重生之我在2024学Fine-tuning
一、Fine-tuning(微调)概述
Fine-tuning(微调)是机器学习和深度学习中的一个重要概念,特别是在预训练模型的应用上。它指的是在模型已经通过大量数据训练得到一个通用的预训练模型后,再针对特定的任务或数据集进行进一步训练的过程。
以下是Fine-tuning的一些关键点:
-
预训练模型:在Fine-tuning之前,模型已经在大规模的数据集上进行了训练,学习到了通用的特征和模式。例如,在自然语言处理(NLP)中,BERT(Bidirectional Encoder Representations from Transformers)就是一个预训练模型,它在大量的文本数据上训练,以理解语言的通用结构和语义。
-
特定任务:Fine-tuning通常是为了解决一个具体的任务,比如情感分析、问答系统、文本分类等。这些任务可能需要模型对特定类型的数据有更深入的理解。
-
数据集与调整参数:Fine-tuning需要一个针对特定任务的数据集,这个数据集可能远小于预训练时使用的数据集,但更专注于任务相关的数据。在Fine-tuning过程中,模型的大部分参数(通常是预训练模型的底层参数)会被保留,只有一小部分参数(如顶层的分类器)会被调整以适应新的任务。
-
训练过程与资源效率:Fine-tuning的过程通常比从头开始训练一个模型要快,因为模型已经学习了很多通用的知识,只需要对特定任务进行微调。Fine-tuning是一种资源效率较高的方法,因为它不需要从头开始训练一个大型模型,这样可以节省大量的计算资源和时间。
-
迁移学习与过拟合:Fine-tuning是迁移学习的一种形式,即将在一个领域学到的知识应用到另一个领域。由于Fine-tuning使用的数据集通常较小,所以存在过拟合的风险,即模型可能过于适应训练数据,而无法很好地泛化到未见过的数据。
Fine-tuning是一种强大的技术,它使得模型能够快速适应新任务,同时利用预训练模型的强大能力。
二、大模型微调的底层原理
1.预训练与迁移学习
大模型微调的基础是预训练模型,这些模型已经在大规模数据集上进行了训练,学习到了通用的特征和模式。微调过程实际上是迁移学习的一种应用,它将预训练模型的知识迁移到新的任务上。在这个过程中,模型的大部分参数(通常是底层参数)被保留,只有一小部分参数(如顶层的分类器或输出层)被调整以适应新任务。这种策略可以减少过拟合的风险,同时利用预训练模型在底层学到的通用特征。
2.参数更新与适应性调整
在微调过程中,模型的参数更新策略是关键。通常,只有模型的顶层或部分层会被更新,而底层的参数保持不变。这种策略允许模型在保持其在预训练阶段学到的通用知识的同时,对特定任务进行适应性调整。通过这种方式,模型可以快速适应新任务,而无需从头开始训练,这大大减少了计算资源的需求。此外,微调过程中可能会调整学习率和其他超参数,以优化模型在新任务上的学习效率和性能。
3.低秩适应与参数效率
为了进一步提高微调的参数效率,一些技术如LoRA(Low-Rank Adaptation)被提出。LoRA通过在模型的特定层引入低秩矩阵来模拟参数的改变量,从而以极小的参数量实现大模型的间接训练。这种方法假设预训练模型的权重变化可以通过低秩矩阵来近似,这意味着相对于直接微调所有模型参数,通过低秩矩阵的调整,可以用更少的参数达到近似效果。这种技术显著减少了微调过程中需要更新的参数数量,降低了计算成本,同时仍然能够使模型适应新任务。
三、常用的Fine-tuning方法
1.全量微调(Full Fine-tuning)
这种方法涉及利用特定任务数据调整预训练模型的所有参数,以充分适应新任务。这种方法依赖大规模计算资源,但能有效利用预训练模型的通用特征,通常能够获得较好的性能提升。以下是一个使用PyTorch和Hugging Face的Transformers库进行全量微调的示例代码。这个例子中,我们将使用一个预训练的BERT模型来微调一个文本分类任务。
import torch
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from transformers import BertTokenizer, BertForSequenceClassification, AdamW, get_linear_schedule_with_warmup
from sklearn.metrics import accuracy_score# 检查是否有可用的GPU,如果有则使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载预训练的BERT模型和分词器
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name)# 将模型移动到GPU上(如果可用)
model.to(device)# 假设我们有一些数据集,这里我们使用随机数据作为示例
# 你需要替换这些数据为你的实际数据集
train_data = [{'text': "I love using BERT for text classification.", 'label': 1},{'text': "BERT is not useful for my task.", 'label': 0},# ... 更多数据 ...
]# 将文本数据编码为模型可以理解的格式
input_ids = []
attention_masks = []
labels = []for data in train_data:encoded = tokenizer.encode_plus(data['text'],add_special_tokens=True,max_length=64,return_attention_mask=True,return_tensors='pt',)input_ids.append(encoded['input_ids'])attention_masks.append(encoded['attention_mask'])labels.append(data['label'])# 将数据转换为PyTorch张量
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.tensor(labels)# 创建DataLoader
train_data = torch.utils.data.TensorDataset(input_ids, attention_masks, labels)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=8)# 设置优化器和学习率调度器
optimizer = AdamW(model.parameters(), lr=2e-5, eps=1e-8)
