【JVM】从零开始深度解析JVM

本篇博客给大家带来的是JVM的知识点, 重点在类加载和垃圾回收机制上.
🐎文章专栏: JavaEE初阶
🚀若有问题 评论区见
❤ 欢迎大家点赞 评论 收藏 分享
如果你不知道分享给谁,那就分享给薯条.
你们的支持是我不断创作的动力 .
王子,公主请阅🚀
- 要开心
- 要快乐
- 顺便进步
- 1. JVM简介
- 1.1 HotSpot VM
- 1.2 Taobao JVM(国产研发)
- 1.3 JDK JRE JVM三者关系(经典面试题)
- 2. JVM 运行流程
- ★3. JVM运行时数据区(内存区域)
- 3.1 堆(线程共享)
- 3.2 Java虚拟机栈(线程私有)/本地方法栈
- 3.3 程序计数器(线程私有)
- 3.4 元数据区(方法区)
- ★4. JVM类加载
- 4.1 类加载过程
- 4.1.1 加载
- 4.1.2 验证
- 4.1.3 准备
- 4.1.4 解析
- 4.1.5 初始化
- 4.2 双亲委派模型
- 4.2.1 什么是双亲委派模型?
- 4.2.2 双亲委派模型的工作过程.
- 4.3 双亲委派模型优点
- 4.4 破坏双亲委派模型
- 5. 垃圾回收机制
- 5.1 死亡对象判断算法.
- 5.1.1 引用计数算法.
- 5.1.2 可达性分析算法
- 5.2 垃圾回收算法
- 5.2.1 标记-清除算法
- 5.2.2 复制算法
- 5.2.3 标记-整理算法
- 5.2.4 分代算法
要开心
要快乐
顺便进步
1. JVM简介
JVM 是 Java Virtual Machine 的简称,意为 Java虚拟机。
虚拟机是指通过软件模拟的具有完整硬件功能的、运行在一个完全隔离的环境中的完整计算机系统。
常见的虚拟机:JVM、VMwave、Virtual Box.
JVM 和其他两个虚拟机的区别:
① VMwave与VirtualBox是通过软件模拟物理CPU的指令集,物理系统中会有很多的寄存器;
② JVM则是通过软件模拟Java字节码的指令集,JVM中只是主要保留了PC寄存器,其他的寄存器都进行了裁剪.
JVM 是一台被定制过的现实当中不存在的计算机.
1.1 HotSpot VM
HotSpot最初由一家名为“Longview Technologies”的小公司设计;
1997年,此公司被Sun收购;2009年,Sun公司被甲骨文收购。
JDK1.3时,HotSpot VM成为默认虚拟机
目前 HotSpot 占用绝对的市场地位,称霸武林。
不管是现在仍在广泛使用JDK6,还是使用比较多的JDK8中,默认的虚拟机都是HotSpot;
Sun/Oracle JDK和OpenJDK的默认虚拟机。从服务器、桌面到移动端、嵌入式都有应用。
名称中的HotSpot指的就是它的热点代码探测技术。它能通过计数器找到最具编译价值的代码,触发即时编译(JIT)或栈上替换;通过编译器与解释器协同工作,在最优化的程序响应时间与最佳执行性能中取得平衡。
1.2 Taobao JVM(国产研发)
阿里是国内使用Java最强大的公司,覆盖云计算、金融、物流、电商等众多领域,需要解决高并发、高可用、分布式的复合问题。有大量的开源产品。
基于OpenJDK 开发了自己的定制版本AlibabaJDK,简称AJDK。是整个阿里JAVA体系的基石;
基于OpenJDK HotSpot JVM发布的国内第一个优化、深度定制且开源的高性能服务器版Java虚拟机,
它具有以下特点(了解):
1. 创新的GCIH(GC invisible heap)技术实现了off-heap,即将生命周期较长的Java对象从heap中移到heap之外,并且GC不能管理GCIH内部的Java对象,以此达到降低GC的回收评率和提升GC的回收效率的目的;
2. GCIH中的对象还能够在多个Java虚拟机进程中实现共享;
3. 使用crc32指令实现JVM intrinsic降低JNI的调用开销;
4. PMU hardware的Java profiling tool和诊断协助功能;
5. 针对大数据场景的ZenGC。
taobaoJVM应用在阿里产品上性能高,硬件严重依赖intel的cpu,损失了兼容性,但提高了性能,目前已经在淘宝、天猫上线,把Oracle官方JVM版本全部替换了.
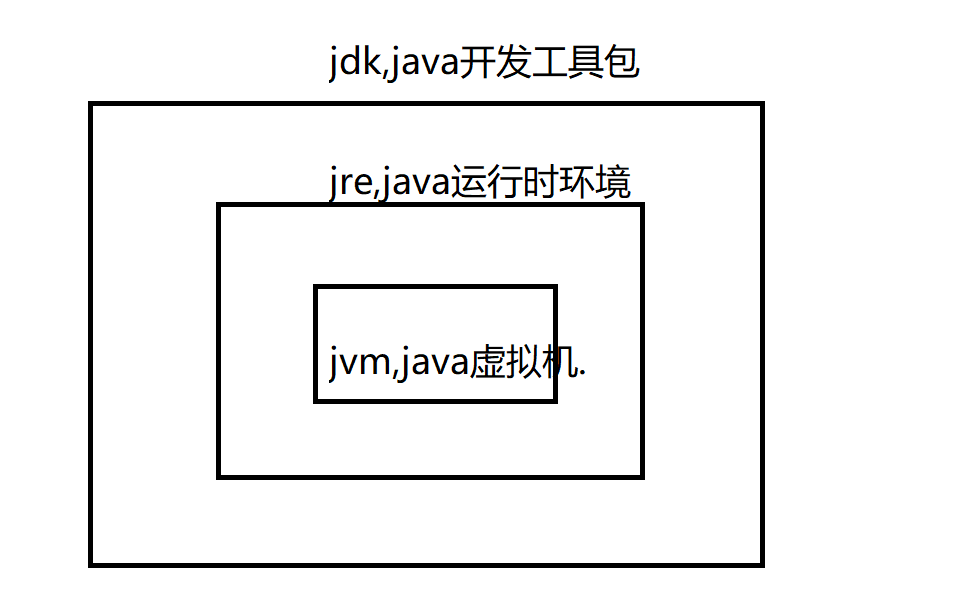
1.3 JDK JRE JVM三者关系(经典面试题)
JDK(Java Development Kit):Java开发工具包,提供给Java程序员使用,包含了JRE,同时还包含了编译器 javac 与自带的调试工具Jconsole、jstack等.
JRE(Java Runtime Environment):Java运行时环境,包含了JVM,Java基础类库。是使用Java语言编写程序运行的所需环境.
JVM:Java虚拟机,运行Java代码.
2. JVM 运行流程
JVM 是 Java 运行的基础,也是实现一次编译到处执行的关键,那么 JVM 是如何执行的呢?
Java程序在执行之前先要把 java 代码转换成字节码(class文件),JVM 首先需要把字节码通过一定的方式类加载器(ClassLoader) 把文件加载到内存中 运行时数据区(Runtime Data Area) ,而字节码文件是 JVM 的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要特定的命令解析器执行引擎(Execution Engine)将字节码翻译成底层系统指令再交由CPU去执行,而这个过程中需要调用其他语言的接口 本地库接口(Native Interface) 来实现整个程序的功能,这就是这4个主要组成部分的职责与功能。
