大模型微调指南之 LLaMA-Factory 篇:一键启动LLaMA系列模型高效微调
文章目录
- 一、简介
- 二、如何安装
- 2.1 安装
- 2.2 校验
- 三、开始使用
- 3.1 可视化界面
- 3.2 使用命令行
- 3.2.1 模型微调训练
- 3.2.2 模型合并
- 3.2.3 模型推理
- 3.2.4 模型评估
- 四、高级功能
- 4.1 分布训练
- 4.2 DeepSpeed
- 4.2.1 单机多卡
- 4.2.2 多机多卡
- 五、日志分析
一、简介
LLaMA-Factory 是一个用于训练和微调模型的工具。它支持全参数微调、LoRA 微调、QLoRA 微调、模型评估、模型推理和模型导出等功能。
二、如何安装
2.1 安装
# 构建虚拟环境
conda create -n llamafactory python=3.10 -y && conda activate llamafactory
# 下载仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# 安装
pip install -e .
2.2 校验
llamafactory-cli version
三、开始使用
3.1 可视化界面
# 启动可视化界面
llamafactory-cli webui
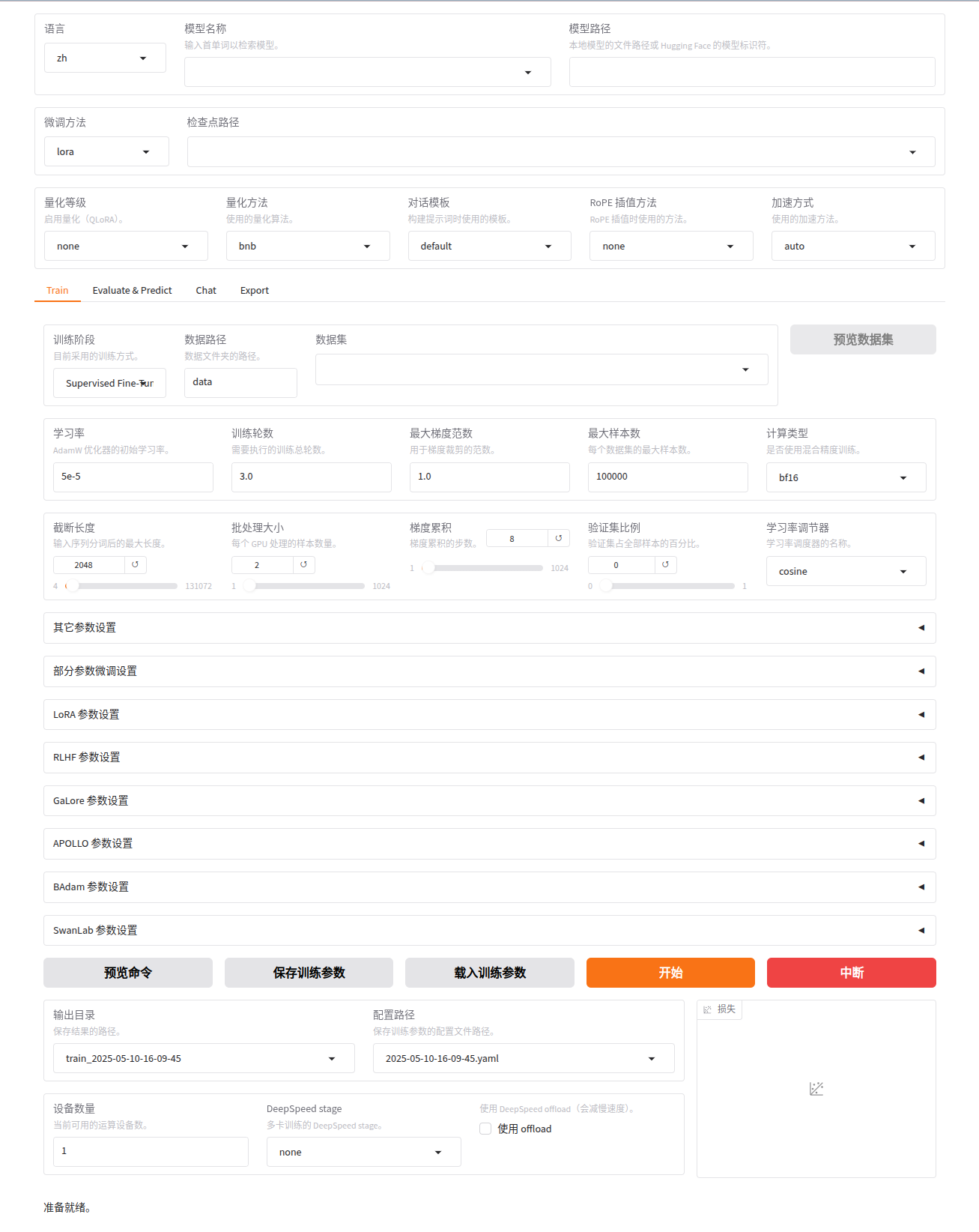
WebUI 主要分为四个界面:训练、评估与预测、对话、导出。
- 训练:
- 在开始训练模型之前,您需要指定的参数有:
- 模型名称及路径
- 训练阶段
- 微调方法
- 训练数据集
- 学习率、训练轮数等训练参数
- 微调参数等其他参数
- 输出目录及配置路径
随后,点击 开始 按钮开始训练模型。
备注:
关于断点重连:适配器断点保存于output_dir目录下,请指定检查点路径以加载断点继续训练。
如果需要使用自定义数据集,需要在data/data_info.json中添加自定义数据集描述并确保数据集格式正确,否则可能会导致训练失败。
-
评估预测
- 模型训练完毕后,可以通过在评估与预测界面通过指定
模型及检查点路径在指定数据集上进行评估。
- 模型训练完毕后,可以通过在评估与预测界面通过指定
-
对话
- 通过在对话界面指定
模型、检查点路径及推理引擎后输入对话内容与模型进行对话观察效果。
- 通过在对话界面指定
-
导出
- 如果对模型效果满意并需要导出模型,您可以在导出界面通过指定
模型、检查点路径、分块大小、导出量化等级及校准数据集、导出设备、导出目录等参数后点击导出按钮导出模型。
- 如果对模型效果满意并需要导出模型,您可以在导出界面通过指定
3.2 使用命令行
3.2.1 模型微调训练
在 examples/train_lora 目录下有多个LoRA微调示例,以 llama3_lora_sft.yaml 为例,命令如下:
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
备注:
LLaMA-Factory 默认使用所有可见的计算设备。根据需求可通过CUDA_VISIBLE_DEVICES或ASCEND_RT_VISIBLE_DEVICES指定计算设备。
参数说明:
| 名称 | 描述 |
|---|---|
| model_name_or_path | 模型名称或路径(指定本地路径,或从 huggingface 上下载) |
| stage | 训练阶段,可选: rm(reward modeling), pt(pretrain), sft(Supervised Fine-Tuning), PPO, DPO, KTO, ORPO |
| do_train | true用于训练, false用于评估 |
| finetuning_type | 微调方式。可选: freeze, lora, full |
| lora_target | 采取LoRA方法的目标模块,默认值为 all。 |
| dataset | 使用的数据集,使用”,”分隔多个数据集 |
| template | 数据集模板,请保证数据集模板与模型相对应。 |
| output_dir | 输出路径 |
| logging_steps | 日志输出步数间隔 |
| save_steps | 模型断点保存间隔 |
| overwrite_output_dir | 是否允许覆盖输出目录 |
| per_device_train_batch_size | 每个设备上训练的批次大小 |
| gradient_accumulation_steps | 梯度积累步数 |
| max_grad_norm | 梯度裁剪阈值 |
| learning_rate | 学习率 |
| lr_scheduler_type | 学习率曲线,可选 linear, cosine, polynomial, constant 等。 |
| num_train_epochs | 训练周期数 |
| bf16 | 是否使用 bf16 格式 |
| warmup_ratio | 学习率预热比例 |
| warmup_steps | 学习率预热步数 |
| push_to_hub | 是否推送模型到 Huggingface |
目录说明:
examples/train_full:包含多个全参数微调示例。examples/train_lora:包含多个LoRA微调示例。examples/train_qlora:包含多个QLoRA微调示例。
3.2.2 模型合并
在 examples/merge_lora 目录下有多个模型合并示例,以 llama3_lora_sft.yaml 为例,命令如下:
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
adapter_name_or_path 需要与微调中的适配器输出路径 output_dir 相对应。