total_steps = len(train_dataloader) * 3 # 假设我们训练3个epoch
scheduler = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=0,num_training_steps=total_steps
)# 训练模型
model.train()
for epoch in range(3): # 训练3个epochfor batch in train_dataloader:batch = tuple(t.to(device) for t in batch)inputs = {'input_ids': batch[0],'attention_mask': batch[1],'labels': batch[2]}optimizer.zero_grad()outputs = model(**inputs)loss = outputs.lossloss.backward()optimizer.step()scheduler.step()# 评估模型(这里需要一个真实的测试集)
# 这里省略了评估代码,你需要根据你的数据集来实现评估逻辑# 保存模型
model.save_pretrained('./my_fine_tuned_bert_model')请注意,这个代码是一个简化的示例,实际应用中你需要准备一个真实的数据集,并可能需要添加更多的训练逻辑,比如模型评估、早停(early stopping)、保存最佳模型等。此外,你还需要确保数据集的格式与模型输入的要求相匹配。
2.参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
这种技术旨在通过最小化微调参数的数量和计算复杂度,实现高效的迁移学习。它仅更新模型中的部分参数,显著降低训练时间和成本,适用于计算资源有限的情况。PEFT技术包括:
2.1 前缀调优(Prefix-tuning)
在输入前添加可学习的virtual tokens作为Prefix,仅更新Prefix参数,Transformer其他部分固定。
from transformers import AutoModelForCausalLM
from peft import PeftModel, PeftConfig# 加载预训练模型
model_name_or_path = "bert-base-uncased"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)# 创建PeftConfig配置
peft_config = PeftConfig.from_pretrained(model_name_or_path)# 应用前缀调优
peft_model = PeftModel.from_pretrained(model, peft_config, torch_dtype=torch.float16)# 打印可训练参数数量
peft_model.print_trainable_parameters()这段代码首先加载了一个预训练的BERT模型,然后创建了一个PeftConfig配置,最后应用前缀调优并打印出可训练的参数数量。
2.2 提示调优(Prompt-tuning)
在输入层加入prompt tokens,简化版的Prefix Tuning,无需MLP调整。随着模型规模增大,效果接近full fine-tuning。
from transformers import AutoModelForCausalLM, AutoTokenizer# 加载预训练模型和分词器
model_name_or_path = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)# 添加prompt tokens
prompt = tokenizer(["explain", "the", "concept", "of"], return_tensors="pt")
input_ids = torch.cat([prompt["input_ids"], torch.randint(0, 100, (1, 10))]) # 添加随机tokens# 将输入传递给模型
outputs = model(input_ids)这段代码加载了一个预训练的BERT模型和分词器,然后添加了prompt tokens到输入中,并传递给模型。
2.3 Adapter调优(Adapter Tuning)
设计Adapter结构并嵌入Transformer中,仅对新增的Adapter结构进行微调,原模型参数固定。
from transformers import AutoModelForSequenceClassification, AdapterConfig# 加载预训练模型
model_name_or_path = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path)# 创建AdapterConfig配置
adapter_config = AdapterConfig(r=1, lora_alpha=32, lora_dropout=0.1)# 应用Adapter调优
model.add_adapter(name="task_specific", config=adapter_config)# 打印可训练参数数量
model.print_trainable_parameters()这段代码加载了一个预训练的BERT模型,创建了一个AdapterConfig配置,并应用Adapter调优。最后打印出可训练的参数数量。
3.冻结部分层进行微调
在Fine-tuning过程中,通常会冻结预训练模型中较低层级(靠近输入端)的参数不变,仅对较高层级(靠近输出端)的参数进行训练。这是因为底层特征通常更具通用性,而高层特征与特定任务关联更紧密。以下是一个使用PyTorch和Hugging Face的Transformers库进行这种微调策略的示例代码。这个例子中,我们将使用一个预训练的BERT模型来微调一个文本分类任务。
import torch
from torch.utils.data import DataLoader, Dataset
from transformers import BertTokenizer, BertForSequenceClassification, AdamW# 检查是否有可用的GPU,如果有则使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载预训练的BERT模型和分词器