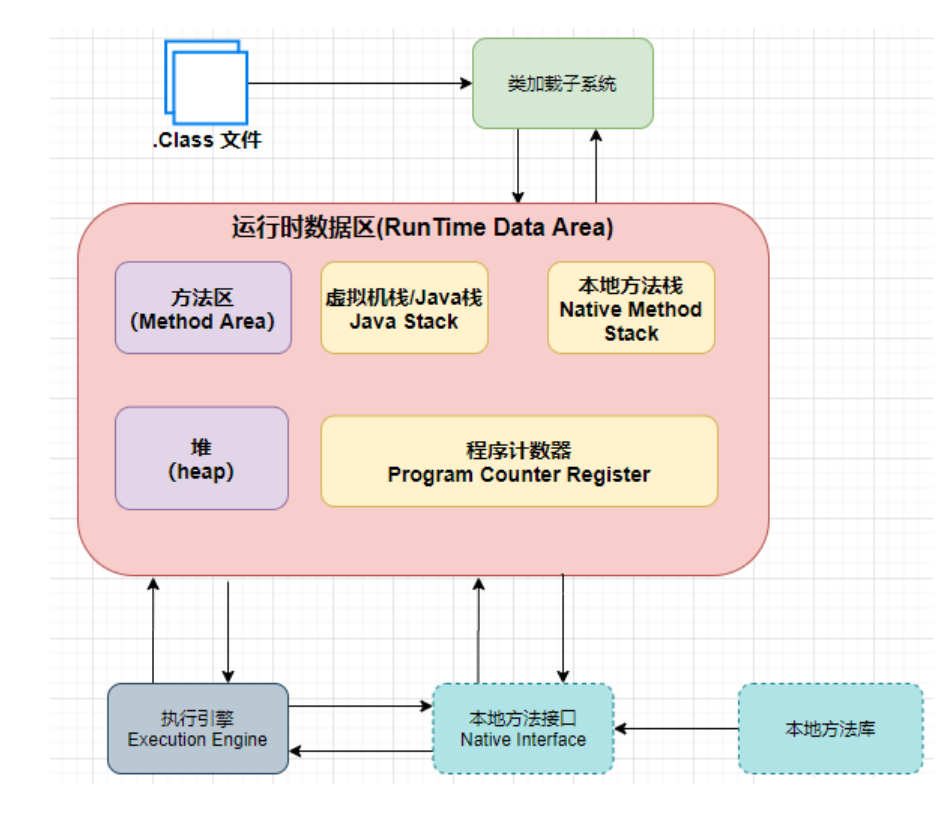
JVM 主要通过分为以下 4 个部分,来执行 Java 程序的,它们分别是:
1. 类加载器(ClassLoader)
2. 运行时数据区(Runtime Data Area)
3. 执行引擎(Execution Engine)
4. 本地库接口(Native Interface)
★3. JVM运行时数据区(内存区域)
JVM 运行时数据区域也叫内存布局,但需要注意的是它和 Java 内存模型((Java Memory Model,简
称 JMM)完全不同,属于完全不同的两个概念,它由以下 五 大部分组成:
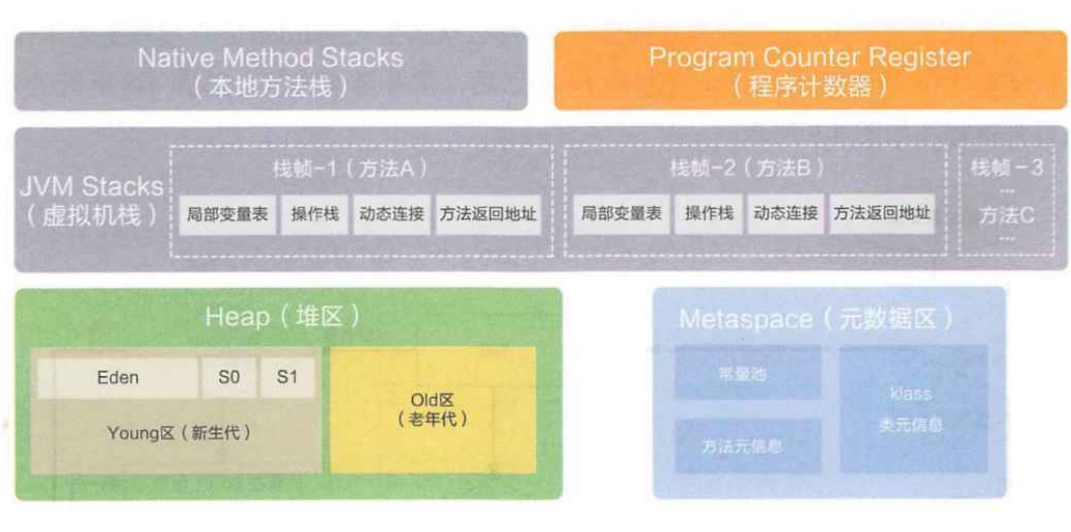
3.1 堆(线程共享)
代码中 new 出来的对象,都是在堆里, 对象中持有的非静态成员变量,也在堆里.
堆里面分为两个区域:新生代和老生代,新生代放新建的对象,当经过一定 GC 次数之后还存活的对象会放入老生代。新生代还有 3 个区域:一个 Endn + 两个 Survivor(S0/S1).
垃圾回收的时候会将 Endn 中存活的对象放到一个未使用的 Survivor 中,并把当前的 Endn 和正在使用的 Survivor 清除掉.
3.2 Java虚拟机栈(线程私有)/本地方法栈
Java 虚拟机栈的作用:Java 虚拟机栈的生命周期和线程相同,Java 虚拟机栈描述的是 Java 方法执行的内存模型: 每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。咱们常说的堆内存、栈内存中,栈内存指的就是虚拟机栈.
1. 局部变量表: 存放了编译器可知的各种基本数据类型(8大基本数据类型)、对象引用。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的空间是完全确定的,在执行期间不会改变局部变量表大小. 简单来说就是存放方法参数和局部变量.
2. 操作栈:每个方法会生成一个先进后出的操作栈.
3. 动态链接:指向运行时常量池的方法引用.
4. 方法返回地址:PC 寄存器的地址.
什么是线程私有?
由于JVM的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现,因此在任何一个确定的时刻,一个处理器(多核处理器则指的是一个内核)都只会执行一条线程中的指令。因此为了切换线程后能恢复到正确的执行位置,每条线程都需要独立的程序计数器,各条线程之间计数器互不影响,独立存储。我们就把类似这类区域称之为"线程私有"的内存。
本地方法栈和虚拟机栈类似,只不过 Java 虚拟机栈是给 JVM 使用的,而本地方法栈是给本地方法使用的。
此处谈到的“堆” "栈"和数据结构中的"堆” "栈"是不同的! 面试中如果被问到堆和栈, 一定要反问面试官,搞清楚问的是哪个堆,哪个栈?
3.3 程序计数器(线程私有)
程序计数器的作用:用来记录当前线程执行的行号的. 也是用来存储下一条要执行的 java 指令的地址.
如果当前线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是一个Native方法,这个计数器值为空.
3.4 元数据区(方法区)
方法区的作用:用来存储被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据的.
运行时常量池是方法区的一部分,存放字面量与符号引用.
字面量 : 字符串(JDK 8 移动到堆中) 、final常量、基本数据类型的值.
符号引用 : 类和结构的完全限定名、字段的名称和描述符、方法的名称和描述符.
★4. JVM类加载
类加载指的是, java 进程运行的时候,需要把 .class 文件从硬盘读取到内存,并进行一系列的校验解析的过程.
4.1 类加载过程
整个 JVM 执行的流程中,和程序员关系最密切的就是类加载的过程了,所以接下来我们来看下类加载的执行流程。
对于一个类来说,它的生命周期是这样的:
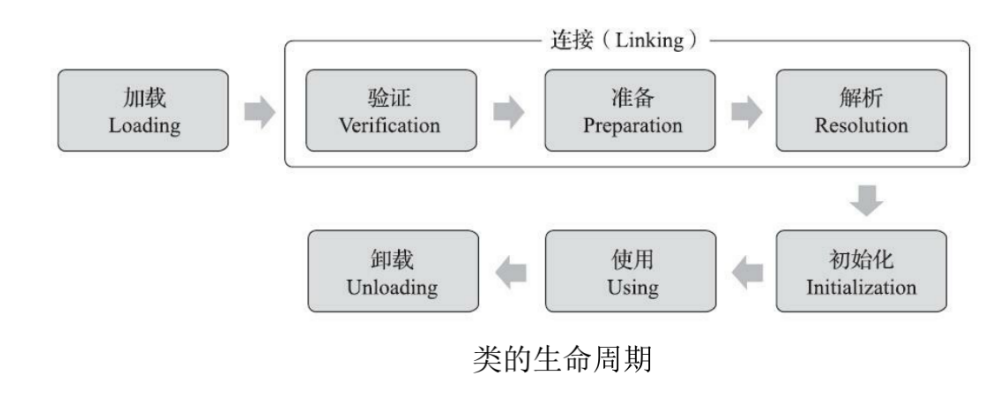
前 5 步是固定的顺序并且也是类加载的过程,其中中间的 3 步我们都属于连接,所以对于类加载来说总共分为以下几个步骤:
1. 加载
2. 连接
a. 验证
b. 准备
c. 解析
3. 初始化
4.1.1 加载
“加载”(Loading)阶段是整个“类加载”(Class Loading)过程中的一个阶段,它和类加载Class Loading 是不同的,一个是加载 Loading 另一个是类加载 Class Loading,不要把二者搞混了。
在加载 Loading 阶段,Java虚拟机需要完成以下三件事情:
1)通过一个类的全限定名来获取定义此类的二进制字节流.
2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构.
3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口.
4.1.2 验证
验证是连接阶段的第一步,这一阶段的目的是确保Class文件的字节流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信息被当作代码运行后不会危害虚拟机自身的安全.
简而言之,就是确保当前读到的文件内容是合法的.
文件格式验证
字节码验证
符号引用验证…
4.1.3 准备
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段。
比如此时有这样一行代码:
public static int value = 888;
它是初始化 value 的 int 值为 0,而非 888.
4.1.4 解析
