[模型选择与调优]机器学习-part4
七 模型选择与调优
1 交叉验证
(1) 保留交叉验证HoldOut
HoldOut Cross-validation(Train-Test Split)
在这种交叉验证技术中,整个数据集被随机地划分为训练集和验证集。根据经验法则,整个数据集的近70%被用作训练集,其余30%被用作验证集。也就是我们最常使用的,直接划分数据集的方法。
优点:很简单很容易执行。
缺点1:不适用于不平衡的数据集。假设我们有一个不平衡的数据集,有0类和1类。假设80%的数据属于 “0 “类,其余20%的数据属于 “1 “类。这种情况下,训练集的大小为80%,测试数据的大小为数据集的20%。可能发生的情况是,所有80%的 “0 “类数据都在训练集中,而所有 “1 “类数据都在测试集中。因此,我们的模型将不能很好地概括我们的测试数据,因为它之前没有见过 “1 “类的数据。
缺点2:一大块数据被剥夺了训练模型的机会。
在小数据集的情况下,有一部分数据将被保留下来用于测试模型,这些数据可能具有重要的特征,而我们的模型可能会因为没有在这些数据上进行训练而错过。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitiris = load_iris()
x = iris.data
y = iris.target
# Hold-Out保留交叉验证
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=1)
print(y_test)
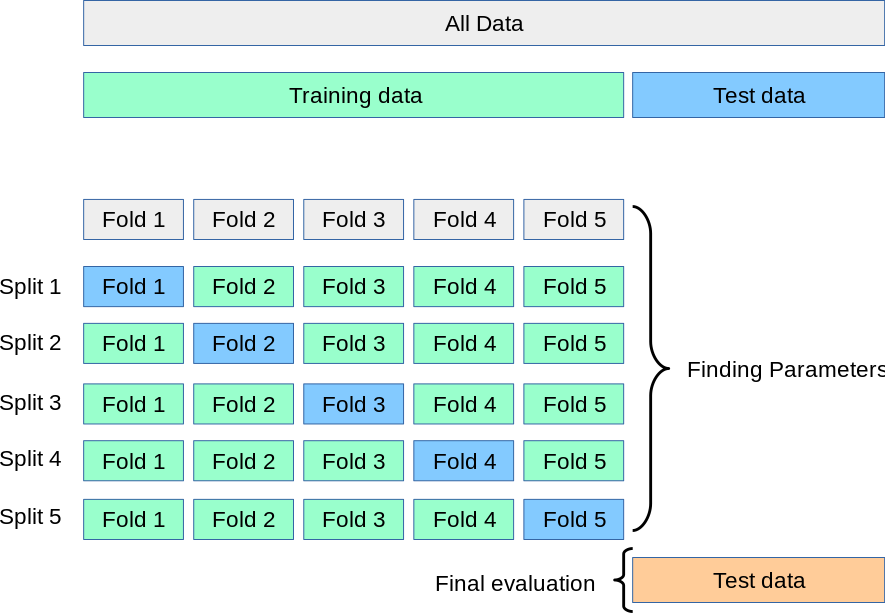
(2) K-折交叉验证(K-fold)
(K-fold Cross Validation,记为K-CV或K-fold)
K-Fold交叉验证技术中,整个数据集被划分为K个大小相同的部分。每个分区被称为 一个”Fold”。所以我们有K个部分,我们称之为K-Fold。一个Fold被用作验证集,其余的K-1个Fold被用作训练集。
该技术重复K次,直到每个Fold都被用作验证集,其余的作为训练集。
模型的最终准确度是通过取k个模型验证数据的平均准确度来计算的。
# 交叉验证
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFoldiris = load_iris()
x = iris.data
y = iris.target# K-Fold 交叉验证
kf = KFold(n_splits=5,shuffle=True,random_state=1)
index = kf.split(x,y)
# print(next(index))
# print("---------------")
# print(next(index))
for train_index,test_index in index:x_train,x_test = x[train_index],x[test_index]y_train,y_test = y[train_index],y[test_index]print(x_train,x_test,y_train,y_test)(3) 分层k-折交叉验证Stratified k-fold
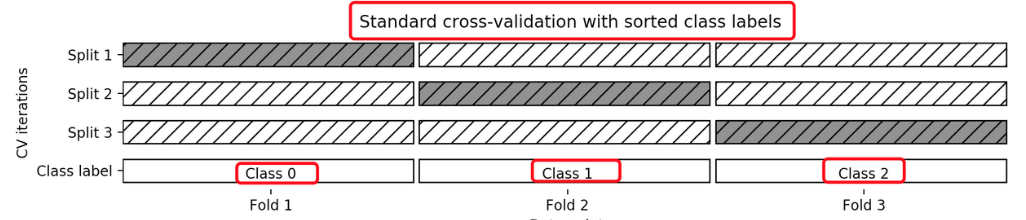
Stratified k-fold cross validation,
K-折交叉验证的变种, 分层的意思是说在每一折中都保持着原始数据中各个类别的比例关系,比如说:原始数据有3类,比例为1:2:1,采用3折分层交叉验证,那么划分的3折中,每一折中的数据类别保持着1:2:1的比例,这样的验证结果更加可信。
# 交叉验证
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFoldiris = load_iris()
x = iris.data
y = iris.target# SSK-Fold 分层k折交叉验证
kf = StratifiedKFold(n_splits=5)
index = kf.split(x,y)
# print(next(index))
# print("---------------")
# print(next(index))
for train_index,test_index in index:x_train,x_test = x[train_index],x[test_index]y_train,y_test = y[train_index],y[test_index]print(x_train,x_test,y_train,y_test)break(4) 其它验证
去除p交叉验证) 留一交叉验证) 蒙特卡罗交叉验证 时间序列交叉验证
(5)API
from sklearn.model_selection import StratifiedKFold
说明:普通K折交叉验证和分层K折交叉验证的使用是一样的 只是引入的类不同
from sklearn.model_selection import KFold
使用时只是KFold这个类名不一样其他代码完全一样
strat_k_fold=sklearn.model_selection.StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
n_splits划分为几个折叠 shuffle是否在拆分之前被打乱(随机化),False则按照顺序拆分 random_state随机因子
indexs=strat_k_fold.split(X,y)
返回一个可迭代对象,一共有5个折叠,每个折叠对应的是训练集和测试集的下标
然后可以用for循环取出每一个折叠对应的X和y下标来访问到对应的测试数据集和训练数据集 以及测试目标集和训练目标集
for train_index, test_index in indexs:
X[train_index] y[train_index] X[test_index ] y[test_index ]
2 超参数搜索
超参数搜索也叫网格搜索(Grid Search)
比如在KNN算法中,k是一个可以人为设置的参数,所以就是一个超参数。网格搜索能自动的帮助我们找到最好的超参数值。

