Spark的缓存
RDD缓存
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存多个数据集。当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的行动算子时,该RDD将会被缓存在计算节点的内存中,并供以后重用。
不带缓存的计算示例
以下通过一个计算斐波那契数列(1,1,2,3,5,8,13,....)第n项的例子,来展示 Spark 中cache方法的运行效果。
先来看看一段代码。
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}object Cache {def main(args: Array[String]): Unit = {// 配置Sparkval conf = new SparkConf().setAppName("CacheExample").setMaster("local[*]")val sc = new SparkContext(conf)
// conf.set("spark.local.dir", "_cache")
sc.setLogLevel("WARN")// 创建一个包含大量随机数的 RDDval largeRDD = sc.parallelize(1 to 1000*1000*10).map(_ => scala.util.Random.nextInt(1000))// 定义一个复杂的转换函数def complexTransformation(num: Int): Int = {var result = numfor (_ <- 1 to 1000) {result = result * 2 % 1000}result}// 不使用 cache 的情况val nonCachedRDD = largeRDD.map(complexTransformation)// 第一次触发行动算子,计算并统计时间val startTime1 = System.currentTimeMillis()val result1 = nonCachedRDD.collect()val endTime1 = System.currentTimeMillis()println(s"不使用 cache 第一次计算耗时: ${endTime1 - startTime1} 毫秒")// 第二次触发行动算子,计算并统计时间val startTime2 = System.currentTimeMillis()val result2 = nonCachedRDD.collect()val endTime2 = System.currentTimeMillis()println(s"不使用 cache 第二次计算耗时: ${endTime2 - startTime2} 毫秒")sc.stop()}
}在 Scala 里,cache 方法定义于 org.apache.spark.rdd.RDD 类中,其方法签名如下:
scaladef cache(): this.type返回类型:this.type,这表明返回的是调用该方法的 RDD 自身,只不过这个 RDD 已经被标记为需要缓存。
// 使用 cache 的情况val cachedRDD = largeRDD.map(complexTransformation).cache()// 第一次触发行动算子,计算并统计时间val startTime3 = System.currentTimeMillis()val result3 = cachedRDD.collect()val endTime3 = System.currentTimeMillis()println(s"使用 cache 第一次计算耗时: ${endTime3 - startTime3} 毫秒")// 第二次触发行动算子,计算并统计时间val startTime4 = System.currentTimeMillis()val result4 = cachedRDD.collect()val endTime4 = System.currentTimeMillis()println(s"使用 cache 第二次计算耗时: ${endTime4 - startTime4} 毫秒")println(s"spark.local.dir 的值: ${conf.get("spark.local.dir")}")sc.stop()核心代码说明:
第一次调用collect时,程序需要对RDD中的每个元素执行fibonacci函数进行计算,这涉及到递归运算,比较耗时。
第二次调用collect时,因为之前已经调用了cache方法,并且结果已被缓存,所以不需要再次执行计算,直接从缓存中读取数据。通过对比两次计算的耗时,可以明显发现第二次计算耗时会远小于第一次(在数据量较大或计算复杂时效果更显著),这就体现了cache方法缓存计算结果、避免重复计算、提升后续操作速度的作用 。
persist和cache方法
在 Spark 中,persist 和 cache 方法都用于将 RDD(弹性分布式数据集)或 DataFrame 持久化,以避免重复计算从而提升性能,但二者存在一些区别。
1. 功能本质
persist:这是一个通用的持久化方法,能够指定多种不同的存储级别。存储级别决定了数据的存储位置(如内存、磁盘)以及存储形式(如是否序列化)。
cache:其实是 persist 方法的一种特殊情况,它等价于调用 persist(StorageLevel.MEMORY_ONLY),也就是将数据以非序列化的 Java 对象形式存储在内存中。
2. 存储级别指定
persist:可以通过传入 StorageLevel 参数来指定不同的持久化级别。常见的持久化级别有:
MEMORY_ONLY:将 RDD 以 Java 对象的形式存储在 JVM 的内存中。若内存不足,部分分区将不会被缓存,需要时会重新计算。
MEMORY_AND_DISK:优先把 RDD 以 Java 对象的形式存储在 JVM 的内存中。若内存不足,会把多余的分区存储到磁盘上。
DISK_ONLY:将 RDD 的数据存储在磁盘上。
MEMORY_ONLY_SER:将 RDD 以序列化的 Java 对象形式存储在内存中,相较于 MEMORY_ONLY,序列化后占用的内存空间更小,但读取时需要进行反序列化操作,会带来一定的性能开销。
MEMORY_AND_DISK_SER:优先将 RDD 以序列化的 Java 对象形式存储在内存中,内存不足时存储到磁盘上。
cache:不能指定存储级别,它固定使用 MEMORY_ONLY 存储级别。
下面我们以DISK_ONLY为例,改写上面的程序,验证它的持久化效果。具体要改动的地方有两个: 指定持久化地址; 把cache改成persist;
import org.apache.spark.{SparkConf, SparkContext}object Main {def main(args: Array[String]): Unit = {//打印hello word!println("Hello World!")//学习sparkRDD中的转换算子//1.map//2.filter:过滤//3.flatMap:flat(扁平化)+map(映射)//4.reduceByKey:键值对的数据(world,1),(hello,1)val conf = new SparkConf().setMaster("local[*]").setAppName("Test")val sc = new SparkContext(conf)//创建一个RDD
// val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))// val rdd1 = rdd.map(x => x * 2)//使用filter算子,保留偶数
// val rdd1 = rdd.filter(x => x % 2 == 0)//有多个句子,每个句子有多个单词,单词之间使用空格隔开//目标,把所有单词找出来,放一个数组中
// val rdd = sc.parallelize(List("hello world", "hello scala"))
// val rdd1 = rdd.flatMap(x => x.split(" "))//hello world hello scala//词频统计的例子val rdd = sc.parallelize(List("apple","banana","apple","banana","apple"))
// val rdd1 = rdd.map(x => (x,1))//(apple,1)(banana,1)(apple,1)(banana,1)(apple,1)
// val rdd3 = rdd1.reduceByKey((x,y) => x+y)//(apple,3)(banana,2)rdd.map(x => (x,1)).reduceByKey((x,y) => x+y).collect().foreach(println)//collect()行动算子
// rdd3.collect().foreach(println)}
}相关文章:

