企业数字化转型背景下的企业知识管理挑战与经验杂谈
一、引言
在数字化转型的浪潮下,企业知识管理正面临前所未有的挑战。随着数据量的急剧增长,企业内部积累的信息呈现出碎片化、分散化的趋势,传统的知识管理体系已难以有效应对这一变革。首先,信息碎片化问题日益严重,企业内部的知识资源往往存储在不同的系统和平台中,如文档管理系统、邮件、数据库、会议记录等,这些信息缺乏统一的组织和标准化的分类方式,导致员工在查找所需信息时往往需要耗费大量时间。此外,多源异构的数据格式也加剧了信息整合的难度,使得知识难以被高效利用。
其次,检索效率低下成为企业知识管理的核心痛点。传统知识管理系统依赖关键词匹配或简单的分类规则进行信息检索,难以满足用户对精准答案的需求。当用户输入查询时,系统往往返回大量无关或冗余的结果,甚至遗漏关键信息,导致员工不得不手动筛选和验证信息,严重影响工作效率。同时,随着企业业务的快速发展,知识库的内容不断更新,传统系统的更新机制较为滞后,导致检索结果与实际需求存在偏差,进一步降低了知识获取的准确性。
这些问题不仅影响了员工的工作效率,也对企业的决策质量和创新能力造成了负面影响。在竞争日益激烈的市场环境中,企业亟需一种更加智能化、高效的知识管理解决方案,以提升信息整合能力,并优化知识获取流程。因此,如何借助先进技术,如大语言模型(LLM)和检索增强生成(RAG)技术,构建新一代企业知识管理体系,成为当前企业数字化转型的重要课题。
二、大语言模型与检索增强生成(RAG)的潜力
面对企业知识管理中的信息碎片化和检索效率低下的问题,大语言模型(LLM)凭借其强大的自然语言理解和生成能力,为构建高效的知识管理系统提供了新的可能性。LLM能够理解用户的查询意图,并基于大规模训练数据生成高质量的回答,从而提升知识检索的准确性和智能化水平。然而,尽管LLM具备强大的语言生成能力,其知识存储仍然受限于训练数据的截止时间,无法动态获取最新的企业内部知识。为了解决这一问题,检索增强生成(RAG)技术应运而生,成为提升LLM实用性的关键方法。
RAG的核心思想是将LLM与外部知识库相结合,使其在生成回答时能够动态检索相关文档,并基于检索结果生成更准确的答案。具体而言,RAG的工作流程包括两个主要阶段:首先,系统会根据用户查询在大规模文档库中进行语义匹配,找到最相关的知识片段;随后,LLM会基于这些检索结果生成最终的回答。这种机制不仅弥补了LLM自身知识的局限性,还能够确保回答内容与企业内部的最新数据保持同步。
在企业知识管理场景中,RAG技术的应用能够显著提升知识检索的精准度和扩展性。传统的关键词匹配方法往往受限于语义理解能力,而RAG通过语义相似度计算,能够更精准地匹配用户查询与相关知识,减少冗余信息的干扰。此外,RAG的模块化特性使得企业可以根据自身需求灵活调整知识库的构建方式,例如结合向量数据库存储和检索技术,以提高系统响应速度和可扩展性。通过LLM与RAG技术的结合,企业能够构建更加智能、高效的知识管理系统,从而优化信息整合与知识获取流程。
三、案例背景:跨国企业的知识问答系统落地
在数字化转型的推动下,某跨国企业决定构建一个高效、低成本的企业知识中枢,以应对信息碎片化和检索低效的挑战。该企业的核心目标是整合分散在不同部门和系统中的知识资源,提升员工获取信息的效率,并支持多语言环境下的智能问答。为了实现这一目标,该企业选择基于DeepSeek本地化部署RAG(检索增强生成)技术,并结合开源工具链构建知识问答系统。
该系统的整体架构由多个关键组件构成,确保知识的高效检索与智能生成。首先,系统采用数据预处理模块,负责对企业的各类知识文档进行清洗、标注和向量化处理。这一阶段利用开源工具链中的自然语言处理(NLP)技术,将非结构化文本转化为可用于检索的向量表示,并存储至向量数据库中,以支持高效的语义搜索。其次,系统的核心部分是RAG架构,它结合了大语言模型(LLM)和检索增强生成技术,使系统能够在用户输入查询时,快速从向量数据库中检索相关知识,并基于检索结果生成精准的回答。
在技术选型方面,该企业选择了DeepSeek作为LLM的基础模型,并基于本地化部署方案进行优化,以确保数据安全性和系统稳定性。同时,为了降低部署成本,企业充分利用开源工具链,如LangChain和LlamaIndex,用于构建高效的RAG流程。LangChain提供了灵活的提示工程和模块化架构,使系统能够根据不同的业务需求调整问答逻辑,而LlamaIndex则负责构建知识索引,优化检索效率。此外,系统还集成了FastAPI框架,以提供高性能的API接口,支持企业内部的多平台集成和自动化查询。
通过这一架构,该企业成功构建了一个低成本、高可用的知识中枢,实现了跨部门、跨系统的知识整合,并显著提升了员工获取信息的效率。该系统不仅能够处理海量知识文档,还能根据用户需求动态调整检索策略,确保回答的准确性和时效性。这一案例表明,基于RAG和开源工具链的知识管理系统,能够为企业提供高效、灵活且可扩展的智能问答解决方案,助力企业在数字化转型中实现知识管理的智能化升级。
3.1 实施过程:从数据预处理到系统优化
在构建基于RAG的企业知识问答系统时,实施过程涵盖了多个关键步骤,包括数据预处理、模型训练、系统集成和测试优化。每个阶段都涉及具体的技术细节和优化措施,以确保系统的高效性和稳定性。
3.2 数据预处理与向量化存储
数据预处理是知识问答系统的第一步,其目标是将企业内部的非结构化文本数据转化为可用于检索的向量表示。该企业首先收集来自文档管理系统、邮件、会议记录等来源的知识内容,并利用自然语言处理(NLP)技术进行清洗和标准化处理。例如,去除无意义的标点符号、停用词,并进行分词和词干化处理,以提升后续向量表示的准确性。
接下来,系统使用开源工具链中的Sentence Transformers模型,将文本转换为高维向量表示。这些向量能够捕捉文本的语义信息,使系统在后续的检索过程中能够基于语义相似度匹配用户查询与知识文档。为了提高检索效率,企业选择将向量化后的数据存储在FAISS(Facebook AI Similarity Search)向量数据库中,该数据库支持高效的近似最近邻搜索,能够在大规模数据集中快速定位相关文档。
3.3 模型训练与优化
在模型训练阶段,企业基于DeepSeek提供的LLM进行微调,以适配特定领域的知识问答需求。微调过程采用监督学习的方式,利用已有的问答对作为训练数据,使模型能够更准确地理解用户查询并生成符合业务需求的回答。此外,为了提升模型的泛化能力,企业还引入了对抗训练和数据增强技术,以增强模型对不同表达方式的理解能力。
与此同时,RAG架构中的检索模块也进行了优化。企业利用LlamaIndex构建知识索引,并采用混合检索策略,结合BM25关键词匹配和向量语义检索,以提高检索的准确率。此外,为了降低计算资源的消耗,系统采用增量更新策略,仅在知识库发生变化时更新受影响的部分,而非全量重建索引,从而提升系统的响应速度和可扩展性。
3.4 关键代码技巧
1. 多源数据清洗管道(含正则陷阱)
代码语言:txt
AI代码解释
import re
