大模型核心运行机制
大模型核心运行机制目录
- 一、核心架构:Transformer的演进与改进
- 1.1 核心组件包括:
- 1.1.1 自注意力机制(Self-Attention)
- 1.1.2 多头注意力(Multi-Head Attention)
- 1.1.3 位置编码(Positional Encoding)
- 1.1.4 前馈网络(FFN)与残差结构
- 1.2 模型架构改进方向
- 稀疏化(如DeepSeek):
- 混合专家模型(MoE)(如GPT-4、DeepSeek-MoE):
- 多模态扩展(如GPT-4 Vision):
- 二、训练流程:三阶段协同优化
- 2.1. 预训练(Pre-training)
- 2.2. 微调(Fine-tuning)
- 2.3. 对齐优化(Alignment)
- 三、推理机制:生成与控制的平衡
- 3.1. 自回归生成
- 3.2. 上下文管理
- 3.3. 安全与可控性
- 四、优化与扩展:效率与性能的权衡
- 4.1. 训练优化
- 4.2. 推理加速
- 4.3. 扩展性提升
- 五、核心挑战与解决方案
- 5.1. 计算成本与能效
- 5.2. 长尾知识与事实性
- 5.3. 偏见与安全性
- 5.4. 多模态与泛化性
大模型(如GPT-4、DeepSeek、ChatGPT)的核心运行机制主要是基于深度学习,尤其是Transformer架构。通过大规模数据训练、高效计算优化、自注意力机制和任务对齐技术实现对复杂任务的理解与生成。
一、核心架构:Transformer的演进与改进
大模型的基础是transformer架构
1.1 核心组件包括:
1.1.1 自注意力机制(Self-Attention)
通过计算输入序列中每个词与其他词的相关性权重,捕捉长距离依赖关系。

