RNN(循环神经网络)原理与结构
1 RNN(循环神经网络)原理与结构
循环神经网络(Recurrent Neural Network, RNN)是一类专门用于处理序列数据(如时间序列、文本、语音等)的深度学习模型。与传统的前馈神经网络不同,RNN在每个时间步都会将前一时刻的隐藏状态(hidden state)作为输入之一,从而能够保留和传递历史信息,捕捉序列内部的时间依赖关系。
1.1 基本计算流程
设输入序列长度为 T T T,每个时间步输入为 x t x_t xt,隐藏状态为 h t h_t ht,输出为 y t y_t yt。RNN 的核心更新公式为:
h t = f h ( W i h x t + W h h h t − 1 + b h ) , y t = f o ( W h o h t + b o ) , \begin{aligned} h_t &= f_h(W_{ih} x_t + W_{hh} h_{t-1} + b_h),\\ y_t &= f_o(W_{ho} h_t + b_o), \end{aligned} htyt=fh(Wihxt+Whhht−1+bh),=fo(Whoht+bo),
其中:
- W i h W_{ih} Wih 为输入到隐藏层的权重矩阵,维度为 H × I H \times I H×I;
- W h h W_{hh} Whh 为隐藏到隐藏的权重矩阵,维度为 H × H H \times H H×H;
- W h o W_{ho} Who 为隐藏到输出的权重矩阵,维度为 O × H O \times H O×H;
- b h b_h bh 与 b o b_o bo 分别为隐藏层和输出层的偏置项;
- f h f_h fh 与 f o f_o fo 分别为隐藏层与输出层的激活函数,常见选择包括 tanh、ReLU、softmax 等。
整个序列的前向计算可视为一个展开的多层网络:
- 初始化:通常将 h 0 h_0 h0 初始化为零向量。
- 时间步循环:从 t = 1 t=1 t=1 到 t = T t=T t=T,依次计算 h t h_t ht 与 y t y_t yt。
- 输出收集:根据任务需求,输出可以取最后一个时间步的 y T y_T yT(如分类、回归),也可以取全序列的 ( y 1 , y 2 , … , y T ) (y_1, y_2, \dots, y_T) (y1,y2,…,yT)(如序列标注)。
1.2 训练与反向传播
RNN 的训练基于梯度下降,需要通过“反向传播通过时间”(Backpropagation Through Time,BPTT)算法计算梯度:
- 损失函数:对全序列或部分时间步的输出计算损失,如均方误差(MSE)或交叉熵(Cross-Entropy)。
- 反向展开:将时间维度展开为深度网络,并在展开后的网络上进行反向传播,累积来自每个时间步的梯度。
- 梯度更新:按常规方式(SGD、Adam、RMSProp 等)更新参数。由于展开后的网络深度较大,可能出现梯度弥散或梯度爆炸问题。
1.3 长期依赖问题及改进
基础 RNN 在处理长序列时容易出现梯度消失或爆炸,导致模型难以捕捉远距离的依赖。为此,研究者提出了多种改进结构:
- LSTM(Long Short-Term Memory):引入了输入门、忘记门和输出门,通过门控机制控制信息流动,有效缓解长期依赖问题。
- GRU(Gated Recurrent Unit):将 LSTM 的输入门和遗忘门合并为重置门和更新门,结构更简洁,性能相当。
- 带门控的 RNN:在基础 RNN 上添加层归一化、残差连接或门控线性单元(GLU)等技巧,提升稳定性和收敛速度。
下面以 LSTM 单元为例,展示其核心计算:
f t = σ ( W f [ h t − 1 , x t ] + b f ) (遗忘门) i t = σ ( W i [ h t − 1 , x t ] + b i ) (输入门) o t = σ ( W o [ h t − 1 , x t ] + b o ) (输出门) c ~ t = tanh ( W c [ h t − 1 , x t ] + b c ) (候选细胞状态) c t = f t ⊙ c t − 1 + i t ⊙ c ~ t (更新细胞状态) h t = o t ⊙ tanh ( c t ) (输出隐藏状态) \begin{aligned} f_t &= \sigma(W_f [h_{t-1}, x_t] + b_f) \quad &\text{(遗忘门)}\\ i_t &= \sigma(W_i [h_{t-1}, x_t] + b_i) \quad &\text{(输入门)}\\ o_t &= \sigma(W_o [h_{t-1}, x_t] + b_o) \quad &\text{(输出门)}\\ \tilde{c}_t &= \tanh(W_c [h_{t-1}, x_t] + b_c) \quad &\text{(候选细胞状态)}\\ c_t &= f_t \odot c_{t-1} + i_t \odot \tilde{c}_t \quad &\text{(更新细胞状态)}\\ h_t &= o_t \odot \tanh(c_t) \quad &\text{(输出隐藏状态)} \end{aligned} ftitotc~tctht=σ(Wf[ht−1,xt]+bf)=σ(Wi[ht−1,xt]+bi)=σ(Wo[ht−1,xt]+bo)=tanh(Wc[ht−1,xt]+bc)=ft⊙ct−1+it⊙c~t=ot⊙tanh(ct)(遗忘门)(输入门)(输出门)(候选细胞状态)(更新细胞状态)(输出隐藏状态)
通过门控机制,LSTM 能够选择性地保留或忘记信息,使得模型在处理长序列时更加稳定。
2 序列到序列模型(Seq2Seq)
序列到序列(Sequence to Sequence, Seq2Seq)模型最早应用于机器翻译任务,其核心思想是:将一个可变长度的输入序列映射为另一个可变长度的输出序列。典型结构由编码器(Encoder)和解码器(Decoder)两部分组成:
- 编码器:逐步读取输入序列,将其压缩为一个固定长度的上下文向量(context vector)。