Spark的缓存
RDD缓存 Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存多个数据集。当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。…...

爬虫工具与编程语言选择指南
有人问爬虫如何选择工具和编程语言。根据我多年的经验来说,是我肯定得先分析不同场景下适合的工具和语言。 如果大家不知道其他语言,比如JavaScript(Node.js)或者Go,这些在特定情况下可能更合适。比如,如果…...

系统平衡与企业挑战
在复杂的系统中,一切都在寻找平衡,而这个平衡从不静止。它在不断的变化与反馈中调整,以适应外界环境的变动。就像一个企业,它无法完全回避变化,但却总是在挑战中寻找新的平衡点。 最近遇到一家企业,引入了…...
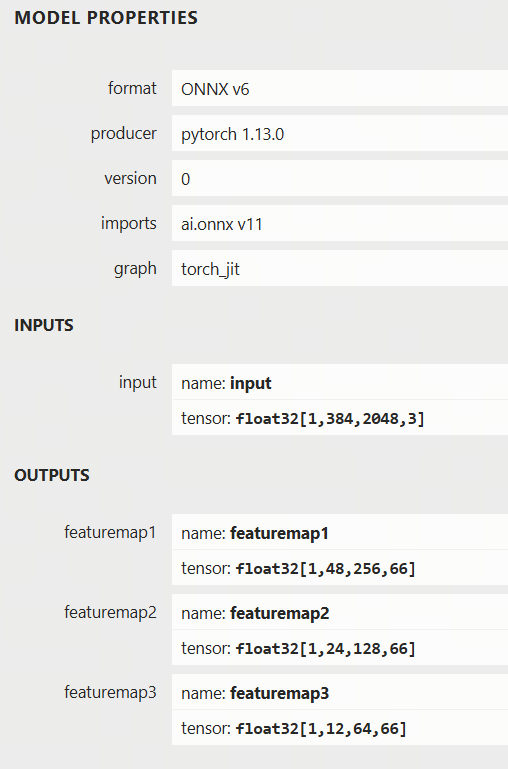
征程 6 yolov5s-rgb-nhwc 量化指南
在 征程 6 平台,我们可以按照这个方式编译 input_typr_rt 为 rgb,且 layout 为 NHWC 的模型。这样做的好处是,当用户的数据输入源本身就是 NHWC 的 rgb 图像时,这么做可以避免额外的数据处理操作。这里以 yolov5s 为例进行介绍。 …...
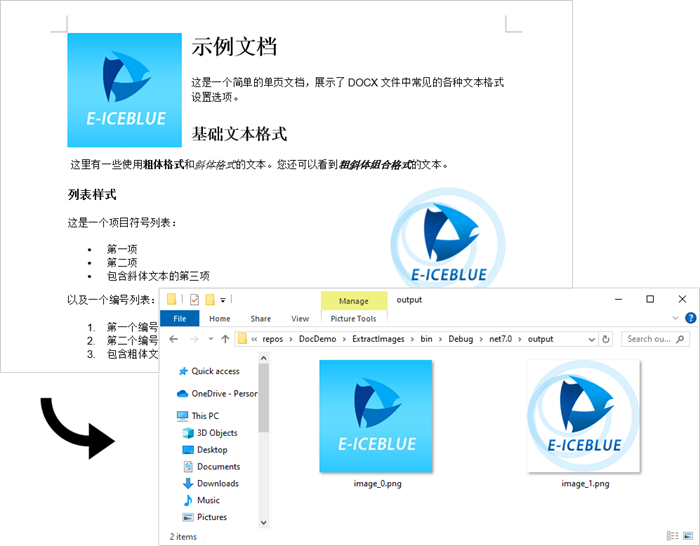
国产化Word处理控件Spire.Doc教程:如何使用 C# 从 Word 中提取图片
通过编程方式从 Word 文档中提取图片,可以用于自动化文档处理任务。E-iceblue旗下Spire系列产品是国产文档处理领域的优秀产品,支持国产化,帮助企业高效构建文档处理的应用程序。本文将演示如何使用 C# 和 Spire.Doc for .NET 库从 Word 文件…...

Telnet 类图解析