解析阶段是 Java 虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。
在硬盘或者文件中不存在地址这样的概念, 虽然没有地址但是可以引入一个偏移量这样的概念来记录字符串常量的位置. 此时的偏移量就可以认为是符号引用.
4.1.5 初始化
初始化阶段,Java 虚拟机真正开始执行类中编写的 Java 程序代码,将主导权移交给应用程序。初始化阶段就是执行类构造器方法的过程.
简单总结:
加载: 找到 .class 文件,并且读文件内容.
验证: 校验 .class 文件的格式是否符合 JVM 规范要求.
准备: 给类对象分配内存(此时内存空间是全0的 =>类的静态成员也就是全 0的值,即 int 默认值为0).
解析: 针对类中的字符串常量进行处理.
初始化: 把类对象的各个部分的属性进行赋值填充 =>触发对父类的加载,初始化静态成员,执行静态代码块.
4.2 双亲委派模型
提到类加载机制,不得不提的一个概念就是“双亲委派模型”。
站在 Java 虚拟机的角度来看,只存在两种不同的类加载器:一种是启动类加载器(Bootstrap
ClassLoader),这个类加载器使用 C++ 语言实现,是虚拟机自身的一部分;另外一种就是其他所有的类加载器,这些类加载器都由Java语言实现,独立存在于虚拟机外部,并且全都继承自抽象类java.lang.ClassLoader.
站在 Java 开发人员的角度来看,类加载器就应当划分得更细致一 些。自 JDK 1.2 以来,Java 一直保持着三层类加载器、双亲委派的类加载架构器。
4.2.1 什么是双亲委派模型?
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载.
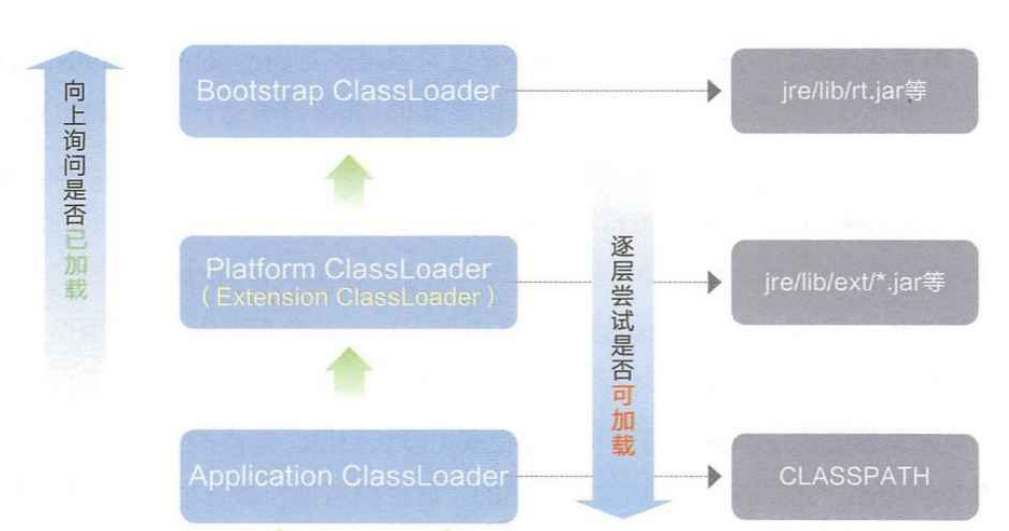
BootstrapClassLoader
负责查找标准库的目录.
ExtensionClassLoader
负责查找扩展库的目录.
ApplicationClassLoader
负责查找当前项目的代码目录
以及第三方库的目录.
4.2.2 双亲委派模型的工作过程.
1.从 ApplicationClassLoader 作为入口,先开始工作.
2. ApplicationClassLoader 不会立即搜索自己负责的目录,而会把搜索的任务交给自己的父亲:
3.代码就进入到 ExtensionClassLoader 范畴了ExtensionClassLoader 也不会立即搜索自己负责的目录也要把搜索的任务交给自己的父亲.
4.代码就进入到 BootstrapClassLoader 范畴了BootstrapClassLoader 也不想立即搜索自己负责的目录也要把搜索的任务交给自己的父亲.
5.BootstrapClassLoader 发现自己没有父亲才会真正搜索负责的目录 (标准库目录)通过全限定类名,尝试在标准库目录中找到符合要求的 .class 文件. 如果找到了,接下来就直接进入到打开文件/读文件等流程中如果没找到,回到孩子这一辈的类加载器中,继续尝试加载.
6. ExtensionClassLoader 收到父亲交回给他的任务之后,自己进行搜索负责目录(扩展库的目录)…
7. ApplicationClassLoader 收到父亲交回给他的任务之后自己进行搜索负责的目录(当前项目目录/第三方库目录)…
4.3 双亲委派模型优点
1. 避免重复加载类:比如 A 类和 B 类都有一个父类 C 类,那么当 A 启动时就会将 C 类加载起来,那么在 B 类进行加载时就不需要在重复加载 C 类了.
2. 安全性:使用双亲委派模型也可以保证了 Java 的核心 API 不被篡改,如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object
类的话,那么程序运行的时候,系统就会出现多个不同的 Object 类,而有些 Object 类又是用户自己提供的因此安全性就不能得到保证了.
4.4 破坏双亲委派模型
上述这一系列规则,只是 JM 自带的类加载器遵守的默认规则. 如果咱们自己写类加载器,也可以打破上述规则比如自己写类加载器, 指定这个加载器就在某个目录中尝试加载. 此时如果类加载器的 parent 不去和已有的这些类加载器连到一起, 此时就是独立的,不涉及到双亲委派了.
5. 垃圾回收机制
堆是垃圾回收的主战场.
Java堆中存放着几乎所有的对象实例,垃圾回收器在对堆进行垃圾回收前, 首先要判断这些对象哪些还存活,哪些已经"死去". 判断对象是否已"死"有如下几种算法.
在 Java 中,所有的对象都是要存在内存中的(也可以说内存中存储的是一个个对象),因此我们将内存回收,也可以叫做死亡对象的回收。
5.1 死亡对象判断算法.
在 Java 中,使用对象一定需要通过引用的方式来使用. (有个例外,匿名对象,但是它执行完之后就被回收了). 如果一个对象没有任何引用指向它, 就视为是无法在代码中使用, 就可以回收掉.
5.1.1 引用计数算法.
给对象增加一个引用计数器,每当有一个地方引用它时,计数器就+1;当引用失效时,计数器就-1;
任何时刻计数器为0的对象就是不能再被使用的,即对象已"死".
引用计数法实现简单,判定效率也比较高,在大部分情况下都是一个不错的算法。比如Python语言就采用引用计数法进行内存管理.
在主流的JVM中没有选用引用计数法来管理内存,最主要的原因就是引用计数法无法解决对象的循环引用问题.
为了解释循环引用问题, 写出下列伪代码:
class Test {Test t;
}
main() {Test a = new Test();Test b = new Test();a.t = b;b.t = a;
}