- 解码器:根据上下文向量,以自回归方式生成输出序列。
2.1 基本架构
- Encoder:一个多层 RNN(如 LSTM/GRU),从 t = 1 t=1 t=1 到 t = T i n t=T_{in} t=Tin 读取输入 x t x_t xt,并最终输出隐藏状态 h T i n h_{T_{in}} hTin(或多层的状态集合)。
- Context Vector:通常取编码器最后一个时间步的隐藏状态或其线性变换,作为定长向量 c c c。
- Decoder:另一个多层 RNN,初始状态由上下文向量 c c c(或映射后的初始隐藏状态)提供。解码器在每一时刻接收上一时刻生成的 y t − 1 y_{t-1} yt−1(训练时可使用真实标签,称为 Teacher Forcing),并输出当前时刻 y t y_t yt。
2.2 注意力机制(Attention)
固定长度的上下文向量在长序列或信息密集场景中可能成为瓶颈。注意力机制为解码器在每一步动态计算与编码器所有隐藏状态的加权和,从而获得更加丰富的上下文信息。核心计算:
e t , s = score ( h t − 1 d e c , h s e n c ) a l p h a t , s = exp ( e t , s ) ∑ s ′ = 1 T i n exp ( e t , s ′ ) c t = ∑ s = 1 T i n α t , s ⋅ h s e n c \begin{aligned} e_{t,s} &= \text{score}(h^{dec}_{t-1}, h^{enc}_s) \\ alpha_{t,s} &= \frac{\exp(e_{t,s})}{\sum_{s'=1}^{T_{in}} \exp(e_{t,s'})} \\ c_t &= \sum_{s=1}^{T_{in}} \alpha_{t,s} \cdot h^{enc}_s \end{aligned} et,salphat,sct=score(ht−1dec,hsenc)=∑s′=1Tinexp(et,s′)exp(et,s)=s=1∑Tinαt,s⋅hsenc
其中,score 函数可以是点积、可学习的前馈网络或双线性形式。最终,解码器将上下文向量 c t c_t ct 与自身隐藏状态拼接或融合后进行生成。注意力机制在机器翻译、文本摘要、图像描述等任务中大幅提升了性能。
3 实际案例:基于 Seq2Seq 的多步时间序列预测
下面通过一个端到端示例,演示如何使用 TensorFlow/Keras 构建并训练一个 Seq2Seq 模型,进行多步时间序列预测。示例目标:根据过去 48 小时传感器采集的温度数据,预测未来 24 小时的温度变化。
3.1 数据集与预处理
-
数据来源:假设 CSV 文件
sensor_temperature.csv包含两列:timestamp与temperature。 -
时间索引:将
timestamp转为 pandas 的 DatetimeIndex,按小时对齐。缺失值使用线性插值。 -
归一化:为了加快收敛并稳定训练,对温度序列做标准化:
x ′ = x − μ σ x' = \frac{x - \mu}{\sigma} x′=σx−μ
其中 μ , σ \mu, \sigma μ,σ 分别为训练集上的均值和标准差。 -
滑动窗口构建:定义输入长度 L i n = 48 L_{in}=48 Lin=48,输出长度 L o u t = 24 L_{out}=24 Lout=24。遍历序列,构造样本对:
X i = [ x i , x i + 1 , … , x i + L i n − 1 ] , Y i = [ x i + L i n , x i + L i n + 1 , … , x i + L i n + L o u t − 1 ] . X_i = [x_i, x_{i+1}, \dots, x_{i+L_{in}-1}],\\ Y_i = [x_{i+L_{in}}, x_{i+L_{in}+1}, \dots, x_{i+L_{in}+L_{out}-1}]. Xi=[xi,xi+1,…,xi+Lin−1],Yi=[xi+Lin,xi+Lin+1,…,xi+Lin+Lout−1].
-
数据拆分:按时间顺序将前 80% 样本作为训练集,后 20% 作为验证集。
import pandas as pd
import numpy as np# 读取与插值
df = pd.read_csv('sensor_temperature.csv', parse_dates=['timestamp'], index_col='timestamp')
df = df.resample('1H').mean().interpolate()# 提取序列并标准化
series = df['temperature'].values
mu, sigma = series.mean(), series.std()
series_norm = (series - mu) / sigma# 滑动窗口函数
def create_sequences(data, L_in, L_out):X, Y = [], []for i in range(len(data) - L_in - L_out + 1):X.append(data[i:i+L_in])Y.append(data[i+L_in:i+L_in+L_out])return np.array(X), np.array(Y)L_in, L_out = 48, 24
X, Y = create_sequences(series_norm, L_in, L_out)# 拆分训练/验证集
split = int(0.8 * len(X))
X_train, Y_train = X[:split], Y[:split]
X_val, Y_val = X[split:], Y[split:]
3.2 模型搭建
采用经典的编码器-解码器结构:
- 编码器:单层 LSTM,隐藏单元数 64。
