sqlalchemy库详细使用
SQLAlchemy 是 Python 中最强大、最受欢迎的 ORM(对象关系映射)库,它允许你使用 Python 对象来操作数据库,而不需要直接编写 SQL 语句。同时,它也提供了对底层 SQL 的完全控制能力,适用于从简单脚本到大型企业级应用的各种场景。
📚 一、简介
✅ 什么是 SQLAlchemy?
- 开源:MIT 许可证
- 作者:Michael Bayer
- 官网:SQLAlchemy - The Database Toolkit for Python
- 核心功能:
- ORM(对象关系映射)
- Core(原生 SQL 构建与执行)
- 连接池、事务管理、类型系统等
🔗 支持的数据库:
PostgreSQL、MySQL、SQLite、Oracle、SQL Server、MariaDB、SQLite、Firebird、Sybase 等。
🛠️ 二、安装
pip install sqlalchemy如果你使用特定数据库驱动(如 PostgreSQL 的 psycopg2),还需要额外安装:
pip install psycopg2-binary # PostgreSQL
pip install pymysql # MySQL🧱 三、基本结构
SQLAlchemy 主要分为两个部分:
- Core:用于构建和执行 SQL 查询语句(适合熟悉 SQL 的用户)
- ORM:面向对象方式操作数据库(适合不想写 SQL 的用户)
📦 四、使用示例(ORM 模式)
1. 创建引擎
from sqlalchemy import create_engineengine = create_engine("sqlite:///example.db", echo=True) # echo=True 显示生成的 SQL支持多种数据库连接格式:
| 数据库类型 | 示例连接字符串 |
|---|---|
| SQLite | sqlite:///example.db |
| PostgreSQL | postgresql+psycopg2://user:password@localhost/dbname |
| MySQL | mysql+pymysql://user:password@localhost/dbname |
2. 定义模型类(Declarative Base)
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, StringBase = declarative_base()class User(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True)name = Column(String)age = Column(Integer)def __repr__(self):return f"<User(name='{self.name}', age={self.age})>"3. 创建表
Base.metadata.create_all(engine)4. 创建 Session 工厂
from sqlalchemy.orm import sessionmakerSession = sessionmaker(bind=engine)
session = Session()5. 插入数据(增)
new_user = User(name="Alice", age=25)
session.add(new_user)
session.commit()6. 查询数据(查)
# 查询所有用户
users = session.query(User).all()# 条件查询
user = session.query(User).filter_by(name="Alice").first()for user in users:print(user.id, user.name, user.age)7. 更新数据(改)
user = session.query(User).filter_by(name="Alice").first()
if user:user.age = 26session.commit()8. 删除数据(删)
user = session.query(User).filter_by(name="Alice").first()
if user:session.delete(user)session.commit()⚙️ 五、高级用法
1. 使用上下文管理器自动提交事务
from sqlalchemy.orm import Sessionwith Session(engine) as session:with session.begin():new_user = User(name="Bob", age=30)session.add(new_user)如果发生异常会自动回滚,否则自动提交。
2. 复杂查询
# and 查询
users = session.query(User).filter(User.age > 25, User.name.like('A%')).all()# 排序
users = session.query(User).order_by(User.age.desc()).all()# 聚合函数
from sqlalchemy import func
count = session.query(func.count(User.id)).scalar()3. 外键与关联表
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationshipclass Address(Base):__tablename__ = 'addresses'id = Column(Integer, primary_key=True)email = Column(String)user_id = Column(Integer, ForeignKey('users.id'))user = relationship("User", back_populates="addresses")User.addresses = relationship("Address", order_by=Address.email, back_populates="user")🔄 六、异步支持(需要搭配 databases 或 asyncmy)
SQLAlchemy 原生不支持异步(async/await),但可以通过以下方式实现:
- 使用
databases+asyncpg(PostgreSQL) - 使用
sqlalchemy.ext.asyncio(SQLAlchemy >= 1.4) - 使用
asyncmy(MySQL 异步驱动)
示例(SQLAlchemy 1.4+ 异步 ORM):
from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine
from sqlalchemy.orm import sessionmakerengine = create_async_engine("postgresql+asyncpg://user:pass@localhost/dbname")
async_session = sessionmaker(engine, class_=AsyncSession)async with async_session() as session:result = await session.execute(select(User))🧪 七、测试建议
- 使用内存数据库进行单元测试(如
sqlite:///:memory:) - 使用 Alembic 做迁移管理
- 使用 pytest + fixture 管理 session 和数据初始化
📚 八、推荐学习资源
- 官方文档(英文)
- 中文社区文档
- GitHub 示例仓库
- 实战项目:Flask + SQLAlchemy / FastAPI + SQLAlchemy
📌 总结
| 特性 | 是否支持 |
|---|---|
| ORM | ✅ |
| 原生 SQL 构建 | ✅ |
| 异步支持 | ✅(需配合扩展) |
| 多数据库支持 | ✅ |
| 迁移工具 | Alembic ✅ |
| 高性能批量操作 | ✅ |
如果你想更深入掌握 SQLAlchemy,可以尝试阅读它的源码或使用在实际项目中,比如 Flask、FastAPI 后端服务中广泛使用的 ORM 模块。
create_engine
create_engine 是 SQLAlchemy 中用于创建数据库引擎的核心函数,它允许你与数据库建立连接,并通过该连接执行 SQL 语句。下面详细介绍 create_engine 的用法。
基本使用
首先,你需要导入 create_engine 函数并提供一个数据库 URL 来创建引擎实例:
from sqlalchemy import create_engine# 创建一个数据库引擎
engine = create_engine('dialect+driver://username:password@host:port/database')这里的 dialect+driver 部分指定数据库类型和驱动程序(例如:postgresql+psycopg2),username 和 password 分别是你的数据库用户名和密码,host 和 port 分别是数据库服务器的地址和端口,最后的 database 是你要连接的具体数据库名称。
例如,要连接到本地运行的 PostgreSQL 数据库,你可以这样做:
engine = create_engine('postgresql+psycopg2://user:password@localhost/mydatabase')连接池设置
create_engine 允许你配置连接池的行为。默认情况下,SQLAlchemy 使用队列式的连接池,限制最大连接数为 5,最小连接数为 5。你可以通过参数自定义这些设置:
engine = create_engine('postgresql+psycopg2://user:password@localhost/mydatabase',pool_size=10, # 设置连接池大小max_overflow=20, # 超出pool_size后的最大溢出连接数
)执行 SQL 语句
一旦有了引擎实例,就可以使用它来执行 SQL 语句。例如,直接执行一条 SQL 查询:
with engine.connect() as connection:result = connection.execute("SELECT * FROM my_table")for row in result:print(row)使用 ORM
如果你计划使用 SQLAlchemy 的 ORM 功能,你需要先定义模型类,然后可以利用 engine 来进行操作。首先,需要初始化一个 MetaData 实例和声明基类:
from sqlalchemy.ext.declarative import declarative_baseBase = declarative_base()class MyTable(Base):__tablename__ = 'my_table'id = Column(Integer, primary_key=True)name = Column(String)# 创建表
Base.metadata.create_all(engine)之后,你可以使用会话(Session)来进行数据库操作:
from sqlalchemy.orm import sessionmakerSession = sessionmaker(bind=engine)
session = Session()# 插入数据
new_record = MyTable(name='example')
session.add(new_record)
session.commit()# 查询数据
records = session.query(MyTable).all()
for record in records:print(record.name)总结
create_engine是用于创建数据库连接的基础方法。- 它支持多种数据库后端,并允许对连接行为进行高度定制。
- 结合 SQLAlchemy 的 Core 或 ORM 功能,
create_engine提供了灵活且强大的数据库交互能力。无论是执行原生 SQL 语句还是通过 ORM 操作数据库对象,都变得简单而直观。
declarative_base
declarative_base 是 SQLAlchemy ORM(对象关系映射)中的一个关键函数,用于创建一个基础类,该类的子类可以与数据库表进行关联。通过使用 declarative_base,你可以定义数据库模型作为 Python 类,从而简化了数据库操作。
基本用法
首先,你需要从 sqlalchemy.ext.declarative 模块中导入 declarative_base 函数,并调用它来创建一个基础类:
from sqlalchemy.ext.declarative import declarative_baseBase = declarative_base()这个 Base 类将作为所有模型类的父类。然后,你可以定义你的数据库模型作为 Base 的子类。
定义模型
下面是一个简单的例子,展示了如何定义一个模型类:
from sqlalchemy import Column, Integer, Stringclass User(Base):__tablename__ = 'users' # 指定数据库表名id = Column(Integer, primary_key=True) # 主键name = Column(String)age = Column(Integer)def __repr__(self):return f"<User(name={self.name}, age={self.age})>"在这个例子中,我们定义了一个名为 User 的模型类,它对应数据库中的 users 表。id, name, 和 age 分别是这个表中的列。
创建表
一旦你定义了模型,你可以使用 Base.metadata.create_all(engine) 方法基于这些模型创建相应的数据库表:
from sqlalchemy import create_engine# 创建一个引擎实例