令 a = null, b = null;

此时虽然Test对象的引用计数为 1, 但确实无法使用, 也无法被回收.
5.1.2 可达性分析算法
在上面讲了,Java并不采用引用计数法来判断对象是否已"死",而采用可达性分析来判断对象是否存活(同样采用此法的还有C#、Lisp-最早的一门采用动态内存分配的语言).
此算法的核心思想为 : 通过一系列称为"GC Roots"的对象作为起始点,从这些节点开始向下搜索,搜索走过的路径称之为"引用链",当一个对象到GC Roots没有任何的引用链相连时(从GC Roots到这个对象不可达)时,证明此对象是不可用的。以下图为例:
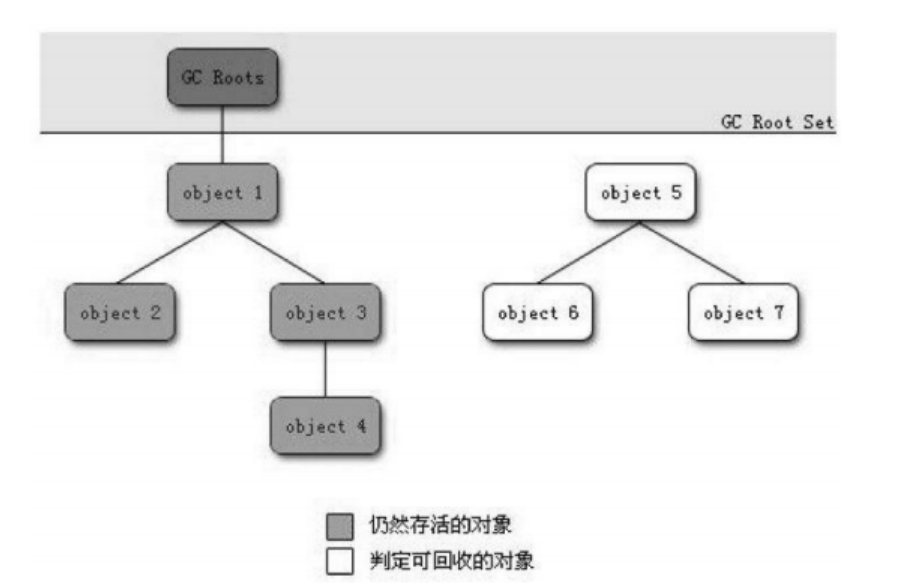
对象Object5-Object7之间虽然彼此还有关联,但是它们到GC Roots是不可达的,因此他们会被判定为可回收对象。
JVM 自身知道一共有哪些对象, 通过可达性分析的遍历, 把可达的对象都标记出来, 剩下的自然就是不可达的.
5.2 垃圾回收算法
将死亡对象标记出来了,标记出来之后我们就可以进行垃圾回收操作了.
5.2.1 标记-清除算法
标记-清除"算法是最基础的收集算法。算法分为"标记"和"清除"两个阶段 : 首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象. 后续的收集算法都是基于这种思路并对其不足加以改进而已.
"标记-清除"算法的不足主要有两个 :
1. 效率问题 : 标记和清除这两个过程的效率都不高.
2. 空间问题 : 标记清除后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行中需要分配较大对象时,无法找到足够连续内存而不得不提前触发另一次垃圾收集。

