利用“Flower”实现联邦机器学习的实战指南
一个很尴尬的现状就是我们用于训练 AI 模型的数据快要用完了。所以我们在大量的使用合成数据!
据估计,目前公开可用的高质量训练标记大约有 40 万亿到 90 万亿个,其中流行的 FineWeb 数据集包含 15 万亿个标记,仅限于英语。
作为参考,最近发布的 Llama 4 在文本、图像和视频数据集上进行了预训练,使用的标记数量超过 30 万亿个,是 Llama 3 的两倍多。
这让我们意识到,我们距离训练数据达到极限可能只有几年的时间了。
但那真的是极限吗?私人数据集呢?
这些数据集的规模可能是公开数据集的 10 到 20 倍(甚至更多),所有存储的消息中大约有 650 万亿个标记,电子邮件中大约有 1200 万亿个标记。
令人惊讶的是,许多公司收集的大量数据从未被分析过,因此被称为暗数据(Dark data)。
再想想政府机构、医院、律师事务所、金融机构、用户设备等存储的数据。
我同意这些数据是敏感的,而且有严格的数据保护法规来规范其处理方式。
其中大部分数据可能确实不适合用于训练机器学习模型,但肯定有一部分数据可以为人类和组织带来巨大价值。
如果有一种方法可以在不共享数据本身的情况下,使用多个组织的敏感合规数据来训练机器学习模型,那该多好啊!
这就是联邦机器学习(Federated Machine Learning)的用武之地!
接下来,我们将深入探讨联邦机器学习是什么,它是如何工作的,然后编写一个联邦学习流程,使用多个医疗机构的数据安全地训练一个可以检测眼部疾病的机器学习模型。
让我们开始吧!
但是,联邦机器学习到底是什么?
为了理解联邦机器学习是什么,我们先来看看传统的机器学习模型训练方法。
举个例子,我们想训练一个可以检测 CT 扫描图像中癌症的机器学习模型。
第一步是收集来自不同地理位置的多家医院的正常和癌症患者的 CT 扫描图像。
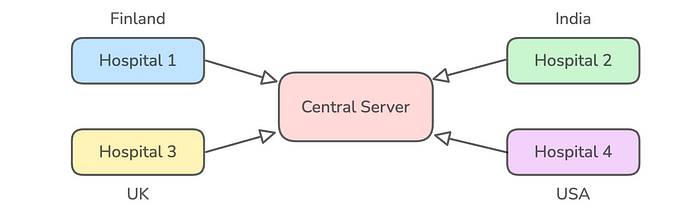
选择多样化数据源的原因是:
- 增加样本量;
- 减少由于不同因素(包括人口统计、专家和机构因素)导致的偏差。
这使得我们的模型即使对于训练数据集中未充分代表的群体也能具有泛化能力。
一旦这些数据被收集到一个中央的强大服务器上,我们就可以使用这些数据来训练模型并对其进行评估。
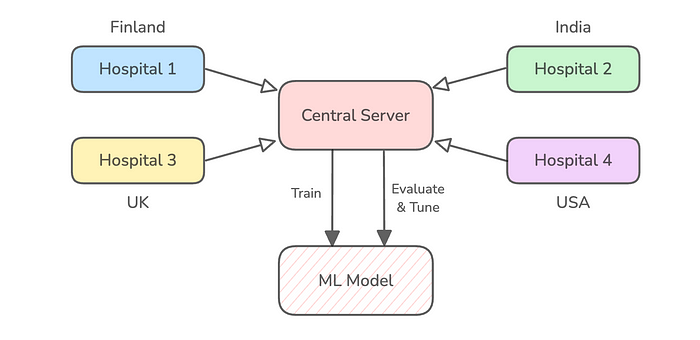
你能发现这种方法有哪些问题,使得执行起来几乎不可能吗?
首先,敏感的医疗数据受到法律(如GDPR和HIPAA)的严格监管,这使得将这些数据传输到中央服务器变得非常困难。
其次,中央服务器必须有足够的计算和存储资源来处理这些数据和训练,这使得这种方法非常昂贵。
如果我们反过来,不是把数据移动到训练中,而是把训练移动到数据那里呢?
这就是联邦机器学习做的事情。
联邦机器学习是一种机器学习技术,多个组织可以在去中心化的方式下协作训练机器学习模型,而无需共享他们的数据集。
以下是使用这种方法的步骤:
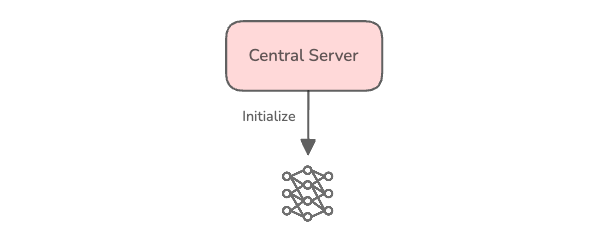
- 在中央服务器上初始化一个基础/全局模型。
- 将该模型的参数发送到参与组织的服务器(称为客户端/节点),这些服务器包含本地数据。
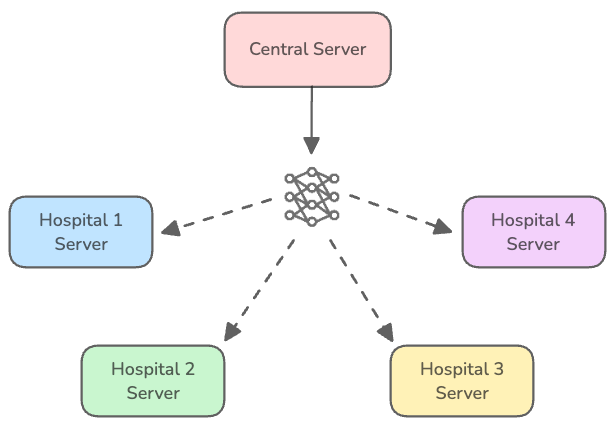
- 每个客户端在其本地数据上训练模型一段时间(不是直到模型收敛,而是进行几步/一到几个周期)。
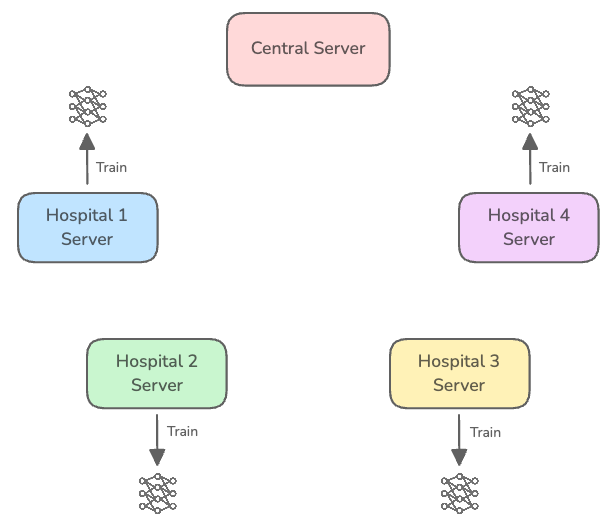
- 在本地训练完成后,每个客户端将其模型参数或累积的梯度发送回中央服务器。
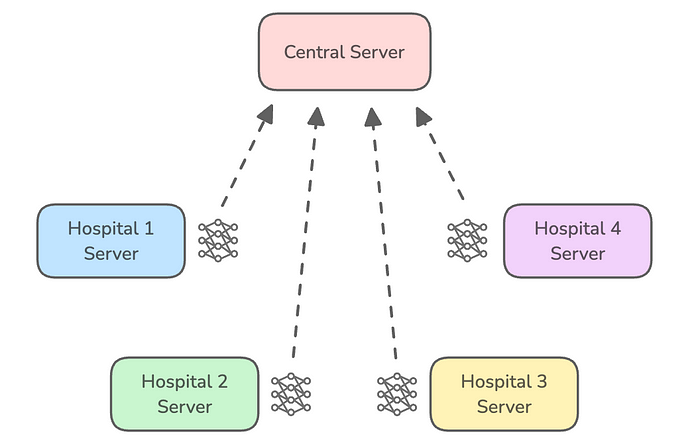
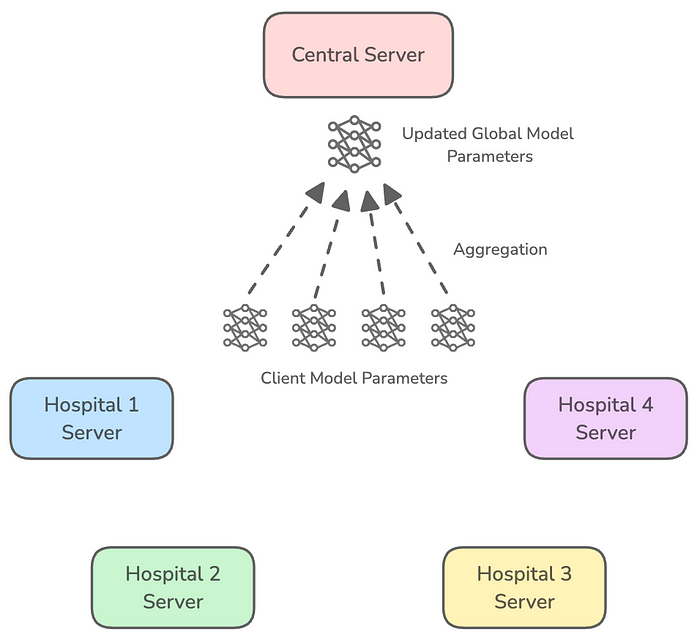
- 由于每个客户端的参数因在不同的本地数据集上训练而与其他客户端不同,因此需要通过一个称为聚合的过程将它们结合起来。聚合的结果用于更新基础/全局模型的参数。
可以使用多种技术进行聚合,其中一种流行的方法是联邦平均(Federated Averaging)。
更新后的全局模型参数 = ∑ i = 1 N 客户端 i 的更新参数 × 客户端 i 的数据量 ∑ i = 1 N 客户端 i 的数据量 \text{更新后的全局模型参数} = \frac{\sum_{i=1}^{N} \text{客户端 } i \text{ 的更新参数} \times \text{客户端 } i \text{ 的数据量}}{\sum_{i=1}^{N} \text{客户端 } i \text{ 的数据量}} 更新后的全局模型参数=∑i=1N客户端 i 的数据量∑i=1N客户端 i 的更新参数×客户端 i 的数据量
在这种方法中,不同客户端的更新会被平均,并根据每个客户端用于训练的数据点数量进行加权。
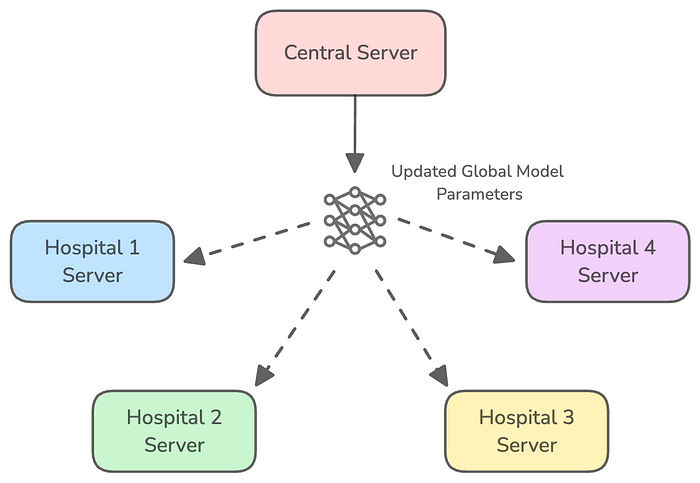
- 更新后的基础模型参数被发送回客户端,然后重复上述训练过程,直到获得一个完全训练好的模型。
你有没有注意到联邦机器学习带来的优势?
首先,数据保留在其生成的地方,从未被传输到一个中央位置,这使得这种方法是去中心化的。
其次,减少了对单一强大基础设施的需求,因为计算是在所有参与服务器之间共享的。
最后,我们有一种称为差分隐私(Differential Privacy)的技术,可以保护客户端数据的隐私。
这是一种技术,通过它,无法从联邦学习过程中共享的模型更新中识别出关于单个数据点的敏感信息。
为了实现差分隐私,使用了两种过程:
- 裁剪客户端模型更新,以限制单个数据点的影响;
- 加噪,即在裁剪后的更新中添加校准后的噪声。
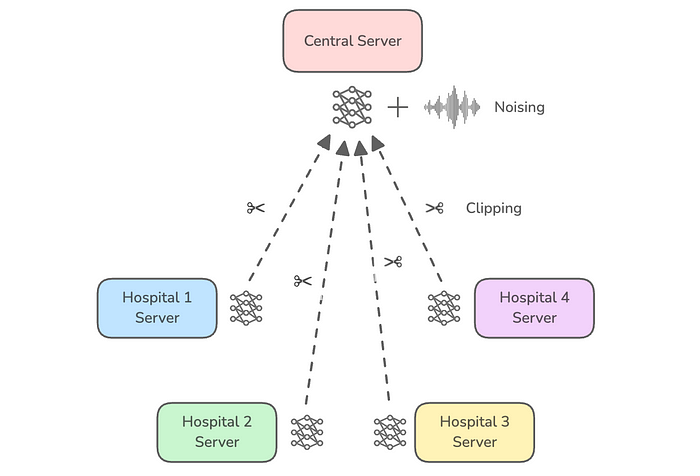
根据这些过程发生的位置,我们有:
- 中央差分隐私:中央服务器在全局参数上进行加噪,这些全局参数是通过接收客户端的裁剪更新进行聚合的,或者是由中央服务器进行裁剪的。
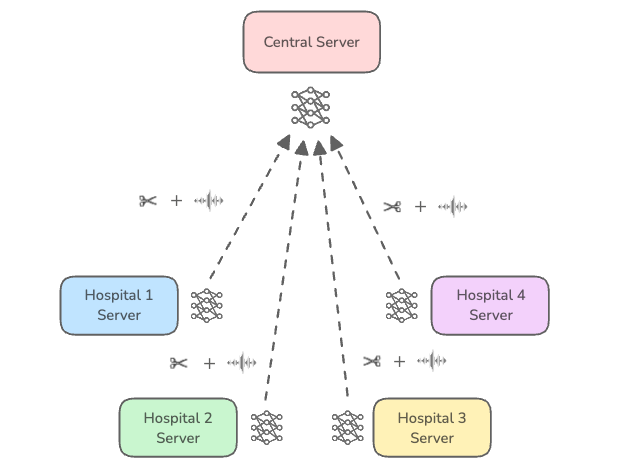
- 本地差分隐私:每个客户端在将模型更新发送到中央服务器之前,本地应用裁剪和加噪。
训练你的第一个联邦学习机器学习模型
现在你已经了解了联邦机器学习的基础知识,是时候动手实践并编写一些代码了。
视网膜疾病影响着全球数亿人,是导致视力丧失和失明的主要原因之一。
**光学相干断层扫描(OCT)**可以为我们提供视网膜及其他眼层的详细横截面图像。
利用这些图像,我们的目标是训练一个机器学习模型,能够区分健康视网膜和受疾病影响的视网膜。
本教程中的所有代码都是使用 PyTorch 框架在 Jupyter 笔记本中编写的。
下载并探索数据集
我们将使用的数据集名为 OCTMNIST。
它是 MedMNIST 数据集的一个子集,包含 109,309 张大小为 28 × 28 像素的灰度、居中裁剪的视网膜 OCT 图像。
OCTMNIST 是一个多分类数据集,包含以下类别/标签:
- 脉络膜新生血管(CNV)
- 糖尿病性黄斑水肿(DME)
- 玻璃膜疣(Drusen)
- 正常
我们先在 Jupyter 笔记本中安装 medmnist 包,并获取有关 OCTMNIST 数据集的一些信息。
!uv pip install medmnist
from medmnist import INFO# 获取 OCTMNIST 数据集信息
info = INFO["octmnist"]print("数据集类型: ", info["task"])
print("数据集标签: ", info["label"])
print("图像通道数: ", info["n_channels"])
print("训练样本数量: ", info["n_samples"]["train"])
print("验证样本数量: ", info["n_samples"]["val"])
print("测试样本数量: ", info["n_samples"]["test"])
