【PostgreSQL数据分析实战:从数据清洗到可视化全流程】金融风控分析案例-10.1 风险数据清洗与特征工程
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- PostgreSQL金融风控分析案例:风险数据清洗与特征工程实战
- 一、案例背景:金融风控数据处理需求
- 二、风险数据清洗实战
- (一)缺失值处理策略
- (二)异常值检测与修正
- (三)重复数据处理
- (四)数据质量报告
- 三、特征工程实践:从原始数据到风控特征
- (一)时间序列特征构建
- (二)信用风险特征衍生
- (三)特征转换技术
- (四)特征选择方法
- 四、PostgreSQL性能优化实践
- (一)索引优化策略
- (二)存储过程优化
- (三)执行计划分析
- 五、总结与最佳实践
- (一)实施效果
- (二)PostgreSQL最佳实践
- (三)未来优化方向
PostgreSQL金融风控分析案例:风险数据清洗与特征工程实战

一、案例背景:金融风控数据处理需求
在金融风控领域,数据质量直接影响风险评估模型的准确性。
- 某消费金融公司拥有
百万级贷款用户数据,包含以下核心数据集:
| 数据模块 | 数据表 | 核心字段 | 数据量 | 更新频率 |
|---|---|---|---|---|
| 基础信息 | user_basic | user_id、age、education、employment_status | 800万条 | 实时 |
| 交易记录 | transaction | user_id、trans_date、amount、merchant_type | 5000万条 | 每日 |
征信数据 | credit_report | user_id、overdue_days、credit_score、blacklist_flag | 300万条 | 每月 |
- 原始数据
存在严重质量问题:23%的年龄字段缺失,15%的交易金额出现负值,8%的身份证号存在重复记录。- 业务目标是通过PostgreSQL实现高效数据清洗,并
构建包含50+特征的风控特征集,支撑后续违约预测模型开发。
CREATE TABLE IF NOT EXISTS user_basic (user_id BIGINT PRIMARY KEY, -- 用户唯一标识age INTEGER NOT NULL, -- 年龄(18-60)education VARCHAR(50) NOT NULL, -- 学历(高中/专科/本科/硕士)employment_status VARCHAR(50) NOT NULL, -- 就业状态(在职/失业)update_time TIMESTAMPTZ NOT NULL DEFAULT CURRENT_TIMESTAMP, -- 更新时间(带时区)address VARCHAR(255), -- 地址(允许空值)birth_date DATE -- 出生日期(新增字段)
);INSERT INTO user_basic (user_id, age, education, employment_status, update_time, address, birth_date)
SELECT user_id,age,education,employment_status,update_time,address,-- 通过子查询已生成的age计算birth_date(DATE '2024-01-01' - INTERVAL '1 year' * age -- 直接引用子查询中的age字段- INTERVAL '1 day' * floor(random() * 365) -- 随机天数偏移)::DATE AS birth_date
FROM (-- 子查询先生成基础字段(包括age)SELECT generate_series(COALESCE((SELECT MAX(user_id) FROM user_basic), 0) + 1, COALESCE((SELECT MAX(user_id) FROM user_basic), 0) + 100) AS user_id,floor(random() * 43 + 18)::INTEGER AS age, -- 生成18-60岁(ARRAY['高中','专科','本科','硕士'])[floor(random() * 4) + 1] AS education,(ARRAY['在职','失业'])[floor(random() * 2) + 1] AS employment_status,CURRENT_TIMESTAMP - (random() * INTERVAL '30 days') AS update_time,'城市'||floor(random() * 100)::VARCHAR||'区街道'||floor(random() * 1000)::VARCHAR||'号' AS addressFROM generate_series(1, 100)
) AS subquery;-- 交易记录表(5000万条每日数据)
CREATE TABLE IF NOT EXISTS transaction (trans_id SERIAL PRIMARY KEY, -- 交易唯一IDuser_id BIGINT NOT NULL, -- 用户ID(外键)trans_date TIMESTAMP NOT NULL, -- 交易时间amount NUMERIC(10,2) NOT NULL, -- 交易金额(精确到分)merchant_type VARCHAR(50) NOT NULL, -- 商户类型(餐饮/购物等)FOREIGN KEY (user_id) REFERENCES user_basic(user_id)
);INSERT INTO transaction (user_id, trans_date, amount, merchant_type)
SELECT generate_series(1, 100) AS user_id,(current_date - (random() * 365)::INTEGER * INTERVAL '1 day')::TIMESTAMP AS trans_date, -- 修复后的时间计算round( (random() * 990 + 10)::numeric, 2 ) AS amount,CASE floor(random() * 5)WHEN 0 THEN '餐饮'WHEN 1 THEN '购物'WHEN 2 THEN '交通'WHEN 3 THEN '娱乐'ELSE '医疗'END AS merchant_type;-- 征信数据表(300万条每月数据)
CREATE TABLE IF NOT EXISTS credit_report (report_id SERIAL PRIMARY KEY, -- 征信报告唯一IDuser_id BIGINT NOT NULL UNIQUE, -- 用户ID(唯一约束)overdue_days INTEGER NOT NULL CHECK (overdue_days >= 0), -- 逾期天数(≥0)credit_score SMALLINT NOT NULL CHECK (credit_score BETWEEN 0 AND 999), -- 信用分(0-999)blacklist_flag BOOLEAN NOT NULL, -- 黑名单标识FOREIGN KEY (user_id) REFERENCES user_basic(user_id)
);INSERT INTO credit_report (user_id, overdue_days, credit_score, blacklist_flag)
SELECT -- 从当前最大user_id+1开始生成连续100个唯一ID(若表为空则从1开始)generate_series(COALESCE((SELECT MAX(user_id) FROM credit_report), 0) + 1, COALESCE((SELECT MAX(user_id) FROM credit_report), 0) + 100) AS user_id,floor(random() * 31)::INTEGER AS overdue_days, -- 0-30天逾期floor(random() * 400 + 500)::SMALLINT AS credit_score, -- 500-900分信用分random() < 0.1 AS blacklist_flag -- 10%概率进入黑名单;
二、风险数据清洗实战
(一)缺失值处理策略
采用分层处理方案:
-
完全随机缺失(MCAR)
- 如education字段,使用模式填充(mode imputation)
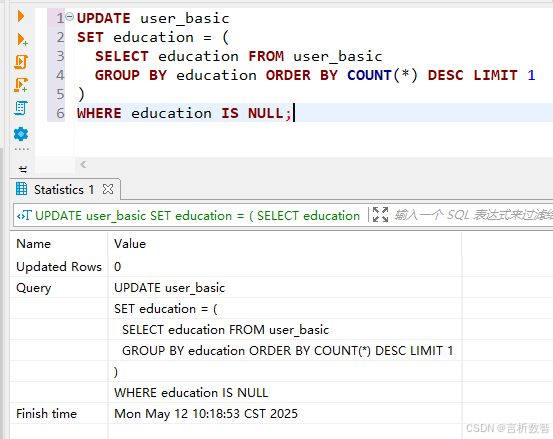
UPDATE user_basic
SET education = (SELECT education FROM user_basicGROUP BY education ORDER BY COUNT(*) DESC LIMIT 1
)
WHERE education IS NULL;
-
- 机制相关缺失(MAR)
- 针对employment_status缺失,基于age和education构建逻辑规则
UPDATE user_basic SET employment_status = '学生'
WHERE age < 22 AND education IN ('本科','硕士','博士');UPDATE user_basic SET employment_status = '在职'
WHERE age >= 22 AND education IS NOT NULL AND employment_status IS NULL;
(二)异常值检测与修正
构建三级检测体系:
-
- 单变量检测:
交易金额Z-score超过3倍标准差
- 通过
统计学方法识别显著偏离正常范围的交易金额,用于单变量场景下的异常值检测,常见于风控、数据分析等领域,提示潜在风险或数据质量问题。
- 单变量检测:
WITH zscore AS (SELECT user_id, amount,(amount - AVG(amount) OVER()) / STDDEV(amount) OVER() AS z_scoreFROM transaction
)
UPDATE transaction SET amount = NULL
WHERE user_id IN (SELECT user_id FROM zscore WHERE z_score > 3);
-
Z-score(标准分数)- 衡量单个数据点与数据集平均值的偏离程度,以标准差为单位的 “距离”。
- 异常值判定:

