# YOLOv3:基于 PyTorch 的目标检测模型实现
YOLOv3:基于 PyTorch 的目标检测模型实现
引言
YOLOv3(You Only Look Once)是一种流行的单阶段目标检测算法,它能够直接在输入图像上预测边界框和类别概率。YOLOv3 的优势在于其高效性和准确性,使其在实时目标检测任务中表现出色。本文将详细介绍如何使用 PyTorch 实现 YOLOv3 模型,并提供完整的代码实现。
1. YOLOv3 简介
YOLOv3 是 YOLO 系列算法的第三个版本,它在前两个版本的基础上进行了改进,提高了检测的准确性和速度。YOLOv3 的主要特点包括:
- 单阶段检测:YOLOv3 直接在输入图像上预测边界框和类别概率,无需生成候选框。
- 多尺度检测:YOLOv3 使用三个不同尺度的特征图进行检测,能够检测不同大小的目标。
- 高效率:YOLOv3 的设计使其能够在实时应用中高效运行。
2. 环境准备
在开始实现之前,确保你已经安装了以下必要的依赖库:
pip install torch numpy matplotlib
3. 代码实现
3.1 导入必要的库
from __future__ import divisionimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import numpy as npfrom utils.parse_config import * # 用于解析配置文件
from utils.utils import build_targets, to_cpu, non_max_suppression # 用于目标构建和后处理import matplotlib.pyplot as plt
import matplotlib.patches as patches
3.2 构建模块列表
create_modules 函数根据配置文件构建网络层:
def create_modules(module_defs):"""Constructs module list of layer blocks from module configuration in module_defs"""hyperparams = module_defs.pop(0) # 获取超参数output_filters = [int(hyperparams["channels"])] # 输出特征图的个数,也是卷积核的个数module_list = nn.ModuleList() # 用于存储网络层的 ModuleListfor module_i, module_def in enumerate(module_defs):modules = nn.Sequential() # 用于线性堆叠网络层if module_def["type"] == "convolutional":# 获取卷积层的参数bn = int(module_def["batch_normalize"])filters = int(module_def["filters"]) # 卷积核的个数kernel_size = int(module_def["size"])pad = (kernel_size - 1) // 2# 添加卷积层modules.add_module(f"conv_{module_i}", # 卷积层名称nn.Conv2d(in_channels=output_filters[-1], # 输入特征图的数量out_channels=filters, # 输出特征图的数量kernel_size=kernel_size, # 卷积核的大小stride=int(module_def["stride"]), # 卷积核滑动的步长padding=pad, # 填充的层数bias=not bn, # 是否添加偏置项),)if bn:# 添加批量归一化层modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(filters, momentum=0.9))if module_def["activation"] == "leaky":# 添加 LeakyReLU 激活函数modules.add_module(f"leaky_{module_i}", nn.LeakyReLU(0.1))elif module_def["type"] == "maxpool":# 获取最大池化层的参数kernel_size = int(module_def["size"])stride = int(module_def["stride"])if kernel_size == 2 and stride == 1:# 添加零填充层modules.add_module(f"_debug_padding_{module_i}", nn.ZeroPad2d((0, 1, 0, 1)))# 添加最大池化层maxpool = nn.MaxPool2d(kernel_size=kernel_size, stride=stride, padding=int((kernel_size - 1) // 2))modules.add_module(f"maxpool_{module_i}", maxpool)elif module_def["type"] == "upsample":# 获取上采样层的参数upsample = Upsample(scale_factor=int(module_def["stride"]), mode="nearest")modules.add_module(f"upsample_{module_i}", upsample)elif module_def["type"] == "route":# 获取路由层的参数layers = [int(x) for x in module_def["layers"].split(",")]filters = sum([output_filters[1:][i] for i in layers])modules.add_module(f"route_{module_i}", EmptyLayer()) # 添加空层elif module_def["type"] == "shortcut":# 获取残差层的参数filters = output_filters[1:][int(module_def["from"])]modules.add_module(f"shortcut_{module_i}", EmptyLayer()) # 添加空层elif module_def["type"] == "yolo":# 获取 YOLO 层的参数anchor_idxs = [int(x) for x in module_def["mask"].split(",")]anchors = [int(x) for x in module_def["anchors"].split(",")]anchors = [(anchors[i], anchors[i + 1]) for i in range(0, len(anchors), 2)]anchors = [anchors[i] for i in anchor_idxs]num_classes = int(module_def["classes"])img_size = int(hyperparams["height"])# 定义检测层yolo_layer = YOLOLayer(anchors, num_classes, img_size)modules.add_module(f"yolo_{module_i}", yolo_layer)# 将当前模块添加到模块列表中module_list.append(modules)output_filters.append(filters) # 保存每一层的卷积核个数return hyperparams, module_list
3.3 上采样层
Upsample 类实现上采样操作:
class Upsample(nn.Module):""" nn.Upsample is deprecated """def __init__(self, scale_factor, mode="nearest"):super(Upsample, self).__init__()self.scale_factor = scale_factor # 上采样比例self.mode = mode # 上采样模式def forward(self, x):# 使用 PyTorch 的 interpolate 函数进行上采样x = F.interpolate(x, scale_factor=self.scale_factor, mode=self.mode)return x
3.4 空层
EmptyLayer 类用于占位,例如在 route 和 shortcut 层中:
class EmptyLayer(nn.Module):"""Placeholder for 'route' and 'shortcut' layers"""def __init__(self):super(EmptyLayer, self).__init__()
3.5 YOLO 检测层
YOLOLayer 类负责预测边界框、置信度和类别概率:
class YOLOLayer(nn.Module):"""Detection layer"""def __init__(self, anchors, num_classes, img_dim=416):super(YOLOLayer, self).__init__()self.anchors = anchors # 锚框self.num_anchors = len(anchors) # 锚框数量self.num_classes = num_classes # 类别数量self.ignore_thres = 0.5 # 忽略阈值self.mse_loss = nn.MSELoss() # 均方误差损失self.bce_loss = nn.BCELoss() # 二元交叉熵损失self.obj_scale = 1 # 有目标的损失权重self.noobj_scale = 100 # 无目标的损失权重self.metrics = {} # 用于存储评估指标self.img_dim = img_dim # 输入图像尺寸self.grid_size = 0 # 网格大小def compute_grid_offsets(self, grid_size, cuda=True):"""计算网格偏移量"""self.grid_size = grid_sizeg = self.grid_sizeFloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensorself.stride = self.img_dim / self.grid_size # 每个网格的像素大小# 计算每个网格的偏移量self.grid_x = torch.arange(g).repeat(g, 1).view([1, 1, g, g]).type(FloatTensor)self.grid_y = torch.arange(g).repeat(g, 1).t().view([1, 1, g, g]).type(FloatTensor)self.scaled_anchors = FloatTensor([(a_w / self.stride, a_h / self.stride) for a_w, a_h in self.anchors])self.anchor_w = self.scaled_anchors[:, 0:1].view((1, self.num_anchors, 1, 1))self.anchor_h = self.scaled_anchors[:, 1:2].view((1, self.num_anchors, 1, 1))def forward(self, x, targets=None, img_dim=None):"""前向传播"""FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensorLongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensorByteTensor = torch.cuda.ByteTensor if x.is_cuda else torch.ByteTensorself.img_dim = img_dimnum_samples = x.size(0)grid_size = x.size(2)# 重塑预测张量prediction = (x.view(num_samples, self.num_anchors, self.num_classes + 5, grid_size, grid_size).permute(0, 1, 3, 4, 2).contiguous())# 提取预测结果x = torch.sigmoid(prediction[..., 0]) # 中心点 xy = torch.sigmoid(prediction[..., 1]) # 中心点 yw = prediction[..., 2] # 宽度h = prediction[..., 3] # 高度pred_conf = torch.sigmoid(prediction[..., 4]) # 置信度pred_cls = torch.sigmoid(prediction[..., 5:]) # 类别预测# 如果网格大小不匹配,重新计算偏移量if grid_size != self.grid_size:self.compute_grid_offsets(grid_size, cuda=x.is_cuda)# 添加偏移量并缩放锚框pred_boxes = FloatTensor(prediction[..., :4].shape)pred_boxes[..., 0] = x.data + self.grid_xpred_boxes[..., 1] = y.data + self.grid_ypred_boxes[..., 2] = torch.exp(w.data) * self.anchor_wpred_boxes[..., 3] = torch.exp(h.data) * self.anchor_h# 拼接最终输出output = torch.cat((pred_boxes.view(num_samples, -1, 4) * self.stride,pred_conf.view(num_samples, -1, 1),pred_cls.view(num_samples, -1, self.num_classes),),-1,)if targets is None:return output, 0else:# 构建目标张量iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf = build_targets(pred_boxes=pred_boxes,pred_cls=pred_cls,target=targets,anchors=self.scaled_anchors,ignore_thres=self.ignore_thres,)# 计算损失loss_x = self.mse_loss(x[obj_mask], tx[obj_mask])loss_y = self.mse_loss(y[obj_mask], ty[obj_mask])loss_w = self.mse_loss(w[obj_mask], tw[obj_mask])loss_h = self.mse_loss(h[obj_mask], th[obj_mask])loss_conf_obj = self.bce_loss(pred_conf[obj_mask], tconf[obj_mask])loss_conf_noobj = self.bce_loss(pred_conf[noobj_mask], tconf[noobj_mask])loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobjloss_cls = self.bce_loss(pred_cls[obj_mask], tcls[obj_mask])total_loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls# 计算评估指标cls_acc = 100 * class_mask[obj_mask].mean()conf_obj = pred_conf[obj_mask].mean()conf_noobj = pred_conf[noobj_mask].mean()conf50 = (pred_conf > 0.5).float()iou50 = (iou_scores > 0.5).float()iou75 = (iou_scores > 0.75).float()detected_mask = conf50 * class_mask * tconfprecision = torch.sum(iou50 * detected_mask) / (conf50.sum() + 1e-16)recall50 = torch.sum(iou50 * detected_mask) / (obj_mask.sum() + 1e-16)recall75 = torch.sum(iou75 * detected_mask) / (obj_mask.sum() + 1e-16)self.metrics = {"loss": to_cpu(total_loss).item(),"x": to_cpu(loss_x).item(),"y": to_cpu(loss_y).item(),"w": to_cpu(loss_w).item(),"h": to_cpu(loss_h).item(),"conf": to_cpu(loss_conf).item(),"cls": to_cpu(loss_cls).item(),"cls_acc": to_cpu(cls_acc).item(),"recall50": to_cpu(recall50).item(),"recall75": to_cpu(recall75).item(),"precision": to_cpu(precision).item(),"conf_obj": to_cpu(conf_obj).item(),"conf_noobj": to_cpu(conf_noobj).item(),"grid_size": grid_size,}return output, total_loss