engine = create_engine('postgresql+psycopg2://user:password@localhost/mydatabase')# 根据模型创建表
Base.metadata.create_all(engine)确保在执行这段代码之前已经正确配置了数据库连接字符串。
使用会话进行数据库操作
为了对数据库执行插入、查询、更新和删除等操作,你需要创建一个会话:
from sqlalchemy.orm import sessionmaker# 创建Session类
Session = sessionmaker(bind=engine)
session = Session()# 插入新记录
new_user = User(name='John Doe', age=30)
session.add(new_user)
session.commit()# 查询记录
users = session.query(User).filter_by(name='John Doe').all()
for user in users:print(user)# 更新记录
user = session.query(User).first()
user.age = 31
session.commit()# 删除记录
session.delete(user)
session.commit()总结
declarative_base提供了一种声明式的方式来定义数据库模型。- 通过继承自
Base的子类,你可以方便地定义与数据库表对应的模型。 - 使用
create_all方法可以基于模型自动创建数据库表。 - 利用
sessionmaker创建的会话,可以轻松实现对数据库的增删改查操作。
这种方法使得处理数据库变得更加直观和易于管理,特别是在大型项目中维护复杂的数据结构时非常有用。
sessionmaker
sessionmaker 是 SQLAlchemy ORM 中用于创建新 Session 对象的工厂类。Session 是 SQLAlchemy 与数据库交互的核心接口之一,通过它你可以执行查询、插入、更新和删除等操作。下面详细介绍 sessionmaker 的用法。
基本使用
首先,你需要导入 sessionmaker 并创建一个 sessionmaker 工厂,同时将其绑定到一个数据库引擎实例上:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker# 创建数据库引擎
engine = create_engine('postgresql+psycopg2://user:password@localhost/mydatabase')# 创建一个配置好连接到该引擎的 sessionmaker 工厂
Session = sessionmaker(bind=engine)# 创建一个新的会话对象
session = Session()使用 Session 进行数据库操作
一旦有了 session 实例,你就可以利用它来对数据库进行各种操作了。
插入数据
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, StringBase = declarative_base()class User(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True)name = Column(String)age = Column(Integer)# 添加新用户
new_user = User(name='John Doe', age=30)
session.add(new_user)
session.commit() # 提交事务以保存更改查询数据
# 查询所有用户
users = session.query(User).all()
for user in users:print(user.name, user.age)# 根据条件查询
johns = session.query(User).filter_by(name='John Doe').all()
for john in johns:print(john.name, john.age)更新数据
# 查找并更新用户信息
user = session.query(User).filter_by(name='John Doe').first()
if user:user.age = 31 # 更新年龄session.commit() # 记得提交更改删除数据
# 删除用户
user = session.query(User).filter_by(name='John Doe').first()
if user:session.delete(user)session.commit()高级用法
-
自动提交:默认情况下,
sessionmaker不启用自动提交(autocommit)。这意味着你需要显式调用session.commit()来提交事务。如果你希望每次操作后自动提交,可以在创建sessionmaker时设置autocommit=True,但通常不推荐这样做,因为它可能导致意外的数据丢失或一致性问题。Session = sessionmaker(bind=engine, autocommit=True) -
事务管理:可以使用上下文管理器来管理事务,确保在发生异常时能正确回滚事务。
with session.begin():# 执行数据库操作user = User(name='Jane Doe', age=28)session.add(user)# 如果这里抛出异常,事务将自动回滚 -
批量操作:当你需要添加多个对象时,可以使用
add_all()方法。session.add_all([User(name='Alice', age=25),User(name='Bob', age=26) ]) session.commit()
通过这些方法,你可以非常灵活地与数据库进行交互,无论是简单的增删改查操作还是更复杂的业务逻辑处理。sessionmaker 提供了一个强大且易于使用的接口,使得数据库编程变得更加简单直接。
事务管理->详解
在 SQLAlchemy 中,sessionmaker 创建的 Session 对象可以通过上下文管理器(即使用 with 语句)来自动管理事务。这种方式非常方便,因为它可以在代码块成功完成时自动提交事务,并在发生异常时自动回滚事务,从而确保数据的一致性和完整性。
使用上下文管理器进行事务管理
当你使用 with 语句结合 session.begin() 来管理事务时,不需要手动调用 session.commit() 或 session.rollback()。如果代码块执行过程中没有抛出异常,则事务会被自动提交;如果发生了异常,则事务会自动回滚。
示例代码
以下是一个使用上下文管理器管理事务的例子:
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmakerBase = declarative_base()class User(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True)name = Column(String)age = Column(Integer)# 创建引擎和 sessionmaker 工厂
engine = create_engine('postgresql+psycopg2://user:password@localhost/mydatabase')
Session = sessionmaker(bind=engine)# 使用上下文管理器管理事务
with Session() as session:with session.begin():# 插入新用户new_user = User(name='John Doe', age=30)session.add(new_user)# 如果在此处抛出异常,事务将自动回滚# 没有异常时,事务将在 with 块结束时自动提交在这个例子中,session.begin() 返回一个上下文管理器,它会在进入 with 块时开始一个新的事务,在退出 with 块时根据是否发生异常来决定是提交还是回滚事务。
结合 try-except 的高级使用
虽然使用 with session.begin() 可以简化事务管理,但在某些情况下,你可能还需要更细致地控制异常处理逻辑。例如,你可能想要在捕获特定类型的异常时执行一些额外的操作。在这种情况下,可以结合 try-except 结构使用:
from sqlalchemy.exc import SQLAlchemyErrorwith Session() as session:try:with session.begin():new_user = User(name='Jane Doe', age=28)session.add(new_user)# 模拟异常raise ValueError("Something went wrong!")except SQLAlchemyError as e:print(f"An error occurred while committing the transaction: {e}")# 注意:由于 with session.begin() 自动处理了回滚,这里不需要显式调用 session.rollback()except Exception as e:print(f"An unexpected error occurred: {e}")在这个示例中,即使发生了异常,事务也会被自动回滚,但你可以通过 except 块来执行额外的错误处理或日志记录操作。
总结
- 简化事务管理:使用
with session.begin()可以大大简化事务管理,使代码更加简洁易读。 - 自动提交与回滚:当代码块成功完成时,事务会自动提交;如果发生异常,事务会自动回滚。
- 灵活性:尽管
with语句提供了便捷的事务管理方式,但在需要更复杂的错误处理时,仍可以通过结合try-except结构来实现。
这种模式非常适合用于需要保证事务完整性的场景,如金融交易、库存管理等关键业务流程。通过这种方式,不仅可以减少代码量,还能提高代码的健壮性和可维护性。
create_all
Base.metadata.create_all(engine) 是 SQLAlchemy 中用于基于已定义的模型创建数据库表的一个方法。这个方法会检查 Base 类(由 declarative_base() 创建)的所有子类,并在数据库中创建对应的表结构,如果这些表还不存在的话。下面详细说明它的用法和一些相关的注意事项。
基本使用
首先,你需要定义你的数据库模型,并通过调用 create_all 方法来创建相应的表:
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.ext.declarative import declarative_baseBase = declarative_base()class User(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True)name = Column(String)age = Column(Integer)# 创建一个引擎实例
engine = create_engine('postgresql+psycopg2://user:password@localhost/mydatabase')# 根据模型创建表
Base.metadata.create_all(engine)在这个例子中,我们定义了一个名为 User 的模型类,并通过 Base.metadata.create_all(engine) 在数据库中创建了对应的 users 表。
参数详解
create_all 方法接受几个可选参数,允许你进一步控制表的创建过程:
-
checkfirst:默认为
True。如果设置为True,则只会创建那些尚未存在的表;如果设置为False,将无条件地尝试创建所有表,即使它们已经存在。Base.metadata.create_all(engine, checkfirst=True) -
tables:可以指定要创建的表集合。如果你只想创建特定的一些表而不是所有表,可以通过此参数传递一个表对象列表。
python深色版本
from sqlalchemy import Table# 假设还有另一个模型叫做 Address Base.metadata.create_all(engine, tables=[User.__table__, Address.__table__])
注意事项
-
外键约束:如果模型之间有外键关系,请确保在执行
create_all时所有相关联的表都包含在内,以避免由于缺失依赖表而导致的错误。 -
数据库URL:确保提供的数据库连接字符串(即创建
engine时使用的 URL)是正确的,并且应用程序对数据库有足够的权限来创建表。 -
已有数据:请注意,
create_all不会处理数据库中的已有数据或修改现有表结构。如果需要更新表结构而不丢失数据,考虑使用迁移工具如 Alembic。 -
事务管理:虽然
create_all和drop_all(删除所有表)操作通常是在没有活动事务的情况下执行的,但最好还是在一个明确的上下文中进行这些操作,例如在应用初始化阶段。
示例:完整流程
以下是一个完整的示例,展示了如何定义模型、创建引擎并生成表:
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.ext.declarative import declarative_baseBase = declarative_base()class User(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True)name = Column(String)age = Column(Integer)if __name__ == "__main__":engine = create_engine('postgresql+psycopg2://user:password@localhost/mydatabase')Base.metadata.create_all(engine)print("Tables created successfully.")通过这种方式,你可以轻松地根据你的 ORM 模型动态地创建数据库表结构。
相关文章:

sqlalchemy库详细使用
SQLAlchemy 是 Python 中最强大、最受欢迎的 ORM(对象关系映射)库,它允许你使用 Python 对象来操作数据库,而不需要直接编写 SQL 语句。同时,它也提供了对底层 SQL 的完全控制能力,适用于从简单脚本到大型企…...
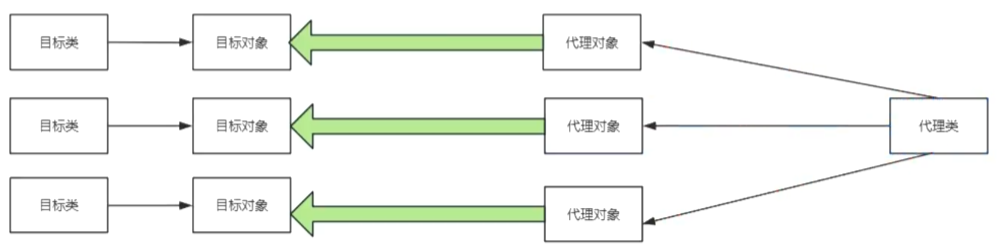
java----------->代理模式
目录 什么是代理模式? 为什么会有代理模式? 怎么写代理模式? 实现代理模式总共需要三步: 什么是代理模式? 代理模式:给目标对象提供一个代理对象,并且由代理对象控制目标对象的引用 代理就是…...
 分析)
ET ProcessInnerSender类(实体) 分析
ProcessInnerSender 作用是进程内部发送Actor消息 字段 TIMEOUT_TIME 超时时间RpcId 用来累加requestCallback 存储RPC的回调事件list 用来获取MessageQueue中的Actor消息 方法 Awake 初始化在MessageQueue中注册待处理的消息队列Destroy 移除在MessageQueue中的消息队列U…...
Untiy基础学习(十四)核心系统—物理系统之碰撞检测代码篇 刚体,碰撞体,材质
目录 一、碰撞器(Collider)与触发器(Trigger) 二、碰撞检测条件 三、碰撞事件与触发器事件,可以理解为特殊的生命周期函数。 四、讲讲如何选择 编辑 五、总结 一、碰撞/触发事件函数对照表 二、Collider 与 …...
SAP学习笔记 - 开发08 - Eclipse连接到 BTP Cockpit实例
有关BTP,之前学了一点儿,今天继续学习。 SAP学习笔记 - 开发02 - BTP实操流程(账号注册,BTP控制台,BTP集成开发环境搭建)_sap btp开发-CSDN博客 如何在Eclipse中连接BTP Cockpit开发环境实例。 1…...