其中,Q(查询)、K(键)、V(值)为输入向量的线性变换, d k d_k dk为维度缩放因子。
1.1.2 多头注意力(Multi-Head Attention)
并行多组注意力头,捕捉不同子空间的语义信息,增强模型表达能力。
1.1.3 位置编码(Positional Encoding)
引入序列位置信息,常用方法包括:
绝对位置编码(如Sinusoidal编码)。
相对位置编码(如旋转位置编码RoPE),支持动态扩展上下文长度。
1.1.4 前馈网络(FFN)与残差结构
每层后接非线性全连接层,并通过残差连接和层归一化(LayerNorm)缓解梯度消失。
模型通过预训练在大规模数据上学习语言规律,再通过微调适应特定任务。训练过程中,使用反向传播和优化算法(如Adam)调整数百万甚至数十亿的参数。
依赖GPU/TPU等高性能硬件和分布式训练加速计算。输入文本经过分词与嵌入转换为向量表示,模型通过推理生成输出,并采用生成策略(如束搜索)确保输出质量。整个过程依赖大规模数据和计算资源,实现复杂的语言理解和生成能力。核心架构图如下:
1.2 模型架构改进方向
稀疏化(如DeepSeek):
动态稀疏注意力(局部窗口注意力、激活部分神经元)降低计算复杂度(从O( n 2 n^2 n2)降至O(n l o g n log^n logn))。
混合专家模型(MoE)(如GPT-4、DeepSeek-MoE):
每个输入Token通过路由机制激活少量专家网络,提升模型容量(万亿参数)而计算成本可控。
多模态扩展(如GPT-4 Vision):
跨模态编码器融合文本、图像等输入,支持图文混合任务。
核心模型树如下:
-
Encoder Only: 对应粉色分支,即BERT派,典型模型: BERT
- 自编码模型(Autoencoder Model):通过重建句子来进行预训练,通常用于理解任务,如文本分类和阅读理解。
- 模型像一个善于分析故事的专家,输入一段文本,能拆解的头头是道,本质上是把高维数据压缩到低维空间。
-
Decoder Only: 对应蓝色分支,GPT派, 典型模型: GPT4,LLaMA,DeepSeek,QWen
- 自回归模型(Autoregressive Model):通过预测序列中的下一个词来进行预训练,通常用于文本生成任务。
- 模型像一个会讲故事的专家,给点提示,就能流畅的接着自说自话。
-
Encoder-Decoder: 对应绿色分支,T5派, 典型模型: T5, ChatGLM
- 序列到序列模型(Sequence to Sequence Model):结合了编码器和解码器,通常用于机器翻译和文本摘要等任务。
- 模型像一个“完型填空专家”,是因为它特别擅长处理这种类型的任务。通过将各种NLP任务统一转换为填空问题,T5派能够利用其强大的语言理解和生成能力来预测缺失的文本。这种方法简化了不同任务之间的差异,使得同一个模型可以灵活地应用于多种不同的NLP任务,并且通常能够在多个任务上取得很好的性能。
二、训练流程:三阶段协同优化
大模型的训练分为预训练-微调-对齐三阶段,从通用表征学习到任务适配与价值观对齐。
2.1. 预训练(Pre-training)
目标:从海量无标注数据中学习通用语言模式。
数据:
规模达TB级,涵盖网页、书籍、代码等多源数据,经去重、质量过滤(如毒性内容剔除)。
多语言混合(如PaLM支持100+语言),但以英语为主。
任务:
自回归建模(如GPT系列):预测下一个词,损失函数为交叉熵。
掩码语言建模(如BERT):预测被遮蔽的词,学习双向上下文。
2.2. 微调(Fine-tuning)
目标:适配下游任务(如对话、翻译)。
策略:
全参数微调:调整所有模型参数,需大量标注数据。
参数高效微调:如LoRA(低秩适配)、Adapter(插入小型网络),仅优化部分参数。
指令微调(如ChatGPT):使用人工标注的指令-回答对,增强指令跟随能力。
2.3. 对齐优化(Alignment)
人类反馈强化学习(RLHF)(如ChatGPT):
奖励模型训练:人工标注回答质量排序,训练奖励模型(Reward Model)。
强化学习优化:使用PPO算法,以奖励模型引导策略模型(Policy Model)生成更符合人类偏好的回答。
直接偏好优化(DPO):
替代RLHF,通过显式偏好数据直接优化模型,降低计算复杂度。
