Linux系统:虚拟文件系统与文件缓冲区(语言级内核级)
本节重点
- 初步理解一切皆文件
- 理解文件缓冲区的分类
- 用户级文件缓冲区与内核级文件缓冲区
- 用户级文件缓冲区的刷新机制
- 两级缓冲区的分层协作
一、虚拟文件系统
1.1 理解“一切皆文件”
我们都知道操作系统访问不同的外部设备(显示器、磁盘、键盘、鼠标、网卡)时都会通过相应的驱动程序,由于各种外设之间的差异在驱动程序中对每个外设的输入输出(如获取设备状态、属性)的相关方法的实现都不尽相同:
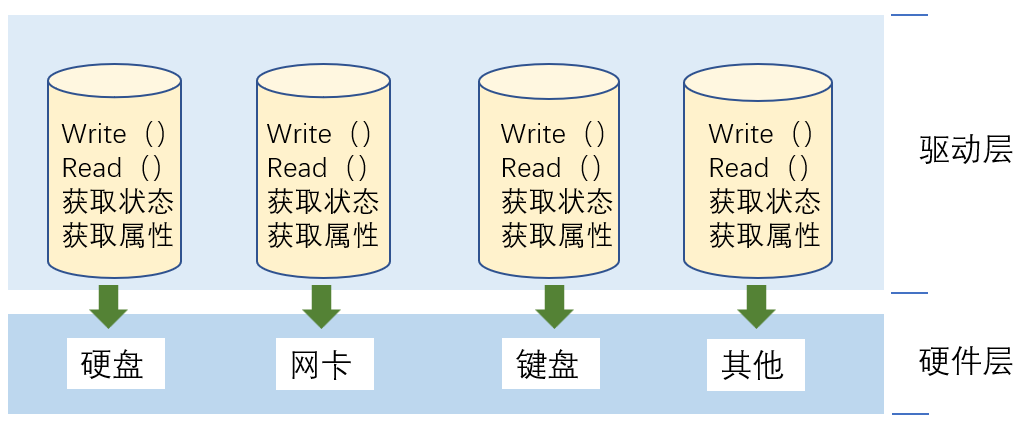
我们说操作系统是对软硬件资源进行管理的软件,在内核中要对硬件资源进行管理首先需要让操作系统看到硬件资源,也就是将硬件资源“先描述再组织”:
在操作系统内核中通过类似struct device的结构体来对每种外设进行描述,再通过链表的方式将硬件资源管理起来,此时这个数据结构就表示操作系统启动时默认看到的和打开的外设资源:
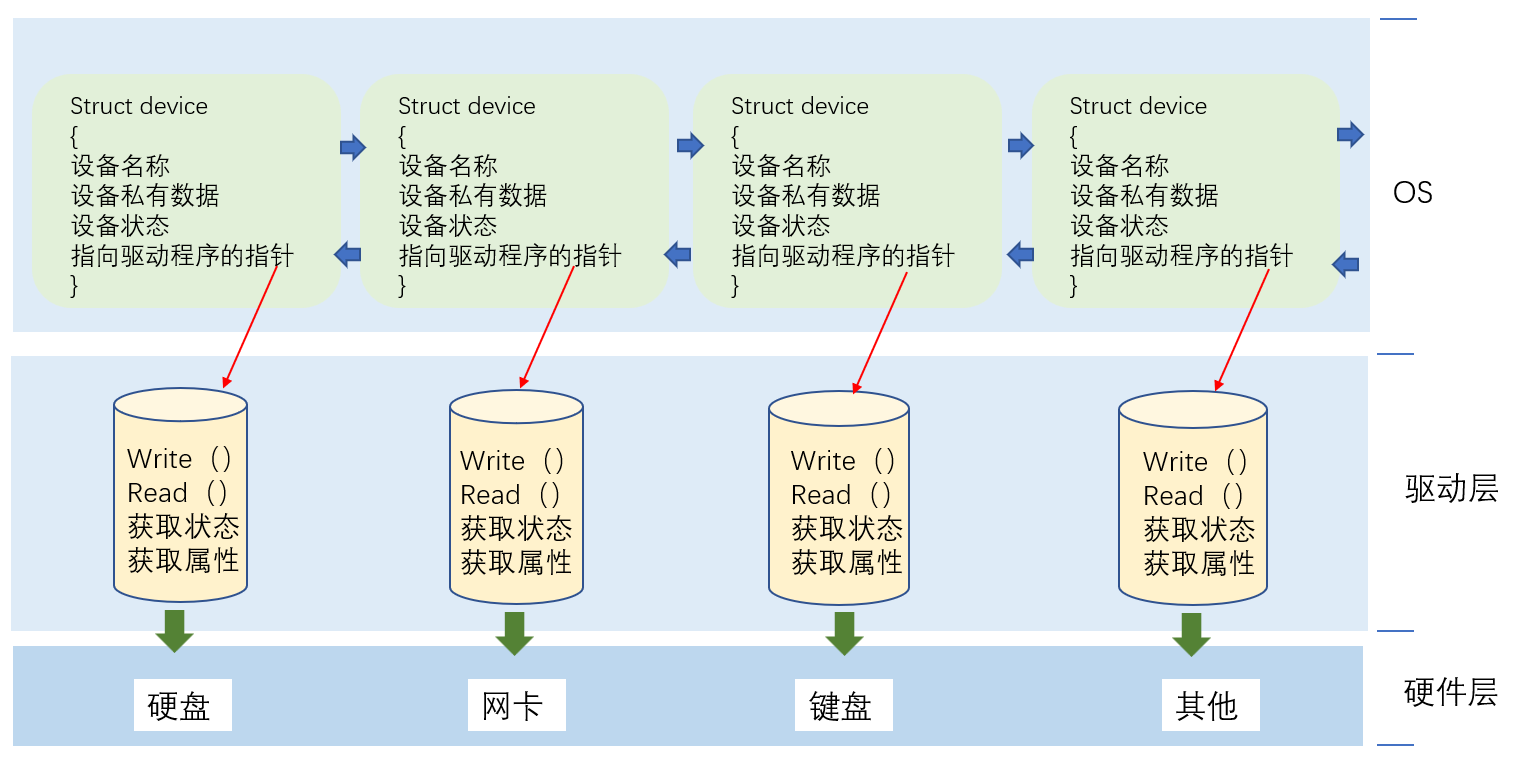 当用户运行自己的代码与数据时,操作系统就会在内核空间创建进程PCB,其中PCB中的struct files struct指针指向的文件描述符表则记录了该进程打开的文件的数量。而我们知道文件描述符表本质上是元素为struct file的一维数组,struct file中则详细记录了被打开文件的文件缓冲区和元数据,关键的是其中还记录了指向文件操作的各种方法的指针(函数指针),这样对文件的操作会通过函数指针跳转到不同的对应外设的驱动层。
当用户运行自己的代码与数据时,操作系统就会在内核空间创建进程PCB,其中PCB中的struct files struct指针指向的文件描述符表则记录了该进程打开的文件的数量。而我们知道文件描述符表本质上是元素为struct file的一维数组,struct file中则详细记录了被打开文件的文件缓冲区和元数据,关键的是其中还记录了指向文件操作的各种方法的指针(函数指针),这样对文件的操作会通过函数指针跳转到不同的对应外设的驱动层。
这样即使外设之间存在差异,驱动程序的设计大相径庭用户访问涉及到不同类型外设的文件时也能获得相似的方法,以为在内核通过函数指针已经帮用户完成了差异化的方法调用。

