(2)Python爬虫--requests
文章目录
- 前言
- 一、 认识requests库
- 1.1 前情回顾
- 1.2 为什么要学习requests库
- 1.3 requests库的基本使用
- 1.4 响应的保存
- 1.5 requests常用的方法
- 1.6 用户代理
- 1.7 requests库:构建ua池(可以先跳过去)
- 1.8 requests库:带单个参数的get请求
- 1.9 requests库:带多个参数的get请求
- 练习1: 下载多页百度贴吧的页面
- 练习2: 下载多页百度贴吧的页面(改写为面向对象的形式)
- 2.0 requests的post请求
- 2.1 requests的session类
- 2.2 SSL证书验证
- 2.3 IP代理
- 2.4 代理的基础使用
- 2.5 验证代理IP有效性
- 总结
前言
在当今数据驱动的时代,网络爬虫成为获取互联网信息的重要工具之一。Python 作为一门简单易用且功能强大的编程语言,提供了许多优秀的库来帮助开发者高效地完成爬虫任务。其中,requests 库以其简洁的 API 和强大的功能,成为 HTTP 请求的首选工具。无论是简单的网页数据抓取,还是复杂的 API 交互,requests 都能以极少的代码实现高效的数据获取。
本文将介绍 requests 库的基本用法,包括发送 GET/POST 请求、处理响应数据、设置请求头与参数,以及应对常见的反爬策略。通过本文的学习,读者将能够掌握使用 requests 进行网络爬虫开发的核心技巧,并能够灵活运用于实际项目中。
一、 认识requests库
1.1 前情回顾
在学习今天的内容之前,我们先来简单回忆一下上节课使用urllib进行页面爬取的操作。
需求:抓取百度首页的源代码
实例代码:
# 需求: 抓取百度首页的源代码# 前提: 爬虫的前提是必须上网# 导包
import urllib.request# 确定url地址
url = 'https://www.baidu.com' # https存在ssl加密协议(使用ua反爬)# ua反爬操作(字典形式)
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36'
}# 定制request
# 第二个参数位置不对,因而使用关键字参数
request = urllib.request.Request(url,headers=header)
# 模拟浏览器发送请求
response = urllib.request.urlopen(request)
# 获取响应数据(二进制数据使用decode()方法解码)
content = response.read().decode()
# 打印数据
print(content)
1.2 为什么要学习requests库
urllib 就像手动挡汽车——能开但麻烦;requests 是自动挡——简单高效,直接起飞!
具体对比:
urllib:要手动拼参数、手动加请求头、手动处理Cookie,代码又臭又长。
requests:一行代码发请求,自动解析JSON,会话保持无痛衔接,爽就一个字!
结论:
除非你被迫用标准库,否则无脑选 requests,省时省力不折腾!
1.3 requests库的基本使用
在上节课的末尾,我们已经成功安装了requests第三方库,那么今天我们就在使用一下requests库,来观察它是如何节省时间,提高效率的
需求:抓取百度首页的源代码
示例代码:
# 需求: 爬取百度页面的源码# 1. 导包
import requests# 2. 发送请求
# 进入百度首页查看请求方法(get)
url = 'https://www.baidu.com'
# 调用requests的get方法--获取响应
response = requests.get(url)
# 通过打印response可以直接获取状态码
# print(response)# 保存响应
# 方式1 调用text方法
# text属性会自动寻找一个解码方式去解码会出现乱码的情况
# print(response.text)
# 解决方式如下
# 设置response的编码格式
# response.encoding = 'utf-8'
# 重新输出
# print(response.text)# 方式二 使用content方法
# print(response.content)
# 获取的是二进制数据 使用decode方法解码即可
print(response.content.decode())
1.4 响应的保存
需求一:使用requests库来保存百度首页的源代码
示例代码:
# 需求一:使用requests库来保存百度首页的源代码
# 导包
import requests# 发送get请求
url = "https://www.baidu.com"
response = requests.get(url)# 下载百度首页源码
# with open 会自动关闭文件
# 含有中文,因此需要带上encoding参数
with open('baidu.html','w',encoding='utf-8') as f:f.write(response.content.decode())# 当然也可以使用上节课讲过的方法
# urllib.request.urlretrieve(url, 'baidu.html')需求二:使用requests库来保存图片
示例代码:
# 需求二:使用requests库来保存图片
import requests# 确定url同时确定请求方法(get)
url = 'https://wx3.sinaimg.cn/mw690/007BFO4lgy1hr3uapmke4j317e1kuh25.jpg'# 调用get方法
response = requests.get(url)# 输出响应内容,调用content方法
# 图片保存的形式为二进制,因而不用解码
# 保存到本地# with open会自动关闭文件
# 切记要带上b模式 否则无法保存字节数据(图片/视频/音频)
with open('kun.jpg', 'wb') as f:f.write(response.content)1.5 requests常用的方法
前面提到的:
text: str类型, requests模块自动根据http头部对响应的编码作出有根据的推测
content: bytes类型,可以通过decode()解码
比较常用的还有另外一些:
import requestsurl = 'https://wx3.sinaimg.cn/mw690/007BFO4lgy1hr3uapmke4j317e1kuh25.jpg'
response = requests.get(url)# 一些较为常用的方法如下:# 打印响应的url
print(response.url)
# 打印响应对象的请求头
print(response.request.headers)
# 打印响应头
print(response.headers)1.6 用户代理
为什么要进行用户代理?
一句话解释:
用户代理(User-Agent)是用来伪装成真实浏览器访问网站的,防止被服务器识别为爬虫直接封杀。
人话版:
不设UA?网站一看你是Python爬虫,立马关门放验证码!
示例代码:
import requests# 我们来看没有使用用户代理的响应长度
url = 'https://www.baidu.com'response = requests.get(url)# print(response.content.decode())
print(len(response.content.decode()))# 通过对百度首页源码的比较,发现未使用用户代理的情况下响应内容是不够的 一些css样式没有展示出来
# 配置用户代理 也就是上节课讲的 配置ua反爬
# 请求头中user-agent字段必不可少,表示客户端的操作系统以及浏览器的信息
# 添加user-agent的目的是为了让服务器认为是浏览器在发送请求,而不是爬虫程序在发送请求
# 配置ua(必须要字典形式)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}# 在get加入headers参数,传入headers字典
# headers使用的是关键字参数,通过ctrl+p 可以观察到,第二个参数暂时用不到被搁置了
response = requests.get(url,headers=headers)
# 重新获取长度
# print(response.content.decode())
# print(len(response.content.decode()))
# 发现内容和长度都变多了
1.7 requests库:构建ua池(可以先跳过去)
大致先了解一下,目前不会大量的爬取一个页面,暂时用不到。
配置ua池的原因:
用多个UA轮换伪装不同浏览器访问,防止单一UA被识别封禁,提高爬虫存活率。
示例代码:
import random
# 构建ua池,防止多次调用被反爬# 自己写ua池
# 通过不断更换页面的打开方式,可以获取多个ua
uAlist = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36','Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1','Mozilla/5.0 (Linux; Android 8.0.0; SM-G955U Build/R16NW) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Mobile Safari/537.36'
]
# 随机获取一个ua
print(random.choice(uAlist))# 方法2 外包生成ua
# 下载fake-useragent包
# 频繁调用的时候可能会报错
from fake_useragent import UserAgent
print(UserAgent().random)
1.8 requests库:带单个参数的get请求
需求:爬取搜索结果为天气的页面
示例代码:
import requests
from urllib.parse import quote# 单参数的get请求
# 需求:爬取搜索结果为天气的页面
# url = https://www.baidu.com/s?ie=UTF-8&wd=%E5%A4%A9%E6%B0%94# 上节课已经讲过,我们的中文要变成这种密文的形式,才能正常的爬取搜索页面
# 需要用到quote方法, 这里不再强调# 可以进行人性化的设置
content = input("请输入搜索内容:")url = f'https://www.baidu.com/s?ie=UTF-8&wd={quote(content)}'
print(url)# 配置ua
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}# 获取响应
response = requests.get(url, headers=headers)