如何用Redis实现分布式锁?RedLock算法的核心思想?Redisson的看门狗机制原理?
一、Redis分布式锁基础实现 public class RedisDistributedLock {private JedisPool jedisPool;private String lockKey;private String clientId;private int expireTime 30; // 默认30秒public boolean tryLock() {try (Jedis jedis jedisPool.getResource()) {// NX表示不…...

Java项目层级介绍 java 层级 层次
java 层级 层次 实体层 控制器层 数据连接层 Service : 业务处理类 Repository :数据库访问类 Java项目层级介绍 https://blog.csdn.net/m0_67574906/article/details/145811846 在Java项目中,层级结构(Layered Architecture…...
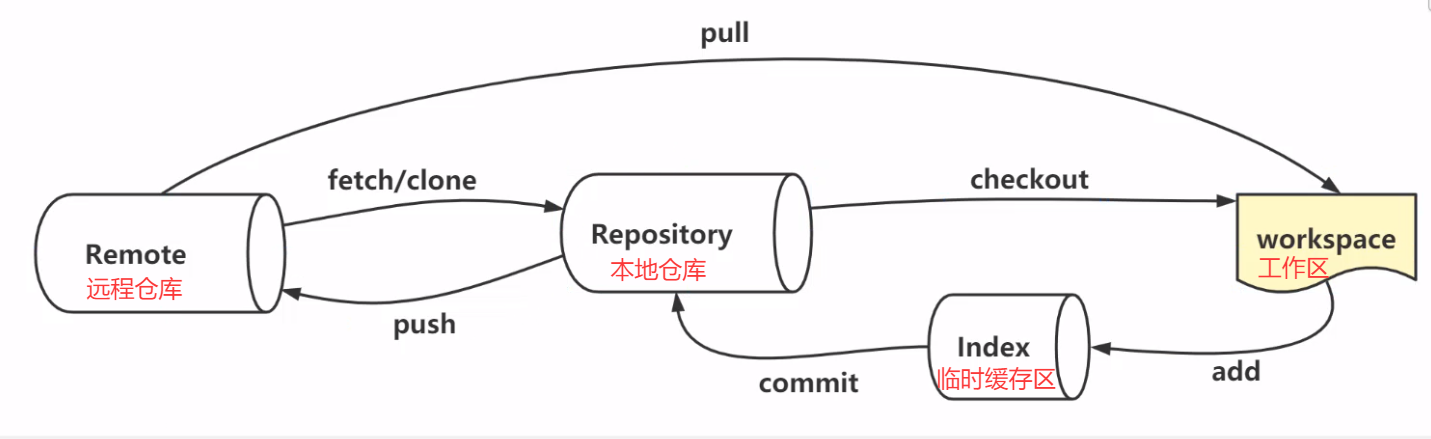
Git的安装和配置(idea中配置Git)
一、Git的下载和安装 前提条件:IntelliJ IDEA 版本是2023.3 ,那么配置 Git 时推荐使用 Git 2.40.x 或更高版本 下载地址:CNPM Binaries Mirror 操作:打开链接 → 滚动到页面底部 → 选择2.40.x或更高版本的 .exe 文件…...
【2025版】Spring Boot面试题
文章目录 1. Spring, Spring MVC, SpringBoot是什么关系?2. 谈一谈对Spring IoC的理解3. Component 和 Bean 的区别?4. Autowired 和 Resource 的区别?5. 注入Bean的方法有哪些?6. 为什么Spring 官方推荐构造函数注入?…...
火山引擎实时音视频 高代码跑通日志
实时音视频 SDK 概览--实时音视频-火山引擎 什么是实时音视频 火山引擎实时音视频(Volcengine Real Time Communication,veRTC)提供全球范围内高可靠、高并发、低延时的实时音视频通信能力,实现多种类型的实时交流和互动。 通…...