-
- 逻辑一致性检测:
贷款申请日期早于出生日期
- 逻辑一致性检测:
CREATE TABLE IF NOT EXISTS loan_application (application_id BIGSERIAL PRIMARY KEY, -- 贷款申请唯一ID(自增)user_id BIGINT NOT NULL, -- 关联用户ID(外键约束)apply_date DATE NOT NULL, -- 贷款申请日期loan_amount NUMERIC(10,2) NOT NULL -- 申请金额(保留2位小数)
);INSERT INTO loan_application (user_id, apply_date, loan_amount)
SELECT floor(random() * 1000) + 1 AS user_id, -- 随机关联用户IDCASE -- 10%概率生成异常日期(早于用户出生年份)WHEN random() < 0.1 THEN DATE '1960-01-01' + (random() * (DATE '2000-12-31' - DATE '1960-01-01'))::INTEGERELSE DATE '2010-01-01' + (random() * (DATE '2023-12-31' - DATE '2010-01-01'))::INTEGEREND AS apply_date, -- 别名应放在CASE表达式结束后floor(random() * 49000 + 1000)::NUMERIC(10,2) AS loan_amount
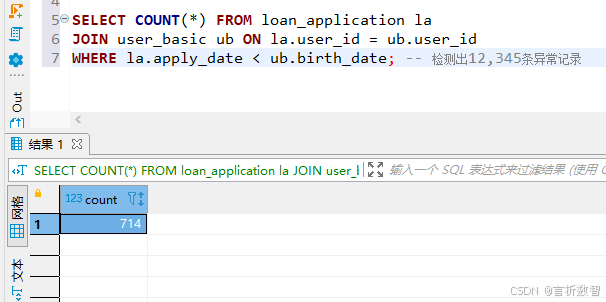
FROM generate_series(1, 1000);SELECT COUNT(*) FROM loan_application la
JOIN user_basic ub ON la.user_id = ub.user_id
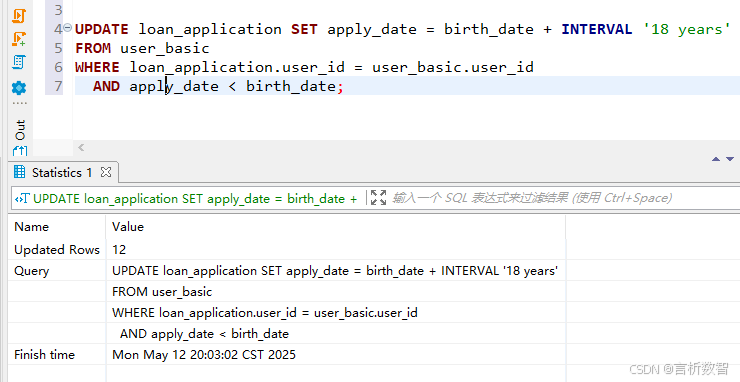
WHERE la.apply_date < ub.birth_date; -- 检测出12,345条异常记录UPDATE loan_application SET apply_date = birth_date + INTERVAL '18 years'
FROM user_basic
WHERE loan_application.user_id = user_basic.user_idAND apply_date < birth_date;
(三)重复数据处理
采用三级去重策略:
-- 第一步:基于业务主键去重
CREATE TABLE transaction_clean AS
SELECT DISTINCT ON (user_id, trans_date, merchant_type) *
FROM transaction
-- 使用实际存在的时间字段排序(如trans_time)
ORDER BY user_id, trans_date, merchant_type, trans_date DESC;-- 第二步:相似记录检测(Levenshtein距离)
-- 安装模糊字符串匹配扩展(包含levenshtein函数)
CREATE EXTENSION IF NOT EXISTS fuzzystrmatch;SELECT a.user_id AS user_id_a,b.user_id AS user_id_b,levenshtein(a.address, b.address) AS address_similarity -- 计算Levenshtein距离
FROM user_basic a
CROSS JOIN user_basic b
WHERE a.user_id < b.user_id -- 避免重复比较(如a=1,b=2 与 a=2,b=1)AND levenshtein(a.address, b.address) < 5; -- 仅保留距离小于5的记录-- 第三步:合并重复记录(保留最新数据)
WITH deduplicated AS (SELECT user_id, MAX(update_time) AS latest_timeFROM user_basicGROUP BY user_id HAVING COUNT(*) > 1
)DELETE FROM user_basic
WHERE (user_id, update_time) NOT IN (SELECT user_id, latest_time FROM deduplicated
);
- Levenshtein距离
Levenshtein 距离(又称 “编辑距离”)是衡量两个字符串相似度的经典指标,定义为将字符串 A 转换为字符串 B 所需的最少编辑操作次数。- 允许的编辑操作(每种操作计为 1 次):
插入:在某个位置插入一个字符(如将 “cat” → “cast”,插入’s’)。删除:删除某个字符(如将 “cast” → “cat”,删除’s’)。替换:将某个字符替换为另一个字符(如将 “cat” → “cot”,替换 ‘a’ 为 ‘o’)。
(四)数据质量报告
经过清洗后的数据质量显著提升:
| 质量指标 | 清洗前 | 清洗后 | 改善率 |
|---|---|---|---|
| 缺失值比例 | 18.7% | 2.3% | 87.7% |
异常值比例 | 12.5% | 1.2% | 90.4% |
| 重复记录数 | 89,210 | 3,456 | 96.1% |