3.6 YOLOv3 模型
Darknet 类是 YOLOv3 模型的主体,负责加载配置文件、构建网络、前向传播、加载和保存权重:
class Darknet(nn.Module):"""YOLOv3 object detection model"""def __init__(self, config_path, img_size=416):super(Darknet, self).__init__()self.module_defs = parse_model_config(config_path) # 解析配置文件self.hyperparams, self.module_list = create_modules(self.module_defs) # 创建网络层self.yolo_layers = [layer[0] for layer in self.module_list if hasattr(layer[0], "metrics")] # 提取 YOLO 层self.img_size = img_size # 输入图像尺寸self.seen = 0 # 训练时看到的图像数量self.header_info = np.array([0, 0, 0, self.seen, 0], dtype=np.int32) # 权重文件的头部信息def forward(self, x, targets=None):"""前向传播"""img_dim = x.shape[2]loss = 0layer_outputs, yolo_outputs = [], []for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):if module_def["type"] in ["convolutional", "upsample", "maxpool"]:x = module(x)elif module_def["type"] == "route":x = torch.cat([layer_outputs[int(layer_i)] for layer_i in module_def["layers"].split(",")], 1)elif module_def["type"] == "shortcut":layer_i = int(module_def["from"])x = layer_outputs[-1] + layer_outputs[layer_i]elif module_def["type"] == "yolo":x, layer_loss = module[0](x, targets, img_dim)loss += layer_lossyolo_outputs.append(x)layer_outputs.append(x)yolo_outputs = to_cpu(torch.cat(yolo_outputs, 1))return yolo_outputs if targets is None else (loss, yolo_outputs)def load_darknet_weights(self, weights_path):"""加载 Darknet 权重"""with open(weights_path, "rb") as f:header = np.fromfile(f, dtype=np.int32, count=5) # 读取头部信息self.header_info = headerself.seen = header[3]weights = np.fromfile(f, dtype=np.float32) # 读取权重cutoff = Noneif "darknet53.conv.74" in weights_path:cutoff = 75ptr = 0for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):if i == cutoff:breakif module_def["type"] == "convolutional":conv_layer = module[0]if module_def["batch_normalize"]:bn_layer = module[1]num_b = bn_layer.bias.numel()bn_b = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.bias)bn_layer.bias.data.copy_(bn_b)ptr += num_bbn_w = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.weight)bn_layer.weight.data.copy_(bn_w)ptr += num_bbn_rm = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.running_mean)bn_layer.running_mean.data.copy_(bn_rm)ptr += num_bbn_rv = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.running_var)bn_layer.running_var.data.copy_(bn_rv)ptr += num_belse:num_b = conv_layer.bias.numel()conv_b = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(conv_layer.bias)conv_layer.bias.data.copy_(conv_b)ptr += num_bnum_w = conv_layer.weight.numel()conv_w = torch.from_numpy(weights[ptr : ptr + num_w]).view_as(conv_layer.weight)conv_layer.weight.data.copy_(conv_w)ptr += num_wdef save_darknet_weights(self, path, cutoff=-1):"""保存 Darknet 权重"""fp = open(path, "wb")self.header_info[3] = self.seenself.header_info.tofile(fp)for i, (module_def, module) in enumerate(zip(self.module_defs[:cutoff], self.module_list[:cutoff])):if module_def["type"] == "convolutional":conv_layer = module[0]if module_def["batch_normalize"]:bn_layer = module[1]bn_layer.bias.data.cpu().numpy().tofile(fp)bn_layer.weight.data.cpu().numpy().tofile(fp)bn_layer.running_mean.data.cpu().numpy().tofile(fp)bn_layer.running_var.data.cpu().numpy().tofile(fp)else:conv_layer.bias.data.cpu().numpy().tofile(fp)conv_layer.weight.data.cpu().numpy().tofile(fp)fp.close()
4. 使用示例
以下是一个简单的示例代码,用于加载 YOLOv3 模型并进行推理:
import torch
from models import * # 确保你的模型定义在 models 模块中# 加载配置文件和权重
config_path = "path/to/your/yolov3.cfg"
weights_path = "path/to/your/yolov3.weights"
img_size = 416model = Darknet(config_path, img_size=img_size)
model.load_darknet_weights(weights_path)# 设置为评估模式
model.eval()# 加载输入图像
# 假设你有一个输入图像 tensor,尺寸为 (1, 3, 416, 416)
input_image = torch.randn(1, 3, img_size, img_size)# 前向传播
with torch.no_grad():detections = model(input_image)# 打印检测结果
print(detections)
5. 结论
本文详细介绍了如何使用 PyTorch 实现 YOLOv3 模型。通过加载配置文件和权重,我们可以轻松地构建和使用 YOLOv3 模型进行目标检测。YOLOv3 的高效性和准确性使其在实时应用中表现出色,适用于多种目标检测任务。
相关文章:

# YOLOv3:基于 PyTorch 的目标检测模型实现
YOLOv3:基于 PyTorch 的目标检测模型实现 引言 YOLOv3(You Only Look Once)是一种流行的单阶段目标检测算法,它能够直接在输入图像上预测边界框和类别概率。YOLOv3 的优势在于其高效性和准确性,使其在实时目标检测任…...

MySQL的Docker版本,部署在ubantu系统
前言 MySQL的Docker版本,部署在ubantu系统,出现问题: 1.执行一个SQL,只有错误编码,没有错误提示信息,主要影响排查SQL运行问题; 2.这个问题,并不影响实际的MySQL运行,如…...

Mac QT水平布局和垂直布局
首先上代码 #include "mainwindow.h" #include "ui_mainwindow.h" #include <QPushButton> #include<QVBoxLayout>//垂直布局 #include<QHBoxLayout>//水平布局头文件 MainWindow::MainWindow(QWidget *parent): QMainWindow(parent), …...

服务器制造业中,L2、L6、L10等表示什么意思
在服务器制造业中,L2、L6、L10等是用于描述服务器生产流程集成度的分级体系,从基础零件到完整机架系统共分为L1-L12共12个等级。不同等级对应不同的生产环节和交付形态,以下是核心级别的具体含义: L2(Level 2…...

回答 | 图形数据库neo4j社区版可以应用小型企业嘛?
刚在知乎上看到了一个提问,挺有意思,于是乎,贴到这里再简聊一二。 转自知乎提问 当然可以,不过成本问题不容小觑。另外还有性能上的考量。 就在最近,米国国家航空航天局——NASA因为人力成本问题,摒弃了使…...

Linux操作系统从入门到实战(二)手把手教你安装VMware17pro与CentOS 9 stream,实现Vim配置,并配置C++环境
Linux操作系统从入门到实战(二)手把手教你安装VMware17pro与CentOS 9.0 stream,实现Vim配置,并编译C文件 前言一、安装VMware17pro二、安装CentOS9.02.1 为什么选择CentOS9,与CentOS7对比2.1 官网下载CentOS9.02.2 国内…...

软考架构师考试-UML图总结
考点 选择题 2-4分 案例分析0~1题和面向对象结合考察,前几年固定一题。近3次考试没有出现。但还是有可能考。 UML图概述 1.用例图:描述系统功能需求和用户(参与者)与系统之间的交互关系,聚焦于“做什么”。 2.类图&…...

后端系统做国际化改造,生成多语言包
要将你当前系统中的 中文文案提取并翻译为英文语言包,建议采用 自动扫描 翻译辅助 语言包生成 的方式,流程如下: ✅ 一、目标总结 提取:扫描后端 C# 和 Java 代码中的 中文字符串 翻译:将中文自动翻译为英文&#x…...