输出结果如下:
数据集类型: 多分类
数据集标签: {'0': '脉络膜新生血管','1': '糖尿病性黄斑水肿', '2': '玻璃膜疣', '3': '正常'}
图像通道数: 1
训练样本数量: 97477
验证样本数量: 10832
测试样本数量: 1000
接下来,我们下载这个数据集,对其应用转换,并绘制其中的一些图像。
!uv pip install torch torchvision
import torch# 如果可用,使用 GPU
if torch.backends.mps.is_available():device = torch.device("mps")
elif torch.cuda.is_available():device = torch.device("cuda")
else:device = torch.device("cpu")print(f"使用设备: {device}")
from torchvision import transforms
from medmnist import OCTMNIST# 定义转换
transform = transforms.ToTensor()# 下载数据集,大小为 64 x 64
train_dataset = OCTMNIST(split='train', transform=transform, download=True, size=64)
val_dataset = OCTMNIST(split='val', transform=transform, download=True, size=64)
test_dataset = OCTMNIST(split='test', transform=transform, download=True, size=64)
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt# 定义标签映射
label_map = {0: '脉络膜新生血管',1: '糖尿病性黄斑水肿',2: '玻璃膜疣',3: '正常'
}# 从数据加载器中获取一批数据
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
images, labels = next(iter(train_loader))# 在 3 x 3 网格中绘制
rows, cols = 3, 3
fig, axes = plt.subplots(rows, cols, figsize=(5, 5))for i in range(rows * cols):ax = axes[i // cols, i % cols]ax.imshow(images[i][0], cmap='gray')ax.set_title(label_map[int(labels[i].item())], fontsize=6)ax.axis('off')plt.tight_layout()
plt.show()
将数据集拆分为子集
现实世界中的医疗数据通常存在类别不平衡和偏差。
为了模拟这种情况,我们将 OCTMNIST 数据集拆分为三个子集。
可以将这些子集视为属于三家不同医院的数据集,每个子集都排除了一种眼部疾病标签。
from torch.utils.data import Subset# 创建子数据集
def create_sub_datasets(full_dataset):targets = torch.tensor([label.item() for _, label in full_dataset])mask_A = (targets == 0) | (targets == 2) | (targets == 3)mask_B = (targets == 0) | (targets == 1) | (targets == 3)mask_C = (targets == 1) | (targets == 2) | (targets == 3)indices_A = mask_A.nonzero(as_tuple=True)[0]indices_B = mask_B.nonzero(as_tuple=True)[0]indices_C = mask_C.nonzero(as_tuple=True)[0]dataset_A = Subset(train_dataset, indices_A) # 包含:CNV、DRUSEN、NORMAL(排除 DME)dataset_B = Subset(train_dataset, indices_B) # 包含:CNV、DME、NORMAL(排除 DRUSEN)dataset_C = Subset(train_dataset, indices_C) # 包含:DME、DRUSEN、NORMAL(排除 CNV)return [dataset_A, dataset_B, dataset_C]dataset_A, dataset_B, dataset_C = create_sub_datasets(train_dataset)
接下来,我们定义一个 ResNet-18 模型,用于将图像分类到相应的类别中。
from torchvision.models import resnet18, ResNet18_Weights
import torch.nn as nn# ResNet-18
def get_resnet_model(num_classes=4):model = resnet18(weights=ResNet18_Weights.DEFAULT)# 修改第一层卷积层以接受 1 通道输入model.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)# 替换最终的全连接层model.fc = nn.Linear(model.fc.in_features, num_classes)return model.to(device)
训练与评估
为了模拟在每个医院使用本地数据进行训练,我们在之前定义的子数据集上分别训练三个 ResNet 模型。
以下是训练和评估的函数。
!uv pip install tqdm
import torch.optim as optim
from tqdm import tqdm# 训练函数
def train_model(model, criterion, optimizer, train_loader, val_loader, epochs=10):for epoch in range(epochs):model.train()running_correct, running_total = 0, 0loop = tqdm(train_loader, desc=f"Epoch [{epoch+1}/{epochs}]", leave=False)for images, labels in loop:images = images.to(device)labels = labels.squeeze().long().to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()preds = torch.argmax(outputs, dim=1)running_correct += (preds == labels).sum().item()running_total += labels.size(0)loop.set_postfix(loss=loss.item(), acc=running_correct / running_total)train_acc = running_correct / running_totalval_acc = evaluate_model(model, val_loader)print(f"Epoch [{epoch+1}/{epochs}] Train Acc: {train_acc:.4f} Val Acc: {val_acc:.4f}")# 评估函数