Telnet 类图(文本描述) --------------------------------------- | Telnet | --------------------------------------- | - host: str | # 目标主机 | - port: int …...

Python之with语句
文章目录 Python中的with语句详解一、基本语法二、工作原理三、文件操作中的with语句1. 基本用法2. 同时打开多个文件 四、with语句的优势五、自定义上下文管理器1. 基于类的实现2. 使用contextlib模块 六、常见应用场景七、注意事项 Python中的with语句详解 with语句是Python…...

【Flask全栈开发指南】从零构建企业级Web应用
目录 🌟 前言🏗️ 技术背景与价值🚧 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🔍 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🧩 关键技术模块说明⚖️ 技术选…...

mac 10.15.7 svn安装
macOS 版本推荐 SVN 安装方式≤10.14Homebrew 安装独立 SVN≥10.15优先使用 CLT 自带 SVN 一、使用 brew 安装 (没成功) brew install subversion 这个方法安装一直不成功,一直在提示说版本旧或都是一些引用工具安装失败, 二、使…...
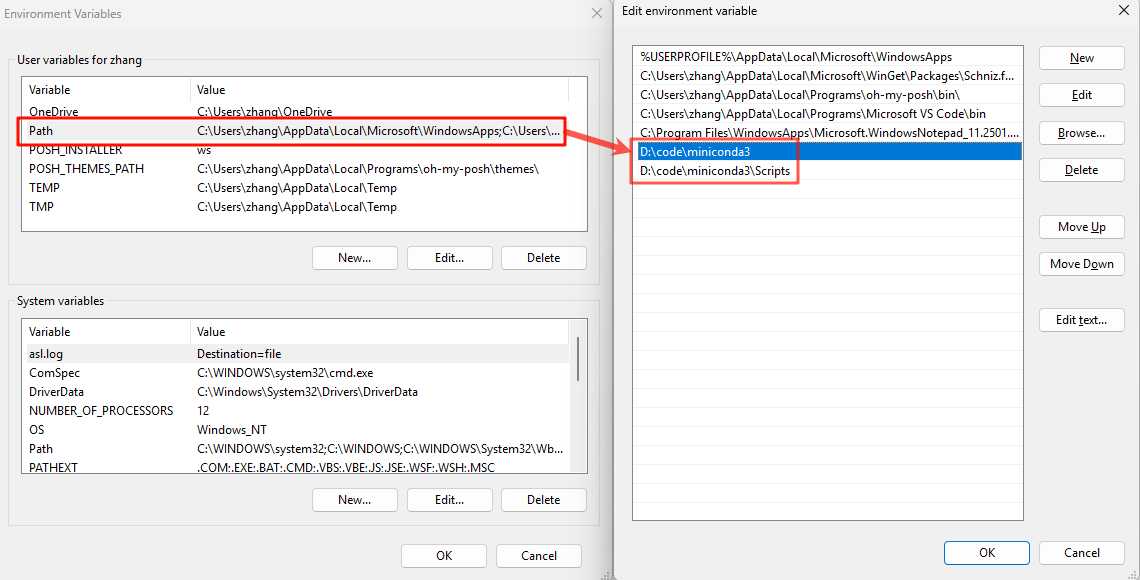
PowerShell 实现 conda 懒加载
问题 执行命令conda init powershell会在 profile.ps1中添加conda初始化的命令。 即使用户不需要用到conda,也会初始化conda环境,拖慢PowerShell的启动速度。 解决方案 本文展示了如何实现conda的懒加载,默认不加载conda环境,只…...