三、推理机制:生成与控制的平衡
3.1. 自回归生成
过程:逐个生成Token,将已生成序列作为输入预测下一Token。
解码策略:
贪婪搜索:选择概率最高词,简单但易陷入重复。
束搜索(Beam Search):保留多个候选序列,平衡质量与多样性。
采样策略:温度调节(Temperature):控制采样随机性(低温度趋确定,高温度趋多样)。
Top-p(核采样):仅从累积概率超过阈值p的词中采样。
重复惩罚:抑制重复生成(如通过repetition_penalty参数)。
3.2. 上下文管理
有限上下文窗口:如GPT-4支持128K tokens,通过位置编码扩展(如RoPE线性插值)突破长度限制。
长文本处理:
分块处理(Chunking)与层次化注意力,分段计算后融合。
KV-Cache缓存:缓存历史Token的Key-Value向量,避免重复计算。
3.3. 安全与可控性
安全层(Safety Layer):
输出前过滤有害内容(如暴力、偏见),调用外部审核API(如OpenAI Moderation)。
系统提示控制:
通过system prompt动态调整模型行为(如“你是一个医生”)。
实时检索增强(RAG):
结合外部知识库(如维基百科)补全长尾知识,提升事实准确性。
四、优化与扩展:效率与性能的权衡
4.1. 训练优化
分布式训练:
数据并行:多卡处理不同数据批次。
模型并行:拆分模型至不同设备(如Megatron-LM的张量并行)。
混合并行:结合数据与模型并行(如DeepSpeed的3D并行)。
显存优化:
梯度检查点:牺牲计算时间换显存,重计算中间激活。
混合精度训练:FP16/FP8降低显存占用,结合Loss Scaling保持数值稳定。
4.2. 推理加速
模型量化:
将FP32权重压缩至INT8/INT4,量化感知训练(QAT)减少精度损失。
动态批处理:
合并不同长度请求,最大化GPU利用率(如NVIDIA Triton)。
硬件适配:
针对边缘设备(手机、IoT)部署,支持自适应量化与剪枝。
4.3. 扩展性提升
参数规模:
从亿级(BERT)到万亿级(GPT-4),遵循缩放定律(Scaling Laws)提升性能。
上下文长度:
通过位置编码改进(如NTK-aware RoPE)、分块注意力支持百万Token级输入。
五、核心挑战与解决方案
5.1. 计算成本与能效
挑战:训练万亿模型需数千张GPU,成本超千万美元,推理能耗高。
解决方案:
MoE架构稀疏化计算,量化与蒸馏降低推理成本。
绿色计算:使用可再生能源,优化数据中心能效。
5.2. 长尾知识与事实性
挑战:模型对低频知识覆盖不足,可能生成错误事实。
解决方案:
检索增强生成(RAG):实时调用外部知识库(如ChatGPT联网插件)。
合成数据增强:利用规则或小模型生成高质量训练样本。
5.3. 偏见与安全性
挑战:训练数据隐含社会偏见,可能生成有害内容。
解决方案:
RLHF与DPO对齐人类价值观。
红队测试(Red Teaming)主动探测漏洞,部署多级内容过滤。
5.4. 多模态与泛化性
挑战:跨模态任务(如图文生成)需统一表征空间。
解决方案:
跨模态编码器(如CLIP)对齐图文特征。
渐进式多模态预训练(如PaLI-X)。
六、可能得发展方向(猜测)
稀疏化与模块化:更高效动态计算路径(如Switch Transformer)。
终身学习:持续学习新知识避免灾难性遗忘。
可解释性:通过注意力可视化、概念神经元分析提升透明度。
边缘计算:轻量化模型(如TinyLLaMA)适配移动端部署。
总结
大模型的核心运行机制以Transformer架构为基础,通过大规模预训练学习通用表征,结合微调与对齐技术适配任务与价值观,最终依赖高效工程优化实现低成本推理。其优势在于强大的泛化能力,但需持续攻克成本、安全与知识更新等挑战。聚焦效率提升、多模态融合及伦理对齐,推动技术从“规模竞赛”向“实用落地”演进。
相关文章:
大模型核心运行机制
大模型核心运行机制目录 一、核心架构:Transformer的演进与改进1.1 核心组件包括:1.1.1 自注意力机制(Self-Attention)1.1.2 多头注意力(Multi-Head Attention)1.1.3 位置编码(Positional Encod…...

