一文读懂 AI
- 2022年11月30日,OpenAI发布了ChatGPT,2023年3月15日,GPT-4引发全球轰动,让世界上很多人认识了ai这个词。如今已过去快两年半,AI产品层出不穷,如GPT-4、DeepSeek、Cursor、自动驾驶等,但很多人仍对AI知之甚少,尤其是“NLP”,“大模型”、“机器学习”和“深度学习”等术语让人困惑🤔。
- 对于普通人来说,AI是否会取代工作😨?网络上说除双一流以外学校搞不了AI又是什么情况😩?AI产业是否像以前一样互联网程序员一样?看一些科普视频,上来就是一顿“Attention”、“神经元”、“涌现现象”等术语,让人感觉是在介绍AI某个领域中的一个名词,本文将通俗易懂地解释AI,让什么都不懂的小白也能变成AI概念的糕手,糕手,糕糕手😎
一:区分AI技术与AI应用
-
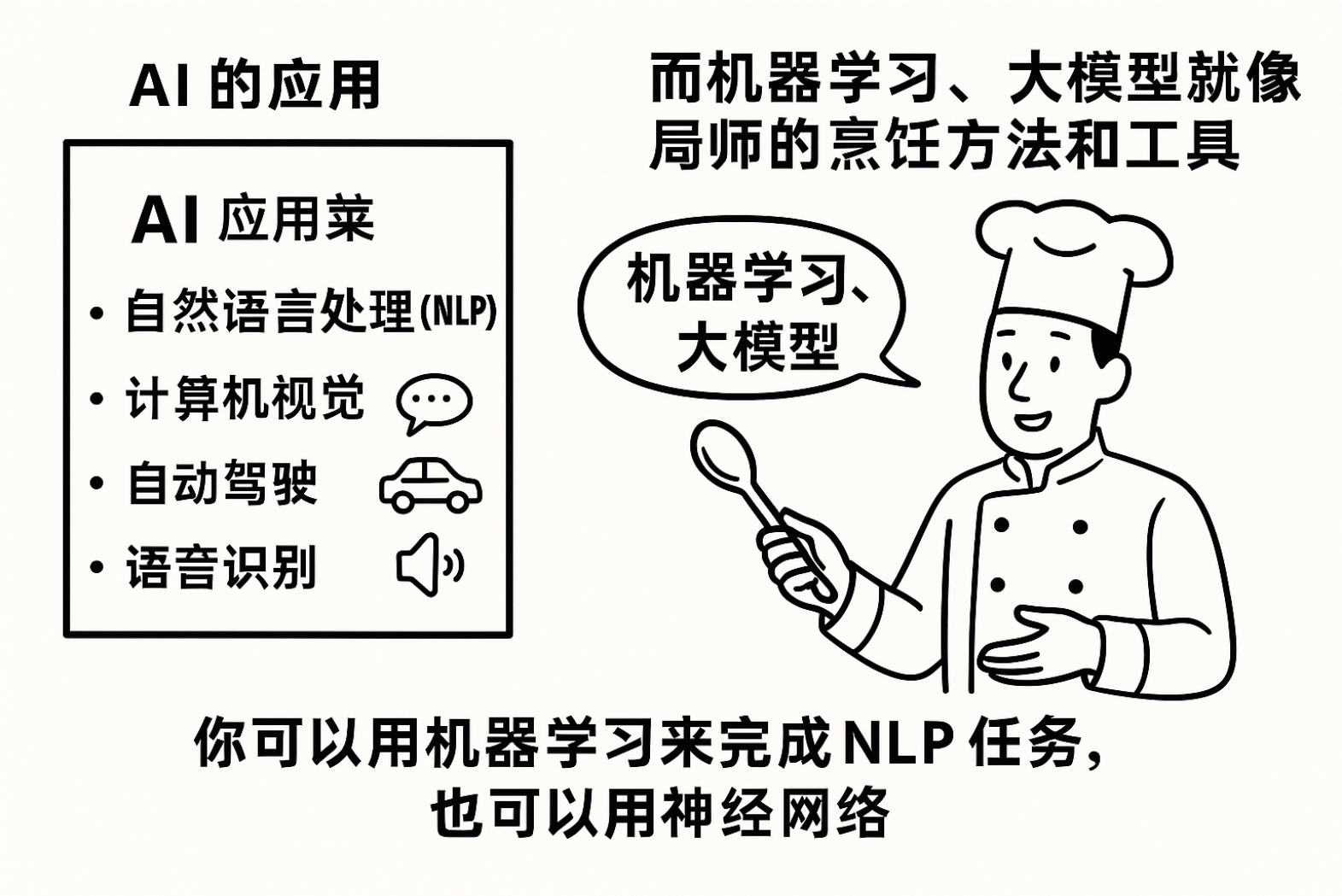
AI 的应用有:自然语言处理(NLP)、计算机视觉、自动驾驶、语音识别等。而机器学习、大语言模型等是实现这些应用的技术手段。
-
AI 的应用 就像是 餐馆的菜单,上面有不同的菜肴(如自然语言处理、计算机视觉等),这些菜肴是顾客需要的服务或产品。
而 **机器学习、大模型就像是 厨师的烹饪方法和工具,它们是实现这些菜肴所用的手段。**你可以用机器来完成 NLP 任务,也可以用神经网做。
二:ChatGPT、DeepSeek是什么东西?
-
我们已经知道AI有不同的应用,而ChatGPT与DeepSeek都是NLP领域的大型语言模型(Large Language Model, LLM)。(NLP中文意思:自然语言处理。不要忘了哦)
-
这又引出了新问题:NLP是什么?大型语言模型又是什么?
NLP是什么?
-
翻译人类语言让计算机听懂就是NLP,其中重点是听懂,而不是你说“吃饭了嘛”,计算机也说“吃饭了嘛”。计算机明白了你在问它吃没吃饭,于是计算机回答:我是机器不需要吃饭😅,或者我打算过一会儿再吃(充电)🔋。
很难想象,没思想的计算机怎么能听懂有思想的人说的话🤔,这其实是个困扰了几十年的问题。
| 阶段 | 时间范围 | 技术特点 | 代表方法/模型 | 应用举例 |
|---|---|---|---|---|
| 规则驱动阶段 | 1950s–1980s | 基于人工编写规则,语言学为主 | 句法规则、词典匹配 | 早期机器翻译、图灵测试 |
| 统计学习阶段 | 1990s–2010 | 依赖大规模语料,采用统计与概率模型 | N-gram、HMM、CRF | 情感分析、搜索引擎、拼写纠正 |
| 神经网络阶段 | 2010–2017 | 引入深度学习,提升语言理解建模能力 | Word2Vec、RNN、LSTM、Seq2Seq | 智能问答、语音识别 |
| 预训练大模型阶段 | 2018至今 | 采用Transformer架构,模型参数大规模增长 | BERT、GPT、T5、ChatGPT、DeepSeek等 | 多任务通用语言处理、对话系统 |
-
规则驱动阶段:意思就是让机器明白主谓宾定状补、什么名词动词名词短语……但很显然,套一万个规则也难以让一台只会010101的机器明白你在说什么。
-
统计学习阶段:这时候,科学家们将统计学引入来解决问题。将人们日常对话收集成库(语料库),通过统计发现对话数据中的规律来实现计算机“理解”人说的话。
- 在第三小结,会构建一个简单的N-Gram模型,让你大概知道什么是模型与统计学习阶段是在干什么。所以先别急。
-
神经网络阶段:科学家们发现统计效果很好后,扩大了语料库,加入了矩阵、向量计算(这不是本文重点,但可以是下一篇)和人工设计特征(早期有,后期减少),计算机硬件发展为该阶段的提供算力支持。
-
预训练大模型阶段:
- 先说大模型,大模型就是有参数量大(亿级甚至千亿级)、数据量大、算力需求高特点的神经网络模型。
- 预训练:就像是一个体育比赛的人,不管这个人参与什么体育项目,先把体能练好了,再训练具体项目。
| 阶段 | 目的 | 数据类型 | 示例任务 |
|---|---|---|---|
| 预训练 | 学通用语言能力 | 无标注语料 | 预测遮盖词、下一个词等 |
| 微调 | 学任务特定能力 | 有标注数据 | 分类、翻译、问答等 |

