【ES】Elasticsearch字段映射冲突问题分析与解决
在使用Elasticsearch作为搜索引擎时,经常会遇到一些映射(Mapping)相关的问题。本文将深入分析字段映射冲突问题,并通过原生的Elasticsearch API请求来复现和解决这个问题。
问题描述
在实际项目中,我们遇到以下错误:
TransportError(400, 'illegal_argument_exception', 'mapper [match_score] cannot be changed from type [integer] to [double]')
类似的:
TransportError(400, 'illegal_argument_exception', 'mapper [score] cannot be changed from type [double] to [integer]')
这两个错误都指向同一个问题:尝试将一个已存在的字段类型从一种数据类型改为另一种数据类型,这在Elasticsearch中是不允许的。
不同文档类型中的同名字段问题
这是一个非常常见但容易被忽视的问题:即使在不同的文档类型(doc type)中定义同名字段,Elasticsearch也会要求它们具有相同的类型定义。很多开发者误以为不同文档类型(doc type)之间的字段是相互独立的,就像关系数据库中不同表的同名字段可以有不同的数据类型一样,但Elasticsearch并非如此。
例如,假设我们有两个文档类型:type1和type2,它们都定义了一个名为score的字段,但在type1中它是integer类型,而在type2中它是double类型。当这两个类型的文档被索引到同一个Elasticsearch索引中时,就会发生冲突。
让我们通过一个简单示例来验证这个问题:
# 创建一个索引,定义type1类型,包含integer类型的score字段
curl -X PUT "http://localhost:9200/conflict_demo" -H "Content-Type: application/json" -d'
{"mappings": {"type1": {"properties": {"score": {"type": "integer"}}}}
}'# 在相同索引中添加type2类型,尝试使用double类型的score字段
curl -X PUT "http://localhost:9200/conflict_demo/_mapping/type2" -H "Content-Type: application/json" -d'
{"properties": {"score": {"type": "double"}}
}'
第二个命令将会失败,并显示以下错误:
{"error": {"root_cause": [{"type": "illegal_argument_exception","reason": "mapper [score] cannot be changed from type [integer] to [double]"}],"type": "illegal_argument_exception","reason": "mapper [score] cannot be changed from type [integer] to [double]"},"status": 400
}
这是因为在Elasticsearch中,一个索引的映射是扁平的。虽然文档可以存储在不同的类型下,但同名字段在内部被视为同一个字段。这是Elasticsearch的设计决策,目的是为了优化存储和搜索效率。
注意:从Elasticsearch 6.0开始,每个索引只允许有一个映射类型,而在Elasticsearch 7.0中,映射类型被完全移除。这一变化进一步强调了Elasticsearch的字段是全局的,而不是按文档类型隔离的设计思想。
环境准备
本文使用Elasticsearch 5.6版本进行验证,您可以通过以下命令检查您的ES版本:
curl -X GET "http://localhost:9200/"
如果一切正常,您将看到类似以下的输出:
{"name" : "CWlnNkA","cluster_name" : "elasticsearch","cluster_uuid" : "vPFGQy83SDaz5cPa_OiX1A","version" : {"number" : "5.6.15","build_hash" : "fe7575a","build_date" : "2019-02-13T16:21:45.880Z","build_snapshot" : false,"lucene_version" : "6.6.1"},"tagline" : "You Know, for Search"
}
问题复现
步骤1:创建带有Integer类型match_score字段的索引
首先,我们创建一个索引,并定义一个类型为Integer的match_score字段:
curl -X PUT "http://localhost:9200/test_index" -H "Content-Type: application/json" -d'
{"mappings": {"doc": {"properties": {"match_score": {"type": "integer"},"title": {"type": "text"},"content": {"type": "text"}}}}
}'
查看索引映射:
curl -X GET "http://localhost:9200/test_index/_mapping"
输出应该类似:
{"test_index": {"mappings": {"doc": {"properties": {"content": {"type": "text"},"match_score": {"type": "integer"},"title": {"type": "text"}}}}}
}
步骤2:添加一些测试数据
curl -X POST "http://localhost:9200/test_index/doc/1" -H "Content-Type: application/json" -d'
{"match_score": 10,"title": "Document 1","content": "This is the first document with integer match_score"
}'
步骤3:尝试修改字段类型(复现错误)
现在,我们尝试将match_score字段的类型从integer更改为double:
curl -X PUT "http://localhost:9200/test_index/_mapping/doc" -H "Content-Type: application/json" -d'
{"properties": {"match_score": {"type": "double"}}
}'
这将导致以下错误:
{"error": {"root_cause": [{"type": "illegal_argument_exception","reason": "mapper [match_score] cannot be changed from type [integer] to [double]"}],"type": "illegal_argument_exception","reason": "mapper [match_score] cannot be changed from type [integer] to [double]"},"status": 400
}
这正是我们在实际项目中遇到的错误。
步骤4:在相同索引中添加另一个文档类型(复现多类型冲突)
为了更清楚地展示不同文档类型中同名字段的冲突,我们尝试在同一个索引中添加另一个文档类型:
curl -X PUT "http://localhost:9200/test_index/_mapping/another_doc" -H "Content-Type: application/json" -d'
{"properties": {"match_score": {"type": "double"},"description": {"type": "text"}}
}'
这个命令也会失败,显示与之前相同的错误,因为match_score字段已经在索引中定义为integer类型,不能在另一个文档类型中将其定义为double类型。
问题根本原因
Elasticsearch不允许对现有字段的类型进行更改,因为这会导致已经索引的数据无法正确解析。这是Elasticsearch的基本设计原则之一。
具体来说,当多个文档类型共享同一个索引时,有三种情况会导致字段映射冲突:
- 同名字段使用了不同的数据类型(如我们示例中的integer vs double)
- 同名字段使用了不兼容的分析器或索引选项
- 一个是父字段,一个是子字段的冲突
重要说明:不同文档类型中的同名字段必须具有完全相同的映射定义。这一限制在实际开发中尤其需要注意,因为它经常导致意想不到的映射冲突,特别是在大型项目中,不同团队可能负责不同的文档类型。
解决方案
方案1:使用别名字段(推荐)
最简单且最灵活的解决方案是为冲突的字段使用不同的名称:
# 首先创建一个新索引,包含两个不同名称的字段
curl -X PUT "http://localhost:9200/test_index_new" -H "Content-Type: application/json" -d'