from bs4 import BeautifulSoupclass DataCleanser:def __init__(self):# 配置敏感词正则(含典型企业数据问题)self.patterns = {'internal_id': r'\b\d{4}[A-Z]-\d{5}\b', # 企业文档编号'date_format': r'\d{4}/\d{2}/\d{2}(?=\D|$)', # 日期格式统一'html_cleaner': re.compile(r'<style>.*?</style>|<script>.*?</script>', re.DOTALL)}def clean_text(self, raw_text):# HTML标签清洗text = BeautifulSoup(raw_text, "lxml").get_text()text = self.patterns['html_cleaner'].sub('', text)# 文档编号脱敏(需保留结构)text = re.sub(self.patterns['internal_id'], lambda m: f'DOCID_{m.group()[5:]}', text)# 日期格式标准化text = re.sub(self.patterns['date_format'], lambda m: m.group().replace('/', '-'), text)return text.strip()
2. 混合检索增强实现
代码语言:txt
AI代码解释
from rank_bm25 import BM25Okapi
from langchain.retrievers import EnsembleRetrieverclass HybridRetrieval:def __init__(self, corpus):# 初始化两种检索器self.tokenized_corpus = [doc.split() for doc in corpus]self.bm25 = BM25Okapi(self.tokenized_corpus)self.vector_retriever = FAISS.from_texts(corpus, embeddings)# 配置混合权重self.ensemble = EnsembleRetriever(retrievers=[self.bm25, self.vector_retriever.as_retriever()],weights=[0.4, 0.6])def query(self, question, top_k=5):# 组合BM25与向量检索return self.ensemble.get_relevant_documents(question, k=top_k)
3. DeepSeek模型微调配置
代码语言:txt
AI代码解释
from peft import LoraConfig
from transformers import TrainingArguments# LoRA微调配置(适配中文场景)
lora_config = LoraConfig(r=64,lora_alpha=32,target_modules=["q_proj", "v_proj"],lora_dropout=0.05,bias="none",task_type="CAUSAL_LM",modules_to_save=["embed_tokens", "lm_head"] # 关键中文嵌入层
)# 训练参数优化配置
training_args = TrainingArguments(output_dir="./deepseek-finetuned",per_device_train_batch_size=8,gradient_accumulation_steps=4,learning_rate=2e-5,fp16=True,logging_steps=100,save_steps=500,warmup_ratio=0.1,num_train_epochs=3,optim="adafactor", # 显存优化选项report_to="none",group_by_length=True # 提升20%训练效率
)
4. 增量索引更新机制
代码语言:txt
AI代码解释
import hashlib
from llama_index import Document
from langchain.docstore import InMemoryDocstoreclass IncrementalFAISS:def __init__(self, index_path):self.index = FAISS.load_local(index_path)self.doc_store = InMemoryDocstore()self.existing_hashes = set()def _generate_hash(self, text):return hashlib.sha256(text.encode()).hexdigest()[:16]def update(self, documents):new_docs = []for doc in documents:doc_hash = self._generate_hash(doc.text)if doc_hash not in self.existing_hashes:new_docs.append(Document(text=doc.text, id_=doc_hash))self.existing_hashes.add(doc_hash)if new_docs:embeddings = [self.embed(doc.text) for doc in new_docs]self.index.add_with_ids(embeddings, [doc.id_ for doc in new_docs])self.doc_store.add({doc.id_: doc for doc in new_docs})return len(new_docs)
3.5 系统集成与部署
在系统集成阶段,企业使用LangChain构建RAG流程,并结合FastAPI框架提供高性能的API接口。LangChain的模块化设计使得系统能够灵活调整提示工程,以优化模型的输出质量。例如,企业采用Few-Shot Prompting技术,在提示词中加入示例问答,以引导模型生成更符合业务需求的回答。此外,系统还集成了缓存机制,对高频查询的问答结果进行存储,以减少重复计算,提高响应速度。
3.6 测试与优化
在测试阶段,企业采用A/B测试方法,对不同检索策略和模型参数进行对比评估。测试结果表明,结合BM25和向量语义检索的混合策略在准确率和召回率方面均优于单一检索方法。此外,企业还对模型的推理速度进行了优化,采用NVIDIA GPU加速推理,并通过模型量化技术降低计算资源消耗,以确保系统在高并发场景下的稳定性。
通过上述实施步骤,该企业成功构建了一个高效、稳定的知识问答系统,实现了知识的智能检索与生成,并显著提升了员工获取信息的效率。
四、成效总结与未来展望
该企业的知识问答系统成功实现了高效、智能的知识管理,显著提升了信息检索的准确性和响应速度。通过RAG架构与本地化部署的LLM结合,系统能够基于企业内部的海量文档提供精准问答,减少了员工手动筛选信息的时间,提高了整体工作效率。此外,该系统基于开源工具链构建,有效降低了部署和维护成本,使企业能够在保证数据安全的前提下,灵活扩展知识管理能力。
这一实践表明,RAG与大语言模型的结合为企业知识管理提供了强有力的支持。未来,随着LLM技术的持续进步,企业可以进一步优化知识检索策略,例如引入多模态信息处理,以支持图像、表格等非文本数据的智能问答。此外,随着模型轻量化和边缘计算的发展,企业有望在本地部署更高性能的LLM,提升系统的实时性和自主性。同时,基于AI驱动的知识管理系统还将向自动化知识更新、个性化推荐等方向发展,使企业能够更智能地管理和利用知识资产。
随着人工智能技术的演进,企业知识管理正朝着更加智能化、自适应的方向发展。未来的知识管理系统不仅能够提供精准的问答服务,还能主动挖掘潜在知识关联,辅助决策制定,推动企业在数字化转型中实现更高的运营效率和创新能力。
相关文章:

企业数字化转型背景下的企业知识管理挑战与经验杂谈
一、引言 在数字化转型的浪潮下,企业知识管理正面临前所未有的挑战。随着数据量的急剧增长,企业内部积累的信息呈现出碎片化、分散化的趋势,传统的知识管理体系已难以有效应对这一变革。首先,信息碎片化问题日益严重,…...
使用frp实现客户端开机自启(含静默运行脚本)
本文整理了如何使用 frp 客户端并实现 Windows 系统下的开机静默自启,适合远程桌面、内网穿透等场景。 📁 目录结构 我将 frp 客户端文件放置在以下路径: F:\git\frp>tree /f 卷 其它 的文件夹 PATH 列表 卷序列号为 A123-0F4E F:. │ …...
list 容器常见用法及实现
文章目录 1. list 的介绍与使用1.1 list 的介绍1.2 list 的使用1.2.1 list 的构造1.2.2 list iterator 的使用1.2.3 list capacity1.2.4 list element access1.2.5 list modifiers1.2.6 迭代器失效问题 2. list 的模拟实现2.1 值得注意的点:2.2 std::initializer_li…...

iOS视频编码详细步骤(视频编码器,基于 VideoToolbox,支持硬件编码 H264/H265)
iOS视频编码详细步骤流程 1. 视频采集阶段 视频采集所使用的代码和之前的相同,所以不再过多进行赘述 初始化配置: 通过VideoCaptureConfig设置分辨率1920x1080、帧率30fps、像素格式kCVPixelFormatType_420YpCbCr8BiPlanarFullRange设置摄像头位置&am…...

