五、Hadoop集群部署:从零搭建三节点Hadoop环境(保姆级教程)
作者:IvanCodes
日期:2025年5月7日
专栏:Hadoop教程
前言:
想玩转大数据,Hadoop集群是绕不开的一道坎。很多小伙伴一看到集群部署就头大,各种配置、各种坑。别慌!这篇教程就是你的“救生圈”。
一、磨刀不误砍柴工:环境准备(虚拟机与网络)
虚拟机克隆与基础配置 (以VMware为例)
第一步:准备一台基础Linux虚拟机:
你需要一台安装好Linux(推荐CentOS 7 或 Ubuntu 24.04.2/20.04)的虚拟机。确保它已安装常用工具,网络能通。
- centos 7的详细安装教程可以参考《安装篇–CentOS 7 虚拟机安装》
- Ubuntu 24.04.2的详细安装教程可以参考《安装篇–Ubuntu24.04.2详细安装教程》
第二步:克隆虚拟机:
1.启动克隆向导: 在VMware Workstation中,右键点击你准备好的虚拟机,选择 “管理” -> “克隆”。
接着会弹出“欢迎使用克隆虚拟机向导”界面,直接点击“下一步”。
2.选择克隆源: 默认选择“虚拟机中的当前状态”,直接点击“下一步”。
3.选择克隆类型: 选择“创建完整克隆”。完整克隆会复制整个虚拟硬盘,确保每台“小鸡”都是独立的,不会相互影响。链接克隆虽然省空间,但不适合我们做集群。点击“下一步”。
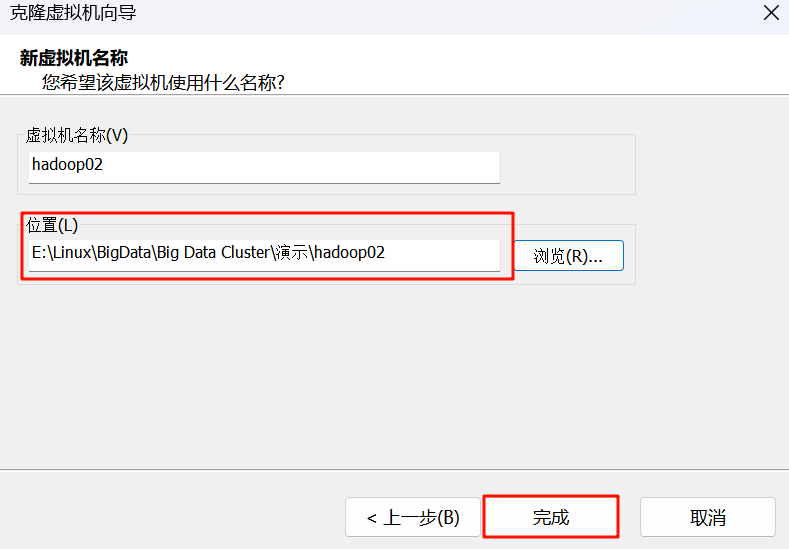
4.命名与存放位置:
第三步:Windows宿主机VMnet8网卡IP配置
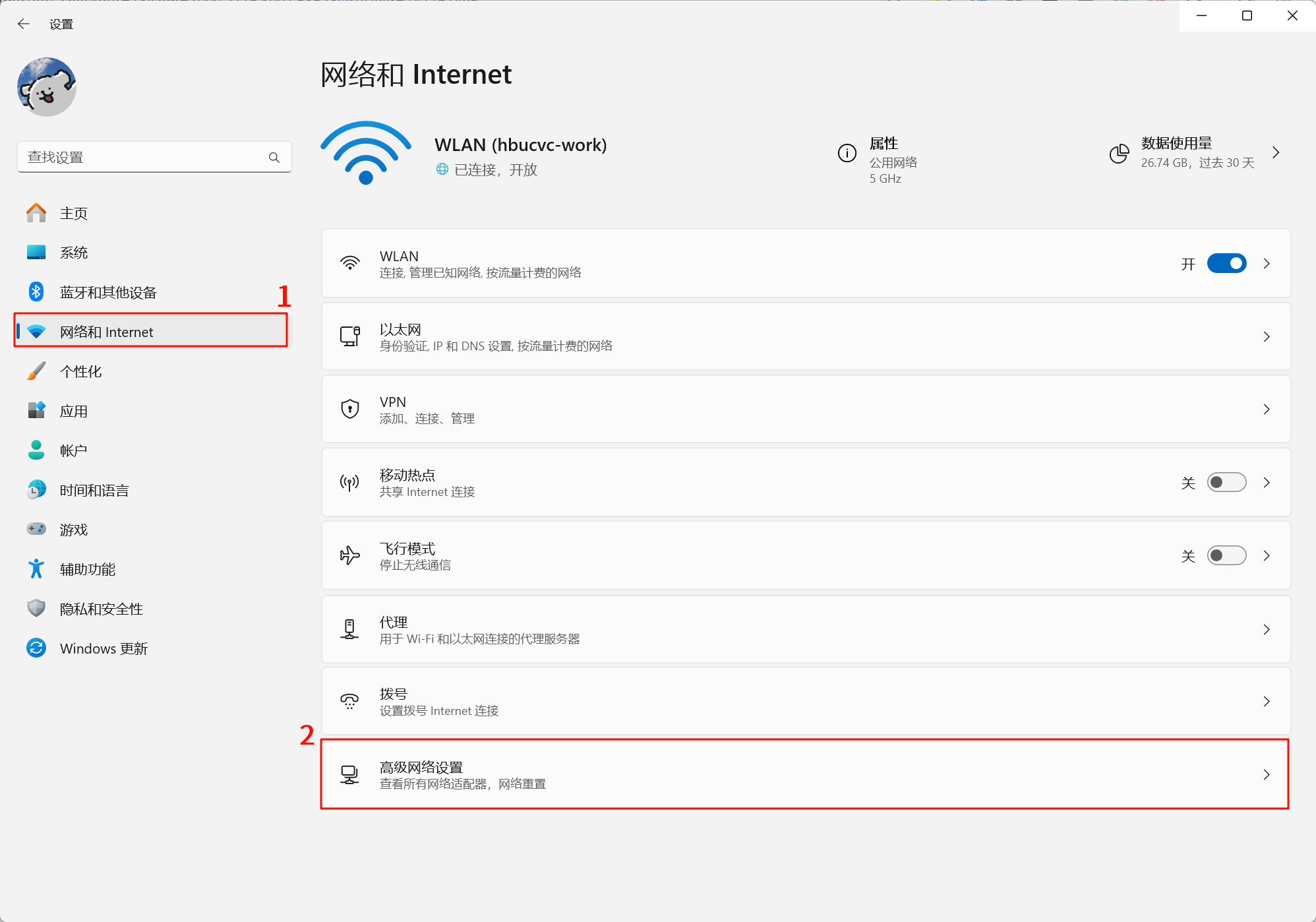
1.在Windows设置中,进入 “网络和 Internet”
2.点击 “高级网络设置”
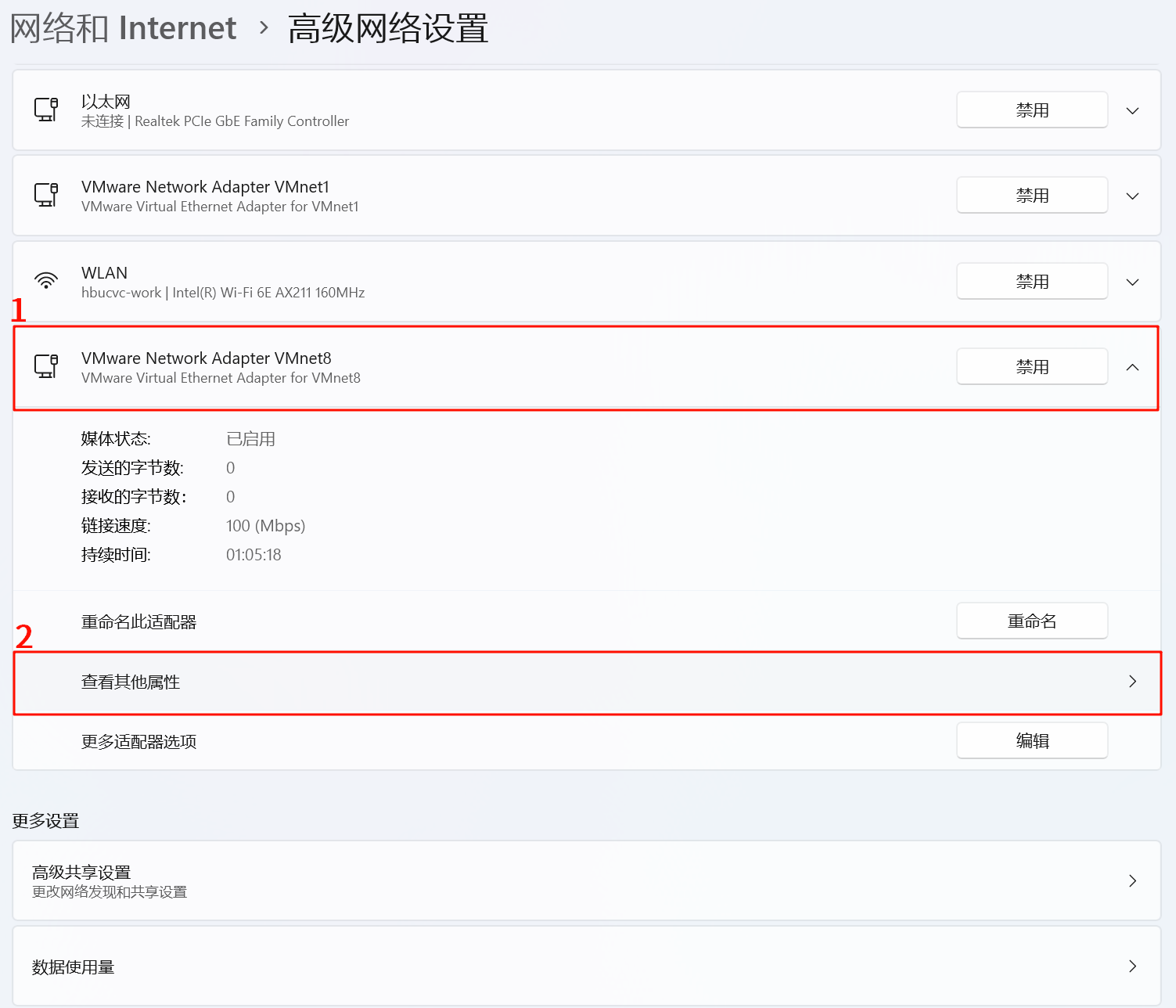
3.找到 “VMware Network Adapter VMnet8”,展开它,点击 “查看其他属性”
4.点击“IP 分配”旁边的“编辑”
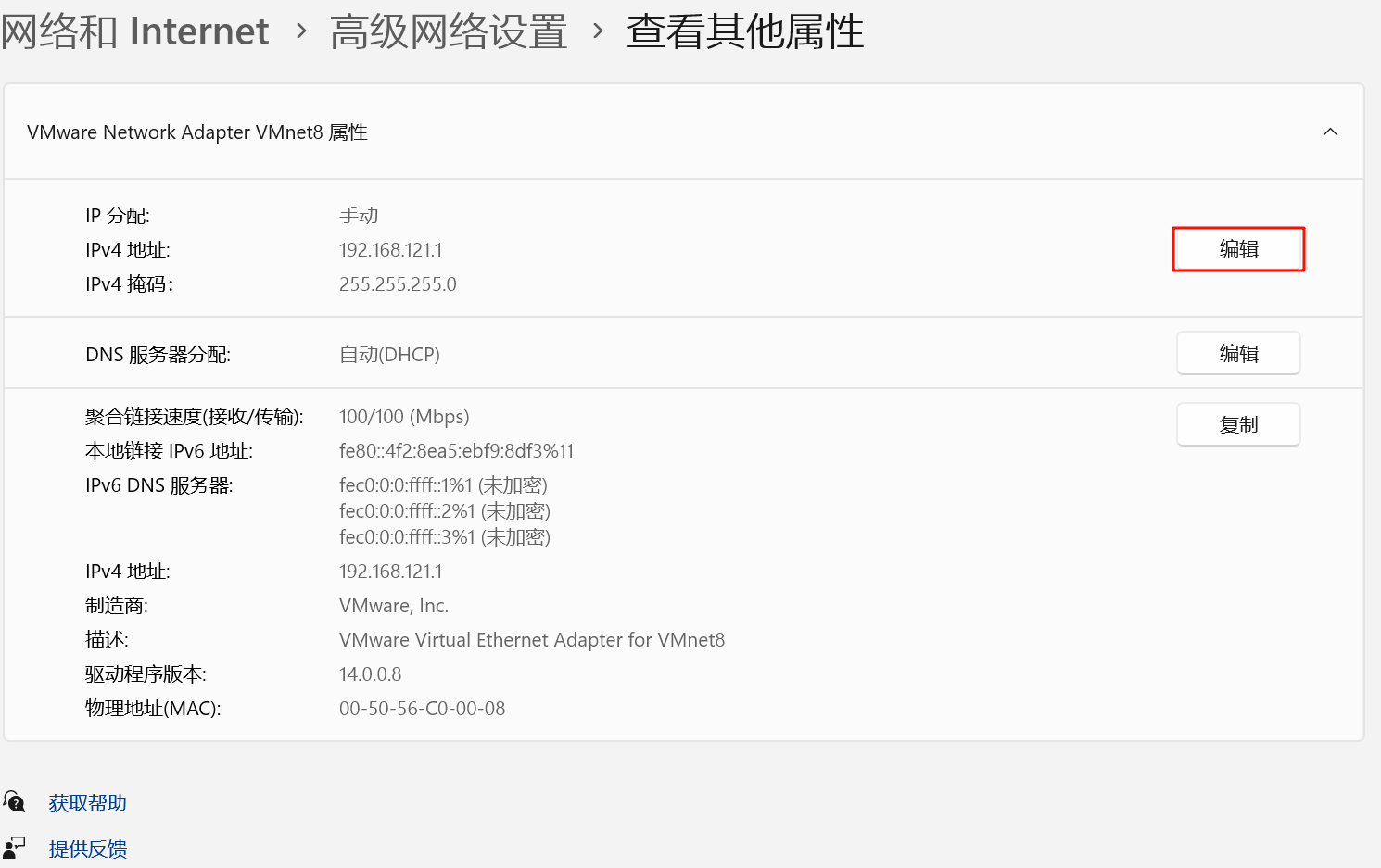
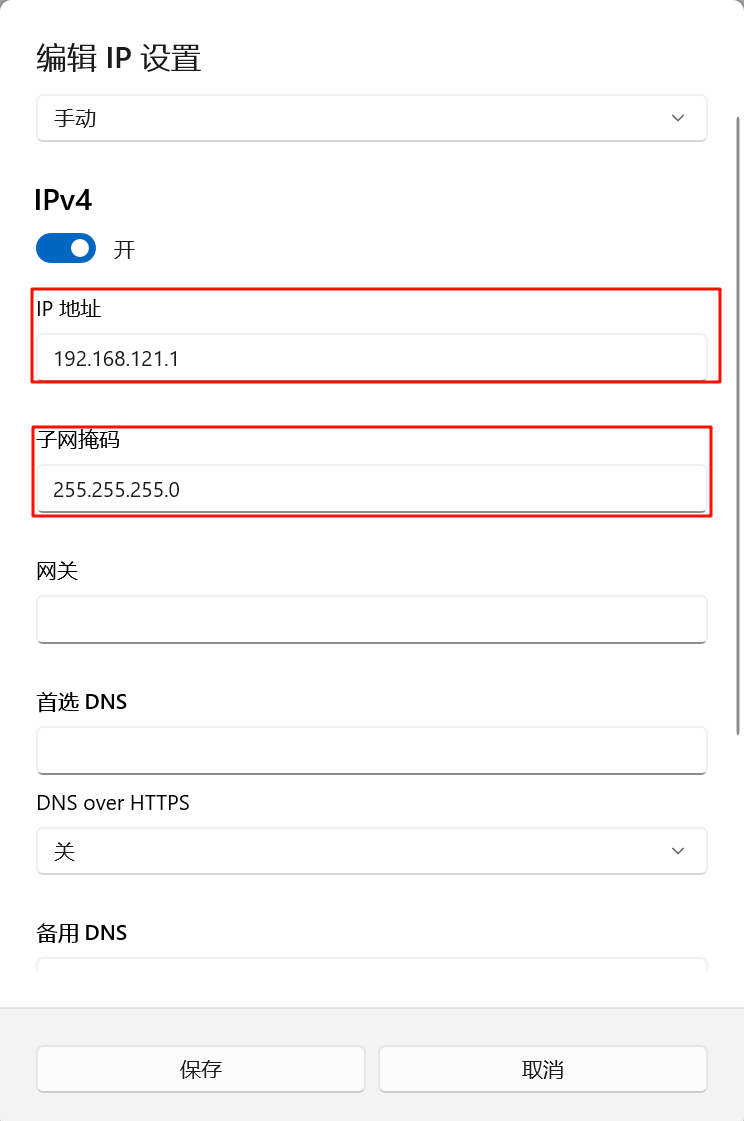
