为什么 cout<<“中文你好“ 能正常输出中文
一, 简答:
受python3字符串模型影响得出的下文C++字符串模型结论 是错的!C++的字符串和python2的字符串模型类似,也就是普通的字符串是ASCII字符串和字节串两种语义,类似重载或多态,有时候解释为整数,有时候是字节串。Unicode字符串有单独的其他类型。并不是像python3一样,普通字符串都是Unicode码点表示也就是都是整数,字节串是单独一种类型。
我们知道"你好中文"是Unicode字符串, 需要用宽字符输出对象wcout<<来输出, 但是为什么用于ASCII输出的cout<<却能正常输出中文呢? 答案: 是终端的作用! 而不是C++的作用.
源代码文本文件的编码方案我们一般是用utf8, 里面的字符串在文本文件中存储内部或说背后就是utf8的字节串, 编译器编译为可执行文件时会按utf8(默认)把源代码中的字符串的字节串解码为程序运行时字符串在内存中的码点序数值. 然后, 在cout<< 输出字符串时, <<运算符会把字符串的码点序列按utf8(默认)编码为字符串(码点)编码为在文本文件存储或终端窗口中打印的字节串. 终端再按utf8(linux和macos里)显示(这里的显示背后还有 字体渲染流程必然包含“字节流→码点→字形→渲染”的转换链)出来. 在Windows里终端默认是gbk编码方案, 所以会显示为乱码, 需要在前面编译程序时加-fexec-charset=gbk编译选项, 就能在终端正常显示中文了.
字符串在编译链接生成的可执行文件内部是字符串中字符序列的码点序数值的序列, cout<<中的<<运算符把内部字符串的码点序数值序列转换为默认用utf8编码的对应字节串(字符串只是在文本文件中展示给人类看时是字符渲染出的样子, 在计算机内部, 在程序运行时内部是码点序数值, 也就是整数类型). cout<<遇到const char* 时<<运算符还会把字节(8位)串序列输出到终端, 但是为什么终端不输出为8位的字节串序列, 而是能在终端输出为 正常的中文字符, 因为 cout<<只是编码原样不改地从程序utf8码点序数指序列向终端窗口传递字符串的utf8编码的字节串(终端和文本文件是一样的), 而终端是会按utf8(ubuntu里)解码, 所以就正常输出了中文字符串. (码点序数值指字符在运行时内存中的某种编码比如utf8下的序数, 字节串指比如字符向文本文件存储时某种编码下的字节串. 这2个名词的详情解释可以看我前面一篇Python学习手册第37章Unicode和字节串解读部分一 学习记录)
如果源代码文本文件是gbk编码, 编译指令要加-finput-charset=gbk, 如果windows终端输出要加-fexe-charset=gbk. 这样会有一个gbk和编译器内部默认编码utf8之间的转换.
需要知道 仅用于输出时才可以用const char* 的常量来指向中文字符串, 如果处理中文字符串(比如strlen获取字符数)用const char* 就不对了, 包括std::string(string是用于存储ASCII字符串, std::wstring才是用于宽字符串)存储中文字符串 用str.size()也会不对, 应该用wchar_t, char16_t, char32_t, char8_t, 或wstring, u16string, u32string, u8string, 来存储中文字符串才是正规的, 但是对于char16_t, char32_t, char8_t, C++好像并没有对应的输出方法.
总归, 用const char* 或std::string 指向或存储中文字符串, 是不好的. c++也应该学Python3一样进行改革, 把char类型默认就用utf-8字符集编码方案, 而不是现在的 ASCII. 当然这样说并没有充足的考虑, 比如后向兼容(新标准要兼容旧标准下写的代码)等考虑.
二, 详细解答:
我们知道在输出字符串时, cout << 是用于ASCII 字符串的. wcout<< 是用于输出wchar_t字符串的. 但是对于char16_t, char32_t, char8_t, C++好像并没有对应的输出方法.
另外要注意wchar_t在Windows和Linux/Macos是不一样的长度: Win里wchar_t是utf16字符集编码方案, Linux和Macos里wchar_t是utf32字符集编码方案.
问AI C++的unicode字符串:
在C++中处理Unicode字符串主要涉及以下几种方式:
1. 字符类型与字符串类
• 使用`wchar_t`(宽字符)、`char16_t`(UTF-16)或`char32_t`(UTF-32)存储Unicode字符。//其中wchar_t在windows系统上是utf-16, 在linux上是utf-32.
• 对应的字符串类为`std::wstring`、`std::u16string`和`std::u32string`。
2. 编码转换
• C++11提供了`std::wstring_convert`和`std::codecvt`(如`std::codecvt_utf8`)进行UTF-8与宽字符的转换。例如:
```cpp
#include <codecvt>
std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;