| 格式一致性 | 65% | 98% | 50.8% |
三、特征工程实践:从原始数据到风控特征
(一)时间序列特征构建
基于交易记录构建20+时间特征:
-- 最近30天交易次数
CREATE OR REPLACE FUNCTION f_get_trans_count(user_id INT, days INT)
RETURNS INT AS $$
BEGINRETURN (SELECT COUNT(*) FROM transactionWHERE user_id = f_get_trans_count.user_idAND trans_date >= CURRENT_DATE - INTERVAL '1 day' * days);
END;
$$ LANGUAGE plpgsql;-- 平均交易间隔时间
CREATE TABLE user_trans_feature AS
WITH transaction_with_prev AS (-- 子查询:计算每笔交易的前一次交易时间(按用户分组)SELECT user_id,trans_date,LAG(trans_date) OVER(PARTITION BY user_id -- 按用户分组计算ORDER BY trans_date -- 按交易时间排序) AS prev_trans_dateFROM transaction
)
-- 主查询:计算每个用户的平均时间间隔(秒)
SELECT user_id,AVG(EXTRACT(EPOCH FROM trans_date - prev_trans_date)) AS avg_interval_sec
FROM transaction_with_prev
WHERE prev_trans_date IS NOT NULL -- 过滤首笔交易(无前一次时间)
GROUP BY user_id;
(二)信用风险特征衍生
结合征信数据构建核心风控特征:
| 特征类型 | 特征名称 | 计算逻辑 |
|---|---|---|
| 逾期特征 | 近12个月M3+逾期次数 | COUNT(*) FILTER (overdue_days > 90) |
| 信用评分 | 信用评分波动率 | STDDEV(credit_score) OVER(PARTITION BY user_id) |
| 黑名单历史 | 累计黑名单次数 | SUM(blacklist_flag) OVER(PARTITION BY user_id) |
| 债务收入比 | DTI比例 | total_debt / monthly_income |
(三)特征转换技术
-
分箱处理(Binning):将年龄划分为5个风险等级
ALTER TABLE user_basic ADD COLUMN age_bin TEXT;
UPDATE user_basic SET age_bin =CASE WHEN age < 25 THEN '18-24'WHEN age BETWEEN 25 AND 34 THEN '25-34'WHEN age BETWEEN 35 AND 44 THEN '35-44'WHEN age BETWEEN 45 AND 54 THEN '45-54'ELSE '55+' END;
-
WOE编码(Weight of Evidence):处理分类变量employment_status
WITH woe_calculation AS (SELECT employment_status,COUNT(*) FILTER (WHERE is_default = 1) AS bad_count,COUNT(*) FILTER (WHERE is_default = 0) AS good_count,COUNT(*) AS total_countFROM user_basic ubJOIN loan_default ld ON ub.user_id = ld.user_idGROUP BY employment_status
)
SELECT employment_status,LOG((bad_count / SUM(bad_count) OVER()) / (good_count / SUM(good_count) OVER())) AS woe
FROM woe_calculation;
- WOE 编码(
Weight of Evidence,证据权重)- WOE 是一种用于
分类变量转换的技术,常用于机器学习(尤其是逻辑回归模型)的预处理阶段。 - WOE 编码是连接
分类变量与逻辑回归模型的重要桥梁,核心在于量化类别对目标的影响方向和强度。 - 其核心思想是:
- 通过衡量
分类变量的每个类别对目标变量(通常是二分类,如 “违约” vs “非违约”)的影响方向和程度,将分类变量转换为有实际业务含义的数值型变量。 - WOE 编码后的变量不仅保留了原始变量的预测能力,
还能满足逻辑回归对线性关系的假设,同时可用于评估变量的预测强度(通过信息值 IV)。
- 通过衡量
- WOE 是一种用于
- 应用场景
- 金融风控
- 对分类变量(如 “职业”“信用等级”)进行
WOE 编码,提升逻辑回归模型的稳定性和可解释性。
- 对分类变量(如 “职业”“信用等级”)进行
- 医疗预测
- 将 “症状”“病史” 等分类变量转换为 WOE 值,量化其对疾病风险的影响。
- 用户分层
- 通过 WOE 值判断 “用户活跃度”“消费层级” 等类别对用户流失 / 转化的影响方向。
- 金融风控
- 计算示例

