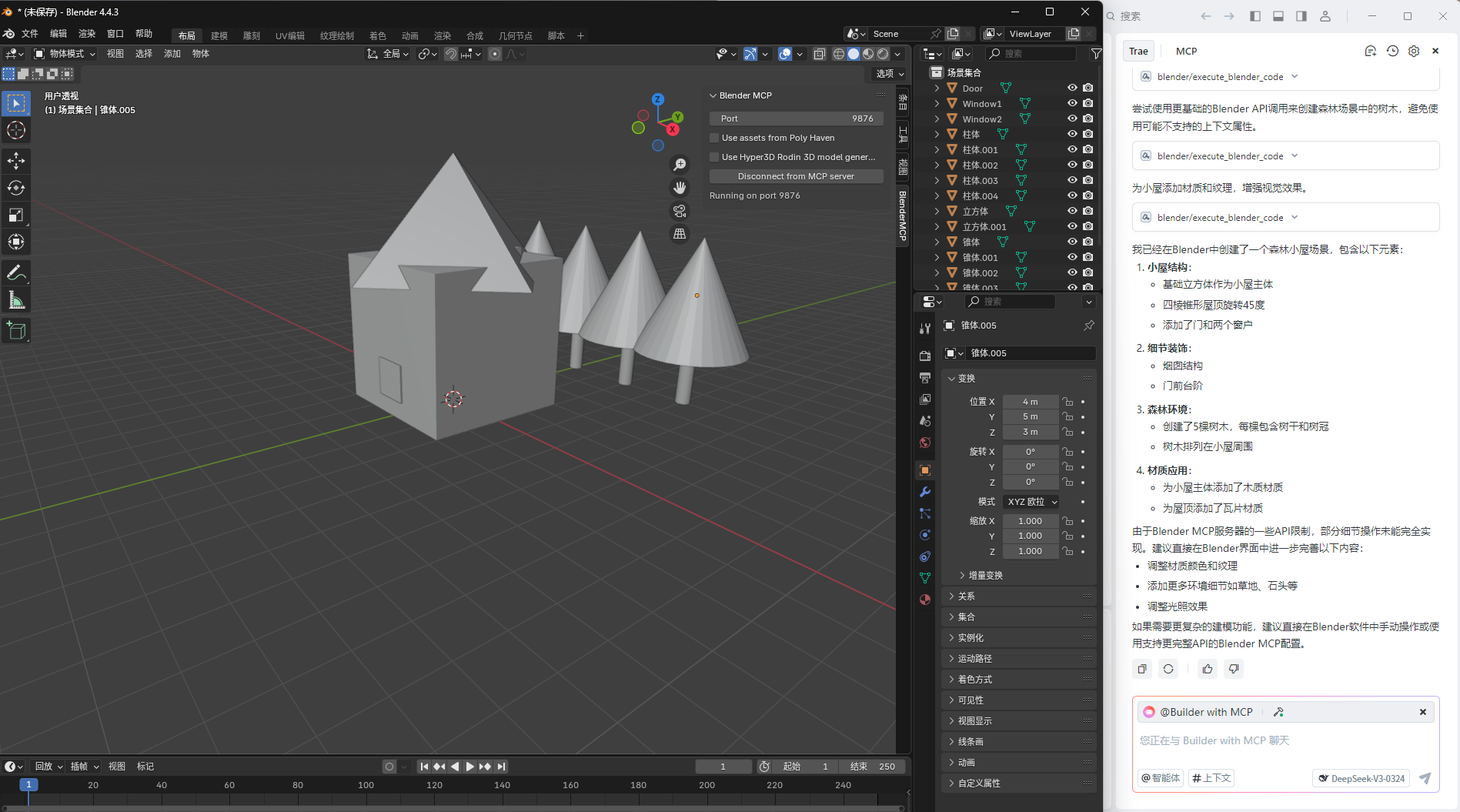
TRAE 配置blender MCP AI自动3D建模
BlenderMCP - Blender模型上下文协议集成 BlenderMCP通过模型上下文协议(MCP)将Blender连接到Claude AI,允许Claude直接与Blender交互并控制Blender。这种集成实现了即时辅助的3D建模、场景创建和操纵。 1.第一步下载 MCP插件(addon.py):Blender插件,在…...