3 sklearn API
class sklearn.model_selection.GridSearchCV(estimator, param_grid)
说明:
同时进行交叉验证(CV)、和网格搜索(GridSearch),GridSearchCV实际上也是一个估计器(estimator),同时它有几个重要属性:best_params_ 最佳参数best_score_ 在训练集中的准确率best_estimator_ 最佳估计器cv_results_ 交叉验证过程描述best_index_最佳k在列表中的下标
参数:estimator: scikit-learn估计器实例param_grid:以参数名称(str)作为键,将参数设置列表尝试作为值的字典示例: {"n_neighbors": [1, 3, 5, 7, 9, 11]}cv: 确定交叉验证切分策略,值为:(1)None 默认5折(2)integer 设置多少折如果估计器是分类器,使用"分层k-折交叉验证(StratifiedKFold)"。在所有其他情况下,使用KFold。
4 示例-鸢尾花分类
用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
# 用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
def knn_iris_gscv():# 1)获取数据iris = load_iris()# 2)划分数据集x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)# 3)特征工程:标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4)KNN算法预估器, 这里就不传参数n_neighbors了,交给GridSearchCV来传递estimator = KNeighborsClassifier()# 加入网格搜索与交叉验证, GridSearchCV会让k分别等于1,2,5,7,9,11进行网格搜索偿试。cv=10表示进行10次交叉验证estimator = GridSearchCV(estimator, param_grid={"n_neighbors": [1, 3, 5, 7, 9, 11]}, cv=10)estimator.fit(x_train, y_train)
# 5)模型评估# 方法1:直接比对真实值和预测值y_predict = estimator.predict(x_test)print("y_predict:\n", y_predict)print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率score = estimator.score(x_test, y_test)print("在测试集中的准确率为:\n", score) #0.9736842105263158
# 最佳参数:best_params_print("最佳参数:\n", estimator.best_params_) #{'n_neighbors': 3}, 说明k=3时最好# 最佳结果:best_score_print("在训练集中的准确率:\n", estimator.best_score_) #0.9553030303030303# 最佳估计器:best_estimator_print("最佳估计器:\n", estimator.best_estimator_) # KNeighborsClassifier(n_neighbors=3)# 交叉验证结果:cv_results_print("交叉验证过程描述:\n", estimator.cv_results_)#最佳参数组合的索引:最佳k在列表中的下标print("最佳参数组合的索引:\n",estimator.best_index_)#通常情况下,直接使用best_params_更为方便return None
knn_iris_gscv()
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
# 超参数搜索
x,y = load_iris(return_X_y=True)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=0)
# 创建knn模型
knn_model = KNeighborsClassifier(n_neighbors=7)
model = GridSearchCV(knn_model,param_grid={'n_neighbors':[3,4,5,6,7]},cv=5)
model.fit(x_train,y_train)
score = model.score(x_test,y_test)
print(score)
y_pred = model.predict(x_test)
print(y_pred)
print(y_test)
print("最佳参数",model.best_params_)
print("最佳模型",model.best_estimator_)
print("最佳结果",model.best_score_)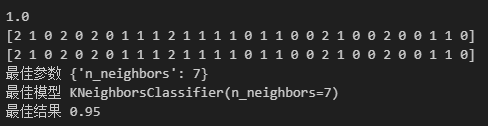
相关文章:
[模型选择与调优]机器学习-part4
七 模型选择与调优 1 交叉验证 (1) 保留交叉验证HoldOut HoldOut Cross-validation(Train-Test Split) 在这种交叉验证技术中,整个数据集被随机地划分为训练集和验证集。根据经验法则,整个数据集的近70%被用作训练集ÿ…...

