Linux——MySQL约束与查询
表的约束
真正约束字段的是数据类型,但是数据类型约束很单一,需要有一些额外的约束,更好的保证数据的合
法性,从业务逻辑角度保证数据的正确性。比如有一个字段是email,要求是唯一的。
表的约束是为了防止插入不合法的数据(并不是人人都知道所有的合法数据)。
最终目的就是为了保证数据的完整性和可预期性。
在创建表的时候加上if not exists,避免重复创建同名表。作用是仅在指定名称的表不存在时,才执行创建操作;如果表已存在,则跳过创建,且不会报错。
空属性
两个值:null(默认的)和not null(不为空)
null是为空,什么都没有,并且不参与计算,也不区分大小写。
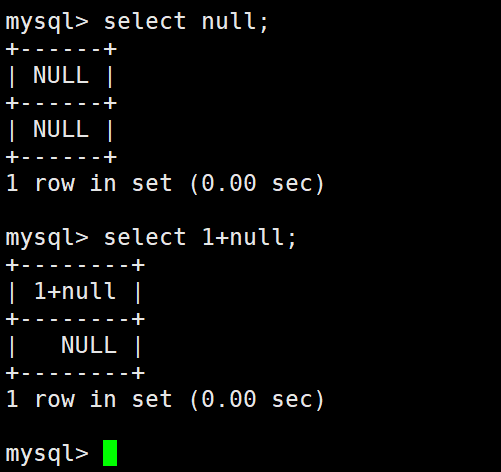
数据库默认字段基本都是字段为空,但是实际开发时,尽可能保证字段不为空,因为数据为空没办
法参与运算。
那么如何保证插入的数据不为空呢?
这时候就要使用not null了。
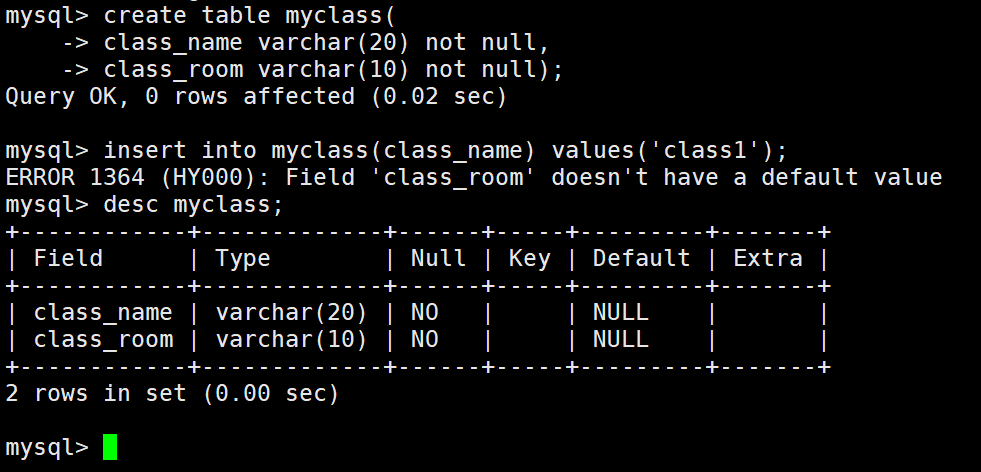