笔记项目 day02
一、用户登录接口 请求参数: 用loginDTO来封装请求参数,要加上RequestBody注解 响应参数: 由于data里内容较多,考虑将其封装到一个LoginUser的实体中,用户登陆后,需要生成jwtToken并返回给前端。 登录功…...

Memcached 服务搭建和集成使用的详细步骤示例
以下是 Memcached 服务搭建和集成使用的详细步骤示例: 一、搭建 Memcached 服务 安装 Memcached Linux 系统 yum 安装:执行命令 yum install -y memcached memcached-devel。源码安装 下载源码:wget http://www.memcached.org/files/memcach…...
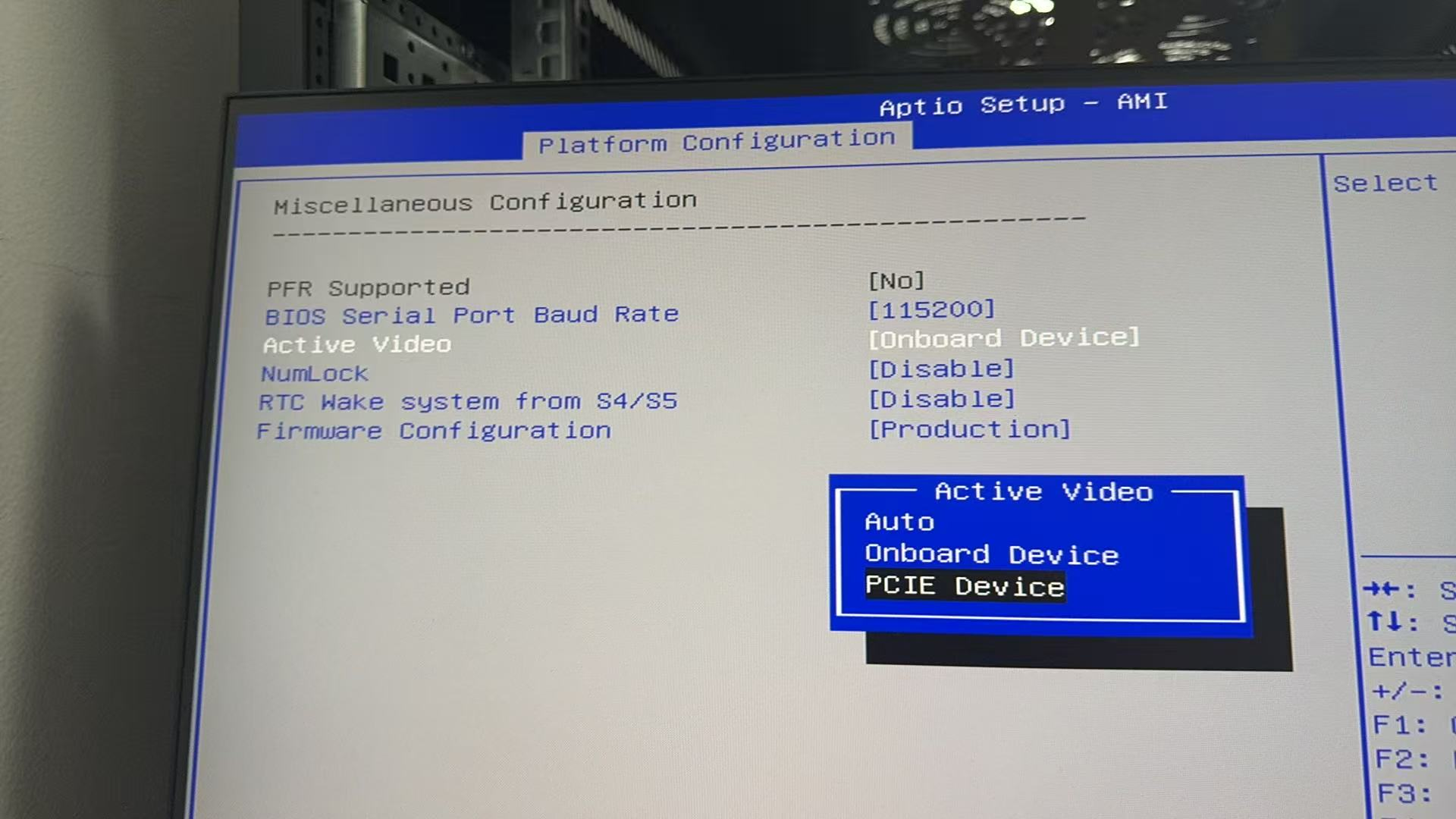
国鑫主板bios切换显示模式为独立显卡
# 进入到Platform Miscellaneous Configuration Active Video 切换为PCIE Device保存退出! 如果之前有安装过nvidia驱动,记得卸载掉再安装一遍。...