- 解码器:RepeatVector 将上下文向量复制为输出序列长度,后接单层 LSTM(64 单元)与 TimeDistributed(Dense(1))。
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, RepeatVector, TimeDistributed, Dense# 输入层
encoder_inputs = Input(shape=(L_in, 1), name='encoder_inputs')
# 编码器 LSTM
encoder_lstm, state_h, state_c = LSTM(64, return_state=True, name='encoder_lstm')(encoder_inputs)
encoder_states = [state_h, state_c]# 解码器输入:重复编码器输出
decoder_inputs = RepeatVector(L_out, name='repeat_vector')(state_h)
# 解码器 LSTM
decoder_lstm = LSTM(64, return_sequences=True, name='decoder_lstm')
decoder_outputs = decoder_lstm(decoder_inputs, initial_state=encoder_states)
# 时间分布的全连接层
decoder_dense = TimeDistributed(Dense(1), name='time_distributed')
decoder_outputs = decoder_dense(decoder_outputs)# 定义模型
model = Model(encoder_inputs, decoder_outputs)
model.compile(optimizer='adam', loss='mse')
model.summary()
3.2.1 超参数与训练策略
- 学习率:Adam 默认
lr=0.001; - 批次大小:32;
- 训练轮次:50 次;
- EarlyStopping:监控验证集损失,
patience=5,以防过拟合。
from tensorflow.keras.callbacks import EarlyStoppingcallbacks = [EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)]
history = model.fit(X_train[..., np.newaxis], Y_train[..., np.newaxis],validation_data=(X_val[..., np.newaxis], Y_val[..., np.newaxis]),epochs=50,batch_size=32,callbacks=callbacks
)
3.3 训练结果与评估
-
收敛曲线:绘制训练与验证损失随轮次变化曲线,以判断过拟合或欠拟合。
-
定量指标:采用均方根误差(RMSE)、平均绝对百分比误差(MAPE)评估预测性能:
RMSE = 1 N ∑ i = 1 N ( y ^ i − y i ) 2 , MAPE = 100 % N ∑ i = 1 N ∣ y ^ i − y i y i ∣ . \text{RMSE} = \sqrt{\frac{1}{N} \sum_{i=1}^N (\hat{y}_i - y_i)^2},\\ \text{MAPE} = \frac{100\%}{N} \sum_{i=1}^N \left|\frac{\hat{y}_i - y_i}{y_i}\right|. RMSE=N1i=1∑N(y^i−yi)2,MAPE=N100%i=1∑N yiy^i−yi .
-
可视化对比:随机选取若干样本,绘制真实值与预测值对比曲线。
import matplotlib.pyplot as plt# 收敛曲线
plt.figure(); plt.plot(history.history['loss'], label='train'); plt.plot(history.history['val_loss'], label='val'); plt.legend(); plt.title('Loss Curve')# 随机样本可视化
def plot_sample(idx):true = Y_val[idx]pred = model.predict(X_val[idx:idx+1])[0,...,0]plt.figure(); plt.plot(true, label='True'); plt.plot(pred, label='Pred'); plt.legend(); plt.title(f'Sample {idx} Prediction')plot_sample(0)
plot_sample(5)
3.4 性能优化与拓展
- 加入注意力机制:在解码器每一步对编码器隐藏状态加权。
- 双向编码器:使用双向 LSTM 捕捉过去和未来上下文。
- 多层堆叠:增加 LSTM 层数以提升表达能力。
- 混合模型:结合卷积神经网络(CNN)进行特征提取。
- 超参数搜索:使用网格搜索(Grid Search)或贝叶斯优化(Bayesian Optimization)寻找最佳超参数。
致谢
感谢阅读!如有疑问或建议,欢迎讨论。
相关文章:
原理与结构)
RNN(循环神经网络)原理与结构
1 RNN(循环神经网络)原理与结构 循环神经网络(Recurrent Neural Network, RNN)是一类专门用于处理序列数据(如时间序列、文本、语音等)的深度学习模型。与传统的前馈神经网络不同,RNN在每个时间…...
mac M2能安装的虚拟机和linux系统系统
目前网上的资料大多错误,能支持M2的很少。 推荐安装的改造过的centos7也无法进行yum操作,建议安装centos8 VMware Fusion下载地址: https://pan.baidu.com/s/14v3Dy83nuLr2xOy_qf0Jvw 提取码: jri4 centos8下载地址: https://…...