export_quantization_bit 为导出模型量化等级,可选 2, 3, 4, 8。
目录说明:
examples/merge_lora:包含多个LoRA合并示例。
3.2.3 模型推理
在 examples/inference 目录下有多个模型推理示例,以 llama3_lora_sft.yaml 为例,命令如下:
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
参数说明:
| 名称 | 描述 |
|---|---|
| model_name_or_path | 模型名称或路径(指定本地路径,或从HuggingFace Hub下载) |
| adapter_name_or_path | 适配器检查点路径(用于LoRA等微调方法的预训练适配器) |
| template | 对话模板(需与模型架构匹配,如LLaMA-2、ChatGLM等专用模板) |
| infer_backend | 推理引擎(可选:vllm、transformers、lightllm等) |
3.2.4 模型评估
-
通用能力评估
llamafactory-cli eval examples/train_lora/llama3_lora_eval.yaml -
NLG 评估
llamafactory-cli train examples/extras/nlg_eval/llama3_lora_predict.yaml获得模型的
BLEU和ROUGE分数以评价模型生成质量。 -
评估相关参数
| 参数名称 | 类型 | 描述 | 默认值 | 可选值/备注 |
|---|---|---|---|---|
| task | str | 评估任务名称 | - | mmlu_test, ceval_validation, cmmlu_test |
| task_dir | str | 评估数据集存储目录 | “evaluation” | 相对或绝对路径 |
| batch_size | int | 每个GPU的评估批次大小 | 4 | 根据显存调整 |
| seed | int | 随机种子(保证可复现性) | 42 | - |
| lang | str | 评估语言 | “en” | en(英文), zh(中文) |
| n_shot | int | Few-shot学习使用的示例数量 | 5 | 0表示zero-shot |
| save_dir | str | 评估结果保存路径 | None | None时不保存 |
| download_mode | str | 数据集下载模式 | DownloadMode.REUSE_DATASET_IF_EXISTS | 存在则复用,否则下载 |
四、高级功能
4.1 分布训练
LLaMA-Factory 支持 单机多卡 和 多机多卡 分布式训练。同时也支持 DDP , DeepSpeed 和 FSDP 三种分布式引擎。
- DDP (DistributedDataParallel) 通过实现模型并行和数据并行实现训练加速。 使用
DDP的程序需要生成多个进程并且为每个进程创建一个DDP实例,他们之间通过torch.distributed库同步。 - DeepSpeed 是微软开发的分布式训练引擎,并提供
ZeRO(Zero Redundancy Optimizer)、offload、Sparse Attention、1 bit Adam、流水线并行等优化技术。 - FSDP 通过全切片数据并行技术(Fully Sharded Data Parallel)来处理更多更大的模型。在
DDP中,每张 GPU 都各自保留了一份完整的模型参数和优化器参数。而FSDP切分了模型参数、梯度与优化器参数,使得每张GPU只保留这些参数的一部分。 除了并行技术之外,FSDP还支持将模型参数卸载至CPU,从而进一步降低显存需求。
| 引擎 | 数据切分 | 模型切分 | 优化器切分 | 参数卸载 |
|---|---|---|---|---|
| DDP | 支持 | 不支持 | 不支持 | 不支持 |
| DeepSpeed | 支持 | 支持 | 支持 | 支持 |
| FSDP | 支持 | 支持 | 支持 | 支持 |
4.2 DeepSpeed
由于 DeepSpeed 的显存优化技术,使得 DeepSpeed 在显存占用上具有明显优势,因此推荐使用 DeepSpeed 进行训练。
DeepSpeed 是由微软开发的一个开源深度学习优化库,旨在提高大模型训练的效率和速度。在使用 DeepSpeed 之前,您需要先估计训练任务的显存大小,再根据任务需求与资源情况选择合适的 ZeRO 阶段。
- ZeRO-1: 仅划分优化器参数,每个GPU各有一份完整的模型参数与梯度。
- ZeRO-2: 划分优化器参数与梯度,每个GPU各有一份完整的模型参数。
- ZeRO-3: 划分优化器参数、梯度与模型参数。
简单来说:从ZeRO-1到ZeRO-3,阶段数越高,显存需求越小,但是训练速度也依次变慢。此外,设置offload_param=cpu参数会大幅减小显存需求,但会极大地使训练速度减慢。因此,如果您有足够的显存, 应当使用ZeRO-1,并且确保offload_param=none。
4.2.1 单机多卡
启动 DeepSpeed 引擎,命令如下:
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_full/llama3_full_sft_ds3.yaml
该配置文件中配置了 deepspeed 参数,具体如下:
deepspeed: examples/deepspeed/ds_z3_config.json
4.2.2 多机多卡
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
备注
关于hostfile:
hostfile的每一行指定一个节点,每行的格式为 slots=<num_slots> , 其中 是节点的主机名, <num_slots> 是该节点上的GPU数量。下面是一个例子:worker-1 slots=4 worker-2 slots=4请在 https://www.deepspeed.ai/getting-started/ 了解更多。
如果没有指定
hostfile变量,DeepSpeed会搜索/job/hostfile文件。如果仍未找到,那么DeepSpeed会使用本机上所有可用的GPU。
五、日志分析
在训练过程中,LLaMA-Factory 会输出详细的日志信息,包括训练进度、训练参数、训练时间等。这些日志信息可以帮助我们更好地了解训练过程,并针对问题进行优化和调整。以下解释训练时的一些参数:
[INFO|trainer.py:2409] 2025-04-01 15:49:20,010 >> ***** Running training *****
[INFO|trainer.py:2410] 2025-04-01 15:49:20,010 >> Num examples = 205
[INFO|trainer.py:2411] 2025-04-01 15:49:20,010 >> Num Epochs = 1,000
[INFO|trainer.py:2412] 2025-04-01 15:49:20,010 >> Instantaneous batch size per device = 8
[INFO|trainer.py:2415] 2025-04-01 15:49:20,010 >> Total train batch size (w. parallel, distributed & accumulation) = 64
[INFO|trainer.py:2416] 2025-04-01 15:49:20,010 >> Gradient Accumulation steps = 8
[INFO|trainer.py:2417] 2025-04-01 15:49:20,010 >> Total optimization steps = 3,000
[INFO|trainer.py:2418] 2025-04-01 15:49:20,013 >> Number of trainable parameters = 73,859,072
参数解释:
-
单设备批大小(Instantaneous batch size per device)
- 指单个 GPU(或设备)在每次前向传播时处理的样本数量。
- 例如,如果
instantaneous_batch_size_per_device=8,则每个 GPU 一次处理 8 条数据。
-
设备数(Number of devices)
- 指并行训练的 GPU 数量(数据并行)。
- 例如,使用 4 个 GPU 时,
device_num=4。
-
梯度累积步数(Gradient accumulation steps)
- 由于显存限制,可能无法直接增大单设备批大小,因此通过多次前向传播累积梯度,再一次性更新参数。通过梯度累积,用较小的单设备批大小模拟大总批大小的训练效果。
- 例如,若
gradient_accumulation_steps=2,则每 2 次前向传播后才执行一次参数更新。
-
总批大小(Total train batch size)
- 是参数更新时实际使用的全局批量大小。总批大小越大,梯度估计越稳定,但需调整学习率(通常按比例增大)
在 LLaMA Factory 中,总批大小(Total train batch size)、单设备批大小(Instantaneous batch size per device)、设备数(Number of devices) 和 梯度累积步数(Gradient accumulation steps) 的关系可以用以下公式表示:
[
\text{总批大小} = \text{单设备批大小} \times \text{设备数} \times \text{梯度累积步数}
]
例如:
- 单设备批大小 = 8
- 设备数 = 4
- 梯度累积步数 = 2
- 则总批大小 = ( 8 \times 4 \times 2 = 64 )。
参考资料:
- Github
- README_zh.md
- 数据集文档
- 说明文档
相关文章:
大模型微调指南之 LLaMA-Factory 篇:一键启动LLaMA系列模型高效微调
文章目录 一、简介二、如何安装2.1 安装2.2 校验 三、开始使用3.1 可视化界面3.2 使用命令行3.2.1 模型微调训练3.2.2 模型合并3.2.3 模型推理3.2.4 模型评估 四、高级功能4.1 分布训练4.2 DeepSpeed4.2.1 单机多卡4.2.2 多机多卡 五、日志分析 一、简介 LLaMA-Factory 是一个…...
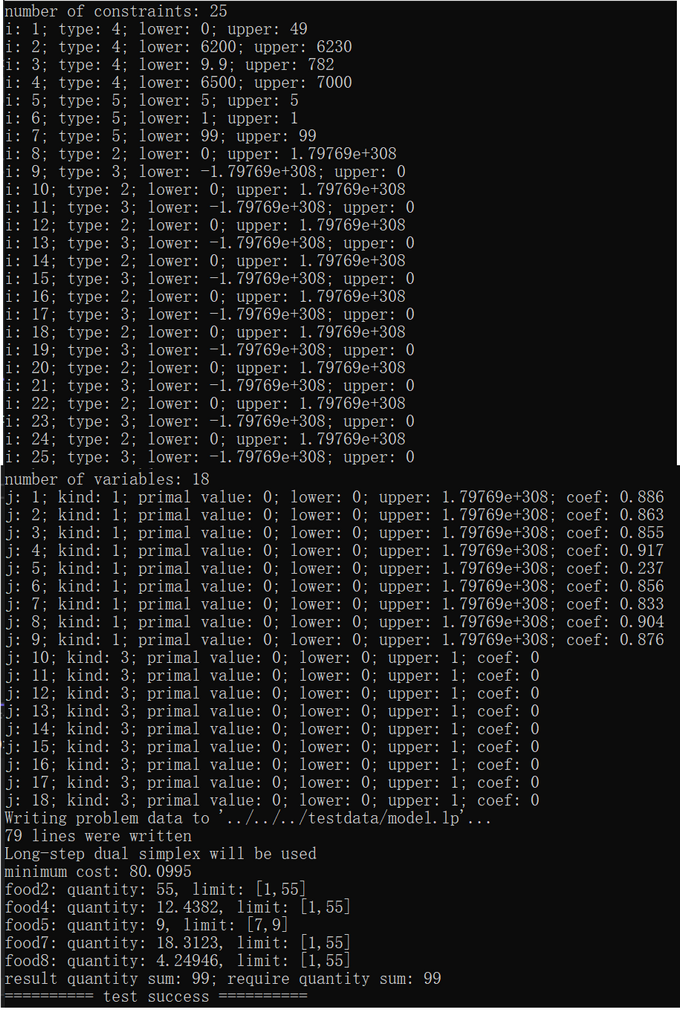
GLPK(GNU线性规划工具包)介绍
GLPK全称为GNU Linear Programming Kit(GNU线性规划工具包),可从 https://sourceforge.net/projects/winglpk/ 下载源码及二进制库,最新版本为4.65。也可从 https://ftp.gnu.org/gnu/glpk/ 下载,仅包含源码,最新版本为5.0。 GLPK是…...
:负载均衡流量分发管理实战指南)
Kubernetes生产实战(十七):负载均衡流量分发管理实战指南
在Kubernetes集群中,负载均衡是保障应用高可用、高性能的核心机制。本文将从生产环境视角,深入解析Kubernetes负载均衡的实现方式、最佳实践及常见问题解决方案。 一、Kubernetes负载均衡的三大核心组件 1)Service资源:集群内流…...