二、文件缓冲区
2.1 什么是缓冲区
缓冲区是内存空间的一部分,用来暂时存储输入或者输出的数据内容,这部分预留的空间就叫做缓冲区。缓冲区根据其对接的是输入设备还是输出设备分为输入缓冲区与输出缓冲区。
2.2 为什么引入缓冲区
关键1:语言级文件操作都会调用系统调用
在介绍操作系统时我们了解到:操作系统为了不直接暴露内核,为上层用户提供了各类系统调用。在语言层面对文件操作的各类函数接口底层都封装了系统调用。
例如,以C语言为例fopen,fread,fwrite底层都分别封装了open,read,write系统调用。
所以本质上我们使用各类编程语言进行文件操作(如I/O操作)都会调用系统调用。
关键2:系统调用是有代价的
在之后的学习中我们会了解到,当程序执行系统调用时,CPU会从用户态切换到内核态这个过程涉及到保护用户程序的寄存器状态,切换页表,加载内核代码段等操作。当系统调用完成时,CPU会从内核态返回到用户态,此时CPU需要恢复用户程序的寄存器状态,整个操作会涉及到数百到数千个CPU周期。
关键3:缓冲区的引入可以减少系统调用次数
以向文件中写入数据为例,当我们引入缓冲区的概念后,对文件的输入操作意味着我们可以逐渐将数据块输入到缓冲区中,然后通过适当的缓冲机制调用系统调用将数据块整体写入到文件中,大大减少了系统调用的次数,大大提高了输入效率。
2.3 缓冲区的分类
2.3.1 用户级(C语言为例)
C标准库中的I/O函数(printf、fwrite、fgets)均围绕流的概念设计。每个流(stdout、stderr、stdin、用户自定义的文件流)都由一个FILE结构体来表示,该结构体包含一个缓冲区以及缓冲策略(行缓冲、全缓冲、无缓冲)。
在C标准库中对结构体FILE的描述如下:
//FILE本质上是定义的一个宏在/usr/include/stdio.h中typedef struct _IO_FILE FILE;//在/usr/include/libio.h
struct _IO_FILE
{
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. *//* The following fields are used to support backing up and undo. */char *_IO_save_base; /* Pointer to start of non-current get area. */char *_IO_backup_base; /* Pointer to first valid character of backup area */char *_IO_save_end; /* Pointer to end of non-current get area. */struct _IO_marker *_markers;struct _IO_FILE *_chain;int _fileno; //封装的⽂件描述符#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};缓冲机制
在C标准库(stdio.h)总共定义了三个缓冲机制,每个流(FILE结构体)在其生命周期中通常只配置一个缓冲机制。以下是对三个缓冲机制的介绍:

注意事项:
除了以上默认的刷新方式下列特殊清空也会引发缓冲区的刷新:
- 缓冲区被写满
- 显式刷新(如调用flush)
当缓冲区为行缓冲但是始终没有遇到换行符(\n)时,当缓冲区满时会自动提交。
当涉及磁盘文件操作时默认为全缓冲,当所操作的流涉及一个终端(显示器)时默认为行缓冲,stderr默认不带缓冲区即无缓冲。
这里举一个代码示例:
//code.c
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{const char* s1="hello printf\n";const char* s2="hello fwrite\n";printf("%s",s1);fwrite(s2,1,strlen(s2),stdout);fork();return 0;
}
运行结果:
 首先printf与fwrite将字符串写入stdout对应的缓冲区中,当涉及到对终端(显示器)的操作时为行缓冲,所以字符串会依次刷新提交。
首先printf与fwrite将字符串写入stdout对应的缓冲区中,当涉及到对终端(显示器)的操作时为行缓冲,所以字符串会依次刷新提交。
此时我们执行以下指令:将程序重定向到一个文本文件(text.txt)中
./code 1> text.txt运行结果:

此时我们发现同一份代码数据被打印了两次,原因是当我们进行重定向操作后就成为了用户对磁盘文件(text.txt)的文件操作,默认缓冲机制变成了全缓冲。
当我们创建子进程之前,父进程的两个数据(hello printf / hello fwrite)还在缓冲区中并没有被刷新提交,而我们知道子进程是父进程的副本,当创建子进程时缓冲区中的数据也一并拷贝给了子进程,当程序结束后会自动刷新text.txt文件流的缓冲区,导致数据被打印了两次。
2.3.2 内核级
在Linux系统中,内核级缓冲区是用于在内核空间和用户空间之间传递数据的关键机制。它通常用于提高I/O操作的效率,减少系统调用的次数,并优化数据的传输。
内核级缓冲区的类型:
1> 页缓存
用于缓存文件数据,减少磁盘I/O操作。当文件被读取时,数据会被缓存在页缓存中,后续的读取操作可以直接从缓存中获取数据,而不需要再次访问磁盘。
2> 块设备缓冲区
