DAY 17 训练
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
DAY 17 训练
- 聚类算法
- 聚类评估指标介绍
- 1. 轮廓系数 (Silhouette Score)
- 2. CH 指数 (Calinski-Harabasz Index)
- 3. DB 指数 (Davies-Bouldin Index)
- 1. KMeans 聚类
- 算法原理
- 确定簇数的方法:肘部法
- KMeans 算法的优缺点
- 优点
- 缺点
- 2.DBSCAN
- 3.层次聚类
聚类算法
聚类算法是一种无监督学习方法,通过将相似的数据样本自动分组到不同的簇(cluster)中,使得同一簇内的样本相似度高而不同簇间的样本差异大。常见的聚类算法包括K-means(基于距离划分)、DBSCAN(基于密度划分)和层次聚类(基于树状结构划分),广泛应用于客户分群、异常检测、图像分割等领域。
聚类评估指标介绍
以下是三种常用的聚类效果评估指标,分别用于衡量聚类的质量和簇的分离与紧凑程度:
1. 轮廓系数 (Silhouette Score)
- 定义:轮廓系数衡量每个样本与其所属簇的紧密程度以及与最近其他簇的分离程度。
- 取值范围:[-1, 1]
- 轮廓系数越接近 1,表示样本与其所属簇内其他样本很近,与其他簇很远,聚类效果越好。
- 轮廓系数越接近 -1,表示样本与其所属簇内样本较远,与其他簇较近,聚类效果越差(可能被错误分类)。
- 轮廓系数接近 0,表示样本在簇边界附近,聚类效果无明显好坏。
- 使用建议:选择轮廓系数最高的
k值作为最佳簇数量。
2. CH 指数 (Calinski-Harabasz Index)
- 定义:CH 指数是簇间分散度与簇内分散度之比,用于评估簇的分离度和紧凑度。
- 取值范围:[0, +∞)
- CH 指数越大,表示簇间分离度越高,簇内紧凑度越高,聚类效果越好。
- 没有固定的上限,值越大越好。
- 使用建议:选择 CH 指数最高的
k值作为最佳簇数量。
3. DB 指数 (Davies-Bouldin Index)
- 定义:DB 指数衡量簇间距离与簇内分散度的比值,用于评估簇的分离度和紧凑度。
- 取值范围:[0, +∞)
- DB 指数越小,表示簇间分离度越高,簇内紧凑度越高,聚类效果越好。
- 没有固定的上限,值越小越好。
- 使用建议:选择 DB 指数最低的
k值作为最佳簇数量。
1. KMeans 聚类
算法原理
KMeans 是一种基于距离的聚类算法,需要预先指定聚类个数,即 k。其核心步骤如下:
- 随机选择
k个样本点作为初始质心(簇中心)。 - 计算每个样本点到各个质心的距离,将样本点分配到距离最近的质心所在的簇。
- 更新每个簇的质心为该簇内所有样本点的均值。
- 重复步骤 2 和 3,直到质心不再变化或达到最大迭代次数为止。
确定簇数的方法:肘部法
- 肘部法(Elbow Method) 是一种常用的确定
k值的方法。 - 原理:通过计算不同
k值下的簇内平方和(Within-Cluster Sum of Squares, WCSS),绘制k与 WCSS 的关系图。 - 选择标准:在图中找到“肘部”点,即 WCSS 下降速率明显减缓的
k值,通常认为是最佳簇数。这是因为增加k值带来的收益(WCSS 减少)在该点后变得不显著。
KMeans 算法的优缺点
优点
- 简单高效:算法实现简单,计算速度快,适合处理大规模数据集。
- 适用性强:对球形或紧凑的簇效果较好,适用于特征空间中簇分布较为均匀的数据。
- 易于解释:聚类结果直观,簇中心具有明确的物理意义。
缺点
- 需预先指定
k值:对簇数量k的选择敏感,不合适的k会导致聚类效果较差。 - 对初始质心敏感:初始质心的随机选择可能导致结果不稳定或陷入局部最优(可通过 KMeans++ 初始化方法缓解)。
- 对噪声和异常值敏感:异常值可能会显著影响质心的位置,导致聚类结果失真。
- 不适合非球形簇:对非线性可分或形状复杂的簇效果较差,无法处理簇密度不均的情况。
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as snsscaler = StandardScaler() #聚类前需要标准化
X_scaled = scaler.fit_transform(X)k_range = range(2, 11)
inertia_values = [] # 存储每个k值对应的inertia值
silhouette_scores = [] # 存储每个k值对应的轮廓系数
ch_scores = [] # 存储每个k值对应的Calinski-Harabasz指数
db_scores = [] # 存储每个k值对应的Davies-Bouldin指数
for k in k_range: # 遍历k值kmeans = KMeans(n_clusters=k, random_state=42) # 创建KMeans对象kmeans.fit(X) # 训练模型inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)silhouette = silhouette_score(X_scaled, kmeans.labels_)silhouette_scores.append(silhouette) # 轮廓系数ch = calinski_harabasz_score(X_scaled, kmeans.labels_)ch_scores.append(ch) # Calinski-Harabasz指数db = davies_bouldin_score(X_scaled, kmeans.labels_)db_scores.append(db) # Davies-Bouldin指数print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")plt.figure(figsize=(15, 10)) # 设置画布大小
# 绘制惯性曲线
plt.subplot(2, 2, 1) # 绘制轮廓系数曲线
plt.plot(k_range, inertia_values, marker='o', label='Inertia') # 绘制惯性曲线
plt.title("手肘法确定最优k值,惯性越小越好")
plt.xlabel("k")
plt.ylabel("Inertia")
plt.grid(True) # 显示网格
# 绘制轮廓系数曲线
plt.subplot(2, 2, 2) # 绘制轮廓系数曲线
plt.plot(k_range, silhouette_scores, marker='o', label='Silhouette Score') # 绘制轮廓系数曲线
plt.title("轮廓系数法确定最优k值,轮廓系数越大越好")
plt.xlabel("k")
plt.ylabel("Silhouette Score")
plt.grid(True) # 显示网格
# 绘制Calinski-Harabasz指数曲线
plt.subplot(2, 2, 3) # 绘制Calinski-Harabasz指数曲线
plt.plot(k_range, ch_scores, marker='o', label='Calinski-Harabasz Index') # 绘制Calinski-Harabasz指数曲线
plt.title("Calinski-Harabasz指数法确定最优k值,CH指数越大越好")
plt.xlabel("k")
plt.ylabel("Calinski-Harabasz Index")
plt.grid(True)
# 绘制Davies-Bouldin指数曲线
plt.subplot(2, 2, 4)
plt.plot(k_range, db_scores, marker='o', label='Davies-Bouldin Index') # 绘制Davies-Bouldin指数曲线
plt.title("Davies-Bouldin指数法确定最优k值,DB指数越小越好")
plt.xlabel("k")
plt.ylabel("Davies-Bouldin Index")
plt.grid(True)
# 提示用户选择 k 值
selected_k = 6# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())
- 先对数据标准化
- 对每个k值进行训练评估并用图像可视化
- 使用最佳k值训练,打印结果
2.DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它通过寻找高密度区域来识别簇,并将稀疏分布的点标记为噪声。其核心思想是基于两个参数:eps(邻域半径)和min_samples(最小样本数)。算法从一个未访问的点开始,查找其eps范围内的邻域点,如果邻域内的点数大于或等于min_samples,则形成一个簇,并递归地扩展该簇;否则,该点被标记为噪声。通过这种方式,DBSCAN能够发现任意形状的簇,并有效处理噪声点。
这段代码实现了DBSCAN聚类的参数优化和结果可视化。它通过遍历不同的eps和min_samples组合,对数据进行聚类,并计算轮廓系数、Calinski-Harabasz指数和Davies-Bouldin指数等评估指标来选择最优参数。最终,使用选定的参数进行聚类,并通过PCA降维可视化聚类结果,同时统计簇的分布情况。
from sklearn.cluster import DBSCANeps_range = np.arange(0.3, 0.8, 0.1) # 测试 eps 从 0.3 到 0.7
min_samples_range = range(3, 8) # 测试 min_samples 从 3 到 7