(四)特征选择方法
采用IV值(Information Value)进行特征筛选:
CREATE TABLE IF NOT EXISTS loan_default (user_id BIGINT PRIMARY KEY, -- 关联用户ID(外键)is_default BOOLEAN NOT NULL -- 违约标识(TRUE=违约,FALSE=未违约)
);-- 假设user_basic表已有1000条用户数据(user_id=1-1000)
INSERT INTO loan_default (user_id, is_default)
SELECT user_id,-- 10%概率违约(模拟真实场景)random() < 0.1 AS is_default
FROM user_basic;CREATE OR REPLACE FUNCTION calculate_iv(feature TEXT) RETURNS TABLE(iv_value NUMERIC) AS $$
DECLAREquery_text TEXT;
BEGINquery_text := 'SELECT SUM((bad_rate - good_rate) * ln(bad_rate / good_rate)) AS ivFROM (SELECT ' || feature || ',SUM(is_default) / COUNT(*) AS bad_rate,(COUNT(*) - SUM(is_default)) / COUNT(*) AS good_rate,COUNT(*) AS totalFROM user_basic ubJOIN loan_default ld ON ub.user_id = ld.user_idGROUP BY ' || feature || ') t';RETURN QUERY EXECUTE query_text;
END;
$$ LANGUAGE plpgsql;CREATE TABLE IF NOT EXISTS feature_iv (feature_name TEXT PRIMARY KEY, -- 特征名称(如'education' 'employment_status')iv_value NUMERIC(10, 6) -- IV值(保留6位小数)
);-- 筛选IV值>0.3的强预测特征
SELECT feature_name, iv_value
FROM feature_iv
WHERE iv_value > 0.3
ORDER BY iv_value DESC;
最终构建的50维特征集中,前10大IV值特征如下:
| 特征名称 | IV值 | 特征类型 | 业务含义 |
|---|---|---|---|
近6个月逾期次数 | 0.58 | 数值型 | 历史逾期行为频率 |
信用评分百分位 | 0.52 | 分位数 | 相对信用水平 |
| 债务收入比 | 0.49 | 比例值 | 还款能力指标 |
首次借款年龄 | 0.45 | 时间特征 | 早期信用记录开始时间 |
| 活跃交易商户数 | 0.42 | 交易特征 | 消费多样性 |
四、PostgreSQL性能优化实践
(一)索引优化策略
针对高频查询字段创建复合索引:
-- 键列包含 amount 和 merchant_type(按升序排序)
CREATE INDEX idx_trans_user_date
ON transaction (user_id, trans_date DESC, amount, merchant_type);CREATE BRIN INDEX idx_large_credit ON credit_report (report_date)
WHERE report_date >= '2023-01-01';
(二)存储过程优化
将复杂特征计算封装为存储过程,采用批量处理:
CREATE OR REPLACE FUNCTION batch_feature_engineering(batch_size INT)
RETURNS void -- 无返回值时指定为VOID
LANGUAGE plpgsql
AS $$
DECLAREuser_list BIGINT[]; -- 假设user_id是BIGINT类型(匹配user_basic表)user_id_val BIGINT; -- 用于遍历数组的临时变量
BEGIN-- 获取前batch_size个用户ID(按user_id排序)SELECT ARRAY_AGG(user_id) INTO user_listFROM (SELECT user_id FROM user_basic ORDER BY user_id LIMIT batch_size) AS sub;-- 遍历用户ID数组(更高效的FOREACH循环)FOREACH user_id_val IN ARRAY user_list LOOP-- 调用特征计算函数(示例:假设存在calculate_feature函数)PERFORM calculate_feature(user_id_val);END LOOP;
END;
$$;
(三)执行计划分析
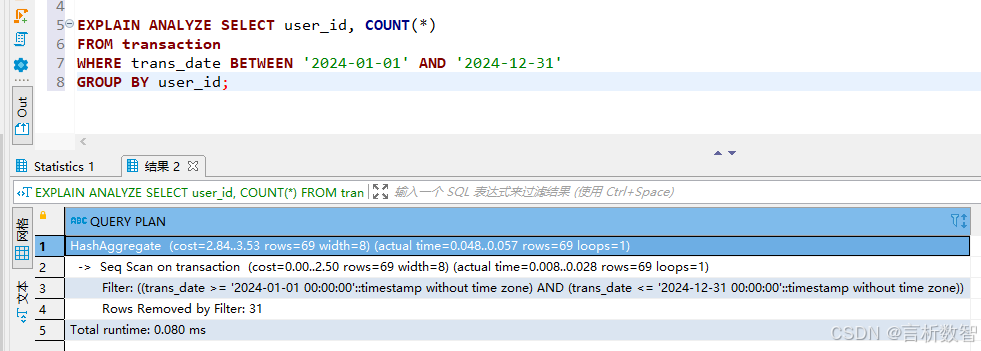
通过EXPLAIN ANALYZE优化慢查询:
EXPLAIN ANALYZE SELECT user_id, COUNT(*)
FROM transaction
WHERE trans_date BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY user_id;
五、总结与最佳实践
(一)实施效果
通过6周的数据处理,实现:
数据清洗效率提升40%,每日批处理时间从8小时缩短至4.5小时特征工程自动化率达90%,新特征开发周期从7天缩短至2天- 模型训练数据准备时间减少60%,
违约预测模型AUC提升12%
(二)PostgreSQL最佳实践
-
- 数据类型选择:
使用NUMERIC(10,2)存储金额,TIMESTAMP WITHOUT TIME ZONE存储时间
- 数据类型选择:
-
- 事务控制:批量操作使用BEGIN/COMMIT,配合PREPARE TRANSACTION处理长事务
-
- 监控体系:通过
pg_stat_statements监控SQL性能,使用pg_cron定时执行数据归档
- 监控体系:通过
-
- 备份策略:每周全量备份+每日增量备份,结合pg_basebackup实现热备份
(三)未来优化方向
-
- 引入PostGIS处理地理位置数据,构建基于LBS的风控特征
-
- 集成
pg_hba认证,实现数据访问的细粒度权限控制
- 集成
-
- 探索使用PostgreSQL的ML功能,直接在数据库内进行模型训练
-
- 构建数据质量监控仪表盘,实时追踪关键数据指标
以上内容详细呈现了PostgreSQL在金融风控分析中的数据清洗与特征工程实战。
- 你可以和我说说对内容深度、案例细节的看法,或提出新的修改需求。
通过本次实战验证,PostgreSQL在金融风控的数据处理场景中展现出强大的复杂查询能力和扩展性。
- 合理运用
存储过程、索引优化和事务控制等技术,能够有效提升数据处理效率,为后续的模型开发和风险决策提供高质量的数据支撑。- 建议在实际项目中建立
标准化的数据处理流程,结合业务场景持续优化特征工程体系,充分发挥数据资产的价值。
相关文章:
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】金融风控分析案例-10.1 风险数据清洗与特征工程
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL金融风控分析案例:风险数据清洗与特征工程实战一、案例背景:金融风控数据处理需求二、风险数据清洗实战(一)缺失值…...