{"mappings": {"doc": {"properties": {"integer_match_score": {"type": "integer"},"double_match_score": {"type": "double"},"title": {"type": "text"},"content": {"type": "text"}}}}
}'
这种方法的优点是,每个字段都可以使用最适合其数据的类型。
对于多文档类型场景,我们可以为每个类型创建特定的字段名:
curl -X PUT "http://localhost:9200/multi_type_index" -H "Content-Type: application/json" -d'
{"mappings": {"type1": {"properties": {"type1_score": {"type": "integer"}}},"type2": {"properties": {"type2_score": {"type": "double"}}}}
}'
方案2:使用通用类型(如keyword或text)
如果必须使用相同的字段名,可以选择一个通用的更宽泛的类型:
curl -X PUT "http://localhost:9200/test_index_common" -H "Content-Type: application/json" -d'
{"mappings": {"doc": {"properties": {"match_score": {"type": "keyword"},"title": {"type": "text"},"content": {"type": "text"}}}}
}'
但这可能会影响搜索和聚合操作的性能。
方案3:重建索引
如果您必须更改字段类型,唯一的方法是创建一个新索引,然后重新索引数据:
# 步骤1:创建新索引
curl -X PUT "http://localhost:9200/test_index_v2" -H "Content-Type: application/json" -d'
{"mappings": {"doc": {"properties": {"match_score": {"type": "double"},"title": {"type": "text"},"content": {"type": "text"}}}}
}'# 步骤2:使用reindex API重新索引数据
curl -X POST "http://localhost:9200/_reindex" -H "Content-Type: application/json" -d'
{"source": {"index": "test_index"},"dest": {"index": "test_index_v2"},"script": {"source": "ctx._source.match_score = (double)ctx._source.match_score"}
}'# 步骤3:删除旧索引
curl -X DELETE "http://localhost:9200/test_index"# 步骤4:创建别名(可选,便于无缝切换)
curl -X POST "http://localhost:9200/_aliases" -H "Content-Type: application/json" -d'
{"actions": [{"add": {"index": "test_index_v2","alias": "test_index_alias"}}]
}'
方案4:使用不同的索引
对于完全不相关的数据,最好使用不同的索引:
# 创建第一个索引,包含integer类型的match_score
curl -X PUT "http://localhost:9200/index_type1" -H "Content-Type: application/json" -d'
{"mappings": {"doc": {"properties": {"match_score": {"type": "integer"}}}}
}'# 创建第二个索引,包含double类型的match_score
curl -X PUT "http://localhost:9200/index_type2" -H "Content-Type: application/json" -d'
{"mappings": {"doc": {"properties": {"match_score": {"type": "double"}}}}
}'
使用多索引查询:
curl -X GET "http://localhost:9200/index_type1,index_type2/_search" -H "Content-Type: application/json" -d'
{"query": {"match_all": {}}
}'
验证解决方案
让我们验证方案1(使用别名字段):
# 添加数据到新索引
curl -X POST "http://localhost:9200/test_index_new/doc/1" -H "Content-Type: application/json" -d'
{"integer_match_score": 10,"title": "Document with integer score","content": "This document uses an integer score"
}'curl -X POST "http://localhost:9200/test_index_new/doc/2" -H "Content-Type: application/json" -d'
{"double_match_score": 9.5,"title": "Document with double score","content": "This document uses a double score"
}'# 查询两种类型
curl -X GET "http://localhost:9200/test_index_new/_search" -H "Content-Type: application/json" -d'
{"query": {"bool": {"should": [{ "range": { "integer_match_score": { "gte": 5 } } },{ "range": { "double_match_score": { "gte": 5.0 } } }]}}
}'
最佳实践
-
预先规划映射:在开始索引数据之前,仔细规划字段类型和名称。
-
字段命名约定:为字段名添加类型前缀或文档类型前缀,例如
int_score、dbl_score或type1_score、type2_score。 -
文档模型设计:认真设计文档模型,避免不必要的类型嵌套和复杂关系,减少冲突可能性。
-
使用动态映射模板:为不同类型的字段定义模板:
curl -X PUT "http://localhost:9200/template_index" -H "Content-Type: application/json" -d'
{"mappings": {"doc": {"dynamic_templates": [{"integers": {"match_pattern": "regex","match": "^int_.*","mapping": {"type": "integer"}}},{"doubles": {"match_pattern": "regex","match": "^dbl_.*","mapping": {"type": "double"}}}]}}
}'
- 索引版本控制:使用时间戳或版本号,方便迁移:
my_index_v1, my_index_v2, my_index_202305
- 使用索引别名:为应用程序使用的索引创建别名,便于无缝切换:
curl -X POST "http://localhost:9200/_aliases" -H "Content-Type: application/json" -d'
{"actions": [{"add": {"index": "my_index_v2","alias": "my_index"}}]
}'
- 定期检查映射冲突:定期检查Elasticsearch日志中的映射错误,及早发现问题。
总结
Elasticsearch的字段映射冲突是一个常见的问题,特别是在多文档类型场景下,同名字段必须使用相同的数据类型。这一限制源于Elasticsearch的内部设计,旨在优化存储和查询效率。解决方案包括使用不同的字段名、选择通用数据类型、重建索引或使用多个索引。通过遵循最佳实践,可以避免这些问题并构建更加稳健的Elasticsearch应用程序。
通过本文的示例,您可以直接使用curl命令复现和测试这些解决方案,帮助您更好地理解和解决Elasticsearch映射冲突问题。
相关文章:

【ES】Elasticsearch字段映射冲突问题分析与解决
在使用Elasticsearch作为搜索引擎时,经常会遇到一些映射(Mapping)相关的问题。本文将深入分析字段映射冲突问题,并通过原生的Elasticsearch API请求来复现和解决这个问题。 问题描述 在实际项目中,我们遇到以下错误: Transport…...