def evaluate_model(model, test_loader):model.eval()correct, total = 0, 0with torch.no_grad():for images, labels in test_loader:images = images.to(device)labels = labels.squeeze().to(device)outputs = model(images)preds = torch.argmax(outputs, dim=1)correct += (preds == labels).sum().item()total += labels.size(0)return correct / total
# 在子数据集上训练的函数
def train_on_subset(subset_dataset, val_loader, epochs=10):loader = DataLoader(subset_dataset, batch_size=64, shuffle=True)model = get_resnet_model()criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)train_model(model, criterion, optimizer, loader, val_loader, epochs)return model
# 在子数据集上评估的函数
def evaluate_on_test(model, test_loader):model.eval()all_preds = []all_labels = []with torch.no_grad():for images, labels in test_loader:images = images.to(device)labels = labels.squeeze().to(device)outputs = model(images)preds = torch.argmax(outputs, dim=1)all_preds.extend(preds.cpu().numpy())all_labels.extend(labels.cpu().numpy())acc = sum([p == t for p, t in zip(all_preds, all_labels)]) / len(all_labels)return acc, all_preds, all_labels
是时候训练这些模型了!
# 在子数据集上训练模型
val_loader = DataLoader(val_dataset, batch_size=64)model_A = train_on_subset(dataset_A, val_loader)
model_B = train_on_subset(dataset_B, val_loader)
model_C = train_on_subset(dataset_C, val_loader)
训练过程的输出如下:
Epoch [1/10] Train Acc: 0.9162 Val Acc: 0.8073
Epoch [2/10] Train Acc: 0.9454 Val Acc: 0.8477
Epoch [3/10] Train Acc: 0.9526 Val Acc: 0.8588
Epoch [4/10] Train Acc: 0.9587 Val Acc: 0.8509
Epoch [5/10] Train Acc: 0.9597 Val Acc: 0.8574
Epoch [6/10] Train Acc: 0.9671 Val Acc: 0.8619
Epoch [7/10] Train Acc: 0.9700 Val Acc: 0.8629
Epoch [8/10] Train Acc: 0.9747 Val Acc: 0.8623
Epoch [9/10] Train Acc: 0.9774 Val Acc: 0.8541
Epoch [10/10] Train Acc: 0.9787 Val Acc: 0.8647
Epoch [1/10] Train Acc: 0.9466 Val Acc: 0.8498
Epoch [2/10] Train Acc: 0.9725 Val Acc: 0.8988
Epoch [3/10] Train Acc: 0.9780 Val Acc: 0.8967
Epoch [4/10] Train Acc: 0.9816 Val Acc: 0.9027
Epoch [5/10] Train Acc: 0.9841 Val Acc: 0.9031
Epoch [6/10] Train Acc: 0.9854 Val Acc: 0.8917
Epoch [7/10] Train Acc: 0.9881 Val Acc: 0.9060
Epoch [8/10] Train Acc: 0.9899 Val Acc: 0.9060
Epoch [9/10] Train Acc: 0.9911 Val Acc: 0.9053
Epoch [10/10] Train Acc: 0.9930 Val Acc: 0.9005
Epoch [1/10] Train Acc: 0.9001 Val Acc: 0.6071
Epoch [2/10] Train Acc: 0.9429 Val Acc: 0.6188
Epoch [3/10] Train Acc: 0.9531 Val Acc: 0.6117
Epoch [4/10] Train Acc: 0.9509 Val Acc: 0.6280
Epoch [5/10] Train Acc: 0.9610 Val Acc: 0.6289
Epoch [6/10] Train Acc: 0.9649 Val Acc: 0.6283
Epoch [7/10] Train Acc: 0.9675 Val Acc: 0.6265
Epoch [8/10] Train Acc: 0.9699 Val Acc: 0.6321
Epoch [9/10] Train Acc: 0.9750 Val Acc: 0.6330
Epoch [10/10] Train Acc: 0.9768 Val Acc: 0.6363
然后,我们在完整的测试集上测试这些模型的性能(这将是我们在实际应用中运行模型的情况)。
# 在完整测试集上评估
test_loader = DataLoader(test_dataset, batch_size=64)acc_A, preds_A, labels_A = evaluate_on_test(model_A, test_loader)
acc_B, preds_B, labels_B = evaluate_on_test(model_B, test_loader)
acc_C, preds_C, labels_C = evaluate_on_test(model_C, test_loader)# 报告准确率
print(f"测试准确率 | 在排除 DME 的数据集上训练的模型: {acc_A:.4f}")
print(f"测试准确率 | 在排除 DRUSEN 的数据集上训练的模型: {acc_B:.4f}")
print(f"测试准确率 | 在排除 CNV 的数据集上训练的模型: {acc_C:.4f}")
输出结果如下:
测试准确率 | 在排除 DME 的数据集上训练的模型: 0.6420
测试准确率 | 在排除 DRUSEN 的数据集上训练的模型: 0.7080
测试准确率 | 在排除 CNV 的数据集上训练的模型: 0.7030
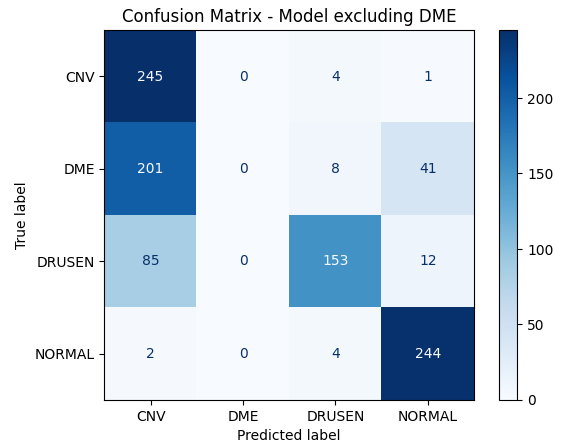