无偿帮写毕业论文
以下教程教你如何利用相关网站和AI免费帮你写一个毕业论文。毕竟毕业论文只要过就行,脱产学习这么多年,终于熬出头了,完成毕设后有空就去多看看亲人好友,祝好! 一、找一个论文模板(最好是overleaf) 废话不多说&#…...

智能网联汽车“内外协同、虚实共生”的通信生态
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界…...

Linux操作系统从入门到实战(六)Linux开发工具(上)详细介绍什么是软件包管理器,Linux下如何进行软件和软件包的安装、升级与卸载
Linux操作系统从入门到实战(六)Linux开发工具(上)详细介绍什么是软件包管理器,Linux下如何进行软件和软件包的安装、升级与卸载 前言一、 软件包管理器1.1 传统安装方式的麻烦:从源代码说起1.2 软件包&…...

物流无人机自动化装卸技术解析!
一、自动化装卸技术模块的技术难点 1. 货物多样性适配 物流场景中货物包装类型、尺寸、材质差异大,如农产品、医疗物资、工业设备等,要求装卸模块具备高度柔性化设计。例如,单元货物需视觉识别系统进行单个抓取,而整托货物需大…...

基于构件的开发方法与传统开发方法的区别
在软件开发领域,基于构件的开发方法和传统开发方法有着截然不同的特点与应用效果,这些差异显著影响着项目的实施过程与最终成果。下面,我们将从多个关键维度展开对比分析。 一、开发模式:线性搭建与模块组装 传统开发方法遵循线性的、自顶向下的流程,就像搭建一座高楼…...

详解 IRC协议 及客户端工具 WeeChat 的使用
本文将详细介绍 Internet Relay Chat(IRC)协议及其历史、基本概念、核心功能,以及流行的 IRC 客户端 WeeChat 的安装、配置和使用方法。内容力求准确、详尽,涵盖 IRC 的技术背景、使用场景,以及 WeeChat 的高级功能和实…...

IOT藍牙探測 C2 架構:社會工程/節點分離防追尋
BMC 地址:https://github.com/MartinxMax/bmc/releases/tag/V1.5 藍牙 MAC 偵測節點的物聯網分散式 C2 架構,可與 S-Cluster 交互。 場景 A:潛伏偵測 駭客組織會將 BMC 裝置秘密部署在目標建築物周圍(例如牆外、通風口或垃圾間等隱蔽地點&…...

Koa知识框架
一、核心概念 1. 基本特点 由 Express 原班人马开发的下一代 Node.js Web 框架 基于中间件的洋葱圈模型 轻量级核心(仅约 600 行代码) 完全使用 async/await 异步流程控制 没有内置任何中间件,高度可定制 2. 核心对象 Application (Ko…...

FreeRTOS学习记录(变量命名规则全解、文件介绍)
目录 FreeRTOS 变量命名规则详解 一、变量命名前缀规则 (一)数据类型相关前缀 (二)功能模块相关前缀 (三)宏定义 二、变量命名与文件的关系 (一)核心源文件中的变…...