论文学习_Trex: Learning Execution Semantics from Micro-Traces for Binary Similarity
摘要:检测语义相似的函数在漏洞发现、恶意软件分析及取证等安全领域至关重要,但该任务面临实现差异大、跨架构、多编译优化及混淆等挑战。现有方法多依赖语法特征,难以捕捉函数的执行语义。对此,TREX 提出了一种基于迁移学习的框架…...
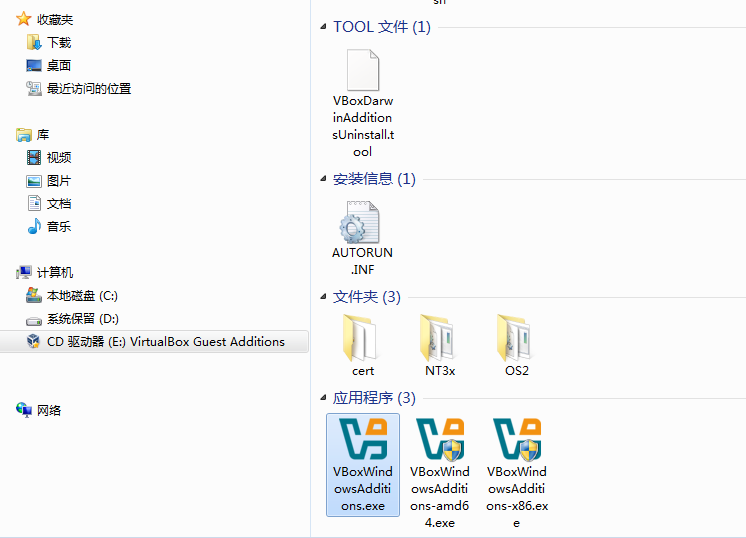
在VirtualBox中安装虚拟机后不能全屏显示的问题及解决办法
在VirtualBox中安装Windows或Linux虚拟机后,将遇到启动虚拟机后,只能在屏幕中的一块区域里显示虚拟机桌面,却不能全屏显示的问题。要解决此问题,需要在虚拟机中安装与VirtualBox版本相对应的VBox GuestAdditons软件。 这里…...

《大规模电动汽车充换电设施可调能力聚合评估与预测》MATLAB实现计划
模型概述 根据论文,我将复刻实现结合长短期记忆网络(LSTM)和条件变分自编码器(CVAE)的预测方法,用于电动汽车充换电设施可调能力的聚合评估与预测。 实现步骤 1. 数据预处理 导入充电数据 (Charging_Data.csv)导入天气数据 (Weather_Data.csv)导入电…...

CSS flex:1
在 CSS 中,flex: 1 是一个用于弹性布局(Flexbox)的简写属性,主要用于控制 flex 项目(子元素)如何分配父容器的剩余空间。以下是其核心作用和用法: 核心作用 等分剩余空间:让 flex …...

Python 字典键 “三变一” 之谜
开头:读者的“玄学”字典谜题 上周,朋友发来了一段让他抓耳挠腮的代码: >>> {True: foo, 1: bar, 1.0: baz} {True: baz} “我明明定义了布尔True、整数1、浮点数1.0三个键,结果字典里只剩True一个键,值…...

Spring Boot中HTTP连接池的配置与优化实践
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、HTTP连接池的核心价值 在微服务架构和分布式系统场景中,HTTP客户端频繁创建/断开连接会产生显著的性能损耗。通过连接池技术可以实现&#x…...

初识XML
初识XML <?xml version"1.0" encoding"utf-8" ?> <!--根标签只能有一个--> <!--第一行永远都是 <?xml version"1.0" encoding"utf-8" ?> 前面不允许出现任何其他东西,空格换行等均不行 --> &…...

element-ui分页的使用及修改样式
1.安装 npm install element-ui -S 2.在main.js中引入,这里是全部引入,也可以按需引入 import ElementUI from element-ui import element-ui/lib/theme-chalk/index.css Vue.use(ElementUI) 3.使用 layout"prev, pager, next, jumper" :jumpe…...

2025年第十六届蓝桥杯软件赛省赛C/C++大学A组个人解题
文章目录 题目A题目C:抽奖题目D:红黑树题目E:黑客题目F:好串的数目 https://www.dotcpp.com/oj/train/1166/ 题目A 找到第2025个素数 #include <iostream> #include <vector> using namespace std; vector<i…...

物理:人的记忆是由基本粒子构成的吗?
问题: 基因属于人体的一部分,记忆也是人体的一部分,那么为什么基因可以代际遗传,但是记忆却被清空重置。如果基因是由粒子构成,那么记忆是不是也应该由粒子构成?如果记忆是粒子构成的,那么能否说明记忆永恒,即使死亡了身体被分解了,那么只要保证其身体有关的所有粒子被…...