用于缓存块设备的数据,如硬盘的块数据。它与页缓存类似,但更专注于块设备的I/O操作。
3> 套接字缓冲区
用于网络通信,管理网络数据包的传输。每个网络数据包都会被封装在sk_buff结构中,以便在内核中进行处理。
与用户级缓冲区类似,内核级缓冲区也有刷新机制但是在实现方面会复杂很多。以为在内核层面操作系统要考虑的因素会更多,比如刷新操作可能涉及大量的内存操作,不当的刷新策略可能导致系统资源耗尽或内存泄漏,还有在多核或多线程环境下,内核级缓冲区的刷新机制需要处理并发访问问题。这通常需要引入复杂的同步机制,如自旋锁或读写锁,以确保数据的一致性和完整性等等
以下是内核级缓冲区的刷新机制,可以来了解一下:
- 定期刷新:内核会定期将缓冲区中的数据写入存储设备。这种刷新通常由内核的守护进程负责,确保数据在一定时间间隔内被写入磁盘。
- 显式刷新:应用程序可以通过系统调用(如
fsync或fdatasync)显式请求将缓冲区中的数据刷新到存储设备。 - 缓冲区满时刷新:当内核缓冲区达到一定容量时,内核会自动将数据刷新到存储设备。
- 文件关闭时刷新:当应用程序关闭文件时,内核会自动将与该文件相关的缓冲区数据刷新到存储设备。
- 内存压力:当系统内存不足时,内核可能会主动刷新缓冲区以释放内存。这种机制确保系统在高内存压力下仍能正常运行。
2.3 两级缓冲区的联系
关键词:分层协作
当应户程序通过用户级缓冲区写入数据时,数据首先存储在用户空间的缓冲区中。当缓冲区满或显式调用刷新函数时,数据会被复制到内核级缓冲区。内核级缓冲区进一步管理数据的物理写入操作,确保数据最终被写入磁盘或发送到网络设备。
我们可以通过下图来理解:
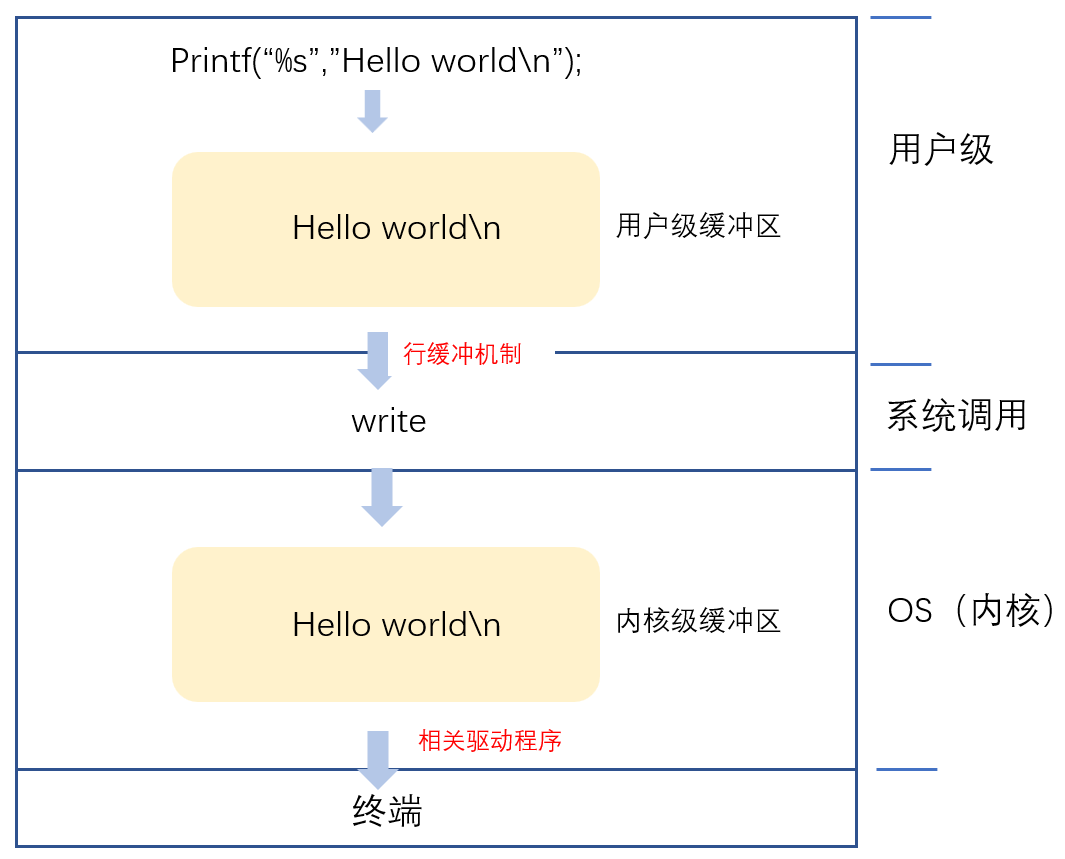
这种分层缓冲机制减少了频繁的系统调用,提高了数据处理的效率。同时,内核级缓冲区还可以利用更高级的优化技术,如延迟写入和批量处理,进一步提升系统性能。
相关文章:
Linux系统:虚拟文件系统与文件缓冲区(语言级内核级)
本节重点 初步理解一切皆文件理解文件缓冲区的分类用户级文件缓冲区与内核级文件缓冲区用户级文件缓冲区的刷新机制两级缓冲区的分层协作 一、虚拟文件系统 1.1 理解“一切皆文件” 我们都知道操作系统访问不同的外部设备(显示器、磁盘、键盘、鼠标、网卡&#…...