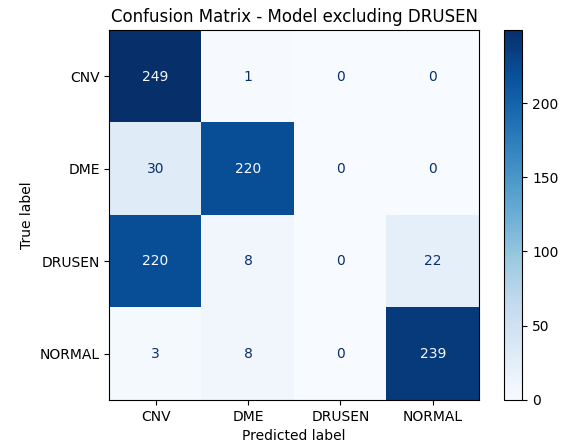
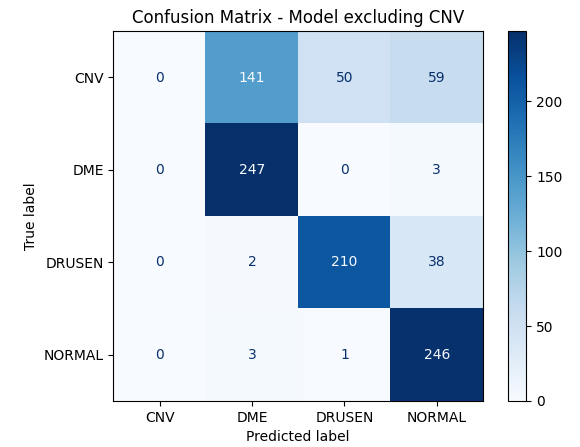
我们可以看到,这些模型在测试数据集中未见过的类别上表现不佳。
当我们绘制混淆矩阵并可视化结果时,这一点更加明显。
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplaydef plot_confusion_matrix(y_true, y_pred, title):cm = confusion_matrix(y_true, y_pred, labels=[0,1,2,3])disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=["CNV", "DME", "DRUSEN", "NORMAL"])disp.plot(cmap=plt.cm.Blues)plt.title(title)plt.show()# 绘制混淆矩阵
plot_confusion_matrix(labels_A, preds_A, "混淆矩阵 - 排除 DME 的模型")
plot_confusion_matrix(labels_B, preds_B, "混淆矩阵 - 排除 DRUSEN 的模型")
plot_confusion_matrix(labels_C, preds_C, "混淆矩阵 - 排除 CNV 的模型")
在子数据集上进行联邦学习
现在轮到联邦学习大显身手了。
我们使用 Flower 框架,它允许我们使用任何机器学习框架和任何编程语言进行联邦学习、分析和评估。
我仍然使用 PyTorch 框架进行本教程,以使其对大多数人更易于理解。
我使用的是 MacBook M4 Max 来运行以下代码,但如果你在 Google Colab 上使用 T4 GPU,这将报错。
这是因为 Colab 只将一个 GPU 暴露给主笔记本进程。当 Flower(使用 Ray 作为其默认后端运行模拟)为每个模拟客户端启动额外的 Python 工作进程时,这些工作进程无法访问 GPU,程序就会崩溃。
如果你想在 Google Colab 上运行代码,建议使用 CPU 作为设备。不过,这会使训练变得非常缓慢。
安装 Flower 包
!uv pip install "flwr[simulation]"
回顾一下我们之前学到的内容,在联邦学习过程中,客户端和中央服务器之间会交换模型参数/权重。
当客户端从中央服务器接收到模型参数时,它将使用这些参数/权重更新其本地模型。
训练完成后,它将这些本地模型参数/权重发送回中央服务器。
定义客户端函数
两个函数可以帮助我们执行这些操作:
get_weights:此函数用于训练完成后获取客户端模型的更新权重,并将其发送回中央服务器。
它接受一个机器学习模型的引用,迭代其 state_dict 中的项,将每个项转换为 Numpy ndarray,并返回这些 ndarray 的列表。
# 获取客户端模型的更新权重
def get_weights(net):return [val.cpu().numpy() for _, val in net.state_dict().items()]
set_weights:此函数用于在训练开始之前,使用从中央服务器收到的新权重更新客户端模型的权重。
它接受一个机器学习模型的引用和一个 ndarray 列表。使用这个列表,它更新模型 state_dict 中的所有项。
from collections import OrderedDict# 更新客户端模型的权重
def set_weights(net, parameters):params_dict = zip(net.state_dict().keys(), parameters)state_dict = OrderedDict({k: torch.tensor(v) for k, v in params_dict})net.load_state_dict(state_dict, strict=True)
接下来,我们定义一个 FlowerClient 类,它将帮助我们在客户端上训练和评估模型。
from flwr.client import NumPyClient
from typing import Dict
from flwr.common import NDArrays, Scalar# Flower 客户端
class FlowerClient(NumPyClient):def __init__(self, net, trainset, valset, testset):self.net = netself.trainset = trainsetself.valset = valsetself.testset = testset# 本地训练def fit(self, parameters, config):set_weights(self.net, parameters)# 数据加载器train_loader = DataLoader(self.trainset, batch_size=64, shuffle=True)val_loader = DataLoader(self.valset, batch_size=64)# 损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(self.net.parameters(), lr=0.001)train_model(self.net,criterion,optimizer,train_loader,val_loader,epochs= 1,)return get_weights(self.net), len(self.trainset), {}# 本地评估def evaluate(self, parameters, config):set_weights(self.net, parameters)loss, acc = evaluate_model(self.net, DataLoader(self.testset, batch_size=64))return loss, len(self.testset), {"accuracy": acc}
client_fn 函数帮助我们根据需要创建此类的实例。
ClientApp 作为客户端逻辑的入口点,当 Flower 客户端从中央服务器接收任务时运行。
from flwr.client import Client, ClientApp
from flwr.common import Contexttrain_sets = [dataset_A, dataset_B, dataset_C]# 创建客户端的函数
def client_fn(context: Context) -> Client:cid = int(context.node_config["partition-id"])trainset = train_sets[cid]return FlowerClient(get_resnet_model(),trainset,val_dataset,test_dataset,).to_client()client = ClientApp(client_fn)
这就是客户端需要的所有内容。
定义服务器函数
接下来,我们定义一个 evaluate 函数,中央服务器在每轮联邦学习之后使用它来评估全局模型。
我们还定义了一个名为 filter_by_classes 的函数,它返回一个测试集的子集,其中只包含指定类别列表中的样本。
这有助于我们在每个客户端可用的类别子集上测试模型。
def filter_by_classes(dataset, class_list):indices = [i for i, (_, label) in enumerate(dataset) if label.item() in class_list]return Subset(dataset, indices)# 包含:CNV、DRUSEN、NORMAL - 排除:DME