Memcached 的特性和使用场景介绍,以及集群搭建
以下是 Memcached 的特性和使用场景介绍,以及集群搭建的详细示例: 特性 高性能 内存存储:数据存储在内存中,读写速度极快。简单协议:使用基于文本的简单协议,通信高效。分布式架构 一致性哈希:采用一致性哈希算法,将数据均匀分布到多个节点,支持动态增减节点,减少数…...

uni-app,小程序中的addPhoneContact,保存联系人到手机通讯录
文章目录 方法详解简介 基本语法参数说明基础用法使用示例平台差异说明注意事项最佳实践 方法详解 简介 addPhoneContact是uni-app框架提供的一个实用API,用于向系统通讯录添加联系人信息。这个方法在需要将应用内的联系人信息快速保存到用户设备通讯录的场景下非…...

从数据中台到数据飞轮:数字化转型的演进之路
从数据中台到数据飞轮:数字化转型的演进之路 数据中台 数据中台是企业为整合内部和外部数据资源而构建的中介层,实现数据的统一管理、共享和高效利用,目标是打破信息孤岛,提高数据使用效率,支持业务决策和创新 实施成本…...

Spring Boot 注解详细解析:解锁高效开发的密钥
一、引言 Spring Boot 以其快速开发、自动配置等特性,成为构建 Java 应用程序的热门框架。而注解在 Spring Boot 中扮演着至关重要的角色,它们如同魔法指令,简化了配置流程,增强了代码的可读性与可维护性。本文将深入剖析 Spring…...
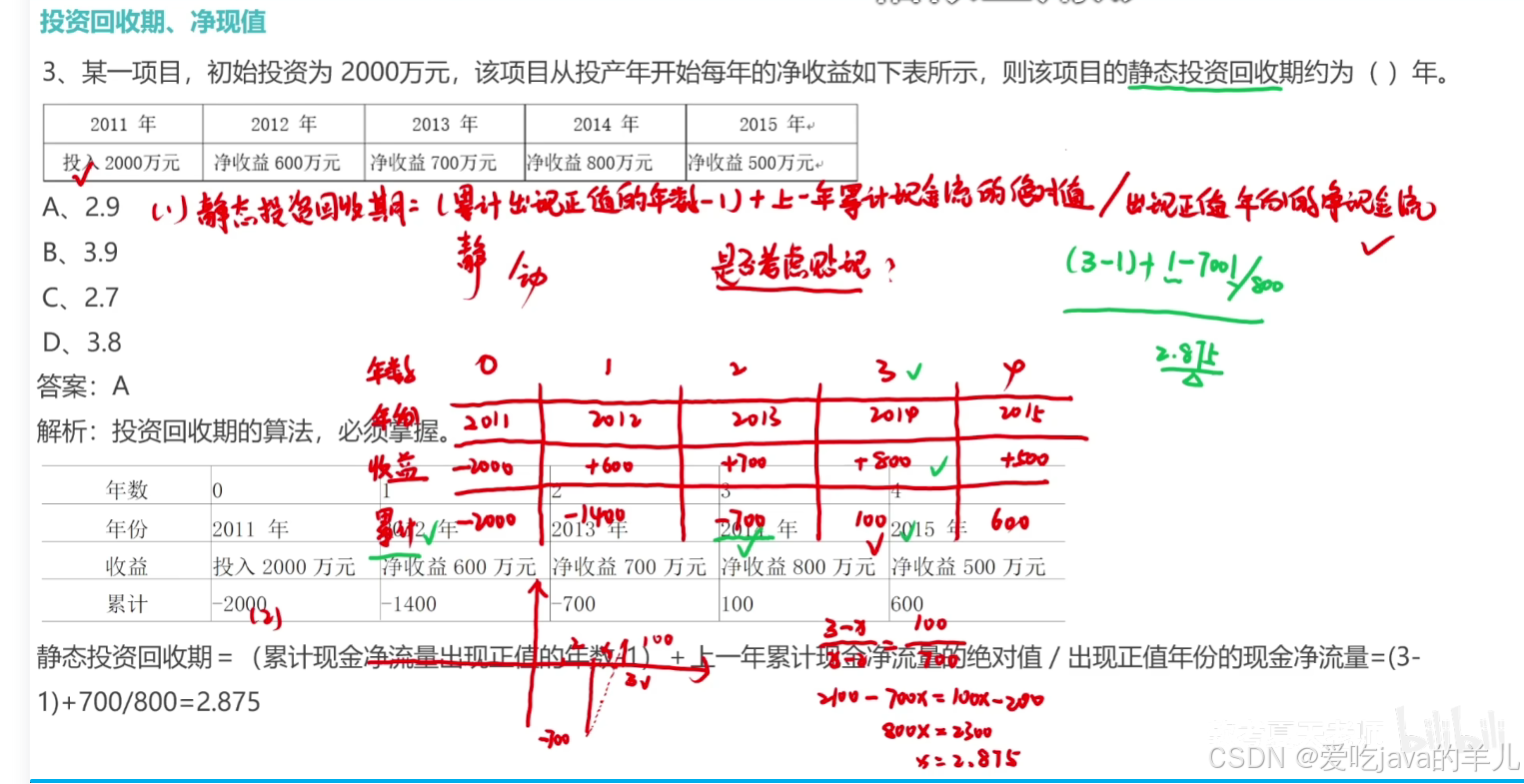
2025年5月-信息系统项目管理师高级-软考高项一般计算题
决策树和期望货币值 加权算法 自制和外购分析 沟通渠道 三点估算PERT 当其他条件一样时,npv越大越好...