昇腾NPU容器内 apt 换源
环境 昊算NPU云910b 问题 缺少vim等,同时无法apt安装新的依赖 解决办法 使用vi修改/etc/apt/sources.list.d/debian.sources Types: deb URIs: http://deb.debian.org/debian Suites: bookworm bookworm-updates bookworm-backports Components: main contrib…...
:索引深度解析 —— 性能优化的核心武器)
MySQL 从入门到精通(五):索引深度解析 —— 性能优化的核心武器
目录 一、索引概述:数据库的 “目录” 1.1 什么是索引? 1.2 索引的性能验证:用事实说话 实验环境准备 无索引查询耗时 有索引查询耗时 索引的 “空间换时间” 特性 二、索引的创建:三种核心方式 2.1 方式 1:C…...

spark-Join Key 的基数/rand函数
在数据处理中,Join Key 的基数 是指 Join Key 的唯一值的数量(也称为 Distinct Key Count)。它表示某个字段(即 Join Key)在数据集中有多少个不同的值。 1. Join Key 基数的意义 高基数:Join Key 的唯一值…...
LLMs之ChatGPT:《Connecting GitHub to ChatGPT deep research》翻译与解读
LLMs之ChatGPT:《Connecting GitHub to ChatGPT deep research》翻译与解读 导读:这篇OpenAI帮助文档全面介绍了将GitHub连接到ChatGPT进行深度代码研究的方法、优势和注意事项。通过连接GitHub,用户可以充分利用ChatGPT强大的代码理解和生成…...

【桌面】【输入法】常见问题汇总
目录 一、麒麟桌面系统输入法概述 1、输入法介绍 2、输入法相关组件与服务 3、输入法调试相关命令 3.1、输入法诊断命令 3.2、输入法配置重新加载命令 3.3、启动fcitx输入法 3.4、查看输入法有哪些版本,并安装指定版本 3.5、重启输入法 3.6、查看fcitx进程…...

R语言学习--Day01--数据清洗初了解andR的经典筛选语法
当我们在拿到一份数据时,是否遇到过想要分析数据却无从下手?通过编程语言去利用它时发现有很多报错不是来源于代码而是因为数据里有很多脏数据;在这个时候,如果你会用R语言来对数据进行清洗,这会让你的效率提升很多。 …...
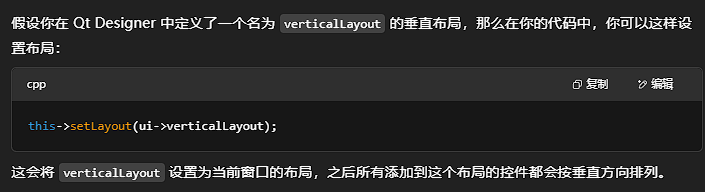
QT的初始代码解读及其布局和弹簧
this指的是真正的当前正在显示的窗口 main函数: Widget w是生成了一个主窗口,QT Designer是在这个主窗口里塞组件 w.show()用来展示这个主窗口 头文件: namespace Ui{class Widget;}中的class Widget和下面的class Widget不是一个东西 Ui…...

Profinet转CanOpen网关,打破协议壁垒的关键技术
在石油化工行业的生产现场,各类自动化设备如同精密运转的神经系统,而通信协议则是传递信号的"语言"。当不同厂商的设备采用Canopen与Profinet这两种主流工业协议时,就像两个使用不同方言的专家需要实时协作,此时开疆智能…...
引用第三方自定义组件——微信小程序学习笔记
1. 使用 npm 安装第三方包 1.1 下载安装Node.js 工具 下载地址:Node.js — Download Node.js 1.2 安装 npm 包 在项目空白处右键弹出菜单,选择“在外部终端窗口打开”,打开命令行工具,输入以下指令: 1> 初始化:…...

Docker、Docker-compose、K8s、Docker swarm之间的区别
1.Docker docker是一个运行于主流linux/windows系统上的应用容器引擎,通过docker中的镜像(image)可以在docker中构建一个独立的容器(container)来运行镜像对应的服务; 例如可以通过mysql镜像构建一个运行mysql的容器,既可以直接进入该容器命…...
SpringAI实现AI应用-使用redis持久化聊天记忆
SpringAI实战链接 1.SpringAl实现AI应用-快速搭建-CSDN博客 2.SpringAI实现AI应用-搭建知识库-CSDN博客 3.SpringAI实现AI应用-内置顾问-CSDN博客 4.SpringAI实现AI应用-使用redis持久化聊天记忆-CSDN博客 5.SpringAI实现AI应用-自定义顾问(Advisor)…...