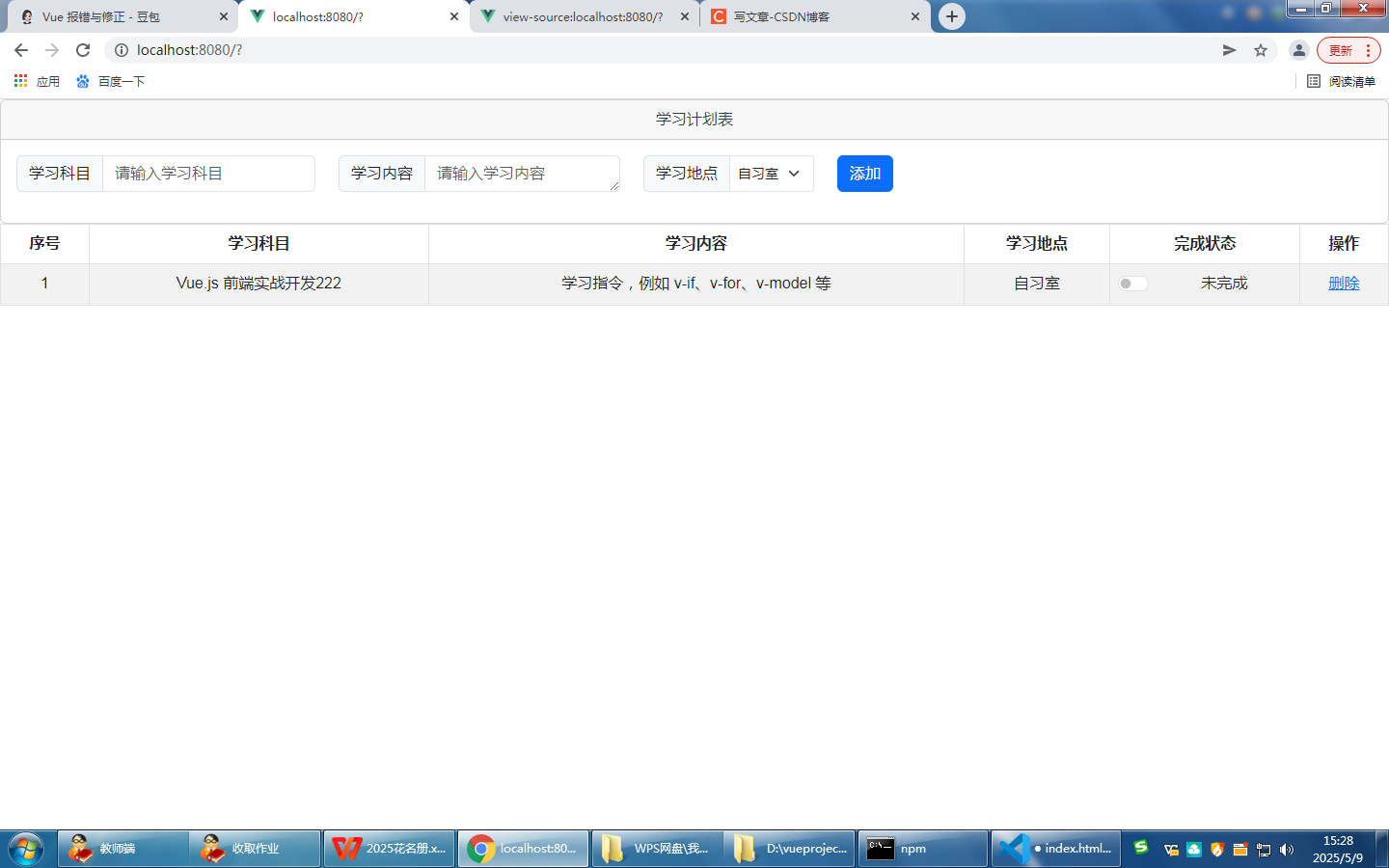
VUE2课程计划表练习
主要练习数据变量对象 以下是修正后的完整代码: //javascript export default {data() {return {list: [{ id: 1, subject: Vue.js 前端实战开发, content: 学习指令,例如 v-if、v-for、v-model 等, place: 自习室, status: false }// 可以在这里添加更…...