【计算机网络-数据链路层】以太网、MAC地址、MTU与ARP协议
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:传输层-TCP协议TCP核心机制与可靠性保障 下篇文章: 网络…...

学习适应对智能软件对对象的属性进行表征、计算的影响
下面的链接是我新发表的文章。这篇文章是关于智能软件对对象进行标志、表征的问题,这是所有智能实体都无法回避的基本问题。 我最近写了一篇关于奖惩系统的文章。并开始写智能是如何在基础编程的基础上涌现出来的文章。 https://www.oalib.com/articles/6857382 …...

vue 组件函数式调用实战:以身份验证弹窗为例
通常我们在 Vue 中使用组件,是像这样在模板中写标签: <MyComponent :prop"value" event"handleEvent" />而函数式调用,则是让我们像调用一个普通 JavaScript 函数一样来使用这个组件,例如:…...

多线程面试题总结
基础概念 进程与线程的区别 进程:操作系统资源分配的基本单位,有独立内存空间线程:CPU调度的基本单位,共享进程资源对比: 创建开销:进程 > 线程通信方式:进程(IPC)、线程(共享内存)安全性:进程更安全(隔离),线程需要同步线程的生命周期与状态转换 NEW → RUNNABLE …...
Kafka 与 RabbitMQ、RocketMQ 有何不同?
一、不同的诞生背景,塑造了不同的“性格” 名称 背景与目标 产品定位 Kafka 为了解决 LinkedIn 的日志收集瓶颈,强调吞吐与持久化 更像一个“可持久化的分布式日志系统” RabbitMQ 出自金融通信协议 AMQP 的实现,强调协议标准与广泛适…...

【比赛真题解析】篮球迷
本次给大家分享一道比赛的题目:篮球迷。 洛谷链接:U561543 篮球迷 题目如下: 【题目描述】 众所周知,jimmy是个篮球迷。众所周知,Jimmy非常爱看NBA。 众所周知,Jimmy对NBA冠军球队的获奖年份和队名了如指掌。 所以,Jimmy要告诉你n个冠军球队的名字和获奖年份,并要求你…...
【MATLAB源码-第277期】基于matlab的AF中继系统仿真,AF和直传误码率对比、不同中继位置误码率对比、信道容量、中继功率分配以及终端概率。
操作环境: MATLAB 2022a 1、算法描述 在AF(放大转发)中继通信系统中,信号的传输质量和效率受到多个因素的影响,理解这些因素对于系统的优化至关重要。AF中继通信的基本架构由发射端、中继节点和接收端组成。发射端负…...