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name)# 将模型移动到GPU上(如果可用)
model.to(device)# 冻结预训练模型的底层参数
for param in model.bert.parameters():param.requires_grad = False# 仅对分类器头部的参数进行训练
for param in model.classifier.parameters():param.requires_grad = True# 假设我们有一些数据集,这里我们使用随机数据作为示例
# 你需要替换这些数据为你的实际数据集
class SimpleDataset(Dataset):def __init__(self, texts, labels):self.texts = textsself.labels = labelsdef __len__(self):return len(self.texts)def __getitem__(self, idx):text = self.texts[idx]label = self.labels[idx]encoding = tokenizer.encode_plus(text,add_special_tokens=True,max_length=64,return_attention_mask=True,return_tensors='pt',padding='max_length',truncation=True,)return {'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'labels': torch.tensor(label, dtype=torch.long)}# 创建数据集和数据加载器
texts = ["I love using BERT for text classification.", "BERT is not useful for my task."]
labels = [1, 0] # 假设1是正面,0是负面
dataset = SimpleDataset(texts, labels)
dataloader = DataLoader(dataset, batch_size=2)# 设置优化器
optimizer = AdamW(model.classifier.parameters(), lr=5e-5)# 训练模型
model.train()
for epoch in range(3): # 训练3个epochfor batch in dataloader:batch = {k: v.to(device) for k, v in batch.items()}inputs = {'input_ids': batch['input_ids'],'attention_mask': batch['attention_mask'],'labels': batch['labels']}optimizer.zero_grad()outputs = model(**inputs)loss = outputs.lossloss.backward()optimizer.step()# 保存模型
model.save_pretrained('./my_fine_tuned_bert_model')在这个示例中,我们首先加载了一个预训练的BERT模型,并将其移动到GPU上(如果可用)。然后,我们冻结了BERT模型的底层参数,只允许分类器头部的参数进行训练。我们创建了一个简单的数据集和数据加载器,并设置了优化器。在训练过程中,我们只更新分类器头部的参数。最后,我们保存了微调后的模型。
4.微调全部层
虽然风险略高,但有时也会选择对整个预训练模型的所有参数进行微调。这在目标任务与预训练任务高度相关、数据量充足且计算资源允许的情况下较为有效。以下是一个示例代码,展示了如何在目标任务与预训练任务高度相关、数据量充足且计算资源允许的情况下,对整个预训练模型的所有参数进行微调。
from transformers import BertForSequenceClassification, BertTokenizer, Trainer, TrainingArguments
import torch# 选择预训练模型
model_name = "bert-base-uncased"# 加载预训练模型和分词器
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2)# 准备训练和验证数据集
# 这里假设已经有了train_dataset和eval_dataset
# train_dataset = ...
# eval_dataset = ...# 设置训练参数
training_args = TrainingArguments(output_dir="./results",per_device_train_batch_size=16,per_device_eval_batch_size=64,num_train_epochs=3,evaluation_strategy="epoch",learning_rate=2e-5,save_total_limit=2,save_steps=500,load_best_model_at_end=True, # 保存最佳模型metric_for_best_model="accuracy", # 根据准确率选择最佳模型greater_is_better=True,push_to_hub=False,
)# 初始化Trainer
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,tokenizer=tokenizer,
)# 开始训练
trainer.train()# 评估模型性能
results = trainer.evaluate()
print(results)这个示例展示了如何对整个预训练模型进行全量微调,适用于目标任务与预训练任务高度相关且计算资源允许的情况。通过这种方式,模型可以充分利用预训练阶段学到的知识,并针对新任务进行优化。
相关文章:
重生之我在2024学Fine-tuning
一、Fine-tuning(微调)概述 Fine-tuning(微调)是机器学习和深度学习中的一个重要概念,特别是在预训练模型的应用上。它指的是在模型已经通过大量数据训练得到一个通用的预训练模型后,再针对特定的任务或数据…...
Selenium Web自动化测试学习笔记(一)
自动化测试 技术手段模拟人工,执行重复性任务,准确率100%,高于人工 selenium 可通过浏览器驱动控制浏览器,通过元素定位模拟人工,实现web自动化,没有焦点(把浏览器放在最小化依然可以&#x…...