print(response.content.decode())1.9 requests库:带多个参数的get请求
需求:爬取搜索结果周杰伦性别为男的结果
示例代码:
import requests
from urllib.parse import quote# 多参数的get请求
# 需求:爬取搜索结果周杰伦性别为男的结果
# url = https://www.baidu.com/s?ie=UTF-8&wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7# 多参数需要配置参数字典url = 'https://www.baidu.com/s?ie=UTF-8&'params = {'wd':'周杰伦','sex':'男'
}# 配置ua
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}# 获得响应
# 使用ctrl + p 可以得到 get请求使用的是params
response = requests.get(url=url,params=params,headers=headers)
print(response.content.decode())
练习1: 下载多页百度贴吧的页面
import requests
from urllib.parse import quote# 需求: 下载多页百度贴吧的内容
# https://tieba.baidu.com/f?kw=%E7%99%BE%E5%BA%A6&ie=utf-8&pn=0
# https://tieba.baidu.com/f?kw=%E7%99%BE%E5%BA%A6&ie=utf-8&pn=50
# https://tieba.baidu.com/f?kw=%E7%99%BE%E5%BA%A6&ie=utf-8&pn=100url = 'https://tieba.baidu.com/f?'# 配置ua
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}name = input('请输入要搜索的内容:')
pages = int(input('请输入要爬取的页数:'))for page in range(pages):params = {'kw': quote(name),'ie': 'utf-8',# 观察每次的url变化'pn': page * 50}response = requests.get(url, headers=headers, params=params)with open(name + str(page + 1) + '.html', 'w', encoding='utf-8') as f:f.write(response.content.decode())
练习2: 下载多页百度贴吧的页面(改写为面向对象的形式)
import requests
from urllib.parse import quote# 需求: 下载多页百度贴吧的内容
# https://tieba.baidu.com/f?kw=%E7%99%BE%E5%BA%A6&ie=utf-8&pn=0
# https://tieba.baidu.com/f?kw=%E7%99%BE%E5%BA%A6&ie=utf-8&pn=50
# https://tieba.baidu.com/f?kw=%E7%99%BE%E5%BA%A6&ie=utf-8&pn=100class TieBa:__url = 'https://tieba.baidu.com/f?'__header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'}# 发送请求def __send(self,params):response = requests.get(self.__url,params=params,headers=self.__header)return response# 保存数据def __save(self,name,page,response):with open(name + str(page + 1) + '.html', 'w', encoding='utf-8') as f:f.write(response.content.decode())def main(self):name = input('请输入要搜索的内容:')pages = int(input('请输入要爬取的页数:'))for page in range(pages):params = {'kw': quote(name),'ie': 'utf-8',# 观察每次的url变化'pn': page * 50}response = self.__send(params)self.__save(name,page,response)# if __name__ == '__main__':相当于一个测试方法
if __name__ == '__main__':tieba = TieBa()tieba.main()2.0 requests的post请求
POST请求通常用于提交敏感或结构化数据,主要场景包括:
-
表单提交(如登录账号、上传文件)
-
API交互(如发送JSON数据给服务端)
-
隐私操作(密码、支付信息等不适合暴露在URL的数据)
需求: post爬取百度翻译的翻译结果
示例代码:
import requests
from urllib.parse import quote# 需求: post爬取百度翻译的翻译结果url = 'https://fanyi.baidu.com/sug'# 与get多参数请求一致
# 配置data参数字典
data = {'kw': 'site'
}# 配置ua反爬
headers = {'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1',# cookie不要复制,而是使用自己当前的cookie
'cookie': 'BIDUPSID=DB58345B891552BB9313D4BDC55106E3; PSTM=1720073445; BAIDUID=DB58345B891552BBD28EB4C334A909DD:FG=1; BDUSS=TdpY0Q2R2VwRU00VElTbmVOYjNZSk5ZOE1QcFZSaDBickNONUdvfkxVRn4xTFZtRVFBQUFBJCQAAAAAAAAAAAEAAAA6EBJVZmRnaGRnZWlnZXJrbAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAH9HjmZ%7ER45mM; BDUSS_BFESS=TdpY0Q2R2VwRU00VElTbmVOYjNZSk5ZOE1QcFZSaDBickNONUdvfkxVRn4xTFZtRVFBQUFBJCQAAAAAAAAAAAEAAAA6EBJVZmRnaGRnZWlnZXJrbAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAH9HjmZ%7ER45mM; H_WISE_SIDS_BFESS=60279_61027_61158_61374_61426_61437_60853_61492_61430; BAIDU_WISE_UID=wapp_1746598206985_847; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_WISE_SIDS=62325_62869_62969_63028_63194; arialoadData=false; delPer=0; ZFY=3As8a8sh:AgGJY4C29Pp9MW:BZkIS3Ax29rHpgANGv2oo:C; BA_HECTOR=8g852520842h0h8h2525a50g0g0l011k1uggn25; BAIDUID_BFESS=DB58345B891552BBD28EB4C334A909DD:FG=1; PSINO=2; H_PS_PSSID=60279_61027_61683_62325_62869_62969_63028_63040_63141_63155_63190_63194_63210; BRAND_LANDING_FROM_PAGE=2231_0_1746880033; BCLID=10420906196303252853; BCLID_BFESS=10420906196303252853; BDSFRCVID=sS-OJexroGWgxWvsXPPREHtYoFweG7bTDYrEtLb2UCSdqB4VvQteEG0Pts1-dEu-S2OOogKKBeOTHgDoc2L2qQCaBcS5ih4EkGibtf8g0M5; BDSFRCVID_BFESS=sS-OJexroGWgxWvsXPPREHtYoFweG7bTDYrEtLb2UCSdqB4VvQteEG0Pts1-dEu-S2OOogKKBeOTHgDoc2L2qQCaBcS5ih4EkGibtf8g0M5; H_BDCLCKID_SF=tRAOoC--tIvqKRopMtOhq4tehHRtLxc9WDTm_DoEbxoZjC3RWMT1jnLbQGr30P3yQjLf-pPKKR71DhQ_060K34A1bJPtWnTZ3mkjbp3Dfn02OPKz0TKVy-4syPRGKxRnWIvRKfA-b4ncjRcTehoM3xI8LNj405OTbIFO0KJDJCFahIPlD6KKePK_hlr0etjK2CntsJOOaCv5VT6Oy4oWK4413UJOLb5eyNRTbq5dbUTos43NQTJD3M04K4oJWPDHQm7g0PjPJUQ-VtbNQft20b0yDecb0RLLLbr92b7jWhvIeq72y-JUhPJXXa5DQxJK0D7g_RTSJp5OsnTP5-DWbT8IjH62btt_Jn-qoUK; H_BDCLCKID_SF_BFESS=tRAOoC--tIvqKRopMtOhq4tehHRtLxc9WDTm_DoEbxoZjC3RWMT1jnLbQGr30P3yQjLf-pPKKR71DhQ_060K34A1bJPtWnTZ3mkjbp3Dfn02OPKz0TKVy-4syPRGKxRnWIvRKfA-b4ncjRcTehoM3xI8LNj405OTbIFO0KJDJCFahIPlD6KKePK_hlr0etjK2CntsJOOaCv5VT6Oy4oWK4413UJOLb5eyNRTbq5dbUTos43NQTJD3M04K4oJWPDHQm7g0PjPJUQ-VtbNQft20b0yDecb0RLLLbr92b7jWhvIeq72y-JUhPJXXa5DQxJK0D7g_RTSJp5OsnTP5-DWbT8IjH62btt_Jn-qoUK; ab_sr=1.0.1_ZjYyNTljZWM5MDRkZTIzMjAwN2FhZmY0MGJhNjc1ZGNlNTVmMjFhOTgyNDk1NGYwOWNjZGYxZmJlYWRjYWQ3ZDY2MjI3OTMxOTgxZTk1YTExZTliYjRjYWRhMGNmYmI5NjhiOGVhODdjNzkxM2QxMTg2YTFlMDg3OWNhYmVjNTQxZTA0NTdlYTNhYmYwYTllNjk1YWExMDlkNzE2MTc2ODc4MzA1NTE0ODU4ZjhjNzQ4MWJhYjZlMjEzYzM1OGQ1ZDBlMTJhY2EyYWQzYmE1ODY4NWJhMmEwNGU2YWU4YjM=; RT="z=1&dm=baidu.com&si=017fbbb0-a34c-4b7c-9a9e-4fe98db29c6b&ss=mai6cdmq&sl=h&tt=ybx&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=xnv7'