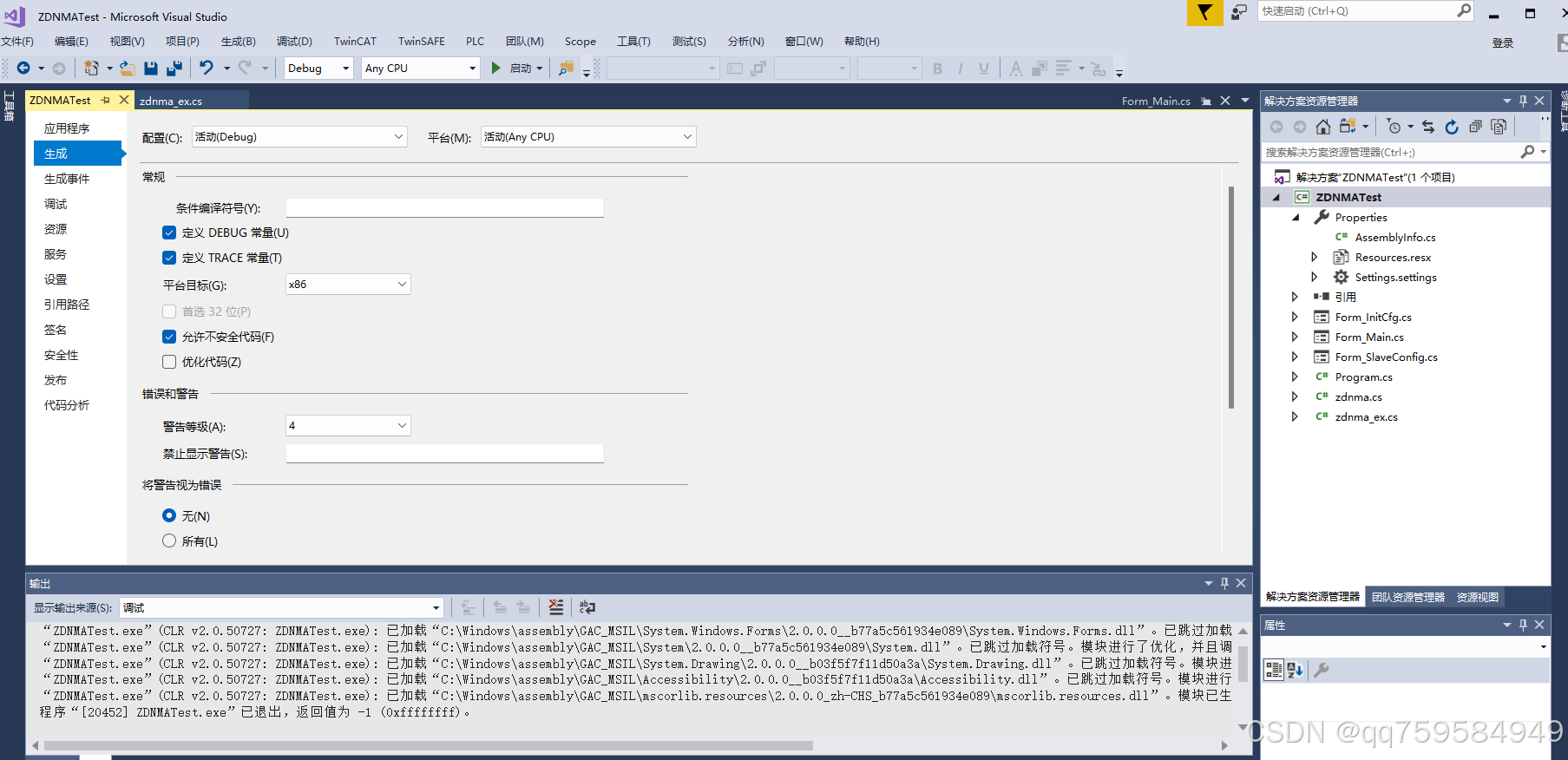
C#问题 加载格式不正确解决方法
出现上面问题 解决办法:C#问题 改成x86 不要选择anycpu...
)
VTK|结合qt创建通用按钮控制显隐(边框、坐标轴、点线面)
文章目录 增加边框BoundingBox添加addBoundingBox添加BoundingBox控制按钮点击按钮之后的槽函数 添加坐标轴增加点线面显隐控制按钮添加控制点线面显隐的按钮到三维显示界面控制面显示槽函数控制线显示槽函数控制点显示槽函数 增加边框BoundingBox 增加边框BoundingBox并通过按…...
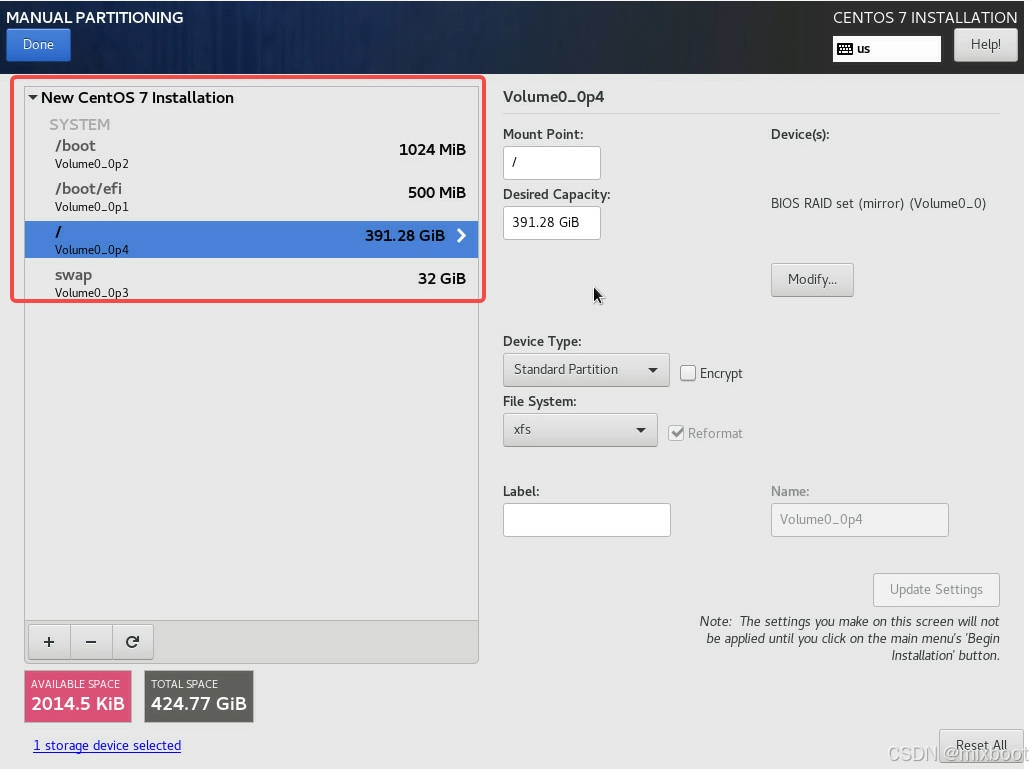
CentOS 7.9 安装详解:手动分区完全指南
CentOS 7.9 安装详解:手动分区完全指南 为什么需要手动分区?CentOS 7.9 基本分区说明1. /boot/efi 分区2. /boot 分区3. swap 交换分区4. / (根) 分区 可选分区(进阶设置)5. /home 分区6. /var 分区7. /tmp 分区 分区方案建议标准…...