testset_no_dme = filter_by_classes(test_dataset, [0, 2, 3])# 包含:CNV、DME、NORMAL - 排除:DRUSEN
testset_no_drusen = filter_by_classes(test_dataset, [0, 1, 3])# 包含:DME、DRUSEN、NORMAL - 排除:CNV
testset_no_cnv = filter_by_classes(test_dataset, [1, 2, 3])
# 评估全局模型
def evaluate(server_round, parameters, config, num_rounds = 20):net = get_resnet_model()set_weights(net, parameters)batch_size = 64acc_tot = evaluate_model(net, DataLoader(test_dataset, batch_size=batch_size))acc_A = evaluate_model(net, DataLoader(testset_no_dme, batch_size=batch_size))acc_B = evaluate_model(net, DataLoader(testset_no_drusen, batch_size=batch_size))acc_C = evaluate_model(net, DataLoader(testset_no_cnv, batch_size=batch_size))print(f"[Round {server_round}] 全局准确率: {acc_tot:.4f}")print(f"[Round {server_round}] (CNV,DRUSEN,NORMAL) 准确率: {acc_A:.4f}")print(f"[Round {server_round}] (CNV,DME,NORMAL) 准确率: {acc_B:.4f}")print(f"[Round {server_round}] (DME,DRUSEN,NORMAL) 准确率: {acc_C:.4f}")# 在最后一轮绘制混淆矩阵if server_round == num_rounds:acc_final, preds_final, labels_final = evaluate_on_test(net, DataLoader(test_dataset, batch_size=64))plot_confusion_matrix(labels_final, preds_final, "最终全局混淆矩阵")
接下来,使用 server_fn 函数,我们设置中央服务器,它使用联邦平均聚合策略。
from flwr.common import ndarrays_to_parameters
from flwr.server import ServerApp, ServerAppComponents, ServerConfig
from flwr.server.strategy import FedAvgnet = get_resnet_model()
params = ndarrays_to_parameters(get_weights(net))# 设置全局服务器的函数
def server_fn(context: Context, num_rounds = 5):# 联邦平均策略strategy = FedAvg(fraction_fit=1.0,fraction_evaluate=0.0,initial_parameters=params,evaluate_fn=evaluate,)config=ServerConfig(num_rounds)return ServerAppComponents(strategy=strategy,config=config,)server = ServerApp(server_fn=server_fn)
现在我们已经准备好训练我们的机器学习模型了。
训练与评估
为了模拟在三个客户端上的训练,我们使用 run_simulation 函数如下:
from flwr.simulation import run_simulation
from logging import ERROR# 为了保持日志输出简洁
backend_setup = {"init_args": {"logging_level": ERROR, "log_to_driver": False}}# 运行训练模拟
run_simulation(server_app=server,client_app=client,num_supernodes=3,backend_config=backend_setup,
)
以下是经过 20 轮联邦学习后的结果。
INFO : aggregate_fit: received 3 results and 0 failures
[Round 20] 全局准确率: 0.7710
[Round 20] (CNV,DRUSEN,NORMAL) 准确率: 0.7933
[Round 20] (CNV,DME,NORMAL) 准确率: 0.8947
[Round 20] (DME,DRUSEN,NORMAL) 准确率: 0.6960
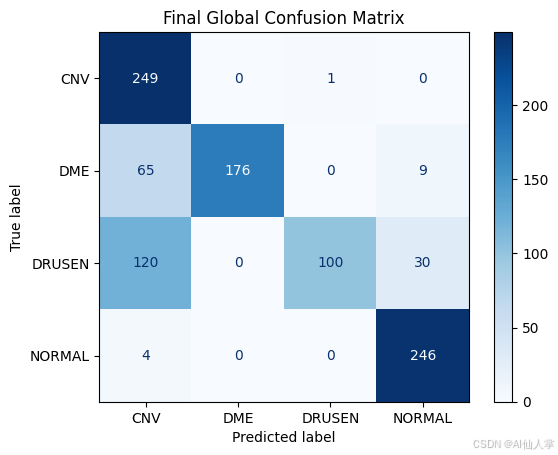
模型在每个客户端的标签分布过滤后的测试数据集上表现良好(如三个测试子集的准确率所示)。
最棒的是,尽管每个客户端在其本地数据集中缺少一个疾病标签,全局模型仍然能够很好地识别所有标签(如完整测试集上的全局准确率所示)。
请注意,训练并不完美,还需要进一步优化和调整超参数以获得更好的结果。
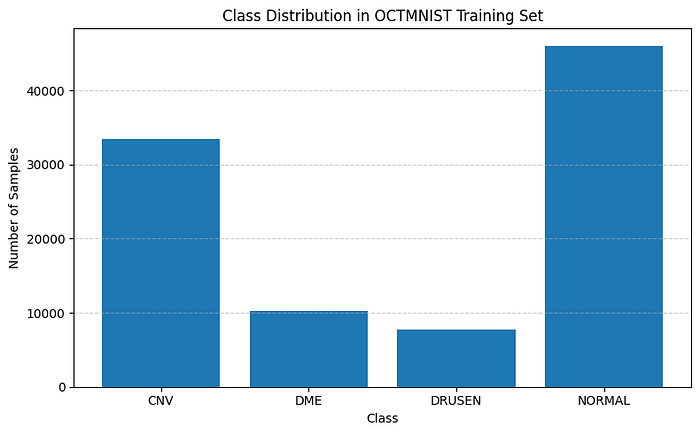
数据集本身也存在类别不平衡问题,正常 OCT 图像的样本最多,而玻璃膜疣(Drusen)的样本最少,这可能解释了在最终全局混淆矩阵中对这一标签的误分类。
我们可以通过绘制 OCTMNIST 训练集中的类别分布来观察类别不平衡。
# 检查类别不平衡import matplotlib.pyplot as plt
from collections import Counter# 统计类别出现次数
labels = [label.item() for _, label in train_dataset]
class_counts = Counter(labels)
print(class_counts)# 准备绘图数据
class_names = ['CNV', 'DME', 'DRUSEN', 'NORMAL']
counts = [class_counts[i] for i in range(4)]# 绘图
plt.figure(figsize=(8, 5))
plt.bar(class_names, counts)
plt.title("OCTMNIST 训练集中的类别分布")
plt.xlabel("类别")
plt.ylabel("样本数量")
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()
阅读参考
- Flower 框架文档
- DeepLearning.ai 上的“联邦学习入门”课程
- 具有差分隐私的 Gboard 语言模型的联邦学习
相关文章:
利用“Flower”实现联邦机器学习的实战指南
一个很尴尬的现状就是我们用于训练 AI 模型的数据快要用完了。所以我们在大量的使用合成数据! 据估计,目前公开可用的高质量训练标记大约有 40 万亿到 90 万亿个,其中流行的 FineWeb 数据集包含 15 万亿个标记,仅限于英语。 作为…...

