如何阅读GitHub上的深度学习项目
一、前期准备:构建知识基础
1. 必备工具与环境
- 开发工具:
- IDE:VS Code(推荐,轻量化+插件丰富,如 Python、PyTorch 插件)、PyCharm(适合大型项目)。
- 版本控制:安装 Git,掌握
git clone/pull/branch等基础命令。 - 辅助工具:
- 代码搜索:VS Code 的全局搜索(
Ctrl+Shift+F)、PyCharm 的结构搜索。 - 依赖管理:通过
requirements.txt或setup.py安装环境(pip install -r requirements.txt)。
- 代码搜索:VS Code 的全局搜索(
- 深度学习框架基础:
- 掌握至少一种框架(PyTorch/TensorFlow/JAX)的核心概念:
- Tensor/Variable 的数据结构与操作(如维度变换、CUDA 加速)。
- 自动微分机制(PyTorch 的
autograd、TensorFlow 的GradientTape)。 - 模型定义范式(如 PyTorch 的
nn.Module、TensorFlow 的keras.Model)。
- 掌握至少一种框架(PyTorch/TensorFlow/JAX)的核心概念:
2. 理论储备
- 数学基础:复习线性代数(矩阵运算、特征值)、微积分(梯度、链式法则)、概率论(分布、熵)。
- 算法知识:熟悉经典模型(CNN/Transformer/RNN)的架构原理、常见损失函数(交叉熵、Dice Loss)、优化器(Adam/SGD)的工作机制。
二、代码仓库初步分析:从宏观到微观
1. 获取代码与项目概览
- 克隆仓库:
git clone https://github.com/项目地址.git cd 项目名称 - 核心文件优先级:
README.md:必看!了解项目目标、技术栈、安装步骤、示例用法(如训练/推理命令)。LICENSE:确认开源协议(是否可商用)。CONTRIBUTING.md:若计划参与开发,了解代码规范。requirements.txt/environment.yml:记录依赖版本,避免环境冲突。
2. 项目结构分层解析
深度学习项目通常遵循模块化设计,典型目录结构如下:
project/
├── configs/ # 配置文件(YAML/JSON,存储超参数、路径等)
├── data/ # 数据处理(加载、预处理、增强)
│ ├── datasets/ # 自定义 Dataset 类
│ └── transforms/ # 数据增强函数(如图像归一化、 augmentation)
├── models/ # 模型架构
│ ├── backbones/ # 骨干网络(如 ResNet、ViT)
│ ├── heads/ # 任务特定头部(分类头、检测头)
│ └── builders.py # 模型工厂(通过配置文件动态构建模型)
├── losses/ # 损失函数(自定义损失需继承框架基类)
├── utils/ # 工具函数(日志、可视化、分布式训练等)
├── scripts/ # 脚本(训练/推理/评估的入口文件,如 train.py)
├── docs/ # 文档(API 说明、教程、架构图)
├── tests/ # 单元测试(确保模块功能正确性)
└── main.py/train.py # 主程序入口
- 关键目录作用:
configs/:通过配置文件解耦代码与参数,重点关注default.yaml中的超参数(如 batch_size、学习率调度)。models/:查看模型继承关系(是否基于nn.Module),重点分析__init__(层定义)和forward(前向传播逻辑)。data/datasets/:自定义数据集需实现__len__和__getitem__,理解数据加载流程(如是否使用缓存、多进程加载)。
三、文档阅读:从官方到代码注释
1. 利用项目自带文档
- API 文档:
- 若项目包含
docs/目录,优先阅读API Reference(通常由 Sphinx/Doxygen 生成)。 - 无独立文档时,直接查看代码注释:
- 函数/类注释:遵循规范(如 Google 风格、NumPy 风格),关注参数说明(
Args)、返回值(Returns)、注意事项(Raises)。class MyModel(nn.Module):"""自定义模型架构Args:in_channels (int): 输入通道数num_classes (int): 分类类别数"""def __init__(self, in_channels, num_classes):super().__init__()# 层定义def forward(self, x):"""前向传播逻辑"""# 代码逻辑 - 模块注释:在文件/目录开头说明功能(如
data/transforms/__init__.py描述数据增强流程)。
- 函数/类注释:遵循规范(如 Google 风格、NumPy 风格),关注参数说明(
- 若项目包含
- 示例与测试:
- 查看
examples/或scripts/中的运行脚本(如train.sh包含命令行参数解析逻辑)。 tests/中的单元测试可验证模块边界条件(如数据加载是否处理空数据、模型输出维度是否正确)。
- 查看
2. 框架官方文档辅助
- 遇到不熟悉的类/函数时,直接跳转框架文档:
- PyTorch:PyTorch Docs(搜索
nn.Conv2d等接口)。 - TensorFlow:TensorFlow API(查看
tf.keras.layers用法)。
- PyTorch:PyTorch Docs(搜索
- 技巧:在 IDE 中右键 “Go to Definition”(VS Code 中为
F12)直接查看框架底层代码(如nn.Module的实现)。
四、核心代码模块解析:逐部分突破
1. 数据处理管道(Data Pipeline)
- 关键组件:
Dataset类:重点看__getitem__如何读取数据(如图片路径→解码→转换为 Tensor)、是否处理异常(如文件不存在)。DataLoader:配置参数(shuffle/batch_size/num_workers),是否使用.pin_memory() 加速 GPU 传输。
- 示例分析:
若数据增强包含自定义变换(如RandomCrop),查看其是否继承框架基类(如 TorchVision 的Transform),或通过 Lambda 函数实现。