如果这时插入NULL会报错,不插入也会报错。(这两者报错是不同的,插入NULL报错是not null检测拦截)
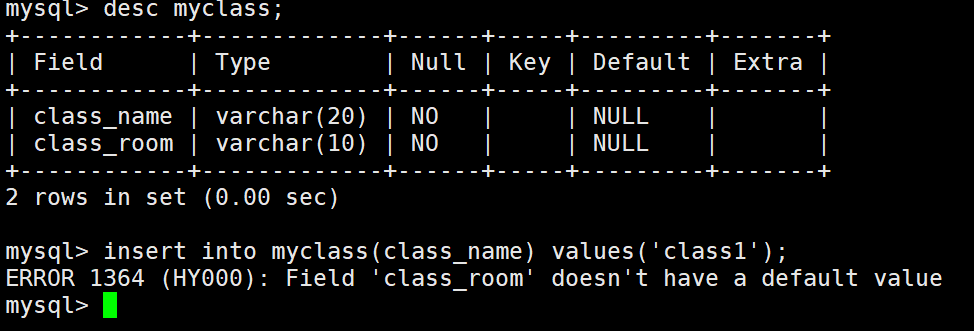
虽然设置了不能为空,但是未传入数据的时候,检测是看你是否有设置缺省值,如果没有就会报没有设置缺省值的错。(缺省值在下面讲解)
默认值
默认值:某一种数据会经常性的出现某个具体的值,可以在一开始就指定好,在需要真实数据的时候,用户可以选择性的使用默认值。
default 作用是缺省。如果设置了,用户将来插入,有具体数据就用用户的,没有就用默认的。
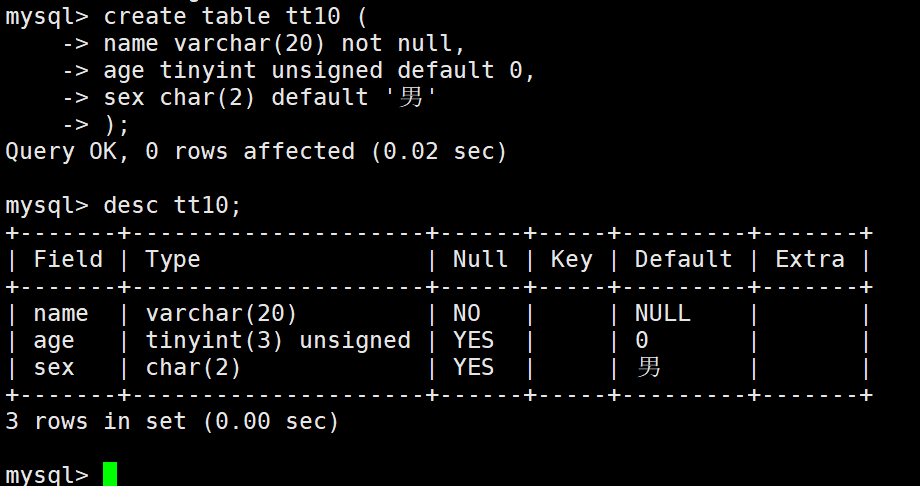
默认值的生效:数据在插入的时候不给该字段赋值,就使用默认值。
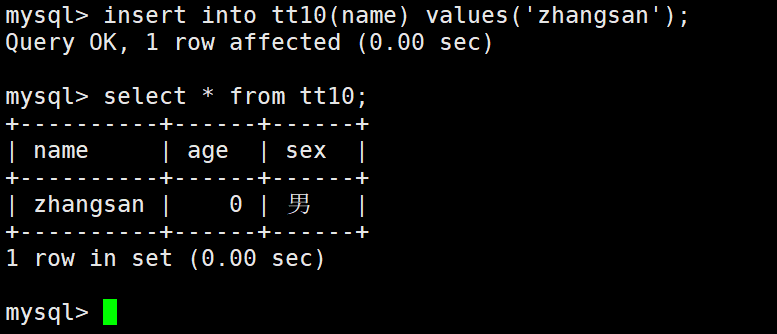
如果not null一项有缺省,也就不用填写数据,直接会用默认值,如果想传入NULL,会被拦截报错。
同时设置了缺省和非空,那么这两者并不会冲突,而是相互补充。
如果既没有设置not null,也没有设置default,系统会默认设置default为null。
列描述
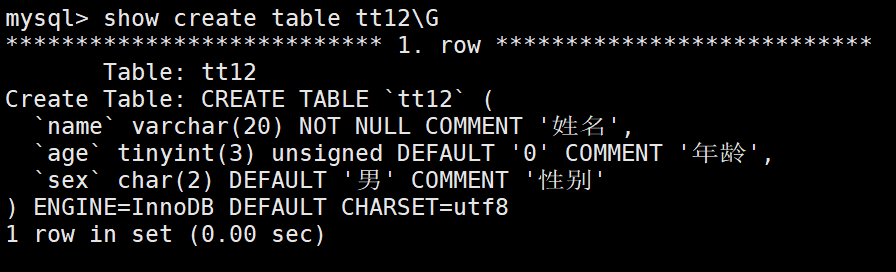
列描述:comment,没有实际含义,专门用来描述字段,会根据表创建语句保存,用来给程序员或DBA来进行了解。(相当于C++当中的注释)
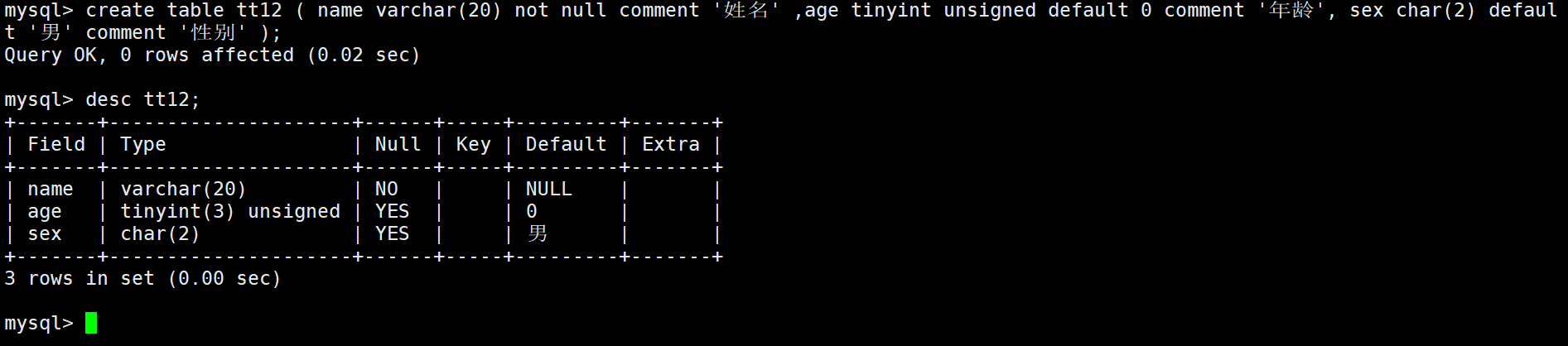
通过desc查看不到注释信息,通过show可以看到:
zerofill
int的数据类型后面带数字是什么意思呢?
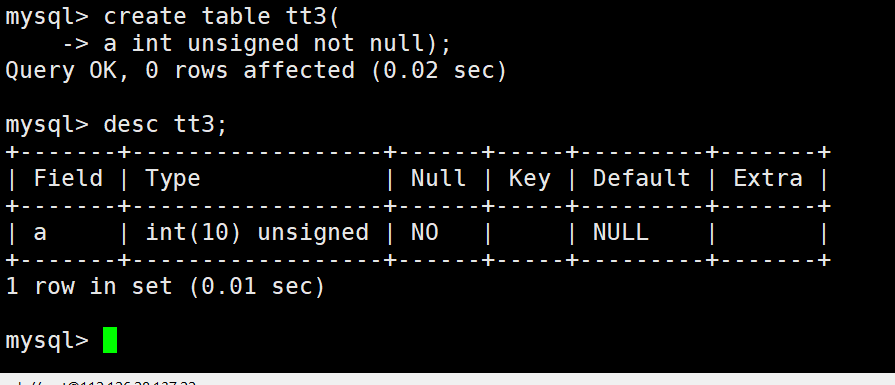
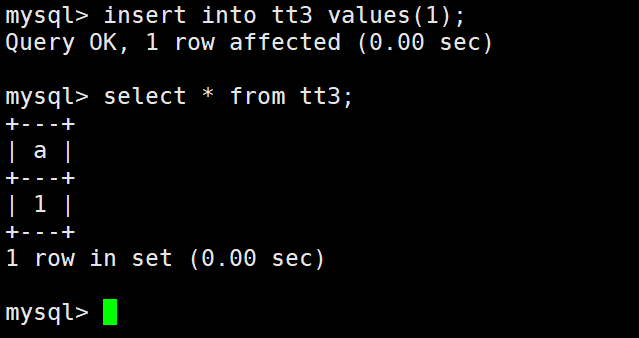
查询没有异常,现在更改一下。
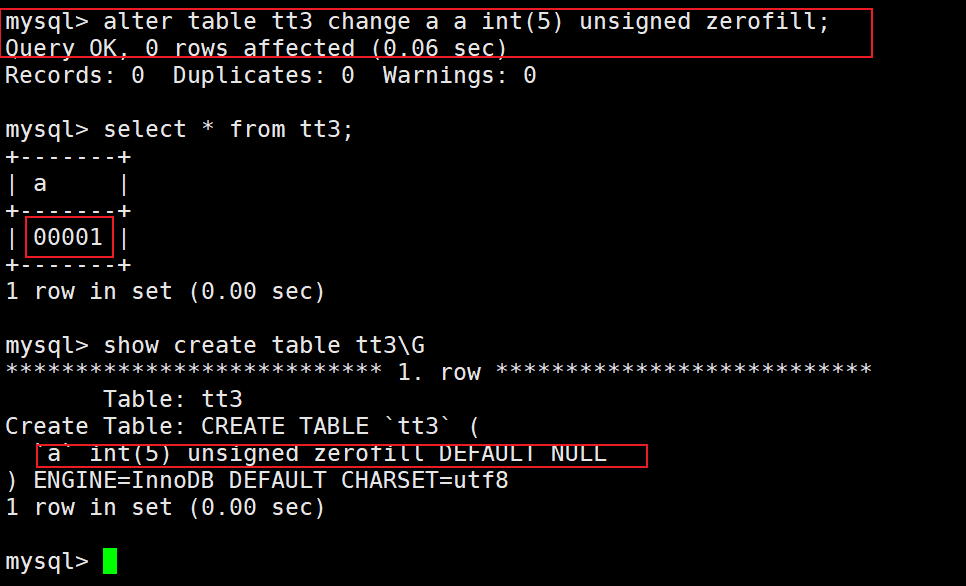
这里直接更改成为了00001,一共是5位,这次可以看到a的值由原来的1变成00001,这就是zerofill属性的作用,如果宽度小于设定的宽度(这里设置的是5),自动填充0。
如果插入的长度足够或者大于这个长度,就是插入的数,不会进行补0。
要注意的是,这只是最后显示的结果,在MySQL中实际存储的还是1。为什么是这样呢?我们可以用hex函数来证明。
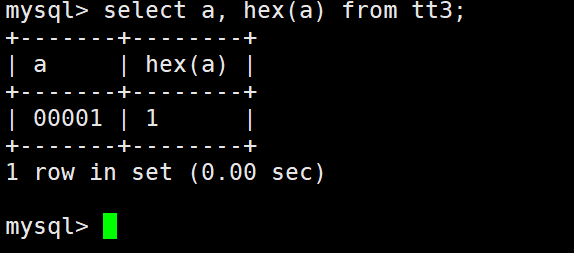
当然,int后面括号当中的数其实就是int的位数,范围就是10位数的范围,如果是无符号整型就是11位。
主键
主键:primary key用来唯一的约束该字段里面的数据,不能重复,不能为空,一张表中最多只能有一个
主键;主键所在的列通常是整数类型。
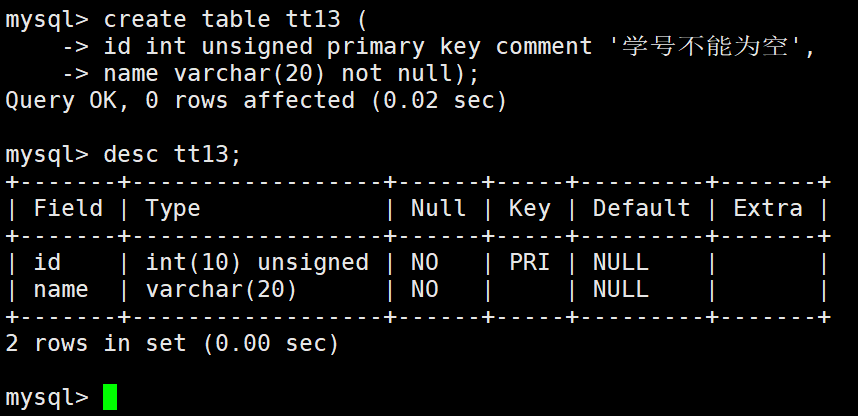
key 中 pri表示该字段是主键,并且会自动设置成为not null。
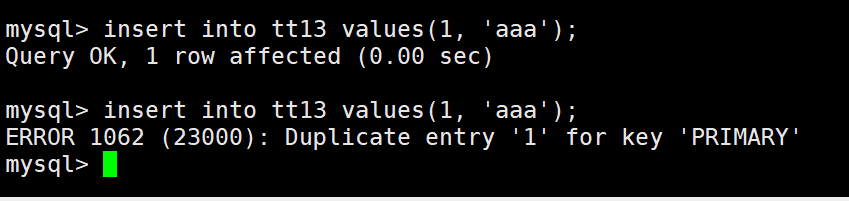
主键约束:主键对应的字段中不能重复,一旦重复,操作失败。
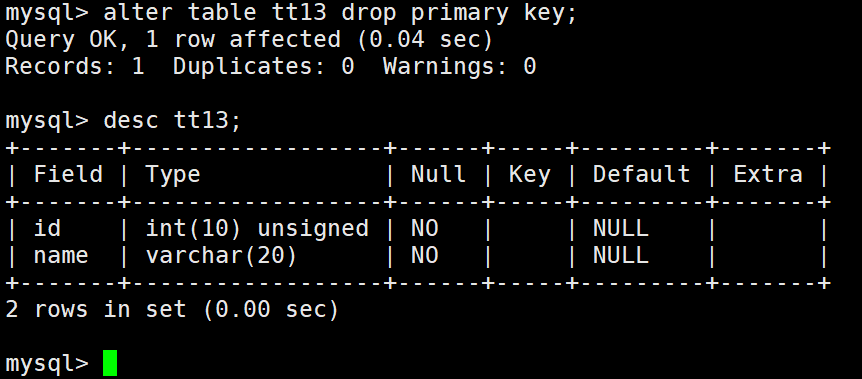
删除主键:因为只有一个主键,所以不用写字段列表
alter table 表名 drop primary key;
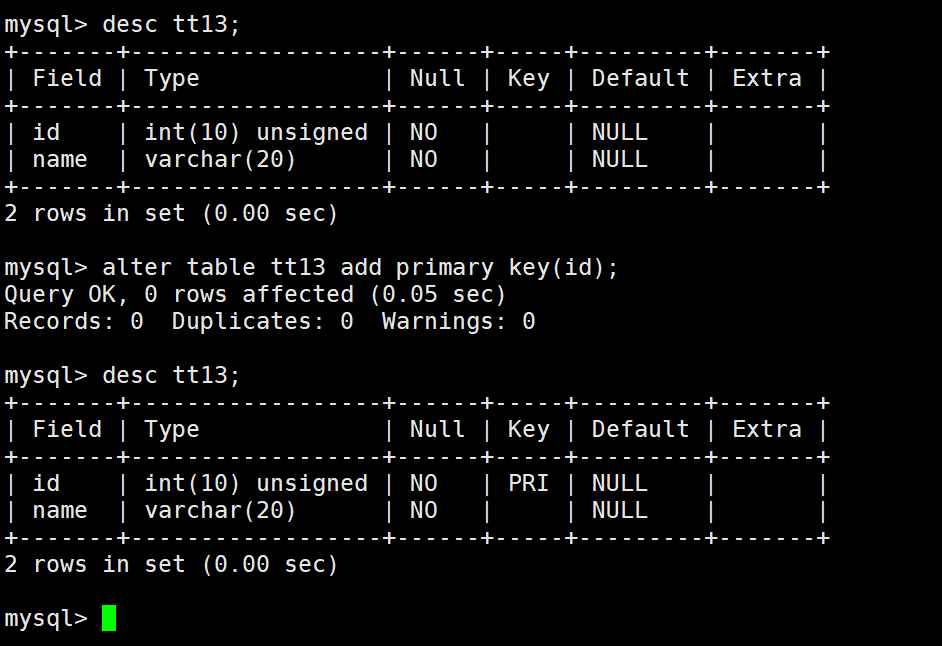
当表创建好以后但是没有主键的时候,可以再次追加主键:
alter table 表名 add primary key(字段列表)
这里要注意,如果出现id相同的字段列表,然后设置id为主键,那么就需要删除id相同的字段列表,只剩下一个,不然会报错不允许设置主键。
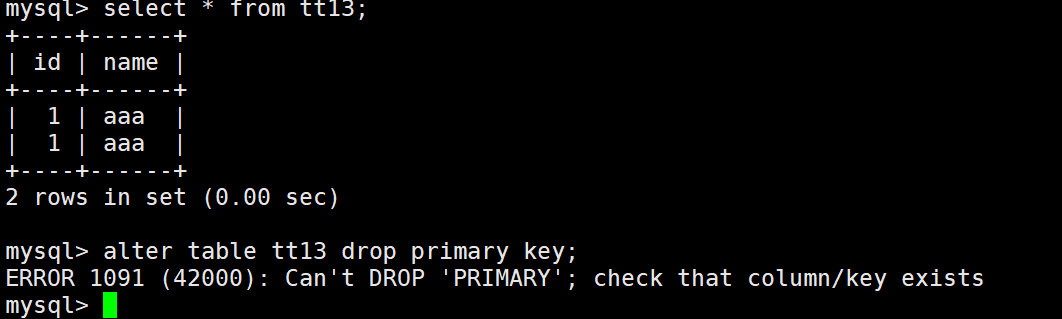
所以最好在一开始就设置主键,尽量不要中途设置主键。
注意:一个主键可以添加到一列或者多列上。
复合主键:
在创建表的时候,在所有字段之后,使用primary key(主键字段列表)来创建主键,如果有多个字段作为主键,可以使用复合主键。
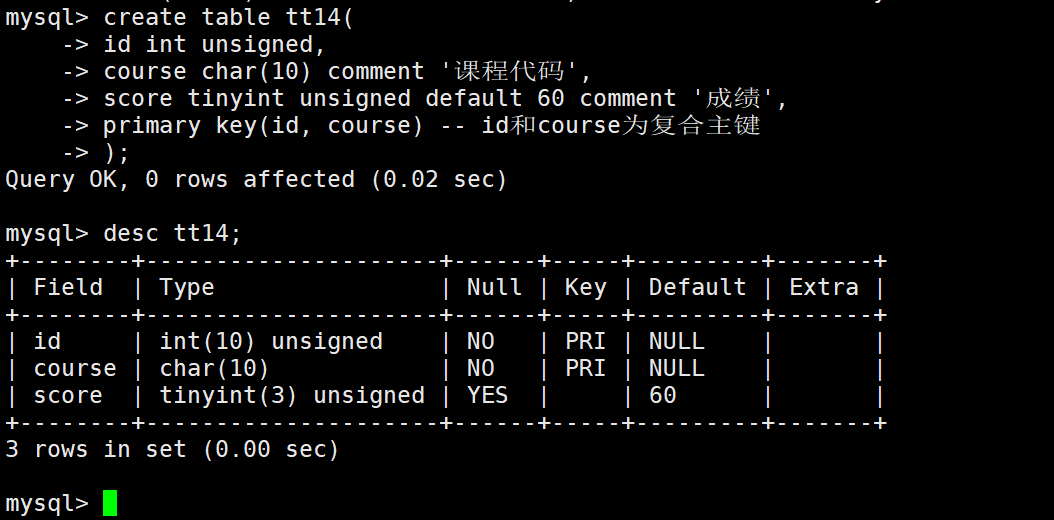
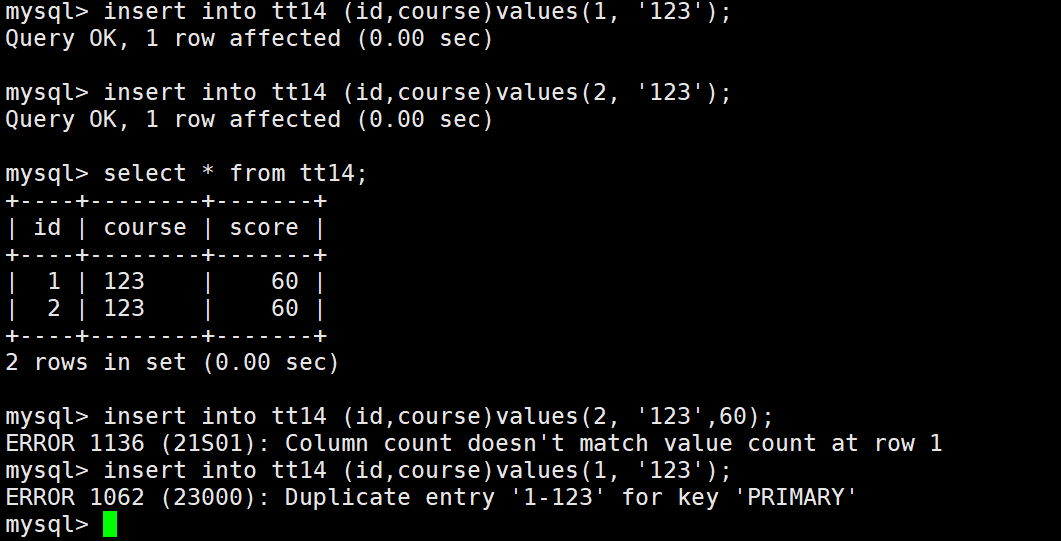
这里两个主键只要一个不同就可以成功插入,但是两个都相同就会报错,也就是说两个主键何在一起才算真正的主键。
自增长
auto_increment:当对应的字段,不给值,会自动的被系统触发,系统会从当前字段中已经有的最大值+1操作,得到一个新的不同的值。通常和主键搭配使用,作为逻辑主键。
自增长的特点:
任何一个字段要做自增长,前提是本身是一个索引(key一栏有值)
自增长字段必须是整数
一张表最多只能有一个自增长
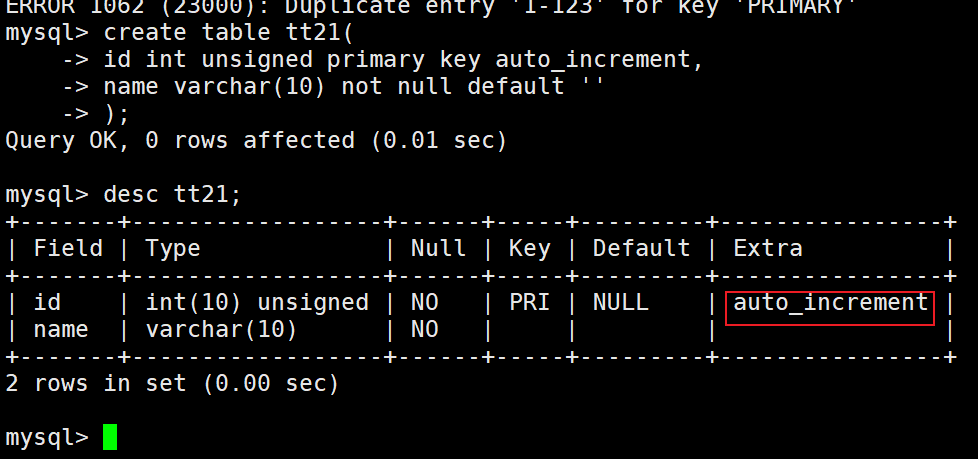
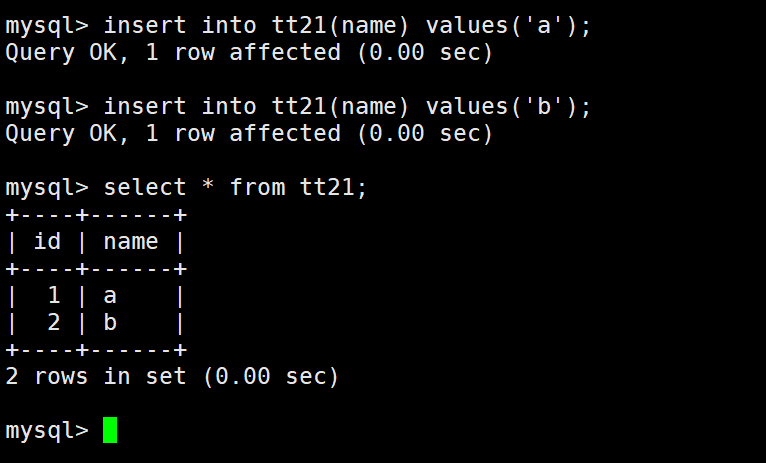
这里两次插入都没有给id的值,最后表中显示id从1开始自己增长,并且不会冲突。
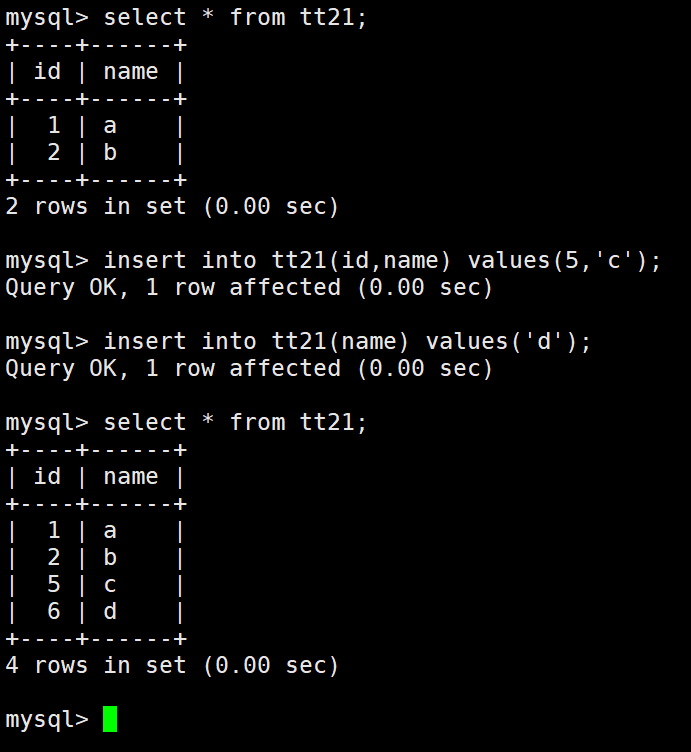
每次增长之前都会根据主键字段最大值进行+1.
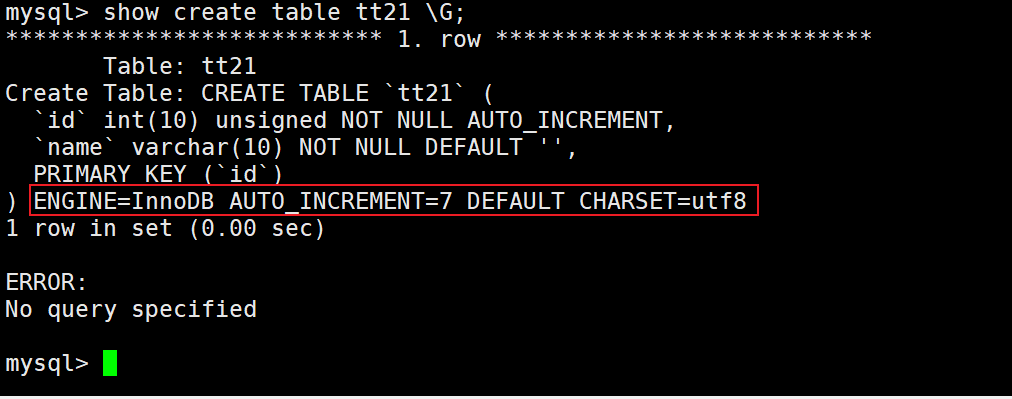
这里发现在表外设置了AUTO_INCREMENT的值。
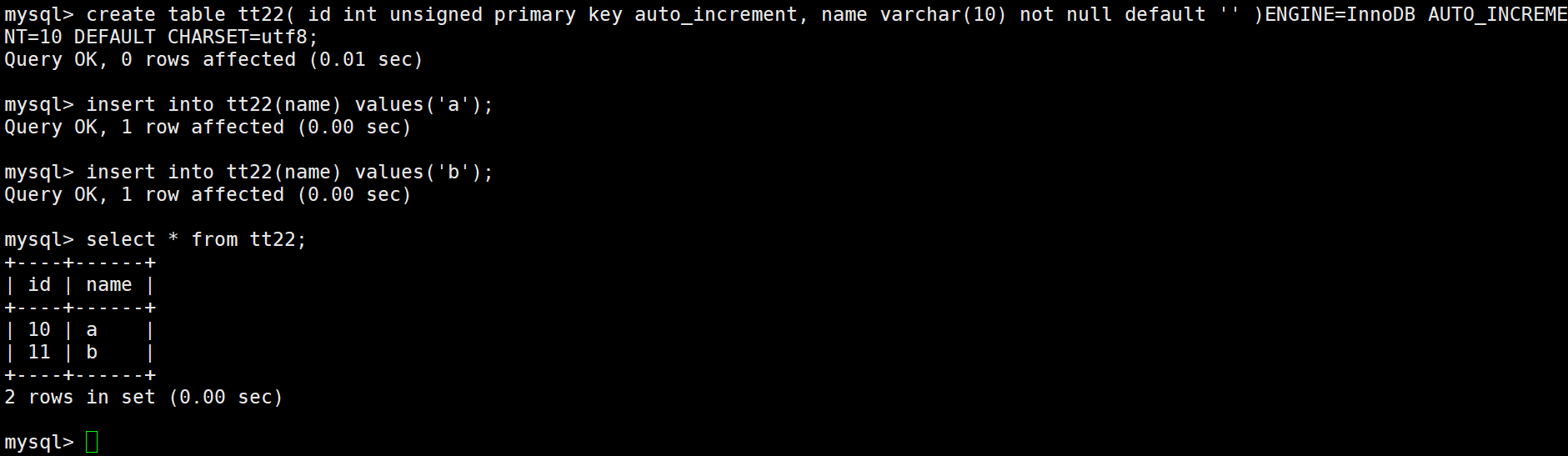
如果创建一个表,在表外设置AUTO_INCREMENT的值,那么主键就会从设置的值开始增长:
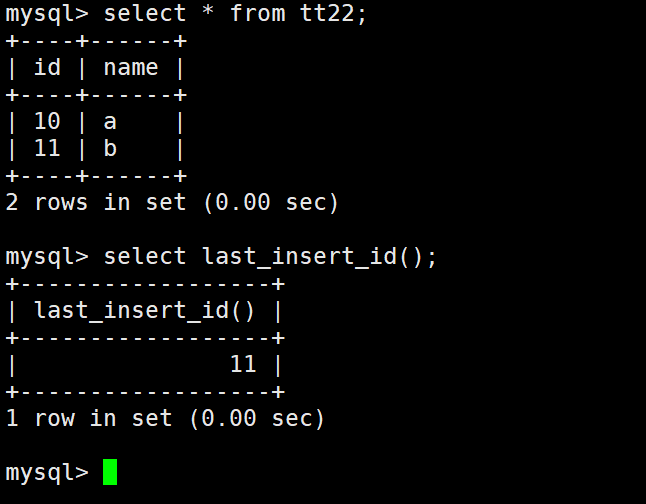
在插入后获取上次插入的 AUTO_INCREMENT 的值(批量插入获取的是第一个值)
简单说明索引:
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结
构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序。
数据库使用索引以找到特定值,然后顺指针找到包含该值的行。这样可以使对应于表的SQL语句执行得更快,可快速访问数据库表中的特定信息。
唯一键
一张表中有往往有很多字段需要唯一性,数据不能重复,但是一张表中只能有一个主键:唯一键就可以解决表中有多个字段需要唯一性约束的问题。
唯一键的本质和主键差不多,唯一键允许为空,而且可以多个为空,空字段不做唯一性比较。
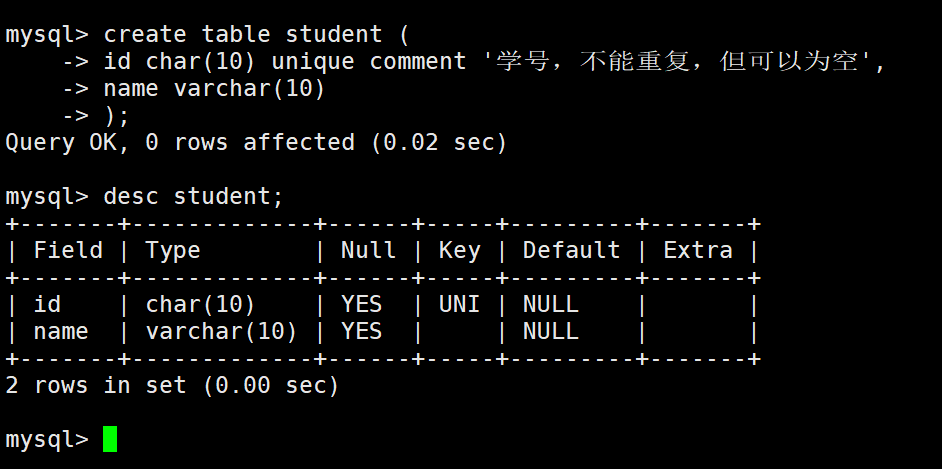
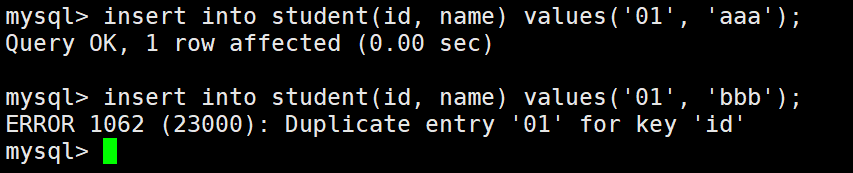
这里冲突是意料之中的,不能重复。
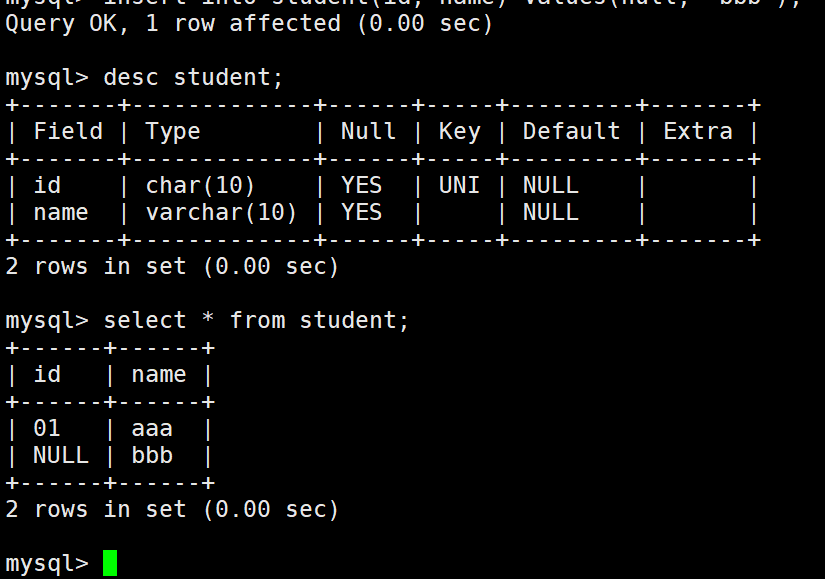
但是可以设置为空,这里就和主键不一样了,主键不能为空。
关于唯一键和主键的区别:
我们可以简单理解成,主键更多的是标识唯一性的。而唯一键更多的是保证在业务上,不要和别的信息出现重复。
比如说,学生排序,可以让序号成为主键,但是学号也不能重复,所以可以设置学号成为唯一键,这也说明学号是有唯一性的。
也就是说唯一键和主键不冲突,并且还是互相补充的,最大的价值就是一个表中可能有很多不能冲突的字段,但是主键只能有一个,唯一键可以有很多个。
如果不想让唯一键可以是空,那么可以后续设置成not null。
当然,唯一键也可以在建表之后设置:
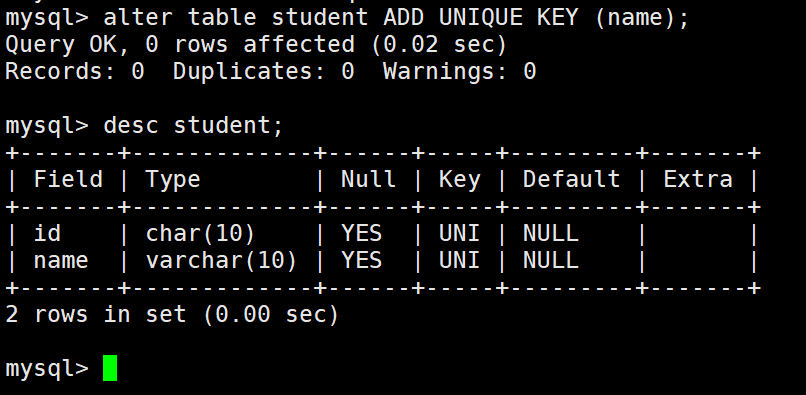
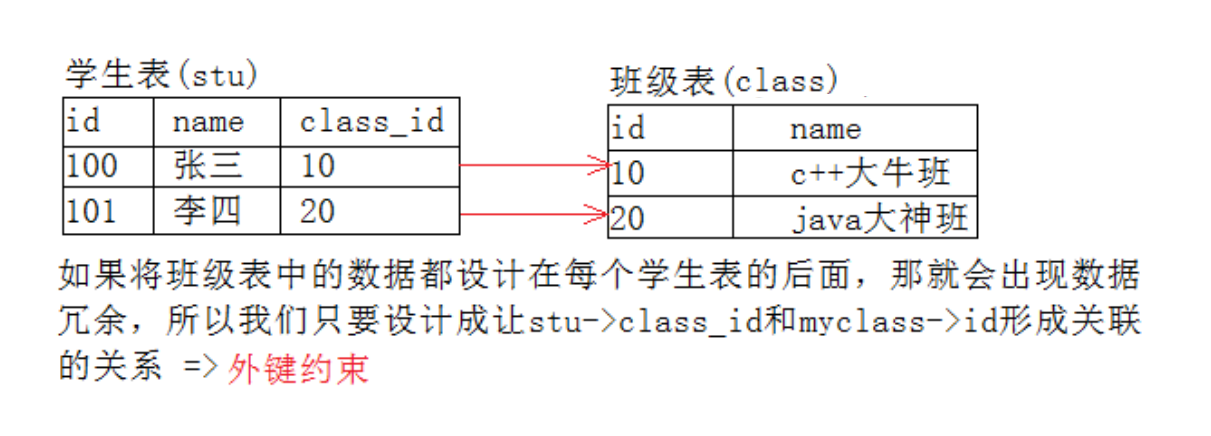
外键
外键用于定义主表和从表之间的关系:外键约束主要定义在从表上,主表则必须是有主键约束或unique约束。当定义外键后,要求外键列数据必须在主表的主键列存在或为null。
foreign key (字段名) references 主表(列)
主表:

从表

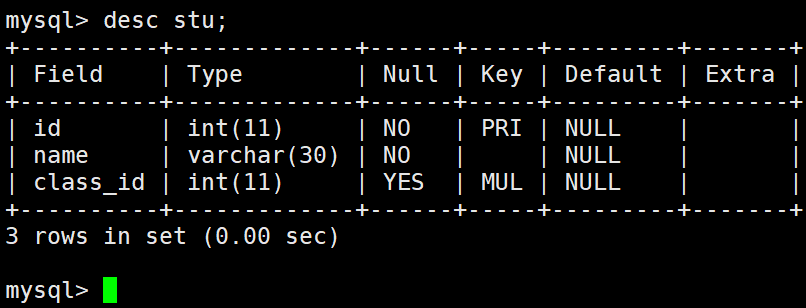
正常插入数据:
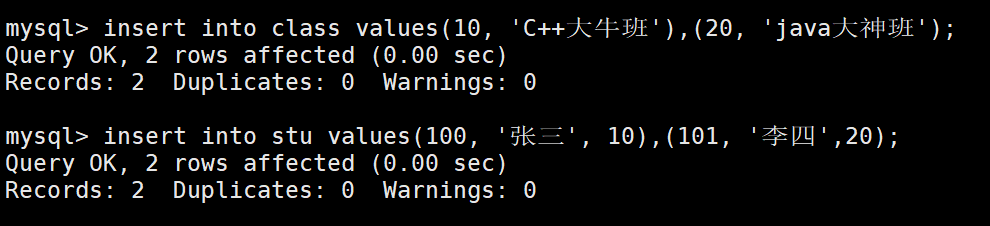
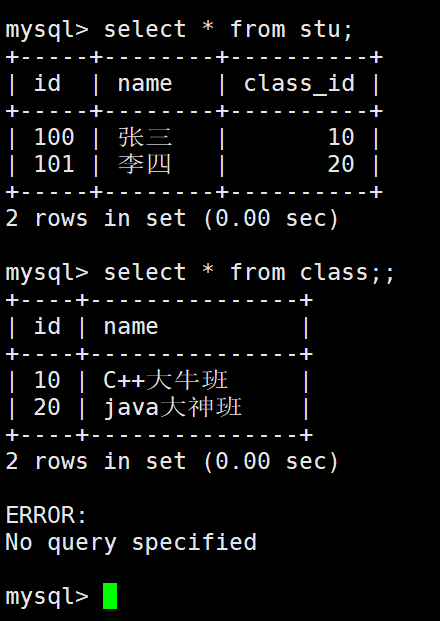

如果插入一个班级30的学生,就会报错,因为不存在班级30。
如果想删除一个主表中和外键有关联的主键字段列表,也是行不通的:

表的增删改查
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
Create
单行数据 + 全列插入;多行数据 + 指定列插入
insert into table_name (要插入的字段列表1,要插入的字段列表2…) values (插入字段列表1的数据,插入字段列表2的数据…);
into是可以省略的。
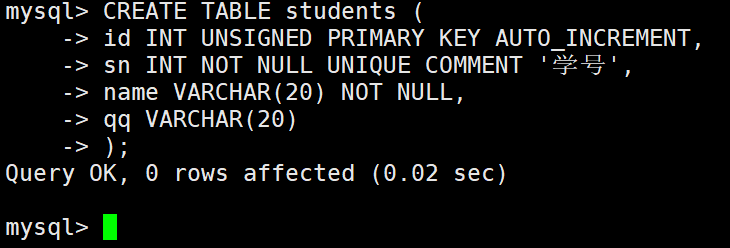
插入两条记录,要插入数据的数量必须和定义表的列的数量及顺序一致。
– 注意,这里在插入的时候,也可以不用指定id(当然,那时候就需要明确插入数据到那些列了),那么mysql会使用默认的值进行自增。
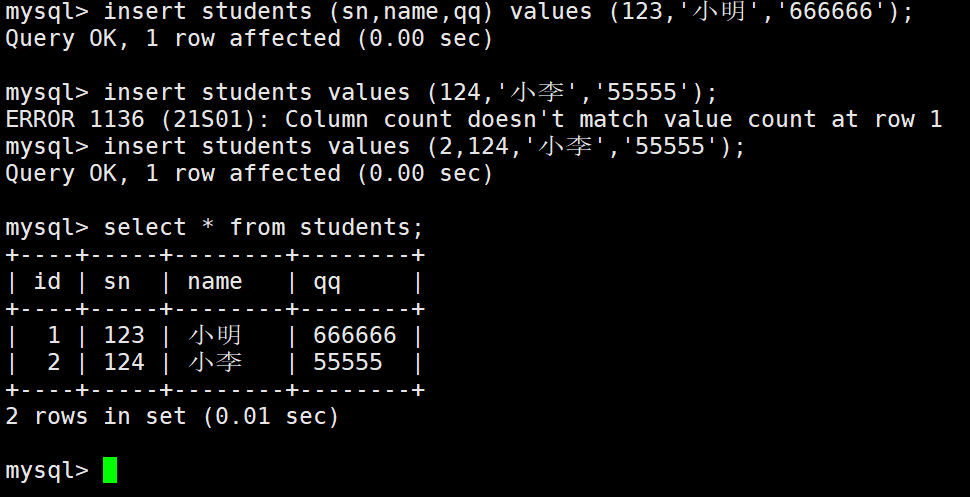
上面如果没有指定values一定要注意后面的插入数据顺序,少一个都会报错。
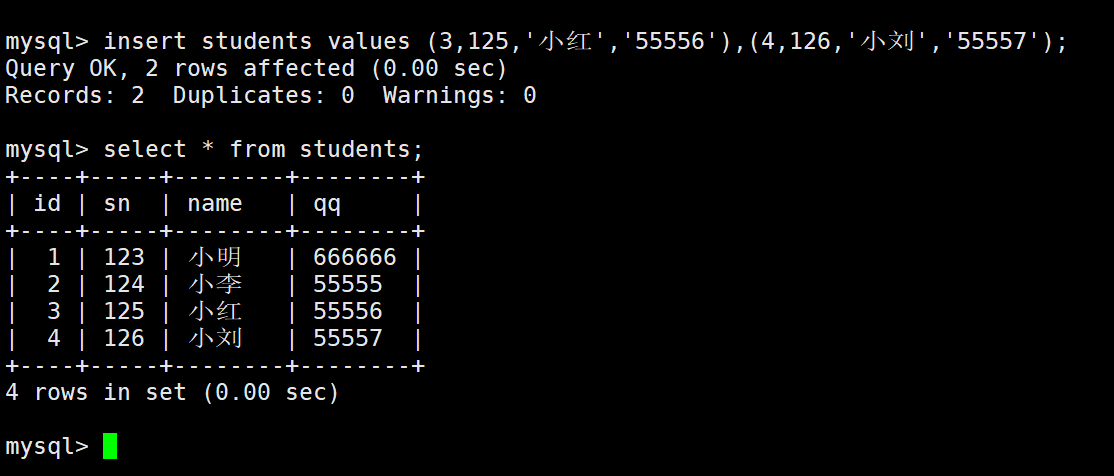
多行数据+ 指定列插入:
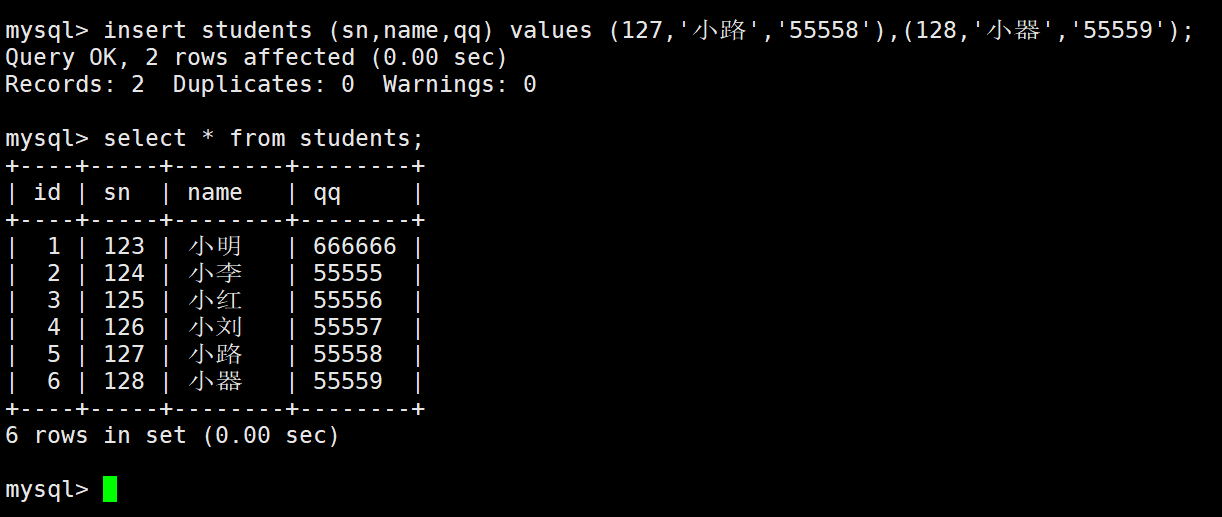
插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败。
这个时候可以选择性的进行同步更新操作:
insert … on duplicate key update (需要更改的值);
如果前面的值表中不冲突,就插入前面的值,冲突就i插入后面的值,也就是说on duplicate key update前后的值也可不一致。
注意:更新不能和其他的唯一键冲突。
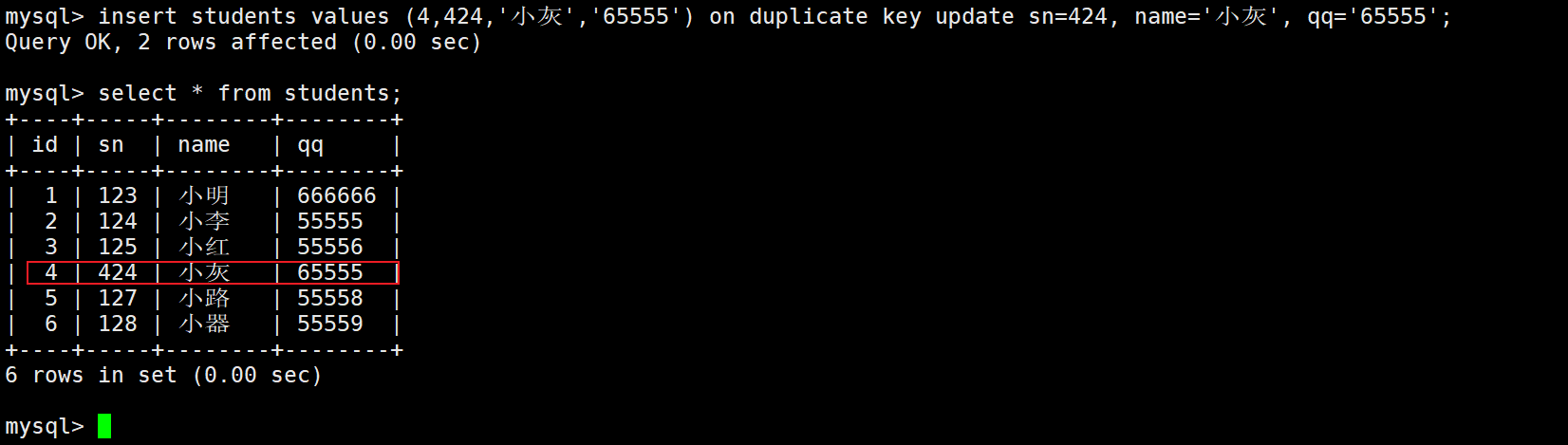
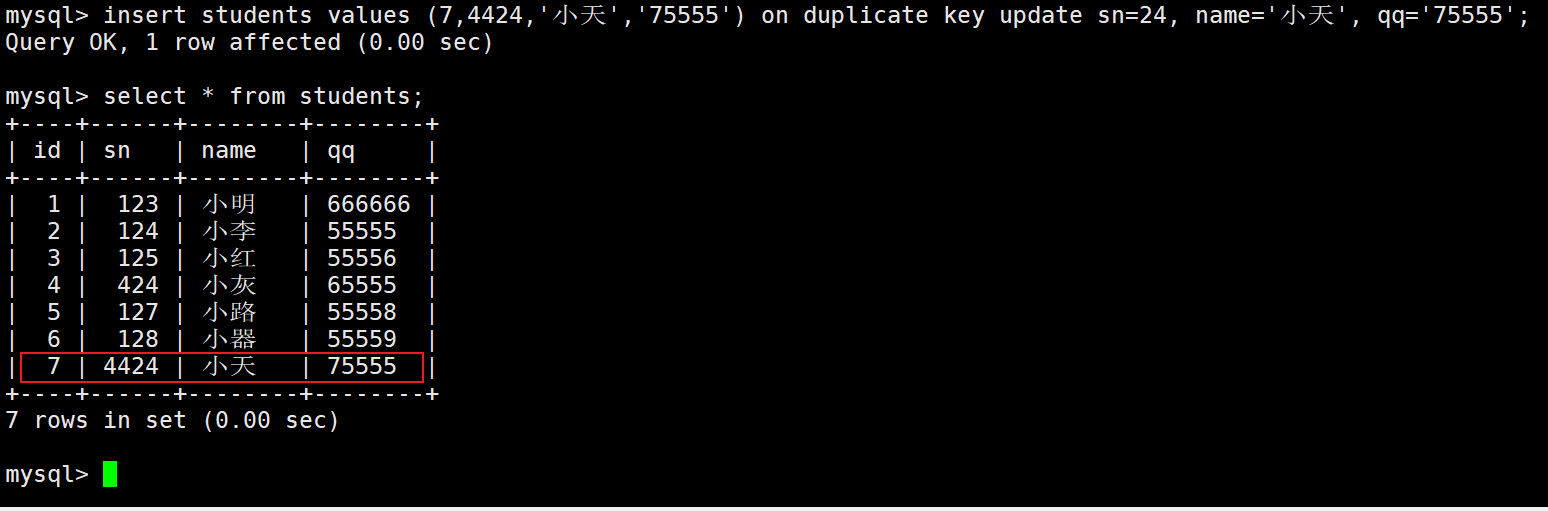
这里就没有数据冲突,所以变成了数据插入。
– 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
– 1 row affected: 表中没有冲突数据,数据被插入
– 2 row affected: 表中有冲突数据,并且数据已经被更新
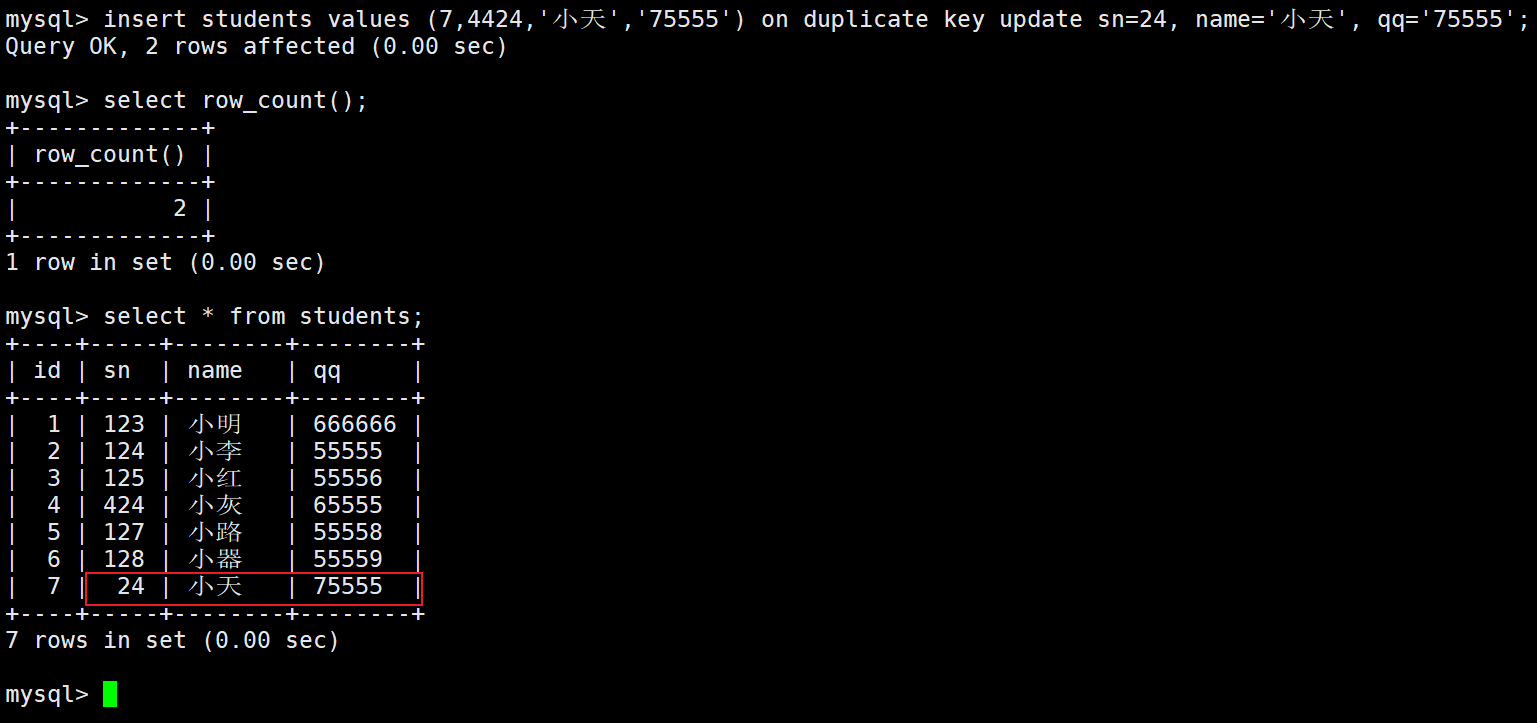
通过 MySQL 函数获取受到影响的数据行数:
SELECT ROW_COUNT();
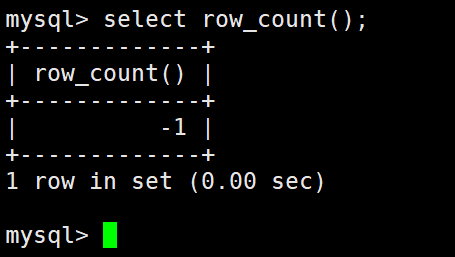
只有执行完一次上面的修改或者插入才不是-1。
替换
– 主键 或者 唯一键 没有冲突,则直接插入;
– 主键 或者 唯一键 如果冲突,则删除后再插入.
replace into table_name (要插入的字段列表1,要插入的字段列表2…) values (插入字段列表1的数据,插入字段列表2的数据…);
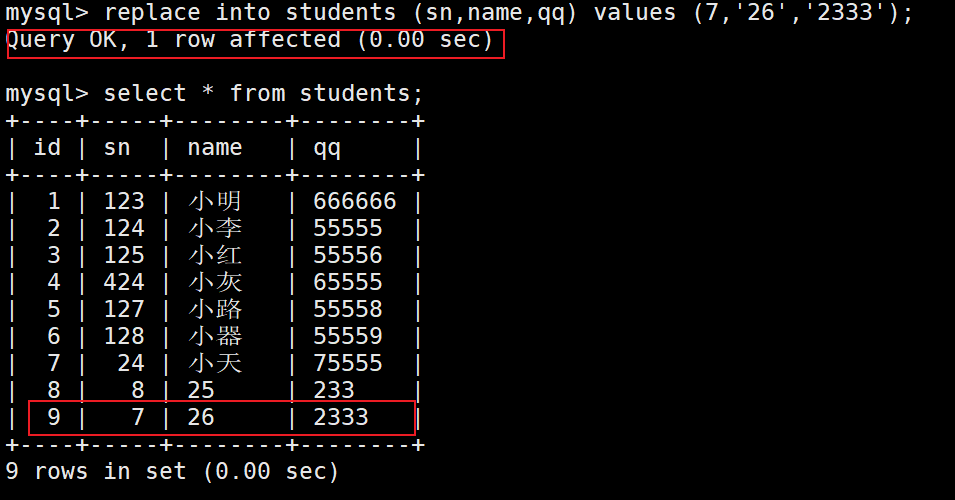
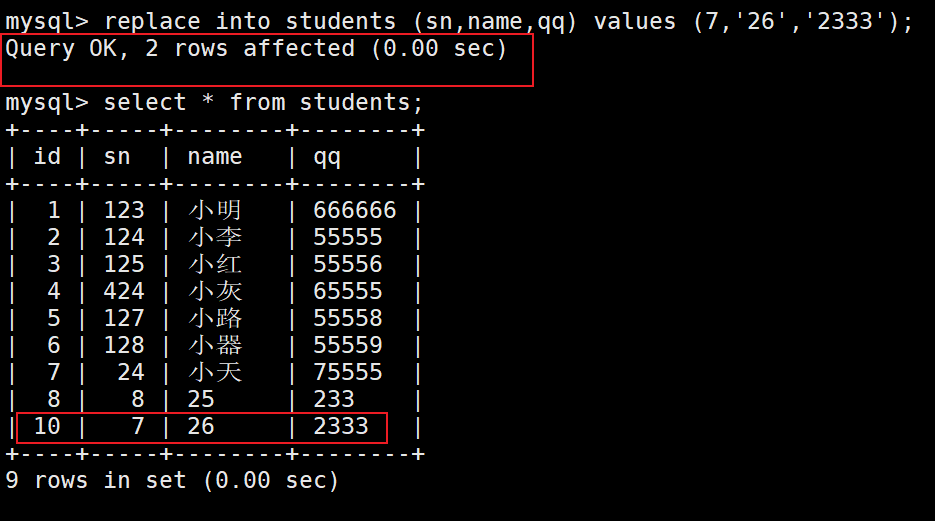
这里能发现,如果冲突就会进行替换而不是修改。
Retrieve
创建一个表为查询做铺垫。
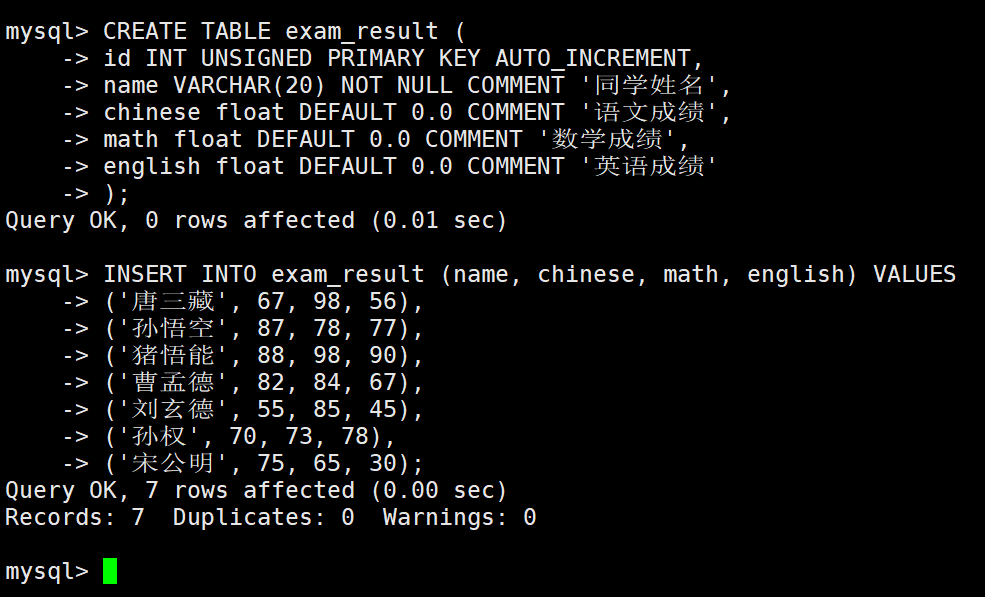
查询语法:
select
[distinct] {* | {column [, column] …}
[from table_name]
[where …]
[order by column [asc | desc], …]
limit …
distinct表示去重。
column代表可以通过指令一个一个筛选要查找的内容,*代表查询全部*后面的内容。
from table_name代表哪个表。
where代表筛选的条件。
order by column [asc | desc]代表排序。
limit代表筛选出来的条数。
SELECT 列
全列查询
– 通常情况下不建议使用 * 进行全列查询
– 1. 查询的列越多,意味着需要传输的数据量越大;
– 2. 可能会影响到索引的使用。
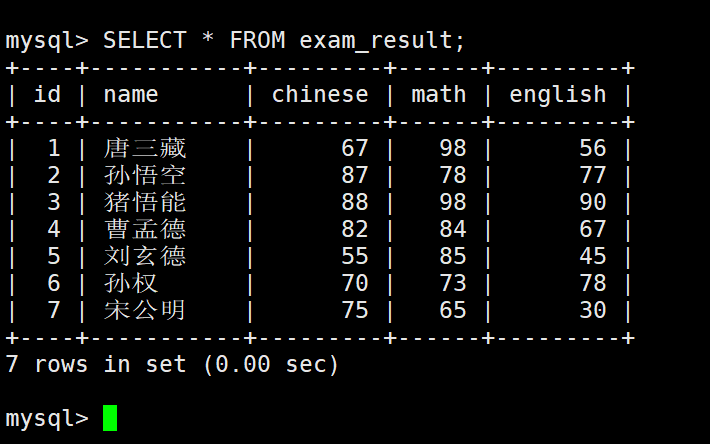
指定列查询
– 指定列的顺序不需要按定义表的顺序来
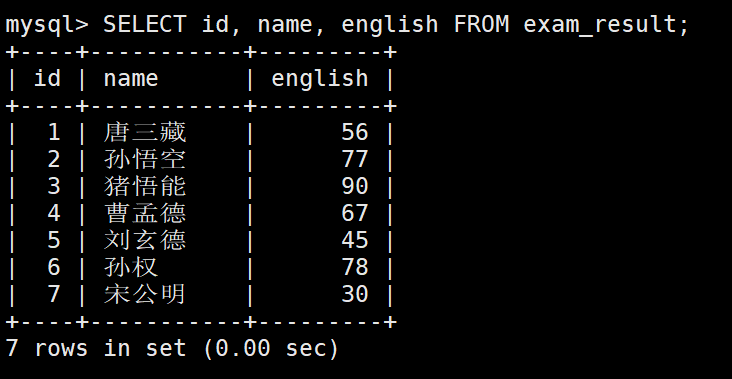
查询字段为表达式
– 表达式不包含字段
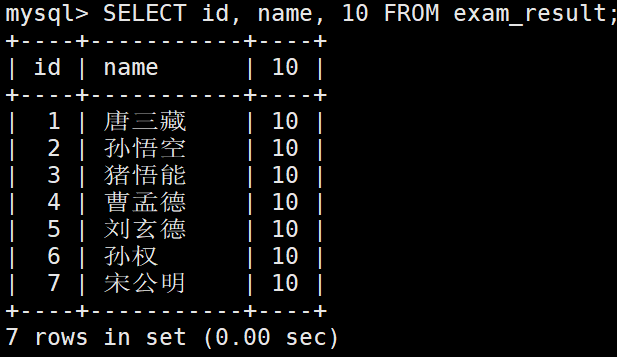
这里相当于查询的结构后面拼上了表达式结果。
– 表达式包含字段
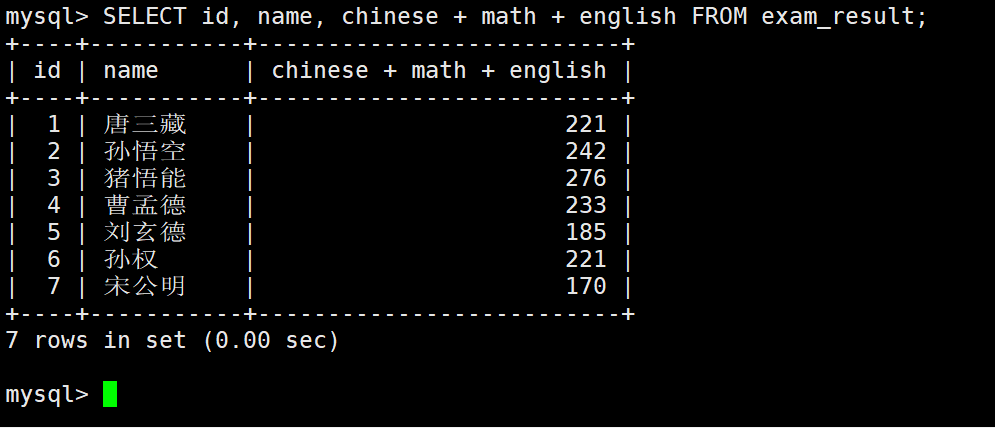
如果觉得结果名字太长:为查询结果指定别名
SELECT column [AS] alias_name […] FROM table_name;
去重
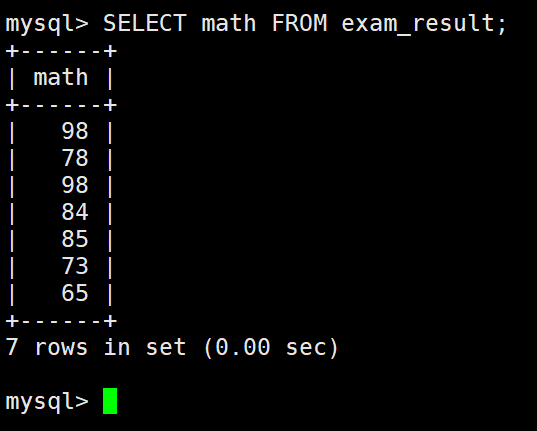
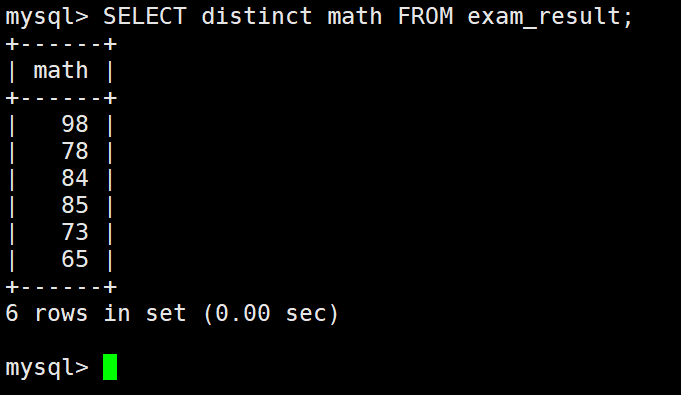
where 条件
比较运算符:
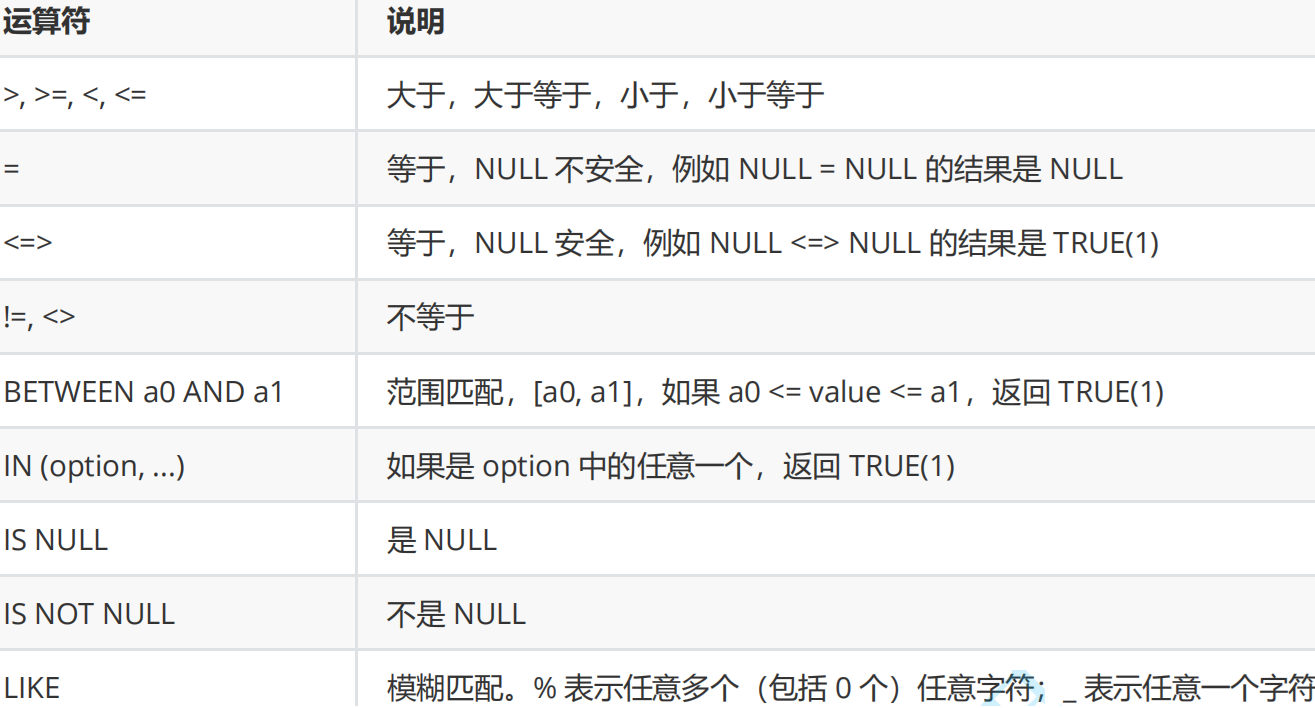
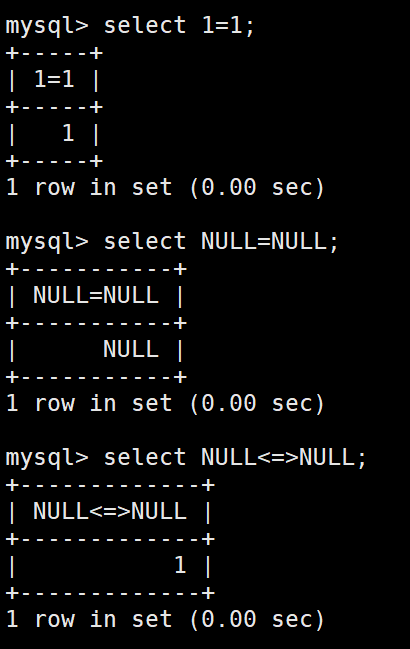
=不能用来进行NULL的比较。(无论=哪一侧,只要有一个都不可以)
!=和=是一样的,不能参与NULL比较。
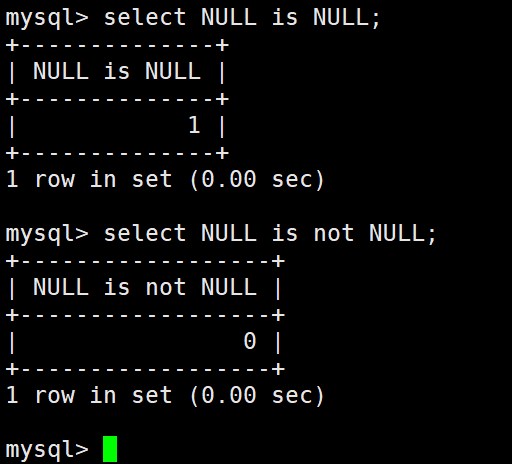
这个用来判断是否有NULL。
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
使用案例
英语不及格的同学及英语成绩 ( < 60 )
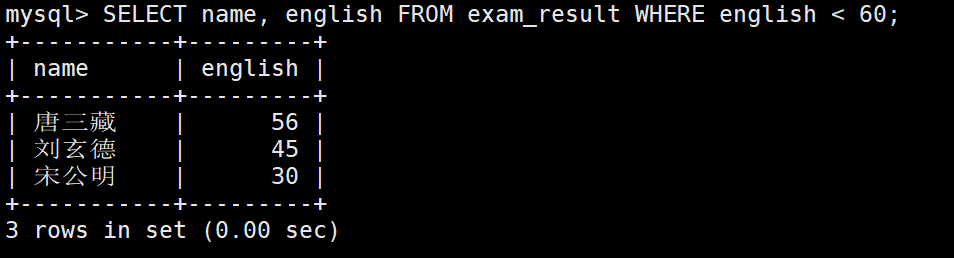
这里可以发现,selcet是筛选哪些列,where是筛选哪些行。
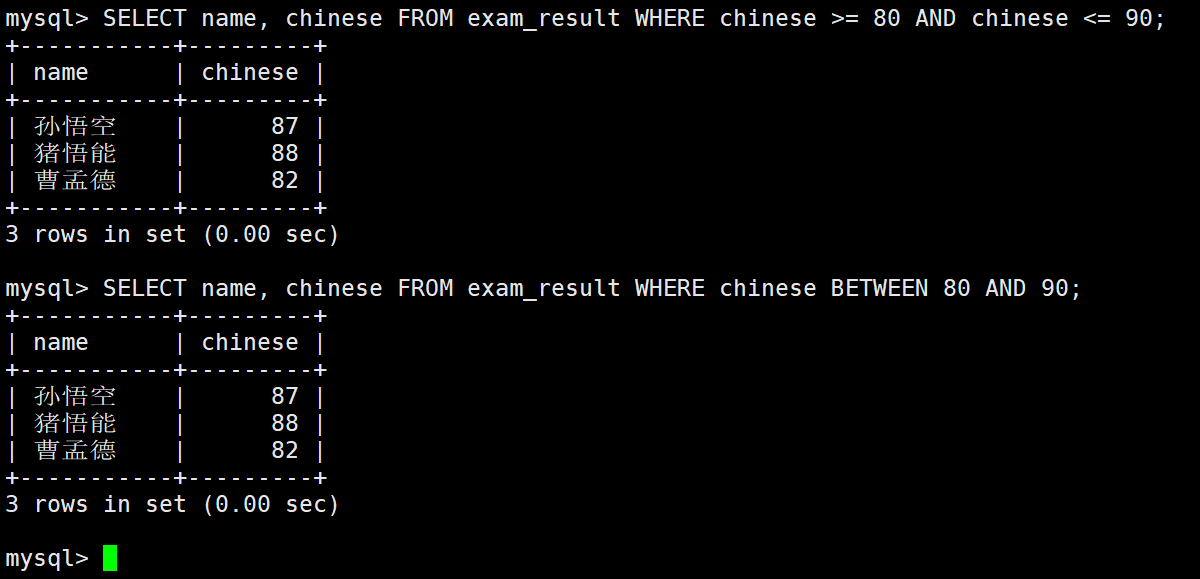
语文成绩在 [80, 90] 分的同学及语文成绩
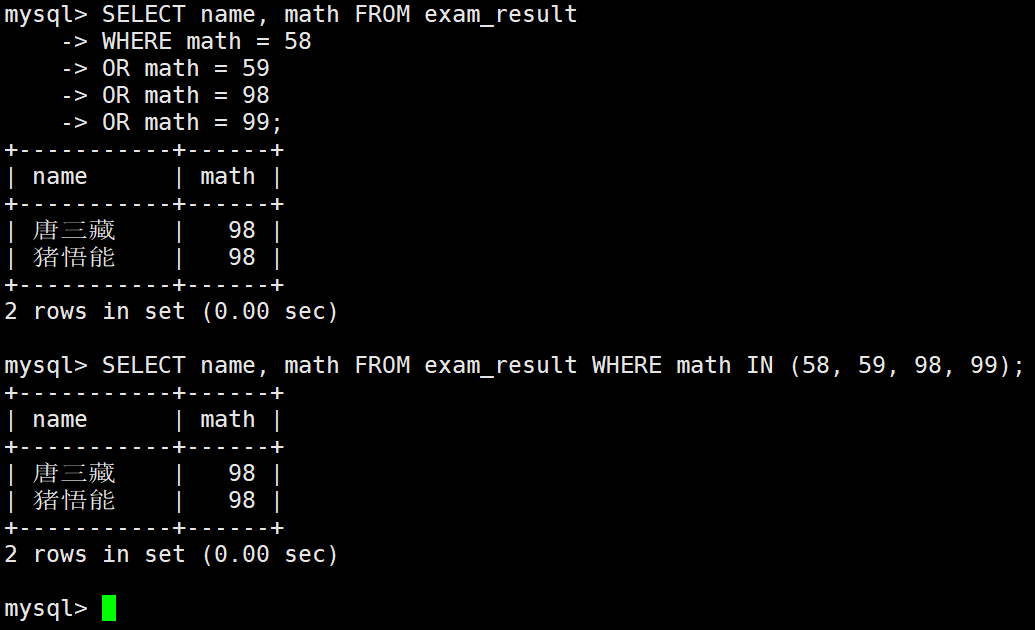
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
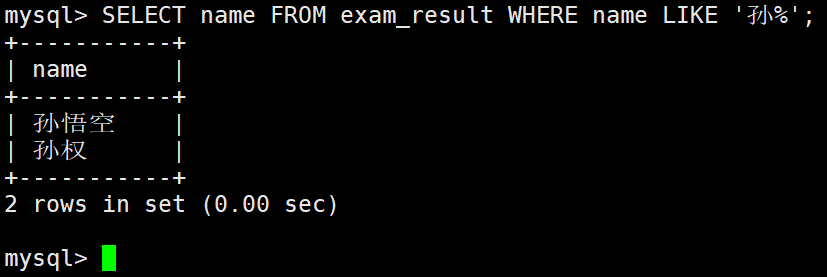
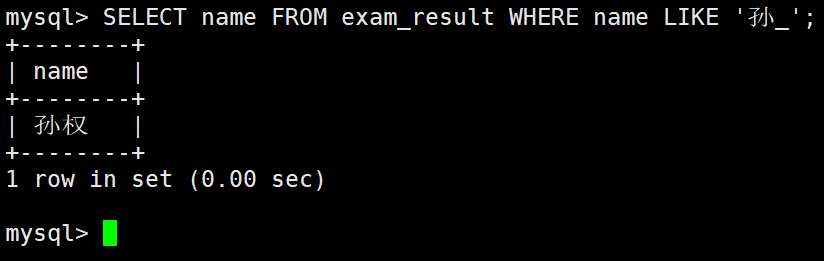
姓孙的同学 及 孙某同学
– % 匹配任意多个(包括 0 个)任意字符
– _ 匹配严格的一个任意字符
语文成绩好于英语成绩的同学
– WHERE 条件中比较运算符两侧都是字段