智能体的典型应用:自动驾驶、智能客服、智能制造、游戏AI与数字人技术
本文为《React Agent:从零开始构建 AI 智能体》专栏系列文章。 专栏地址:https://blog.csdn.net/suiyingy/category_12933485.html。项目地址:https://gitee.com/fgai/react-agent(含完整代码示例与实战源)。完整介绍…...

【技巧】使用UV创建python项目的开发环境
回到目录 【技巧】使用UV创建python项目的开发环境 0. 为什么用UV 下载速度快、虚拟环境、多版本python支持、清晰的依赖关系 1. 安装基础软件 1.1. 安装python 下载地址:https://www.python.org/downloads/windows/ 1.2. 安装UV > pip install uv -i ht…...

什么是时序数据库?
2025年5月13日,周二清晨 时序数据库(Time Series Database,TSDB)是一种专门用于高效存储、管理和分析时间序列数据的数据库系统。时间序列数据是指按时间顺序记录的数据点,通常包含时间戳和对应的数值或事件࿰…...

react父组件往孙子组件传值Context API
步骤: 创建一个 Context 在父组件中用 Provider 提供值 在孙子组件中用 useContext 消费值 // 创建 Context const MyContext React.createContext();// 父组件 const Parent () > {const value "Hello from parent";return (<MyContext.Provid…...

2025年第十六届蓝桥杯大赛软件赛C/C++大学B组题解
第十六届蓝桥杯大赛软件赛C/C大学B组题解 试题A: 移动距离 问题描述 小明初始在二维平面的原点,他想前往坐标(233,666)。在移动过程中,他只能采用以下两种移动方式,并且这两种移动方式可以交替、不限次数地使用: 水平向右移动…...