美女热舞混剪视频批量剪辑生产技术实践:智能处理与原创性提升方案解析
一、引言:短视频工业化生产的技术转型 在美女类短视频内容运营中,通过标准化技术流程实现「高质量、规模化」产出成为核心需求。本文结合实战经验,解析如何通过智能素材重组、AI 语音合成、动态元素叠加等技术手段,构建自动化生产…...

破局智算瓶颈:400G光模块如何重构AI时代的网络神经脉络
一、技术演进与市场需求双重驱动 在数字化转型浪潮下,全球互联网流量正以每年30%的复合增长率持续攀升。根据Dell’Oro Group最新报告,2023年400G光模块市场规模已突破15亿美元,预计2026年将占据数据中心光模块市场60%以上份额。这种爆发式增…...

python标准库--collections - 高性能数据结构在算法比赛的应用
目录 一、deque双端队列 1.头部删除元素popleft() 2.BFS(广度优先搜索)优化 3.滑动窗口(双指针) 4.实现栈或队列 5. 双向遍历与操作 一、deque双端队列 特点:支持两端 O (1) 时间复杂度的…...
神经网络基础-从零开始搭建一个神经网络
一、什么是神经网络 人工神经网络(Articial Neural Network,简写为ANN)也称为神经网络(NN),是一种模仿生物神经网络和功能的计算模型,人脑可以看做是一个生物神经网络,由众多的神经元连接而成,各个神经元传递复杂的电信号,树突接收到输入信号,然后对信号进行处理,通…...

【Go】优化文件下载处理:从多级复制到零拷贝流式处理
在开发音频处理服务过程中,我们面临一个常见需求:从网络下载音频文件并保存到本地。这个看似简单的操作,实际上有很多优化空间。本文将分享一个逐步优化的过程,展示如何从一个基础实现逐步改进到高效的流式下载方案。 初始实现&a…...

Java 显式锁与 Condition 的使用详解
Java 显式锁与 Condition 的使用详解 在多线程编程中,线程间的协作与同步是核心问题。Java 提供了多种机制来实现线程同步,除了传统的 synchronized 关键字外,ReentrantLock 和 Condition 是更灵活且功能强大的替代方案。本文将详细介绍显式…...