uniapp跨平台开发HarmonyOS NEXT应用初体验
之前写过使用uniapp开发鸿蒙应用的教程,简单介绍了如何配置开发环境和运行项目。那时候的HbuilderX还是4.22版本,小一年过去了HbuilderX的正式版本已经来到4.64,历经了多个版本的更新后,跨平台开发鸿蒙应用的体验大幅提升。今天再…...
2025软考【系统架构设计师】:两周极限冲刺攻略(附知识点解析+答题技巧)
距离2025上半年“系统架构设计师”考试已经只剩最后两周了,还没有准备好的小伙伴赶紧行动起来。为了帮助大家更好的冲刺学习,特此提供一份考前冲刺攻略。本指南包括考情分析、答题技巧、注意事项三个部分,可以参考此指南进行最后的复习要领&a…...

C语言主要标准版本的演进与核心区别的对比分析
以下是C语言主要标准版本的演进与核心区别的对比分析 K&R C(1978年) 定位:非标准化的原始版本,由Brian Kernighan和Dennis Ritchie定义 特性: 基础语法:函数声明无参数列表(如int func…...
使用 goaccess 分析 nginx 访问日志
介绍 goaccess 是一个在本地解析日志的工具, 可以直接在命令行终端环境中使用 TUI 界面查看分析结果, 也可以导出为更加丰富的 HTML 页面. 官网: https://goaccess.io/ 下载安装 常见的 Linux 包管理器中都包含了 goaccess, 直接安装就行. 以 Ubuntu 为例: sudo apt instal…...

vue3与springboot交互-前后分离【完成登陆验证及页面跳转】
vue3实现与springboot交互【完成登陆及页面跳转】 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是node.js和vue的使用。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:…...

【Hot 100】208. 实现 Trie (前缀树)
目录 引言实现 Trie (前缀树)我的解题代码解析代码思路分析优化建议1. 内存泄漏问题2. 使用智能指针优化内存管理3. 输入合法性校验(可选)4. 其他优化 总结 🙋♂️ 作者:海码007📜 专栏:算法专栏…...
【2025最新】Vm虚拟机中直接使用Ubuntu 免安装过程直接使用教程与下载
Ubuntu 是一个基于 Debian 的自由开源 Linux 操作系统,面向桌面、服务器和云计算平台广泛应用。 由英国公司 Canonical Ltd. 维护和发布,Ubuntu 强调易用性、安全性和稳定性,适合个人用户、开发者以及企业部署使用。 Ubuntu 默认使用 GNOME …...

思路解析:第一性原理解 SQL
目录 题目描述 🎯 应用第一性原理来思考这个 SQL 题目 ✅ 第一步:还原每个事件的本质单位 ✅ 第二步:如果一个表只有事件,如何构造事件对? ✅ 第三步:加过滤条件,只保留“同一机器、同一进…...