atoi函数,sprintf函数,memcmp函数,strchar函数的具体原型,功能,返回值;以及使用方法
以下是这四个C语言标准库函数的详细说明: 1. atoi() - 字符串转整数 **原型**: int atoi(const char *str); **功能**: 将字符串参数str转换为整数(int类型)。函数会跳过前面的空白字符(如空格、制表符&am…...

C++学习之打车软件git版本控制
目录 01 3-git的简介 02 4-git的下载和提交代码 03 5-git添加一个新文件 04 5-删除一个文件 05 6-git的批量添加和提交文件 06 7-git重命名文件名 07 8-git解决代码冲突 08 9-git的分支的概念 09 10-创建项目代码仓库 10 1-git提交代码复习 01 3-git的简介 1 --------…...

基于 PostgreSQL 的 ABP vNext + ShardingCore 分库分表实战
🚀 基于 PostgreSQL 的 ABP vNext ShardingCore 分库分表实战 📑 目录 🚀 基于 PostgreSQL 的 ABP vNext ShardingCore 分库分表实战✨ 背景介绍🧱 技术选型🛠️ 环境准备✅ Docker Compose(多库 & 读…...
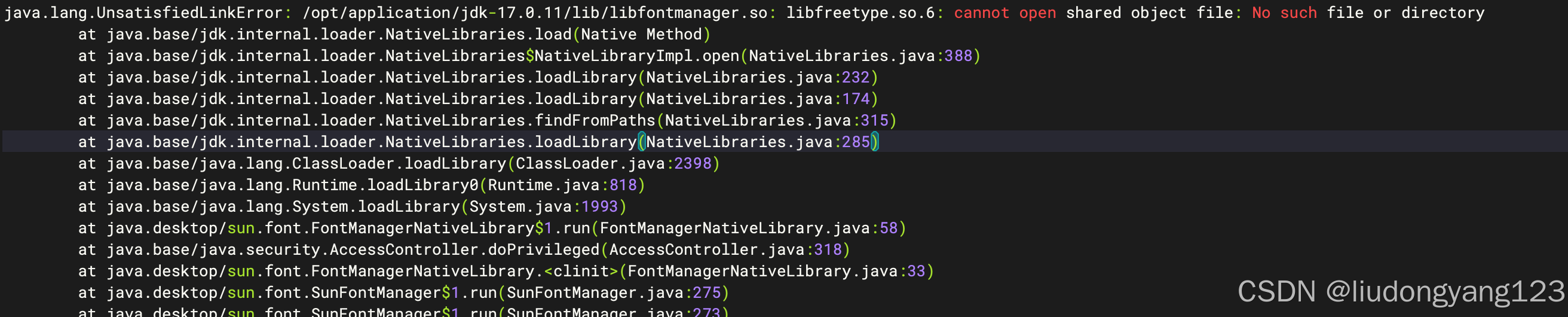
jenkins 启动报错
java.lang.UnsatisfiedLinkError: /opt/application/jdk-17.0.11/lib/libfontmanager.so: libfreetype.so.6: cannot open shared object file: No such file or directory。 解决方案: yum install freetype-devel 安装完成之后重启jenkins。...

C++ 套接字函数详细介绍
目录 头文件1. 套接字创建与配置2. 绑定地址与端口3. 连接建立4. 数据传输5. 套接字选项6. 地址转换7. 套接字关闭8. 其他实用函数 C 套接字函数详细介绍 套接字(Socket)是网络通信的基本端点,C中通常使用BSD套接字API进行网络编程。以下是主要的套接字相关函数及其…...

【合新通信】无人机天线拉远RFOF(射频光纤传输)解决方案
无人机天线拉远RFOF方案通过光纤替代传统射频电缆,实现无人机与地面控制站之间的高保真、低损耗信号传输,尤其适用于高频段(如毫米波)、远距离或复杂电磁环境下的无人机作业场景。 核心应用场景 军事侦察与电子战 隐蔽部署&…...

程序设计语言----软考中级软件设计师(自用学习笔记)
目录 1、解释器和编译器 2、程序的三种控制结构 3、程序中的数据必须具有类型 4、编译、解释程序翻译阶段 5、符号表 6、编译过程 7、上下文无关文法 8、前、中、后缀表达式 9、前、后缀表达式计算 10、语法树中、后序遍历 11、脚本语言和动态语言 12、语法分析方法…...

火山RTC 7 获得远端裸数据
一、获得远端裸数据 1、获得h264数据 1)、远端编码后视频数据监测器 /*** locale zh* type callback* region 视频管理* brief 远端编码后视频数据监测器<br>* 注意:回调函数是在 SDK 内部线程(非 UI 线程)同步抛出来的&a…...