}
# 不同的是,post请求用到的是data而不是params
response = requests.post(url=url, data=data, headers=headers)# 获取结果 直接调用json方法即可 非常方便
# 请求出现错误的时候加上cookie即可(后续会讲解)
print(response.json())
2.1 requests的session类
需求1: 爬取QQ空间登录后的页面
示例代码:
import requests
# 当我们在登录之后才能显示的页面 换到其他浏览器打开之后就会直接跳转到登录页面
# 那么这样的网页我们可以爬取么?可以的 需要用到我们的cookie即可
url = 'https://user.qzone.qq.com/你的QQ号'
# 携带当前的cookie(目前你的cookie)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36','cookie': 'ptcz=6a497602ea5465be8a61bfe1423f9acbddb3b810c5d52e41c80bbfb70aedda80; pgv_pvid=4211887676; fqm_pvqid=b3500b22-caa8-46c2-88c1-77f857a3eaab; pac_uid=0_kjknKBPDA0d8D; _qimei_uuid42=1911c0e0e3a100ab8c892bfefb7acf342afd3c7d41; _qimei_fingerprint=28e27f13e024b4e72ed41740c05847af; _qimei_q36=; _qimei_h38=2db807598c892bfefb7acf340200000441911c; eas_sid=G1Q7X4d346C4W9e0I1u840S0Y9; _qpsvr_localtk=0.43827129920220864; pgv_info=ssid=s3904169120; uin=o3286179271; skey=@mvtpMO6pz; RK=b//Mn8OeyR; p_uin=o3286179271; pt4_token=NH-q3Rk933*QZ3IrHSZZ7DcA1DxeTJLBiq1oqs-*9sI_; p_skey=6quXxaJ7OMLPi7QZzoOCBNw9I9ZhPyxc0AKNMo-M6m8_; Loading=Yes; qz_screen=1549x872; 3286179271_todaycount=0; 3286179271_totalcount=107; QZ_FE_WEBP_SUPPORT=1; cpu_performance_v8=0'
}
response = requests.get(url=url, headers=headers)
print(response.content.decode())需求2:通过session访问登录后的页面
步骤:
- 1对访问登录后才能访问的页面去进行抓包
- 2.确定登录请求的ur1地址,请求方法和所需的参数
- 3.确定登录才能访问的页面ur1和请求方法白
- 4.利用requests.session完成代码
示例代码:
import requests# session可以保存同一个cookie 进而进行爬取登录后的页面# 创建会话
session = requests.Session()
# 用session来代替requests发送请求
session.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
# 再次用session来获取数据响应(再次发送请求)
response = session.get('http://httpbin.org/cookies')
print(response.text)
如果两次调用requests的get请求,看看会不会是同样的效果
import requestsrequests.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
# 再次发送请求
response = requests.get('http://httpbin.org/cookies')
print(response.text)
发现结果与上述使用session不一致,原因就是因为cookie发生了变化。
2.2 SSL证书验证
当使用Requests调用请求函数发送请求时,由于请求函数的verify参数的默认值为True,所以每次请求网站时默认都会进行SSL证书的验证。不过,有些网站可能没有购买SSL证书,或者SSL证书失效,当程序访问这类网站时会因为找不到SSL证书而抛出SSLError异常。例如,使用Requests请求国家数据网站
2.3 IP代理
代理ip是一个ip,指向的是一个代理服务器代理服务器能够帮我们向目标服务器转发请求
正向代理和反向代理:
-
正向代理: 给客户端做代理,让服务器不知道客户端的真实身份保护自己的ip地址不会被封,要封也是封代理ip
-
反向代理: 给服务器做代理,让浏览器不知道服务器的真实地址
总结:
-
正向代理: 保护客户端,反向代理保护服务端
-
反向代理: 给服务器做代理,让浏览器不知道服务器的真实地址
2.4 代理的基础使用
import requests# 代理的使用(可以在快代理中找一个)# 代理参数
proxies = {# 这个http也可以不带"http": "http://117.42.94.11:21021",
}# ua反爬
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36"
}
url = "https://www.baidu.com"
# 带上我们的代理参数即可
response = requests.get(url, headers=headers, proxies=proxies)# IP无效时,会自动使用本机真实的ip,因而访问有效
print(response.text)
2.5 验证代理IP有效性
import requests# 代理的有效性测试
# 代理ip无效的时候自动使用本机ip
# 免费代理ip网站: http://www.ip3366.net/free/?stype=3
proxies = {'https:': '93.188.161.84:80'
}headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36"
}url = 'https://2025.ip138.com/'response = requests.get(url, headers=headers, proxies=proxies)print(response.text)
总结
requests 库以其简单、优雅的设计,极大地简化了 Python 中的 HTTP 请求操作,使其成为爬虫开发中的利器。本文从基础的请求发送、响应解析,到高级的会话管理、代理设置和异常处理,全面介绍了 requests 的核心功能。无论是数据采集、接口测试,还是自动化任务,requests 都能提供稳定高效的解决方案。
当然,在实际爬虫开发中,除了掌握 requests 的基本使用,还需要结合 BeautifulSoup、Scrapy 等工具进行数据解析,并注意遵守网站的爬取规则,避免因频繁请求导致 IP 被封禁。希望本文能帮助读者快速上手 requests,并在实际项目中灵活运用,高效完成数据采集任务。
相关文章:
Python爬虫--requests)
(2)Python爬虫--requests
文章目录 前言一、 认识requests库1.1 前情回顾1.2 为什么要学习requests库1.3 requests库的基本使用1.4 响应的保存1.5 requests常用的方法1.6 用户代理1.7 requests库:构建ua池(可以先跳过去)1.8 requests库:带单个参数的get请求1.9 requests库&#x…...
MiniCPM-V
一、引言 在多模态大语言模型(MLLMs)快速发展的背景下,现有模型因高参数量(如 72B、175B)和算力需求,仅能部署于云端,难以适配手机、车载终端等内存和算力受限的端侧设备。MiniCPM-V聚焦 “轻量高效” 与 “端侧落地”,通过架构创新、训练优化和部署适配,打造高知识密…...
Screeps Arena基础入门
本文主要内容 JavaSsript语法使用VScode编译环境Screeps Arena游戏规则 JavaSsript语法使用 基本数据类型 // String, Numker,Boolean,null, undefined const username "John"; const age 30; const rate 4.5; const iscool true; const x null; #表示值为…...
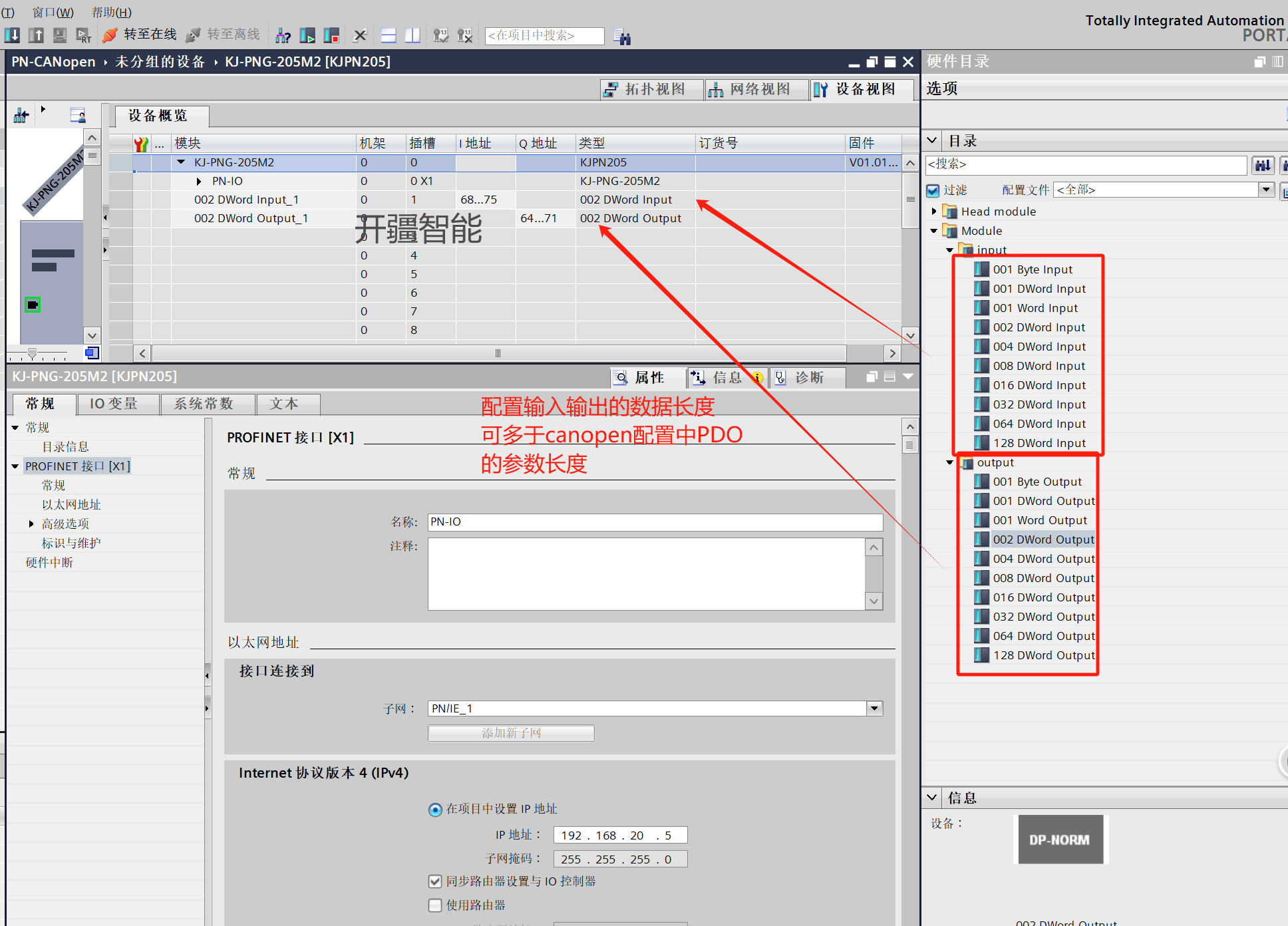
开疆智能Profinet转Canopen网关连接sick RFID读写器配置案例
打开CANopen总线配置软件设置CANopen参数: 1. 使用Profinet转CANopen网关的配置软件修改CANopen主站参数: 首先新建项目,选择对应网关模块 2. 设置波特率:250 kbps(需与SICK RFID读写器一致)。 设置同步…...
17.three官方示例+编辑器+AI快速学习webgl_buffergeometry_lines
本实例主要讲解内容 这个Three.js示例展示了如何使用BufferGeometry创建大量线段,并通过**变形目标(Morph Targets)**实现动态变形效果。通过随机生成的点云数据,结合顶点颜色和变形动画,创建出一个视觉效果丰富的3D线条场景。 核心技术包括…...
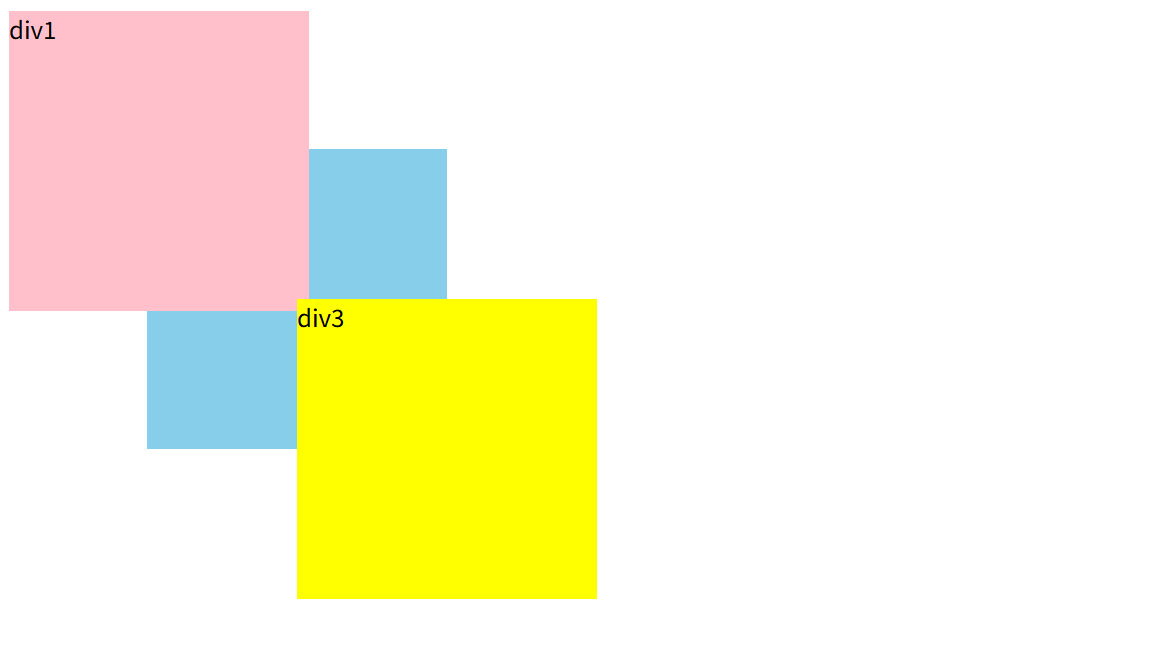
深入掌握CSS定位:构建精密布局的核心技术
一、定位的定义 定位(Positioning)是CSS中用于控制元素在网页中的具体位置的一种机制。通过定位,可以将元素放置在页面的任意位置,并控制其与其他元素的层叠关系。 二、定位的特点与作用 自由摆放位置: 允许元素摆放…...