5.在“编辑 IP 设置”中,选择“手动”,打开IPv4,然后填写IP地址(如 192.168.121.1)和子网掩码(255.255.255.0)。网关和DNS对于这个宿主机的虚拟网卡通常不需要填写,或者可以填写VMnet8的网关(192.168.121.2)和你的常用DNS。
第四步:VMware虚拟网络配置 (关键步骤!)
1.在VMware Workstation主界面,点击菜单栏的 “编辑” -> “虚拟网络编辑器”
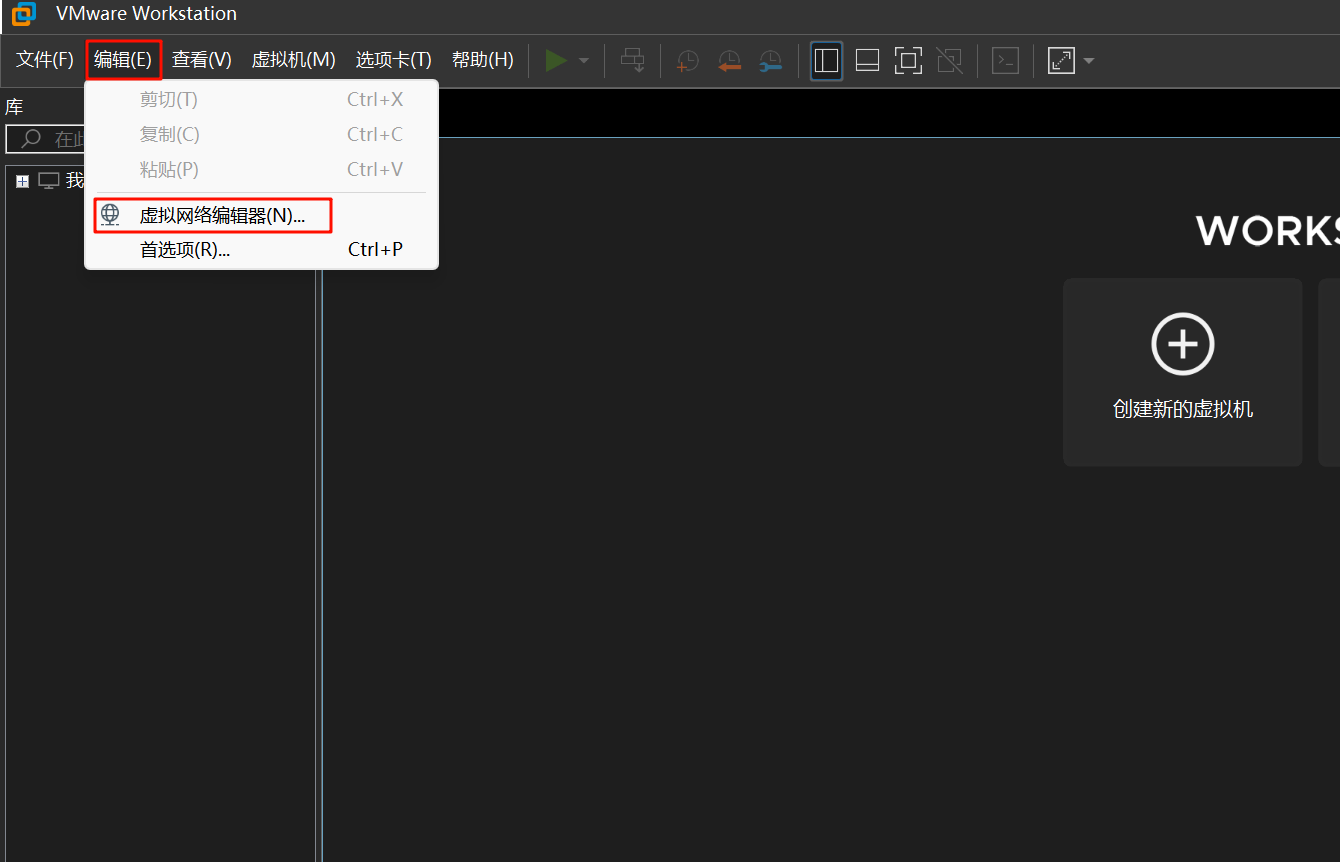
2.在“虚拟网络编辑器”中,你会看到一个网络列表,找到 VMnet8 (通常类型是NAT模式)
3.如果下方的配置选项是灰色的,你需要点击右下角的 “更改设置” 按钮,并可能需要提供管理员权限
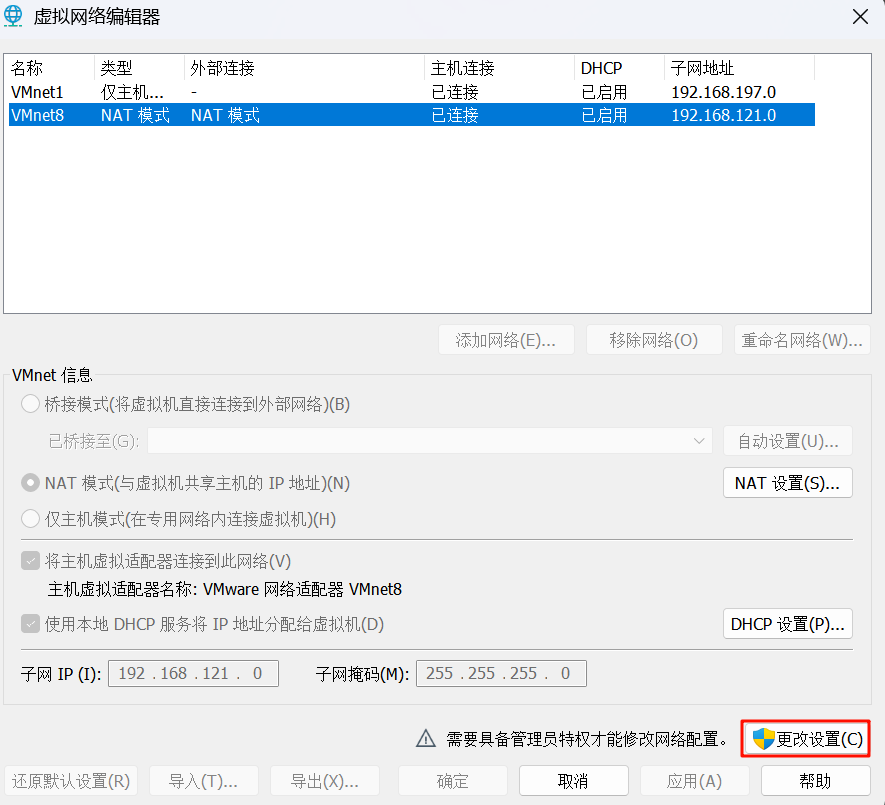
4.选中VMnet8,然后进行以下配置:
4.1.确保连接类型选择 “NAT模式(与虚拟机共享主机的IP地址)”。
4.2.取消勾选 “使用本地DHCP服务将IP地址分配给虚拟机”
子网IP: 输入 192.168.121.0
子网掩码: 输入 255.255.255.0
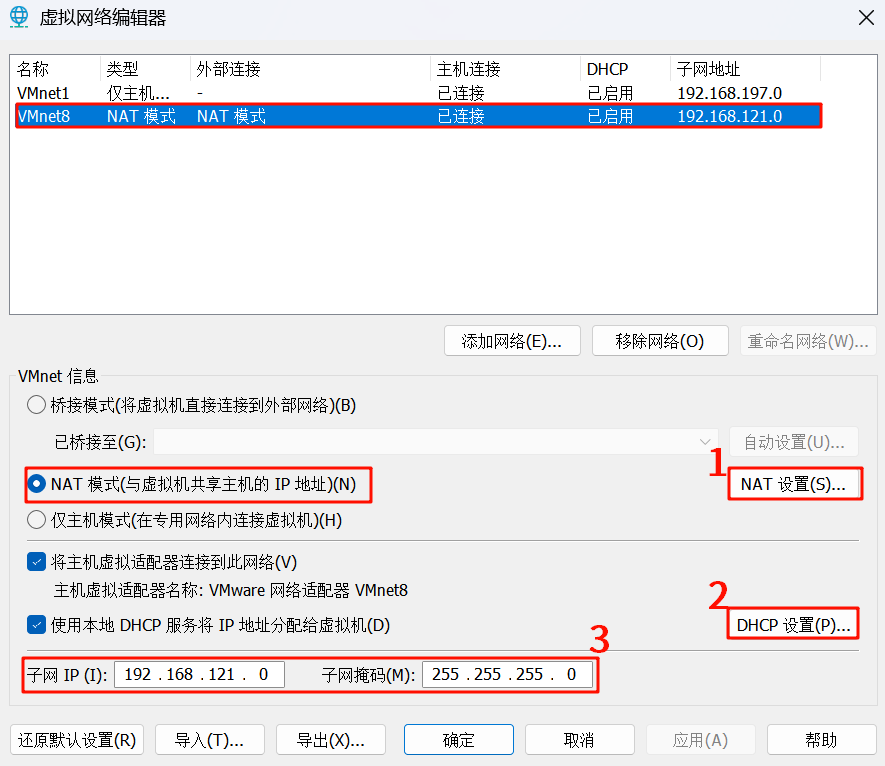
5.配置NAT设置 (网关):
将 “网关 IP(G):” 设置为 192.168.121.2
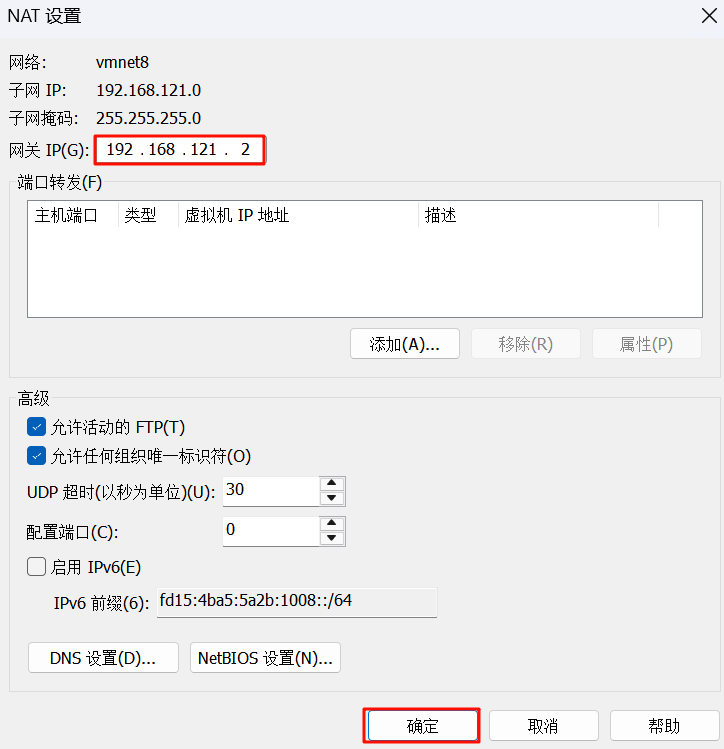
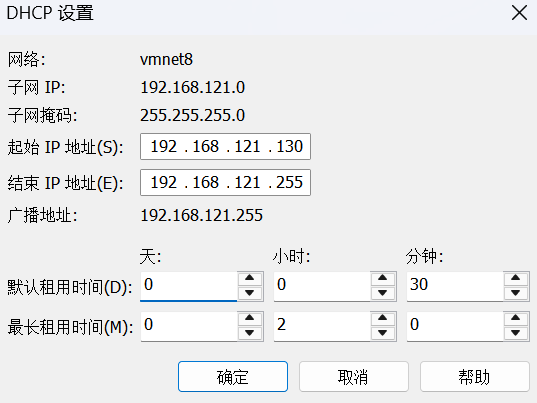
配置DHCP设置 (定义IP地址范围,可选但推荐检查):
起始 IP 地址(S): 192.168.121.130
结束 IP 地址(E): 192.168.121.255
第五步:Linux虚拟机静态IP配置 (核心!以CentOS 7为例):
在每台Linux虚拟机上,编辑网络配置文件,例如 /etc/sysconfig/network-scripts/ifcfg-ens33 (你的网卡名可能不同)。
vim /etc/sysconfig/network-scripts/ifcfg-ens33
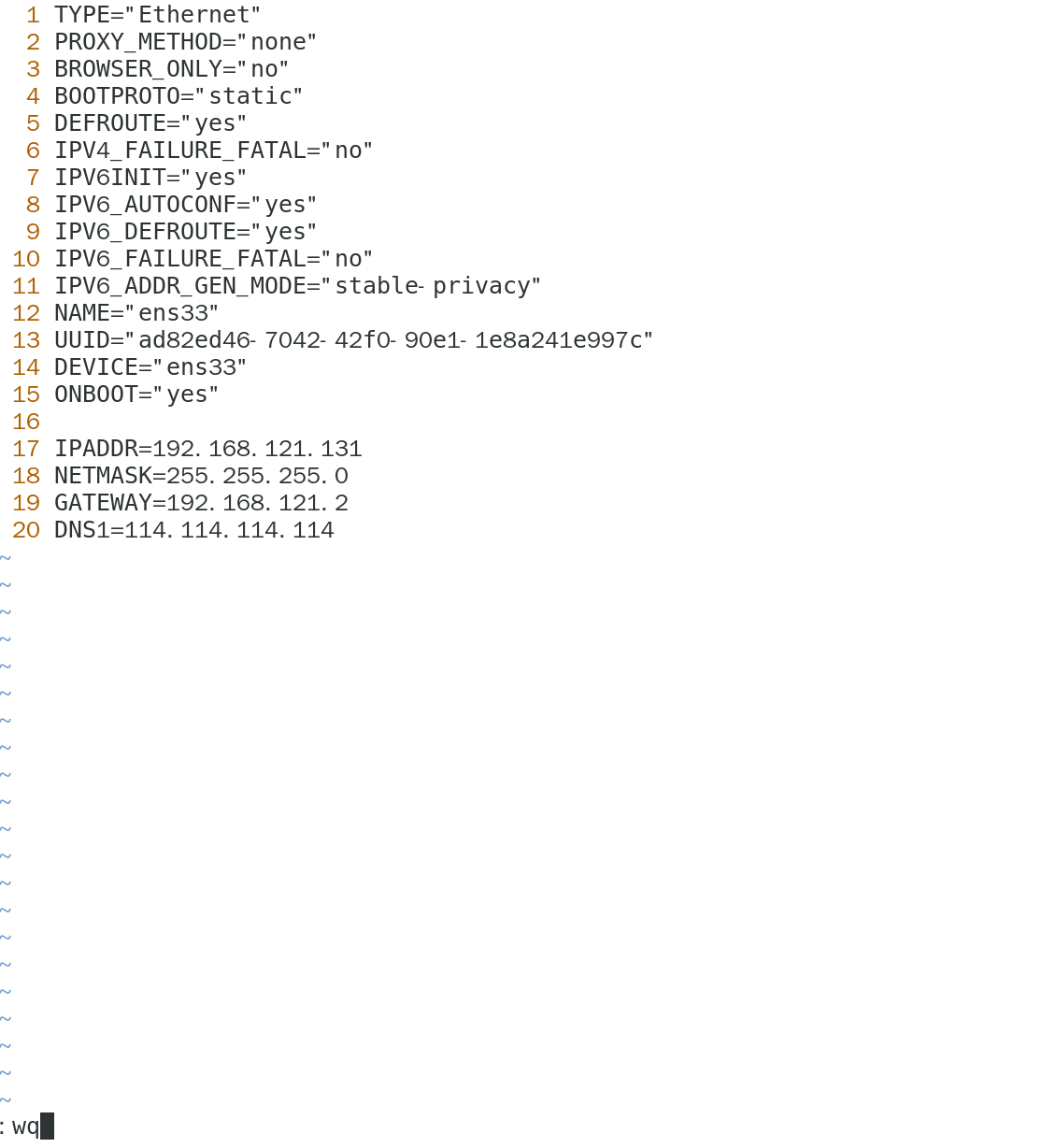
hadoop02 的配置:将 IPADDR 改为 192.168.121.132。
hadoop03 的配置:将 IPADDR 改为 192.168.121.133。