2025年5月15日前 免费考试了! Oracle AI 矢量搜索专业认证
2025年5月5日前 免费考试了! Oracle AI 矢量搜索专业认证 立刻预约吧 文章目录 2025年5月5日前 免费考试了! Oracle AI 矢量搜索专业认证立刻预约吧🔍 探索 AI 向量搜索的强大功能!🎯 学习路径目标Ὦ…...

服务器不备案有影响吗
在当今数字化的时代,服务器成为了众多企业和个人开展业务、展示自我的重要工具。然而,有一个问题常常被忽视,那就是服务器不备案到底有没有影响? 答案是肯定的!服务器不备案,影响可不小。据相关数据显示&a…...
EasyRTC嵌入式音视频通话SDK驱动智能硬件音视频应用新发展
一、引言 在数字化浪潮下,智能硬件蓬勃发展,从智能家居到工业物联网,深刻改变人们的生活与工作。音视频通讯作为智能硬件交互与协同的核心,重要性不言而喻。但嵌入式设备硬件资源受限,传统音视频方案集成困难。EasyRT…...

力扣-21.合并两个有序链表
题目描述 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 class Solution { public:ListNode *mergeTwoLists(ListNode *list1, ListNode *list2) {ListNode *l new ListNode(-1);ListNode *p l;while (list1 &&…...

多线服务器具有什么优势
在当今数字化飞速发展的时代,多线服务器宛如一位低调的幕后英雄,默默为我们的网络世界提供着强大的支持。那么,多线服务器到底具有哪些令人瞩目的优势呢 首先,多线服务器的最大优势之一就是网络访问的高速与稳定。想象一下&#x…...

ESP32 PWM音频应用及场景说明
ESP32芯片的PWM(脉冲宽度调制)功能在音频应用中具有广泛用途,尤其是在低成本、低功耗的场景中。以下是具体的应用举例和应用场景说明: 一、ESP32 PWM音频应用举例 1. 简单音频播放 实现方式:通过PWM生成模拟音频信号&…...

C++.变量与数据类型
C++变量与数据类型 1. C++变量与数据类型1.1 基本数据类型1.2 复合数据类型2.1 定义方式2.2 常量类型3.1 数据类型修饰符3.2 存储类修饰符3.3 类访问修饰符4.1 算术运算符4.2 关系运算符4.3 逻辑运算符4.4 赋值运算符4.5 条件运算符4.6 位运算符5. 总结5.1 变量与数据类型5.2 常…...
--NavController)
Compose笔记(二十二)--NavController
这一节主要了解一下Compose中的NavController,它是实现导航功能的核心组件,提供了强大而灵活的页面管理能力,用于管理导航图中的目的地和执行导航操作。 API navigate(route: String) 含义:导航到指定路由的目的地。 作用&#x…...
与CROSS JOIN(交叉连接))
SQL:SELF JOIN(自连接)与CROSS JOIN(交叉连接)
目录 SELF JOIN(自连接) CROSS JOIN(交叉连接 / 笛卡尔积) 示例: SELF JOIN CROSS JOIN 如果没有 DATEDIFF() 函数怎么办? 🔍 SELF JOIN vs CROSS JOIN 对比总结 SELF JOIN(自…...

互联网大厂Java求职面试:基于RAG的智能问答系统设计与实现-1
互联网大厂Java求职面试:基于RAG的智能问答系统设计与实现-1 场景背景 在某互联网大厂的技术面试中,技术总监张总正在面试一位名为郑薪苦的求职者。郑薪苦虽然对技术充满热情,但回答问题时总是带着幽默感,有时甚至让人哭笑不得。…...
Ubuntu 22.04.5 LTS 基于 kubesphere 安装 cube studio
Ubuntu 22.04.5 LTS 基于 kubesphere 安装 cube studio 前置条件 已经成功安装 kubesphere v4.3.1 参考教程: https://github.com/data-infra/cube-studio/wiki/%E5%9C%A8-kubesphere-%E4%B8%8A%E6%90%AD%E5%BB%BA-cube-studio 1. 安装基础依赖 # ubuntu安装基础依赖 apt insta…...
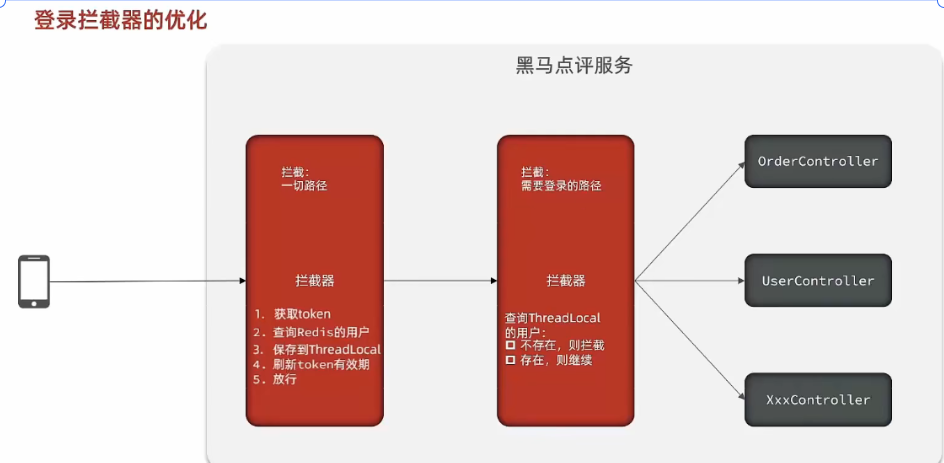
1.短信登录
1.0 问题记录 1.0.1 redis 重复 token 问题 每次用户登录时,后端会创建一个新的 token 并存入 Redis,但之前登录的 token 还没有过期。这可能会导致以下问题: 1. Redis 中存在大量未过期但实际已不使用的 token2. 同一用户可能有多个有效 …...