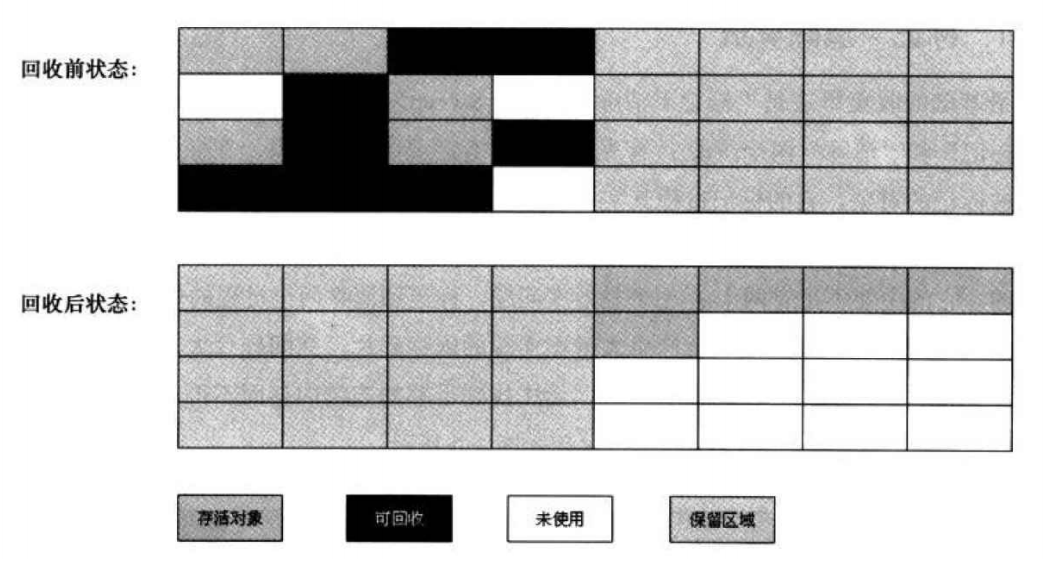
5.2.2 复制算法
"复制"算法是为了解决"标记-清理"的效率问题。它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这块内存需要进行垃圾回收时,会将此区域还存活着的对象复制到另一块上面,然后再把已经使用过的内存区域一次清理掉. 这样做的好处是每次都是对整个半区进行内存回收,内存分配时也就不需要考虑内存碎片等复杂情况,只需要移动堆顶指针,按顺序分配即可。此算法实现简单,运行 , 高效。
5.2.3 标记-整理算法
引入概念: 对象的年龄.
JVM 中有专门的线程负责周期性扫描/释放一个对象(初始年龄相当于是 0), 如果被线程扫描了一次,不是垃圾,年龄就+1.
JVM 中就会根据对象年龄的差异,把整个堆内存分成两个大的新生代(年龄小的对象)和老年代(年龄大的对象).
复制收集算法在对象存活率较高时会进行比较多的复制操作,效率会变低。因此在老年代一般不能使用复制算法.
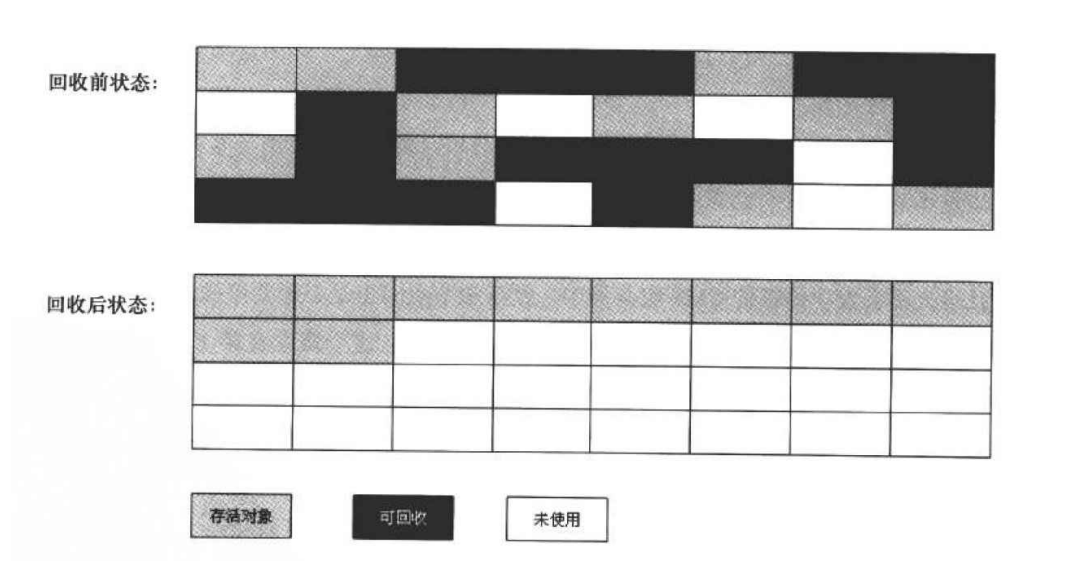
针对老年代的特点,提出了⼀种称之为"标记-整理算法"。标记过程仍与"标记-清除"过程一致,但后续步骤不是直接对可回收对象进行清理,而是让所有存活对象都向一端移动,然后直接清理掉端边界以外的内存.
5.2.4 分代算法
分代算法和上面讲的 3 种算法不同,分代算法是通过区域划分,实现不同区域和不同的垃圾回收策略,从而实现更好的垃圾回收.
这个算法并没有新思想,只是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代。在新生代中,每次垃圾回收都有大批对象死去,只有少量存活,因此我们采用复制算法;而老年代中对象存活率高、没有额外空间对它进行分配担保,就必须采用"标记-清理"算法。
老年代中有大量对象存活,是因为如果要死亡, 在新生代中早就死了, 能活到老年代的对象,说明其生命周期长.
总结来看:
新生代中, 只有少量存活,因此我们采用复制算法; 老年代中有大量存活, 采用"标记-清理"算法.
本篇博客到这里就结束啦, 感谢观看 ❤❤❤
🐎期待与你的下一次相遇😊😊😊
相关文章:
【JVM】从零开始深度解析JVM
本篇博客给大家带来的是JVM的知识点, 重点在类加载和垃圾回收机制上. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅🚀 …...
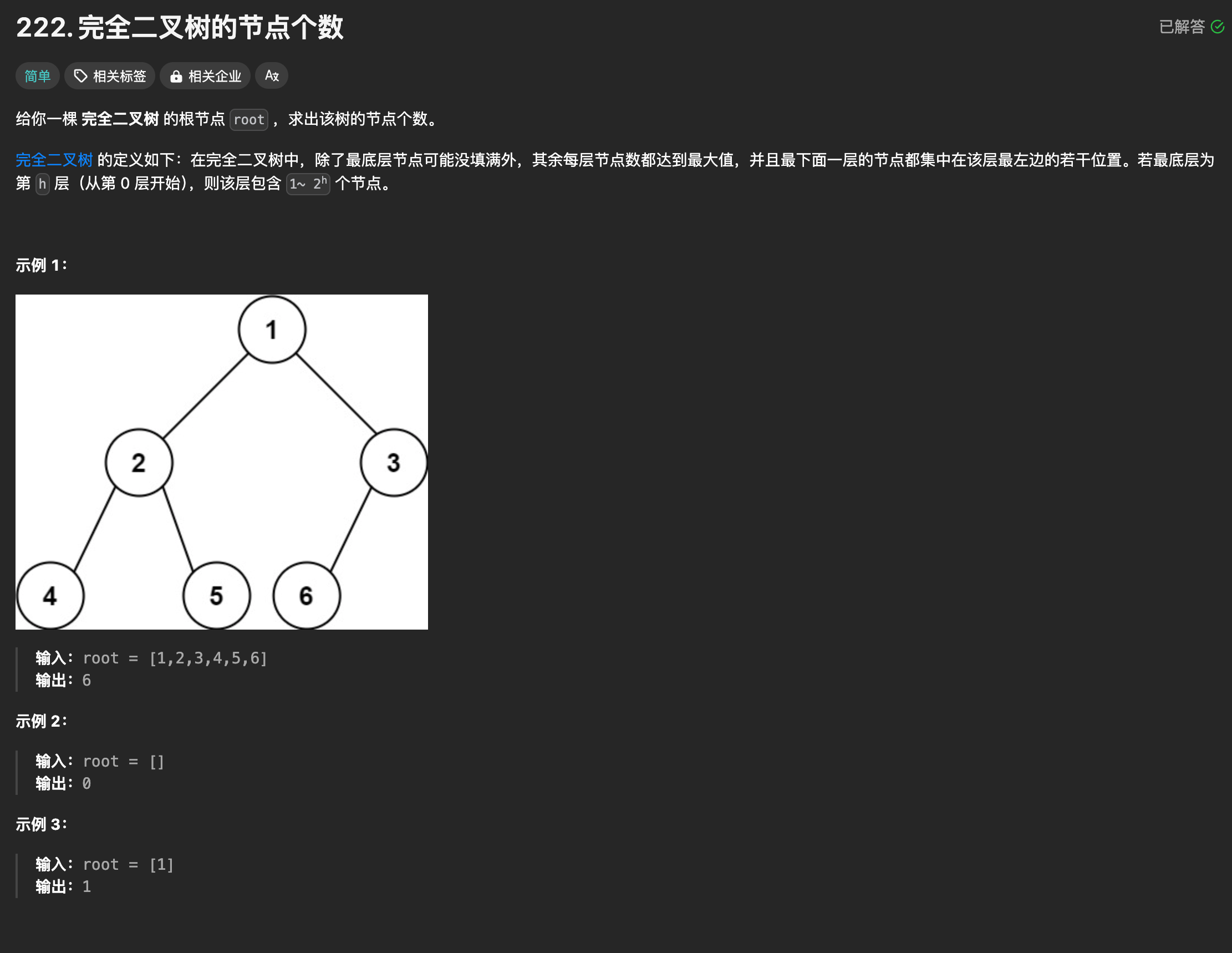
算法训练营第十四天|110. 平衡二叉树、257. 二叉树的所有路径、404. 左叶子之和、222.完全二叉树的节点个数
110.平衡二叉树 题目 思路与解法 # Definition for a binary tree node. # class TreeNode: # def __init__(self, val0, leftNone, rightNone): # self.val val # self.left left # self.right right class Solution:def isBalanced(self, r…...