webRtc之指定摄像头设备绿屏问题
摘要:最近发现,在使用navigator.mediaDevices.getUserMedia({ deviceId: ‘xxx’}),指定设备的时候,video播放总是绿屏,发现关闭浏览器硬件加速不会出现,但显然这不是一个最好的方案; 播放后张这样 修复后 上代码 指定…...
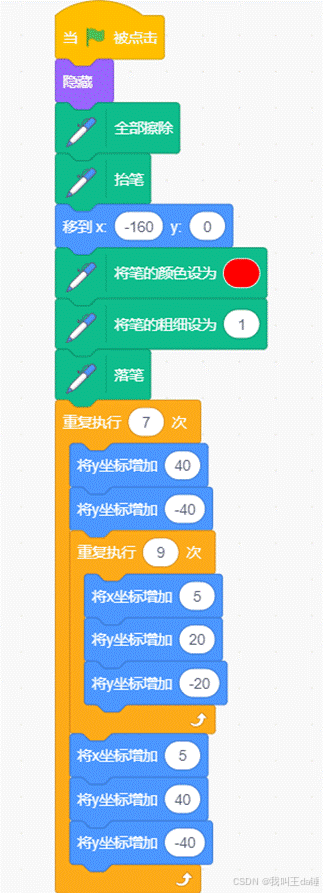
2023年03月青少年软件编程(图形化)等级考试四级编程题
求和 1.准备工作 (1)保留舞台中的小猫角色和白色背景。 2.功能实现 (1)计算1~100中,可以被3整除的数之和; (2)说出被3整除的数之和。 标准答案: 参考程序&…...
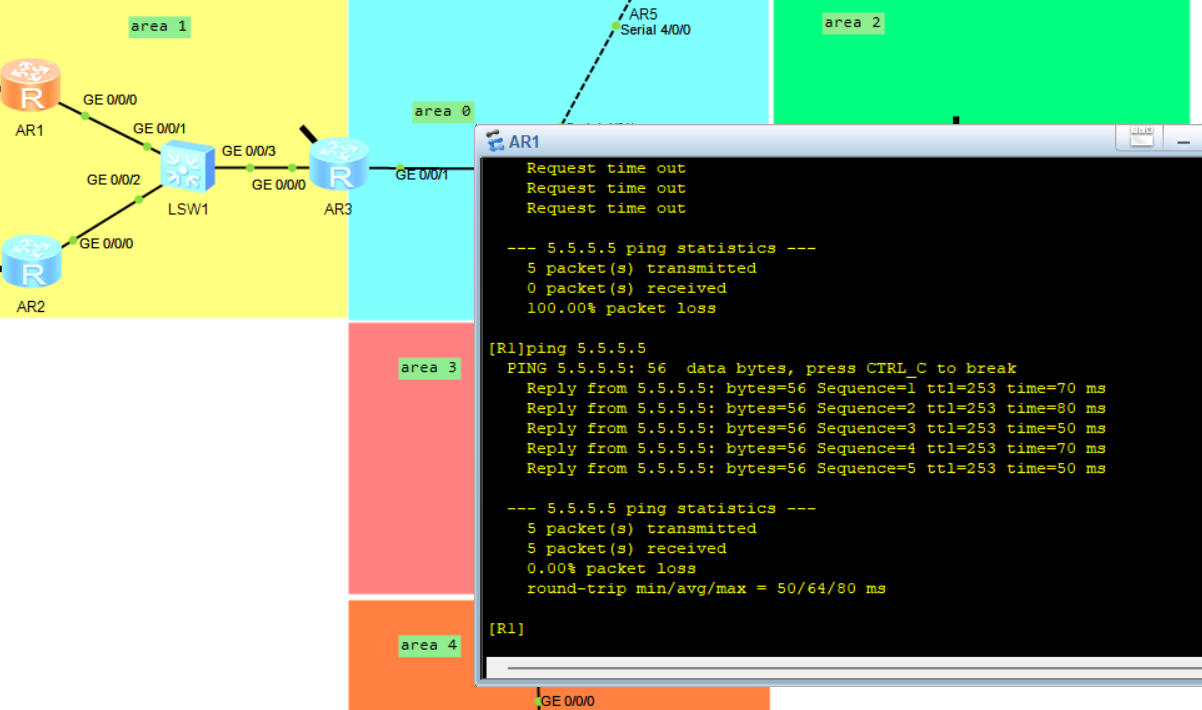
ensp的华为小实验
1.先进行子网划分 2.进行接口的IP地址配置和ospf的简易配置,先做到全网小通 3.进行ospf优化 对区域所有区域域间路由器进行一个汇总 对区域1进行优化 对区域2.3进行nssa设置 4.对ISP的路由进行协议配置 最后ping通5.5.5.5...
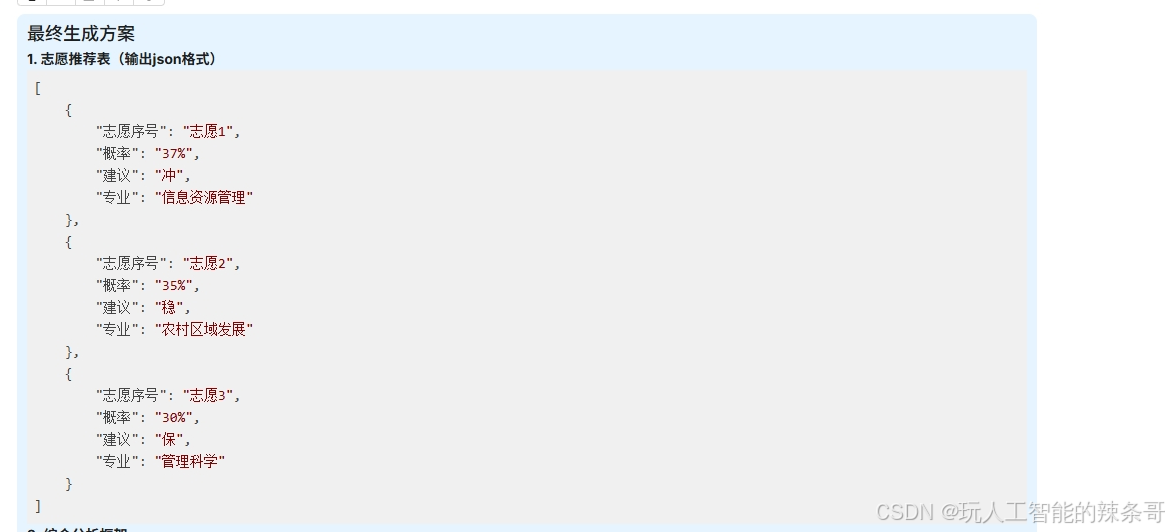
ragflow报错:KeyError: ‘\n “序号“‘
环境: ragflowv 0.17.2 问题描述: ragflow报错:KeyError: ‘\n “序号”’ **1. 推荐表(输出json格式)** [{"},{},{"},{} ]raceback (most recent call last): May 08 20:06:09 VM-0-2-ubuntu ragflow-s…...

Java大数据可视化在城市空气质量监测与污染溯源中的应用:GIS与实时数据流的技术融合
随着城市化进程加速,空气质量监测与污染溯源成为智慧城市建设的核心议题。传统监测手段受限于数据离散性、分析滞后性及可视化能力不足,难以支撑实时决策。2025年4月27日发布的《Java大数据可视化在城市空气质量监测与污染溯源中的应用》一文,…...
FHE与后量子密码学
1. 引言 近年来,关于 后量子密码学(PQC, Post-Quantum Cryptography) 的讨论愈发热烈。这是因为安全专家担心,一旦有人成功研发出量子计算机,会发生什么可怕的事情。由于 Shor 算法的存在,量子计算机将能够…...