results = []for eps in eps_range:for min_samples in min_samples_range:dbscan = DBSCAN(eps=eps, min_samples=min_samples)dbscan_labels = dbscan.fit_predict(X_scaled)# 计算簇的数量(排除噪声点 -1)n_clusters = len(np.unique(dbscan_labels)) - (1 if -1 in dbscan_labels else 0)# 计算噪声点数量n_noise = list(dbscan_labels).count(-1)# 只有当簇数量大于 1 且有有效簇时才计算评估指标if n_clusters > 1:# 排除噪声点后计算评估指标mask = dbscan_labels != -1if mask.sum() > 0: # 确保有非噪声点silhouette = silhouette_score(X_scaled[mask], dbscan_labels[mask])ch = calinski_harabasz_score(X_scaled[mask], dbscan_labels[mask])db = davies_bouldin_score(X_scaled[mask], dbscan_labels[mask])results.append({'eps': eps,'min_samples': min_samples,'n_clusters': n_clusters,'n_noise': n_noise,'silhouette': silhouette,'ch_score': ch,'db_score': db})print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, "f"轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")else:print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, 无法计算评估指标")# 将结果转为 DataFrame 以便可视化和选择参数
results_df = pd.DataFrame(results)
# 绘制评估指标图,增加点论文中的工作量
plt.figure(figsize=(15, 10))
# 轮廓系数图
plt.subplot(2, 2, 1)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples] # plt.plot(subset['eps'], subset['silhouette'], marker='o', label=f'min_samples={min_samples}')
plt.title('轮廓系数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('轮廓系数')
plt.legend()
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 2)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['ch_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Calinski-Harabasz 指数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('CH 指数')
plt.legend()
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 3)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['db_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Davies-Bouldin 指数确定最优参数(越小越好)')
plt.xlabel('eps')
plt.ylabel('DB 指数')
plt.legend()
plt.grid(True)# 簇数量图
plt.subplot(2, 2, 4)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['n_clusters'], marker='o', label=f'min_samples={min_samples}')
plt.title('簇数量变化')
plt.xlabel('eps')
plt.ylabel('簇数量')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()
# 选择 eps 和 min_samples 值(根据图表选择最佳参数)
selected_eps = 0.6 # 根据图表调整
selected_min_samples = 6 # 根据图表调整# 使用选择的参数进行 DBSCAN 聚类
dbscan = DBSCAN(eps=selected_eps, min_samples=selected_min_samples)
dbscan_labels = dbscan.fit_predict(X_scaled)
X['DBSCAN_Cluster'] = dbscan_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# DBSCAN 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=dbscan_labels, palette='viridis')
plt.title(f'DBSCAN Clustering with eps={selected_eps}, min_samples={selected_min_samples} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 DBSCAN 聚类标签的分布
print(f"DBSCAN Cluster labels (eps={selected_eps}, min_samples={selected_min_samples}) added to X:")
print(X[['DBSCAN_Cluster']].value_counts())
本实验中效果差
3.层次聚类
Agglomerative Clustering 是一种自底向上的层次聚类方法,初始时每个样本是一个簇,然后逐步合并最相似的簇,直到达到指定的簇数量或满足停止条件。由于它需要指定簇数量(类似于 KMeans),我将通过测试不同的簇数量 n_clusters 来评估聚类效果,并使用轮廓系数(Silhouette Score)、CH 指数(Calinski-Harabasz Index)和 DB 指数(Davies-Bouldin Index)作为评估指标。
import numpy as np
import pandas as pd
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as snssacler = StandardScaler()
X_scaled = scaler.fit_transform(X)n_clusters_range = range(2,11)
silhouette_scores = []
ch_scores = []
db_scores = []for n_clusters in n_clusters_range:agglo = AgglomerativeClustering(n_clusters=n_clusters,linkage='ward')agglo_labels = agglo.fit_predict(X_scaled)silhouette = silhouette_score(X_scaled,agglo_labels)ch = calinski_harabasz_score(X_scaled,agglo_labels)db = davies_bouldin_score(X_scaled,agglo_labels)silhouette_scores.append(silhouette)ch_scores.append(ch)db_scores.append(db)print(f"For n_clusters={n_clusters}, silhouette score={silhouette:.4f}, CH score={ch:.4f}, DB score={db:.4f}")plt.figure(figsize=(15, 5))# 轮廓系数图
plt.subplot(1, 3, 1)
plt.plot(n_clusters_range, silhouette_scores, marker='o')
plt.title('轮廓系数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(1, 3, 2)
plt.plot(n_clusters_range, ch_scores, marker='o')
plt.title('Calinski-Harabasz 指数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(1, 3, 3)
plt.plot(n_clusters_range, db_scores, marker='o')
plt.title('Davies-Bouldin 指数确定最优簇数(越小越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()
# 提示用户选择 n_clusters 值(这里可以根据图表选择最佳簇数)
selected_n_clusters = 10 # 示例值,根据图表调整# 使用选择的簇数进行 Agglomerative Clustering 聚类
agglo = AgglomerativeClustering(n_clusters=selected_n_clusters, linkage='ward')
agglo_labels = agglo.fit_predict(X_scaled)
X['Agglo_Cluster'] = agglo_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# Agglomerative Clustering 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=agglo_labels, palette='viridis')
plt.title(f'Agglomerative Clustering with n_clusters={selected_n_clusters} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 Agglomerative Clustering 聚类标签的分布
print(f"Agglomerative Cluster labels (n_clusters={selected_n_clusters}) added to X:")
print(X[['Agglo_Cluster']].value_counts())
@浙大疏锦行
相关文章:

DAY 17 训练
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 DAY 17 训练 聚类算法聚类评估指标介绍1. 轮廓系数 (Silhouette Score)2. CH 指数 (Calinski-Harabasz Index)3. DB 指数 (Davies-Bouldin Index) 1. KMeans 聚类算法原理确定…...

如何修改进程优先级?
文章目录 1. 摘要2. 命令实现2.1 使用 renice(调整普通进程的优先级)2.2 使用 chrt(调整实时进程的优先级) 3. 代码实现 1. 摘要 在实际开发中,我们经常会遇到创建进程的场景,但是往往并不关心它的优先级…...

Mind Over Machines 公司:技术咨询与创新的卓越实践
在信息技术飞速发展的时代,企业面临着前所未有的机遇与挑战。如何巧妙运用技术,优化业务流程、提升竞争力,成为众多企业亟待解决的关键问题。Mind Over Machines(MOM)公司,作为一家在技术咨询领域深耕多年的…...
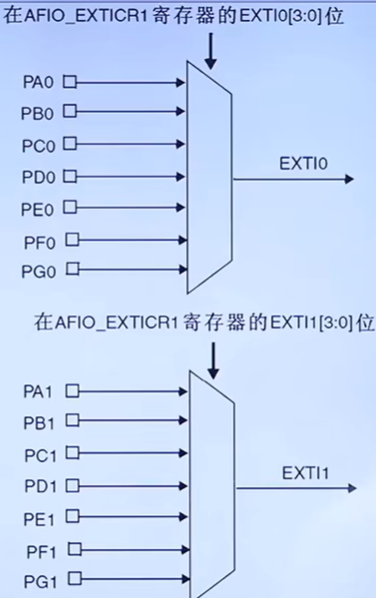
stm32week15
stm32学习 十一.中断 2.NVIC Nested vectored interrupt controller,嵌套向量中断控制器,属于内核(M3/4/7) 中断向量表:定义一块固定的内存,以4字节对齐,存放各个中断服务函数程序的首地址,中断向量表定…...