zst-2001 上午题-历年真题 算法(5个内容)
回溯 算法 - 第1题 找合适的位置,如果没有位置就按B回家 d 分治 算法 - 第2题 b 算法 - 第3题 a 算法 - 第4题 划分一般就是分治 a 算法 - 第5题 分治 a 0-1背包 算法 - 第6题 c 算法 - 第7题 最小的为c 3100 c 算法 - 第8题 …...

【愚公系列】《Manus极简入门》036-物联网系统架构师:“万物互联师”
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! …...

3d关键点 可视化
目录 pygame pygame保存mp4 mayavi pygame import pygame from pygame.locals import * import numpy as np import sys# 初始化Pygame pygame.init() width, height 800, 600 screen pygame.display.set_mode((width, height)) clock pygame.time.Clock()# 生成示例数据…...
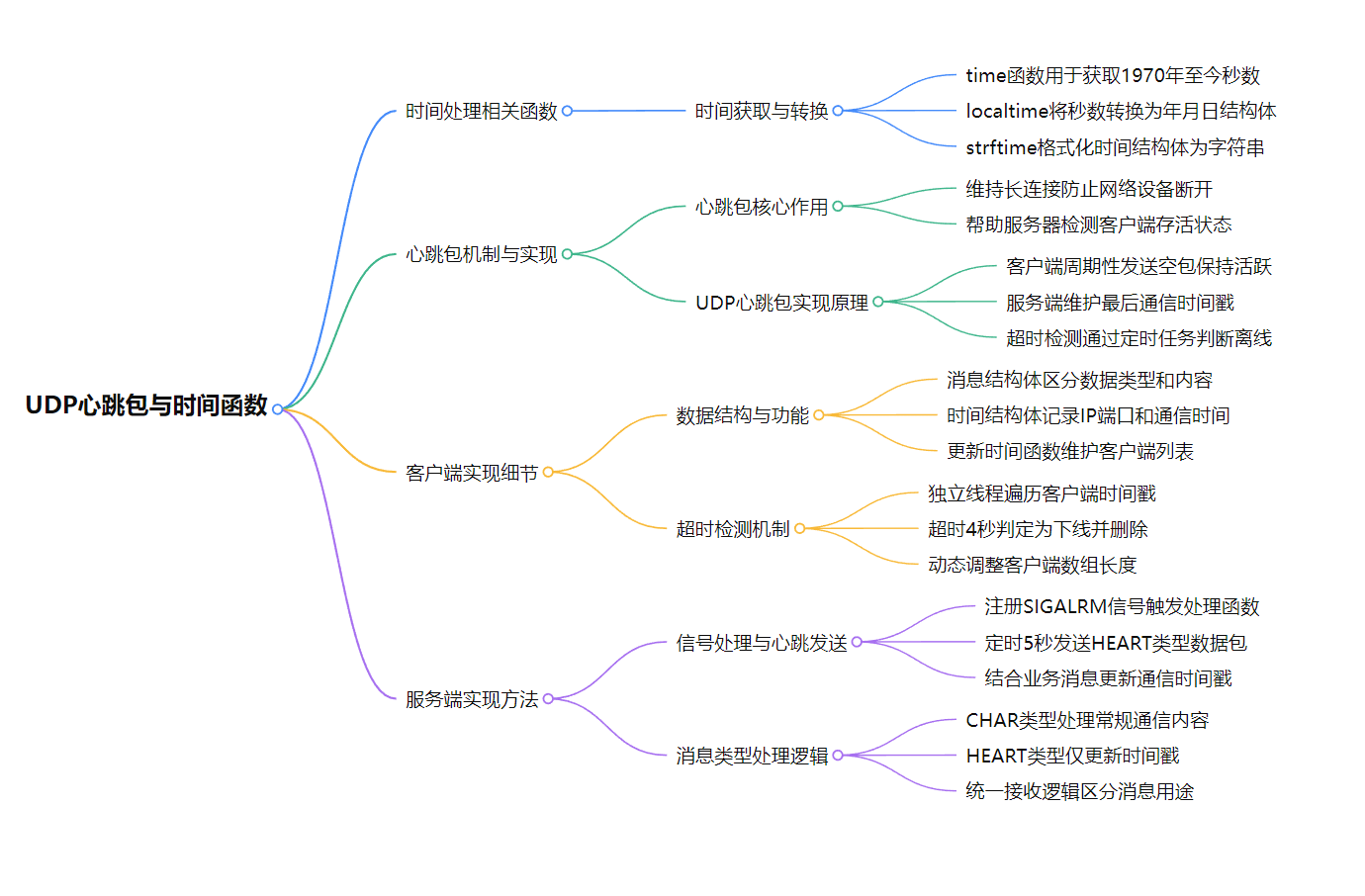
udp多点通信和心跳包
刷题 # UDP多点通信核心要点## 基础通信模式### 单播通信- 一对一通信方式- UDP默认通信模式- 地址指向具体目标主机### 广播通信- 一对多通信机制- 地址范围:xxx.xxx.xxx.255- 仅限局域网传输- 需设置SO_BROADCAST标志### 组播通信- 多对多群组通信- 地址范围&…...

