代码随想录第41天:图论2(岛屿系列)
一、岛屿数量(Kamacoder 99)

深度优先搜索:
# 定义四个方向:右、下、左、上,用于 DFS 中四向遍历
direction = [[0, 1], [1, 0], [0, -1], [-1, 0]]def dfs(grid, visited, x, y):"""对一块陆地进行深度优先遍历并标记相邻陆地:param grid: 二维网格:param visited: 是否访问过的标记表:param x: 当前所在的行坐标:param y: 当前所在的列坐标"""for dx, dy in direction:next_x = x + dxnext_y = y + dy# 判断是否越界if next_x < 0 or next_x >= len(grid) or next_y < 0 or next_y >= len(grid[0]):continue# 如果相邻格子是陆地且未被访问,标记并递归继续 DFSif not visited[next_x][next_y] and grid[next_x][next_y] == 1:visited[next_x][next_y] = Truedfs(grid, visited, next_x, next_y)if __name__ == '__main__': # 输入行数 n 和列数 mn, m = map(int, input().split())# 构建网格:n 行,每行 m 个整数(0 表示水,1 表示陆地)grid = []for _ in range(n):grid.append(list(map(int, input().split())))# 初始化访问标记表,初始均为 Falsevisited = [[False] * m for _ in range(n)]res = 0 # 统计岛屿数量(连通块个数)for i in range(n):for j in range(m):# 如果当前位置是陆地,且未被访问过,则为新的岛屿if grid[i][j] == 1 and not visited[i][j]:res += 1 # 新岛屿计数 +1visited[i][j] = True # 标记起点已访问dfs(grid, visited, i, j) # DFS 遍历整块陆地# 输出岛屿总数print(res)
广度优先搜索:只要加入队列,立即标记该节点走过。
from collections import deque # 使用 deque 作为队列,提高效率# 定义四个方向:右、下、左、上
directions = [[0, 1], [1, 0], [0, -1], [-1, 0]]def bfs(grid, visited, x, y):"""使用广度优先搜索(BFS)遍历并标记一整块陆地:param grid: 输入的地图(二维数组):param visited: 访问标记矩阵:param x, y: 起始坐标(陆地)"""que = deque()que.append([x, y]) # 将起始节点加入队列visited[x][y] = True # 标记该点已访问while que:cur_x, cur_y = que.popleft() # 弹出当前处理的节点for dx, dy in directions: # 遍历四个方向next_x = cur_x + dxnext_y = cur_y + dy# 越界检查if next_x < 0 or next_y < 0 or next_x >= len(grid) or next_y >= len(grid[0]):continue# 如果是未访问的陆地,则加入队列并标记为已访问if not visited[next_x][next_y] and grid[next_x][next_y] == 1: visited[next_x][next_y] = Trueque.append([next_x, next_y])def main():# 输入网格行数 n 和列数 mn, m = map(int, input().split())# 读取 n 行数据构造 gridgrid = []for i in range(n):grid.append(list(map(int, input().split())))# 初始化访问标记数组visited = [[False] * m for _ in range(n)]res = 0 # 记录岛屿数量for i in range(n):for j in range(m):# 遇到未访问的陆地,开始 BFS,并增加岛屿计数if grid[i][j] == 1 and not visited[i][j]:res += 1bfs(grid, visited, i, j)print(res) # 输出岛屿数量if __name__ == "__main__":main()
二、岛屿的最大面积(Kamacoder 100)

DFS:
# 四个方向:右、下、左、上(用于搜索相邻的格子)
position = [[0, 1], [1, 0], [0, -1], [-1, 0]]count = 0 # 用于记录当前连通块的陆地面积(全局变量)def dfs(grid, visited, x, y):"""使用深度优先搜索(DFS)标记一整块陆地并统计面积:param grid: 输入地图(二维矩阵):param visited: 访问标记矩阵:param x, y: 当前坐标"""global count # 使用全局变量记录当前连通块的面积for dx, dy in position:cur_x = x + dxcur_y = y + dy# 越界检查if cur_x < 0 or cur_x >= len(grid) or cur_y < 0 or cur_y >= len(grid[0]):continue# 若是未访问的陆地,递归访问并增加面积if not visited[cur_x][cur_y] and grid[cur_x][cur_y] == 1:visited[cur_x][cur_y] = Truecount += 1dfs(grid, visited, cur_x, cur_y)# 输入网格的行列数 n 行 m 列
n, m = map(int, input().split())# 构造地图(邻接矩阵)
grid = []
for _ in range(n):grid.append(list(map(int, input().split())))# 构造访问矩阵,记录哪些节点已访问
visited = [[False] * m for _ in range(n)]result = 0 # 记录最大陆地面积(即最大连通块中1的数量)# 遍历每一个格子
for i in range(n):for j in range(m):# 遇到一个未访问的陆地,开始 DFS 并更新最大面积if grid[i][j] == 1 and not visited[i][j]:count = 1 # 初始化当前连通块的面积visited[i][j] = True # 标记当前格子已访问dfs(grid, visited, i, j)result = max(result, count) # 更新最大面积# 输出最大陆地面积
print(result)
BFS:
from collections import deque# 四个方向:右、下、左、上(用于搜索相邻格子)
position = [[0, 1], [1, 0], [0, -1], [-1, 0]]count = 0 # 记录当前连通块面积(使用全局变量)def bfs(grid, visited, x, y):"""广度优先搜索,对一整块陆地进行标记并统计面积:param grid: 地图矩阵:param visited: 访问标记矩阵:param x, y: 当前陆地坐标"""global count # 使用全局变量记录当前连通块面积que = deque()que.append([x, y]) # 将起点入队while que:cur_x, cur_y = que.popleft() # 弹出队首元素# 遍历四个方向for dx, dy in position:next_x = cur_x + dxnext_y = cur_y + dy# 越界处理if next_x < 0 or next_x >= len(grid) or next_y < 0 or next_y >= len(grid[0]):continue# 如果是未访问的陆地,则入队并更新访问记录与面积if grid[next_x][next_y] == 1 and not visited[next_x][next_y]:visited[next_x][next_y] = Truecount += 1que.append([next_x, next_y])# 输入地图尺寸 n 行 m 列
n, m = map(int, input().split())# 构造地图矩阵(邻接矩阵)
grid = []
for i in range(n):grid.append(list(map(int, input().split())))# 构造访问标记矩阵
visited = [[False] * m for _ in range(n)]result = 0 # 记录所有陆地块中面积最大的那一块# 遍历地图
for i in range(n):for j in range(m):# 如果当前是未访问的陆地,则开始BFSif grid[i][j] == 1 and not visited[i][j]:count = 1 # 初始面积为1(当前格子)visited[i][j] = True # 标记已访问bfs(grid, visited, i, j) # 广度优先遍历整块陆地result = max(result, count) # 更新最大面积# 输出最大陆地面积
print(result)
三、孤岛的总面积(Kamacoder 101)