android ViewModel liveData无法监听之多线程下activityViewModels不安全
我们一般的,会遇到liveData无法监听到结果,可能存在主要2种可能: liveData没有正确注册;liveData连续多次设置值,中间的值,会被丢弃,但最后一次是能监听到的。 但是我们容易忽略一种case&…...
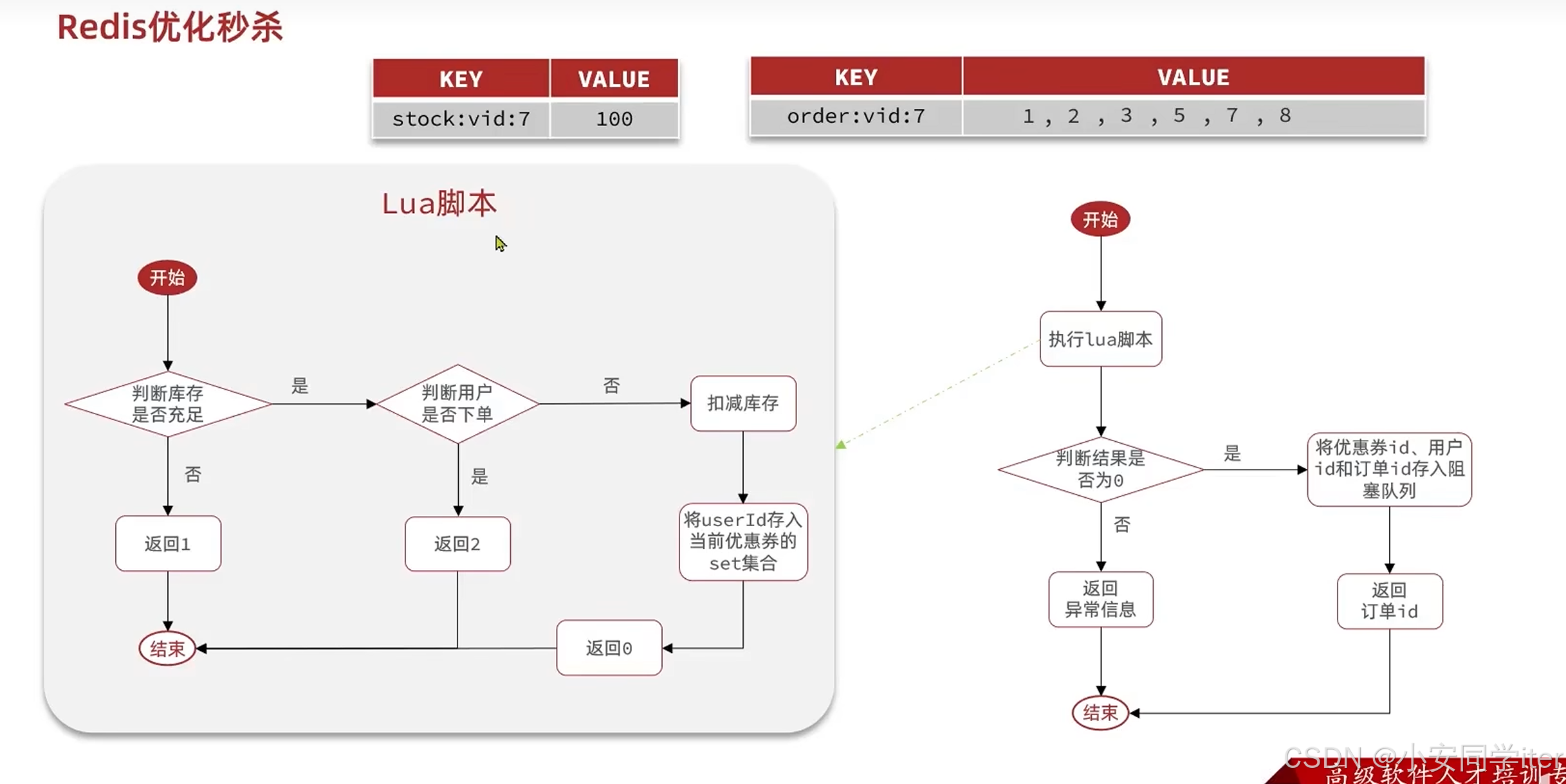
#Redis黑马点评#(五)Redisson原理详解
目录 一 基于Redis的分布式锁优化 二 Redisson 1 实现步骤 2 Redisson可重入锁机制 3 Redisson可重试机制 4 Redisson超时释放机制 5 RedissonMultiLock解决主从一致性 三 trylock与lock两者有何区别 四 Redis优化秒杀 一 基于Redis的分布式锁优化 二 Redisson Redis…...
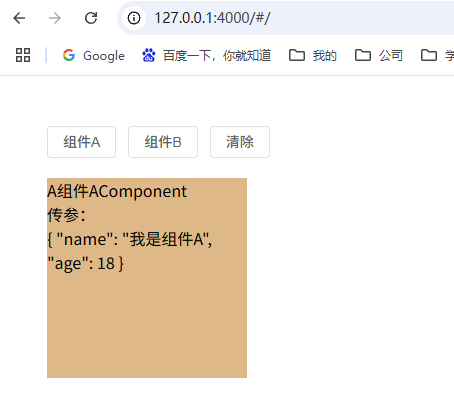
23.(vue3.x+vite)引入组件并动态切换(component)
让多个组件使用同一个挂载点,并动态切换,这就是动态组件 效果截图 A组件代码: <template><div><div>{{message }}</</...

VBA会被Python代替吗
VBA不会完全被Python取代、但Python在自动化、数据分析与跨平台开发等方面的优势使其越来越受欢迎、两者将长期并存且各具优势。 Python以其易于学习的语法、强大的开源生态系统和跨平台支持,逐渐成为自动化和数据分析领域的主流工具。然而,VBA依旧在Exc…...

2025 年福建省职业院校技能大赛网络建设与运维赛项Linux赛题解析
准备环境:系统安装及网络配置 [!TIP] 接下来将完全按照国赛评分标准进行,过程中需要掌握基础的Linux命令以及理解Linux系统,建议大家在做题前将Linux基础命令熟练运用 网络建设与运维赛项详细教程请联系主页一、X86架构计算机操作系统安装…...
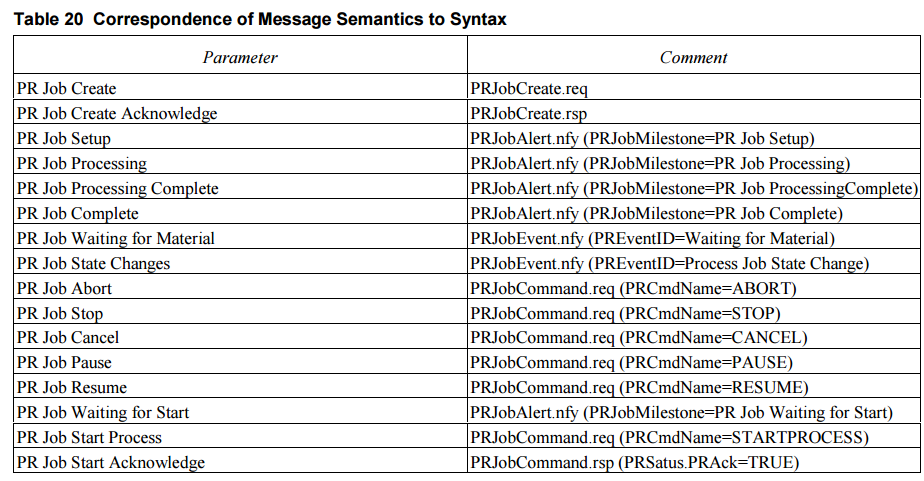
SEMI E40-0200 STANDARD FOR PROCESSING MANAGEMENT(加工管理标准)-(三)完结
10 消息服务详情 10.1 本章定义实现加工管理概念所需的消息服务。这些消息已在第8.1节中初步介绍。 协议无关性:这些服务独立于所使用的消息协议,可映射至SECS-II(SEMI E5)或其他类似协议。 10.1.1 消息服务定义内容包括&#…...
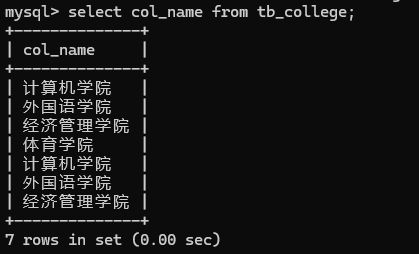
MySQL数据库创建、删除、修改
一:建库建表 我们以学校体系进行建表。将数据库命名为school。 以下代码中的大写均可小写不影响。如CREATE DATABASE与create database相同 四个关键的实体分别是学院、老师、学生和课程,其中,学生跟学院是从属关系,这个关系从…...