嵌入式硬件篇---CAN
文章目录 前言1. CAN协议基础1.1 物理层特性差分信号线终端电阻通信速率总线拓扑 1.2 帧类型1.3 数据帧格式 2. STM32F103RCT6的CAN硬件配置2.1 硬件连接2.2 CubeMX配置启用CAN1模式波特率引脚分配过滤器配置(可选) 3. HAL库代码实现3.1 CAN初始化3.2 发…...
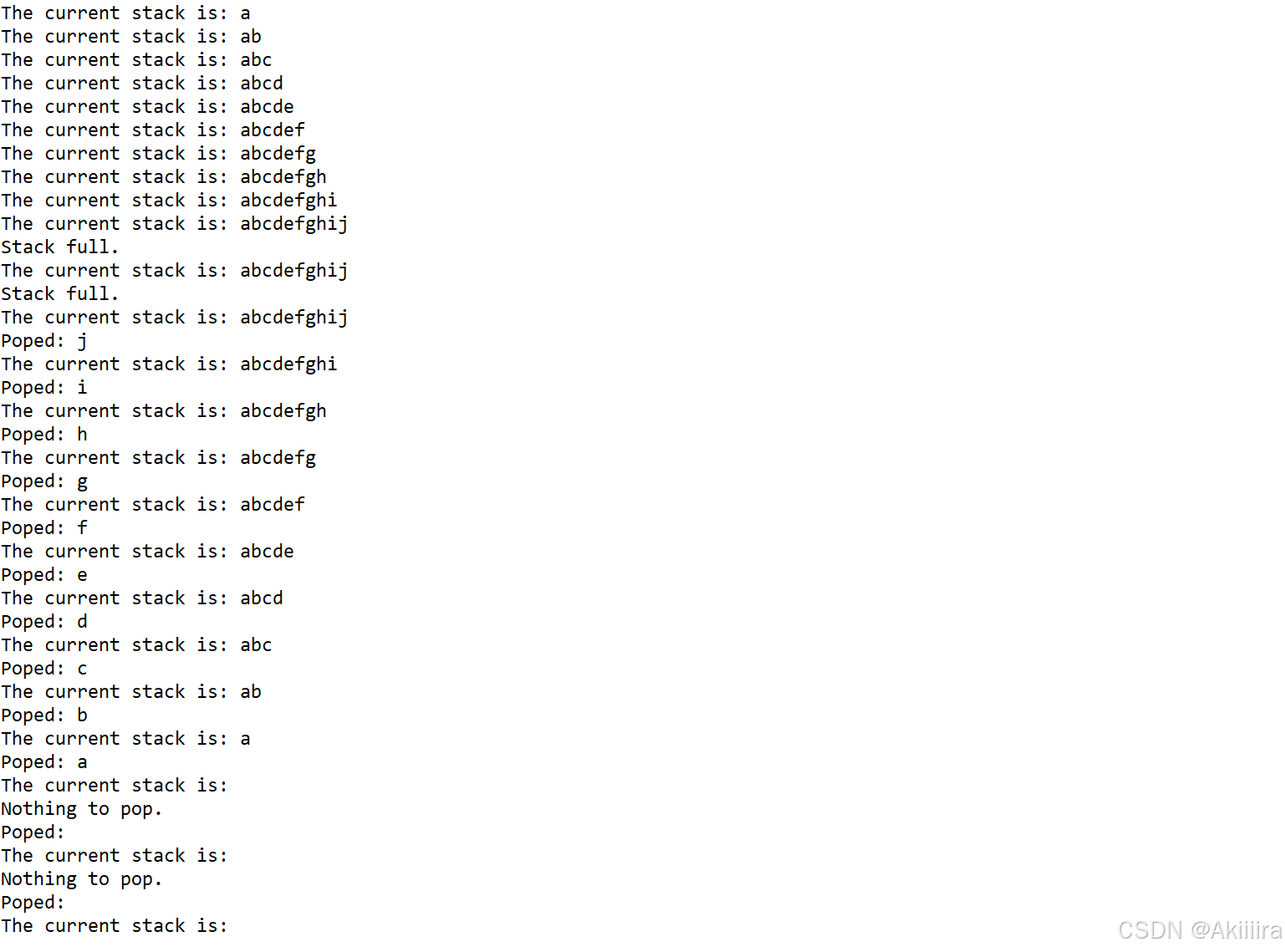
【日撸 Java 300行】Day 14(栈)
目录 Day 14:栈 一、栈的基本知识 二、栈的方法 1. 顺序表实现栈 2. 入栈 3. 出栈 三、代码及测试 拓展: 小结 Day 14:栈 Task: push 和 pop 均只能在栈顶操作.没有循环, 时间复杂度为 O(1). 一、栈的基本知识 详细的介…...