DFS:先遍历边界的陆地将他们变成海洋,然后再统计非边界的“孤岛”面积。
# 四个方向:下、右、上、左
position = [[1, 0], [0, 1], [-1, 0], [0, -1]]
count = 0 # 用于统计当前岛屿面积def dfs(grid, x, y):"""深度优先搜索,沉没当前岛屿,统计其面积"""global countgrid[x][y] = 0 # 将陆地“沉没”为水count += 1for i, j in position:next_x = x + inext_y = y + j# 越界处理if next_x < 0 or next_y < 0 or next_x >= len(grid) or next_y >= len(grid[0]):continue# 如果是陆地,递归搜索if grid[next_x][next_y] == 1: dfs(grid, next_x, next_y)# 输入读取
n, m = map(int, input().split())
grid = []
for _ in range(n):grid.append(list(map(int, input().split())))# 第一步:清除所有接触边缘的岛屿
for i in range(n):if grid[i][0] == 1: # 左边界dfs(grid, i, 0)if grid[i][m - 1] == 1: # 右边界dfs(grid, i, m - 1)for j in range(m):if grid[0][j] == 1: # 上边界dfs(grid, 0, j)if grid[n - 1][j] == 1: # 下边界dfs(grid, n - 1, j)# 第二步:统计内部的孤岛面积
count = 0 # 重置计数器
for i in range(n):for j in range(m):if grid[i][j] == 1:dfs(grid, i, j)print(count)
这里需要注意:统计内部的孤岛面积之前要把计数器count清零,因为遍历边界的时候count在dfs函数内部有赋值操作。
BFS:
from collections import deque# 定义四个方向:右、下、左、上(用于遍历相邻的陆地)
direct = [[0, 1], [1, 0], [0, -1], [-1, 0]]count = 0 # 用于统计孤岛的总面积def bfs(grid, x, y):"""广度优先搜索:从 (x, y) 开始,将连通的陆地单元格全部“淹掉”(设为0)并累计面积"""global countque = deque()que.append([x, y])grid[x][y] = 0 # 将当前格子标记为已访问(水)count += 1 # 当前陆地面积 +1while que:x, y = que.popleft()for dx, dy in direct:next_x = x + dxnext_y = y + dy# 越界检查if next_x < 0 or next_x >= len(grid) or next_y < 0 or next_y >= len(grid[0]):continue# 如果是陆地,则加入队列,继续“淹掉”if grid[next_x][next_y] == 1:que.append([next_x, next_y])grid[next_x][next_y] = 0count += 1 # 每找到一个陆地格子,面积 +1# 读取输入
n, m = map(int, input().split()) # 行数、列数
grid = []
for _ in range(n):grid.append(list(map(int, input().split()))) # 构建地图矩阵# 第一步:清除所有与边界相连的岛屿(不计入孤岛)
for i in range(n):if grid[i][0] == 1:bfs(grid, i, 0)if grid[i][m - 1] == 1:bfs(grid, i, m - 1)
for j in range(m):if grid[0][j] == 1:bfs(grid, 0, j)if grid[n - 1][j] == 1:bfs(grid, n - 1, j)# 第二步:正式统计所有内部孤岛的总面积
count = 0 # 重置计数器
for i in range(n):for j in range(m):if grid[i][j] == 1:bfs(grid, i, j)# 输出所有孤岛的总面积
print(count)
四、沉没孤岛(Kamacoder 102)
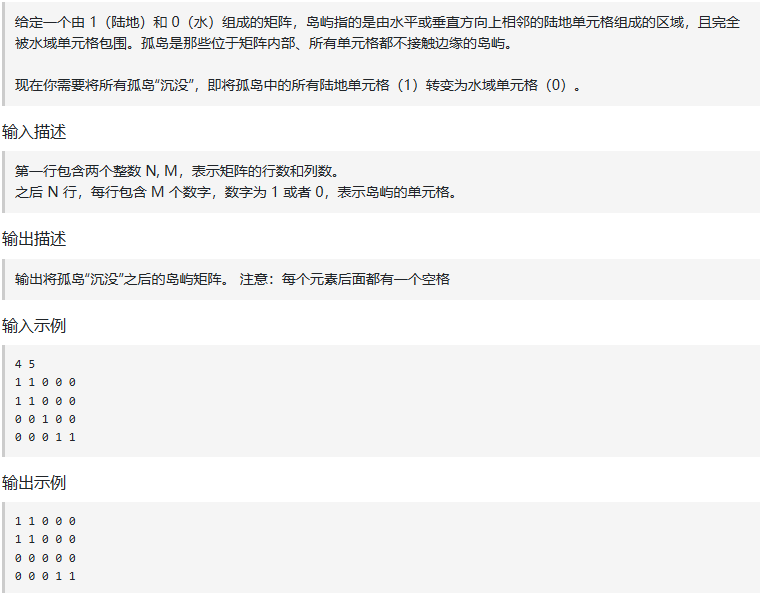