Flask 调试的时候进入main函数两次
在 Flask 开启 Debug 模式时,程序会因为自动重载(reloader)的机制而启动两个进程,导致if __name__ __main__底层的程序代码被执行两次。以下说明其原理与常见解法。 Flask Debug 模式下自动重载机制 Flask 使用的底层服务器 Wer…...
)
cv_area_center()
主题 用opencv实现了halcon中area_center算子的功能, 返回region的面积,中心的行坐标和中心的列坐标 代码很简单 def cv_area_center(region):area[]row []col []for re in region:retval cv2.moments(re)area.append(retval[m00])row.append(int(r…...
CSS: 选择器与三大特性
标签选择器 标签选择器就是选择一些HTML的不同标签,由于它们的标签需求不同,所以CSS需要设置标签去选择它们,为满足它们的需求给予对应的属性 基础选择器 标签选择器 <!DOCTYPE html> <head><title>HOME</title>…...

2505d,d的借用检查器
void func(scope ref int*) {}unique(int*) a ...; assert(a !is null);unique(int*) b a; assert(a is null); assert(b !is null);func(b); // ok用live作为检查器,不必有断定了. int* a ...; int* b a; // 所有权转至b *a 3; // 不能再用a.编译器保证约束指针. live…...

力扣-2.两数相加
题目描述 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字 0 之外,这两个数都…...
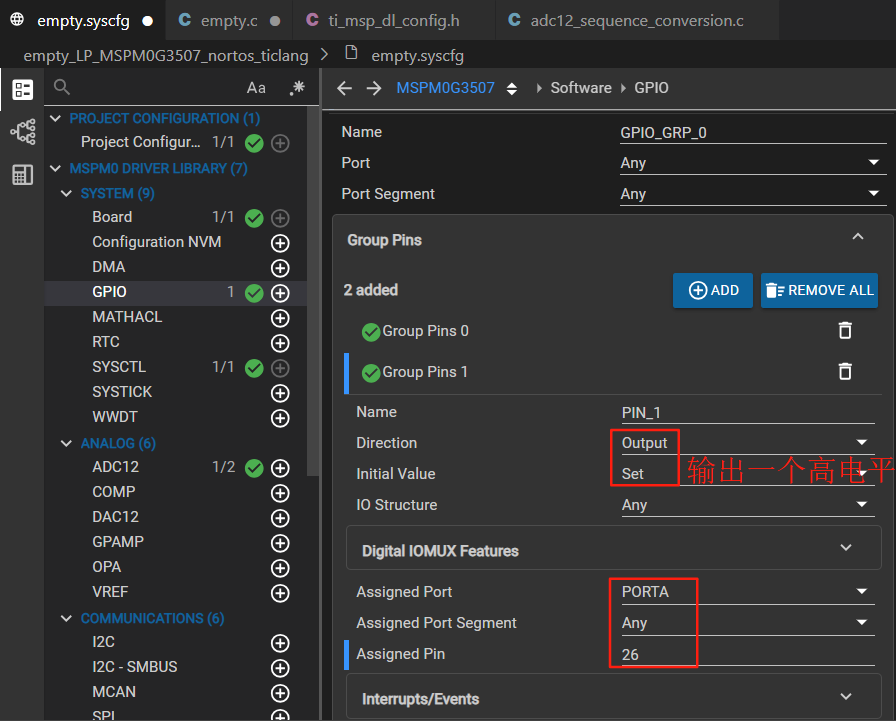
M0基础篇之ADC
本节课使用到的例程 一、Single模式例程基本配置的解释 在例程中我们只使用到了PA25这一个通道,因此我们使用的是Single这个模式,也就是我们在配置模式的时候使用的是单一转换。 进行多个通道的测量我们可以使用Sequence这个模式。 二、Single模式例程基…...

Nginx安全防护与HTTPS部署
一、安全防护与HTTPS概念 一、安全防护与HTTPS概念 为什么要隐藏版本号? 当访问网站时,能从响应标头查看到server的信息,这里面就包含了是什么web应用及其版本为你提供的服务。如果不隐藏server的版本,会导致别有用心的人知晓…...