Go语言多线程爬虫与代理IP反爬
有个朋友想用Go语言编写一个多线程爬虫,并且使用代理IP来应对反爬措施。多线程在Go中通常是通过goroutine实现的,所以应该使用goroutine来并发处理多个网页的抓取。然后,代理IP的话,可能需要一个代理池,从中随机选择代…...
)
配置集群(yarn)
在配置 YARN 集群前,要先完成以下准备工作: 集群环境规划:明确各节点的角色,如 ResourceManager、NodeManager 等。网络环境搭建:保证各个节点之间能够通过网络互通。时间同步设置:安装 NTP 服务࿰…...
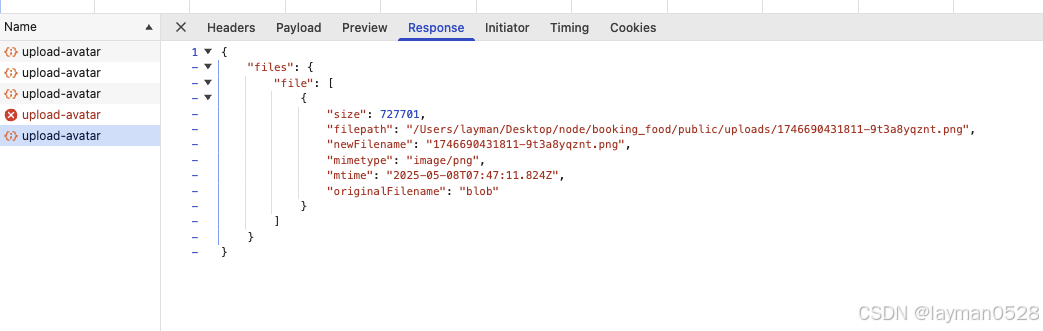
node.js 实战——express图片保存到本地或服务器(七牛云、腾讯云、阿里云)
本地 ✅ 使用formidable 读取表单内容 npm i formidable ✅ 使用mime-types 获取图片后缀 npm install mime-types✅ js 中提交form表单 document.getElementById(uploadForm).addEventListener(submit, function(e){e.preventDefault();const blob preview._blob;if(!blob)…...