DFS:
def dfs(grid, x, y):# 将当前位置标记为2,表示访问过并来自边界的陆地grid[x][y] = 2directions = [(-1, 0), (0, -1), (1, 0), (0, 1)] # 上、左、下、右四个方向for dx, dy in directions:nextx, nexty = x + dx, y + dy# 如果越界,则跳过if nextx < 0 or nextx >= len(grid) or nexty < 0 or nexty >= len(grid[0]):continue# 如果是水(0)或已经标记过的陆地(2),也跳过if grid[nextx][nexty] == 0 or grid[nextx][nexty] == 2:continue# 继续向相邻陆地递归搜索dfs(grid, nextx, nexty)def main():n, m = map(int, input().split()) # 输入行列数# 读取整个地图矩阵grid = [[int(x) for x in input().split()] for _ in range(n)]# 步骤一:处理边界上的陆地,使用DFS将它们和相连的陆地标记为2for i in range(n):if grid[i][0] == 1: # 左边界dfs(grid, i, 0)if grid[i][m - 1] == 1: # 右边界dfs(grid, i, m - 1)for j in range(m):if grid[0][j] == 1: # 上边界dfs(grid, 0, j)if grid[n - 1][j] == 1: # 下边界dfs(grid, n - 1, j)# 步骤二和三:# 遍历所有格子for i in range(n):for j in range(m):if grid[i][j] == 1:# 还剩下的1是被水包围的孤岛,置为0(清除孤岛)grid[i][j] = 0elif grid[i][j] == 2:# 原本在边缘或连通边缘的陆地,恢复为1grid[i][j] = 1# 打印最终结果矩阵for row in grid:print(' '.join(map(str, row)))if __name__ == "__main__":main()
BFS:
from collections import deque# 输入地图的行列数
n, m = list(map(int, input().split()))# 读取地图网格 g
g = []
for _ in range(n):row = list(map(int, input().split()))g.append(row)# 定义四个方向(上下左右)
directions = [(1, 0), (-1, 0), (0, 1), (0, -1)]
count = 0 # 可选统计被访问的节点数(未实际使用)# 广度优先搜索函数,用于将与边界连通的陆地标记
def bfs(r, c, mode):global count q = deque()q.append((r, c)) # 起始位置加入队列count += 1while q:r, c = q.popleft()if mode:g[r][c] = 2 # 标记为已访问(与边界相连)for di in directions:next_r = r + di[0]next_c = c + di[1]# 越界跳过if next_c < 0 or next_c >= m or next_r < 0 or next_r >= n:continue# 若为陆地(1),则入队继续扩展if g[next_r][next_c] == 1:q.append((next_r, next_c))if mode:g[r][c] = 2 # 标记当前格子为边界连通count += 1# 遍历边界四周,找到所有与边界连通的陆地,并进行 BFS 标记
for i in range(n):if g[i][0] == 1: bfs(i, 0, True) # 左边界if g[i][m - 1] == 1: bfs(i, m - 1, True) # 右边界for j in range(m):if g[0][j] == 1: bfs(0, j, True) # 上边界if g[n - 1][j] == 1: bfs(n - 1, j, True) # 下边界# 处理最终输出:
# - 被标记为 2 的陆地(与边界连通)恢复为 1
# - 其余陆地为封闭岛屿,置为 0(沉没)
for i in range(n):for j in range(m):if g[i][j] == 2:g[i][j] = 1else:g[i][j] = 0# 打印最终地图结果
for row in g:print(" ".join(map(str, row)))
五、水流问题(Kamacoder 103)


-
每个 DFS 逻辑是“水可以流向高度大于等于自己的相邻格子”。
-
从两个边界(上/左、下/右)出发分别进行 DFS。
-
最终取两个集合交集,得到的是能从两边都能流到的点。
first = set() # 记录能从第一边界(上边和左边)流到的点
second = set() # 记录能从第二边界(下边和右边)流到的点# 四个方向:上、右、下、左
directions = [[-1, 0], [0, 1], [1, 0], [0, -1]]def dfs(i, j, graph, visited, side):# 如果已经访问过,直接返回if visited[i][j]:return# 标记已访问visited[i][j] = Trueside.add((i, j)) # 加入当前方向的集合中# 遍历四个方向for x, y in directions:new_x = i + xnew_y = j + y# 保证下标合法且水能从当前格子流向相邻格子(即相邻格子值 >= 当前值)if (0 <= new_x < len(graph)and 0 <= new_y < len(graph[0])and int(graph[new_x][new_y]) >= int(graph[i][j])):dfs(new_x, new_y, graph, visited, side)def main():global firstglobal secondN, M = map(int, input().strip().split()) # 输入矩阵的行数和列数graph = []for _ in range(N):row = input().strip().split()graph.append(row) # 构造二维矩阵# 第一步:从第一边界(上边和左边)出发进行 DFSvisited = [[False] * M for _ in range(N)]for i in range(M): # 上边界dfs(0, i, graph, visited, first)for i in range(N): # 左边界dfs(i, 0, graph, visited, first)# 第二步:从第二边界(下边和右边)出发进行 DFSvisited = [[False] * M for _ in range(N)]for i in range(M): # 下边界dfs(N - 1, i, graph, visited, second)for i in range(N): # 右边界dfs(i, M - 1, graph, visited, second)# 第三步:找出同时能从两个边界流通的交集点res = first & second# 打印所有可以从两个边界都流通到的坐标点for x, y in res:print(f"{x} {y}")if __name__ == "__main__":main()
六、建造最大岛屿(Kamacoder 104)