2025最新出版 Microsoft Project由入门到精通(七)
目录 优化资源——在资源使用状况视图中查看资源的负荷情况 在资源图表中查看资源的负荷情况 优化资源——资源出现冲突时的原因及处理办法 资源过度分类的处理解决办法 首先检查任务工时的合理性并调整 增加资源供给 回到资源工作表中双击对应的过度分配资源 替换资…...

修改(替换)文件中的指定内容并保留文件修改前的时间(即修改前后文件的最后修改时间保持不变)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 修改(替换)文件中的指…...
)
Linux云计算训练营笔记day07(MySQL数据库)
数据库 DataBase 保存数据的仓库 数据库管理系统 DBMS 这是一个可以独立运行,用于维护磁盘上的数据的一套软件 特点: 维护性高,灵活度高,效率高,可扩展性强 常见的DBMS Mysql Mariadb Oracle DB2 SQLServer MySQL是一个关系型…...

应用探析|千眼狼PIV测量系统在职业病防治中的应用
1、职业病防治背景 随着《职业病防治法》及各省市“十四五”职业病防治规划的深入推进,工作场所粉尘危害监测与防控已成为疾控部门的核心任务。以矿山、建材、冶金、化工等行业为例,粉尘浓度、分布及传播特性的精准测量是评估职业病风险的关键。 传统的…...

获取accesstoken时,提示证书解析有问题,导致无法正常获取token
错误: https://qyapi.weixin.qq.com/cgi-bin/gettoken": sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested targ…...