Qt 中 QWidget涉及的常用核心属性介绍
欢迎来到干货小仓库 一匹真正的好马,即使在鞭子的影子下,也能飞奔 1.enabled API说明isEnabled()获取到控件的可用状态setEnabled()设置控件是否可使用.true:可用,false:禁用 禁用:指该控件不能接收任何用…...
Open CASCADE学习|由大量Edge构建闭合Wire:有序与无序处理的完整解析
在CAD建模中,构建闭合的Wire(线框)是拓扑结构生成的基础操作。OpenCascade(OCCT)作为强大的几何建模库,支持从离散的Edge(边)构建Wire,但在实际应用中,边的有序性直接影响构建的成功率。本文将详细探讨有序与无序两种场景下的实现方法,并提供完整代码示例。 一、有序…...
linux 开发小技巧之git增加指令别名
众所周知,git的指令执行时都得敲好几个字符才能补充上来,比如常用的git status,是不是要将全部的字符一个个地在键盘敲上来,有没有更懒惰点办法,可以将经常用到的git命令通过其他的别名的方式填充,比如刚刚…...
一文读懂如何使用MCP创建服务器
如果你对MCP(模型上下文协议)一窍不通,在阅读本篇文章之前(在获得对MCP深度认识之前),你可以理解为学习MCP就是在学习一个python工具库mcp,类似于其它python工具库一样,如numpy、sys…...
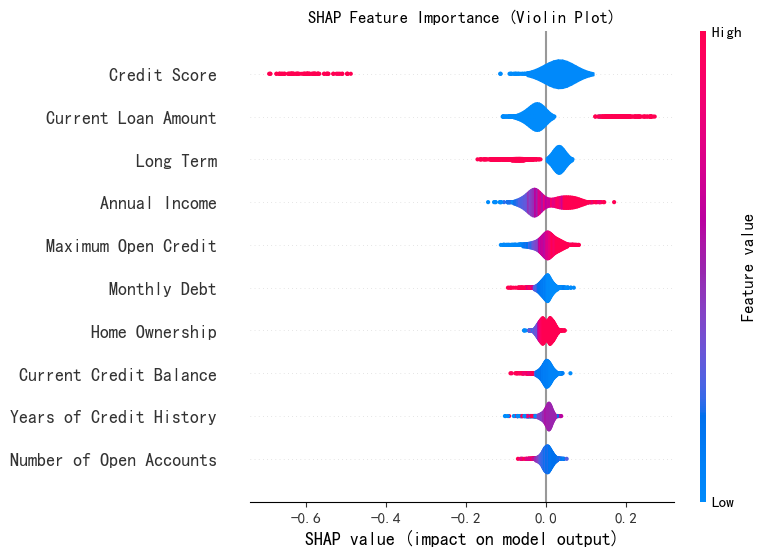
Python Day23 学习
继续SHAP图绘制的学习 1. SHAP特征重要性条形图 特征重要性条形图(Feature Importance Bar Plot)是 SHAP 提供的一种全局解释工具,用于展示模型中各个特征对预测结果的重要性。以下是详细解释: 图的含义 - 横轴:表示…...
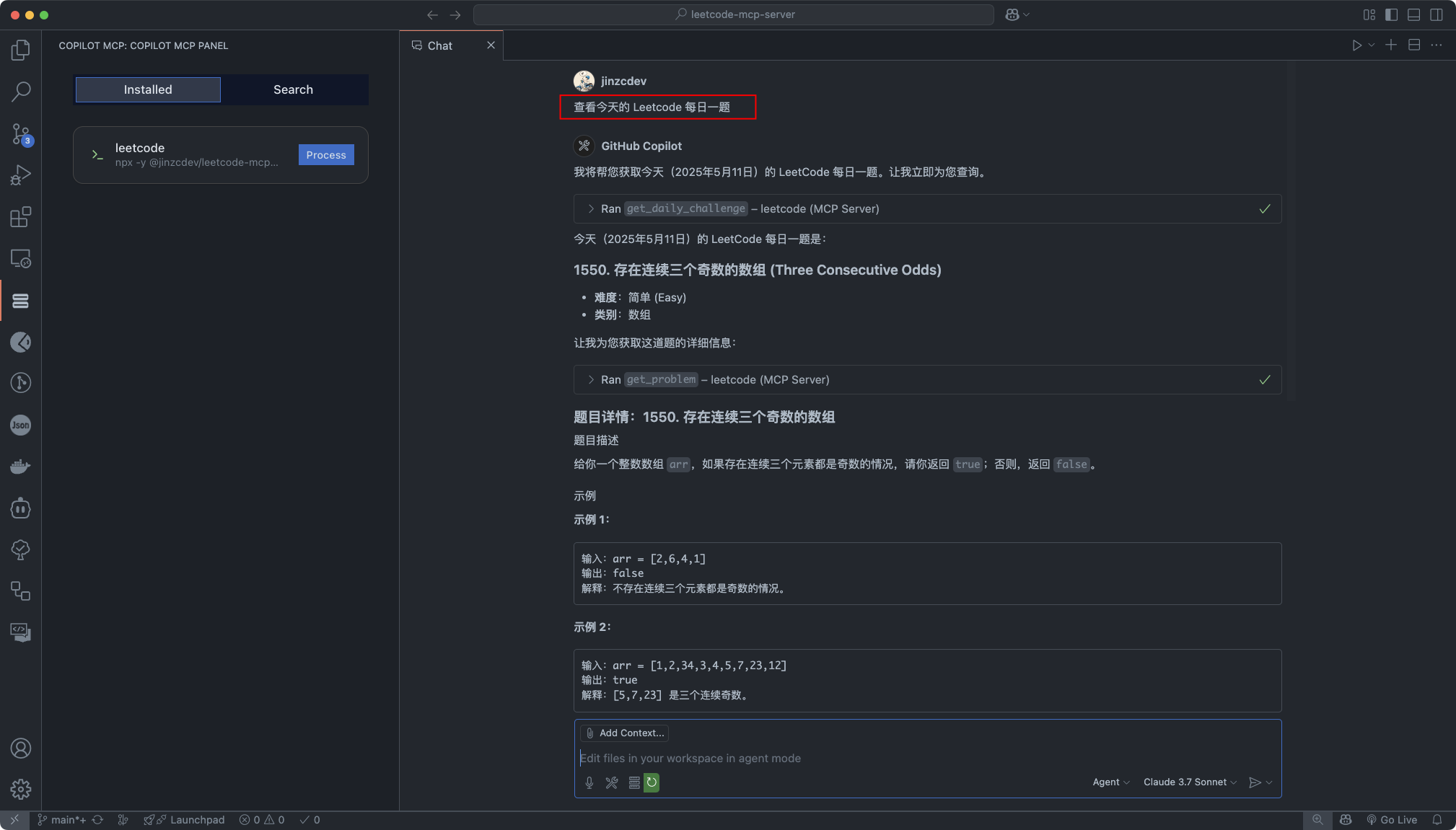
VS Code 重磅更新:全新 MCP 服务器发现中心上线
目前各种 MCP 客户端层出不穷,但是安装 MCP 服务却格外繁琐,尤其 VS Code 中无界面化的 MCP 服务配置方式,效率较低。 Copilot MCP 是一个 VS Code 插件,在今天发布的新版本中,插件支持了自动发现与安装开源 MCP 服务…...