MongoDB使用x.509证书认证
文章目录 自定义证书生成CA证书生成服务器之间的证书生成集群证书生成用户证书 MongoDB配置java使用x.509证书连接MongoDBMongoShell使用证书连接 8.0版本的mongodb开启复制集,配置证书认证 自定义证书 生成CA证书 生成ca私钥: openssl genrsa -out ca…...

创始人 IP 的破局之道:从技术突围到生态重构的时代启示|创客匠人评述
在 2025 年的商业版图上,创始人 IP 正以前所未有的深度介入产业变革。当奥雅股份联合创始人李方悦在 “中国上市公司品牌价值榜” 发布会上,将 IP 赋能与城市更新大模型结合时,当马斯克在特斯拉财报电话会议上宣称 “未来属于自动驾驶和人形机…...

Gin 框架入门
Gin 框架入门 一、响应数据 JSON 响应 在 Web 开发中,JSON 是一种常用的数据交换格式。Gin 提供了简便的方法来响应 JSON 数据。 package mainimport ("github.com/gin-gonic/gin" )func main() {r : gin.Default()r.GET("/json", func(c *…...
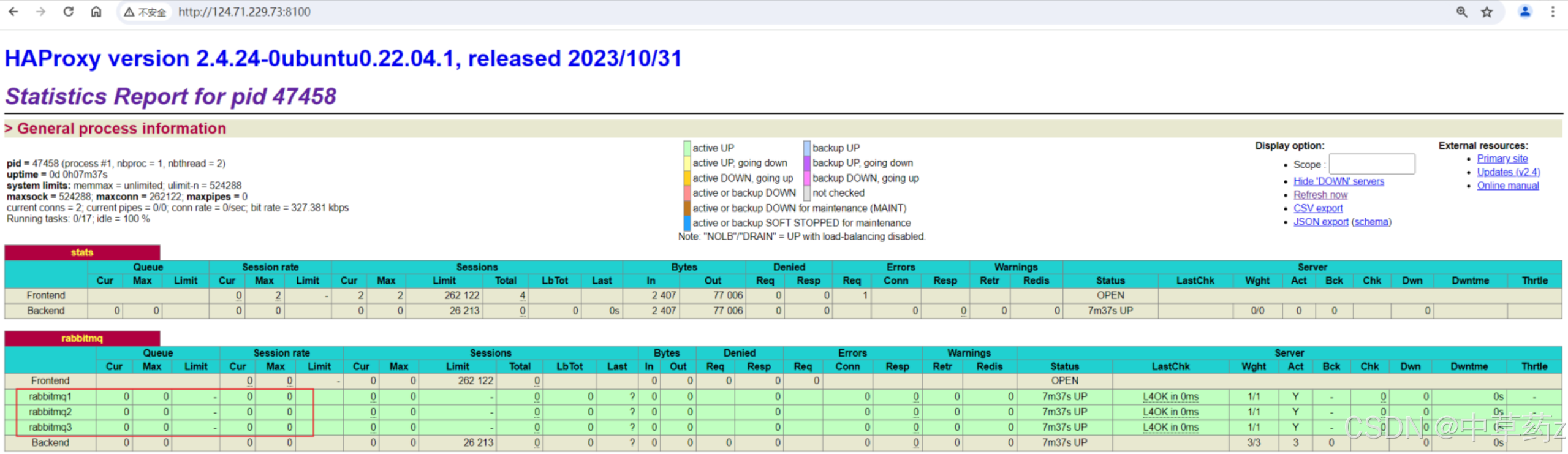
【RabbitMQ】应用问题、仲裁队列(Raft算法)和HAProxy负载均衡
🔥个人主页: 中草药 🔥专栏:【中间件】企业级中间件剖析 一、幂等性保障 什么是幂等性? 幂等性是指对一个系统进行重复调用(相同参数),无论同一操作执行多少次,这些请求…...