PCB设计实践(十三)PCB设计中差分线间距与线宽设置的深度解析
一、差分信号的基本原理与物理背景 差分信号技术通过两条等幅反相的传输线实现信号传输,其核心优势体现在电磁场耦合的对称性上。根据麦克斯韦方程组的对称解原理,两条线产生的电磁场在远场区域相互抵消,形成以下特性: 1. 共模噪…...
2025python学习笔记
一.Python语言基础入门 第一章 01.初识Python Python的起源: 1989年,为了打发圣诞节假期,Gudio van Rossum吉多范罗苏姆(龟叔)决心开发一个新的解释程序(Python维形)1991年,第一个…...

前端取经路——入门取经:初出师门的九个CSS修行
大家好,我是老十三,一名前端开发工程师。CSS就像前端修行路上的第一道关卡,看似简单,实则暗藏玄机。在今天的文章中,我将带你一起应对九大CSS难题,从Flexbox布局到响应式设计,从选择器优先级到B…...

【Pandas】pandas DataFrame corr
Pandas2.2 DataFrame Computations descriptive stats 方法描述DataFrame.abs()用于返回 DataFrame 中每个元素的绝对值DataFrame.all([axis, bool_only, skipna])用于判断 DataFrame 中是否所有元素在指定轴上都为 TrueDataFrame.any(*[, axis, bool_only, skipna])用于判断…...