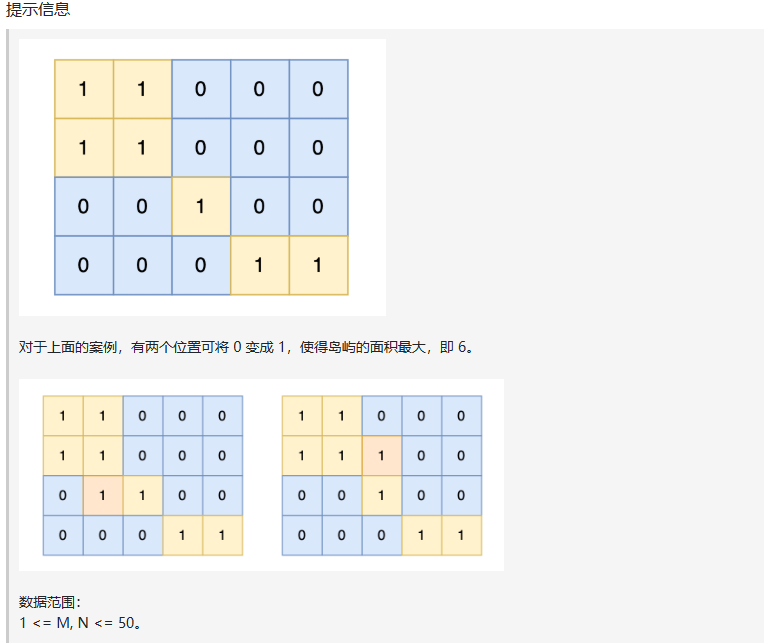
-
把每个岛屿编号并计算面积。
-
遍历所有水域格子,尝试变成陆地并连接周围不同的岛屿。
-
记录最大可能岛屿面积。
-
边界处理和重复统计都已通过
visited和set控制。
import collections# 四个方向:上、右、左、下
directions = [[-1, 0], [0, 1], [0, -1], [1, 0]]area = 0 # 当前岛屿的面积def dfs(i, j, grid, visited, num):"""深度优先搜索,将岛屿上的所有陆地格子标记为同一个编号num,并统计当前岛屿的总面积"""global areaif visited[i][j]:returnvisited[i][j] = Truegrid[i][j] = num # 用编号num标记该岛屿area += 1 # 累加岛屿面积for x, y in directions:new_x = i + xnew_y = j + y# 判断是否在边界内且是未访问的陆地if (0 <= new_x < len(grid)and 0 <= new_y < len(grid[0])and grid[new_x][new_y] == "1"):dfs(new_x, new_y, grid, visited, num)def main():global areaN, M = map(int, input().strip().split()) # 读入行列数grid = []for _ in range(N):grid.append(input().strip().split()) # 读取每一行visited = [[False] * M for _ in range(N)] # 记录访问情况rec = collections.defaultdict(int) # 记录每个岛屿编号对应的面积cnt = 2 # 编号从2开始,避免与"0"(水)和"1"(未编号陆地)混淆for i in range(N):for j in range(M):if grid[i][j] == "1":area = 0dfs(i, j, grid, visited, cnt)rec[cnt] = area # 保存当前岛屿面积cnt += 1res = 0 # 最终最大岛屿面积for i in range(N):for j in range(M):if grid[i][j] == "0": # 尝试将水变成陆地max_island = 1 # 当前面积初始为1(假设这里是陆地)v = set() # 防止重复统计相邻岛屿for x, y in directions:new_x = i + xnew_y = j + yif (0 <= new_x < len(grid)and 0 <= new_y < len(grid[0])and grid[new_x][new_y] != "0"and grid[new_x][new_y] not in v):max_island += rec[grid[new_x][new_y]]v.add(grid[new_x][new_y])res = max(res, max_island)if res == 0:# 如果没有水可变为陆地,返回最大岛屿面积return max(rec.values())return resif __name__ == "__main__":print(main())
BFS:
from typing import List
from collections import defaultdictclass Solution:def __init__(self):# 定义四个方向(上、下、左、右)self.direction = [(1,0),(-1,0),(0,1),(0,-1)]self.res = 0 # 存放结果:最大可能的连通面积self.count = 0 # 当前岛屿的面积计数器self.idx = 1 # 当前岛屿的编号,从2开始(因为1已经是初始岛屿标记)self.count_area = defaultdict(int) # 记录每个岛屿编号对应的面积def max_area_island(self, grid: List[List[int]]) -> int:if not grid or len(grid) == 0 or len(grid[0]) == 0:return 0# Step 1: DFS 标记每个岛屿为不同编号(从 2 开始),并记录每个岛屿的面积for i in range(len(grid)):for j in range(len(grid[0])):if grid[i][j] == 1:self.count = 0self.idx += 1self.dfs(grid, i, j) # 递归标记岛屿# Step 2: 统计每个编号的面积self.check_area(grid)# Step 3: 尝试将一个 0 变成 1,看是否能连接多个岛屿,获取最大可能面积if self.check_largest_connect_island(grid=grid):return self.res + 1 # +1 是把0变成1后的面积增加return max(self.count_area.values()) # 若没有0,返回最大岛屿面积def dfs(self, grid, row, col):# 使用 DFS 给岛屿打编号,并统计面积grid[row][col] = self.idxself.count += 1for dr, dc in self.direction:_row = dr + row _col = dc + col if 0 <= _row < len(grid) and 0 <= _col < len(grid[0]) and grid[_row][_col] == 1:self.dfs(grid, _row, _col)returndef check_area(self, grid):# 遍历整张图,统计每个岛屿编号的面积(包含编号为 2 及以上)m, n = len(grid), len(grid[0])for row in range(m):for col in range(n):self.count_area[grid[row][col]] = self.count_area.get(grid[row][col], 0) + 1returndef check_largest_connect_island(self, grid):# 检查每个值为0的位置,看是否能连接多个岛屿m, n = len(grid), len(grid[0])has_connect = False # 是否存在0可用作连接点for row in range(m):for col in range(n):if grid[row][col] == 0:has_connect = Truearea = 0visited = set() # 避免重复计算同一编号岛屿for dr, dc in self.direction:_row = row + dr _col = col + dcif (0 <= _row < len(grid)and 0 <= _col < len(grid[0])and grid[_row][_col] != 0and grid[_row][_col] not in visited):visited.add(grid[_row][_col])area += self.count_area[grid[_row][_col]]self.res = max(self.res, area) # 更新最大面积return has_connect # 返回是否存在可以转换的0def main():# 输入处理m, n = map(int, input().split())grid = []for i in range(m):grid.append(list(map(int, input().split())))# 创建对象并调用主函数sol = Solution()print(sol.max_area_island(grid))if __name__ == '__main__':main()
七、岛屿的周长(Kamacoder 106)