浅析 Golang 内存管理
文章目录 浅析 Golang 内存管理栈(Stack)堆(Heap)堆 vs. 栈内存逃逸分析内存逃逸产生的原因避免内存逃逸的手段 内存泄露常见的内存泄露场景如何避免内存泄露?总结 浅析 Golang 内存管理 在 Golang 当中,堆…...
)
记录: Windows下远程Liunx 系统xrdp 用到的一些小问题(免费踩坑 记录)
采用liunx Ubuntu22.04版本以下,需要安装 xrdp 或者VNC 具体过程就是下载 在linux命令行里 首先更新软件包:sudo apt update 安装xrdp服务:sudo apt install xrdp 启动XRDP:sudo systemctl start xrdp(如果在启动的…...
C++ 并发编程(1)再学习,为什么子线程不调用join方法或者detach方法,程序会崩溃? 仿函数的线程启动问题?为什么线程参数默认传参方式是值拷贝?
本文的主要学习点,来自 这哥们的视频内容,感谢大神的无私奉献。你可以根据这哥们的视频内容学习,我这里只是将自己不明白的点,整理记录。 C 并发编程(1) 线程基础,为什么线程参数默认传参方式是值拷贝?_哔…...
【Python 算法零基础 2.模拟 ④ 基于矩阵】
目录 基于矩阵 Ⅰ、 2120. 执行所有后缀指令 思路与算法 ① 初始化结果列表 ② 方向映射 ③ 遍历每个起始位置 ④ 记录结果 Ⅱ、1252. 奇数值单元格的数目 思路与算法 ① 初始化矩阵 ② 处理每个操作 ③ 统计奇数元素 Ⅲ、 832. 翻转图像 思路与算法 ① 水平翻转图像 ② 像素值…...