CSS3 伪类和使用场景
CSS3 伪类(Pseudo-classes)大全 CSS3 引入了许多新的伪类,以下是完整的 CSS3 伪类分类列表(包括 CSS2 的伪类): 一、结构性伪类(Structural Pseudo-classes) 这些伪类根据元素在文…...

Shadertoy着色器移植到Three.js经验总结
Shadertoy是一个流行的在线平台,用于创建和分享WebGL片段着色器。里面有很多令人惊叹的画面,甚至3D场景。本人也移植了几个ShaderToy上的着色器。本文将详细介绍移植过程中需要注意的关键点。 1. 基本结构差异 想要移植ShaderToy的shader到three.js&am…...
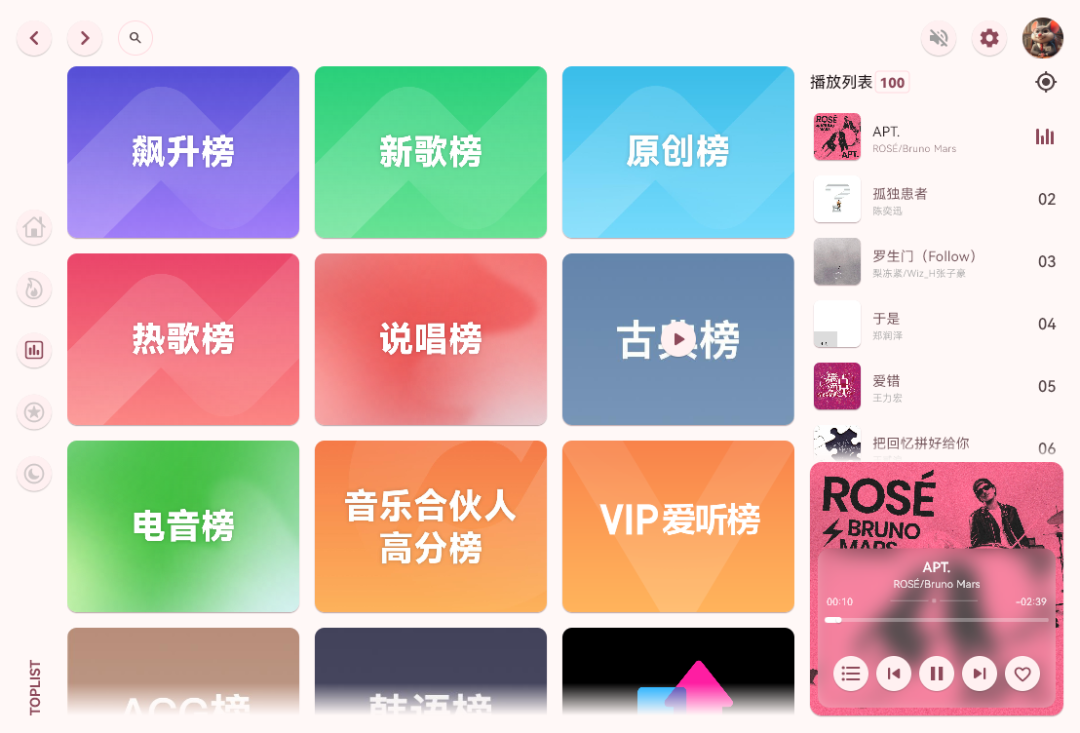
电脑端音乐播放器推荐:提升你的听歌体验!
在快节奏的职场环境中,许多上班族都喜欢用音乐为工作时光增添色彩。今天要分享的这款音乐工具,或许能为你的办公时光带来意想不到的惊喜。 一、软件介绍-澎湃 澎湃音乐看似是个普通的播放器,实则藏着强大的资源整合能力。左侧功能栏清晰陈列着…...
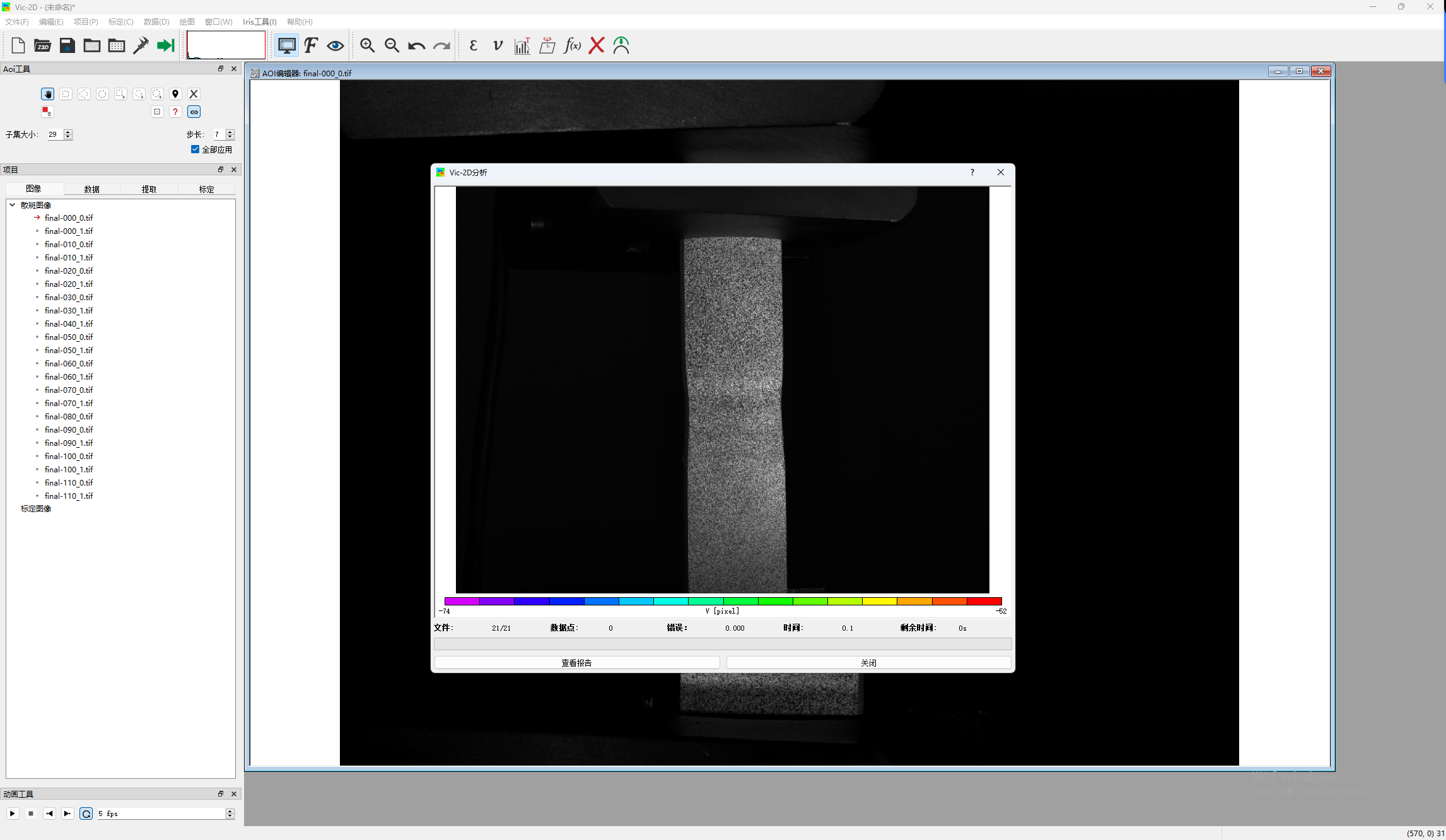
VIC-2D 7.0 为平面样件机械试验提供全视野位移及应变数据软件
The VIC-2D系统是一个完全集成的解决方案,它基于优化的相关算法为平面试样的力学测试提供非接触、全场的二维位移和应变数据,可测量关注区域内的每个像素子集的面内位移,并通过多种张量选项计算全场应变。The VIC-2D 系统可测量超过 2000%变形…...