相机Camera日志分析之八:高通Camx HAL架构opencamera三级日志详解及关键字
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:相机Camera日志分析之七:高通Camx HAL架构opencamera二级日志详解及关键字 这一篇我们开始讲: 相机Camera日志分析之八:高通Camx HAL架构opencamera三级日志详解及关键字 目录 【关注我,后续持续…...
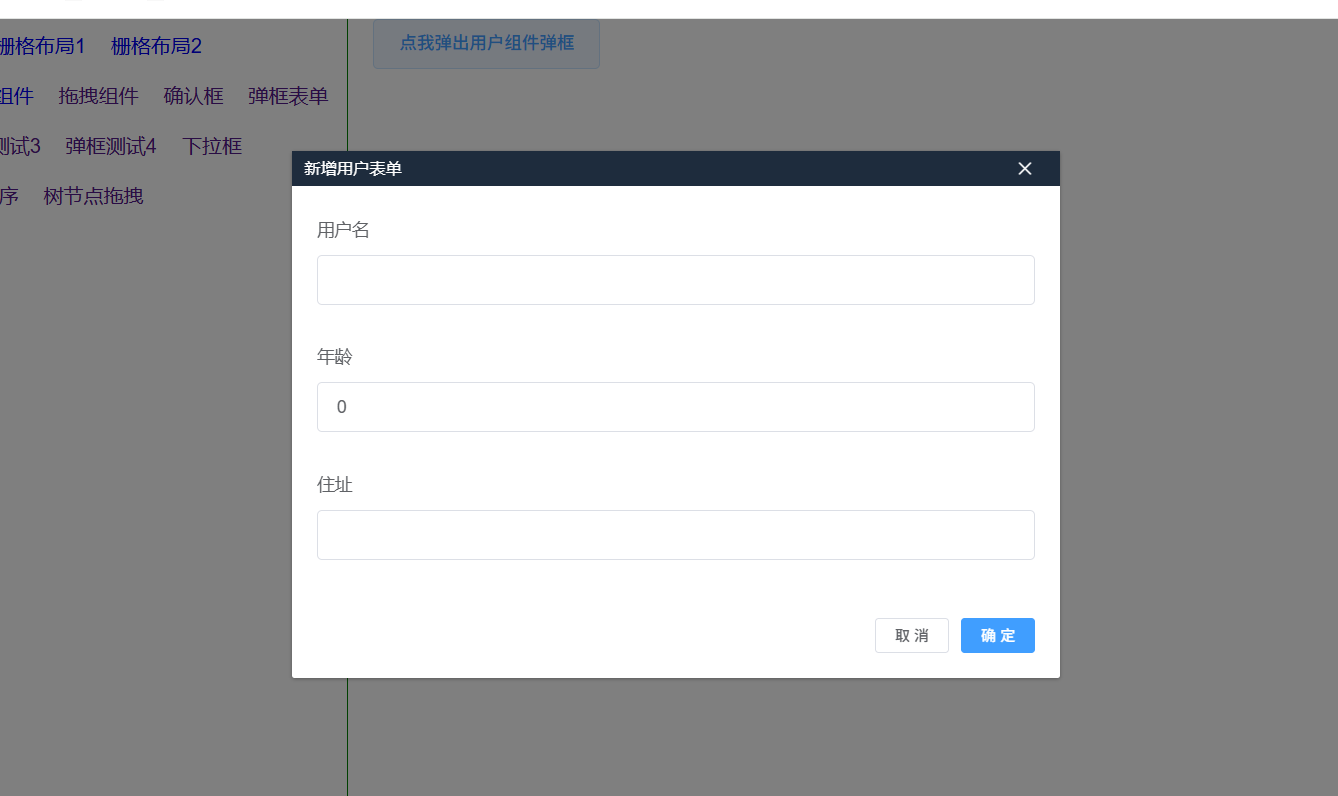
Vue2 elementUI 二次封装命令式表单弹框组件
需求:封装一个表单弹框组件,弹框和表单是两个组件,表单组件以插槽的形式动态传入弹框组件中。 外部组件使用的方式如下: 直接上代码: MyDialog.vue 弹框组件 <template><el-dialog:titletitle:visible.syn…...

Docker入门教程:常用命令与基础概念
目录 简介常用命令Docker 常用命令汇总docker run 命令格式与参数解析 简介 Docker 是一个客户端-服务器(client-server)架构的应用程序,其中包含两个主要组件:Docker 客户端和 Docker 守护进程(也称为 Docker Daemon…...

Antd中Form详解:
1.获取Form表单值的方式: ① 使用Form.useForm()钩子(推荐方式) const [form] Form.useForm();const getFormValues () > {const values form.getFieldsValue();};<Form form{form}>...<Form.Item label{null}><Button onClick{ge…...

探索C语言中的二叉树:原理、实现与应用
一、引言 二叉树作为一种重要的数据结构,在计算机科学领域有着广泛的应用,无论是在操作系统的文件系统管理,还是在数据库的索引构建中,都能看到它的身影。在C语言中,我们可以利用指针灵活地构建和操作二叉树。接下来&…...

docker系列-DockerDesktop报错信息(Windows Hypervisor is not present)
Docker Desktop 报错信息 Docker Desktop - Windows Hypervisor is not present Docker Desktop is unable to detect a Hypervisor. Hardware assisted virtualization and data execution protection must be enabled in the BIOS.这是因为 Docker Desktop 需要启用 虚拟化技…...