【教程】Docker方式本地部署Overleaf
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 背景说明 下载仓库 初始化配置 修改监听IP和端口 自定义网站名称 修改数据存放位置 更换Docker源 更换Docker存储位置 启动Overleaf 创…...
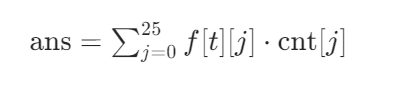
3337|3335. 字符串转换后的长度 I(||)
1.字符串转换后的长度 I 1.1题目 3335. 字符串转换后的长度 I - 力扣(LeetCode) 1.2解析 递推法解析 思路框架 我们可以通过定义状态变量来追踪每次转换后各字符的数量变化。具体地,定义状态函数 f(i,c) 表示经过 i 次转换后࿰…...
PHP黑白胶卷底片图转彩图功能 V2025.05.15
关于底片转彩图 传统照片底片是摄影过程中生成的反色图像,为了欣赏照片,需要通过冲印过程将底片转化为正像。而随着数字技术的发展,我们现在可以使用数字工具不仅将底片转为正像,还可以添加色彩,重现照片原本的色彩效…...
字符串检索算法:KMP和Trie树
目录 1.引言 2.KMP算法 3.Trie树 3.1.简介 3.2.Trie树的应用场景 3.3.复杂度分析 3.4.Trie 树的优缺点 3.5.示例 1.引言 字符串匹配,给定一个主串 S 和一个模式串 P,判断 P 是否是 S 的子串,即找到 P 在 S 中第一次出现的位置。暴力匹…...

Java大师成长计划之第22天:Spring Cloud微服务架构
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 随着企业应用的不断扩展,…...

瀑布模型VS敏捷模型VS喷泉模型
目录 1. 瀑布模型(Waterfall Model) 2. 敏捷模型(Agile Model) 3. 喷泉模型(Fountain Model)...
基于.Net开发的网络管理与监控工具
从零学习构建一个完整的系统 平常项目上线后,不仅意味着开发的完成,更意味着项目正式进入日常运维阶段。在这个阶段,网络的监控与管理也是至关重要的,这时候就需要一款网络管理工具,可以协助运维人员用于日常管理&…...

Python并发编程:开启性能优化的大门(7/10)
1.引言 在当今数字化时代,Python 已成为编程领域中一颗璀璨的明星,占据着编程语言排行榜的榜首。无论是数据科学、人工智能,还是 Web 开发、自动化脚本编写,Python 都以其简洁的语法、丰富的库和强大的功能,赢得了广大…...

Linux 中 open 函数的本质与细节全解析
一、open简介 在 Linux 下,一切皆文件。而对文件的读写,离不开文件的“打开”操作。虽然 C 语言标准库提供了方便的 fopen,但更底层、更强大的是系统调用 open,掌握它能让你对文件系统控制更细致,在系统编程、驱动开发…...

llama.cpp无法使用gpu的问题
使用cuda编译llama.cpp后,仍然无法使用gpu。 ./llama-server -m ../../../../../model/hf_models/qwen/qwen3-4b-q8_0.gguf -ngl 40 报错如下 ggml_cuda_init: failed to initialize CUDA: forward compatibility was attempted on non supported HW warning: n…...

Python Unicode字符串和普通字符串转换
Unicode 是一种字符编码标准,旨在为世界上所有书写系统的每个字符提供一个唯一的数字标识(称为码点)。 码点: 每个 Unicode 字符被分配一个唯一的数字,称为码点表示形式:u 后跟 4-6 位十六进制数…...

Ansible Roles 是一种用于层次化和结构化组织 Ansible Playbook 的机制。
Ansible Roles 是一种用于层次化和结构化组织 Ansible Playbook 的机制。它通过将变量、文件、任务、模板和处理器等放置在单独的目录中,简化了 Playbook 的管理和复用。Roles 自 Ansible 1.2 版本引入,极大地提高了代码的可维护性和可重用性。 目录结构 一个标准的 Ansibl…...
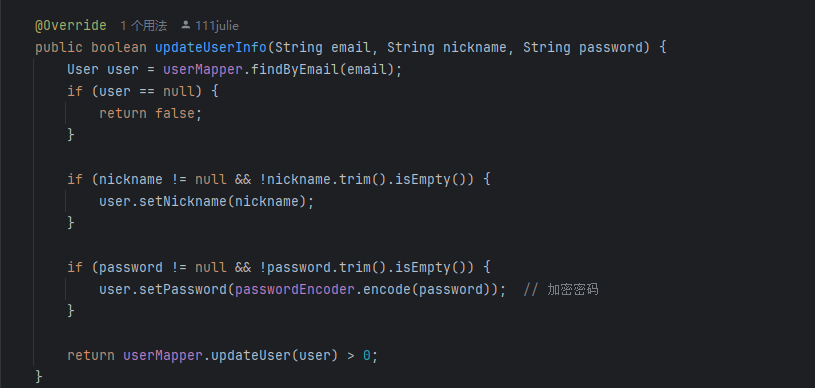
易学探索助手-个人记录(十)
在现代 Web 应用中,用户体验的重要性不断上升。近期我完成了两个功能模块 —— 语音播报功能 与 用户信息修改表单,分别增强了界面交互与用户自管理能力。 一、语音播报功能(SpeechSynthesis) 功能特点 支持播放、暂停、继续、停…...