在过滤器中获取body中的json数据并且使得后续的controller层也能获取使用
前景提示: ①我需要在filter中获取到json数据->对key名首字母进行排序,然后拼接,进行验签 ②所以就需要在filer获取到json的数据,因为请求数据是一次性读取的流。如果过滤器中调用了request.json或request.get_json()ÿ…...
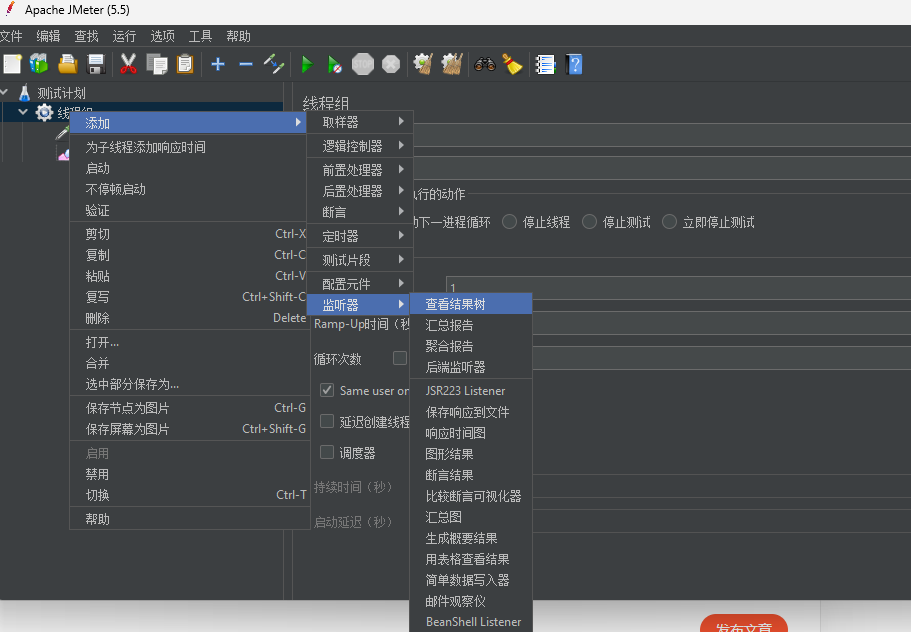
如何使用测试软件 Jmeter
第一步,点击 编辑 添加线程组 第二步,右键单击线程组,添加取样器 HTTP 请求 第三步,设置请求路径 第四步,添加 查看结果树 用于查看请求响应 最后点击绿色小三角启动即可...
2025盘古石初赛WP
来不及做,还有n道题待填坑 文章目录 手机取证 Mobile Forensics分析安卓手机检材,手机的IMSI是? [答案格式:660336842291717]养鱼诈骗投资1000,五天后收益是? [答案格式:123]分析苹果手机检材&a…...
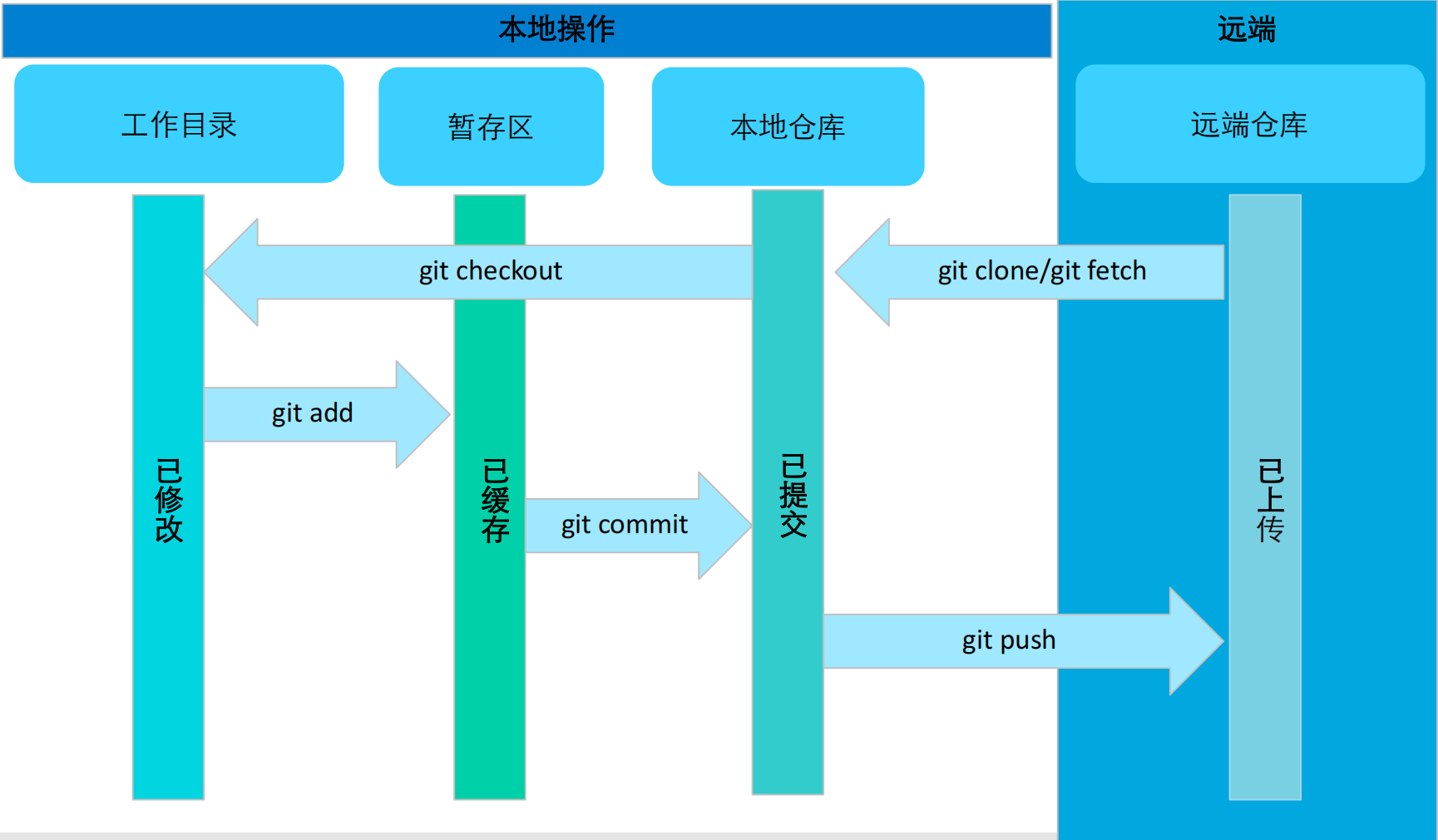
系统分析与设计期末复习
第一章 系统的五个特性 整体性、目的性、相关性、环境适应性、层次性 软件系统的四个特性 复杂性、一致性、可变性、不可见性 第二章 系统规划 系统开发生命周期 系统规划->系统分析->系统设计->系统实施->系统运行维护->系统规划 诺兰阶段模型 阶段&a…...