什么是序列化与反序列化
序列化与反序列化:概念、作用及应用 一、基本定义 序列化(Serialization) 将 ** 对象的状态(数据、属性等)转换为可存储或传输的字节流(二进制或文本格式)** 的过程。 目的:使对象能…...
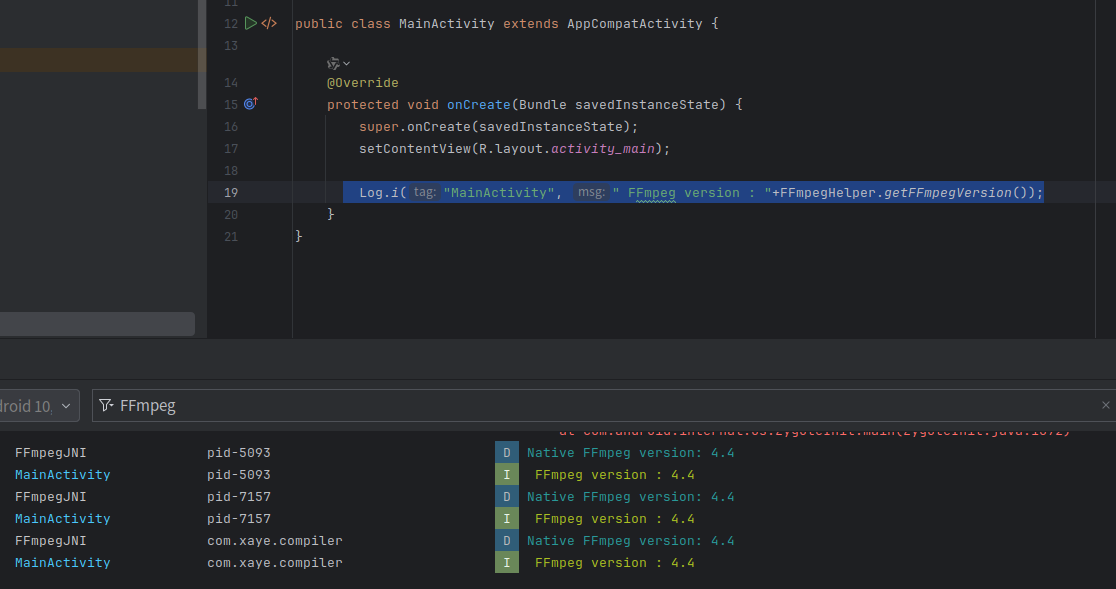
音视频学习:使用NDK编译FFmpeg动态库
1. 环境 1.1 基础配置 NDK 22b (r22b)FFmpeg 4.4Ubuntu 22.04 1.2 下载ffmpeg 官网提供了 .tar.xz 包,可以直接下载解压: wget https://ffmpeg.org/releases/ffmpeg-4.4.tar.xz tar -xvf ffmpeg-4.4.tar.xz cd ffmpeg-4.41.3 安装基础工具链 sudo …...

如何使用 Qwen3 实现 Agentic RAG?
今天,我们将学习如何部署由阿里巴巴最新Qwen 3驱动的Agentic RAG。 这里是我们的工具栈: CrewAI用于代理编排。 Firecrawl用于网络搜索。 LightningAI的LitServe用于部署。 顶部的视频展示了这一过程。 图表显示了我们的Agentic RAG流程࿱…...