- 配置源码 (
ifcfg-ensXX):
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ensXX
DEVICE=ensXX
ONBOOT=yes
IPADDR=192.168.121.131
NETMASK=255.255.255.0
GATEWAY=192.168.121.2
DNS1=114.114.114.114
- 配置主机映射
- 在
hadoop01,hadoop02,hadoop03上都执行:
vim /etc/hosts
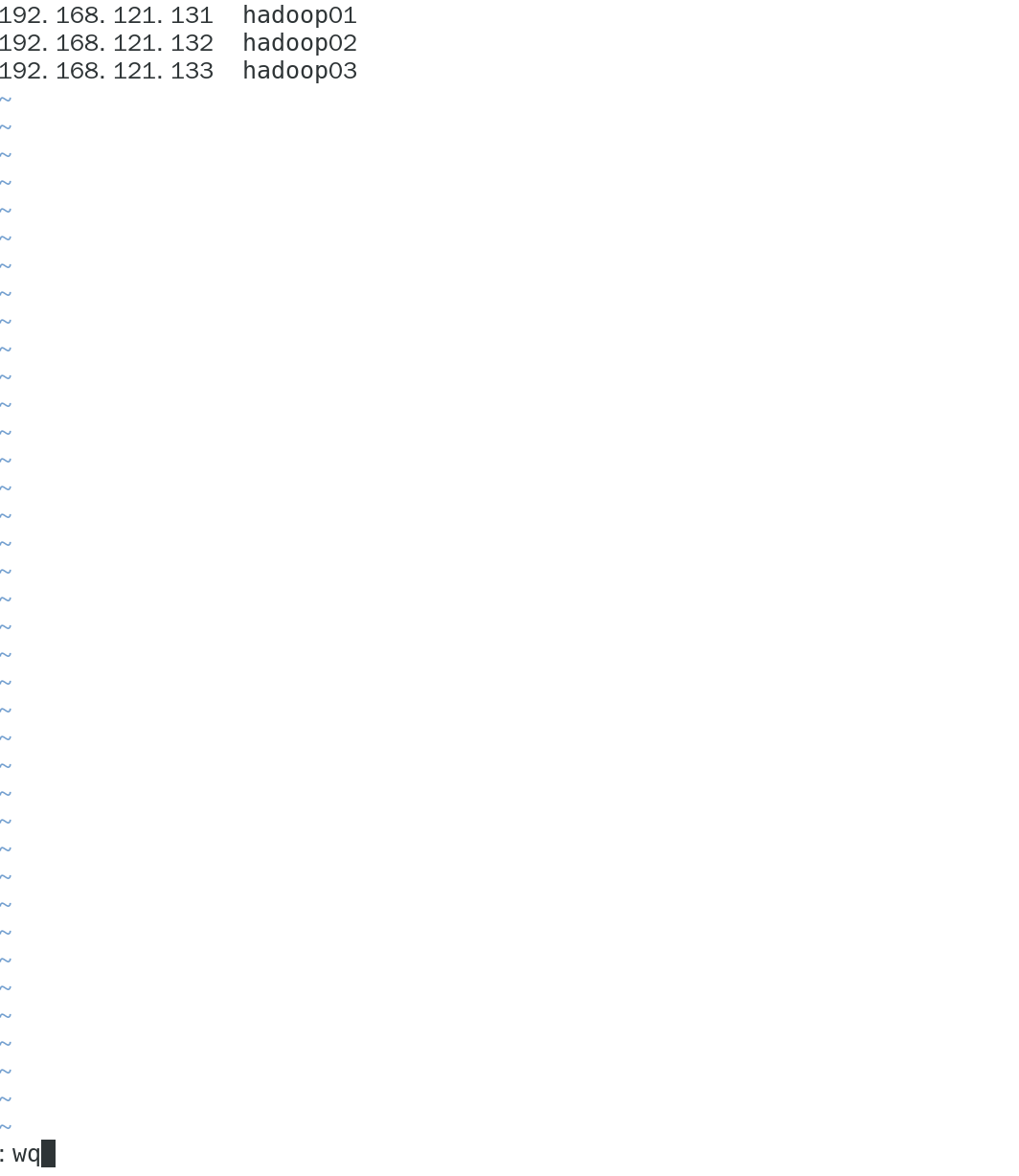
- 修改
hadoop01的主机名:
hostnamectl set-hostname hadoop01
- 重启主机
reboot
- 用
ip a验证ip是否改正 - 查看网络能否正常
ping通
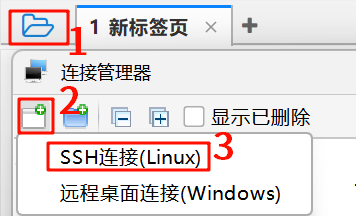
第六步:使用FinalShell连接虚拟机:
2. 关闭防火墙和selinux
- 关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
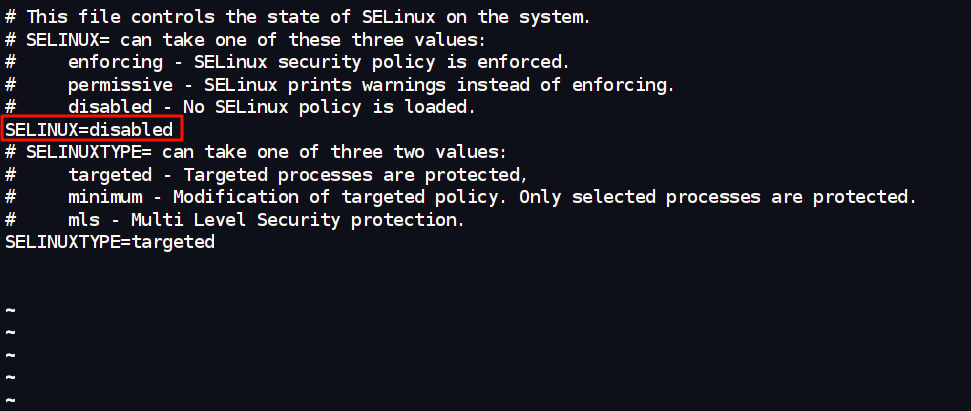
- 关闭SELinux:
vim /etc/selinux/config
# SELINUX=disabled
#需重启虚拟机
3.配置SSH免密登录 (核心):
在 hadoop01 中执行:
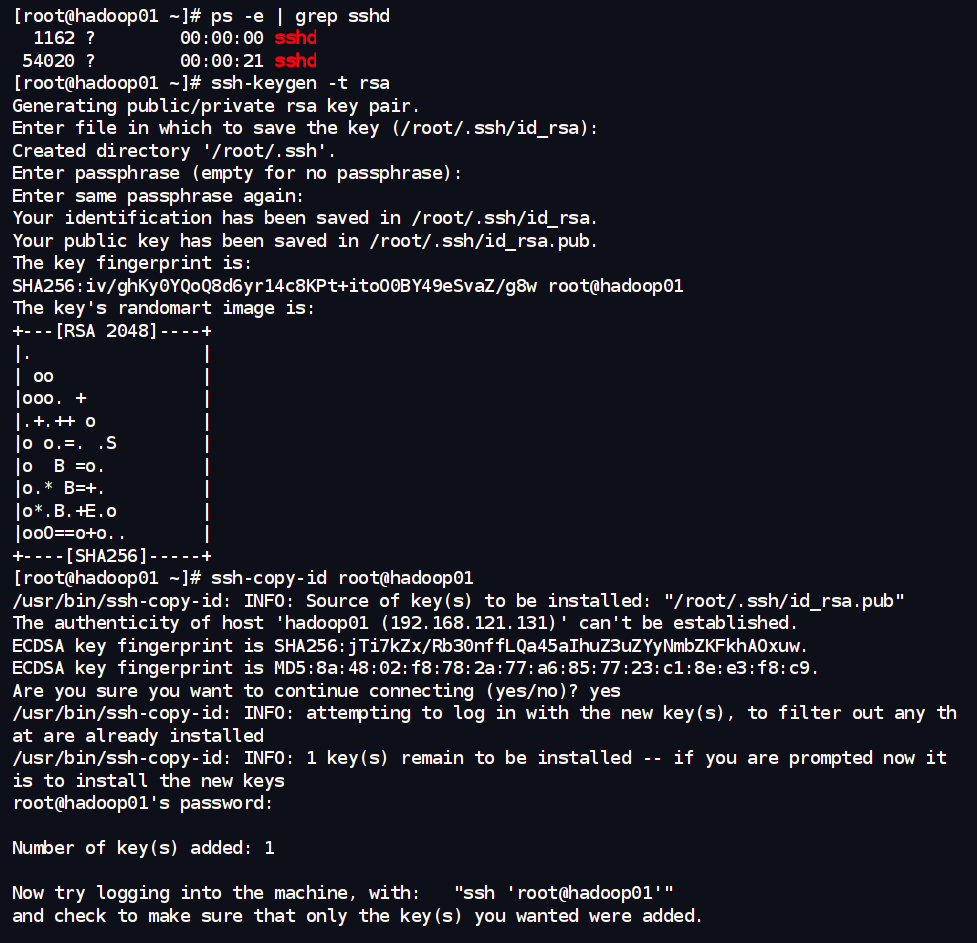
#验证ssh协议
ps -e | grep sshd
#生成钥匙
ssh-keygen -t rsa
#复制密码发送到其他设备
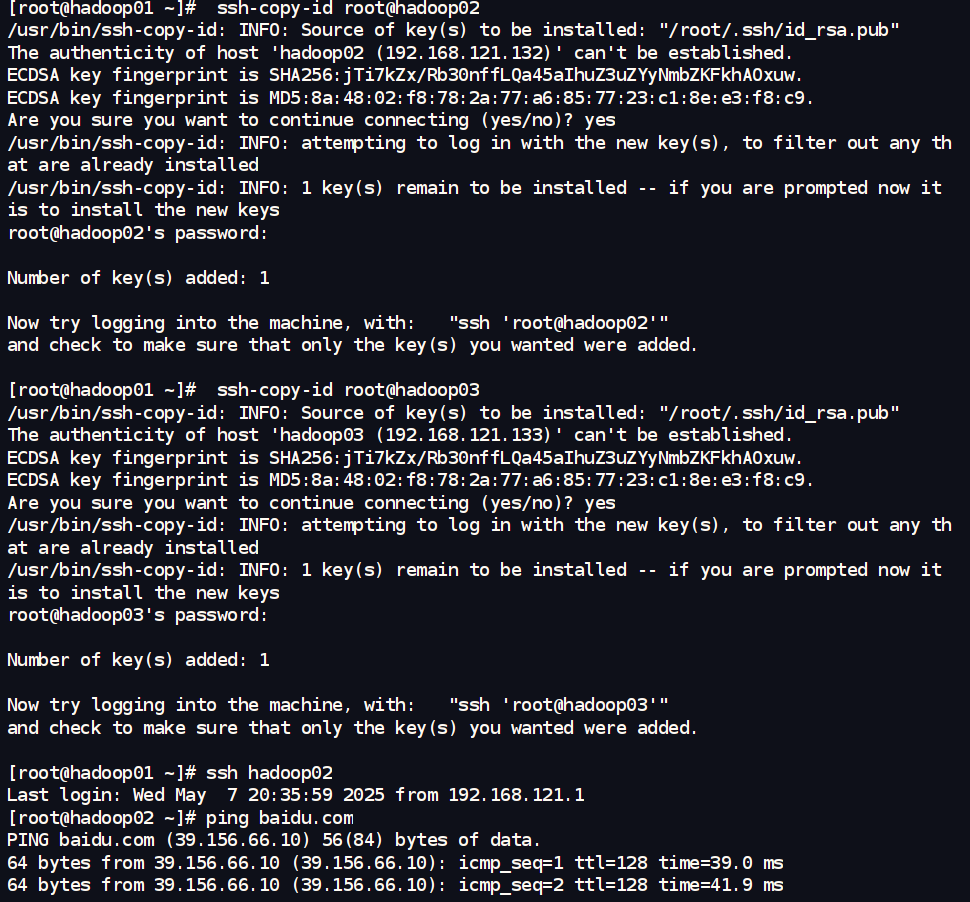
ssh-copy-id root@hadoop01
ssh-copy-id root@hadoop02
ssh-copy-id root@hadoop03
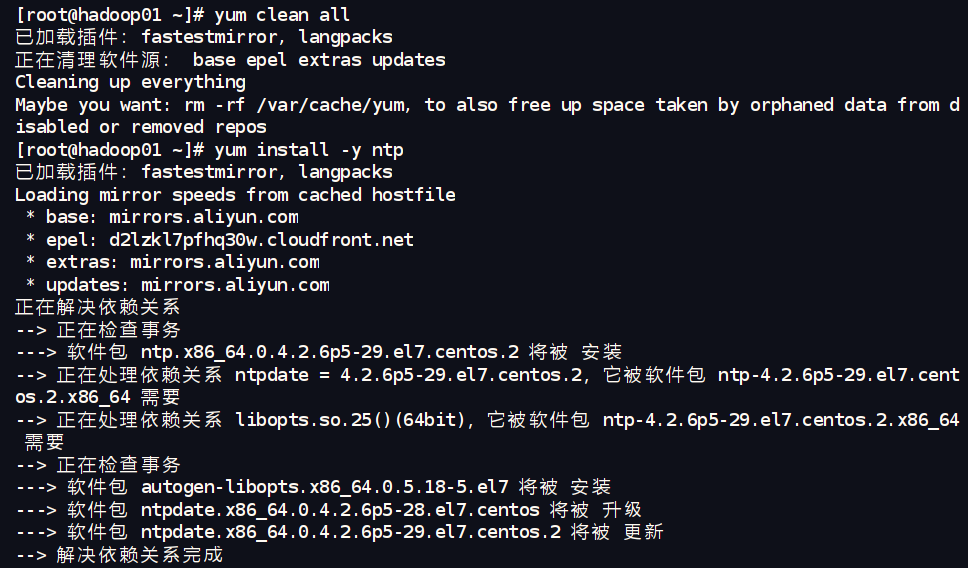
4.时间同步 (NTP):
yum install -y ntp
systemctl start ntpd
systemctl enable ntpd