大型语言模型是什么?
- 你应该已经知道了,大型语言模型是一种大模型。
三:一个基础NLP模型实现:N-Gram模型
-
-Gram 模型是一种基于统计的语言模型,其核心思想是:一个词(或字)出现的概率,只依赖于它前面的 n−1n-1n−1 个词(或字),用来解决已知的上下文生成合理的文本问题。
-
工作原理:
- 将文本序列拆分为连续的 N 个词(或字)的组合,称为“N-Gram”。
- 通过统计语料中各个 N-Gram 出现的频率,估计下一个词(或字)出现的概率。
-
计算公式
-
模型流程
- 收集语料
- 切分为 N-Gram
- 统计每种 N-Gram 出现频率
- 根据频率计算概率
- 根据历史词语预测下一个词

from collections import defaultdict, Counter
import random
# 第一步:创建语料库
corpus = ["我早上去了图书馆","我早上听了一节英语课","我中午看了一部电影","我中午睡了一会儿","我晚上写了一篇作文","我晚上复习了功课",
]# 第二步:分词函数(按字分词,这里只是按照字符分词)
def split_words(text):return [char for char in text]# 第三步:统计Bigram词频(Bigram 是一个N-Gram 模型中的特例,其中N=2,即考虑连续的两个词或字符的组合。)
bigram_freq = defaultdict(Counter)
for sentence in corpus:words = split_words(sentence)for i in range(len(words) - 1):first, second = words[i], words[i+1]bigram_freq[first][second] += 1
# 打印词频率
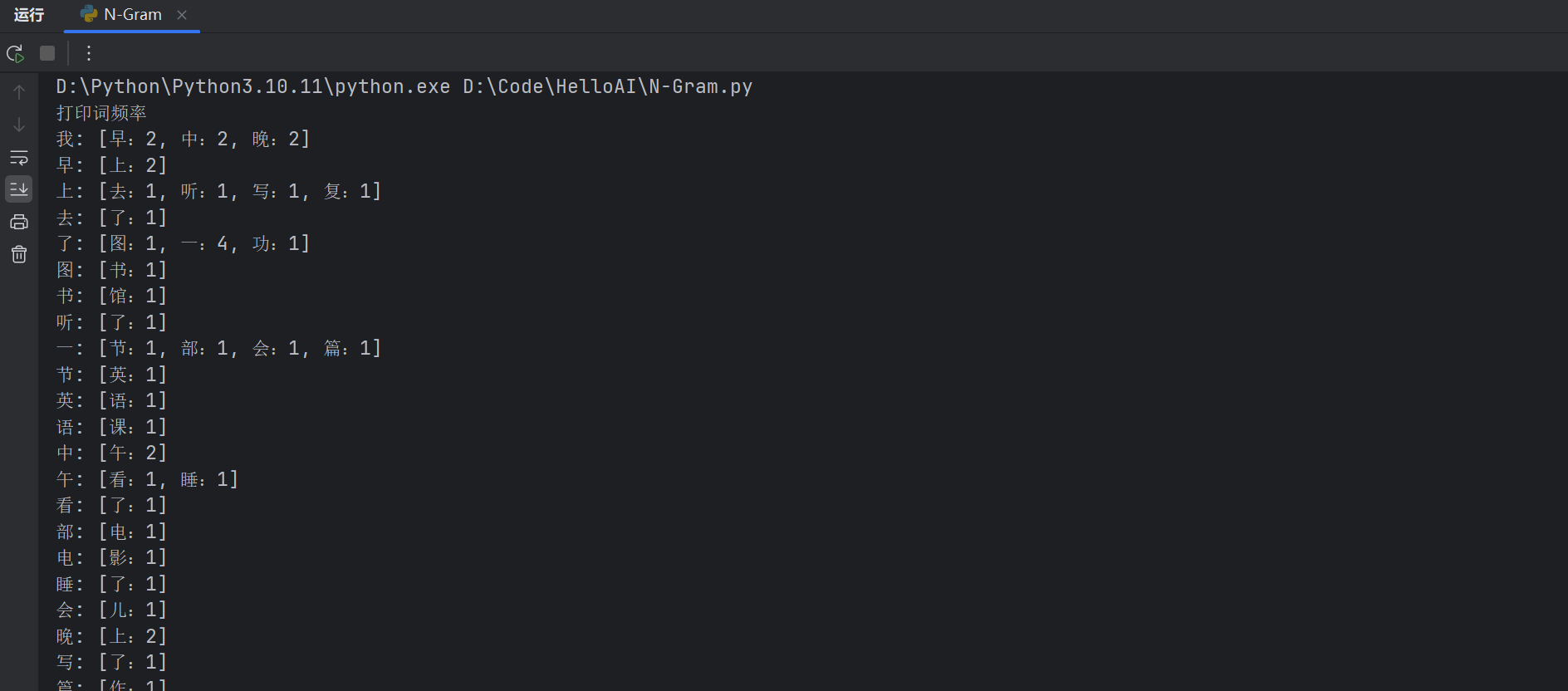
# print("打印词频率")
# for first, counter in bigram_freq.items():
# freq_list = [f"{second}:{freq}" for second, freq in counter.items()]
# print(f"{first}: [{', '.join(freq_list)}]")# 第四步:计算Bigram概率(转为概率分布)
bigram_prob = {}