def main():import sysinput = sys.stdin.readdata = input().split()# 读取行数 n 和列数 mn = int(data[0])m = int(data[1])# 初始化 grid 网格grid = []index = 2 # 从第3个数据开始是地图数据for i in range(n):# 读取每一行的 m 个数据grid.append([int(data[index + j]) for j in range(m)])index += msum_land = 0 # 记录陆地格子的总数cover = 0 # 记录相邻的陆地边对数(每对相邻边减少2个周长)for i in range(n):for j in range(m):if grid[i][j] == 1:sum_land += 1 # 统计陆地格子数量# 检查上方是否是陆地,如果是,说明这两个格子共享一条边if i - 1 >= 0 and grid[i - 1][j] == 1:cover += 1# 检查左方是否是陆地,同样共享一条边if j - 1 >= 0 and grid[i][j - 1] == 1:cover += 1# 不检查下方和右方,是为了避免重复计算边界# 每个陆地格子原始贡献 4 个边界,所有相邻对共享 2 个边界result = sum_land * 4 - cover * 2print(result)if __name__ == "__main__":main()
相关文章:
代码随想录第41天:图论2(岛屿系列)
一、岛屿数量(Kamacoder 99) 深度优先搜索: # 定义四个方向:右、下、左、上,用于 DFS 中四向遍历 direction [[0, 1], [1, 0], [0, -1], [-1, 0]]def dfs(grid, visited, x, y):"""对一块陆地进行深度…...
详解)
Vue插槽(Slots)详解
文章目录 1. 插槽简介1.1 什么是插槽?1.2 为什么需要插槽?1.3 插槽的基本语法 2. 默认插槽2.1 什么是默认插槽?2.2 默认插槽语法2.3 插槽默认内容2.4 默认插槽实例:创建一个卡片组件2.5 Vue 3中的默认插槽2.6 默认插槽的应用场景 …...

中国古代史1
朝代歌 三皇五帝始,尧舜禹相传。 夏商与西周,东周分两段。 春秋和战国,一统秦两汉。 三分魏蜀吴,二晋前后延。 南北朝并立,隋唐五代传。 宋元明清后,皇朝至此完。 原始社会 元谋人,170万年前…...

vue +xlsx+exceljs 导出excel文档
实现功能:分标题行导出数据过多,一个sheet表里表格条数有限制,需要分sheet显示。 步骤1:安装插件包 npm install exceljs npm install xlsx 步骤2:引用包 import XLSX from xlsx; import ExcelJS from exceljs; 步骤3&am…...

nginx之proxy_redirect应用
一、功能说明 proxy_redirect 是 Nginx 反向代理中用于修改后端返回的响应头中 Location 和 Refresh 字段的核心指令,主要解决以下问题:协议/地址透传错误:当后端返回的 Location 包含内部 IP、HTTP 协议或非标准端口时,需修正为…...

在 Flink + Kafka 实时数仓中,如何确保端到端的 Exactly-Once
在 Flink Kafka 构建实时数仓时,确保端到端的 Exactly-Once(精确一次) 需要从 数据消费(Source)、处理(Processing)、写入(Sink) 三个阶段协同设计,结合 Fli…...

Qt 中基于 spdlog 的高效日志管理方案
在开发 Qt 应用程序时,日志记录是一项至关重要的功能,它能帮助我们追踪程序的运行状态、定位错误和分析性能。本文将介绍如何在 Qt 项目中集成 spdlog 库,并封装一个简单易用的日志管理类 QtLogger,实现高效的日志记录和管理。 为什么选择 spdlog? spdlog 是一个快速、头…...

VUE CLI - 使用VUE脚手架创建前端项目工程
前言 前端从这里开始,本文将介绍如何使用VUE脚手架创建前端工程项目 1.预准备(编辑器和管理器) 编辑器:推荐使用Vscode,WebStorm,或者Hbuilder(适合刚开始练手使用),个…...