【并发编程】基于 Redis 手写分布式锁
目录 一、基于 Redis 演示超卖现象 1.1 Redis 超卖现象 1.2 超卖现象解决方案 二、Redis 的乐观锁机制 2.1 原生客户端演示 2.2 业务代码实现 三、单机部署 Redis 实现分布式锁 3.1 分布式锁的演变和升级 3.2 setnx 实现分布式锁 3.2.1 递归调用实现分布式锁 3.2.2 循…...

Web3 初学者的第一个实战项目:留言上链 DApp
目录 📌 项目简介:留言上链 DApp(MessageBoard DApp) 🧠 技术栈 🔶 1. Solidity 智能合约代码(MessageBoard.sol) 🔷 2. 前端代码(index.html script.js…...

Jsp技术入门指南【十二】自定义标签
Jsp技术入门指南【十二】自定义标签 前言一、什么是标签二、标签的类型有哪些?1. 空标签2. 带有属性的标签3. 带主体的标签 三、自定义标签的部件3.1 自定义标签的四步骤3.2 标签处理程序3.3 自定义标签的开发及使用步骤第一步:创建标签助手类第二步&…...

Java—— 泛型详解
泛型概述 泛型是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。 泛型的格式:<数据类型> 注意:泛型只能支持引用数据类型。 泛型的好处 没有泛型的时候,可以往集合中添加任意类型的数据&#x…...

GPT-4o, GPT 4.5, GPT 4.1, O3, O4-mini等模型的区别与联系
大模型时代浪潮汹涌,作为其中的领军者,OpenAI 其推出的系列模型以强大的能力深刻影响着整个行业,并常常成为业界其他公司对标和比较的基准。因此,深入了解 OpenAI 的大模型,不仅是为了使用它们,更是为了理解当前大模型的能力边界和发展趋势,这对于我们评估和选择其他各类…...

Harness: 全流程 DevOps 解决方案,让持续集成如吃饭般简单
引言 在当今快速发展的软件开发世界中,高效的 DevOps 工具变得越来越重要。Harness 作为一个开源的运维平台,为开发和运维团队提供了从代码托管到 CI/CD 的全流程解决方案,同时实现自动化的开发环境和制品管理。这种集中化的工具可以显著减少运维难度,提高团队效率,真正解…...
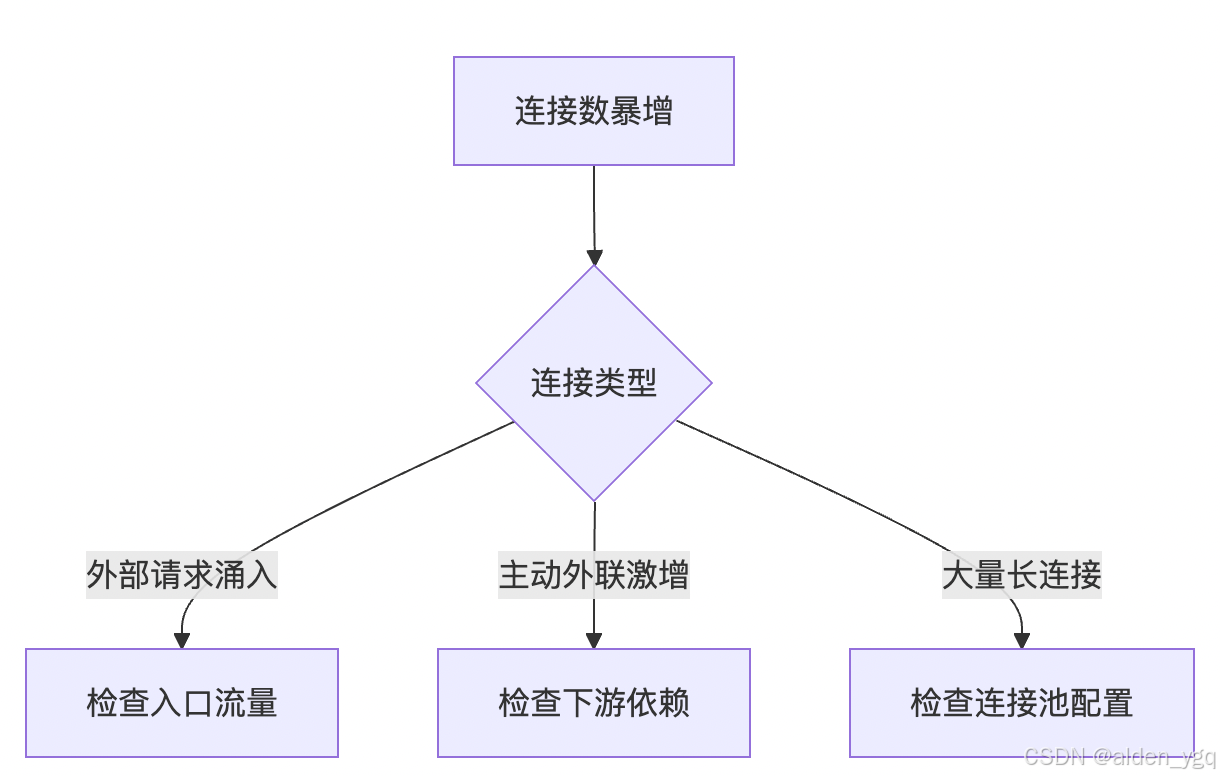
Kubernetes生产实战(十二):无工具容器网络连接数暴增指南
当线上容器突然出现TCP连接数暴涨,而容器内又没有安装任何调试工具时,如何快速定位问题?本文将分享一套经过大型互联网公司验证的排查方案,涵盖从快速应急到根因分析的全流程。 一、快速锁定问题容器 查看pod 连接数方式&#x…...