5. 安装Java JDK
# 创建存放软件和安装包的目录
mkdir -p /export/server /export/softwares
5.1.上传并解压JDK安装包:
将你准备好的 jdk-8u361-linux-x64.tar.gz 文件,通过 FinalShell 的上传功能(或者其他sftp工具),上传到三台虚拟机的 /export/softwares/ 目录下。
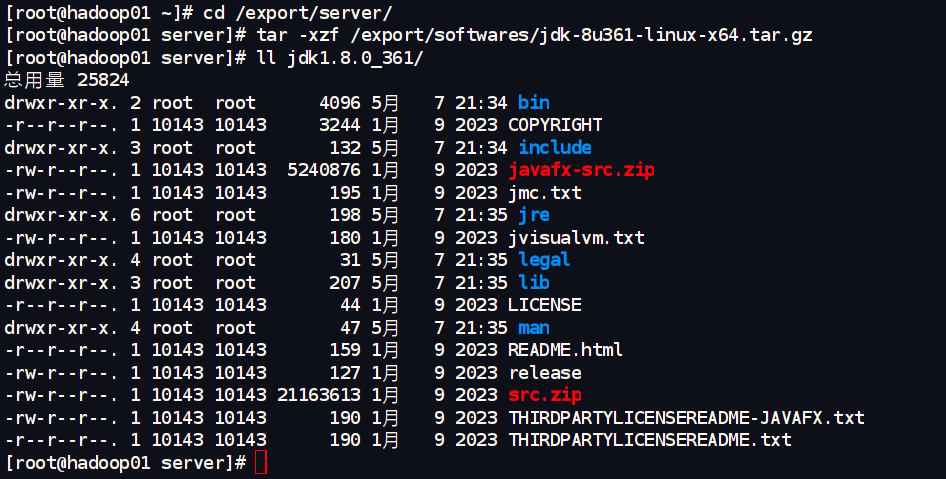
进入 /export/server/ 目录,并解压 JDK 安装包:
cd /export/server/ # 进入我们计划安装软件的目录
# 解压 JDK 安装包
tar -xzf /export/softwares/jdk-8u361-linux-x64.tar.gz
# 解压后通常会得到一个名为 jdk1.8.0_361 的目录,用ls确认一下
ls /export/server/
5.2.配置 JAVA_HOME 环境变量:
在每台机器上,编辑环境变量文件 ~/.bashrc:
vim ~/.bashrc
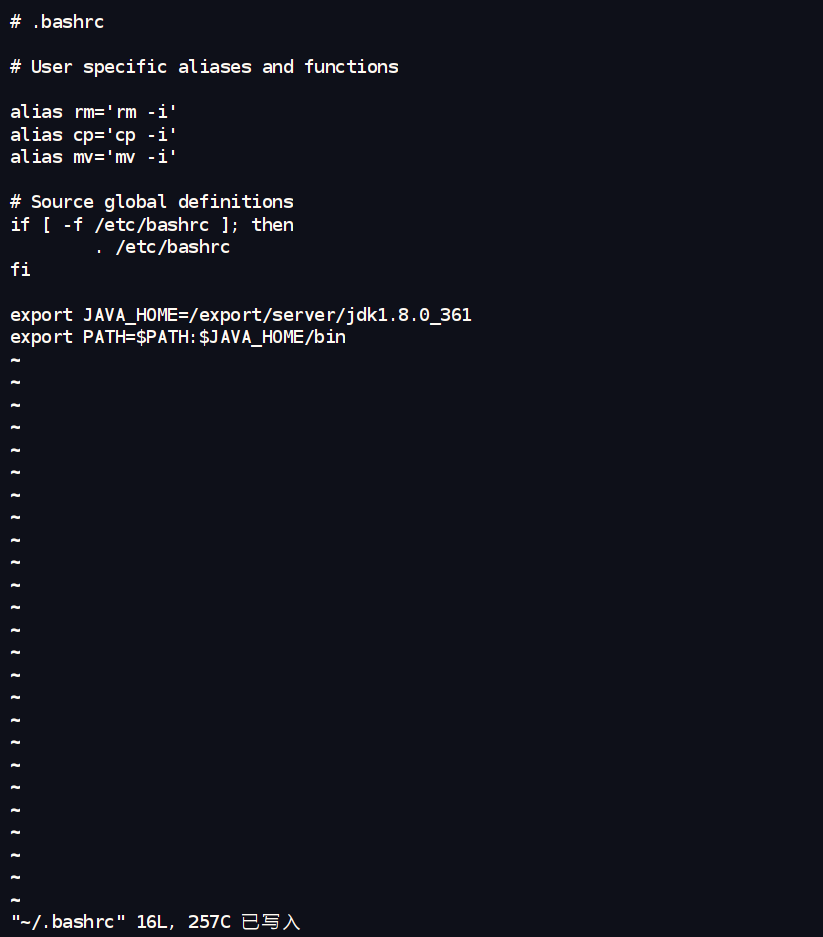
export JAVA_HOME=/export/server/jdk1.8.0_361 # 注意这里的路径和解压出来的目录名一致
export PATH=$PATH:$JAVA_HOME/bin
source ~/.bashrc