Linux 学习笔记2
Linux 学习笔记2 一、定时任务调度操作流程注意事项 二、磁盘分区与管理添加新硬盘流程磁盘管理命令 三、进程管理进程操作命令服务管理(Ubuntu) 四、注意事项 一、定时任务调度 操作流程 创建脚本 vim /path/to/script.sh # 编写脚本内容设置可执行权…...

JS DOM操作与事件处理从入门到实践
对于前端开发者来说,让静态的 HTML 页面变得生动、可交互是核心技能之一。实现这一切的关键在于理解和运用文档对象模型 (DOM) 以及 JavaScript 的事件处理机制。本文将带你深入浅出地探索 DOM 操作的奥秘,并掌握JavaScript 事件处理的方方面面。 目录 …...
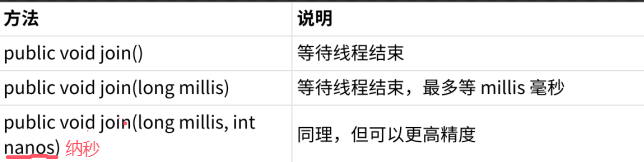
Java EE初阶——初识多线程
1. 认识线程 线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。 基本概念:一个进程可以包含多个线程,这些线程共享进程的资源,如内存空间、文件描述符等,但每个线程都有自己独…...
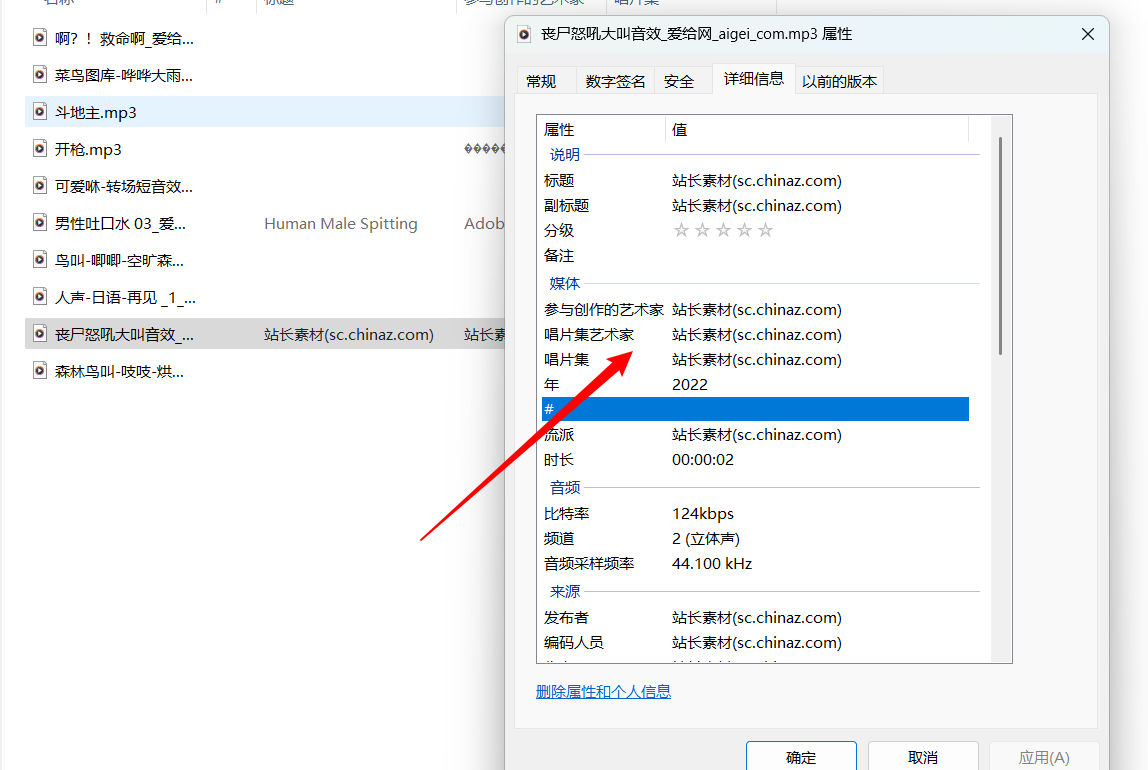
如何删除网上下载的资源后面的文字
这是我在爱给网上下载的音效资源,但是发现资源后面跟了一大段无关紧要的文本,但是修改资源名称后还是有。解决办法是打开属性然后删掉资源的标签即可。...

深入解析C++11委托构造函数:消除冗余初始化的利器
一、传统构造函数的痛点 在C11之前,当多个构造函数需要执行相同的初始化逻辑时,开发者往往面临两难选择: class DataProcessor {std::string dataPath;bool verbose;int bufferSize; public:// 基础版本DataProcessor(const std::string&am…...

Python中的事件循环是什么?事件是怎么个事件?循环是怎么个循环
在Python异步编程中,事件循环(Event Loop)是核心机制,它通过单线程实现高效的任务调度和I/O并发处理。本文将从事件的定义、循环的运行逻辑以及具体实现原理三个维度展开分析。 一、事件循环的本质:协程与任务的调度器…...
FPGA图像处理(5)------ 图片水平镜像
利用bram形成双缓冲,如下图配置所示: wr_flag 表明 buffer0写 还是 buffer1写 rd_flag 表明 buffer0读 还是 buffer1读 通过写入逻辑控制(结合wr_finish) 写哪个buffer ;写地址 进而控制ip的写使能 通过状态缓存来跳转buffer的…...