新手在使用宝塔Linux部署前后端分离项目时可能会出现的问题以及解决方案
常见问题与解决方案 1. 环境配置错误 问题:未正确安装Node.js/Python/JDK等运行时环境解决: 通过宝塔面板的软件商店安装所需环境验证版本: node -v # 查看Node.js版本 python3 --version # 查看Python3版本2. 端口未正确开放 问题&am…...

《从零构建一个简易的IOC容器,理解Spring的核心思想》
大家好呀!今天我们要一起探索Java开发中最神奇的魔法之一 —— Spring框架的IOC容器!🧙♂️ 我会用最最最简单的方式,让你彻底明白这个看似高深的概念。准备好了吗?Let’s go! 🚀 一、什么是IOC容器&…...

QSFP+、QSFP28、QSFP-DD接口分别实现40G、100G、200G/400G以太网接口
常用的光模块结构形式: 1)QSFP等效于4个SFP,支持410Gbit/s通道传输,可通过4个通道实现40Gbps传输速率。与SFP相比,QSFP光模块的传输速率可达SFP光模块的四倍,在部署40G网络时可直接使用QSFP光模块…...

tensorflow 1.x
简介 TensorFlow:2015年谷歌,支持python、C,底层是C,主要用python。支持CNN、RNN等算法,分CPU TensorFlow/GPU TensorFlow。 TensorBoard:训练中的可视化。 快捷键:shiftenter执行命令,Tab键进…...

vue3模版语法
Vue 的模板语法(template syntax)是 Vue 框架中用于声明式地绑定 DOM 的方式,核心是将 HTML 与 Vue 实例的数据绑定起来。 下面是常用的 Vue 模板语法总结(以 Vue 3 Composition API 为基础,也适用于 Vue 2 的 Options…...

java加强 -List集合
List集合是Collection集合下的集合的一种,它有序,可重复,有索引。但由于存在不同的底层实现方法,适合的场景也不同。 ArrayList底层是基于数组存储数据的,而LinkedList底层是基于链表存储数据的。因此,前者…...
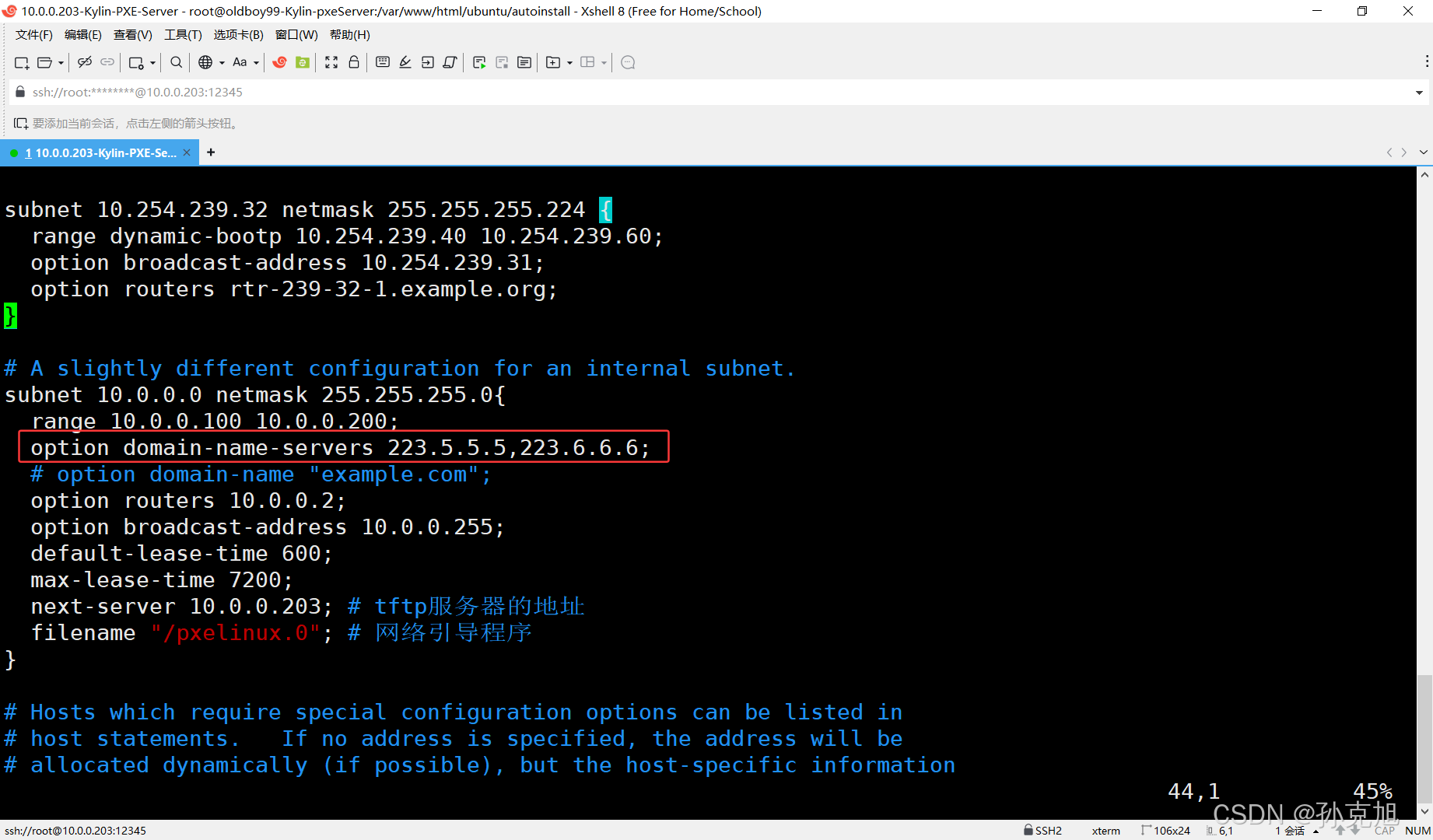
PXE安装Ubuntu系统
文章目录 1. 服务器挂载Ubuntu镜像2. 修改dhcp配置文件3. 修改tftp配置文件4.复制网络驱动文件和其他配置文件5. http目录下配置文件6. 踩坑记录6.1 Failed to load ldlinux.c326.2 no space left on device6.3 为啥用pxe安装系统时,客户端需要较大的内存࿱…...