for first, counter in bigram_freq.items():total = sum(counter.values())bigram_prob[first] = {second: count / total for second, count in counter.items()}
# print("词频概率为:", bigram_prob)# 第五步:根据前缀生成下一个字
def predict_next_char(prev_char):if prev_char not in bigram_prob:return Nonecandidates = list(bigram_prob[prev_char].items())chars, probs = zip(*candidates)return random.choices(chars, probs)[0]# 第六步:输入前缀,生成文本
def generate_text(start_char, length=10):result = [start_char]current = start_charfor _ in range(length - 1):next_char = predict_next_char(current)if not next_char:breakresult.append(next_char)current = next_charreturn ''.join(result)# 示例
print(generate_text("我"))- 代码不难,不懂问AI就好了。
- https://github.com/Qiuner/HelloAI ,这里会陆续复现几个ai发展的经典模型
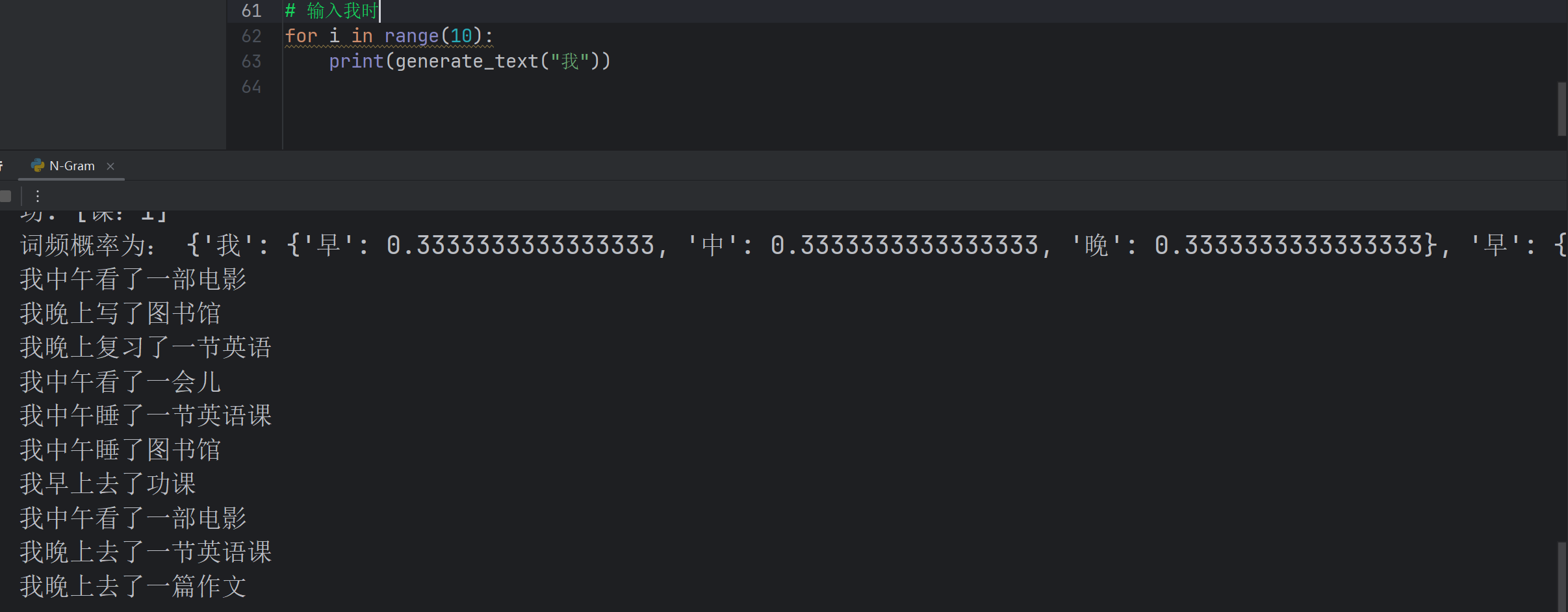
- 可以看到,出现了我早晨去了功课这样不存在词库的句子
- 实际要做的更多
尾与推荐
-
N-Gram模型是不是让你觉得非常简单?简单就对了,**这是1913年提出的模型,在1950年被引入NLP。**而现在是2025年,AI已经过Word2Vec 、RNN、 HMM、Transformer、BERT、GPT……等模型,且上面这些只是AI中NLP领域的。
-
推荐:
注
- 本文的一些术语并列,因根据我日常看到的词频率而并列,可能其并非并列关系。