一周学完计算机网络之三:1、数据链路层概述
简单的概述 数据链路层是计算机网络体系结构中的第二层,它在物理层提供的基本服务基础上,负责将数据从一个节点可靠地传输到相邻节点。可以将其想象成一个负责在两个相邻的网络设备之间进行数据 “搬运” 和 “整理” 的 “快递中转站”。 几个重要概念…...

网卡网孔速率的协商是如何进行的?
网卡与交换机等网络设备之间的速率协商主要通过**自动协商(Auto-Negotiation)**机制实现,其核心是物理层(PHY)芯片之间的信息交互。以下是协商过程的详细解析: 一、自动协商的核心流程 1. 发送配置帧&am…...
单片机-STM32部分:13-1、蜂鸣器
飞书文档https://x509p6c8to.feishu.cn/wiki/V8rpwIlYIiEuXLkUljTcXWiKnSc 一、应用场景 大部分的电子产品、家电(风扇、空调、电水壶)都会有蜂鸣器,用于提示设备的工作状态 二、原理 蜂鸣器是一种将电信号转换为声音信号的器件࿰…...

动态IP技术赋能业务创新:解锁企业数字化转型新维度
在数字经济高速发展的今天,IP地址已不再是简单的网络标识符,而是演变为支撑企业数字化转型的核心基础设施之一。动态IP技术凭借其灵活、高效、安全的特性,正在重塑传统业务模式,催生出诸多创新应用场景。本文将深入剖析动态IP的技…...

使用Python删除PDF中多余或空白的页面
目录 为什么需要删除 PDF 中的多余或空白页面? 所需工具 环境准备 如何使用Python删除PDF中的多余页面 实现思路 详细实现步骤 实现代码 如何使用Python检测并删除PDF中的空白页 实现思路 详细实现步骤 实现代码 在处理 PDF 文件时,常常会遇到…...