C语言_程序的段
在 C 语言程序中,内存通常被分为多个逻辑段,每个段存储不同类型的数据。理解这些段的结构和功能,有助于你更高效地编写、调试和优化程序。以下是 C 语言程序中主要的内存段及其特点: 1. 代码段(Text Segment) 存储内容:编译后的机器指令(程序代码)。特性: 只读:防止…...
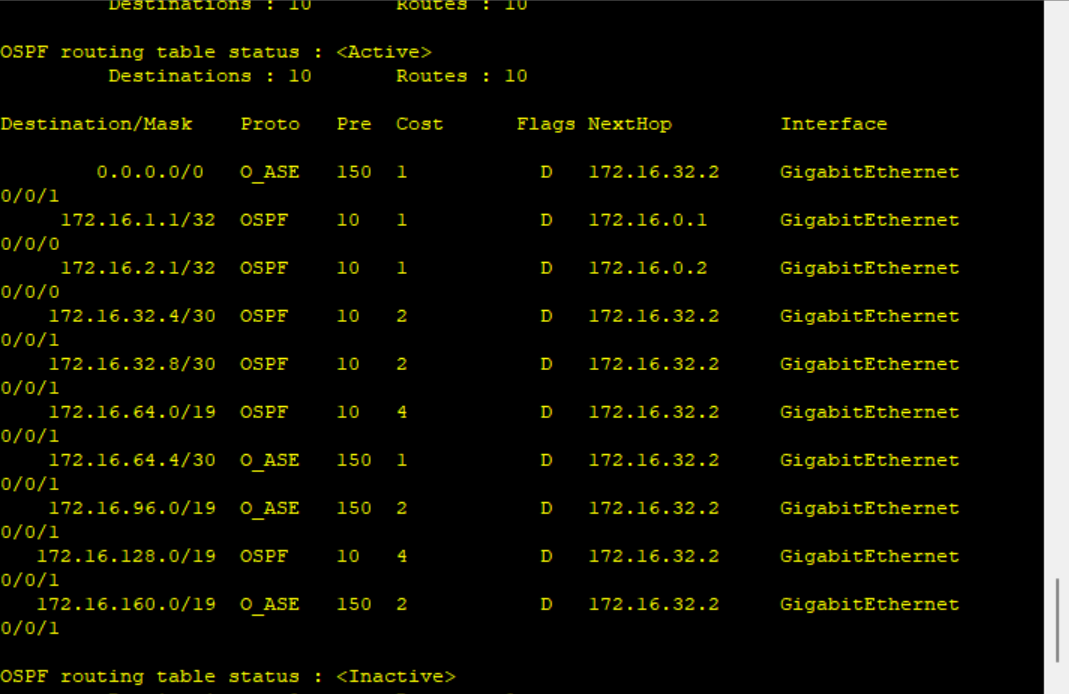
OSPF综合实验实验报告
OSPF综合实验实验报告 一、实验拓扑 二、实验要求 1.R5为ISP,其上只能配置IP地址;R4作为企业边界路由器, 出口公网地址需要通过PPP协议获取,并进行chap认证 2,整个OSPF环境IP基于172.16.0.0/16划分; 3&…...
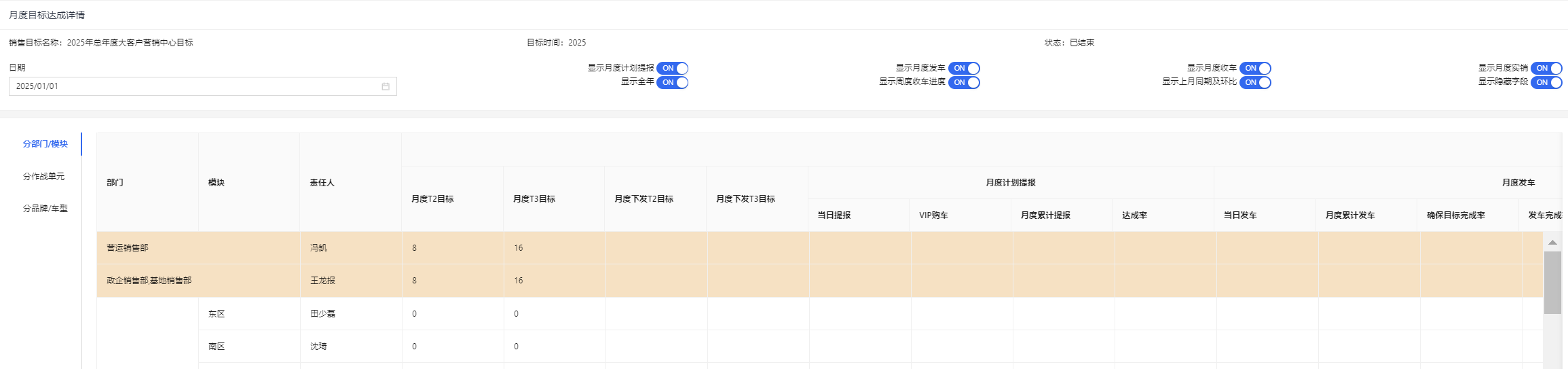
vue3+ant design vue + Sortable实现多级表格列拖动
1、最近遇到个需求,需使用vue3ant design vue Sortable实现多级表格的表头允许用户拖拽移动。即当用户拖拽一级表头时,其对应的子级表头及数据应同步移动,并且只允许一级非固定表头允许拖拽。 2、代码 <a-table:data-source"rowDat…...