国联股份卫多多与七腾机器人签署战略合作协议
5月13日,七腾机器人有限公司(以下简称“七腾机器人”)市场部总经理孙永刚、销售经理吕娟一行到访国联股份卫多多,同卫多多/纸多多副总裁、产发部总经理段任飞,卫多多机器人产业链总经理郭碧波展开深入交流,…...
)
python学习笔记七(文件)
文章目录 Python 文件操作与异常处理全面指南一、文件基本知识1. 文件类型2. 文件操作基本步骤 二、文件操作1. 打开文件2. 读取文件内容3. 写入文件4. 关闭文件5. 使用with语句(推荐) 三、CSV文件操作1. 使用csv模块2. 读取CSV文件3. 写入CSV文件 四、异…...
WebGL 开发的前沿探索:开启 3D 网页的新时代
你是否曾好奇,为何如今网页上能呈现出如同游戏般逼真的 3D 场景?这一切都要归功于 WebGL。它看似神秘,却悄然改变着我们浏览网页的体验。以往,网页内容大多局限于二维平面,可 WebGL 打破了这一限制。它究竟凭借什么&am…...

高防服务器部署实战:从IP隐匿到协议混淆
1. IP隐匿方案设计 传统高防服务器常因源站IP暴露遭针对性攻击,群联通过三层架构实现深度隐藏: 流量入口层:域名解析至动态CNAME节点(如ai-protect.example.com)。智能调度层:AI模型分配清洗节点…...
激光雷达定位算法在FPGA中的实现——section3 Matlab实现和校验
1、校验section2的计算方法是否正确 以section1里面的图示 举个例子: 1.1 手动计算...

AI+可视化:数据呈现的未来形态
当AI生成的图表开始自动“美化”数据,当动态可视化报告能像人类一样“讲故事”,当你的眼球运动直接决定数据呈现方式——数据可视化的未来形态,正在撕裂传统认知。某车企用AI生成的3D可视化方案,让设计师集体失业;某医…...

[免费]微信小程序医院预约挂号管理系统(uni-app+SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序医院预约挂号管理系统(uni-appSpringBoot后端Vue管理端),分享下哈。 项目视频演示 【免费】微信小程序医院预约挂号管理系统(uni-appSpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩…...

【网络入侵检测】基于源码分析Suricata的IP分片重组
【作者主页】只道当时是寻常 【专栏介绍】Suricata入侵检测。专注网络、主机安全,欢迎关注与评论。 目录 目录 1.概要 2. 配置信息 2.1 名词介绍 2.2 defrag 配置 3. 代码实现 3.1 配置解析 3.1.1 defrag配置 3.1.2 主机系统策略 3.2 分片重组模块 3.2.1…...

Spring框架请求注解
Spring框架请求注解 1.RequestParam 作用:从请求的 查询参数(Query Parameters) 或 表单数据(Form Data) 中提取参数。适用场景: GET 请求的 URL 参数(如 /users?nameTom&age20ÿ…...

LVGL简易计算器实战
文章目录 📁 文件结构建议🔹 eval.h 表达式求值头文件🔹 eval.c 表达式求值实现文件(带详细注释)🔹 ui.h 界面头文件🔹 ui.c 界面实现文件🔹 main.c 主函数入口✅ 总结 项目效果&…...

【FMMT】基于模糊多模态变压器模型的个性化情感分析
遇到很难的文献看不懂,不应该感到气馁,应该激动,因为外审估计也看不太懂,那么学明白了可以吓唬他 缺陷一:输入依赖性与上下文建模不足 缺陷描述: 传统自注意力机制缺乏因果关系,难以捕捉序列历史背景多模态数据间的复杂依赖关系未被充分建模CNN/RNN类模型在…...