英语复习笔记 1
前言 我们知道英语最重要就是单词和阅读理解,因为时间安排和自己懒惰的原因,英语复习实际上进行得非常缓慢。实际上英语复习得比较少,但是我想考一个高分,这样下去肯定是废掉了。所以从今天开始我要好好复习英语。之前有个大佬说…...

UART16550 IP core笔记二
XIN时钟 表示use external clk for baud rate选型,IP核会出现Xin时钟引脚 XIN输入被外部驱动,也就是外部时钟源,那么外部时钟必须要满足特定的要求,就是XIN 的range范围是xin<S_AXI_CLK/2,如果不满足这个条件,那么A…...
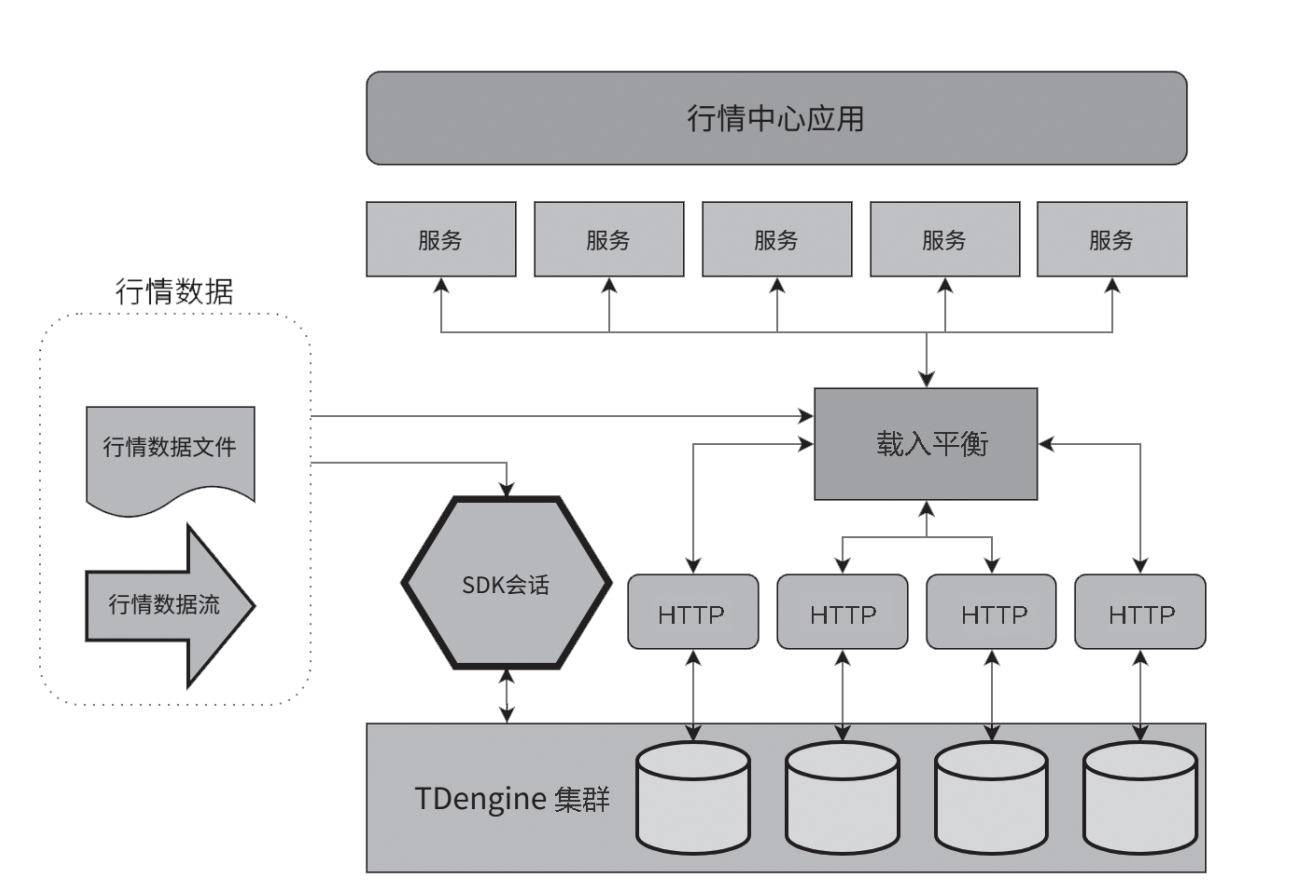
TDengine 在金融领域的应用
简介 金融行业正处于数据处理能力革新的关键时期。随着市场数据量的爆炸式增长和复杂性的日益加深,金融机构面临着寻找能够高效处理大规模、高频次以及多样化时序数据的大数据处理系统的迫切需求。这一选择将成为金融机构提高数据处理效率、优化交易响应时间、提高…...

OSCP - Hack The Box - Sau
主要知识点 CVE-2023-27163漏洞利用systemd提权 具体步骤 执行nmap扫描,可以先看一下55555端口 Nmap scan report for 10.10.11.224 Host is up (0.58s latency). Not shown: 65531 closed tcp ports (reset) PORT STATE SERVICE VERSION 22/tcp o…...

大模型的Lora如何训练?
大模型LoRA(Low-Rank Adaptation)训练是一种参数高效的微调方法,通过冻结预训练模型权重并引入低秩矩阵实现轻量化调整。以下是涵盖原理、数据准备、工具、参数设置及优化的全流程指南: 一、LoRA的核心原理 低秩矩阵分解 在原始权重矩阵$ W 旁添加两个低秩矩阵 旁添加两个…...