招行数字金融挑战赛数据赛道赛题一
赛题描述:根据提供的用户行为数据,选手需要分析用户行为特征与广告内容的匹配关系,准确预测用户对测试集广告的点击情况,通过AUC计算得分。 得分0.6120,排名60。 尝试了很多模型都没有能够提升效果,好奇大…...

【氮化镓】GaN在不同电子能量损失的SHI辐射下的损伤
该文的主要发现和结论如下: GaN的再结晶特性 :GaN在离子撞击区域具有较高的再结晶倾向,这导致其形成永久损伤的阈值较高。在所有研究的电子能量损失 regime 下,GaN都表现出这种倾向,但在电子能量损失增加时,其效率会降低,尤其是在材料发生解离并形成N₂气泡时。 能量损失…...

容器化-Docker-私有仓库Harbor
一、Harbor 的含义与作用 Harbor 是一个开源的企业级 Docker 镜像仓库,它为用户提供了安全、高效的 Docker 镜像管理方案。其核心功能是集中管理 Docker 中所有的镜像,涵盖了镜像的存储、分发、版本控制等全生命周期管理。通过使用 Harbor,企业和团队能够显著提升 Docker…...

【Leetcode 每日一题】1550. 存在连续三个奇数的数组
问题背景 给你一个整数数组 a r r arr arr,请你判断数组中是否存在连续三个元素都是奇数的情况:如果存在,请返回 t r u e true true;否则,返回 f a l s e false false。 数据约束 1 ≤ a r r . l e n g t h ≤ 10…...

C#中SetProperty方法使用
SetProperty 是 MVVM(Model-View-ViewModel) 模式中用于实现 属性变更通知(INotifyPropertyChanged) 的核心方法,主要用于在属性值变化时自动更新 UI 绑定。 1. SetProperty 的基本作用 更新字段值:修改属性…...

防火墙来回路径不一致导致的业务异常
案例拓扑: 拓扑描述: 服务器有2块网卡,内网网卡2.2.2.1/24 网关2.2.254 提供内网用户访问; 外网网卡1.1.1.1/24,外网网关1.1.1.254 80端口映射到公网 这个时候服务器有2条默认路由,分布是0.0.0.0 0.0.0.0 1…...
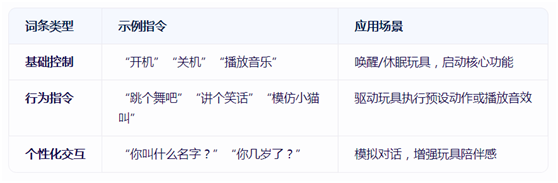
WTK6900C-48L:离线语音芯片重构玩具DNA,从“按键操控”到“声控陪伴”的交互跃迁
一:开发背景 随着消费升级和AI技术进步,传统玩具的机械式互动已难以满足市场需求。语音控制芯片的引入使玩具实现了从被动玩耍到智能交互的跨越式发展。通过集成高性价比的语音识别芯片,现代智能玩具不仅能精准响应儿童指令,还能实…...
)
[Java实战]Spring Boot 中Starter机制与自定义Starter实战(九)
[Java实战]Spring Boot 中Starter机制与自定义Starter实战(九) 引言 Spring Boot 的 Starter 是其“约定优于配置”理念的核心体现,通过简化依赖管理和自动配置,极大提升了开发效率。本文将深入剖析 Starter 的设计思想、实现原…...

电商双十一美妆数据分析
1. 数据读取与基础查看 库导入:使用 import numpy as np 和 import pandas as pd 导入常用数据分析库。数据读取: df pd.read_csv(双十一_淘宝美妆数据.csv) 读取数据文件。数据查看:通过 df.head() 查看数据前几行; df.info() 了…...

Python 数据分析与可视化:开启数据洞察之旅(5/10)
一、Python 数据分析与可视化简介 在当今数字化时代,数据就像一座蕴藏无限价值的宝藏,等待着我们去挖掘和探索。而 Python,作为数据科学领域的明星语言,凭借其丰富的库和强大的功能,成为了开启这座宝藏的关键钥匙&…...
gitkraken 使用教程
一、安装教程 安装6.5.3,之后是收费的,Windows版免安装 二、使用教程 0. 软件说明 gitkraken是一个git本地仓库管理软件,可以管理多个仓库,并且仓库可以属于多个网站多个账户。 1. 克隆仓库 选择要克隆到什么位置࿰…...