Ubuntu 服务器管理命令笔记
这份命令笔记涵盖了 Ubuntu 服务器管理的各个方面,包括系统更新、用户管理、安全配置、网络诊断等,适合日常使用与技术分享。 系统管理命令 sudo apt update && sudo apt upgrade -y # 更新系统 sudo reboot …...

web 自动化之 Unittest 四大组件
文章目录 一、如何开展自动化测试1、项目需求分析,了解业务需求 web 功能纳入自动化测试2、选择何种方式实现自动化测试 二、Unittest 框架三、TestCase 测试用例四、TestFixture 测试夹具 执行测试用例前的前置操作及后置操作五、TestSuite 测试套件 & TestLoa…...
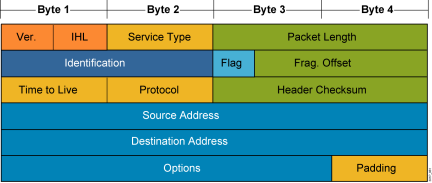
一、网络基础
IPv4:32位二进制 -- 点分十进制标识 192.168.1.1(连续的32位,为了好看方便每8位一段) IPv6:128位二进制 IP(Internet协议) 洪泛:除流量进入接口外的所有接口的复制 OSI模型&#…...

基于HTML+JavaScript+CSS实现教学网站
摘要 21世纪是信息化的时代,信息化物品不断地涌入我们的生活。同时,教育行业也产生了重大变革。传统的身心教授的模式,正在被替代。互联网模式的教育开辟了一片新的热土。 这算是对教育行业的一次重大挑战。截至目前,众多教育行…...
告别卡顿,图片查看界的“速度与激情”
嘿,小伙伴们!今天电脑天空给大家介绍一款超好用的图片查看神器——ImageGlass!这可不是普通的图片查看软件哦,它简直就是图片界的“全能王”。首先,它能打开的图片格式多到让你眼花缭乱,什么PNG、JPEG、GIF…...

基于STM32、HAL库的RN8209C电能计量芯片驱动程序设计
一、简介: RN8209C是一款高精度电能计量芯片,主要应用于单相电能表、智能插座、电力监控等领域。它具有以下特点: 支持全差分输入,可测量电压、电流、有功功率、无功功率、视在功率、功率因数等参数 内置24位Σ-Δ ADC,提供高精度测量 支持SPI和UART通信接口 内置温度传感…...