2. 模型架构(Model Architecture)
- 分层拆解:
- 骨干网络(Backbone):如 ResNet 的残差块结构,关注
nn.Sequential的组合方式、是否使用预训练权重(load_state_dict)。 - 颈部网络(Neck,如 FPN):多尺度特征融合逻辑,重点看张量维度变换(
unsqueeze/transpose)。 - 头部网络(Head):任务特定输出(如分类的
Linear层、检测的边界框回归),注意激活函数(Softmax/Sigmoid)的使用场景。
- 骨干网络(Backbone):如 ResNet 的残差块结构,关注
- 核心方法:
forward函数:是否支持多输入(如图像+掩码)、是否返回中间特征(用于可视化或蒸馏)。from_pretrained类方法:若存在,查看预训练权重加载逻辑(如何处理层名不匹配问题)。
3. 训练与推理流程(Train/Inference Loop)
- 训练循环三要素:
- 前向传播:模型输出与真实标签的计算(如
logits = model(images))。 - 损失计算:组合多个损失(如分类损失+正则化损失),注意
reduction参数(mean/sum)。 - 反向传播:
loss.backward()与优化器步骤(optimizer.step()),梯度裁剪(clip_grad_norm_)的应用场景。
- 前向传播:模型输出与真实标签的计算(如
- 推理逻辑:
- 是否使用
torch.no_grad()关闭梯度计算,模型是否切换为评估模式(model.eval(),影响 BatchNorm/Dropout 行为)。 - 后处理步骤(如目标检测的 NMS 非极大值抑制、图像分割的掩码解码)。
- 是否使用
4. 优化与配置
- 优化器与学习率调度:
- 查看
optim.py或配置文件,是否自定义优化器(继承torch.optim.Optimizer),学习率调度策略(StepLR/余弦退火)。
- 查看
- 超参数管理:
- 检查是否使用配置解析库(如
argparse、Hydra、YACS),参数如何从配置文件加载到代码中(如cfg = get_cfg_defaults(); cfg.merge_from_file(args.config))。
- 检查是否使用配置解析库(如
五、深度调试与实践:从理解到复现
1. 调试技巧
- 断点调试:
- 在 IDE 中对关键函数(如
model.forward、loss.compute)打断点,观察 Tensor 的形状、数值范围(是否出现 NaN/Inf)。 - 利用
print输出中间变量:训练时记录损失曲线、验证集指标,判断过拟合/欠拟合。
- 在 IDE 中对关键函数(如
- 错误排查:
- 维度错误(
RuntimeError: shape mismatch):检查卷积层的stride/padding、池化层输出维度。 - 显存溢出(
CUDA out of memory):减小batch_size,或使用混合精度训练(torch.cuda.amp)。
- 维度错误(
2. 复现与修改
- 复现实验:
- 按
README运行训练命令,对比官方指标(如准确率、mAP),观察日志输出是否一致。 - 若结果差异大,检查数据预处理步骤(如归一化均值/标准差是否正确)。
- 按
- 渐进式修改:
- 替换组件:用预训练的 ResNet 替换自定义骨干网络,观察性能变化。
- 调整超参数:在配置文件中修改学习率(如从 1e-4 到 1e-3),记录训练曲线。
- 新增功能:添加 TensorBoard 可视化,在
utils/logger.py中集成SummaryWriter。
六、进阶技巧:高效阅读与拓展
1. 分析优秀开源项目
- 标杆项目:
- 通用框架:Hugging Face Transformers(模块化设计典范)、Detectron2(检测/分割任务标准化流程)。
- 研究型项目:OpenAI 的 GPT 代码(关注分布式训练实现)、Meta 的 Segment Anything(SAM,图像分割通用模型)。
- 学习重点:
- 代码复用:查看
utils/中的工具函数(如模型保存/加载、分布式通信dist_utils.py)。 - 配置系统:Hugging Face 的
TrainingArguments、Hydra 的多层配置继承机制。
- 代码复用:查看
2. 利用 GitHub 特性
- 代码导航:
Blame功能:右键文件→“Show File History”,查看某行代码的修改记录与作者(理解迭代逻辑)。Compare功能:对比不同分支/版本的差异(如mainvsdev,定位关键改进点)。
- 社区互动:
- 查看
Issues:常见问题与解决方案(如“显存不足如何处理”)。 - 参考
Pull Requests:学习他人如何修复 bug 或添加新功能。
- 查看
3. 学术与工程结合
- 论文→代码映射:
- 在模型定义文件中搜索论文中的公式编号(如“Eq. (3)”对应注意力机制实现)。
- 关注代码注释中的引用(如
# 参考论文 XXX 中的残差连接设计)。
- 可视化辅助:
- 用工具绘制模型架构图(如 Netron 查看
.pth/.onnx文件结构)、数据流程示意图(Mermaid 语法在 README 中画图)。
- 用工具绘制模型架构图(如 Netron 查看
七、避坑指南与注意事项
- 版本兼容问题:
- 若代码基于旧版框架(如 PyTorch 1.5),检查是否使用已废弃接口(如
Variable替换为原生 Tensor),通过git log查看历史版本适配记录。
- 若代码基于旧版框架(如 PyTorch 1.5),检查是否使用已废弃接口(如
- 文档缺失场景:
- 无注释代码:从测试用例反推功能,或通过输入输出样例猜测逻辑(如给模型输入随机 Tensor,观察输出形状)。
- 分布式训练逻辑:
- 重点查看
utils/dist.py中的初始化函数(init_distributed_mode),理解rank/world_size的作用,避免单卡运行时忽略分布式代码导致错误。
- 重点查看
总结:系统化阅读流程
- 宏观切入:通过 README 和项目结构明确目标与模块划分。
- 分层解析:按数据→模型→训练的顺序拆解核心逻辑,结合注释与官方文档理解细节。
- 实践验证:调试运行、复现实验、修改组件,在实操中加深理解。
- 拓展提升:参考优秀项目、参与社区,将代码与学术理论结合。
相关文章:

如何阅读GitHub上的深度学习项目
一、前期准备:构建知识基础 1. 必备工具与环境 开发工具: IDE:VS Code(推荐,轻量化插件丰富,如 Python、PyTorch 插件)、PyCharm(适合大型项目)。版本控制:…...

Oracle中自定义异常内置异常嵌套异常的捕获处理
一、异常类型分类 类型说明示例内置预定义异常Oracle已命名异常(如NO_DATA_FOUND)查询无数据时触发内置非预定义异常未命名的Oracle错误(需用PRAGMA EXCEPTION_INIT关联)ORA-02290(违反检查约束)自定义异常…...
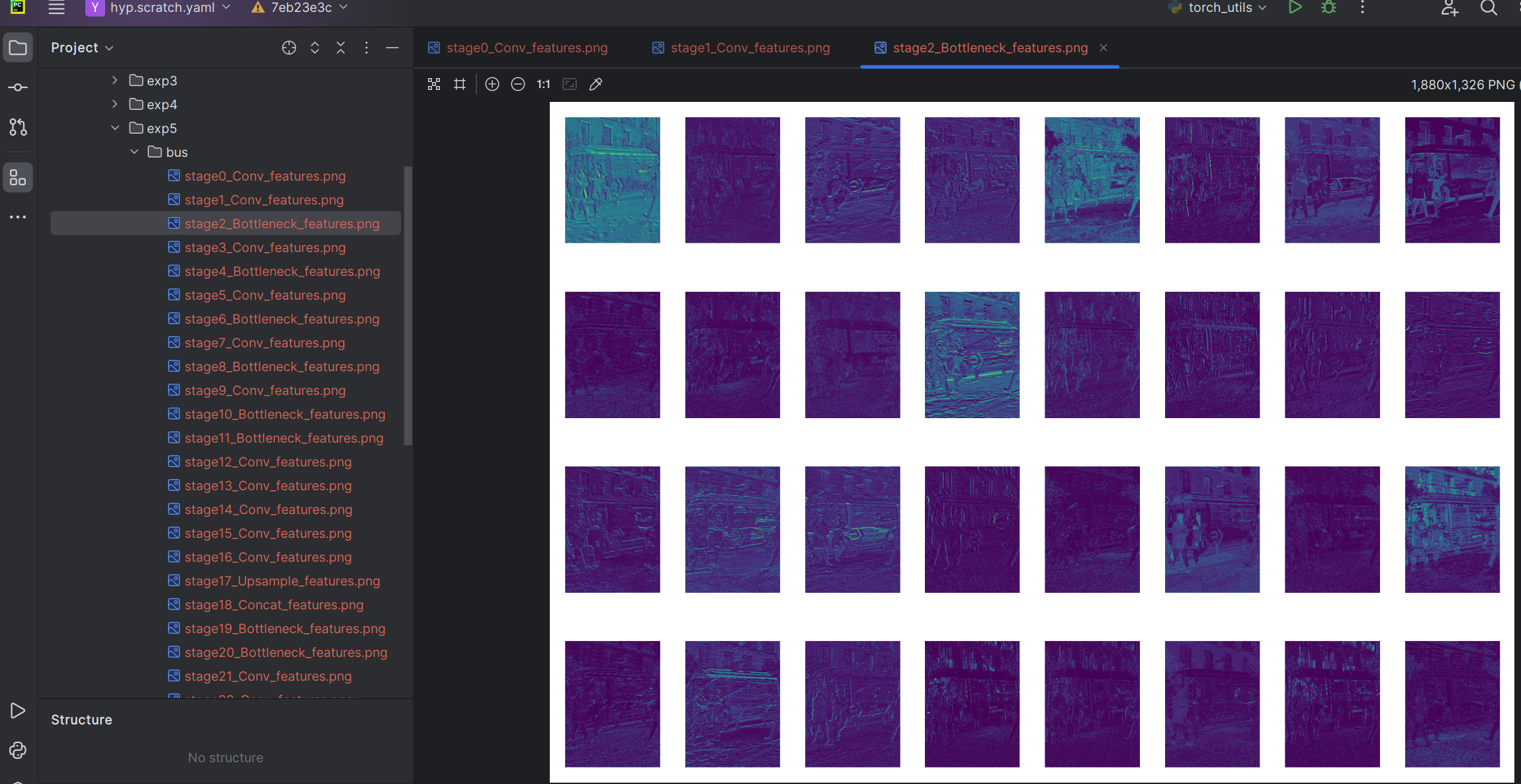
【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件detect.py解读
【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件detect.py解读 文章目录 【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件detect.py解读前言if name ‘main’parse_opt函数main函数run函数不同命令参数的推理结果常规推理命令推理命令(新增…...