二、Hadoop 安装与配置
1. 解压Hadoop到指定目录 (/export/server/)
-
上传Hadoop安装包:将
hadoop-3.3.4.tar.gz安装包,通过 FinalShell 上传到三台虚拟机的/export/softwares/目录下。 -
解压Hadoop到
/export/server/并重命名:
# 解压 Hadoop 安装包
tar -xzf /export/softwares/hadoop-3.3.4.tar.gz
# 为了方便,我们把它重命名为简洁的 hadoop
mv hadoop-3.3.4 hadoop

2. 配置Hadoop环境变量
编辑~/.bashrc 文件,追加 Hadoop 相关的环境变量:
vim ~/.bashrc
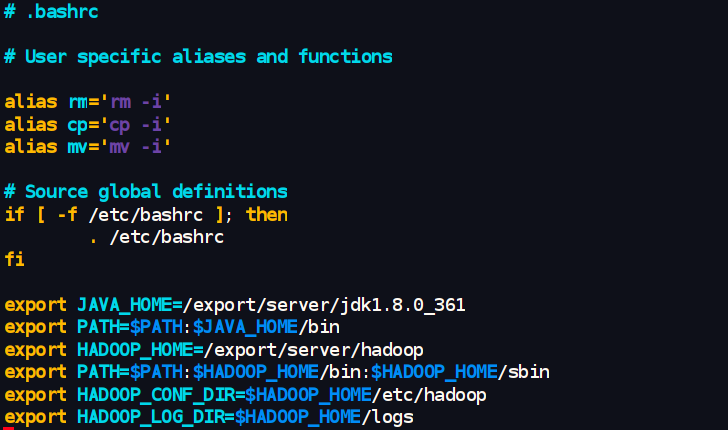
在文件末尾添加:
export HADOOP_HOME=/export/server/hadoop # 注意这里的路径是自定义安装路径
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # 将 Hadoop 的命令加入到 PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop # 指定 Hadoop 配置文件的位置
export HADOOP_LOG_DIR=$HADOOP_HOME/logs # 指定 Hadoop 日志文件的位置
让环境变量生效:
source ~/.bashrc