1 计算机网络
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言:点击跳转飞书文档[ 1. 第一章:概述:计网初识 ](https://zcny77krlrp8.feishu.cn/docx/U8T8d3PUOoMi7vxD4vGc8O51nrb)[2. 第…...
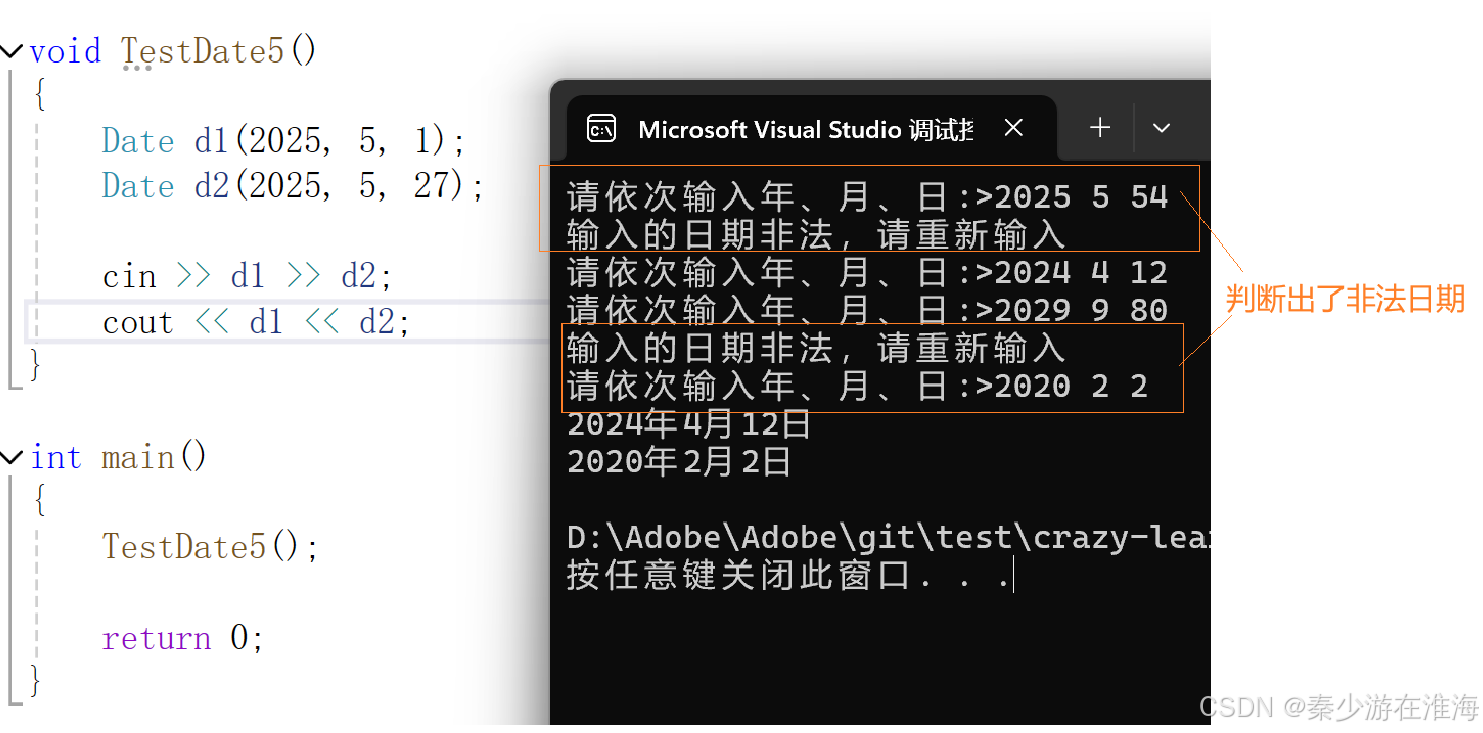
C++ - 类和对象 #日期类的实现
文章目录 前言 一、导言 二、构造 三、比较大小 1、实现大于 2、等于 3、大于等于 4、小于 5、小于等于 6、不等于 二、加减 1、加与加等 2、减与减等 3、、-- 4、日期-日期 三、流提取、流插入 1、流插入 2、流提取 四、日期类所有代码汇总 总结 前言 路…...