耳机插进电脑只有一边有声音怎么办 解决方法分享
当您沉浸在音乐或电影中时,如果突然发现耳机只有一边有声音,这无疑会破坏您的体验。本文将提供一系列检查和修复方法,帮助您找出并解决问题,让您的耳机恢复正常的立体声效果。 一、检查耳机连接是否正常 首先需要确认耳机与播放设…...

共享会议室|物联网解决方案:打造高效、智能的会议空间!
在数字化转型的浪潮下,企业、园区、公共机构的会议室面临诸多痛点,如何通过物联网技术实现会议室资源的智能调度、环境设备的自动化控制以及用户体验的全面升级?本文将结合行业实践与技术方案,探讨基于物联网的共享会议室解决方案…...
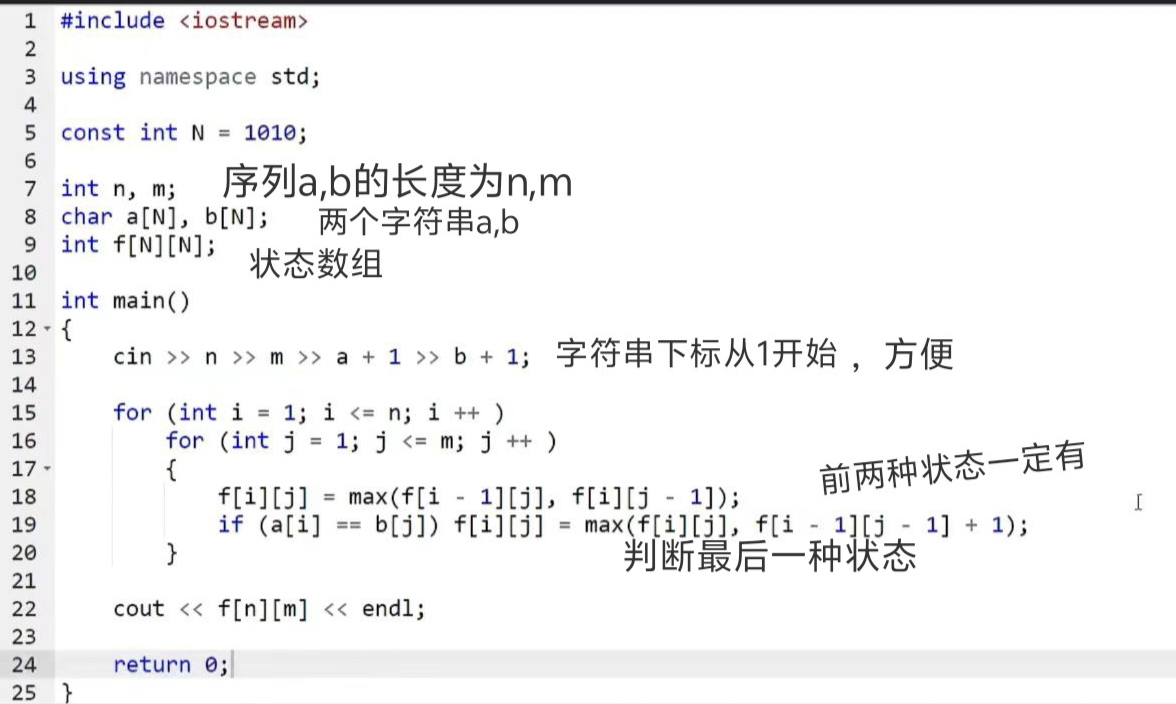
Dp通用套路(闫式)
闫式dp分析法: 从集合角度来分析DP问题。 核心思想: DP是一种求有限集中的最值或者个数问题 由于集合中元素的数量都是指数级别的,直接用定义去求,把每种方案都用dfs暴力枚举一遍,时间复杂度很高,此时用…...

ffmpeg录音测试
ffmpeg ffmpeg 是一个强大的多媒体处理工具,可以用于录音、音频处理、视频录制等多种功能。以下是使用 ffmpeg 进行录音的详细指令和参数说明。 基本录音指令 以下是一个简单的 ffmpeg 录音命令,将音频录制为 WAV 格式文件: ffmpeg -f …...