面试中被问到谈谈你对threadlocal的理解
ThreadLocal 的核心理解 1. 基本概念 ThreadLocal 是 Java 提供的线程局部变量机制,用于在多线程环境中为每个线程维护独立的变量副本,实现线程隔离。其核心思想是空间换时间,通过避免共享变量带来的同步开销,提升并发性能。 2…...
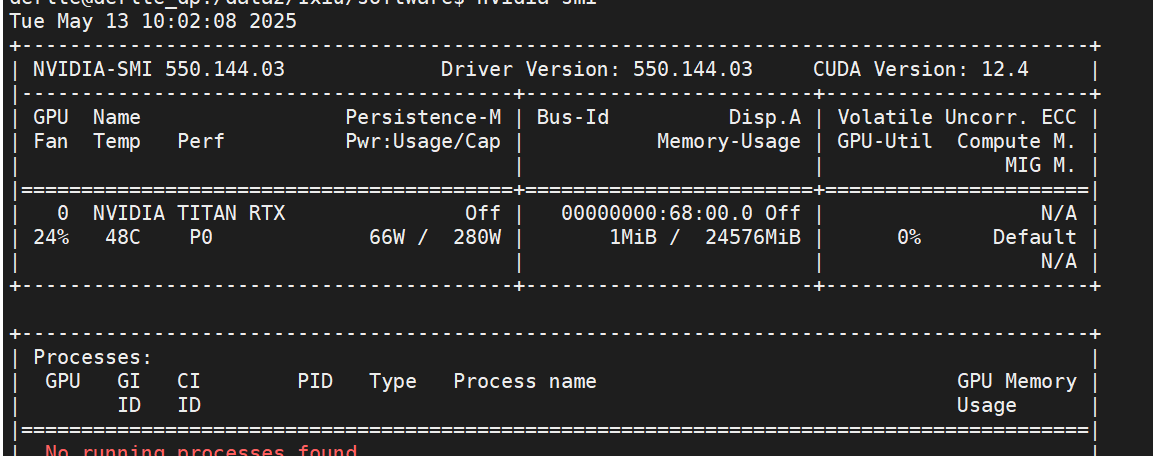
nvidia驱动更新-先卸载再安装-ubuntu
显卡驱动升级前,卸载旧版本,可采用两种方式。 1.命令行 (1)查找已安装的 NVIDIA 驱动和相关包:dpkg -l | grep nvidia (2)完全卸载 NVIDIA 驱动:sudo apt remove purge nvidia-*…...

FlashInfer - 安装
FlashInfer - 安装 flyfish 一、JIT 版安装FlashInfer 对于 JIT 版本(即每次都从源代码编译每个内核,此过程需要 NVCC),可通过 PyPI 进行安装。 解释 JIT 版本(JIT Version) JIT 即 Just-In-Time Compi…...

推荐算法工程化:ZKmall模板商城的B2C 商城的用户分层推荐策略
在 B2C 电商竞争激烈的市场环境中,精准推荐已成为提升用户体验、促进商品销售的关键。ZKmall 模板商城通过推荐算法工程化手段,深度挖掘用户数据价值,制定科学的用户分层推荐策略,实现 “千人千面” 的个性化推荐,帮助…...

jackson-dataformat-xml引入使用后,响应体全是xml
解决方案: https://spring.io/blog/2013/05/11/content-negotiation-using-spring-mvc import org.springframework.context.annotation.Configuration; import org.springframework.http.MediaType; import org.springframework.web.servlet.config.annotation.Con…...

嵌入式硬件篇---TOF|PID
文章目录 前言1. 硬件准备主控芯片ToF模块1.VL53L0X2.TFmini 执行机构:电机舵机其他 2. 硬件连接(1) VL53L0X(IC接口)(2) TFmini(串口通信) 3. ToF模块初始化与数据读取(1) VL53L0X(基于HAL库)(…...