03.Python 字符串中的空白字符处理
Python 字符串中的空白字符处理 什么是空白字符? 在处理字符串时,常常需要去除多余的空白字符。空白字符包括: 空格( )制表符(\t)换行符(\n)回车符(\r&#x…...
《基于 Kubernetes 的 WordPress 高可用部署实践:从 MariaDB 到 Nginx 反向代理》
手把手教你用 Kubernetes 部署高可用 WordPress 博客 本实验通过 Kubernetes 容器编排平台,完整部署了一个高可用的 WordPress 网站架构,包含 MariaDB 数据库、WordPress 应用和 Nginx 反向代理三大核心组件。实验涵盖了从基础环境准备到最终服务暴露的…...
Ubuntu源码版comfyui的安装
Comfyui也出桌面版了,但是想让大家多个人都使用怎么办呢?也有方法,安装Linux版,启动后会生成个网页地址,打开就能用了。 1、先来看下本地安装环境配置: 系统:Ubuntu 22.04 内存:2…...

多模态RAG与LlamaIndex——1.deepresearch调研
摘要 关键点: 多模态RAG技术通过结合文本、图像、表格和视频等多种数据类型,扩展了传统RAG(检索增强生成)的功能。LlamaIndex是一个开源框架,支持多模态RAG,提供处理文本和图像的模型、嵌入和索引功能。研…...

C++ 命令模式详解
命令模式(Command Pattern)是一种行为设计模式,它将请求封装为对象,从而使你可以参数化客户端使用不同的请求、队列或日志请求,以及支持可撤销的操作。 核心概念 设计原则 命令模式遵循以下设计原则: 单…...
制作一款打飞机游戏47:跳转
编辑器的问题 我们开始为不同的敌人编写一些行为,到目前为止进展顺利,一切都很棒。但上次我们遇到了一些问题,我们发现在这个编辑器中编写代码有时有点困难,因为当你想要在某行之间插入内容时,你不得不删除一切然后重…...
本地部署ollama及deepseek(linux版)
一、安装ollama export OLLAMA_MIRROR"https://ghproxy.cn/https://github.com/ollama/ollama/releases/latest/download"curl -fsSL https://ollama.com/install.sh | sed "s|https://ollama.com/download|$OLLAMA_MIRROR|g" | shexport OLLAMA_MIRROR&q…...

Java Spring Boot项目目录规范示例
以下是一个典型的 Java Spring Boot 项目目录结构规范示例,结合了分层架构和模块化设计的最佳实践: text 复制 下载 src/ ├── main/ │ ├── java/ │ │ └── com/ │ │ └── example/ │ │ └── myapp/ │…...

针对共享内存和上述windows消息机制 在C++ 和qt之间的案例 进行详细举例说明
针对共享内存和上述windows消息机制 在C++ 和qt之间的案例 进行详细举例说明 以下是关于在 C++ 和 Qt 中使用共享内存(QSharedMemory)和 Windows 消息机制(SendMessage / PostMessage)进行跨线程或跨进程通信的详细示例。 🧩 使用 QSharedMemory 进行进程间通信(Qt 示例…...

vue H5解决安卓手机软键盘弹出,页面高度被顶起
开发中安卓机上遇到的软键盘弹出导致布局问题 直接上代码_ 在这里插入代码片 <div class"container"><div class"appContainer" :style"{height:isKeyboardOpen? Heights :inherit}"><p class"name"><!-- 绑定…...

CSS专题之自定义属性
前言 石匠敲击石头的第 12 次 CSS 自定义属性是现代 CSS 的一个强大特性,可以说是前端开发需知、必会的知识点,本篇文章就来好好梳理一下,如果哪里写的有问题欢迎指出。 什么是 CSS 自定义属性 CSS 自定义属性英文全称是 CSS Custom Proper…...