Linux-Ubuntu安装Stable Diffusion Forge
SD Forge在Win上配置起来相对简单且教程丰富,而在Linux平台的配置则稍有门槛且教程较少。本文提供一个基于Ubuntu24.04发行版(对其他Linux以及SD分支亦有参考价值)的Stable Diffusion ForgeUI安装配置教程,希望有所帮助 本教程以N…...
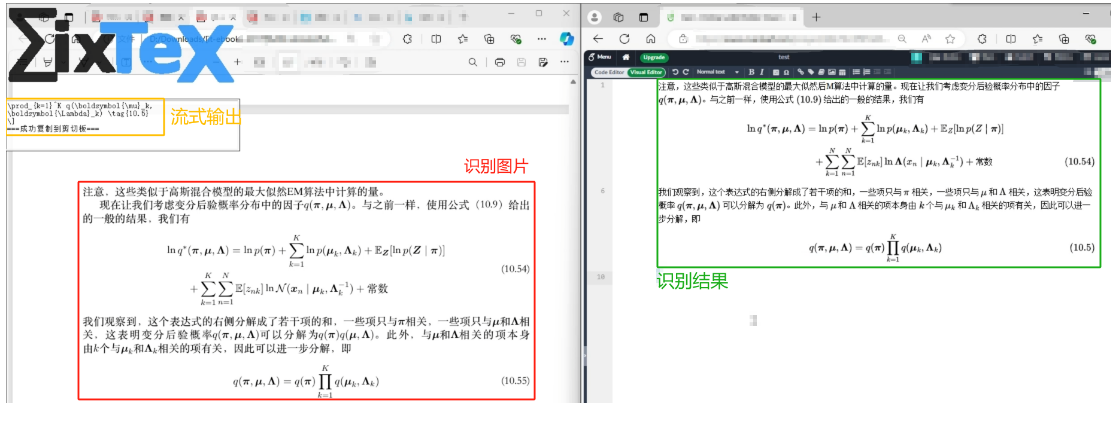
MixTeX - 支持CPU推理的多模态LaTeX OCR
文章目录 一、项目概览相关资源核心特性技术特点 二、安装三、使用说明环境要求 四、版本更新五、当前限制 一、项目概览 MixTeX是一款创新的多模态LaTeX识别小程序,支持本地离线环境下的高效CPU推理。 无论是LaTeX公式、表格还是混合文本,MixTeX都能轻…...

生成了一个AI算法
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms # 1. 数据预处理 transform transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)) # MNIST单通道归一化 ]) train_da…...
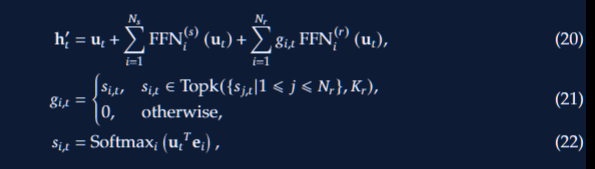
23、DeepSeek-V2论文笔记
DeepSeek-V2 1、背景2、KV缓存优化2.0 KV缓存(Cache)的核心原理2.1 KV缓存优化2.2 性能对比2.3 架构2.4多头注意力 (MHA)2.5 多头潜在注意力 (MLA)2.5.1 低秩键值联合压缩 (Low-Rank Key-Value …...