std::string utf8Str = converter.to_bytes(L"你好"); // 宽字符转UTF-8
std::wstring wideStr = converter.from_bytes("Hello"); // UTF-8转宽字符
```
3. 输入输出
• 使用宽字符流(如`std::wcout`、`std::wcin`)输出Unicode字符串时,需设置正确的本地化环境:
```cpp
std::wcout.imbue(std::locale("en_US.utf8"));
std::wcout << L"你好,世界!" << std::endl;
```
4. 第三方库
• 复杂场景(如跨平台编码处理)推荐使用ICU库或Boost.Locale。
5. 注意事项
• `wchar_t`的大小因平台而异(Windows为16位,Linux通常为32位),建议优先使用`char16_t`/`char32_t`明确编码。
• 文件操作时需用宽字符文件流(如`std::wifstream`)并指定编码。
第一, 在程序内部(编译时和运行时), 码点序数值是某个字符集编码方案下的! 这里的字符集编码方案就是通常说的C++编译器的字符集编码方案.
第二, 源代码文本文件的字符集编码方案, 都是用utf-8, 如果用gbk, 则要加-finput-charset=gbk, 来编译. 这行编译指令会进行编码转换,如把gbk转为utf8的码点.
关于 字符集和编码方案名词所指: utf-8, utf-16, utf-32都是一样的字符集, 包括的所有字符是一样的, 这3个是不一样的编码方案, utf16是2或4字节, utf-32是固定的所有字符都用32位(4字节), utf-8对不同的字符是不一样的尺寸来表示.
输入编码解析
GCC默认假设源文件为UTF-8编码。通过-finput-charset=gbk,编译器会将文件内容按GBK编码解析,而非UTF-8。例如,GBK编码的“你好”(0xC4E3 0xBAC3)会被正确识别为两个汉字,而非UTF-8的字节序列。
内部转换机制
GCC调用系统的字符转换功能,将GBK编码的字符转换为内部使用的UTF-8格式(即使未显式指定-fexec-charset,默认输出仍为UTF-8)。若同时指定-fexec-charset=gbk,则编译器会跳过内部转换,直接输出GBK编码的二进制数据.
为什么char类型的字符串里放中文字符串而用cout<<能正确输出为中文 ??
首先, 只限于char字符串, 如果char字符, 是不能放一个中文字符的!
第二, const char* p_str = "中文你好"; //gcc编译器是utf-8编码, "中文你好"能被编码为utf8的码点序数值,
这里, p_str只是一个指针, 而且不会解引用, cout<< 遇到p_str输出, 关键在cout<<的<<运算符按空字符来终止输出!
关键在cout<<的<<重载定义:
在C++中,`cout`的`operator<<`对`const char*`的重载不直接处理编码转换,其行为本质上是按字节序列输出直到遇到空字符,具体机制如下:
1. 编码无关性
`operator<<(ostream&, const char*)`的重载仅负责将指针指向的字节序列逐字节输出,不感知编码。若字符串是UTF-8编码(如`const char* p_str = "中文你好";`),且终端环境支持UTF-8解码(如Linux Console默认UTF-8),则能正确显示;否则输出乱码。
2. UTF-8的隐式支持
• 编译器会将源码中的字符串字面量(如`"中文你好"`)按源文件编码(如UTF-8)转换为二进制序列存储在可执行文件中。
• `cout << p_str`输出时,若终端编码与字符串编码一致(均为UTF-8),则显示正常;否则需显式转换编码(如使用`std::wstring_convert`或第三方库ICU)。
3. 宽字符重载
对于UTF-16/32编码的字符串,需使用`wchar_t*`和`std::wcout`,并通过`std::locale`或`std::codecvt`指定编码转换规则。例如:
```cpp
std::wcout.imbue(std::locale("en_US.utf8"));
std::wcout << L"中文你好"; // 显式宽字符UTF-16/32输出
```
4. 关键结论
• `operator<<`对`const char*`的重载不涉及UTF-8解码,仅传递字节流。
• 正确显示UTF-8需终端编码匹配,跨平台场景建议使用宽字符或显式编码转换。
若需直接操作UTF-8字符串(如验证、字符遍历),需依赖第三方库(如ICU)或C++20的`std::u8string`(编译器支持有限)。
char* 的能力
指向连续内存:char* 是一个指针,可以指向多字节的字符序列(如字符串)。中文字符串在内存中以连续字节存储(如UTF-8的 "你好" 占6字节),char* 通过地址访问整个序列。
终止符机制:cout << char* 会从指针地址开始输出字节,直到遇到空字符 \0,因此能正确输出多字节的中文字符串(前提是终端编码匹配)
cout<<遇到char*应该逐字节输出, 但是怎么会按utf8来解码输出呢?
这样一问, AI 就解决了疑问:
`cout <<` 遇到 `char*` 时,本质上是逐字节输出,但最终显示为 UTF-8 解码的字符,是由以下机制共同作用的结果:
---
1. **`cout` 对 `char*` 的处理机制**
• 逐字节输出:`operator<<` 对 `char*` 的重载会从指针地址开始,逐个字节输出直到遇到 `\0`,不主动解析编码(如UTF-8或GBK)。
• 编码无关性:`cout` 仅传递字节流,不负责解码。若字符串是UTF-8编码(如 `const char* p = "中文"`),输出的是原始的UTF-8字节序列(如 `0xE4B8AD 0xE69687`)。
2. **终端显示的UTF-8解码** // 这里是重点!!! 能显示正确的utf8字符串, 是终端的作用!!
• 终端匹配编码:若终端(如Linux Console、现代IDE)默认使用UTF-8编码,它会将接收到的字节流按UTF-8规则解码,从而正确显示中文字符。
• 乱码场景:若终端编码不匹配(如Windows默认GBK),UTF-8字节流会被错误解码,显示乱码。
3. **编译器与文件编码的作用**
• 源码文件编码:编译器会将源码中的字符串字面量(如 `"中文"`)按文件编码(如UTF-8)转换为二进制序列。若文件保存为UTF-8,生成的二进制数据即为UTF-8字节流。
• 无运行时转换:除非显式指定(如 `-fexec-charset=utf-8`),编译器不会在运行时主动转换编码。
4. **关键结论**
• `cout << char*` 不涉及UTF-8解码,仅是字节流的传递者。
• 正确显示依赖终端编码与字符串编码一致。例如:
```cpp
const char* utf8_str = u8"你好"; // 显式UTF-8编码
std::cout << utf8_str; // 需终端支持UTF-8
```
---
5. **验证示例**
```cpp
#include <iostream>
#include <cstring>
int main() {
const char* str = "中文"; // 文件保存为UTF-8
// 输出字节流(十六进制)
for (size_t i = 0; i < strlen(str); i++) {
std::cout << std::hex << (int)(unsigned char)str[i] << " ";
}
// 输出字符串
std::cout << "\n" << str << std::endl;
return 0;
}
```
• 输出结果:
• 字节流:`e4 b8 ad e6 96 87`(UTF-8编码的“中文”)
• 字符串:若终端为UTF-8,显示“中文”;否则乱码。
6. **扩展建议**
• 跨平台兼容:使用 `std::wcout` 和宽字符(`wchar_t`)或C++20的 `std::u8string`。
• 显式编码转换:如需处理混合编码,可用 `iconv` 或 `std::codecvt`。
字符串在计算机中的表示既可以是码点序数值(Unicode码点)的序列,也可以是字符集编码下的字节串序列,具体取决于所处的上下文和处理阶段。
1. **字符串的本质:码点序列**
• Unicode码点:字符串在逻辑上是由Unicode码点(Code Point)组成的序列。每个字符对应唯一的Unicode编号(如 `'A'` 的码点是 `U+0041`,`'中'` 的码点是 `U+4E2D`)。
• 抽象表示:在内存中(如Python的`str`类型或Java的`String`),字符串通常以Unicode码点的形式存储,与具体编码无关。
2. **存储与传输:字节序列**
• 编码后的字节流:当字符串需要存储到文件或通过网络传输时,必须通过字符编码(如UTF-8、GBK)转换为字节序列。例如:
• UTF-8将`'中'`(`U+4E2D`)编码为3字节:`0xE4 0xB8 0xAD`。
• GBK将`'中'`编码为2字节:`0xD6 0xD0`。
• 编码与解码:
• 编码(Encode):将码点序列转换为字节序列(如`"中文".encode("UTF-8")`)。
• 解码(Decode):将字节序列还原为码点序列(如`b"\xE4\xB8\xAD".decode("UTF-8")`)。
4. **编程语言中的体现**
• Python:`str`类型是Unicode码点序列,`bytes`类型是编码后的字节序列。
• C/C++:`char*`直接操作字节序列,需手动处理编码(如UTF-8的变长编码)。
• Java:`String`内部使用UTF-16编码的码点序列,但对外表现为逻辑字符。
5. **总结**
• 字符串本质是Unicode码点序列,属于逻辑层的抽象。
• 具体存储时需转换为字节序列,依赖字符编码规则(如UTF-8的变长编码)。
• 乱码问题通常源于编码与解码时字符集不匹配(如UTF-8字节流用GBK解码)。
用char* 可以正常在终端输出为中文, 但如果要处理,比如strlen()获得字符个数, 就不能用char*或std::string来指向或存储中文字符串了, 而要用wchar_t或char16_t, char32_t, 或std::wstring 来存储中文字符串. 用wchar_t能wcout正常输出, 但是char16_t怎样输出呢?