软件设计师-错题笔记-系统开发与运行
1. 解析: A:模块是结构图的基本成分之一,用矩形表示 B:调用表示模块之间的调用关系,通过箭头等符号在结构图中体现 C:数据用于表示模块之间的传递的信息,在结构图中会涉及数据的流向等表示 …...

硬件设备基础
一、ARM9 内核中有多少个通用寄存器?其中 sp、lr、pc、cpsr、spsr 的作用是什么? 在 ARM9 内核中,寄存器组织包含 37 个 通用寄存器,其中,有 13 个通用目的寄存器(R0 - R12)。 S3C2440 是 ARM 架…...

[编程基础] PHP · 学习手册
🔥 《PHP 工程师修炼之路:从零构建系统化知识体系》 🔥 🛠️ 专栏简介: 这是一个以工业级开发标准打造的 PHP 全栈技术专栏,涵盖语法精粹、异步编程、Zend引擎原理、框架源码、高并发架构等全维度知识体系…...
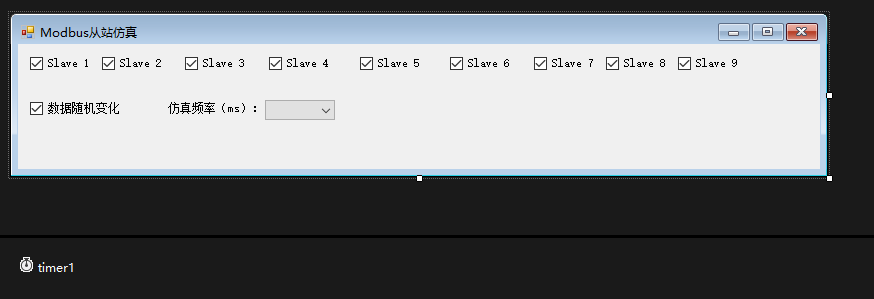
C#简易Modbus从站仿真器
C#使用NModbus库,编写从站仿真器,支持Modbus TCP访问,支持多个从站地址和动态启用/停用从站(模拟离线),支持数据变化,可以很方便实现,最终效果如图所示。 项目采用.net framework 4.…...
 dapper sqlite)
Error parsing column 10 (YingShou=-99.5 - Double) dapper sqlite
在使用sqlite 调取 dapper的时候出现这个问题提示: 原因是 在 sqlite表中设定的字段类型是 decimel而在C#的字段属性也是decimel,结果解析F负数 小数的时候出现这个错误提示: 解决办法:使用默认的sqlite的字段类型来填入 REAL描述…...

Spring AI系列——使用大模型对文本进行内容总结归纳分析
一、技术原理与架构设计 1. 技术原理 本项目基于 Spring AI Alibaba 框架,结合 DashScope 大模型服务 实现文本内容的自动摘要和结构化输出。核心原理如下: 文档解析: 使用 TikaDocumentReader 解析上传的文件(如 PDF、Word 等&…...
【深度学习】目标检测算法大全
目录 一、R-CNN 1、R-CNN概述 2、R-CNN 模型总体流程 3、核心模块详解 (1)候选框生成(Selective Search) (2)深度特征提取与微调 2.1 特征提取 2.2 网络微调(Fine-tuning) …...

5.1.1 WPF中Command使用介绍
WPF 的命令系统是一种强大的输入处理机制,它比传统的事件处理更加灵活和可重用,特别适合 MVVM (Model, View, ViewModel)模式开发。 一、命令系统核心概念 1.命令系统基本元素: 命令(Command): 即ICommand类,使用最多的是RoutedCommand,也可以自己继承ICommand使用自定…...

excel大表导入数据库
前文介绍了数据量较小的excel表导入数据库的方法,在数据量较大的情况下就不太适合了,一个是因为mysql命令的执行串长度有限制,二是node-xlsx这个模块加载excel文件是整个文件全部加载到内存,在excel文件较大和可用内存受限的场景就…...

《让歌声跨越山海:Flutter借助Agora SDK实现高质量连麦合唱》
对于Flutter开发者而言,借助Agora SDK实现这一功能,不仅能为用户带来前所未有的社交体验,更是在激烈的市场竞争中脱颖而出的关键。 Agora SDK作为实时通信领域的佼佼者,拥有一系列令人瞩目的特性,使其成为实现高质量连…...
 寻路)
A* (AStar) 寻路
//调用工具类获取路线 let route AStarSearch.getRoute(start_point, end_point, this.mapFloor.map_point); map_point 是所有可走点的集合 import { _decorator, Component, Node, Prefab, instantiate, v3, Vec2 } from cc; import { oops } from "../../../../../e…...

单词短语0512
当然可以,下面是“opportunity”在考研英语中的常用意思和高频短语,采用大字体展示,便于记忆: ✅ opportunity 的考研常用意思: 👉 机会,良机 表示有利的时机或条件,尤指成功的可能…...
视觉-语言-动作模型:概念、进展、应用与挑战(下)
25年5月来自 Cornell 大学、香港科大和希腊 U Peloponnese 的论文“Vision-Language-Action Models: Concepts, Progress, Applications and Challenges”。 视觉-语言-动作 (VLA) 模型标志着人工智能的变革性进步,旨在将感知、自然语言理解和具体动作统一在一个计…...

一键解锁嵌入式UI开发——LVGL的“万能配方”
面对碎片化的嵌入式硬件生态,LVGL堪称开发者手中的万能配方。它通过统一API接口屏蔽底层差异,配合丰富的预置控件(如按钮、图表、滑动条)与动态渲染引擎,让工程师无需深入图形学原理,效率提升肉眼可见。 L…...
)
C# NX二次开发:宏录制实战讲解(第一讲)
今天要讲的是关于NX软件录制宏操作的一些案例。 下面讲如何在NX软件中复制Part体的录制宏。 NXOpen.Session theSession NXOpen.Session.GetSession(); NXOpen.Part workPart theSession.Parts.Work; NXOpen.Part displayPart theSession.Parts.Display; NXOpe…...

记录裁员后的半年前端求职经历
普通的人生终起波澜 去年下半年应该算是我毕业以来发生人生变故最多的一段时间。 先是 7 月份的时候发作了一次急性痛风,一个人在厦门,坐在床上路都走不了,那时候真的好想旁边能有个人能扶我去医院,真的是感受到 10 级的孤独。尝…...

Linux 文件查看|查找|压缩|解压 常用命令
cat 连接文件并打印到标准输出设备上 指令备注cat aaa.txt连接文件aaa并打印到标准输出设备上 more 以全屏幕的方式按页显示文本文件的内容 按Space键:显示文本的下一屏内容 按Enier键:只显示文本的下一行内容 指令备注more aaa.txt查看文件aaa le…...