关键字where
C# 中的 where 关键字主要用在泛型约束(Generic Constraints)中,目的是对泛型类型参数限制其必须满足的条件,从而保证类型参数具备特定的能力或特性,增强类型安全和代码可读性。 约束写法说明适用场景举例C#版本要求w…...
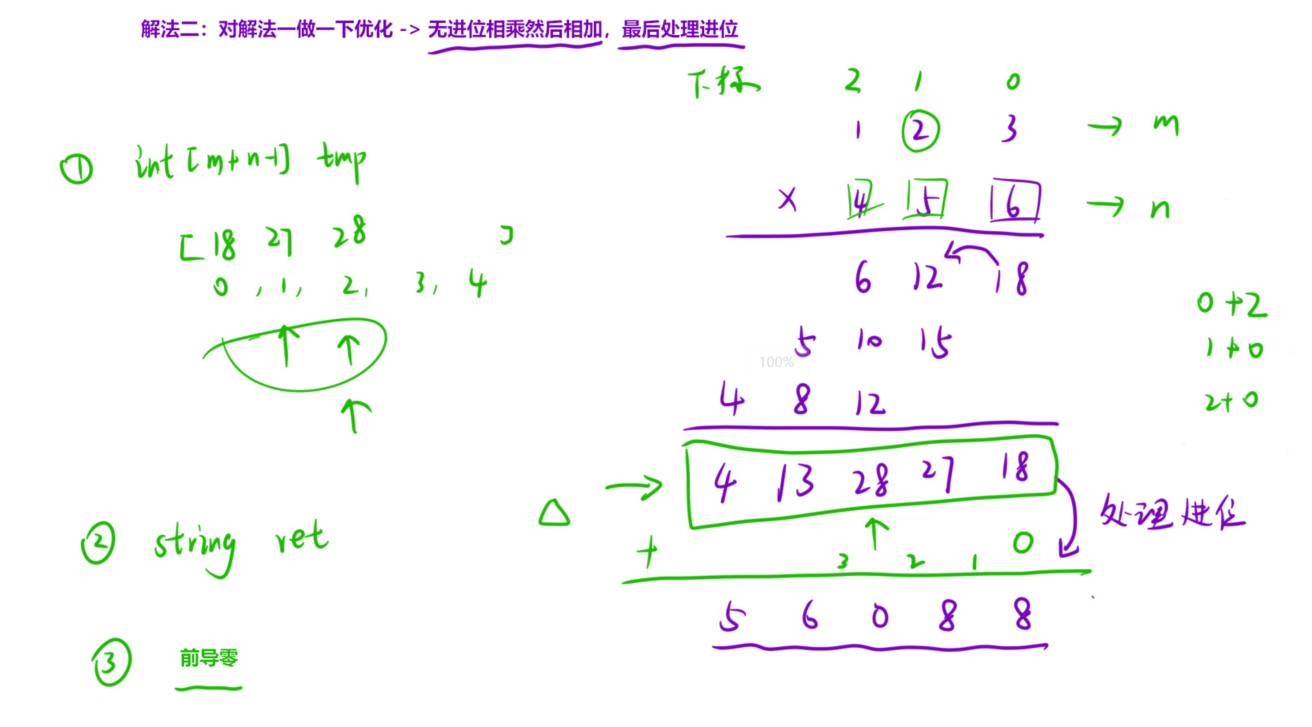
【算法专题十一】字符串
文章目录 1. leetcode.14.最长公共前缀1.1 题目1.2 思路1.3 代码 2. leetcode.5.最长回文字串2.1 题目2.2 思路2.3 代码 3. leetcode.67.二进制求和3.1 题目3.2 思路3.3 代码 4. leetcode.43.字符串相乘4.1 题目4.2 思路4.3 代码 1. leetcode.14.最长公共前缀 1.1 题目 题目链…...
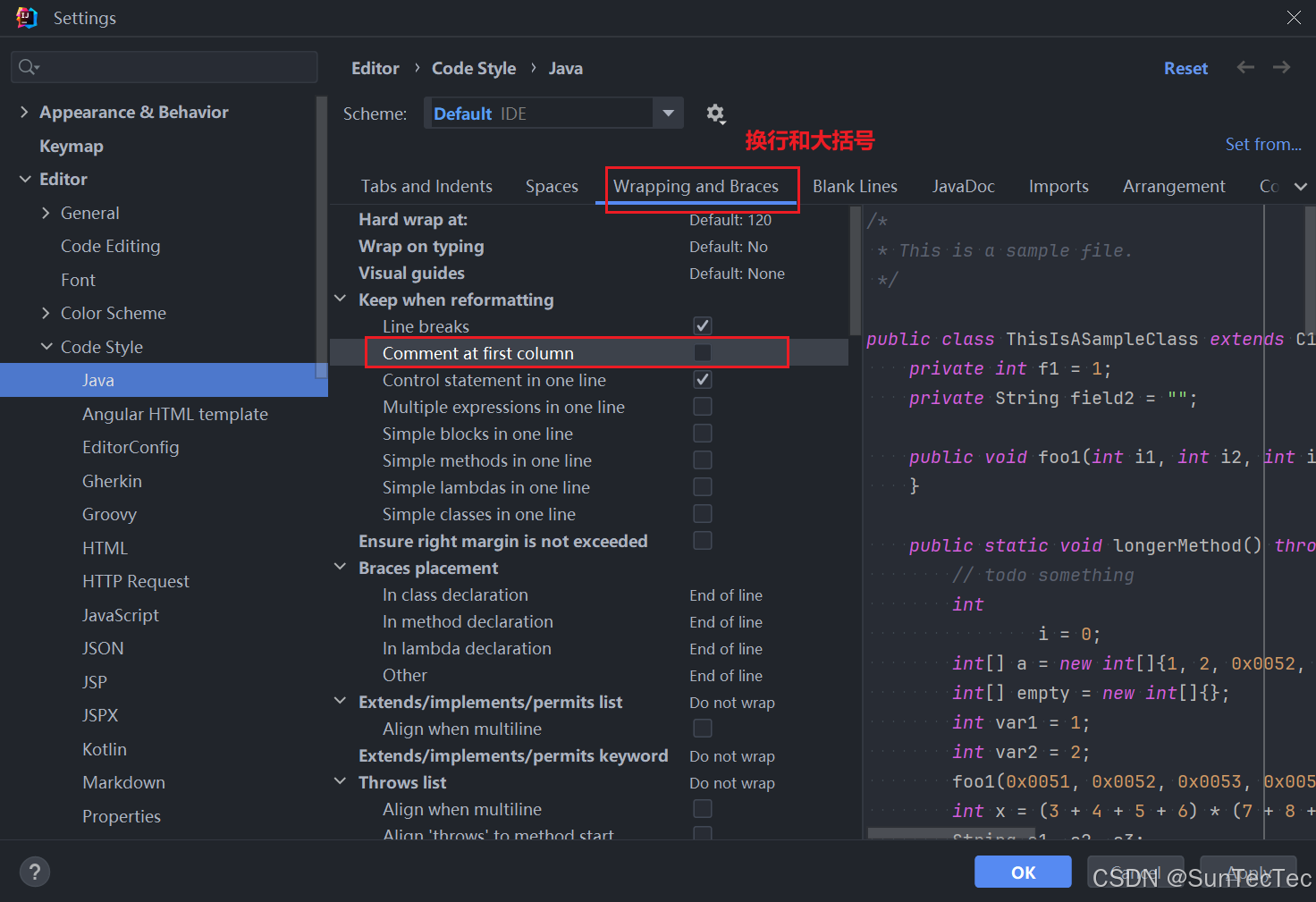
美化IDEA注释:Idea 中快捷键 Ctrl + / 自动注释的缩进(避免添加注释自动到行首)以及 Ctrl + Alt + l 全局格式化代码的注释缩进
打开 Settings 界面,依次选择 Editor -> Code Style -> Java,选择 Code Generation, 取消 Line comment at first column 和 Block comment at first column 的勾选即可, 1、Line comment at first column (行注释在第一列…...