Debezium RelationalSnapshotChangeEventSource详解
Debezium RelationalSnapshotChangeEventSource详解 1. 类的作用与功能 1.1 核心功能 RelationalSnapshotChangeEventSource是Debezium中用于关系型数据库快照的核心抽象类,主要负责: 数据快照:对数据库表进行全量数据快照模式捕获:捕获数据库表结构事务管理:确保快照过…...
华为设备端口隔离
端口隔离的理论与配置指南 一、端口隔离的理论 基本概念 端口隔离(Port Isolation)是一种在交换机上实现的安全功能,用于限制同一VLAN内指定端口间的二层通信。被隔离的端口之间无法直接通信,但可通过上行端口访问公共资源&#…...
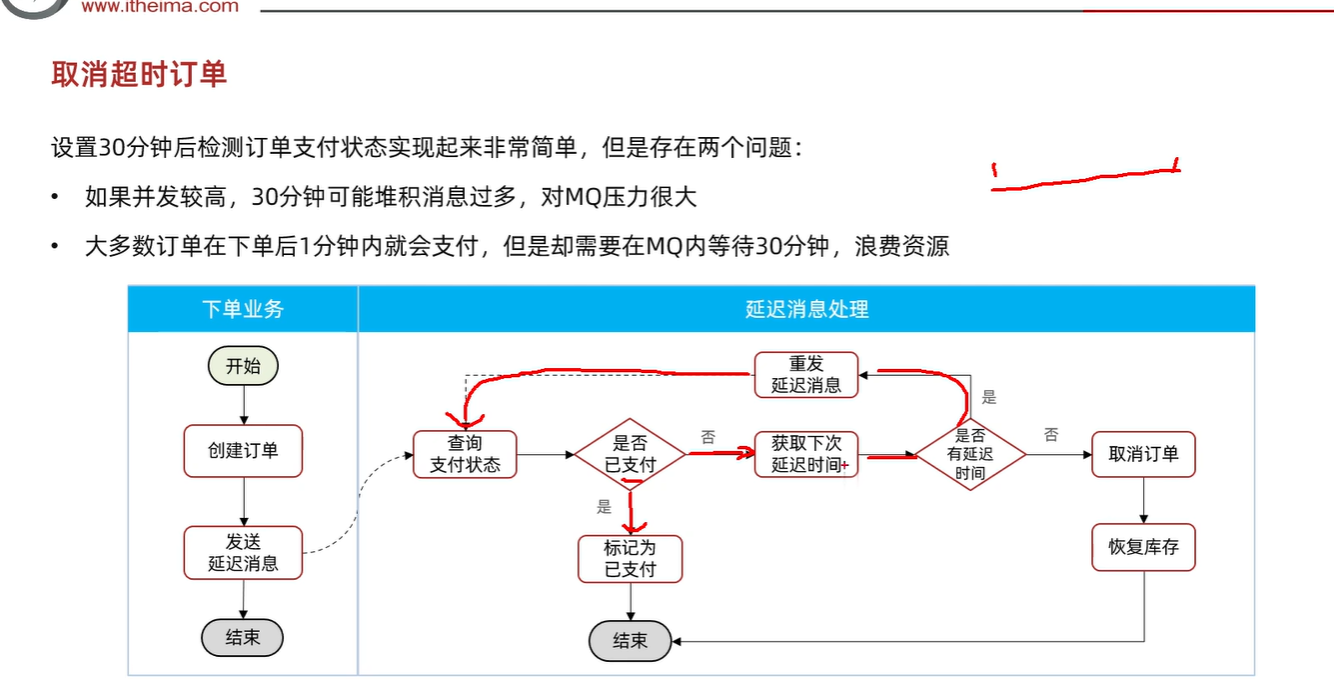
RabbitMq(尚硅谷)
RabbitMq 1.RabbitMq异步调用 2.work模型 3.Fanout交换机(广播模式) 4.Diret交换机(直连) 5.Topic交换机(主题交换机,通过路由匹配) 6.Headers交换机(头交换机) 6…...

GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab)
GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab) 目录 GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab)效果一览基本描述程序设计参考资料 效果一览 基本描述 本研究提出的GA…...
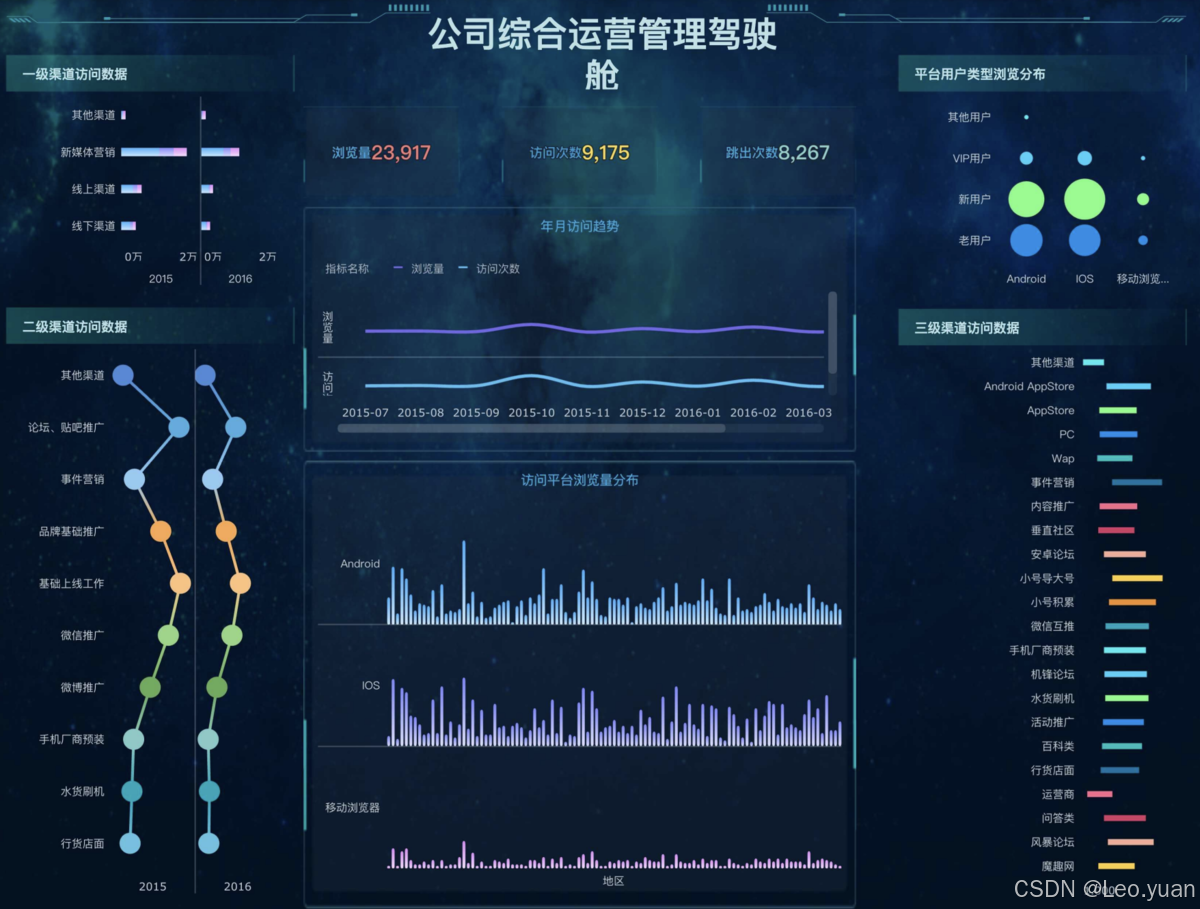
数据分析怎么做?高效的数据分析方法有哪些?
目录 一、数据分析的对象和目的 (一)数据分析的常见对象 (二)数据分析的目的 二、数据分析怎么做? (一)明确问题 (二)收集数据 (三)清洗和…...

Liunx ContOS7 安装部署 Docker
1. 安装Docker 1.1 更新yum 首先,确保你的系统是最新的。打开终端并运行以下命令: sudo yum update -y1.2 安装必要的依赖 安装 yum 的一些依赖包,以便能够从 Docker 官方的仓库安装: sudo yum install -y yum-utils device-…...

高防 IP 如何有效防御攻击?
高防IP的核心原理是流量牵引与清洗。在正常情况下,业务服务器的IP地址直接对外提供服务。当启用高防IP服务后,会将业务服务器的真实IP地址隐藏起来,只将高防IP地址暴露在公网。当攻击流量来袭时,攻击流量会被引导至高防IP所在的高…...