MySQL的Order by与Group by优化详解!
目录 前言核心思想:让索引帮你“排好序”或“分好组”Part 1: ORDER BY 优化详解1.1 什么是 Filesort?为什么它慢?1.2 如何避免 Filesort?—— 利用索引的有序性1.3 EXPLAIN 示例 (ORDER BY) Part 2: GROUP BY 优化详解2.1 什么是…...

Spring MVC中跨域问题处理
在Spring MVC中处理跨域问题可以通过以下几种方式实现,确保前后端能够正常通信: 方法一:使用 CrossOrigin 注解 适用于局部控制跨域配置,直接在Controller或方法上添加注解。 示例代码: RestController CrossOrigin…...
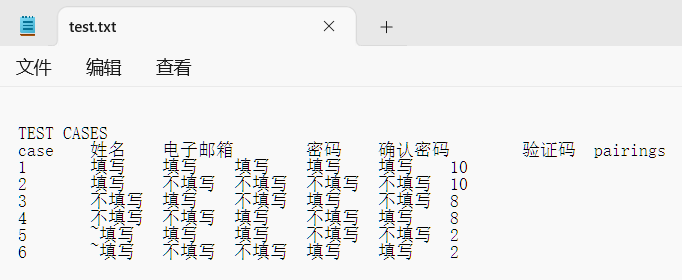
软件测试——用例篇(3)
目录 一、设计测试用例的具体方法 1.1等价类 1.1.1等价类概念介绍 1.1.2等价类分类 1.2边界值 1.2.1边界值分析法 1.2.2边界值分类 1.3正交法 1.3.1正交表 1.3.2正交法设计测试用例步骤 1.4判定表法 1.4.1判定表 1.4.2判定表方法设计测试用例 1.5 场景法 1.6错误…...

在 Win11 下安装 Wireshark 的详细步骤
目录 一、了解 Wireshark1. 作用和功能2. 使用步骤 二、下载安装包三、运行安装包四、使用 Wireshark1. 抓包2. 窗口介绍3. 过滤器(显示 / 捕获过滤器)4. 保存过滤后的报文1)显示过滤器表达式(了解)2)过滤表…...
AI编程: 使用Trae1小时做成的音视频工具,提取音频并识别文本
背景 在上个月,有网页咨询我怎么才能获取视频中的音频并识别成文本,我当时给他的回答是去问一下AI,让AI来给你答案。 他觉得我在敷衍他,大骂了我一顿,大家觉得我的回答对吗? 小编心里委屈,我…...

区块链技术中的Java SE实战:从企业级应用到5大核心问题解析
区块链技术中的Java SE实战:从企业级应用到5大核心问题解析 问题1:如何在Java SE中实现区块链的基本数据结构? 回答1: 区块链的核心数据结构是链式区块,每个区块包含数据、哈希值以及前一个区块的哈希值。以下是一个…...