最大公约数gcd和最小公倍数lcm
一、相关公式及其性质 文章只服务于竞赛,所以不会涉及证明。 辗转相除法:gcd(a, b) gcd(b, a % b); 直到 b 0,就可以知道上一层递归中的 a % b 0,所以上一层的 b 就是答案,也就是这一层递归的 a gcd(a, b) * lcm…...
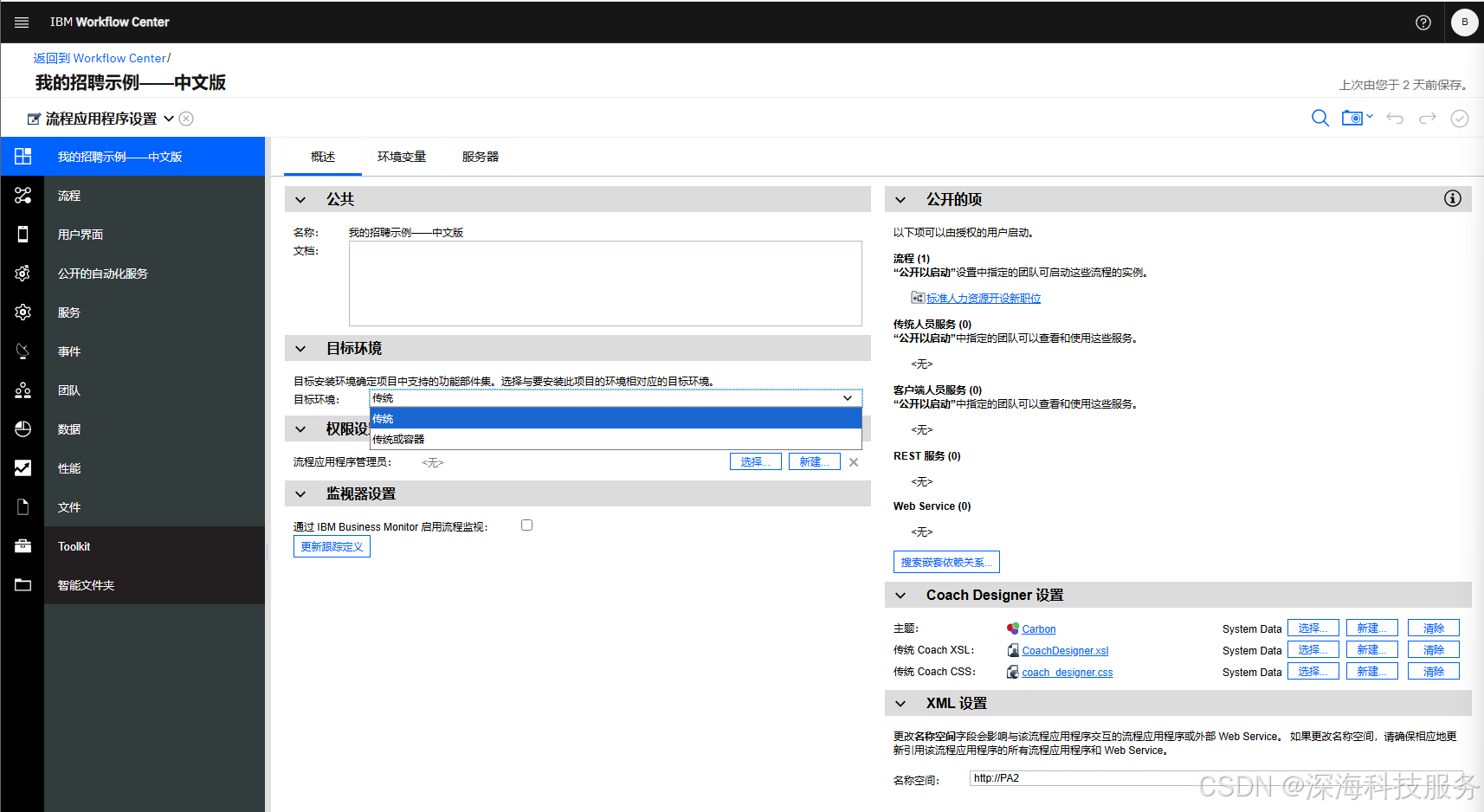
IBM BAW(原BPM升级版)使用教程第八讲
续前篇! 一、流程开发功能模块使用逻辑和顺序 前面我们已经对 流程、用户界面、公开的自动化服务、服务、事件、团队、数据、性能、文件各个模块进行了详细讲解,现在统一进行全面统一讲解。 在 IBM Business Automation Workflow (BAW) 中,…...