你好,我是Qiuner. 为帮助别人少走弯路而写博客 这是我的 github https://github.com/Qiuner⭐ gitee https://gitee.com/Qiuner 🌹
如果本篇文章帮到了你 不妨点个赞吧~ 我会很高兴的 😄 (^ ~ ^) 。想看更多 那就点个关注吧 我会尽力带来有趣的内容 😎。
代码都在github或gitee上,如有需要可以去上面自行下载。记得给我点星星哦😍
如果你遇到了问题,自己没法解决,可以去我掘金评论区问。私信看不完,CSDN评论区可能会漏看 掘金账号 https://juejin.cn/user/1942157160101860 掘金账号
更多专栏:
- 📊 一图读懂系列
- 📝 一文读懂系列
- 🌟 持续更新
- 🎯 人生经验
掘金账号 CSDN账号
感谢订阅专栏 三连文章
相关文章:
一文读懂 AI
2022年11月30日,OpenAI发布了ChatGPT,2023年3月15日,GPT-4引发全球轰动,让世界上很多人认识了ai这个词。如今已过去快两年半,AI产品层出不穷,如GPT-4、DeepSeek、Cursor、自动驾驶等,但很多人仍…...

第三天 车联网云架构
一、车联网技术演进与行业变革 1.1 从传统Telematics到智能网联汽车 当我们驾驶着搭载智能网联系统的汽车时,车辆每秒会产生超过1GB的数据流量。这些数据包括: 高精度地图的实时更新ADAS传感器采集的环境信息车载娱乐系统交互数据车辆状态监控信息传统基于2G/3G的Telematic…...