通过SMTP协议实现Linux邮件发送配置指南
一、环境准备与基础配置 1. SMTP服务开通(以qq邮箱为例) 登录qq邮箱网页端,进入「设置」-「POP3/SMTP/IMAP」 开启「SMTP服务」并获取16位授权码(替代邮箱密码使用) 记录关键参数: SMTP服务器地址&#…...
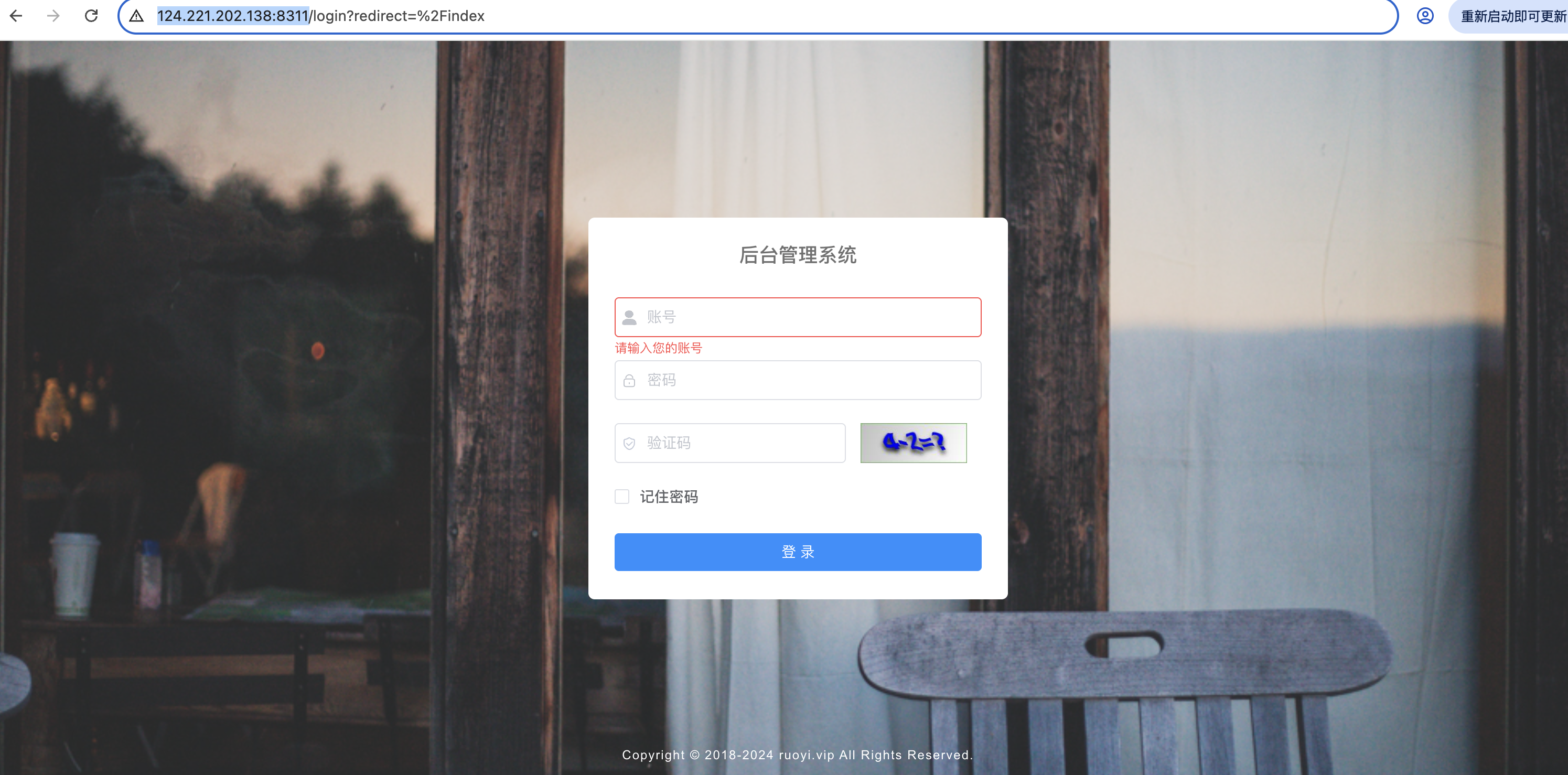
若依框架页面
1.页面地址 若依管理系统 2.账号和密码 管理员 账号admin 密码admin123 运维 账号yuwei 密码123456 自己搭建的地址方便大家学习,不要攻击哦,谢谢啊...

44、私有程序集与共享程序集有什么区别?
私有程序集(Private Assembly)与共享程序集(Shared Assembly)是.NET框架中程序集部署的两种不同方式,它们在部署位置、版本控制、访问权限等方面存在显著差异,以下是对二者的详细比较: 1. 部署…...

【Java面试题】——this 和 super 的区别
🎁个人主页:User_芊芊君子 🎉欢迎大家点赞👍评论📝收藏⭐文章 🔍系列专栏:【Java】内容概括 【前言】 在Java的世界里,this和 super是两个非常重要且容易混淆的关键字。无论是在日常…...
Linux下QFileDialog没反应))
记录 QT 在liunx 下 QFileDialog 类调用问题 ()Linux下QFileDialog没反应)
1. 2025.05.14 踩坑记录 因为QT 在 liunx 文件系统不同导致的 Windows : QString filePath QFileDialog::getOpenFileName(nullptr, "选择文件", ".", "文本文件 (*.txt);所有文件 (*.*)"); 没问题 liunx 下 打不开ÿ…...

CentOS 7 内核升级指南:解决兼容性问题并提升性能
点击上方“程序猿技术大咖”,关注并选择“设为星标” 回复“加群”获取入群讨论资格! CentOS 7 默认搭载的 3.10.x 版本内核虽然稳定,但随着硬件和软件技术的快速发展,可能面临以下问题: 硬件兼容性不足:新…...