问题 | 当前计算机视觉迫切解决的问题
当前计算机视觉领域虽然在技术上取得了显著进展,但仍面临一系列关键挑战。结合最新研究与应用现状,以下是最迫切需要解决的几大问题: 1. 数据质量与多样性不足 高质量标注数据的获取:训练高效模型依赖大量精准标注的数据&#x…...
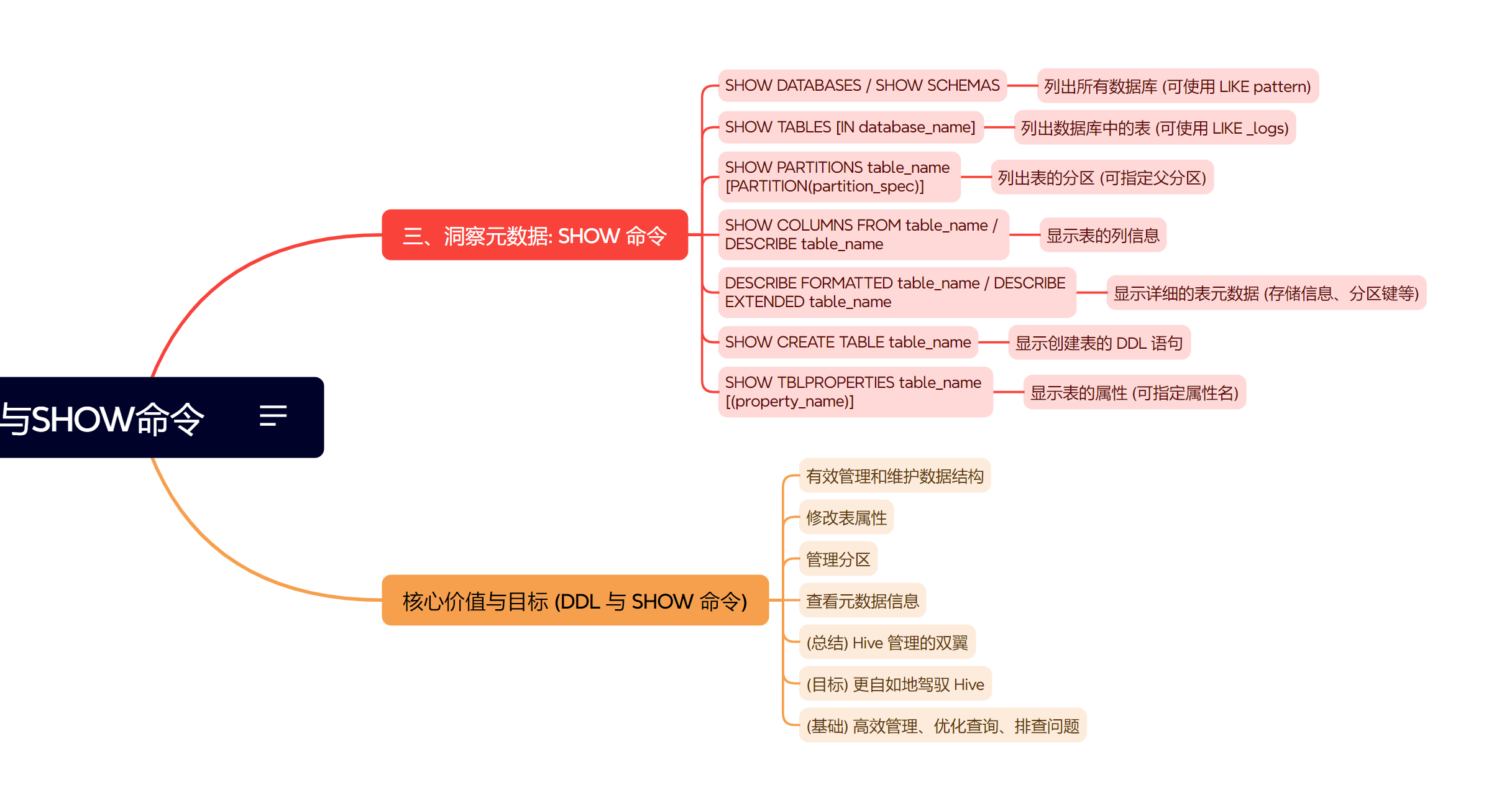
七、深入 Hive DDL:管理表、分区与洞察元数据
作者:IvanCodes 日期:2025年5月13日 专栏:Hive教程 内容导航 一、表的 DDL 操作 (非创建)二、分区的 DDL 操作三、洞察元数据:SHOW 命令的威力结语:DDL 与 SHOW,Hive 管理的双翼练习题一、选择题二、代码题…...
)
Qt6.x检查网络是否在线(与Qt 5.x不同)