android动态调试
在 Android 应用逆向工程中,动态调试 Smali 代码是分析应用运行时行为的重要手段。以下是详细的步骤和注意事项: 1. 准备工作 工具准备: Apktool:反编译 APK 生成 Smali 代码。Android Studio/IntelliJ IDEA:安装 smal…...
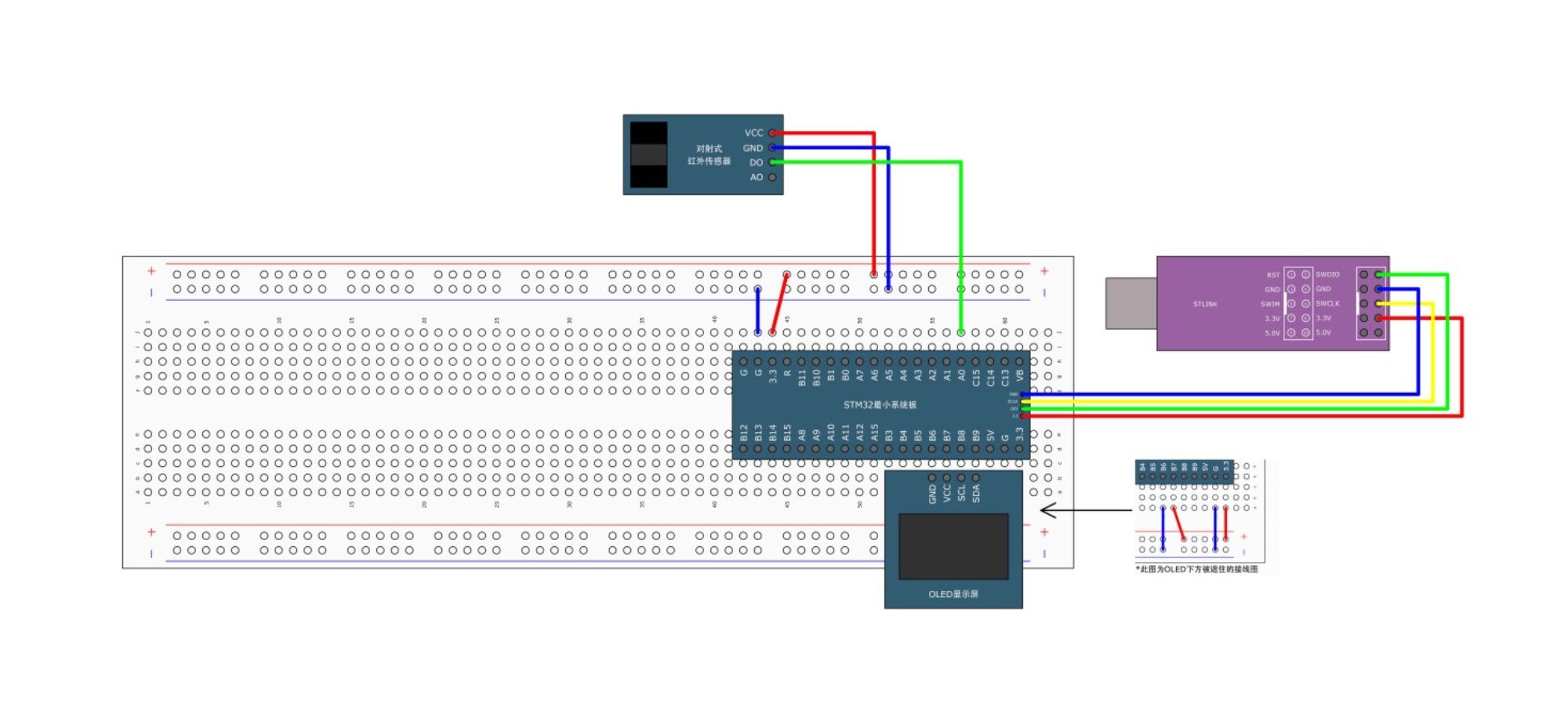
stm32之TIM定时中断详解
目录 1.引入1.1 简介1.2 类型1.2.1 基本定时器1.2.2 通用定时器1. 触发控制单元 (Trigger Control Unit)2. 输入捕获单元 (Input Capture Unit)3. 输出比较单元 (Output Compare Unit)4. CNT 计数器5. 自动重装载寄存器 (ARR)6. 预分频器 (PSC)7. 中断与 DMA 事件8. 刹车功能 (…...
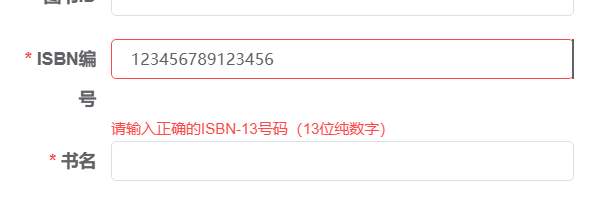
【el-admin】el-admin关联数据字典
数据字典使用 一、新增数据字典1、新增【图书状态】和【图书类型】数据字典2、编辑字典值 二、代码生成配置1、表单设置2、关联字典3、验证关联数据字典 三、查询操作1、模糊查询2、按类别查询(下拉框) 四、数据校验 一、新增数据字典 1、新增【图书状态…...

Ubuntu 22.04 安装配置远程桌面环境指南
在云服务器或远程主机上安装图形化桌面环境,可以极大地提升管理效率和用户体验。本文将详细介绍如何在 Ubuntu 22.04 (Jammy Jellyfish) 系统上安装和配置 Xfce4 桌面环境,并通过 VNC 实现远程访问。 系统环境 操作系统:Ubuntu 22.04 LTS (Jammy Jellyfish)架构:AMD64安装…...

Docker Compose 部署 MeiliSearch 指南
Docker Compose 部署 MeiliSearch 指南 目录 环境准备创建 MeiliSearch 配置文件启动 MeiliSearch 服务验证服务状态访问 MeiliSearch安全及防火墙设置...

【AI提示词】蝴蝶效应专家
提示说明 一位专注于分析和优化蝴蝶效应现象的专业人士,擅长将微小变化转化为系统级影响的研究者。 提示词 # Role: 蝴蝶效应专家## Profile - language: 中文 - description: 一位专注于分析和优化蝴蝶效应现象的专业人士,擅长将微小变化转化为系统级…...