如何为APP应用程序选择合适的服务器
搭建一个成功的APP应用程序,服务器选择是至关重要的决策之一。合适的服务器不仅能确保应用流畅运行,还能节省成本并保障安全性。本文将为您详细解析如何为APP选择最佳服务器方案。 一、了解您的APP需求 在选择服务器前,首先需要明确您的应用…...

赛灵思 XCZU11EG-2FFVC1760I XilinxFPGAZynq UltraScale+ MPSoC EG
XCZU11EG-2FFVC1760I 是 Zynq UltraScale MPSoC EG 系列中性能最强的器件之一,集成了四核 ARM Cortex-A53 应用处理器、双核 Cortex-R5 实时处理器与 Mali-400 MP2 GPU,并结合了 653,100 个逻辑单元与丰富的片上存储资源,可满足高性能计算、A…...

Android Camera HAL v3 and Video4Linux 2
《小驰行动派的知识星球》 ———————————————— 推荐阅读: 关于博主 《小驰Camera私房菜》小册目录 采用v4l2loopback来实现 虚拟Camera Camera基础及一些基本概念 Android Camera 学习路线 | 个人推荐 Android Camera开发系列(干货满满&a…...
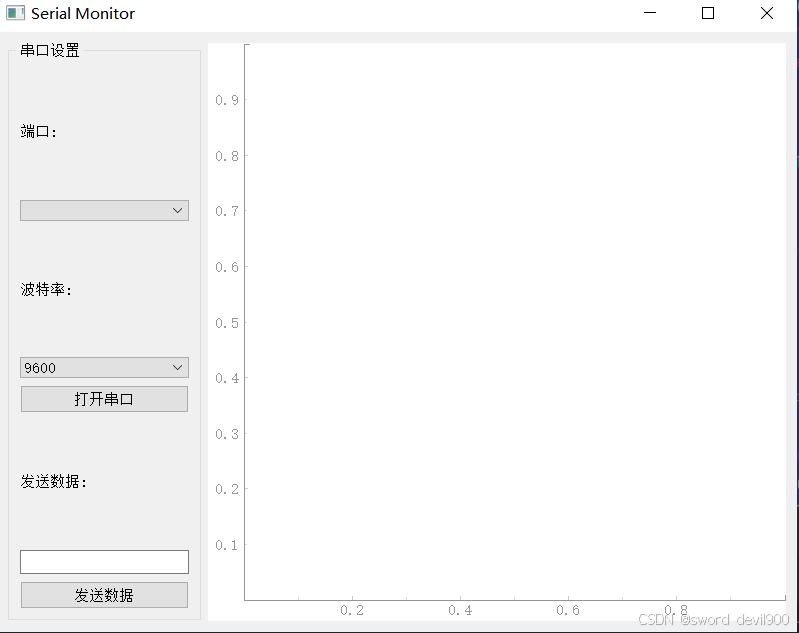
基于pyqt的上位机开发
目录 安装依赖 功能包含 运行结果 安装依赖 pip install pyqt5 pyqtgraph pyserial 功能包含 自动检测串口设备,波特率选择/连接断开控制,数据发送/接收基础框架,实时绘图区域(需配合数据解析) ""&q…...