Linux基础 -- SSH 流式烧录与压缩传输笔记
Linux SSH 流式烧录与压缩传输指南 一、背景介绍 在嵌入式开发和维护中,常常需要通过 SSH 从 PC 向设备端传输大文件(如系统镜像、固件)并将其直接烧录到指定磁盘(如 /dev/mmcblk2)。然而,设备端存储空间…...

学习51单片机01(安装开发环境)
新学期新相貌.......哈哈哈,我终于把贪吃蛇结束了,现在我们来学stc51单片机! 要求:c语言的程度至少要到函数,指针尽量!如果c语言不好的,可以回去看看我的c语言笔记。 1.开发环境的安装&#x…...

事件驱动reactor的原理与实现
fdset 集合:(就是说) fd_set是一个位图(bitmap)结构 每个位代表一个文件描述符 0表示不在集合中,1表示在集合中 fd_set结构(简化): [0][1][2][3][4][5]...[1023] …...

大模型训练简介
在人工智能蓬勃发展的当下,大语言模型(LLM)成为了众多应用的核心驱动力。从智能聊天机器人到复杂的内容生成系统,LLM 的卓越表现令人瞩目。而这背后,大模型的训练过程充满了奥秘。本文将深入探讨 LLM 训练的各个方面&a…...
)
深度解析 MySQL 与 Spring Boot 长耗时进程:从故障现象到根治方案(含 Tomcat 重启必要性分析)
一、典型故障现象与用户痛点 在高并发业务场景中,企业级 Spring Boot 应用常遇到以下连锁故障: 用户侧:网页访问超时、提交表单无响应,报错 “服务不可用”。运维侧:监控平台报警 “数据库连接池耗尽”,To…...
)
More Effective C++:改善编程与设计(上)
More Effective C: 目录 More Effective C: 条款1:仔细区别pointers和 references 条款2:最好使用C转型操作符 条款3:绝对不要以多态方式处理数组 条款4:非必要不要提供default constructor 条款5:对定制的“类型转换函数”保持警觉 …...