Java单例模式总结
说明:单例模式的核心是确保一个类只有一个实例,并提供全局访问点。饿汉式和懒汉式是两种常见的实现方式 一、饿汉式和懒汉式 1. 饿汉式(Eager Initialization) public class EagerSingleton {// 类加载时直接初始化实例private…...

在 Elasticsearch 中删除文档中的某个字段
作者:来自 Elastic Kofi Bartlett 探索在 Elasticsearch 中删除文档字段的方法。 更多有关 Elasticsearch 文档的操作,请详细阅读文章 “开始使用 Elasticsearch (1)”。 想获得 Elastic 认证?查看下一期 Elasticsear…...
后端的逐元素操作(Per-element Operations))
OpenCV中适用华为昇腾(Ascend)后端的逐元素操作(Per-element Operations)
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 针对华为昇腾(Ascend)后端的逐元素操作(Per-element Operations),这些操作通常用于图…...

Jenkins集成Maven
一、概述 Jenkins是一个开源的持续集成工具,用于自动化各种开发任务。Maven是一个项目管理和构建自动化工具,主要用于Java项目。通过将Jenkins和Maven集成,可以实现自动化构建、测试和部署,提高开发效率和代码质量。 二、前提条…...

初识Linux · TCP基本使用 · 回显服务器
目录 前言: 回显服务器 TCPserver_v0 TCPserver_v1--多进程版本 TCPserver_v2--多线程版本 前言: 前文我们介绍了UDP的基本使用,本文我们介绍TCP的基本使用,不过TCP的使用我们这里先做一个预热,即只是使用TCP的A…...

Qwen:Qwen3,R1 在 Text2SQL 效果评估
【对比模型】 Qwen3 235B-A22B(2350亿总参数,220亿激活参数),32B,30B-A3B;QwQ 32B(推理模型)DeepSeek-R1 671B(满血版)(推理模型) 1&a…...
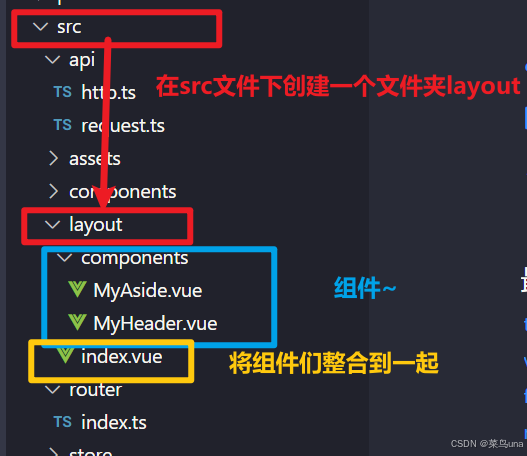
【layout组件 与 路由镶嵌】vue3 后台管理系统
前言 很多同学在第一次搭建后台管理系统时,会遇到一个问题,layout组件该放哪里?如何使用?路由又该如何设计? 这边会讲一下我的思考过程和最后的结果,大家可以参考一下,希望大家看完能有所收获。…...
mobile自动化测试-appium webdriverio
WebdriverIO是一款支持mobile app和mobile web自动化测试框架,与appium集成,完成对mobile应用测试。支持ios 和android两种平台,且功能丰富,是mobile app自动化测试首选框架。且官方还提供了mobile 应用测试example代码࿰…...