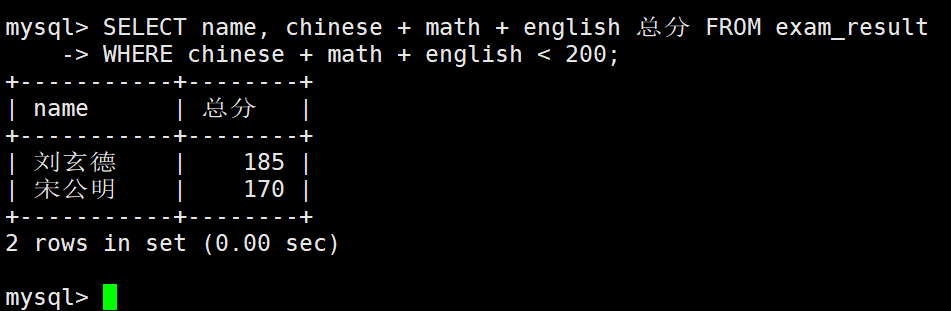
总分在 200 分以下的同学
– WHERE 条件中使用表达式
– 别名不能用在 WHERE 条件中(如果用了会报错)
为什么用别名就会报错呢?
因为第一步执行的是from找表,第二步是执行where,第三步才是执行select。
也就是说where执行的时候还没有别名,根本不认识。
并且where当中也不能进行定义别名的操作。
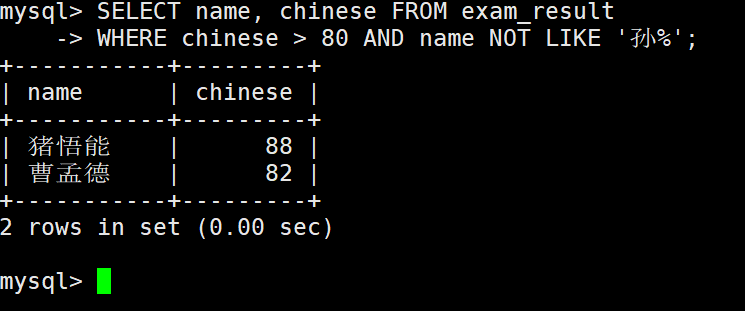
语文成绩 > 80 并且不姓孙的同学
– AND 与 NOT 的使用
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
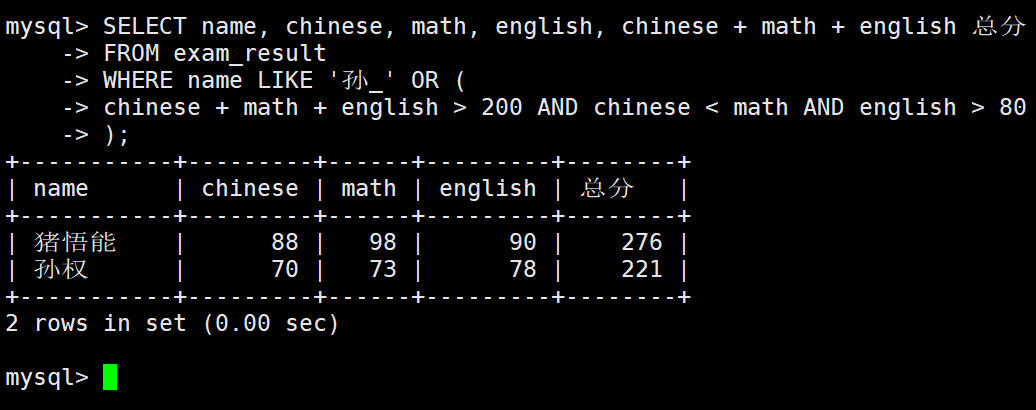
结果排序
– asc 为升序(从小到大)
– desc 为降序(从大到小)
– 默认为 asc
select … from table_name [where …] order by column [asc|desc], […];
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
NULL 视为比任何值都小,升序出现在最上面。
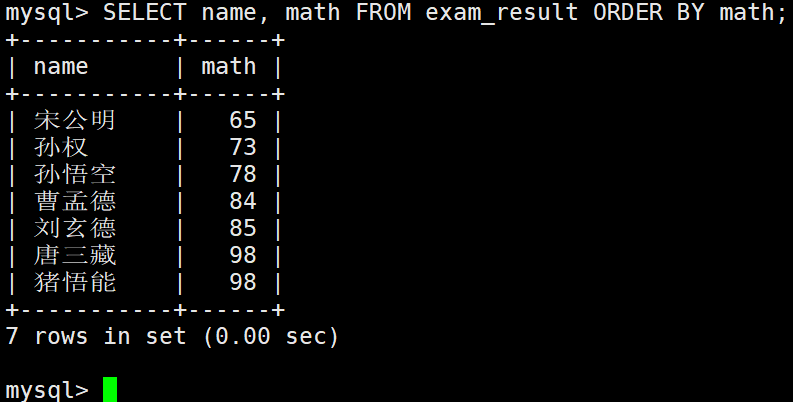
使用案例
同学及数学成绩,按数学成绩升序显示
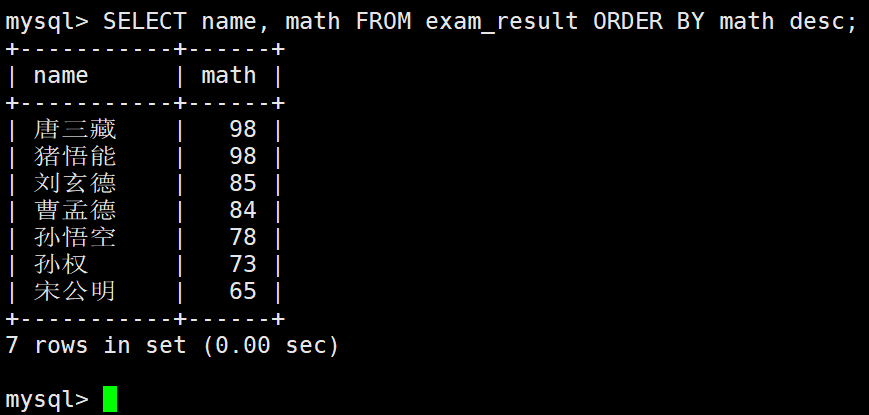
同学及数学成绩,按数学成绩降序显示
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
意思就是,先按照数学成绩排序,如果数学成绩想等就按照英语成绩排序,英语成绩在想等就按照语文成绩排序。
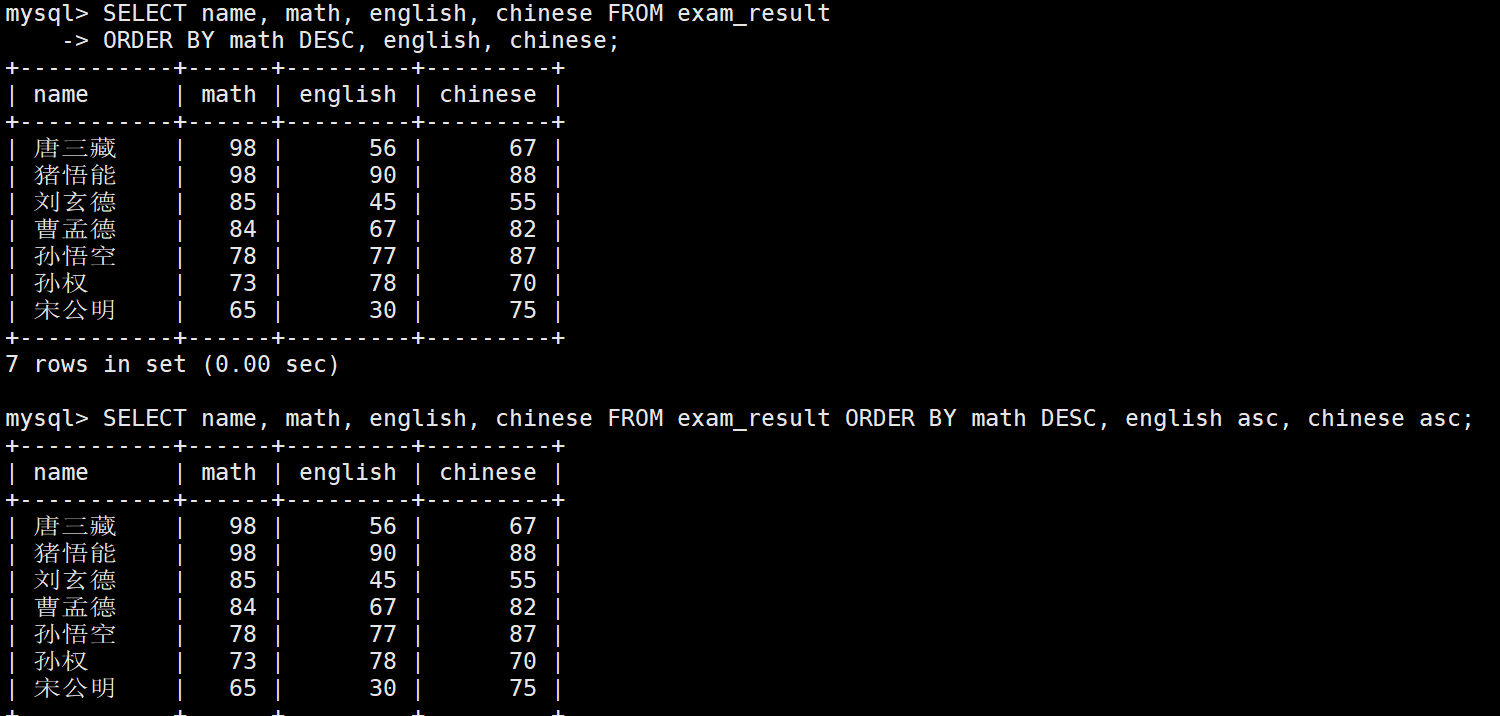
可以写全,也可以不写全,因为ORDER BY排序的默认方式是升序的。
查询同学及总分,由高到低
– ORDER BY 子句中可以使用列别名
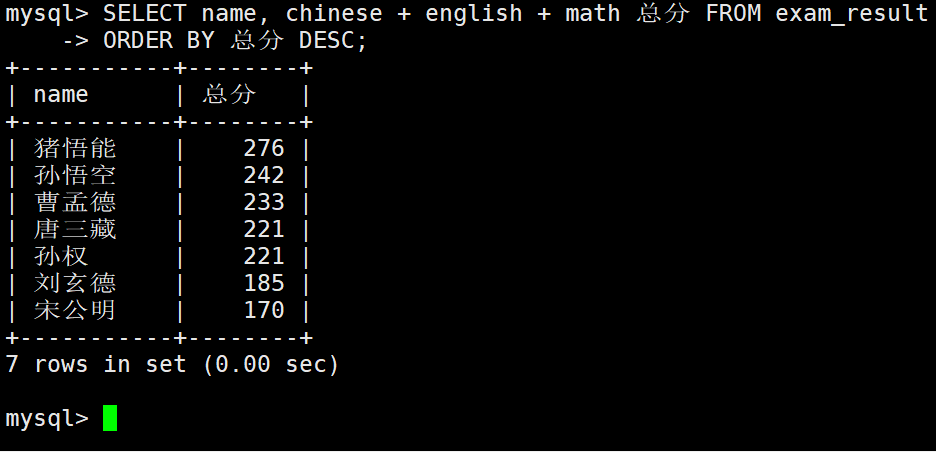
这里为什么可以使用别名了呢?
因为要排序肯定是现有需要排序的数据,需要先给mysql要排序的数据才会进行排序。
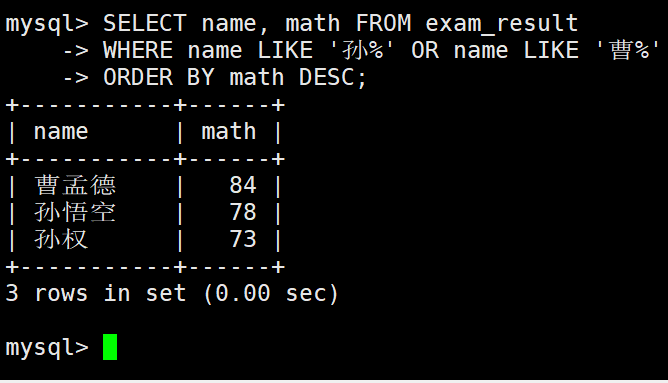
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
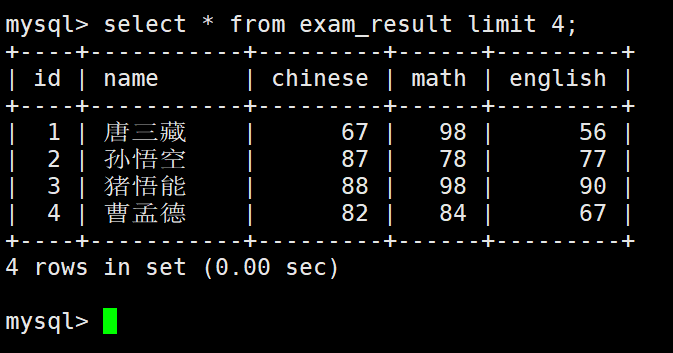
筛选分页结果
– 起始下标为 0
– 从 0 开始,筛选 n 条结果
select … from table_name [where …] [order by …] limit n;
– 从 s 开始,筛选 n 条结果
select … from table_name [where …] [order by …] limit s, n
– 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
select … from table_name [where …] [order by …] limit n offset s;
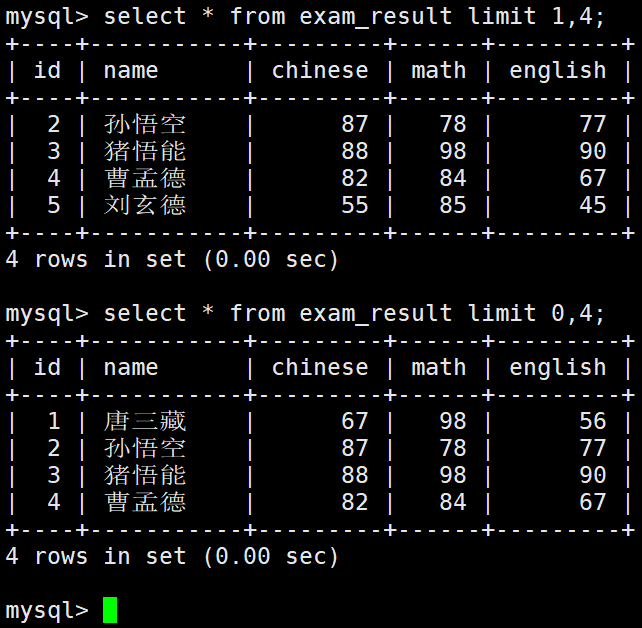
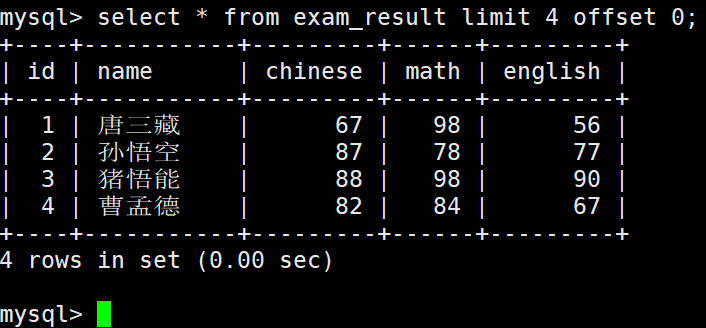
建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
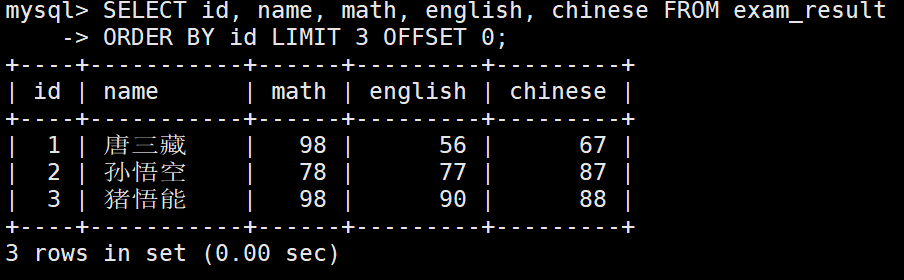
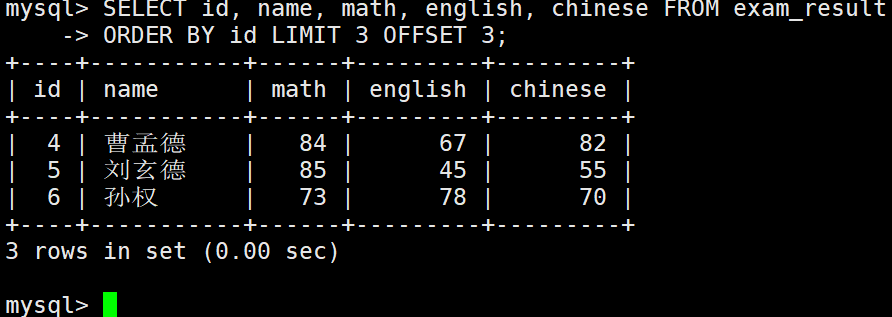
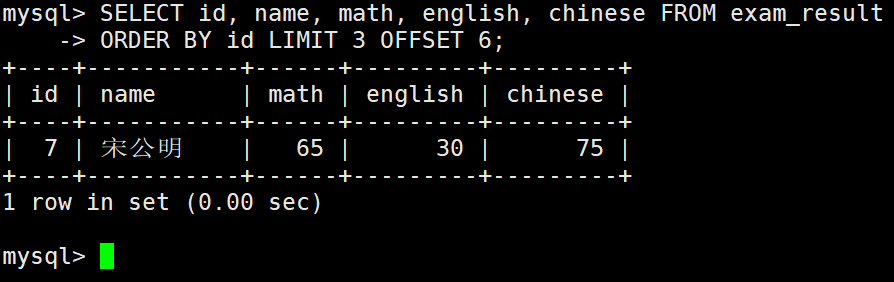
如果结果不足 3 个,不会有影响。
并且,只有有数据才能排序,只有数据准备好了,才能被显示,limit的本质功能就是显示,所以执行的顺序在排序后面。
Update
update table_name set column = expr [, column = expr …] [where …] [order by …] [limit …];
对查询到的结果进行列值更新。
使用案例
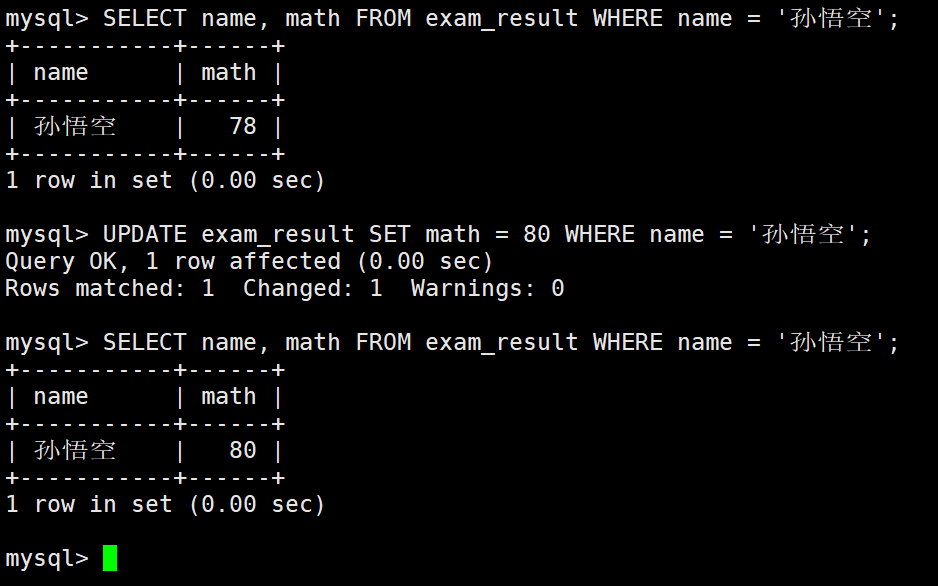
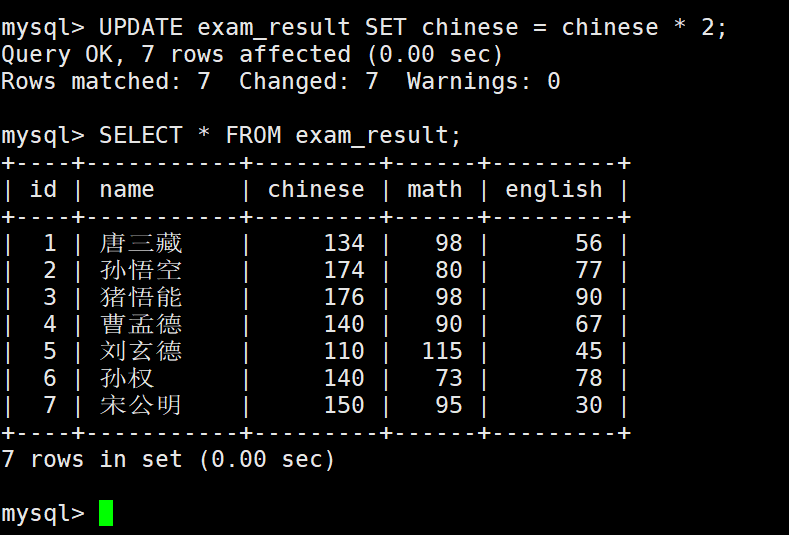
将孙悟空同学的数学成绩变更为 80 分
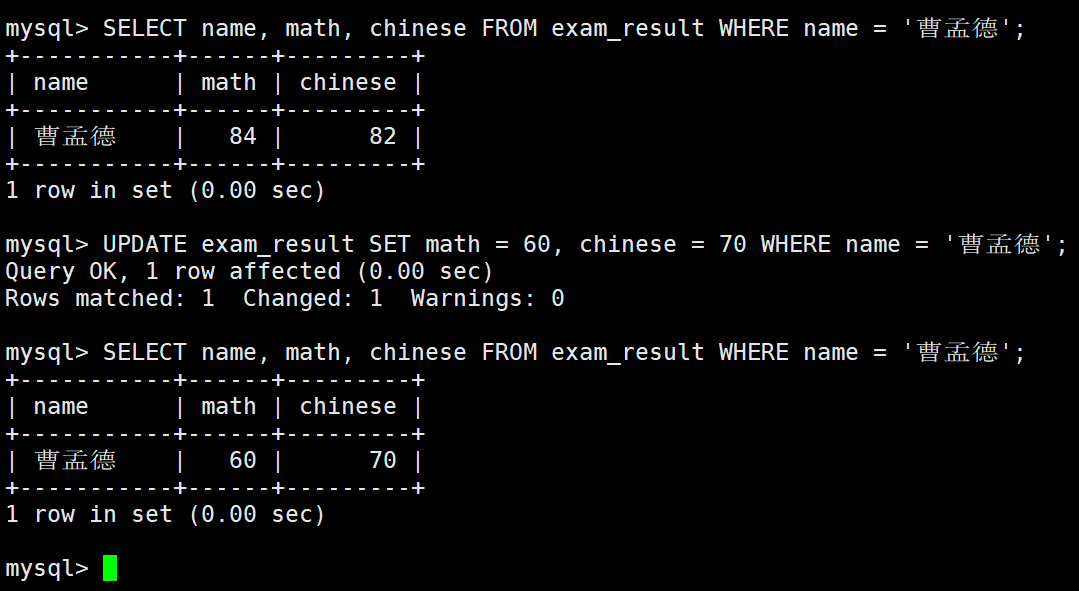
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
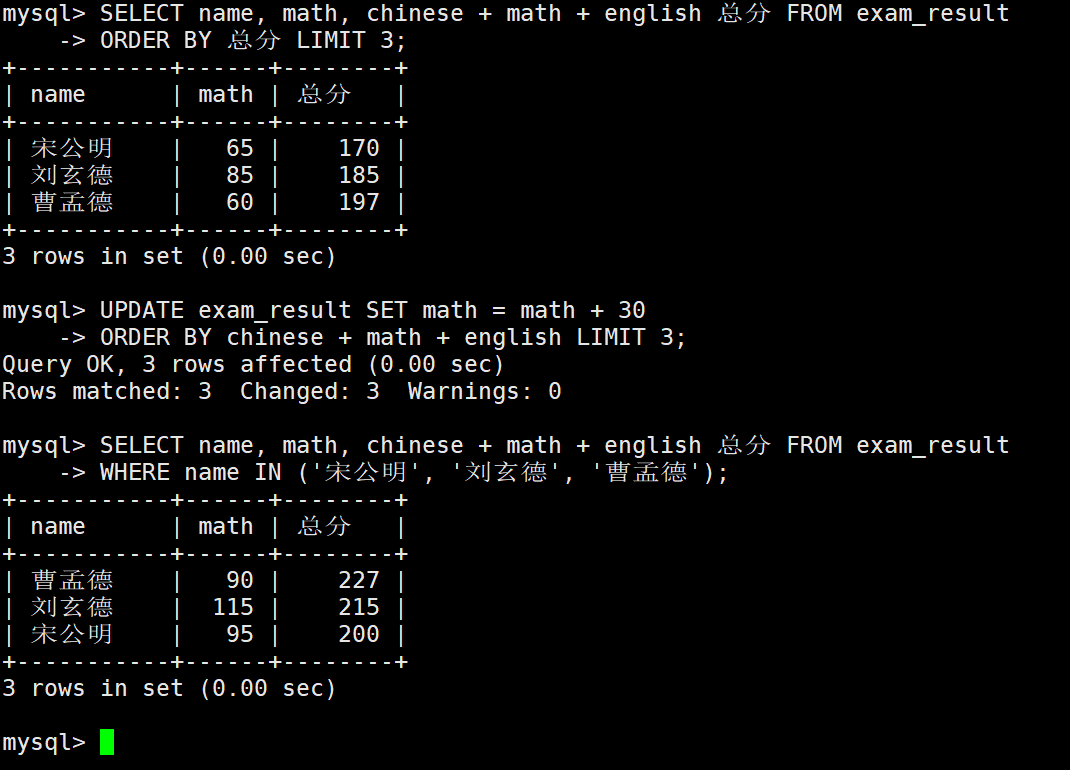
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
– 按总成绩排序后查询结果
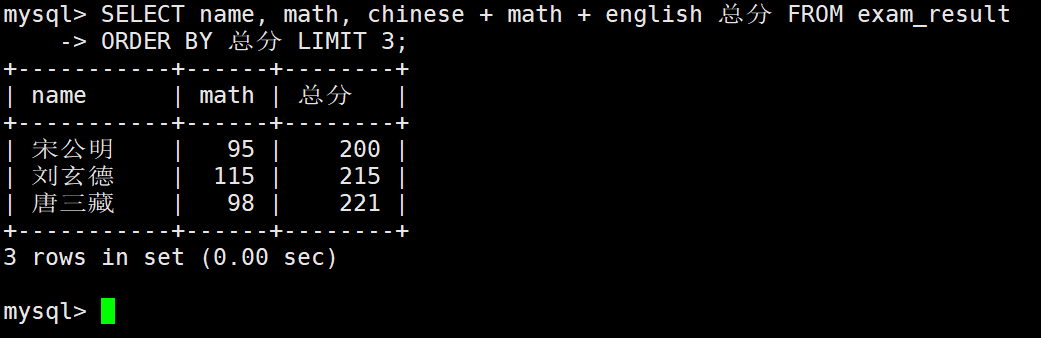
这里曹孟德把唐三藏给挤下去了。
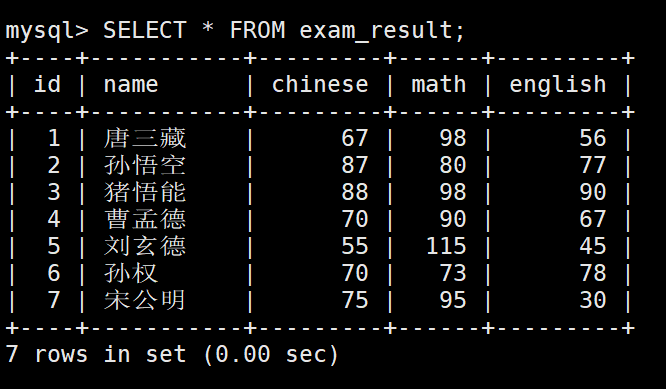
将所有同学的语文成绩更新为原来的 2 倍
注意:更新全表的语句慎用
Delete
删除数据
delete from table_name [where …] [order by …] [limit …]
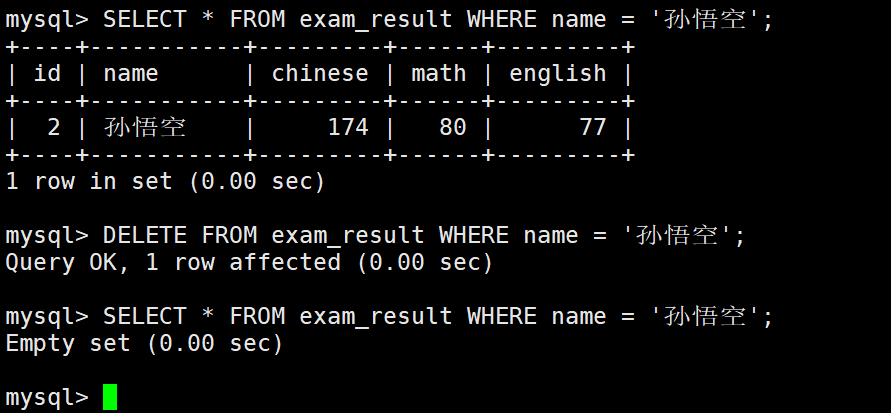
删除孙悟空同学的考试成绩
删除整张表数据
注意:删除整表操作要慎用!
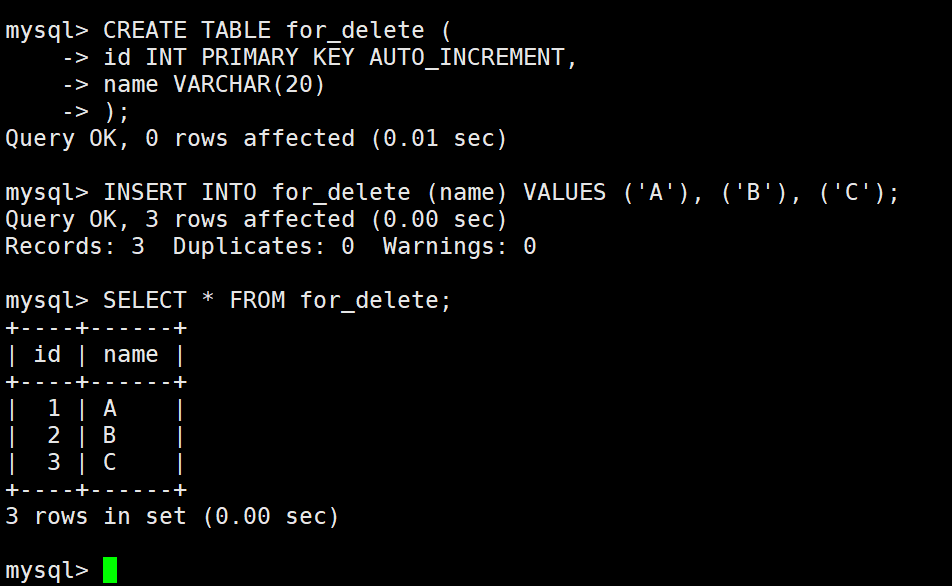
先创建一张表:
在删除之前首先查看一个数据:
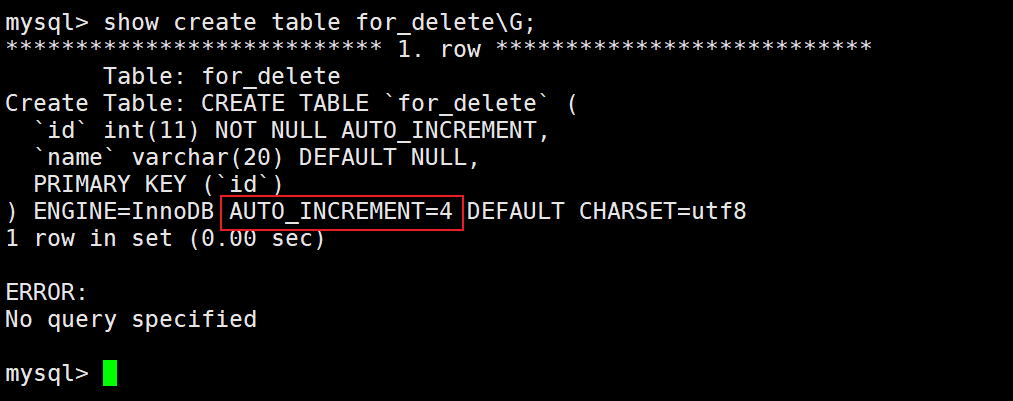
这里是4,代表下一个插入的数据是从4开始。
删除整表数据:
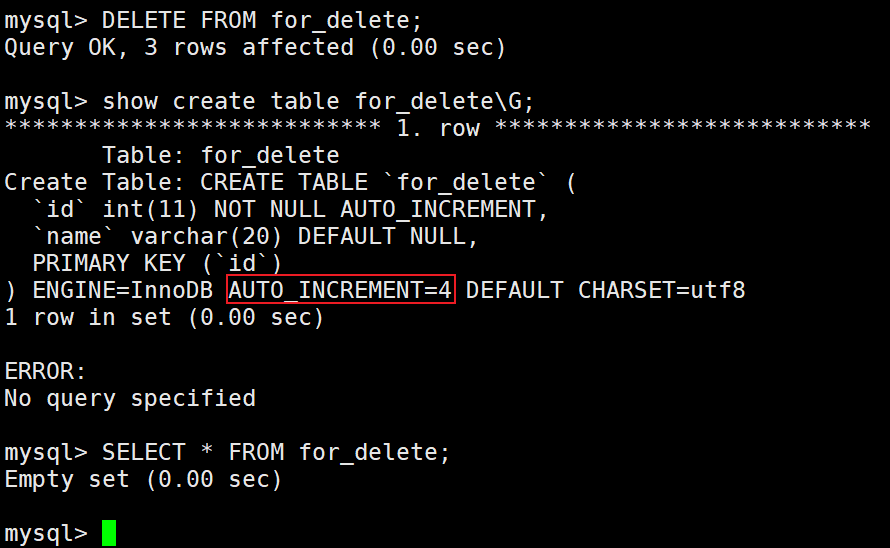
这里虽然删除了整张表,但是这里的技术并没有被清零,还是从4开始。
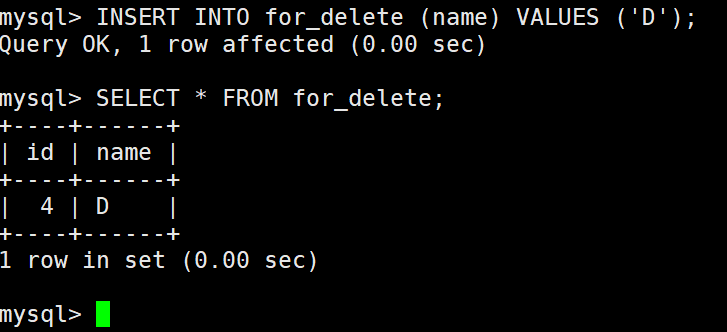
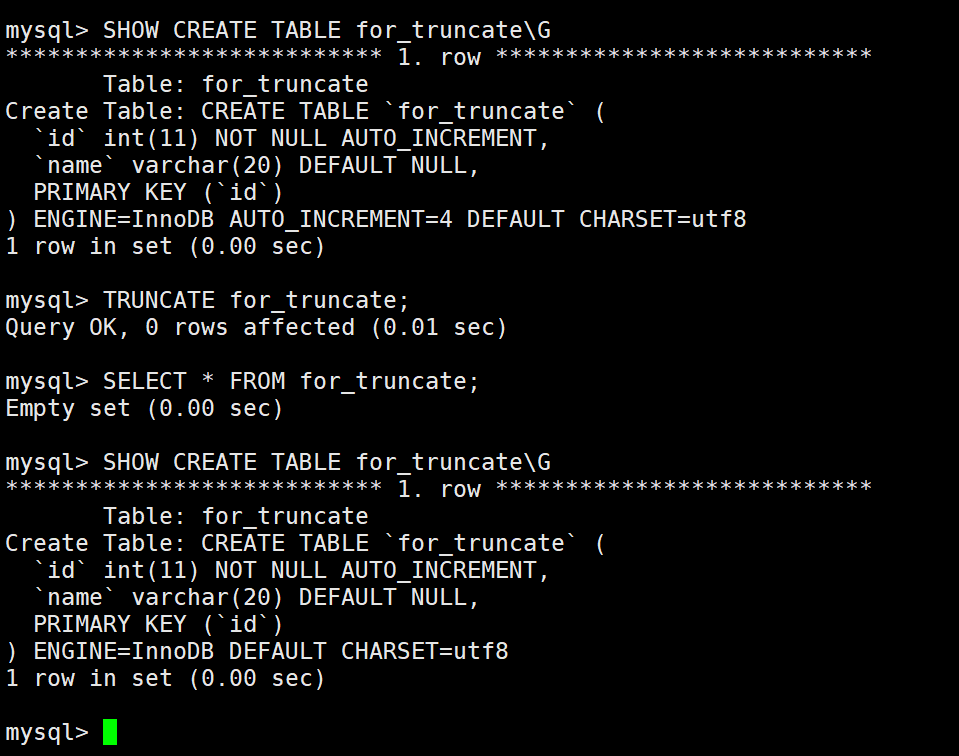
截断表
truncate [table] table_name
注意:这个操作慎用
- 只能对整表操作,不能像 delete 一样针对部分数据操作;
- 实际上 mysql 不对数据操作,所以比 delete 更快,但是truncate在删除数据的时候,并不经过真正的事物,所以无法回滚(truncate不会记录在日志上)
- 会重置 auto_increment 项
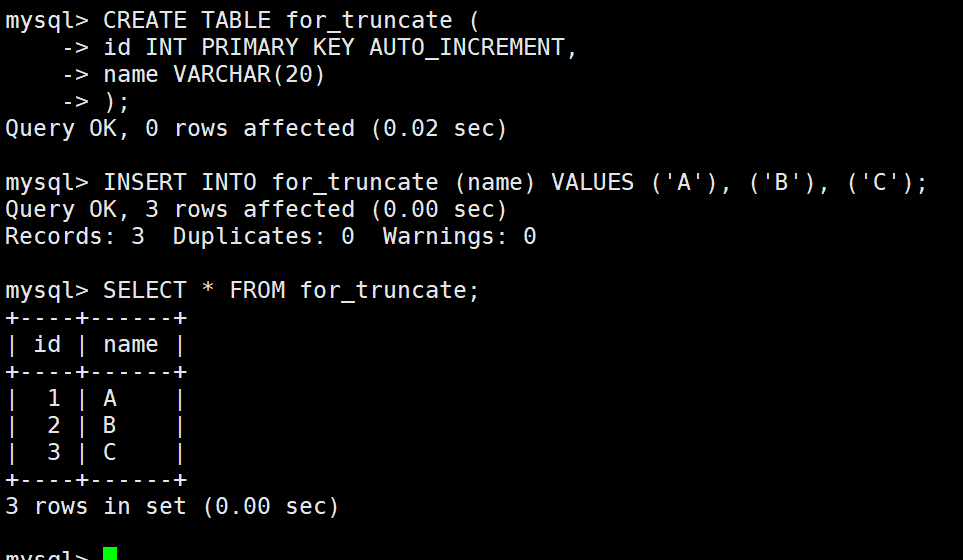
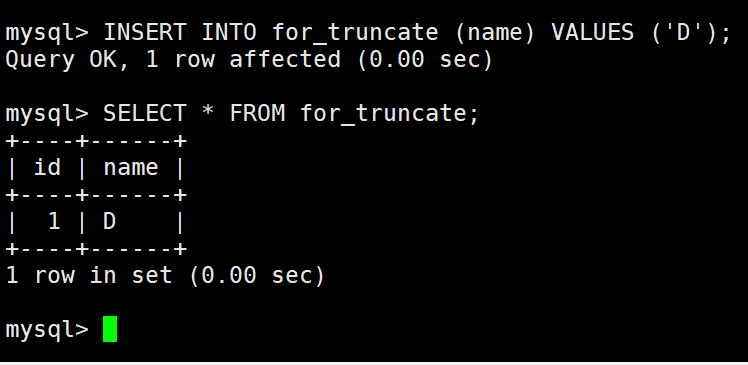
插入查询结果
insert into table_name [(column [, column …])] select …
删除表中的的重复复记录,重复的数据只能有一份
先创建一个表:
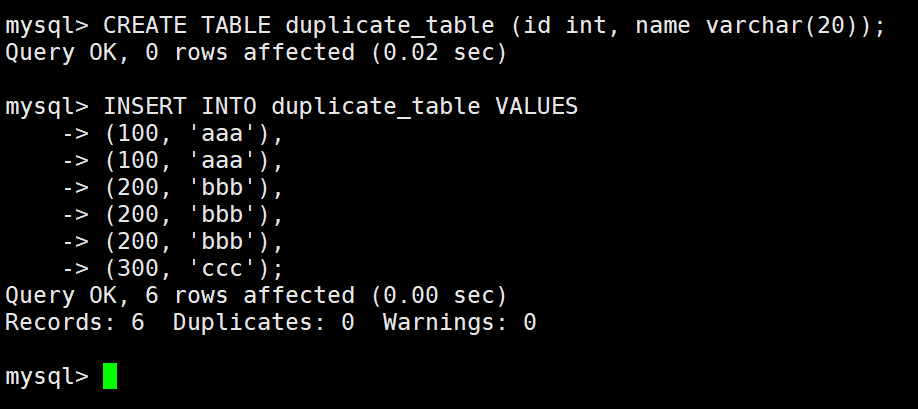
然后在创建一个空表:结构和 duplicate_table 一样