聊一聊接口测试依赖第三方服务变更时如何处理?
目录 一、依赖隔离与模拟 二、契约测试 三、版本控制与兼容性 四、变更监控与告警 五、容错设计 六、自动化测试维护 七、协作机制与文档自动化 第三方API突然改了参数或者返回结构,导致我们的测试用例失败,这时候该怎么办呢?首先想到…...

代码随想录算法训练营第60期第三十四天打卡
大家好,我们今天的内容依旧是贪心算法,我们上次的题目主要是围绕多维问题,那种时候我们需要分开讨论,不要一起并发进行很容易顾此失彼,那么我们今天的问题主要是重叠区间问题,又是一种全新的贪心算法思想&a…...

Midscene.js Chrome 插件实战:基于 AI 驱动 WEB UI 自动化测试「喂饭教程」
Midscene.js Chrome 插件实战:基于 AI 驱动 WEB UI 自动化测试「喂饭教程」 前言一、Midscene.js 简介二、环境准备与插件安装1. 安装 Chrome 插件2. 配置模型与 API Key三、插件界面与功能总览四、实战演练:用自然语言驱动网页自动化1. 典型场景一(Action):账号登录步骤一…...

JVM——方法内联之去虚化
引入 在Java虚拟机的即时编译体系中,方法内联是提升性能的核心手段,但面对虚方法调用(invokevirtual/invokeinterface)时,即时编译器无法直接内联,必须先进行去虚化(Devirtualizationÿ…...

Objective-C Block 底层原理深度解析
Objective-C Block 底层原理深度解析 1. Block 是什么? 1.1 Block 的本质 Block 是 Objective-C 中的特殊对象,实现了匿名函数的功能 通过 isa 指针继承自 NSObject,可以响应(如 copy、retain、release)等内存管理方…...

关于IDE的相关知识之二【插件推荐】
成长路上不孤单😊😊😊😊😊😊 【14后😊///计算机爱好者😊///持续分享所学😊///如有需要欢迎收藏转发///😊】 今日分享关于ide插件推荐的相关内容!…...

Python+Streamlit实现登录页
PythonStreamlit实现登录页 Streamlit 是一个开源的 Python 库,专为数据科学家和机器学习工程师设计,用于快速构建交互式 Web 应用。 其核心功能与特点包括: 1.快速原型开发 2.交互式数据展示 3.极简开发 4.实时更新 5.内置组件 6.无前端依赖…...

RDD案例数据清洗
在 Spark 中,RDD(Resilient Distributed Dataset)是分布式数据集的基本抽象。数据清洗是数据预处理中的一个重要步骤,通常包括去除重复数据、过滤无效数据、转换数据格式等操作。以下是一个使用 RDD 进行数据清洗的完整示例。 示…...
)
按键精灵ios脚本新增元素功能助力辅助工具开发(三)
元素节点功能(iOSElement) 在按键精灵 iOS 新版 APP v2.2.0 中,新增了元素节点功能 iOSElement,该功能包含共 15 个函数。这一功能的出现,为开发者在处理 iOS 应用界面元素时提供了更为精准和高效的方式。通过这些函…...
Axure RP9:列表新增
文章目录 列表新增思路新增按钮操作说明保存新增交互设置列表新增 思路 利用中继器新增行实现列表新增功能 新增按钮操作说明 工具栏中添加新增图标及标签,在图标标签基础上添加热区;对热区添加鼠标单击时交互事件,同步插入如下动作:显示/隐藏动作,设置目标元件为新增窗…...
06 mysql之DML
一、什么是DML DML 用于操作数据库中的数据。主要命令包括: INSERT:添加数据SELECT:查询数据UPDATE:修改数据DELETE:删除数据 二、插入数据(INSERT) 2.1 插入单条记录 -- 插入学生记录&…...