3. 修改Hadoop核心配置文件 (重点)
主要在 hadoop01 上修改,然后分发给其他节点。
- (A)
hadoop-env.sh(所有节点一致修改)- 这个文件主要配置 Hadoop 运行的环境,比如指定 Java。
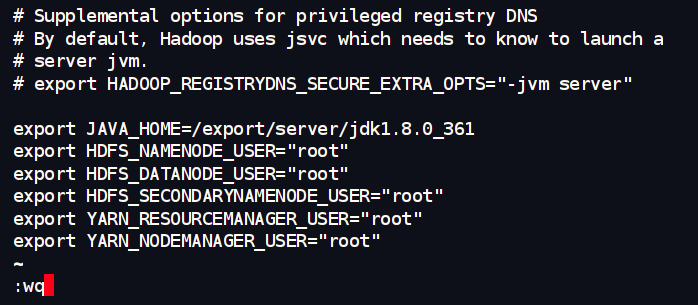
cd /export/server/hadoop/etc/hadoop/
vim hadoop-env.sh
export JAVA_HOME=/export/server/jdk1.8.0_361
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
- (B)
core-site.xml(所有节点一致修改)- 这是 Hadoop 的核心配置文件,配置HDFS的地址、临时文件目录等。
vim /core-site.xml
<configuration><!-- 指定HDFS中NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop01:9000</value></property><!-- 指定Hadoop运行时产生文件的存储目录,比如MapReduce的临时数据 --><property><name>hadoop.tmp.dir</name><value>/export/data/hadoop</value> <!-- 修改为自定义路径下的临时数据目录 --></property><!-- (可选但推荐) 用于WebHDFS和HTTPFS的用户模拟配置,让指定用户(这里是hadoopuser)可以模拟其他用户 --><property><name>hadoop.proxyuser.hadoopuser.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hadoopuser.groups</name><value>*</value></property>
<!-- 整合hive 用户代理设置 -->
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
</configuration>
- ©
hdfs-site.xml(所有节点一致修改)- 这个文件配置 HDFS 的具体参数,比如副本数量、NameNode和DataNode数据存放位置等。
vim hdfs-site.xml
<configuration><!-- NameNode的Web UI访问地址 (Hadoop 3.x默认端口9870) --><property><name>dfs.namenode.http-address</name><value>hadoop01:9870</value></property><!-- SecondaryNameNode的Web UI访问地址 (Hadoop 3.x默认端口9868) --><property><name>dfs.secondary.http-address</name><value>hadoop01:9868</value> <!-- 我们也让它在hadoop01上 --></property><!-- SecondaryNameNode所在的主机和端口,NameNode会向它发送元数据 --><property><name>dfs.namenode.secondary.http-address</name><value>hadoop01:9868</value></property><!-- HDFS副本数量,我们有3个节点,可以设置为2或3。这里先设为2,至少保证有两个DataNode时数据有冗余 --><property><name>dfs.replication</name><value>2</value></property><!-- NameNode元数据(fsimage和editlog)存放的本地磁盘路径 --><property><name>dfs.namenode.name.dir</name><value>file:/export/server/hadoop/dfs_data/name</value> <!-- 修改为自定义路径 --></property><!-- DataNode数据块存放的本地磁盘路径 --><property><name>dfs.datanode.data.dir</name><value>file:/export/server/hadoop/dfs_data/data</value> <!-- 修改为自定义路径 --></property><!-- 开启WebHDFS功能,可以通过HTTP访问HDFS文件 --><property><name>dfs.webhdfs.enabled</name><value>true</value></property>
</configuration>
- (D)
yarn-site.xml(所有节点一致修改)- 这是 YARN (资源管理器) 的配置文件。
vim yarn-site.xml
<configuration><!-- 指定YARN的ResourceManager(RM)的主机名 --><property><name>yarn.resourcemanager.hostname</name><value>hadoop01</value></property><!-- NodeManager上运行的附属服务,MapReduce Shuffle是必须的 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- ResourceManager的Web UI访问地址 (默认端口8088) --><property><name>yarn.resourcemanager.webapp.address</name><value>hadoop01:8088</value></property><!-- (可选) 开启日志聚集功能,方便在Web UI上查看已完成任务的日志 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- MapReduce JobHistory Server 的日志服务地址 --><property><name>yarn.log.server.url</name><value>http://hadoop01:19888/jobhistory/logs</value> <!-- 指向JobHistoryServer的Web UI --></property><!-- (可选) 日志保留时间 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value> <!-- 日志保留7天 (604800秒) --></property>
</configuration>
- (E)
mapred-site.xml(所有节点一致修改)- 这个文件配置 MapReduce 的运行时框架和 JobHistory Server。
vim mapred-site.xml
<configuration><!-- 指定MapReduce作业运行在YARN上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- MapReduce JobHistory Server 地址 --><property><name>mapreduce.jobhistory.address</name><value>hadoop01:10020</value></property><!-- MapReduce JobHistory Server Web UI 地址 (默认端口19888) --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop01:19888</value></property><!-- (Hadoop 3.x需要) 使YARN能够正确找到和分发MapReduce相关的JAR包 --><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
</configuration>
- (F)
workers文件 (仅在hadoop01上修改,然后分发)- 这个文件告诉
start-dfs.sh和start-yarn.sh脚本,需要在哪些机器上启动 DataNode 和 NodeManager 进程。
- 这个文件告诉
vim workers
hadoop01
hadoop02
hadoop03
4. 分发配置文件 (在 hadoop01 上执行)
好了,配置文件修改完了。把 hadoop01 上的配置文件同步到 hadoop02 和 hadoop03 去。
- 确保你在
hadoopuser用户下,且在$HADOOP_HOME/etc/目录下(也就是/export/server/hadoop/etc/)。
cd /export/server
scp ~/.bashrc hadoop02:~/.bashrc
scp ~/.bashrc hadoop03:~/.bashrc
#传完之后要在hadoop02和hadoop03上分别执行 source /etc/profile 命令,来刷新配置文件
scp -r hadoop hadoop02:$PWD
scp -r jdk1.8.0_361 hadoop02:$PWD
scp -r hadoop hadoop03:$PWD
scp -r jdk1.8.0_361 hadoop03:$PWD
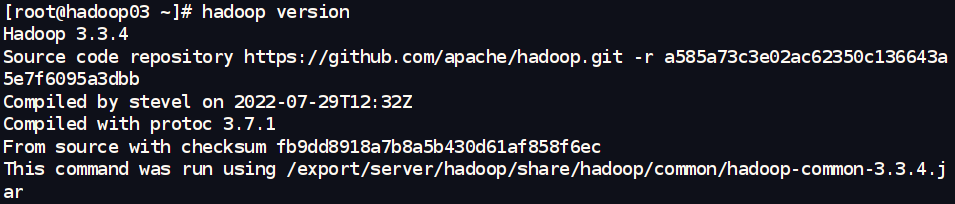
5.验证是否成功
相关文章:
五、Hadoop集群部署:从零搭建三节点Hadoop环境(保姆级教程)
作者:IvanCodes 日期:2025年5月7日 专栏:Hadoop教程 前言: 想玩转大数据,Hadoop集群是绕不开的一道坎。很多小伙伴一看到集群部署就头大,各种配置、各种坑。别慌!这篇教程就是你的“救生圈”。 …...
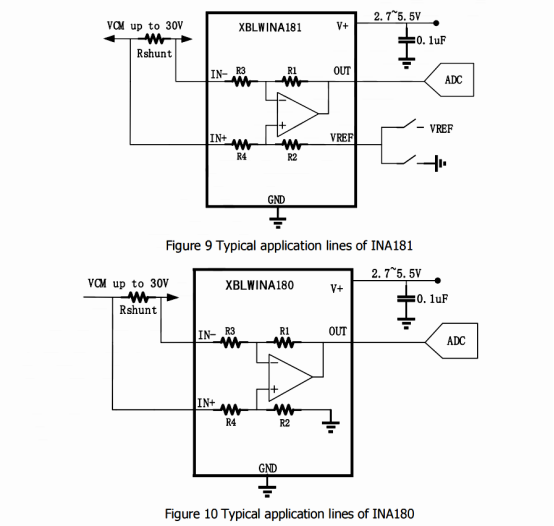
电流检测放大器的优质选择XBLW-INA180/INA181
前言: 在当前复杂的国际贸易环境下,关税的增加使得电子元器件的采购成本不断攀升,电子制造企业面临着巨大的成本压力。为了有效应对这一挑战,实现国产化替代已成为众多企业降低生产成本、保障供应链稳定的关键战略。对此芯伯乐推出…...