uniapp tabBar 中设置“custom“: true 在H5和app中无效解决办法
uniapp小程序自定义底部tabbar,但是在转成H5和app时发现"custom": true 无效,原生tabbar会显示出来 解决办法如下 在tabbar的list中设置 “visible”:false 代码如下:"tabBar": {"custom": true,//"cust…...
ABP-Book Store Application中文讲解 - 前期准备 - Part 2:创建Acme.BookStore + Angular
ABP-Book Store Application中文讲解-汇总-CSDN博客 因为本系列文章使用的.NET8 SDK,此处仅介绍如何使用abp cli .NET 8 SDK SQL sevrer 2014创建Angular模板的Acme.BookStore。 目录 1. ABP cli创建项目 1.1 打开cmd.exe 1.2 创建项目 2. ABP Studio创建项…...
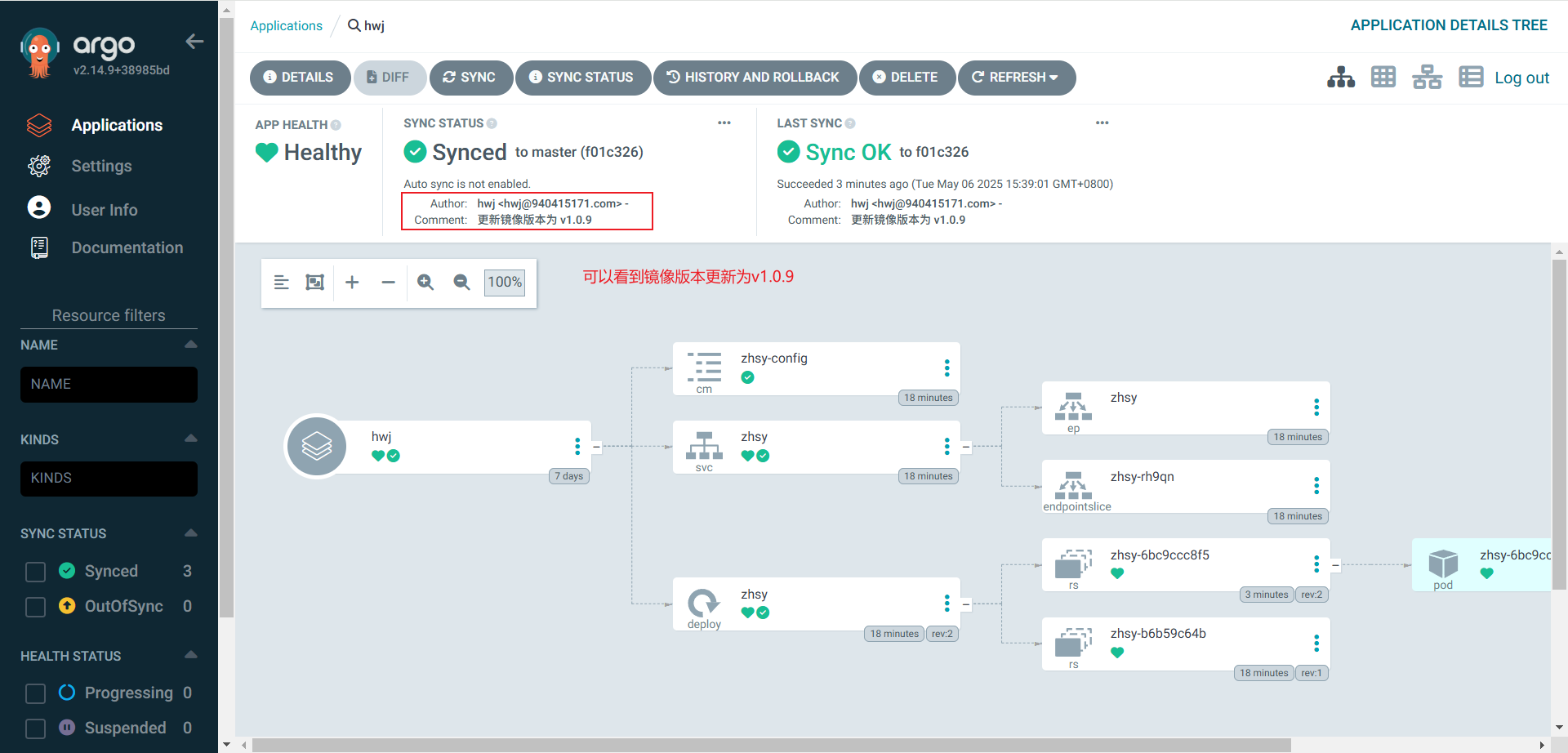
基于k8s的Jenkins CI/CD平台部署实践(三):集成ArgoCD实现持续部署
基于k8s的Jenkins CI/CD平台部署实践(三):集成ArgoCD实现持续部署 文章目录 基于k8s的Jenkins CI/CD平台部署实践(三):集成ArgoCD实现持续部署一、Argocd简介二、安装Helm三、Helm安装ArgoCD实战1. 添加Arg…...