分词器工作流程和Ik分词器详解
切分词语,normalization 给你一段句子,然后将这段句子拆分成一个一个的单个的单词,同时对每个单词进行 normalization(时态转换,单复数转换),分词器 recall,召回率:搜索的…...
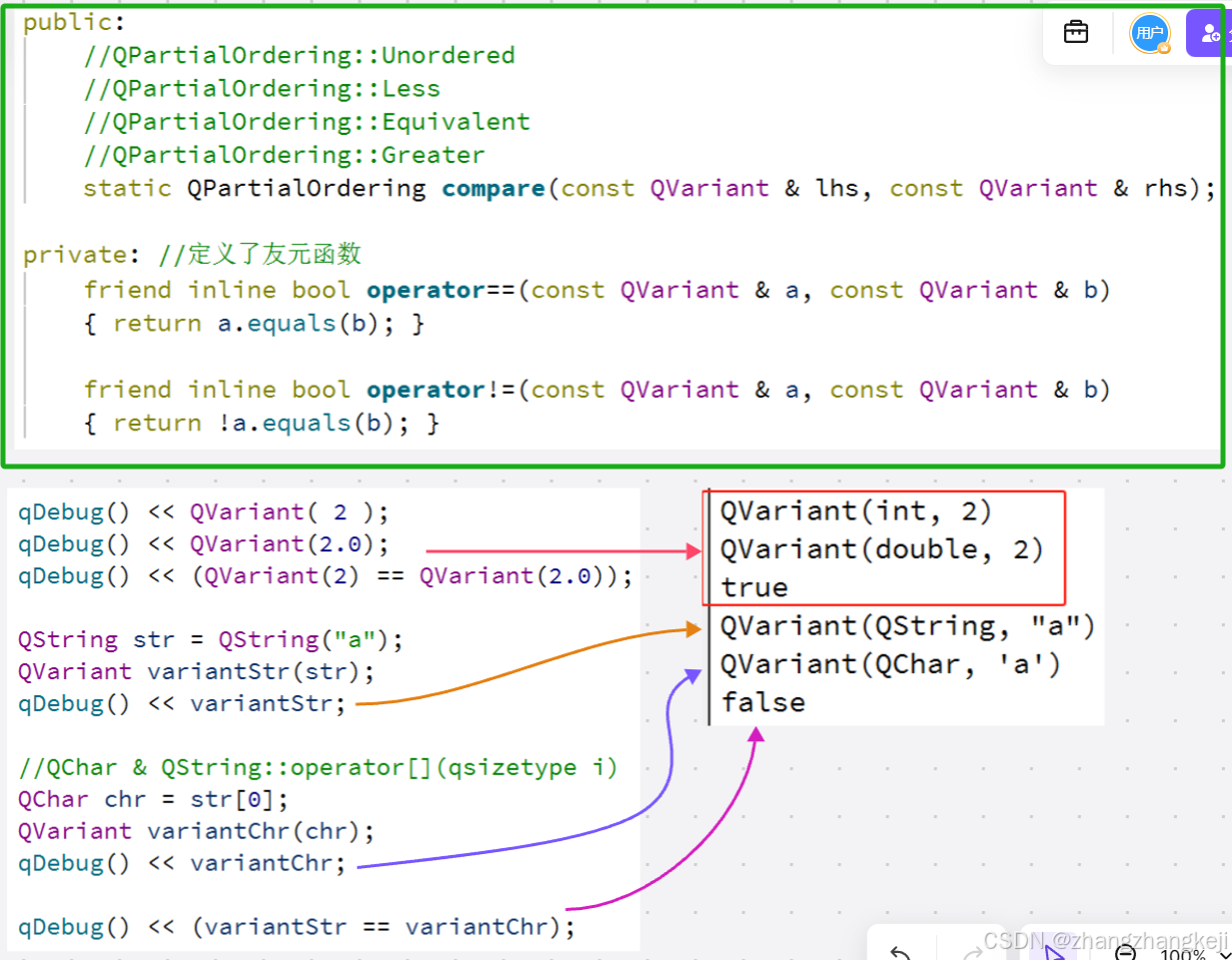
QT6 源(93)篇三:阅读与注释共用体类 QVariant 及其源代码,本类支持比较运算符 ==、!=。
(9) 本类支持比较运算符 、! : 可见, QString 类型里可存储多个 unicode 字符,即使只存储一个 unicode 字符也不等于 QChar。 (10)本源代码来自于头文件 qvariant . h : #ifndef Q…...
Maven私服搭建与登录全攻略
目录 1.背景2.简介3.安装4.启动总结参考文献 1.背景 回顾下maven的构建流程,如果没有私服,我们所需的所有jar包都需要通过maven的中央仓库或者第三方的maven仓库下载到本地,当一个公司或者一个团队所有人都重复的从maven仓库下载jar包&#…...

力扣210(拓扑排序)
210. 课程表 II - 力扣(LeetCode) 这是一道拓扑排序的模板题。简单来说,给出一个有向图,把这个有向图转成线性的排序就叫拓扑排序。如果有向图中有环就没有办法进行拓扑排序了。因此,拓扑排序也是图论中判断有向无环图…...

1.1 文章简介
前因后果链 行业需求 → 技能断层 → 课程设计响应 (高薪岗位要求数学基础) → (符号/公式理解困难) → (聚焦原理与应用) 行业驱动因素 • 前因:机器学习/AI等领域的高薪岗位激增,但数学能力成为主要门槛 • 关键矛盾:算法论文中的数学…...

将本地文件上传到云服务器上
使用 SCP 命令(最常用) # 基本语法 scp [本地文件路径] [用户名][服务器IP]:[目标路径]# 示例:上传单个文件 scp /path/to/local/file.txt root192.168.1.100:/path/to/remote/# 上传整个目录 scp -r /path/to/local/directory root192.168.…...
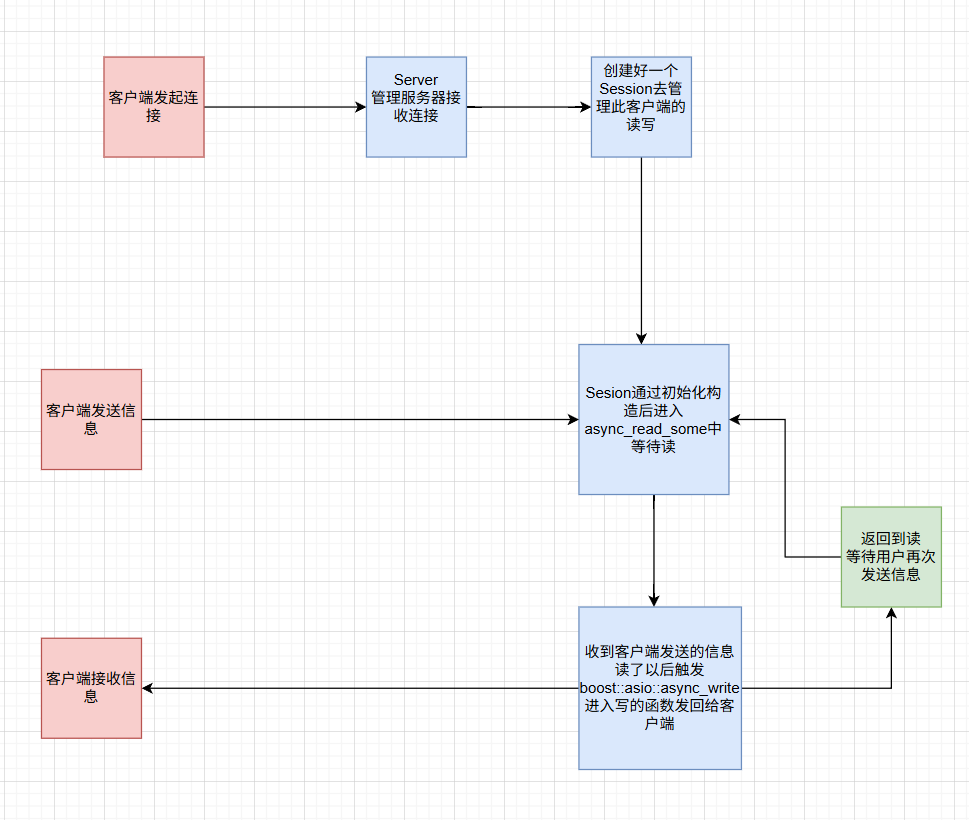
C++ asio网络编程(5)简单异步echo服务器
上一篇文章:C asio网络编程(4)异步读写操作及注意事项 文章目录 前言一、Session类1.代码2.代码详解3.实现Session类1.构造函数2.handle_read3.介绍一下boost的封装函数和api4.handle_write 二、Server类1.代码2.代码思路详解 三、客户端四、运行截图与流程图 前言 提示&…...