【前端】:单 HTML 去除 Word 批注
在现代办公中,.docx 文件常用于文档编辑,但其中的批注(注释)有时需要在分享或归档前被去除。本文将从原理出发,深入剖析如何在纯前端环境下实现对 .docx 文件注释的移除,并提供完整的实现源码。最后&#x…...
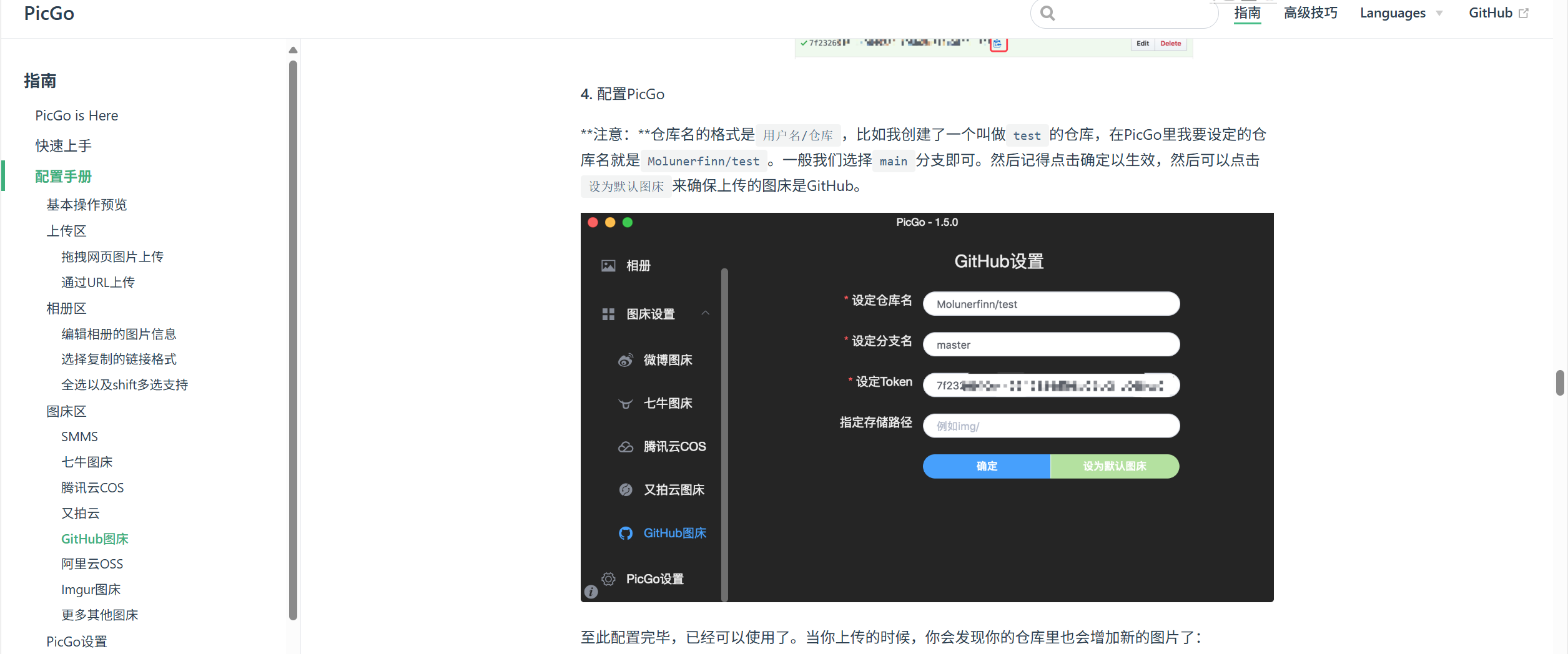
解决 PicGo 上传 GitHub图床及Marp中Github图片编译常见难题指南
[目录] 0.行文概述 1.PicGo图片上传失败 2.*关于在Vscode中Marp图片的编译问题* 3.总结与启示行文概述 写作本文的动机是本人看到了Awesome Marp,发现使用 Markdown \texttt{Markdown} Markdown做PPT若加持一些 CSS , JavaScript \texttt{CSS},\texttt{JavaScript} …...
软考 系统架构设计师系列知识点之杂项集萃(59)
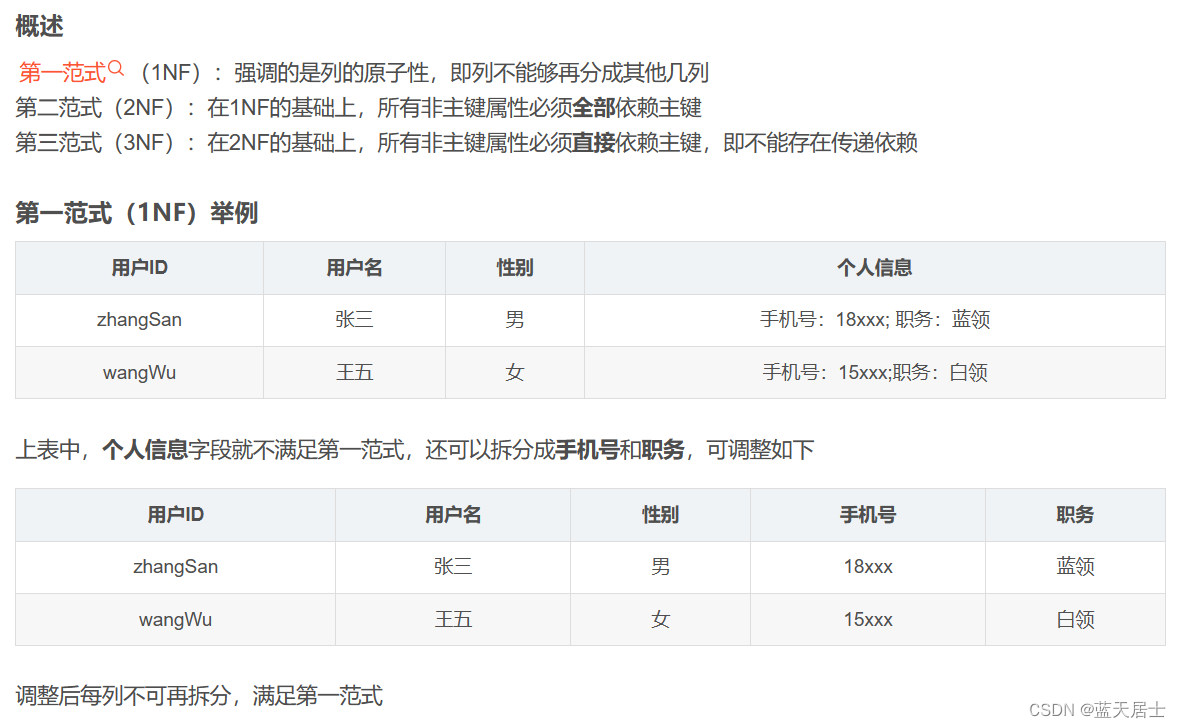
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(58) 第96题 假设关系模式R(U, F),属性集U{A, B, C},函数依赖集F{A->B, B->C}。若将其分解为p{R1(U1, F1), R2(U2, F2),其中U1{A, B}, U2{A, …...
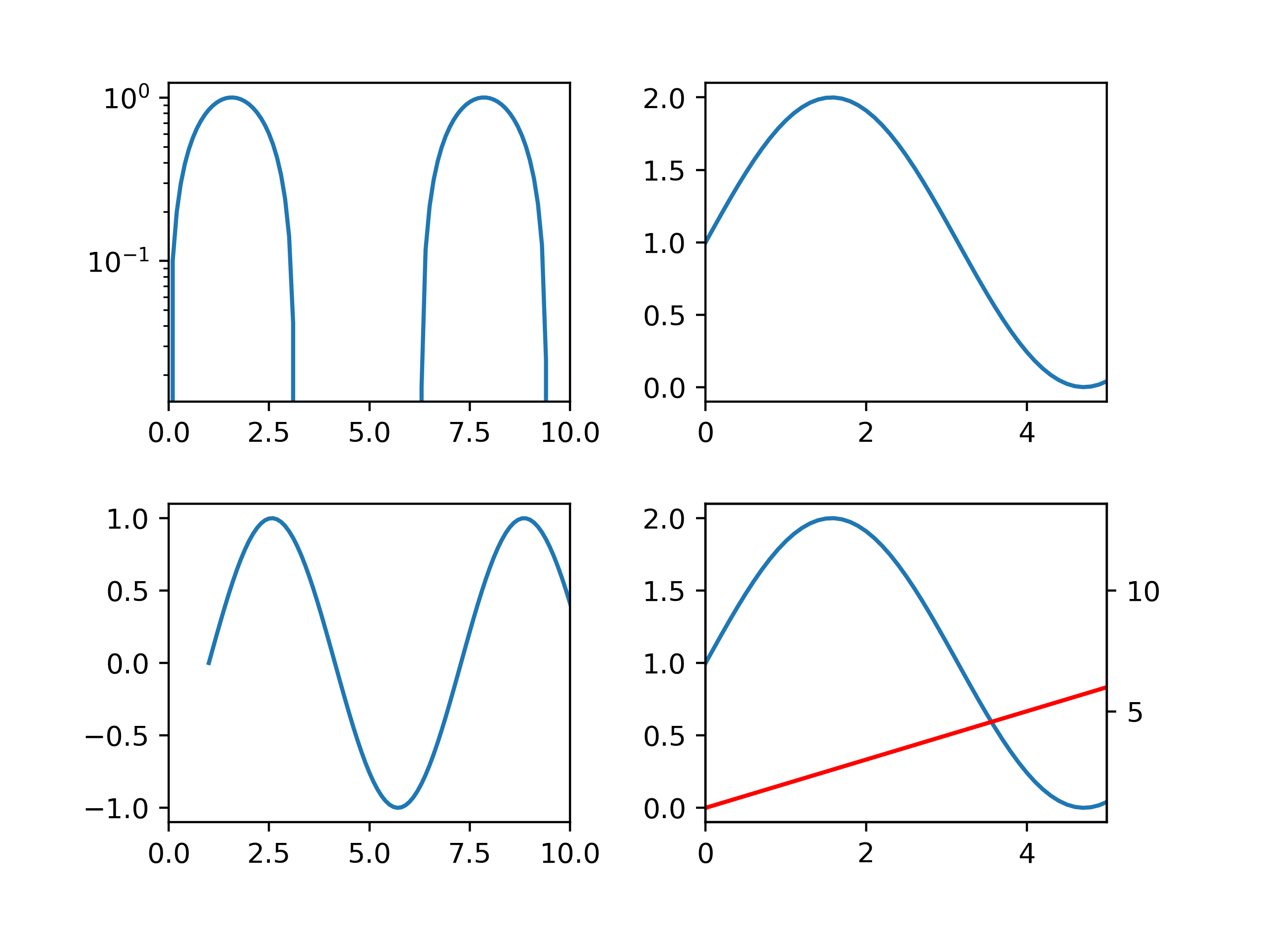
python使用matplotlib画图
【README】 plot画图有两种方法:包括 plt.plot(), ax.plot()-画多个子图 ,其中ax表示某个坐标轴; 【1】画单个图 import matplotlib # 避免兼容性问题:明确指定 matplotlib 使用兼容的后端,TkAgg 或 Agg matplotlib.use(TkAgg) …...