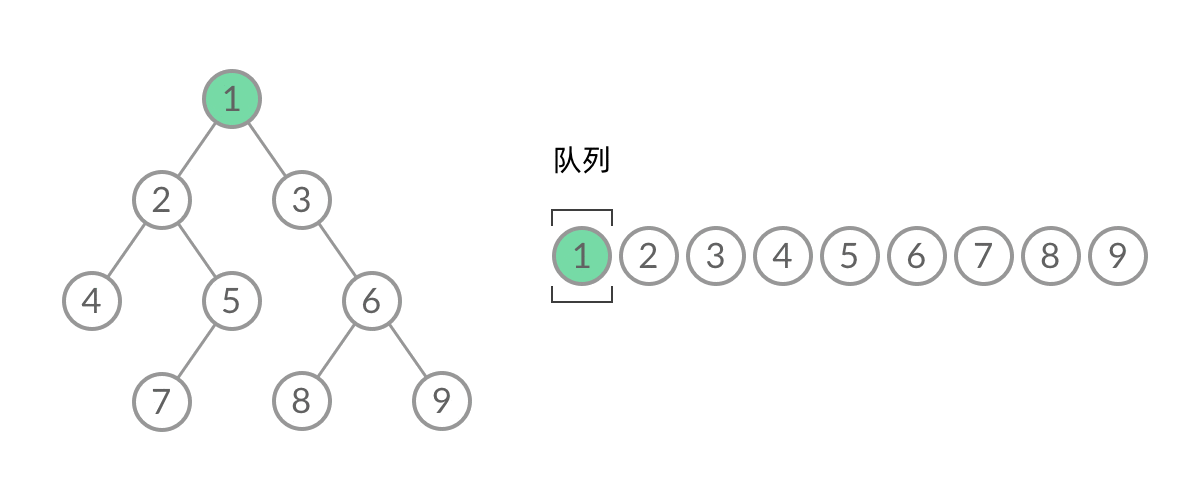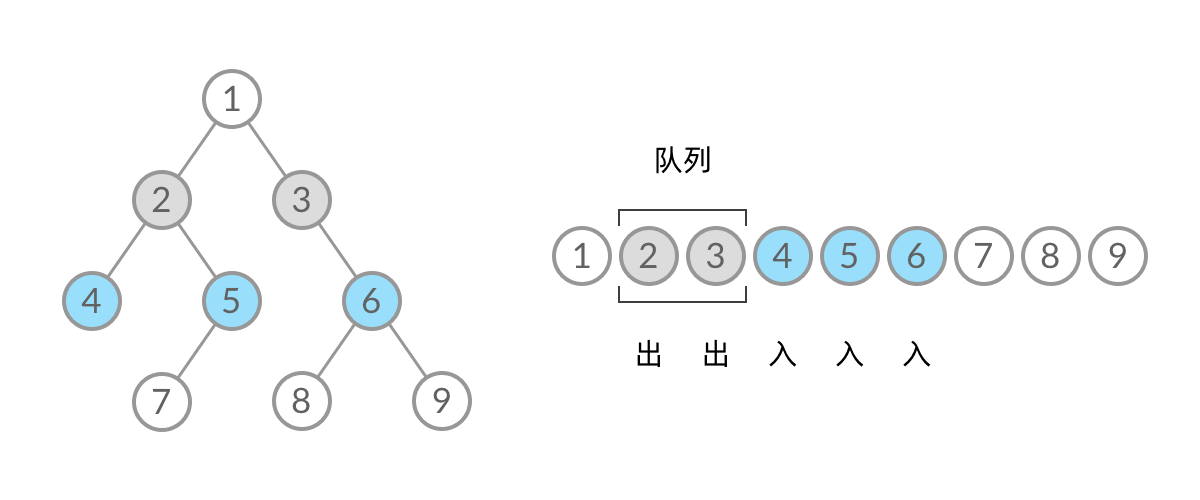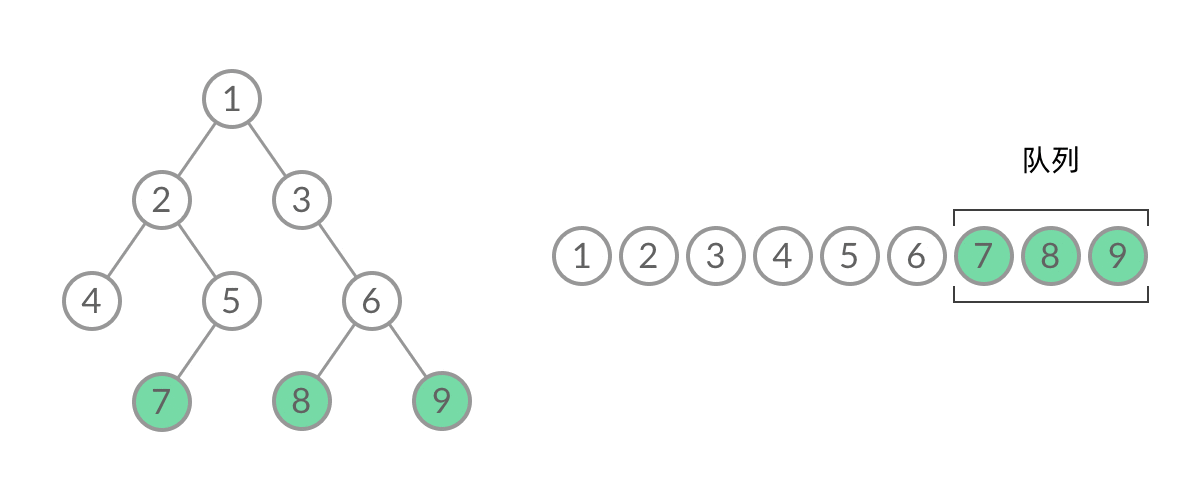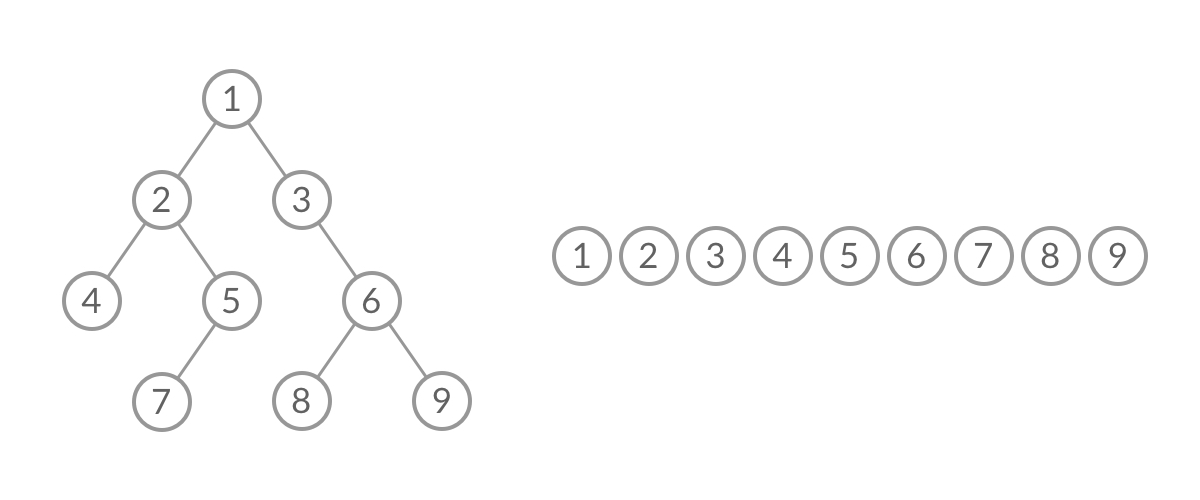
【LeetCode Hot100 | 每日刷题】二叉树的层序遍历
题目: 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]]示例 2&a…...
)
Unity垃圾回收(GC)
1.GC的作用:定期释放不再使用的内存空间。 注:C不支持GC,需要手动管理内存,使用new()申请内存空间,使用完后通过delete()释放掉,但可能出现忘记释放或者指针…...
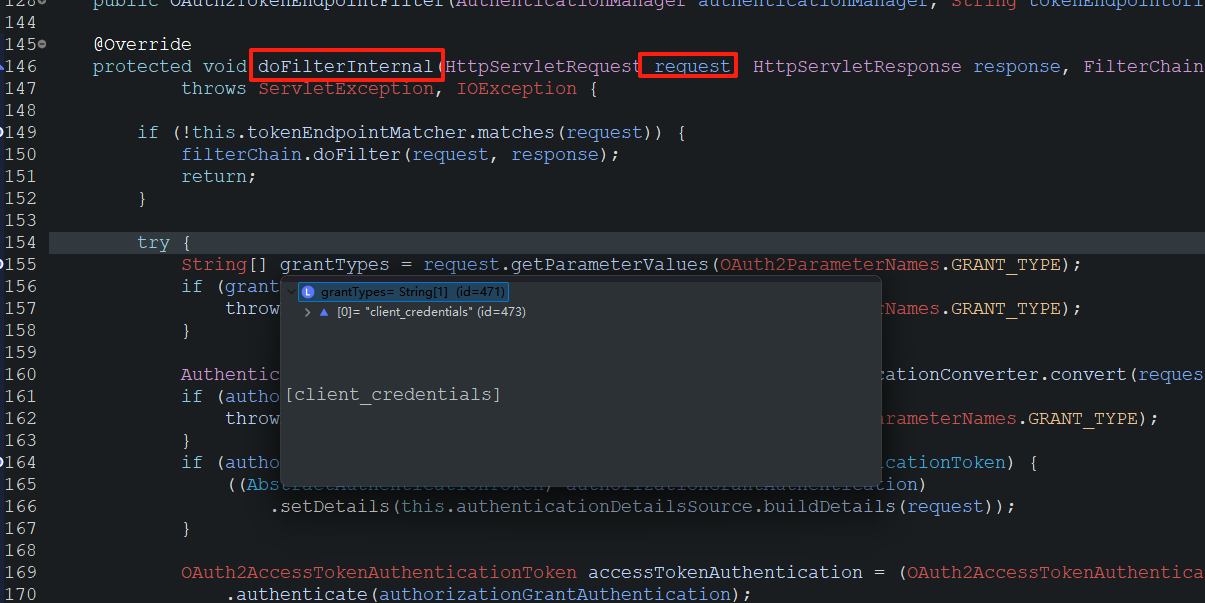
SpringBoot3集成Oauth2——1(/oauth2/token方法的升级踩坑)
备注:本文适用于你在SpringBoot2.7以前集成过oauth2,并且项目已经正式投入使用的情况,否则,我建议你直接学习或者找资料学习最新的oauth2集成,就不要纠结于老版本的oauth2。 原因:Spring Security 5.x和Sp…...