基于开源链动2+1模式AI智能名片S2B2C商城小程序的分销价格管控机制研究
摘要:本文聚焦开源链动21模式AI智能名片S2B2C商城小程序在分销体系中的价格管控机制,通过解析其技术架构与商业模式,揭示平台如何通过"去中心化裂变中心化管控"双轨机制实现价格统一。研究显示,该模式通过区块链存证技术…...
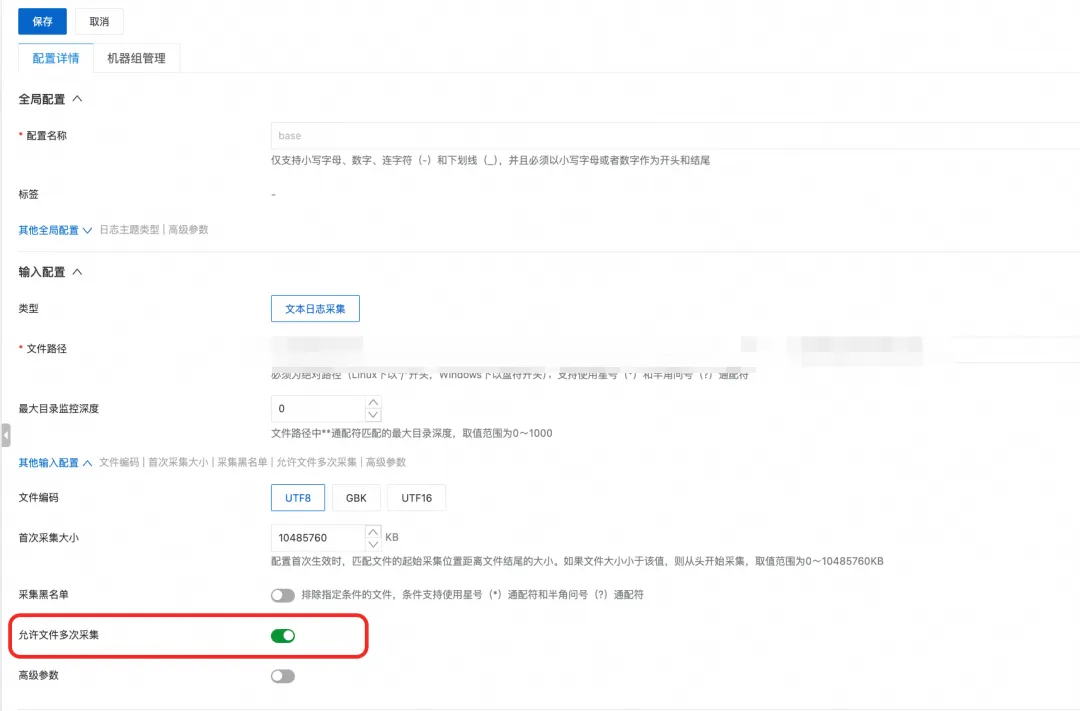
阿里云 SLS 多云日志接入最佳实践:链路、成本与高可用性优化
作者:裘文成(翊韬) 摘要 随着企业全球化业务的扩展,如何高效、经济且可靠地将分布在海外各地的应用与基础设施日志统一采集至阿里云日志服务 (SLS) 进行分析与监控,已成为关键挑战。 本文聚焦于阿里云高性能日志采集…...