Starrocks 的 ShortCircuit短路径
背景 本文基于 Starrocks 3.3.5 本文主要来探索一下Starrocks在FE端怎么实现 短路径,从而加速点查查询速度。 在用户层级需要设置 enable_short_circuit 为true 分析 数据流: 直接到StatementPlanner.createQueryPlan方法: ... OptExpres…...

JVM——Java字节码基础
引入 Java字节码(Java Bytecode)是Java技术体系的核心枢纽,所有Java源码经过编译器处理后,最终都会转化为.class文件中的字节码指令。这些指令不依赖于具体的硬件架构和操作系统,而是由Java虚拟机(JVM&…...

控制台打印带格式内容
1. 场景 很多软件会在控制台打印带颜色和格式的文字,需要使用转义符实现这个功能。 2. 详细说明 2.1.转义符说明 样式开始:\033[参数1;参数2;参数3m 可以多个参数叠加,若同一类型的参数(如字体颜色)设置了多个&…...

外网访问内网海康威视监控视频的方案:WebRTC + Coturn 搭建
外网访问内网海康威视监控视频的方案:WebRTC Coturn 需求背景 在仓库中有海康威视的监控摄像头,内网中是可以直接访问到监控摄像的画面,由于项目的需求,需要在外网中也能看到监控画面。 实现这个功能的意义在于远程操控设备的…...
)
DA14585墨水屏学习(2)
一、user_svc2_wr_ind_handler函数 void user_svc2_wr_ind_handler(ke_msg_id_t const msgid,struct custs1_val_write_ind const *param,ke_task_id_t const dest_id,ke_task_id_t const src_id) {// sprintf(buf2,"HEX %d :",param->length);arch_printf("…...
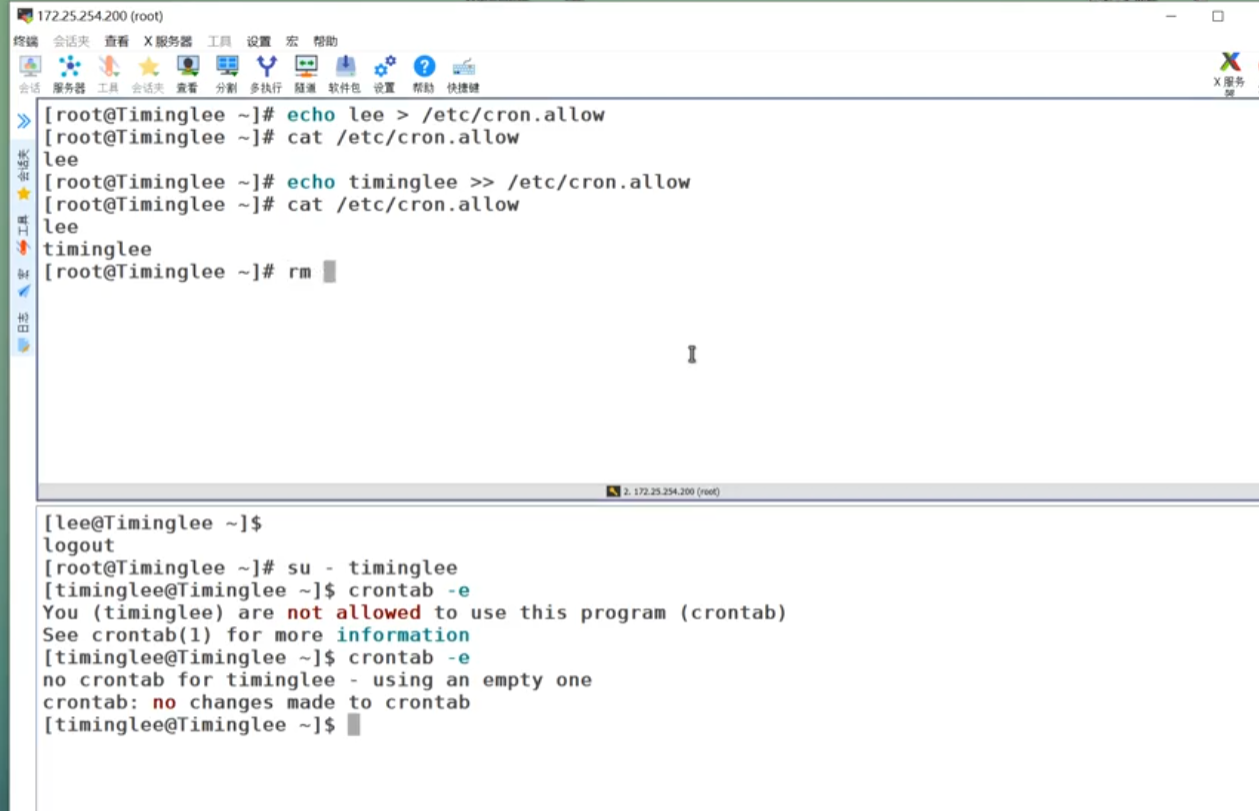
Linux系统下的延迟任务及定时任务
1、延迟任务 概念: 在系统中我们的维护工作大多数时在服务器行对闲置时进行 我们需要用延迟任务来解决自动进行的一次性的维护 延迟任务时一次性的,不会重复执行 当延迟任务产生输出后,这些输出会以邮件的形式发送给延迟任务发起者 在 RH…...