《 C++ 点滴漫谈: 三十七 》左值?右值?完美转发?C++ 引用的真相超乎你想象!
摘要 本文全面系统地讲解了 C 中的引用机制,涵盖左值引用、右值引用、引用折叠、完美转发等核心概念,并深入探讨其底层实现原理及工程实践应用。通过详细的示例与对比,读者不仅能掌握引用的语法规则和使用技巧,还能理解引用在性能…...
Redis 8.0携新功能,重新开源
01 引言 Redis从7.4版本起,将开源许可证改成 RSALv2(Redis 源代码可用许可证)与 SSPLv1(服务器端公共许可证)的双重授权策略。简单来说,就是不能随意商用。为了抵制Redis,Redis的替代品Valkey、…...
)
基于卡尔曼滤波的传感器融合技术的多传感器融合技术(附战场环境模拟可视化代码及应用说明)
基于卡尔曼滤波的传感器融合技术的多传感器融合技术(附战场环境模拟可视化代码及应用说明) 1 目标运动状态空间建模1.1 状态向量定义1.2 状态转移方程1.3 观测模型构建2 卡尔曼滤波核心算法实现2.1 初始化2.2 预测步骤2.3 更新步骤3 多传感器融合仿真验证3.1 传感器模型模拟3…...
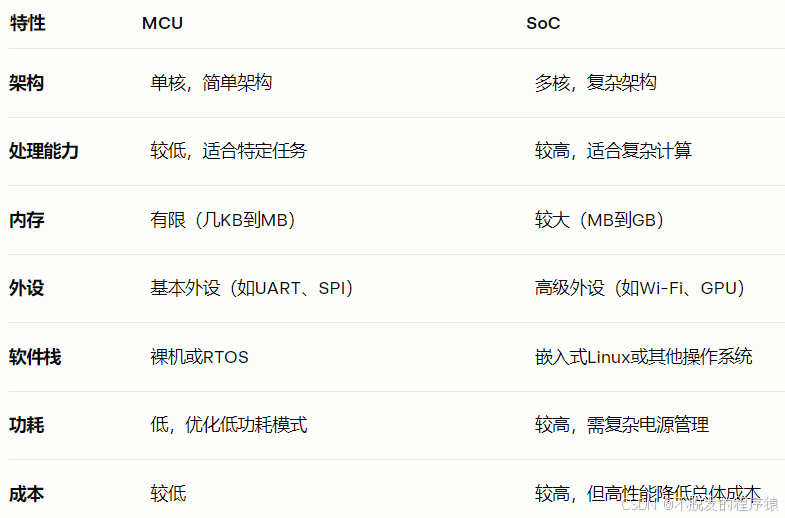
从MCU到SoC的开发思维转变
目录 1、硬件设计 2、软件开发 3、调试与测试 4、电源管理 微控制器单元(MCU)和系统级芯片(SoC)是嵌入式开发中最常见的两种处理器类型。MCU以其简单、低功耗的特点,广泛应用于特定控制任务;而SoC凭借强…...
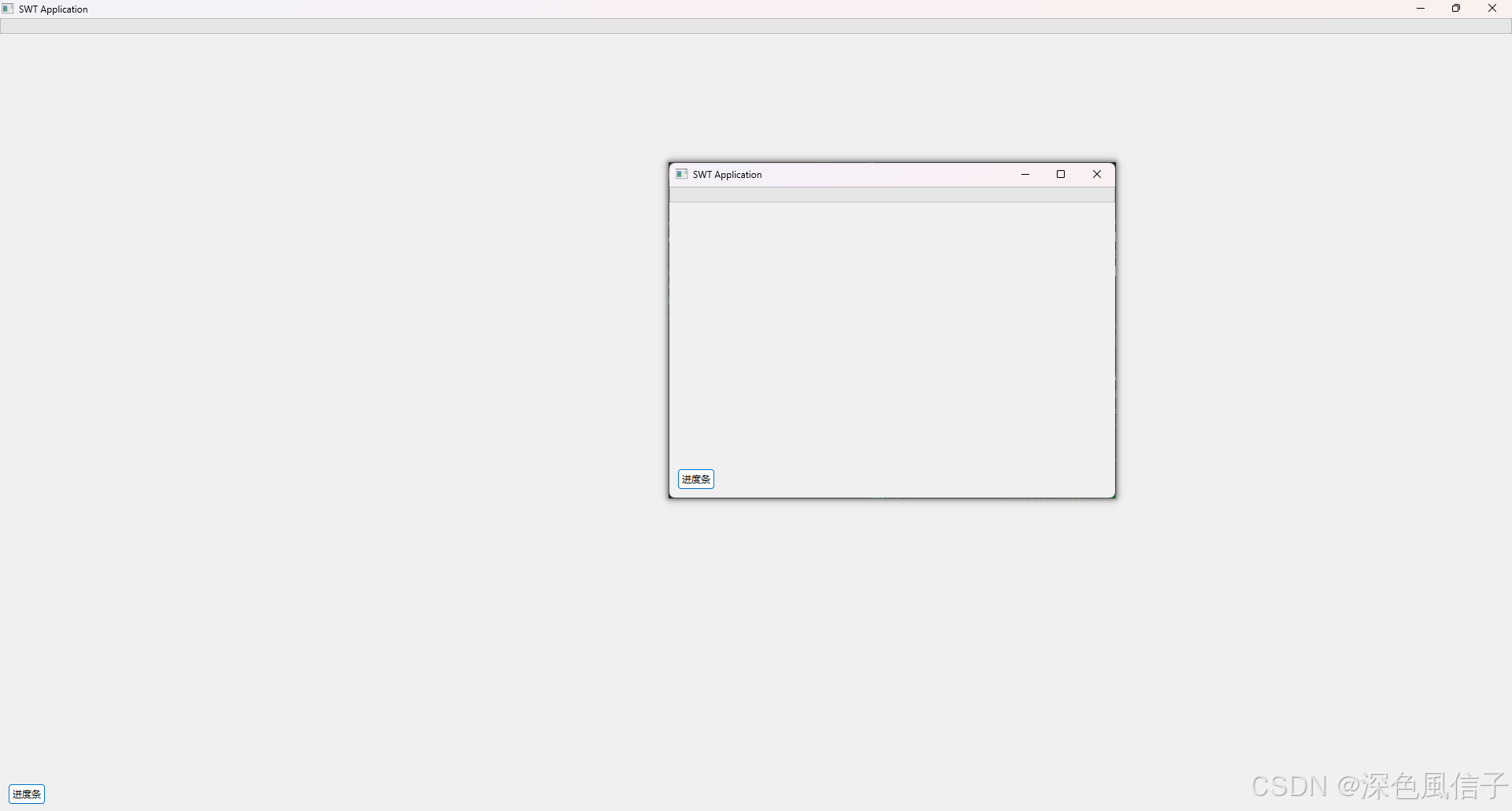
Eclipse SWT 1 等比缩放
Eclipse SWT 1 等比缩放 1 布局方式2 测试代码 1 布局方式 布局名称特点说明适合场景AbsoluteLayout绝对定位,控件位置和大小完全由开发者手动设置。特殊定制界面、不规则排版FillLayout简单线性布局,将所有子控件填满容器(水平或垂直方向&a…...