MySQL 索引与事务详解
目录 一、索引(Index) 二、事务(Transaction) 三、总结 一、索引(Index) 索引的本质:一种数据结构(如 BTree、Hash),用于快速定位数据,避免全…...
基于Qt开发的多线程TCP服务端
目录 一、Qt TCP服务端开发环境准备1. 项目配置2. 核心类说明 二、服务端搭建步骤详解步骤1:初始化服务端对象步骤2:启动端口监听步骤3:处理客户端连接 三、数据通信与状态管理1. 数据收发实现2. 客户端状态监控 四、进阶功能扩展1. 多客户端…...

【Debian】关于LubanCat-RK3588s开发板安装Debian的一些事
琐碎的事问题不少,甚至一度让我以为核心坏了 按照指引烧录完Debian11-gnome镜像后启动,此时输出的分辨率不一定匹配显示器,进而导致黑屏,此时需要使用MobaXterm的串口终端以运行一些指令,下载链接用xrandr指令查看显示…...

Python爬虫实战:研究网站动态滑块验证
1. 引言 1.1 研究背景与意义 在当今信息时代,Web 数据的价值日益凸显。通过爬虫技术获取公开数据并进行分析,能够为企业决策、学术研究等提供有力支持。然而,为了防止数据被恶意爬取,许多网站采用了各种反爬机制,其中动态滑块验证是一种常见且有效的方式。动态滑块验证通…...

Centos离线安装mysql、redis、nginx等工具缺乏层层依赖的解决方案
Centos离线安装mysql、redis、nginx等工具缺乏层层依赖的解决方案 引困境yum-utils破局 引 前段时间,有个项目有边缘部署的需求,一台没有的外网的Centos系统服务器,需要先安装jdk,node,mysql,reids…...
从零开始开发纯血鸿蒙应用之XML解析
从零开始开发纯血鸿蒙应用 〇、前言一、鸿蒙SDK中的 XML API1、ohos.xml2、ohos.convertxml 三、XML 解析实践1、源数据结构2、定义映射关系3、定义接收对象4、获取文章信息 四、总结 〇、前言 在前后端的数据传输方面,论格式化形式,JSON格式自然是首选…...

10.王道_HTTP
1. 互联网时代的诞生 2. HTTP的基本特点 2.1客户端-服务端模型 2.2 无状态协议 2.3 可靠性 2.4 文本协议 3. HTML,CSS和JS 4. HTTP的各个组件 4.1 客户端 4.2 服务端 4.3 代理 5. URI和URL 6. HTTP报文 HTTP报文分为两种——请求报文和响应报文。 6.1 GET请求示例 注意&#…...
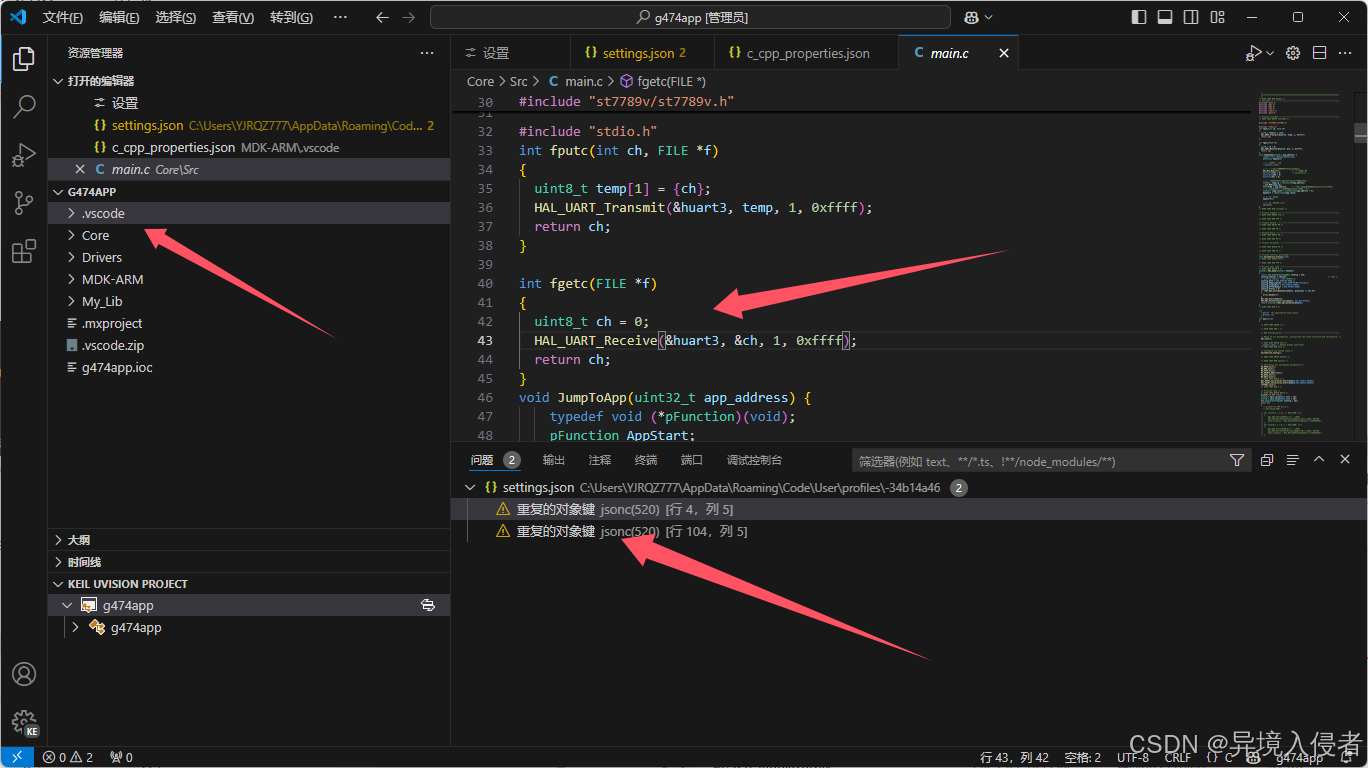
解决stm32HAL库使用vscode打开,识别不到头文件及uint8_t等问题
解决stm32HAL库使用vscode打开,识别不到头文件及uint8_t等问题 结论,问题有2问题1问题2解决办法将Keil Assistant自动生成的.vscode目录复制到MDK-ARM上层目录将Keil Assistant自动生成的.vscode目录复制到MDK-ARM上层目录将Keil Assistant自动生成的.vs…...