Spring Bean有哪几种配置方式?
大家好,我是锋哥。今天分享关于【Spring Bean有哪几种配置方式?】面试题。希望对大家有帮助; Spring Bean有哪几种配置方式? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Spring Bean的配置方式主要有三种ÿ…...
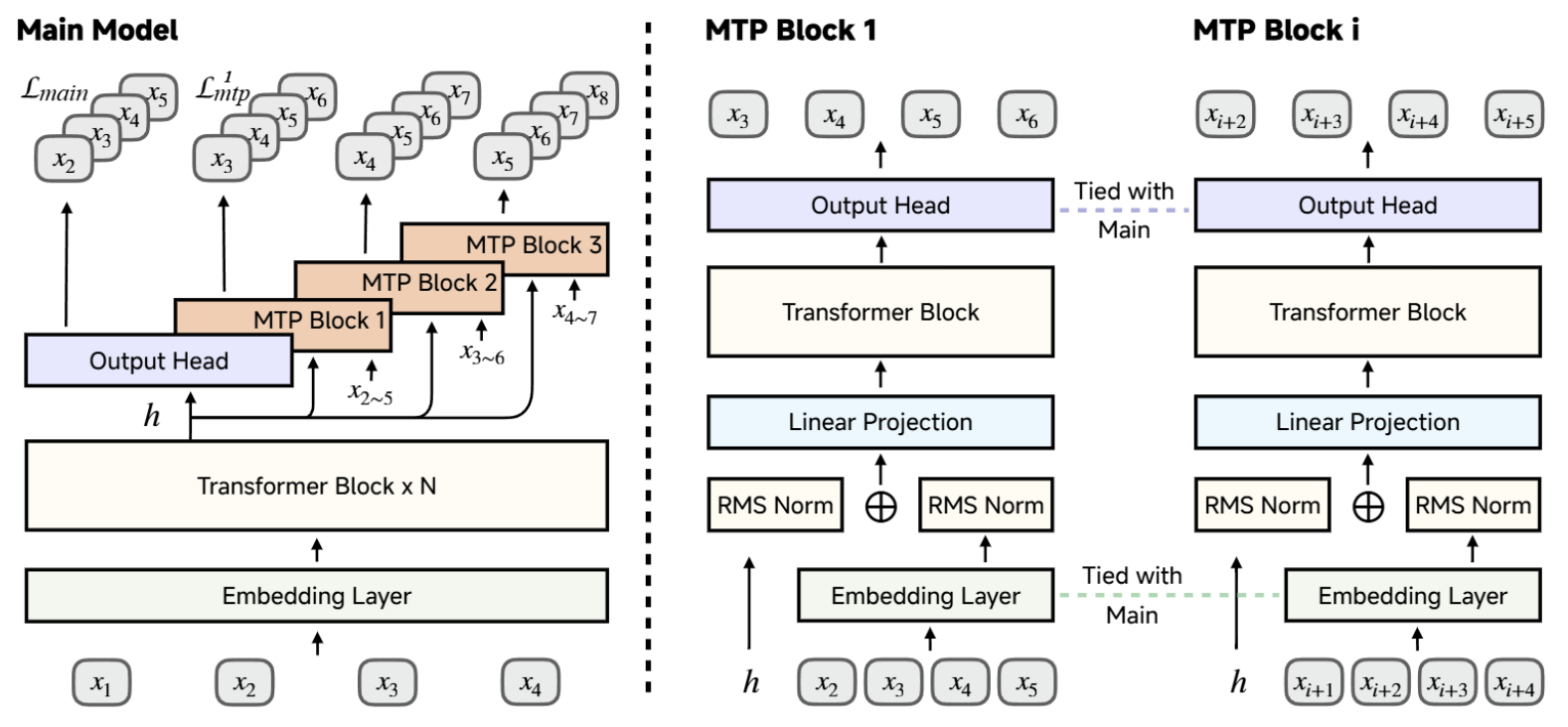
解析小米大模型MiMo:解锁语言模型推理潜力
一、基本介绍 1.1 项目背景 在大型语言模型快速发展的背景下,小米AI团队推出MiMo系列模型,突破性地在7B参数规模上实现卓越推理能力。传统观点认为32B以上模型才能胜任复杂推理任务,而MiMo通过创新的训练范式证明:精心设计的预训练和强化学习策略,可使小模型迸发巨大推理…...
证券行业数字化转型:灵雀云架设云原生“数字高速路”
01 传统架构难承重负,云原生破局成必然 截至2024年,证券行业总资产突破35万亿元,线上交易占比达85%,高频交易、智能投顾等业务对算力与响应速度提出极限要求。然而,以虚拟化为主导的传统IT架构面临四大核心瓶颈&#…...

Centos系统详解架构详解
CentOS 全面详解 一、CentOS 概述 CentOS(Community Enterprise Operating System) 是基于 Red Hat Enterprise Linux(RHEL) 源代码构建的免费开源操作系统,专注于稳定性、安全性和长期支持,广泛应用于服…...

【后端】SpringBoot用CORS解决无法跨域访问的问题
SpringBoot用CORS解决无法跨域访问的问题 一、跨域问题 跨域问题指的是不同站点之间,使用 ajax 无法相互调用的问题。跨域问题本质是浏览器的一种保护机制,它的初衷是为了保证用户的安全,防止恶意网站窃取数据。但这个保护机制也带来了新的…...
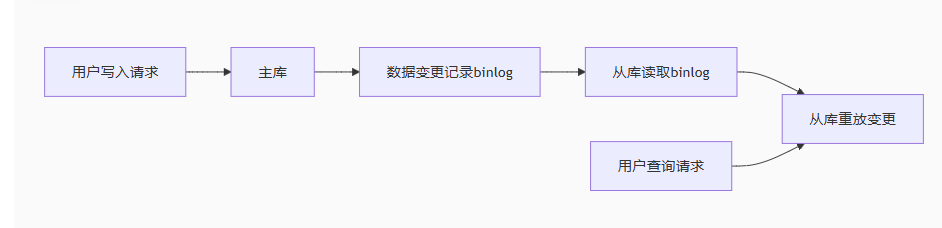
MySQL 8.0(主从复制)
MySQL 8.0 的 主从复制(Master-Slave Replication) 是一种数据库高可用和数据备份的核心技术,下面用 一、什么是主从复制? 就像公司的「领导-秘书」分工: 主库(Master):负责处理所…...

TCPIP详解 卷1协议 十 用户数据报协议和IP分片
10.1——用户数据报协议和 IP 分片 UDP是一种保留消息边界的简单的面向数据报的传输层协议。它不提供差错纠正、队列管理、重复消除、流量控制和拥塞控制。它提供差错检测,包含我们在传输层中碰到的第一个真实的端到端(end-to-end)校验和。这…...
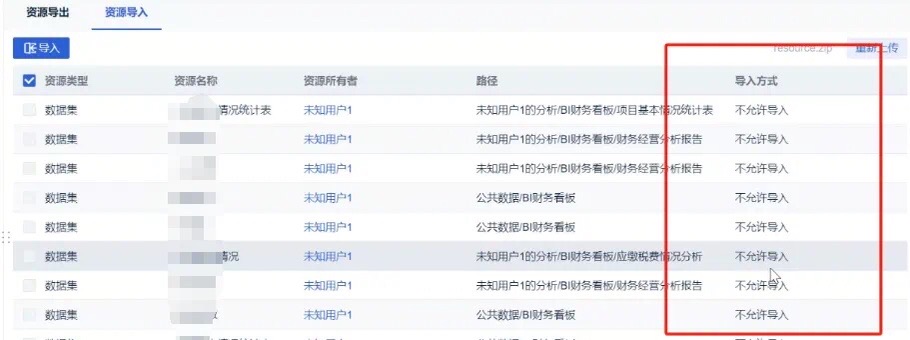
finebi使用资源迁移无法导入资源,解决方法
finebi使用资源迁移无法导入资源,解决方法 最近在使用finebi开发finebi报表,报表开发之后,从一台电脑将资源导入另一台电脑后,出现不允许导入的提示,如下: 原因: 两个finebi的管理员名称不一致…...

【ASR学习笔记】:语音识别领域基本术语
一、基础术语 ASR (Automatic Speech Recognition) 自动语音识别,把语音信号转换成文本的技术。 VAD (Voice Activity Detection) 语音活动检测,判断一段音频里哪里是说话,哪里是静音或噪音。 Acoustic Model(声学模型࿰…...
:双边市场模式指标全解析与运营策略深度探讨)
精益数据分析(53/126):双边市场模式指标全解析与运营策略深度探讨
精益数据分析(53/126):双边市场模式指标全解析与运营策略深度探讨 在创业与数据分析的探索之路上,深入了解各类商业模式的关键指标和运营策略至关重要。今天,我们依然怀揣着与大家共同进步的信念,深入研读…...
分布式锁redisson的中断操作
1、先贴代码 RequestMapping(value "/update", method RequestMethod.POST)ResponseBodypublic Result update(RequestBody Employee employee) { // 修改数据库(存在线程不安全 需要使用redison设置分布式锁 防止被修改) // 设…...