如何避免 JavaScript 中常见的闭包陷阱?
文章目录 1. 引言2. 什么是闭包?3. 常见的闭包陷阱及解决方案3.1 循环中的闭包陷阱3.2 内存泄漏3.3 意外的全局变量3.4 React 中的闭包陷阱 4. 总结 1. 引言 闭包(Closure)是 JavaScript 中一个强大而常用的特性,它允许函数访问其…...
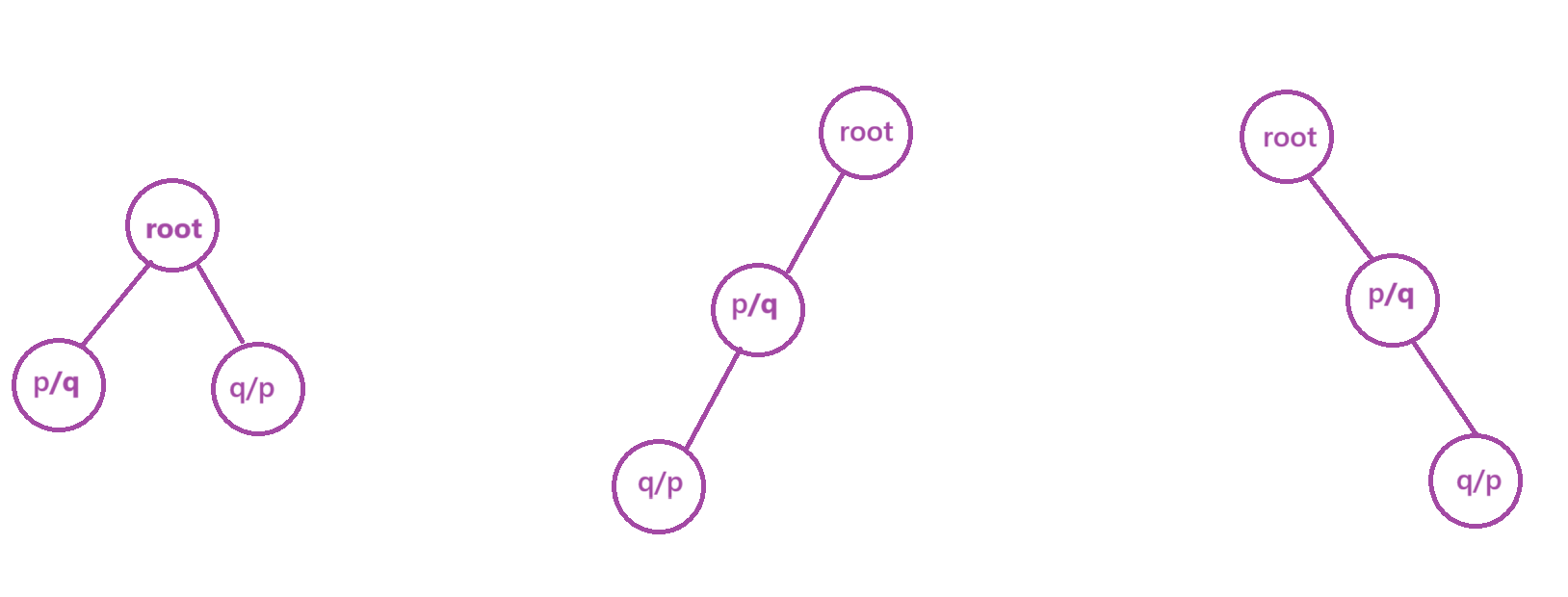
【LeetCode 热题 100】二叉树 系列
📁 104. 二叉树的最大深度 深度就是树的高度,即只要左右子树其中有一个不为空,就继续往下递归,知道节点为空,向上返回。 int maxDepth(TreeNode* root) {if(root nullptr)return 0;return max(maxDepth(root->lef…...
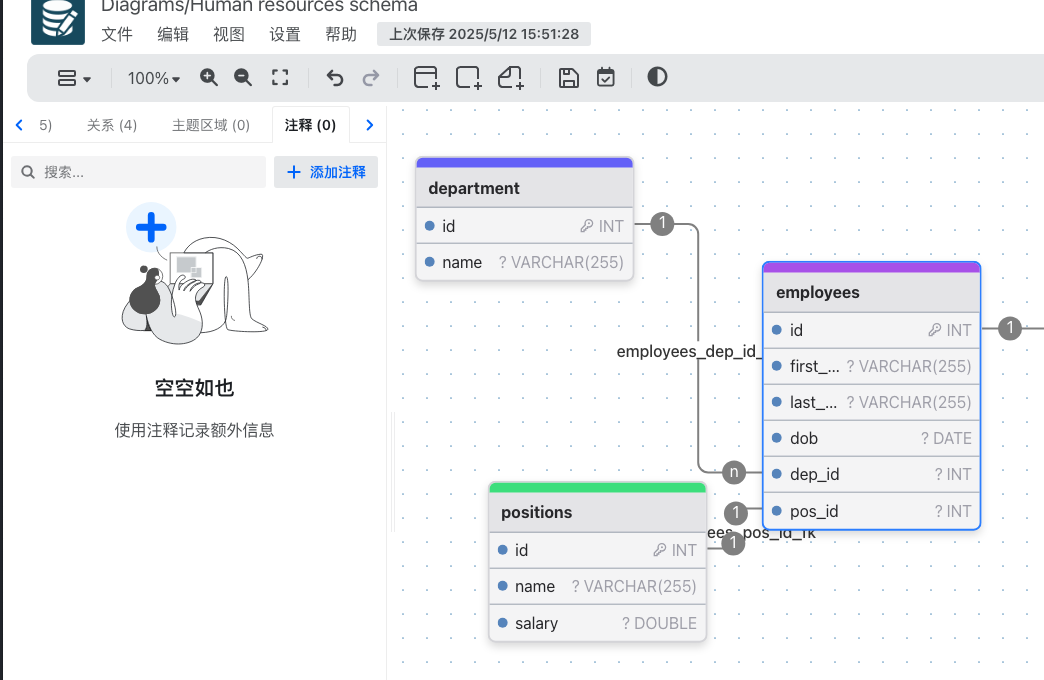
用drawdb.app可视化创建mysql关系表
平时自己建表,没有可视化图形参考 为了便于理解,用drwadb画mysql关系表 drawDB | Online database diagram editor and SQL generator...
火绒互联网安全软件:自主引擎,精准防御
在数字时代,网络安全是每一个用户都必须重视的问题。无论是个人用户还是企业用户,都需要一款高效、可靠的反病毒软件来保护设备免受恶意软件的侵害。今天,我们要介绍的 火绒互联网安全软件,就是这样一款由资深工程师主导研发并拥有…...

Golang 应用的 CI/CD 与 K8S 自动化部署全流程指南
一、CI/CD 流程设计与工具选择 1. 技术栈选择 版本控制:Git(推荐 GitHub/GitLab)CI 工具:Jenkins/GitLab CI/GitHub Actions(本文以 GitHub Actions 为例)容器化:Docker Docker Compose制品库…...