游戏引擎学习第277天:稀疏实体系统
回顾并为今天定下基调 上次我们结束的时候,基本上已经控制住了跳跃的部分,达到了我想要的效果,现在我们主要是在等待一些新的艺术资源。因此,等新艺术资源到位后,我们可能会重新处理跳跃的部分,因为现在的…...
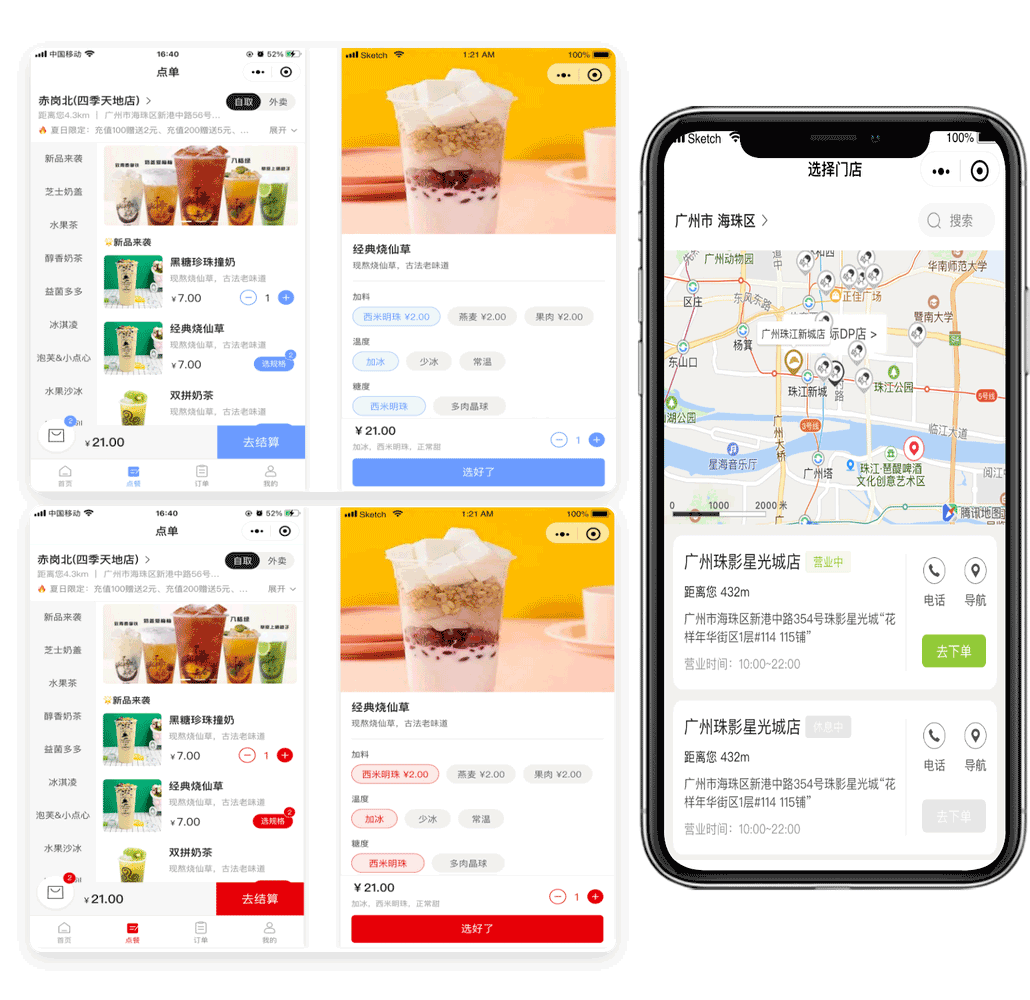
【最新版】likeshop连锁点餐系统-PHP版+uniapp前端全开源
一.系统介绍 likeshop外卖点餐系统适用于茶饮类的外卖点餐场景,搭建自己的一点点、奈雪、喜茶点餐系统。 系统基于总部多门店的连锁模式,拥有门店独立管理后台,支持总部定价和门店定价LBS定位点餐,可堂食可外卖。无论运营还是二开…...