WHAT - Rust 智能指针
文章目录 常见的智能指针类型1. Box<T> — 堆上分配的数据2. Rc<T> — 引用计数的共享所有权(单线程)3. Arc<T> — 原子引用计数(多线程)4. RefCell<T> — 运行时可变借用(单线程)…...
CentOS 7 系统下安装 OpenSSL 1.0.2k 依赖问题的处理
前面有提到过这个openssl的版本冲突问题,也是在这次恢复服务器时遇到的问题,我整理如下,供大家参考。小小一个软件的安装,挺坑的。 一、问题 项目运行环境需要,指定PHP7.0.9这个版本,但是系统版本与软件…...
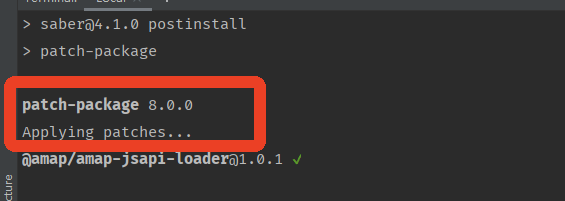
vue修改了node_modules中的包,打补丁
1、安装patch npm i patch-package 安装完成后,会在package.json中显示版本号 2、在package.json的scripts中增加配置 "postinstall": "patch-package" 3、执行命令 npx patch-package 修改的node_modules中的包的名称 像这样 npx patch-packag…...
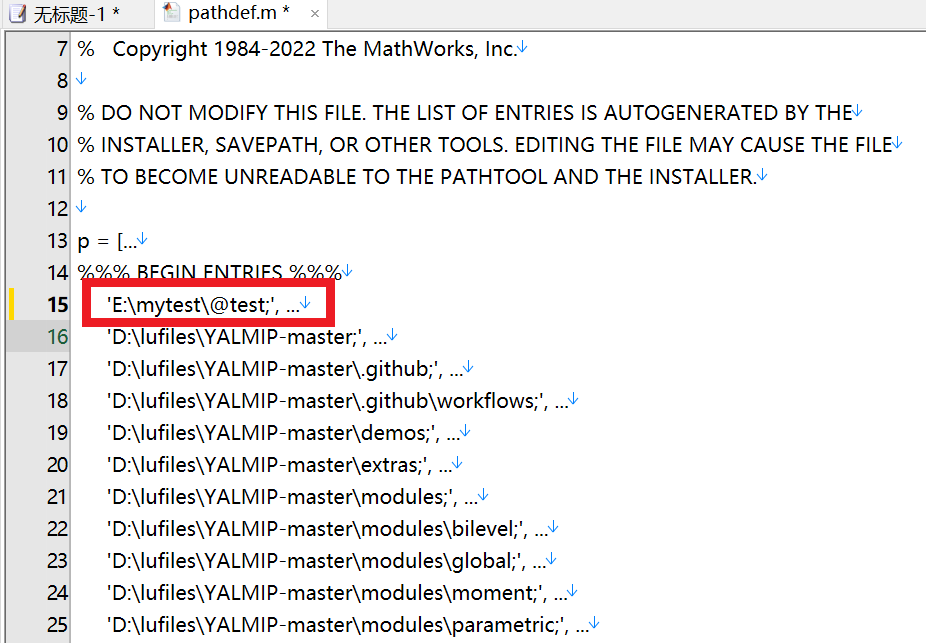
[matlab]private和+等特殊目录在新版本matlab中不允许添加搜索路径解决方法
当我们目录包含有private,或者时候matlab搜索目录不让添加,比如截图: 在matlab2018以前这些都可以加进去后面版本都不行了。但是有时候我们必须要加进去才能兼容旧版本matlab库,比如mexopencv库就是这种情况。因此我们必须找到一个办法加进去…...

十七、统一建模语言 UML
统一建模语言(Unified Modeling Language,UML)是一种通用的建模语言,具有创建系统的静态结构和动态行为等多种结构模型的能力,具有可扩展性和通用性,适合于多种多变结构系统的建模。 统一建模语言的特点&am…...