在C++中,`char16_t` 是用于存储UTF-16编码的字符类型,但标准库(如`std::cout`)不直接支持其输出。以下是几种输出`char16_t`字符串的方法:
---
1. **转换为UTF-8后输出**
使用 `std::wstring_convert` 或 `std::codecvt`(C++11/C++14,但C++17后已弃用)将UTF-16转换为UTF-8,再通过`std::cout`输出:
```cpp
#include <iostream>
#include <codecvt>
#include <locale>
int main() {
const char16_t* u16str = u"你好"; // UTF-16字符串
std::wstring_convert<std::codecvt_utf8_utf16<char16_t>, char16_t> converter;
std::string utf8_str = converter.to_bytes(u16str); // 转为UTF-8
std::cout << utf8_str << std::endl; // 输出UTF-8字节流
return 0;
}
```
注意:`std::codecvt`在C++17后被标记为弃用,建议使用第三方库(如ICU)替代。
---
2. **直接输出UTF-16编码值**
遍历`char16_t`数组,输出每个字符的十六进制值:
```cpp
#include <iostream>
#include <iomanip>
int main() {
const char16_t u16str[] = u"你好";
for (size_t i = 0; u16str[i] != 0; ++i) {
std::cout << "U+" << std::hex << std::setw(4) << std::setfill('0')
<< static_cast<uint16_t>(u16str[i]) << " ";
}
return 0;
}
```
输出示例:`U+4f60 U+597d`(对应“你好”的UTF-16码点)。
---
3. **平台特定方法(Windows)**
在Windows上,`wchar_t`与`char16_t`均为16位,可直接转换后使用`std::wcout`:
```cpp
#include <iostream>
#include <locale>
int main() {
setlocale(LC_ALL, "en_US.utf8"); // 设置本地化支持UTF-8
const char16_t* u16str = u"你好";
const wchar_t* wstr = reinterpret_cast<const wchar_t*>(u16str);
std::wcout << wstr << std::endl; // 需终端支持UTF-16
return 0;
}
```
注意:此方法依赖平台(Windows的`wchar_t`为UTF-16,Linux/macOS为UTF-32)。
---
4. **使用第三方库(推荐)**
对于跨平台场景,推荐使用ICU或Boost.Locale:
```cpp
#include <unicode/unistr.h>
#include <iostream>
int main() {
icu::UnicodeString ustr(u"你好"); // UTF-16字符串
std::string utf8;
ustr.toUTF8String(utf8); // 转为UTF-8
std::cout << utf8 << std::endl;
return 0;
}
```
建议:优先使用ICU等库处理Unicode字符串,避免直接依赖弃用功能。
在字体渲染流程中,确实存在从文本文件存储的字节串到程序运行时解码为Unicode码点序数值的过程。以下是关键步骤分析:
-
字节串到码点的解码
文本文件中的字符通常以特定编码(如UTF-8、GBK)存储为字节序列。程序运行时需先通过编码规则(如UTF-8的变长编码)将字节流解码为Unicode码点序列。例如:
• UTF-8编码的0xE4 0xB8 0xAD→ Unicode码点U+4E2D(汉字“中”)。• 浏览器或文本处理库(如
std::codecvt)会解析HTTP头或文件元数据确定编码方式,再执行解码。 -
码点到字形的映射
解码后的码点通过字体文件的cmap表(字符映射表)转换为字形索引(Glyph Index)。例如:
• TrueType/OpenType字体中,U+4E2D可能映射到字形编号123。• 渲染引擎(如FreeType)根据字形索引加载轮廓数据或位图。
-
字形渲染
字形数据经栅格化(矢量→像素)或直接渲染,最终显示为可视字符。
总结:字体渲染流程必然包含“字节流→码点→字形→渲染”的转换链,其中解码为码点是关键前置步骤。
总归, 用const char* 或std::string 指向或存储中文字符串, 是不好的. c++也应该学Python3一样进行改革, 把char类型默认就用utf-8字符集编码方案, 而不是现在的 ASCII. 当然这样说并没有充足的考虑, 比如后向兼容(新标准要兼容旧标准下写的代码)等考虑.
相关文章:

为什么 cout<<“中文你好“ 能正常输出中文
一, 简答: 受python3字符串模型影响得出的下文C字符串模型结论 是错的!C的字符串和python2的字符串模型类似,也就是普通的字符串是ASCII字符串和字节串两种语义,类似重载或多态,有时候解释为整数,有时候是字节串。Uni…...

Leetcode 3547. Maximum Sum of Edge Values in a Graph
Leetcode 3547. Maximum Sum of Edge Values in a Graph 1. 解题思路2. 代码实现 题目链接:3547. Maximum Sum of Edge Values in a Graph 1. 解题思路 这一题主要是在问题的分析上面。由题意易知,事实上给定的图必然只可能存在三种可能的结构&#x…...

关于Go语言的开发环境的搭建
1.Go开发环境的搭建 其实对于GO语言的这个开发环境的搭建的过程,类似于java的开发环境搭建,我们都是需要去安装这个开发工具包的,也就是俗称的这个SDK,他是对于我们的程序进行编译的,不然我们写的这个代码也是跑不起来…...
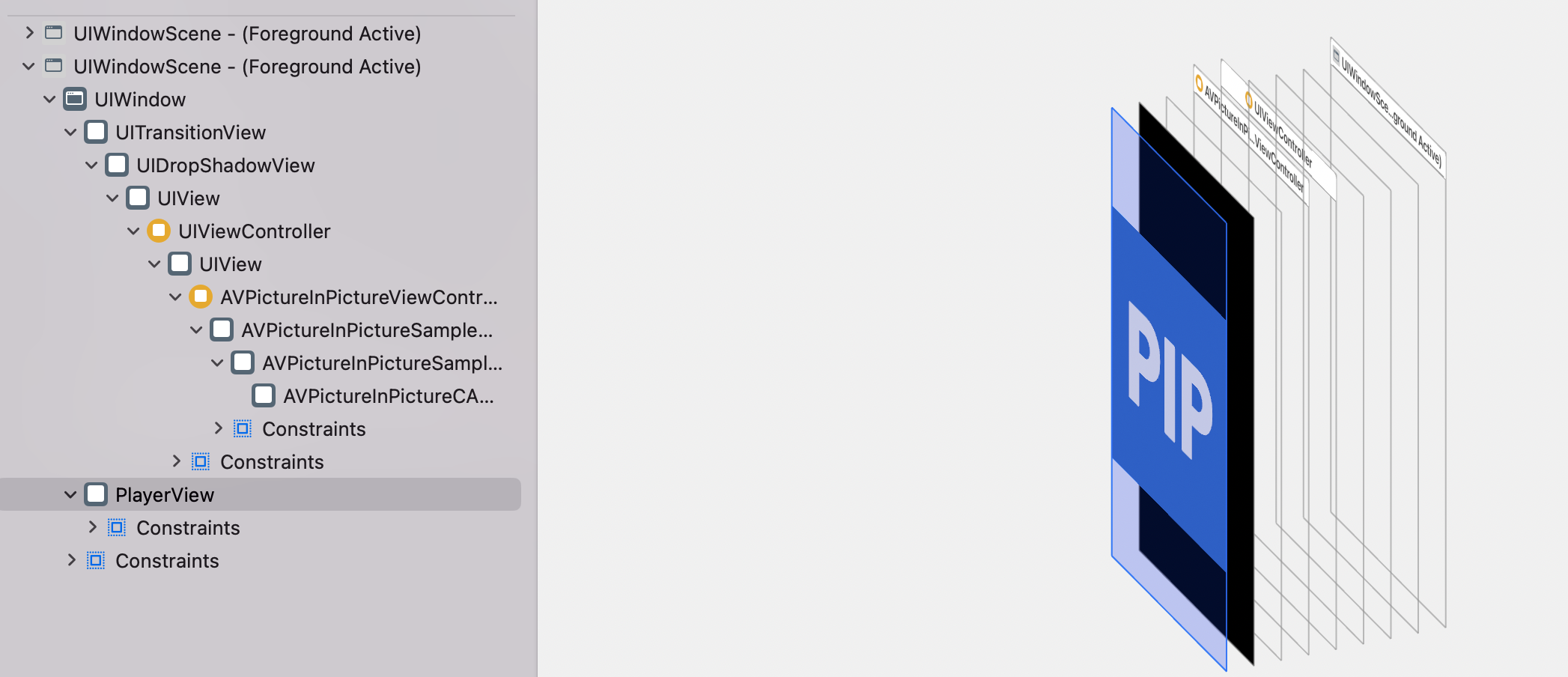
Flutter PIP 插件 ---- 为iOS 重构PipController, Demo界面,更好的体验
接上文 Flutter PIP 插件 ---- 新增PipActivity,Android 11以下支持自动进入PIP Mode 项目地址 PIP, pub.dev也已经同步发布 pip 0.0.3,你的加星和点赞,将是我继续改进最大的动力 在之前的界面设计中,还原动画等体验一…...