Docker Compose 完全指南:从入门到生产实践
Docker Compose 完全指南:从入门到生产实践 1. Docker Compose 简介与核心价值 Docker Compose 是一个用于定义和运行多容器 Docker 应用程序的工具。通过一个 YAML 文件来配置应用的服务,只需简单命令就能创建和启动所有服务。 核心优势:…...

Android Framework 记录之一
1、下载源码,目录如下: 2、Android系统的层次如下: 3、项目目录简单分析如下: 4、telphony目录 文件描述CellIdentityCdma...
uniapp-商城-50-后台 商家信息(输入进行自定义规则验证)
本文介绍了如何在后台管理系统中添加和展示商家信息,包括商家logo、名称、电话、地址和介绍等内容,并支持后期上传营业许可等文件。通过使用uni-app的uni-forms组件,可以方便地实现表单的创建、校验和管理操作。文章详细说明了组件的引入、页…...

XSS ..
Web安全中的XSS攻击详细教学,Xss-Labs靶场通关全教程(建议收藏) - 白小雨 - 博客园跨站脚本攻击(XSS)主要是攻击者通过注入恶意脚本到网页中,当用户访问该页面时,恶意脚本会在用户的浏览器中执行…...

网页版部署MySQL + Qwen3-0.5B + Flask + Dify 工作流部署指南
1. 安装MySQL和PyMySQL 安装MySQL # 在Ubuntu/Debian上安装 sudo apt update sudo apt install mysql-server sudo mysql_secure_installation# 启动MySQL服务 sudo systemctl start mysql sudo systemctl enable mysql 安装PyMySQL pip install pymysql 使用 apt 安装 My…...
WEBSTORM前端 —— 第2章:CSS —— 第8节:网页制作2(小兔鲜儿)
目录 1.项目目录 2.SEO 三大标签 3.Favicon 图标 4.版心 5.快捷导航(shortcut) 6.头部(header) 7.底部(footer) 8.banner 9.banner – 圆点 10.新鲜好物(goods) 11.热门品牌(brand) 12.生鲜(fresh) 13.最新专题(topic) 1.项目目录 【xtx-pc】 ima…...

仓储车间安全革命:AI叉车防撞装置系统如何化解操作风险
在现代物流体系中,仓储承担着货物储存、保管、分拣和配送等重要任务。但现代仓储行业的安全现状却不容乐观,诸多痛点严重制约着其发展,其中叉车作业的安全问题尤为突出。相关数据显示,全球范围内,每年因叉车事故导致的…...

gin + es 实践 08
自动扩缩容 本文档详细介绍如何在Kubernetes环境中实现Go-ES应用的自动扩缩容,包括水平Pod自动扩缩容(HPA)、垂直Pod自动扩缩容(VPA)和集群自动扩缩容。 1. 自动扩缩容概述 自动扩缩容是指根据负载变化自动调整计算资源的过程,主要目标是:…...

在Postman中高效生成测试接口:从API文档到可执行测试的完整指南
引言 在API开发与测试流程中,Postman是一款高效的工具,能将API文档快速转化为可执行的测试用例。本文以《DBC协议管理接口文档》为例,详细讲解如何通过Postman实现接口的创建、配置、批量生成及自动化测试,帮助开发者和测试人员提升效率,确保接口质量。 一、准备工作:理…...

修改图像分辨率
在这个教程中,您将学习如何使用Python和深度学习技术来调整图像的分辨率。我们将从基础的图像处理技术开始,逐步深入到使用预训练的深度学习模型进行图像超分辨率处理。 一、常规修改方法 1. 安装Pillow库 首先,你需要确保你的Python环境中…...

2025.05.08-得物春招算法岗-第二题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 02. 数字魔术分割 问题描述 LYA是一位数字魔术师,他有一个特殊的技能可以对任意一个正整数的数字进行重新排列,然后将排列后的数字序列分割成若干段,每段组成一个新的数字,最后…...