[python] 类
一 介绍 具有相同属性和行为的事物的通称,是一个抽象的概念 三要素: 类名,属性,方法 格式: class 类名: 代码块 class Pepole:name "stitchcool"def getname(self):return self.name 1.1 创建对象(实例化) 格式: 对象名 类名() p1 Pepole()…...
day21python打卡
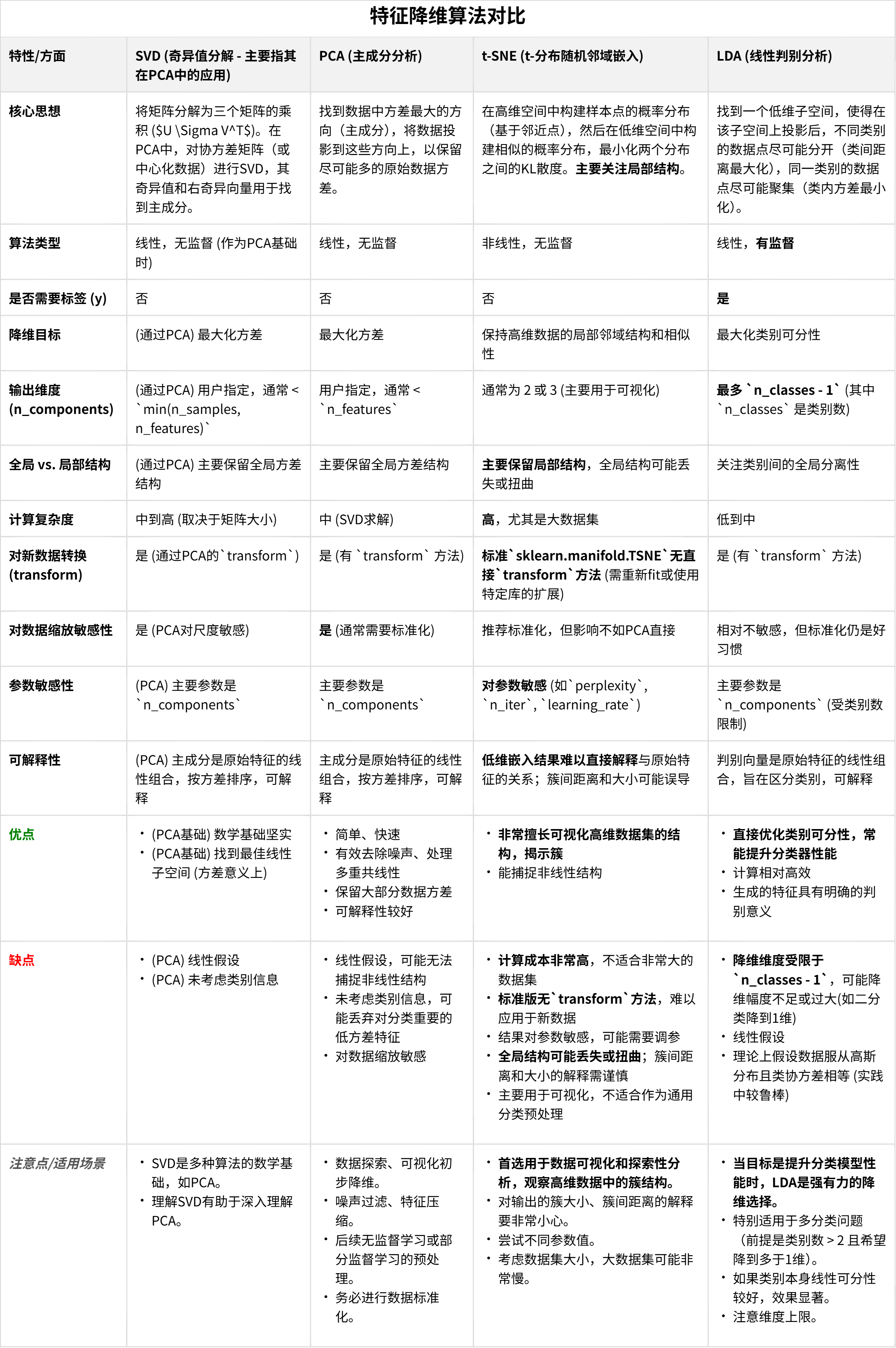
知识点回顾: LDA线性判别PCA主成分分析t-sne降维 还有一些其他的降维方式,也就是最重要的词向量的加工,我们未来再说 作业: 自由作业:探索下什么时候用到降维?降维的主要应用?或者让ai给你出题&…...

Android开发-Activity启停
在Android应用开发中,Activity是构建用户界面的基本组件之一。它代表了一个单一的、专注的操作,比如查看一张图片或者撰写一封电子邮件。每个Activity都有其生命周期,从创建到销毁,会经历一系列的状态变化。了解并正确管理这些状态…...
ERP学习(一): 用友u8安装
安装: https://www.bilibili.com/video/BV1Pp4y187ot/?spm_id_from333.337.search-card.all.click&vd_sourced514093d85ee628d1f12310b13b1e59b 我个人用vmware16,这位up已经把用友软件和环境(sqlserver2008) 都封城vmx文件了…...