Qt 5.x.x 要判断客户端网络是否联通,一般用如下方法: #include <QNetworkConfigurationManager>auto netWorkCheck new QNetworkConfigurationManager(); auto flag netWorkCheck->isOnline(); Qt 6.x.x 废弃了 QNetworkConfigurationManag…...
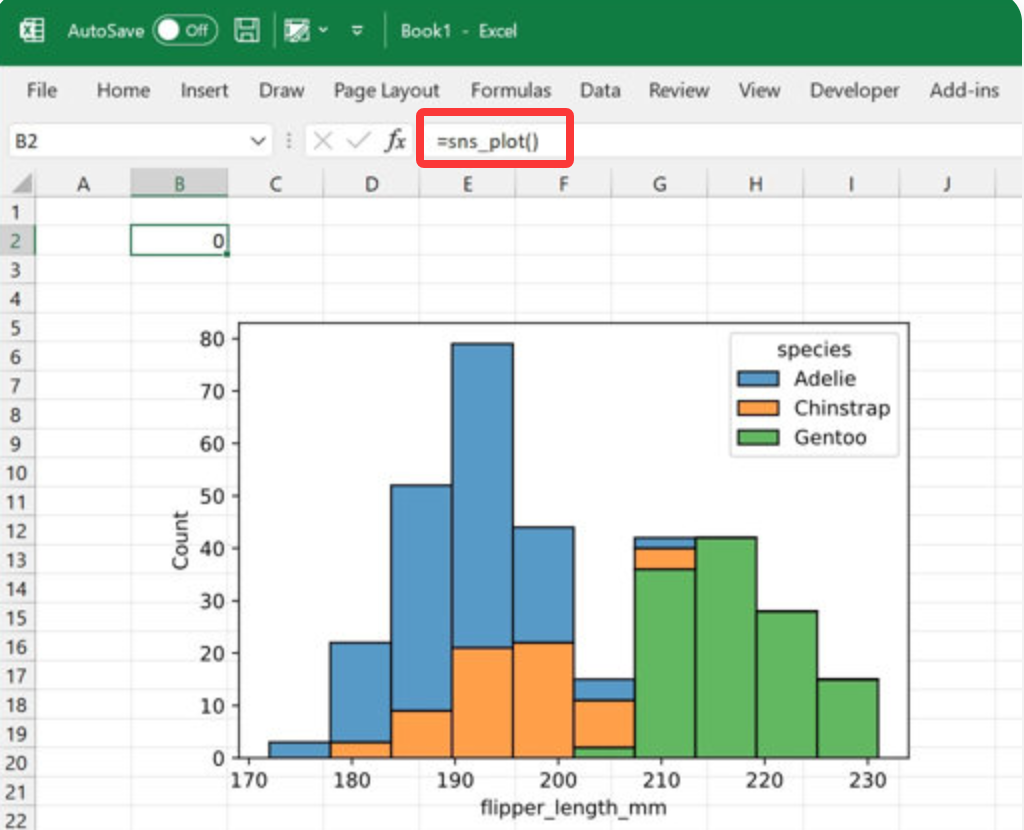
直接在Excel中用Python Matplotlib/Seaborn/Plotly......
本次分享如何利用pyxll包,实现直接在Excel中使用Python Matplotlib/Seaborn/Plotly等强大可视化工具。 pyxll配置 pyxll安装 pip install pyxll pyxll install pyxll自定义方法 例如,自定义一个计算斐波那契数的方法fib,并使用pyxll装饰器…...