Realtek 8126驱动分析第四篇——multi queue相关
Realtek 8126是 5G 网卡,因为和 8125 较为接近,第四篇从这里开始也无不可。本篇主要是讲 multi queue 相关,其他的一些内容在之前就已经提过,不加赘述。 1 初始化 1.1 rtl8126_init_one 从第一篇我们可以知道每个 PCI 驱动都注…...
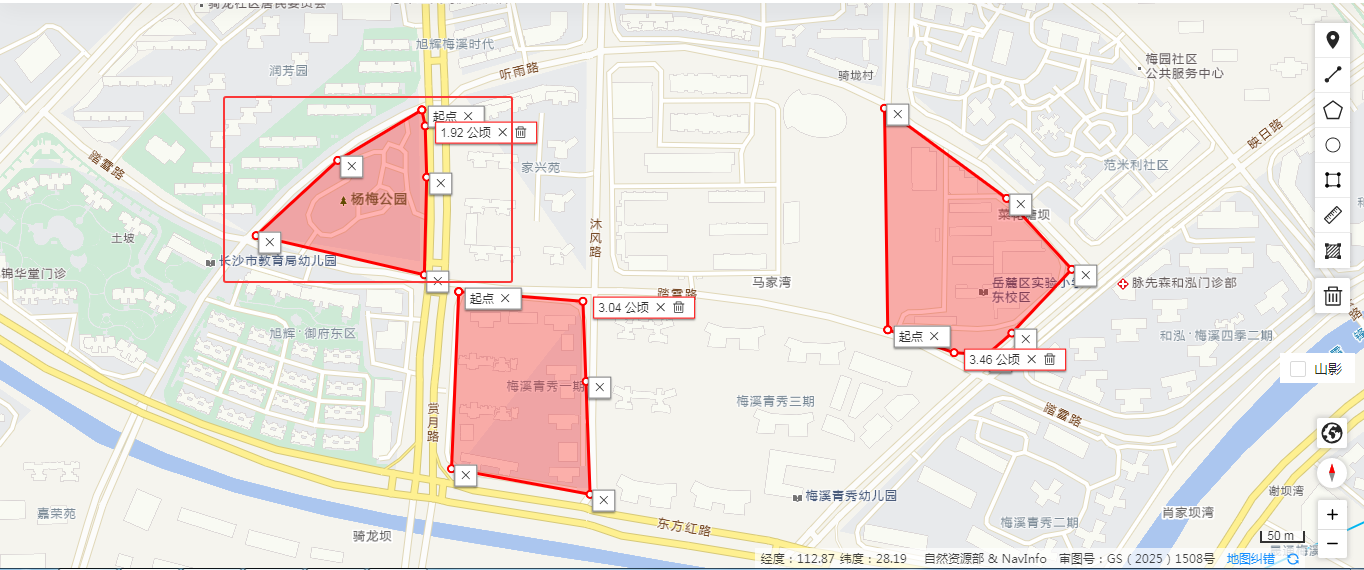
基于Java和PostGIS的AOI面数据球面面积计算实践
目录 前言 一、计算方法简介 二、球面面积计算 1、AOI数据转Polygon 2、Geotools面积计算 3、GeographicLib面积计算 4、PostGIS面积计算 三、结果分析 1、不同算法结果对比 2、与互联网AOI对比 3、与天地图测面对比 四、总结 前言 在现代地理信息系统(G…...
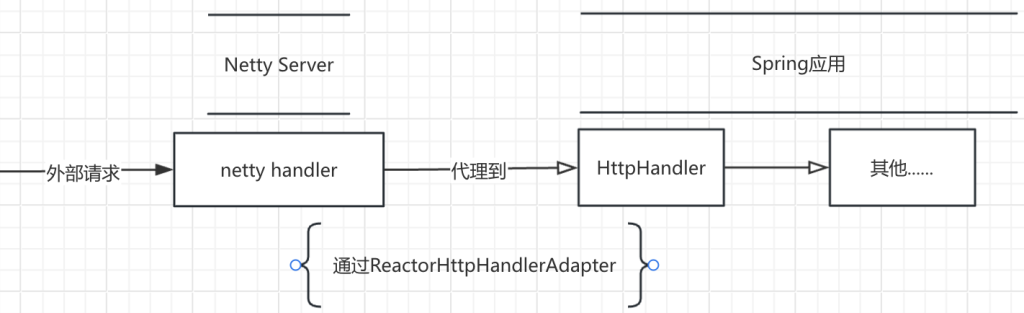
Spring Boot之Web服务器的启动流程分析
如何判断创建哪种web容器:servlet?reactive? 我们在启动Spring Boot程序的时候,会使用SpringApplication.run方法来启动,在启动流程中首先要判断的就是需要启动什么类型的服务器,是servlet?或者…...

C# SQLite高级功能示例
目录 1 主要功能 2 程序结构和流程 3 详细实现说明 3.1 基础设置 3.2 事务演示 3.3 索引演示 3.4 视图演示 3.5 触发器演示 3.6 全文搜索演示 3.7 窗口函数演示 3.8 外键约束演示 4 高级功能示例 5 单个方法详细介绍 5.1 SetupExampleData()方法 5.2 UseTransact…...