TNNLS-2020《Autoencoder Constrained Clustering With Adaptive Neighbors》
核心思想分析 该论文提出了一种名为ACC_AN(Autoencoder Constrained Clustering with Adaptive Neighbors)的深度聚类方法,旨在解决传统子空间聚类方法在处理非线性数据分布和高维数据时的局限性。核心思想是将深度自编码器(Auto…...
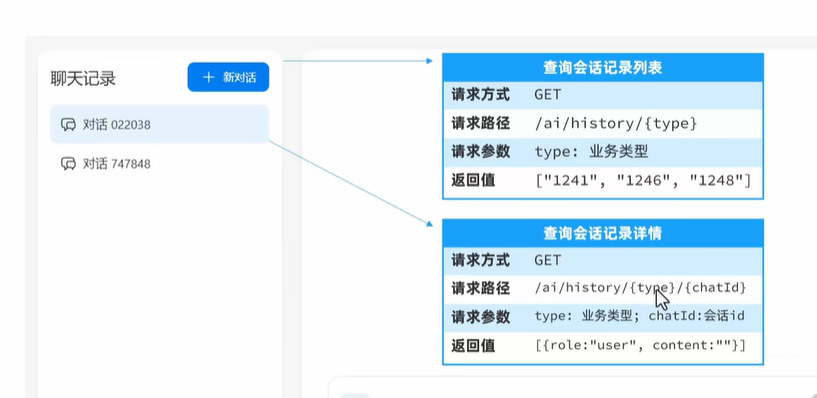
SpringAI
机器学习: 定义:人工智能的子领域,通过数据驱动的方法让计算机学习规律,进行预测或决策。 核心方法: 监督学习(如线性回归、SVM)。 无监督学习(如聚类、降维)。 强化学…...
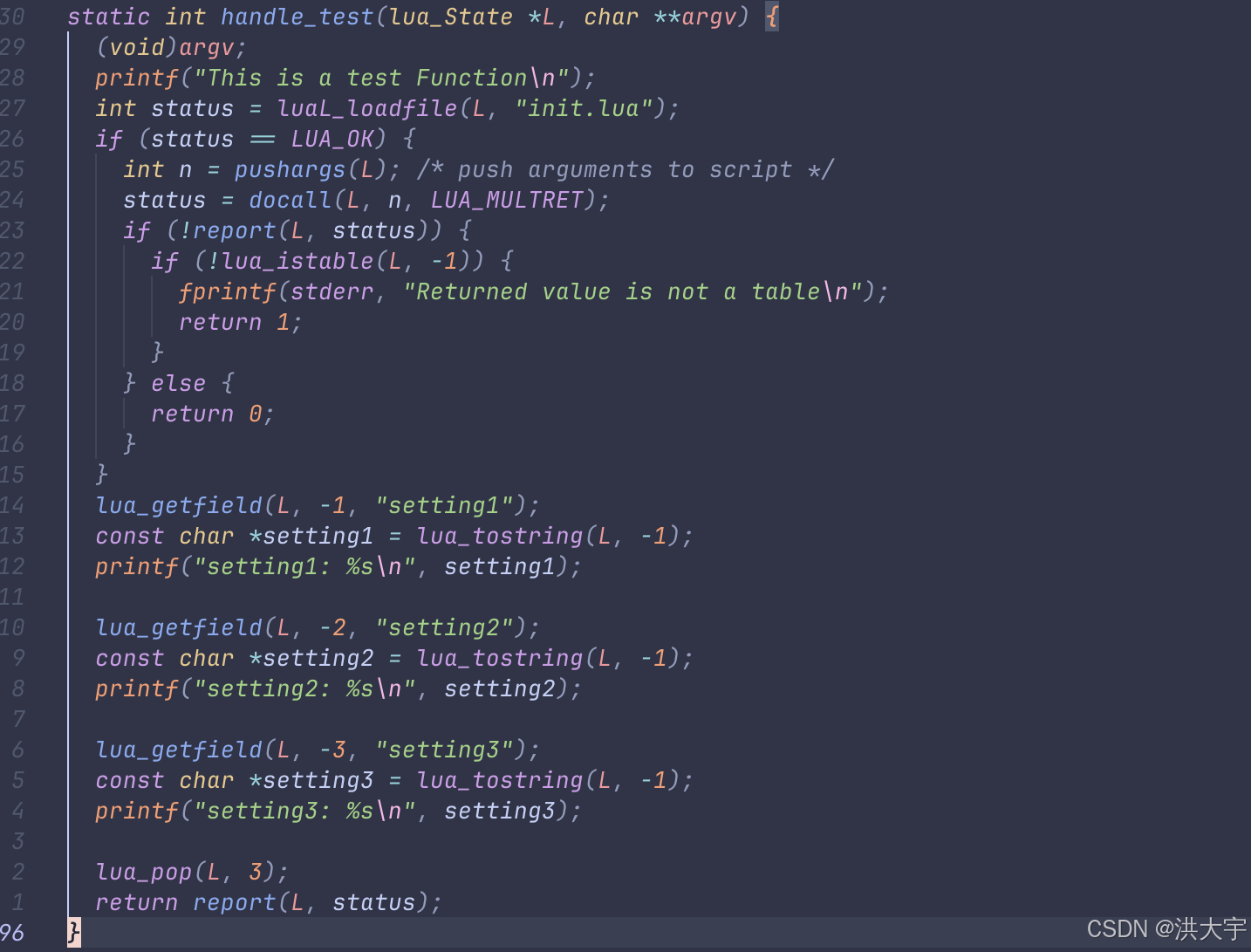
lua 作为嵌入式设备的配置语言
从lua的脚本中获取数据 lua中栈的索引 3 | -1 2 | -2 1 | -3 可以在lua的解释器中加入自己自定的一些功能,其实没啥必要,就是为了可以练习下lua...