鸿蒙OSUniApp 开发实时聊天页面的最佳实践与实现#三方框架 #Uniapp
使用 UniApp 开发实时聊天页面的最佳实践与实现 在移动应用开发领域,实时聊天功能已经成为许多应用不可或缺的组成部分。本文将深入探讨如何使用 UniApp 框架开发一个功能完善的实时聊天页面,从布局设计到核心逻辑实现,带领大家一步步打造专…...
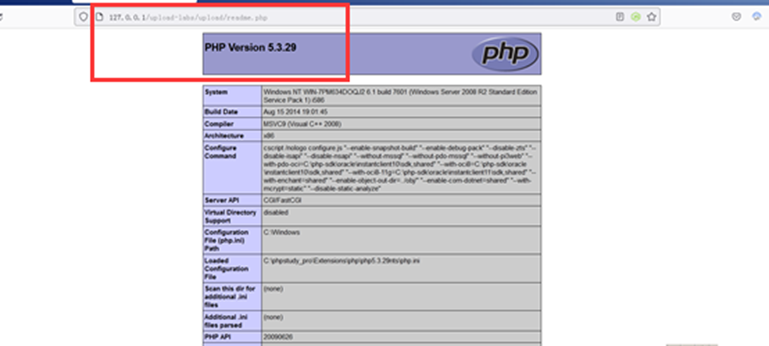
upload-labs通关笔记-第5关 文件上传之.ini绕过
目录 一、ini文件绕过原理 二、源码审计 三、渗透实战 1、查看提示 2、制作.user.ini文件 (1)首先创建一个文本文件 (2)保存文件名为.user.ini 2、制作jpg后缀脚本 (1)创建一个文本文件 …...