Spark 之 YarnCoarseGrainedExecutorBackend
YarnCoarseGrainedExecutorBackend executor ID , 在日志里也有体现。 25/05/06 12:41:58 INFO YarnCoarseGrainedExecutorBackend: Successfully registered with driver 25/05...
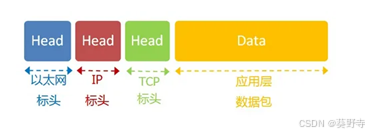
【网络原理】数据链路层
目录 一. 以太网 二. 以太网数据帧 三. MAC地址 四. MTU 五. ARP协议 六. DNS 一. 以太网 以太网是一种基于有线或无线介质的计算机网络技术,定义了物理层和数据链路层的协议,用于在局域网中传输数据帧。 二. 以太网数据帧 1)目标地址 …...
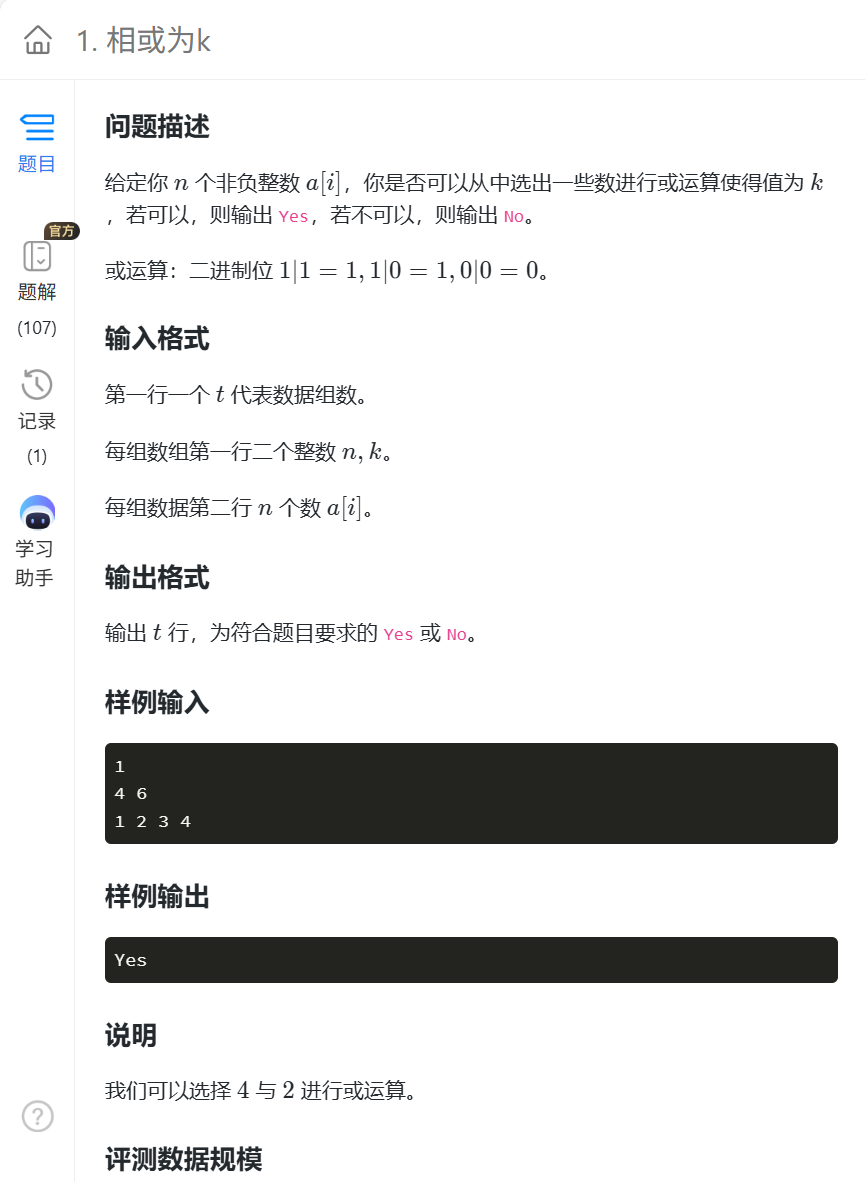
相或为K(位运算)蓝桥杯(JAVA)
这个题是相或为k,考察相或的性质,用俩个数举例子,011001和011101后面的数不管和哪个数相或都不可能变成前面的数,所以利用这个性质我们可以用相与运算来把和k对应位置的1都积累起来,看最后能不能拼起来k如果能拼起来k那…...
AI汽车时代的全面赋能者:德赛西威全栈能力再升级
AI汽车未来智慧出行场景正在描绘出巨大的商业图景,德赛西威已经抢先入局。 在2025年上海车展开幕前夕,德赛西威发布2030年全新使命愿景——“创领安全、愉悦和绿色的出行生活”,并推出全栈式智慧出行解决方案Smart Solution3.0、车路云一体式…...