RTC实时时钟DS1337S/PT7C4337WEX国产替代FRTC1337S
NYFEA徕飞公司的FRTC1337S串行实时时钟是一种低功耗时钟/日历,被设计成可以无缝替代市场上流行的DS1337S和PT7C4337WEX(SOP8)两种型号, 具有两个可编程的时钟闹钟和一个可编程方波输出。 地址和数据通过2线双向总线串行传输。时钟/日历提供秒、分钟、小时、天、日期…...
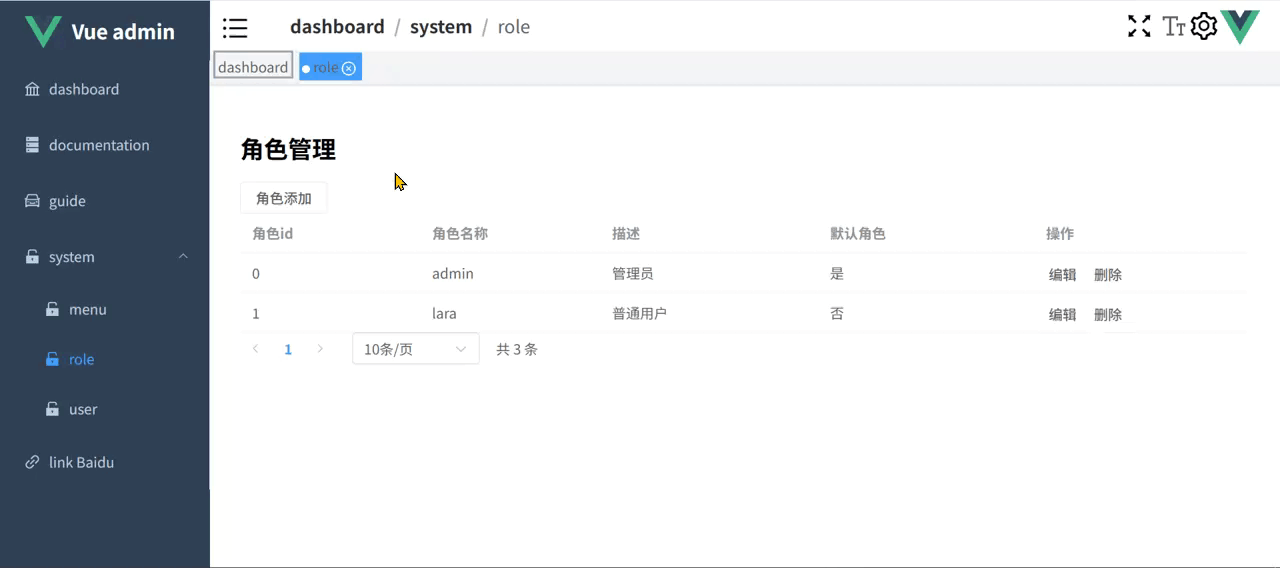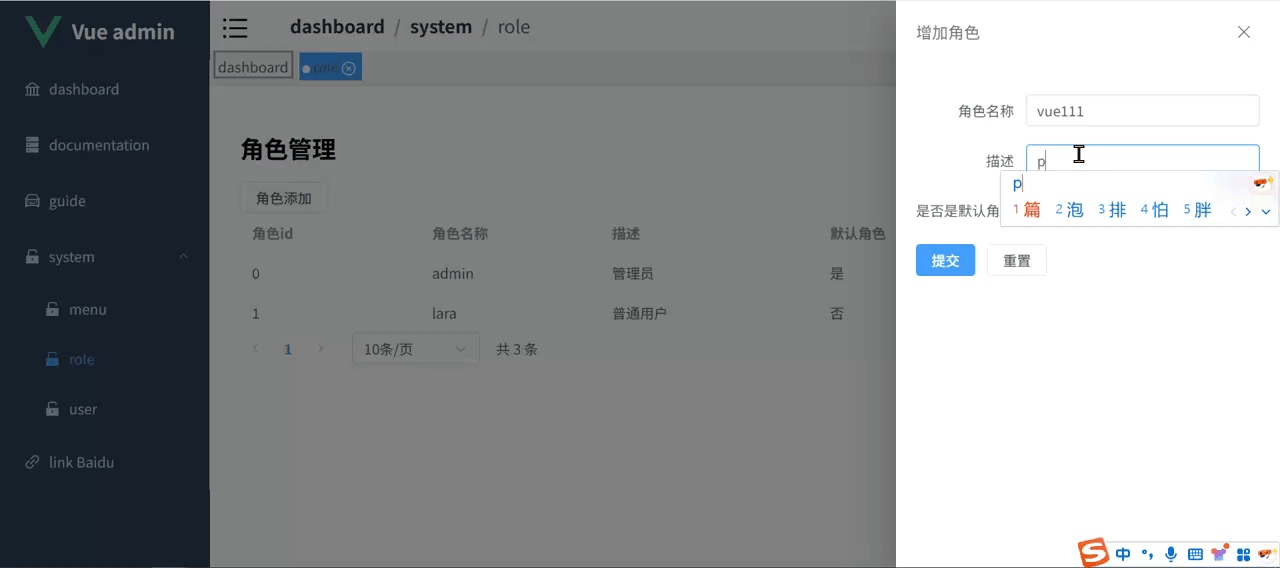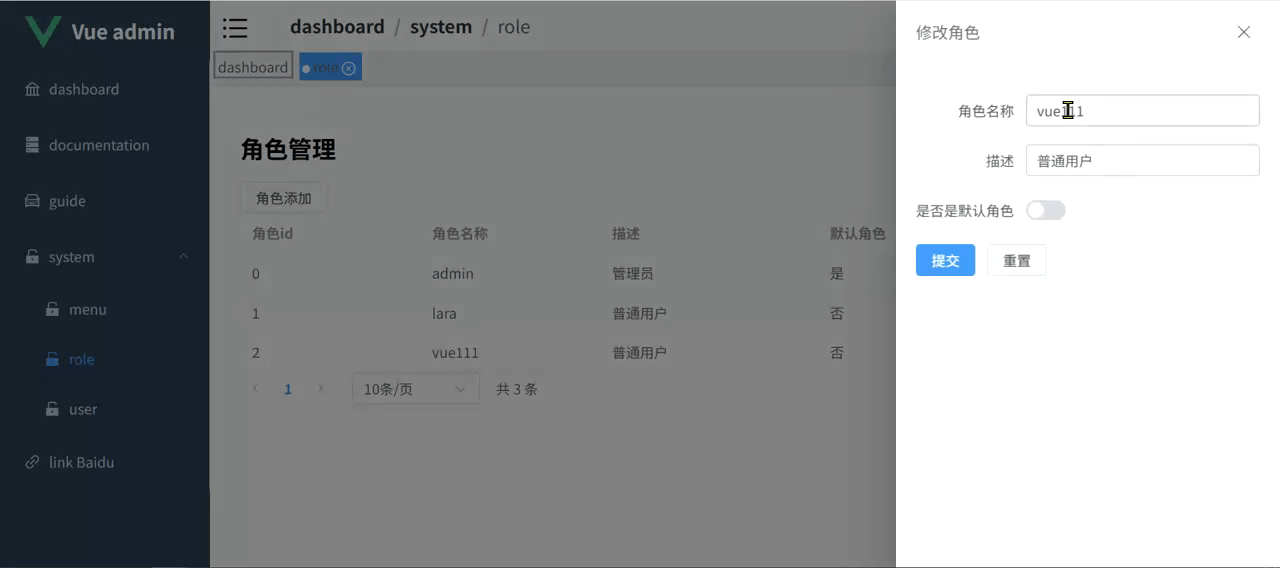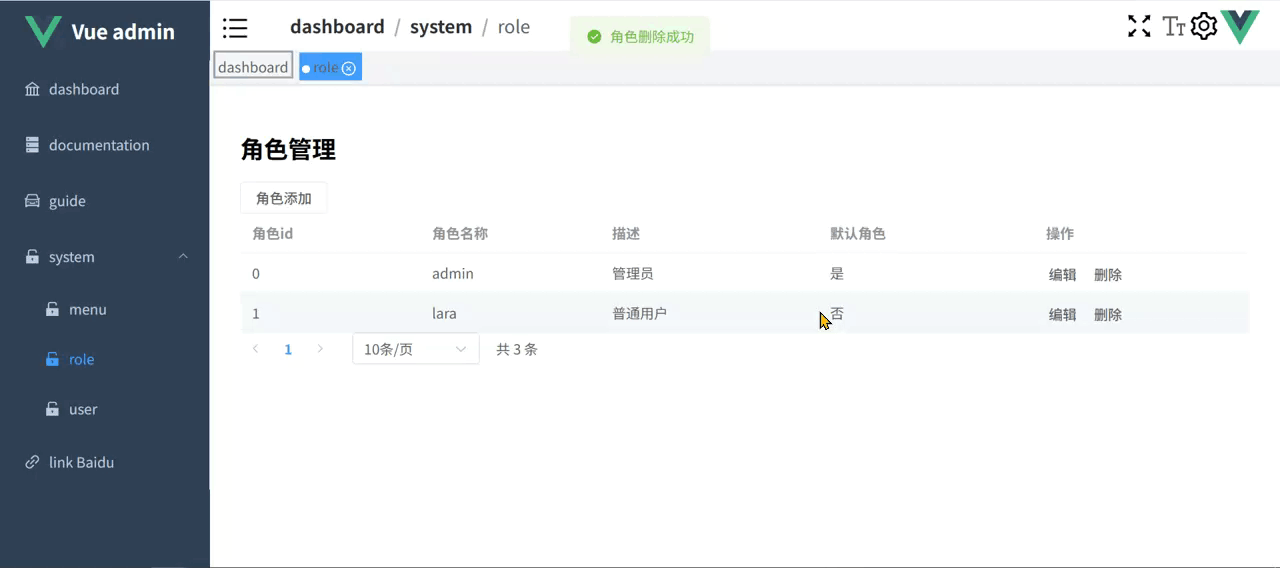
Vue3.5 企业级管理系统实战(十七):角色管理
本篇主要探讨角色管理功能,其中菜单权限这里先不实现,后续在菜单管理中再进行实现。接口部分依然是使用 Apifox mock 的。 1 角色 api 在 src/api/role.ts 中添加角色相关 api,代码如下: //src/api/role.ts import service fro…...