Node.js面试题
一、什么是Node.js? Node.js 是一个开源的跨平台 JavaScript 运行时环境,允许开发者在服务器端运行 JavaScript 代码。它基于 Chrome 的 V8 JavaScript 引擎构建,能够高效地处理 I/O 操作,适合构建高性能的网络应用。 异步非阻塞&…...

Spring MVC Controller 方法的返回类型有哪些?
Spring MVC Controller 方法的返回类型非常灵活,可以根据不同的需求返回多种类型的值。Spring MVC 会根据返回值的类型和相关的注解来决定如何处理响应。 以下是一些常见的 Controller 方法返回类型: String: 最常见的类型之一,用于返回逻辑…...
Redis 主从同步与对象模型(四)
目录 1.淘汰策略 1.1 expire/pexpire(设置键的过期时间) 1.2 配置 1.maxmemory 2.maxmemory-policy 3.maxmemory-samples 2.持久化 2.1背景 2.2 fork 的写时复制机制 2.3 大 key 3.持久化方式 3.1 aof(Apped Only File)…...
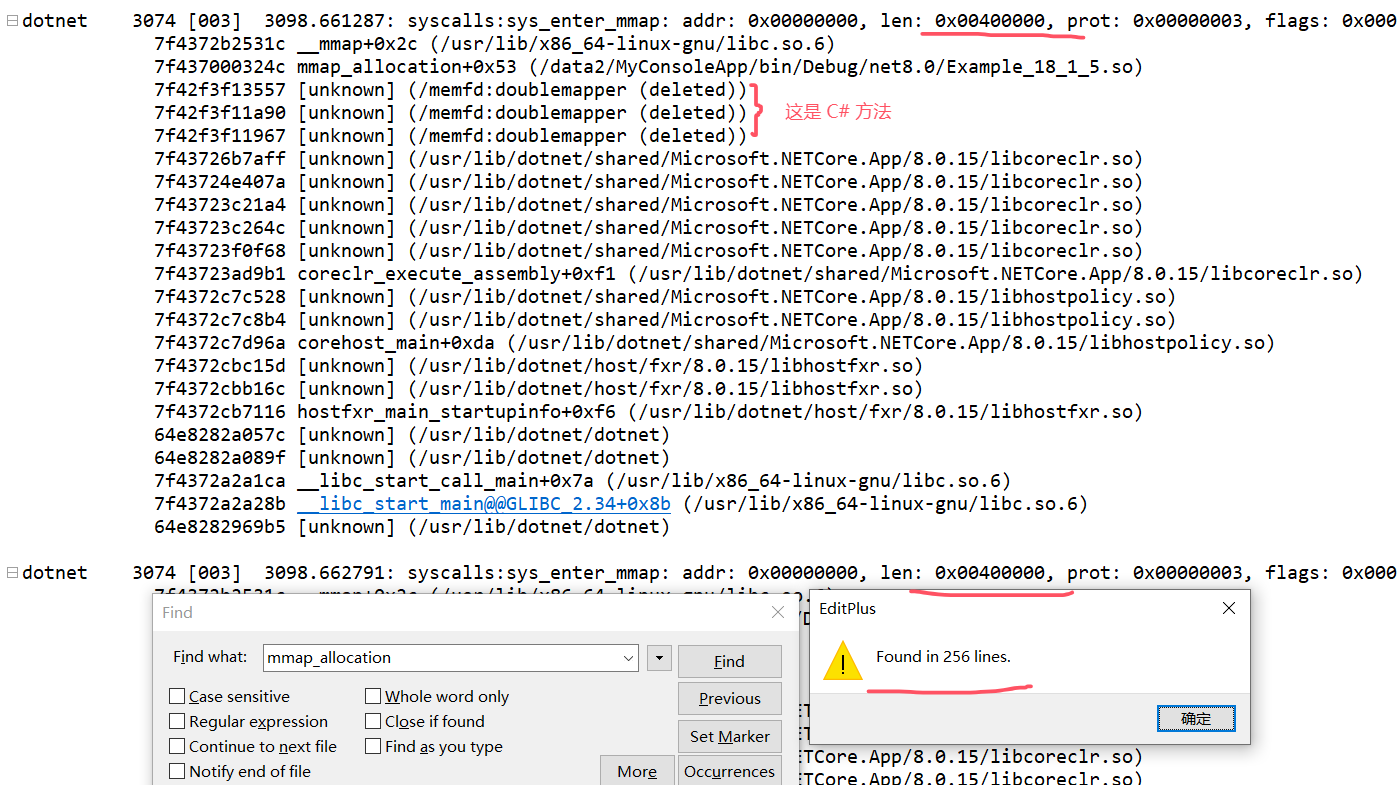
Linux系列:如何用perf跟踪.NET程序的mmap泄露
一:背景 1. 讲故事 如何跟踪.NET程序的mmap泄露,这个问题困扰了我差不多一年的时间,即使在官方的github库中也找不到切实可行的方案,更多海外大佬只是推荐valgrind这款工具,但这款工具底层原理是利用模拟器ÿ…...

如何租用服务器并通过ssh连接远程服务器终端
这里我使用的是智算云扉 没有打广告 但确实很便宜 还有二十小时免费额度 链接如下 注册之后 租用新实例 选择操作系统 选择显卡型号 点击租用 选择计费方式 选择镜像 如果跑深度学习的话 就选项目对应的torch版本 没有的话 就创建纯净的cuda 自己安装 点击创建实例 创建之后 …...

Git的核心作用详解
一、版本控制与历史追溯 Git作为分布式版本控制系统,其核心作用是记录代码的每一次修改,形成完整的历史记录。通过快照机制,Git会保存每次提交时所有文件的完整状态(而非仅记录差异),确保开发者可以随时回…...