Python函数:从基础到进阶的完整指南
在Python编程中,函数是构建高效、可维护代码的核心工具。无论是开发Web应用、数据分析还是人工智能模型,函数都能将复杂逻辑模块化,提升代码复用率与团队协作效率。本文将从函数基础语法出发,深入探讨参数传递机制、高阶特性及最佳实践,助你掌握这一编程基石。 一、函数基…...
学习Python的第四天之网络爬虫
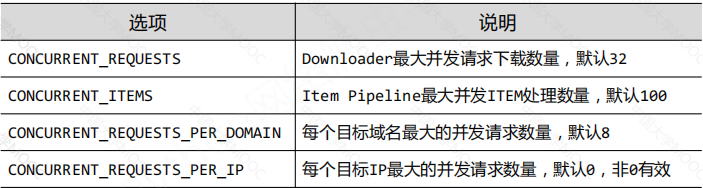
30岁程序员学习Python的第四天之网络爬虫的Scrapy库 Scrapy库的基本信息 Scrapy库的安装 在windows系统中通过管理员权限打开cmd。运行pip install scrapy即可安装。 通过命令scrapy -h可查看scrapy库是否安装成功. Scrapy库的基础信息 scrapy库是一种爬虫框架库 爬虫框…...
5、开放式PLC梯形图编程组件 - /自动化与控制组件/open-plc-programming
76个工业组件库示例汇总 开放式PLC编程环境 这是一个开放式PLC编程环境的自定义组件,提供了一个面向智能仓储堆垛机控制的开放式PLC编程环境。该组件采用苹果科技风格设计,支持多厂商PLC硬件,具有直观的界面和丰富的功能。 功能特点 多语…...

数据指标和数据标签
数据指标和数据标签是数据管理与分析中的两个重要概念,它们在用途、形式和应用场景上有显著区别。以下是两者的详细对比: 1. 核心定义 维度数据指标(Data Metrics)数据标签(Data Tags/Labels)定义量化衡量…...

linux中常用的命令(三)
目录 1- ls(查看当前目录下的内容) 2- pwd (查看当前所在的文件夹) 3- cd [目录名](切换文件夹) 4- touch [文件名] (如果文件不存在,新建文件) 5- mkdir[目录名] (创建目录) 6-rm[文件名]&…...
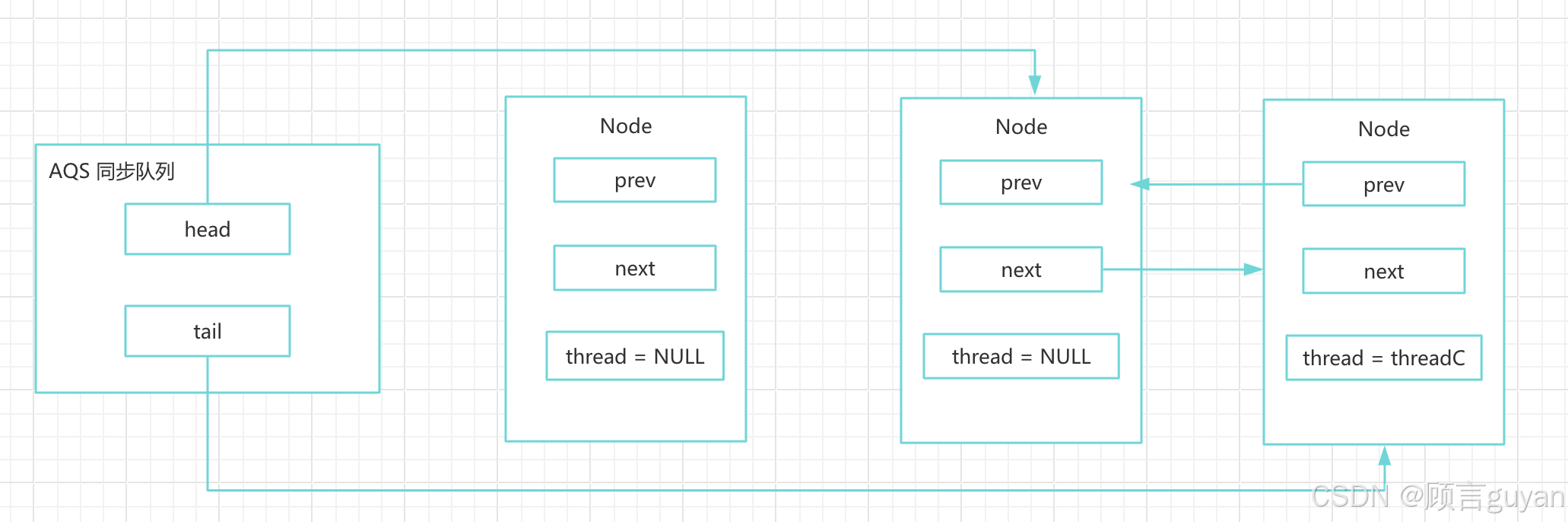
Java 中 AQS 的实现原理
AQS 简介 AQS(全称AbstractQueuedSynchronizer)即抽象同步队列,它是实现同步器的基础组件,并发包中锁的底层就是使用AQS实现的。 由类图可以看到,AQS是一个FIFO的双向队列,其内部通过节点head和tail记录队首和队尾元素࿰…...