将 duplicate_table 的去重数据插入到 no_duplicate_table

通过重命名表,实现原子的去重操作

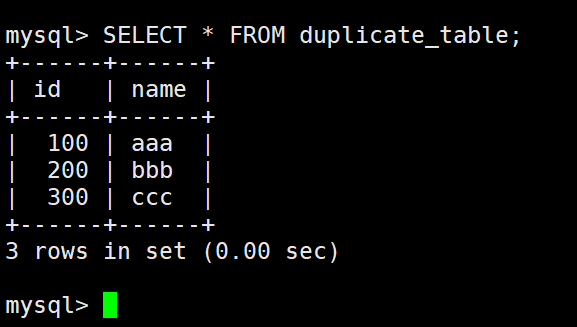
为什么最后是通过rename进行的呢?
假设我们要上传一个大文件,要放入指定的目录之下,但是这个目录里面又在进行各种的读写操作,这时候再放进去无法确保原子性,所以先将这个大文件上传到一个临时文件,然后再move(原子的)到指定目录下,这样可靠。
同理改名也是一样的,就是为了等一切都就绪,然后统一放入,更新,生效等。并且改名是轻量化的,耗时非常少,只需要更改inode映射即可。
聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
使用案例
统计班级共有多少同学
– 使用 * 做统计,不受 NULL 影响
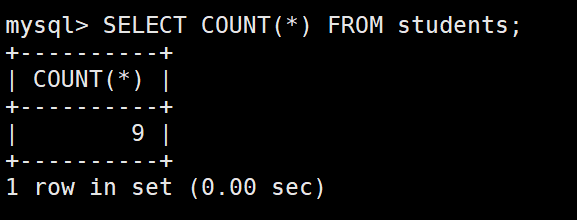
– 使用表达式做统计
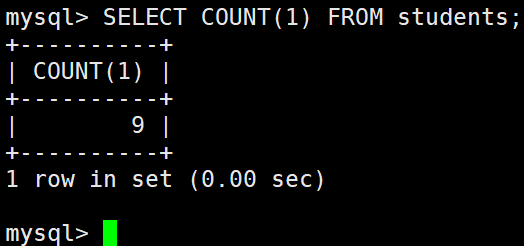
统计本次考试的数学成绩分数个数
– COUNT(math) 统计的是全部成绩
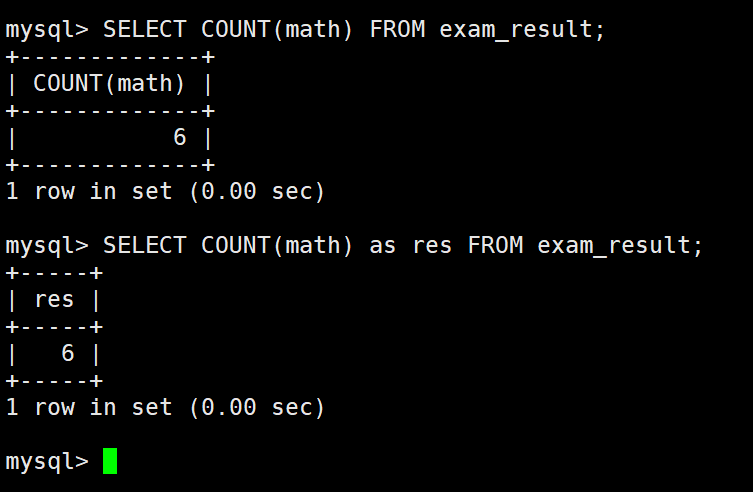
统计数学成绩总分
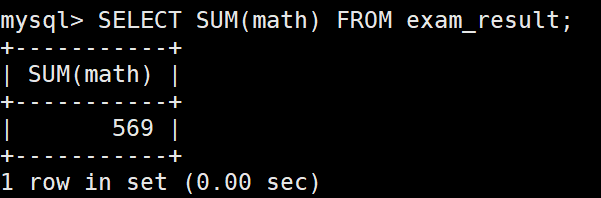
– 不及格 < 60 的总分,没有结果,返回 NULL
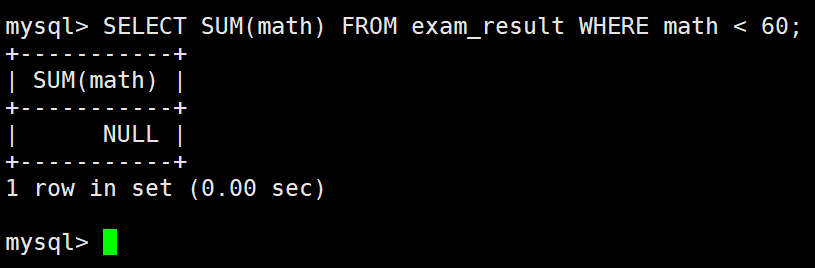
统计平均总分