01 | 大模型微调 | 从0学习到实战微调 | AI发展与模型技术介绍
一、导读 作为非AI专业技术开发者(我是小小爬虫开发工程师😋) 本系列文章将围绕《大模型微调》进行学习(也是我个人学习的笔记,所以会持续更新),最后以上手实操模型微调的目的。 (本文如若有…...
海康相机无损压缩
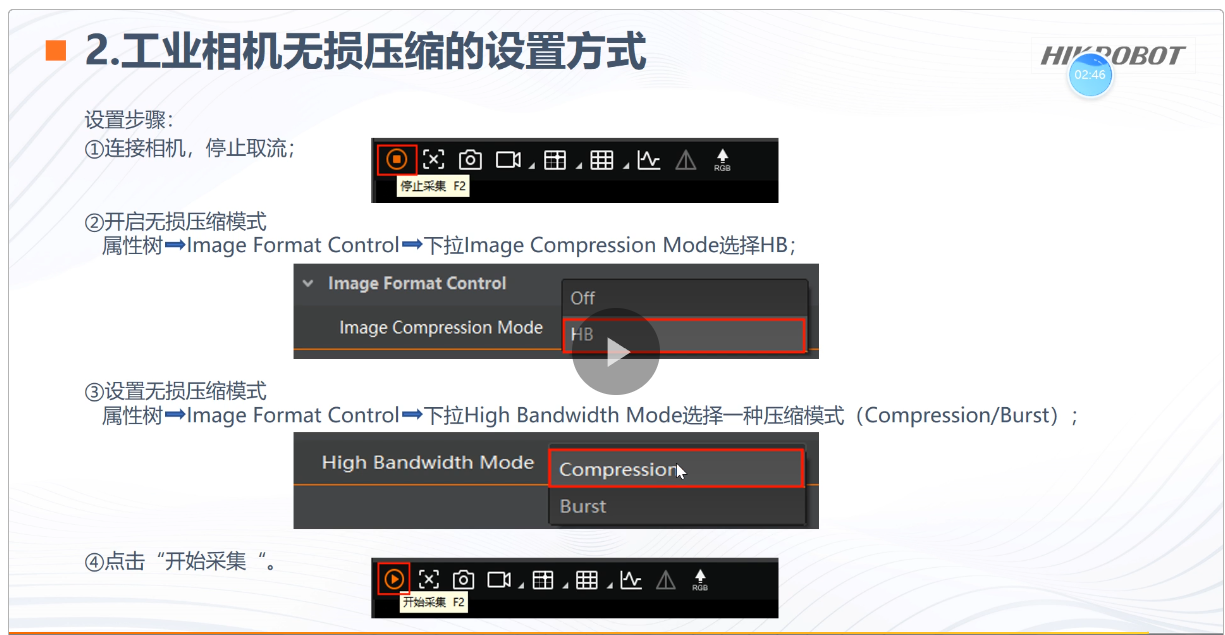
设置无损压缩得到更高的带宽和帧率!...

从机器人到调度平台:超低延迟RTMP|RTSP播放器系统级部署之道
✅ 一、模块定位:跨平台、超低延迟、系统级稳定的音视频直播播放器内核 在无人机、机器人、远程操控手柄等场景中,低延迟的 RTSP/RTMP 播放器并不是“可有可无的体验优化”,而是系统能否闭环、操控是否安全的关键组成。 Windows和安卓播放RT…...

研发效率破局之道阅读总结(5)管理文化
研发效率破局之道阅读总结(5)管理文化 Author: Once Day Date: 2025年5月10日 一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦… 漫漫长路,有人对你微笑过嘛… 全系列文章可参考专栏: 程序的艺术_Once-Day…...
单因子实验 方差分析
本文是实验设计与分析(第6版,Montgomery著傅珏生译)第3章单因子实验 方差分析python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您可以从 下载实验设计与分析(第6版&a…...

一、ArkTS语法学习
一、ArkTS语法学习 1 ArkTS语法简介2 声明2.1 变量声明2.2 常量声明2.3 自动类型推断 3 类型3.1 基本类型和引用类型3.2 基本数据类型3.2.1 number类型3.2.2 boolean类型3.2.3 string类型3.2.4 void类型 3.3 引用类型3.3.1 Object类型3.3.2 arry类型3.3.3 enum类型3.3.4 Union类…...

MySQL 1366 - Incorrect string value:错误
MySQL 1366 - Incorrect string value:错误 错误如何发生发生原因: 解决方法第一种尝试第二种尝试 错误 如何发生 在给MySQL添加数据的时候发生了下面的错误 insert into sys_dept values(100, 0, 0, 若依科技, 0, 若依, 15888888888, ryqq.com, 0,…...
Bitacora:基因组组件中基因家族识别和注释的综合工具
软件教程 | Bitacora:基因组组件中基因家族识别和注释的综合工具 https://zhangzl96.github.io/tags#生物信息工具) 📅 官方地址:https://github.com/molevol-ub/bitacora 🔬 教程版本:BITACORA 1.4 📋 …...
【WebRTC-13】是在哪,什么时候,创建编解码器?
Android-RTC系列软重启,改变以往细读源代码的方式 改为 带上实际问题分析代码。增加实用性,方便形成肌肉记忆。同时不分种类、不分难易程度,在线征集问题切入点。 问题:编解码器的关键实体类是什么?在哪里&什么时候…...

青少年编程与数学 02-019 Rust 编程基础 01课题、环境准备
青少年编程与数学 02-019 Rust 编程基础 01课题、环境准备 一、Rust核心特性应用场景开发工具社区与生态 二、Rust 和 Python 比较1. **内存安全与并发编程**2. **性能**3. **零成本抽象**4. **跨平台支持**5. **社区与生态系统**6. **错误处理**7. **安全性**适用场景总结 三、…...
Redis持久化存储介质评估:NFS与Ceph的适用性分析
#作者:朱雷 文章目录 一、背景二、Redis持久化的必要性与影响1. 持久化的必要性2. 性能与稳定性问题 三、NFS作为持久化存储介质的问题1. 性能瓶颈2. 数据一致性问题3. 存储服务单点故障4. 高延迟影响持久化效率.5. 吞吐量瓶颈 四、Ceph作为持久化存储介质的问题1.…...