什么是:Word2Vec + 余弦相似度
什么是:Word2Vec + 余弦相似度 目录 什么是:Word2Vec + 余弦相似度示例文本基于Word2Vec的文本向量化计算余弦相似度Word2Vec不是基于Transformer架构的Word2Vec是一种将单词转化为向量表示的模型,而Word2Vec + 余弦相似度则是一种利用Word2Vec得到的向量来计算文本相似性的…...

智慧城市综合运营管理系统Axure原型
这款Axure原型的设计理念紧紧围绕城市管理者的需求展开。它旨在打破传统城市管理中信息孤岛的局面,通过统一标准接入各类业务系统,实现城市运营管理信息资源的全面整合与共享。以城市管理者为中心,为其提供一个直观、便捷、高效的协同服务平台…...

[学习]RTKLib详解:convkml.c、convrnx.c与geoid.c
RTKLib详解: datum.c、download.c 与 lambda.c 本文是 RTKLlib详解 系列文章的一篇,目前该系列文章还在持续总结写作中,以发表的如下,有兴趣的可以翻阅。 [学习] RTKlib详解:功能、工具与源码结构解析 [学习]RTKLib详解ÿ…...
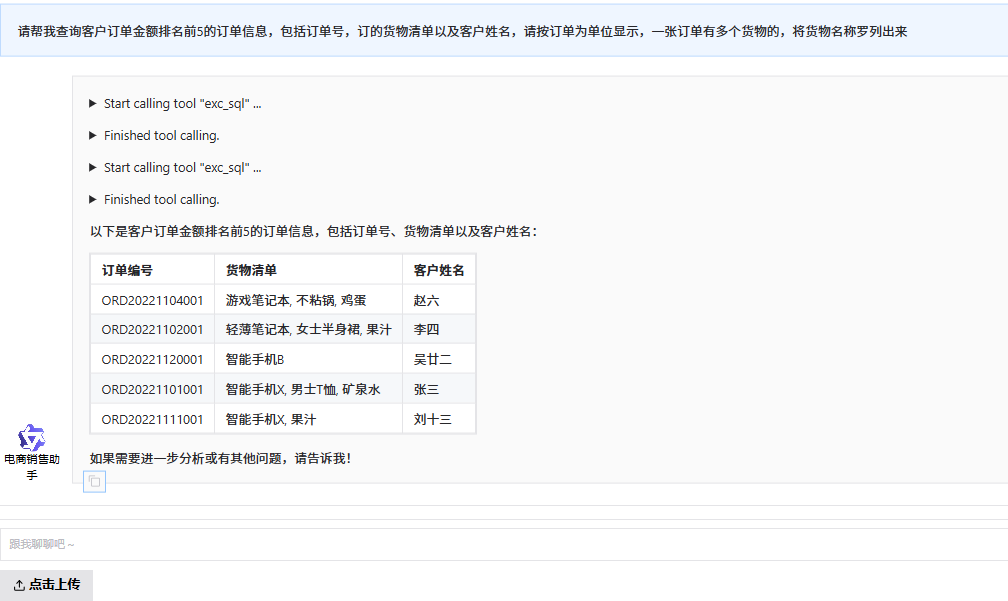
Qwen智能体qwen_agent与Assistant功能初探
Qwen智能体qwen_agent与Assistant功能初探 一、Qwen智能体框架概述 Qwen(通义千问)智能体框架是阿里云推出的新一代AI智能体开发平台,其核心模块qwen_agent.agent提供了一套完整的智能体构建解决方案。该框架通过模块化设计,将L…...

LayerNorm vs RMSNorm 技术对比
1. 核心概念 LayerNorm (层归一化) 思想:对单个样本的所有特征维度进行归一化目标:使每个样本的特征分布 μ 0 \mu0 μ0, σ 1 \sigma1 σ1特点:同时调整均值和方差 RMSNorm (均方根归一化) 思想:基于均方根的简…...
可视化图解算法37:序列化二叉树-II
1. 题目 描述 请实现两个函数,分别用来序列化和反序列化二叉树,不对序列化之后的字符串进行约束,但要求能够根据序列化之后的字符串重新构造出一棵与原二叉树相同的树。 二叉树的序列化(Serialize)是指:把一棵二叉树按照某种遍…...
C++GO语言微服务和服务发现②
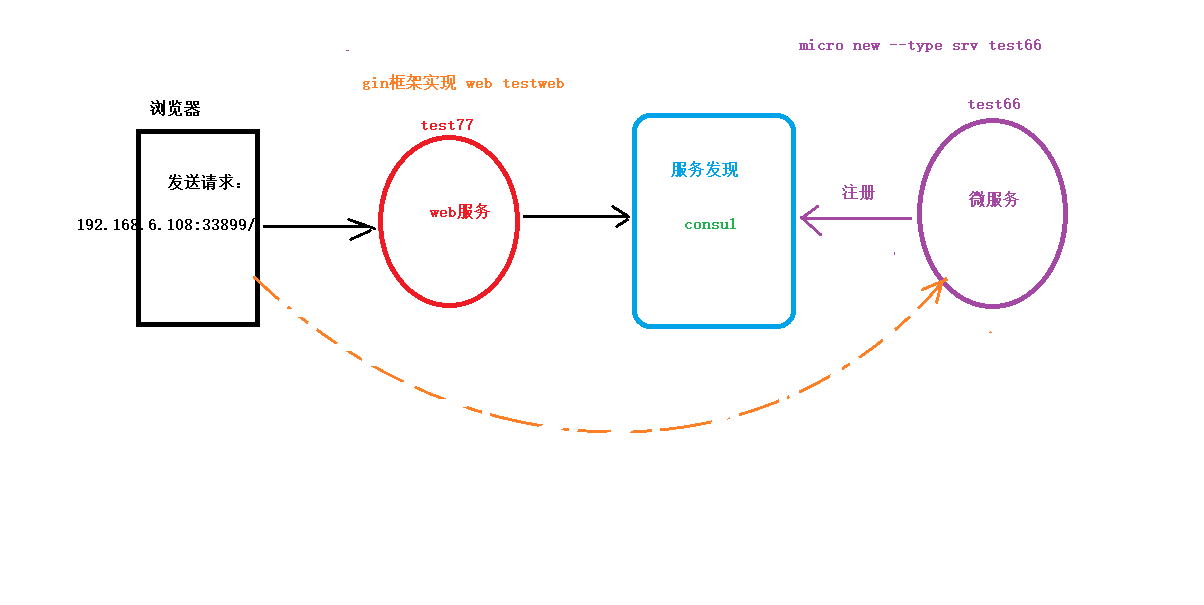
01 创建go-micro项目-查看生成的 proto文件 02 创建go-micro项目-查看生成的main文件和handler ## 创建 micro 服务 命令:micro new --type srv test66 框架默认自带服务发现:mdns。 使用consul服务发现: 1. 初始consul服务发现&…...

【Web前端开发】CSS基础
2.CSS 2.1CSS概念 CSS是一组样式设置的规则,称为层叠样式表,用于控制页面的外观样式。 使用CSS能够对网页中元素位置的排版进行像素控制,实现美化页面的效果,也能够做到页面的样式和结构分离。 2.2基本语法 通常都是ÿ…...