Redis 基本命令与操作全面解析:从入门到实战
前言 Redis 作为高性能内存数据库,其丰富的命令体系是发挥强大功能的基础。掌握 Redis 的基本命令,不仅能实现数据的高效读写,还能深入理解其内存模型与工作机制。本文将系统梳理 Redis 的核心命令,涵盖连接操作、键管理、数据类…...

数据库管理-第325期 ADG Failover后该做啥(20250513)
数据库管理325期 2025-05-13 数据库管理-第325期 ADG Failover后该做啥(20250513)1 故障处置2 恢复原主库3 其他操作总结 数据库管理-第325期 ADG Failover后该做啥(20250513) 作者:胖头鱼的鱼缸(尹海文&a…...
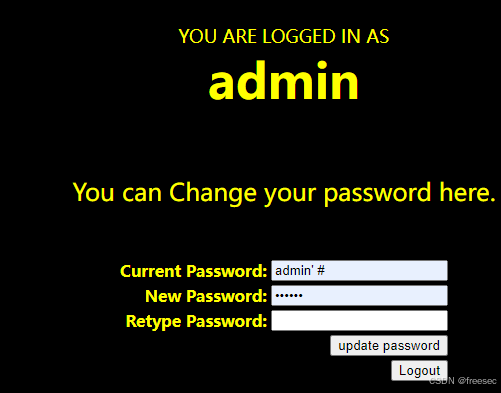
SQLi-Labs 第21-24关
Less-21 http://127.0.0.1/sqli-labs/Less-21/ 1,抓个请求包看看 分析分析cookie被base64URL编码了,解码之后就是admin 2,那么这个网站的漏洞利用方式也是和Less-20关一样的,只是攻击语句要先base64编码,再URL编码&…...

Oracle — 数据管理
介绍 Oracle数据库作为全球领先的关系型数据库管理系统,其数据管理能力以高效性、安全性和智能化为核心。系统通过多维度技术实现海量数据的存储与实时处理,支持高并发事务操作与复杂分析查询,满足企业关键业务需求。在安全领域,O…...

在 Qt Creator 中为 QDockWidget 设置隐藏和显示按钮
在 Qt Creator 中为 QDockWidget 设置隐藏和显示按钮 是的,QDockWidget 内置了隐藏和显示的功能,可以通过以下几种方式实现: 1. 使用 QDockWidget 自带的关闭按钮 QDockWidget 默认带有一个关闭按钮,可以通过以下代码启用&…...

LS-NET-012-TCP的交互过程详解
LS-NET-012-TCP的交互过程详解 附加:TCP如何保障数据传输 TCP的交互过程详解 一、TCP协议核心交互流程 TCP协议通过三次握手建立连接、数据传输、四次挥手终止连接三大阶段实现可靠传输。整个过程通过序列号、确认应答、窗口控制等机制保障传输可靠性。 1.1 三次…...

每日算法刷题Day1 5.9:leetcode数组3道题,用时1h
1.LC寻找数组的中心索引(简单) 数组和字符串 - LeetBook - 力扣(LeetCode)全球极客挚爱的技术成长平台 思想: 计算总和和左侧和,要让左侧和等于右侧和,即左侧和总和-左侧和-当前数字 代码 c代码: class Solution { public:i…...

解构认知边界:论万能方法的本体论批判与方法论重构——基于跨学科视阈的哲学-科学辩证
一、哲学维度的本体论批判 (1)理性主义的坍缩:从笛卡尔幻想到哥德尔陷阱 笛卡尔在《方法论》中构建的理性主义范式,企图通过"普遍怀疑-数学演绎"双重机制确立绝对方法体系。然而哥德尔不完备定理(Gdel, 19…...
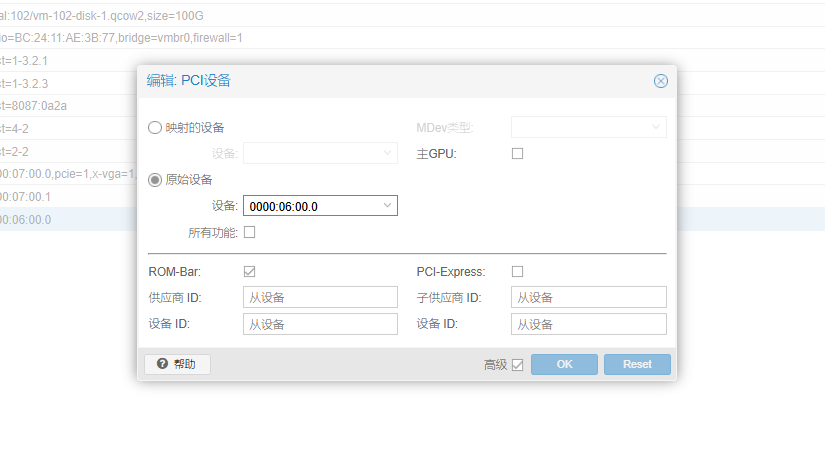
PVE WIN10直通无线网卡蓝牙
在 Proxmox VE (PVE) 中直通 Intel AC3165 无线网卡的 **蓝牙模块**(通常属于 USB 设备,而非 PCIe 设备)需要特殊处理,因为它的蓝牙部分通常通过 USB 连接,而 Wi-Fi 部分才是 PCIe 设备。以下是详细步骤: …...