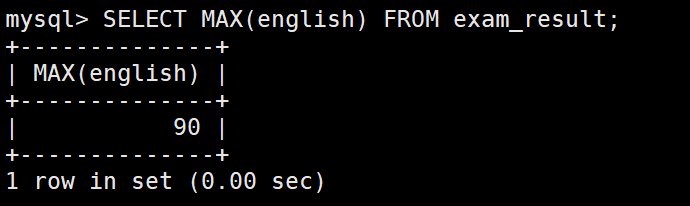
返回英语最高分
返回 > 70 分以上的数学最低分
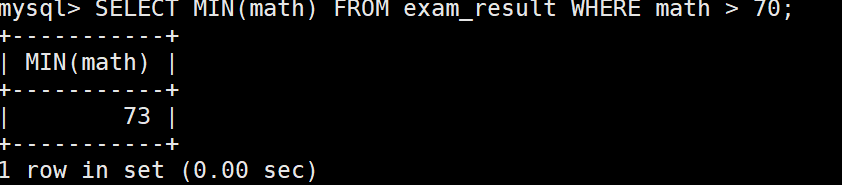
聚合之前先要找到对应的范围数据才会进行函数使用。
group by子句的使用
分组的目的是为了进行分组之后,方便进行聚合统计。
在select中使用group by 子句可以对指定列进行分组查询。
select column1, column2, … from table group by column;
使用案例
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
EMP员工表
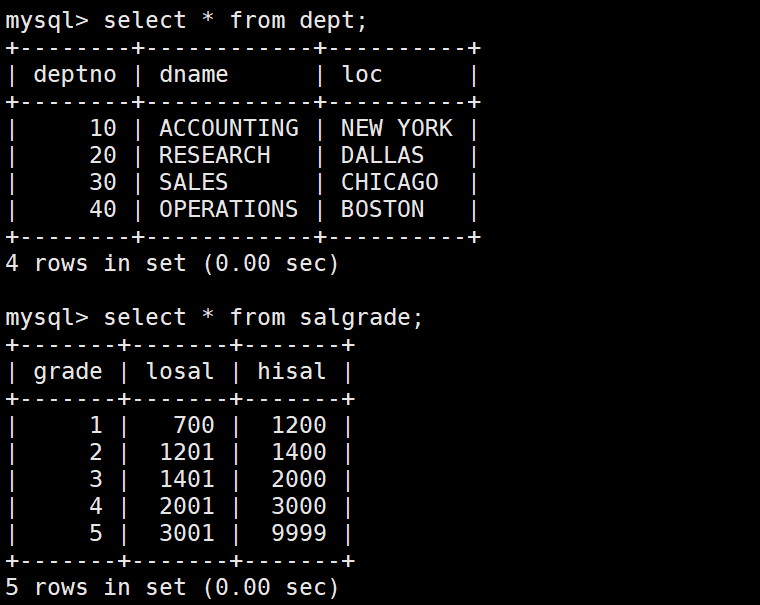
DEPT部门表
SALGRADE工资等级表
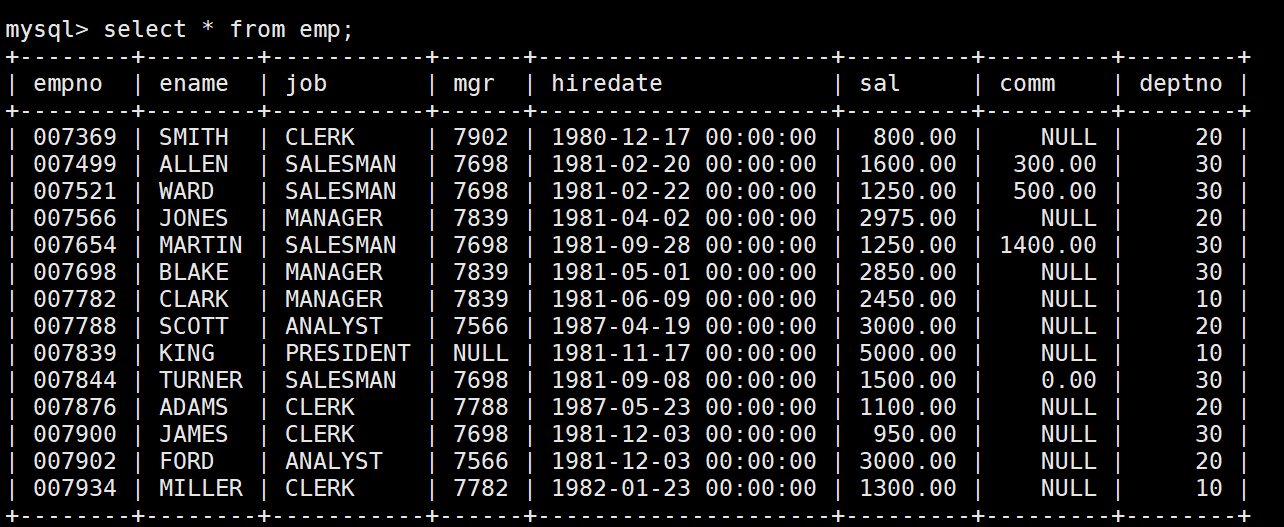
如何显示每个部门的平均工资和最高工资。
select deptno,avg(sal),max(sal) from EMP group by deptno;
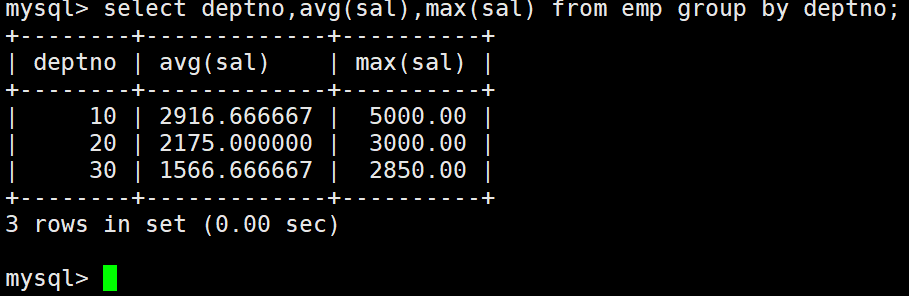
group by deptno是指定列名,实际分组使用该列的不同的行数据来进行分组。
分组的条件deptno,组内一定是相同的,可以被聚合压缩。
分组,可以理解为是把一组按照条件拆成了多个组,进行各自组内的统计。
但是换一种思路,分组就是分表,是把一张表按照条件在逻辑上拆成了多个子表,然后分别对各自的子表进行聚合统计。
显示每个部门的每种岗位的平均工资和最低工资
这里无非是多了一层,在每个部门的基础上在细分各个岗位。
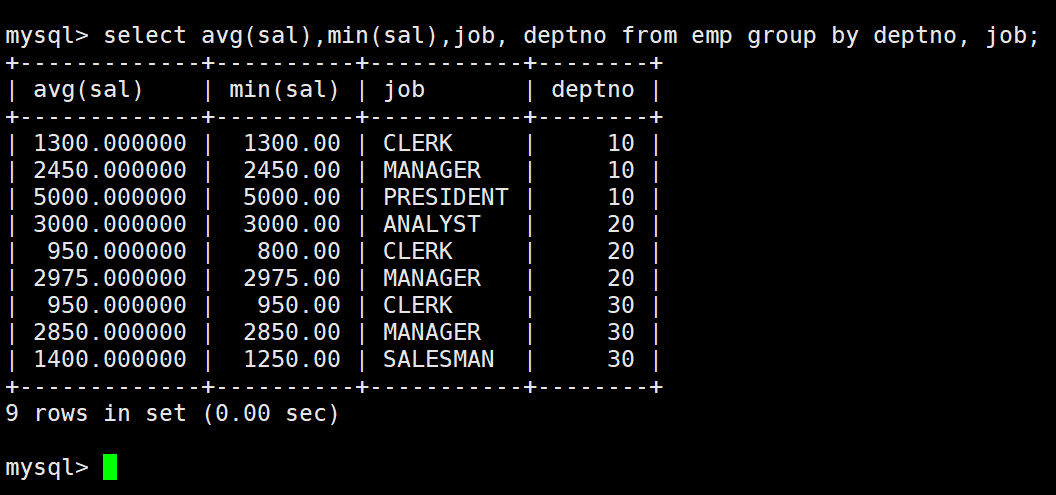
这里也要注意,在使用group by的时候,只有在group by后面出现的字段才能出现在select后面,不然会报错:

显示平均工资低于2000的部门和它的平均工资
首先统计各个部门的平均工资:
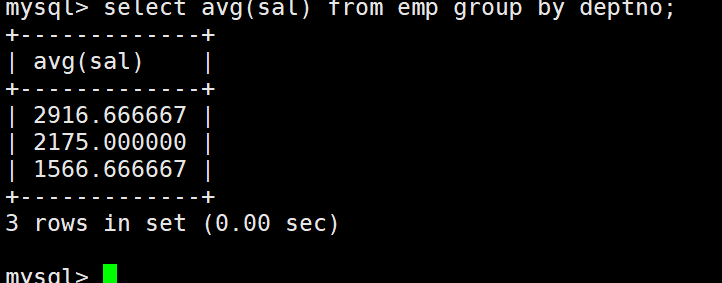
第二步在进行判断,对聚合的结果进行判断:
先介绍having,这个语句是对于聚合完毕之后的结果进行判断,之后筛选。

having和where的区别是什么呢?
执行顺序的不同,查询表是第一步,也就是from,第二步就是where对具体条件字段列表进行筛选,第三步就是group by进行的分组,第四步是select语句进行查询,聚合,第五步才是having语句对分组聚合之后的结果进行筛选。(条件筛选的阶段是不同的)
并且,不是只有磁盘上的表结构导入到mysql的才是表,虽然这才是真实存在的表,但是在逻辑上,中途筛选出来的,包括最终结果,全都是表,MySQL下,一切皆表。
相关文章:
Linux——MySQL约束与查询
表的约束 真正约束字段的是数据类型,但是数据类型约束很单一,需要有一些额外的约束,更好的保证数据的合 法性,从业务逻辑角度保证数据的正确性。比如有一个字段是email,要求是唯一的。 表的约束是为了防止插入不合法的…...

Asp.Net Core IIS发布后PUT、DELETE请求错误405
一、方案1 1、IIS管理器,处理程序映射。 2、找到aspNetCore,双击。点击请求限制...按钮,并在谓词选项卡上,添加两者DELETE和PUT. 二、方案2 打开web.config文件,添加<remove name"WebDAVModule" />&…...
STL-to-ASCII-Generator 实用教程
参阅:STL-to-ASCII-Generator 使用教程 开源项目网址 下载 STL-to-ASCII-Generator-main.zip 解压到 D:\js\ index.html 如下 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta id"ascii&q…...

关于数据库查询速度优化
本人接手了一个关于项目没有任何文档信息的代码,代码也没有相关文档说明信息!所以在做数据库查询优化的时候不敢改动。 原因1: 老板需要我做一个首页的统计查询。明明才几十万条数据,而且我加了筛选条件为什么会这么慢ÿ…...

sql serve 多表联合查询,根据一个表字段值动态改变查询条件
在SQL Server中进行多表联合查询时,如果需要根据一个表的字段值动态改变查询条件,可以采用几种不同的方法来实现这一需求。这里介绍两种常用的方法:CASE表达式和动态SQL。 方法1: 使用 CASE 表达式 这种方法适合于查询条件可以在单个SQL语句…...

巡检机器人数据处理技术的创新与实践
摘要 随着科技的飞速发展,巡检机器人在各行业中逐渐取代人工巡检,展现出高效、精准、安全等显著优势。当前,巡检机器人已从单纯的数据采集阶段迈向对采集数据进行深度分析的新阶段。本文探讨了巡检机器人替代人工巡检的现状及优势,…...
国产linux系统(银河麒麟,统信uos)使用 PageOffice 在线打开Word文件,并用前端对话框实现填空填表
不管是政府机关、公司企业,还是金融行业、教育行业等单位,在办公过程中都经常需要填写各种文书和表格,比如通知、报告、登记表、计划表、申请表等。这些文书和表格往往是用Word文件制作的模板,比方说一个通知模板中经常会有“关于…...

Kubernetes应用发布方式完整流程指南
Kubernetes(K8s)作为容器编排领域的核心工具,其应用发布流程体现了自动化、弹性和可观测性的优势。本文将通过一个Tomcat应用的示例,详细讲解从配置编写到高级发布的完整流程,帮助开发者掌握Kubernetes应用部署的核心步…...

视频编解码学习8之视频历史
视频技术的发展历史可以追溯到19世纪,至今已跨越近200年。以下是视频技术发展的主要阶段和里程碑: 1. 早期探索阶段(19世纪-1920年代) 1832年:约瑟夫普拉托(Joseph Plateau)发明"费纳奇镜&…...

RabbitMQ-高级特性1
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言消息确认机制介绍手动确认方法代码前言代码编写消息确认机制的演示自动确认automanual 持久化介绍交换机持久化队列持久化消息持久化 持久化代码持久化代码演示…...
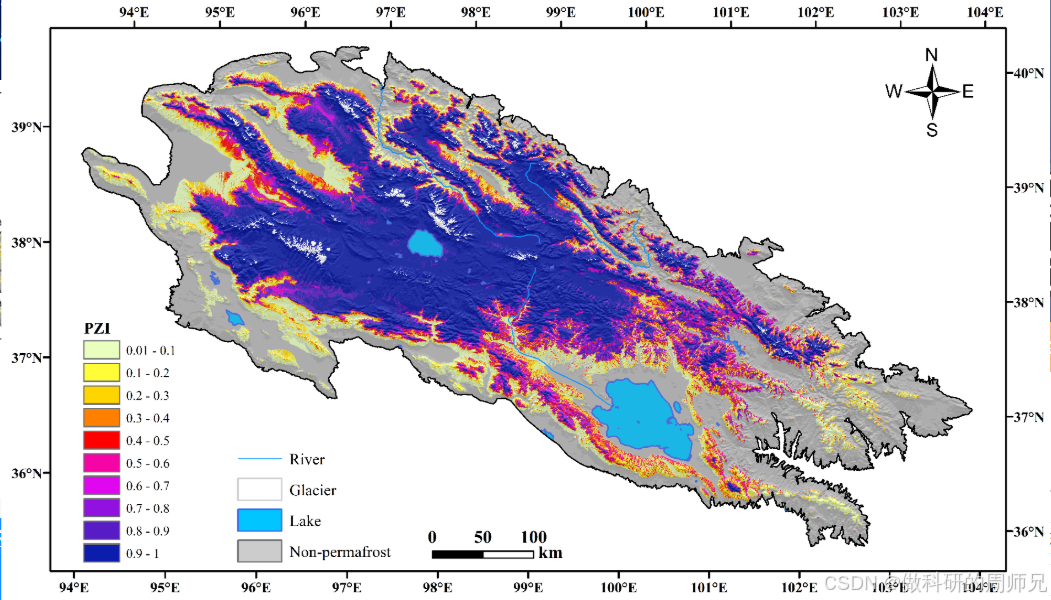
青藏高原东北部祁连山地区250m分辨率多年冻土空间分带指数图(2023)
时间分辨率:10年 < x < 100年空间分辨率:100m - 1km共享方式:开放获取数据大小:24.38 MB数据时间范围:近50年来元数据更新时间:2023-10-08 数据集摘要 多年冻土目前正在经历大规模的退化,…...