QTableWidget实现多级表头、表头冻结效果
最终效果: 实现思路:如果只用一个表格的话写起来比较麻烦,可以考虑使用两个QTableWidget组合,把复杂的表头一个用QTableWidget显示,其他内容用另一个QTableWidget。 #include "mainwindow.h" #include &qu…...

A2A大模型协议及Java示例
A2A大模型协议概述 1. 协议作用 A2A协议旨在解决以下问题: 数据交换:不同应用程序之间的数据格式可能不一致,A2A协议通过定义统一的接口和数据格式解决这一问题。模型调用:提供标准化的接口,使得外部应用可以轻松调…...

单脉冲前视成像多目标分辨算法——论文阅读
单脉冲前视成像多目标分辨算法 1. 论文的研究目标及实际意义1.1 研究目标1.2 实际问题与产业意义2. 论文的创新方法及公式解析2.1 核心思路2.2 关键公式与模型2.2.1 单脉冲雷达信号模型2.2.2 匹配滤波输出模型2.2.3 多目标联合观测模型2.2.4 对数似然函数与优化2.2.5 MDL准则目…...

CMake 入门实践
CMake 入门实践 第一章 概念与基础项目1.1 CMake 基础认知1.2 最小 CMake 项目1.3 构建流程验证 第二章 多文件项目管理2.1 项目结构2.2 源码示例2.3 CMake 配置 第三章 库文件管理实战3.1 项目结构3.2 核心配置3.3 接口设计 第四章 构建类型与编译优化4.1 构建类型配置4.2 构建…...

异地多活单元化架构下的微服务体系
治理服务间的跨IDC调用,而数据库层面还是要跨IDC 服务注册中心拆开、 金融要求,距离太远,异地备库,如果延迟没读到数据就可能有资损,IDC3平时不能用,IDC1挂了还是有数据同步问题,IDC3日常维护…...
HarmonyOS NEXT——DevEco Studio的使用(还没写完)
一、IDE环境的搭建 Windows环境 运行环境要求 为保证DevEco Studio正常运行,建议电脑配置满足如下要求: 操作系统:Windows10 64位、Windows11 64位 内存:16GB及以上 硬盘:100GB及以上 分辨率:1280*8…...

《Python星球日记》 第46天:决策树与随机森林
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、前言二、决策树算法原理1. 决策树简介2. 决策树的分裂准则(1) 信息熵与信息增益(2) 基尼不纯…...
Windows系统Jenkins企业级实战
目标 在Windows操作系统上使用Jenkins完成代码的自动拉取、编译、打包、发布工作。 实施 1.安装Java开发工具包(JDK) Jenkins是基于Java的应用程序,因此需要先安装JDK。可以从Oracle官网或OpenJDK下载适合的JDK版本。推荐java17版本&#x…...