5.18-AI分析师
强化练习1 神经网络训练案例(SG) #划分数据集 #以下5行需要背 folder datasets.ImageFolder(rootC:/水果种类智能训练/水果图片, transformtrans_compose) n len(folder) n1 int(n*0.8) n2 n-n1 train, test random_split(folder, [n1, n2]) #训…...

毕业论文,如何区分研究内容和研究方法?
这个问题问得太好了!😎 “研究内容”和“研究方法”经常被初学者(甚至一些老油条)混淆,尤其写论文开题报告时,一不小心就“内容”和“方法”全混在一块儿,连导师都看懵。 今天就来给大家一文讲…...
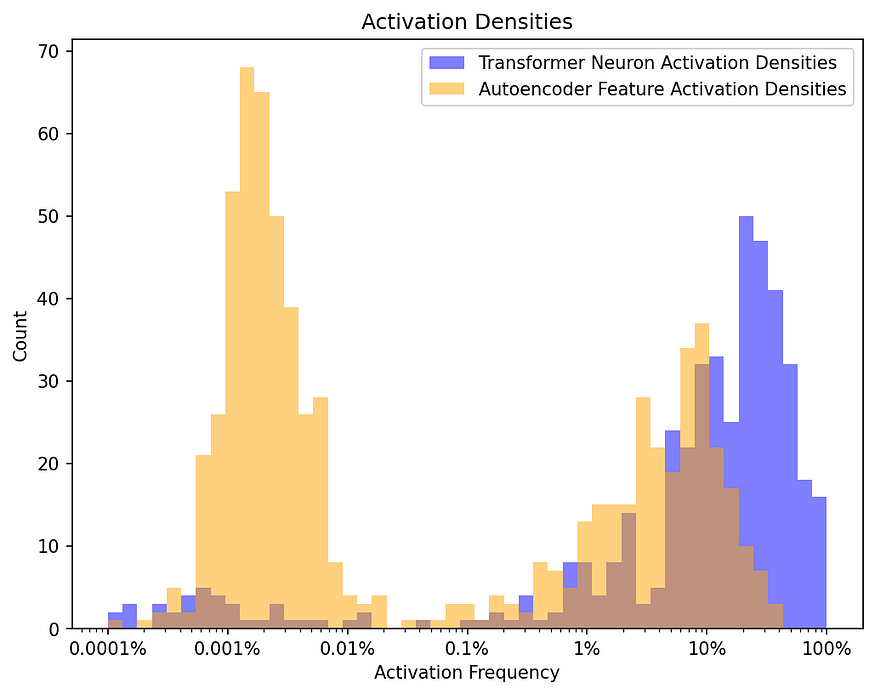
# 深度剖析LLM的“大脑”:单层Transformer的思考模式探索
简单说一下哈 —— 咱们打算训练一个单层 Transformer 加上稀疏自编码器的小型百万参数大型语言模型(LLM),然后去调试它的思考过程,看看这个 LLM 的思考和人类思考到底有多像。 LLMs 是怎么思考的呢? 开源 LLM 出现之后…...
)
三种常见接口测试工具(Apipost、Apifox、Postman)
三种常见接口测试工具(Apipost、Apifox、Postman)的用法及优缺点对比总结: 🔧 一、Apipost ✅ 基本用法 支持 RESTful API、GraphQL、WebSocket 等接口调试自动生成接口文档支持环境变量、接口分组、接口测试用例编写可进行前置…...

EF Core 数据库迁移命令参考
在使用 Entity Framework Core 时,若你希望通过 Package Manager Console (PMC) 执行迁移相关命令,以下是常用的 EF Core 迁移命令: PMC 方式 ✅ 常用 EF Core PMC 命令(适用于迁移) 操作PMC 命令添加迁移Add-Migra…...

剖析提示词工程中的递归提示
递归提示:解码AI交互的本质,构建复杂推理链 递归提示的核心思想,正如示例所示,是将一个复杂任务分解为一系列更小、更易于管理、逻辑上前后关联的子任务。每个子任务由一个独立的提示来驱动,而前一个提示的输出(经过必要的解析和转换)则成为下一个提示的关键输入。这种…...

互联网大厂Java求职面试:AI内容生成平台下的高并发架构设计与性能优化
互联网大厂Java求职面试:AI内容生成平台下的高并发架构设计与性能优化 场景背景: 郑薪苦是一名经验丰富的Java开发者,他正在参加一家匿名互联网大厂的技术总监面试。这家公司专注于基于AI的内容生成平台,支持大规模用户请求和复杂…...

用Redis的List实现消息队列
介绍如何在 Spring Boot 中使用 Redis List 的 BRPOPLPUSH命令来实现一个线程安全且可靠的消息队列。 整合Redis 整合Redis 用Redis的List实现消息队列 Redis的List相关指令 **「LPUSH key element [element ...]」**把元素插入到 List 的首部,如果 List 不存在…...
【C++】类与对象【下】
文章目录 再谈构造函数构造函数的赋值构造函数体赋值:初始化列表explicit关键字 static成员概念特性 C11中成员初始化的新玩法友元友元类 内部类概念 再谈构造函数 构造函数的赋值 构造函数体赋值: 在创建对象时,编译器会通过调用构造函数…...

Python uv包管理器使用指南:从入门到精通
Python uv包管理器使用指南:从入门到精通 作为一名Python开发者,你是否曾经为虚拟环境管理和依赖包安装而头疼?今天我要向大家介绍一个强大的工具——uv包管理器,它将彻底改变你的Python开发体验。 什么是uv包管理器?…...
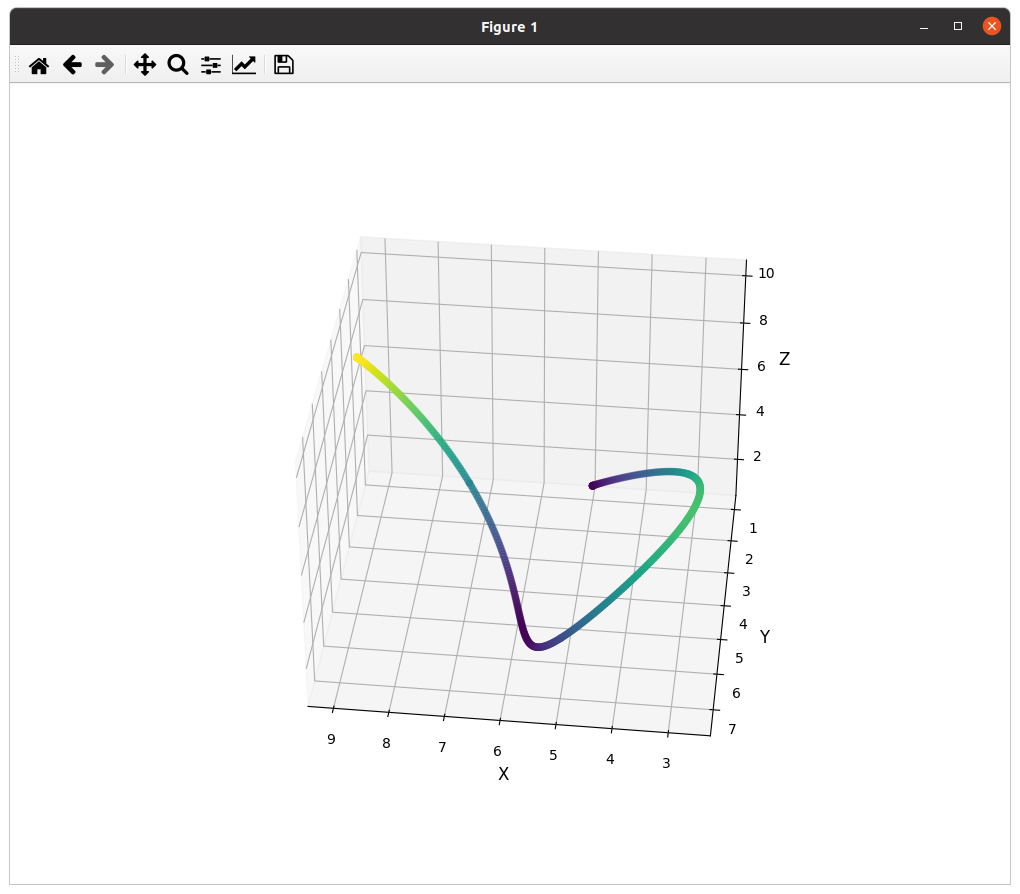
无人机避障——如何利用MinumSnap进行对速度、加速度进行优化的轨迹生成(附C++python代码)
🔥轨迹规划领域的 “YYDS”——minimum snap!作为基于优化的二次规划经典,它是无人机、自动驾驶轨迹规划论文必引的 “开山之作”。从优化目标函数到变量曲线表达,各路大神疯狂 “魔改”,衍生出无数创新方案。 &#…...

高德地图在Vue3中的使用方法
1.地图初始化 容器创建:通过 <div> 标签定义地图挂载点。 <div id"container" style"height: 300px; width: 100%; margin-top: 10px;"></div> 密钥配置:绑定高德地图安全密钥,确保 API 合法调用。 参…...

Llama:开源的急先锋
Llama:开源的急先锋 Llama1:开放、高效的基础语言模型 Llama1使用了完全开源的数据,性能媲美GPT-3,可以在社区研究开源使用,只是不能商用。 Llama1提出的Scaling Law 业内普遍认为如果要达到同一个性能指标,训练更…...

SDIO EMMC中ADMA和SDMA简介
在SDIO和eMMC技术中,ADMA(Advanced Direct Memory Access)和SDMA(Simple Direct Memory Access)是两种不同的DMA(直接内存访问)模式,用于优化主机控制器与存储器(如eMMC&…...
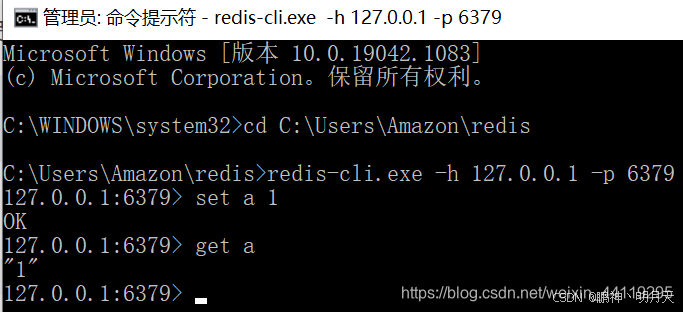
“redis 目标计算机积极拒绝,无法连接” 解决方法,每次开机启动redis
如果遇到以上问题 先打开“服务” 找到App Readiness 右击-启动 以管理员身份运行cmd,跳转到 安装redis的目录 运行:redis-server.exe redis.windows.conf 以管理员身份打开另一cmd窗口,跳转到安装redis的目录 运行:redis-…...