视觉革命来袭!ComfyUI-LTXVideo 让视频创作更高效
探索LTX-Video 支持的ComfyUI 在数字化视频创作领域,视频制作效果的提升对创作者来说无疑是一项重要的突破。LTX-Video支持的ComfyUI便是这样一款提供自定义节点的工具集,它专为改善视频质量、提升生成速度而开发。接下来,我们将详细介绍其功…...

从电动化到智能化,法雷奥“猛攻”中国汽车市场
当前,全球汽车产业正在经历前所未有的变革,外资Tier1巨头开始向中国智能电动汽车市场发起新一轮“猛攻”。 在4月23日-5月2日上海国际车展期间,博世、采埃孚、大陆集团、法雷奥等全球百强零部件厂商纷纷发布战略新品与转型计划。在这其中&am…...
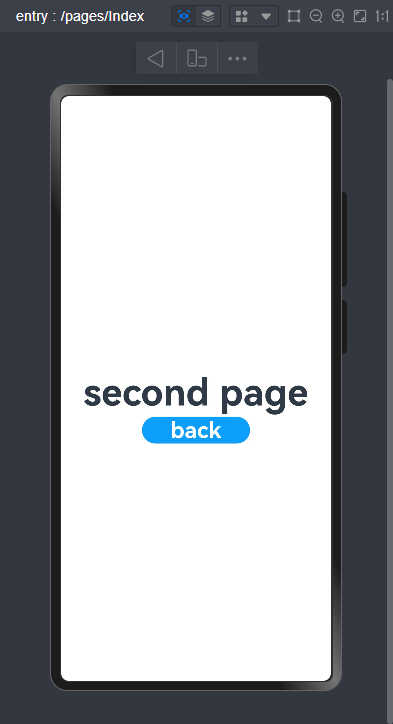
鸿蒙开发——3.ArkTS声明式开发:构建第一个ArkTS应用
鸿蒙开发——3.ArkTS声明式开发:构建第一个ArkTS应用 一、创建ArkTS工程二、ArkTS工程目录结构(Stage模型)三、构建第一个页面四、构建第二个页面五、实现页面之间的跳转六、模拟器运行 一、创建ArkTS工程 1、若首次打开DevEco Studio,请点击…...
word换行符和段落标记
换行符:只换行不分段 作用:我们需要对它进行分段,但它是一个信息群组,我希望它们有同样的段落格式! 快捷键:shiftenter 段落标记:分段 快捷键:enter 修改字体格式或段落格式 …...
AI时代的数据可视化:未来已来
你有没有想过,数据可视化在未来会变成什么样?随着人工智能(AI)的飞速发展,数据可视化已经不再是简单的图表和图形,而是一个充满无限可能的智能领域。AI时代的可视化不仅能自动解读数据,还能预测…...

spark基本介绍
Spark 是基于内存计算的分布式大数据处理框架,由加州大学伯克利分校 AMPLab 开发,现已成为 Apache 顶级项目。以下是其核心要点: 核心特点 1. 内存计算:数据可驻留内存,大幅提升迭代计算(如机器学习、图计算…...
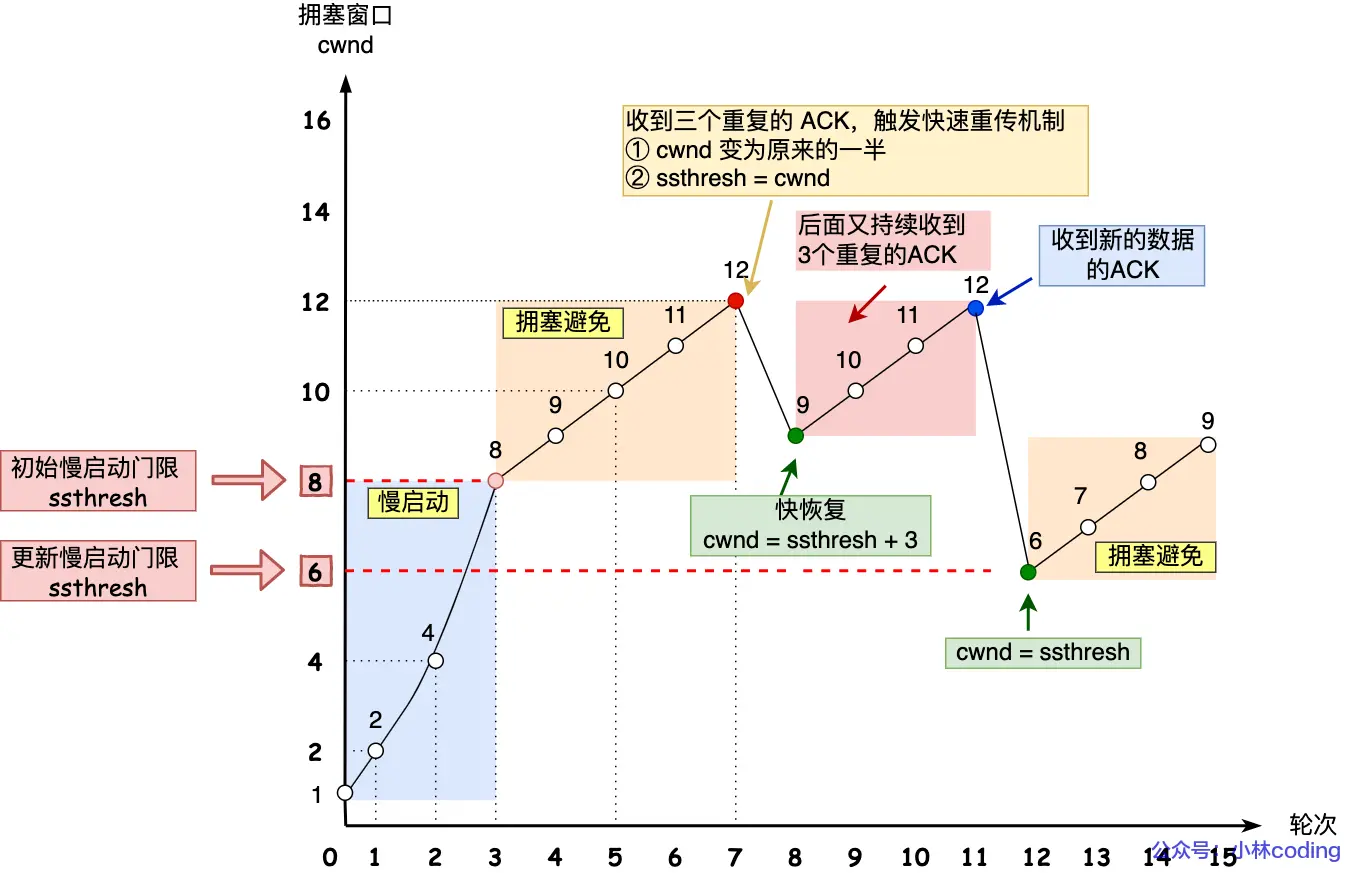
深入理解 TCP:重传机制、滑动窗口、流量控制与拥塞控制
TCP(Transmission Control Protocol)是一个面向连接、可靠传输的协议,支撑着绝大多数互联网通信。在实现可靠性的背后,TCP 引入了多个关键机制:重传机制、滑动窗口、流量控制 和 拥塞控制。这些机制共同协作࿰…...