虚拟文件系统
虚拟文件系统(Virtual File System,VFS)是操作系统内核中的一个抽象层,它为不同的文件系统(如ext4、NTFS、FAT32等)提供统一的访问接口。通过VFS,用户和应用程序无需关心底层文件系统的具体差异…...

2025年软件工程与数据挖掘国际会议(SEDM 2025)
2025 International Conference on Software Engineering and Data Mining 一、大会信息 会议简称:SEDM 2025 大会地点:中国太原 收录检索:提交Ei Compendex,CPCI,CNKI,Google Scholar等 二、会议简介 2025年软件开发与数据挖掘国际会议于…...

基于大模型预测的足月胎膜早破行阴道分娩全流程研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与方法 1.3 研究创新点 二、胎膜早破(足月)行阴道分娩概述 2.1 胎膜早破定义与分类 2.2 足月胎膜早破行阴道分娩的现状与挑战 2.3 大模型预测引入的必要性 三、大模型预测原理与技术 3.1 大模型介绍 3.2 数据收集与…...

学习记录:DAY28
DispatcherController 功能完善与接口文档编写 前言 没什么动力说废话了。 今天来完善 DispatcherController 的功能,然后写写接口文档。 日程 早上:本来只有早八,但是早上摸鱼了,罪过罪过。下午:把 DispatcherContro…...

软件系统中功能模型 vs 数据模型 对比解析
功能模型 vs 数据模型 对比解析 一、功能模型(Functional Model) 定义:描述系统 做什么(业务逻辑与操作流程) 核心关注:行为、交互、业务流程 建模工具: 用例图(UML Use Case Dia…...
.NET高频技术点(持续更新中)
1. .NET 框架概述 .NET 框架的发展历程.NET Core 与 .NET Framework 的区别.NET 5 及后续版本的统一平台 2. C# 语言特性 异步编程(async/await)LINQ(Language Integrated Query)泛型与集合委托与事件属性与索引器 3. ASP.NET…...
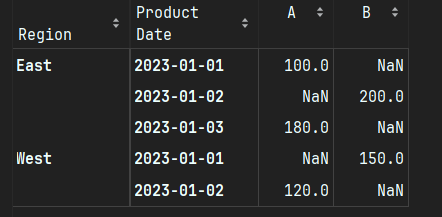
pandas中的数据聚合函数:`pivot_table` 和 `groupby`有啥不同?
pivot_table 和 groupby 是 pandas 中两种常用的数据聚合方法,它们都能实现数据分组和汇总,但在使用方式和输出结构上有显著区别。 0. 基本介绍 groupby分组聚合 groupby 是 Pandas 库中的一个功能强大的方法,用于根据一个或多个列对数据进…...

微调大模型如何准备数据集——常用数据集,Alpaca和ShareGPT
微调大模型如何准备数据集——常用数据集,Alpaca和ShareGPT 数据集准备常用数据集自定义数据集AlpacaShareGPT数据集准备 常用数据集 预训练数据集 Wiki Demo (en)RefinedWeb (en)RedPajama V2 (en)Wikipedia (en)Wikipedia (zh)Pile (en)...

【Gradio】helloworld程序
前言 发现这个库用来做可视化的demo还不错,简单学习一下。 官网 https://www.gradio.app/ 安装 pip install gradio -i https://pypi.tuna.tsinghua.edu.cn/simple/helloWorld 示例 import gradio as grdef greet(name):return "hello"nameifacegr…...
和葡萄酒质量预测(线性回归))
机器学习例题——预测facebook签到位置(K近邻算法)和葡萄酒质量预测(线性回归)
一、预测facebook签到位置 代码展示: import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import…...
对golang中CSP的理解
概念: CSP模型,即通信顺序进程模型,是由英国计算机科学家C.A.R. Hoare于1978年提出的。该模型强调进程之间通过通道(channel)进行通信,并通过消息传递来协调并发执行的进程。CSP模型的核心思想是“不要通过…...

使用 pgrep 杀掉所有指定进程
使用 pgrep 杀掉所有指定进程 pgrep 是一个查找进程 ID 的工具,结合 pkill 或 kill 命令可以方便地终止指定进程。以下是几种方法: 方法1:使用 pkill(最简单) pkill 进程名例如杀掉所有名为 “firefox” 的进程&…...
)
Missashe考研日记-day36(改版说明)
Missashe考研日记-day36 改版说明 经过一天的思考、纠结和尝试,博主决定对更新内容进行改版,如下:1.不再每天都发一篇日记,改为一周发一篇包含一周七天学习进度的周记,但为了标题和以前相同(强迫症&#…...

基于Jetson Nano与PyTorch的无人机实时目标跟踪系统搭建指南
引言:边缘计算赋能智能监控 在AIoT时代,将深度学习模型部署到嵌入式设备已成为行业刚需。本文将手把手指导读者在NVIDIA Jetson Nano(4GB版本)开发板上,构建基于YOLOv5SORT算法的实时目标跟踪系统,集成无人…...