第六节第二部分:抽象类的应用-模板方法设计模式
模板方法设计模式的写法 建议使用final关键字修饰模板方法 总结 代码: People(父类抽象类) package com.Abstract3; public abstract class People {/*设计模板方法设计模式* 1.定义一个模板方法出来*/public final void write(){System.out.println("\t\t\t…...
在另一个省发布抖音作品,IP属地会随之变化吗?
你是否曾有过这样的疑惑:出差旅游时在外地发布了一条抖音视频,评论区突然冒出“IP怎么显示xx省了?”的提问?随着各大社交平台上线“IP属地”功能,用户的地理位置标识成为公开信息,而属地显示的“灵敏性”也…...
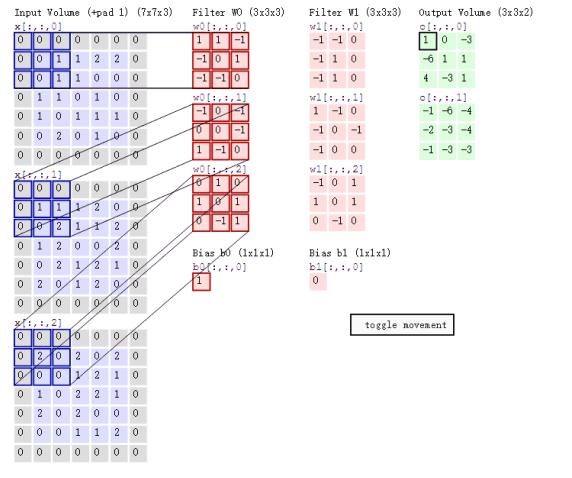
卷积神经网络-从零开始构建一个卷积神经网络
目录 一、什么是卷积神经网络CNN 1.1、核心概念 1.2、卷积层 二、什么是卷积计算 2.1、卷积计算的例子: 2.2、点积 2.3、卷积与点积的关系 2.4、Padding(填充) 2.4.1、Padding的主要作用 1、控制输出特征图尺寸 2、保留边缘信息 3. 支持深层网络训练 2.4.2、Str…...

力扣-101.对称二叉树
题目描述 给你一个二叉树的根节点 root , 检查它是否轴对称。 class Solution { public:bool check(TreeNode* p,TreeNode* q){if(!p&&!q)return true;if(!p&&q||!q&&p)return false;if(p->val!q->val)return false;return check(p…...

Tomcat和Nginx的主要区别
1、功能定位 Nginx:核心是高并发HTTP服务器和反向代理服务器,擅长处理静态资源(如HTML、图片)和负载均衡。Tomcat:是Java应用服务器,主要用于运行动态内容(如JSP、Servlet)…...