论文分享➲ arXiv2025 | TTRL: Test-Time Reinforcement Learning
TTRL: Test-Time Reinforcement Learning TTRL:测试时强化学习 https://github.com/PRIME-RL/TTRL 📖导读:本篇博客有🦥精读版、🐇速读版及🤔思考三部分;精读版是全文的翻译,篇幅较…...
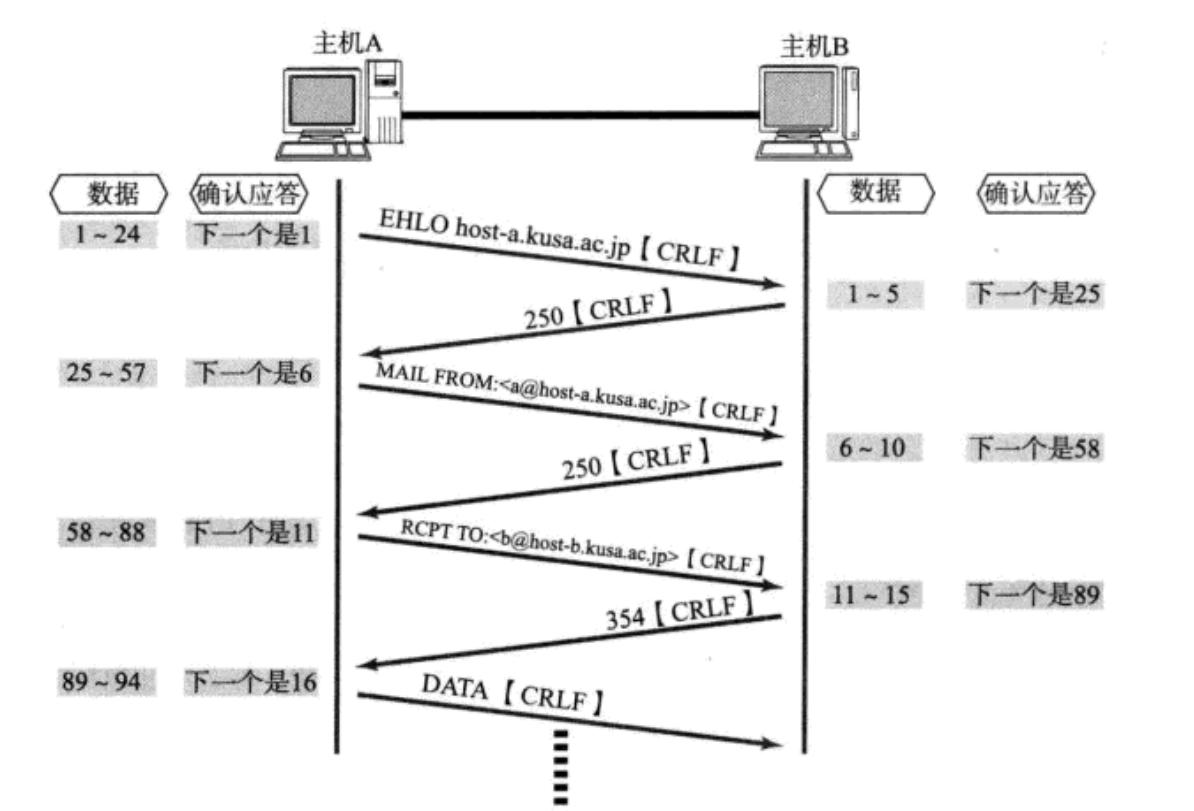
【计算机网络-传输层】传输层协议-TCP核心机制与可靠性保障
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:传输层协议-UDP 下篇文章: 网络层 我们的讲解顺序是&…...
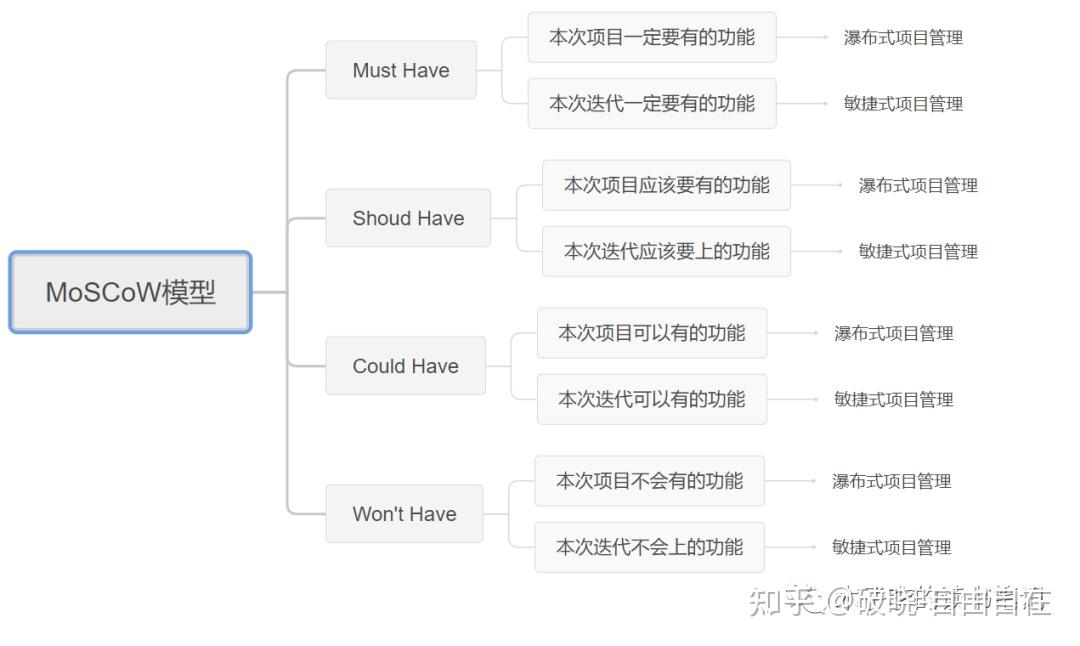
项目管理从专家到小白
敏捷开发 Scrum 符合敏捷开发原则的一种典型且在全球使用最为广泛的框架。 三个角色 产品负责人Product Ower:专注于了解业务、客户和市场要求,然后相应地确定工程团队需要完成的工作的优先顺序。 敏捷教练Scrum Master:确保 Scrum 流程顺…...
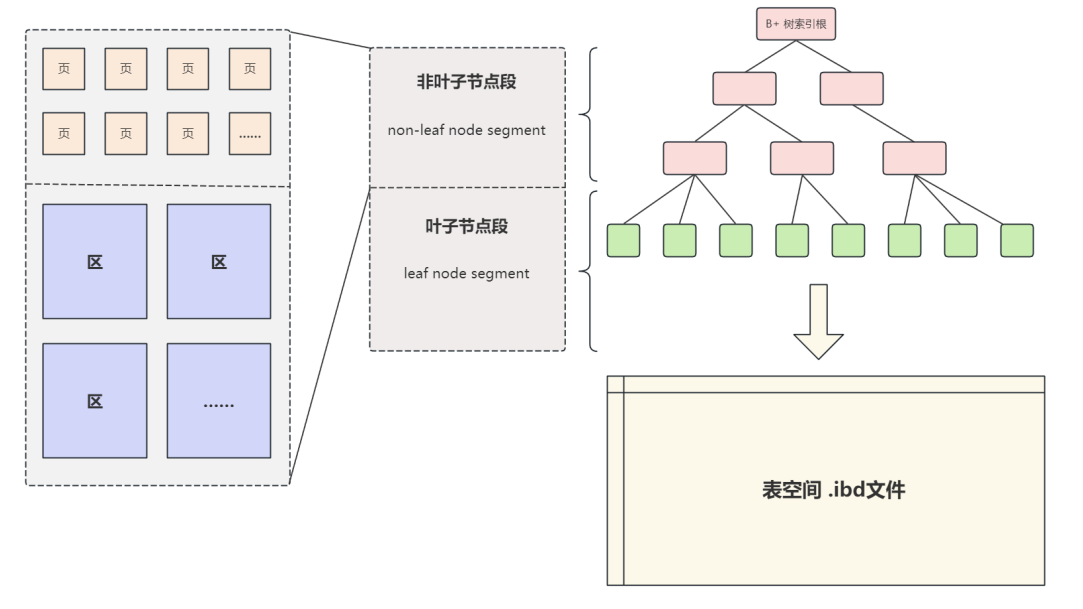
InnoDB结构与表空间文件页的详解
目录 1.InnoDB的概览 表空间文件在哪里? 为什么要设计成内存结构和磁盘结构? 表空间与表空间文件关系? 用户数据如何在表空间文件存储? 2.页 如何设置页的大小? 页的结构及在表空间的位置? 页头包…...
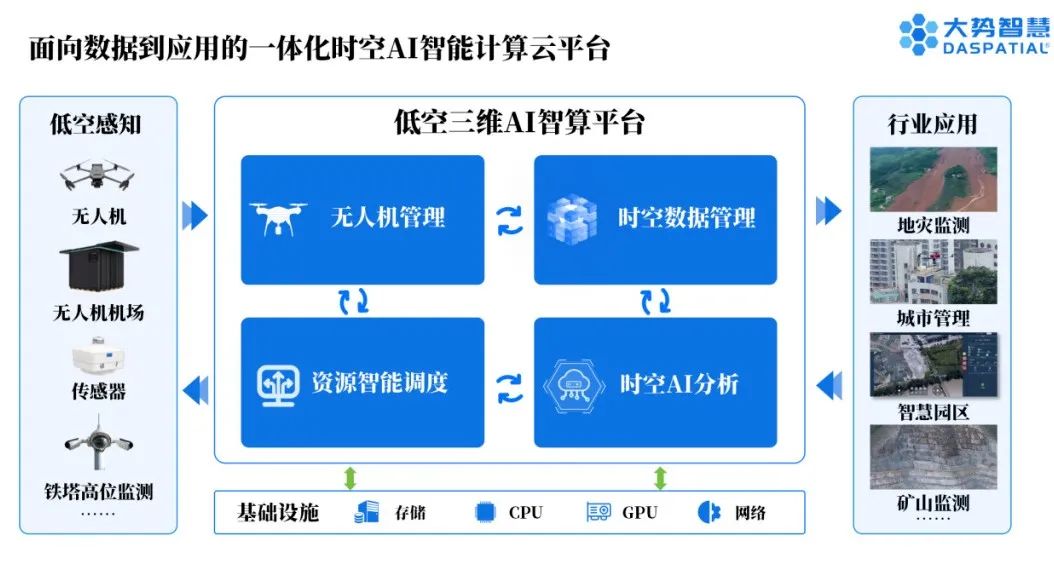
世界无人机大会将至,大势智慧以“AI+实景三维”赋能低空经济
近日,“2025第九届世界无人机大会暨国际低空经济与无人系统博览会和第十届深圳国际无人机展览会”组委会召开新闻发布会,宣布本届大会主题为“步入低空经济新时代”,将于5月23-25日在深圳会展中心(福田)举行࿰…...
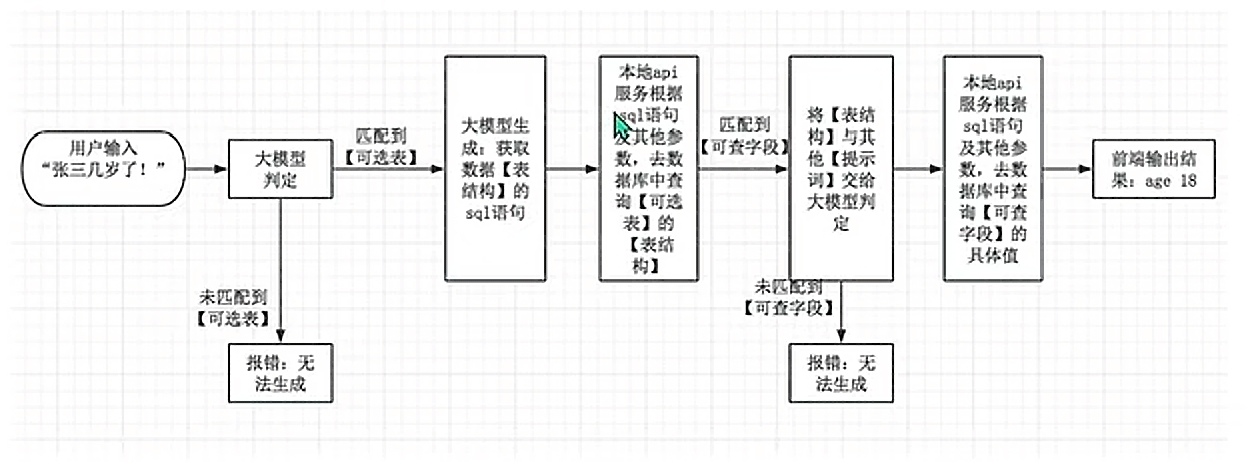
AI 驱动数据库交互技术路线详解:角色、提示词工程与输入输出分析
引言 在人工智能与数据库深度融合的趋势下,理解AI在数据库交互流程中的具体角色、提示词工程的运用以及各步骤的输入输出情况,对于把握这一先进技术路线至关重要。本文将对其展开详细剖析。 一、AI 在数据库交互流程中的角色 (一࿰…...

AI 助力,轻松进行双语学术论文翻译!
在科技日新月异的今天,学术交流中的语言障碍仍然是科研工作者面临的一大挑战。尤其是对于需要查阅大量外文文献的学生、科研人员和学者来说,如何高效地理解和翻译复杂的学术论文成为了一大难题。然而,由Byaidu团队推出的开源项目PDFMathTrans…...
stm32错误记录
1.使用LCD屏幕时,只用st-link时,亮度很暗,需要用usb数据线额外给屏幕供电; 2.移植freertos到f103c8t6芯片时,工程没有错误,但单片机没有反应; 需要将堆的大小改成10*1024; 3.在找已经…...

Baumer工业相机堡盟工业相机的工业视觉中为什么偏爱“黑白相机”
Baumer工业相机堡盟工业相机的工业视觉中为什么偏爱“黑白相机” Baumer工业相机为什么偏爱“黑白相机”?工业视觉中为什么倾向于多使用黑白相机黑白相机在工业视觉中的应用场景有哪些? Baumer工业相机 工业相机是常用与工业视觉领域的常用专业视觉…...

前端取经路——现代API探索:沙僧的通灵法术
大家好,我是老十三,一名前端开发工程师。在现代Web开发中,各种强大的API就像沙僧的通灵法术,让我们的应用具备了超乎想象的能力。本文将带你探索从离线应用到实时通信,从多线程处理到3D渲染的九大现代Web API,让你的应用获得"通灵"般的超能力。 在前端取经的第…...
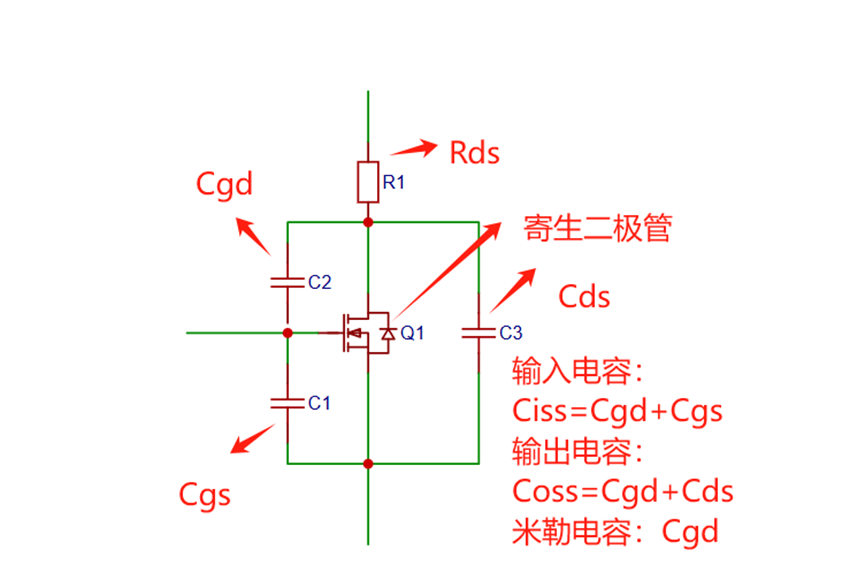
一个电平转换电路导致MCU/FPGA通讯波形失真的原因分析
文章目录 前言一、问题描述二、原因分析三、 仿真分析四、 尝试的解决方案总结前言 一、问题描述 一个电平转换电路,800kHz的通讯速率上不去,波形失真,需要分析具体原因。输出波形如下,1码(占空比75%)低于5V,0码(占空比25%)低于4V。,严重失真。 电平转换电路很简单,M…...
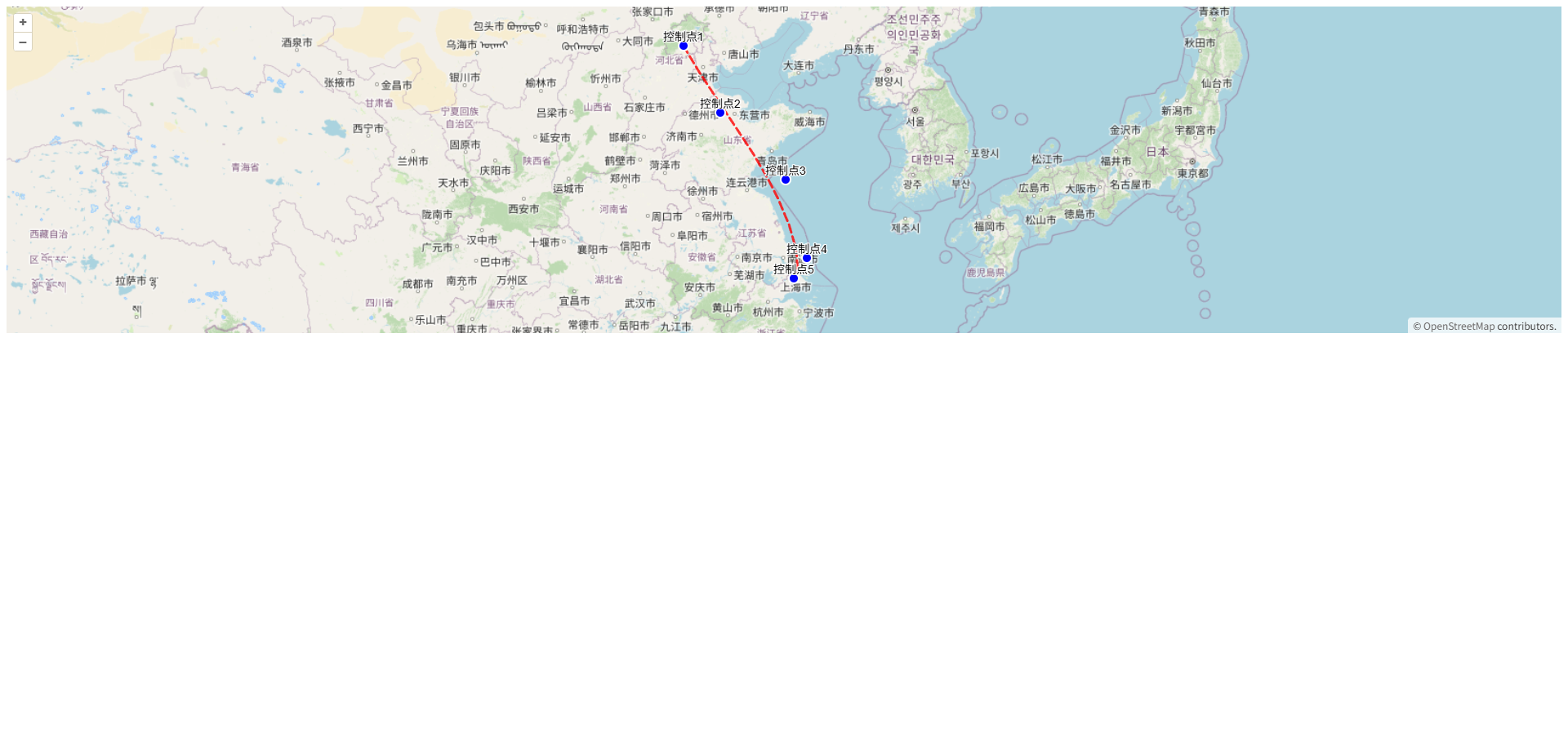
OpenLayers根据任意数量控制点绘制贝塞尔曲线
以下是使用OpenLayers根据任意数量控制点绘制贝塞尔曲线的完整实现方案。该方案支持三个及以上控制点,使用递归算法计算高阶贝塞尔曲线。 实现思路 贝塞尔曲线原理:使用德卡斯特里奥算法(De Casteljau’s Algorithm)递归计算任意…...
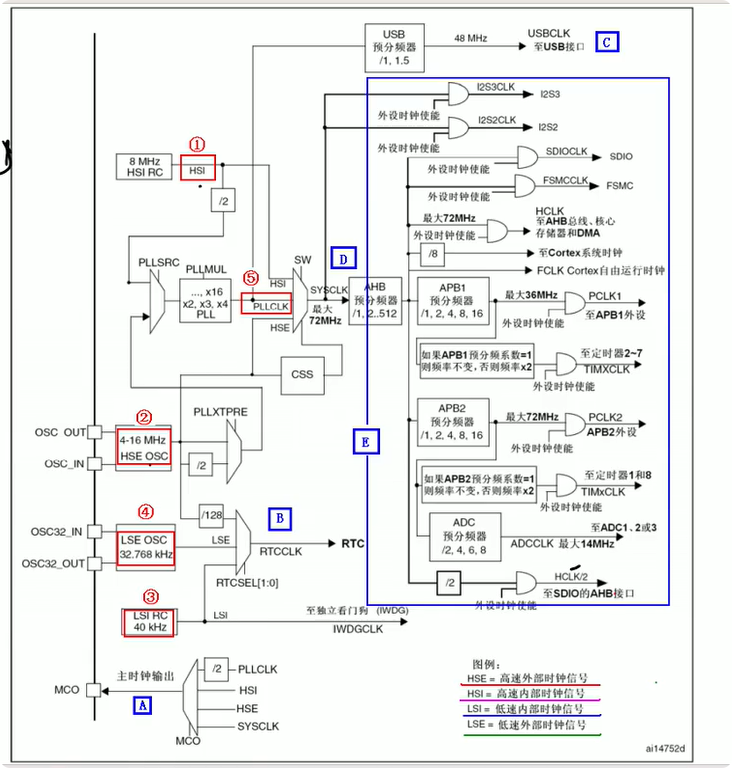
STM32--RCC--时钟
教程 系统时钟 RCC RCC(Reset and Clock Control)是STM32微控制器中管理时钟和复位系统的关键外设模块,负责整个芯片的时钟树配置和复位控制。 RCC主要功能 时钟系统管理: 内部/外部时钟源选择 时钟分频/倍频配置 各外设时钟门…...

uniapp 不同路由之间的区别
在UniApp中,路由跳转是实现页面导航的核心功能,常见的路由跳转方式包括navigateTo、redirectTo、reLaunch、switchTab和navigateBack。这些方法在跳转行为和适用场景上有所不同。 一、路由跳转的类型与区别 1. uni.navigateTo(OBJECT) 特点࿱…...

mysql 已经初始化好,但是用 dbeaver 连接报错:Public Key Retrieval is not allowed
MySQL 已经初始化好,但用 DBeaver 连接时报错 “Public Key Retrieval is not allowed”,这是 MySQL 8 默认认证插件 caching_sha2_password 导致的安全限制问题。解决方法如下: 解决方案 1. 在 DBeaver 中开启 allowPublicKeyRetrievaltru…...

Spring 项目无法连接 MySQL:Nacos 配置误区排查与解决
在开发过程中,我们使用 Nacos 来管理 Spring Boot 项目的配置,其中包括数据库连接配置。然而,在实际操作中,由于一些概念的混淆,我们遇到了一些连接问题。本文将分享我的故障排查过程,帮助大家避免类似的错…...
仿腾讯会议——创建房间加入房间
等等...

Linux系统入门第十二章 --Shell编程之正则表达式
一、正则表达式 之前学习了 Shell 脚本的基础用法,已经可以利用条件判断、循环等语句编辑 Shell脚本。接下来我们将开始介绍一个很重要的概念-正则表达式(RegularExpression,RE) 1.正则表达式的定义 正则表达式又称正规表达式、常规表达式。在代码中常…...

[架构之美]Spring Boot多环境5种方案实现Dev/Test/Prod环境隔离
[架构之美]Spring Boot多环境5种方案实现Dev/Test/Prod环境隔离(十六) 摘要:本文深入剖析Spring Boot多环境配置的5种实现方案,涵盖YAML分组配置、Maven Profile集成、Kubernetes适配等企业级实践,并附赠配置加密方案…...