MySQL 窗口函数入门到精通
目录 常用窗口函数速查表 1. 什么是"窗口"(不是你想的那种窗口) "窗口"≠电脑界面的窗口 那么,SQL 中的"窗口"是什么? 用表格形式理解"窗口"概念 2. 窗口函数解决了什么问题 场景…...
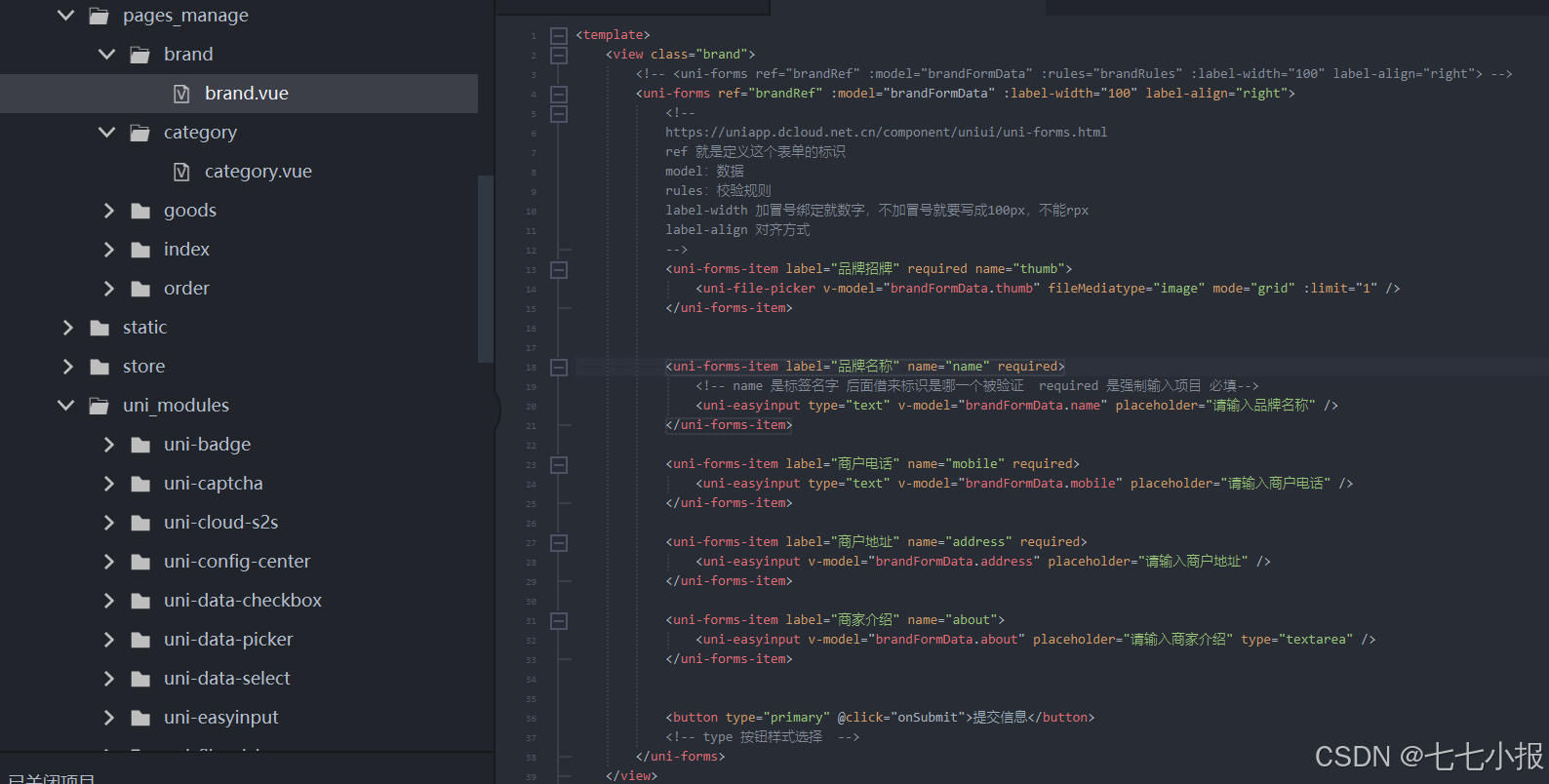
uniapp-商城-51-后台 商家信息(logo处理)
前面对页面基本进行了梳理和说明,特别是对验证规则进行了阐述,并对自定义规则的兼容性进行了特别补充,应该说是干货满满。不知道有没有小伙伴已经消化了。 下面我们继续前进,说说页面上的logo上传组件,主要就是uni-fil…...