贪心算法:最小生成树
假设无向图为: A-B:1 A-C:3 B-C:1 B-D:4 C-D:1 C-E:5 D-E:6 一、使用Prim算法: public class Prim {//声明了两个静态常量,用于辅助 Prim 算法的实现private static final int V 5;//点数private static final int INF Integer.MA…...
uniapp-文件查找失败:‘@dcloudio/uni-ui/lib/uni-icons/uni-icons.vue‘
uniapp-文件查找失败:‘dcloudio/uni-ui/lib/uni-icons/uni-icons.vue’ 今天在HBuilderX中使用uniapp开发微信小程序时遇到了这个问题,就是找不到uni-ui组件 当时创建项目,选择了一个中间带的底部带选项卡模板,并没有选择内置u…...
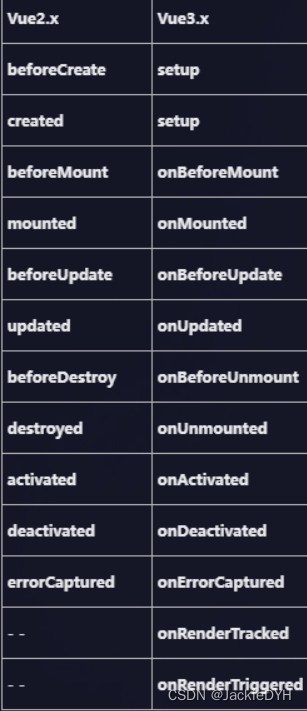
Vue2.x 和 Vue3.x 对比-差异
Vue3的优点 diff算法的提升 vue2中的虚拟DOM是全量的对比,也就是不管是写死的还是动态节点都会一层层比较,浪费时间在静态节点上。 vue3新增静态标记(patchflag ),与之前虚拟节点对比,只对比带有patch fla…...
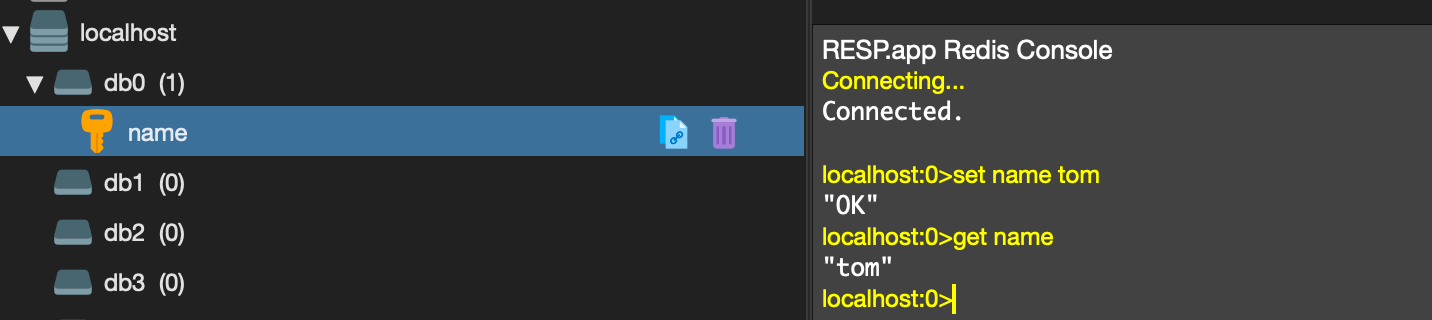
MacOS 用brew 安装、配置、启动Redis
MacOS 用brew 安装、配置、启动Redis 一、安装 brew install redis 二、启动 brew services start redis 三、用命令行检测 set name tom get name...
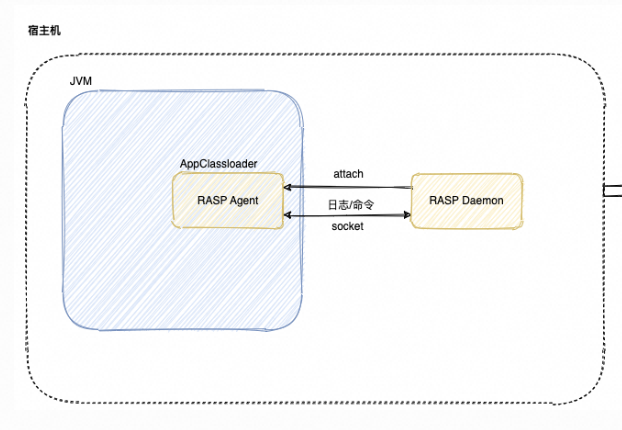
agentmain对业务的影响
前面一篇已经说了java agent技术主要有premain和agentmain两种形式,如果大部分业务已经在线上运行的话,不方便用premain的方式来实现,所以agentmain的方式是更加通用、灵活的 由于RASP是与用户业务运行在同一个jvm中的 ,所以RASP…...
:创业阶段的划分与精益数据分析实践)
精益数据分析(56/126):创业阶段的划分与精益数据分析实践
精益数据分析(56/126):创业阶段的划分与精益数据分析实践 在创业和数据分析的探索之旅中,理解创业阶段的划分以及与之对应的精益数据分析方法至关重要。今天,依旧怀揣着与大家共同进步的心态,深入研读《精…...

archlinux中挂载macOS的硬盘
问: 你好,我如何在archlinux中挂载macOS的硬盘呢?/dev/sda4 5344161792 7813773311 2469611520 1.2T Apple HFS/HFS AI回答: 你好!在 Arch Linux 中挂载 macOS 的 HFS 或 HFS 硬盘(例如 /dev/sda4&#x…...
-GC)
JVM Optimization Learning(七)-GC
一、JVM Optimization 1、进程溢出调查 模拟 如何开启GC日志 如何开启GC日志 一般来说,JDK8及以下版本通过以下参数来开启GC日志: -XX:PrintGCDetails -XX:PrintGCDateStamps -Xloggc:gc.log如果是在JDK9及以上的版本,则格式略有不同&…...
uniapp小程序轮播图高度自适应优化详解
在微信小程序开发过程中,轮播图组件(swiper)是常用的UI元素,但在实际应用中经常遇到高度不匹配导致的空白问题。本文详细记录了一次轮播图高度优化的完整过程,特别是针对固定宽高比图片的精确适配方案。 问题背景 在开发"零工市场&quo…...

CSS从入门到精通:全面解析CSS核心知识体系
引言 CSS(层叠样式表)是前端开发的基石,掌握其核心知识能显著提升页面设计与布局能力。本文基于系统化学习资料,深入讲解CSS语法、选择器优先级、盒子模型、定位等核心概念,结合代码示例与实用技巧,助你从入…...

基于ESP32控制的机器人摄像头车
DIY Wi-Fi 控制的机器人摄像头车:从零开始的智能探索之旅 在当今科技飞速发展的时代,机器人技术已经逐渐走进了我们的生活。今天,我将带你一起探索如何制作一个 Wi-Fi 控制的机器人摄像头车,它不仅可以远程操控,还能通…...

基于STM32的LCD信号波形和FFT频谱显示
一、项目准备 主要利用LCD驱动中的画点和画连线函数,驱动是正点原子给我写好了的画点和画线的函数等些相关函数 void LCD_Draw_Circle(u16 x0,u16 y0,u8 r); //画圆 void LCD_DrawLine(u16 x1, u16 y1, u16 x2, u16 y2); //画线 二、画波形图函数实…...