【技巧】使用frpc点对点安全地内网穿透访问ollama服务
回到目录 【技巧】使用frpc点对点安全地内网穿透访问ollama服务 0. 为什么需要部署内网穿透点对点服务 在家里想访问单位强劲机器,但是单位机器只能单向访问互联网,互联网无法直接访问到这台机器。通过在云服务器、单位内网服务器、源端访问机器上&am…...

Django缓存框架API
这里写自定义目录标题 访问缓存django.core.cache.cachesdjango.core.cache.cache 基本用法cache.set(key, value, timeoutDEFAULT_TIMEOUT, versionNone)cache.get(key, defaultNone, versionNone)cache.add(key, value, timeoutDEFAULT_TIMEOUT, versionNone)cache.get_or_se…...

克隆虚拟机组成集群
一、克隆虚拟机 1. 准备基础虚拟机 确保基础虚拟机已安装好操作系统(如 Ubuntu)、Java 和 Hadoop。关闭防火墙并禁用 SELinux(如适用): bash sudo ufw disable # Ubuntu sudo systemctl disable firewalld # CentO…...
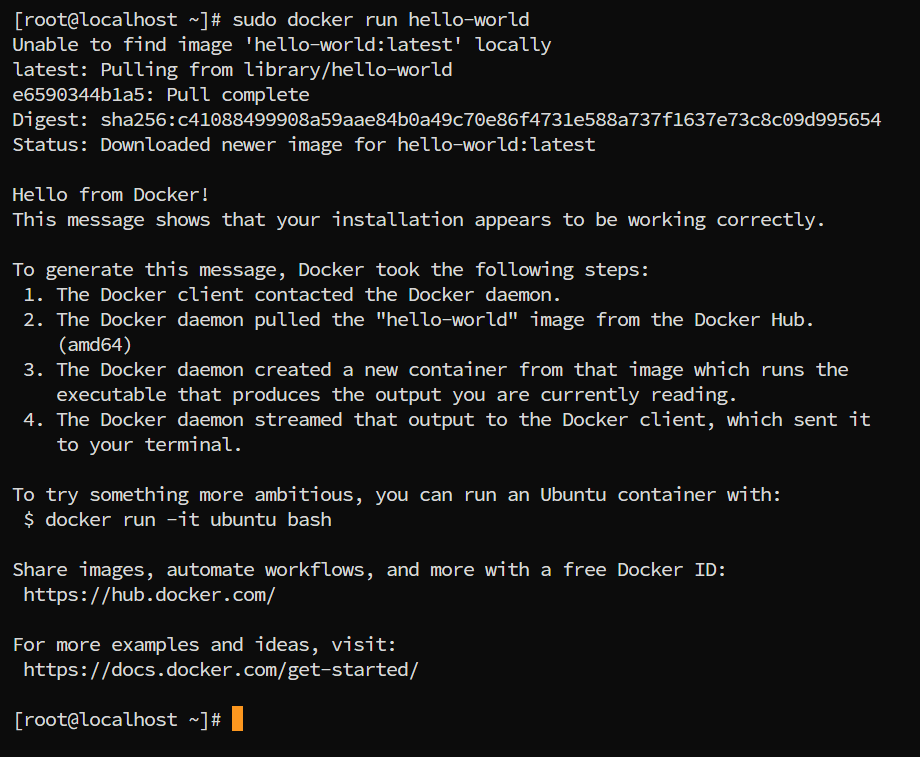
Docker:安装配置教程(最新版本)
文章目录 一、前言二、具体操作2.1 卸载 Docker (可选)2.2 重新安装(使用清华大学镜像)2.3 配置轩辕镜像加速2.4 Docker 基本命名2.5 测试是否成功 三、结语 一、前言 Docker 是一种容器化技术,在软件开发和部署中得到广泛的应用,…...
)
R语言实战第5章(1)
第一部分:数学、统计和字符处理函数 数学和统计函数:R提供了丰富的数学和统计函数,用于执行各种计算和分析。这些函数可以帮助用户快速完成复杂的数学运算、统计分析等任务,例如计算均值、方差、相关系数、进行假设检验等。字符处…...

Redis设计与实现——单机Redis实现
RedisDB RedisDB的核心结构 键空间(dict*dict) 结构:哈希表(字典),键为字符串对象(SDS),值为 Redis 对象(字符串、列表、哈希等)。 功能&#x…...
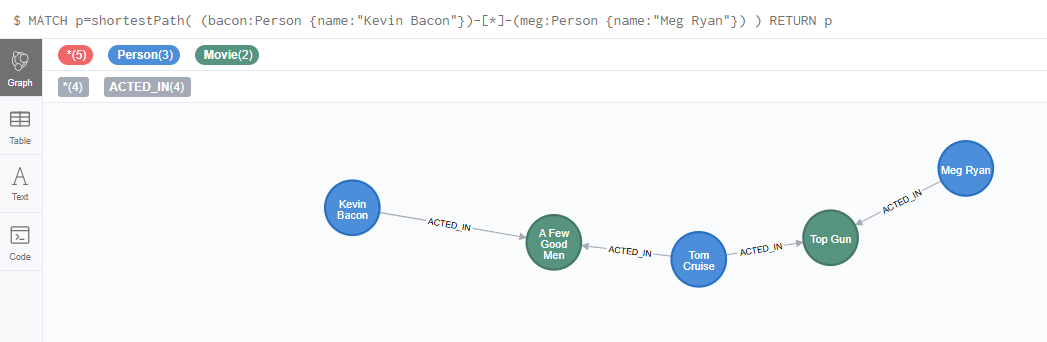
neo4j官方示例
目录 一、准备数据 1.执行查看结果 二、操作 1.find 单个节点 2.同上,已某个属性去查询 3. 指定查询个数 4.条件查询 5.查询某个人出演的电影汇总 6.查询tom出演的电影中,还有其他演员的信息。 7.查询跟电影(Cloud Atlas)有关的演员࿰…...
结合 Dify、大语言模型(LLM)以及 Qwen-3 模型的项目或概念)
探讨关于智能体(Agent)结合 Dify、大语言模型(LLM)以及 Qwen-3 模型的项目或概念
1. Dify 的作用 Dify 是一个开源的 AI 框架,它可以帮助开发者快速搭建和部署 AI 应用。它可以作为一个基础架构,为智能体提供以下支持: 应用开发与部署:Dify 可以帮助开发者快速搭建智能体的前端和后端架构,包括用户界…...

前端自学入门:HTML 基础详解与学习路线指引
在互联网的浪潮中,前端开发如同构建数字世界的基石,而 HTML 则是前端开发的 “入场券”。对于许多渴望踏入前端领域的初学者而言,HTML 入门是首要挑战。本指南将以清晰易懂的方式,带大家深入了解 HTML 基础,并梳理前端…...