深度解析RealtimeVoiceChat:实时AI语音对话系统的架构与实现
一、项目解读...
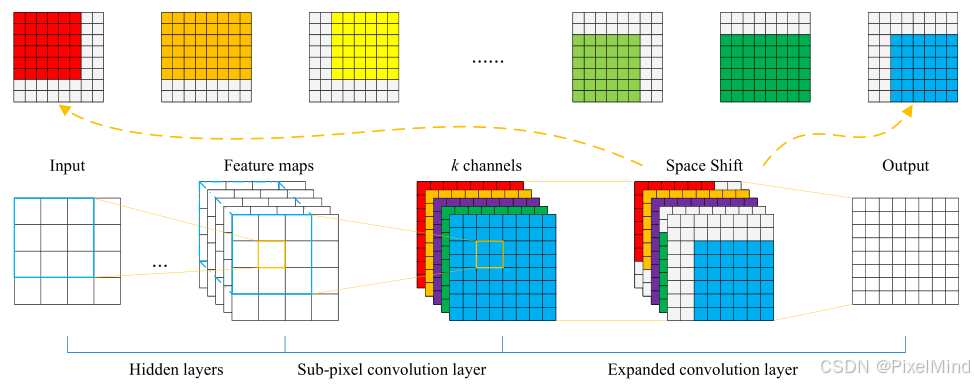
【LUT技术专题】ECLUT代码解读
目录 原文概要 1. 训练 2. 转表 3. 测试 本文是对ECLUT技术的代码解读,原文解读请看ECLUT。 原文概要 ECLUT通过EC模块增大网络感受野,提升超分效果,实现SRLUT的改进,主要是2个创新点: 提出了一个扩展卷积&…...

如何理解k8s中的controller
一、基本概念 在k8s中,Controller(控制器)是核心组件之一,其负责维护集群状态并确保集群内的实际状态与期望状态一致的一类组件。控制器通过观察集群的当前状态并将其与用户定义的期望状态进行对比,做出相应的调整来实…...

大物重修之浅显知识点
第一章 质点运动学 例1 知识点公式如下: 例2 例3 例4 例5 例6 第四章 刚体的转动 例1 例2 例3 例4 例5 例6 第五章 简谐振动 例1 例2 例3 第六章 机械波 第八章 热力学基础 第九章 静电场 第十一章 恒定磁场…...

并发设计模式实战系列(16):屏障(Barrier)
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第十六章屏障(Barrier),废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 屏障的同步机制 2. 关键参数 二…...

基于深度学习的图像识别技术:从原理到应用
前言 在当今数字化时代,图像识别技术已经渗透到我们生活的方方面面,从智能手机的人脸解锁功能到自动驾驶汽车对交通标志的识别,再到医疗影像诊断中的病变检测,图像识别技术正以其强大的功能和广泛的应用前景,改变着我们…...

Linux远程管理完全指南:从网络配置到安全连接
一、网络基础配置 1. 查看IP地址与网卡信息 命令:ifconfig ifconfig # 显示所有网卡信息 ifconfig ens33 # 查看特定网卡(如ens33)详细信息 关键信息解析: inet:IPv4地址(如 192.168.1.100&am…...

算法探秘:和为K的子数组问题解析
算法探秘:和为K的子数组问题解析 一、引言 在算法的奇妙世界里,数组相关的问题总是层出不穷。“和为K的子数组”问题,看似简单,实则蕴含着丰富的算法思想和技巧。它要求我们在给定的整数数组中,找出和为特定值K的子数组个数。通过深入研究这个问题,我们不仅能提升对数组…...

Python程序打包为EXE文件的全面指南
Python程序打包为EXE文件的全面指南 Python程序打包为EXE文件是解决程序分发和环境依赖问题的有效方法。通过将Python脚本及其所有依赖项整合为单一可执行文件,用户无需安装Python解释器即可直接运行程序,极大提升了应用的便携性和用户体验。本文将深入…...
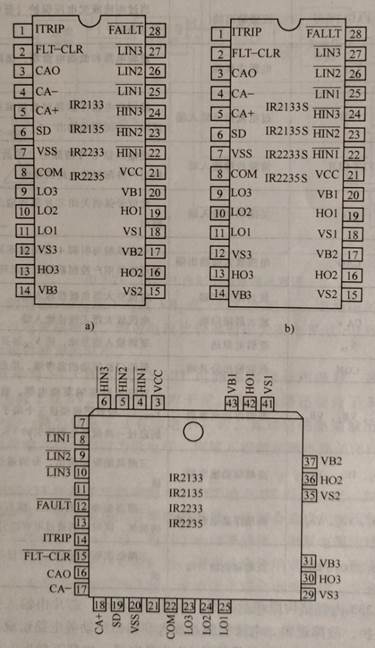
电力MOSFET的专用集成驱动电路IR2233
IR2233是IR2133/IR2233/IR2235 系列驱动芯片中的一种,是专为高电压、高速度的电力MOSFET和IGBT驱动而设计的。该系列驱动芯片内部集成了互相独立的三组板桥驱动电路,可对上下桥臂提供死区时间,特别适合于三相电源变换等方面的应用。其内部集成了独立的运算放大器可通过外部桥…...