体育培训的实验室管理痛点 质检LIMS如何重构体育检测价值链
在竞技体育与全民健身并行的时代背景下,体育培训机构正面临双重挑战:既要通过科学训练提升学员竞技水平,又需严格把控运动安全风险。作为实验室数字化管理的核心工具,质检LIMS系统凭借其标准化流程管控与智能化数据分析能力&#…...
)
第二节:Vben Admin 最新 v5.0 对接后端登录接口(上)
文章目录 前言一、登录页面调整二、登录表单调整三、后端接口(Python)对接对接准备1. Flask项目介绍2. User模型创建3. 迁移模型4. Token创建5. 编写蓝图6. 注册蓝图四、测试登录总结前言 这里是Vben Admin V5版本实战体验,上一节我们前端已正常运行,但是没有实现登录。本节…...
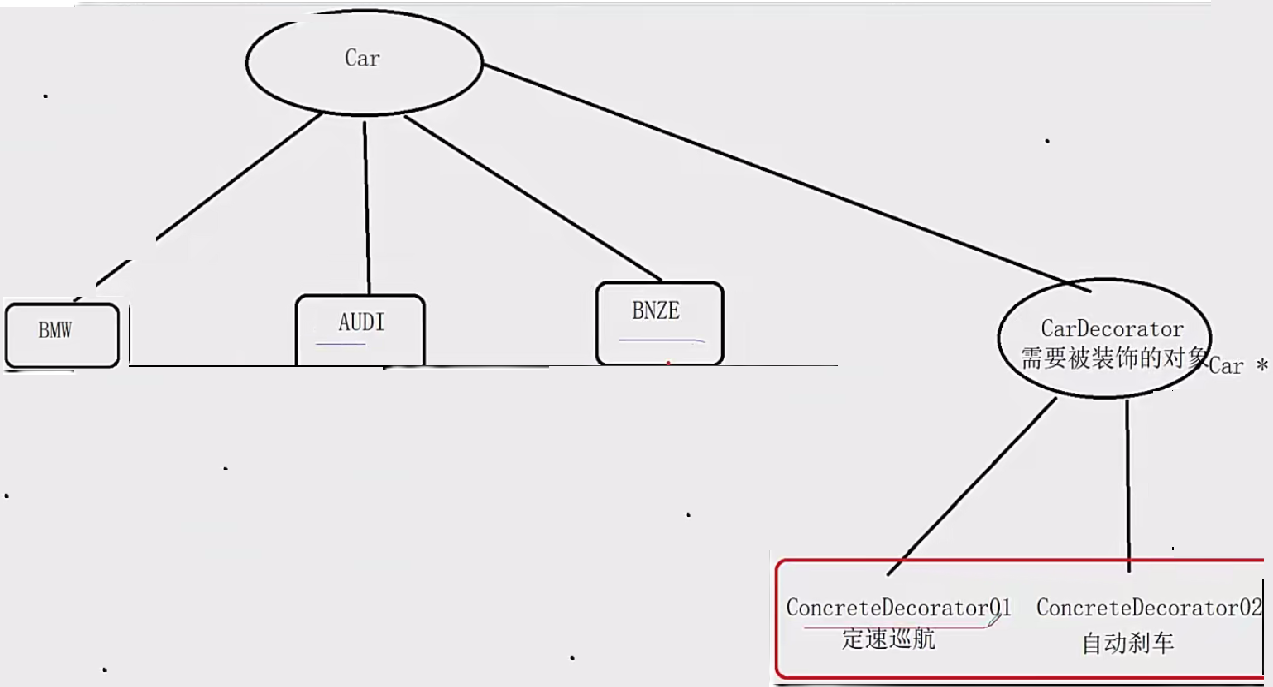
设计模式【cpp实现版本】
文章目录 设计模式1.单例模式代码设计1.饿汉式单例模式2.懒汉式单例模式 2.简单工厂和工厂方法1.简单工厂2.工厂方法 3.抽象工厂模式4.代理模式5.装饰器模式6.适配器模式7.观察者模式 设计模式 1.单例模式代码设计 为什么需要单例模式,在我们的项目设计中&…...
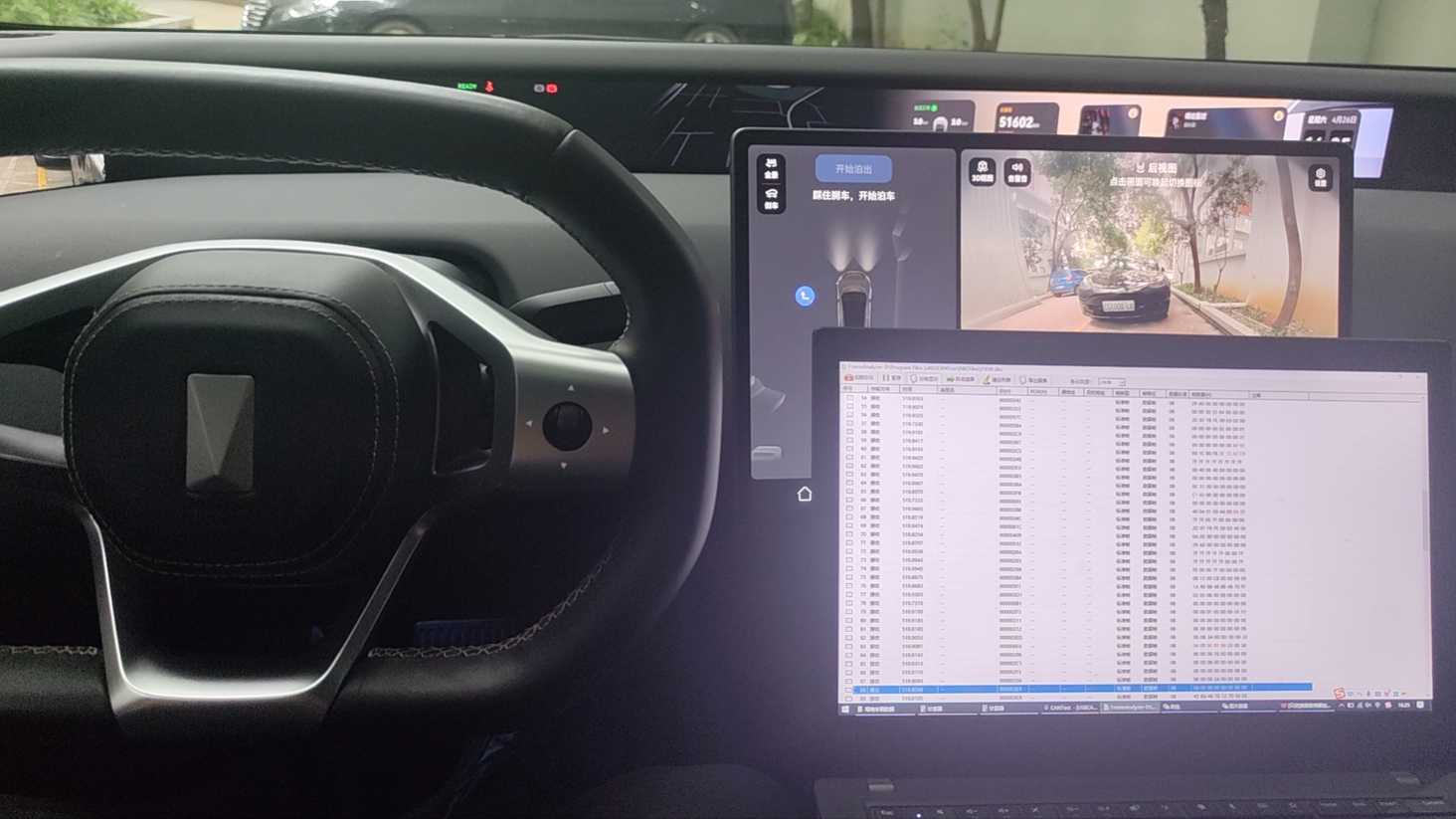
阿维塔汽车CAN总线数据适配技术解析与免破线数据采集实践
在智能电动汽车快速迭代的背景下,阿维塔凭借其高度集成的电子电气架构成为行业焦点。昨天我们经过实测,适配了该车型CAN总线数据适配的核心技术,从硬件接口定位、无损伤接线方案到关键动力系统数据解码进行系统性剖析,为智能诊断、…...