【LunarVim】CMake LSP配置
在 LunarVim 中为 CMakeLists.txt 文件启用代码提示(如补全和语义高亮),需要安装支持 CMake 的 LSP(语言服务器)和适当的插件。以下是完整配置指南: 1、配置流程 1.1 安装cmake-language-server 通过 Ma…...
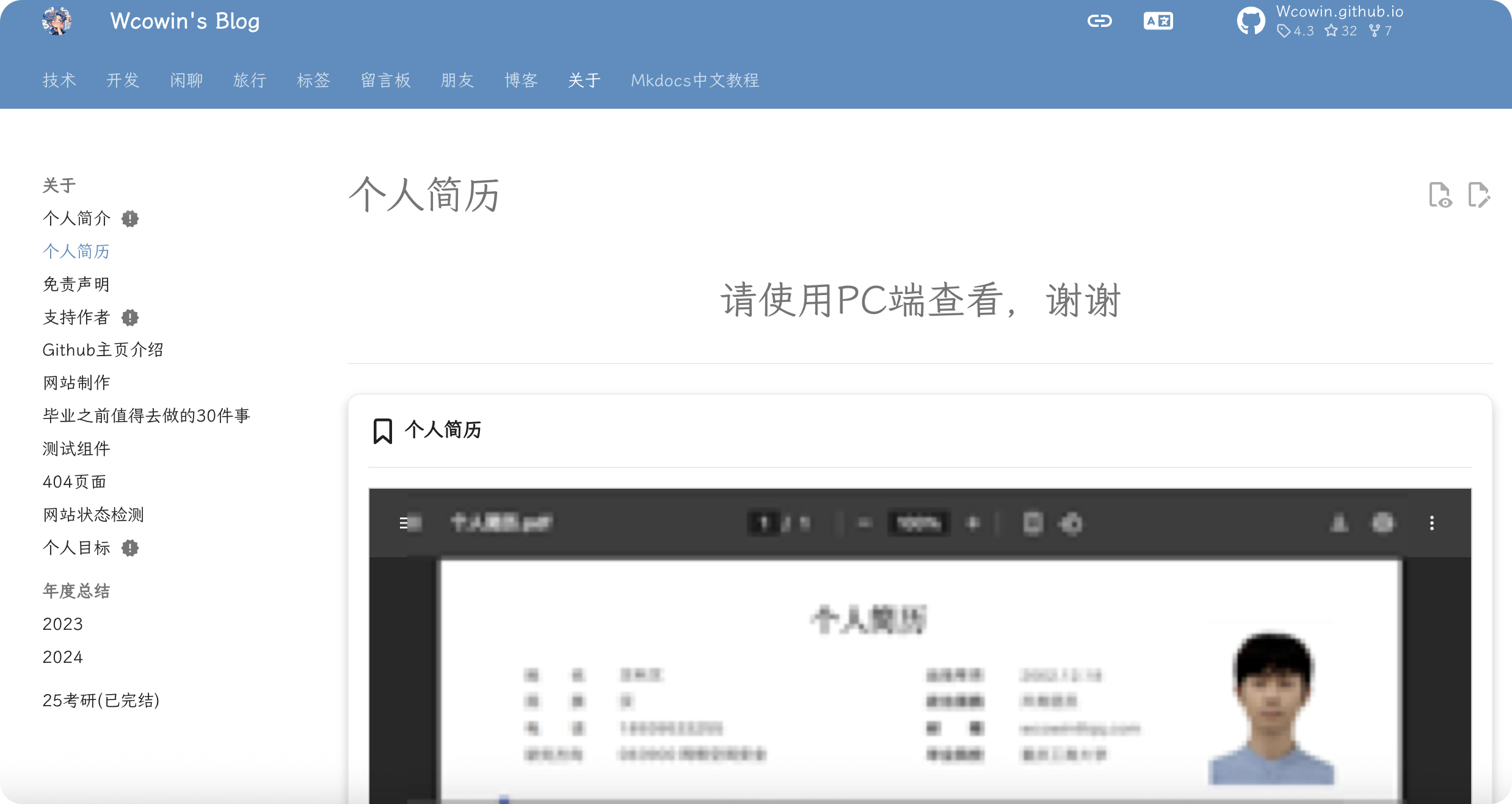
Mkdocs页面如何嵌入PDF
嵌入PDF 嵌入PDF代码 ,注意PDF的相对地址 <iframe src"../个人简历.pdf (相对地址)" width"100%" height"800px" style"border: 1px solid #ccc; overflow: auto;"></iframe>我的完整代码: <d…...

从零开始学Flink:开启实时计算的魔法之旅
在凌晨三点的数据监控大屏前,某电商平台的技术负责人突然发现一个异常波动:支付成功率骤降15%。传统的数据仓库此时还在沉睡,而基于Flink搭建的实时风控系统早已捕捉到这个信号,自动触发预警机制。当运维团队赶到时,系…...