LeetCode 热题 100 35.搜索插入位置
目录 题目: 题目描述: 题目链接: 思路: 核心思路: 思路详解: 代码: Java代码: 题目: 题目描述: 题目链接: 35. 搜索插入位置 - 力扣&…...

【THRMM】追踪情绪动态变化的多模态时间背景网络
1. 单一模态的局限性 不足:传统方法依赖生理信号(如EEG、ECG)或静态图像特征,数据收集成本高,且无法捕捉动态交互,导致模型泛化性差。 改进:提出THRMM模型,整合多模态数据(面部表情、声学特征、对话语义、场景信息),利用Transformer的全…...

labview硬件采集<2>——使用布尔控件控制硬件的LED
当布尔按键按下时,开发板的LED亮...

从 “学会学习” 到高效适应:元学习技术深度解析与应用实践
一、引言:当机器开始 “学会学习”—— 元学习的革命性价值 在传统机器学习依赖海量数据训练单一任务模型的时代,元学习(Meta Learning)正掀起一场范式革命。 这项旨在让模型 “学会学习” 的技术,通过模仿人类基于经验…...

AI开发者的算力革命:GpuGeek平台全景实战指南(大模型训练/推理/微调全解析)
目录 背景一、AI工业化时代的算力困局与破局之道1.1 中小企业AI落地的三大障碍1.2 GpuGeek的破局创新1.3 核心价值 二、GpuGeek技术全景剖析2.1 核心架构设计 三、核心优势详解3.1 优势1:工业级显卡舰队3.2 优势2:开箱即用生态3.2.1 预置镜像库…...
AWS SNS:解锁高并发消息通知与系统集成的云端利器
导语 在分布式系统架构中,如何实现高效、可靠的消息通知与跨服务通信?AWS Simple Notification Service(SNS)作为全托管的发布/订阅(Pub/Sub)服务,正在成为企业构建弹性系统的核心组件。本文深度…...

Redis数据结构详解
文章目录 引言<center> 一、字符串1 常用命令2 应用场景3 注意事项 <center>二、列表1 常用命令2 应用场景3 注意事项 <center> 三、集合1 常用命令2 应用场景3 注意事项 <center> 四、有序集合1 常用命令2 应用场景3 注意事项 <center> 五、哈希…...
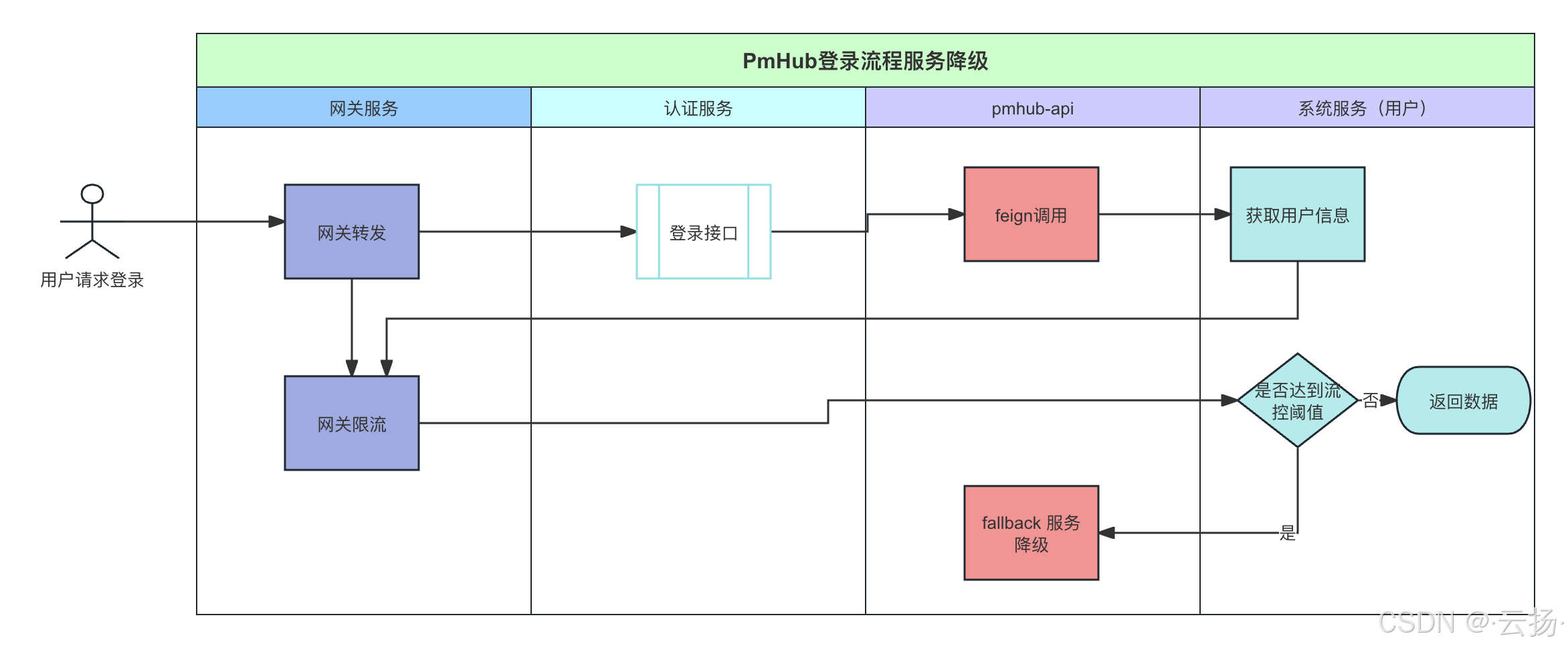
【PmHub后端篇】PmHub集成 Sentinel+OpenFeign实现网关流量控制与服务降级
在微服务架构中,保障服务的稳定性和高可用性至关重要。本文将详细介绍在 PmHub 中如何利用 Sentinel Gateway 进行网关限流,以及集成 Sentinel OpenFeign 实现自定义的 fallback 服务降级。 1 熔断降级的必要性 在微服务架构中,服务间的调…...
2025最新出版 Microsoft Project由入门到精通(八)
目录 查找关键路径方法 方法1:格式->关键任务 方法2:插入关键属性列 方法3:插入“可宽延的总时间”进行查看,>0不是关键路径,剩余的全是关键路径 方法4:设置关键路径的工作表的文本样式编辑 方法5:突出显示/筛选器…...

3.0/Q2,Charls最新文章解读
文章题目:Development of a visualized risk prediction system for sarcopenia in older adults using machine learning: a cohort study based on CHARLS DOI:10.3389/fpubh.2025.1544894 中文标题:使用机器学习开发老年人肌肉减少症的可视…...
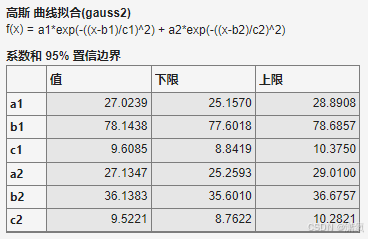
使用matlab进行数据拟合
目录 一、工作区建立数据 二、曲线拟合器(在"APP"中) 三、曲线拟合函数及参数 四、 在matlab中编写代码 一、工作区建立数据 首先,将数据在matlab工作区中生成。如图1所示: 图 1 二、曲线拟合器(在"APP"中) 然后,…...

分布式1(cap base理论 锁 事务 幂等性 rpc)
目录 分布式系统介绍 一、定义与概念 二、分布式系统的特点 三、分布式系统面临的挑战 四、分布式系统的常见应用场景 CAP 定理 BASE 理论 BASE理论是如何保证最终一致性的 分布式锁的常见使用场景有哪些? 1. 防止多节点重复操作 2. 资源互斥访问 3. 分…...
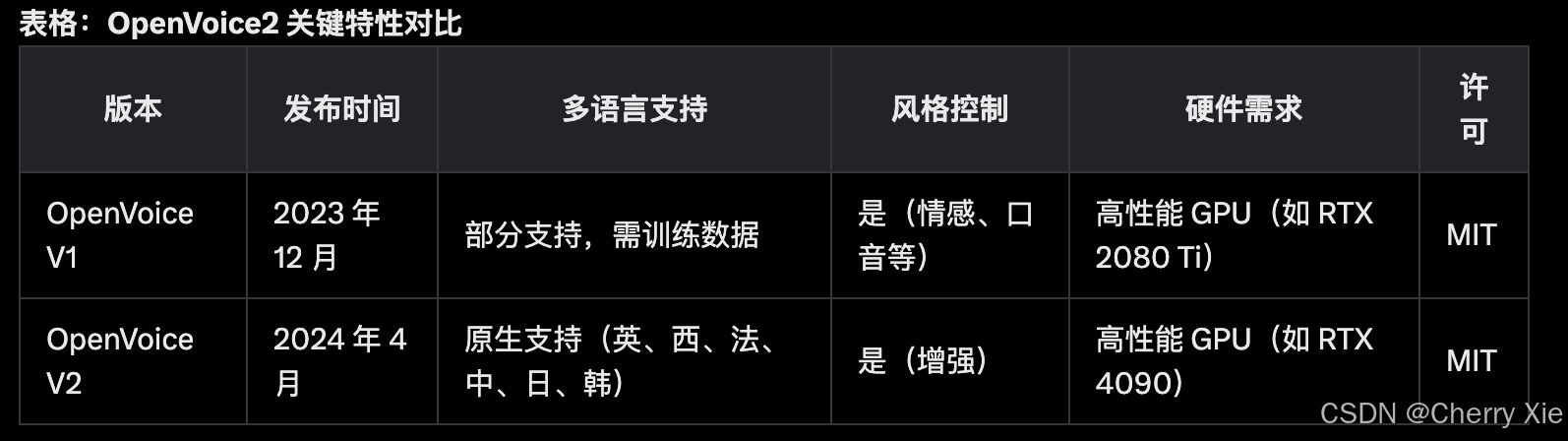
Myshell与清华联合开源TTS模型OpenVoiceV2,多语言支持,风格控制进一步增强~
项目背景 开发团队与发布 OpenVoice2 由 MyShell AI(加拿大 AI 初创公司)与 MIT 和清华大学的研究人员合作开发,技术报告于 2023 年 12 月发布 ,V2 版本于 2024 年 4 月发布 。 项目目标是提供一个高效、灵活的语音克隆工具&…...